Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
輪講資料:生成モデルに対するディープラーニング - RBM, DBNなど /deep-gene...
Search
Yuichiro Tachibana (Tsuchiya)
January 26, 2017
Science
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
輪講資料:生成モデルに対するディープラーニング - RBM, DBNなど /deep-generative-model
Yuichiro Tachibana (Tsuchiya)
January 26, 2017
More Decks by Yuichiro Tachibana (Tsuchiya)
See All by Yuichiro Tachibana (Tsuchiya)
キーバインド拡張を作るときに やってよかったこと・後悔したこと (VS Code Conference Japan 2021 LT)
whitphx
0
860
機械学習インフラ入門 (Docker, AWS) /ml-docker-aws
whitphx
0
480
EM algorithm
whitphx
0
130
機械学習を使ったサービスのプロダクションコードを書く話 /ml-production
whitphx
1
2.3k
Other Decks in Science
See All in Science
SpatialRDDパッケージによる空間回帰不連続デザイン
saltcooky12
0
260
NDCG is NOT All I Need
statditto
2
3.2k
データベース05: SQL(2/3) 結合質問
trycycle
PRO
0
1.2k
共生概念の整理と AIアライメントの構想
hiroakihamada
0
230
機械学習 - K-means & 階層的クラスタリング
trycycle
PRO
0
1.8k
俺たちは本当に分かり合えるのか? ~ PdMとスクラムチームの “ずれ” を科学する
bonotake
2
2.4k
見上公一.pdf
genomethica
0
150
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.2k
データベース03: 関係データモデル
trycycle
PRO
1
570
フィードフォワードニューラルネットワークを用いた記号入出力制御系に対する制御器設計 / Controller Design for Augmented Systems with Symbolic Inputs and Outputs Using Feedforward Neural Network
konakalab
0
150
データベース02: データベースの概念
trycycle
PRO
2
1.2k
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
540
Featured
See All Featured
Building AI with AI
inesmontani
PRO
1
1.1k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
The Curious Case for Waylosing
cassininazir
1
410
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.6k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
860
YesSQL, Process and Tooling at Scale
rocio
174
15k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Agile that works and the tools we love
rasmusluckow
331
22k
Transcript
4節 生成モデルに対するディープラーニング Yuichiro Tsuchiya
資料 http://www.vision.is.tohoku.ac.jp/files/9313/6601/7876/CVIM_tutorial_deep_learning.pdf スライド作った後で気づきました… よくまとまったスライドがWebにありました
