Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
立ち上げ期のサービスでレコメンドを導入した際の機械学習モデルの開発とアーキテクチャの事例
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
tsuzuki
August 27, 2022
Technology
1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
立ち上げ期のサービスでレコメンドを導入した際の機械学習モデルの開発とアーキテクチャの事例
tsuzuki
August 27, 2022
More Decks by tsuzuki
See All by tsuzuki
LLMとEC
tsuzukid
0
360
Github Codespace で始めるリモート開発
tsuzukid
1
690
AWS Fargate を使ってコストを抑えつつ 機械学習のバッチ処理を構築した話
tsuzukid
2
1k
Other Decks in Technology
See All in Technology
SteampipeとExcel Power QueryでAWS構成定義書の作成を自動化する
jhashimoto
0
170
【NRUG vol.18】KubernetesにおけるNew Relicデータ取得量削減の考え方
nrug_member
0
170
現場のトークンマネジメント
dak2
1
160
2026年6月23日 Syncable Tech + Start Python Club にて
hamukazu
0
140
[AWS Summit Japan 2026]迷っているあなたへ_小さな一歩が、やがて自分を助けてくれる
sh_fk2
1
340
人材育成分科会.pdf
_awache
4
310
iAEONの段階的リアーキテクト戦略 / iAEON's_Gradual_Re-architecture_Strategy
aeonpeople
0
240
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
0
190
AI 不只幫你寫 Code: 當專案從 300 暴增到 1500, 我們如何撐住 DevOps
appleboy
0
110
LayerX コーポレートエンジニアリング室におけるサプライチェーンセキュリティへの取り組み / Supply Chain Security at LayerX Corporate Engineering
