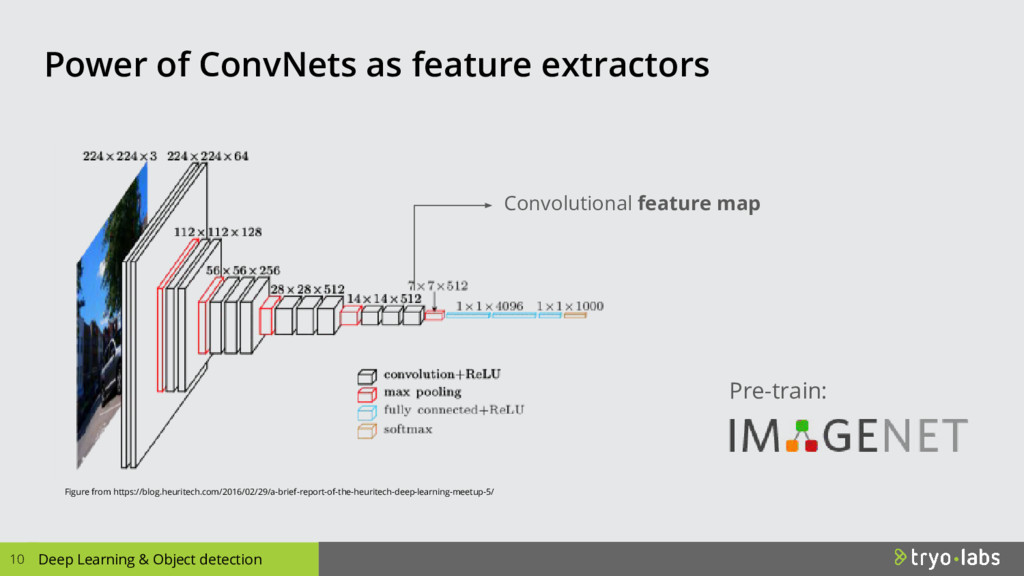
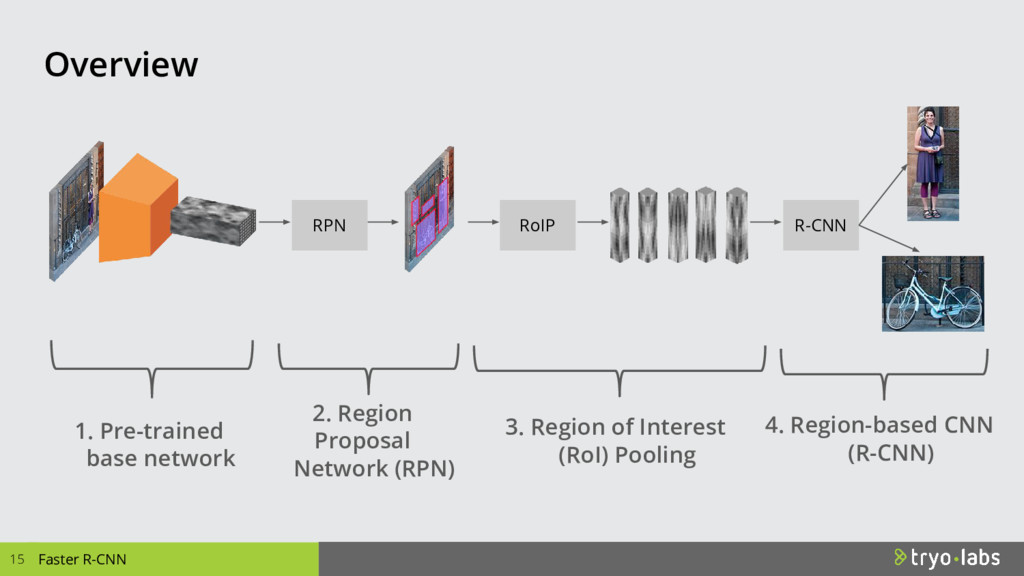
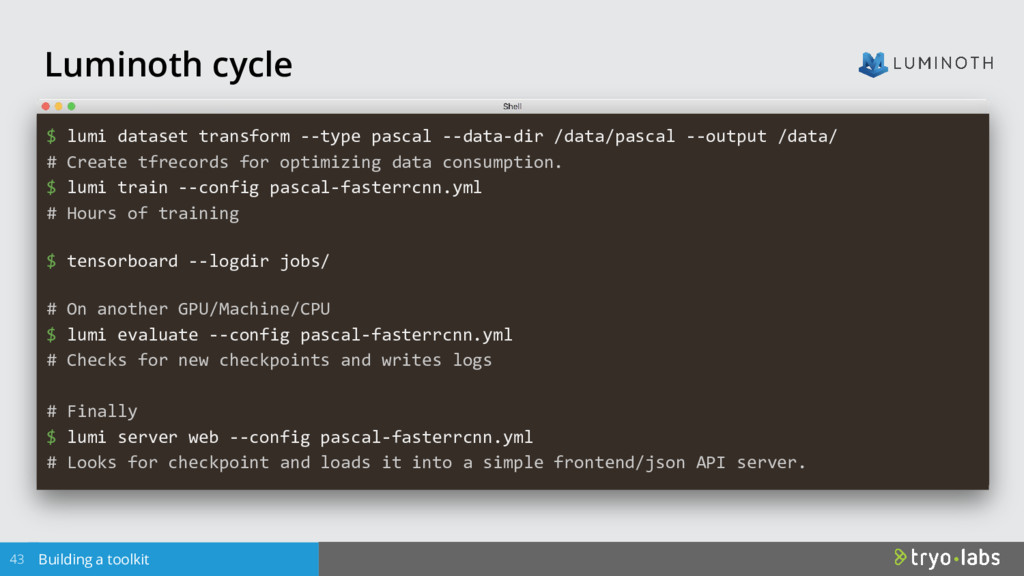
In recent years, models based on Convolutional Neural Networks (CNNs) have revolutionized the entire field of computer vision. Problems like image classification can now be considered solved, and it is easy to construct implementations with any modern Deep Learning framework using fine tuning with pre-trained weights on datasets such as ImageNet. However, the harder problems of object detection and segmentation require much more complex methods to solve. Object detection consists of picking up the objects and drawing a