program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new “features.” • Expect the output of every program to become the input to another, as yet unknown, program.
one thing well - Streams - Simple, powerful interface Problems : - Single machine only - One to one communication only - Input parsing, output escaping - No fault tolerance The simplest possible interface : • ordered sequence of bytes • maybe with EOF • often ASCII • \n = record separator • [ \t] = field separator
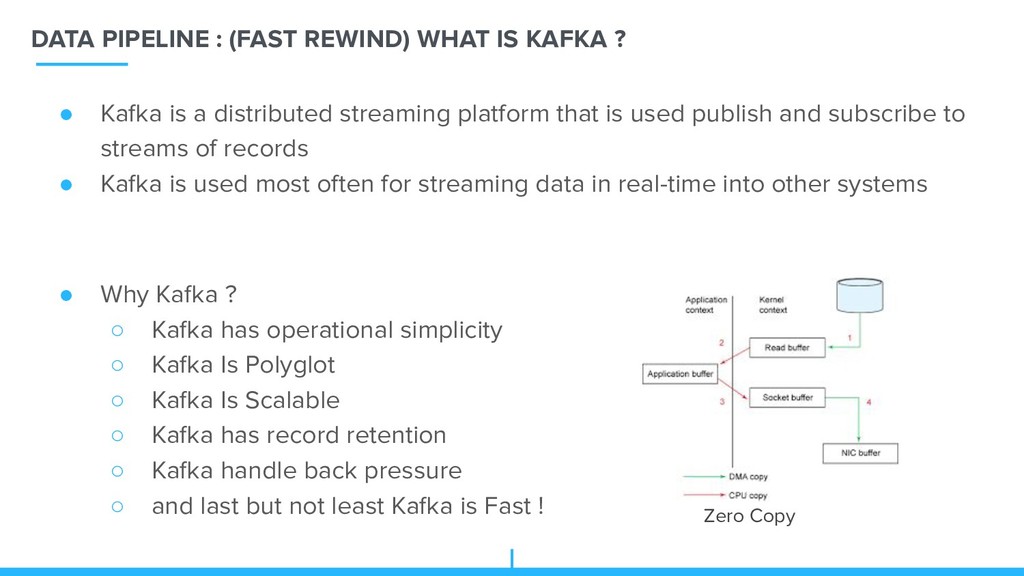
Copy • Kafka is a distributed streaming platform that is used publish and subscribe to streams of records • Kafka is used most often for streaming data in real-time into other systems • Why Kafka ? ◦ Kafka has operational simplicity ◦ Kafka Is Polyglot ◦ Kafka Is Scalable ◦ Kafka has record retention ◦ Kafka handle back pressure ◦ and last but not least Kafka is Fast !
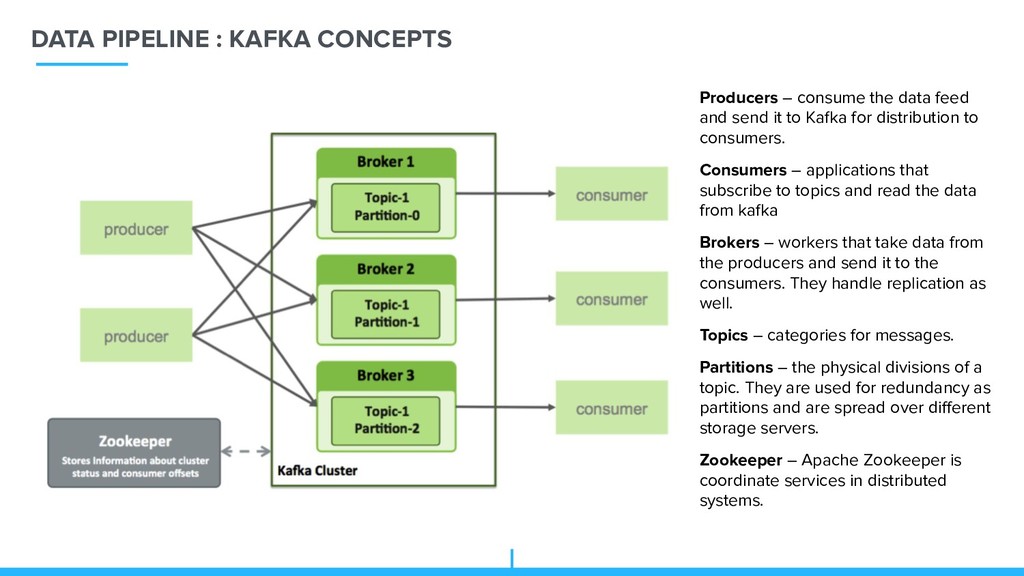
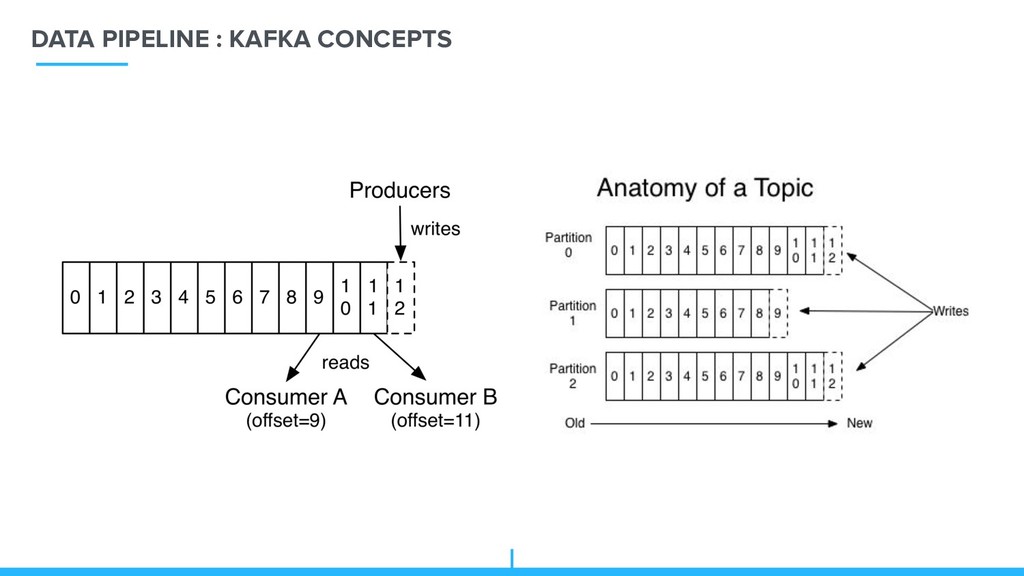
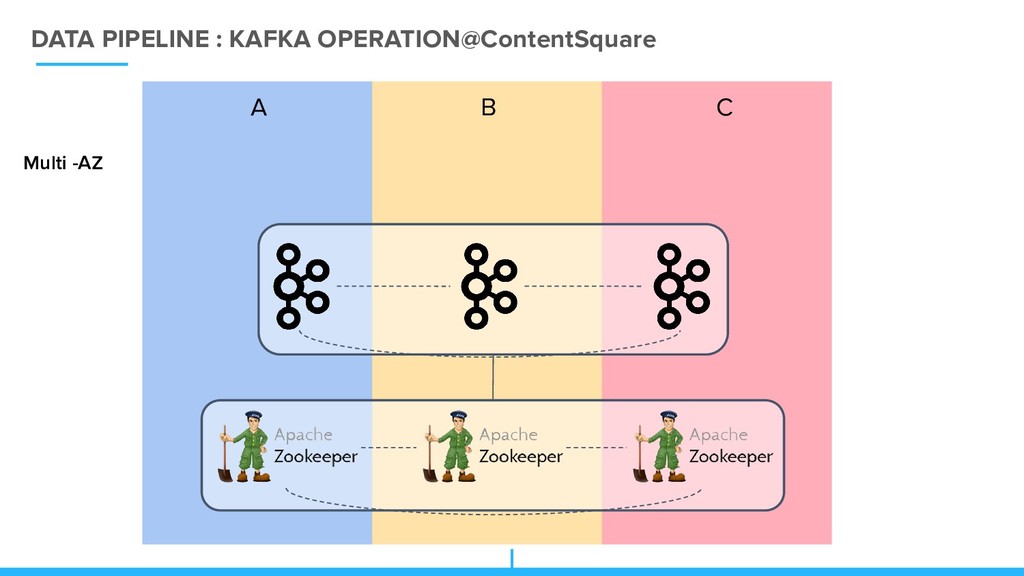
feed and send it to Kafka for distribution to consumers. Consumers – applications that subscribe to topics and read the data from kafka Brokers – workers that take data from the producers and send it to the consumers. They handle replication as well. Topics – categories for messages. Partitions – the physical divisions of a topic. They are used for redundancy as partitions and are spread over different storage servers. Zookeeper – Apache Zookeeper is coordinate services in distributed systems.