4節の目的 Deep Learningで生成モデルをつかう
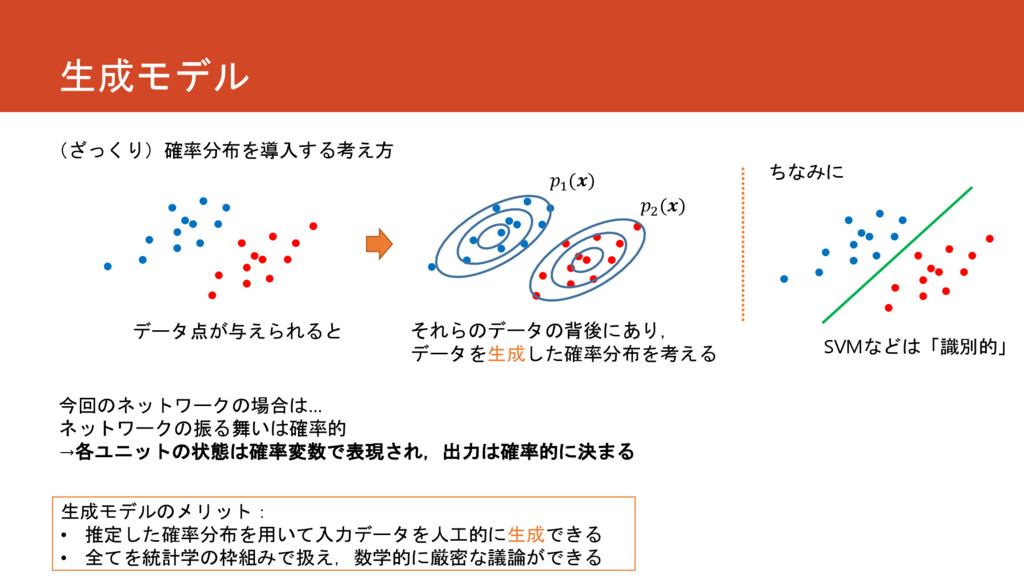
生成モデル 今回のネットワークの場合は… ネットワークの振る舞いは確率的 →各ユニットの状態は確率変数で表現され,出力は確率的に決まる (ざっくり)確率分布を導入する考え方 1 () 2 () データ点が与えられると
それらのデータの背後にあり, データを生成した確率分布を考える 生成モデルのメリット: • 推定した確率分布を用いて入力データを人工的に生成できる • 全てを統計学の枠組みで扱え,数学的に厳密な議論ができる ちなみに SVMなどは「識別的」
4.1 ボルツマンマシン
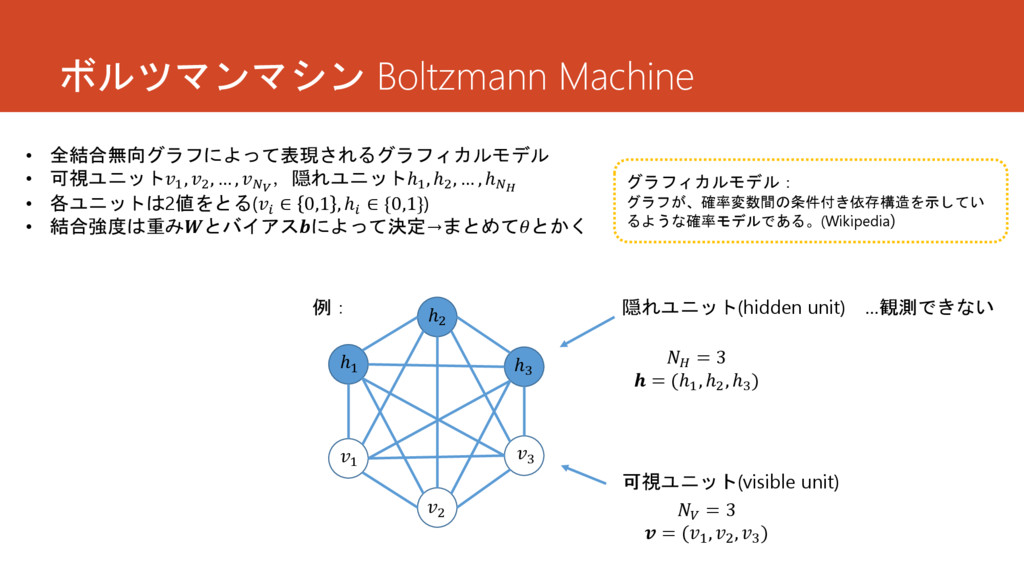
ボルツマンマシン Boltzmann Machine 隠れユニット(hidden unit) …観測できない 可視ユニット(visible unit) 1 2
3 ℎ1 ℎ2 ℎ3 • 全結合無向グラフによって表現されるグラフィカルモデル • 可視ユニット1 , 2 , … , ,隠れユニットℎ1 , ℎ2 , … , ℎ • 各ユニットは2値をとる( ∈ 0,1 , ℎ ∈ {0,1}) • 結合強度は重みとバイアスによって決定→まとめてとかく 例: = 3 = (1 , 2 , 3 ) = 3 = (ℎ1 , ℎ2 , ℎ3 ) グラフィカルモデル: グラフが、確率変数間の条件付き依存構造を示してい るような確率モデルである。(Wikipedia)
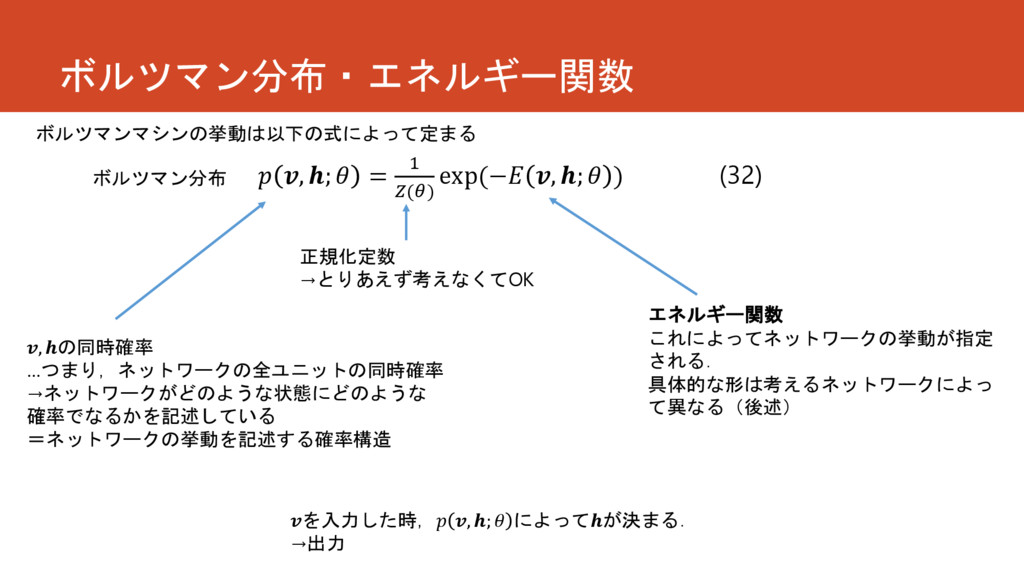
ボルツマン分布・エネルギー関数 , ; = 1 () exp(− , ; )
(32) , の同時確率 …つまり,ネットワークの全ユニットの同時確率 →ネットワークがどのような状態にどのような 確率でなるかを記述している =ネットワークの挙動を記述する確率構造 正規化定数 →とりあえず考えなくてOK エネルギー関数 これによってネットワークの挙動が指定 される. 具体的な形は考えるネットワークによっ て異なる(後述) ボルツマン分布 を入力した時, , ; によってが決まる. →出力 ボルツマンマシンの挙動は以下の式によって定まる
ボルツマンマシンの学習 ネットワークのパラメータを学習によって決めたい. 1.(教師あり) 学習データ(, )を与えて,最尤推定 尤度 , ; を最大化 2.(教師なし)
学習データはだけ → , ; をについて周辺化した周辺分布 ; = , ; を考え,これを用いて 最尤推定 →尤度 ; を最大化 →対数尤度 ℒ = ln ; = =1 ln ; = =1 ln , ; (35) を最大化 ∗ = argmax ℒ θ (34) 「 , ; をについて周辺化」… , ; を, について総和をとる → が消えてだけの分布になる 尤度… 確率分布 , ; からデータ群 , ( = 1,2, … , )が生 成されるもっともらしさ. n番目のデータ , が確率分布 , ; から生成され る確率 , ; を全データについて掛け合わせる
対数尤度最大化→KL情報量最小化 経験分布 経験分布は、n個のデータが等確率で起こる確率関数によって定義された分 布を指します。(http://stat.biopapyrus.net/computational/html.html) 0 () ≡ 1 =1 =1
( , ) (36) →データセット{}をそのまま表現している ex.) 1 = 0,0,0 2 = 1,0,0 3 = 1,0,0 のとき, 0 0,0,0 = 1 3 , 0 1,0,0 = 2 3 この経験分布0 ()を用いて, 尤度最大化の式(34),(35) ∗ = argmax ℒ θ (34) ℒ = =1 ln ; = ln , ; (35) は, ∗ = argmin [ 0 || ; ] (37) と書き直せる. ここで, [| = ln () () (38) はKL情報量(KLダイバージェンス). KL情報量は2つの確率分布, の距離(のようなもの). 尤度最大化問題がKL情報量最小化問題に変わった! (つまり,経験分布0 ()になるべく近いパラメトリック な分布 ; を探す問題とも解釈できる?)