yuyatakeyama
3
760
Bucharest Tech Week 2026 - Reinventing testing practices in the AI era
edeandrea
PRO
1
170
MUSUBI 田中裕一『AIと共に行う「しごとのリデザイン」- スモールバックオフィス編』AI Ops Lab #4
musubi
0
280
Featured
See All Featured
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
490
Statistics for Hackers
jakevdp
799
230k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
1
210
It's Worth the Effort
3n
188
29k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
540
Deep Space Network (abreviated)
tonyrice
0
210
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
330
30 Presentation Tips
portentint
PRO
1
330
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
320
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
A Tale of Four Properties
chriscoyier
163
24k
Transcript
立ち上げ期のサービスでレコメンドを導入した際の機械 学習モデルの開発とアーキテクチャの事例 株式会社DROBE CTO 都筑友昭
自己紹介 都筑友昭 株式会社DROBE CTO 新卒で半導体の会社に就職 ソーシャルゲームの開発やコンサルティング会社を 経て2019年より株式会社 DROBE の CTO
機械学習よりはサービス / システム開発を得意とし ています 出身地 : 千葉県 他 : 2児の父
検索からパーソナライズへ SEARCH PERSONALIZATION
サービス立ち上げ期の課題 1. 開発メンバーが足りない 2. 専門家が居ない 3. データが無い 4. パーソナライズ機能の設計と運用の経験が無い
DROBE というサービスの立ち上げを事例として あらゆるリソースが足りない中でどうやって パーソナライズ機能を開発したかについてお話しします 本日お伝えすること
