LOCALLY is a global leader in location data intelligence and real-time consumer engagement. Our innovative and highly precise location technology merges physical places and digital devices with powerful AI and ML models, along with the transparency of blockchain, to deliver insights that are actionable at scale.
We have been working with CakePHP 3.x since the inception of the company (and personally as developers over 8 years), where we were processing around 500K records per month through a standard MQ workflow, over the past year we have scaled up to be ingesting over 20B records each month.
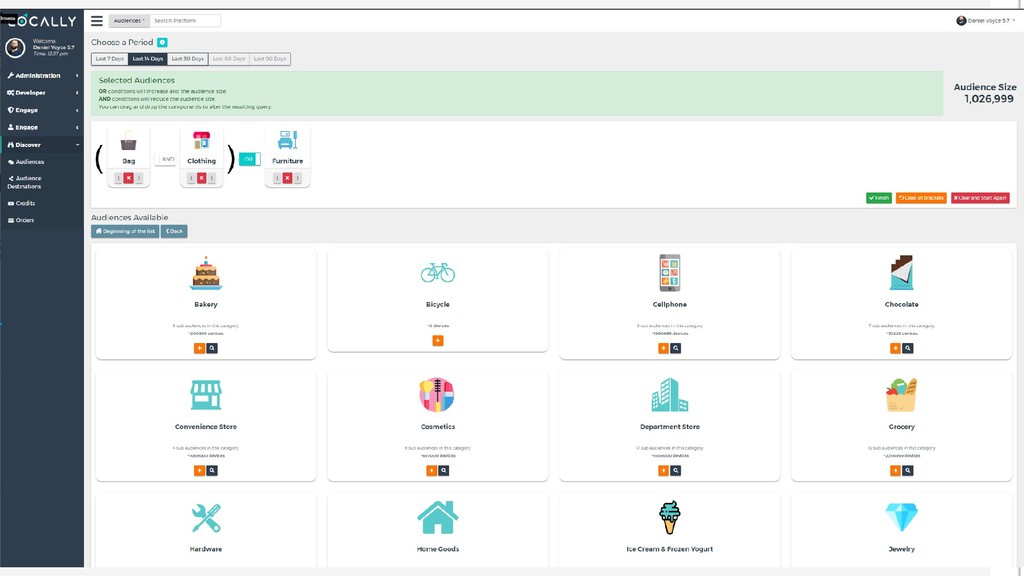
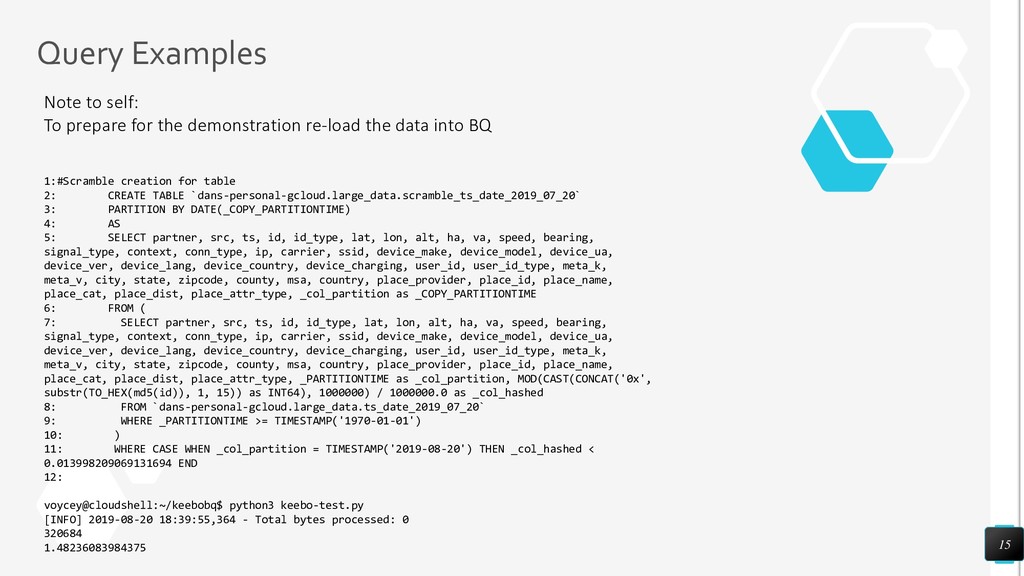
This talk will discuss how we interface our Data Warehouse with CakePHP to produce sub-second aggregation counts over Billions of rows over a variety of metrics, we talk about how we integrate with Presto (A Facebook open-source Big Data Query Engine) to provide an SQL like interface to our data-warehouse that is accessible by CakePHP and how