KL情報量最小化 ∗ = argmin [ 0 || ; ] (37)
を解きたい. →勾配降下法 ← − () = (|; )0 () − (, ; ) = data − model をパラメータについて微分すると, (39) 正項(positive phase) 負項(negative phase) のdata = (|; )0 ()についての期待値 のmodel = (, ; )についての期待値 勾配が求まるので, パラメータを逐次更新して 解を得る 勾配 を計算 • 正項 • 負項 パラメータを更新
4.2 Restricted Boltzmann Machine
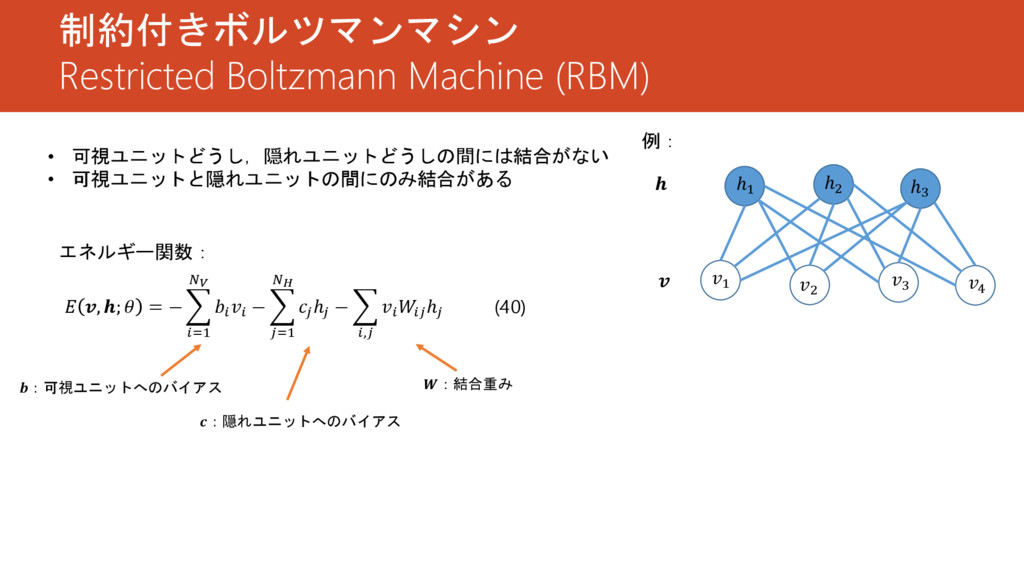
制約付きボルツマンマシン Restricted Boltzmann Machine (RBM) 1 2 3 ℎ1 ℎ2
ℎ3 例: 4 • 可視ユニットどうし,隠れユニットどうしの間には結合がない • 可視ユニットと隠れユニットの間にのみ結合がある , ; = − =1 − =1 ℎ − , ℎ エネルギー関数: (40) :可視ユニットへのバイアス :隠れユニットへのバイアス :結合重み
解析的に正項を計算 RBMは可視ユニットどうし,隠れユニットどうしに結合がない →条件付き確率 , (ℎ |)が計算できる = (|; )0 ()
− (, ; ) = data − model (39) →正項が計算できる! = 1 ; = + , ℎ ℎ = 1 ; = + , (41) (42) − , data = 1 + ′ ′ ′, − data = 1 − data = 1 + ′ ′ ′, (ちなみに) 計算すると… (43a) (43b) (43c) 正項(positive phase)
負項の近似計算 を(, )の全組み合わせについて平均 →組み合わせが爆発して解けない! データ数と同じ数の(, )の組で平均をとって近似する →分布(, ; ) に従うデータ点(,
)が個欲しい Method • ギブスサンプリング • Contrastive Divergence (CD)法 計算効率がよい.現在はコレ. (39) = (|; )0 () − (, ; ) 負項(negative phase)
ギブスサンプリング 直接サンプリングが難しい確率分布の代わりにそれを近似するサンプル列を生成する MCMC法(Markov chain Monte Carlo algorithm)の1つである(Wikipedia) 1. 個のサンプルの初期値を以下のように生成する •
可視ユニット: 個の学習サンプル 1, 2, … , をそのまま初期値 0 1, 0 2, … , 0 とする • 隠れユニット:条件付き確率(0 |0 ; )を使い, 0 1, 0 2, … , 0 をもとに ℎ0 1, ℎ0 2, … , ℎ0 をサンプリングす る.条件付き確率(0 |0 ; )は ℎ = 1 ; = + , (式42)によって評価できる. 2. 以下のようにサンプルを回反復更新していく • 可視ユニットのサンプル :条件付き確率(+1 | ; )に従って+1 をサンプリングし,更新値とする • 隠れユニットのサンプル :条件付き確率(+1 |+1 ; )に従って+1 をサンプリングし,更新値とする 3. 回目の隠れユニットのサンプル のサンプリングは行わず, (+1 |+1 ; )を求めて終了 適当なサンプルの初期値を用意し,回の反復更新によってサンプルを対象の分布に近づけていく 結局, 個の可視ユニットのサンプル( 1 , 2 , … , )と,条件付き確率(|; )が求まる 1 1 2 0 2 0
