Elasticsearch has become a popular tool for distributed search, log analytics, and data visualization. What's the best way to scale out your deployment when you've reached capacity? In this presentation, we'll cover topics like shard allocation, clustering, and best practices to increase performance and stability of an Elasticsearch cluster. A good talk for those both working with existing deployments or looking to learn about the scaling capabilities of Elasticsearch.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
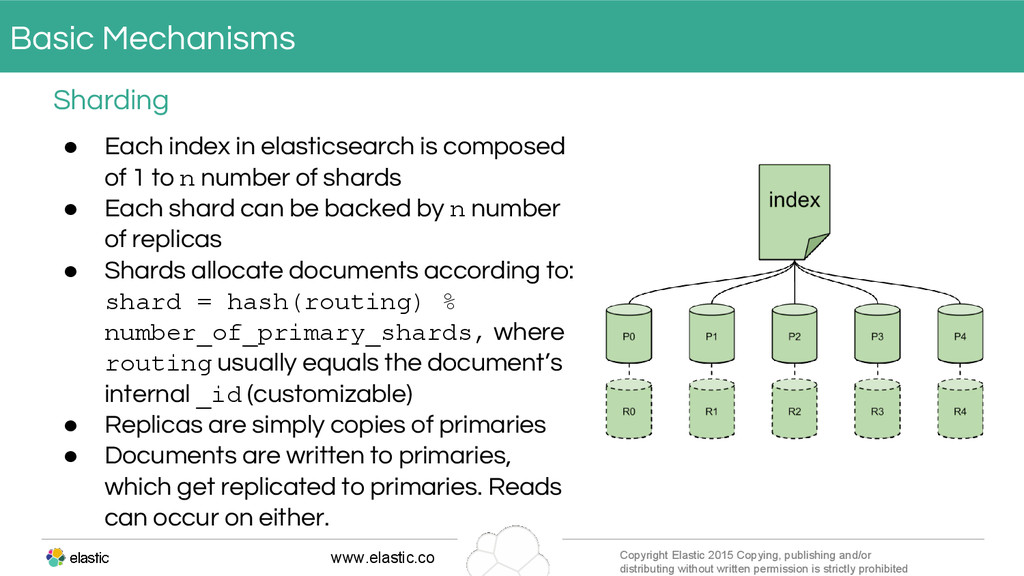{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
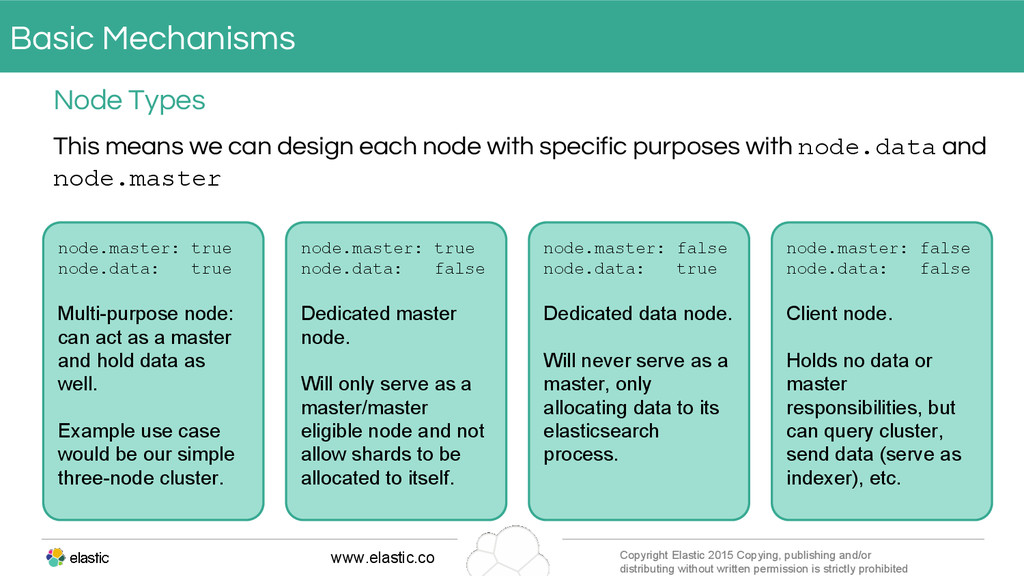{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}