rectangular bounding box, while segmentation aims to identify the exact pixels that belong to each object. One of the main differences with image classification is that the same image may contain several objects and those could be in very different proportions, sizes, lighting and partially occluded. In this talk, we will discuss how state of the art object detection techniques work. In particular, we will take a look at Region Proposal Networks (RPNs), which propose candidate object locations (“proposals”) which are later refined to achieve precise localization. We will then look at the architecture of an object detection system, and the performance considerations of different algorithms. Moreover, we will explore an implementation of an open source Python object detection toolkit based on TensorFlow, going through the details and tricks of the trade when using such ecosystem on production ready applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
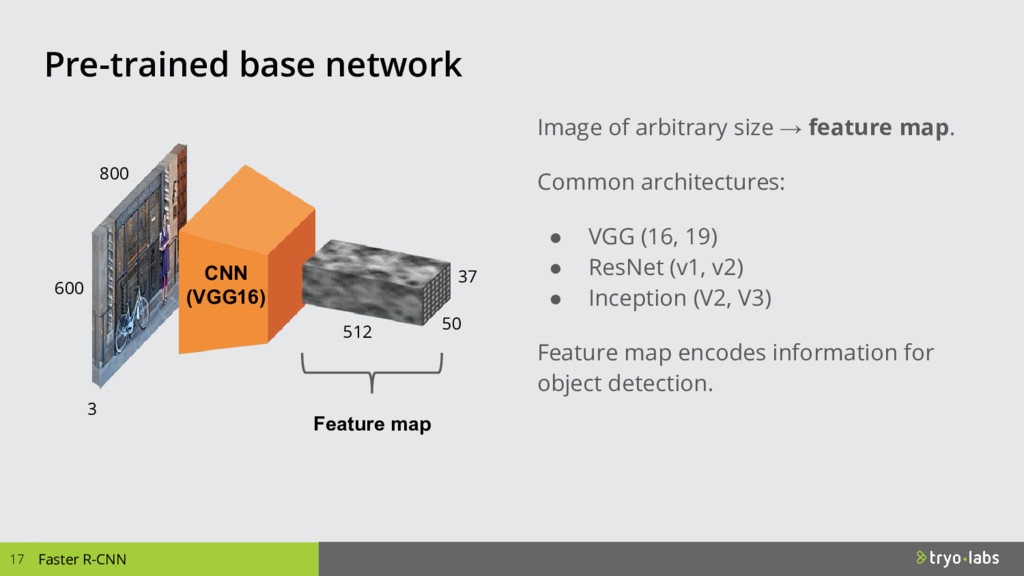{kind=link}
{kind=link}
{kind=link}
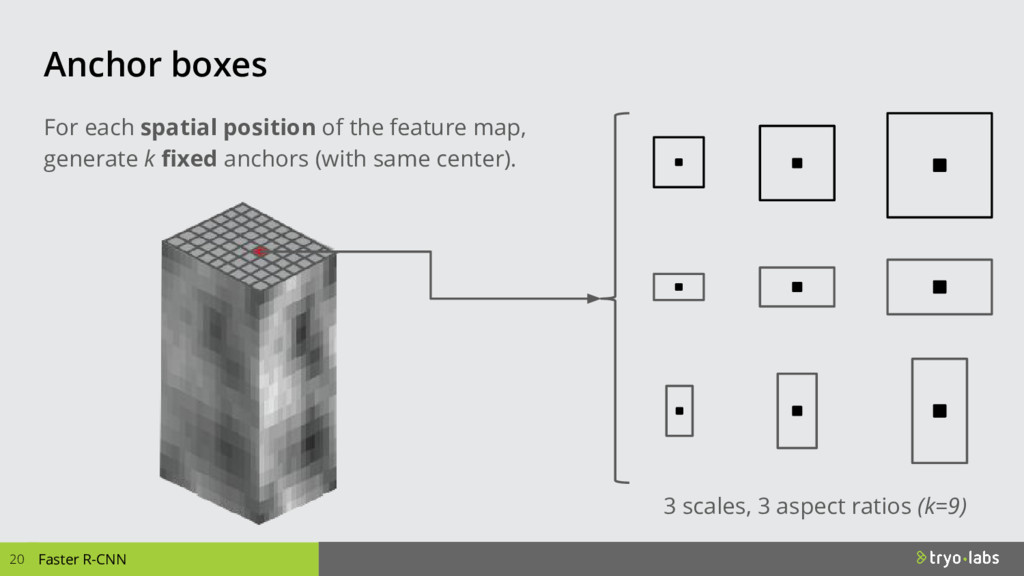{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
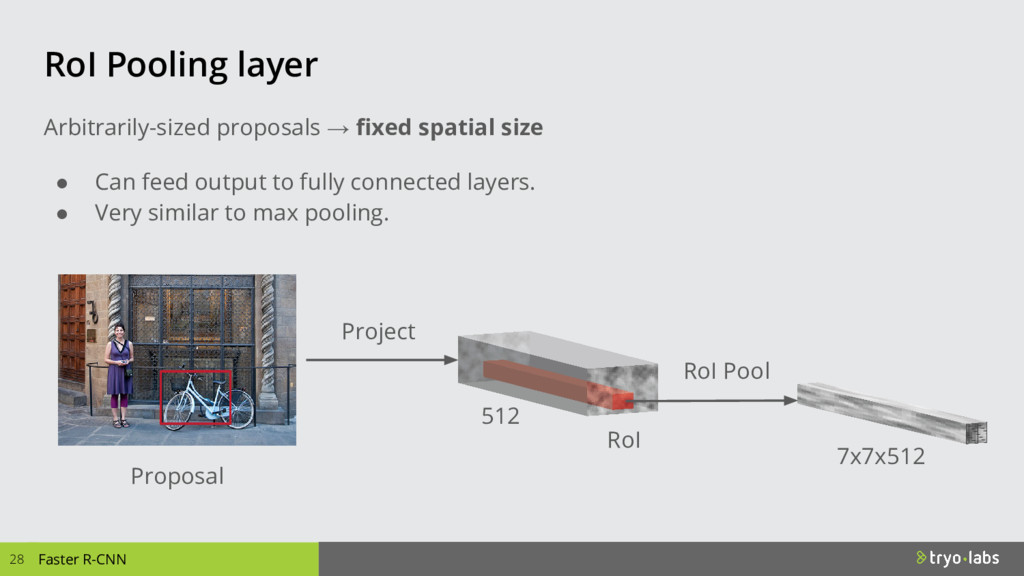{kind=link}
{kind=link}
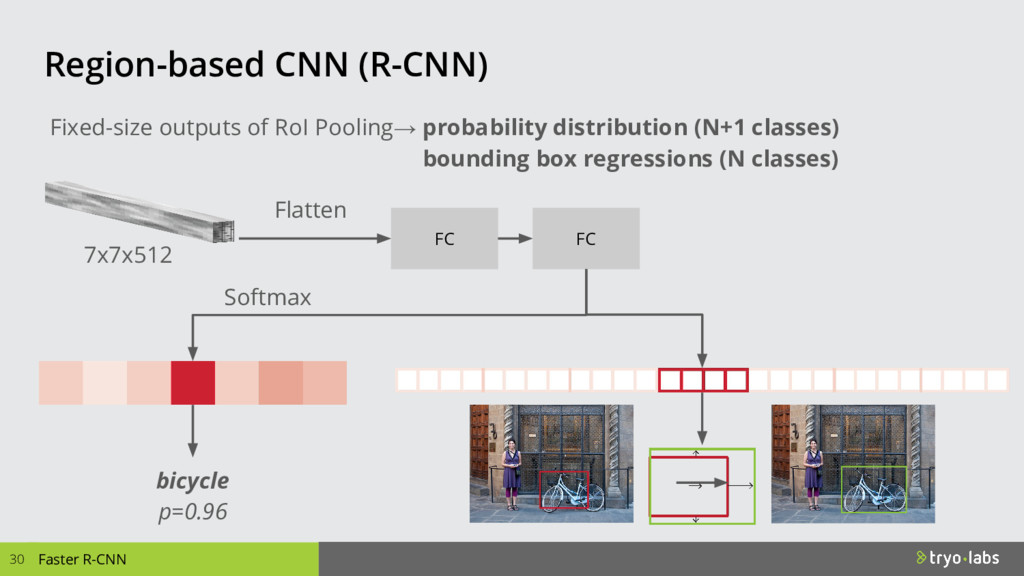{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}