サンプルによる負項の近似計算 得られた個の可視ユニットのサンプル( 1 , 2 , … , )と,条件付き確率(|; )を使って
(, ; )を近似計算する , ; ≈ (|; ) = 1 =1 =1 ( , ) =1 + ′ ′ ′, (44) 反復時のの経験分布≈ の周辺分布() 反復時に得られた条件付き確率(|;) ただし, は回更新後の可視ユニットのサンプル これを用いて,負項を計算できる − , model = 1 + ′ ′, − model = 1 − model = 1 + ′ ′, (45) (46) (47)
ギブスサンプリングの問題点 近似の精度を十分なものとするには多くのサンプルの生成を必要とし,それには膨大な計算コストを要する ため,大規模なネットワークの学習は現実的でなかった →CD法 計算コストの問題を大きく改善
Contrastive Divergence CD法 ギブスサンプリングの繰り返し数に対するContrastive Divergence (T-CD)を以下のように定義する [0 | ; −
[ || ; ] (48) (48)を最小化する(勾配降下法による) このとき,勾配降下法によるパラメータ更新のたびに学習サンプルを初期値とする回のギブスサンプリング を行う 小さなでも( = 1でも!)十分精度の高いパラメータが得られる PCD (Persistent Contrastive Divergence) • さらに精度の高いCD法の改良 • パラメータ更新時のギブスサンプリングの初期値として, 前回更新時に用いたギブスサンプリングの結果を用いる • 現在,RBMの学習にはこのPCDを用いることが多い
RBMの学習まとめ ∗ = argmin [ 0 || ; ] (37)
を解くために, 勾配降下法 ← − () = (|; )0 () − (, ; ) = data − model (39) 解析的に解ける CD法で近似的に解く 教師なし学習の場合: 学習データはだけ →周辺尤度 ; を最大化 ; は周辺分布 ; = , ; →KLダイバージェンス最小化に書き直せる
スパースRBM RBMの可視ユニットに学習サンプルを入力したとき,活性化する(ℎ = 1)隠れユニットの数を少なくする (3.3節と同じモチベーション.スパース表現で性能が上がる) Leeらの手法(最も一般的だと思われる) 最小化したい目的関数(=負の対数尤度)−ℒ()に活性化する隠れユニットの数を制限する項を加える −ℒ + −
ℎ 0 (ℎ|) 2 0 () ≡ 1 =1 =1 ( , ) (36) (49) ℎ の期待値 (参考) 最適化は対数尤度の最小化とスパース項の最小化を交互に行う
可視ユニットが連続値をとる場合 エネルギー関数: , ; = =1 − 2 2 2
− =1 ℎ − , , ℎ (50) ; = ; + , ℎ , 2 ℎ = 1 ; = + , (51a) (51b) 条件付き確率: 以下のようになる 実際は,ギブスサンプリングでを生成する際に使う式を(51a)に置き換えればよい 学習による の決定は(理論的には可能だが)良い結果を得るのは難しい. Hintonは入力ベクトルを正規化し, = 1と固定して残りのパラメータを学習した.
