ElasticSearch is quickly becoming one of the primary contenders in the search space: it is distributed, highly available, fast, RESTful, and ready to be plugged into Web applications. Its developers have been busy in the last year; this talk will do a quick introduction to ElasticSearch and cover some of the most interesting and exciting new features. We might even take down a live server or two to illustrate a point.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![API structure http://host:port/[index]/[type]/[_action/id] GET http://es:9200/twitter/_status GET http://es:9200/twitter/tweet/1 GET http://es:9200/twitter/tweet/_search GET](https://files.speakerdeck.com/presentations/4fd1f062469d2001a401b318/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
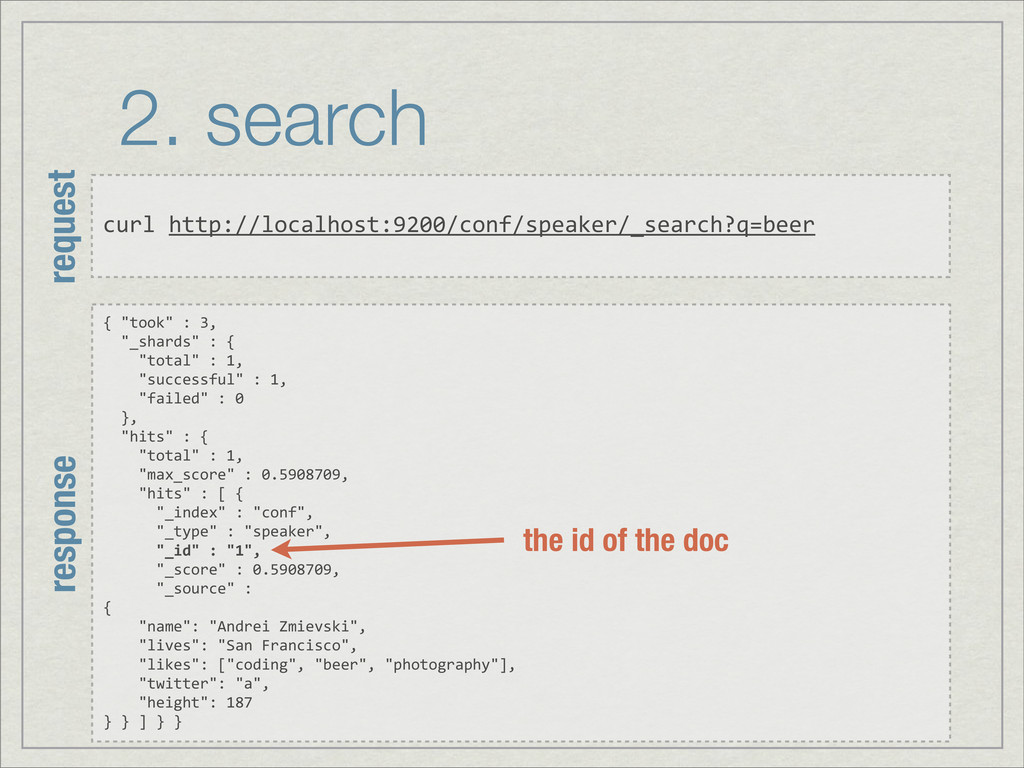{kind=link}
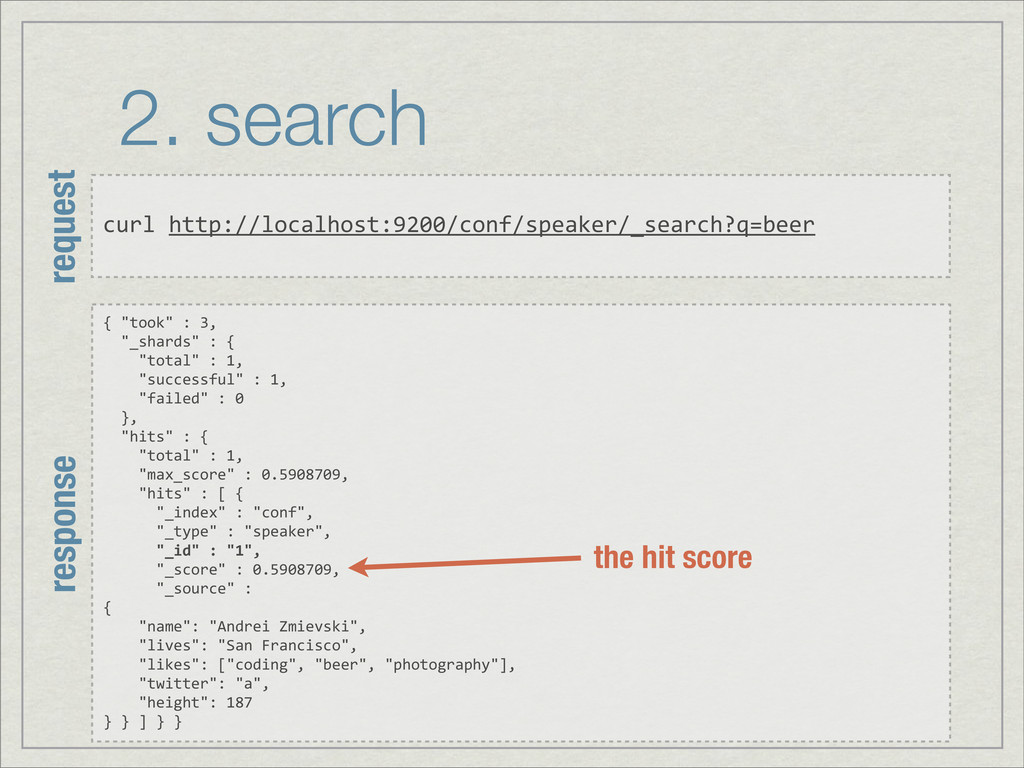{kind=link}
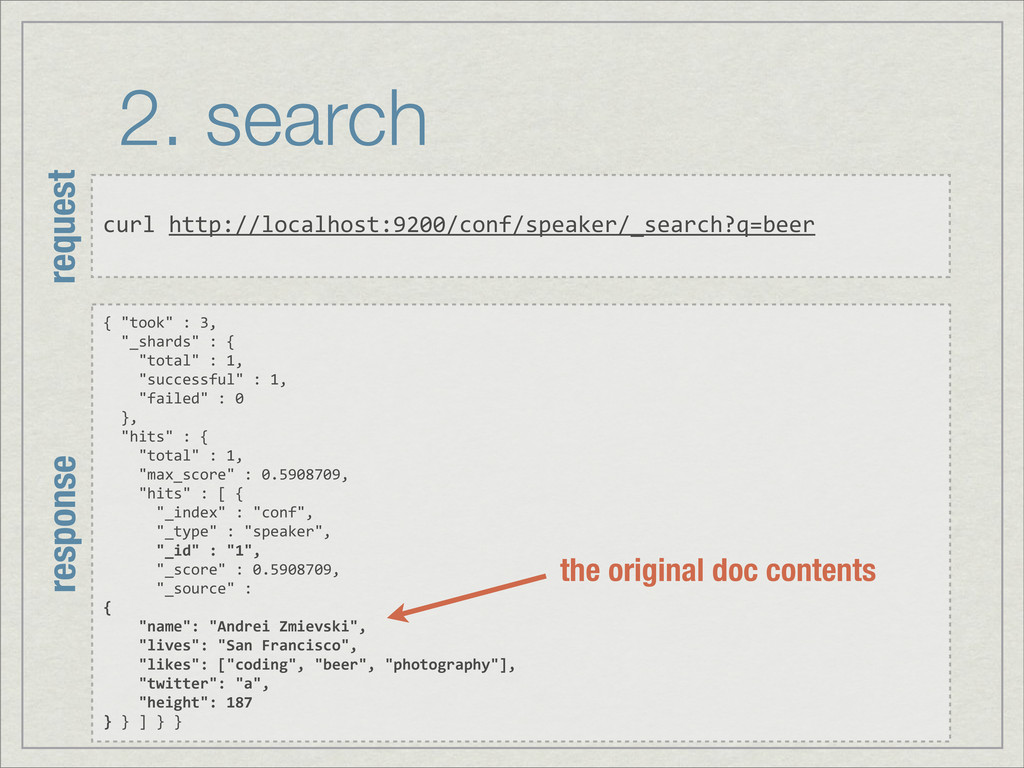{kind=link}
