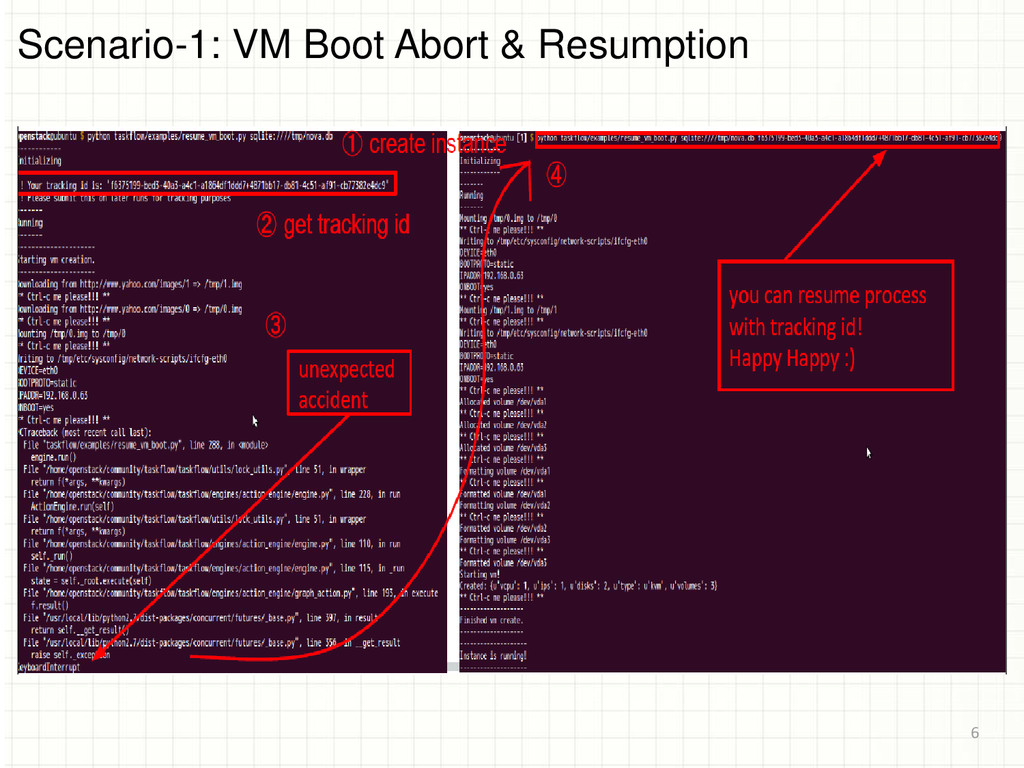
makes these hard to follow, alter and recover • Unreliable workflow and resource state It is hard to maintain correctness and consistency of distributed systems • RPC boundaries are a constant balance of improving scalability but decreasing consistency • Race conditions occur more often than desired • Manager Driver API boundary • Application and state recovery typically patched on after the fact instead of built-in from the ground up (e.g. periodic tasks) • Capability to service stop an application cleanly without manual (or periodic) clean up is crucial for features like live upgrades 3
service reliability • Resource and/or state corruption (or people to fix manually these problems) costs $$$ • Easy understanding of workflows and states allows the development and alteration of existing workflows • Upgrades (not even live), just upgrades Just say no to destroy the cloud to upgrade 4
