Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Mobility Technologiesにおける数100台規模のnodeを使うEKSのAI推論環境
Search
Toyama Hiroshi
March 20, 2021
Technology
1.4k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Mobility Technologiesにおける数100台規模のnodeを使うEKSのAI推論環境
JAWS DAYS 2021で発表した資料になります。
https://jawsdays2021.jaws-ug.jp/timetable/track-c-1720/
Toyama Hiroshi
March 20, 2021
More Decks by Toyama Hiroshi
See All by Toyama Hiroshi
DRIVE CHARTにおけるSageMaker Migration
toyama0919
0
96
Strata Hadoop 2016 at San Jose
toyama0919
0
90
SaaS WITH Infrastructure
toyama0919
1
710
Other Decks in Technology
See All in Technology
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
340
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
340
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
160
システム監視入門
grimoh
3
580
Jitera Company Deck
jitera
0
580
CTOキーノート:AI時代の「つなぐ」を再定義 ― 真のIoTとリアルワールドAI【SORACOM Discovery 2026】
soracom
PRO
0
140
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
670
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
490
そのドキュメント、自動化しませんか?
yuksew
1
450
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
1
310
「休む」重要さ
smt7174
7
1.7k
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
450
Featured
See All Featured
The Language of Interfaces
destraynor
162
27k
Balancing Empowerment & Direction
lara
6