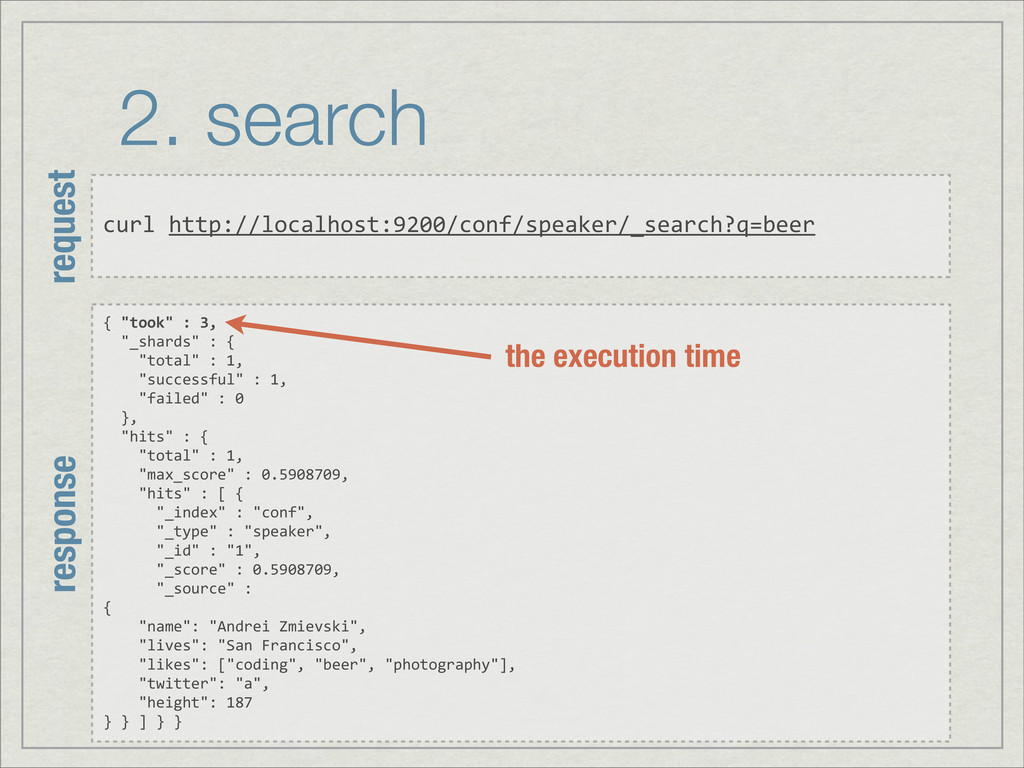{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
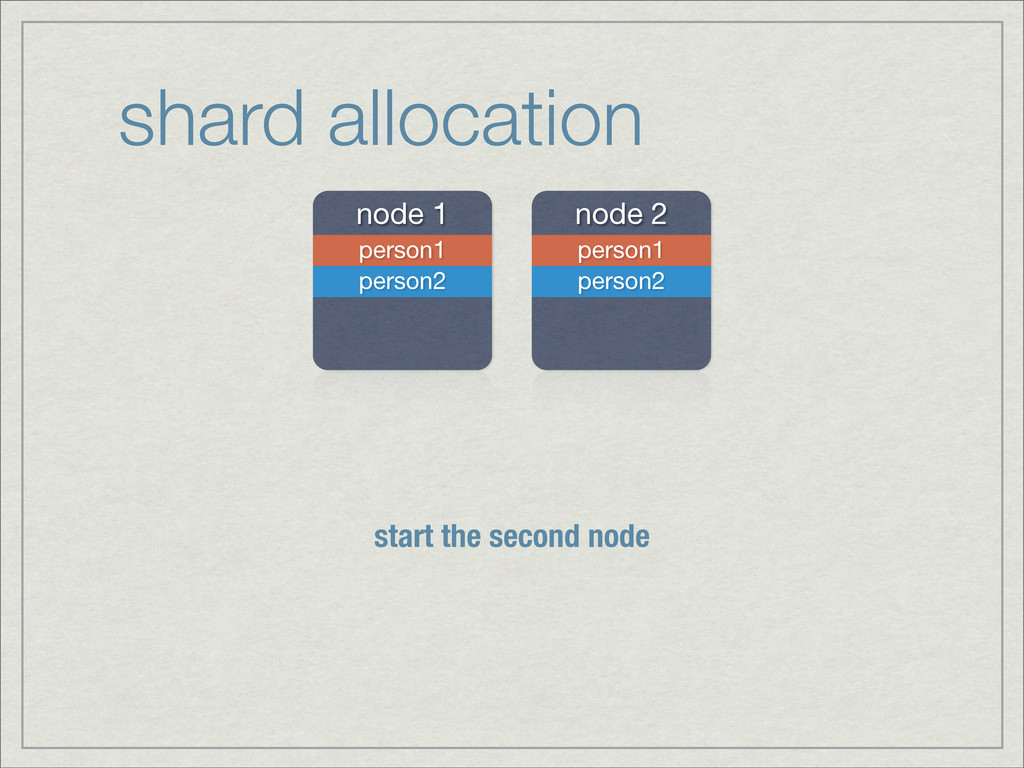{kind=link}
{kind=link}
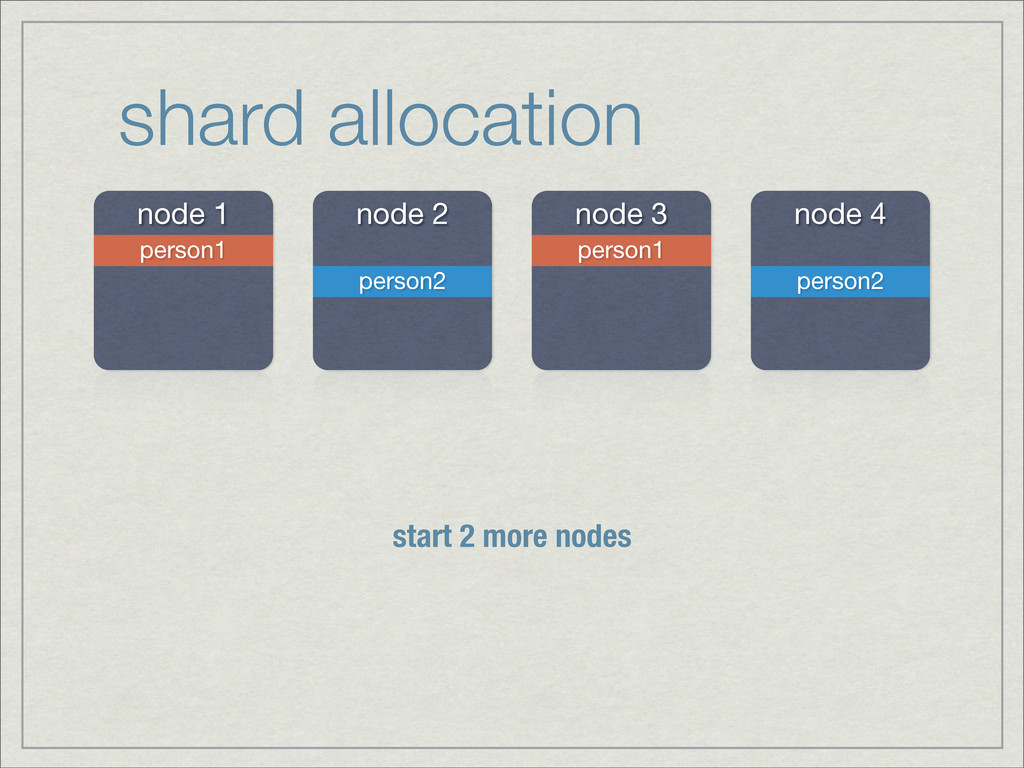{kind=link}
