My session at OSCAFest (Open Source Community Africa) 2025.
OSCAFest is one of Africa’s largest gatherings of developers, designers and tech professionals.
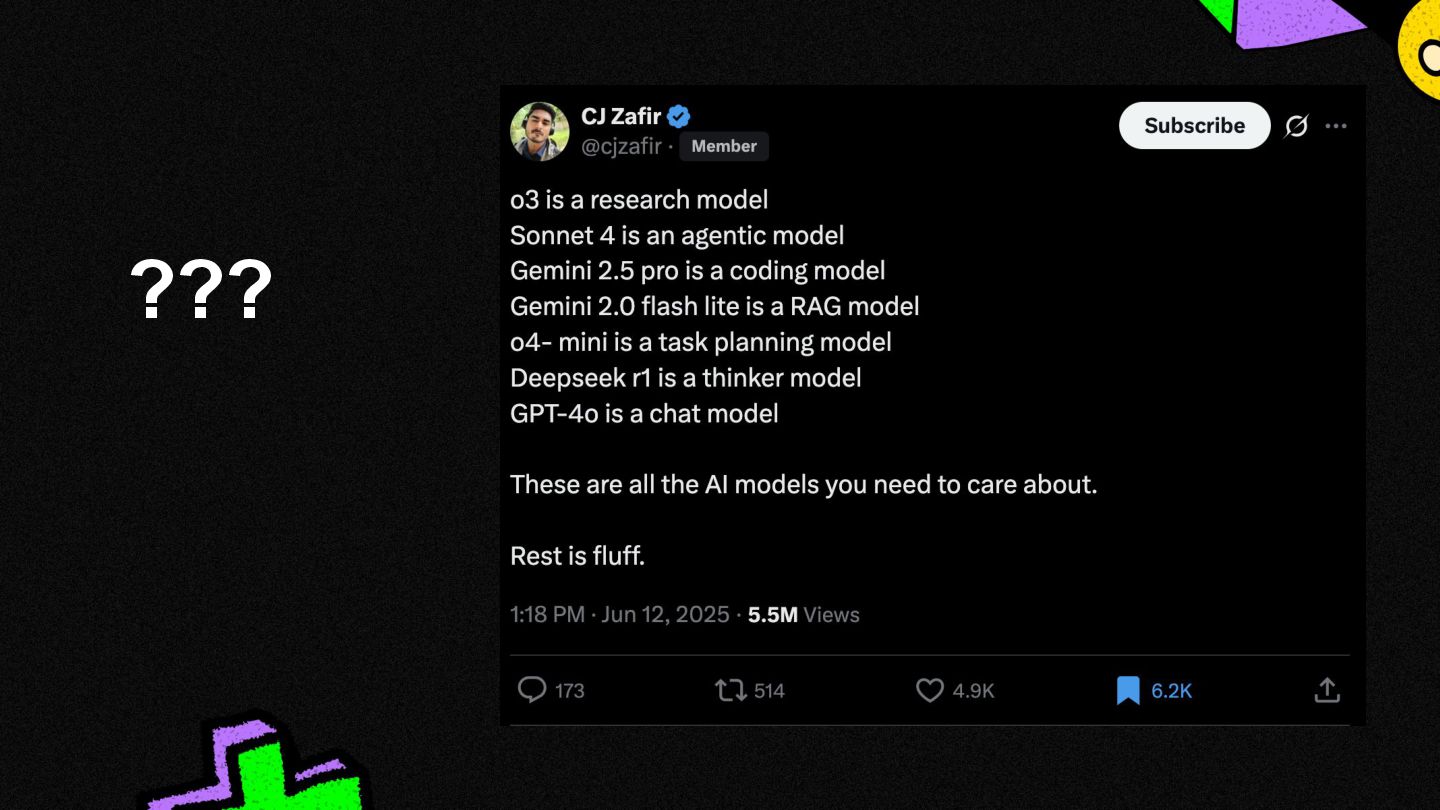
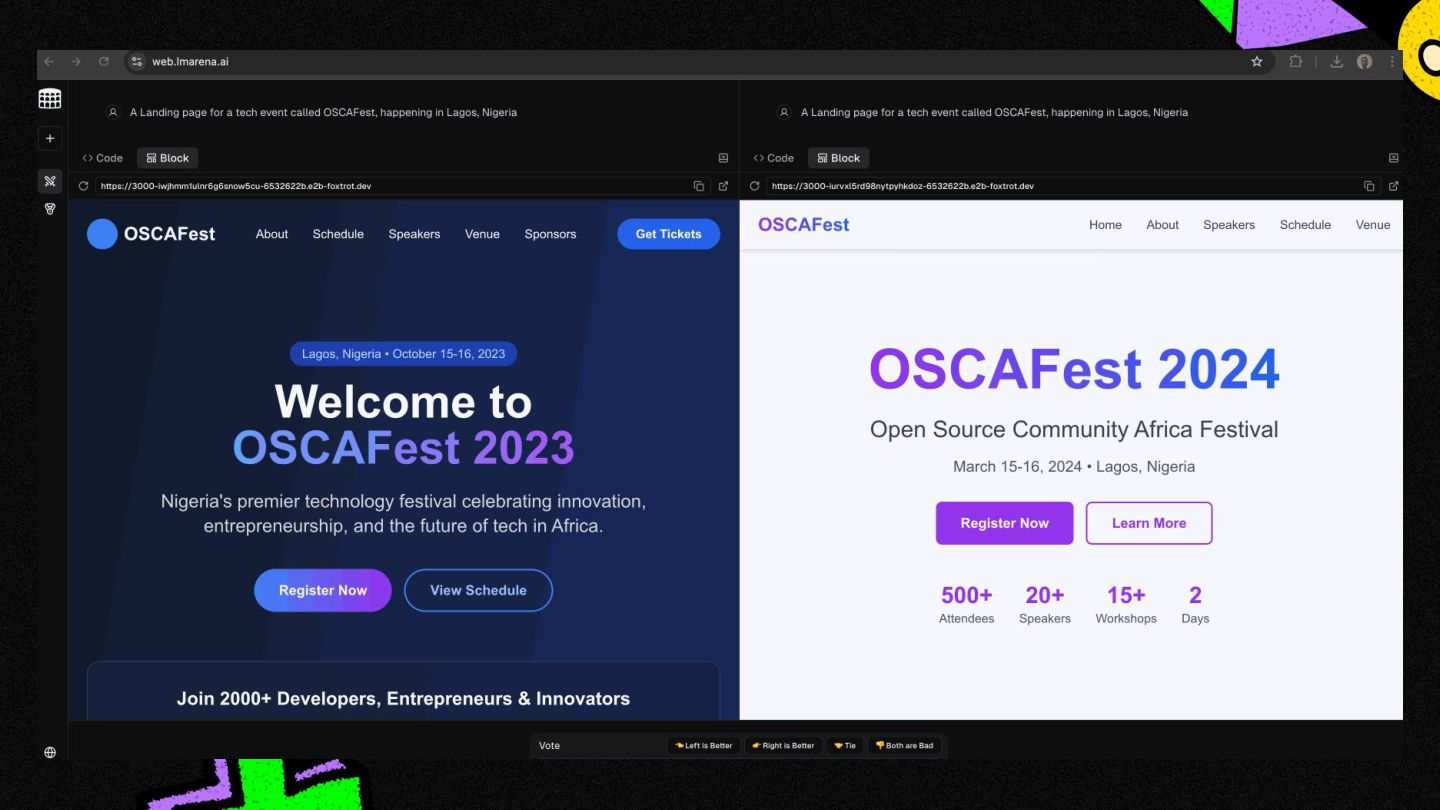
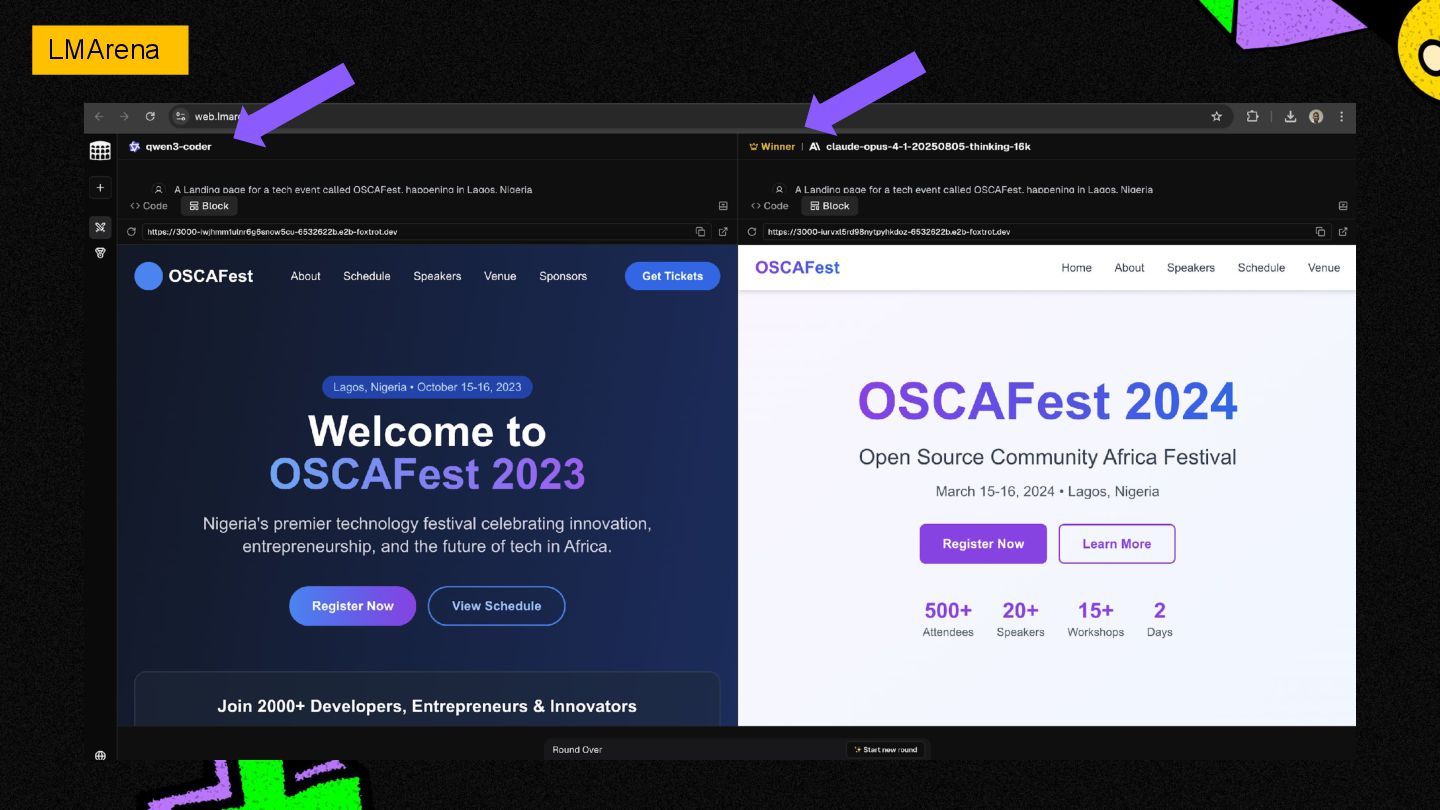
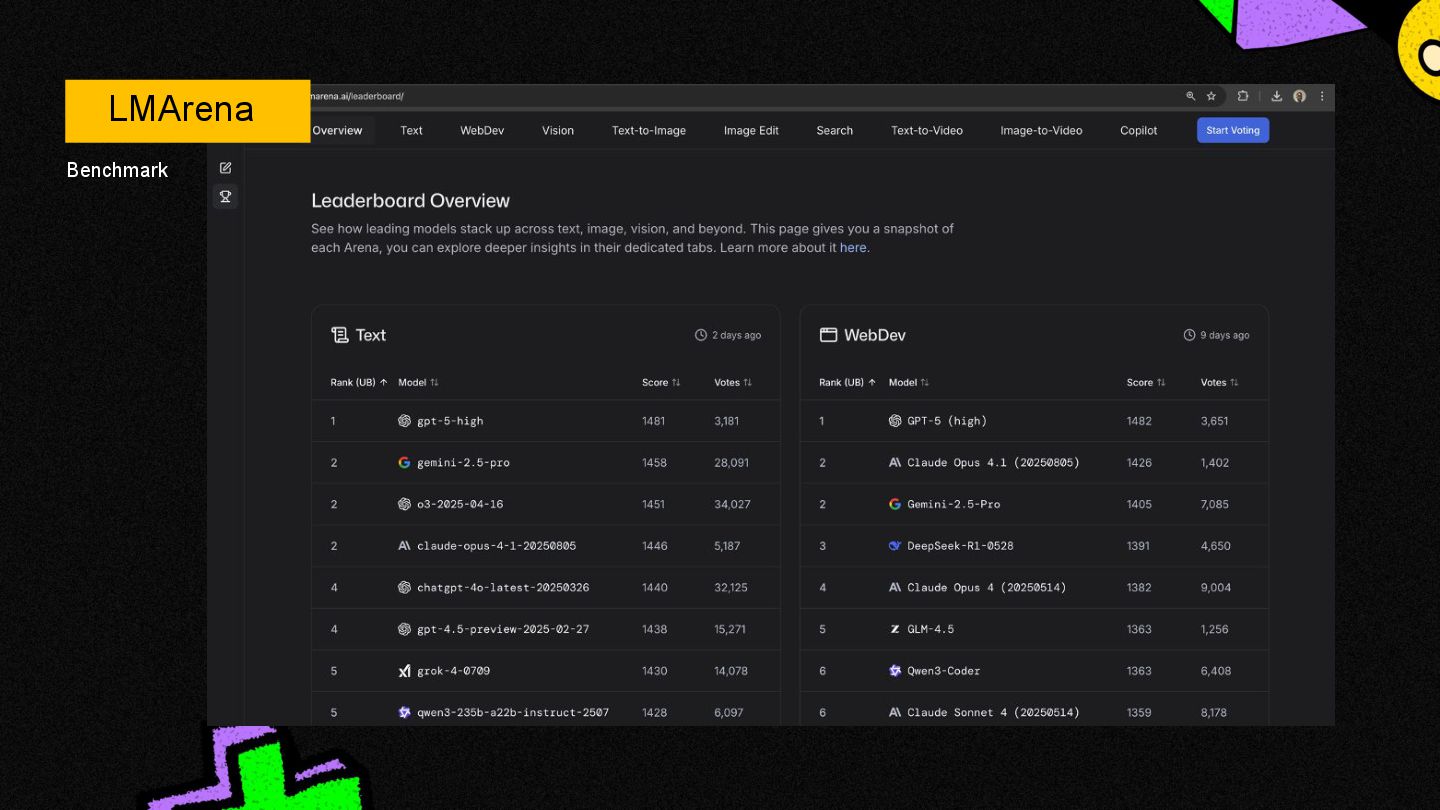