we use HyperLogLog++ Sketches to allow for dynamic up-to-the second unique aggregation counts of both standard metrics and Geospatial Joins to be achieved in sub-second times.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
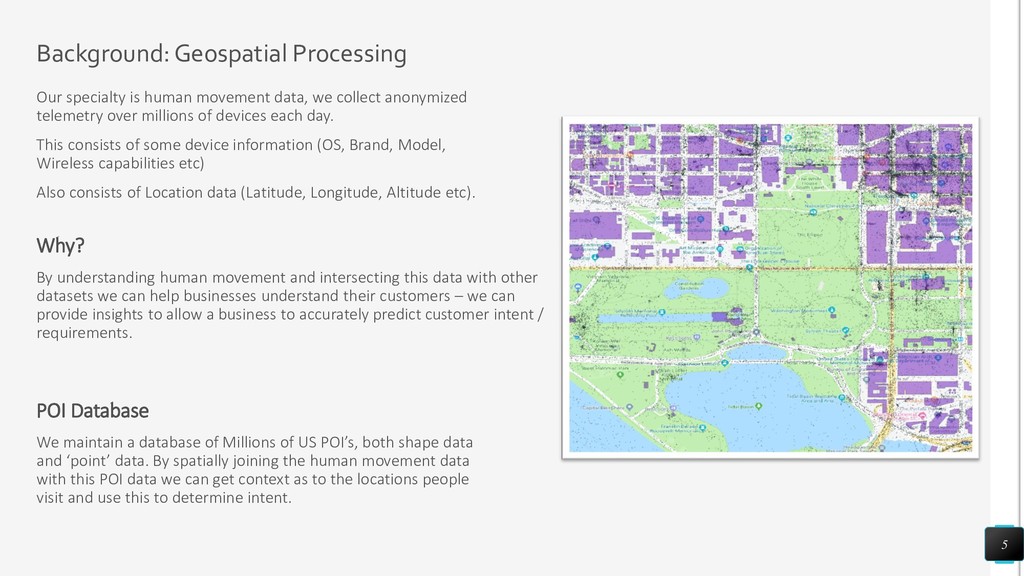{kind=link}
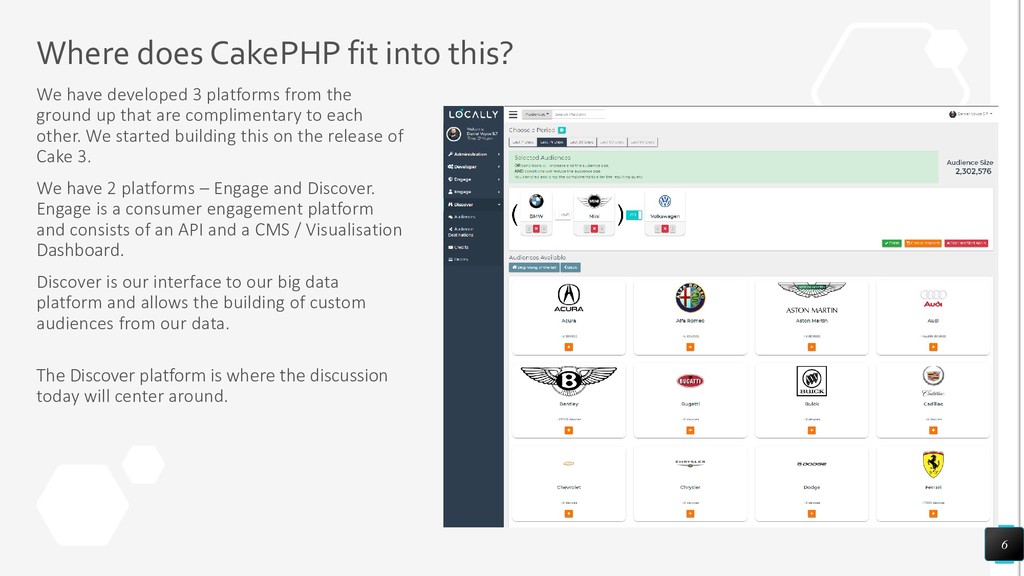{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
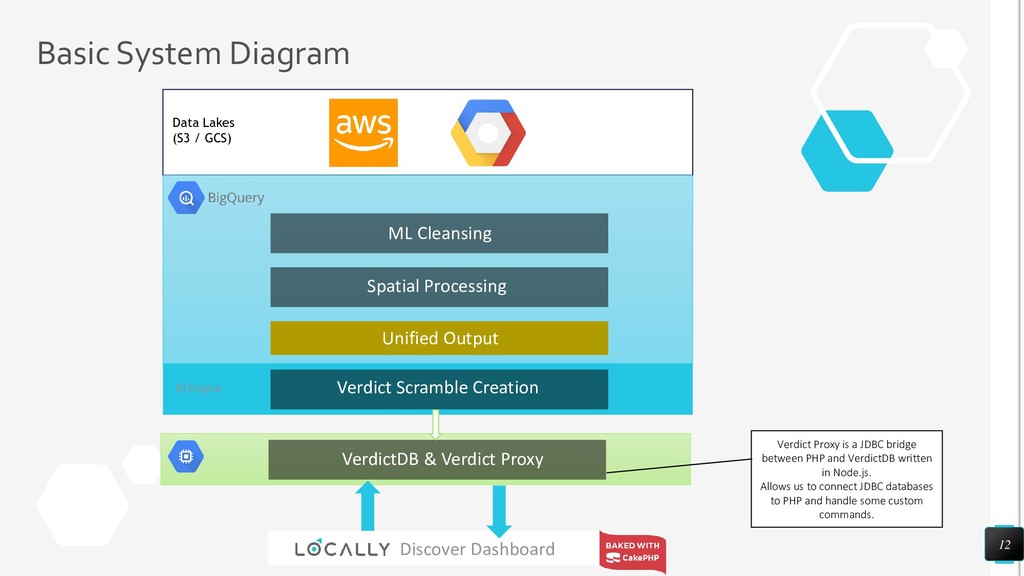{kind=link}
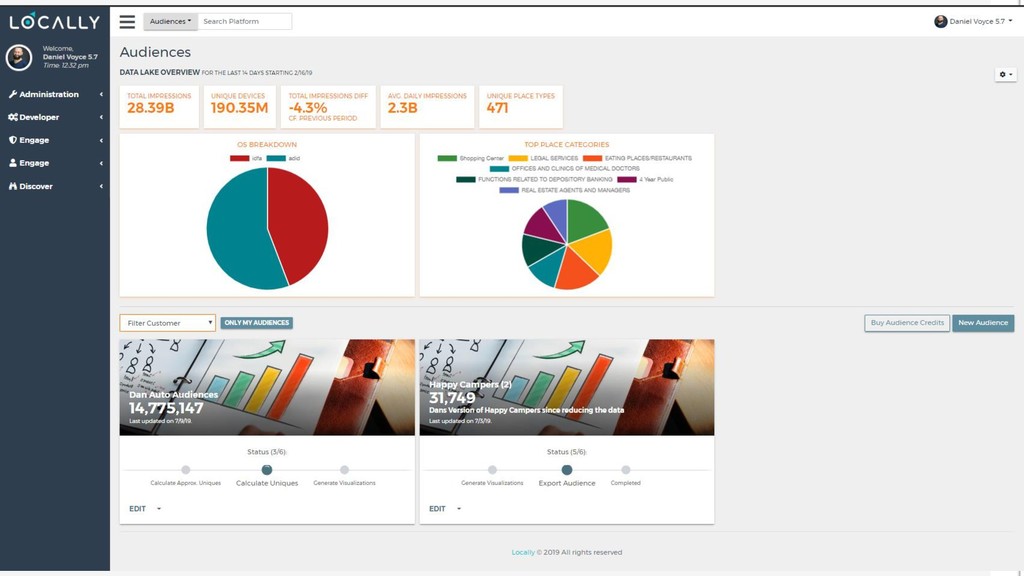{kind=link}
{kind=link}
{kind=link}
{kind=link}