Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ニューラルネットワークを使った学習/Learning with Neural Networks
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Toshiyuki Imaizumi
June 16, 2024
Programming
77
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ニューラルネットワークを使った学習/Learning with Neural Networks
ニューラルネットワークを使った学習方法と画像分類を行う方法の紹介
Toshiyuki Imaizumi
June 16, 2024
More Decks by Toshiyuki Imaizumi
See All by Toshiyuki Imaizumi
Java8の新機能/Java8 New Feature
tsyki
0
150
ジェネリクスについて/Java Generics
tsyki
0
260
Java並行処理の基本/Java Concurrency
tsyki
0
430
Other Decks in Programming
See All in Programming
Observability in Practice:Grafana 與 Edge Device SRE 的那些事
blueswen
0
130
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
110
柔軟なPDFレイアウトエディタを支える型システム設計 — Discriminated UnionとConditional Typeの実践
minako__ph
4
1.4k
AIで効率化できた業務・日常
ochtum
0
100
AI 時代のソフトウェア設計の学び方
masuda220
PRO
29
12k
dRuby over BLE
makicamel
2
320
JavaDoc 再入門
nagise
0
290
Lemonade + Foundry Toolkit でお手軽アプリ開発
seosoft
1
310
net-httpのHTTP/2対応について
naruse
0
450
技術記事、AIに書かせるか、自分で書くか? 〜それでも私が自分の手で書く理由〜 / #QiitaConference
jnchito
2
1.3k
AIエージェントの隔離技術の徹底比較
kawayu
0
470
タクシーアプリ『GO』の バックエンド開発のおける AI利活用と若者のすべて
pyama86
3
1.9k
Featured
See All Featured
Product Roadmaps are Hard
iamctodd
PRO
55
12k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Why Our Code Smells
bkeepers
PRO
340
58k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
720
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Building an army of robots
kneath
306
46k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
WENDY [Excerpt]
tessaabrams
11
38k
A Tale of Four Properties
chriscoyier
163
24k
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
Transcript
ニューラルネットワークを使った学習 2024/6/18 今泉俊幸 1
目次 • ニューラルネットワークについて • パーセプトロン • パーセプトロンを使った計算 • パーセプトロンを使った学習 •
ニューラルネットワーク • ニューラルネットワークを使った計算 • ニューラルネットワークを使った画像分類 • 誤差逆伝播法 • 畳み込みニューラルネットワーク 2
ニューラルネットワークについて • ニューラルネットワークとは • 人工知能を実現する為のアプローチとして、生物の学習の仕組みを模倣 したもの • 脳の中にはニューロンという細胞があり、それらが繋がっている • ニューロンは受け取った刺激(=入力信号)に対し、ある閾値を超えていれ
ば次のニューロンに信号を送る。また、その信号は増大させたり減小さ せたりしている • ニューラルネットワークを使った学習方法がディープラーニング • ニューラルネットワークの前身のアルゴリズムとしてパーセプトロン がある 3
ニューラルネットワークのメリット • データさえあれば、人間がアルゴリズムを考えずに学習ができる • 画像認識の歴史 1. 人が考えたアルゴリズムで認識 • 画像→人が考えたアルゴリズム→答え 2.
人が特微量を抽出し、それを使って学習する • 画像→人が考えた特微量→機械学習(SVM、KNN等)→答え • 特微量:入力から本質的なデータを抽出するための変換器 • 問題に応じて適切な特微量を人間が考える必要がある。数字を認識と、犬を認識 は特微量が異なる 3. 特微量を含めて学習する • 画像→ニューラルネットワークで学習→答え 4
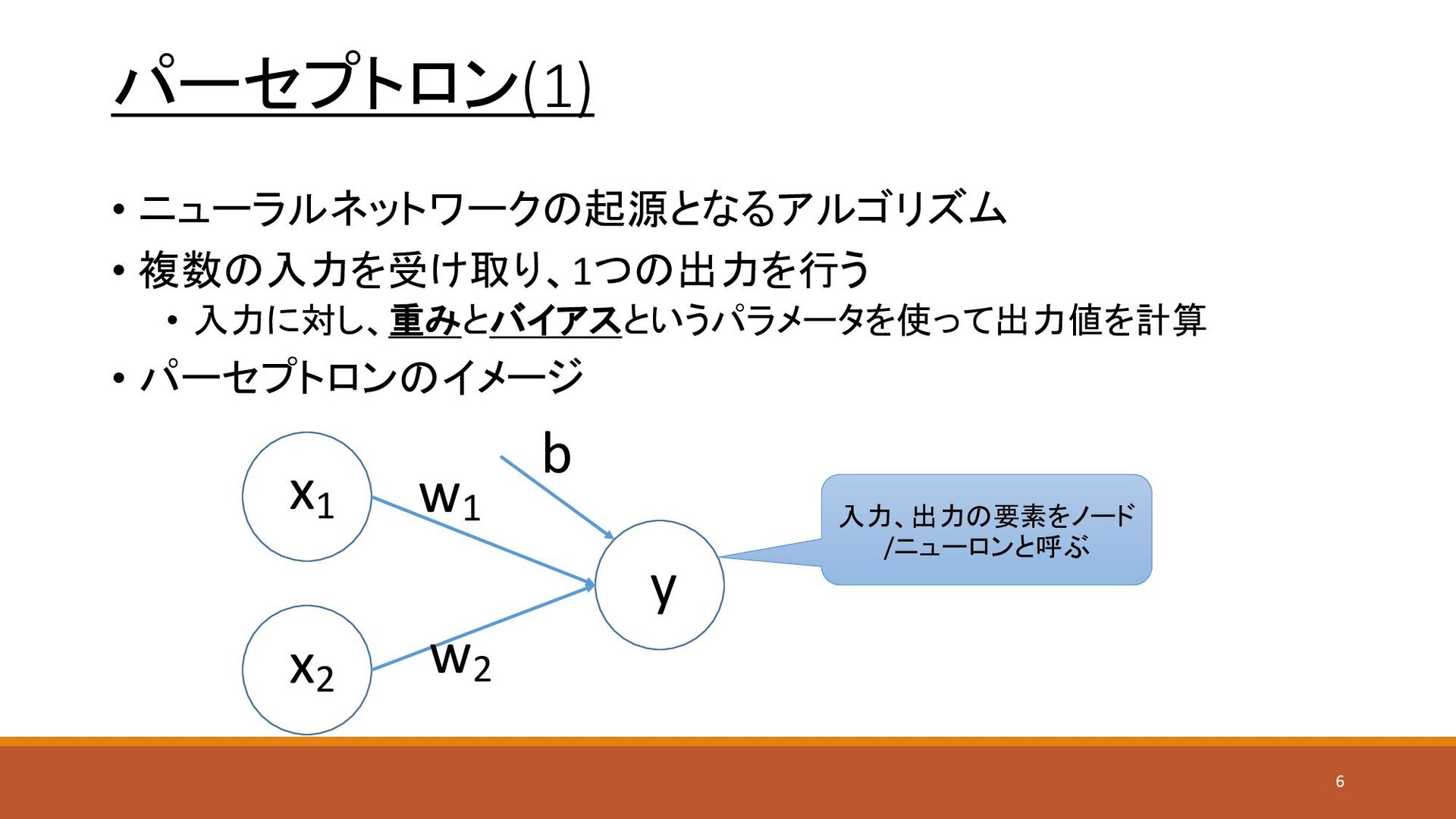
パーセプトロン 5
パーセプトロン(1) • ニューラルネットワークの起源となるアルゴリズム • 複数の入力を受け取り、1つの出力を行う • 入力に対し、重みとバイアスというパラメータを使って出力値を計算 • パーセプトロンのイメージ x1
x2 y w1 w2 b 入力、出力の要素をノード /ニューロンと呼ぶ 6
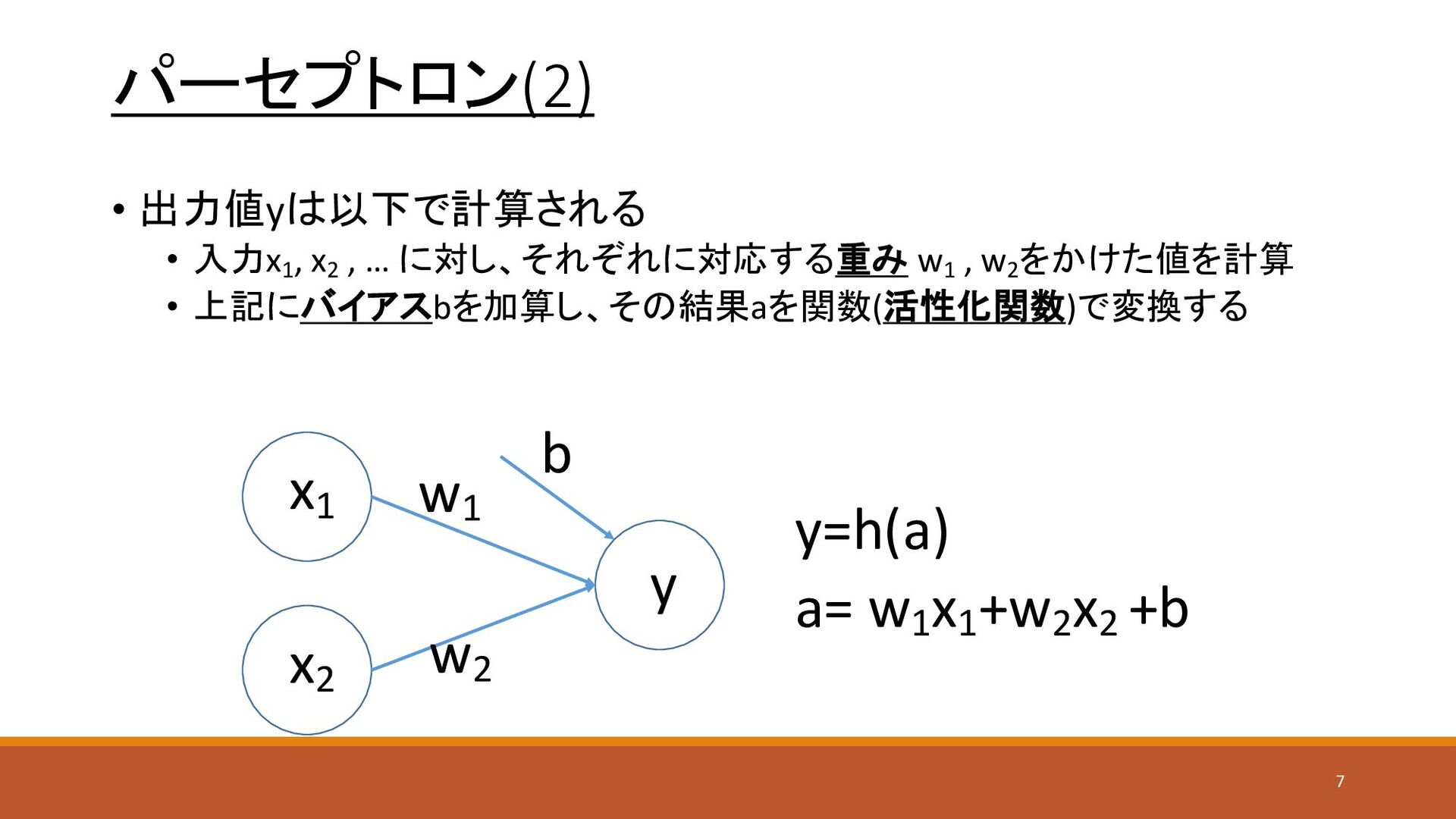
パーセプトロン(2) • 出力値yは以下で計算される • 入力x1 , x2 , … に対し、それぞれに対応する重み
w1 , w2 をかけた値を計算 • 上記にバイアスbを加算し、その結果aを関数(活性化関数)で変換する y=h(a) a= w1 x1 +w2 x2 +b x1 x2 y w1 w2 b 7
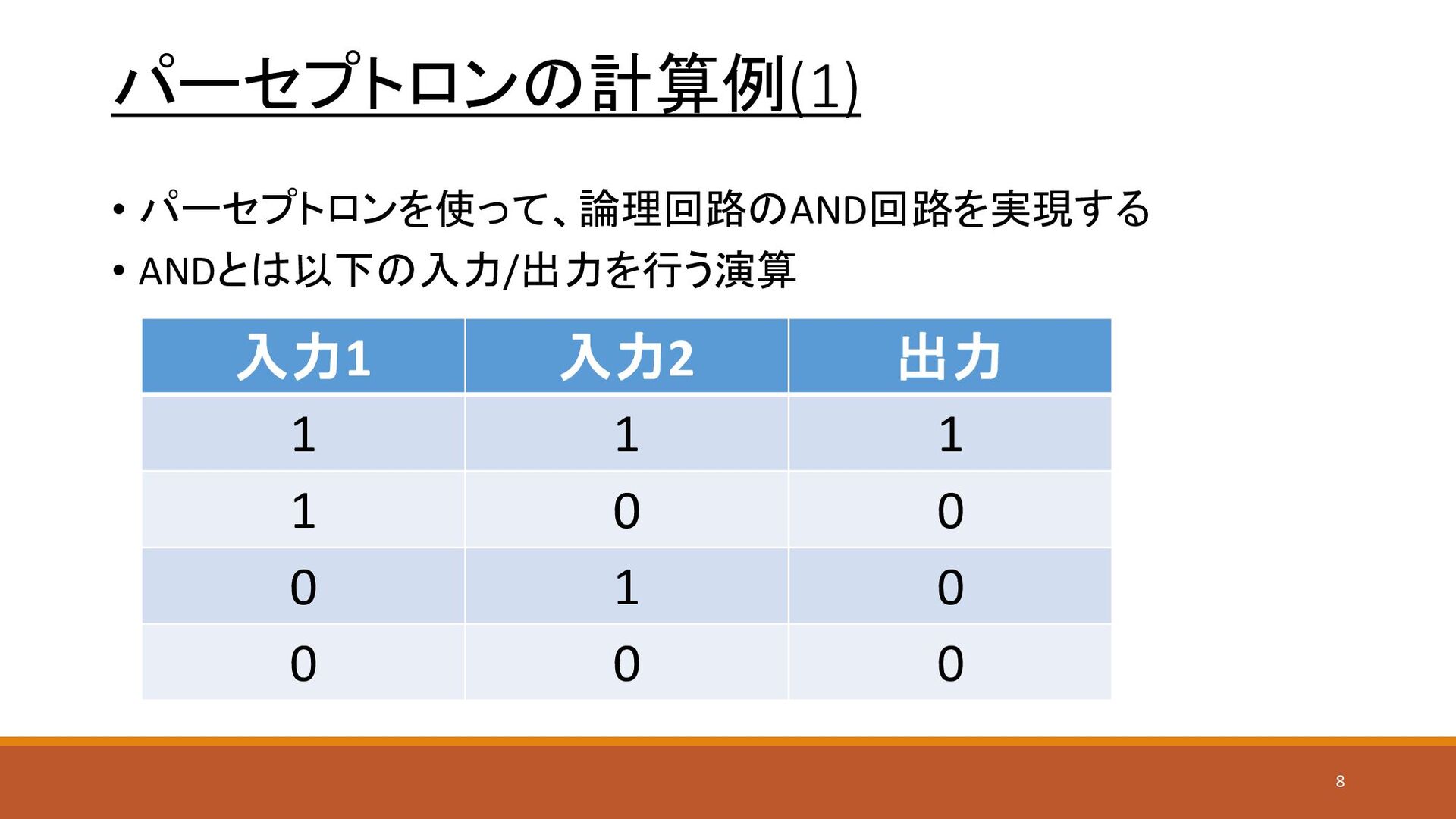
パーセプトロンの計算例(1) • パーセプトロンを使って、論理回路のAND回路を実現する • ANDとは以下の入力/出力を行う演算 入力1 入力2 出力 1 1
1 1 0 0 0 1 0 0 0 0 8
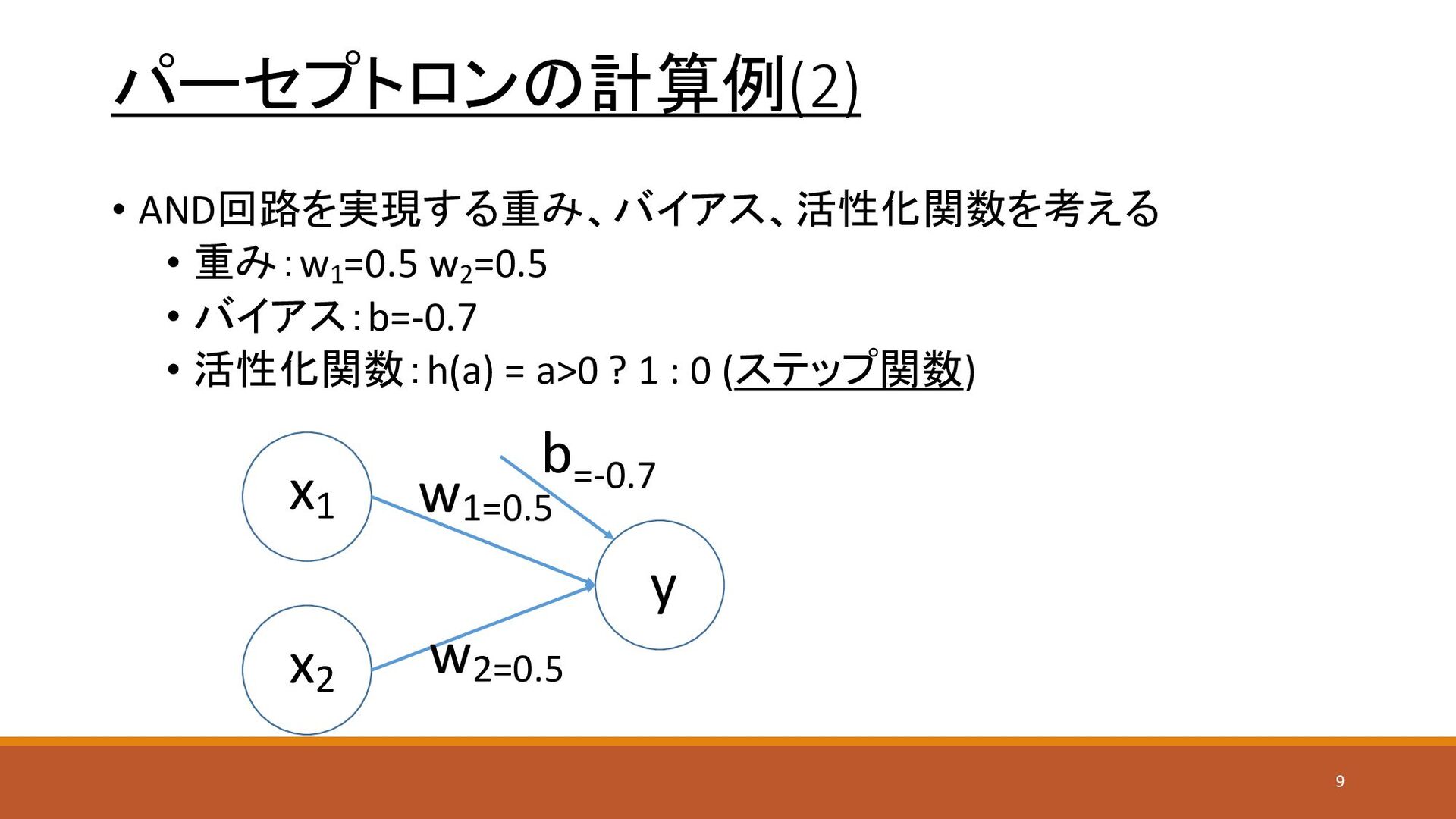
パーセプトロンの計算例(2) • AND回路を実現する重み、バイアス、活性化関数を考える • 重み:w1 =0.5 w2 =0.5 • バイアス:b=-0.7
• 活性化関数:h(a) = a>0 ? 1 : 0 (ステップ関数) x1 x2 y w1=0.5 w2=0.5 b=-0.7 9