There are hundreds of large language models (LLMs) out in the wild, and the list keeps on growing.
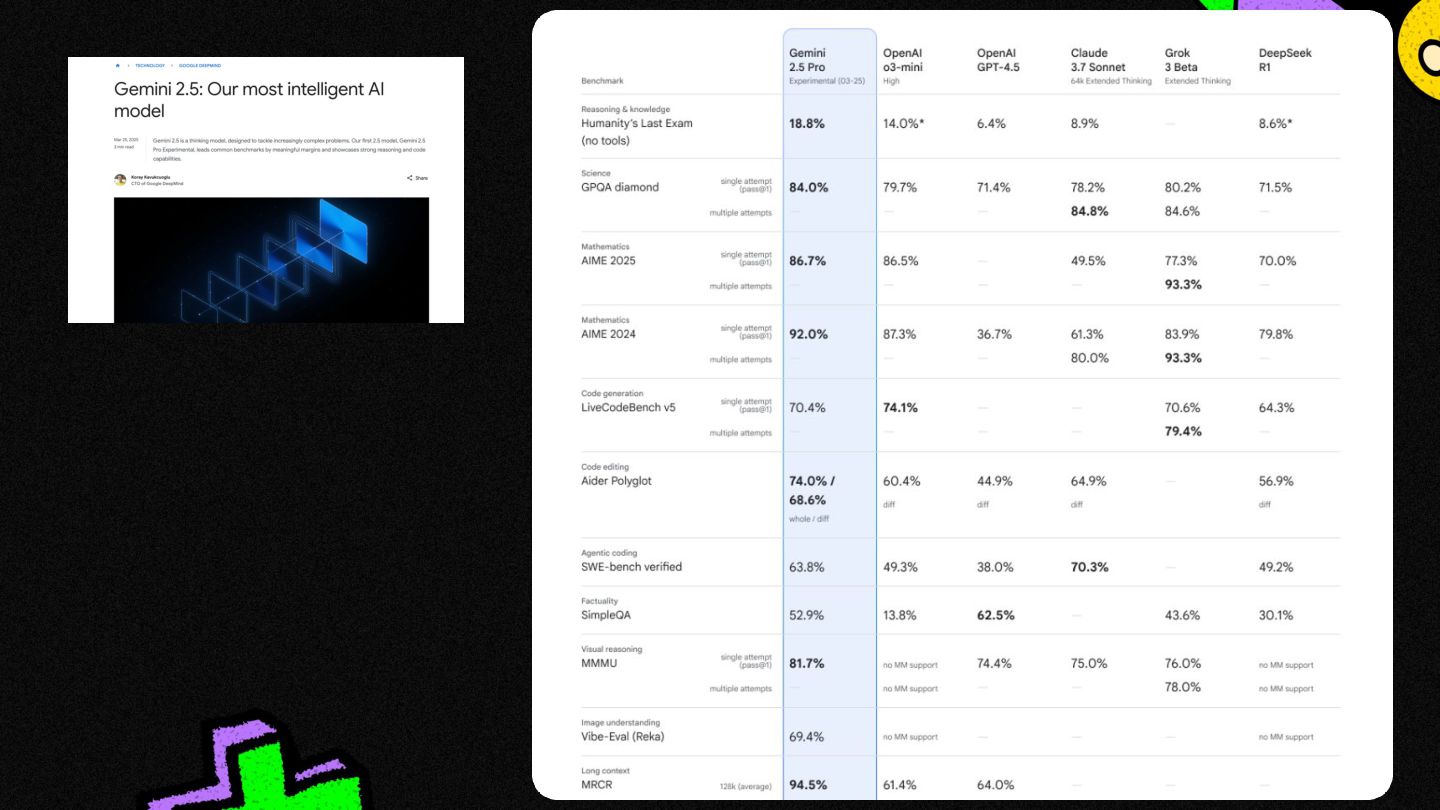
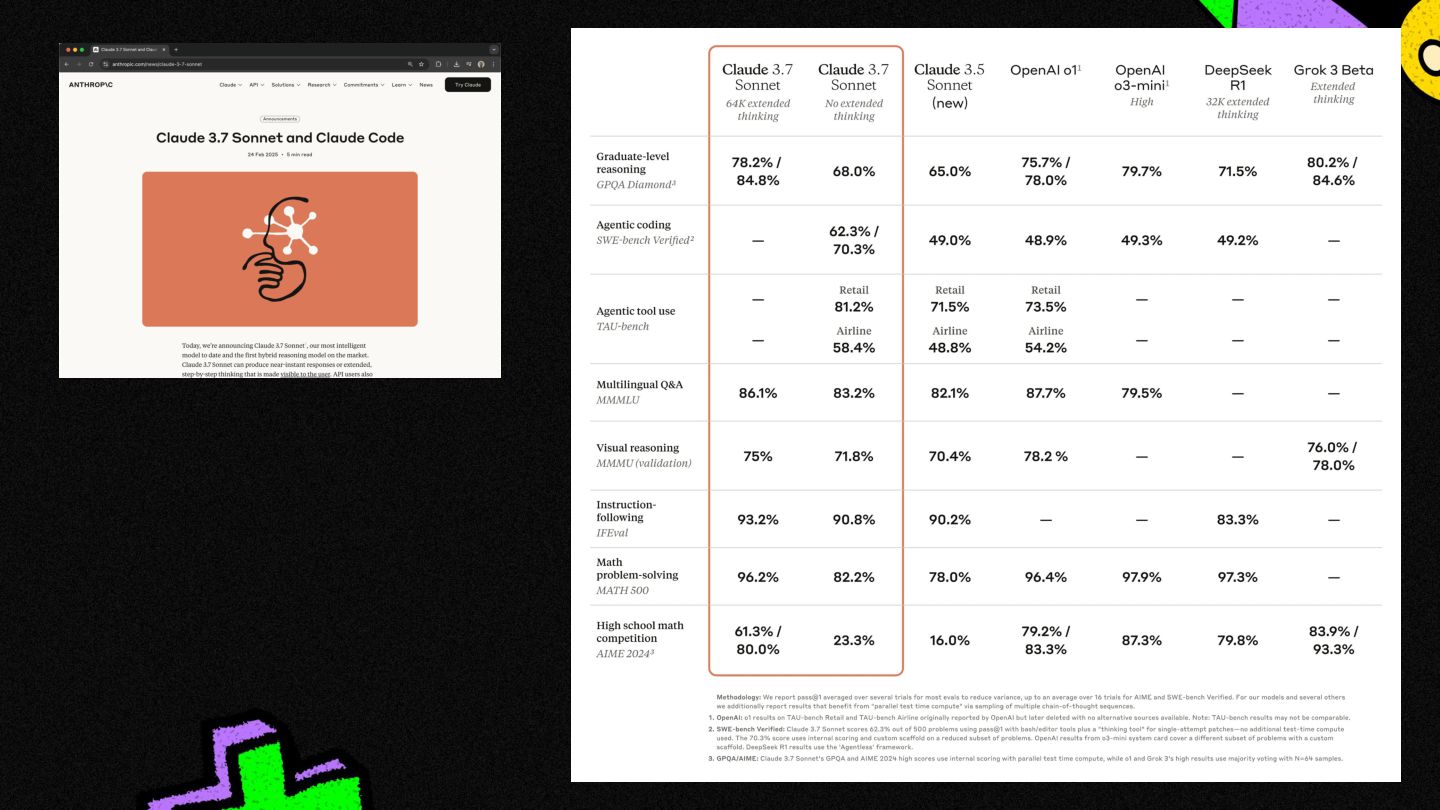