1.2k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Fireside Chat
paigeccino
42
4k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
First, design no harm
axbom
PRO
2
1.2k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
How to Think Like a Performance Engineer
csswizardry
28
2.7k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Transcript
Mobility Technologiesにおける 数100台規模のnodeを使うEKSのAI 推論環境 外山 寛 AI本部AIシステム部MLエンジニアリングG 株式会社ディー・エヌ・エー (株式会社Mobility Technologies
業務委託)
自己紹介 2 • 外山 寛 • @toyama0919 • 株式会社ディー・エヌ・エー ◦
AIシステム部MLエンジニアリングG • 2020/4から株式会社Mobility Technologiesに業 務委託 • 普段やってること ◦ DeNAのAI projectのインフラ構築 ◦ MoT社DRIVE CHARTのML-OPS ◦ MoT社DRIVE CHARTのk8s運用
目次 3 システム概要 コスト削減の取り組み 工夫したこと、苦戦したこと 1 3 kubeflow pipelines 4
2
システム概要 4
使い始めた当初の状態 5 • K8Sの運用経験のあるメンバーはいない • K8Sに興味を持っているメンバーが多く、自分もそのうちの一人 だった。 • 社内ではGKEを触っているprojectはいくつかあったが、自分の 周りでEKSの知見は0に近かった。
• ECSの知見はかなりあった。 ◦ ECSは他のAI projectも含めて使っていた
当初の基本方針 6 • インフラの大部分がterraformで構成されている。 • terraformで極力完結させる ◦ よってeksctlやalb-ingressは使わない ◦ インフラはコードで管理を徹底
• Managed Nodegroupを使い、インスタンスを自前で管理はしな い。 • spot instanceを使いたい(後述)
AI Test環境 7 7 Amazon EKS AWS Cloud preprocess predict
output Test X Test Y Test Z Movie
AI Test環境 8 • AI Test環境を刷新したいという動機でK8Sの検討が始まった ◦ 旧環境はec2(autoscaling)とsqsをベースに組み合わせた方 式をとっていた。 •
「前処理>推論>出力」のpipelineをkubeflow pipelinesで実施 している。 • 複数人のデータサイエンティストが同時にTestできる。 ◦ 並列でpipelineが処理できる ◦ sourceとなる動画がs3に大量にあり、それらを並列で処理し ている。