1 DROBEとは
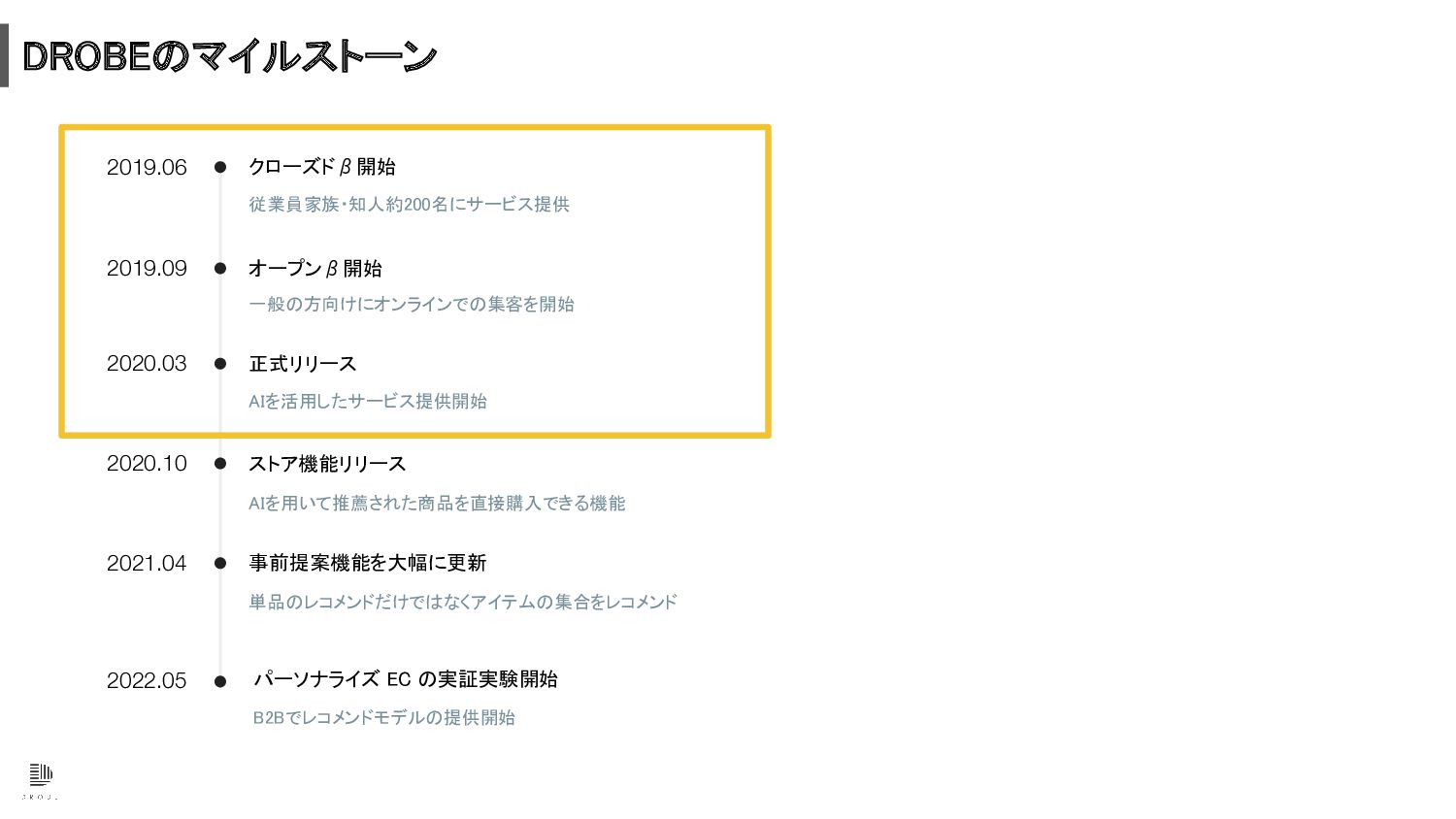
DROBEのマイルストーン 従業員家族・知人約200名にサービス提供 クローズドβ開始 一般の方向けにオンラインでの集客を開始 オープンβ開始 AIを活用したサービス提供開始 正式リリース AIを用いて推薦された商品を直接購入できる機能 ストア機能リリース 事前提案機能を大幅に更新
単品のレコメンドだけではなくアイテムの集合をレコメンド 2019.06 2019.09 2020.03 2020.10 2021.04 2022.05 パーソナライズ EC の実証実験開始 B2Bでレコメンドモデルの提供開始
スタイリストがつくネットショッピング 8 70問のアンケートに答える 1 2 3 自宅にスタイリストが選んだ商品 が届く 気に入ったもののみ購入、 それ以外を返品
スタイリストが使う商品検索画面
ユーザーに直接商品を提案する機能
カテゴリや色などのバランスを加味しつつ提案を作る
DROBEのマイルストーン 従業員家族・知人約200名にサービス提供 クローズドβ開始 一般の方向けにオンラインでの集客を開始 オープンβ開始 AIを活用したサービス提供開始 正式リリース AIを用いて推薦された商品を直接購入できる機能 ストア機能リリース 事前提案機能を大幅に更新
単品のレコメンドだけではなくアイテムの集合をレコメンド 2019.06 2019.09 2020.03 2020.10 2021.04 2022.05 パーソナライズ EC の実証実験開始 B2Bでレコメンドモデルの提供開始
2 パーソナライズ機能
パーソナライズ機能 • 一人一人のユーザーに合わせて商品やコンテンツを最適化する機能 • 性年代といったユーザーの属性情報やサイト内での行動を元に、最適化する •
機械学習等によるレコメンドや事前に設定したルール、またそれらの組み合わせで実現される
パーソナライズ機能を実現するには? 1. データを貯めて 2. レコメンドモデルを開発し 3. 機能設計をする
データを貯める 1
課題1 どんなデータを貯めれば良いかわからない 機械学習に使えそうだという仮説が立てられそうなデータにフォーカスする
課題2 データの規模・更新頻度などが予測できない マネージドサービスを使う
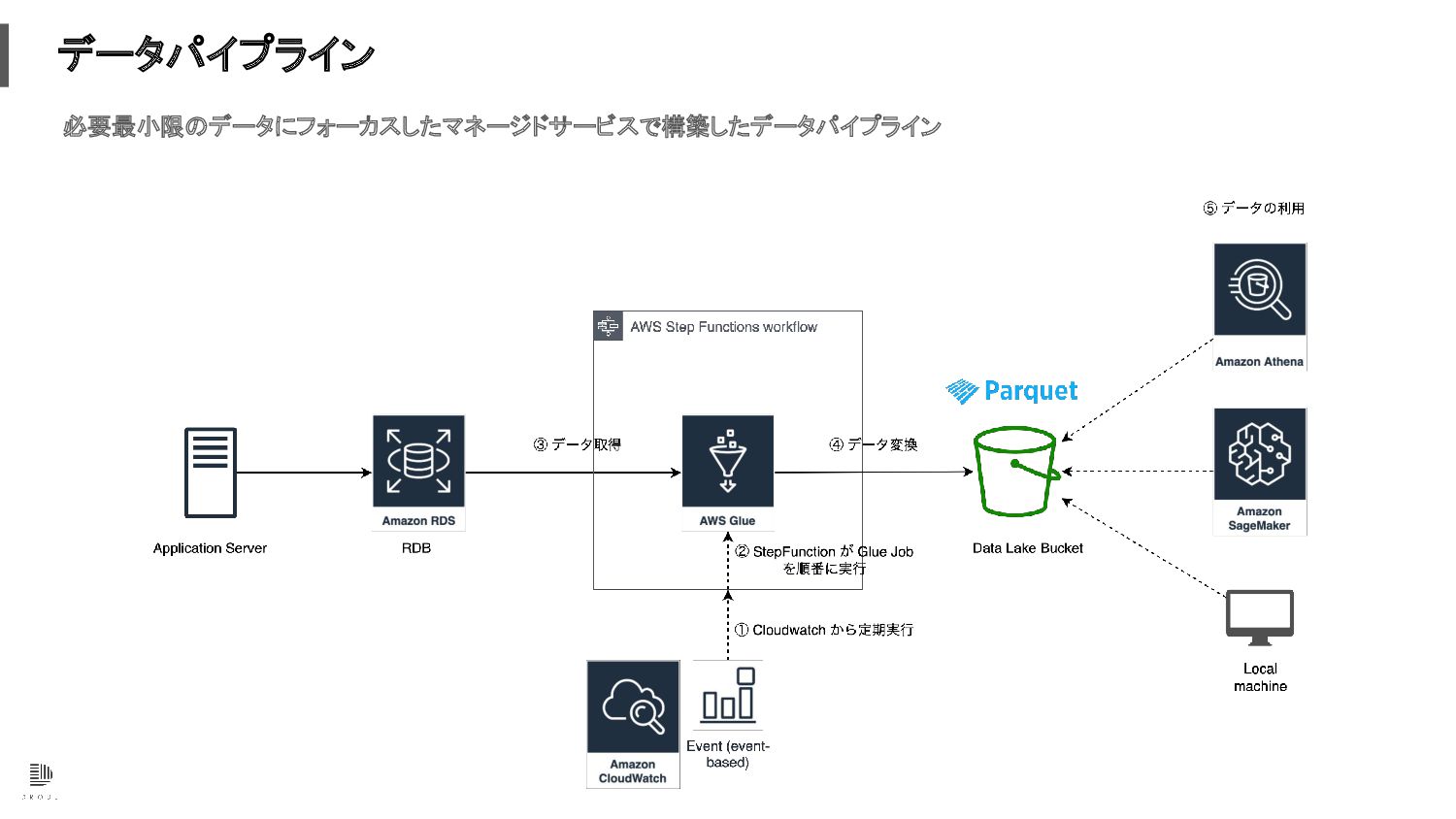
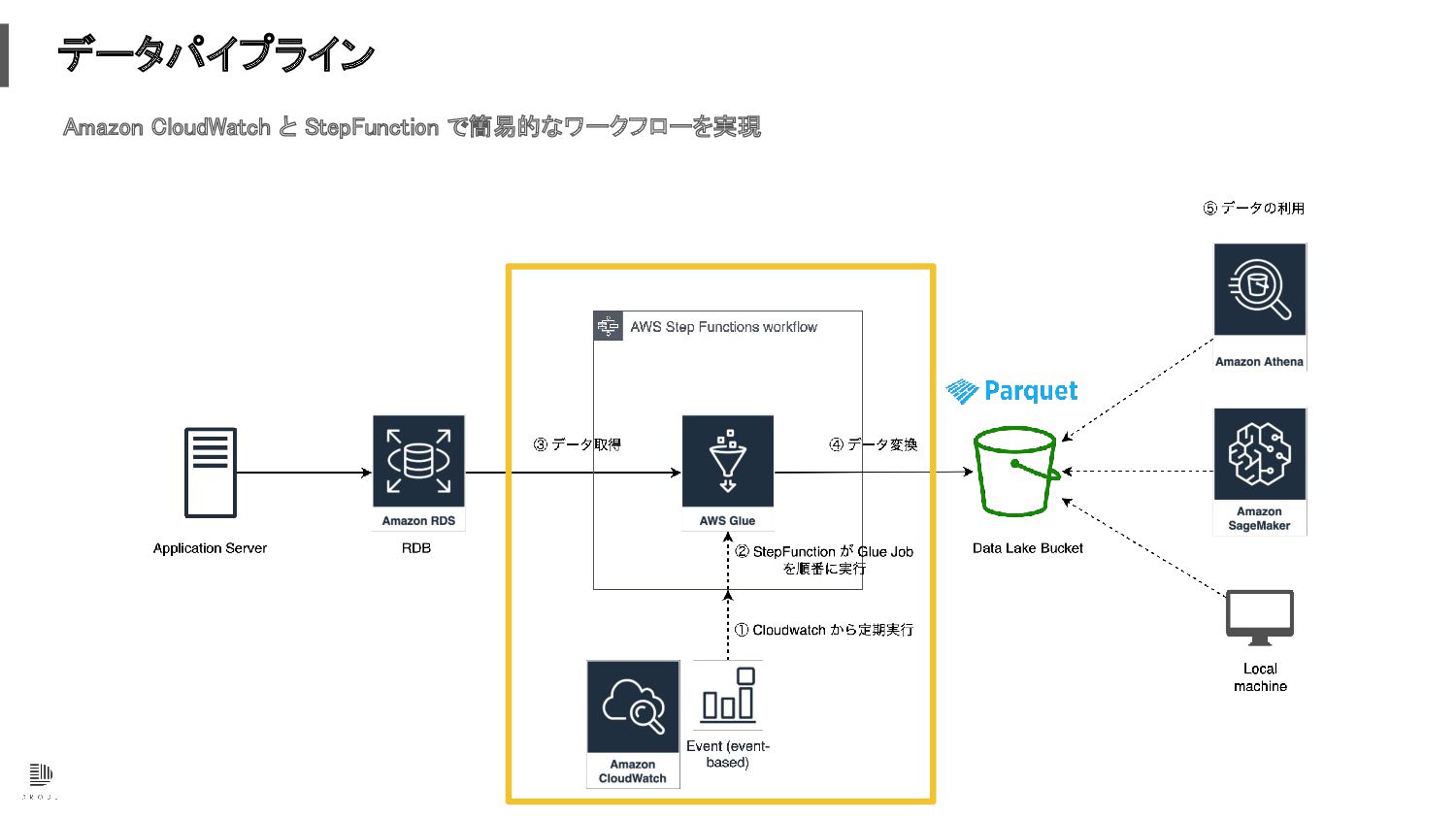