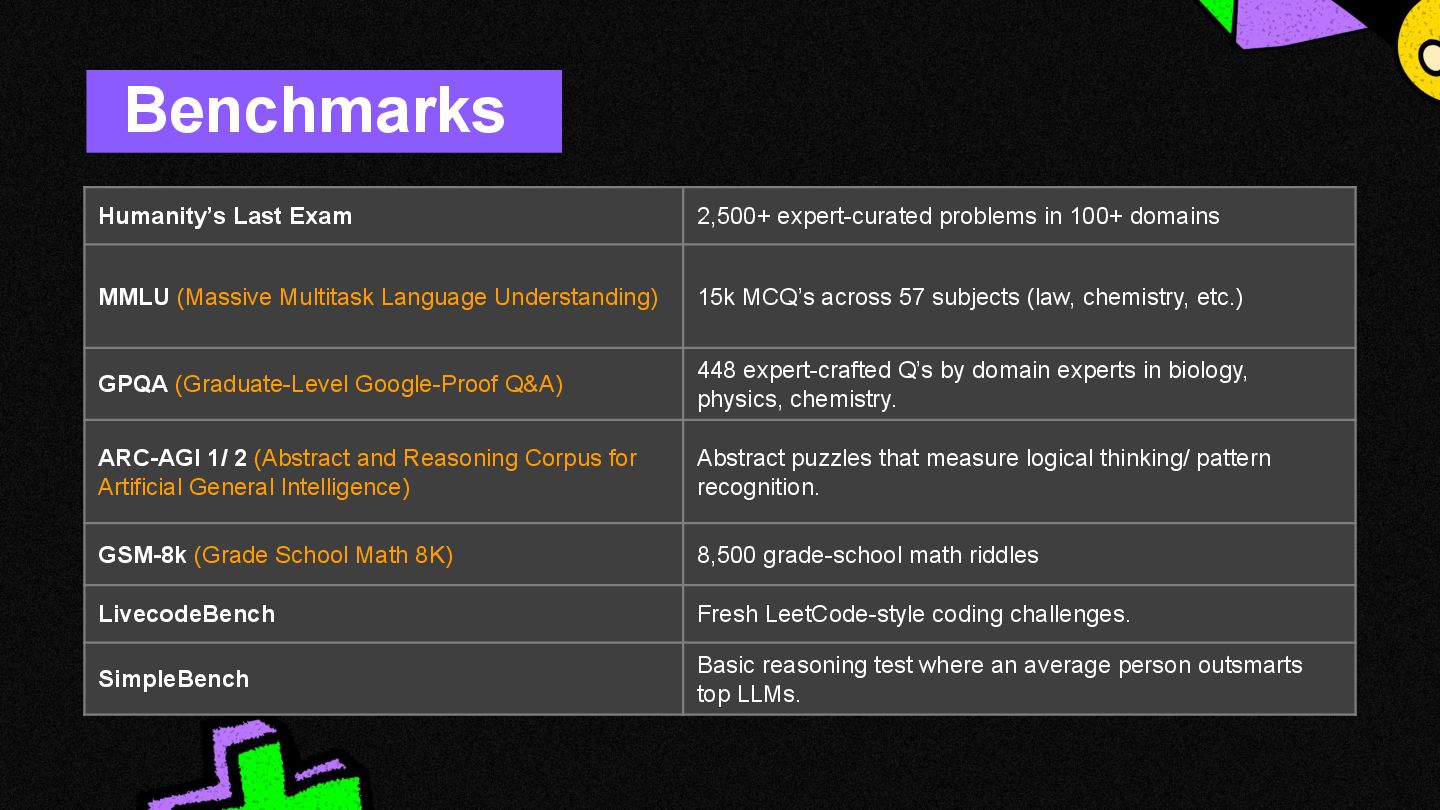
Every other month, the big players (Google, OpenAI, Anthropic, etc.) release shiny new models, along