execution easy, consistent, and reliable • Provides a framework for executing flow of operations such that those flows can be paused, resumed, revoked at any time • A paradigm and lightweight framework • Community driven & well documented • Library and code available though pypi & github https://pypi.python.org/pypi/taskflow https://github.com/openstack/taskflow 9
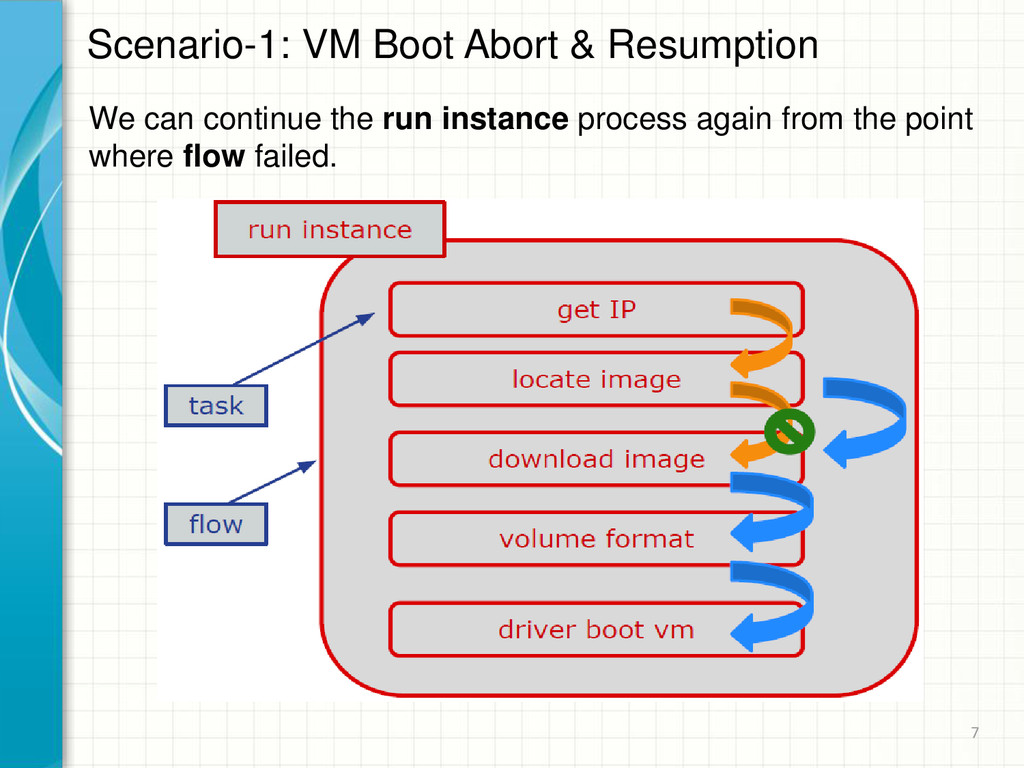
execution Who & what manages the overall execution • Persistence (how you know what was executed) • Work recovery How you recover from failure/partial progress 10
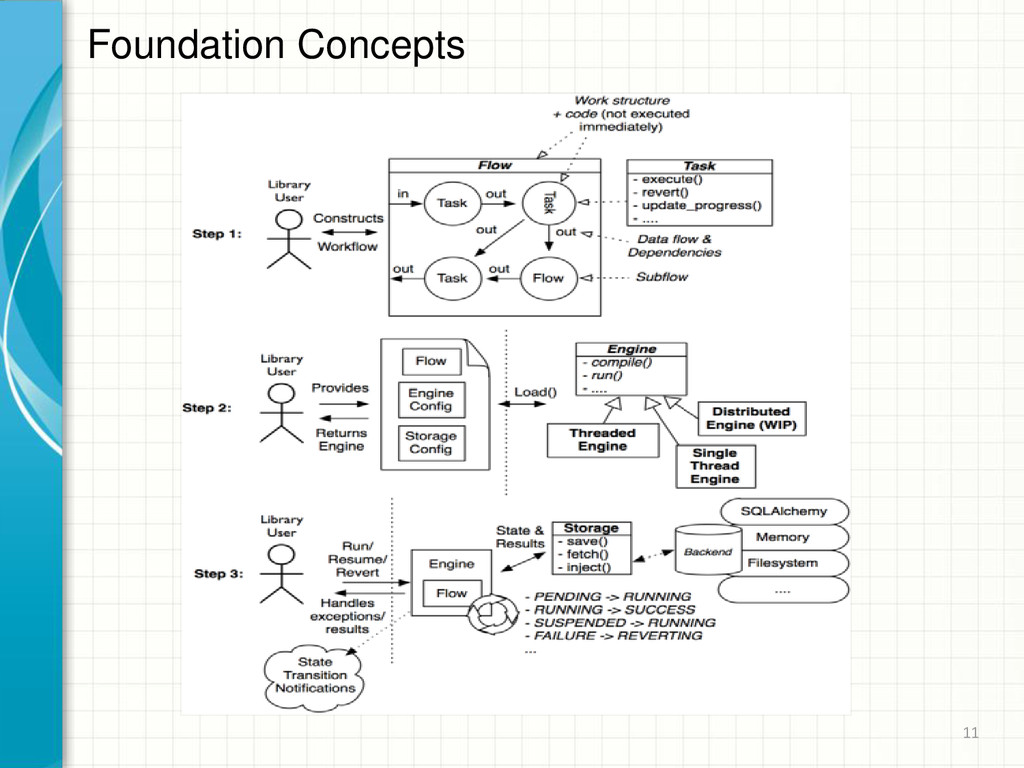
inputs and declares outputs • Flows Composes tasks (or subflows) into useful structures Imposes some definition of order also called patterns onto the running of your tasks or subflows Foundation Concepts 12
tasks & flows required to fulfil an action Can be transferred to a worker for completion Can be re-associated on worker failure (or timeout) for resumption or undo/reversion • Job Board A system where jobs can be atomically posted, reposted, claimed, marked as completed Backed by varying implementations Message queue, zookeeper, database… Foundation Concepts 13