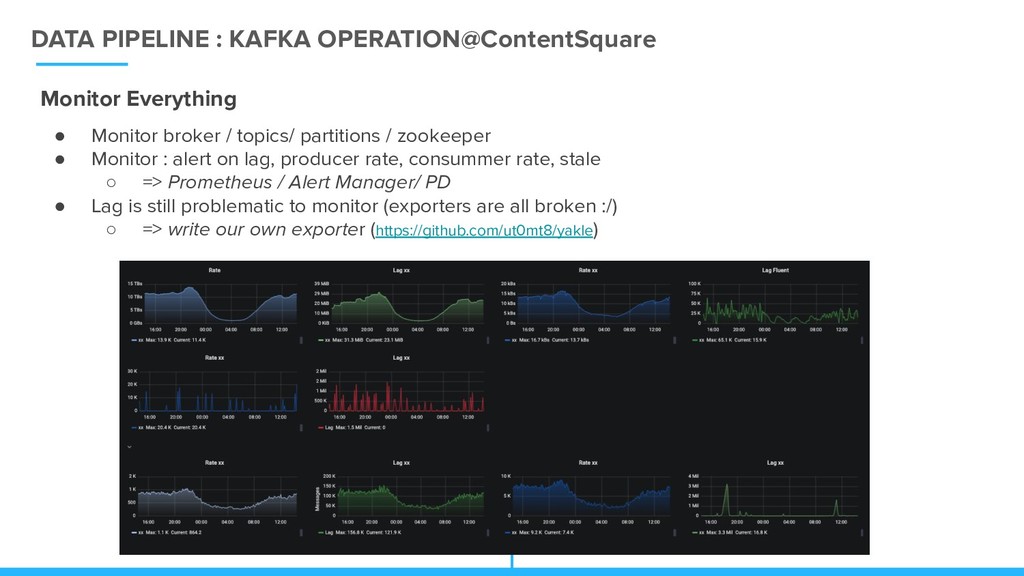
/ topics/ partitions / zookeeper • Monitor : alert on lag, producer rate, consummer rate, stale ◦ => Prometheus / Alert Manager/ PD • Lag is still problematic to monitor (exporters are all broken :/) ◦ => write our own exporter (https://github.com/ut0mt8/yakle)
is hard ◦ size based retention vs ◦ time based retention • we made some spreadsheet magic to forecast • and then you need to check it ! ◦ we wrote a custom tool to find the oldest message in a topic (https://github.com/ut0mt8/kafka-oldest-message)