with their benchmarks, (MMLU, GPQA, etc.)
...but what do these cryptic benchmarks really mean? ...and how can one tell what model is best for their $100m "AI" app use case.
(Views are mine, and do not reflect that of my employer)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
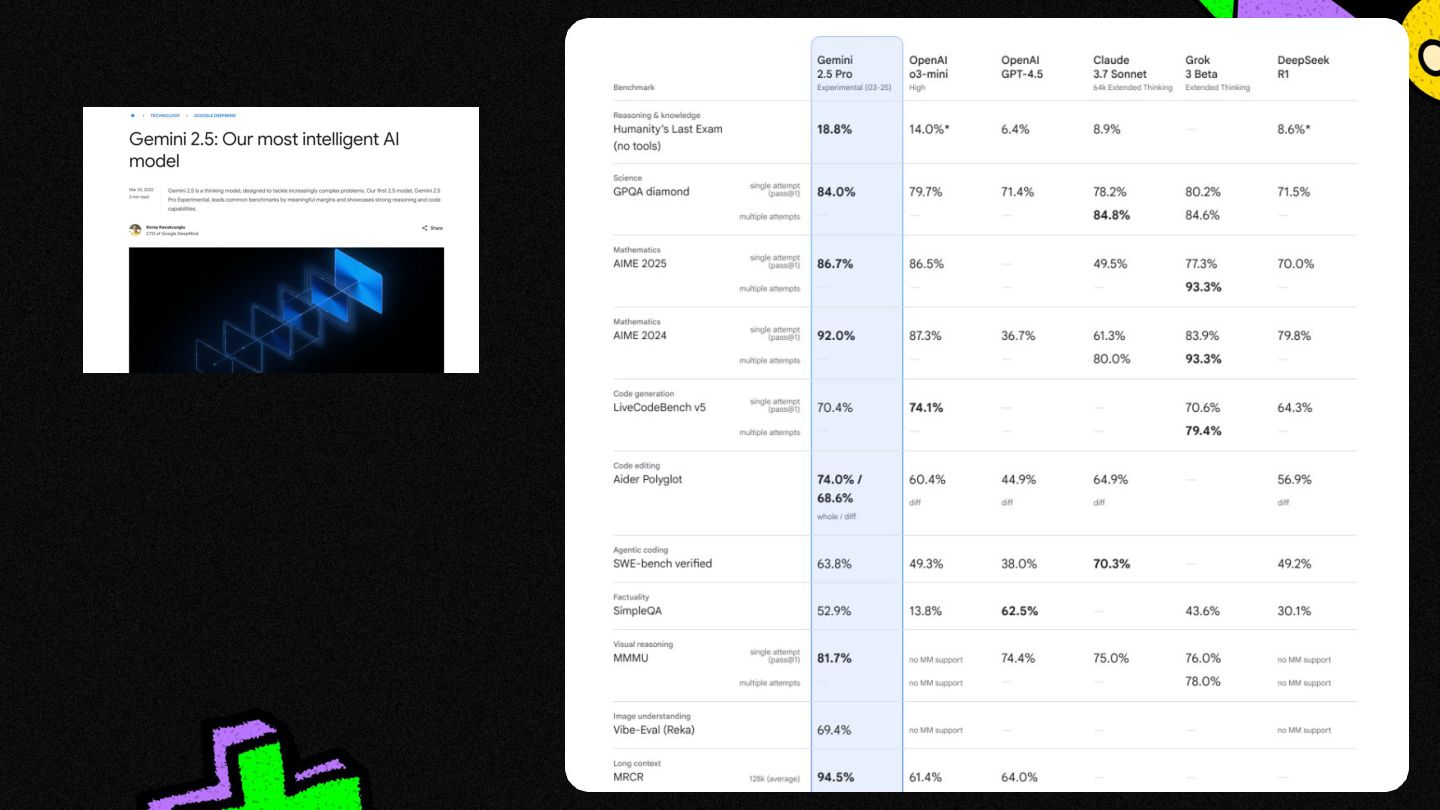