パーセプトロンの計算例(3) • 前ページの重み、バイアス、活性関数を使った場合の計算過程 入力1 入力2 aの値 出力y 1 1 (1*0.5)+(1*0.5)-0.7=
0.3 1 1 0 (1*0.5)+(0*0.5)-0.7= -0.2 0 0 1 (0*0.5)+(1*0.5)-0.7= -0.2 0 0 0 (0*0.0)+(0*0.5)-0.7= -0.7 0 10
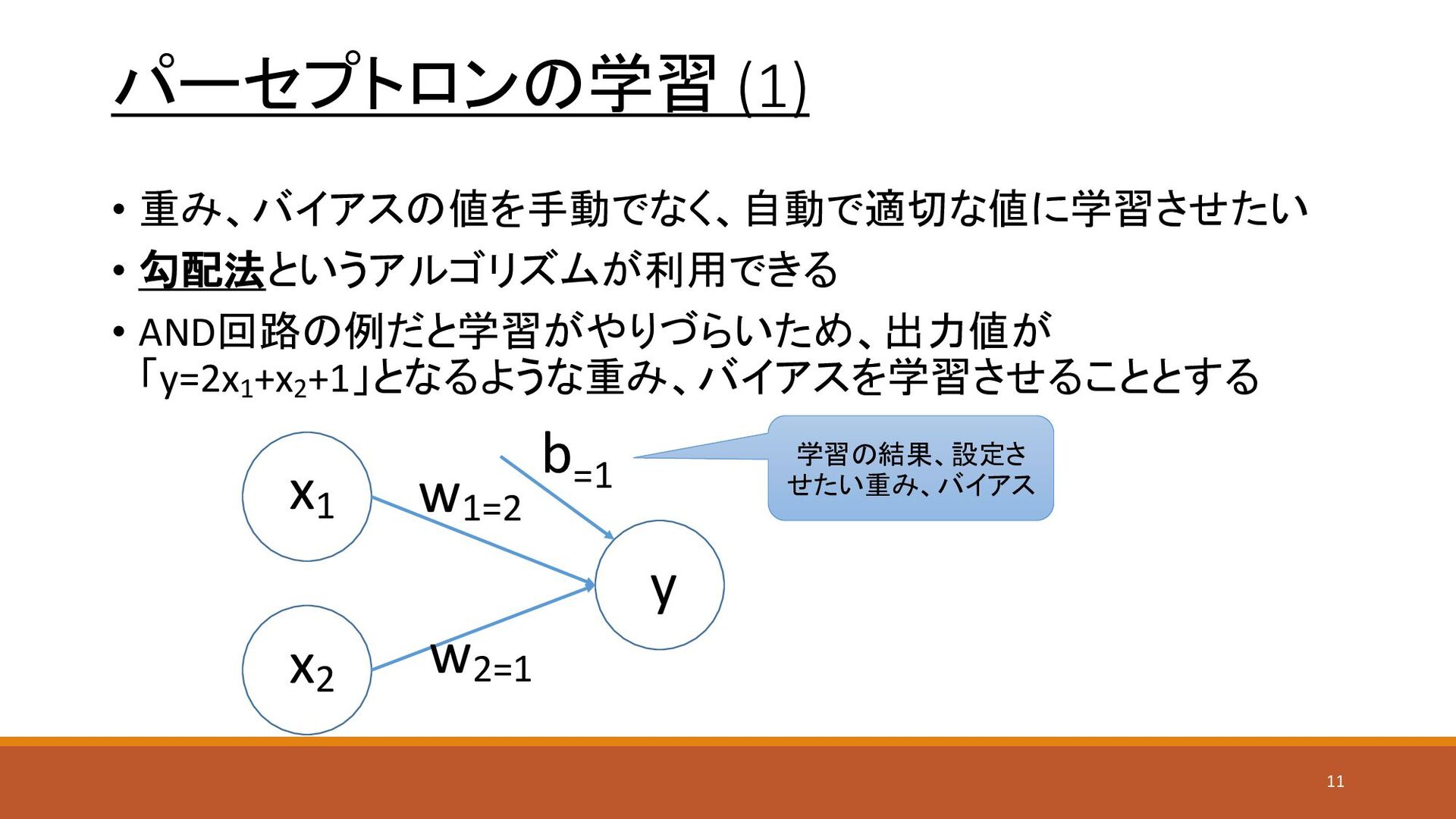
パーセプトロンの学習 (1) • 重み、バイアスの値を手動でなく、自動で適切な値に学習させたい • 勾配法というアルゴリズムが利用できる • AND回路の例だと学習がやりづらいため、出力値が 「y=2x1 +x2
+1」となるような重み、バイアスを学習させることとする x1 x2 y w1=2 w2=1 b=1 学習の結果、設定さ せたい重み、バイアス 11
パーセプトロンの学習 (2) • 勾配法の考え方 • 損失関数 • 重みパラメータが適切かどうかの指標 • 値が大きいほど不適切→損失関数の値を最小にするように学習させる
• 勾配 • 重みを変えた時、どれだけ損失関数の値が変わるかの値 • 勾配の値に学習率をかけた値だけ重みをずらすことを繰り返すことで、 損失関数の値を良くしていく 12
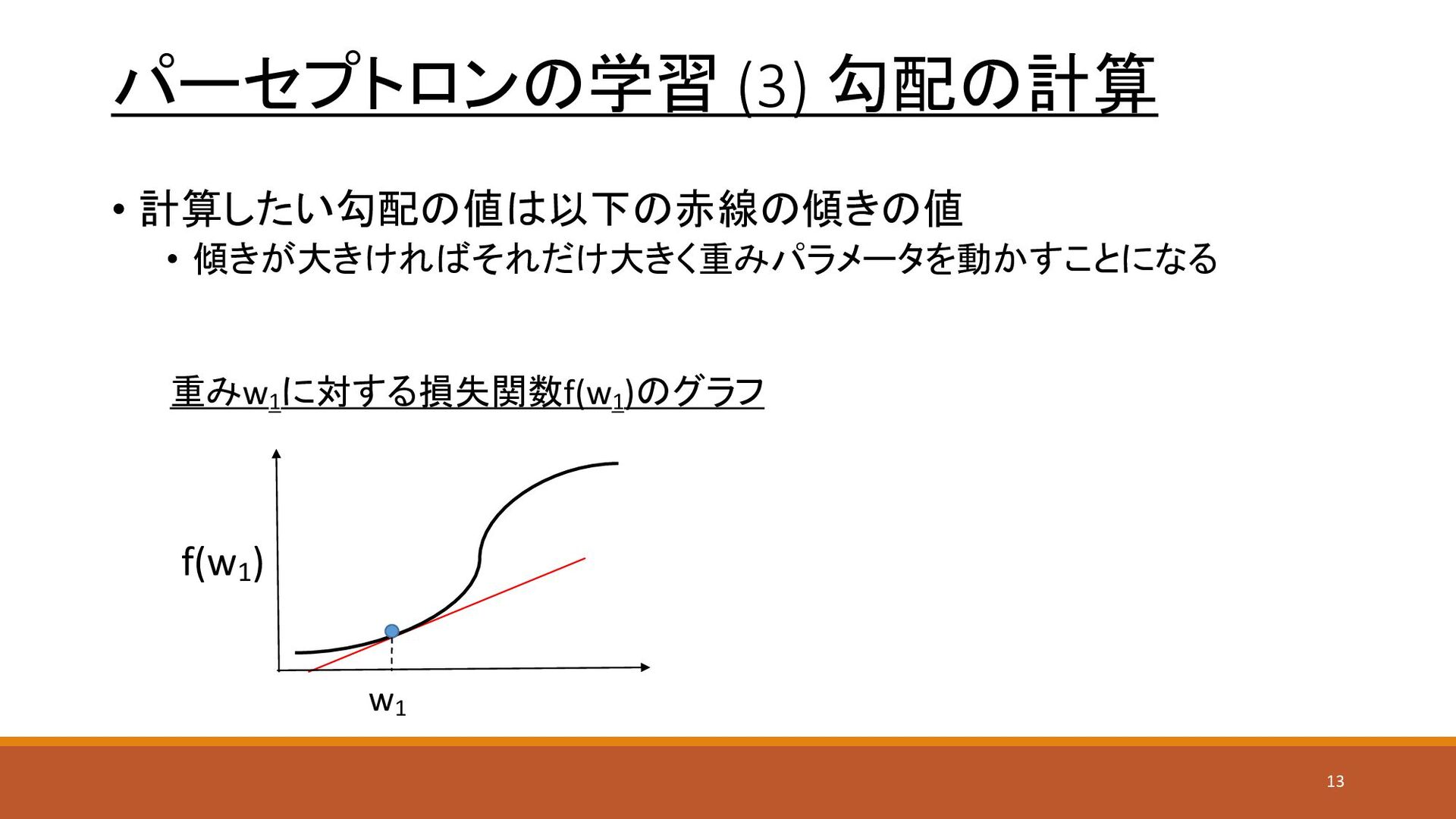
パーセプトロンの学習 (3) 勾配の計算 • 計算したい勾配の値は以下の赤線の傾きの値 • 傾きが大きければそれだけ大きく重みパラメータを動かすことになる 重みw1 に対する損失関数f(w1 )のグラフ
f(w1 ) w1 13
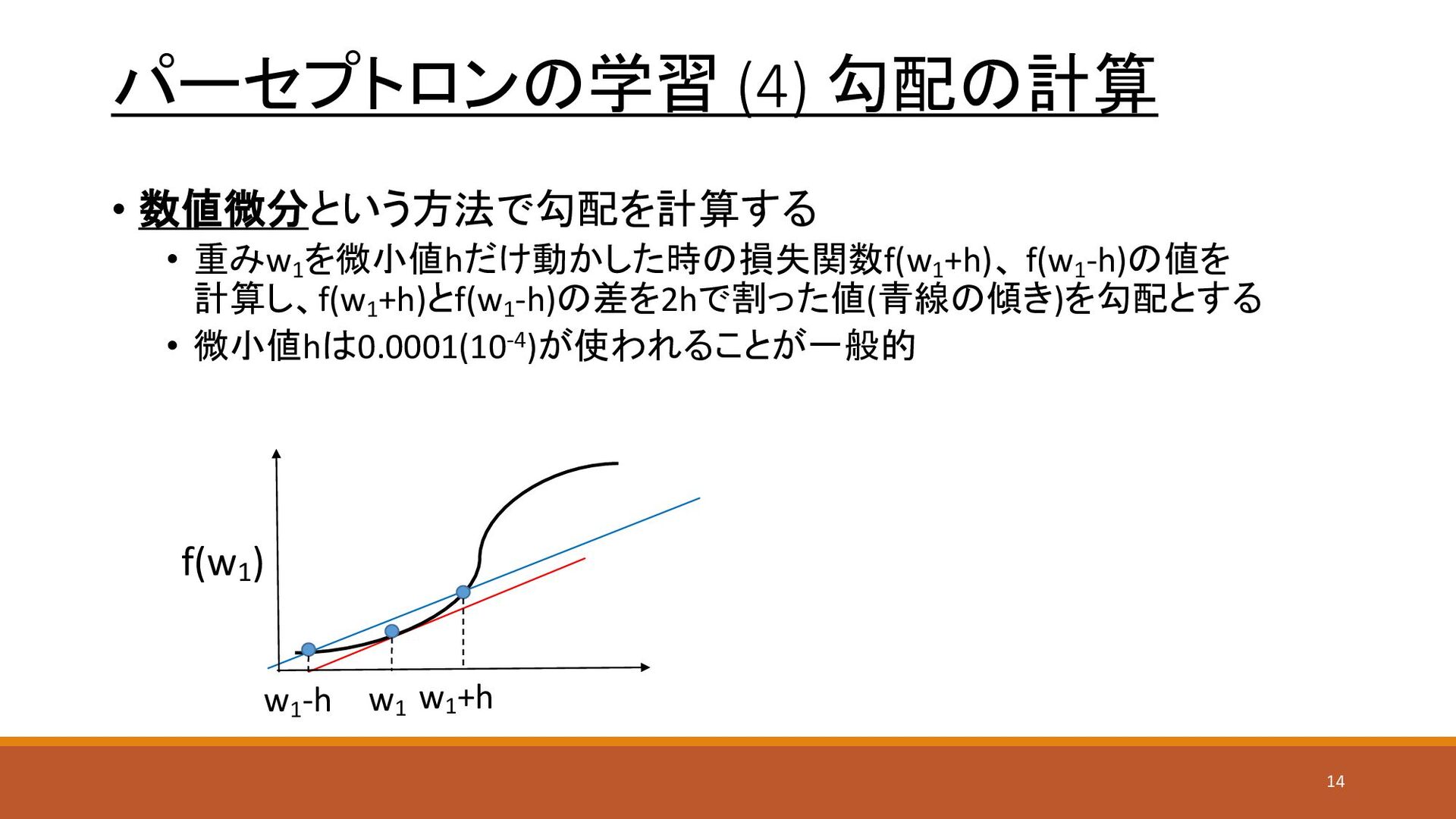
パーセプトロンの学習 (4) 勾配の計算 • 数値微分という方法で勾配を計算する • 重みw1 を微小値hだけ動かした時の損失関数f(w1 +h)、 f(w1
-h)の値を 計算し、f(w1 +h)とf(w1 -h)の差を2hで割った値(青線の傾き)を勾配とする • 微小値hは0.0001(10-4)が使われることが一般的 f(w1 ) w1 w1 +h w1 -h 14
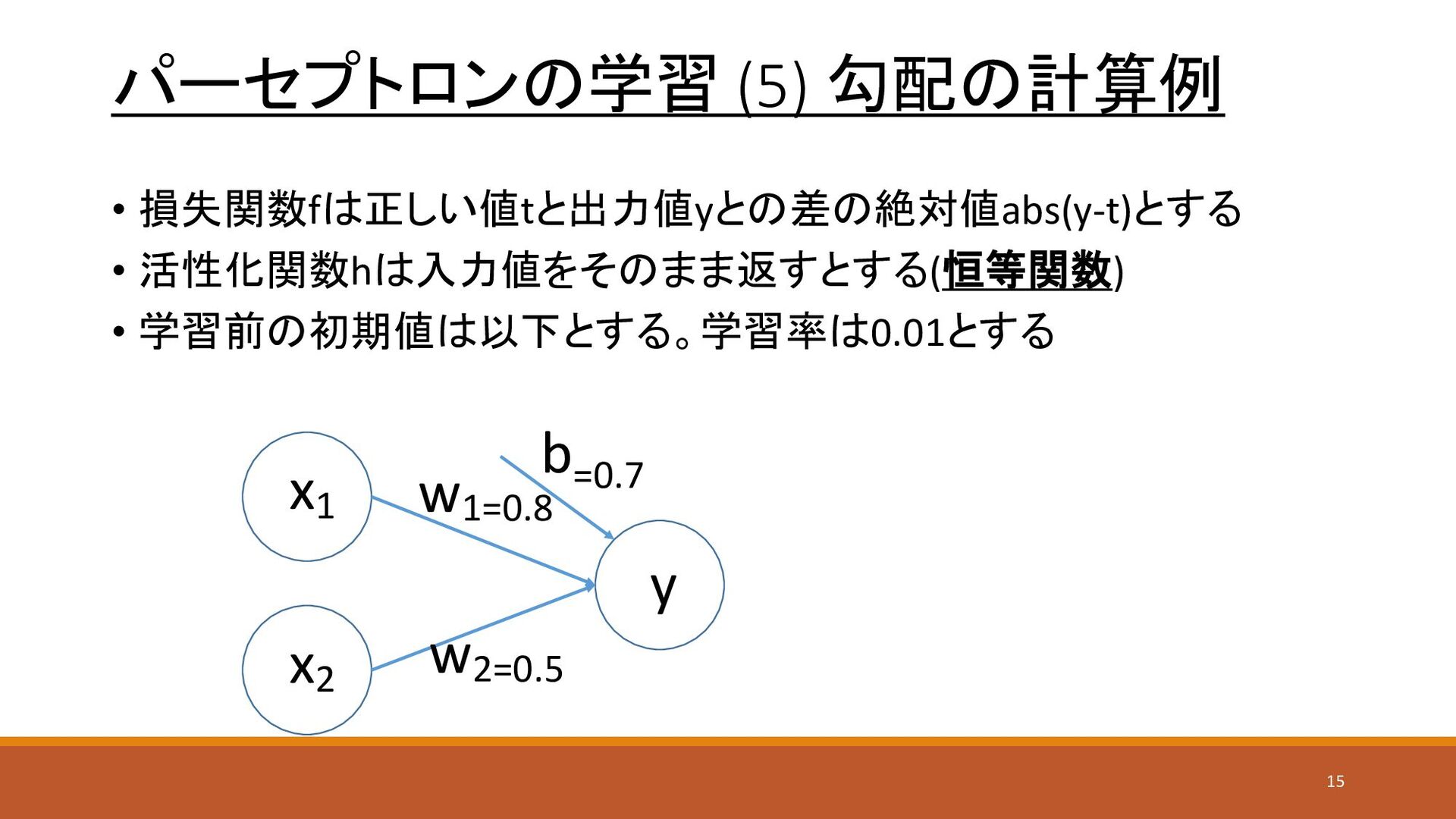
パーセプトロンの学習 (5) 勾配の計算例 • 損失関数fは正しい値tと出力値yとの差の絶対値abs(y-t)とする • 活性化関数hは入力値をそのまま返すとする(恒等関数) • 学習前の初期値は以下とする。学習率は0.01とする x1
x2 y w1=0.8 w2=0.5 b=0.7 15
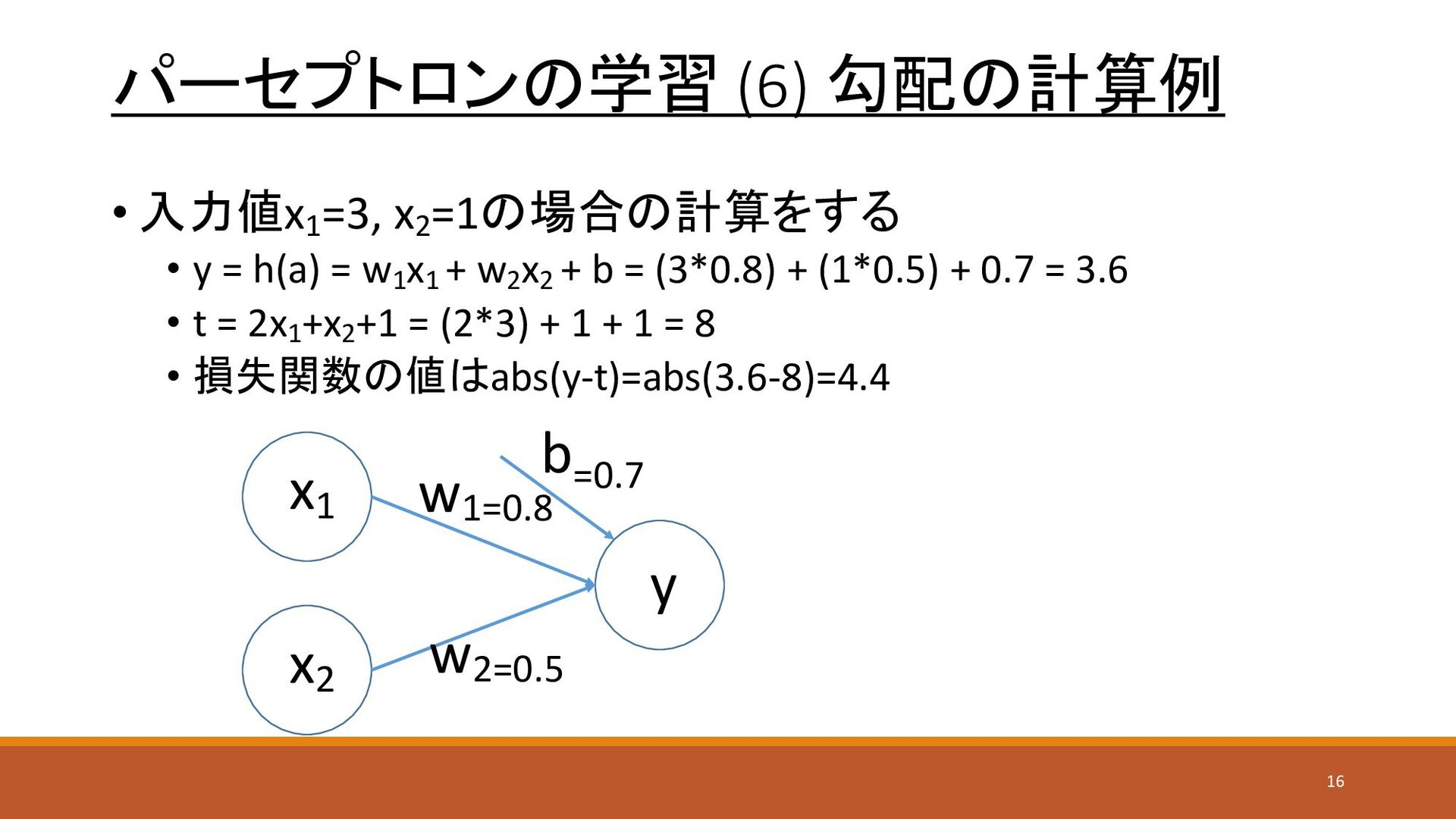
パーセプトロンの学習 (6) 勾配の計算例 • 入力値x1 =3, x2 =1の場合の計算をする • y
= h(a) = w1 x1 + w2 x2 + b = (3*0.8) + (1*0.5) + 0.7 = 3.6 • t = 2x1 +x2 +1 = (2*3) + 1 + 1 = 8 • 損失関数の値はabs(y-t)=abs(3.6-8)=4.4 x1 x2 y w1=0.8 w2=0.5 b=0.7 16
パーセプトロンの学習 (7) 勾配の計算例 • w1 の勾配を数値微分で計算する • f(w1 +h)= (3*0.8001)
+ (1*0.5) + 0.7 = 3.6003 • 損失関数の値= abs(3.6003-8)=3.3997 • f(w1 -h)= (3*0.7999) + (1*0.5) + 0.7 = 3.5997 • 損失関数の値はabs(3.5997-8)=3.4003 • f(w1 +h)-f(w1 -h)/2h = (4.3997 - 4.4003) / 0.0002 = -3 17
パーセプトロンの学習 (8) 重みの更新 • 重みパラメータの更新 • 勾配が-3と分かった • プラス方向に進むと損失関数の値が減る(=結果が良くなる) •
勾配の符号を反転させた方向に重みを変更すればよい • 勾配-3の符号を反転させ、学習率0.01をかけた値0.03だけw1 の値を更新 • これをw2 、bに対しても行い、一定回数繰り返す • 複数種類のデータの対応 • 入力が1パターンだけだとその入力に特化したパラメータになってしまう • 大量の入力とその答えのデータを用意し、それら全てを使って損失関数を計 算するように 18
パーセプトロンの学習 (9) ミニバッチ学習 • 大量に入力データがある場合、それら全てから損失関数を計算して 学習するとコストがかかる • 学習用のデータから無作為に一部のデータ(ミニバッチ)を取り出し学習する • 例:10000件の入力がある場合
• ランダムに100件を取り出し損失関数を計算、重みパラメータを更新 • 再度ランダムに100件を取り出し、損失関数を計算、重みパラメータを更新 • これを指定回数(10000回など)繰り返す • 学習時に人の手で設定が必要な値をハイパーパラメータと呼ぶ • 学習率(例:0.01) • ミニバッチの件数(例:100) • 学習の回数(例:10000) 19
パーセプトロンの学習 (10) 学習の流れ • 1.入力データからミニバッチのデータを取り出す • 2.ミニバッチの損失関数、勾配を計算する • 3.各重みパラメータを勾配×-1×学習率だけ更新する •
4.指定回数に達するまで1~3を繰り返す 20
ニューラルネットワーク 21
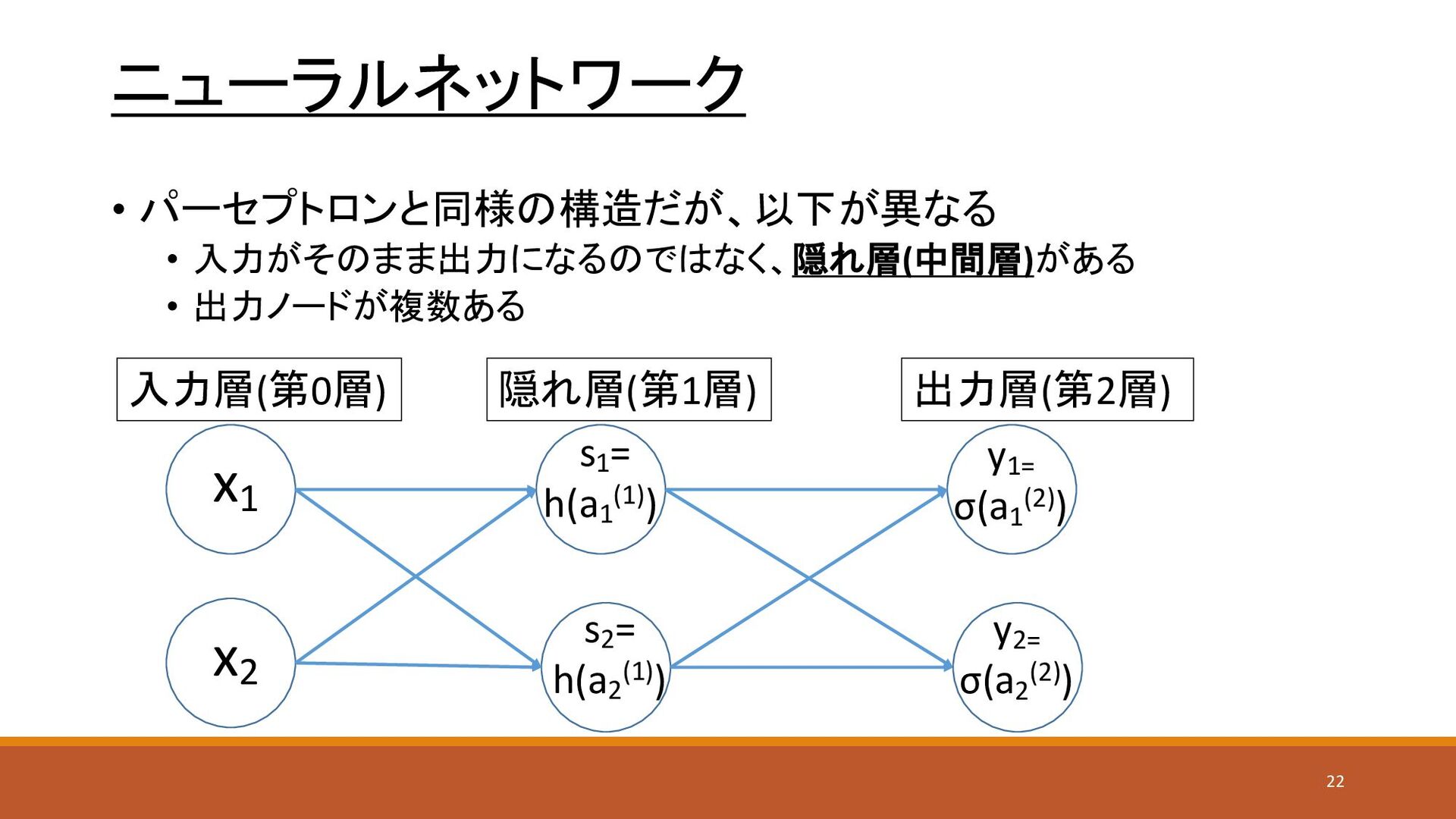
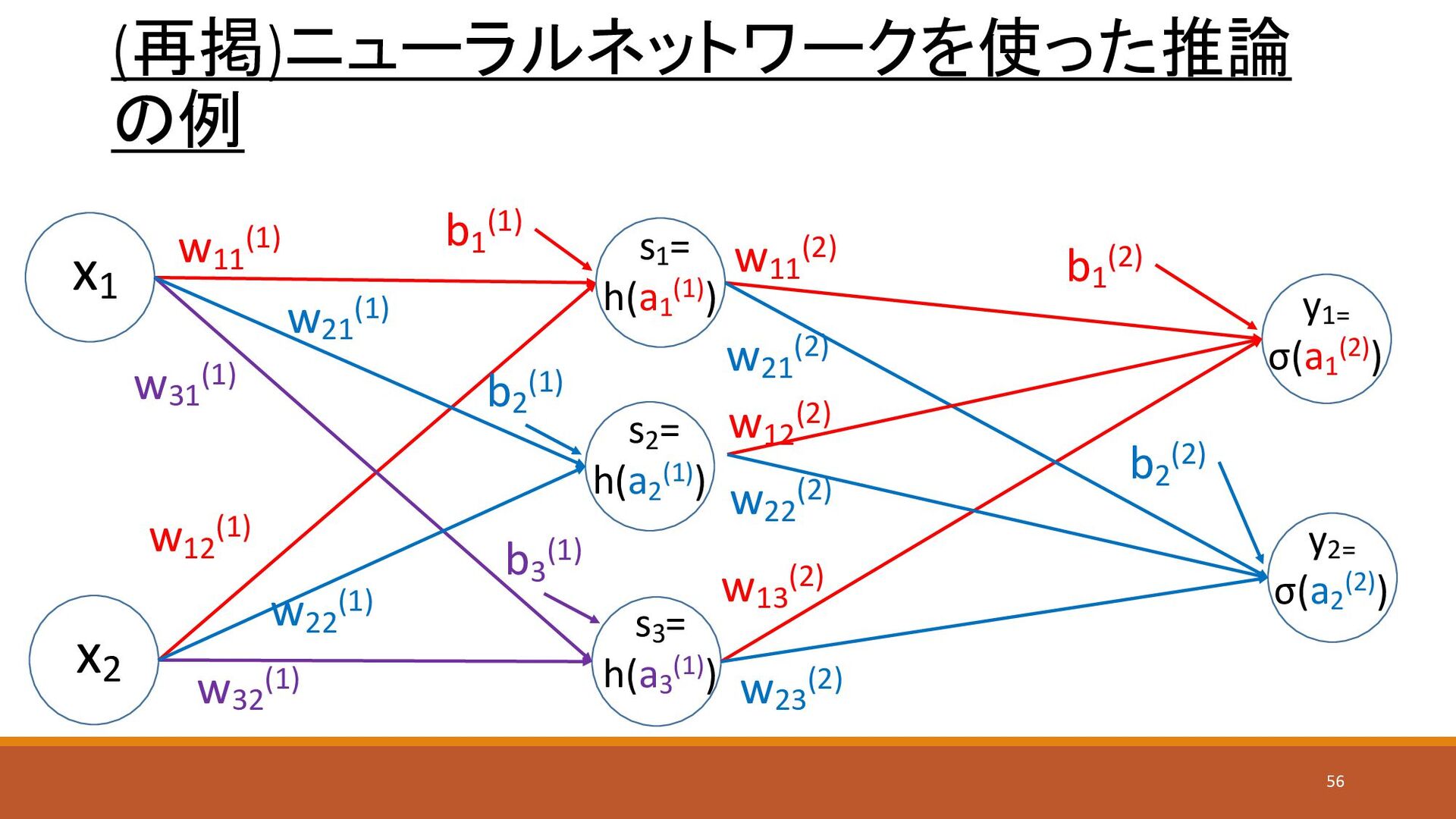
ニューラルネットワーク • パーセプトロンと同様の構造だが、以下が異なる • 入力がそのまま出力になるのではなく、隠れ層(中間層)がある • 出力ノードが複数ある x1 x2 y1=
σ(a1 (2)) s1 = h(a1 (1)) s2 = h(a2 (1)) y2= σ(a2 (2)) 入力層(第0層) 隠れ層(第1層) 出力層(第2層) 22
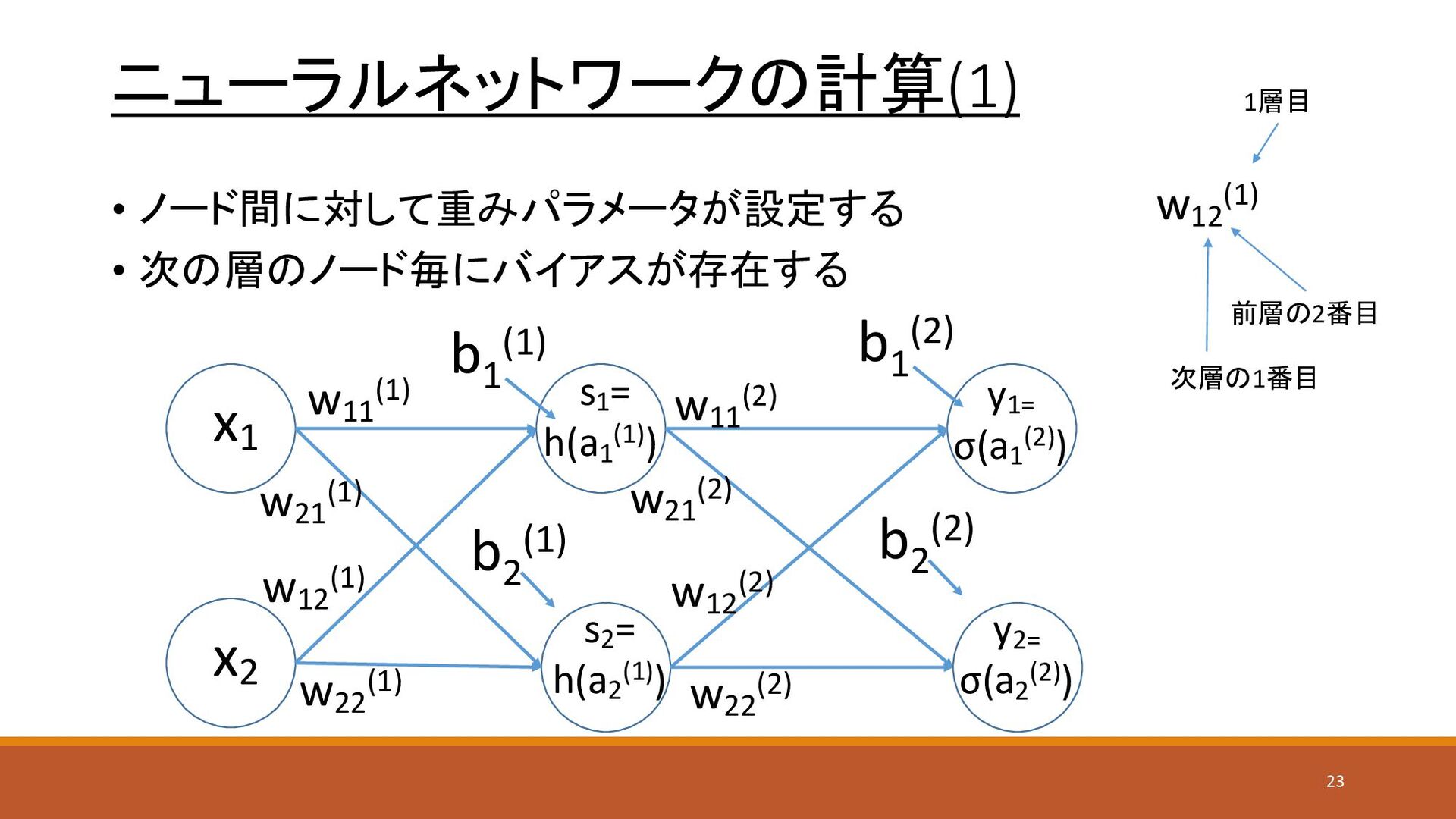
ニューラルネットワークの計算(1) • ノード間に対して重みパラメータが設定する • 次の層のノード毎にバイアスが存在する x1 x2 y1= σ(a1 (2))
s1 = h(a1 (1)) w11 (1) w21 (1) w12 (1) w22 (1) w11 (2) w12 (2) w21 (2) w22 (2) s2 = h(a2 (1)) y2= σ(a2 (2)) b1 (1) b2 (1) b1 (2) b2 (2) w12 (1) 1層目 前層の2番目 次層の1番目 23
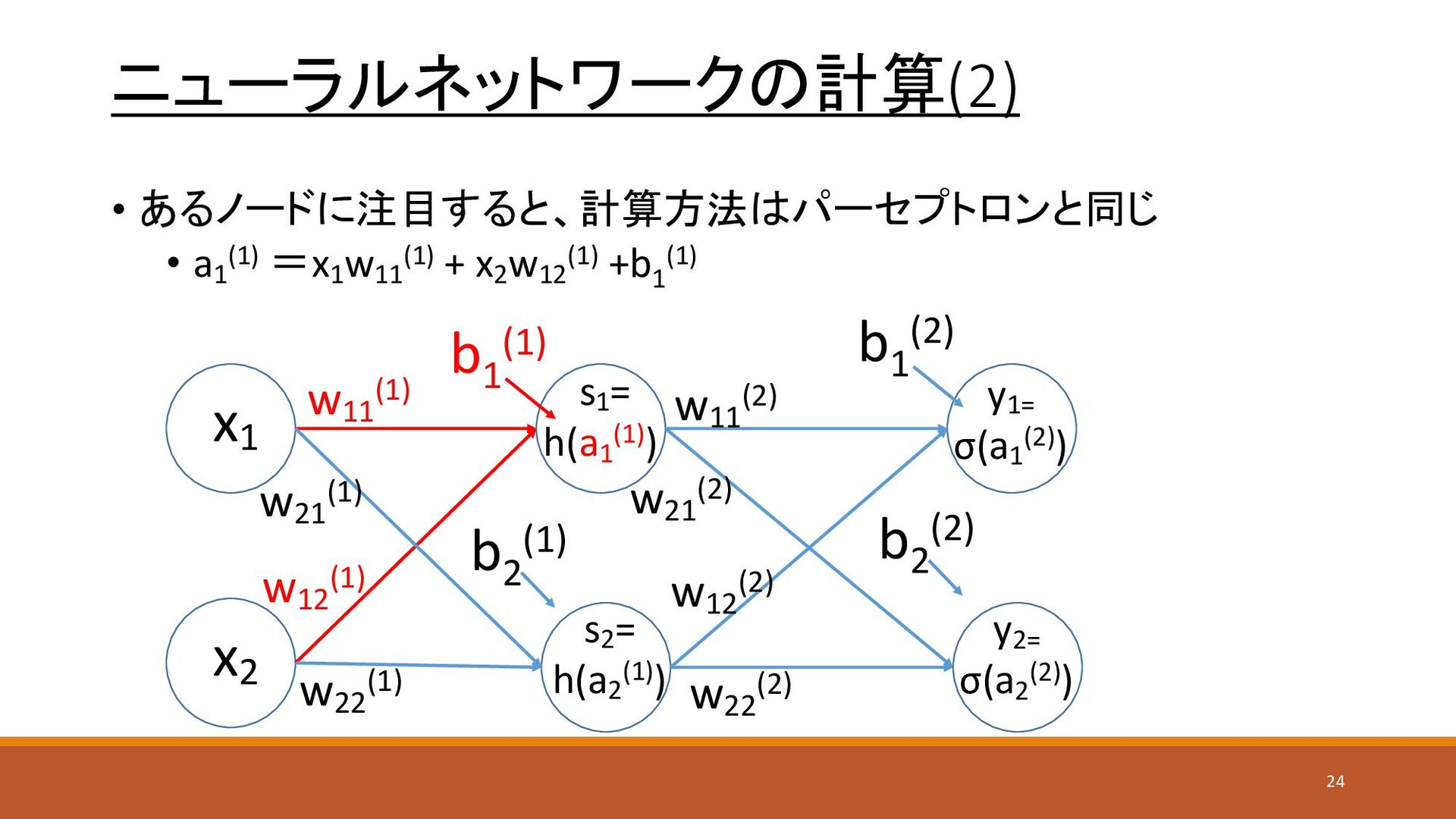
ニューラルネットワークの計算(2) • あるノードに注目すると、計算方法はパーセプトロンと同じ • a1 (1) =x1 w11 (1) +