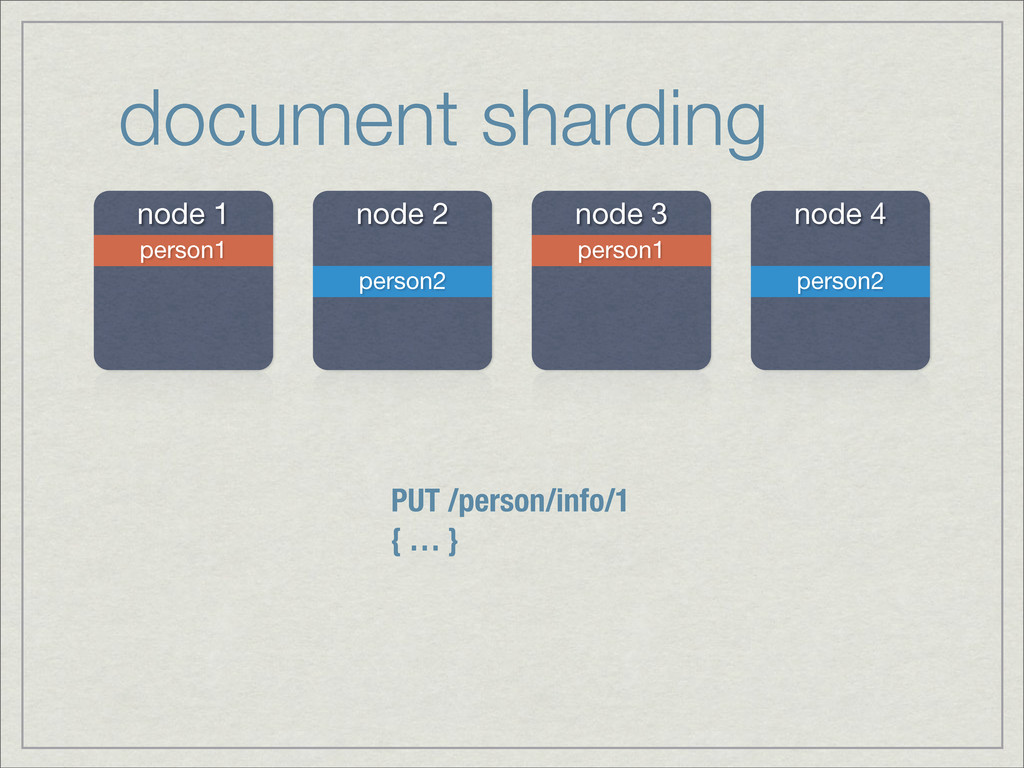{kind=link}
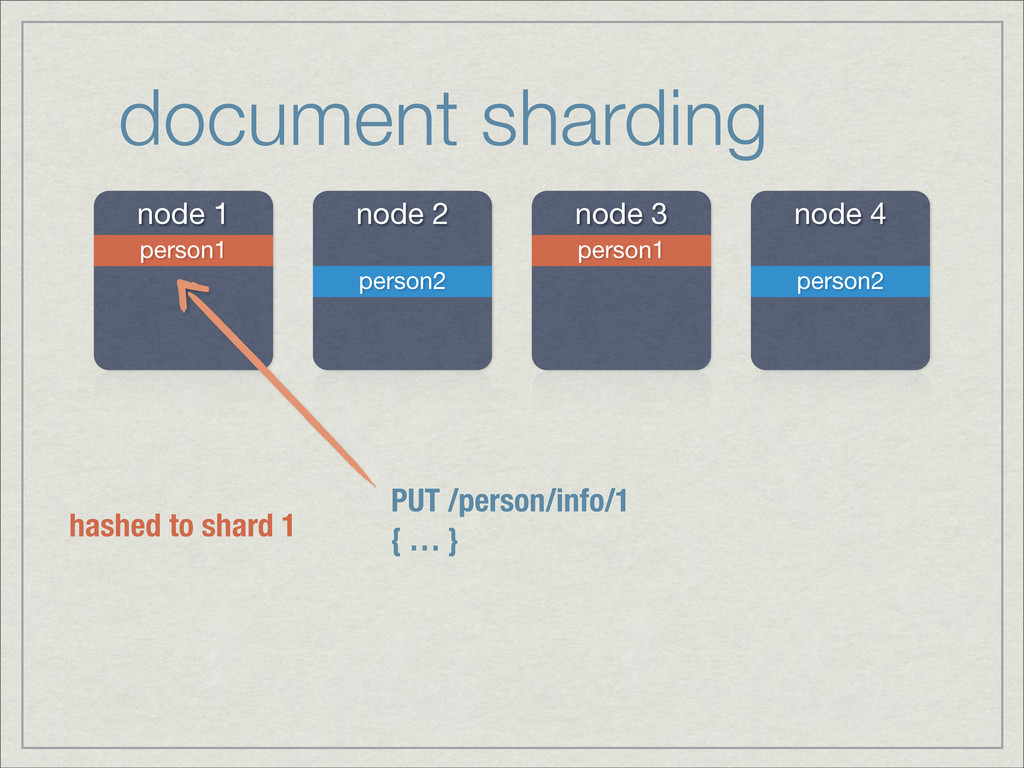{kind=link}
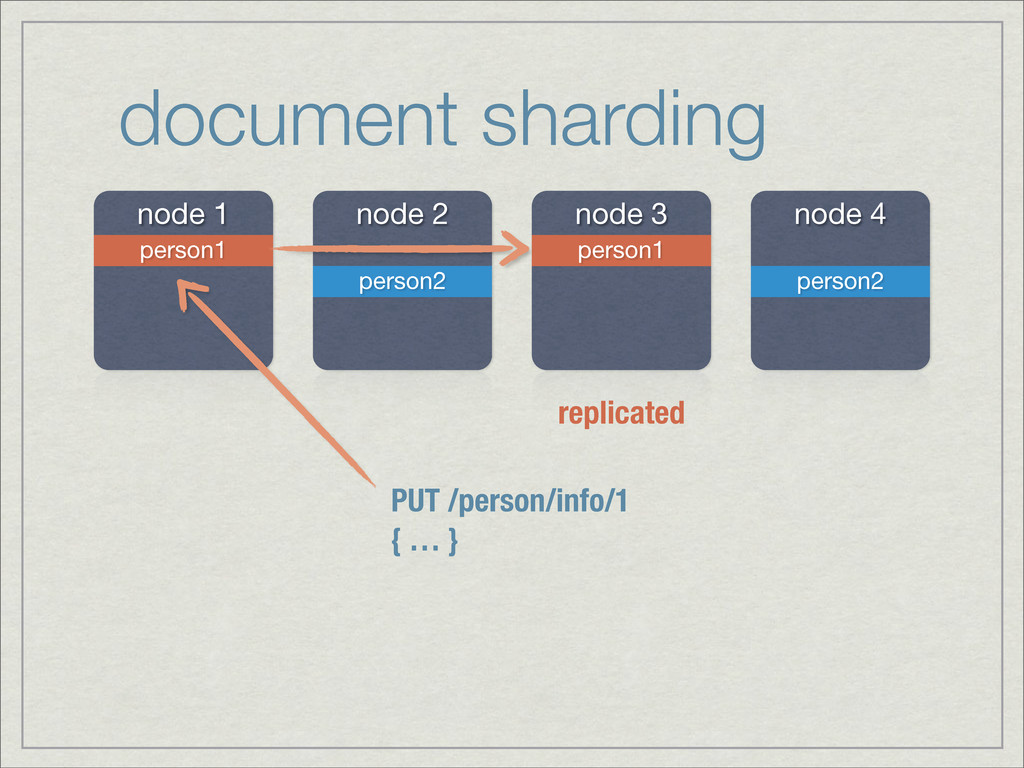{kind=link}