{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
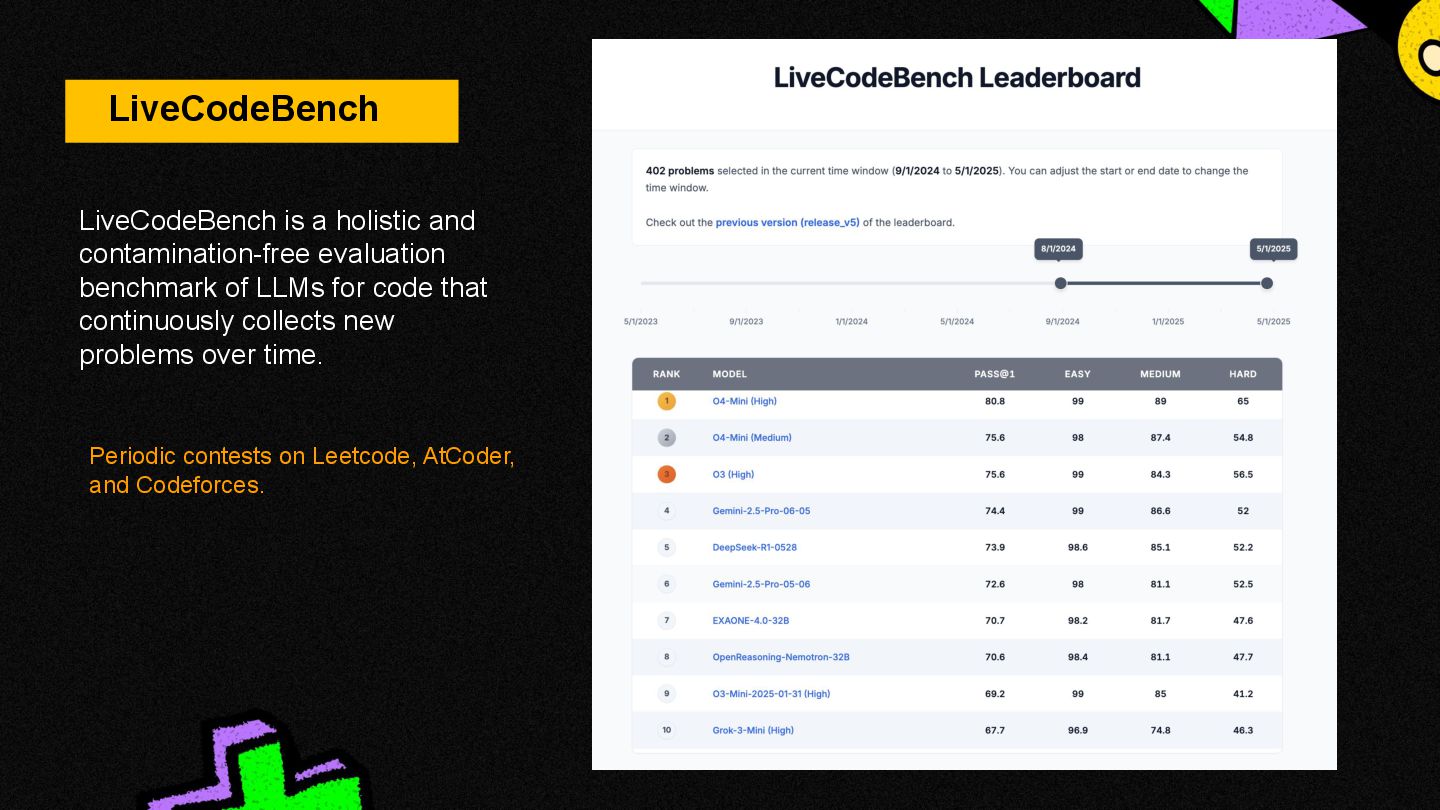{kind=link}
{kind=link}
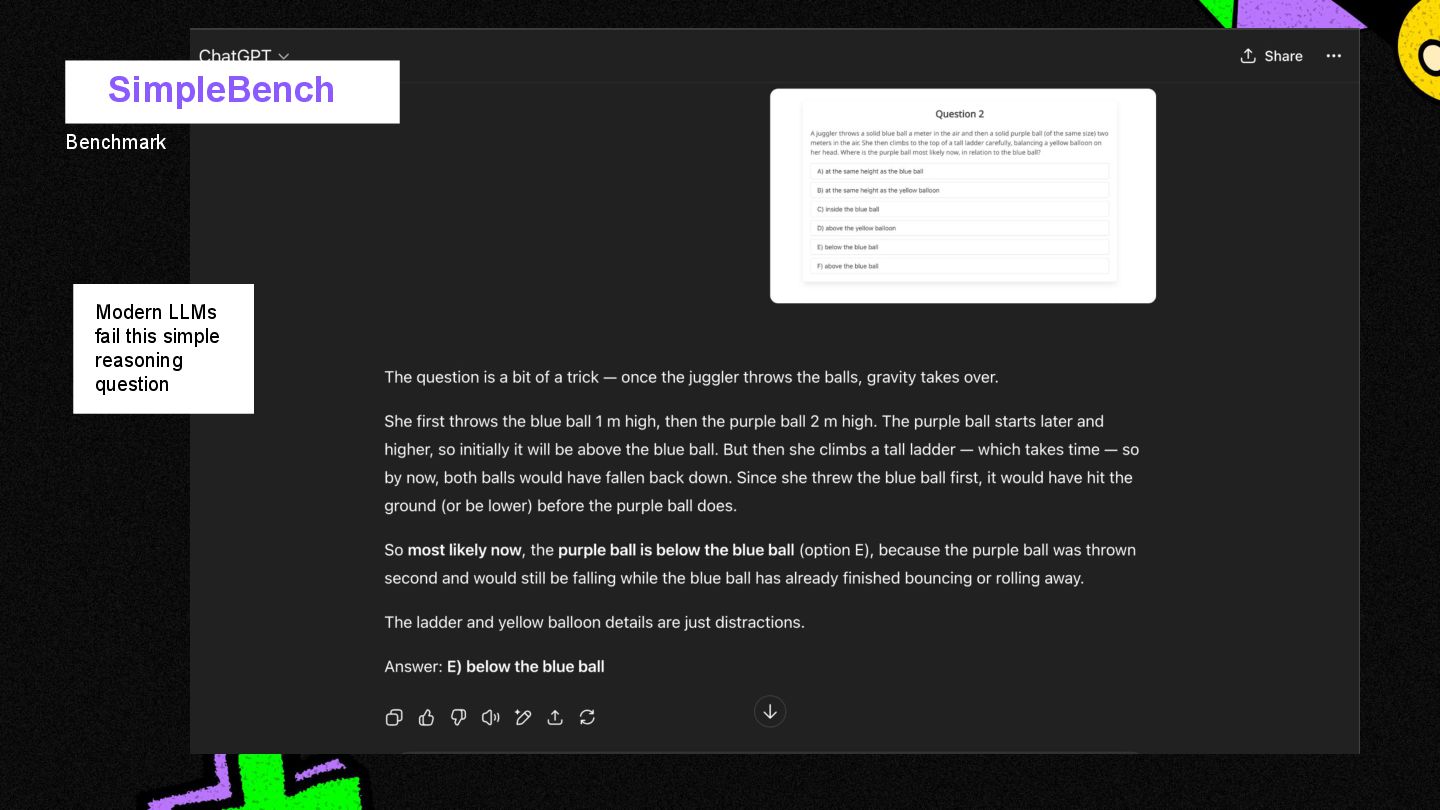
