Fukushima, Japan | 30 Jan - 2 Feb, 2021 BDF-SDN: A Big Data Framework for DDoS Attack Detection in Large-Scale SDN-Based Cloud D. Phuc Trinh, Minho Park - Soongsil University, Seoul, South Korea [email protected]
– Proposed Framework IV. Implemental Setup V. Performance Evaluation VI. Conclusion & Future Work DSC 2021: The IEEE Conference on Dependable and Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021
and Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 • Currently, there are two main approaches of DDoS attack detection methods in the SDN environment. • A threshold-based approach: several traffic indicators such as traffic rate, and packet delay are kept track of; if the indicators exceed a predetermined threshold, then an attack may occur in the network. This approach results in high false-error rates because of a hard threshold. • A feature-based approach: using machine-learning algorithms to classify normal and attack traffic, which performs better and is widely adopted by many researchers. This approach is highly resource-intensive and is unable to perform reliably since traditional data processing workflows impose several limitations of processing a large amount of data in large- scale networks including cloud servers and data centers. In addition, big data analytics based on machine learning and deep learning techniques require a scalable big data solution to process data and make predictions in real-time with high accuracy, robust, and efficiency. 1/18
Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 2/18 Understanding the difficulties given above: • We propose a ➢ Scalable ➢ high availability ➢ fault tolerance framework to process big data in an SDN context where applications as feature-based DDoS detection need a framework to operate efficiently and reliably. • Our simulations showed that such applications improve performance and reliability, and it is a must workflow to follow in a large-scale SDN network.
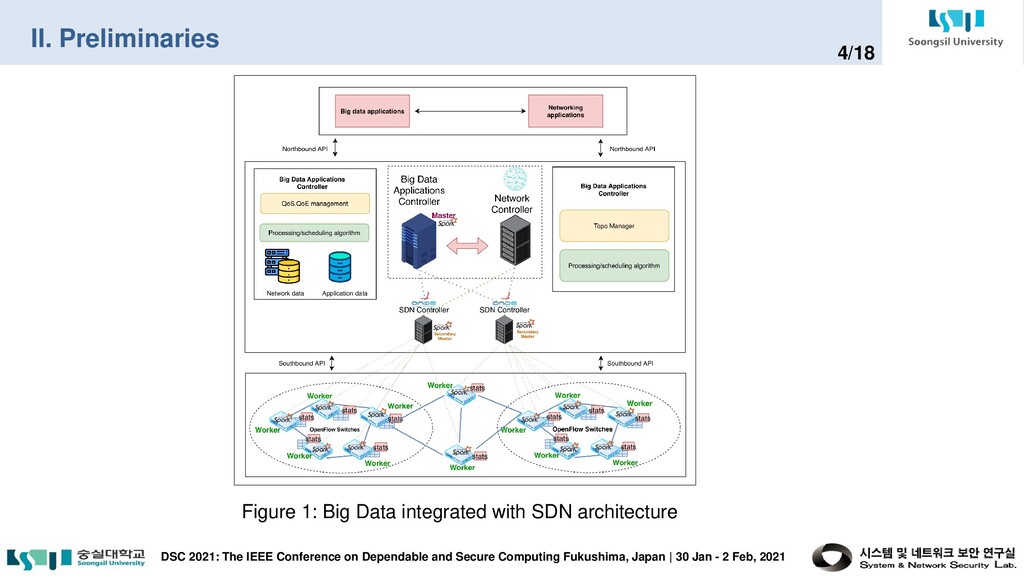
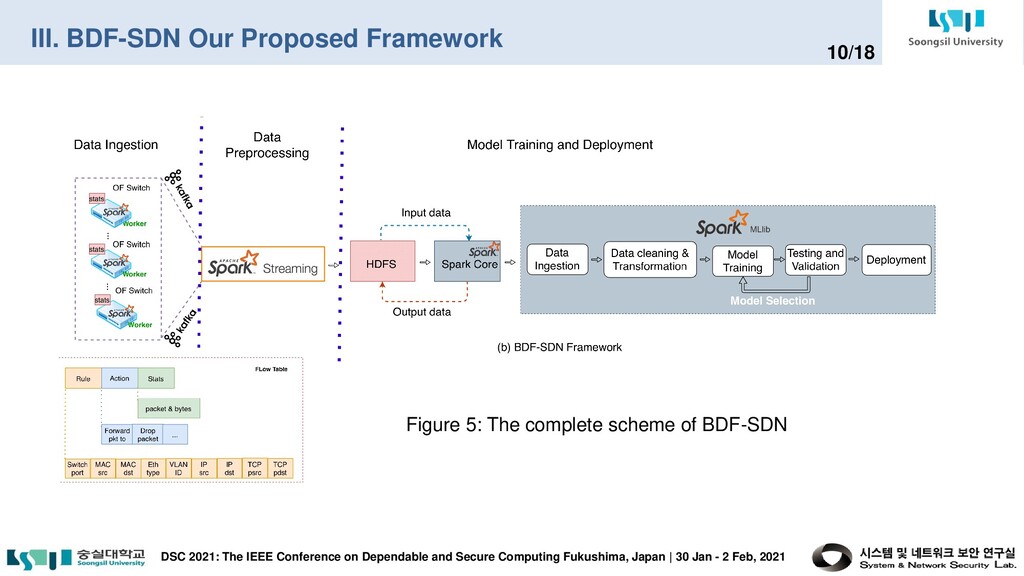
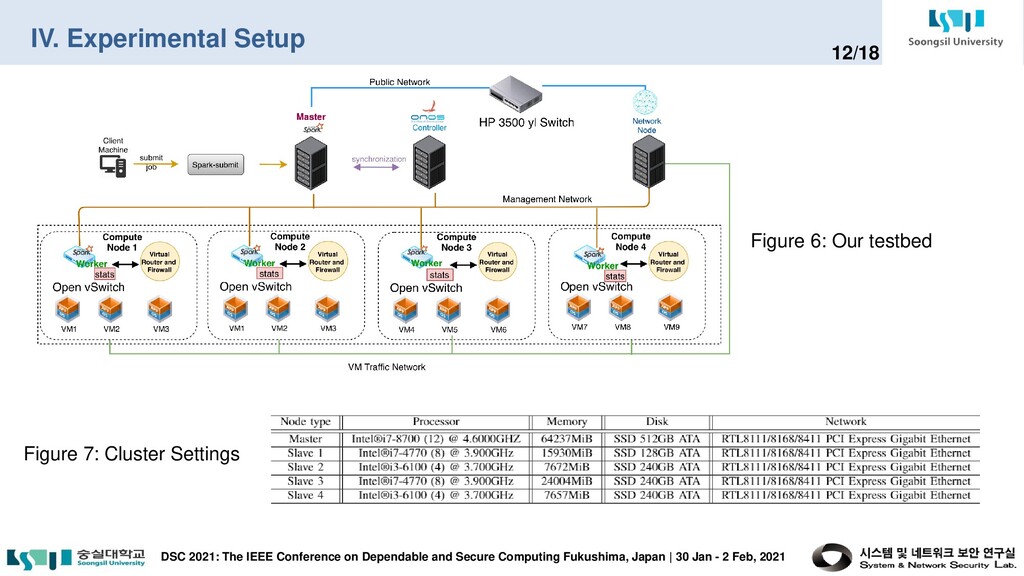
and Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 3/18 In summary, our major contributions are as follows: • First, we investigate limitations on machine learning workflows of existing DDoS detection schemes in a large-scale SDN network. • Second, we propose a complete framework called Big Data Framework for Large-Scale SDN (BDF-SDN) to overcome the limitations and to exploit distributed resources in an SDN context efficiently. • Our framework was conducted in a real computing environment including OpenStack integrated with the SDN environment using both ONOS controller and big data platforms such as Apache Kafka, Apache Hadoop, and Apache Spark. • Lastly, we present a comprehensive performance analysis of BDF-SDN.