データパイプライン 必要最小限のデータにフォーカスしたマネージドサービスで構築したデータパイプライン
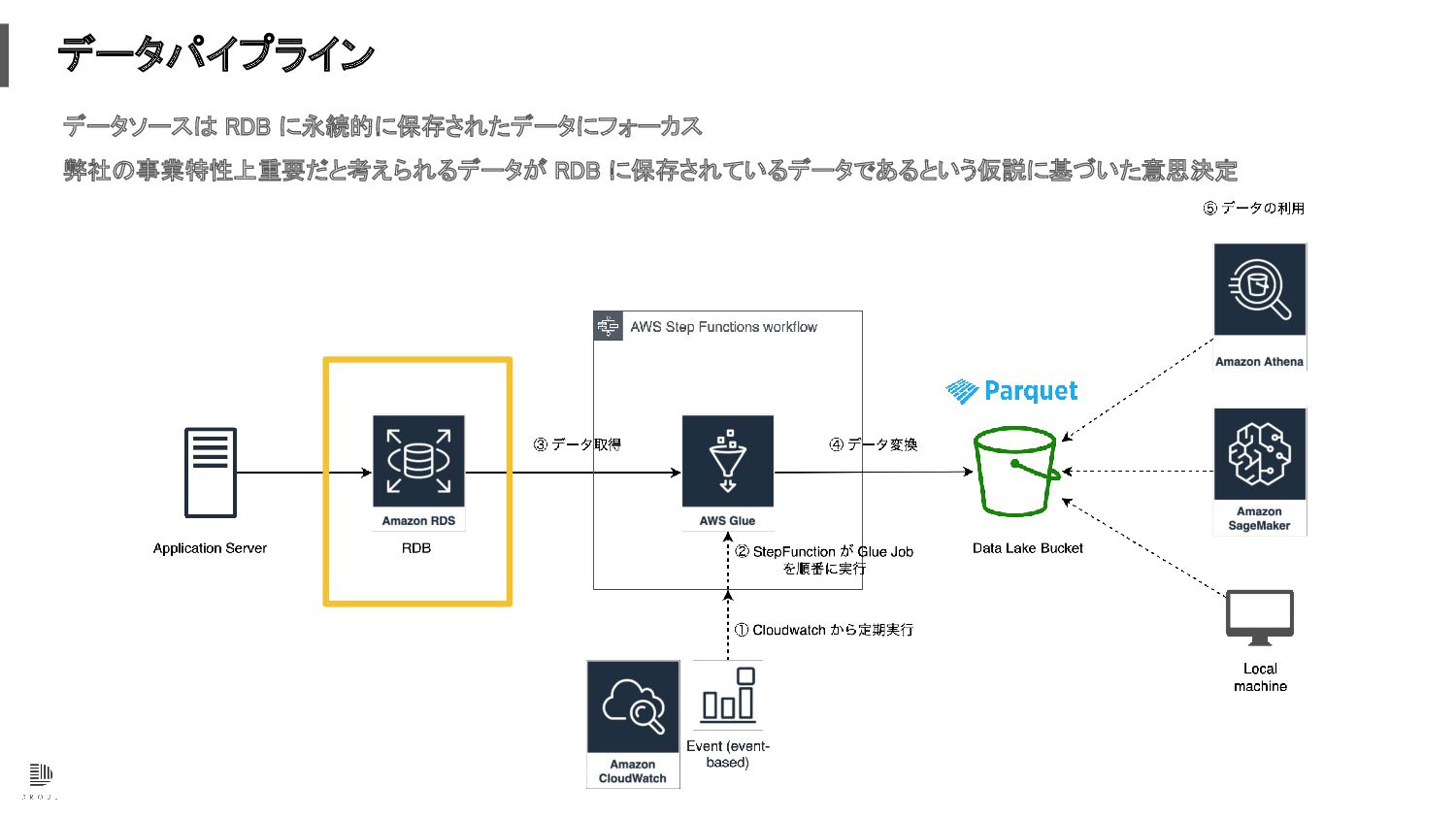
データパイプライン データソースは RDB に永続的に保存されたデータにフォーカス 弊社の事業特性上重要だと考えられるデータが RDB に保存されているデータであるという仮説に基づいた意思決定
データパイプライン Amazon CloudWatch と StepFunction で簡易的なワークフローを実現
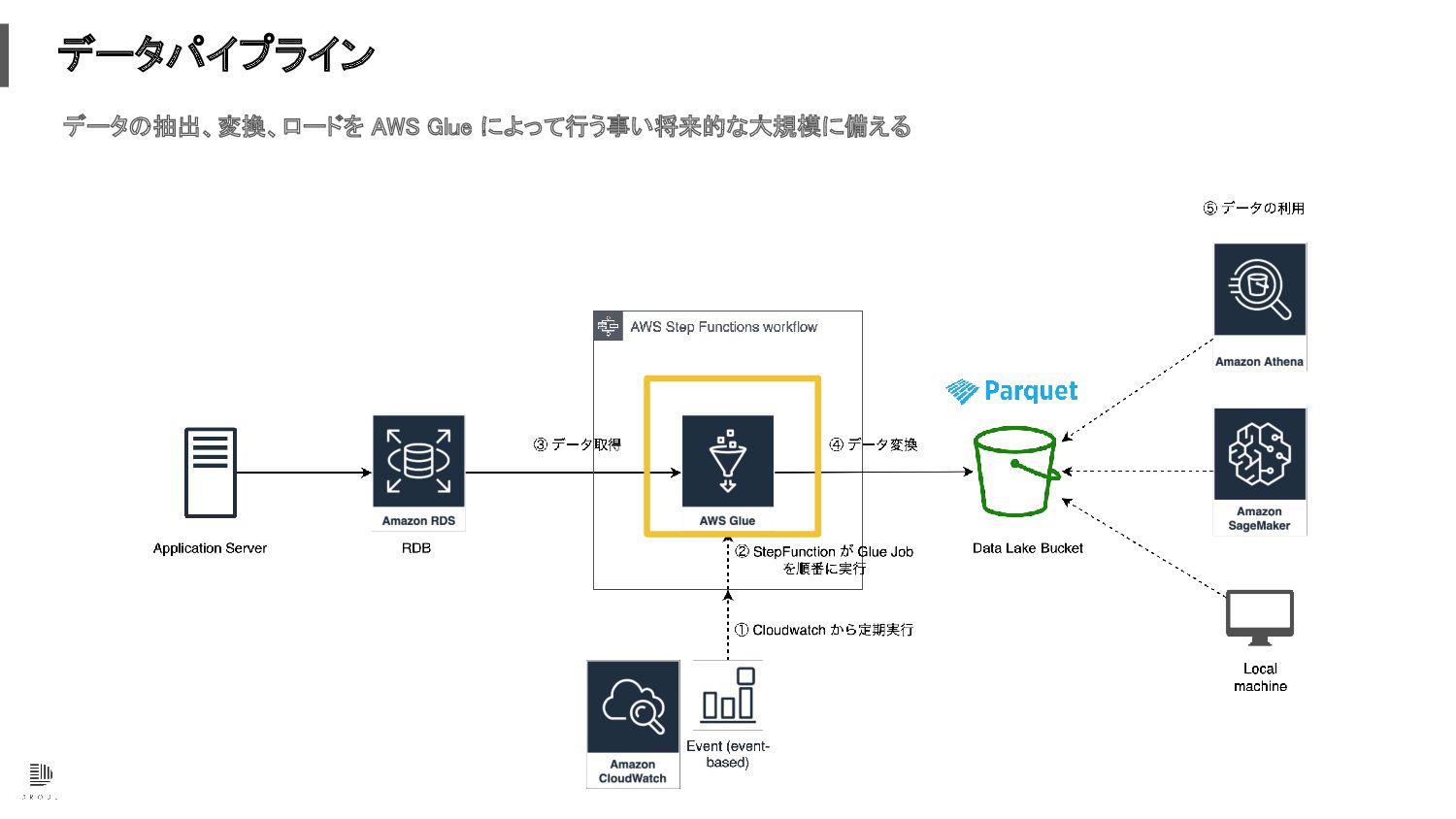
データパイプライン データの抽出、変換、ロードを AWS Glue によって行う事い将来的な大規模に備える
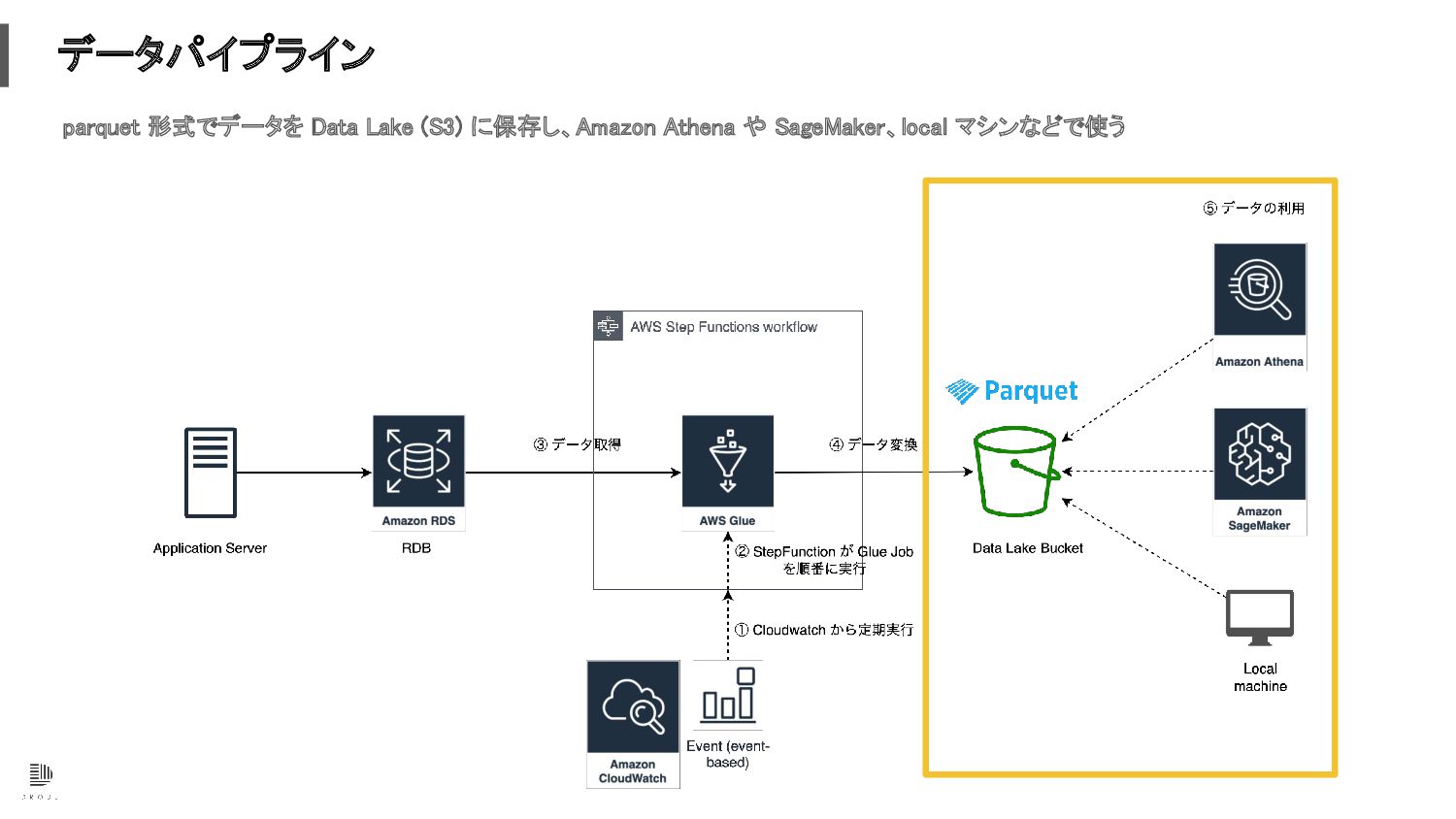
データパイプライン parquet 形式でデータを Data Lake (S3) に保存し、Amazon Athena や SageMaker、local
マシンなどで使う
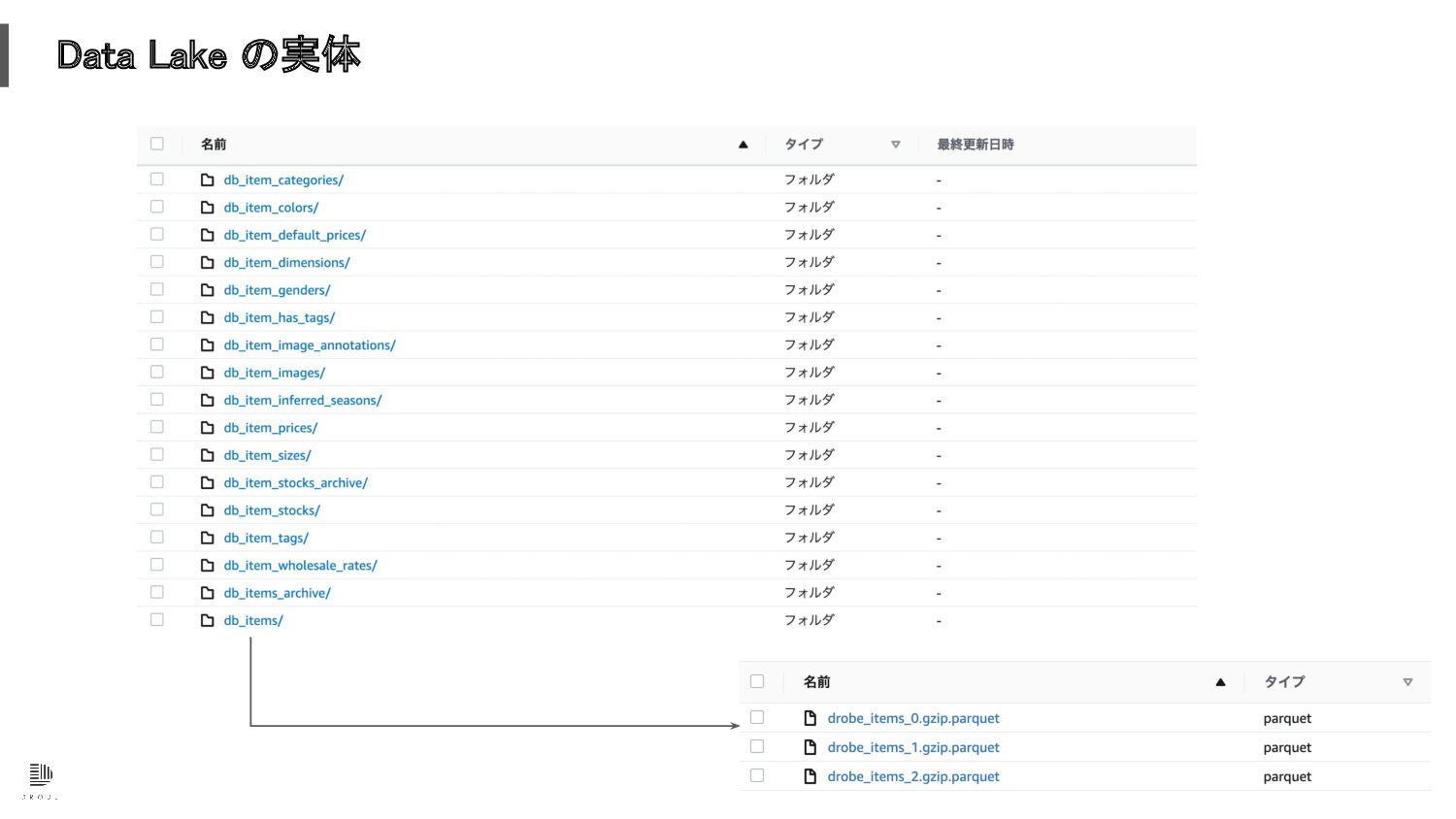
Data Lake の実体
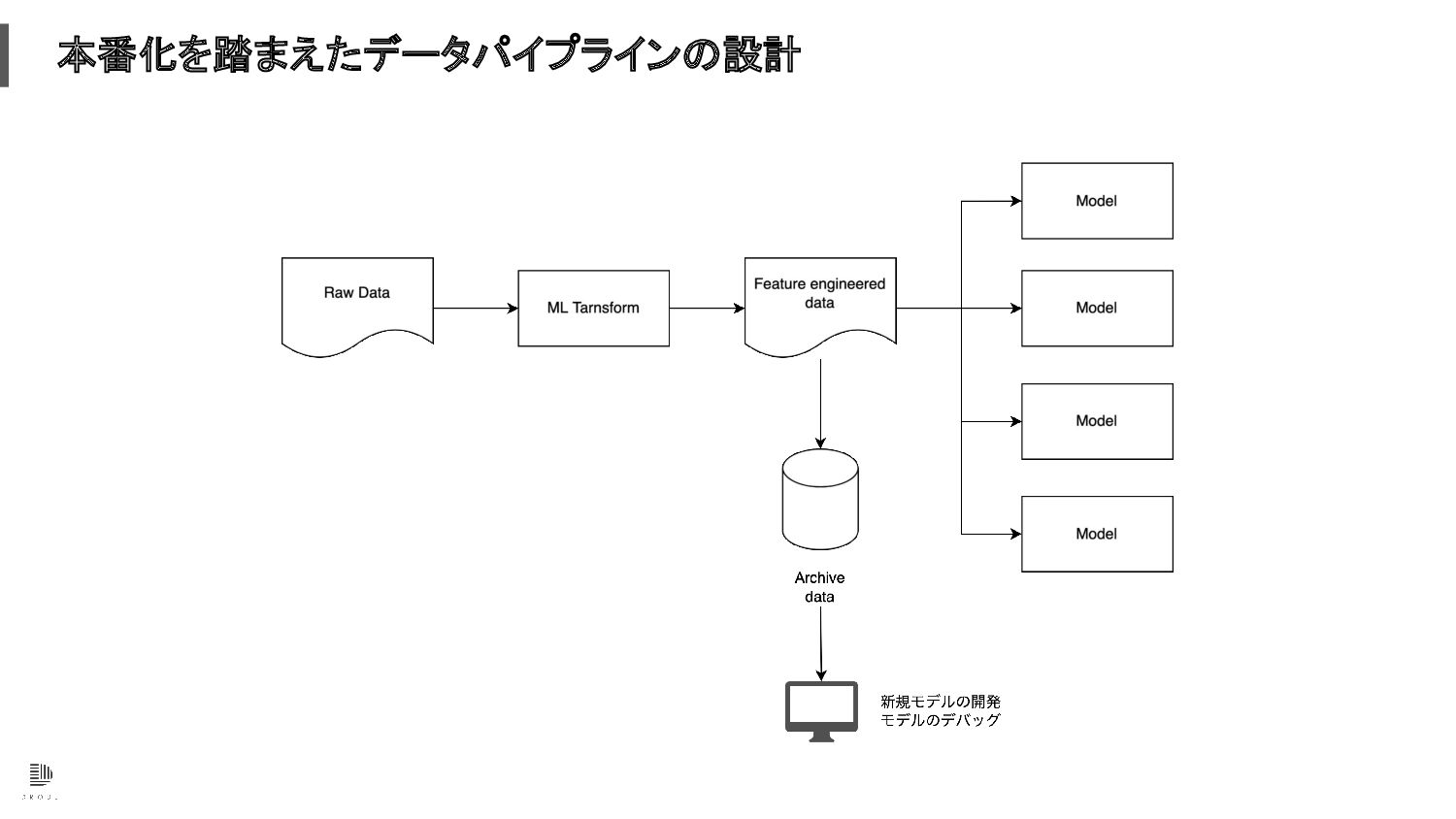
貯めたデータの活用 • 毎日の Data warehouse のスナップショットを zip に固めてアーカイブしておくと便利 ◦ ビジネス職のメンバーや社外のエンジニアと簡単にシェア出来る
◦ 再現性のある検証や開発が出来る
• データパイプラインは特別な理由が無い限りマネージドサービスを使う • データは共有しやすい形式で保存しておく データを貯める まとめ
レコメンドモデルを開発する 2
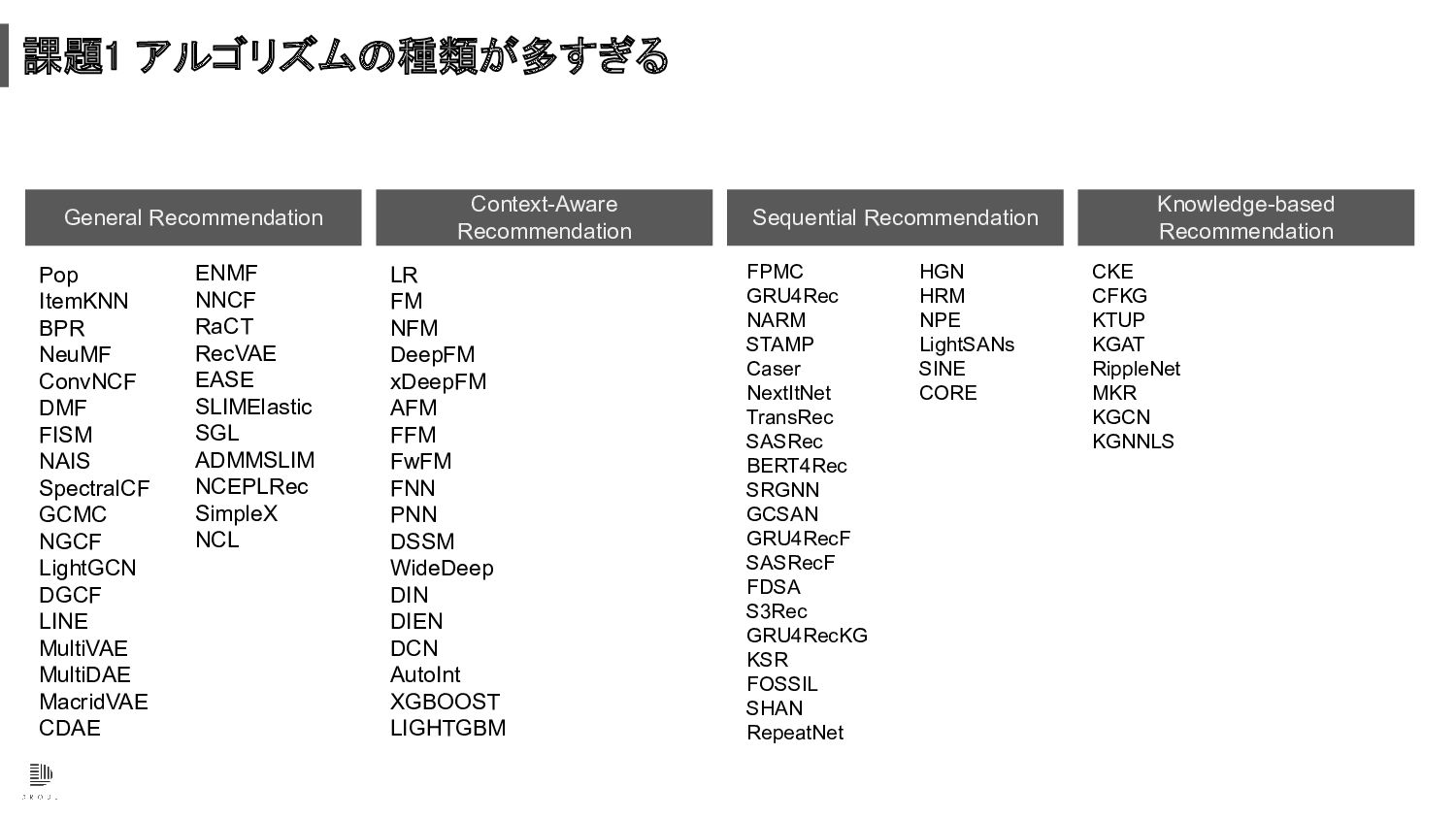
課題1 アルゴリズムの種類が多すぎる Context-Aware Recommendation Pop ItemKNN BPR NeuMF ConvNCF DMF
FISM NAIS SpectralCF GCMC NGCF LightGCN DGCF LINE MultiVAE MultiDAE MacridVAE CDAE LR FM NFM DeepFM xDeepFM AFM FFM FwFM FNN PNN DSSM WideDeep DIN DIEN DCN AutoInt XGBOOST LIGHTGBM FPMC GRU4Rec NARM STAMP Caser NextItNet TransRec SASRec BERT4Rec SRGNN GCSAN GRU4RecF