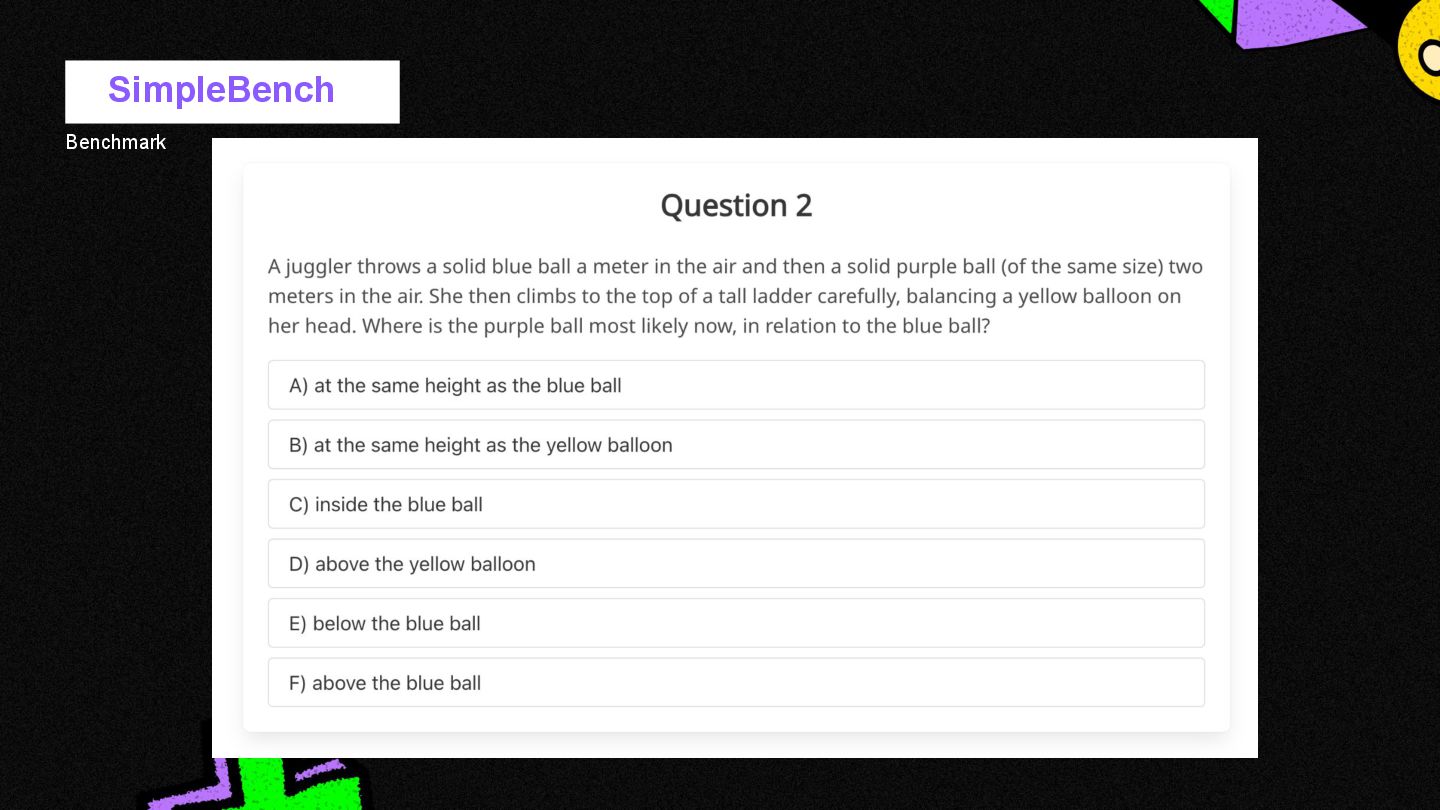{kind=link}
{kind=link}
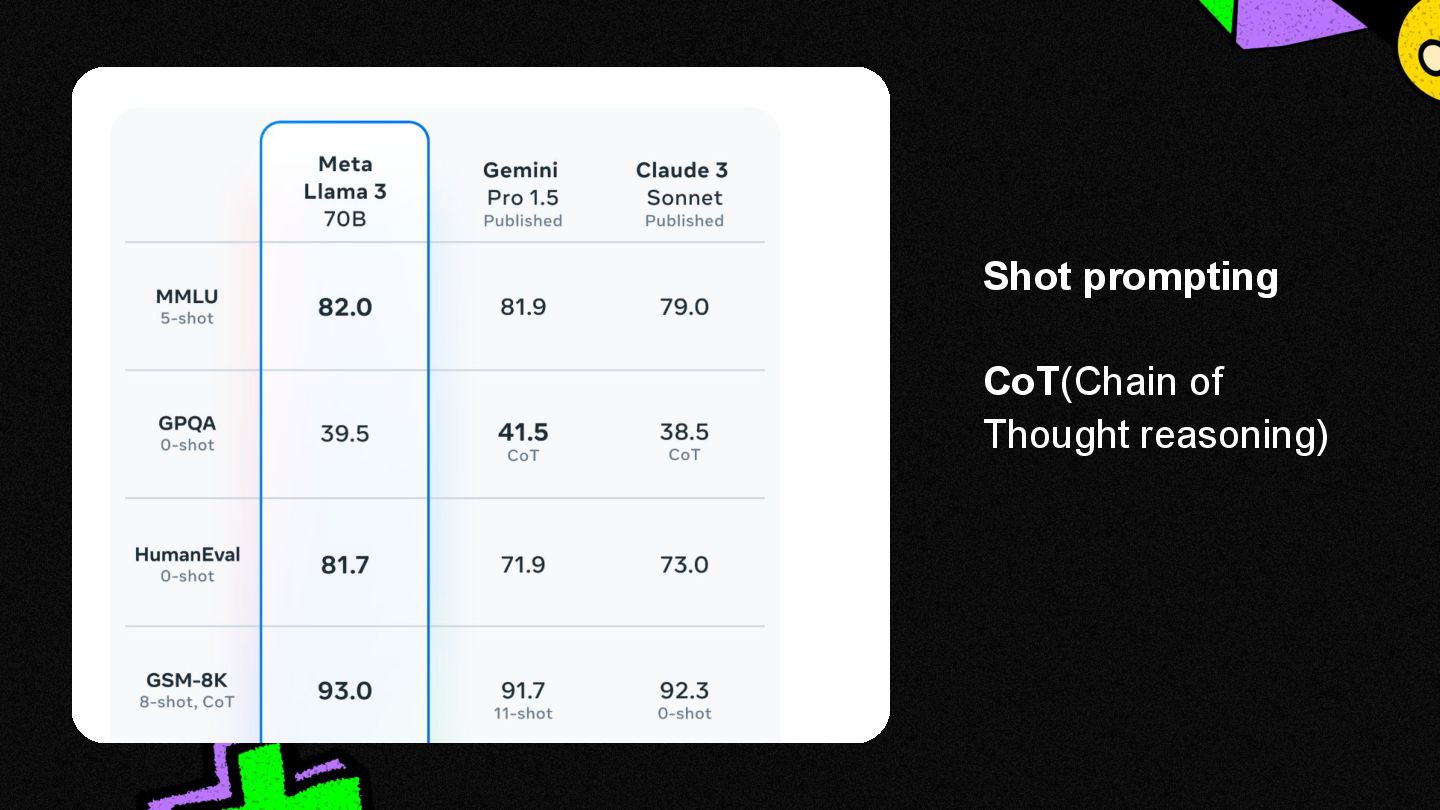{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}