コスト削減の取り組み 9
spotインスタンスを活用 10 • 構築早期の段階で数百台のnodeが立つことが頻繁にあったた め、インスタンスの費用を極力抑える必要があった。 • spot instance + autoscalingの知見はec2やecsで運用していた
ため既にあった。 • 2020年12月にspot instanceをmanaged nodegroupがサポート したが、当初はサポートされていなかった。 • 何故かeksctlからは使える • terraformでも使えないのか調査し始めた • どうも生成されたautoscaling groupを直接書き換えているらしい => それならterraformでもできるはず
terraformでspotインスタンスを活用 11 • terraformでManaged Nodegroupを管理する。 • Managed Nodegroupはlaunch templateとautoscaling groupを
自動生成する。 • 自動生成されたautoscaling groupの OnDemandPercentageAboveBaseCapacityと OnDemandBaseCapacityを上書きすることでspotとondemand の比率が調整できる ◦ awscliだとaws autoscaling update-auto-scaling-group ~~ • またWeightedCapacityも書き換えることで、instance typeごとの 重みを調節できる
(公式)Managed Nodegroupのspotインスタンス対応 12 • 2020年12月にspot instanceをEKS managed nodegroupがサ ポートした。 •
(良い)SpotAllocationStrategy=capacity-optimizedと CapacityRebalance=trueがopt-inされている。 • (良い)spotが中断する際に、drainとcordonをEKSのcontrol planeがmanageしてくれる(aws-node-termination-handler相当 の機能) • (辛い)複数instance typeを組み合わせる場合のweightは autoscaling groupのupdateが必要、またオンデマンドの比率調 整も同様
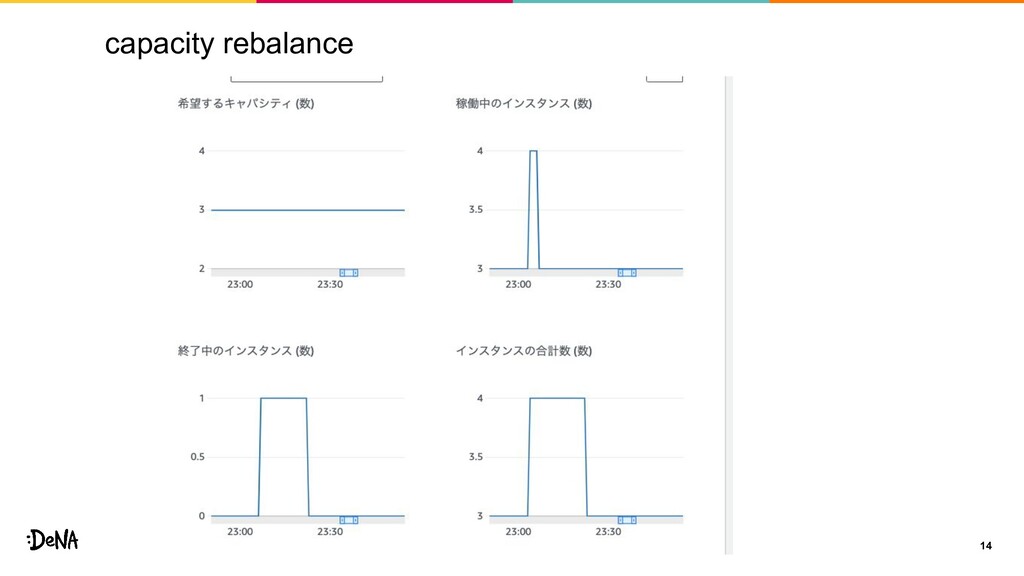
capacity rebalance 13 • 従来の中断通知より前にEC2 Instance rebalance recommendationが通知される。 • rebalance
recommendationをinstanceが受け取ると新規で instanceの作成が開始されるため容量が一時的に不足する可能 性が大幅に下る。 • EKSのManaged Nodegroupのspot機能は上記がopt-inされて おり, podがpendingになりにくい状況を作れる。 • SpotAllocationStrategy=capacity-optimizedにすると効果的(こ れもopt-inされている)
