Getting into GPU computing is often both promising and frustrating. I worked at NVIDIA in Finland, and was an early user of CUDA. I will provide a brief overview of the current ecosystem, and the strengths and weaknesses of the key technologies.
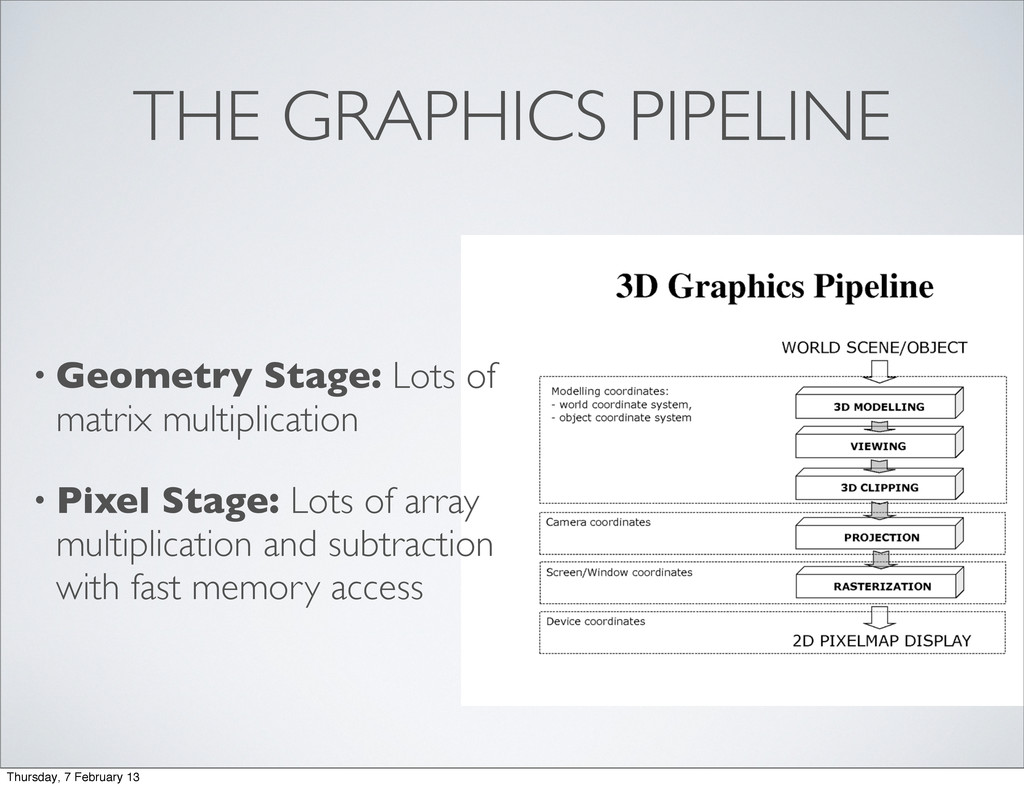
triangles in colored pixels. • (Now) Massively parallel thread based processor with fast memory, a large (fast) registry file, separated from the main processor and memory by a slow bus. Thursday, 7 February 13
