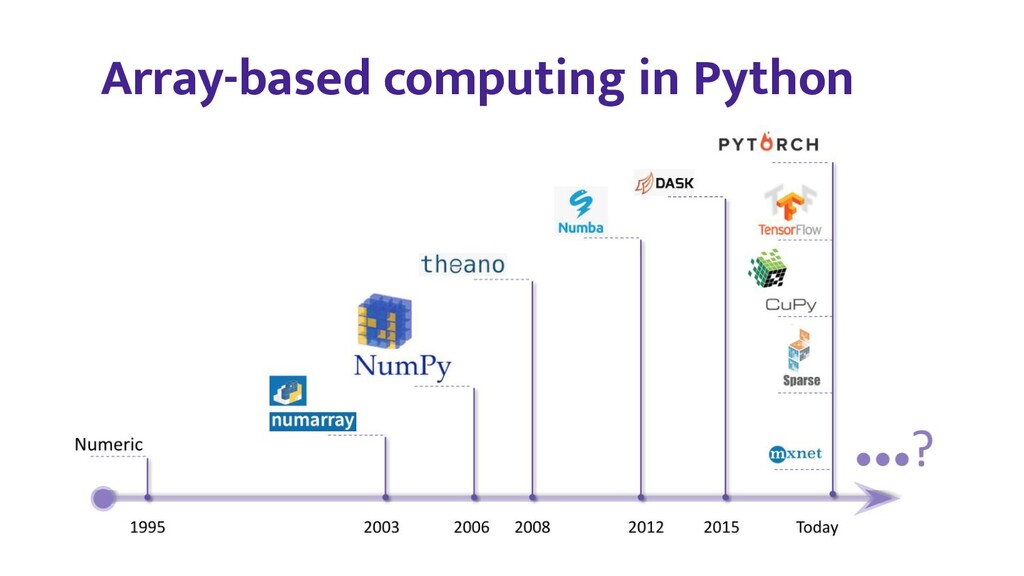
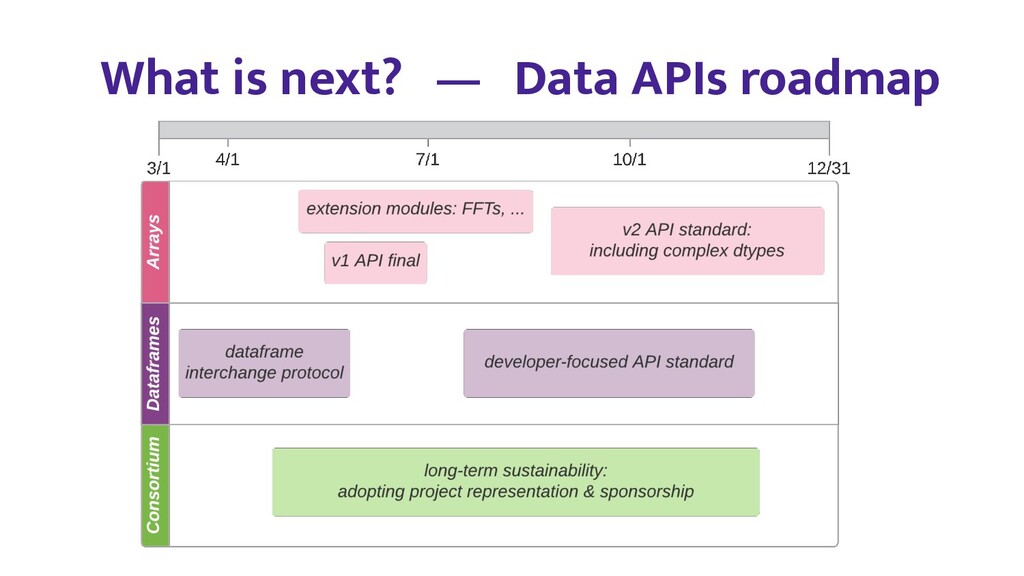
Numerical computing and deep learning libraries for Python all offer array (or tensor) data structures and associated compute functionality with similar APIs. There are many subtle differences however, making it hard for users to migrate from one library to another, or for library authors to write code that supports multiple array libraries. The Consortium for Python Data API Standards (https://data-apis.org/) recently released a first version of its array API standard - which aims to address these issues - for community review.