4.3 Deep Belief Network
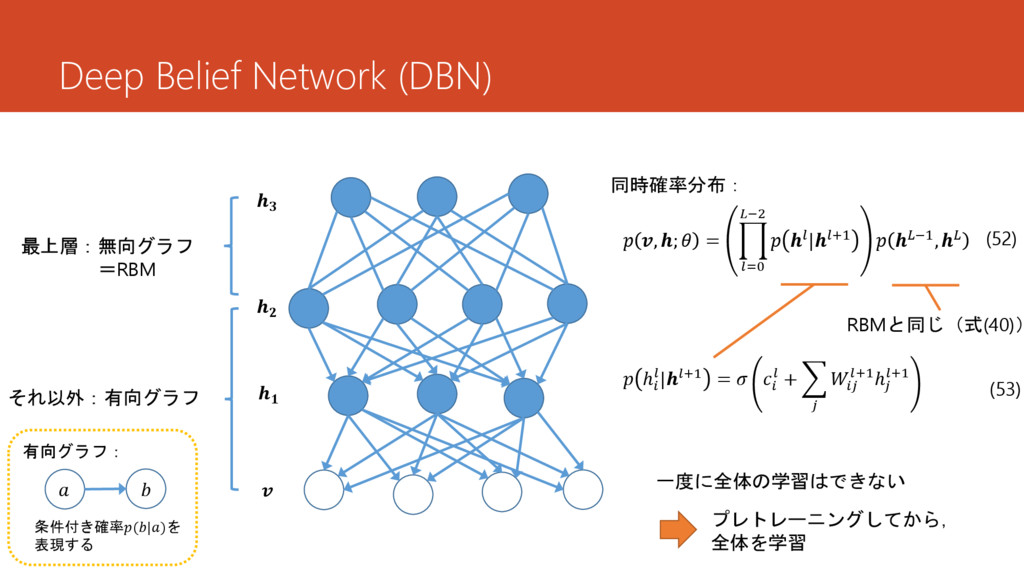
Deep Belief Network (DBN) 最上層:無向グラフ =RBM それ以外:有向グラフ , ; =
=0 −2 |+1 −1, 同時確率分布: (52) ℎ |+1 = + +1ℎ +1 (53) RBMと同じ(式(40)) 一度に全体の学習はできない プレトレーニングしてから, 全体を学習 有向グラフ: 条件付き確率(|)を 表現する
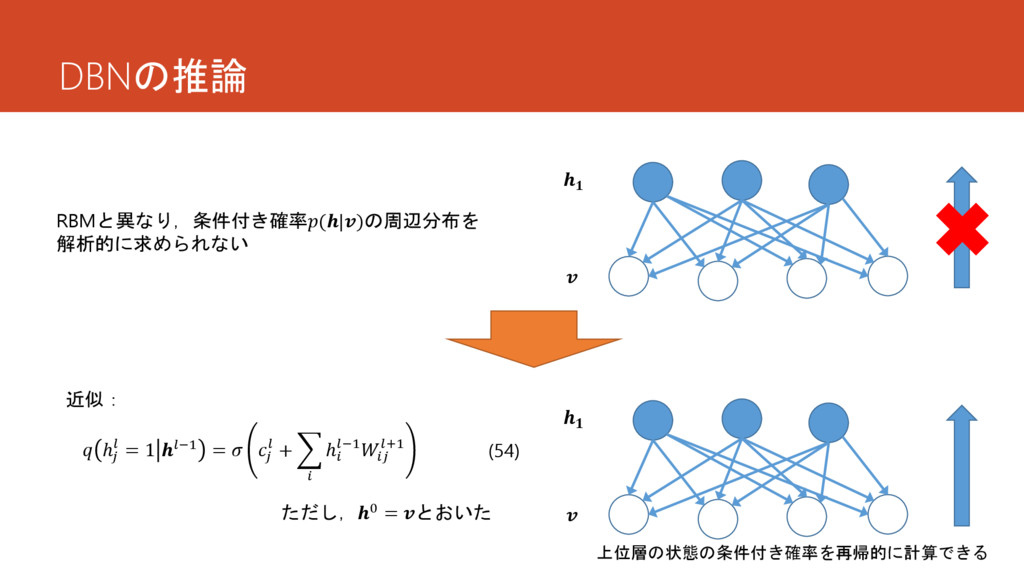
DBNの推論 RBMと異なり,条件付き確率(|)の周辺分布を 解析的に求められない 近似: ℎ = 1 −1 = +
ℎ −1 +1 ただし,0 = とおいた (54) 上位層の状態の条件付き確率を再帰的に計算できる
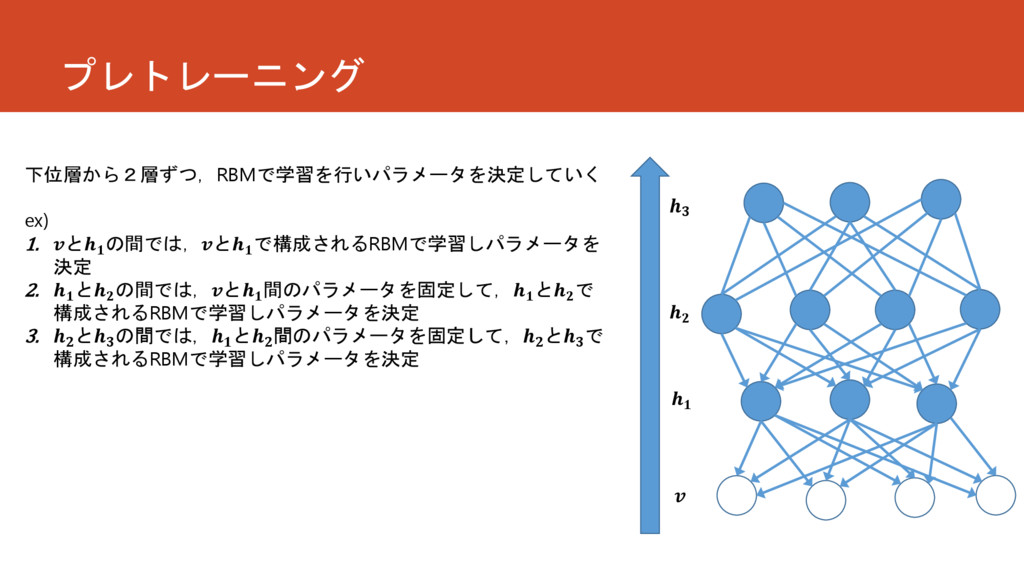
プレトレーニング 下位層から2層ずつ,RBMで学習を行いパラメータを決定していく ex) 1. と の間では,と で構成されるRBMで学習しパラメータを 決定 2. と
の間では,と 間のパラメータを固定して, と で 構成されるRBMで学習しパラメータを決定 3. と の間では, と 間のパラメータを固定して, と で 構成されるRBMで学習しパラメータを決定