• ~2003 NV30 generation introduced limited programmability • Required mapping onto triangles, textures, and pixels • Easy to fall off hardware, only had fp16 registers • Hard to efficiently use both geometry and pixel blocks • 2007 NVIDIA released CUDA Thursday, 7 February 13
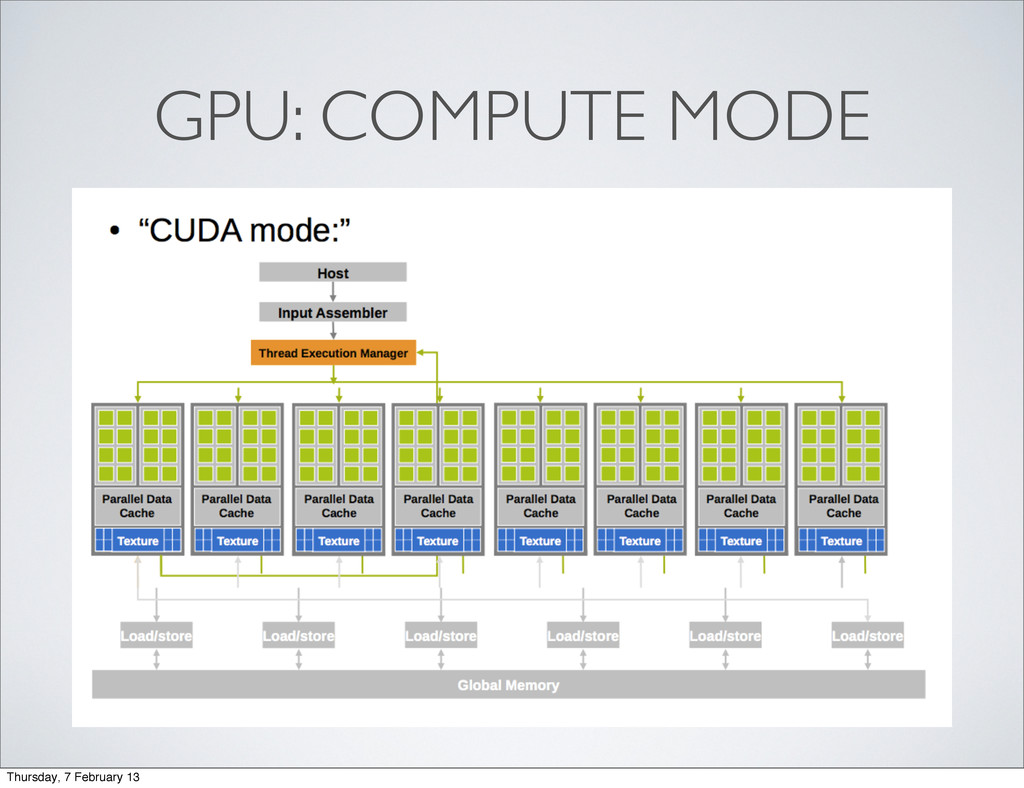
used now) • 3 different parts • Hardware dedicated to compute (not graphics) • Driver layer to access GPU as compute device • C/C++ extensions and a compiler Thursday, 7 February 13
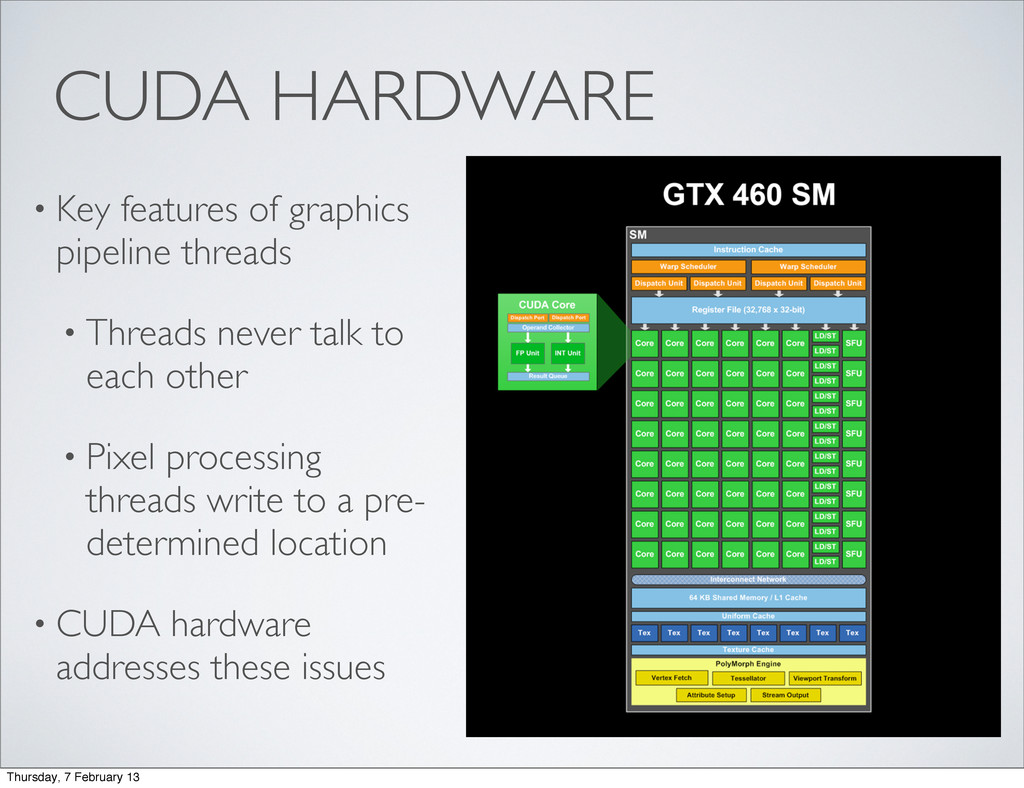
Threads never talk to each other • Pixel processing threads write to a pre- determined location • CUDA hardware addresses these issues Thursday, 7 February 13