capacity rebalance 14
苦戦したこと、 工夫したこと 15
corednsの負荷増大 16 • kube-system用のnodegroupを作成し、ondemandを最低1台稼 働させて残りはspotで運用 • corednsなどのsystem的なpodはnodeSelectorで専用nodeに所 属させて他の負荷が高いnodeと共存させないようにする • また,
corednsのpod数を5-10程度に増やした(デフォルトはは2) • kubeflowのpodが大半の通信を行うため、kubeflow上は部分的 にFQDNで通信させることによりDNSのsearchを少なくした。
corednsの負荷増大(失敗したこと) 17 • namespace=kube-systemをFargateで動かしてみたが(Fargate profile)、DNSエラーが多発しシステム障害が起きた。 • 稼働させはじめた当初は1つのNodegroupで全podを稼働させて おり、かつspot instanceも併用していたためcorednsが突然死し てしまうことがあった(笑
IAM RoleのNoCredentialsErrorが多発 18 • podを大量に(1000podくらい)起動した際に、aws resourceへの アクセス(主にs3)でNoCredentialsErrorが多発する。 • Managed NodegroupはデフォルトではnodeについているIAM
Roleの権限をpodが使うことになる。 • EC2 に付与されている IAM Role の認証情報はインスタンスメタ データから取得される。 • インスタンスごとにこのmetadataにアクセスできるTPSに上限が あり、スロットリングされた場合には Boto3 での API Call 時に NoCredentialsError が発生する。
IAM RoleのNoCredentialsErrorが多発(解決) 19 • AWS_METADATA_SERVICE_TIMEOUTを増やしたり、 AWS_METADATA_SERVICE_NUM_ATTEMPTS(retry回数)を 増やしたりもしたが根本解決はしなかった • IAM Roles
for Service AccountsでpodごとにIAM Roleを設定す ることにより解決した。 • 各Podはk8sから払い出されるservice account tokenを AWS STS に OIDC tokenの形で渡すことにより、IAM の認証情報を 使うことができる。 • instance metadataにアクセスしないため、metadataのthrottling は発生しない
他にもいろいろ 20 • podが増えすぎてIPアドレスが枯渇してしまった。 ◦ VPC-CNI-pluginにVPCのIPを動的にreleaseする WARM_IP_TARGETやMINIMUM_IP_TARGETなどの設定 があるが、apiを内部でたくさん叩くためthrottlingが発生 ◦ 結局secondaryのsubnetを追加した