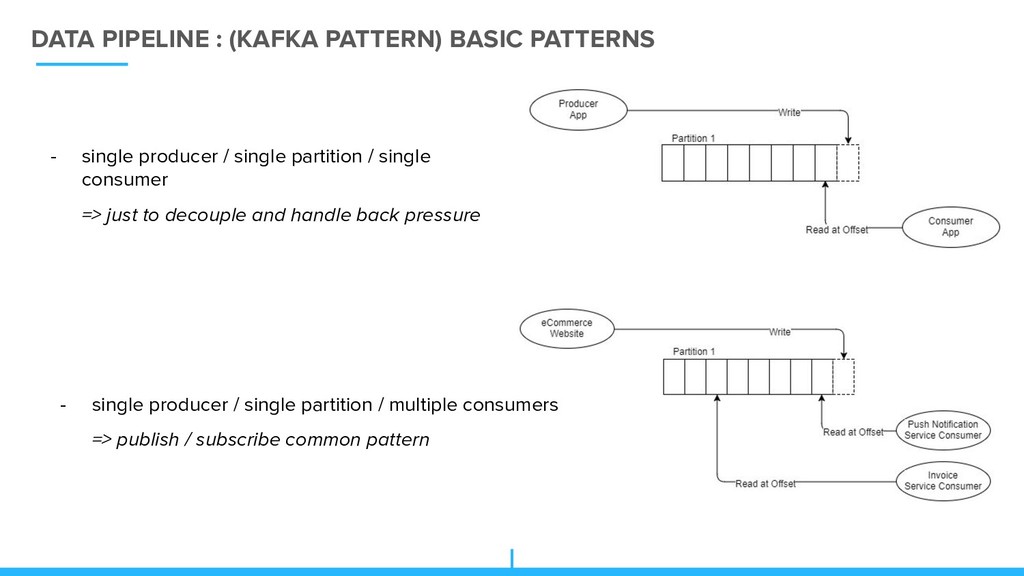
/ single partition / single consumer => just to decouple and handle back pressure - single producer / single partition / multiple consumers => publish / subscribe common pattern
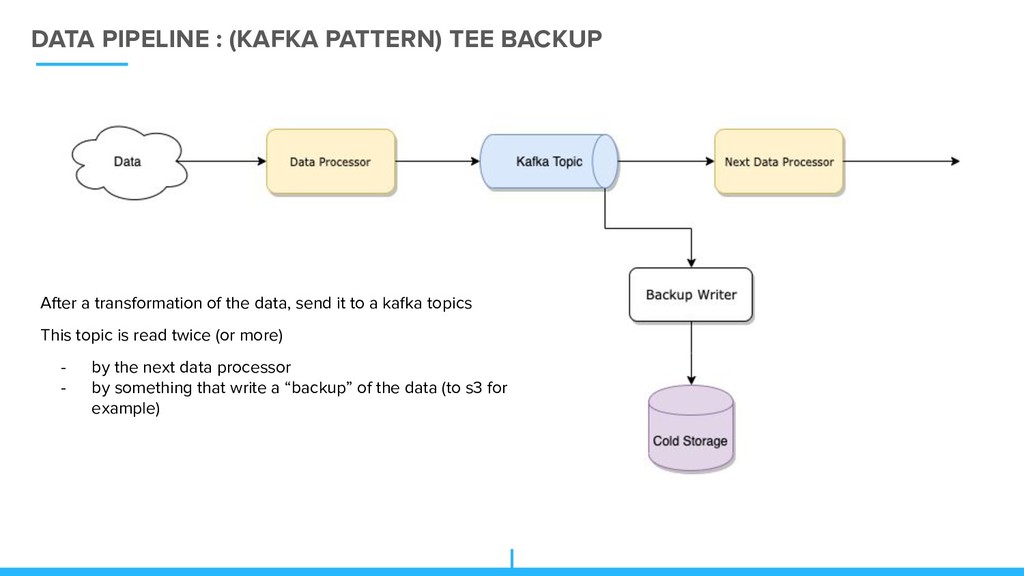
of the data, send it to a kafka topics This topic is read twice (or more) - by the next data processor - by something that write a “backup” of the data (to s3 for example)
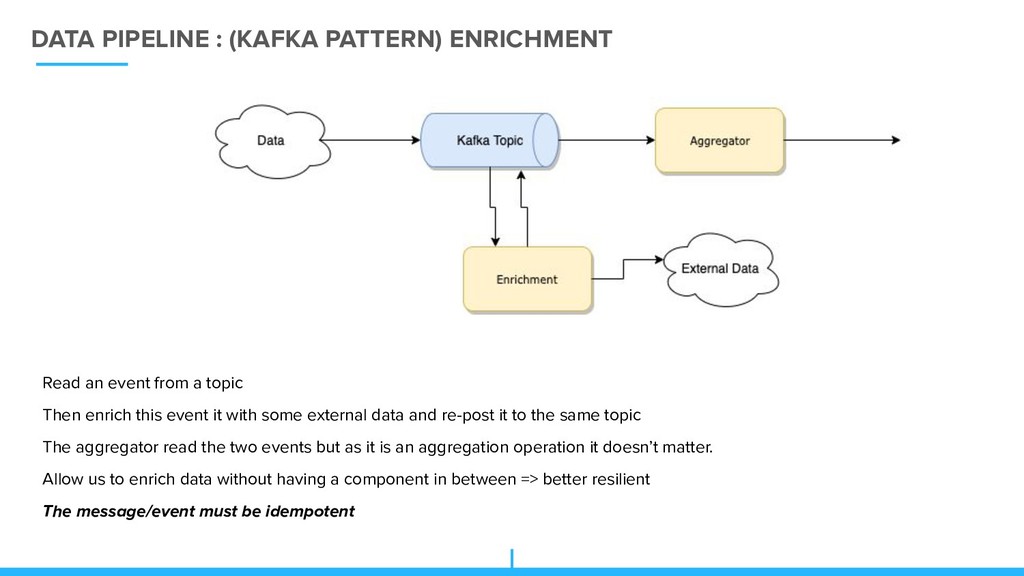