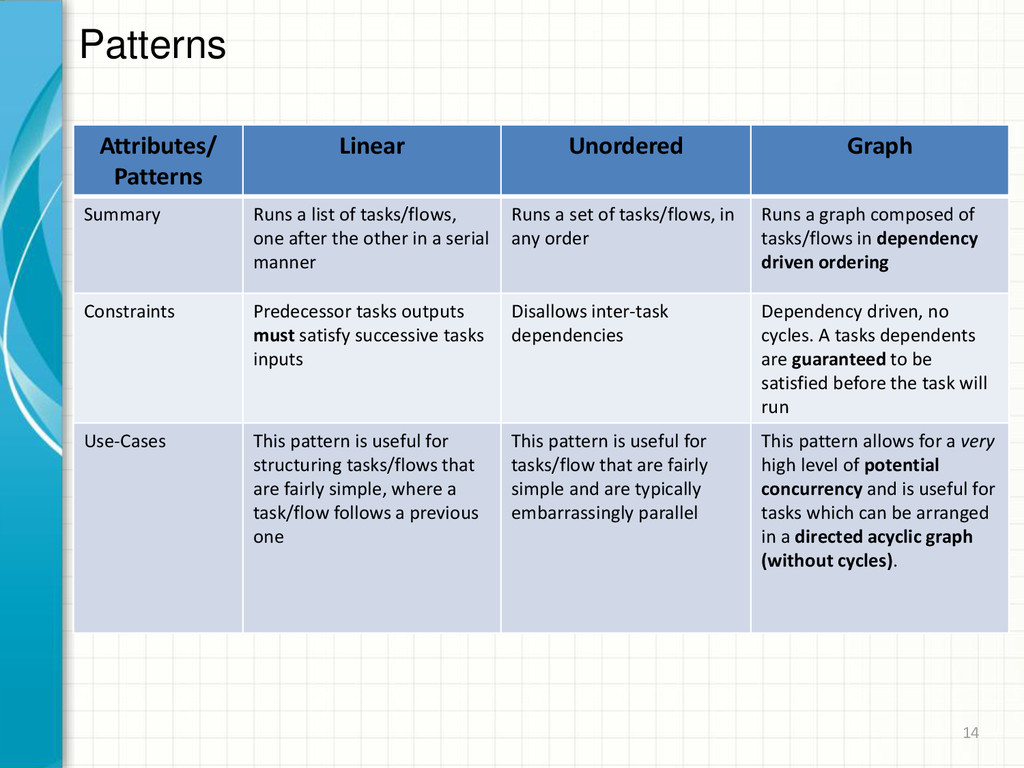
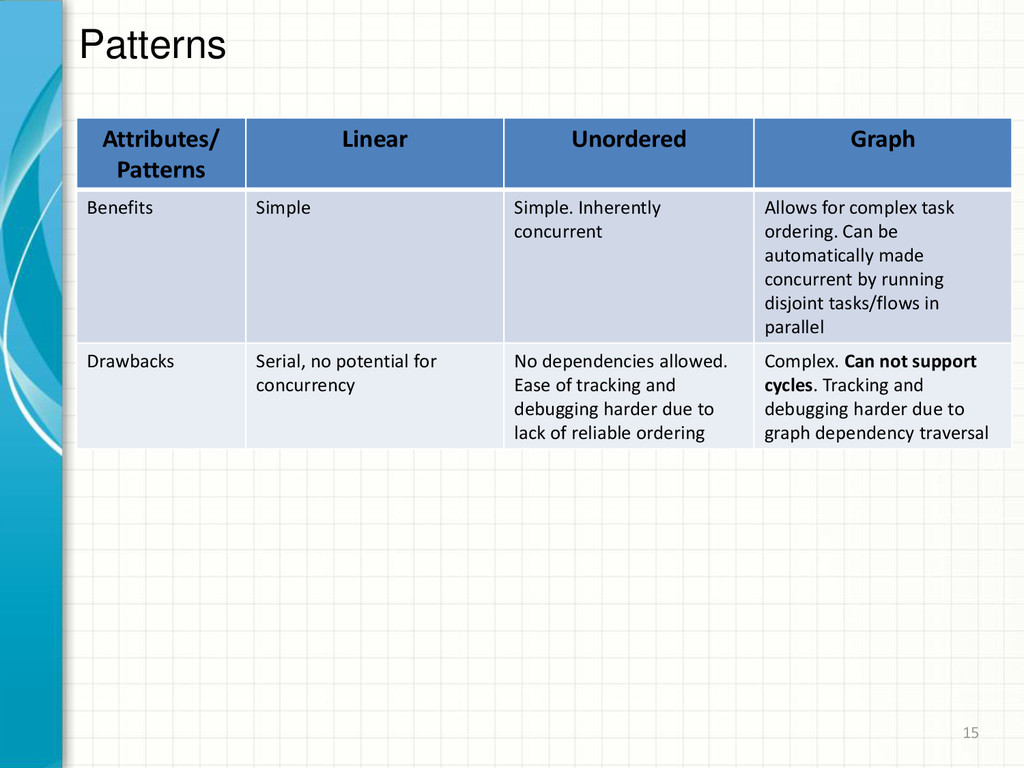
of tasks/flows, one after the other in a serial manner Runs a set of tasks/flows, in any order Runs a graph composed of tasks/flows in dependency driven ordering Constraints Predecessor tasks outputs must satisfy successive tasks inputs Disallows inter-task dependencies Dependency driven, no cycles. A tasks dependents are guaranteed to be satisfied before the task will run Use-Cases This pattern is useful for structuring tasks/flows that are fairly simple, where a task/flow follows a previous one This pattern is useful for tasks/flow that are fairly simple and are typically embarrassingly parallel This pattern allows for a very high level of potential concurrency and is useful for tasks which can be arranged in a directed acyclic graph (without cycles). 14
Allows for complex task ordering. Can be automatically made concurrent by running disjoint tasks/flows in parallel Drawbacks Serial, no potential for concurrency No dependencies allowed. Ease of tracking and debugging harder due to lack of reliable ordering Complex. Can not support cycles. Tracking and debugging harder due to graph dependency traversal Patterns 15
reliable, consistent and resumable manner Follows well defined state transitions • Allows for deployers/developers of a service that uses taskflow to select an engine that suites their setup best • Backed by varying implementations Single-threaded Multi-threaded via native or green threads Distributed • Support for other engines: Message based(RPC), oslo.messaging Celery Engines 16
reconstruction and resumption of flows and associated tasks • Allows the user to view the play-by-play action history of flows and associated tasks Facilitates debugging of taskflow usage and integration • Backed by varying implementations File system, memory, database… Persistence 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}