• EKSのmanaged nodegroupのhealth checkでエラーが止まらな い。(実害はなかったが) ◦ aws-authのconfigmapでnodeのrbacをsystem:mastersにし ていた。 ◦ rbacのapiGroupsでcertificates.k8s.ioを許可しないとhealth checkが失敗してしまう
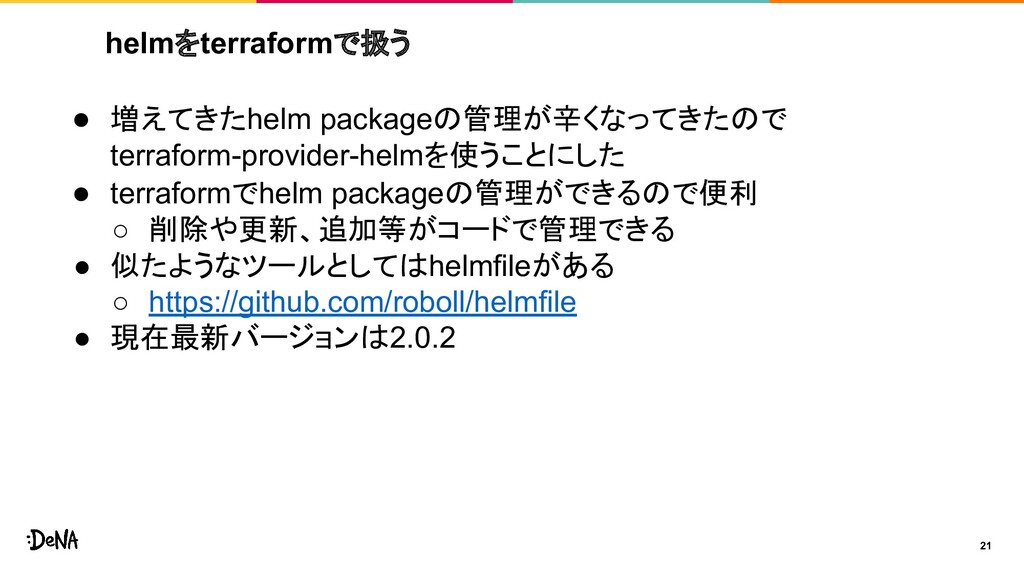
helmをterraformで扱う 21 • 増えてきたhelm packageの管理が辛くなってきたので terraform-provider-helmを使うことにした • terraformでhelm packageの管理ができるので便利 ◦
削除や更新、追加等がコードで管理できる • 似たようなツールとしてはhelmfileがある ◦ https://github.com/roboll/helmfile • 現在最新バージョンは2.0.2
helmをterraformで扱う(why) 22 • インフラの管理はterraformに集約したい ◦ eksctlやalb-ingressなどインフラを作れるツールは多数ある が分散させたくない • helm packageもコードで管理したい
◦ 直接installしているとどのpackageをインフラで管理している のかがわかりにくくなっていく • helmも含めてmodule化しておけば、cluster構成+packageまま でterraform applyだけで量産できる
helmで管理するpackage(why) 23 • 以下のpackageをterraformで管理 ◦ aws-ebs-csi-driver ◦ kubernetes-external-secrets ◦ aws-node-termination-handler
◦ cluster-autoscaler ◦ nvidia-device-plugin ◦ cloudwatch-agent(自作package) ◦ fluentd(自作package) • packageも含めてterraformだけで管理できるのが便利 • EKS add-onsで管理できるようになるかもしれないが、現状は VPC-CNIのみ
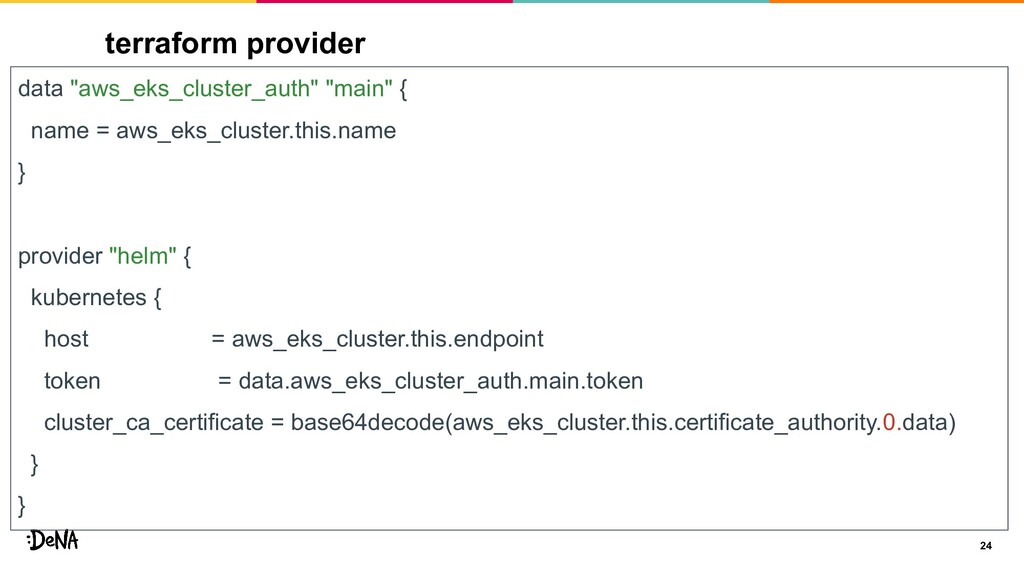
terraform provider 24 data "aws_eks_cluster_auth" "main" { name = aws_eks_cluster.this.name
} provider "helm" { kubernetes { host = aws_eks_cluster.this.endpoint token = data.aws_eks_cluster_auth.main.token cluster_ca_certificate = base64decode(aws_eks_cluster.this.certificate_authority.0.data) } }
