Share
It is a material presented at the 9th sagemaker case festival.
https://aws.amazon.com/jp/blogs/news/amazon-sagemaker-fes-9/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
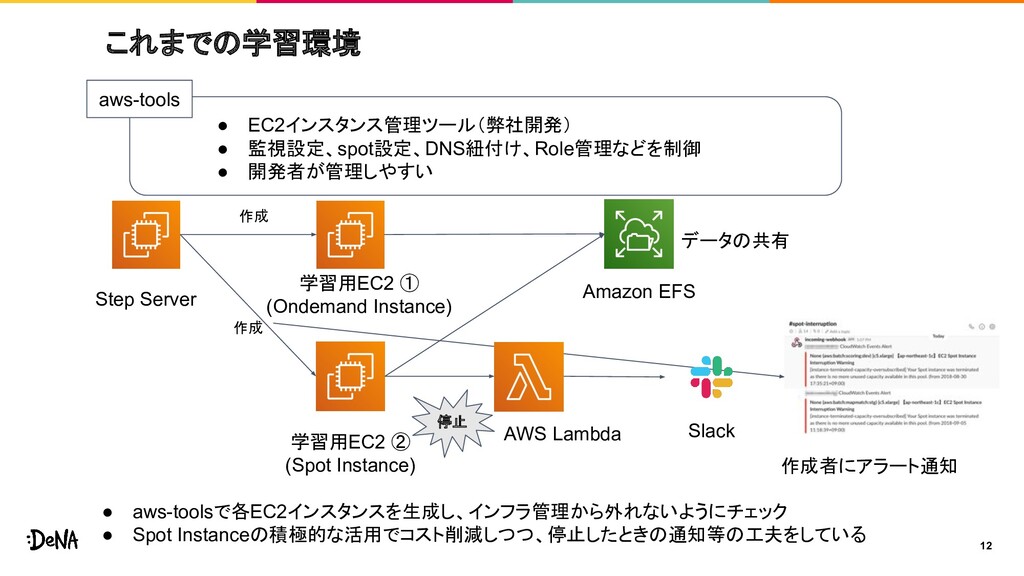{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