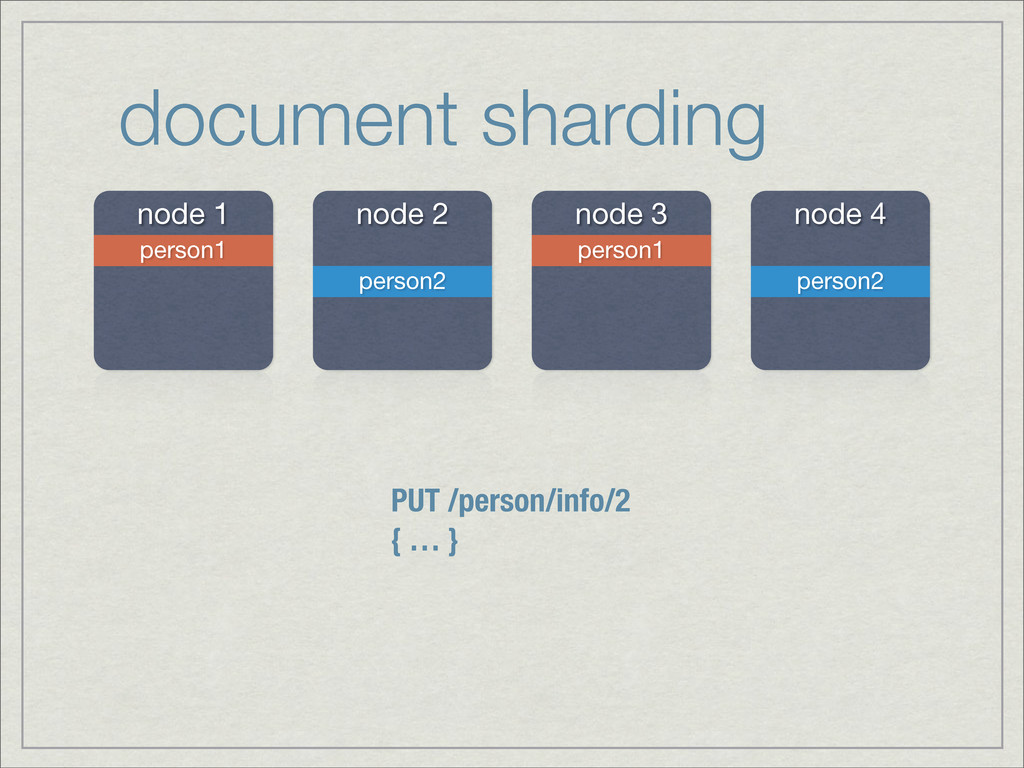{kind=link}
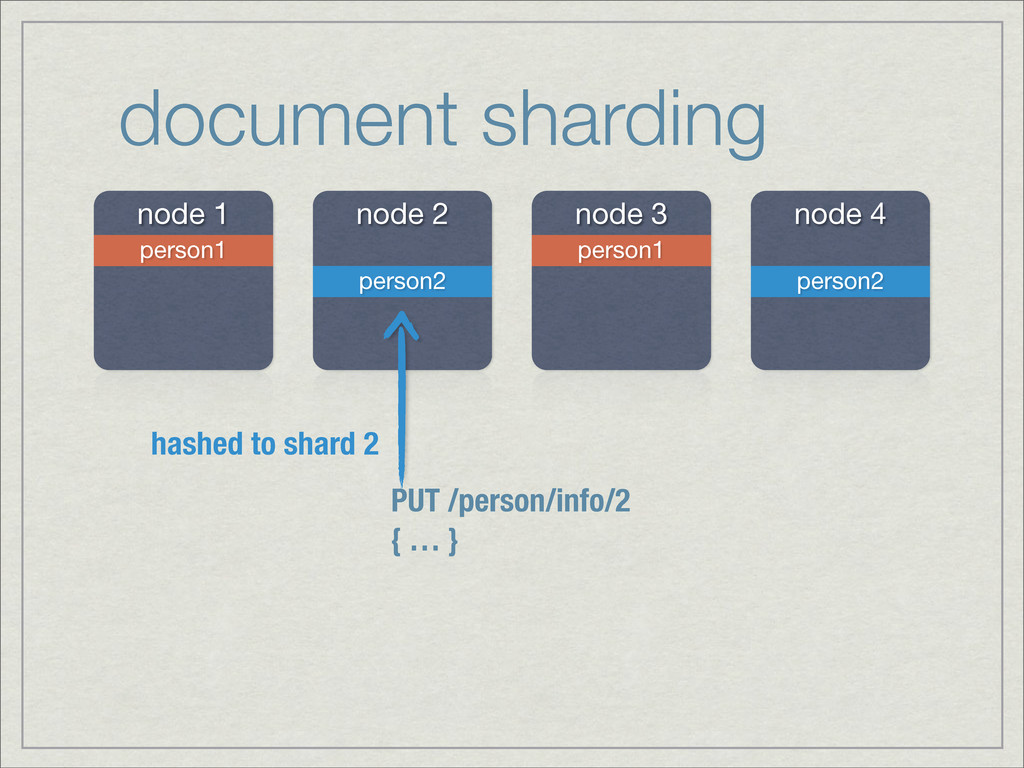{kind=link}
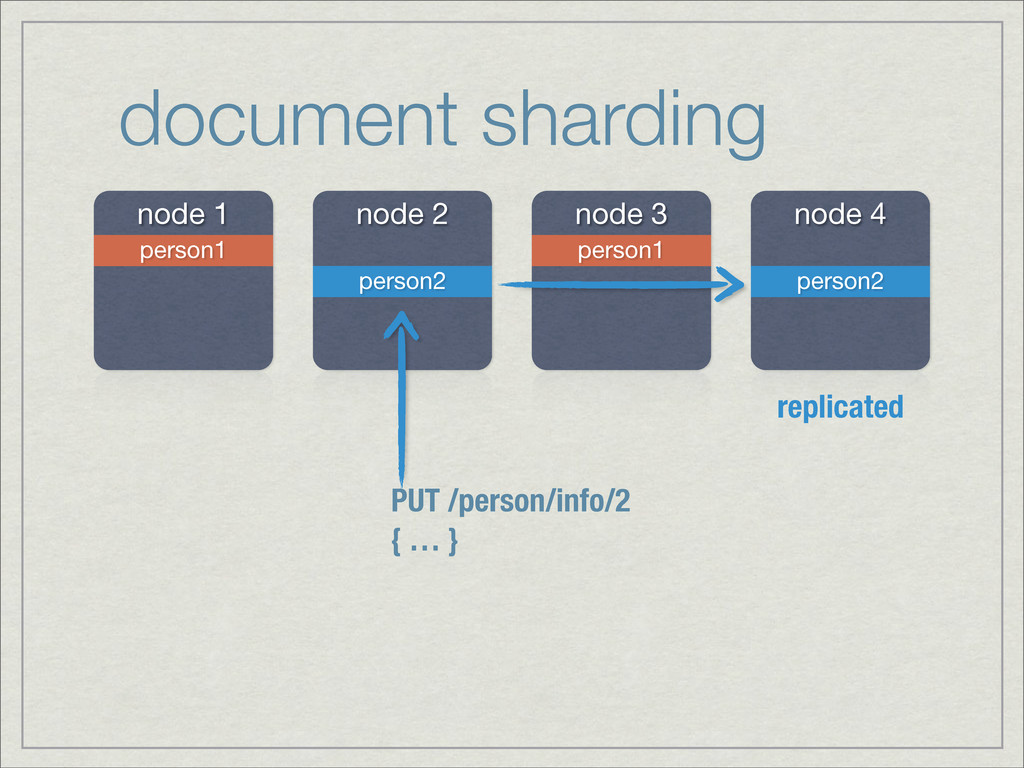{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}