terraform provider 25 resource "helm_release" "cluster_autoscaler" { name = "cluster-autoscaler"
chart = "autoscaler/cluster-autoscaler-chart" namespace = "kube-system" # repositoryを指定する repository = data.helm_repository.autoscaler.metadata[0].name set { name = "autoDiscovery.clusterName" value = data.aws_eks_cluster.main.name } }
monitoring 26 • 規模が大きくなってきたためpodも含めたmonitoringをやっていこ うと話になった。 • 人的コスト、クラウドコストの観点で極力コストを掛けずに monitoringをしたい。
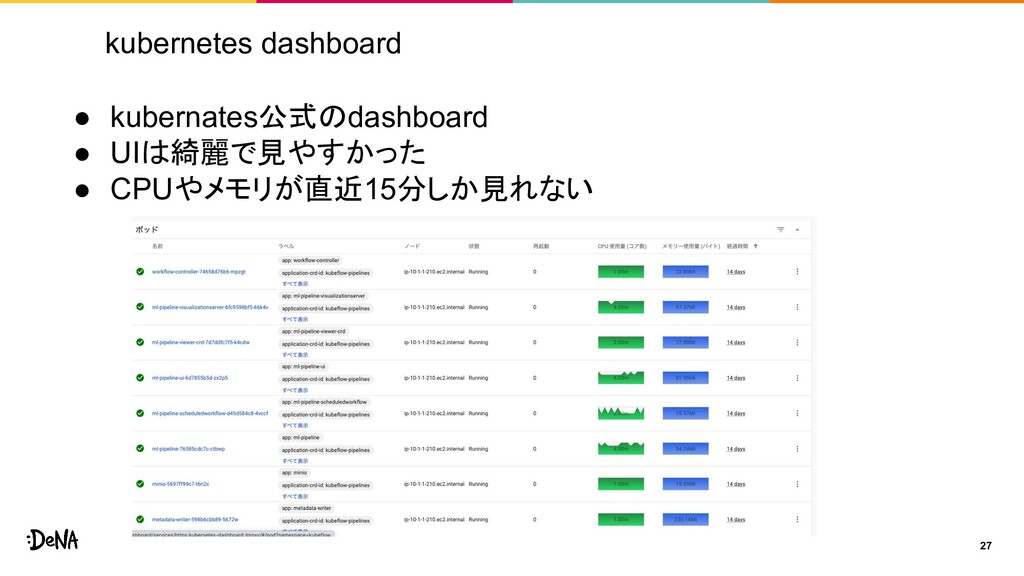
kubernetes dashboard 27 • kubernates公式のdashboard • UIは綺麗で見やすかった • CPUやメモリが直近15分しか見れない
prometheus 28 • OSSのmonitoringツールでは一番有名かも • クエリが書くのが難しい上、メンバーに覚えさせられると思えな かった。 • メモリの消費が激しく、m5.xlargeでも頻繁にpodが落ちてしまっ た。
◦ r5.xlarge(32GB)でなんとか耐えられるという状況 • インフラ的にも学習コスト的にも運用出来るイメージが沸かなかっ た。 • helmで一発でdeploy出来るのは良かった。
cloudwatch container insights 29 • 非常に手軽にAWSマネージドな仕組みだけで詳細なメトリクスが 取得可能 • deployは簡単だが、helm化はされていない。 •
ECSも使っているため、EKSと並べてメトリクスを見れるは良い。 • UIは見やすく、Managed Serviceであり運用コストも低めで採用 決定 ◦ cluster別やnamespace別のcpu平均使用率みたいな高度な metricsも見れる。
cloudwatch container insights 30
Kubeflow pipelines 31
kubeflow 32 • k8s上で動作する機械学習platform • こんな感じで機械学習の機能が盛りだくさん ◦ jupyter notebook ◦
fairing(trainingの実行、deploy) ◦ MPI Operator ◦ Katib(ハイパーパラメーター最適化) ◦ arena(computing込みのtraining環境) ◦ pipelines(機械学習workflow実行)
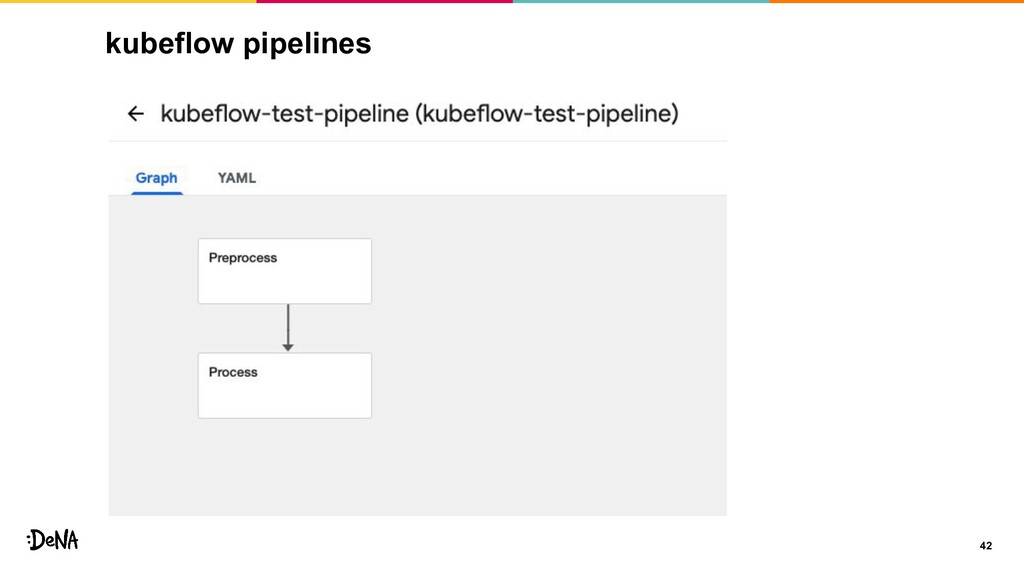
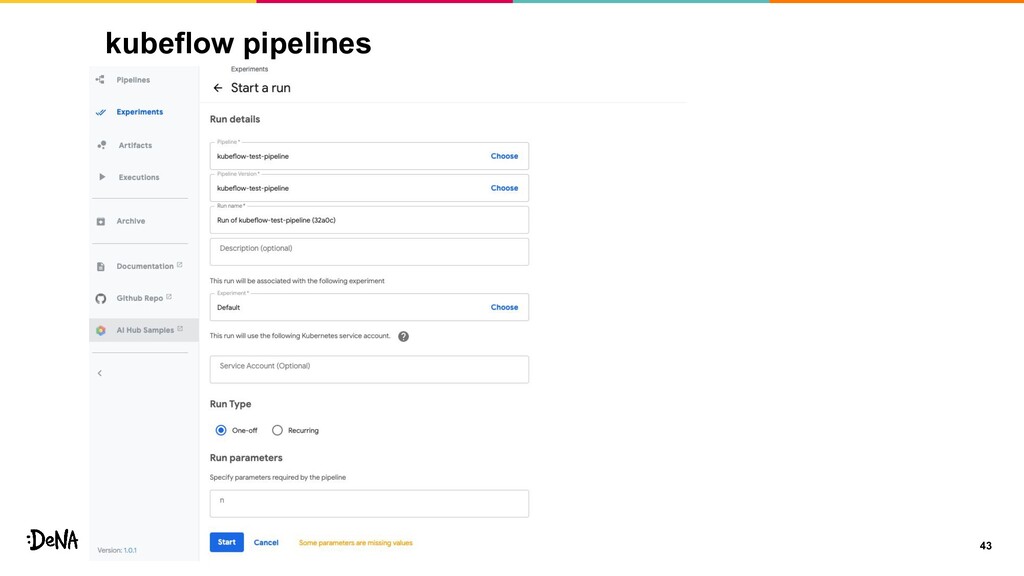