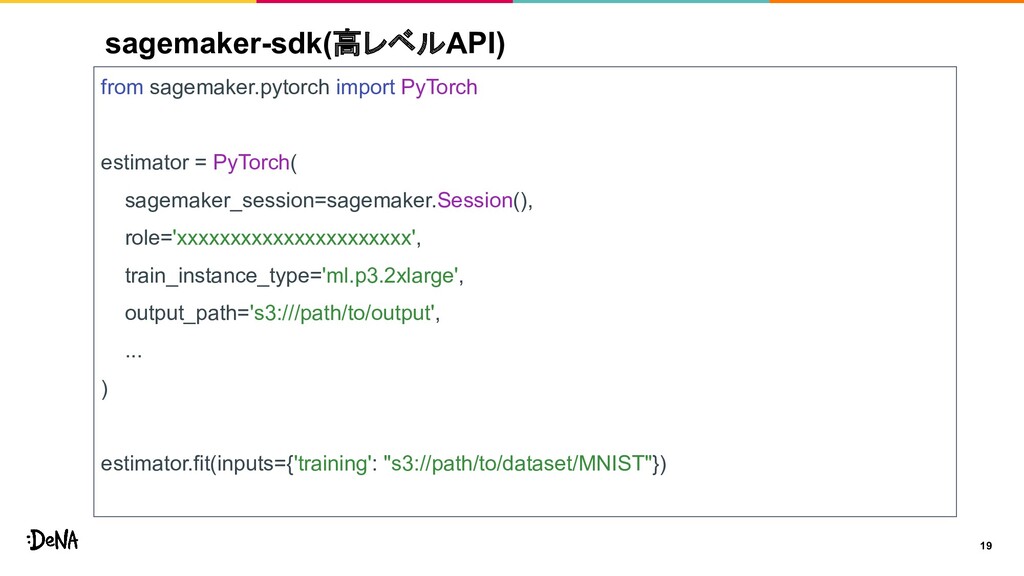{kind=link}
{kind=link}
{kind=link}
{kind=link}
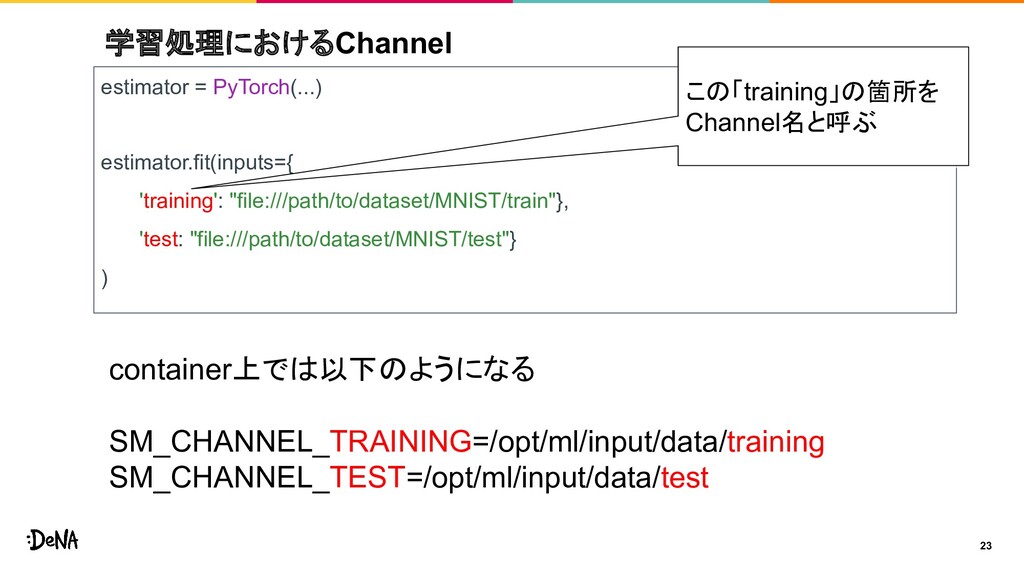{kind=link}
![argparseで使う 24 parser = argparse.ArgumentParser() parser.add_argument('--train-data-dir', type=str, default=os.environ['SM_CHANNEL_TRAINING']) parser.add_argument('--test-data-dir', type=str,](https://files.speakerdeck.com/presentations/425d6a23ea5543f3ad3a38c61ac01a42/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
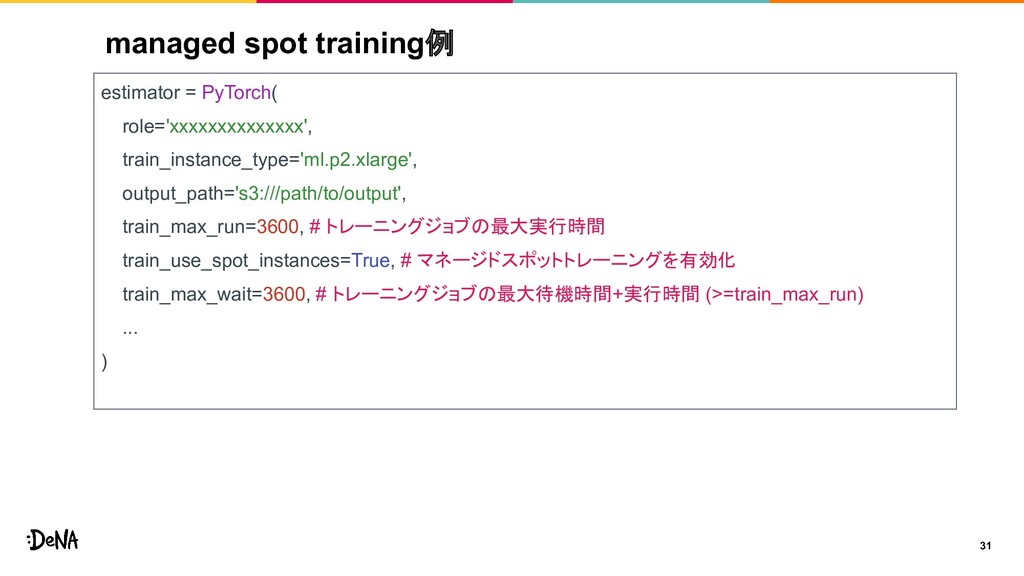{kind=link}
{kind=link}
![datasetにEFSを使う 33 estimator = PyTorch( ... subnets=['subnet-1', 