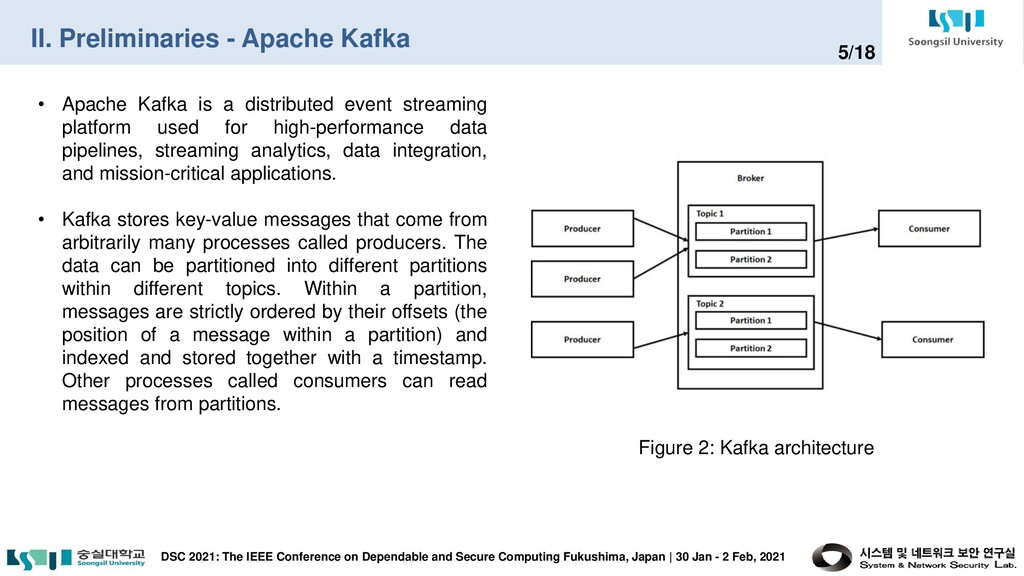
on Dependable and Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 5/18 • Apache Kafka is a distributed event streaming platform used for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. • Kafka stores key-value messages that come from arbitrarily many processes called producers. The data can be partitioned into different partitions within different topics. Within a partition, messages are strictly ordered by their offsets (the position of a message within a partition) and indexed and stored together with a timestamp. Other processes called consumers can read messages from partitions. Figure 2: Kafka architecture
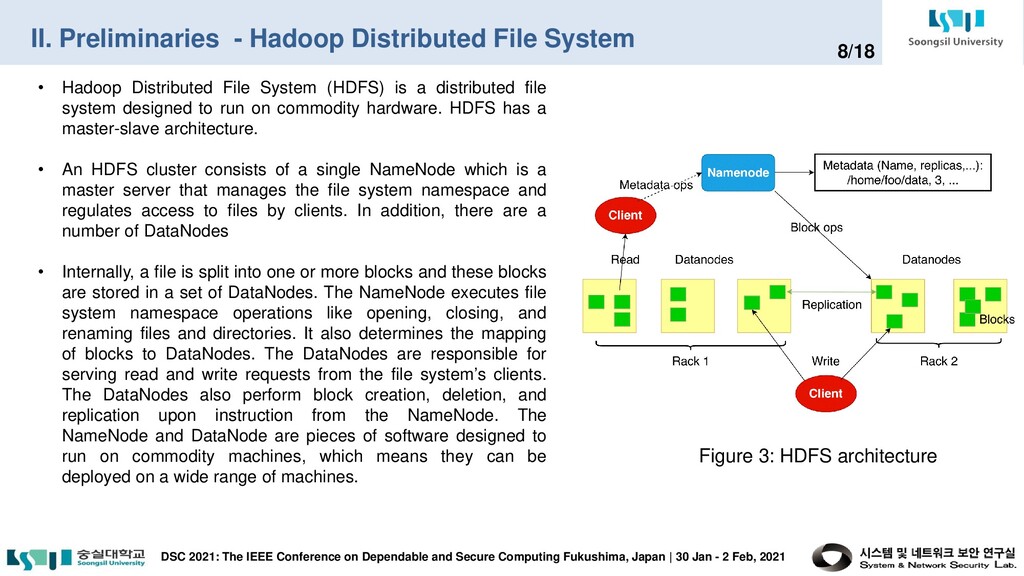
IEEE Conference on Dependable and Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 8/18 • Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. HDFS has a master-slave architecture. • An HDFS cluster consists of a single NameNode which is a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes • Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode. The NameNode and DataNode are pieces of software designed to run on commodity machines, which means they can be deployed on a wide range of machines. Figure 3: HDFS architecture
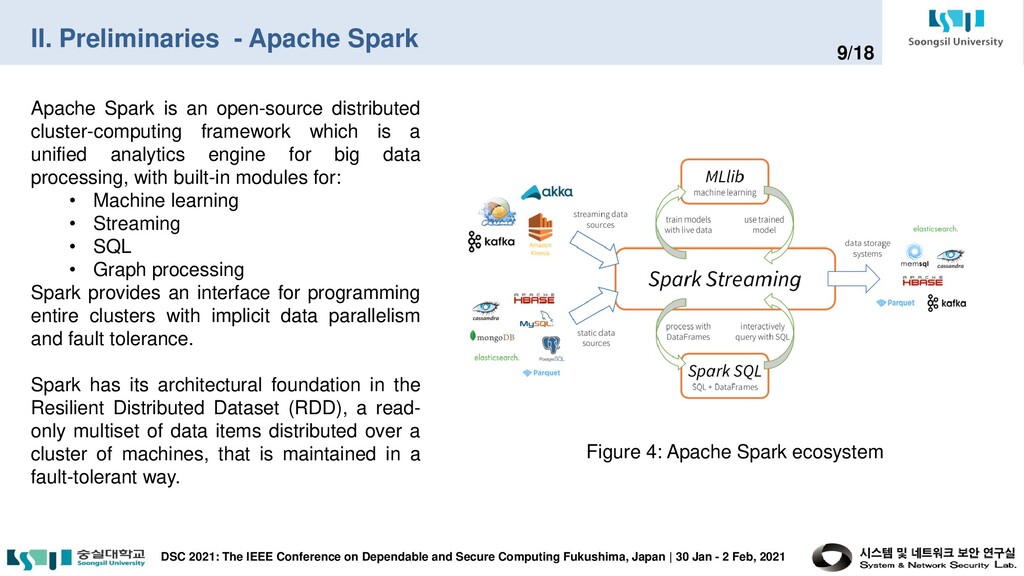
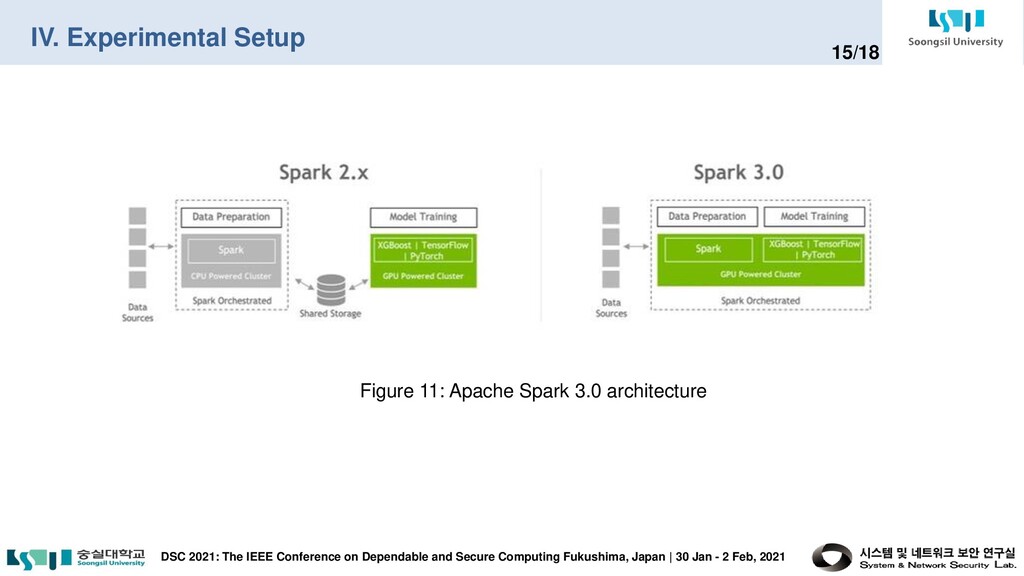
on Dependable and Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 9/18 Apache Spark is an open-source distributed cluster-computing framework which is a unified analytics engine for big data processing, with built-in modules for: • Machine learning • Streaming • SQL • Graph processing Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Spark has its architectural foundation in the Resilient Distributed Dataset (RDD), a read- only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way. Figure 4: Apache Spark ecosystem
on Dependable and Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 11/18 Algorithm 1 shows a typical DDoS attack traffic classification using Logistic Regression. Here, points is being re-evaluated upon every iteration, which is unnecessary and consumes high resource usage. To evade this issue, persist() function (as shown below) provided by Apache Spark can be used to avoid evaluating points on every iteration so that the dataset sitting in memory can be re-used each time. This can save time and resource computation.
Secure Computing Fukushima, Japan | 30 Jan - 2 Feb, 2021 18/18 • In this work, we proposed a high-performance framework used for machine-learning- based DDoS attack solutions. • Our framework covers all stages of detecting DDoS attacks from collecting streaming statistics coming from different OpenFlow switches to removing/deleting detected abnormal flows. • For the future work, we expect to improve the proposed framework and compare our framework with other works using more evaluation criteria.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}