kubeflow pipelines 33 • k8s上で動作させる機械学習に特化したworkflow engine • experimentsの概念があり、実行するpipeline(workflow)には experimentsが必須となる •
後から実験結果を見る際にexperimentsから成功失敗が一覧で 見れる • パラメータを画面から細かく設定できる ◦ この辺はjenkinsっぽいが、可変にするパラメータもcodeで管 理できる
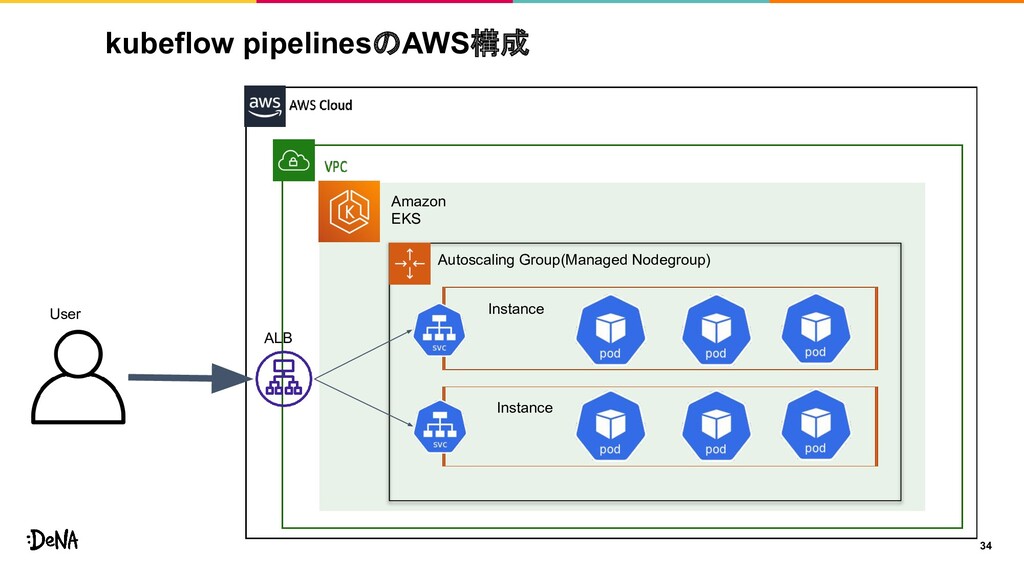
kubeflow pipelinesのAWS構成 34 User Amazon EKS Instance Autoscaling Group(Managed Nodegroup)
Instance ALB
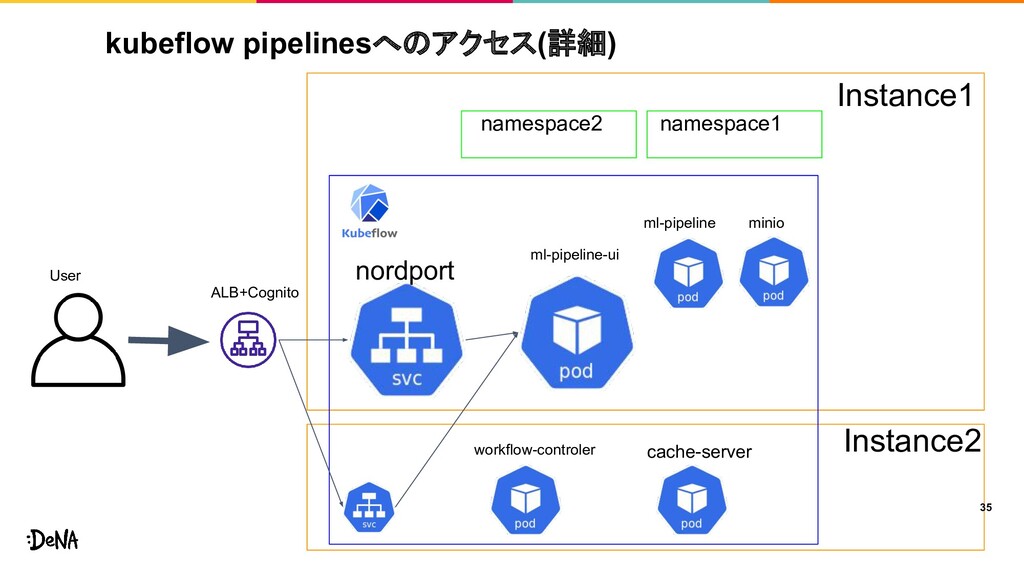
kubeflow pipelinesへのアクセス(詳細) 35 User Instance1 ALB+Cognito ml-pipeline-ui ml-pipeline minio workflow-controler
nordport namespace1 namespace2 Instance2 cache-server
kubeflow pipelines standalone 36 • chartではnotebookはsagemakerを使っており、trainingも sagemaker及びec2でやっているためfairingはいらない • kubeflowをdeployすると無駄なpodがたくさんdeployされるた め、kubeflow
pipelinesをstandaloneでdeploy。 • これなら平常時はc5.xlarge1台程度のリソースしか使わない ◦ fullでdeployすると3-4台程度になってしまう
kubeflow pipelinesでハマったこと(S3, RDS) 37 • ドキュメント通りにdeployすると、artifactの書き出し先がEBSに なってしまいcontainerが別AZに生まれ変わったりするとEBSに アクセスできず起動しない。 • pipelineの保存先もpodとして起動したmysqlになっており、これ
もEBSに保存されるため上記と同じ問題が発生 • artifactはs3, pipelineはRDSに保存するようにしないとnodeの zoneが変わったりすると起動しなくなる • artifactの保存先設定(algo)とpipelineのyamlの保存先設定 (minio)が同じs3なのに別々で存在する • 要はebs依存を取り去るのが大変だった
kubeflow pipelinesでハマったこと(ALB) 38 • ALBとpodを通信させる際に最初はALB Ingressを検討したが、 terraform管理との相性が悪く断念 ◦ AWSのresourceはterraformに集約したかった •