4.4 Deep Boltzmann Machine
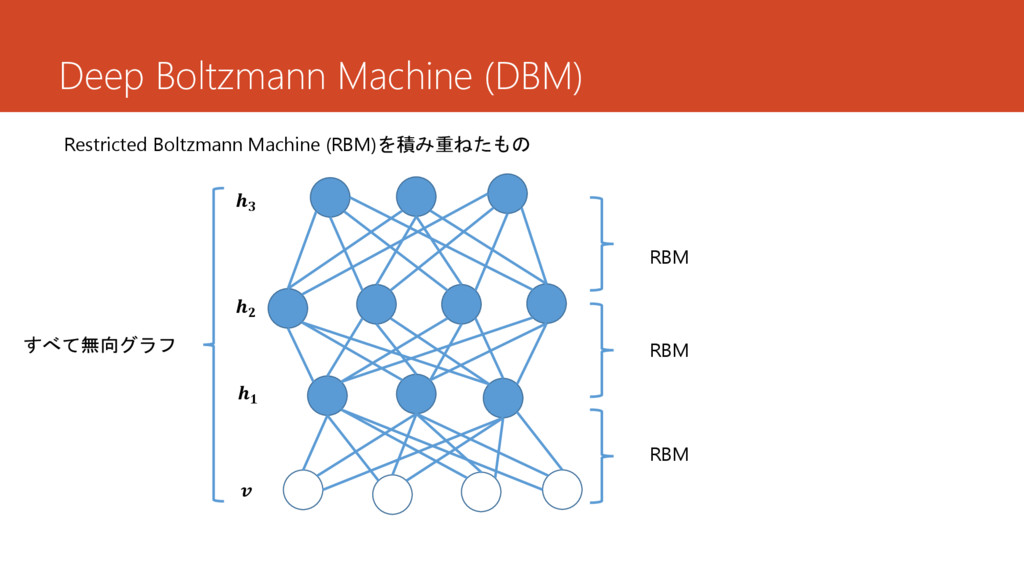
Deep Boltzmann Machine (DBM) すべて無向グラフ Restricted Boltzmann Machine (RBM)を積み重ねたもの RBM
RBM RBM
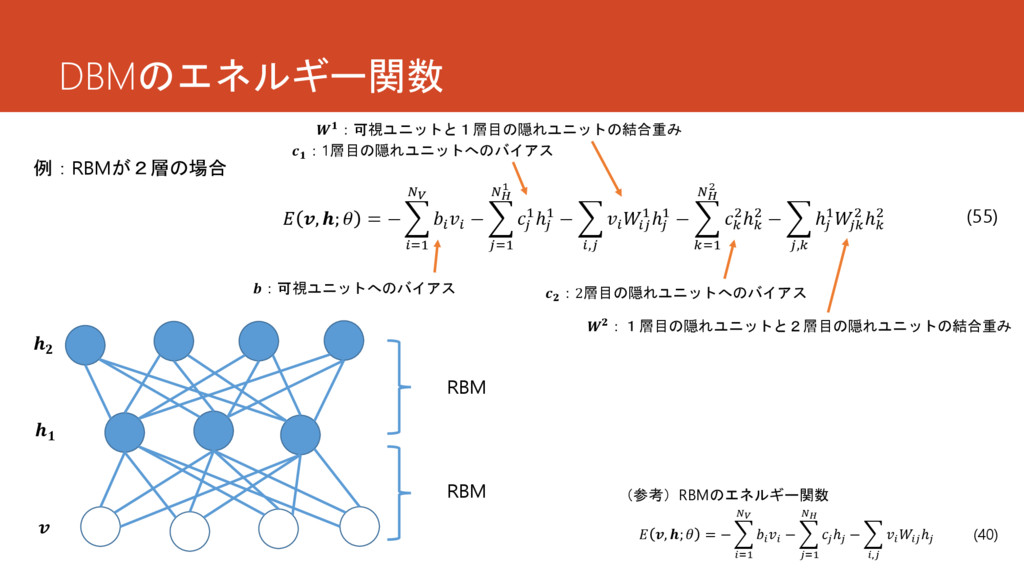
DBMのエネルギー関数 RBM RBM 例:RBMが2層の場合 , ; = − =1 −
=1 ℎ − , ℎ (40) , ; = − =1 − =1 1 1ℎ 1 − , 1ℎ 1 − =1 2 2ℎ 2 − , ℎ 1 2 ℎ 2 (55) (参考)RBMのエネルギー関数 :可視ユニットへのバイアス :1層目の隠れユニットへのバイアス :可視ユニットと1層目の隠れユニットの結合重み :2層目の隠れユニットへのバイアス :1層目の隠れユニットと2層目の隠れユニットの結合重み
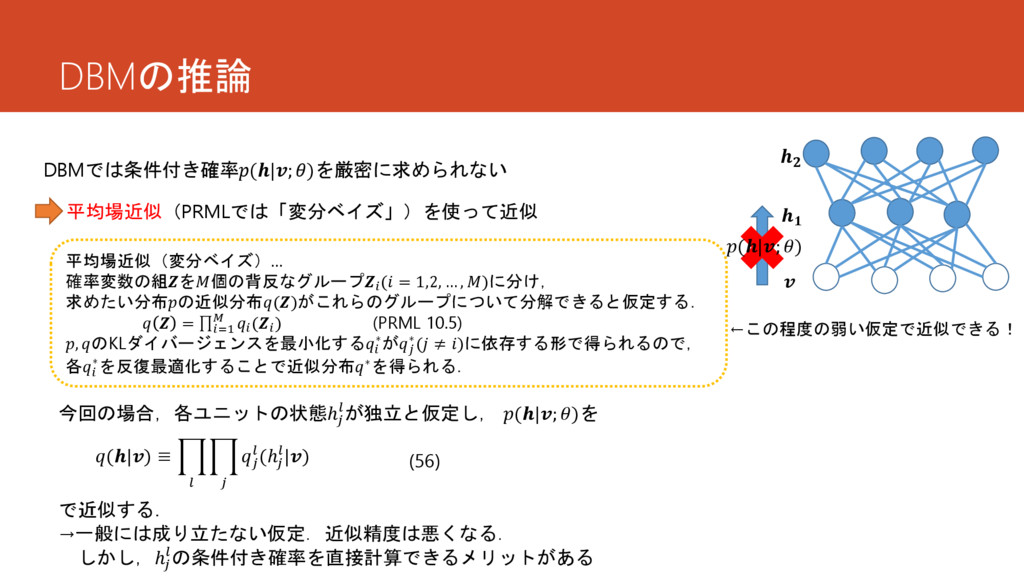
DBMの推論 DBMでは条件付き確率(|; )を厳密に求められない 平均場近似(PRMLでは「変分ベイズ」)を使って近似 平均場近似(変分ベイズ)… 確率変数の組を個の背反なグループ ( = 1,2, …
