binary required! Almost complete abstraction of the Git object model Brought to you by E-butik.se Friday, June 8, 12 Now, what is gittern, besides an instrument? It’s a Git library, written in pure PHP, that doesn’t require the Git binary. It abstracts most of the Git object model, at least the most interesting parts. And it’s brought to you by E-butik.se, my employer.
Easily extendable beyond “ordinary” Git Cache objects in Redis, Memcache Multiple indexes Friday, June 8, 12 It also has Gaufrette adapters for your git repos, allowing easy access, where apps don’t even know it’s Git they’re accessing. And it’s easily extendable, even beyond what the ordinary git binary can do. You could e.g. cache your git objects in Redis, or Memcache, or you could have multiple git indexes.
Commit time Message Parents Tree Commit Id (sha) Nodes (with name and mode) Tree Id (sha) Contents Blob Git Objects (simplified) Friday, June 8, 12 I know what you’re thinking, though. What’s the git index? What’s a git object? First things first. This is a simplified view of the Git object model. Some parts are missing, but those are more rare, and not yet supported by Gittern. You probably know what a commit is? You might say that it’s a snapshot of your content or something like that, but to Git, a commit is basically just a tree, with some metadata. There’s an author, a commiter, timestamps, a message, and zero or more parents. The tree, on the other hand, basically just references a bunch of other git objects, along with their name and their mode. Same kind of mode as in UNIX filesystems. The tree can either reference other trees, or commits (but we’re not gonna talk about that), or it can reference blobs. A blob is basically just data. These three objects are known as Git objects, and almost every repo you’re using has them.
objects are stored as separate compressed files, in dirs Packed objects are stored in packfiles, huge binary files containing lots of objects Friday, June 8, 12 The git objects are stored in the Git object store. This is more or less an implementation detail, but it’s notable because it affects performance. They’re either stored in loose or packed form. Loose objects are just a bunch of separate compressed files, stored in directories based on their SHAs. Packed objects are stored in packfiles, which is a usually pretty big binary file containing loads of objects, usually delta compressed. This is what you get when you pull, and this is what’s created when you notice a commit taking longer and see something about “delta compression”. Packed objects are great for history because it’s storage efficient, not so great for current data accessed by web apps. But there is a silver lining, there’s a packfile index, which speeds up finding stuff significantly. Be mindful though, if you have performance problems, cache or unpack objects.
create a tree And then some! The place Git stages your files when you do “git add” Friday, June 8, 12 There’s also the git index, which stores everything needed to create a tree, and then some. Basically, it’s references to a bunch of blobs, the file paths where they’re found, and the results of a stat() call to speed up comparisons against a working copy. This is where git stages your files when you do a git add. The observant listener will of course have drawn the conclusion that whenever you do a git add, git actually creates a blob with the contents of the file and stores it in the object store. This is correct. And no, there’s no delta storage in the loose object store. However, if an object isn’t referenced by anything, it will be cleaned out, sooner or later by git’s garbage collection.
tags) Reflog † Hooks † Index (unless bare) Friday, June 8, 12 Then there’s the top of the list. The Git Repository. It stores the object store, configuration, references, both to branches and light tags. The reflog, which is nice, but sadly out of scope since Gittern doesn’t yet support it. There’s hooks, and unless the repo is bare, i.e. doesn’t have a working directory, there’s an index. Speaking of the working copy, that exists too, but it’s boring, just your plain old files, and Gittern doesn’t use it.
Git objects like any other PHP object, persist them to the repo, flush your changes Fetch objects, read them, get proxies when they’re not directly loaded * Or at least a lot of it Friday, June 8, 12 What Gittern does use is the most important of the stuff I mentioned there. The object store, references and the index. Gittern is inspired, interface-wise, by Doctrine 2. You can just create your git objects like any other PHP Object, you persist them to the repository, and then you flush your changes. To read from the repo, you fetch your object, and any object which isn’t directly loaded (which will be a lot) you will get a proxy for. The proxy can give you the SHA without faulting, but otherwise the proxy faults and loads the object. It’s pretty neat.
it for storing customer-editable templates Whenever you want to push things to a server, because it’s cool (But this requires the git binary) Friday, June 8, 12 So, when would you want to use Git in your project? Well, when you’re storing unstructured data, that you want to be able to version. Of course, Git isn’t a database, you can’t do a fast indexed query for commits that contain files with this or that data. That’s what a database is for. At E-butik we use it to store our customer’s store layouts. I personally use it to store blog entries for my blog (which isn’t searchable, mind you, and wouldn’t be without a separate index). As a corollary to my blog, you should definitely use it when you want to push things to a server to publish it, just because it’s cool. This requires the git binary on the server though. I’ll show it to you if there’s time, and you can all revel in it’s coolness.