is costly • Avoid context switching • CPUs are very smart • Branch prediction, out of order execution, prefetch GPU • Context switching is cheap • Context switching is everything • GPUs (SMs) are dumb • None of that stuff - its your job! Thursday, 7 February 13
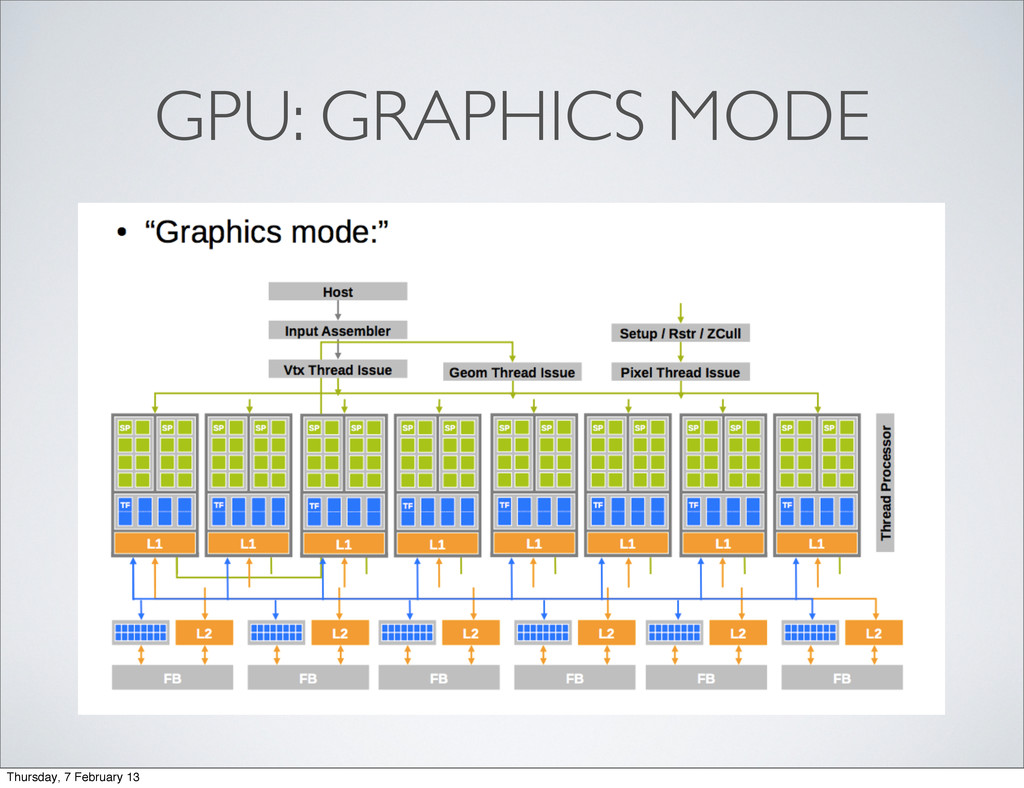
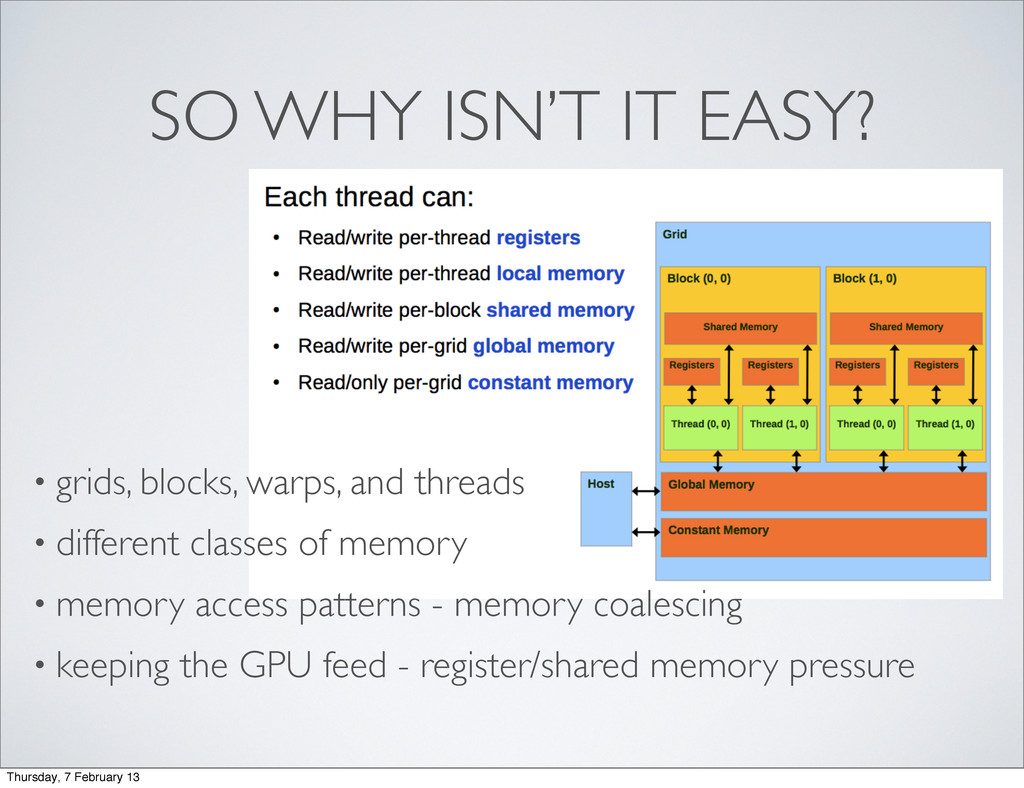
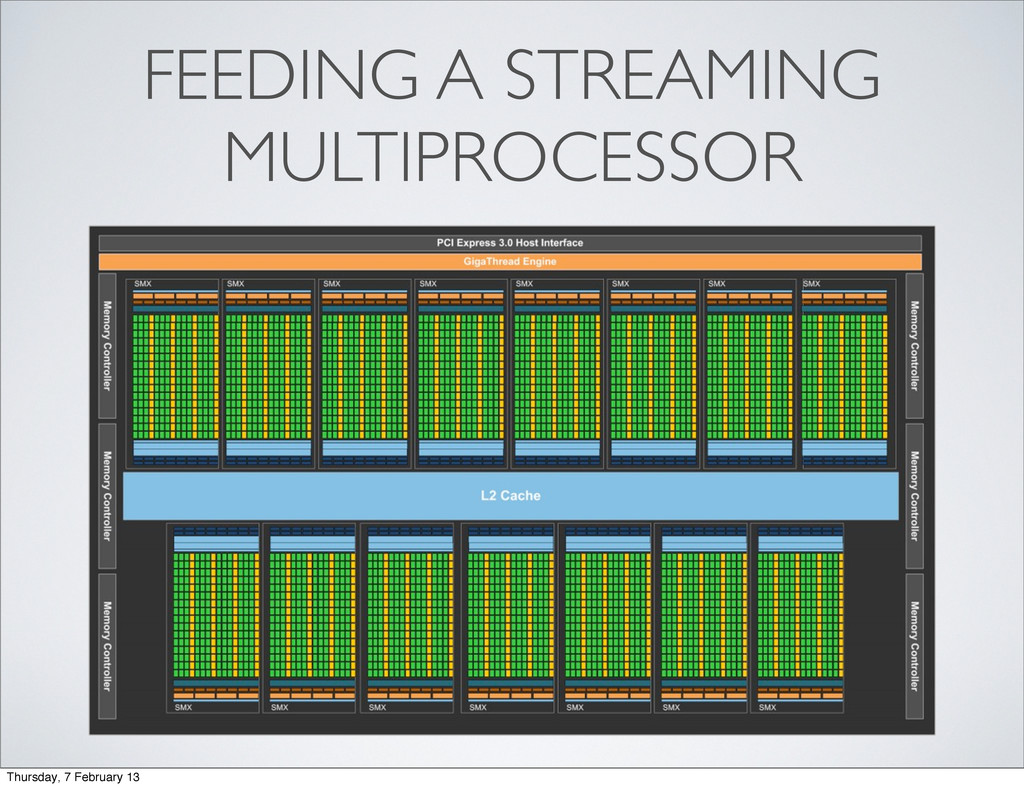
least not with reasonable efficiency ...) • You can only (efficiently) communicate between threads running on the same streaming multiprocessor • Problems need to be decomposed into and SM friendly structure Thursday, 7 February 13
or 3D block of threads to execute • Block: Sub-domain of grid that can be loaded into a single SM • Thread: Kernel is executed once per thread • Warp: A bundle of threads scheduled together Thursday, 7 February 13
Won’t fit onto a SM • Restricts the amount of shared memory and register space available to a given thread • Thread occupancy • Block is too small • Not enough warps available leading to idle time Thursday, 7 February 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}