x2 w12 (1) +b1 (1) x1 x2 y1= σ(a1 (2)) s1 = h(a1 (1)) w11 (1) w21 (1) w12 (1) w22 (1) w11 (2) w12 (2) w21 (2) w22 (2) s2 = h(a2 (1)) y2= σ(a2 (2)) b1 (1) b2 (1) b1 (2) b2 (2) 24
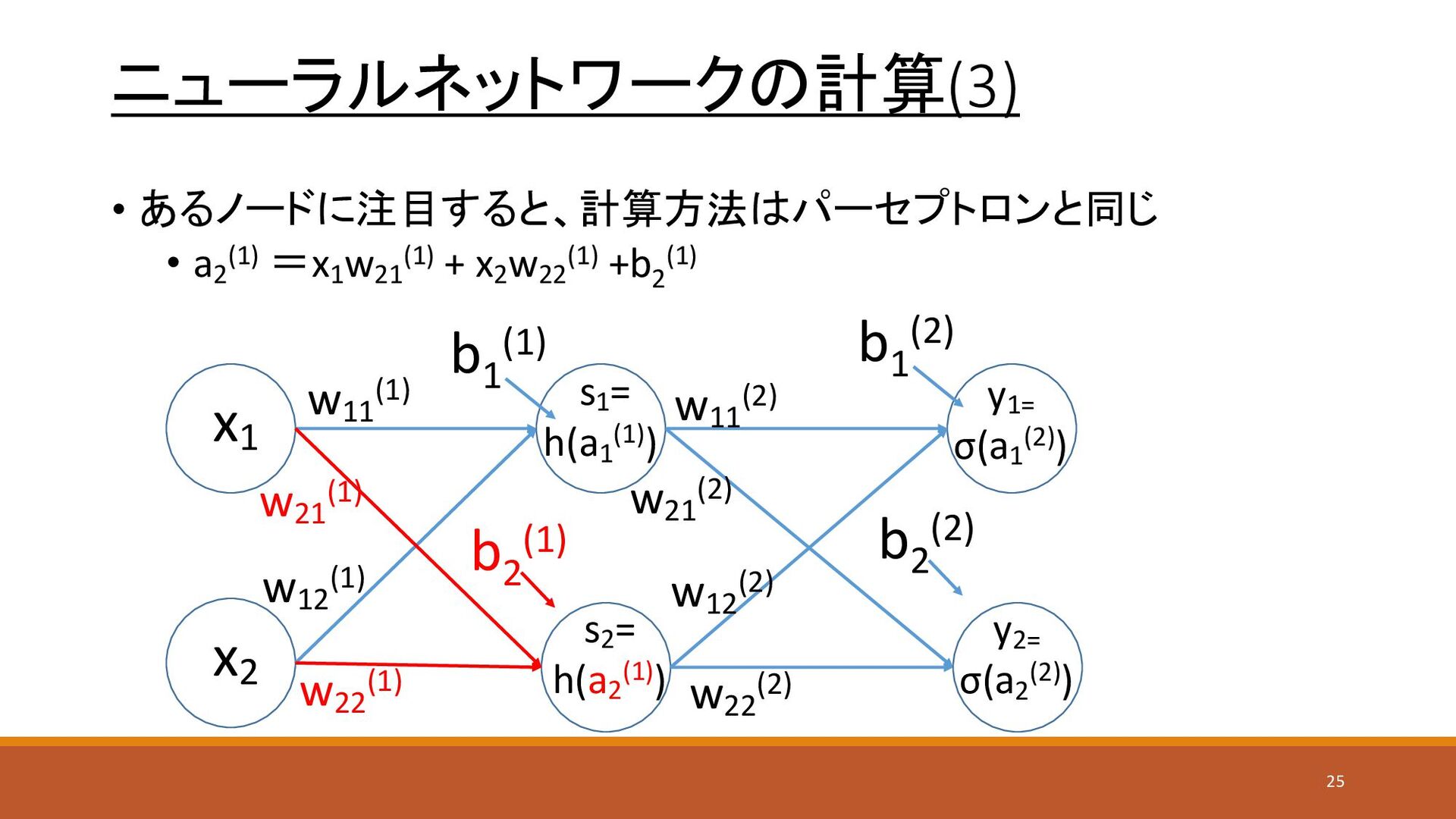
ニューラルネットワークの計算(3) • あるノードに注目すると、計算方法はパーセプトロンと同じ • a2 (1) =x1 w21 (1) +
x2 w22 (1) +b2 (1) x1 x2 y1= σ(a1 (2)) s1 = h(a1 (1)) w11 (1) w21 (1) w12 (1) w22 (1) w11 (2) w12 (2) w21 (2) w22 (2) s2 = h(a2 (1)) y2= σ(a2 (2)) b1 (1) b2 (1) b1 (2) b2 (2) 25
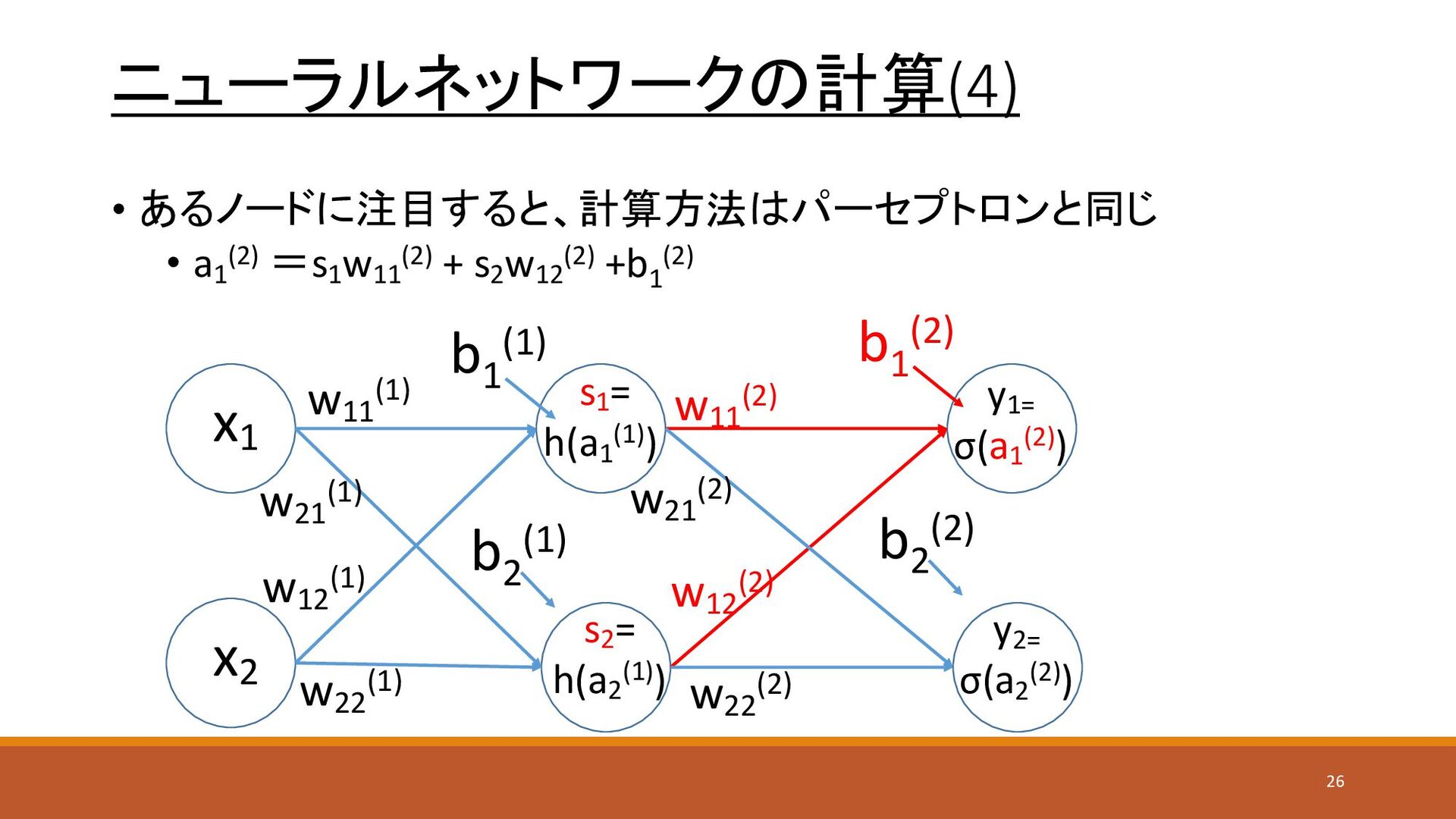
ニューラルネットワークの計算(4) • あるノードに注目すると、計算方法はパーセプトロンと同じ • a1 (2) =s1 w11 (2) +
s2 w12 (2) +b1 (2) x1 x2 y1= σ(a1 (2)) s1 = h(a1 (1)) w11 (1) w21 (1) w12 (1) w22 (1) w11 (2) w12 (2) w21 (2) w22 (2) s2 = h(a2 (1)) y2= σ(a2 (2)) b1 (1) b2 (1) b1 (2) b2 (2) 26
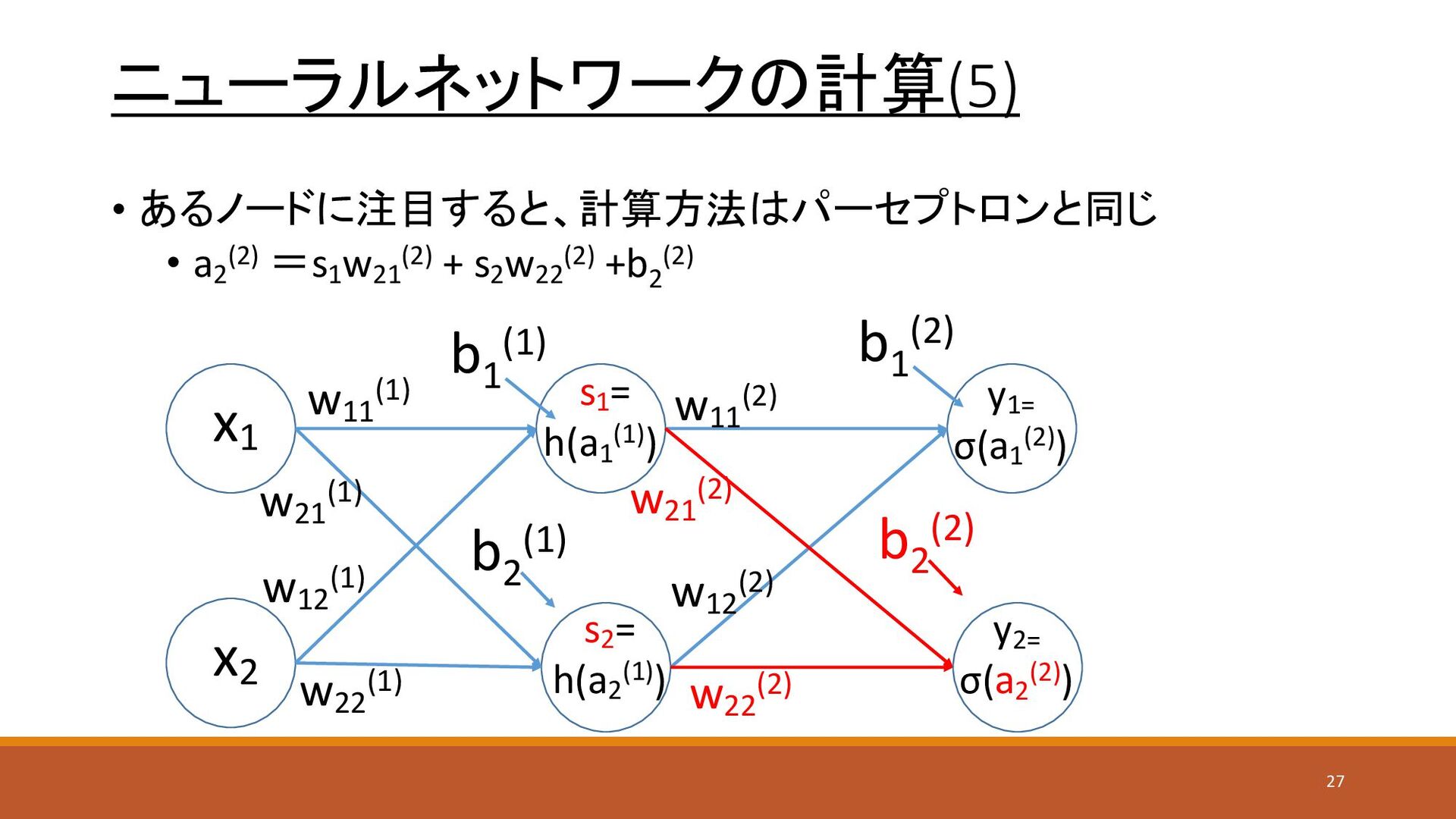
ニューラルネットワークの計算(5) • あるノードに注目すると、計算方法はパーセプトロンと同じ • a2 (2) =s1 w21 (2) +
s2 w22 (2) +b2 (2) x1 x2 y1= σ(a1 (2)) s1 = h(a1 (1)) w11 (1) w21 (1) w12 (1) w22 (1) w11 (2) w12 (2) w21 (2) w22 (2) s2 = h(a2 (1)) y2= σ(a2 (2)) b1 (1) b2 (1) b1 (2) b2 (2) 27
ニューラルネットワークを使った推論(1) • ニューラルネットワークを使い、入力として2つの数値を受け取り、そ の結果がパターン1かパターン2かを推測してみる(分類問題) • 出力層のノードを2つとし、それぞれパターン1,2とみなす • 出力層のノードの値は推測の確度を意味するとみなす • 出力がy1
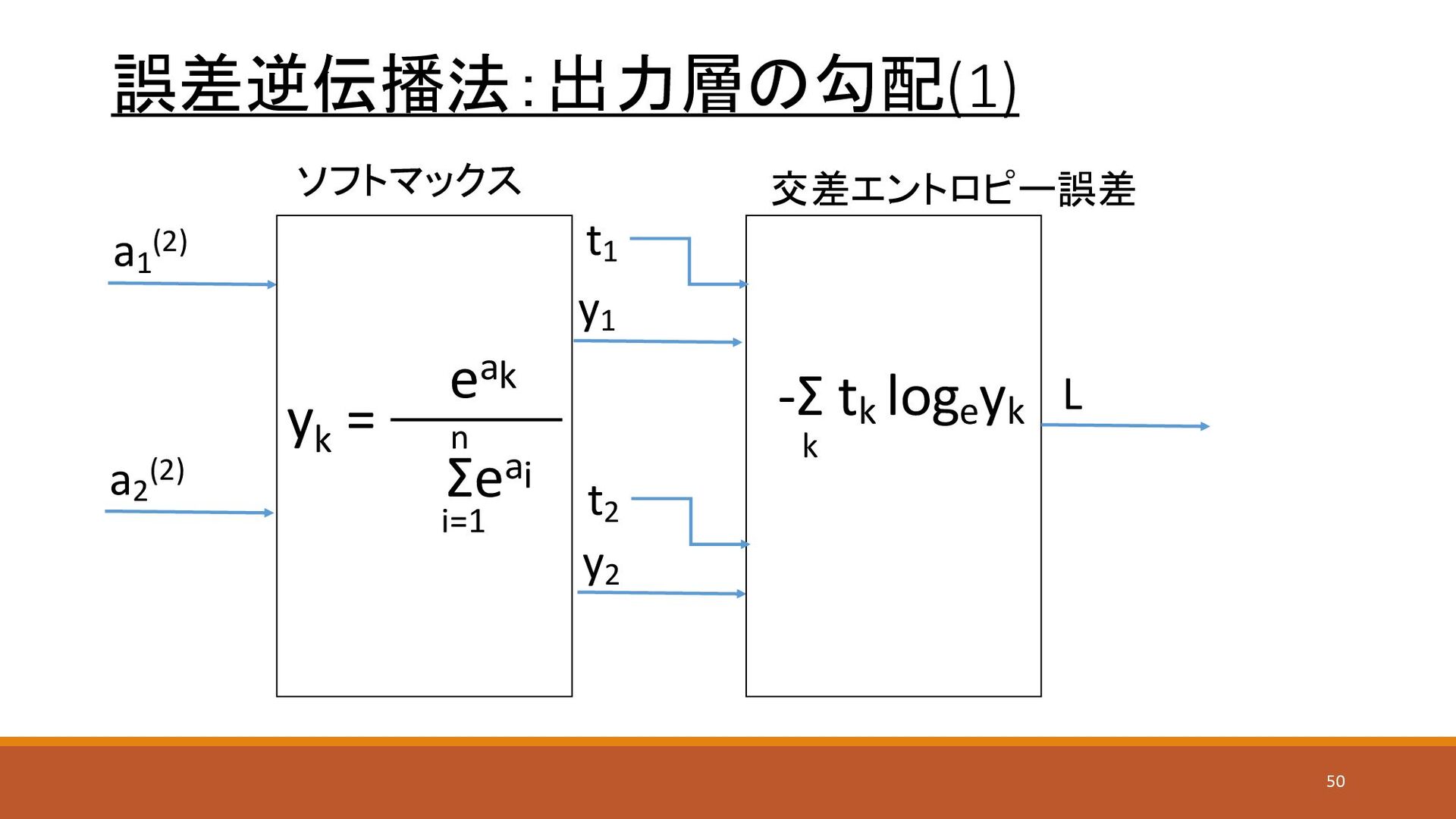
=0.7、y2 =0.3となった場合、パターン1の確率が70%、パターン2 の確率が30%とみなす • 隠れ層の活性化関数としてReLU関数を使う • 出力層の活性化関数としてソフトマックス関数を使う • 損失関数として交差エントロピー誤差を使う 28
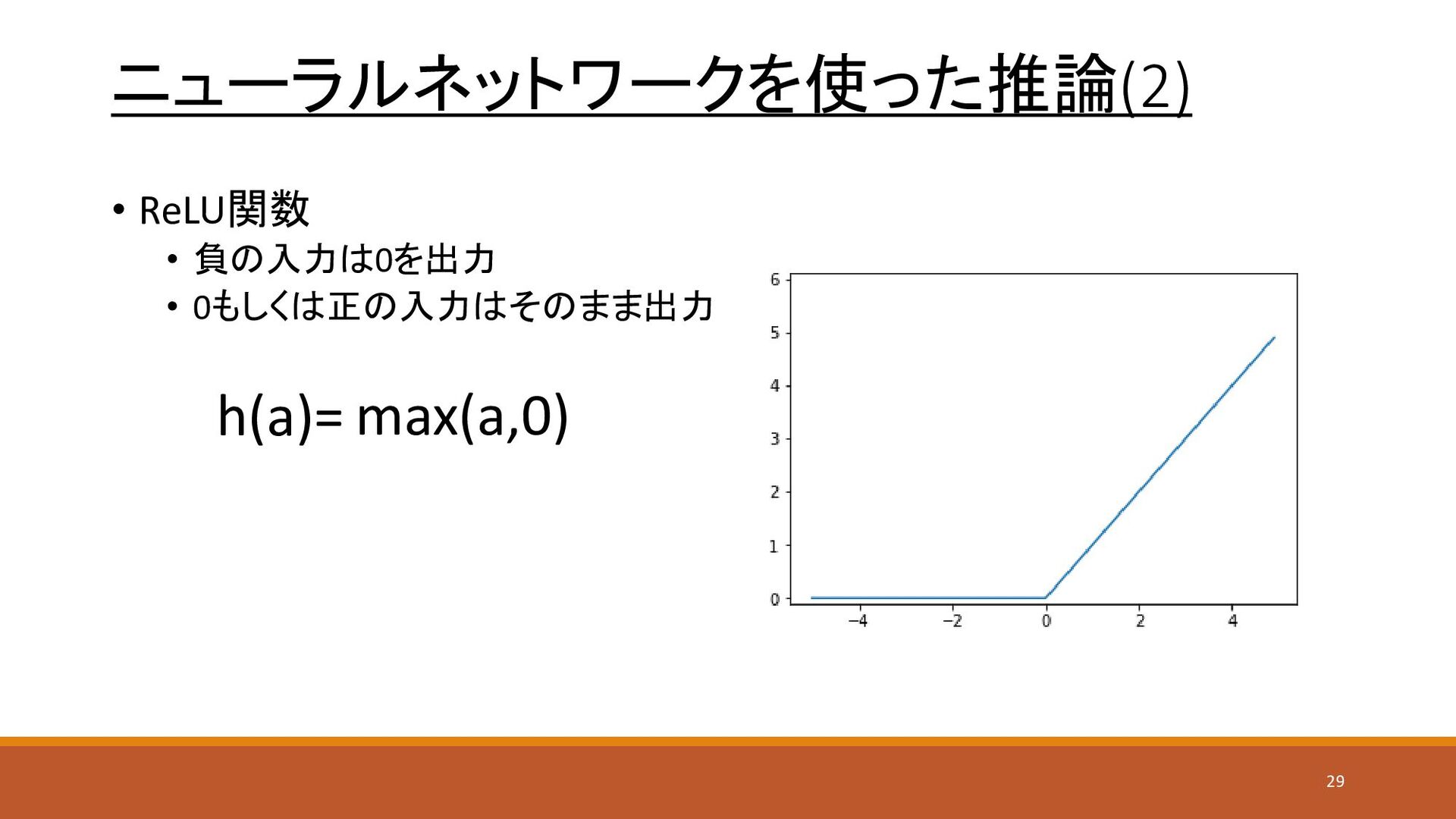
ニューラルネットワークを使った推論(2) • ReLU関数 • 負の入力は0を出力 • 0もしくは正の入力はそのまま出力 h(a)= max(a,0) 29
ニューラルネットワークを使った推論(3) • ソフトマックス関数 • 出力は0~1の実数かつ、総和が1になる • 計算例 • a1 =1,
a2 =2, a3 =3 • 分母=e1+e2+e3=2.7182 + 7.3890 +20.0855 = 30.1727 • y1 =2.7182/30.1727 = 0.0900, y2 =7.3890/30.1727 = 0.2448, y3 =20.0855/30.1727 = 0.6656 • y1 = = 9.0%, y2 =24.4%, y3 =66.5% 合計99.9% yk = eak Σeai i=1 n 30
ニューラルネットワークを使った推論(4) • 交差エントロピー誤差 • tは正解ラベル。正解のみ1、それ以外は0とする想定 • 先ほどの例y1 = 0.0900, y2
= 0.2448, y3 = 0.6656で各正解ケースを計算 • E = -(t1 log y1 + t2 log y2 + t3 log y2 ) • t1 =1、 t2 =0、 t3 =0: -(log 0.0900) = 2.4079 • t1 =0、 t2 =1、 t3 =0: -(log 0.2448) = 1.4073 • t1 =0、 t2 =0、 t3 =1: -(log 0.6656) = 0.4070 • y3 が正解であると予測しているので、 t3 =1の場合が一番値が小さい • なぜこのような面倒な計算をするかは、後述の誤差逆伝播法で便利なため E = -Σ tk loge yk k 31
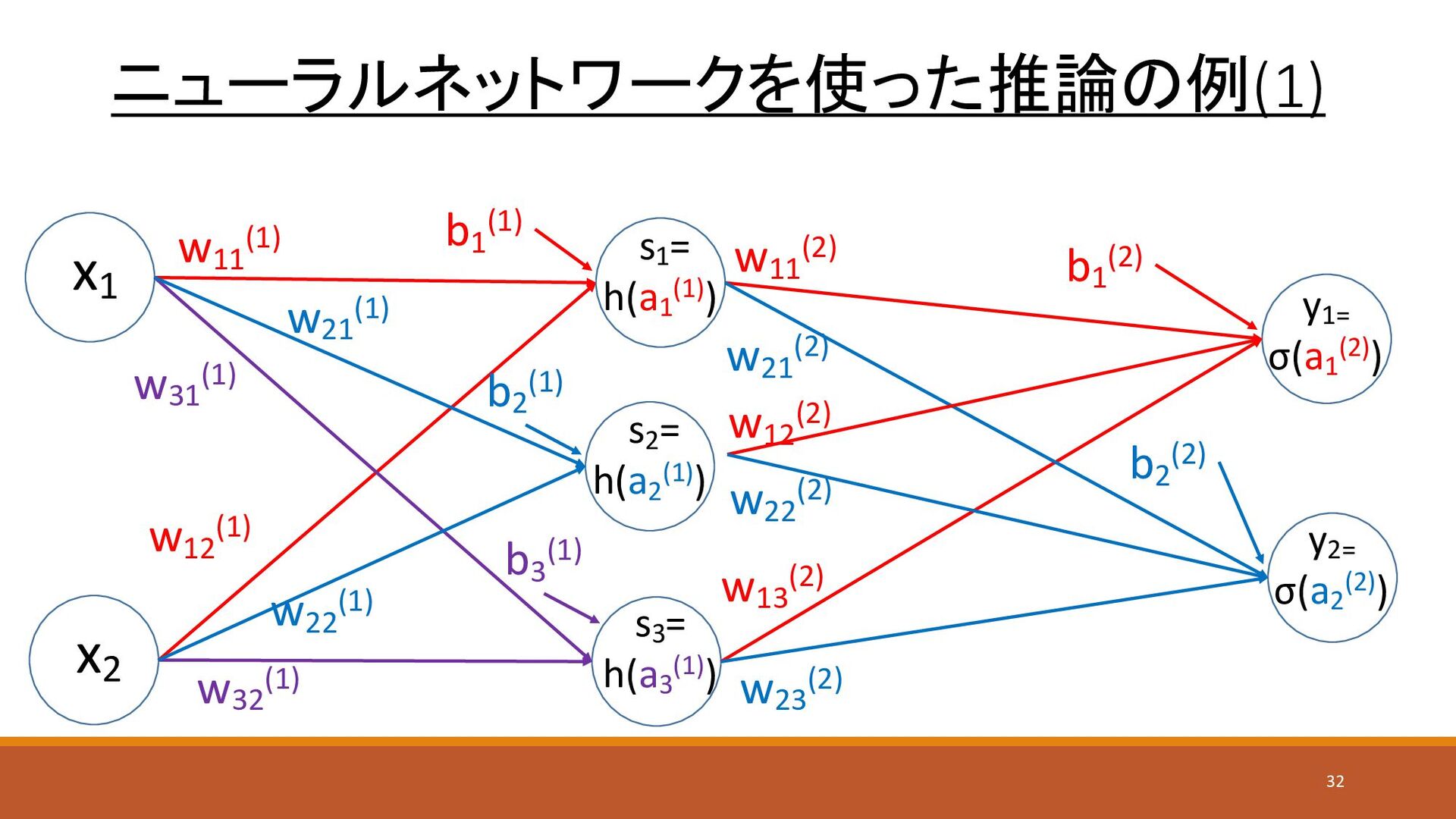
ニューラルネットワークを使った推論の例(1) x1 x2 y1= σ(a1 (2)) s1 = h(a1 (1))
w11 (1) w22 (1) w12 (1) w32 (1) w11 (2) w13 (2) w21 (2) w23 (2) s3 = h(a3 (1)) y2= σ(a2 (2)) s2 = h(a2 (1)) w21 (1) w31 (1) w12 (2) w22 (2) b1 (1) b2 (1) b3 (1) b1 (2) b2 (2) 32
ニューラルネットワークを使った推論の例(2) • 入力:x1 =1、x2 =2 • 重みパラメータ(入力層→隠れ層): • w11 (1)
=0.1、 w21 (1) =0.3 、 w31 (1) =0.5 • w12 (1) =0.2、 w22 (1) =0.4 、 w32 (1) = -0.6 • b1 (1) =0.1、 b2 (1) =0.2、 b3 (1) =0.3 • 重みパラメータ(隠れ層→出力層): • w11 (2) =0.1、 w21 (2) =0.4 • w12 (2) =0.2、 w22 (2) =0.5 • w13 (2) =0.3、 w23 (2) =0.6 • b1 (2) =0.1、 b2 (2) =0.2 33
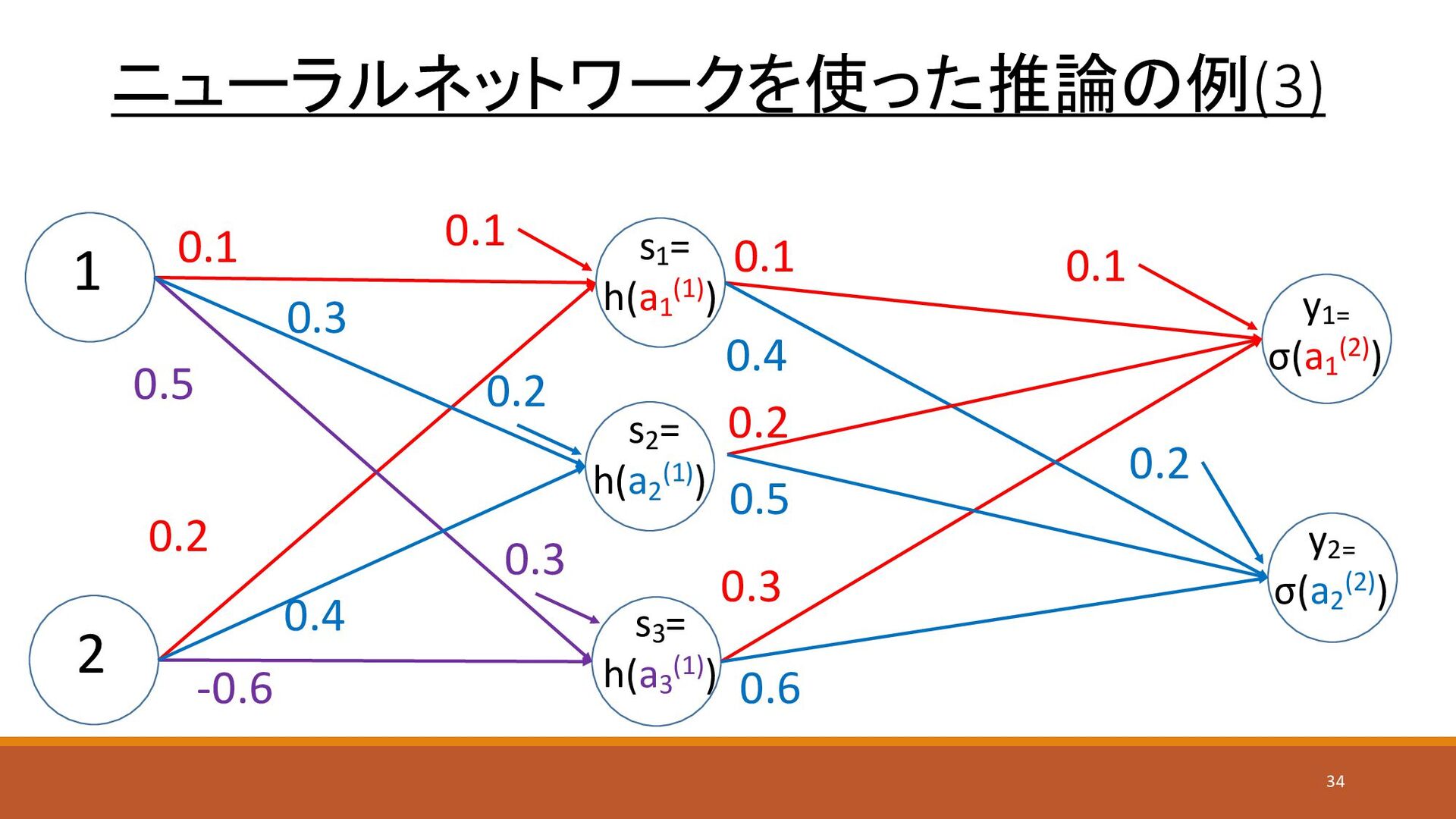
ニューラルネットワークを使った推論の例(3) 1 2 y1= σ(a1 (2)) s1 = h(a1 (1))
0.1 0.4 0.2 -0.6 0.1 0.3 0.4 0.6 s3 = h(a3 (1)) y2= σ(a2 (2)) s2 = h(a2 (1)) 0.3 0.5 0.2 0.5 0.1 0.2 0.3 0.1 0.2 34
ニューラルネットワークを使った推論の例(4) • 隠れ層1つ目への入力 • a1 (1) = x1 × w11