they have a SHA Clone them to get mutable copies (without a SHA) But not using the clone keyword… Do your changes, then persist into the repo and flush. Friday, June 8, 12 So, a few things to consider when working with Gittern. Reading is easy. You just fetch your object (usually a commit at first), and then you traverse the object structure, getting the tree, getting blobs et c. That’s easy. Writing is a little bit harder, but not all too difficult. You need to remember though, that object’s are immutable once they have a SHA. This of course means that you cannot change them. To change stuff, you first need to clone it, but don’t use the clone keyword. It wouldn’t work all to well with proxies. Gittern throws exceptions if you try to use the clone keyword. There’s a method you should use instead. Once you’ve cloned your objects, though, you can just do your changes, persist them into the repo, and flush them. Working with the Index might also be a good idea here.
object manipulations so Git almost seems like any other filesystem Leaky abstraction, either read-only or manual commits. * Rhyme intended, feel free to use as catchy slogan Friday, June 8, 12 Better yet, use Gaufrette. Gittern has two adapters, a read-only adapter that you just input a commitish, like “master” into, and an index adapter. These abstracts the object manipulations, so your git repo almost seems like any other filesystem. This is however a leaky abstraction. Either your adapter is read-only, or you have to manually commit from the index. At E-butik, we use this to our advantage. We store the customer’s working copy in the index, and the published current version in a regular branch. Whenever they want to publish, we just commit the data. It’s quite a sweet setup.
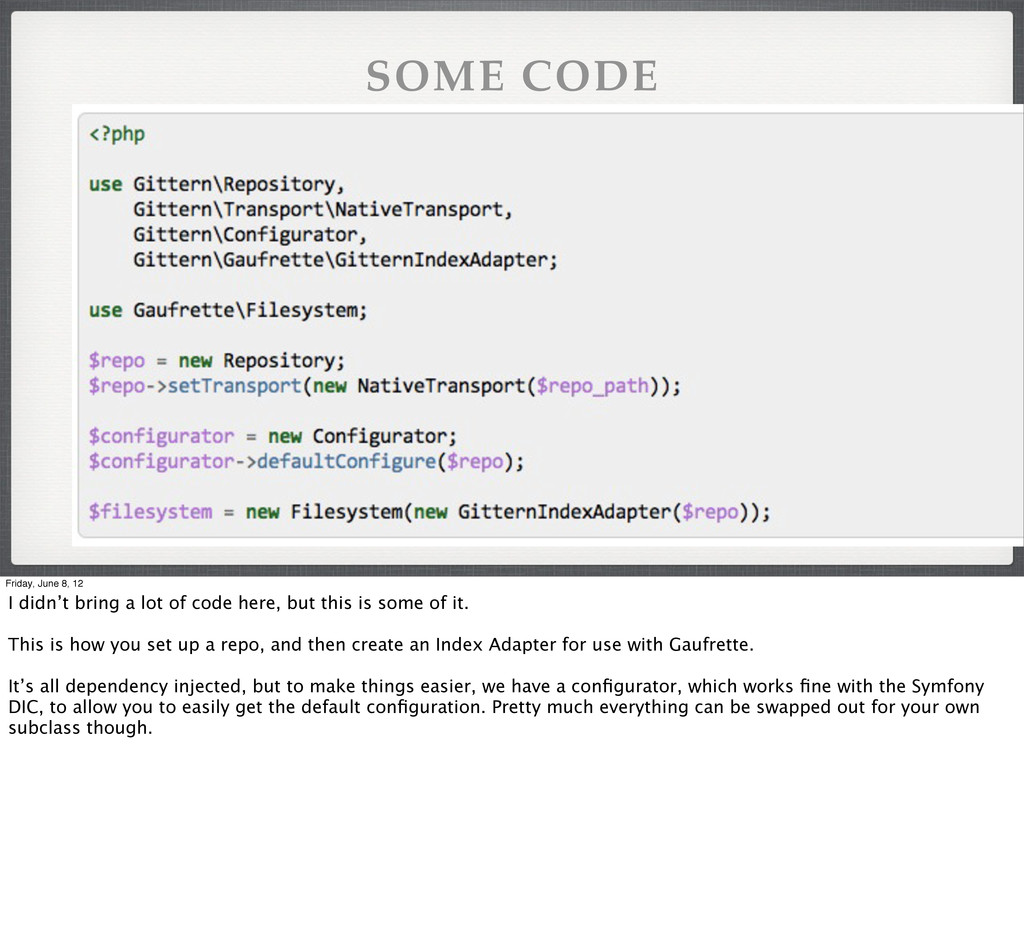
lot of code here, but this is some of it. This is how you set up a repo, and then create an Index Adapter for use with Gaufrette. It’s all dependency injected, but to make things easier, we have a configurator, which works fine with the Symfony DIC, to allow you to easily get the default configuration. Pretty much everything can be swapped out for your own subclass though.