a topic Then enrich this event it with some external data and re-post it to the same topic The aggregator read the two events but as it is an aggregation operation it doesn’t matter. Allow us to enrich data without having a component in between => better resilient The message/event must be idempotent
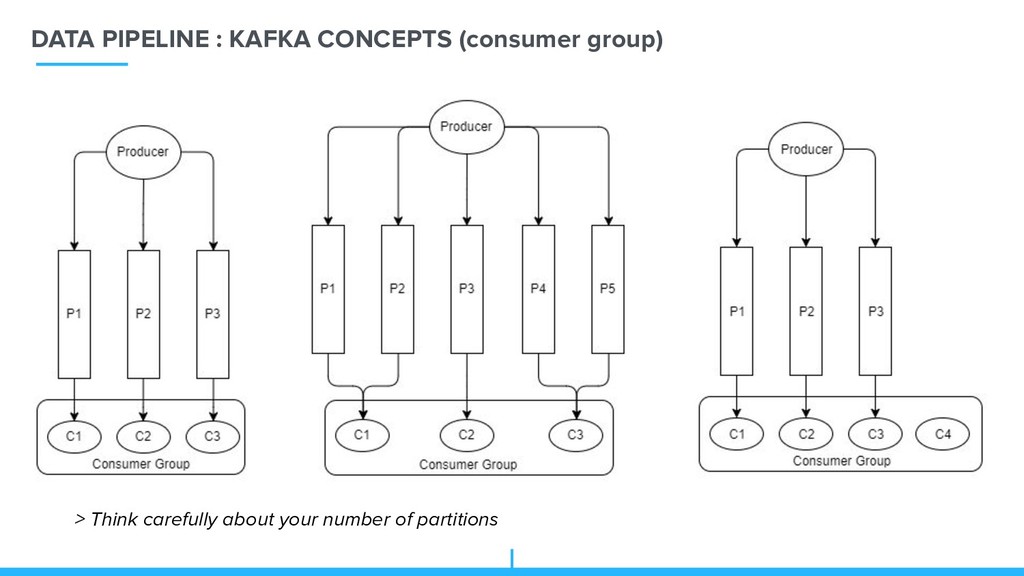
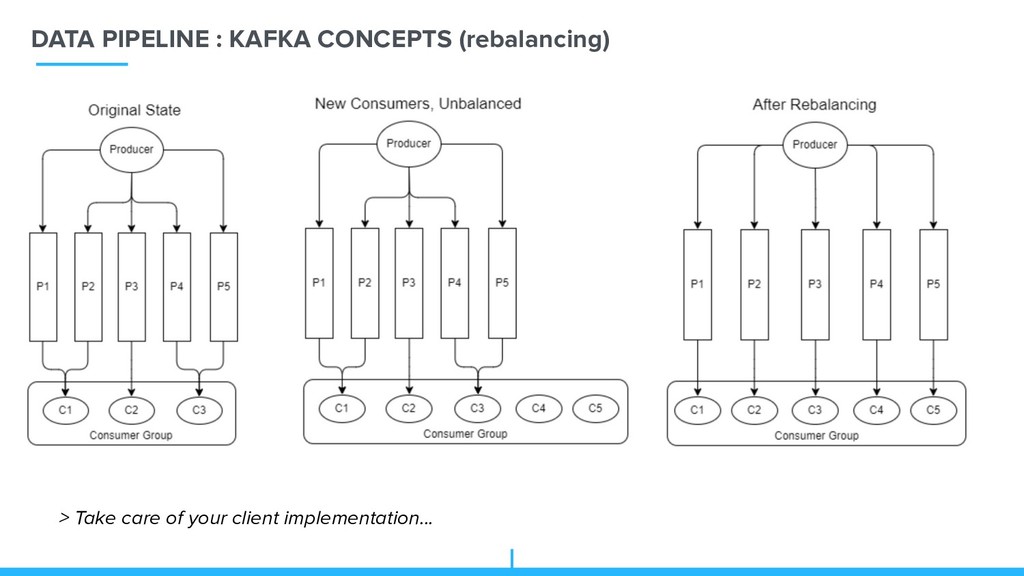
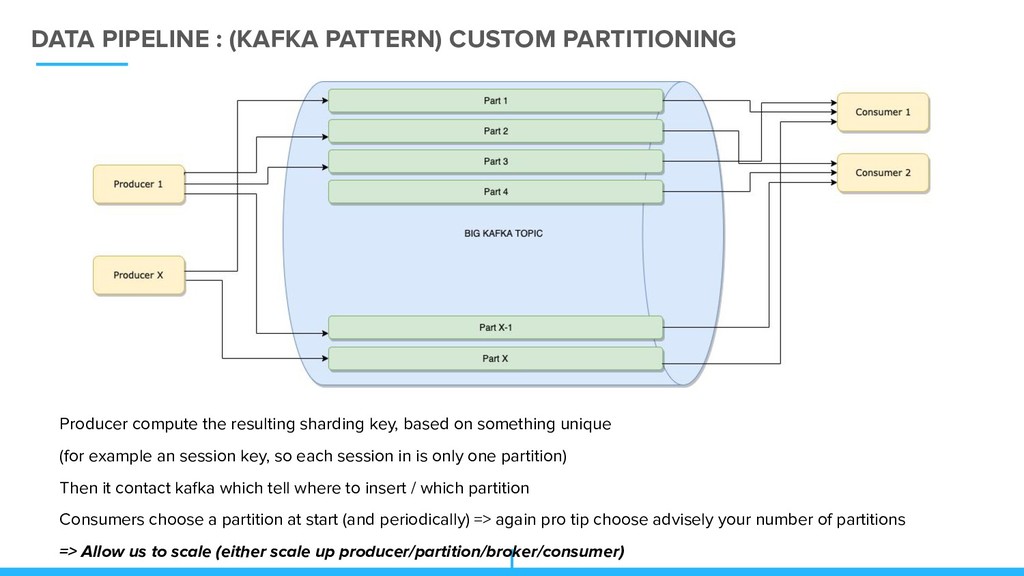
resulting sharding key, based on something unique (for example an session key, so each session in is only one partition) Then it contact kafka which tell where to insert / which partition Consumers choose a partition at start (and periodically) => again pro tip choose advisely your number of partitions => Allow us to scale (either scale up producer/partition/broker/consumer)
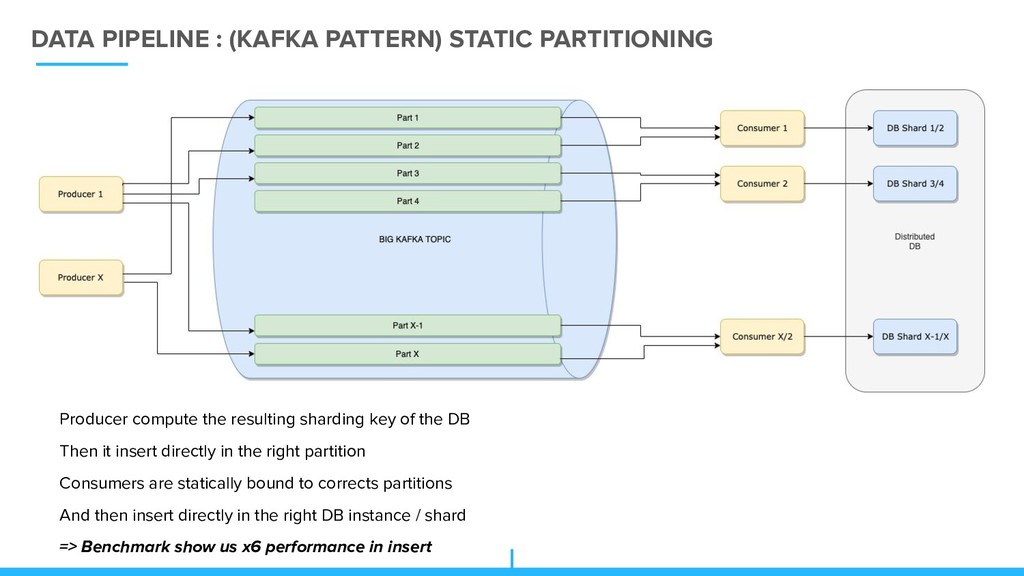
resulting sharding key of the DB Then it insert directly in the right partition Consumers are statically bound to corrects partitions And then insert directly in the right DB instance / shard => Benchmark show us x6 performance in insert
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}