'subnet-2'] security_group_ids=['sg-1'] )](https://files.speakerdeck.com/presentations/425d6a23ea5543f3ad3a38c61ac01a42/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
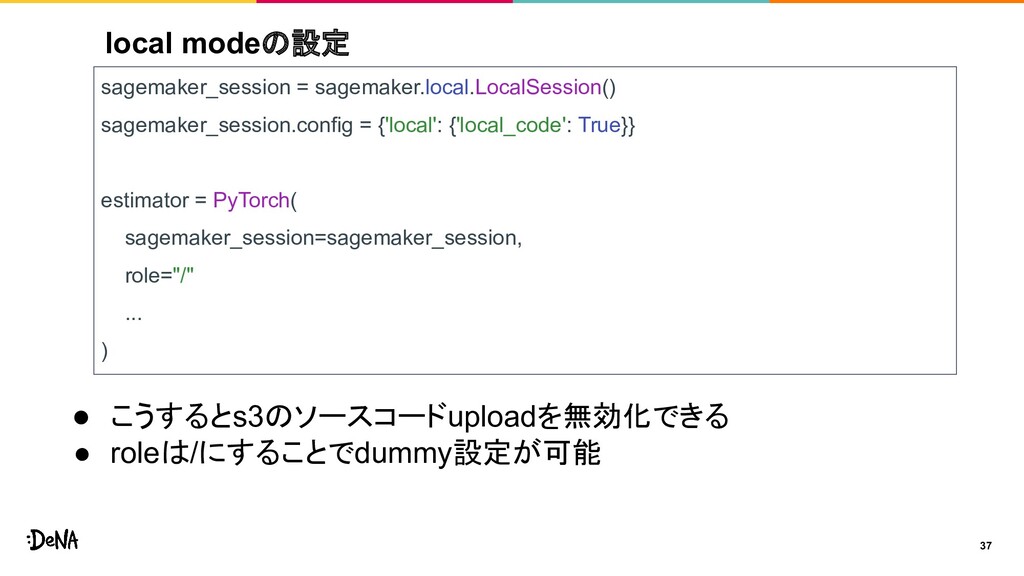{kind=link}
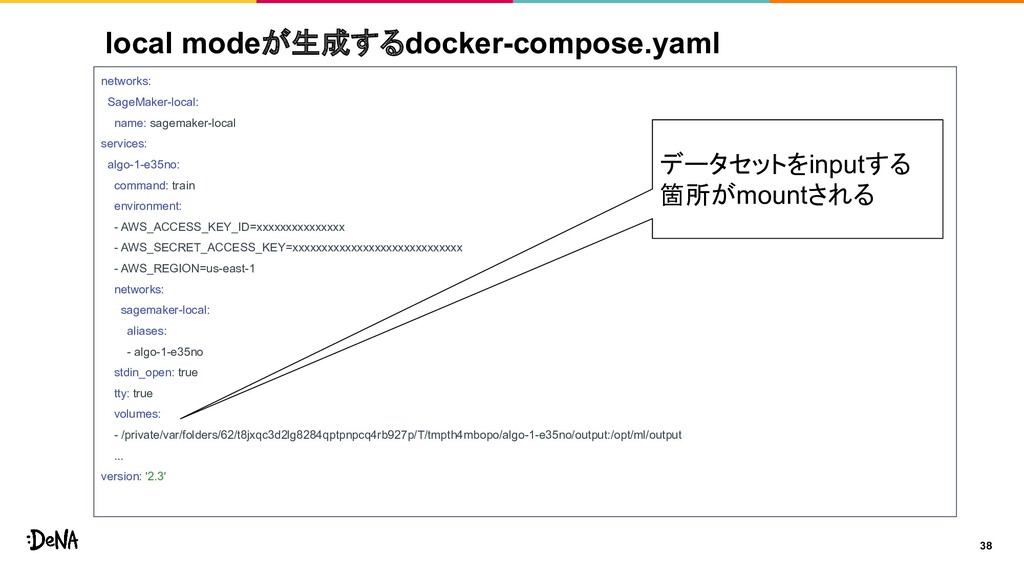{kind=link}