(1) + x2 × w12 (1) + b1 (1) = (1 ×0.1) + (2 ×0.2) + 0.1 = 0.6 • a2 (1) = x1 × w21 (1) + x2 × w22 (1) + b2 (1) = (1 ×0.3) + (2 ×0.4) + 0.2 = 1.3 • a3 (1) = x1 × w31 (1) + x2 × w32 (1) + b3 (1) = (1 ×0.5) + (2 ×-0.6) + 0.3 = -0.4 • 隠れ層の活性化関数の適用(ReLU関数) • h(a1 (1)) = 0.6、h(a2 (1)) = 1.3、h(a3 (1)) = 0 35
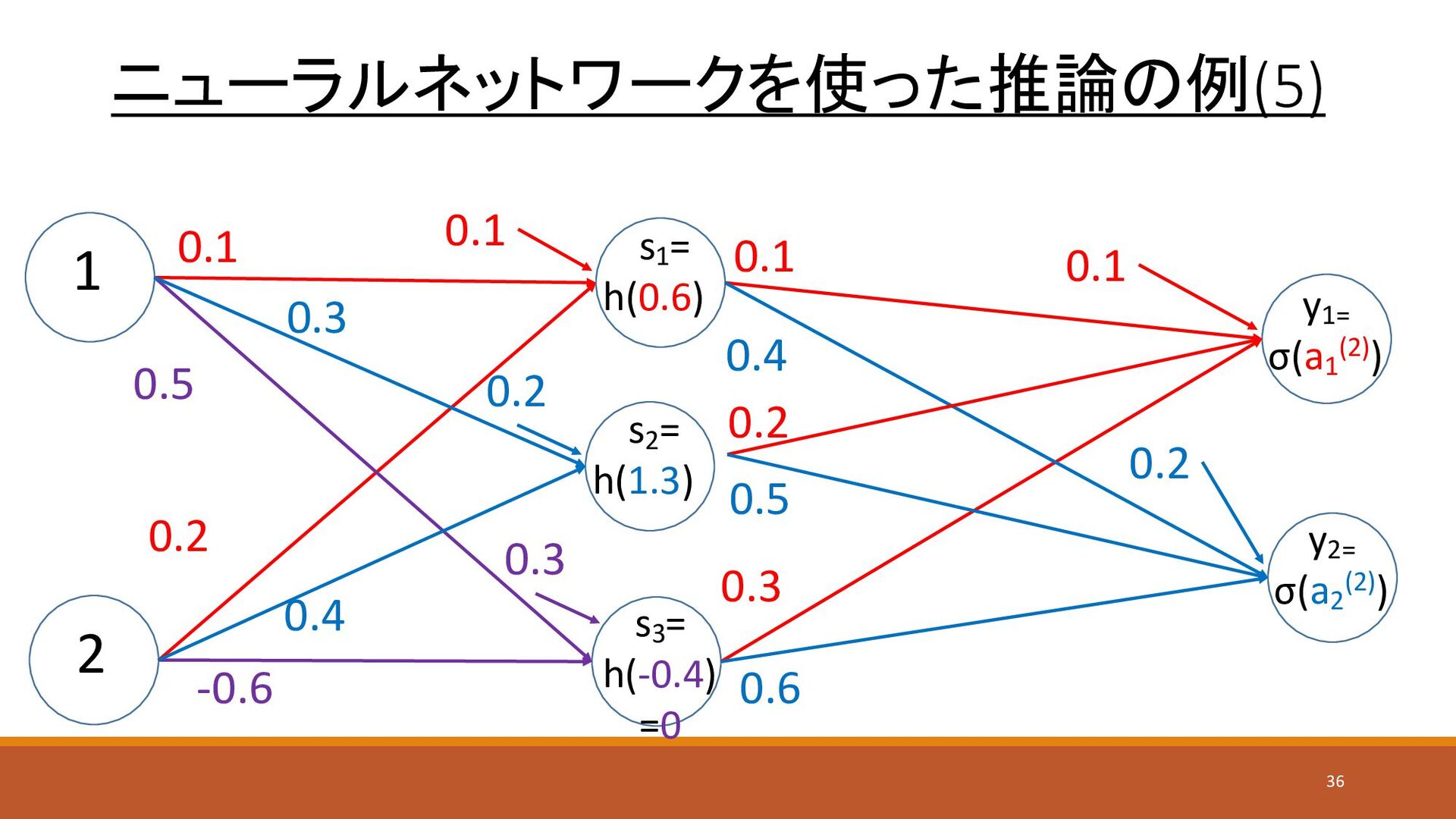
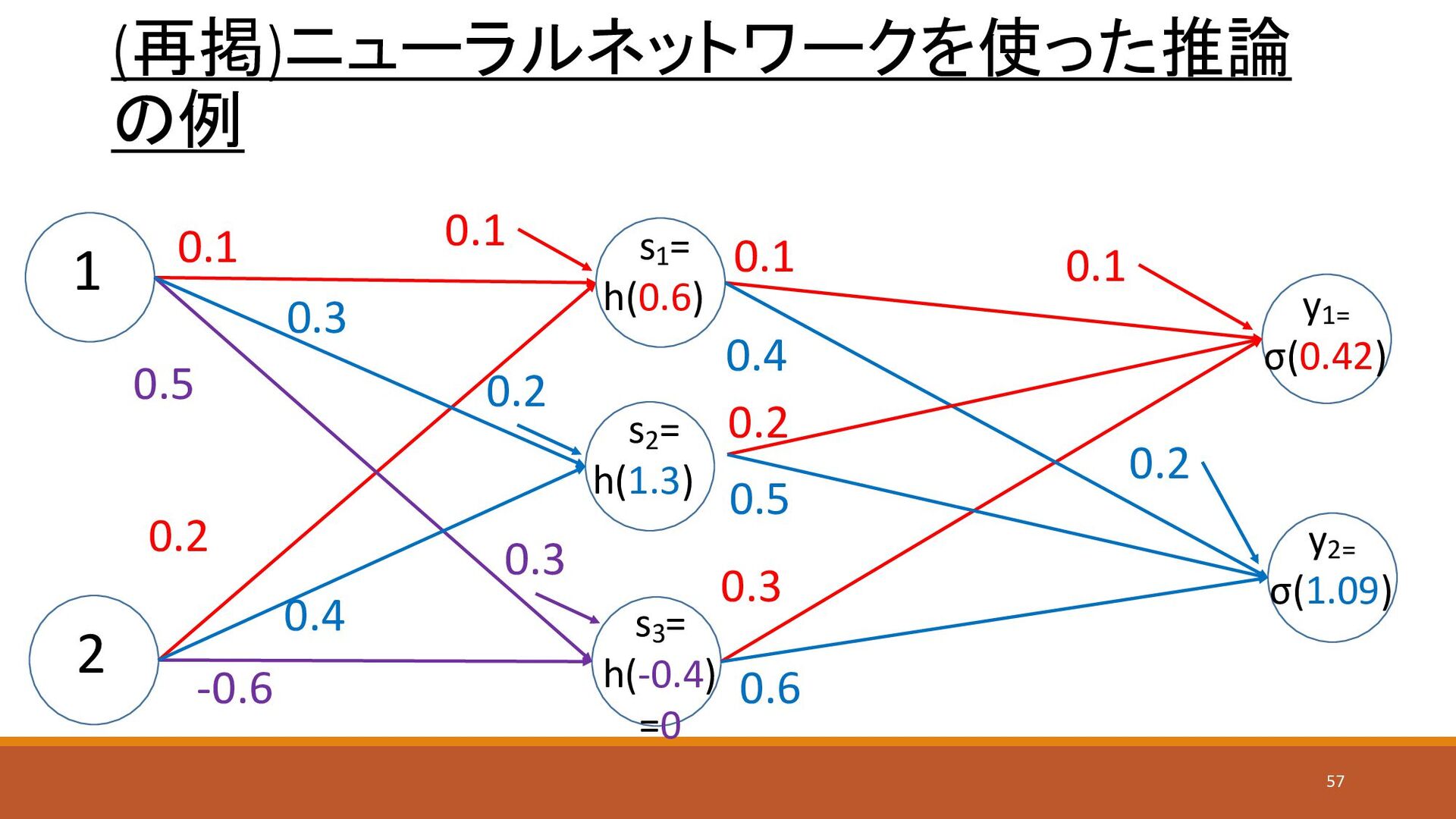
ニューラルネットワークを使った推論の例(5) 1 2 y1= σ(a1 (2)) s1 = h(0.6) 0.1
0.4 0.2 -0.6 0.1 0.3 0.4 0.6 s3 = h(-0.4) =0 y2= σ(a2 (2)) s2 = h(1.3) 0.3 0.5 0.2 0.5 0.1 0.2 0.3 0.1 0.2 36
ニューラルネットワークを使った推論の例(6) • 出力層への入力 • a1 (2) = h(a1 (1) )
× w11 (2) + h(a2 (1) ) × w12 (2) + h(a3 (1) ) × w12 (2) + b1 (2) = (0.6×0.1) + (1.3 ×0.2) + (0 ×0.3) + 0.1 = 0.42 • a2 (2) = h(a1 (1) ) × w21 (2) + h(a2 (1) ) × w22 (2) + h(a3 (1) ) × w23 (2) + b2 (2) = (0.6×0.4) + (1.3 ×0.5) + (0 ×0.6) + 0.2 = 1.09 37
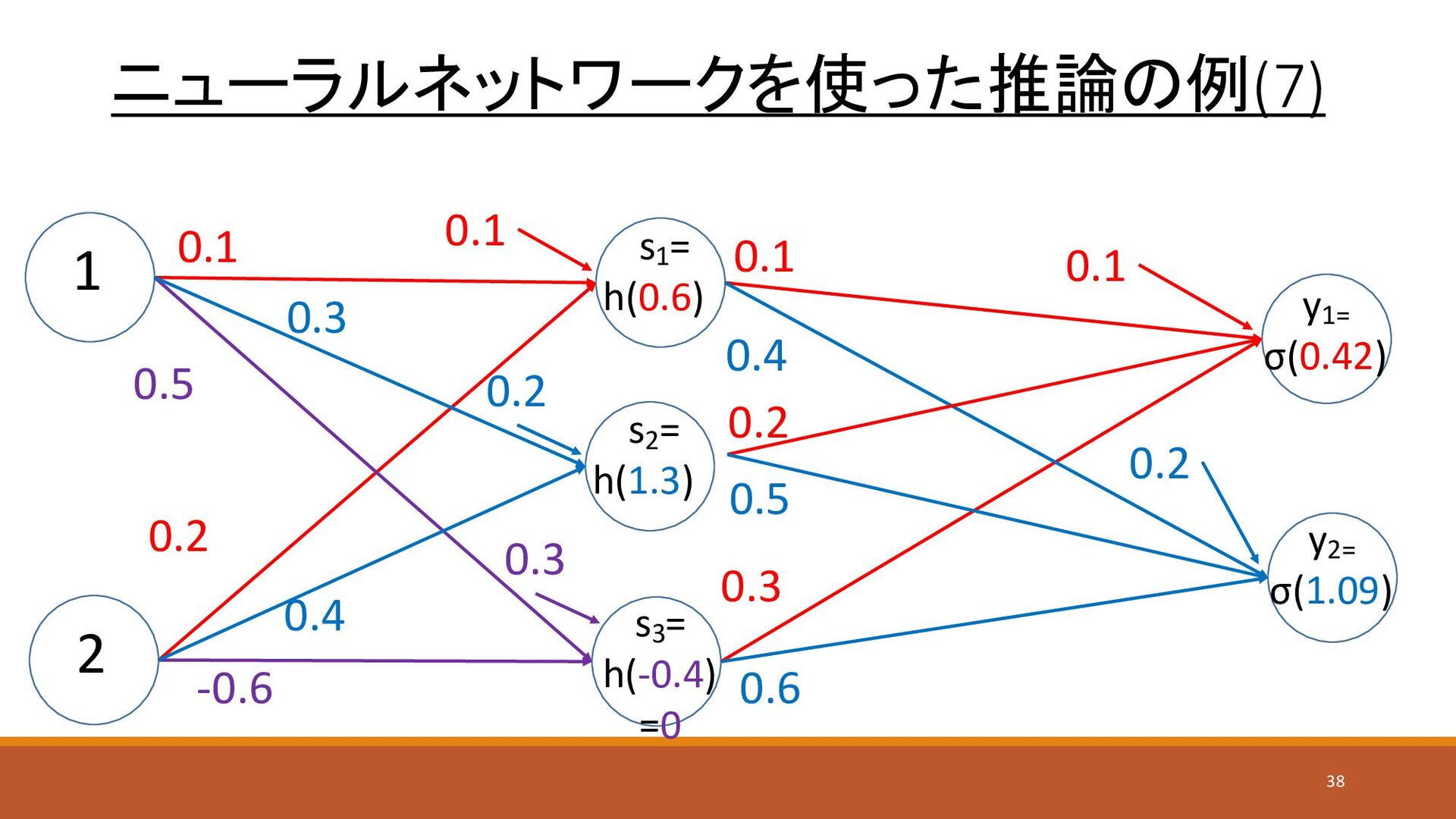
ニューラルネットワークを使った推論の例(7) 1 2 y1= σ(0.42) s1 = h(0.6) 0.1 0.4
0.2 -0.6 0.1 0.3 0.4 0.6 s3 = h(-0.4) =0 y2= σ(1.09) s2 = h(1.3) 0.3 0.5 0.2 0.5 0.1 0.2 0.3 0.1 0.2 38
ニューラルネットワークを使った推論の例(8) • 出力層の活性化関数(ソフトマックス)の適用 • 計算例 • y1 = ea1 /
(ea1 + ea2) = e0.42 / (e0.42 + e1.09) = 0.33849684079 • y2 = ea2 / (ea1 + ea2) = e1.09 / (e0.42 + e1.09) = 0.6615031592 • 0.33849684079 + 0.6615031592 = 0.99999999999 yk = eak Σeai i=1 n 39
ニューラルネットワークを使った推論の例(9) • 損失関数(交差エントロピー誤差)の計算 • 正解は2番目である場合(t1 =0、 t2 =1) • -(t1
log y1 + t2 log y2 ) = -(0×log 0.33849684079 + 1×log 0.6615031592) = 0.413240519625984 • 正解は1番目である場合(t1 =1、 t2 =0) • -log 0.33849684079 = 1.08324051964234 • 正解である2番目に対応するy2 がy1 より値が大きい場合の方が損失 関数の値が小さい(=適切な値である) E = -Σ tk loge yk k 40
ニューラルネットワークを使った学習の例(1) • パーセプトロンと同様に勾配法を用いて学習が出来る • w11 (1)の計算例 • 隠れ層1つ目への入力 • a1
(1) = x1 × w11 (1) + x2 × w12 (1) + b1 (1) = (1 ×0.1001) + (2 ×0.2) + 0.1 = 0.6001 • a2 (1) = x1 × w21 (1) + x2 × w22 (1) + b2 (1) = (1 ×0.3) + (2 ×0.4) + 0.2 = 1.3 • a3 (1) = x1 × w31 (1) + x2 × w32 (1) + b3 (1) = (1 ×0.5) + (2 ×-0.6) + 0.3 = -0.4 → 0 • 出力層への入力 • a1 (2) = h (a1 (1) )× w11 (2) + h(a2 (1) )× w12 (2) + h(a3 (1) )× w31 (2) + b1 (2) = (0.6001×0.1) + (1.3 ×0.2) + (0 ×0.3) + 0.1 = 0.42001 • a2 (2) = h(a1 (1) ) × w21 (2) + h(a2 (1) ) × w22 (2) + h(a3 (1) ) × w32 (2) + b2 (2) = (0.6001×0.4) + (1.3 ×0.5) + (0 ×0.6) + 0.2 = 1.09004 41
ニューラルネットワークを使った学習の例(2) • 出力層の活性化関数(ソフトマックス関数) • y1 = ea1 / (ea1 +
ea2) = e0.42001 / (e0.42001 + e1.09004) = 0.33849012332 • y2 = ea2 / (ea1 + ea2) = e1.09004 / (e0.42001 + e1.09004) = 0.66150987667 • 損失関数(交差エントロピー誤差) • -(t1 log y1 + t2 log y2 ) = -(0×log 0.33849012332 + 1×log 0.66150987667) = 0.413230364820524 • 勾配の計算(※f(x-h)の計算は省略してf(x)を使う) • f(x+h)-f(x)=0.413230364820524 - 0.413240519625984 = -0.0000101548 • f(x+h)-f(x)/h=-0.0000101548/ 0.0001 = -0.101548 • 勾配の値-0.101548 ×-1×学習率だけ w11 (1) をずらす 42
ニューラルネットワークを使った画像分類(1) • MNISTデータセットという手書き数字の画像を使う • 28×28ピクセルのグレー画像(1ピクセルは0~255の値を持つ) • その画像が0~9までのどれに対応するかの情報も持つ • 入力層の値として、各ピクセルの値を使う •
28×28=x1 ~x784 • 出力層のノードは0~9に対応する10個を用意する • 隠れ層として第1層に50ノード、第2層に100ノードを用意 • これはハイパーパラメータなので個数は適当 • 上記で勾配法で学習すると、90%程度の正答率が出せる 43
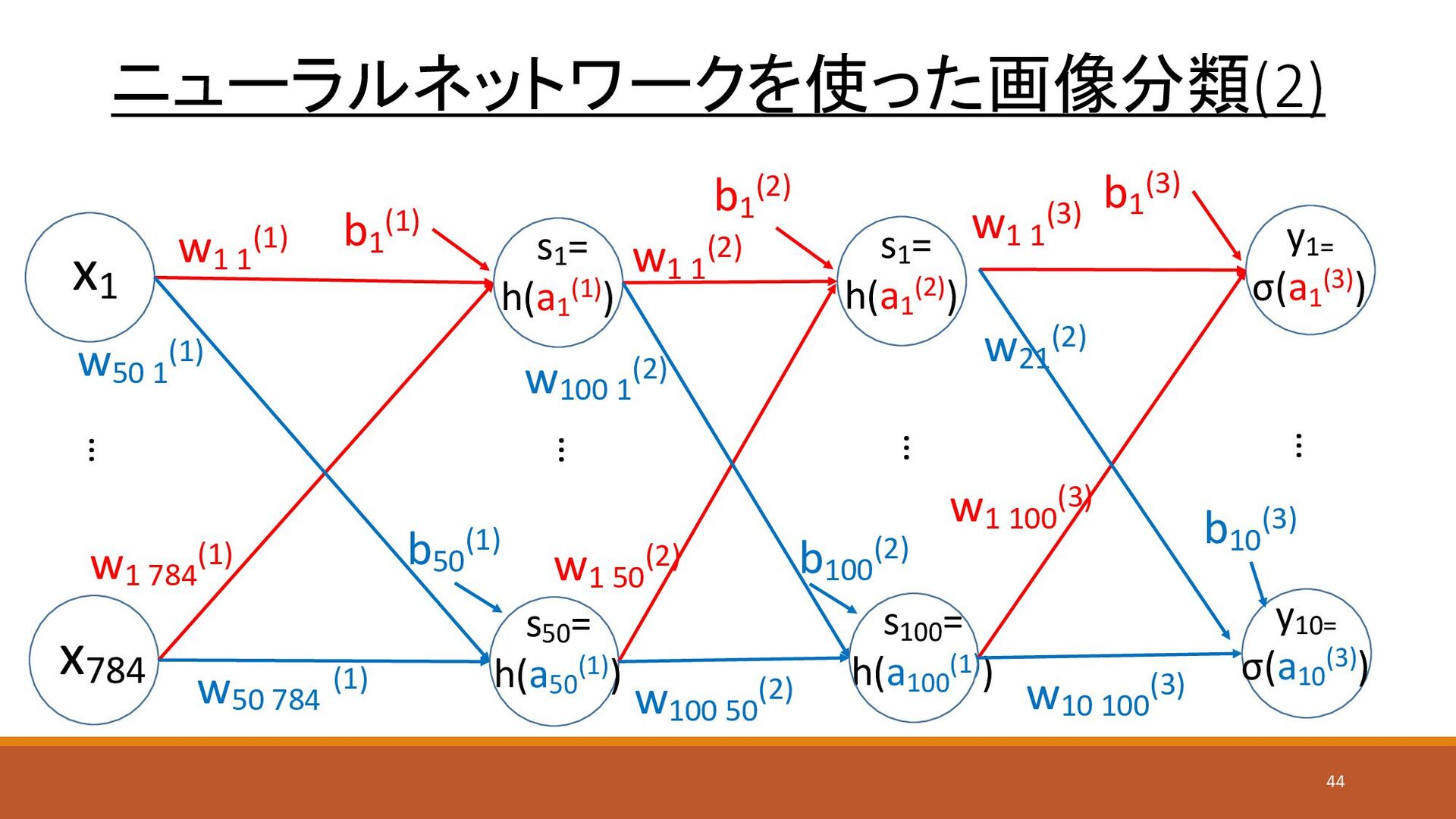
s100 = h(a100 (1)) ニューラルネットワークを使った画像分類(2) x1 x784 y1= σ(a1 (3))