SASRecF FDSA S3Rec GRU4RecKG KSR FOSSIL SHAN RepeatNet CKE CFKG KTUP KGAT RippleNet MKR KGCN KGNNLS General Recommendation ENMF NNCF RaCT RecVAE EASE SLIMElastic SGL ADMMSLIM NCEPLRec SimpleX NCL Sequential Recommendation Knowledge-based Recommendation HGN HRM NPE LightSANs SINE CORE
課題1 アルゴリズムの種類が多すぎる 自社サービスの仕様や要件をまとめ、相性が良さそうなアルゴリズムの仮説をたてる
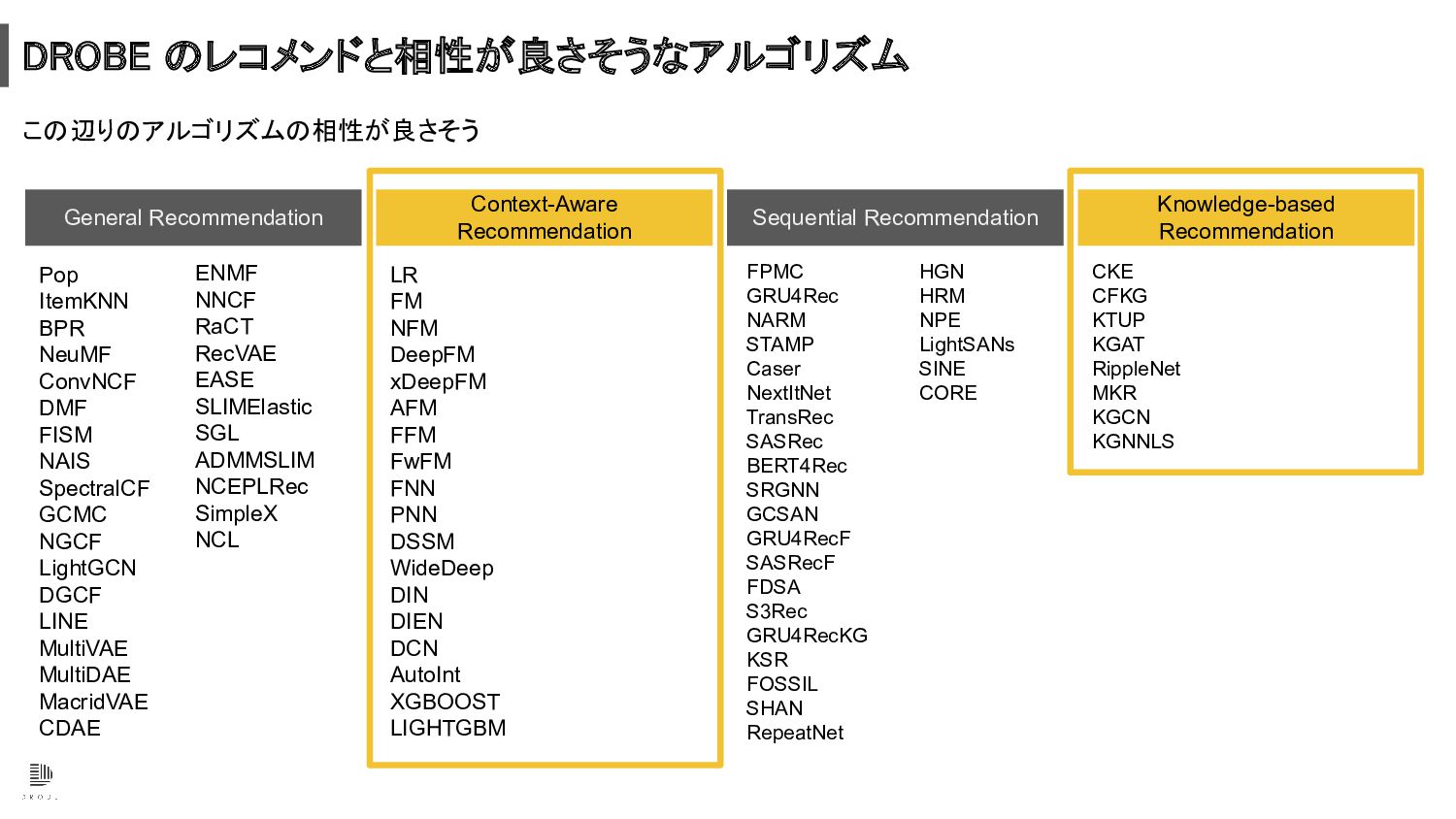
DROBE のレコメンドに関わる仕様や制約条件 • サインアップ時に豊富なユーザーデータを取得出来る • ユーザーが能動的に商品を探索などしないので行動ログがほぼ使えない (当時) • ユーザーからは返品も含め明示的なフィードバックが得られる •
商品の種類が豊富 • 商品の入れ替わりが激しい • 利用の間隔が長いユーザーが多い サービスの特徴 相性が良さそうなア ルゴリズム • ID だけではなくユーザーやアイテムの特徴を使える • 明示的フィードバックを利用可能
Context-Aware Recommendation Pop ItemKNN BPR NeuMF ConvNCF DMF FISM NAIS
SpectralCF GCMC NGCF LightGCN DGCF LINE MultiVAE MultiDAE MacridVAE CDAE LR FM NFM DeepFM xDeepFM AFM FFM FwFM FNN PNN DSSM WideDeep DIN DIEN DCN AutoInt XGBOOST LIGHTGBM FPMC GRU4Rec NARM STAMP Caser NextItNet TransRec SASRec BERT4Rec SRGNN GCSAN GRU4RecF SASRecF FDSA S3Rec GRU4RecKG KSR FOSSIL SHAN RepeatNet CKE CFKG KTUP KGAT RippleNet MKR KGCN KGNNLS General Recommendation ENMF NNCF RaCT RecVAE EASE SLIMElastic SGL ADMMSLIM NCEPLRec SimpleX NCL Sequential Recommendation Knowledge-based Recommendation HGN HRM NPE LightSANs SINE CORE DROBE のレコメンドと相性が良さそうなアルゴリズム この辺りのアルゴリズムの相性が良さそう