, )に分け, 求めたい分布の近似分布()がこれらのグループについて分解できると仮定する. = =1 ( ) (PRML 10.5) , のKLダイバージェンスを最小化する ∗が ∗( ≠ )に依存する形で得られるので, 各 ∗を反復最適化することで近似分布∗を得られる. 今回の場合,各ユニットの状態ℎ が独立と仮定し, (|; )を (|) ≡ (ℎ |) (56) で近似する. →一般には成り立たない仮定.近似精度は悪くなる. しかし,ℎ の条件付き確率を直接計算できるメリットがある (|; ) ←この程度の弱い仮定で近似できる!
平均場近似(変分ベイズ) (|) ≡ (ℎ |) (56) とおいた. このようなのなかで,もっとも(|; )をよく近似する, すなわち,
のKLダイバージェンスを最小化する∗をの近似分布として得たい. ∗ = argmin [(|)||(|; )] (57) ≡ (ℎ = 1|)と定義する. 式(57)に式(40), (56)を代入し, の停留点を求めると,以下の更新式を得る = + −1 + +1 +1 (58) ← を求めるために −1と +1が必要,という構造 この式に従って, を収束するまで更新する.得られる は(|; )の推定値となる ただし, 0 =
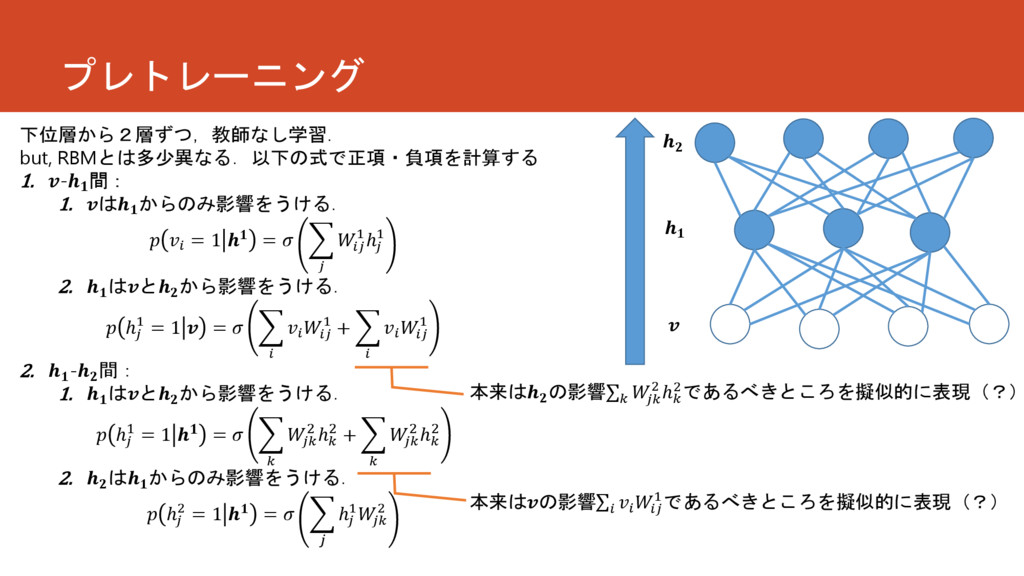
プレトレーニング 下位層から2層ずつ,教師なし学習. but, RBMとは多少異なる.以下の式で正項・負項を計算する 1. - 間: 1. は からのみ影響をうける.