s1 = h(a1 (1)) w1 1 (1) w1 784 (1) w50 784 (1) w1 1 (2) w1 50 (2) w100 1 (2) w100 50 (2) s50 = h(a50 (1)) y10= σ(a10 (3)) … w50 1 (1) b1 (1) b50 (1) b1 (3) b10 (3) … s1 = h(a1 (2)) w1 1 (3) w1 100 (3) w21 (2) w10 100 (3) b1 (2) b100 (2) … … 44
誤差逆伝播法 45
誤差逆伝播法 • 勾配法の数値微分の計算は非常にコストが高い • 重みやバイアス1つごとに、損失関数の計算を1から行うため • 誤差逆伝播法を使うことで計算コストを抑えることができる • あるノードに対する入力と、次のノードの勾配だけを使って、そのノードの勾 配を計算できる
• y=f(x)という関数で計算されるノードの勾配は、f(x)をxで微分した値(dy/dx)× その次のノードの勾配(=E)で計算できる(連鎖律) f x y E E dx dy 46
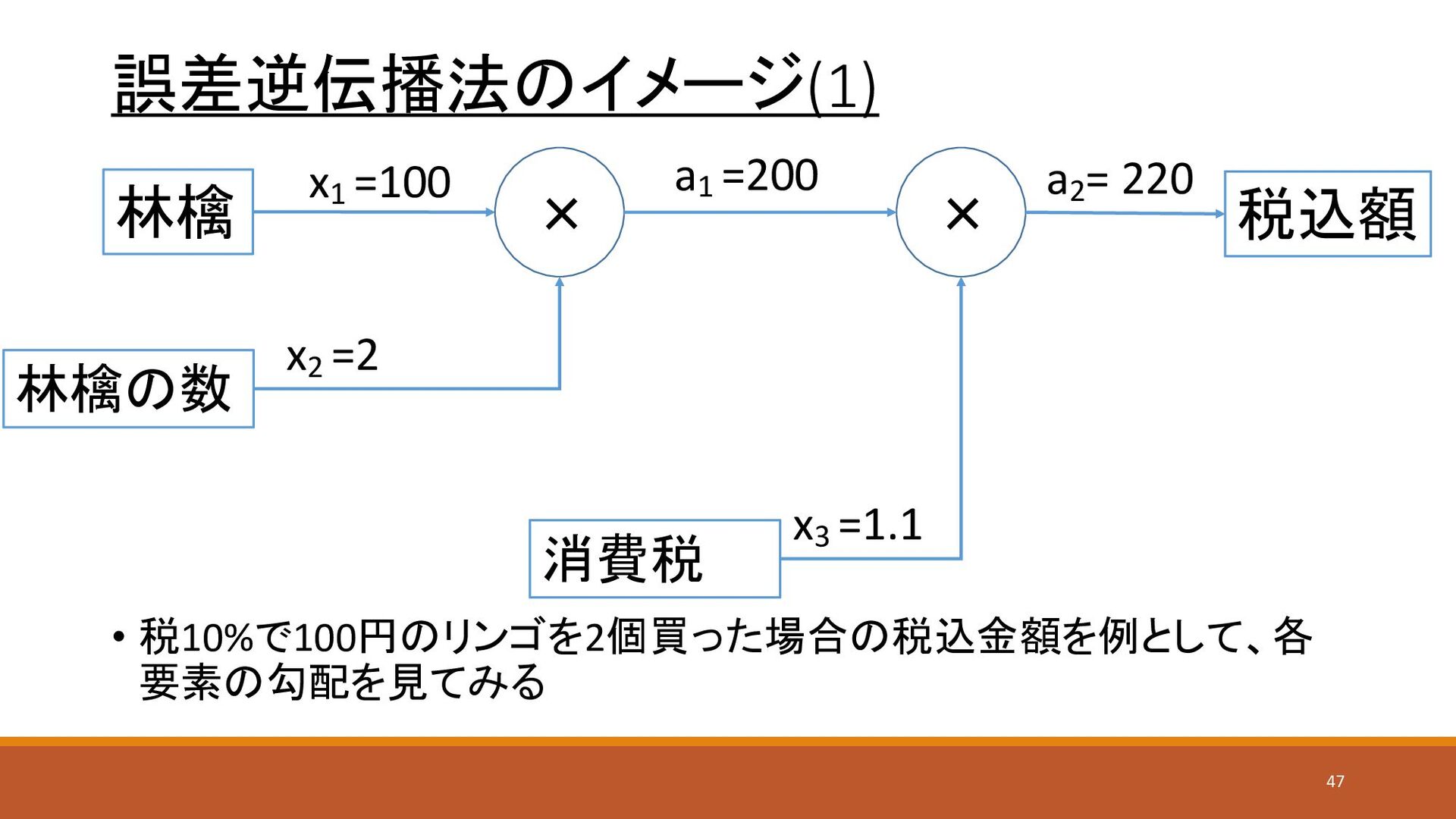
誤差逆伝播法のイメージ(1) × 林檎 林檎の数 消費税 × 税込額 a2 = 220
x1 =100 x2 =2 x3 =1.1 a1 =200 • 税10%で100円のリンゴを2個買った場合の税込金額を例として、各 要素の勾配を見てみる 47
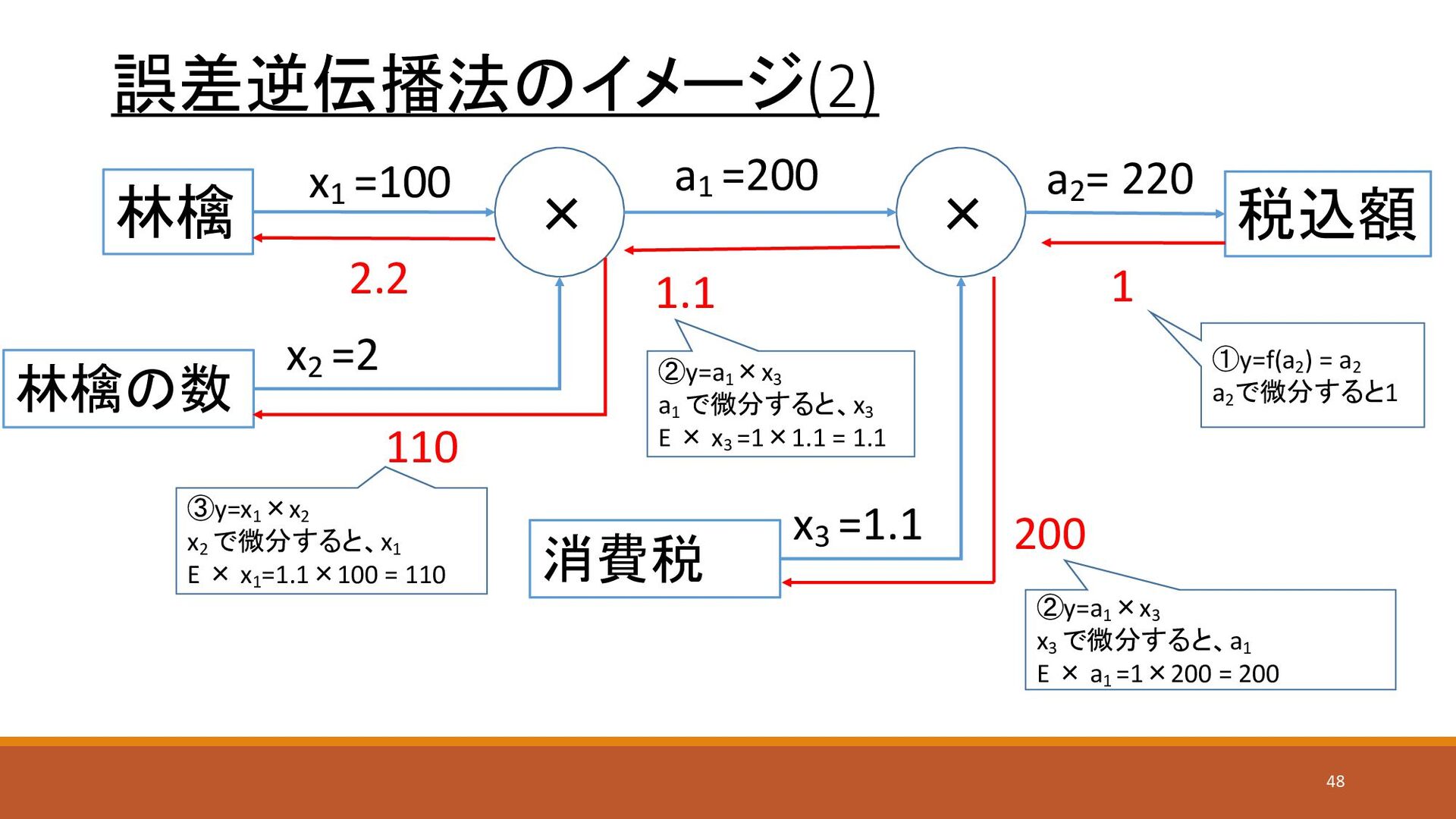
誤差逆伝播法のイメージ(2) × 林檎 林檎の数 消費税 × 税込額 a2 = 220
①y=f(a2 ) = a2 a2 で微分すると1 1 ②y=a1 ×x3 a1 で微分すると、x3 E × x3 =1×1.1 = 1.1 200 1.1 110 2.2 ③y=x1 ×x2 x2 で微分すると、x1 E × x1 =1.1×100 = 110 x1 =100 x2 =2 x3 =1.1 a1 =200 ②y=a1 ×x3 x3 で微分すると、a1 E × a1 =1×200 = 200 48
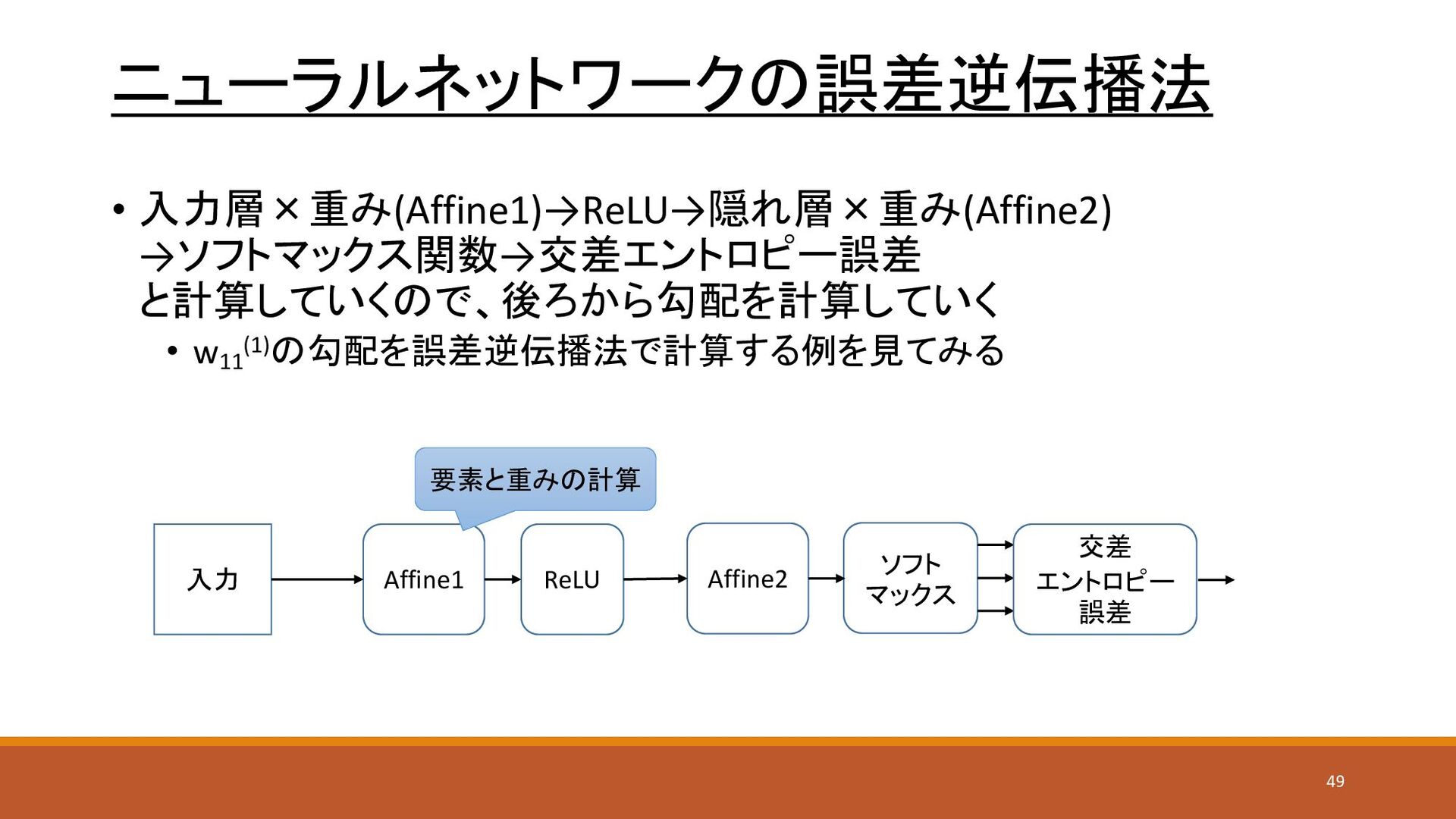
ニューラルネットワークの誤差逆伝播法 • 入力層×重み(Affine1)→ReLU→隠れ層×重み(Affine2) →ソフトマックス関数→交差エントロピー誤差 と計算していくので、後ろから勾配を計算していく • w11 (1)の勾配を誤差逆伝播法で計算する例を見てみる 入力 Affine1
ReLU ソフト マックス Affine2 要素と重みの計算 交差 エントロピー 誤差 49
誤差逆伝播法:出力層の勾配(1) ソフトマックス a1 (2) a2 (2) y1 y2 交差エントロピー誤差 L
t1 t2 yk = eak Σeai i=1 n -Σ tk loge yk k 50
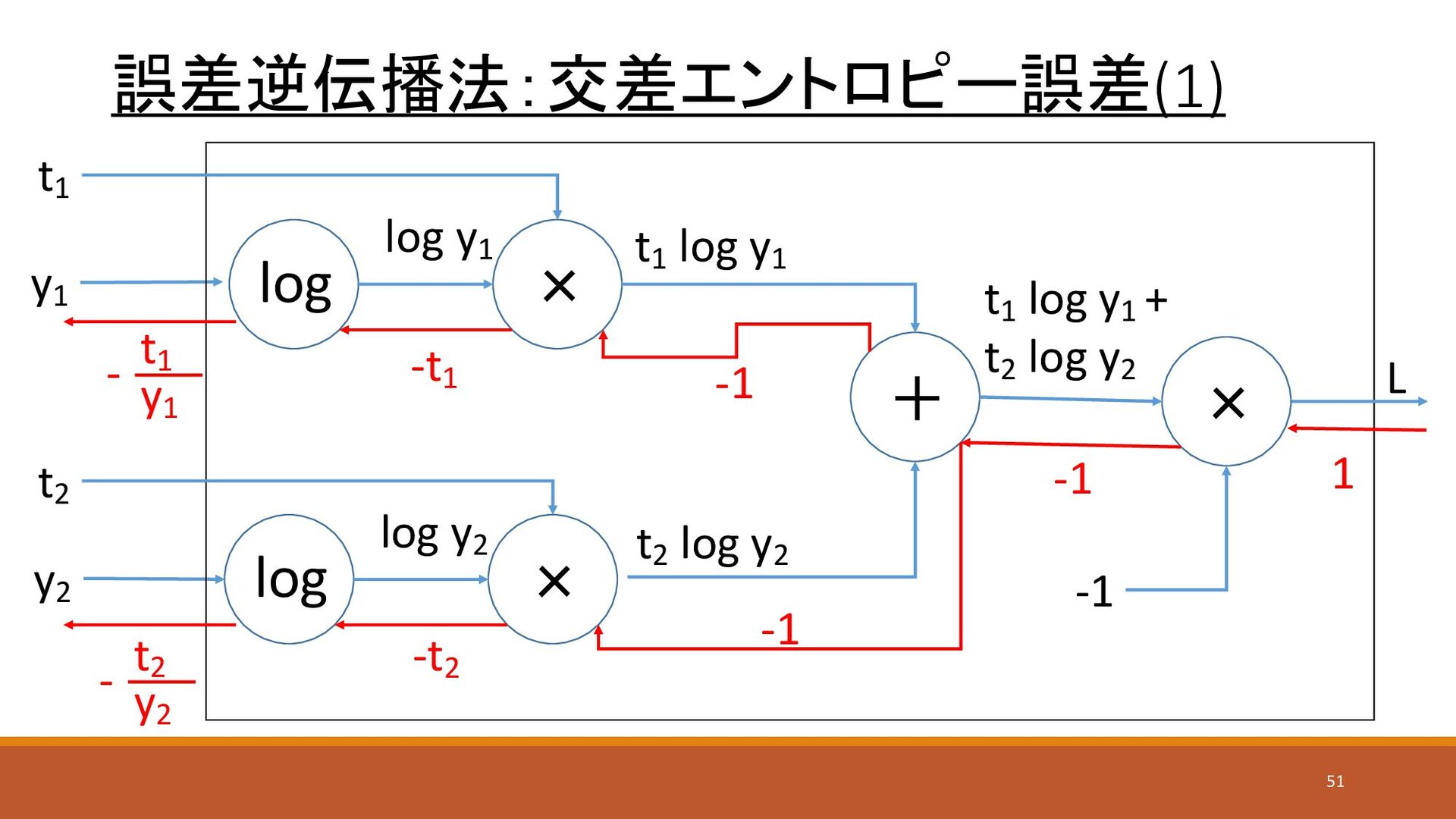
誤差逆伝播法:交差エントロピー誤差(1) y1 y2 L t1 t2 × 1 -1 log
× log y1 + log × log y2 t1 log y1 t2 log y2 t1 log y1 + t2 log y2 -1 -1 -1 -t1 -t2 y1 t1 - y2 t2 - 51
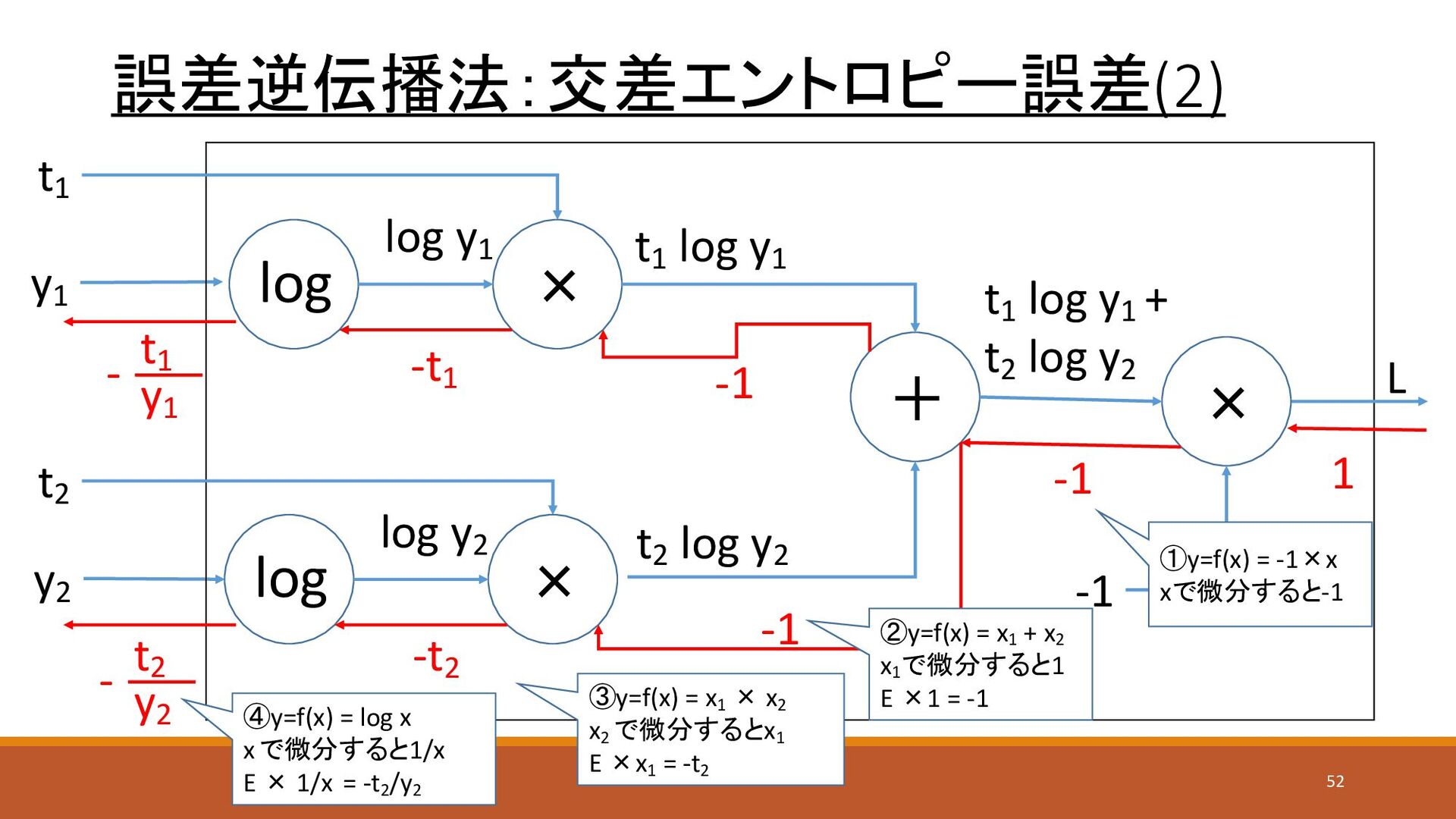
誤差逆伝播法:交差エントロピー誤差(2) y1 y2 L t1 t2 × 1 -1 log
× log y1 + log × log y2 t1 log y1 t2 log y2 t1 log y1 + t2 log y2 -1 -1 -1 -t1 -t2 y1 t1 - ①y=f(x) = -1×x xで微分すると-1 ②y=f(x) = x1 + x2 x1 で微分すると1 E ×1 = -1 ③y=f(x) = x1 × x2 x2 で微分するとx1 E ×x1 = -t2 y2 t2 - ④y=f(x) = log x xで微分すると1/x E × 1/x = -t2 /y2 52
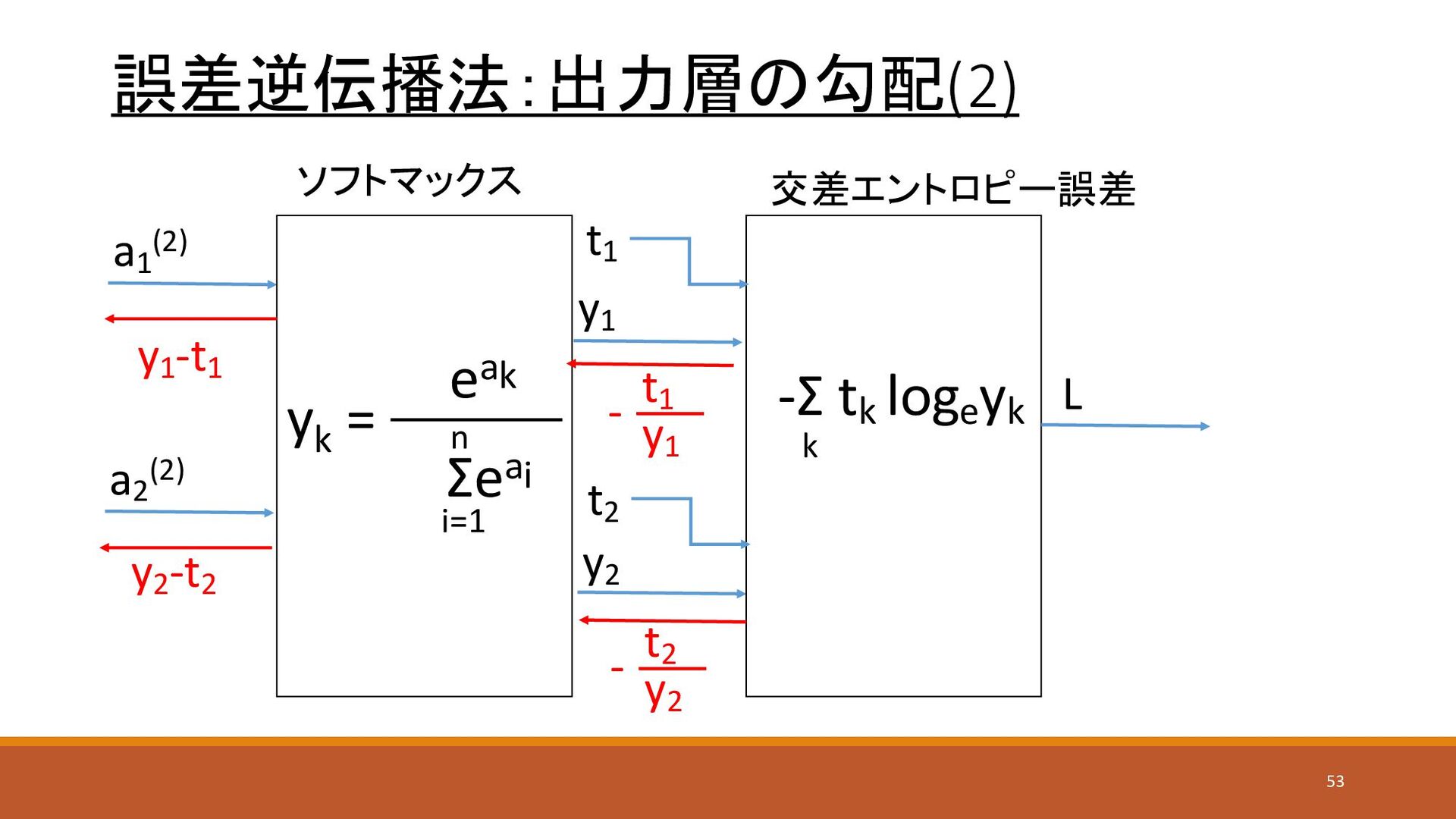
誤差逆伝播法:出力層の勾配(2) ソフトマックス a1 (2) a2 (2) y1 y2 交差エントロピー誤差 L
t1 t2 yk = eak Σeai i=1 n -Σ tk loge yk k y1 t1 - y2 t2 - y2 -t2 y1 -t1 53
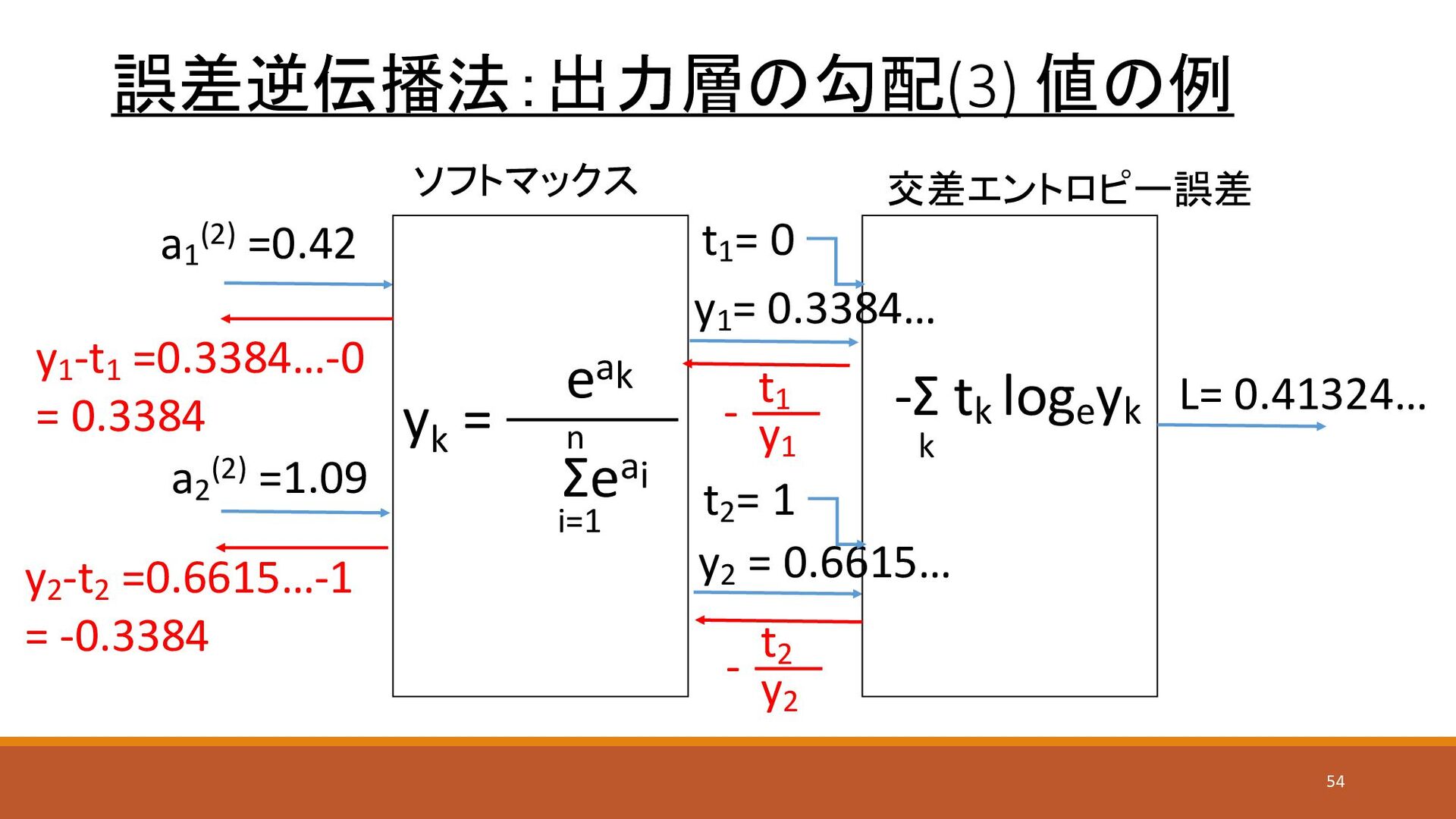
誤差逆伝播法:出力層の勾配(3) 値の例 ソフトマックス a1 (2) =0.42 a2 (2) =1.09 y1
= 0.3384… y2 = 0.6615… 交差エントロピー誤差 L= 0.41324… t1 = 0 t2 = 1 yk = eak Σeai i=1 n -Σ tk loge yk k y1 t1 - y2 t2 - y1 -t1 =0.3384…-0 = 0.3384 y2 -t2 =0.6615…-1 = -0.3384 54
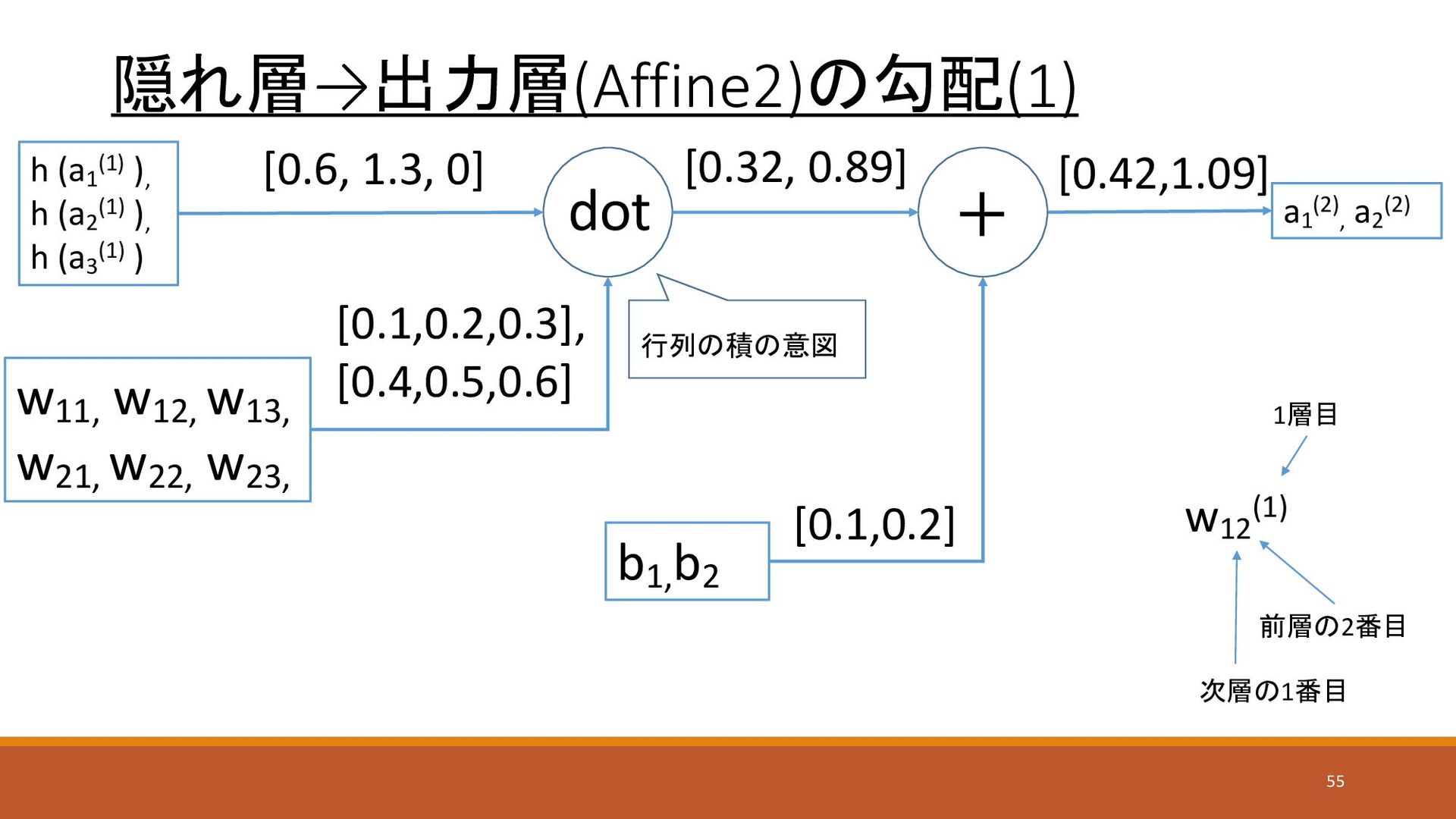
隠れ層→出力層(Affine2)の勾配(1) dot w11, w12, w13, w21, w22, w23, b1, b2
a1 (2) , a2 (2) [0.1,0.2,0.3], [0.4,0.5,0.6] [0.1,0.2] [0.32, 0.89] + [0.6, 1.3, 0] [0.42,1.09] w12 (1) 1層目 前層の2番目 次層の1番目 55 行列の積の意図 h (a1 (1) ), h (a2 (1) ), h (a3 (1) )
(再掲)ニューラルネットワークを使った推論 の例 x1 x2 y1= σ(a1 (2)) s1 = h(a1
(1)) w11 (1) w22 (1) w12 (1) w32 (1) w11 (2) w13 (2) w21 (2) w23 (2) s3 = h(a3 (1)) y2= σ(a2 (2)) s2 = h(a2 (1)) w21 (1) w31 (1) w12 (2) w22 (2) b1 (1) b2 (1) b3 (1) b1 (2) b2 (2) 56
(再掲)ニューラルネットワークを使った推論 の例 1 2 y1= σ(0.42) s1 = h(0.6) 0.1
0.4 0.2 -0.6 0.1 0.3 0.4 0.6 s3 = h(-0.4) =0 y2= σ(1.09) s2 = h(1.3) 0.3 0.5 0.2 0.5 0.1 0.2 0.3 0.1 0.2 57
隠れ層→出力層(Affine2)の勾配(2) dot b1, b2 [0.1,0.2] [0.32, 0.89] + [0.6, 1.3,
0] [0.42,1.09] [y1 -t1 ], [y2 -t2 ] =[0.338…,-0.338…] [0.338…], [-0.338] xT×E [0.338…, -0.338…] wT×E xT =行と列を入れ替 えたもの(転置行列) 58 h (a1 (1) ), h (a2 (1) ), h (a3 (1) ) a1 (2) , a2 (2) y = dot + b b で微分すると、1 E × 1 = E w11, w21, w12, w22, w13, w23, [0.1,0.4] [0.2,0.5], [0.3,0.6]