課題2 チームに専門家が居ない 機械学習に詳しくなくてもマネージドサービスや OSS などを利用した開発は可能
開発の方針 マネージド 独自実装 OSS 実装難易度 本番化難易度 カスタマイズ性 具体的選択肢 中 低
中 低 中 低 DLRM 高 高 高
開発の方針 Managed 独自実装 OSS 実装難易度 本番化難易度 カスタマイズ性 具体的選択肢 中 低
中 低 中 低 DLRM 高 高 高 DROBEの場合は • ある程度知識のある ML エンジニアが居た • レコメンドをサービスの中で重要な機能と位置付けた • 想定している結果を出すまで PDCA を回す前提 という事を背景に、OSS を中心に検証を開始
検証中に出てきた問題 • 学習は回るがパーソナライズされない • 一般的に使われるメトリクス (Accuracy や Precision) だけだとサービスにとって良いレコメン ドかどうかの判断がつかない
同じランキングが別のユーザーに提案されてしまう (パーソナライズされない )
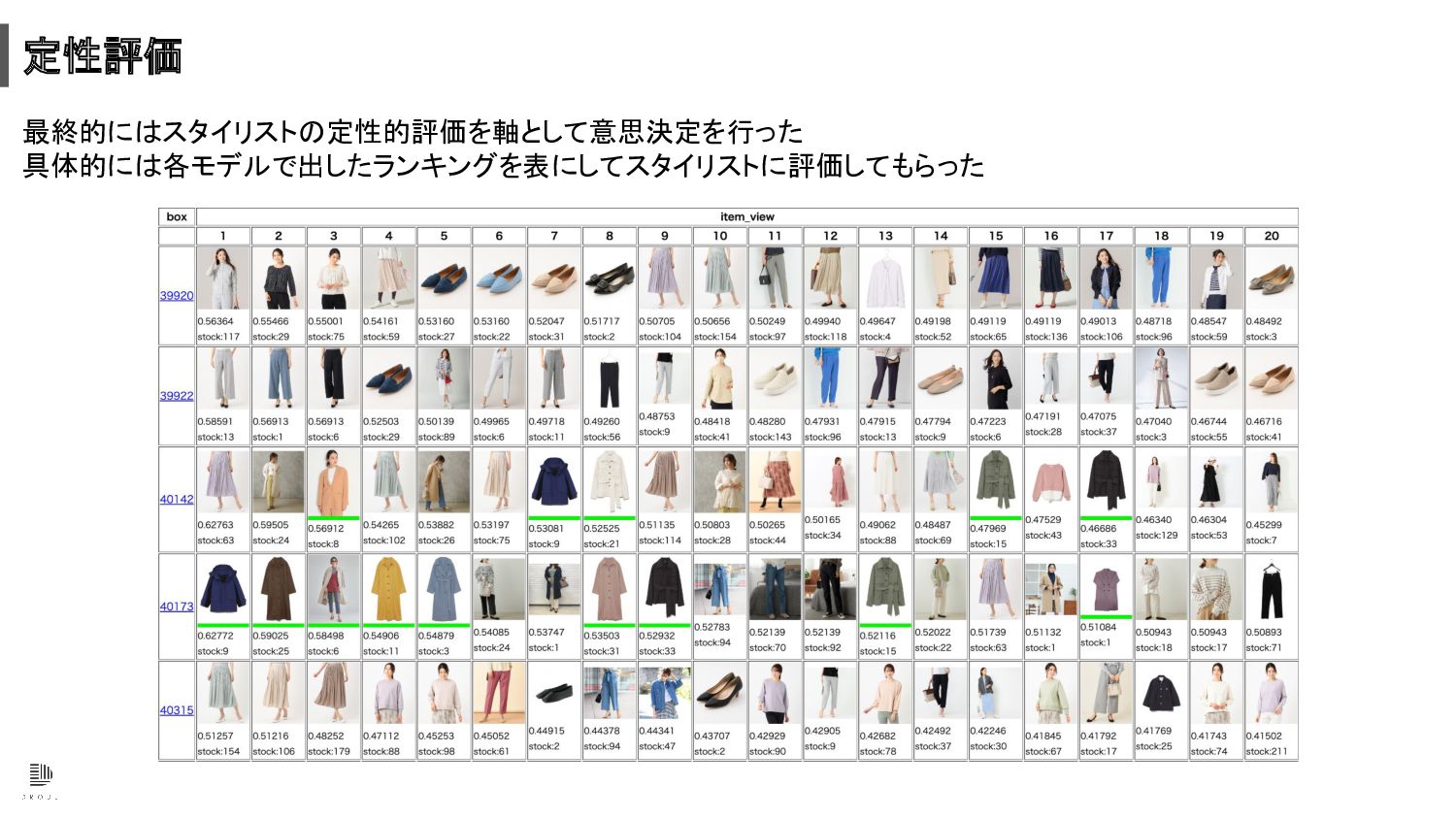
定性評価 最終的にはスタイリストの定性的評価を軸として意思決定を行った 具体的には各モデルで出したランキングを表にしてスタイリストに評価してもらった
https://arxiv.org/pdf/1507.08439.pdf LightFM Metadata Embeddings for User and Item Cold-start Recommendations
という論文の python 実装 主な特徴 • user, item 両方の cold start 問題に対応出来る • Cython を使って書かれているため CPU でもある程 度高速に動作する
レコメンドモデルの開発 まとめ • 自社サービスの特徴を踏まえどういったアルゴリズムが良さそうかの当りをつける • チームの状況に合わせ実装方法を選択する
• 導入初期には定量的な数値だけではなく、定性的な意見も含めて意思決定を行う
機能として設計する 3
課題 レコメンドやルールをどのように協調動作させるか 各種機能を Filter と Ranker (Sorter) と捉えて整理し、設計する