がpodのIP等はterraformで検出できないため、nordportで通信 させるようにした。 ◦ ALBのtarget groupとautoscaling groupを関連付ける事がで きるのでその設定をした。 • terraform k8s providerでingressが使えるのでそっちで管理する のもありかもしれない(と思い始めた • kustomizeがあんまり好きではない(笑
kubeflow pipelines 39
kubeflow pipelines 40
kubeflow pipelineのサンプルコード 41 import kfp from kfp import compiler, dsl,
components def _preprocess(n: int) -> str: return f"preprocess {n}" def _process(nums: str) -> int: return 1 @kfp.dsl.pipeline(name="parallel-pipeline") def pipeline(n: int) -> None: image = "python:3.8-alpine" preprocess_func = components.func_to_container_op(_preprocess, base_image=image) preprocess_op = preprocess_func(n) process_func = components.func_to_container_op(_process, base_image=image) process_op = process_func(preprocess_op.output) # preprocessの後にprocess process_op.after(preprocess_op) return process_op.output
kubeflow pipelines 42
kubeflow pipelines 43
まとめ 44
k8sを触って感じたこと(メリット) 45 • kubectl execでcloud上に即containerを起動できるため、debug がしやすい ◦ と思ったらECSもcontainerに直接アクセス出来るecs-execが 出た! •
インターネット上(SNS, ブログ含む)にとにかく情報が多く、やりた いことに対する情報がまずみつかる • ECSはアプリ開発者に嫌でもAWSを意識させないといけない (IAM Roleやsubnetなど)が、k8sはインフラとアプリの切り分けが しやすい。
k8sを触って感じたこと(デメリット) 46 • 最初に構築する際の学習コストが高い, これに尽きる ◦ helmやkustomizeなど管理ツール ◦ awsを知っていれば普通に使えるEBS, ALB,
Autoscalingな どにもk8sのresourceになっている必要があり一手間かかる • バージョンアップが手間 ◦ これも学習コストの1つとも言える ◦ バージョンに依存しているコンポーネントが多く、各コンポーネ ントが新バージョンに対応しているか確認する必要がある。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}