of recent work on dynamic/containerized environments Come talk to me about Arm SBCs (or if you want to yell about the Elastic Puppet modules) ____________________ < angry at computers > -------------------- \ ^__^ \ (oo)\_______ (__)\ )\/\ ||----w | || ||
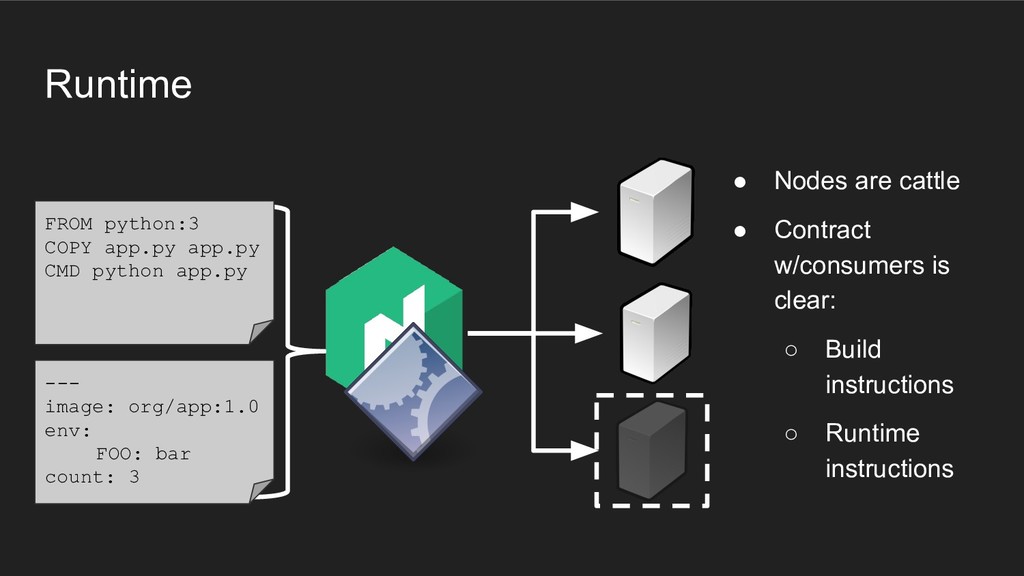
Nodes are cattle • Contract w/consumers is clear: ◦ Build instructions ◦ Runtime instructions FROM python:3 COPY app.py app.py CMD python app.py • Deployments are always the same bits - repeatability • Updates are hands-off for both dev and ops - rolling container upgrades • Application changes async from backend (container build instructions)
the box • Easily build custom tools atop this data for out of the box alerting as well • Logs/metrics become self-service with appropriate visualization solutions
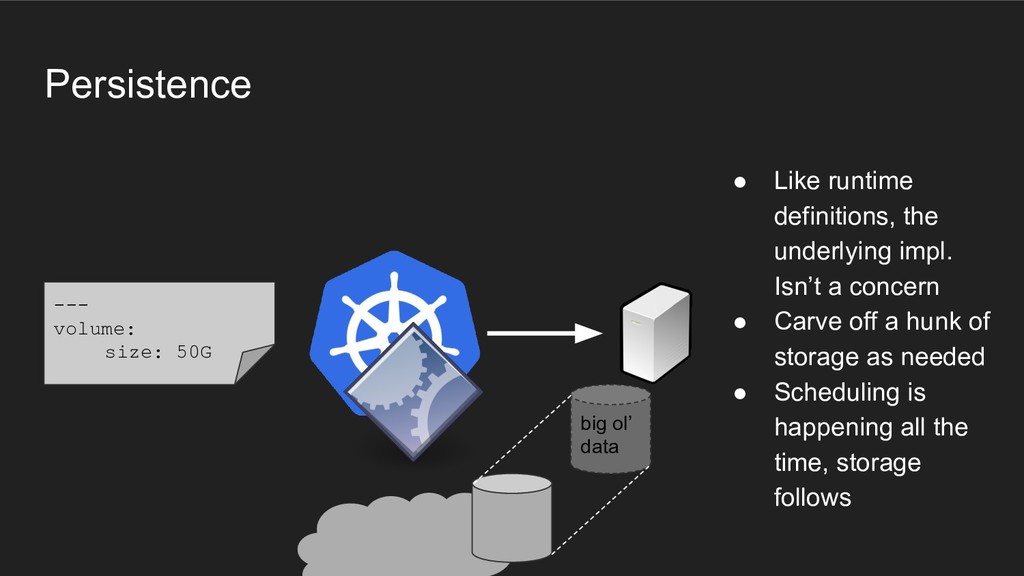
setups • Dynamically attached storage in the case of cloud environments (EBS) • Works, but: ◦ What ties them together, provisions them, migrates them, backs up? big ol’ data ?
underlying impl. Isn’t a concern • Carve off a hunk of storage as needed • Scheduling is happening all the time, storage follows big ol’ data • Nobody cares where or what the persistence base is, we just have space now • Infra can develop tools to enhance storage for everyone (automated backups, snapshotting, etc.) • Backend-agnostic - GCP, AWS, Azure, etc.
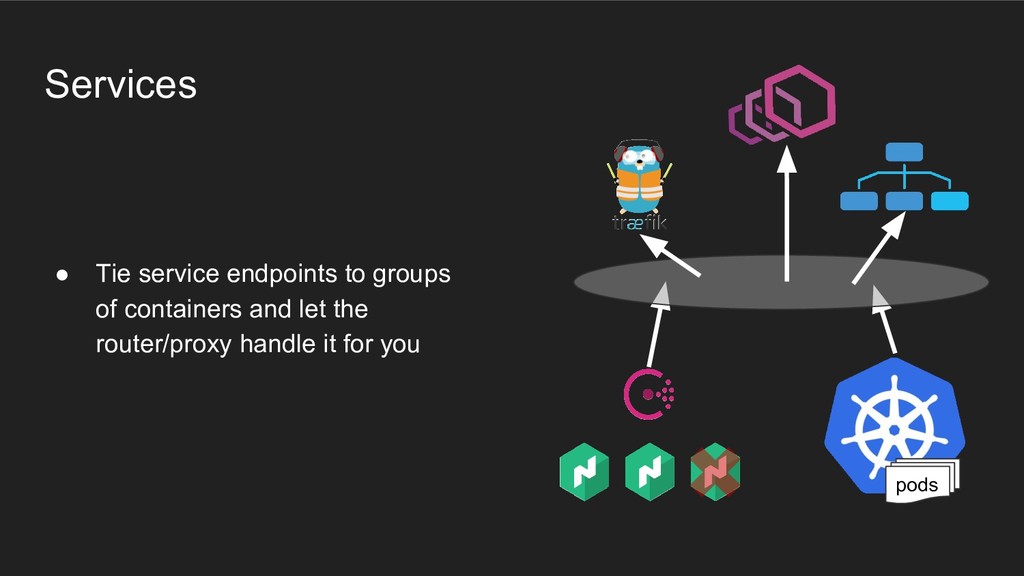
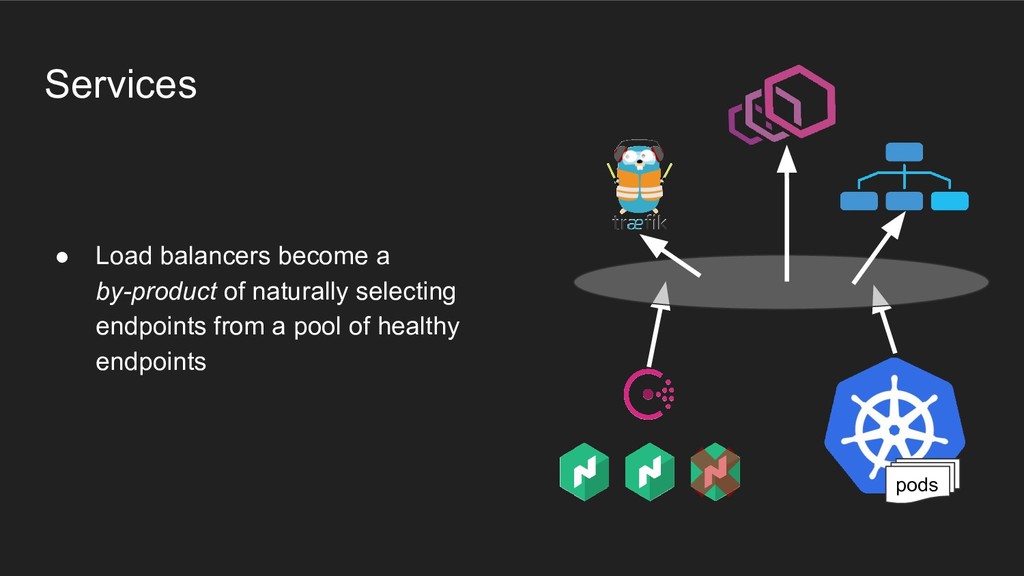
- no one needs to learn another team’s tools if they don’t want to • Improvements and iteration are completely unblocked on either side • Infra tooling becomes immediately useful for everyone on the platform
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}