Part 1 of this talk will give an overview of how Python scales to supercomputer-sized programming and a brief introduction to using the message passing interface (MPI) library to scale a Python program to large distributed memory cluster systems.
Part 2 will cover Python libraries for access to 'big data' -- hdf5, netcdf, pytables -- mostly in reference to Earth observation data.
Python scales from smart phones to supercomputers. There are two pillars to huge computing problems: high performance computing and massive data.
The fastest and largest high-performance computing (HPC) systems are all distributed memory cluster systems. The message passing interface (MPI) was developed and designed to allow many programming threads to communicate efficiently across the high-speed network of a cluster supercomputer and effectively act as a single HPC program on thousands of processors. Python has access to the MPI library through the mpi4py module. An overview of HPC will be followed by an introduction to MPI with examples in Python using the mpi4py module.
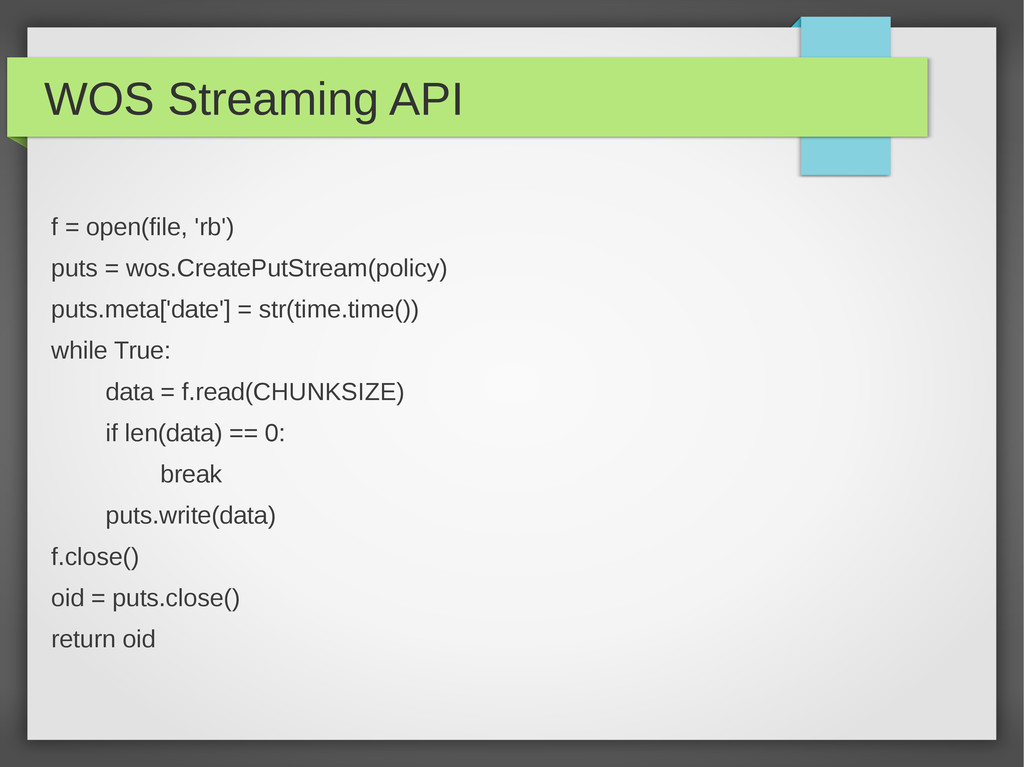
In part 2, Andy will show example routines accessing NASA and ESA Earth observation data -- and routines for storing large files on CHPC DIRISA data store. This also requires a local database to store metadata -- in this case PostGIS.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}