隠れ層→出力層(Affine2)の勾配(3) 59 w11, w12, w13, w21, w22, w23, [0.1,0.2,0.3], [0.4,0.5,0.6]
wT = [0.1,0.4], [0.2,0.5] [0.3,0.6] w= w11, w21, w12, w22, w13, w23 [0.338…, -0.338…] E= wT×E = [[w11 , w12 , w13 ], [w21 , w22 , w23 ]], ×[[y1 -t1 ], [y2 -t2 ]] =[[0.1×0.338…+ 0.4×-0.338…], [0.2×0.338… + 0.5×-0.338…], [0.3×0.338… + 0.6×-0.338…]] =[[-0.101549], [-0.101549], [-0.101549]] y1 -t1 , y2 -t2
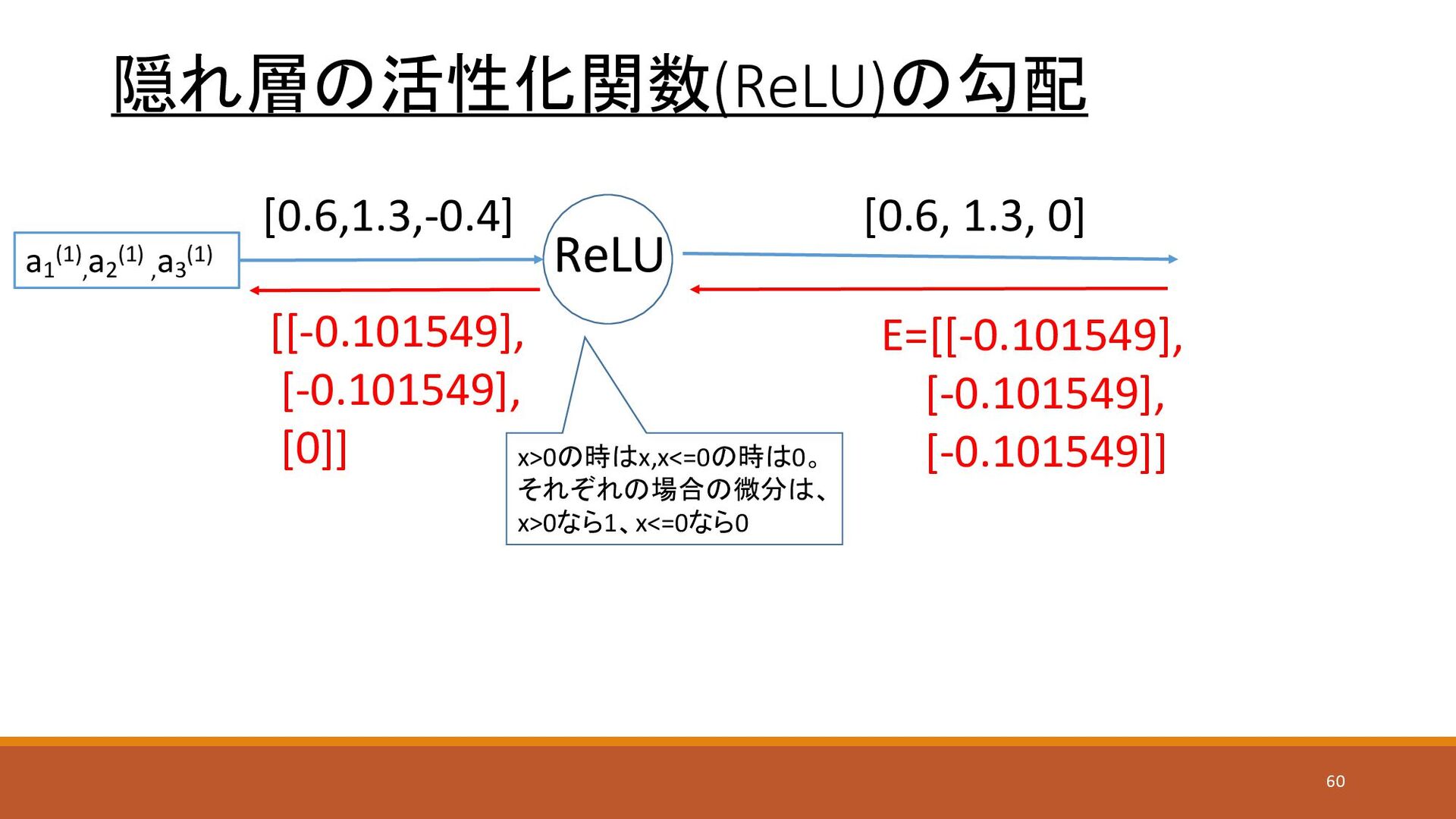
隠れ層の活性化関数(ReLU)の勾配 ReLU a1 (1) , a2 (1) , a3 (1)
[0.6,1.3,-0.4] [0.6, 1.3, 0] E=[[-0.101549], [-0.101549], [-0.101549]] [[-0.101549], [-0.101549], [0]] x>0の時はx,x<=0の時は0。 それぞれの場合の微分は、 x>0なら1、x<=0なら0 60
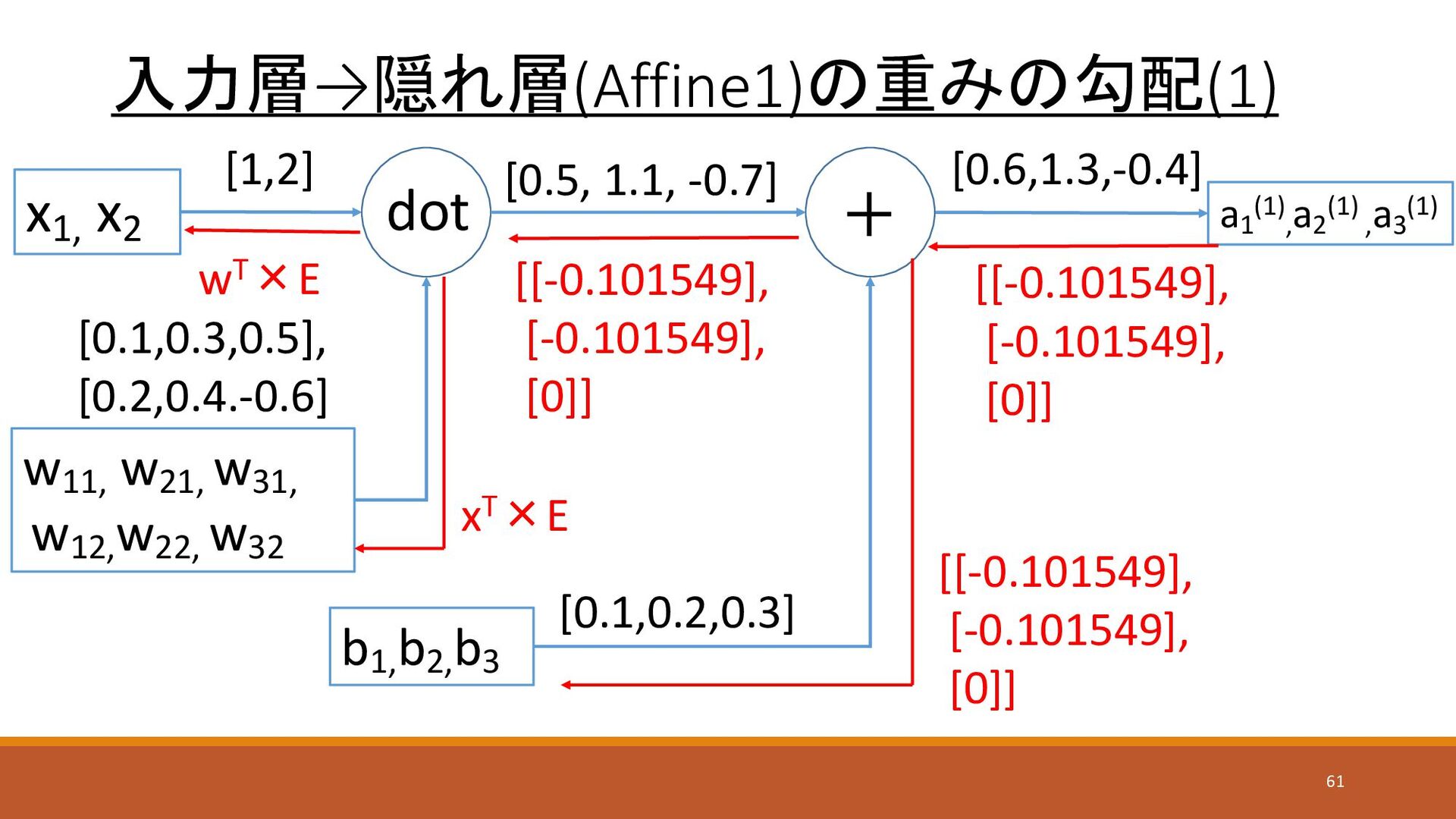
入力層→隠れ層(Affine1)の重みの勾配(1) dot x1, x2 w11, w21, w31, w12, w22, w32
b1, b2, b3 a1 (1) , a2 (1) , a3 (1) [0.1,0.3,0.5], [0.2,0.4.-0.6] [0.1,0.2,0.3] [0.5, 1.1, -0.7] + [1,2] [0.6,1.3,-0.4] [[-0.101549], [-0.101549], [0]] [[-0.101549], [-0.101549], [0]] [[-0.101549], [-0.101549], [0]] wT×E xT×E 61
入力層→隠れ層(Affine1)の重みの勾配(2) 62 x1, x2 [1] [2] x= xT= x1, x2
E= [1],[2] [-0.101549], [-0.101549], [0] xT×E = [[x1 ], [x2 ]]×[[E1 ], [E2 ], [E3 ]] =[[1×-0.101549, 1×- 0.101549…, 1×0], [2×-0.101549, 2×- 0.101549…, 2×0]] =[[-0.101549, -0.101549, 0], [-0.203098, -0.203098,0]] 数値微分で計算したw11 の勾配は -0.101548であり、誤差逆伝播法で計算さ れた-0.101549とほぼ一致している
畳み込みニューラルネットワーク (CNN) 63
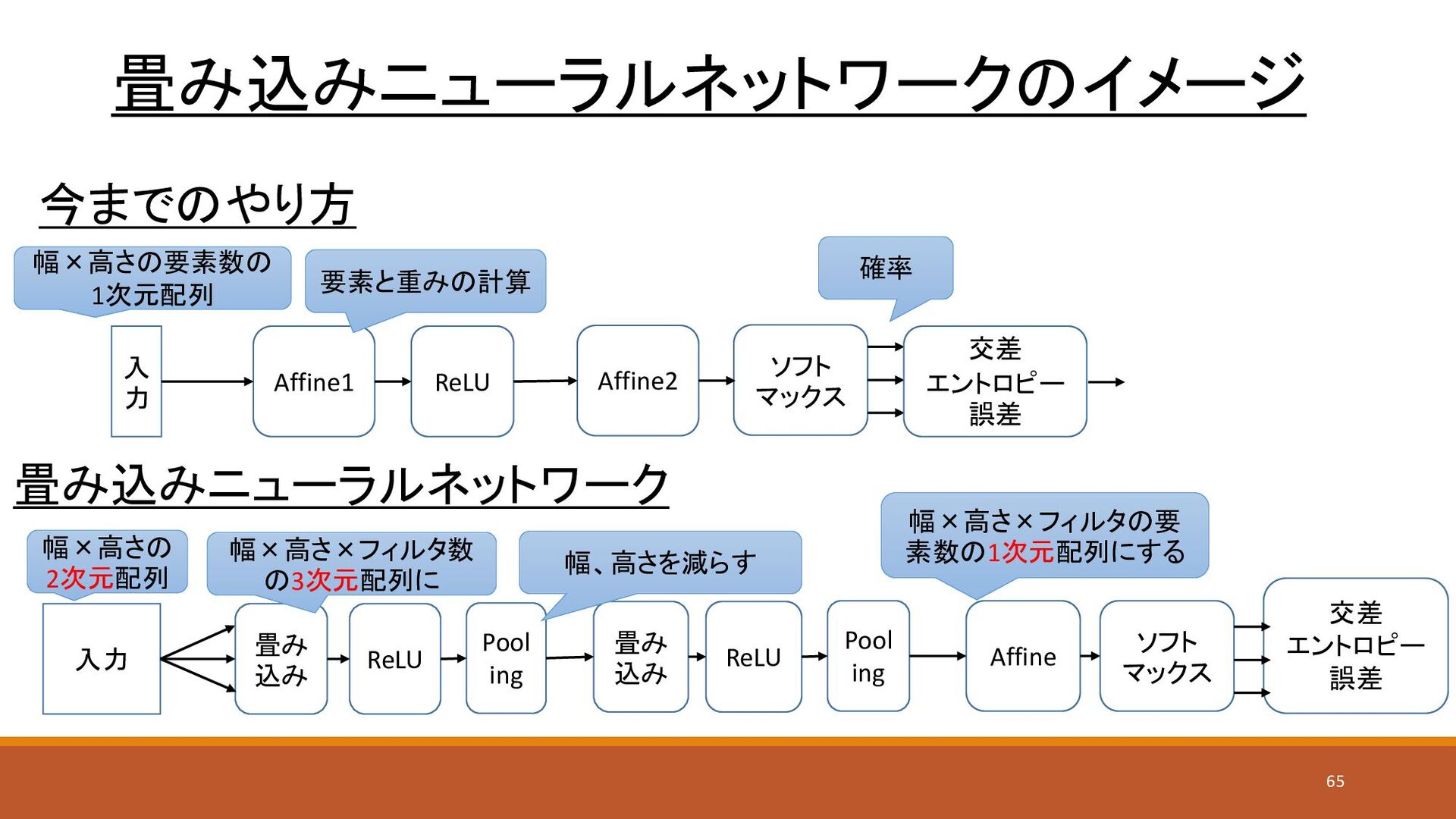
畳み込みニューラルネットワーク(CNN) • 今までのニューラルネットワークは全結合だった • 隣接する層の全てのノード間が繋がっていた • 全結合の欠点 • データの形状が無視される •
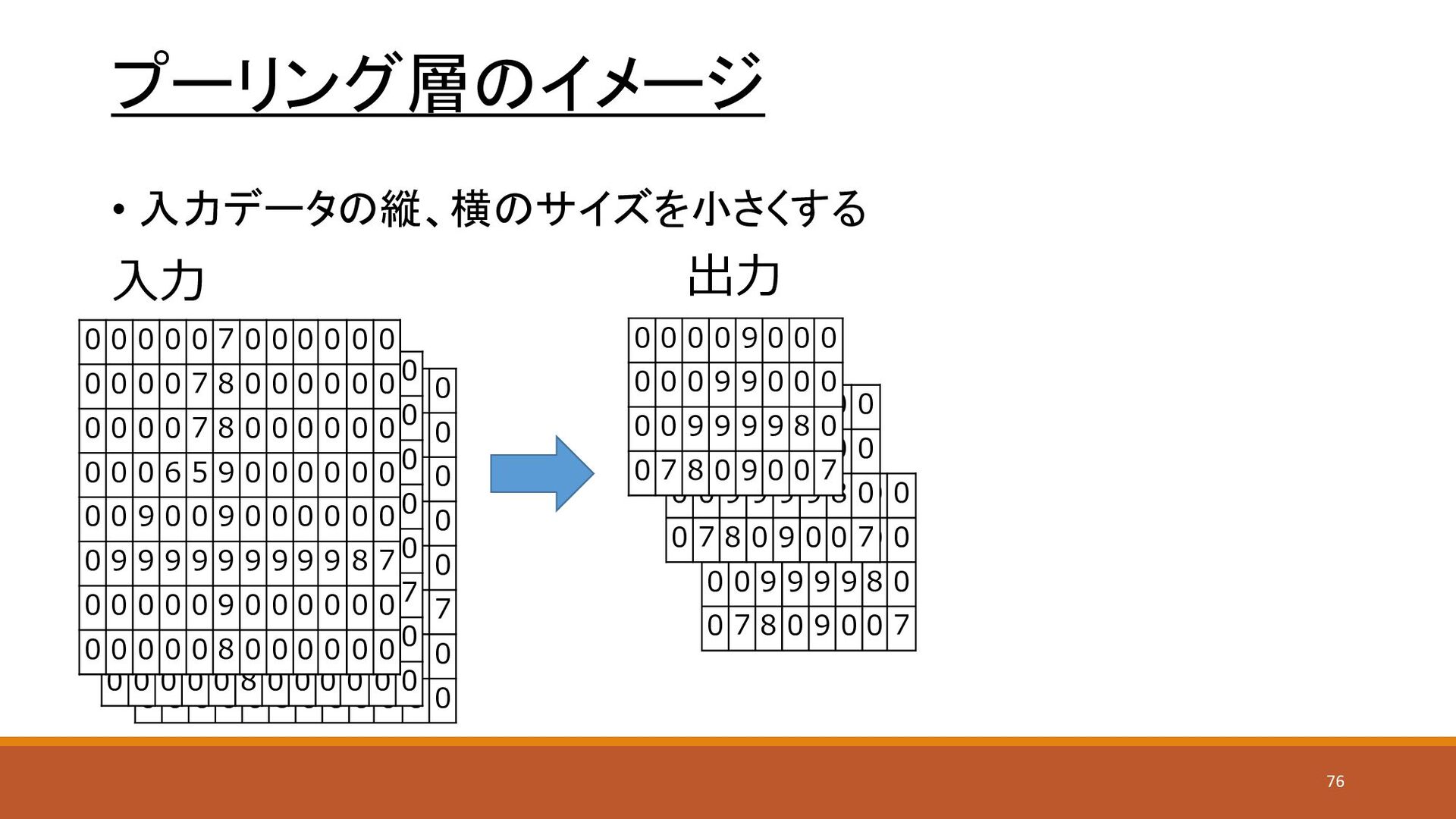
先の画像の例では縦×横の数だけのノードを作って入力としていたが、位 置の情報が失われてしまっている • 畳み込み層(Convolution)を使うことで、位置の情報を維持したまま 重みの計算を行う • プーリング層(Pooling)を使って情報を圧縮する 64
Pool ing 畳み込みニューラルネットワークのイメージ 入力 畳み 込み ReLU Pool ing 幅×高さの
2次元配列 畳み 込み ReLU 交差 エントロピー 誤差 Affine 幅×高さ×フィルタ数 の3次元配列に 幅×高さ×フィルタの要 素数の1次元配列にする 入 力 Affine1 ReLU ソフト マックス Affine2 幅×高さの要素数の 1次元配列 確率 要素と重みの計算 交差 エントロピー 誤差 今までのやり方 畳み込みニューラルネットワーク 幅、高さを減らす 65 ソフト マックス
0 0 0 0 0 7 0 0 0 0
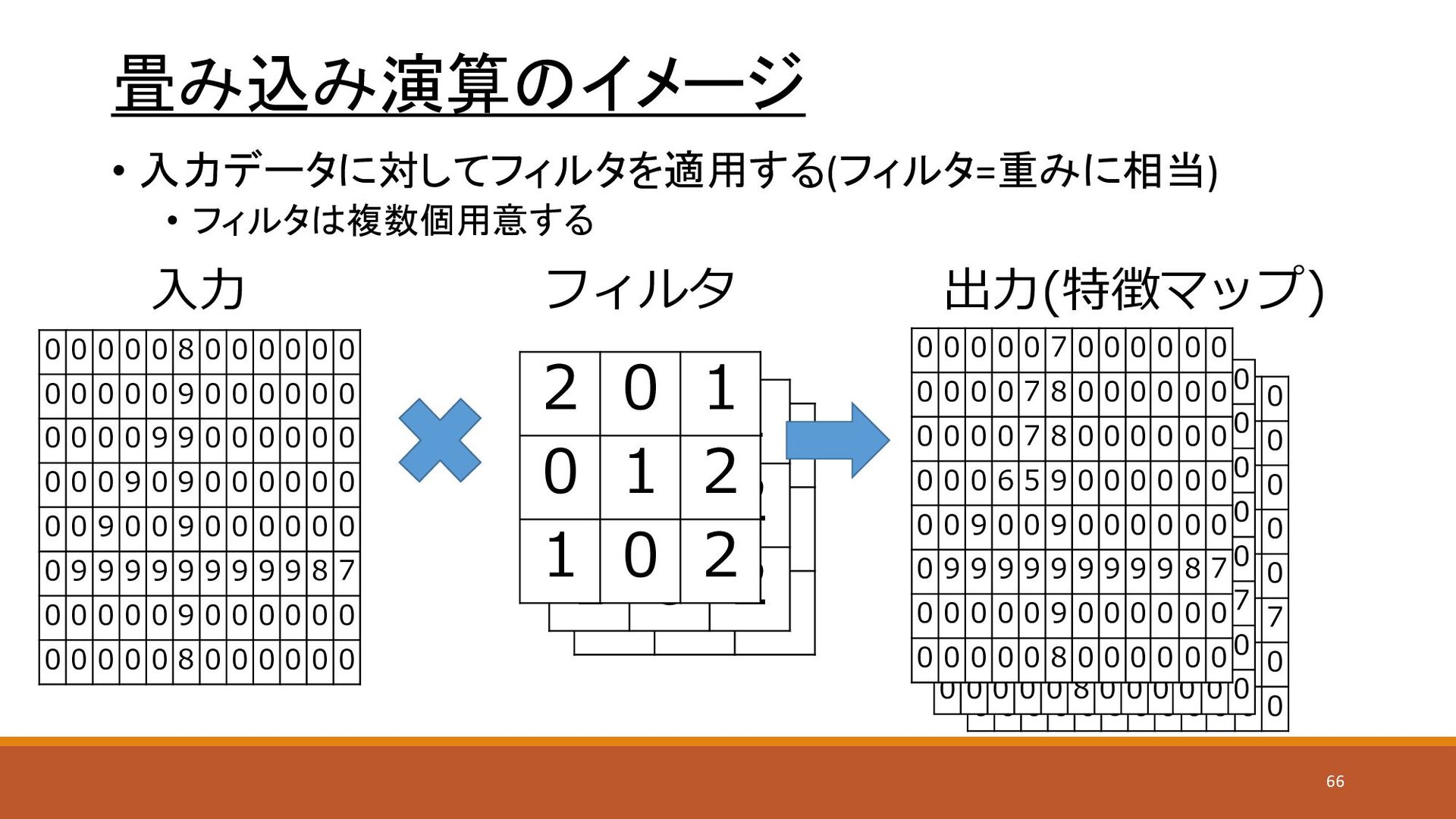
0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 6 5 9 0 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 9 9 9 9 9 9 9 9 9 8 7 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 6 5 9 0 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 9 9 9 9 9 9 9 9 9 8 7 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 2 0 1 0 1 2 1 0 2 2 0 1 0 1 2 1 0 2 畳み込み演算のイメージ • 入力データに対してフィルタを適用する(フィルタ=重みに相当) • フィルタは複数個用意する 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 9 9 0 0 0 0 0 0 0 0 0 9 0 9 0 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 9 9 9 9 9 9 9 9 9 8 7 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 2 0 1 0 1 2 1 0 2 入力 フィルタ 出力(特徴マップ) 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 6 5 9 0 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 9 9 9 9 9 9 9 9 9 8 7 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 66
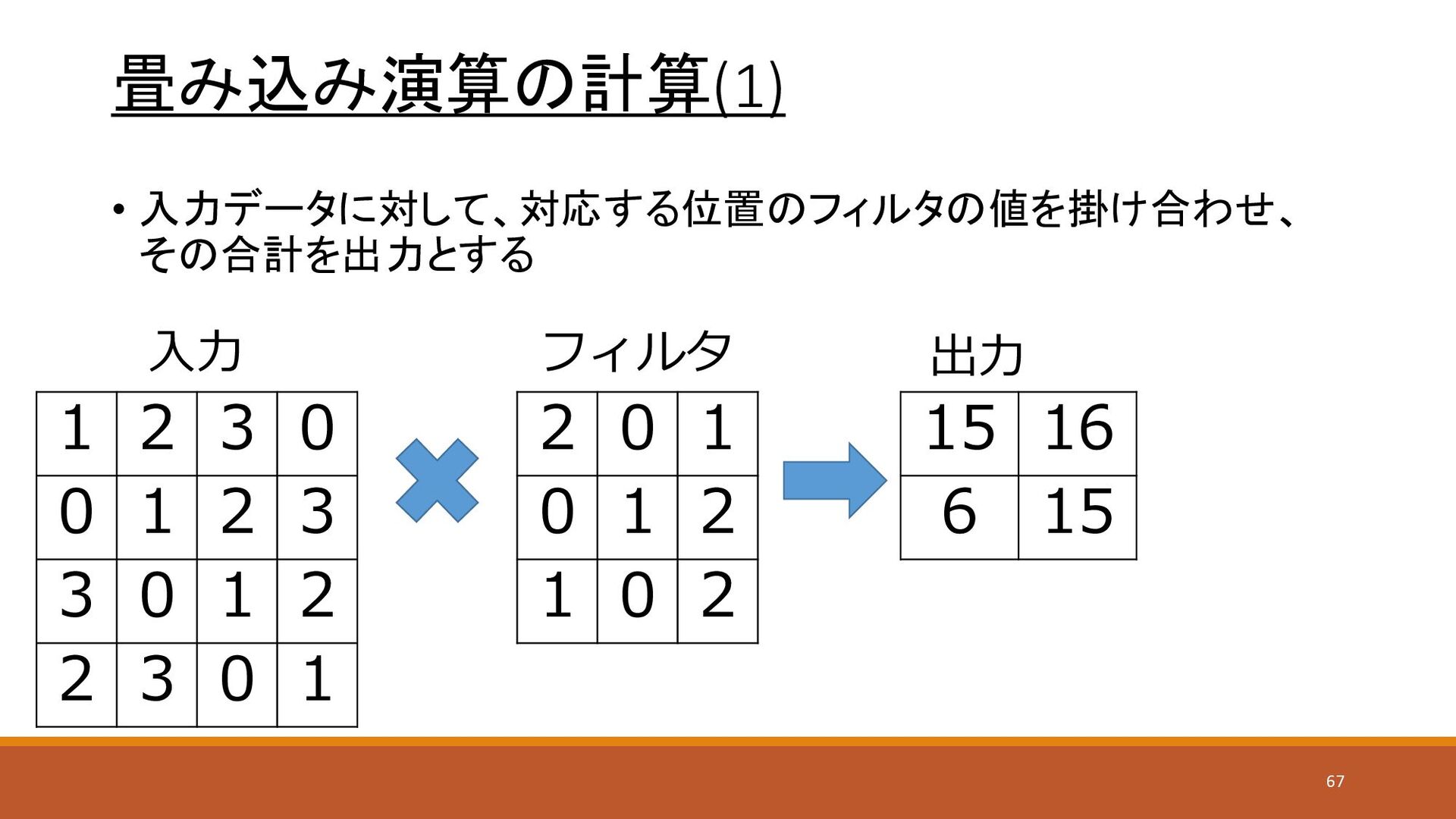
畳み込み演算の計算(1) • 入力データに対して、対応する位置のフィルタの値を掛け合わせ、 その合計を出力とする 1 2 3 0 0 1
2 3 3 0 1 2 2 3 0 1 2 0 1 0 1 2 1 0 2 15 16 6 15 入力 フィルタ 出力 67
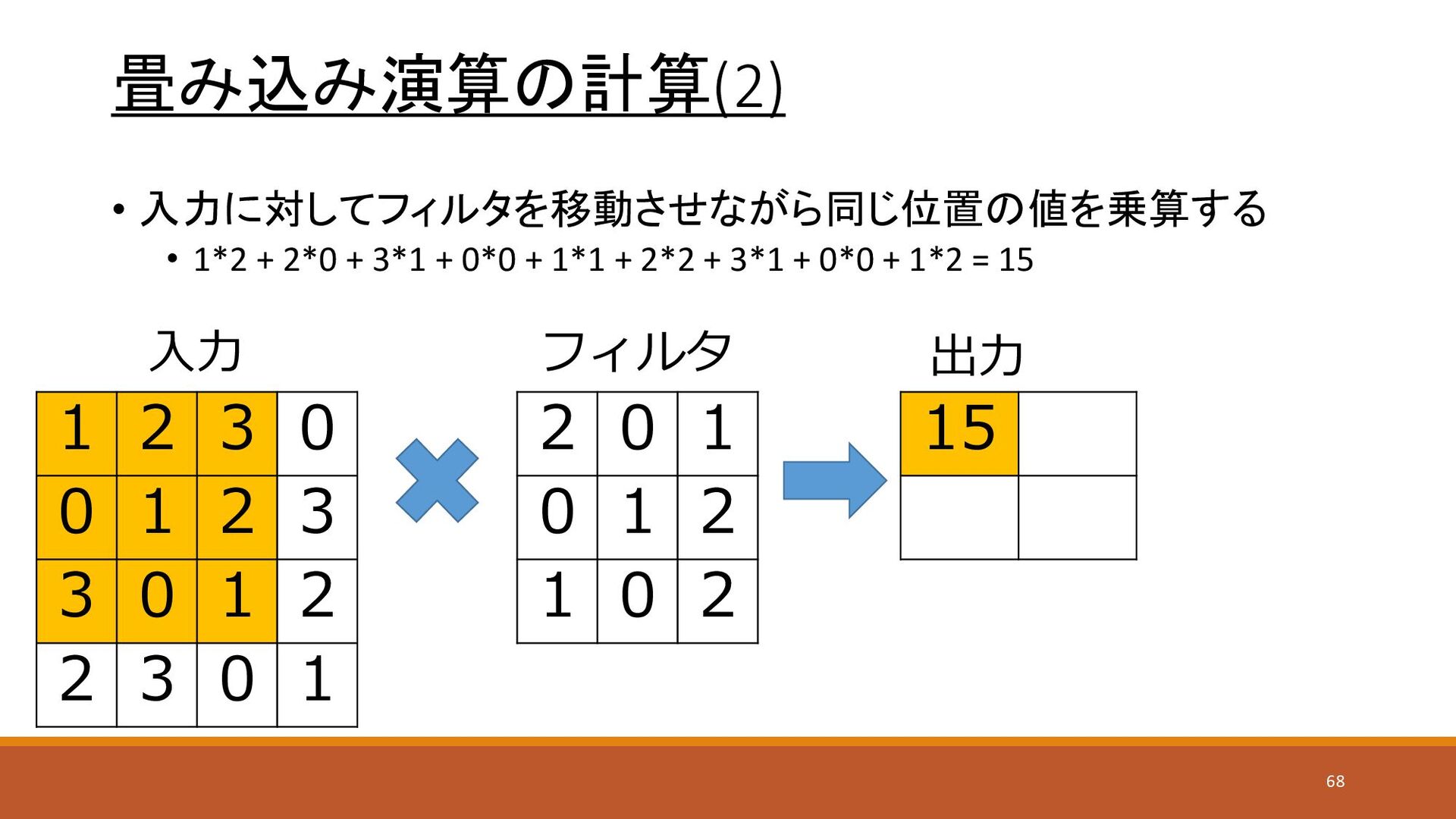