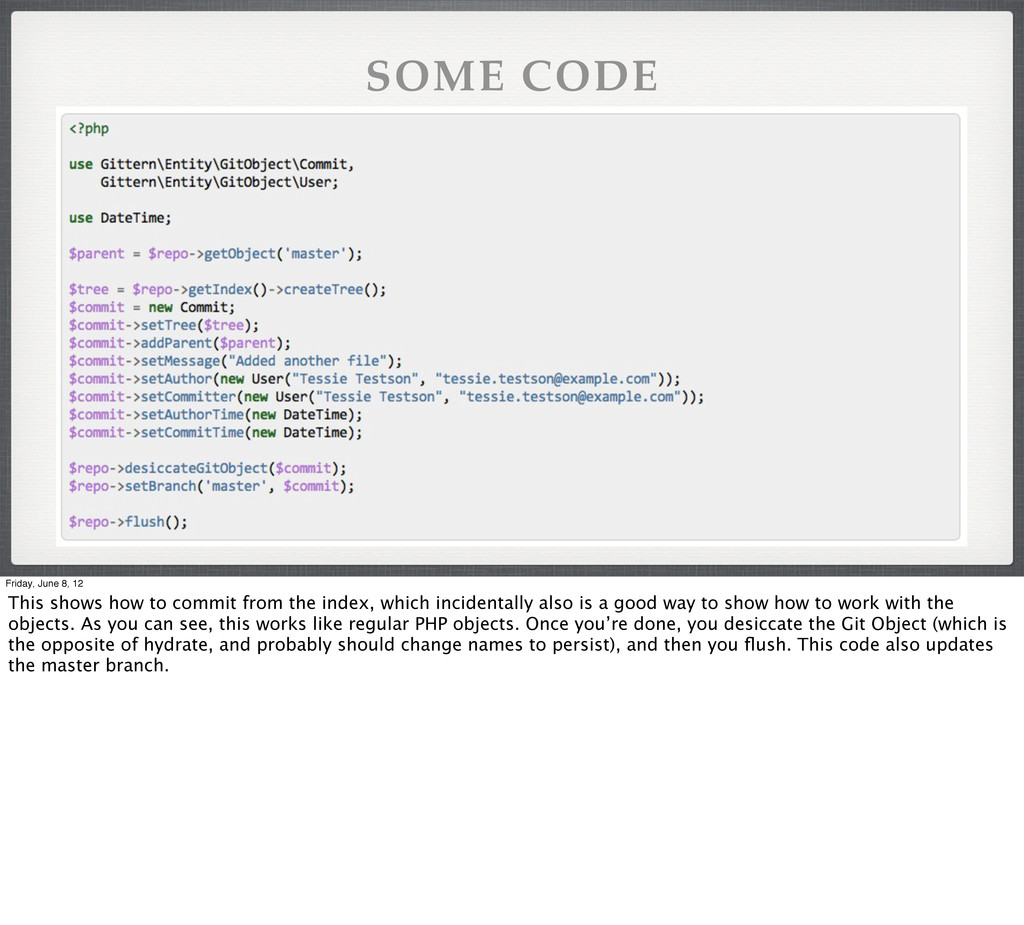
commit from the index, which incidentally also is a good way to show how to work with the objects. As you can see, this works like regular PHP objects. Once you’re done, you desiccate the Git Object (which is the opposite of hydrate, and probably should change names to persist), and then you flush. This code also updates the master branch.
line coverage though) Full object model coverage (annotated tags, symlinks and submodules) Reflog Full commitish parsing Configuration Remote? Friday, June 8, 12 So, what’s next for Gittern? Well, we need more docs. Right now it’s mostly overview docs, and the code. We also need more tests, even though we do have about 90% line coverage. We also want to cover the entire git object model. This includes stuff like annotated tags, symlinks and submodules. We want to support the reflog, because it’s a very handy log. Full support for parsing commitishes, would be nice. Right now we support branches and shas. We definitely need to add support for tags, but it would be nice to do relative commitishes, like the n:th parent of a commit et c. We also want to support the configuration files, and possibly in the future, git remotes, because right now, internally, we use a git binary dependent subclass to handle stuff related to these things.
8, 12 That’s about it. I hope you can find some use for Gittern in your projects. These are some resources on Gittern. There’s the github repo, and our developer blog, where you’ll find these slides. If there’s time, and if you have any questions, I’d be happy to answer them. Otherwise, you can also e-mail me at [email protected]. So. Any questions?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RESOURCES https://github.com/e-butik/Gittern http://developer.e-butik.se E-mail me: [email protected] Twitter: @drrotmos Friday, June](https://files.speakerdeck.com/presentations/4fd203b7469d20059c00555b/slide_14.jpg){kind=link}