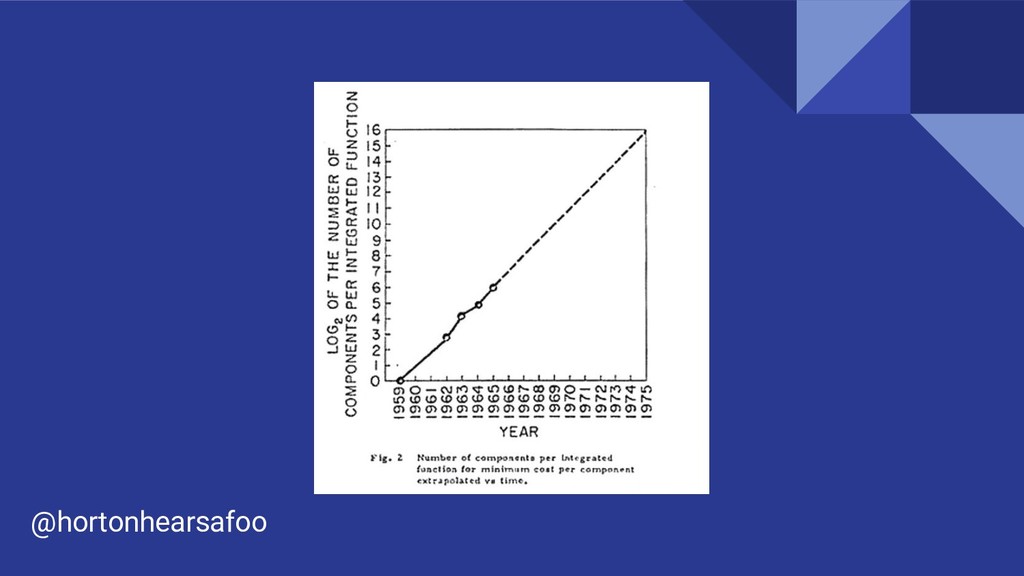
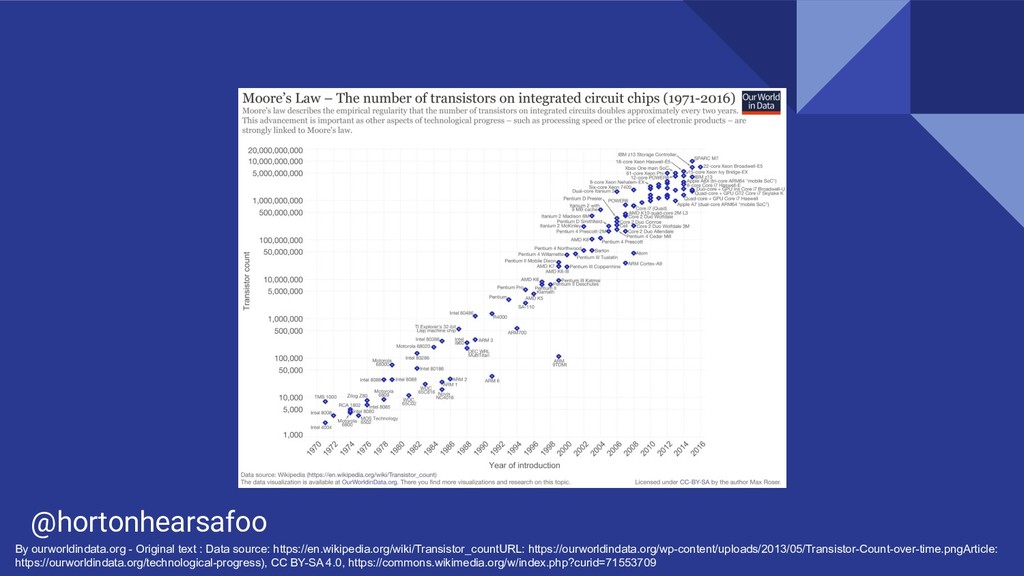
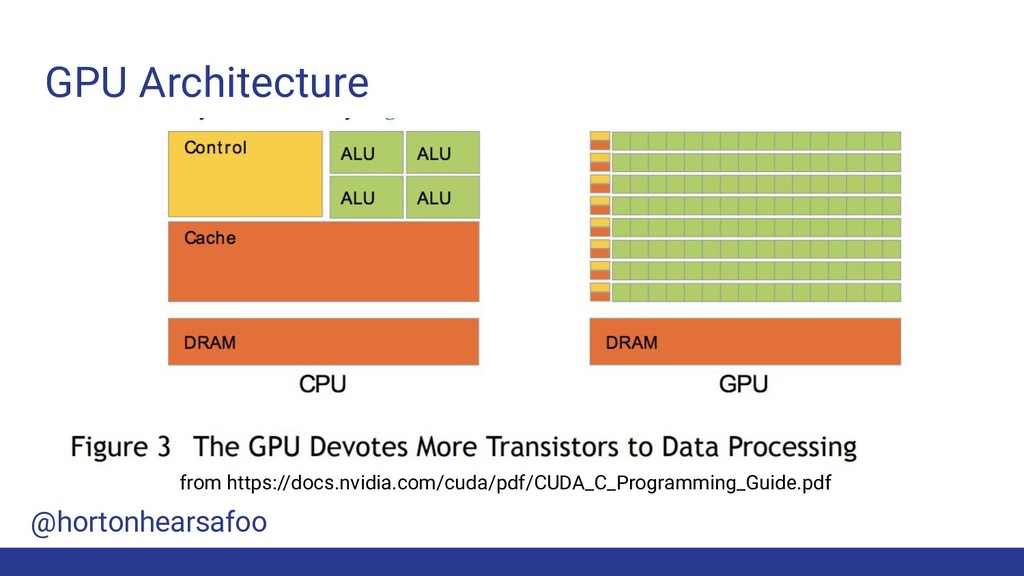
It’s 2019, and Moore’s Law is dead. CPU performance is plateauing, but GPUs provide a chance for continued hardware performance gains, if you can structure your programs to make good use of them. In this talk you will learn how to speed up your Python programs using Nvidia’s CUDA platform.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2-D example [[0, 1, 2], [3, 4, 5], [6, 7,](https://files.speakerdeck.com/presentations/f5f3043b950049b1b8cd44b25a299445/slide_43.jpg){kind=link}
{kind=link}
![2-D example [[0, 1, 2], [3, 4, 5], [6, 7,](https://files.speakerdeck.com/presentations/f5f3043b950049b1b8cd44b25a299445/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Automatic Error Checking “[I]f an asynchronous error occurs, it will](https://files.speakerdeck.com/presentations/f5f3043b950049b1b8cd44b25a299445/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}