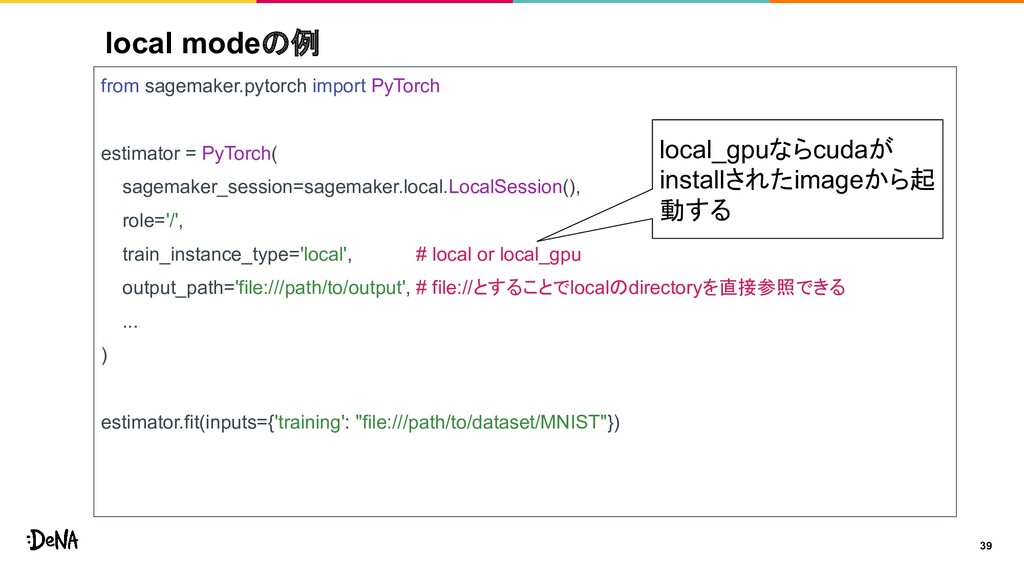{kind=link}
{kind=link}
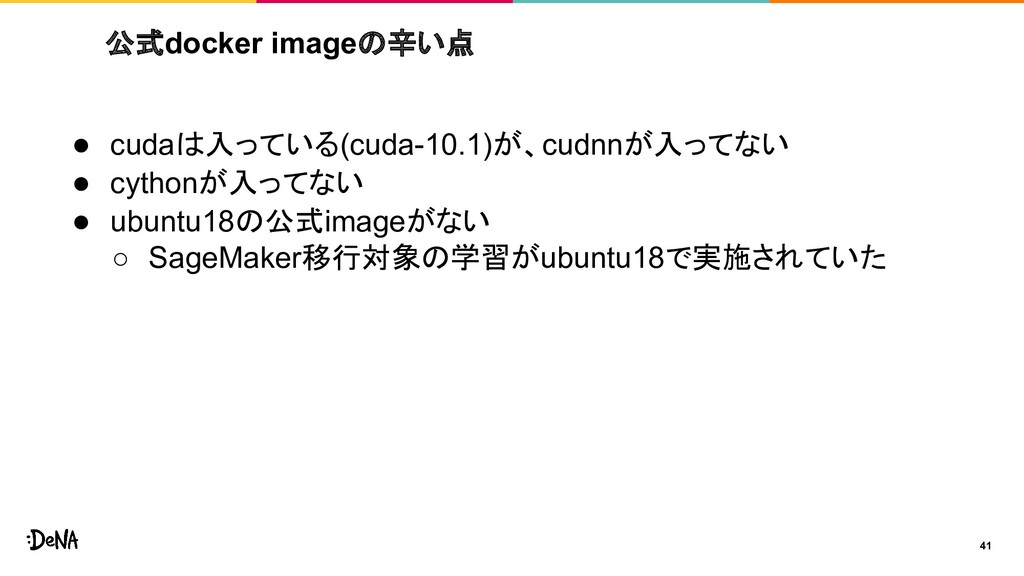{kind=link}
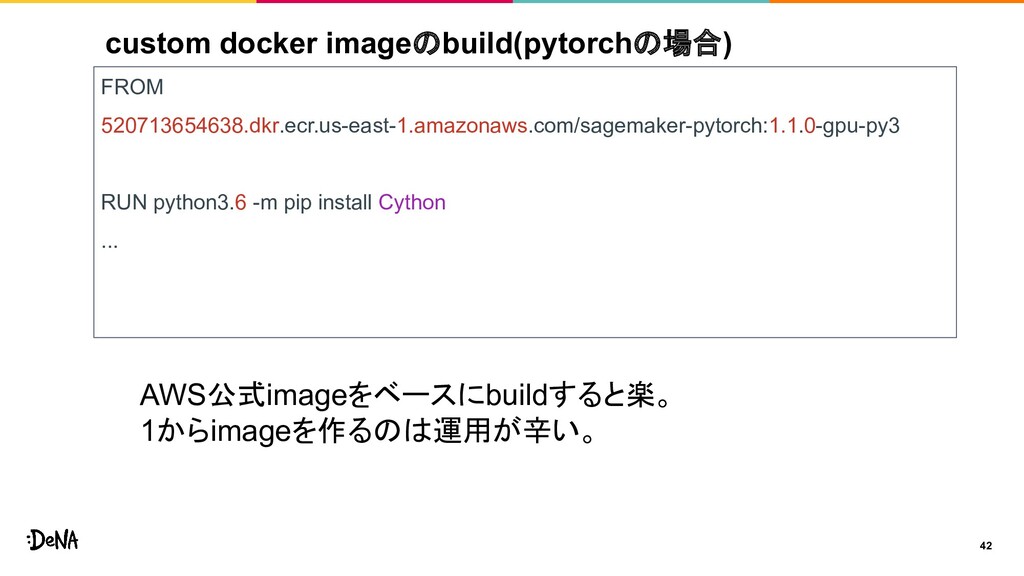{kind=link}
{kind=link}
{kind=link}
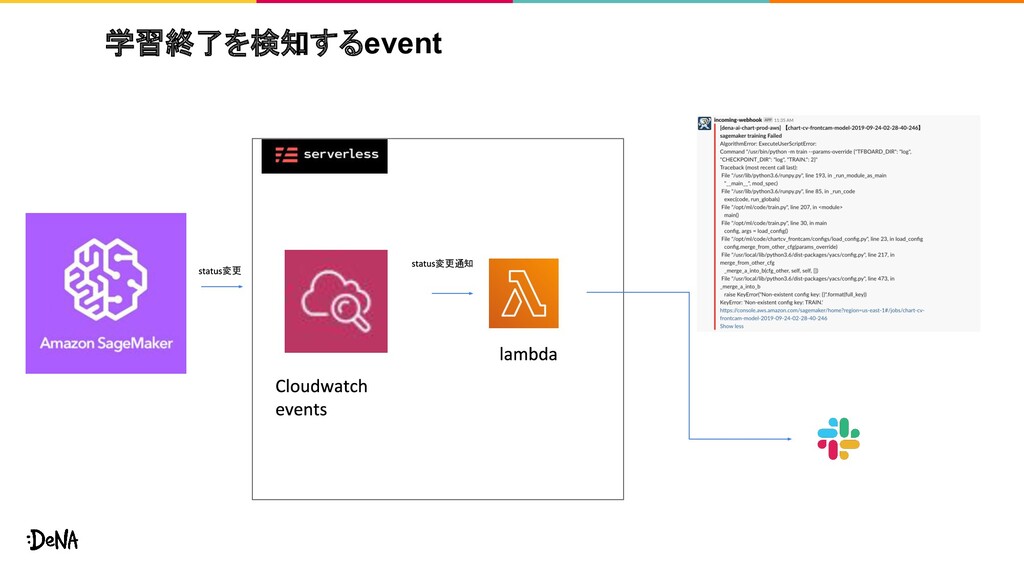{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}