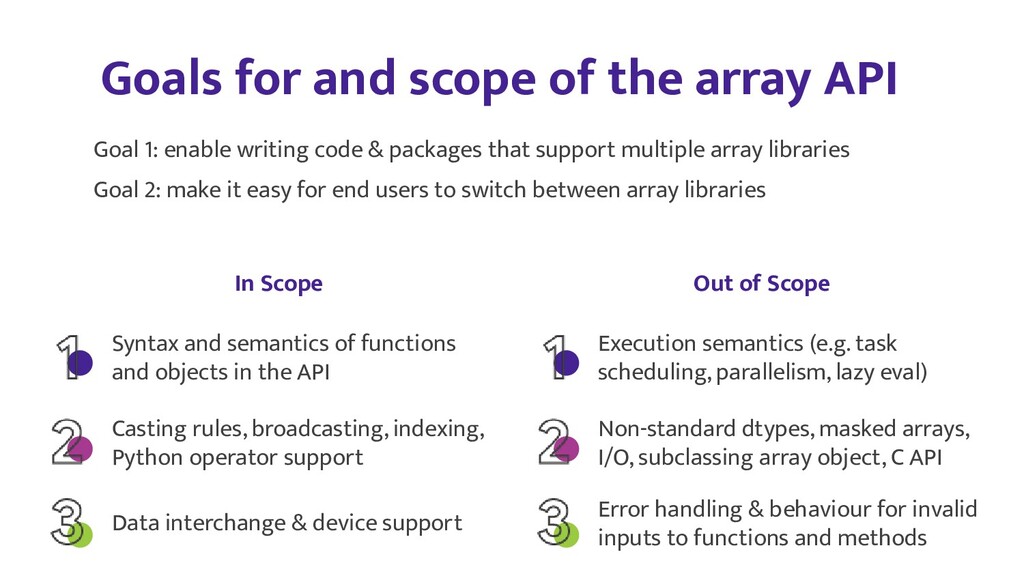
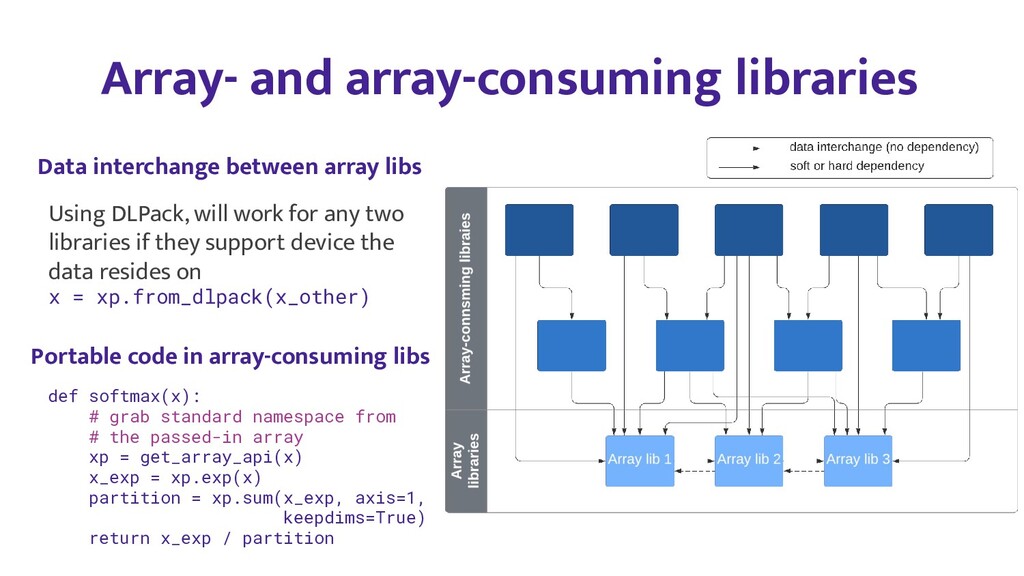
In this talk, we will start with an overview of array API standard goals, benefits and API surface, and then focus on some of the key technical issues, such as reconciling in-place operations with immutable/mutable array data models, dtype casting rules, and zero-copy exchange protocols. Finally we will look at initial implementations in NumPy and PyTorch, and plans for use in downstream libraries like SciPy and scikit-learn.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}