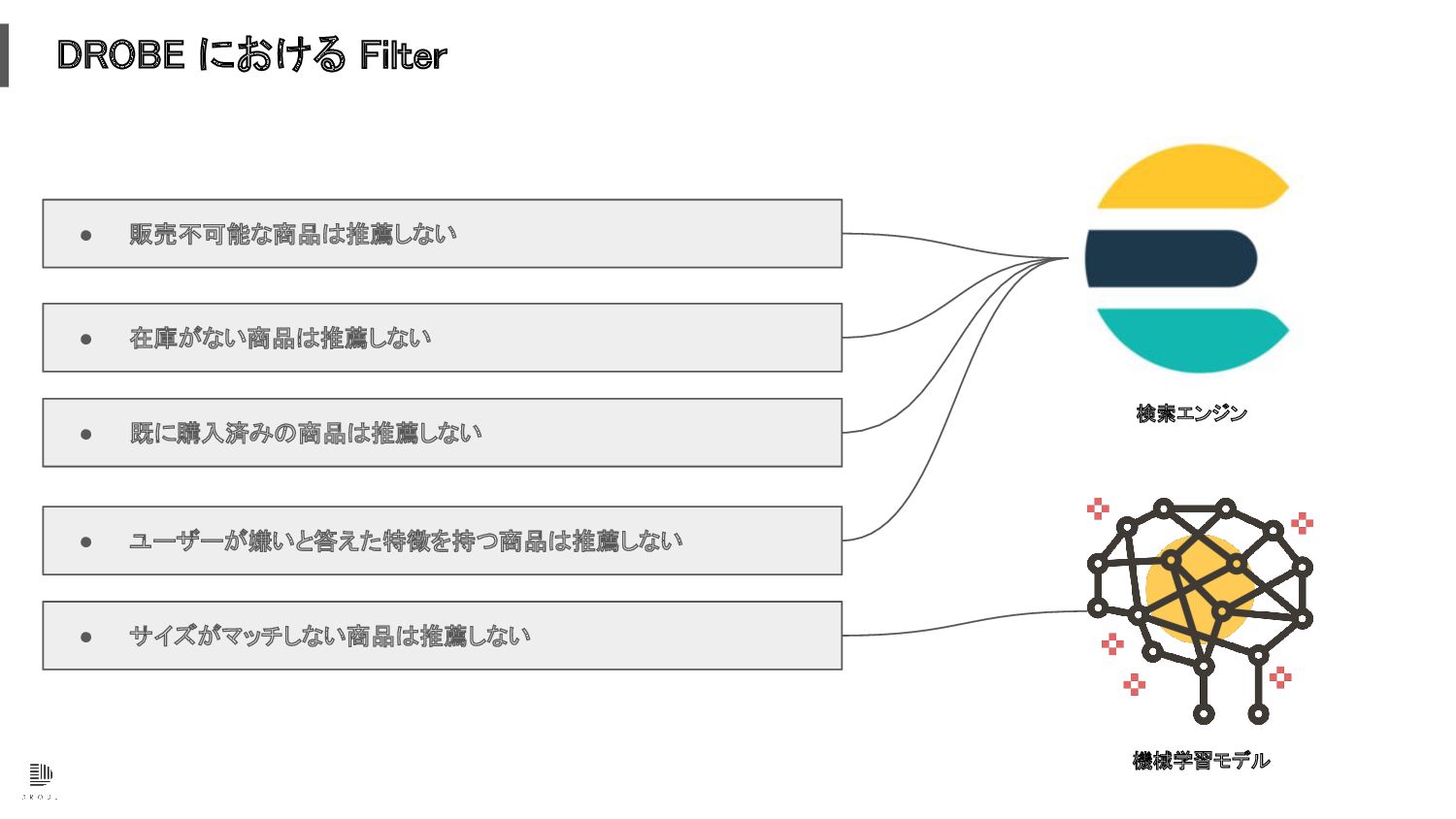
DROBE における Filter • サイズがマッチしない商品は推薦しない • ユーザーが嫌いと答えた特徴を持つ商品は推薦しない • 既に購入済みの商品は推薦しない •
在庫がない商品は推薦しない • 販売不可能な商品は推薦しない
DROBE における Filter • サイズがマッチしない商品は推薦しない • ユーザーが嫌いと答えた特徴を持つ商品は推薦しない • 既に購入済みの商品は推薦しない •
在庫がない商品は推薦しない • 販売不可能な商品は推薦しない 検索エンジン 機械学習モデル
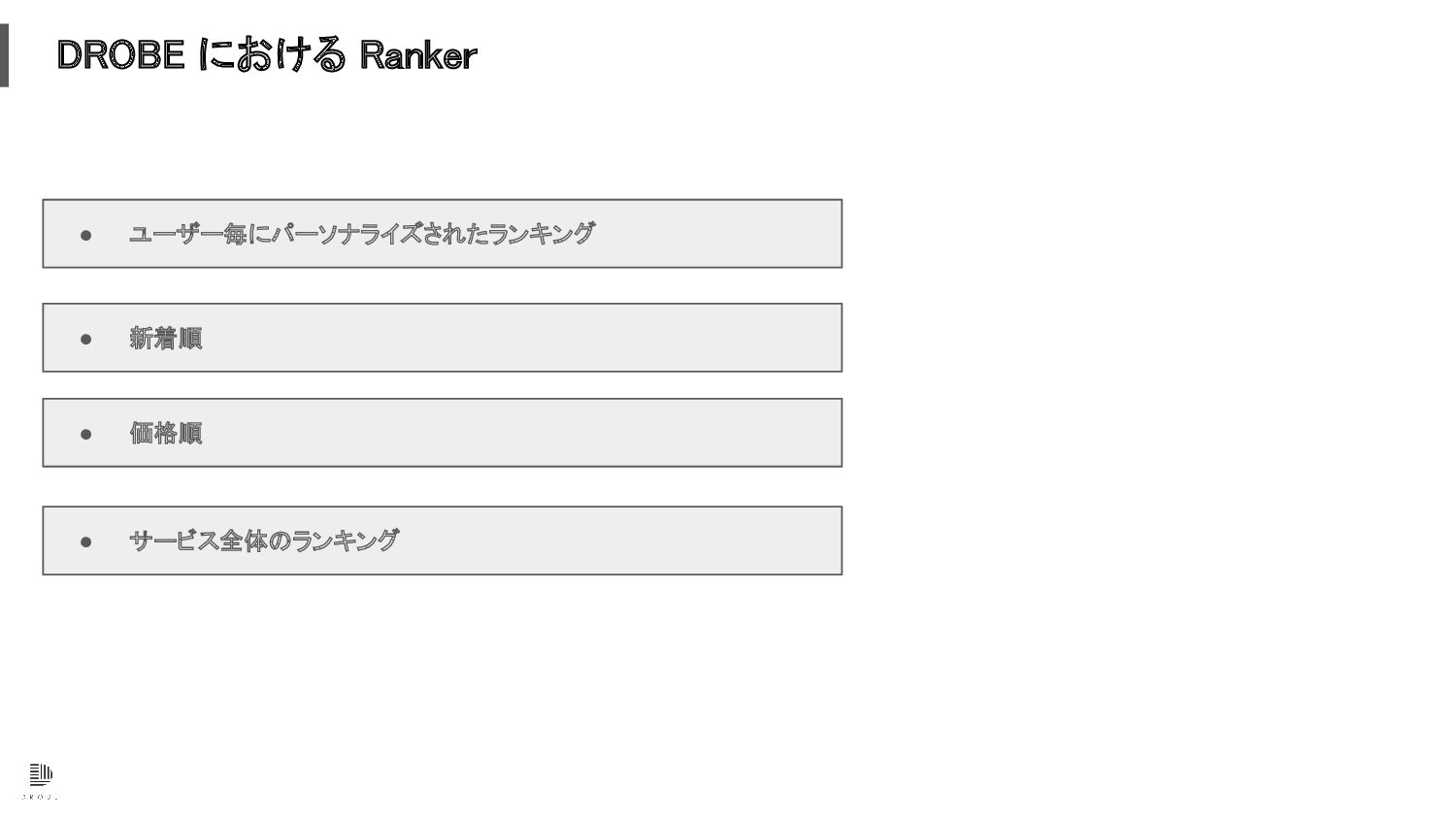
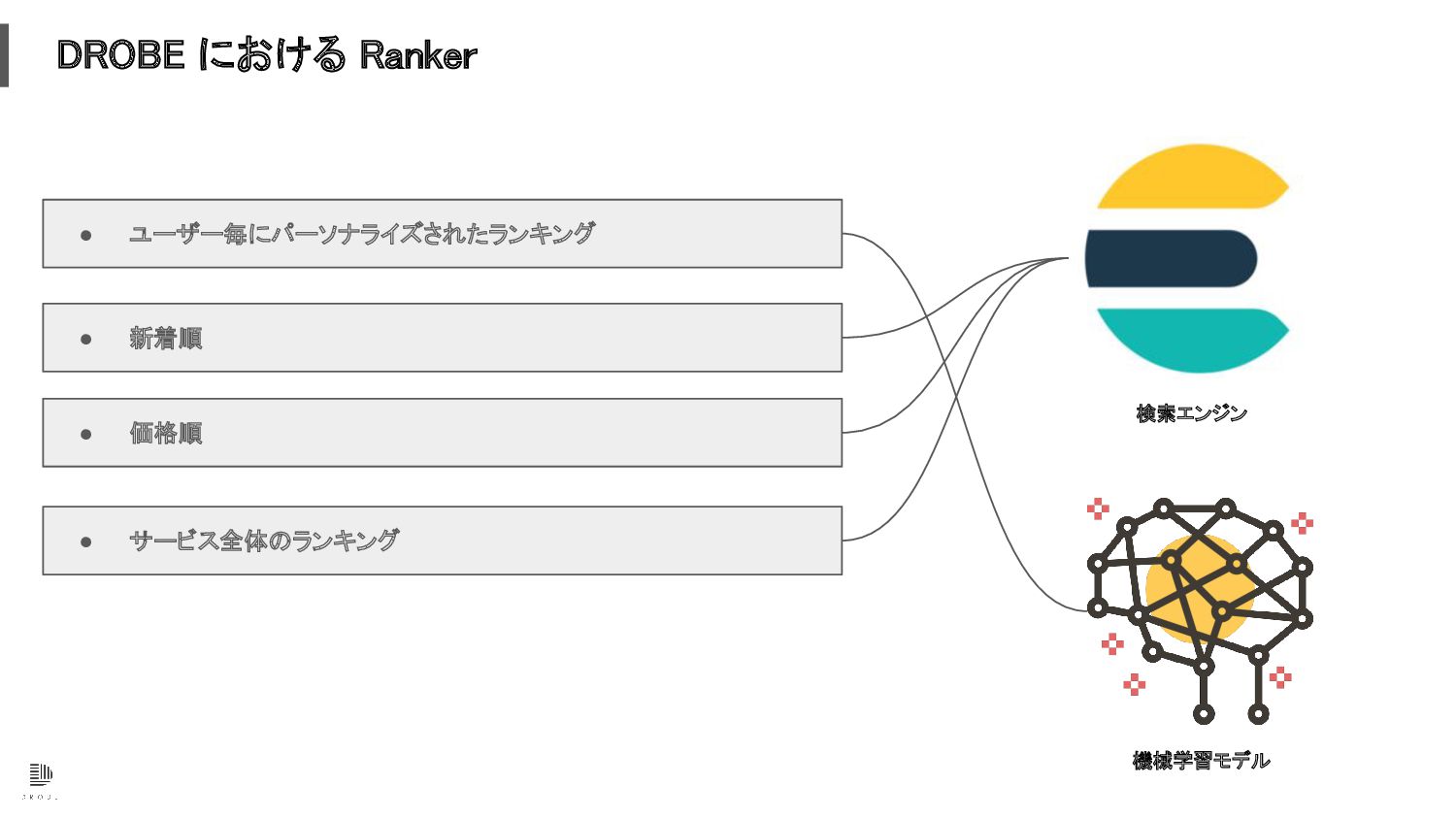
DROBE における Ranker • サービス全体のランキング • 価格順 • 新着順 •
ユーザー毎にパーソナライズされたランキング
DROBE における Ranker • サービス全体のランキング • 価格順 • 新着順 •
ユーザー毎にパーソナライズされたランキング 検索エンジン 機械学習モデル
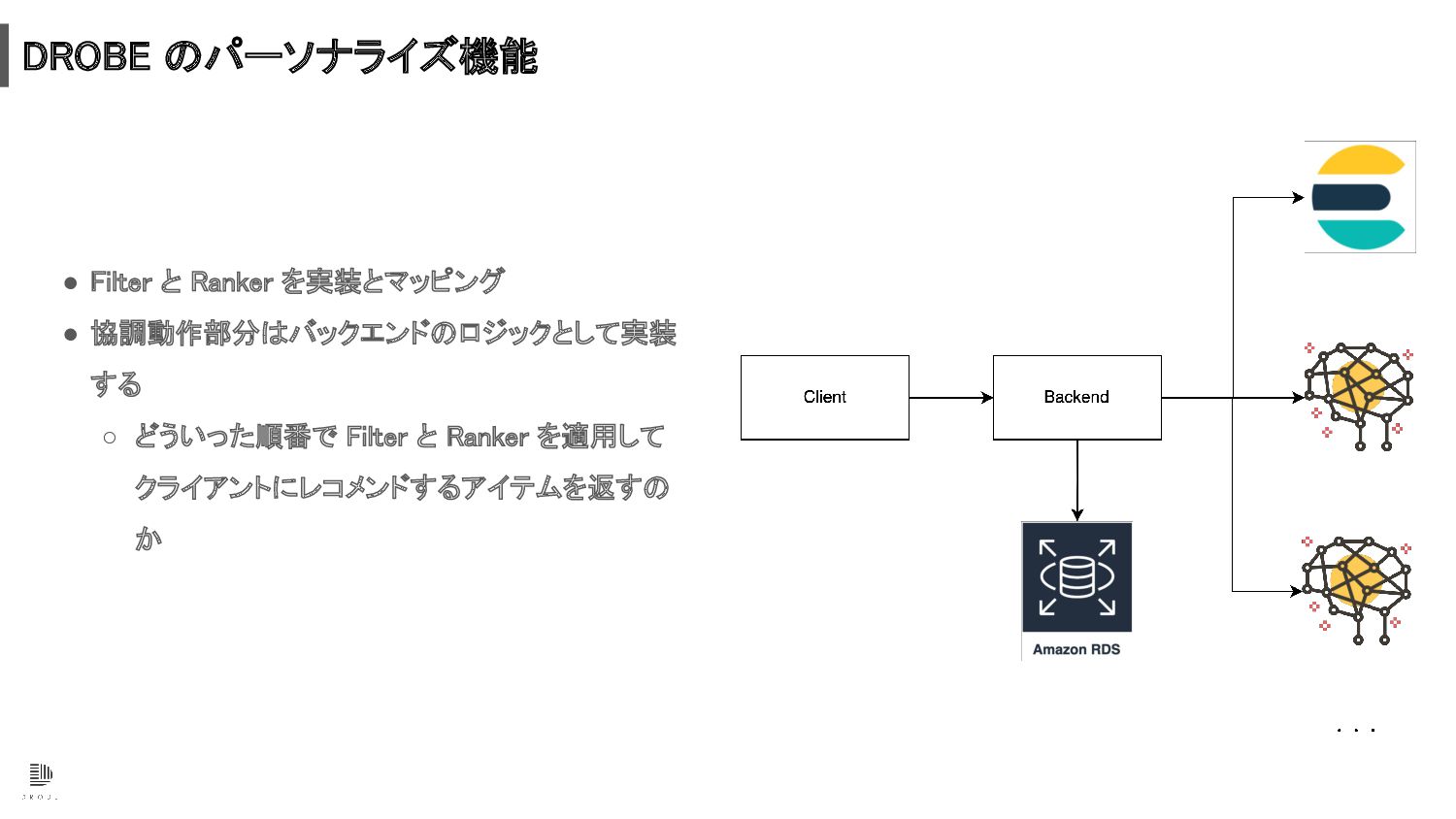
DROBE のパーソナライズ機能 • Filter と Ranker を実装とマッピング • 協調動作部分はバックエンドのロジックとして実装
する ◦ どういった順番で Filter と Ranker を適用して クライアントにレコメンドするアイテムを返すの か
3 本番運用
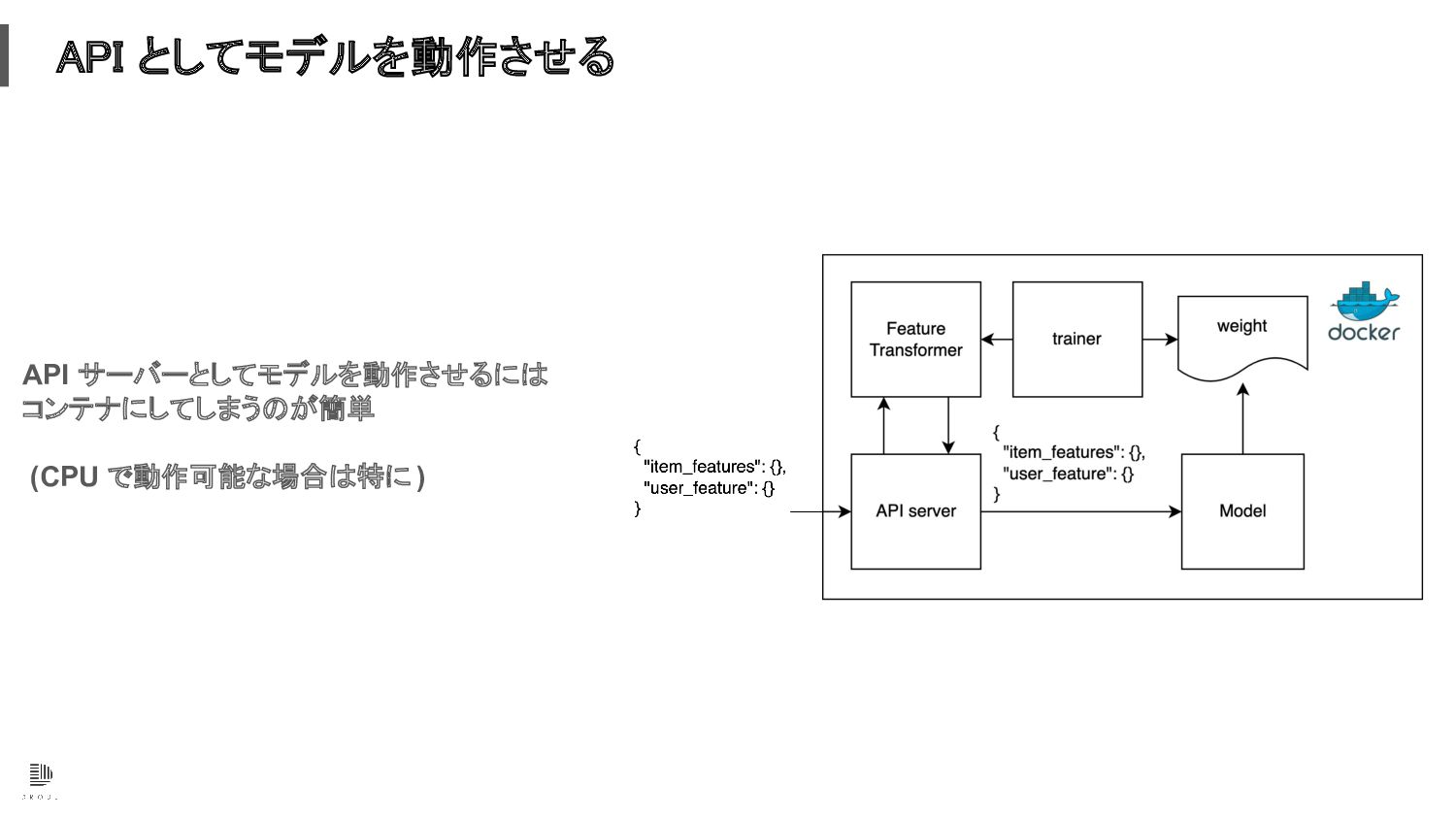
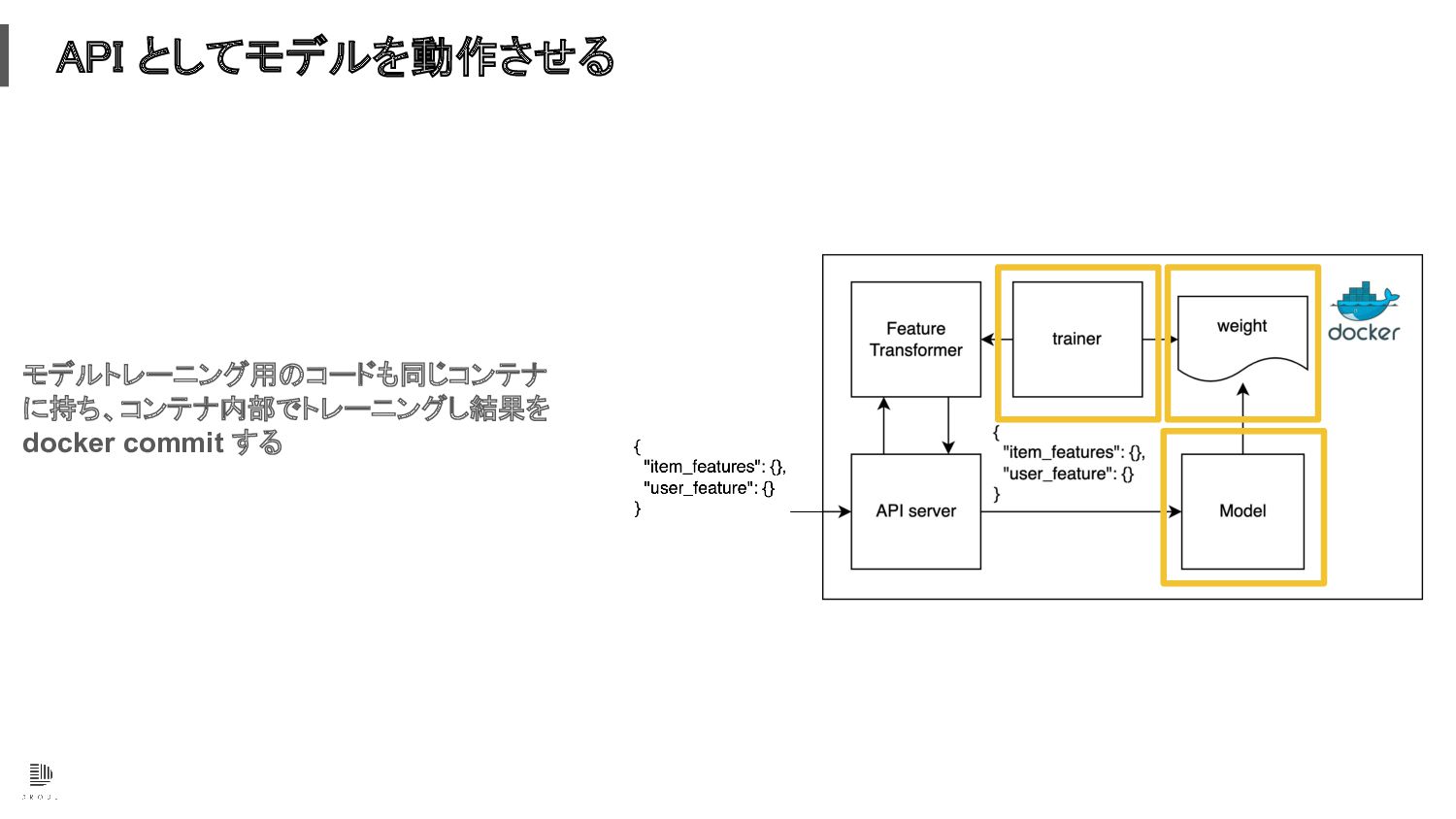
API としてモデルを動作させる API サーバーとしてモデルを動作させるには コンテナにしてしまうのが簡単 (CPU で動作可能な場合は特に )
API としてモデルを動作させる モデルトレーニング用のコードも同じコンテナ に持ち、コンテナ内部でトレーニングし結果を docker commit する
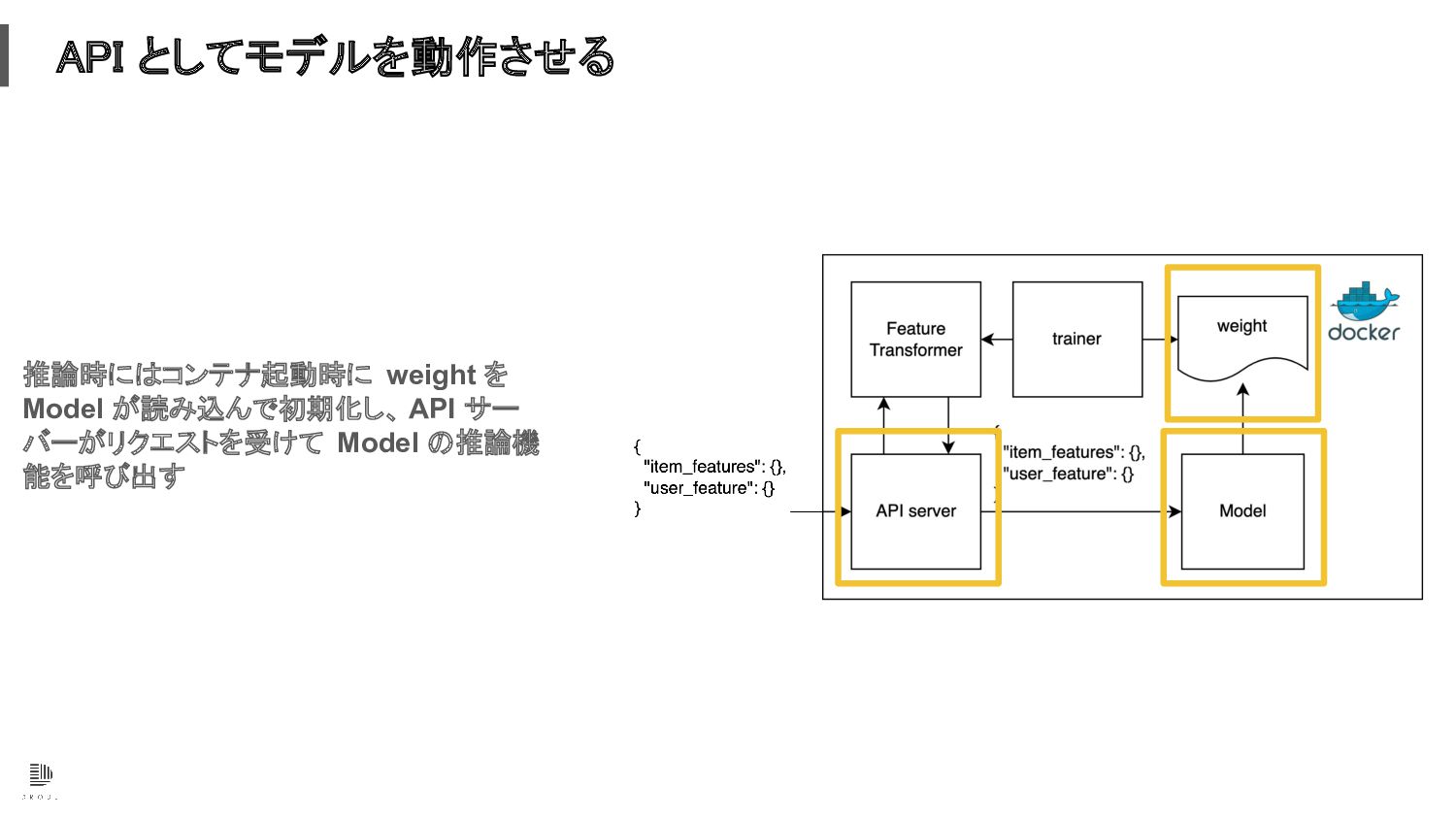
API としてモデルを動作させる 推論時にはコンテナ起動時に weight を Model が読み込んで初期化し、 API サー バーがリクエストを受けて
Model の推論機 能を呼び出す
本番化を踏まえたデータパイプラインの設計
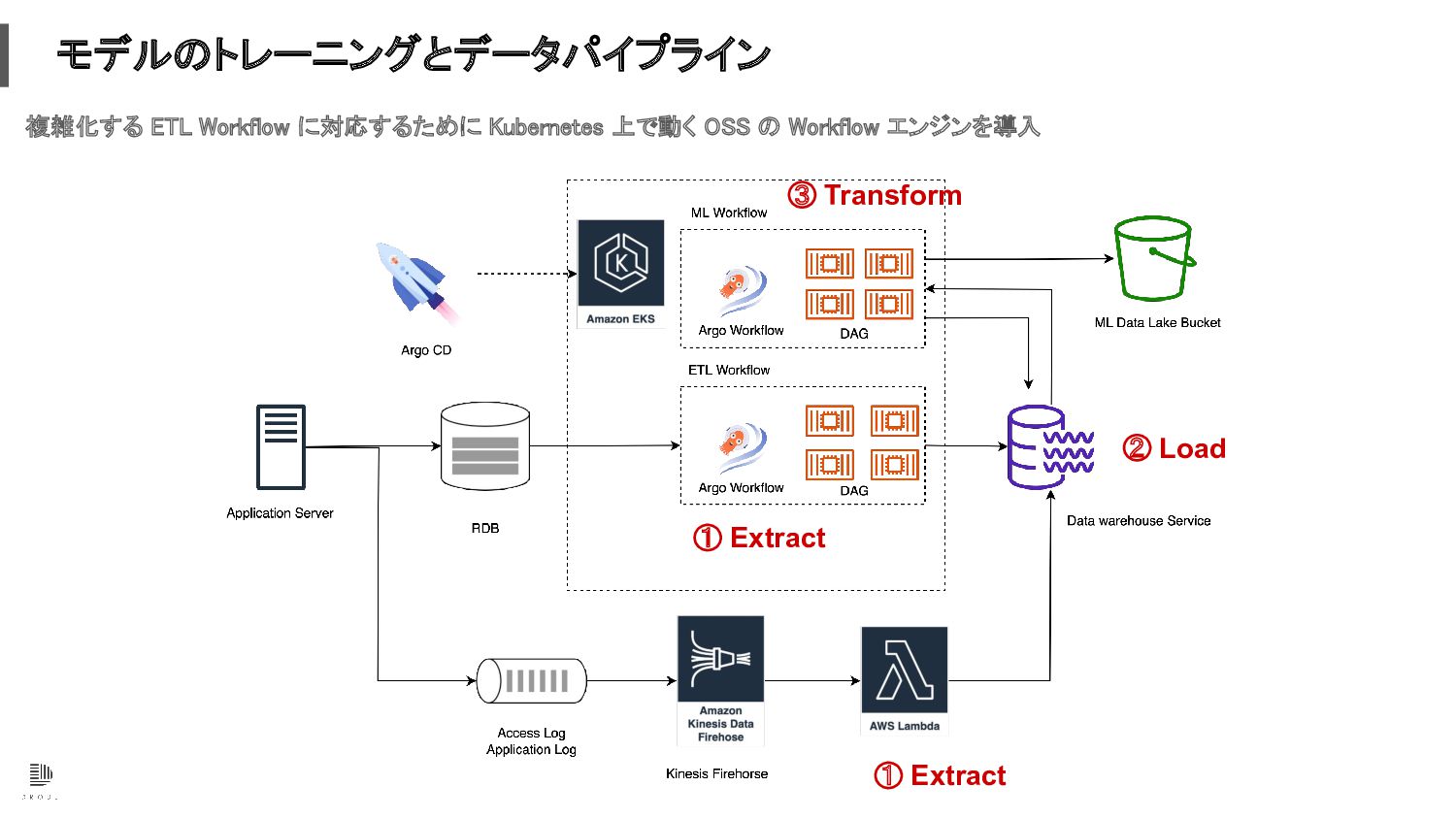