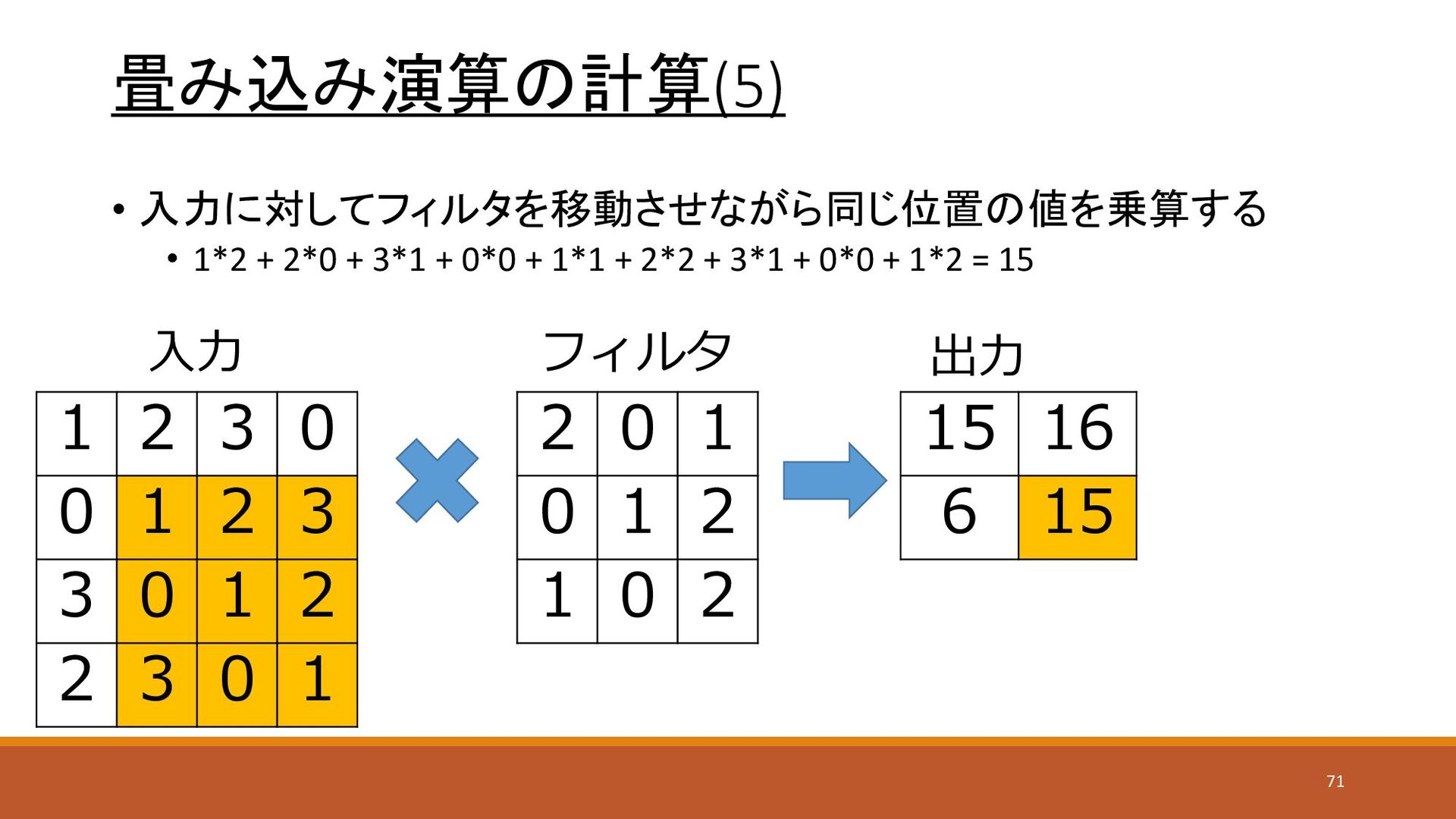
畳み込み演算の計算(2) • 入力に対してフィルタを移動させながら同じ位置の値を乗算する • 1*2 + 2*0 + 3*1 +
0*0 + 1*1 + 2*2 + 3*1 + 0*0 + 1*2 = 15 1 2 3 0 0 1 2 3 3 0 1 2 2 3 0 1 2 0 1 0 1 2 1 0 2 15 入力 フィルタ 出力 68
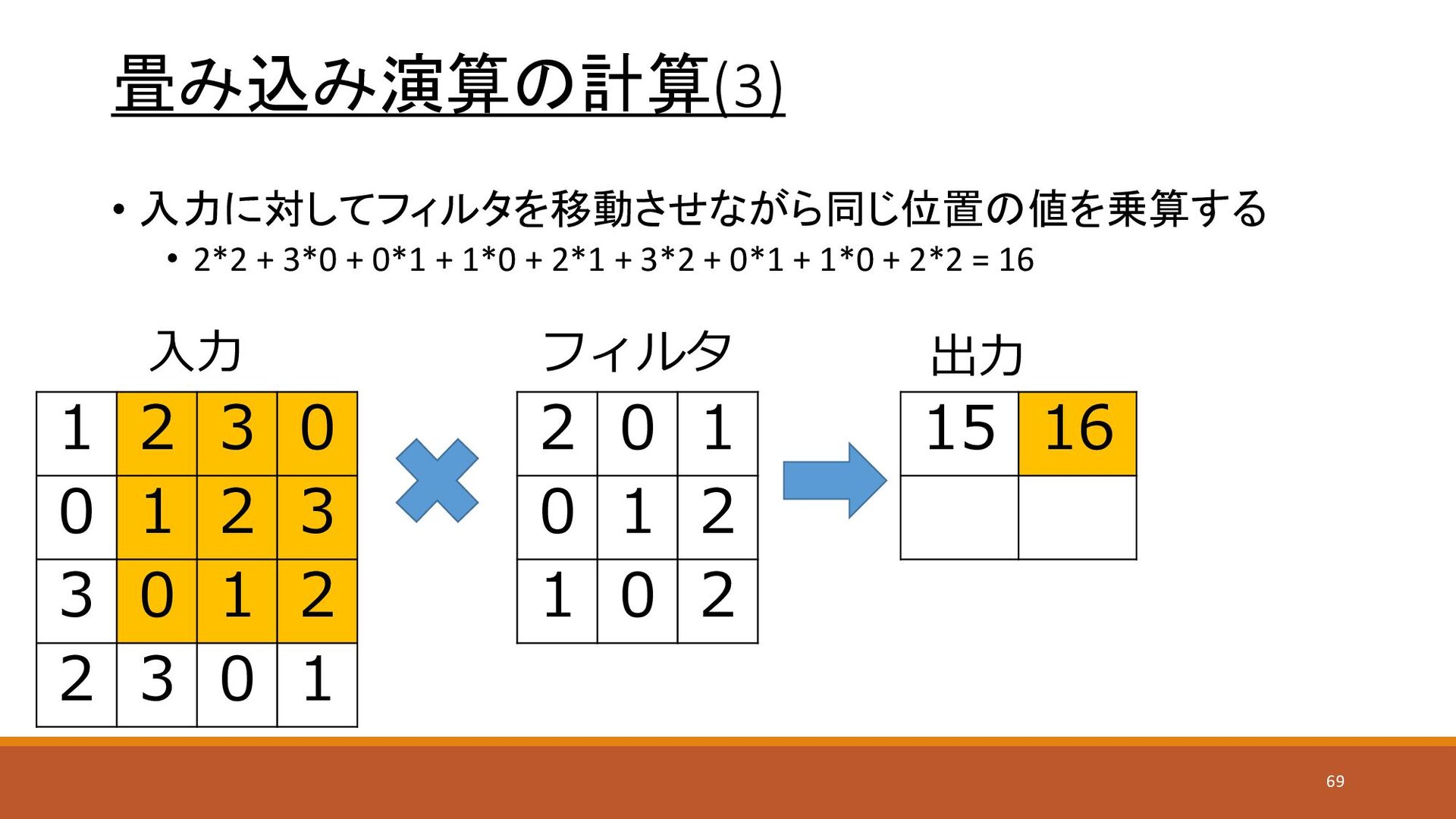
畳み込み演算の計算(3) • 入力に対してフィルタを移動させながら同じ位置の値を乗算する • 2*2 + 3*0 + 0*1 +
1*0 + 2*1 + 3*2 + 0*1 + 1*0 + 2*2 = 16 1 2 3 0 0 1 2 3 3 0 1 2 2 3 0 1 2 0 1 0 1 2 1 0 2 15 16 入力 フィルタ 出力 69
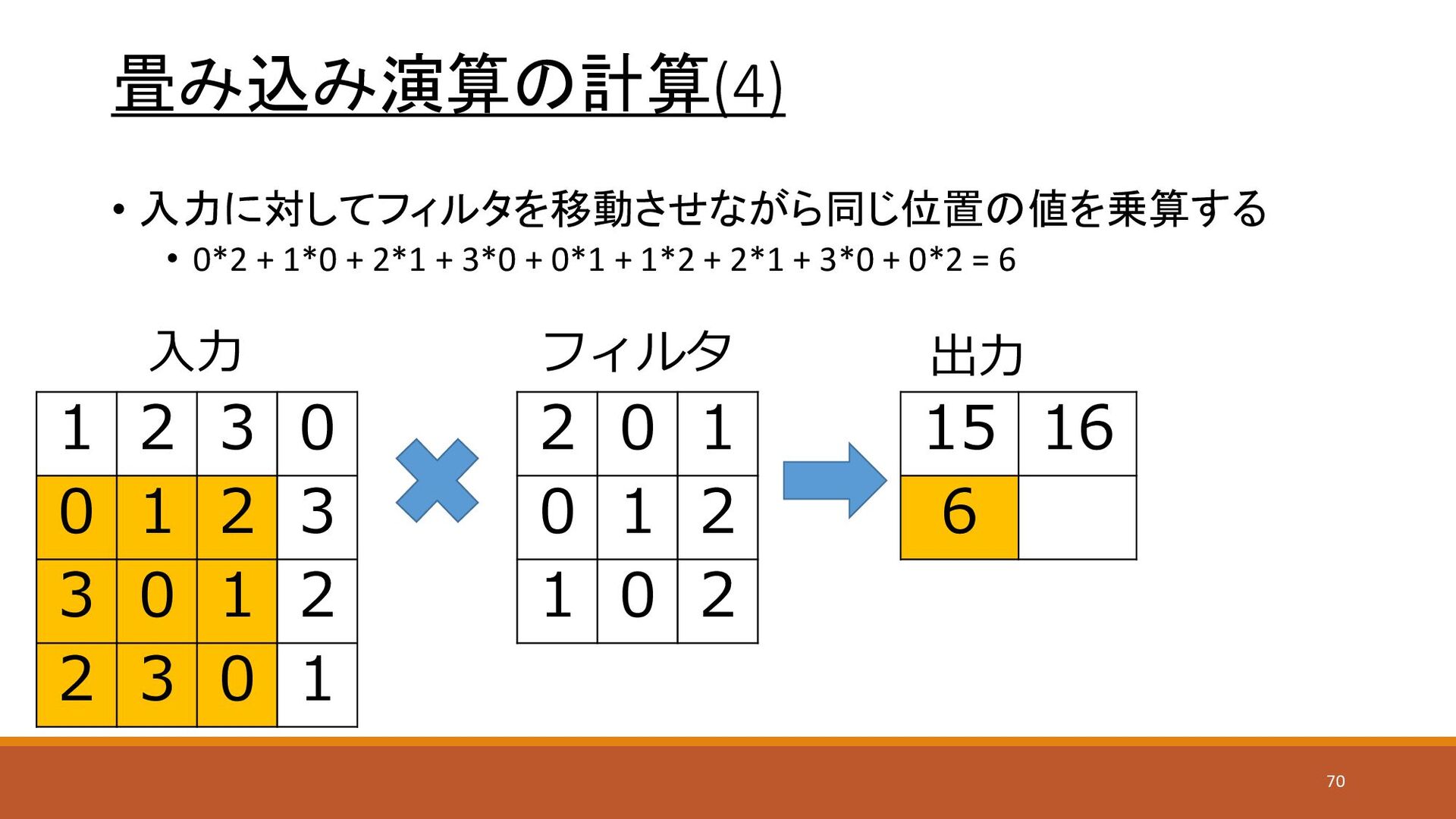
畳み込み演算の計算(4) • 入力に対してフィルタを移動させながら同じ位置の値を乗算する • 0*2 + 1*0 + 2*1 +
3*0 + 0*1 + 1*2 + 2*1 + 3*0 + 0*2 = 6 1 2 3 0 0 1 2 3 3 0 1 2 2 3 0 1 2 0 1 0 1 2 1 0 2 15 16 6 入力 フィルタ 出力 70
畳み込み演算の計算(5) • 入力に対してフィルタを移動させながら同じ位置の値を乗算する • 1*2 + 2*0 + 3*1 +
0*0 + 1*1 + 2*2 + 3*1 + 0*0 + 1*2 = 15 1 2 3 0 0 1 2 3 3 0 1 2 2 3 0 1 2 0 1 0 1 2 1 0 2 15 16 6 15 入力 フィルタ 出力 71
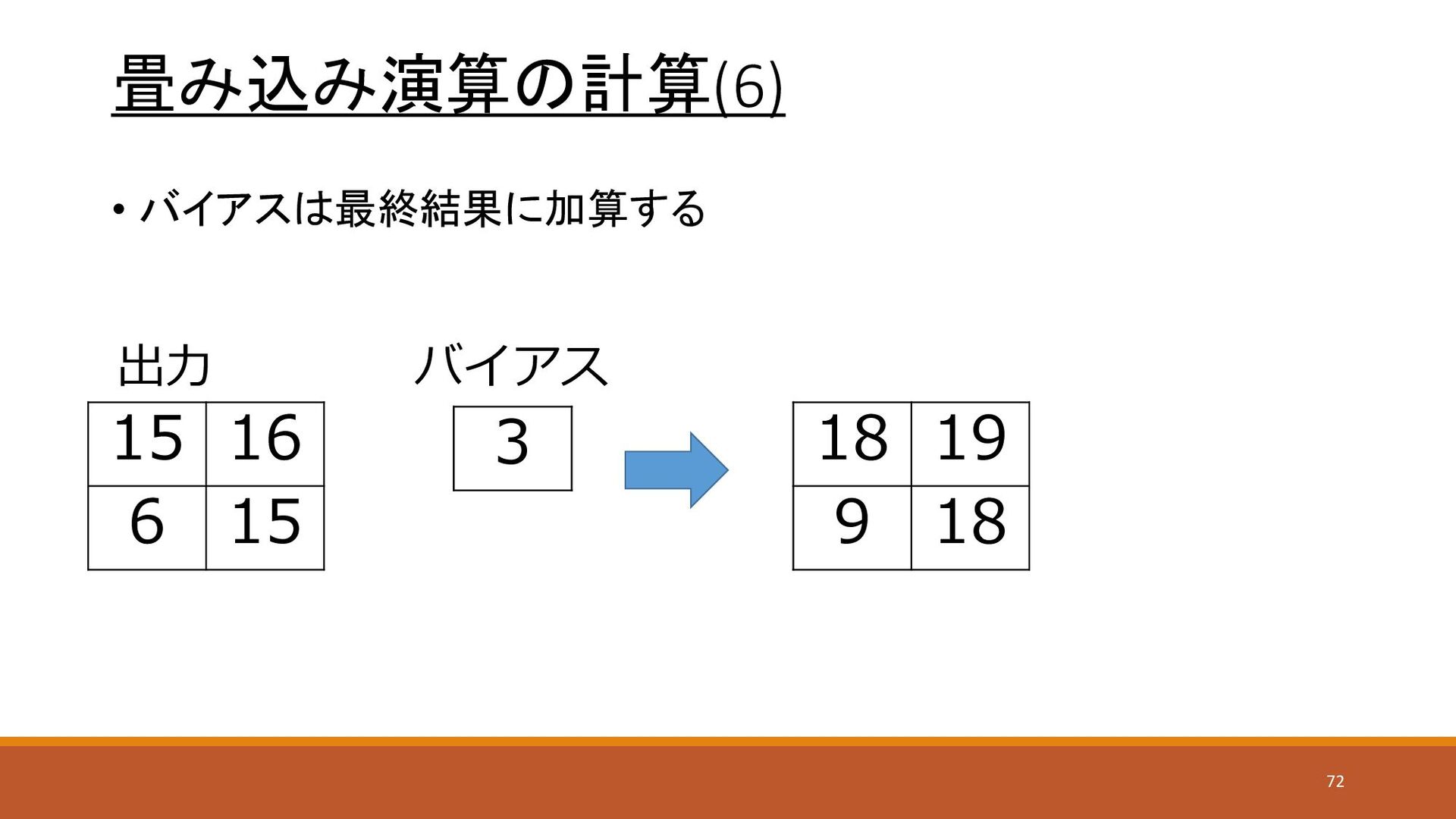
畳み込み演算の計算(6) • バイアスは最終結果に加算する 15 16 6 15 出力 バイアス 3
18 19 9 18 72
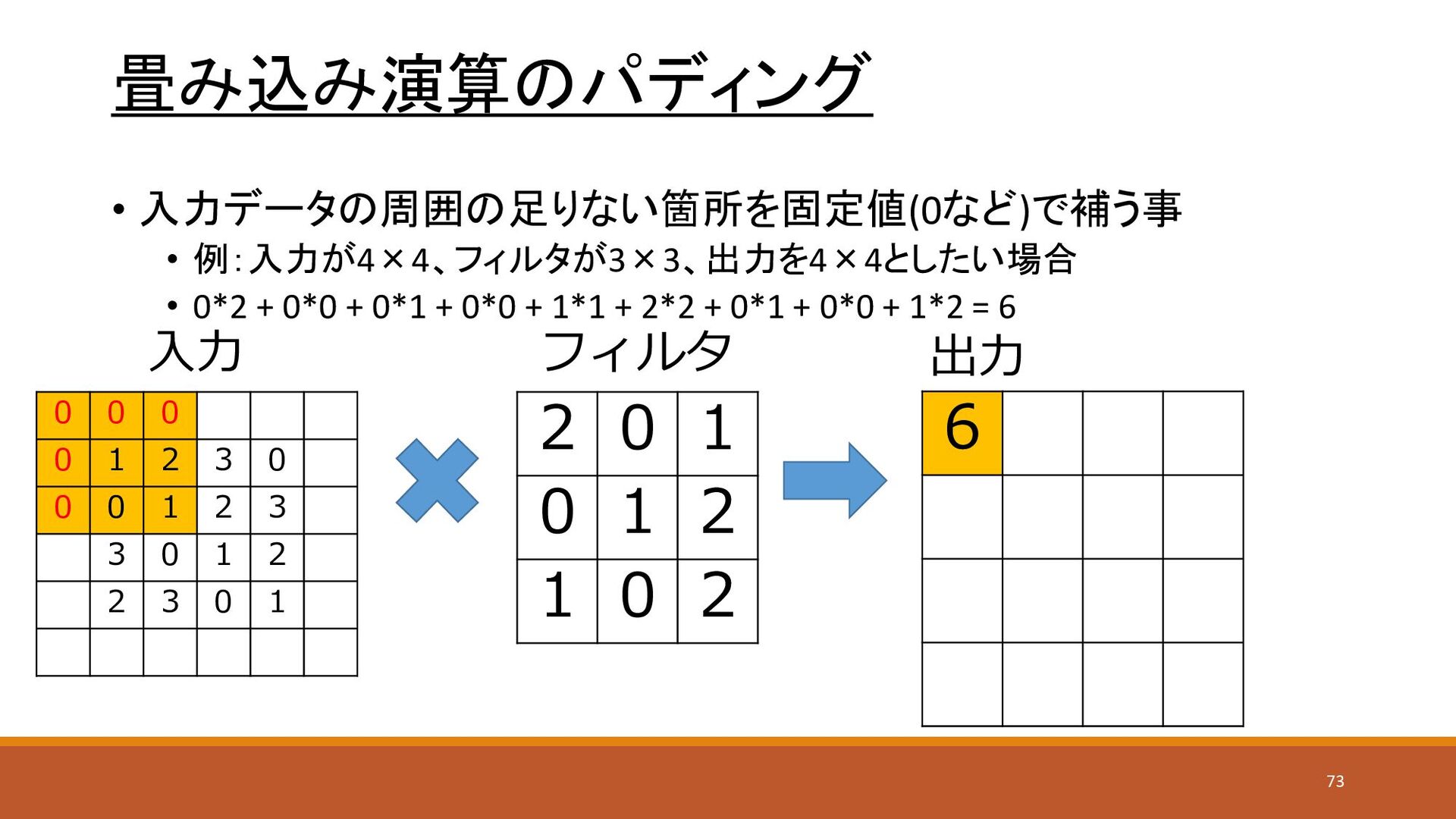
畳み込み演算のパディング • 入力データの周囲の足りない箇所を固定値(0など)で補う事 • 例:入力が4×4、フィルタが3×3、出力を4×4としたい場合 • 0*2 + 0*0 +
0*1 + 0*0 + 1*1 + 2*2 + 0*1 + 0*0 + 1*2 = 6 0 0 0 0 1 2 3 0 0 0 1 2 3 3 0 1 2 2 3 0 1 2 0 1 0 1 2 1 0 2 入力 フィルタ 出力 6 73
2 0 1 0 1 2 1 0 2 2
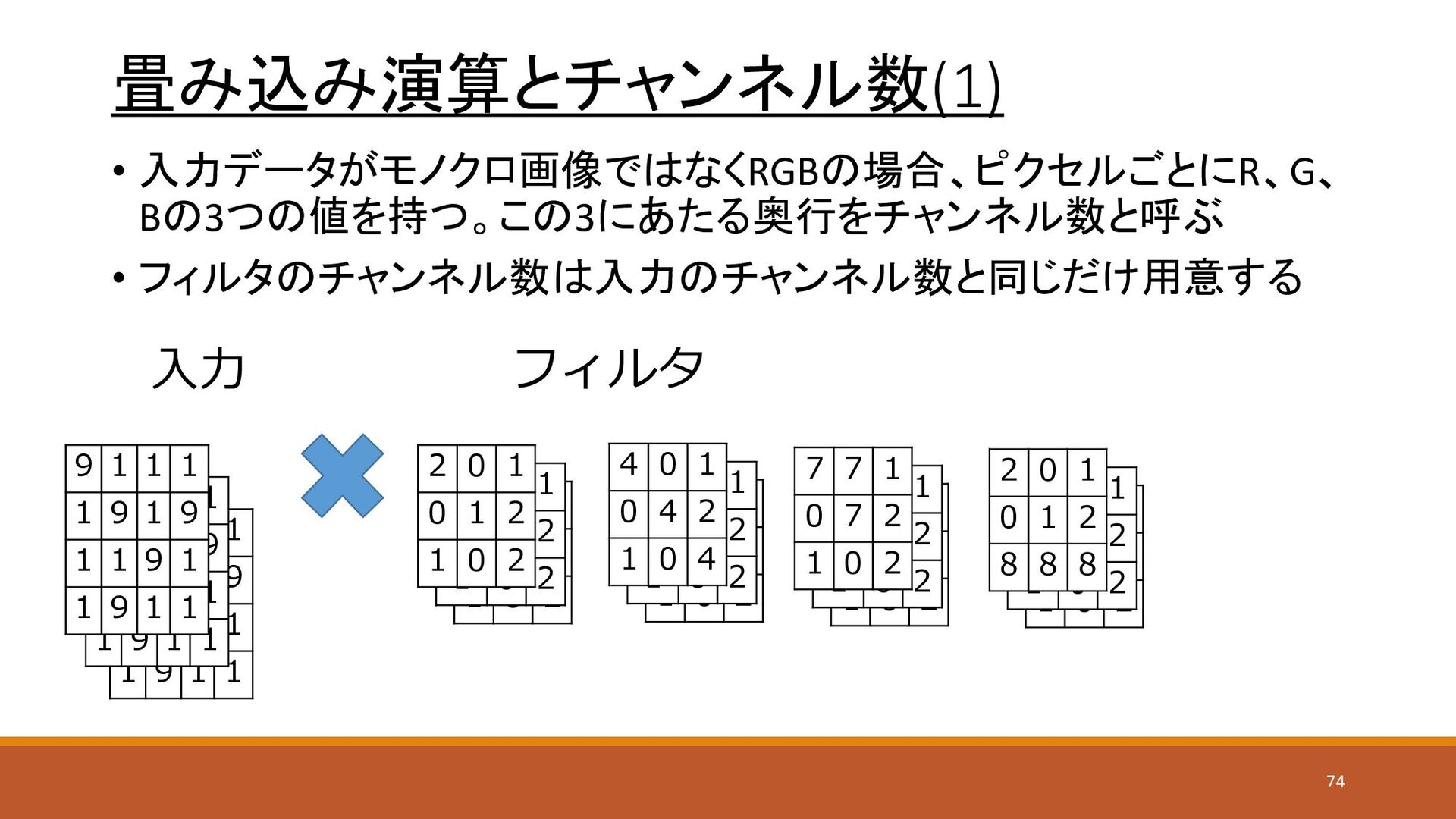
0 1 0 1 2 1 0 2 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 畳み込み演算とチャンネル数(1) • 入力データがモノクロ画像ではなくRGBの場合、ピクセルごとにR、G、 Bの3つの値を持つ。この3にあたる奥行をチャンネル数と呼ぶ • フィルタのチャンネル数は入力のチャンネル数と同じだけ用意する 入力 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 2 0 1 0 1 2 1 0 2 2 0 1 0 1 2 1 0 2 2 0 1 0 1 2 1 0 2 4 0 1 0 4 2 1 0 4 2 0 1 0 1 2 1 0 2 2 0 1 0 1 2 1 0 2 7 7 1 0 7 2 1 0 2 2 0 1 0 1 2 1 0 2 2 0 1 0 1 2 1 0 2 2 0 1 0 1 2 8 8 8 フィルタ 74
2 0 1 0 1 2 1 0 2 2
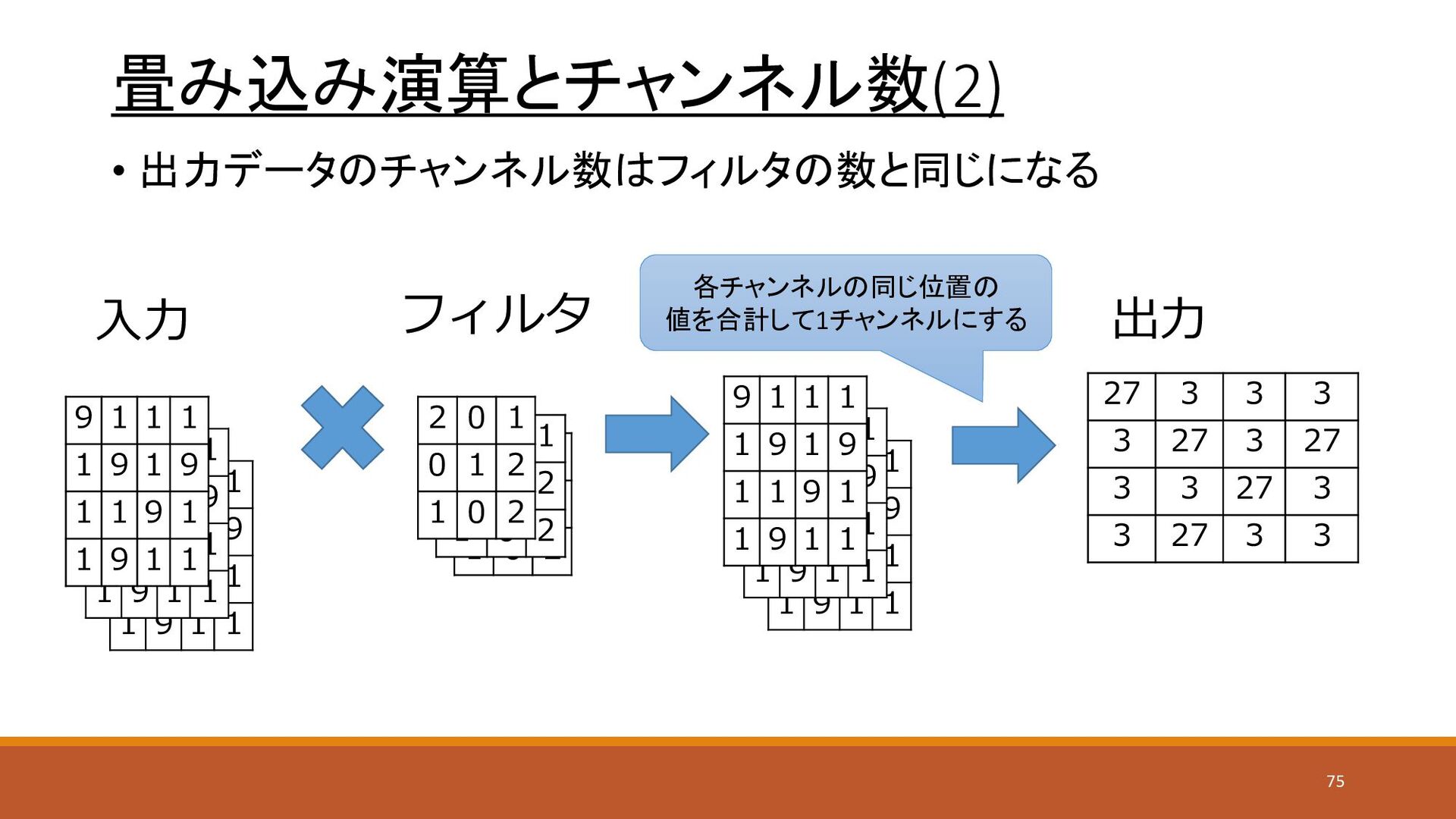
0 1 0 1 2 1 0 2 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 畳み込み演算とチャンネル数(2) • 出力データのチャンネル数はフィルタの数と同じになる 入力 フィルタ 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 2 0 1 0 1 2 1 0 2 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 9 1 1 1 1 9 1 9 1 1 9 1 1 9 1 1 27 3 3 3 3 27 3 27 3 3 27 3 3 27 3 3 出力 各チャンネルの同じ位置の 値を合計して1チャンネルにする 75
0 0 0 0 9 0 0 0 0 0
0 9 9 0 0 0 0 0 9 9 9 9 8 0 0 7 8 0 9 0 0 7 0 0 0 0 9 0 0 0 0 0 0 9 9 0 0 0 0 0 9 9 9 9 8 0 0 7 8 0 9 0 0 7 プーリング層のイメージ • 入力データの縦、横のサイズを小さくする 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 6 5 9 0 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 9 9 9 9 9 9 9 9 9 8 7 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 6 5 9 0 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 9 9 9 9 9 9 9 9 9 8 7 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 入力 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 0 7 8 0 0 0 0 0 0 0 0 0 6 5 9 0 0 0 0 0 0 0 0 9 0 0 9 0 0 0 0 0 0 0 9 9 9 9 9 9 9 9 9 8 7 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 9 0 0 0 0 0 0 9 9 0 0 0 0 0 9 9 9 9 8 0 0 7 8 0 9 0 0 7 出力 76
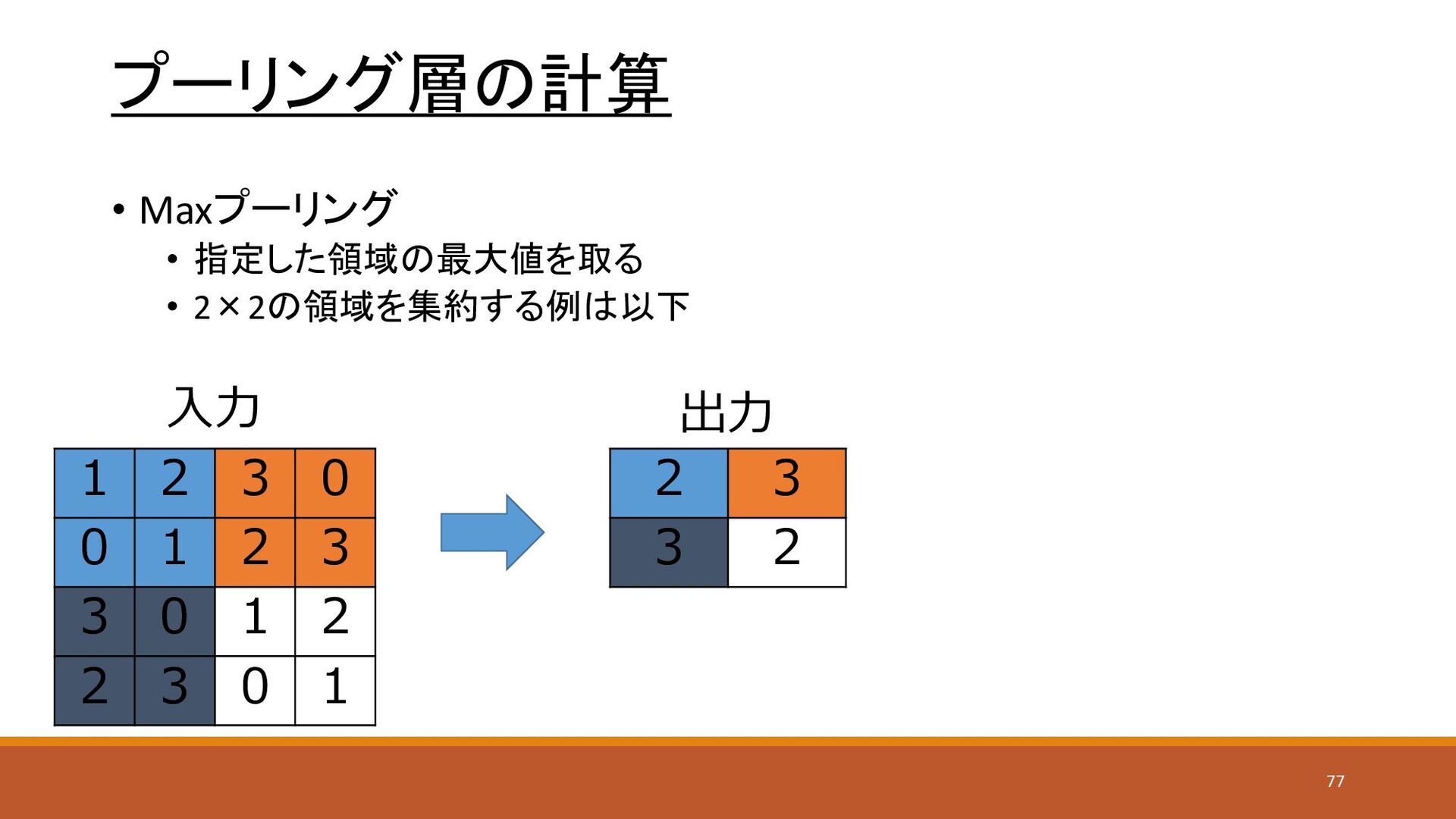
プーリング層の計算 • Maxプーリング • 指定した領域の最大値を取る • 2×2の領域を集約する例は以下 1 2 3
0 0 1 2 3 3 0 1 2 2 3 0 1 入力 2 3 3 2 出力 77
2 3 3 1 2 3 3 2 Affine層の入力の変換 •
幅×高さ×チャンネル数の3次元のデータを1次元配列にする 2 3 3 2 畳み込みの出力(2×2×3) Affine層の入力(12ノード) 2 3 1 … 78
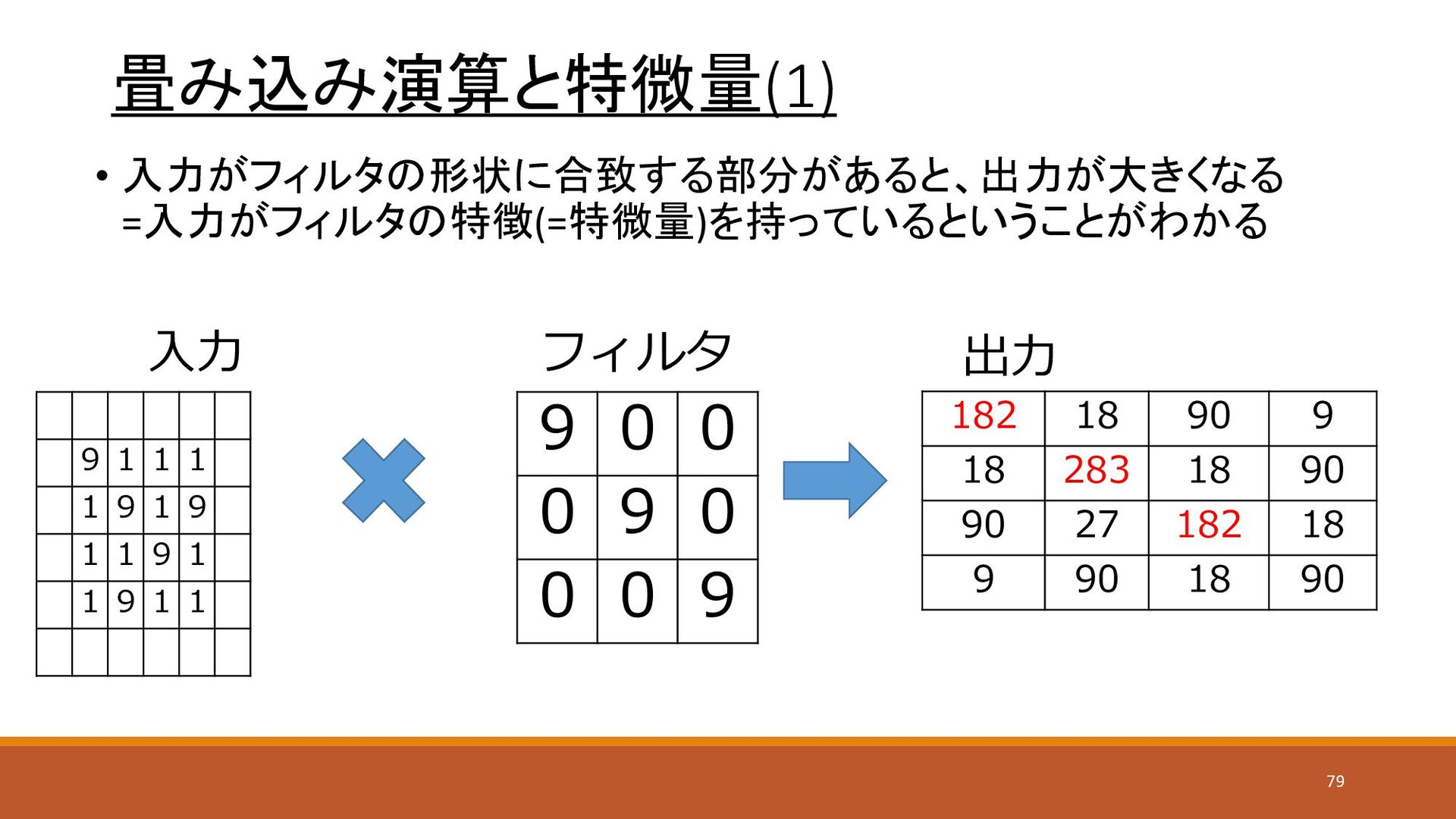