モデルのトレーニングとデータパイプライン 複雑化する ETL Workflow に対応するために Kubernetes 上で動く OSS の Workflow
エンジンを導入 ① Extract ① Extract ② Load ③ Transform
モデルのトレーニングとデータパイプライン トレーニングは CodePipleine で行う Build して Push するコンテナイメージ
動作確認と評価 stg や QA 環境はデータが本番と違う場合が多い レコメンドモデルは本番のデータを使ってトレーニングする事が多い
本番のデータを使ってトレーニングしたレコメンドモデルを QA 環境にあげても API の動作確認は出来るがモデ ルの動作確認は難しい
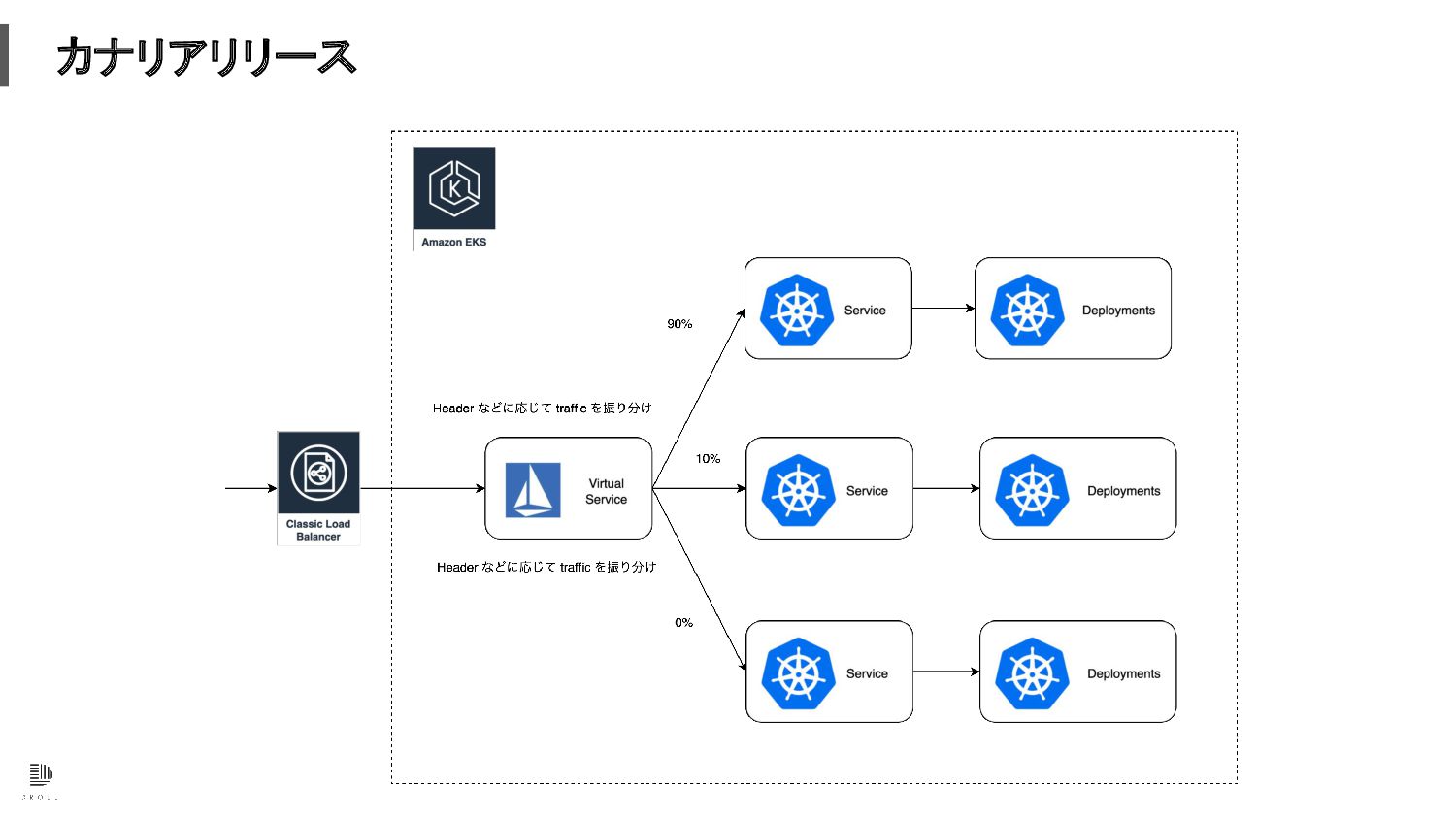
カナリアリリース
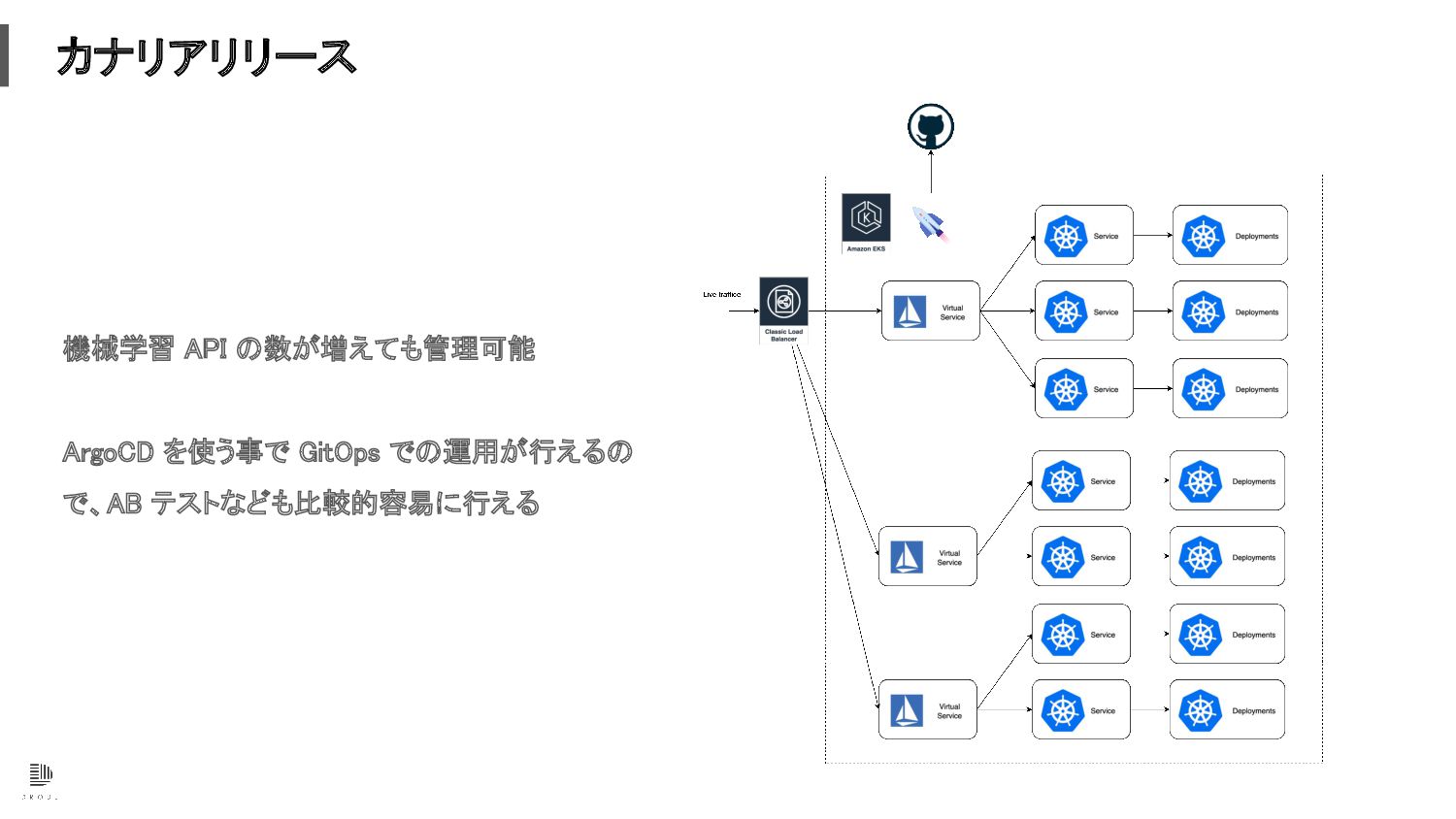
カナリアリリース 機械学習 API の数が増えても管理可能 ArgoCD を使う事で GitOps での運用が行えるの
で、AB テストなども比較的容易に行える
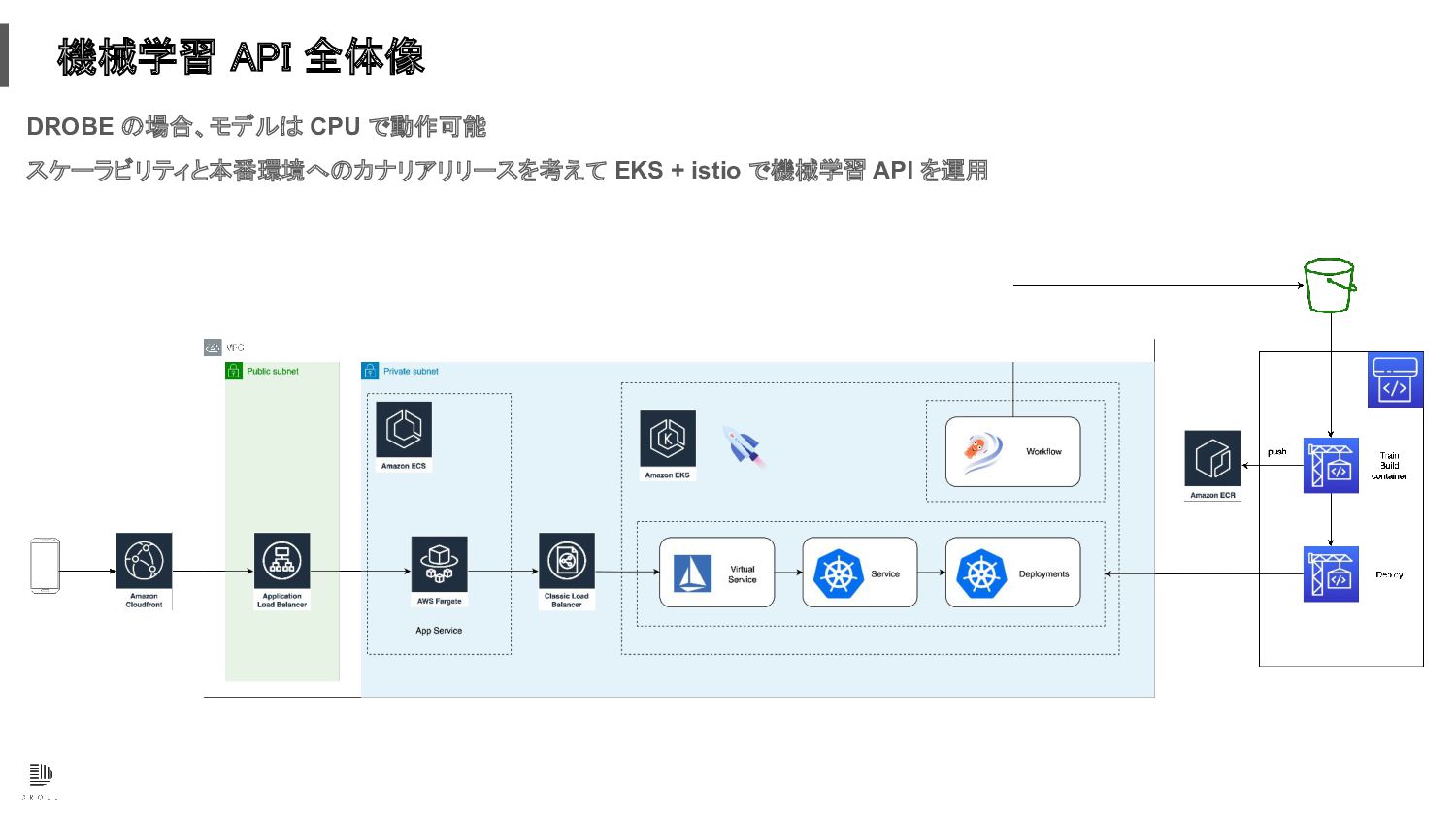
機械学習 API 全体像 DROBE の場合、モデルは CPU で動作可能 スケーラビリティと本番環境へのカナリアリリースを考えて EKS +
istio で機械学習 API を運用
• 開発と本番で同じデータを使えるようにしておく • CPU で動作させる事ができれば通常の Web インフラが使える
• 機械学習機能は動作確認や性能の判断が困難な場合が多いので、本番環境で検証出来る仕 組みを考えておく 本番運用 まとめ
まとめ
まとめ 本日お話したこと あらゆるリソースが足りないスタートアップでも、パーソナライズ機能の導入は可能 アルゴリズムの選定や評価を除けば基本的には Web の一般的な開発の知識だけでも機能の実装 を行う事は出来る 運用面では機械学習モデルがあるがゆえの難しさはある
We are hiring!! 60 採用情報 https://info.drobe.co.jp/jobs エンジニアリング資料 https://info.drobe.co.jp/engineering 少しでも気になった方、お気軽にご連絡ください!!
カジュアルに技術話をするだけでも大歓迎です! Twitter Meety
株式会社DROBE CTO 都筑友昭 ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}