畳み込み演算と特微量(1) • 入力がフィルタの形状に合致する部分があると、出力が大きくなる =入力がフィルタの特徴(=特微量)を持っているということがわかる 9 1 1 1 1 9
1 9 1 1 9 1 1 9 1 1 9 0 0 0 9 0 0 0 9 入力 フィルタ 出力 182 18 90 9 18 283 18 90 90 27 182 18 9 90 18 90 79
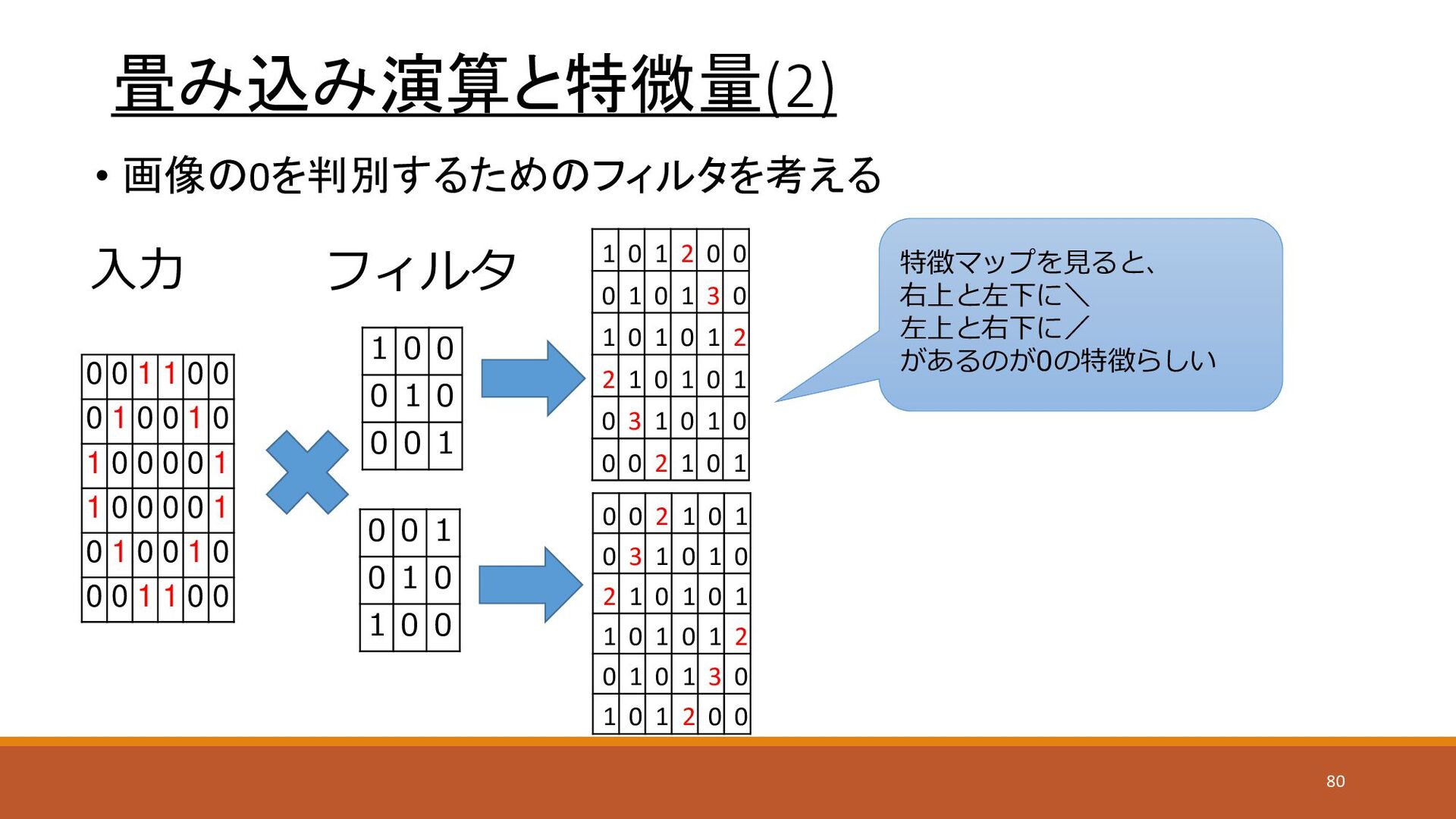
畳み込み演算と特微量(2) • 画像の0を判別するためのフィルタを考える 1 0 0 0 1 0 0
0 1 0 0 1 0 1 0 1 0 0 入力 フィルタ 0 0 1 1 0 0 0 1 0 0 1 0 1 0 0 0 0 1 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 1 2 0 0 0 1 0 1 3 0 1 0 1 0 1 2 2 1 0 1 0 1 0 3 1 0 1 0 0 0 2 1 0 1 0 0 2 1 0 1 0 3 1 0 1 0 2 1 0 1 0 1 1 0 1 0 1 2 0 1 0 1 3 0 1 0 1 2 0 0 特徴マップを見ると、 右上と左下に\ 左上と右下に/ があるのが0の特徴らしい 80
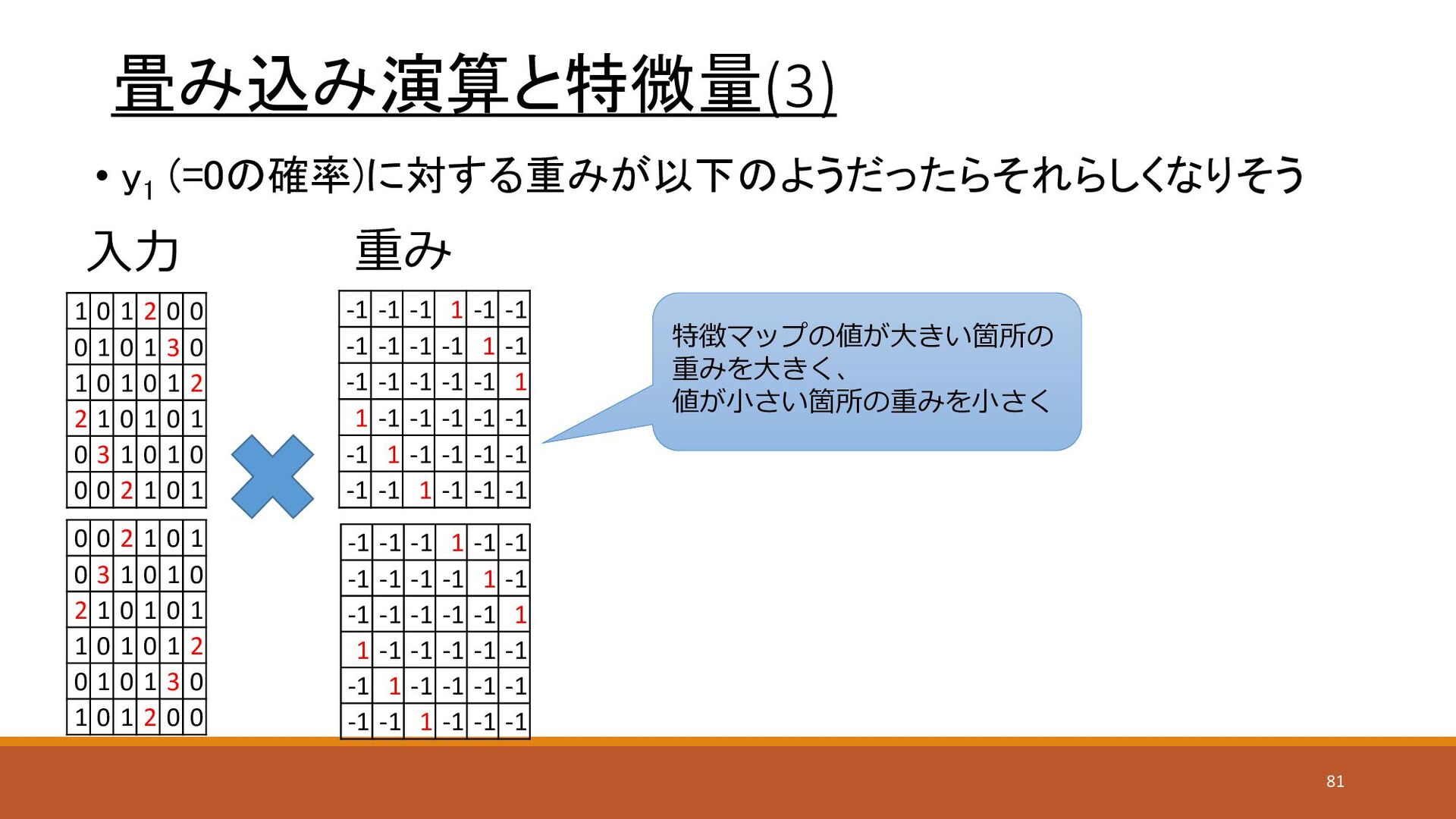
畳み込み演算と特微量(3) • y 1 (=0の確率)に対する重みが以下のようだったらそれらしくなりそう 入力 重み -1 -1 -1
1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 0 1 2 0 0 0 1 0 1 3 0 1 0 1 0 1 2 2 1 0 1 0 1 0 3 1 0 1 0 0 0 2 1 0 1 0 0 2 1 0 1 0 3 1 0 1 0 2 1 0 1 0 1 1 0 1 0 1 2 0 1 0 1 3 0 1 0 1 2 0 0 特徴マップの値が大きい箇所の 重みを大きく、 値が小さい箇所の重みを小さく 81
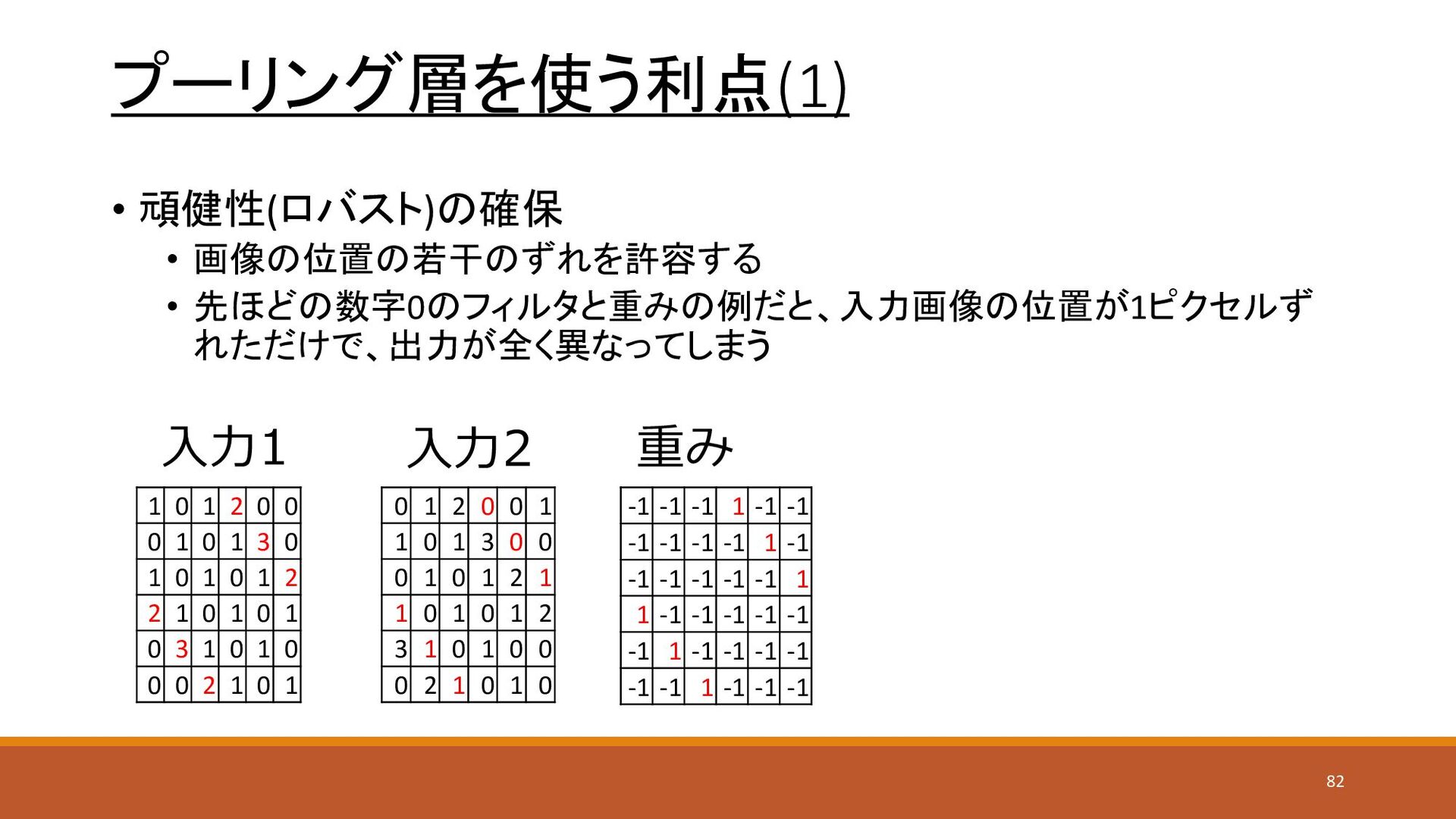
プーリング層を使う利点(1) • 頑健性(ロバスト)の確保 • 画像の位置の若干のずれを許容する • 先ほどの数字0のフィルタと重みの例だと、入力画像の位置が1ピクセルず れただけで、出力が全く異なってしまう 入力1 重み
-1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 0 1 2 0 0 0 1 0 1 3 0 1 0 1 0 1 2 2 1 0 1 0 1 0 3 1 0 1 0 0 0 2 1 0 1 入力2 0 1 2 0 0 1 1 0 1 3 0 0 0 1 0 1 2 1 1 0 1 0 1 2 3 1 0 1 0 0 0 2 1 0 1 0 82
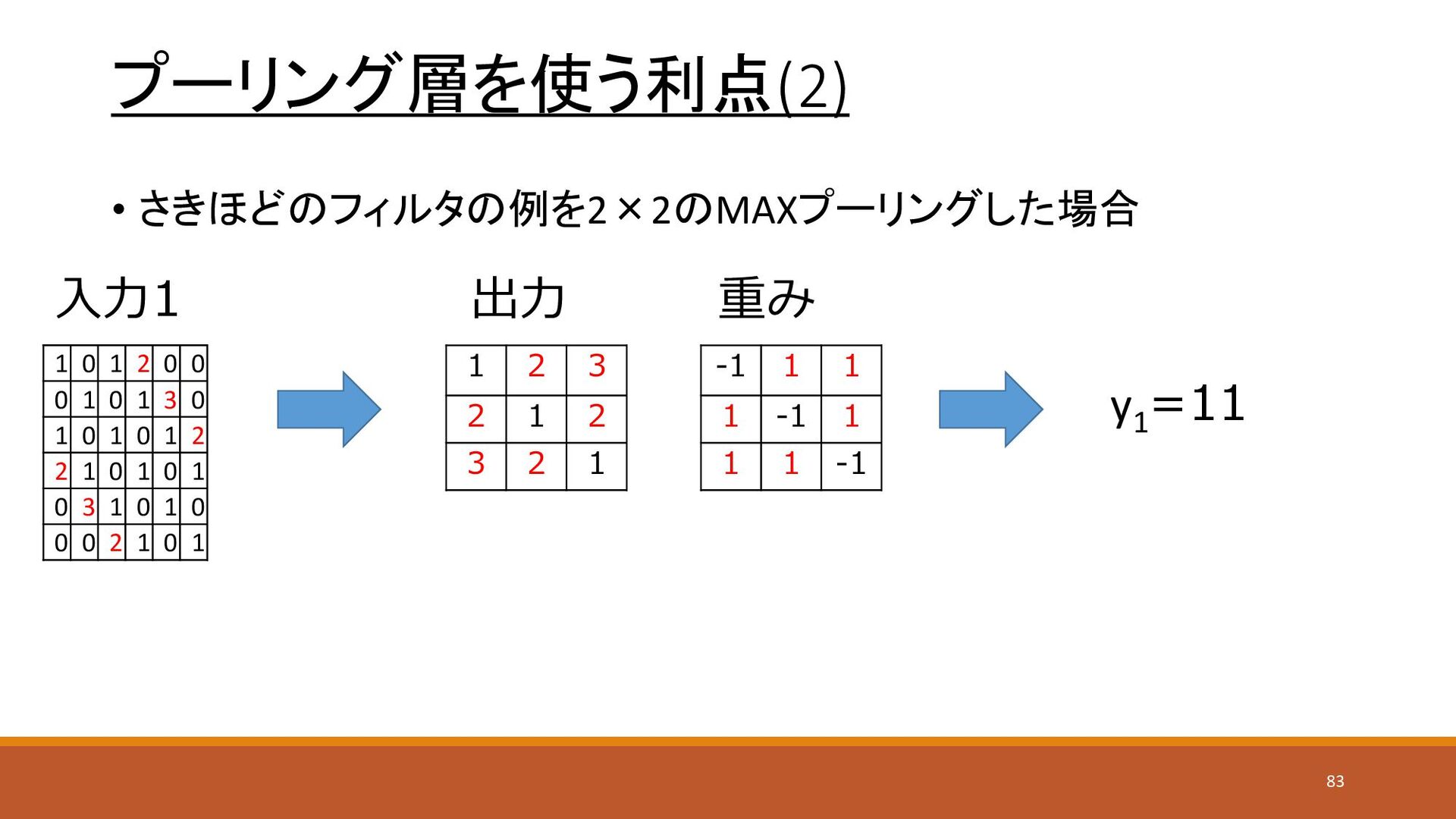
プーリング層を使う利点(2) • さきほどのフィルタの例を2×2のMAXプーリングした場合 入力1 重み 出力 1 2 3 2
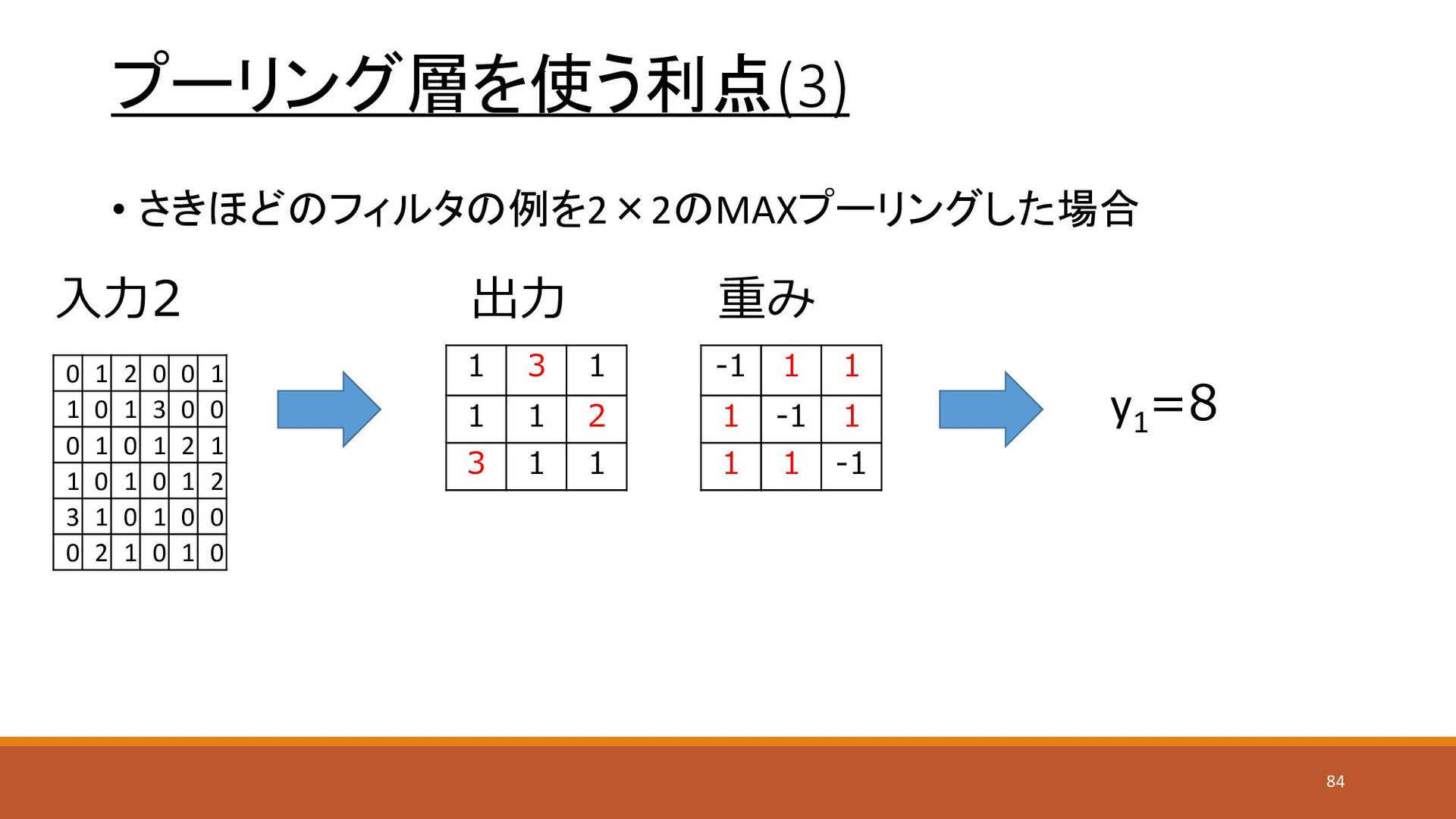
1 2 3 2 1 -1 1 1 1 -1 1 1 1 -1 1 0 1 2 0 0 0 1 0 1 3 0 1 0 1 0 1 2 2 1 0 1 0 1 0 3 1 0 1 0 0 0 2 1 0 1 y1 =11 83
プーリング層を使う利点(3) • さきほどのフィルタの例を2×2のMAXプーリングした場合 入力2 重み 出力 1 3 1 1
1 2 3 1 1 -1 1 1 1 -1 1 1 1 -1 0 1 2 0 0 1 1 0 1 3 0 0 0 1 0 1 2 1 1 0 1 0 1 2 3 1 0 1 0 0 0 2 1 0 1 0 y1 =8 84
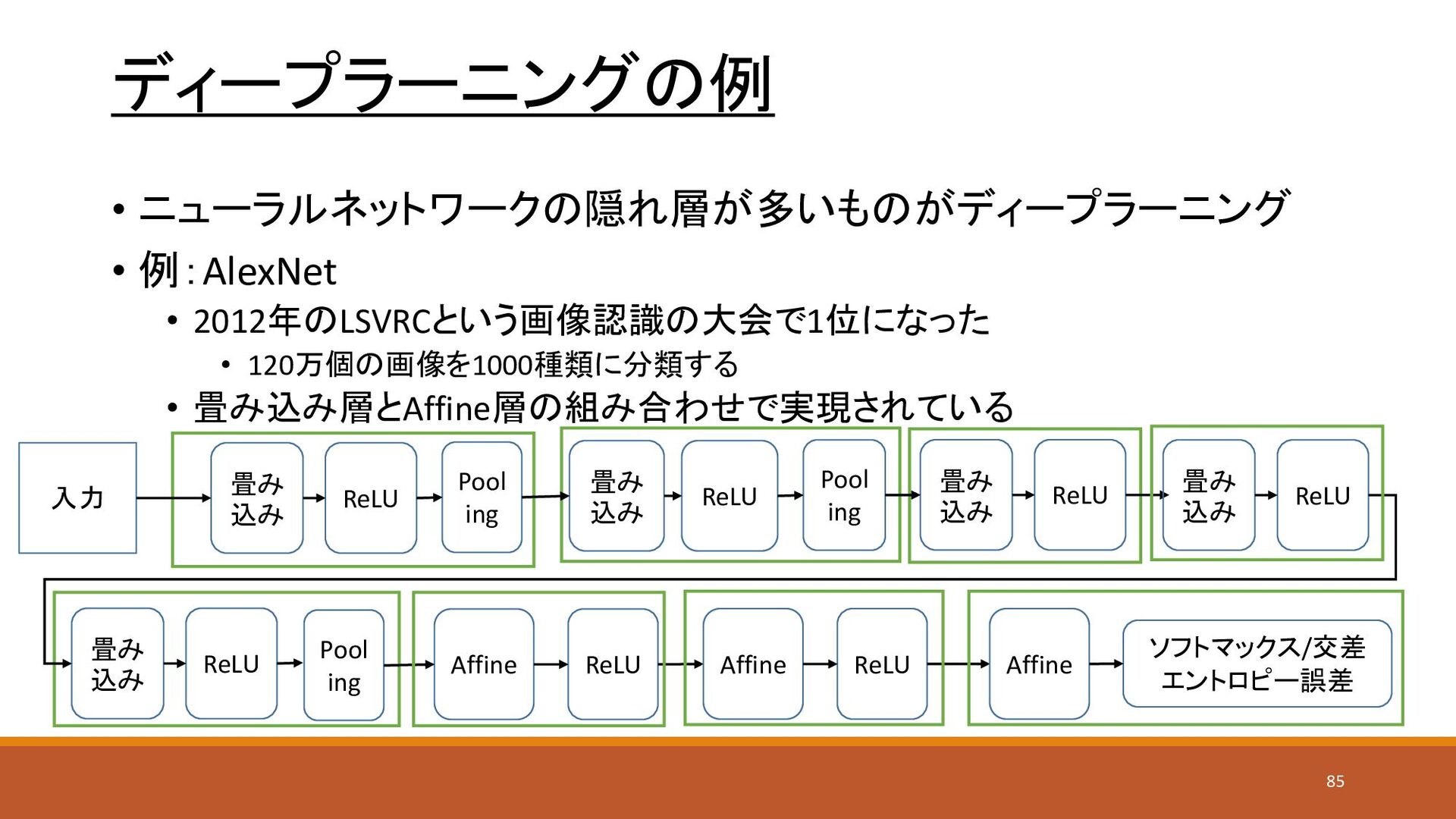
• ニューラルネットワークの隠れ層が多いものがディープラーニング • 例:AlexNet • 2012年のLSVRCという画像認識の大会で1位になった • 120万個の画像を1000種類に分類する • 畳み込み層とAffine層の組み合わせで実現されている
ディープラーニングの例 Pool ing 入力 畳み 込み ReLU Pool ing 畳み 込み ReLU ソフトマックス/交差 エントロピー誤差 Affine ReLU 畳み 込み ReLU 畳み 込み ReLU 畳み 込み ReLU Pool ing Affine ReLU Affine 85
まとめ • ニューラルネットワークはデータだけあれば、人がアルゴリズムを 考えたり、特微量の抽出をしたりしなくても学習ができる • ただしハイパーパラメータの調整は人手で必要 • ニューラルネットワークの学習は、学習するパラメータである重み、 バイアスを変えたらどれだけ損失関数に影響を与えるか=勾配を計 算し、勾配に沿ってパラメータを動かしていくことで行う
• 誤差逆伝播法を使うことで勾配の計算コストを下げることできる • 畳み込みニューラルネットワークを使う事で、元データの形状を維持 したまま学習を行うことができる 86
参考 • 参考書籍 • 斎藤 康毅(2016) ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの 理論と実装
オライリージャパン • サンプルコード • https://github.com/tsyki/deep-learning-example 87
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![隠れ層→出力層(Affine2)の勾配(2) dot b1, b2 [0.1,0.2] [0.32, 0.89] + [0.6, 1.3,](https://files.speakerdeck.com/presentations/b52c0f3d6b134bf7b040eb7bca4879ad/slide_57.jpg){kind=link}
![隠れ層→出力層(Affine2)の勾配(3) 59 w11, w12, w13, w21, w22, w23, [0.1,0.2,0.3], [0.4,0.5,0.6]](https://files.speakerdeck.com/presentations/b52c0f3d6b134bf7b040eb7bca4879ad/slide_58.jpg){kind=link}
{kind=link}
{kind=link}
![入力層→隠れ層(Affine1)の重みの勾配(2) 62 x1, x2 [1] [2] x= xT= x1, x2](https://files.speakerdeck.com/presentations/b52c0f3d6b134bf7b040eb7bca4879ad/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}