= 1 = 1ℎ 1 2. はと から影響をうける. ℎ 1 = 1 = 1 + 1 2. - 間: 1. はと から影響をうける. ℎ 1 = 1 = 2 ℎ 2 + 2 ℎ 2 2. は からのみ影響をうける. ℎ 2 = 1 = ℎ 1 2 本来は の影響 2 ℎ 2であるべきところを擬似的に表現(?) 本来はの影響 1であるべきところを擬似的に表現(?)
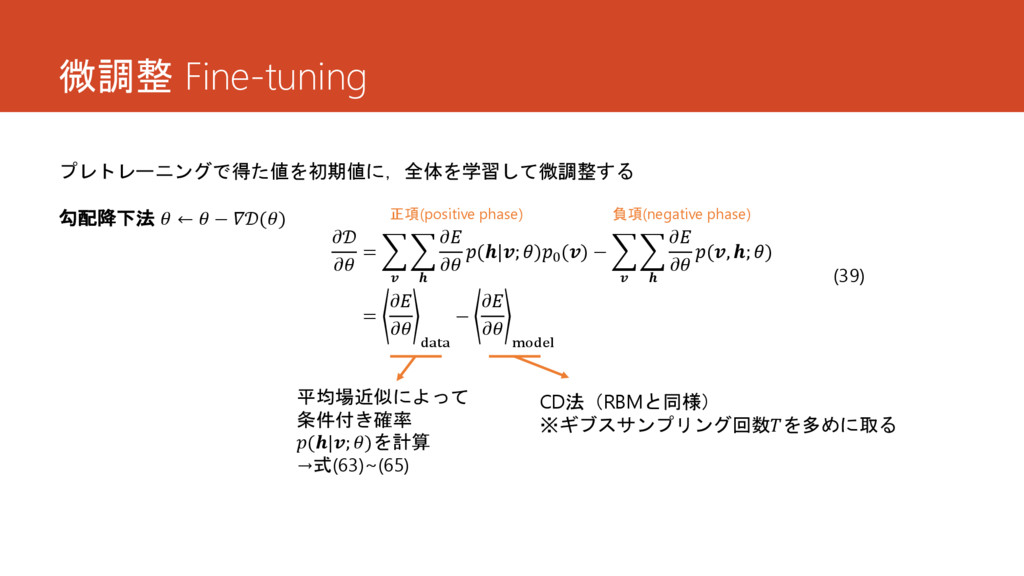
微調整 Fine-tuning プレトレーニングで得た値を初期値に,全体を学習して微調整する = (|; )0 () − (, ;
) = data − model (39) 勾配降下法 ← − () 正項(positive phase) 負項(negative phase) 平均場近似によって 条件付き確率 (|; )を計算 →式(63)~(65) CD法(RBMと同様) ※ギブスサンプリング回数を多めに取る
4.5 Convolutional DBN
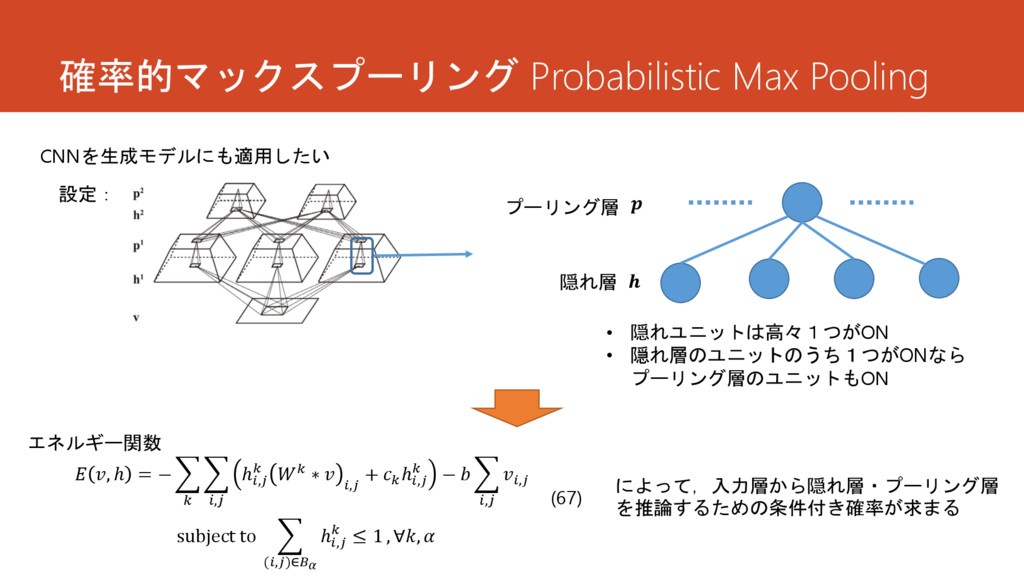
確率的マックスプーリング Probabilistic Max Pooling 隠れ層 プーリング層 • 隠れユニットは高々1つがON • 隠れ層のユニットのうち1つがONなら
プーリング層のユニットもON CNNを生成モデルにも適用したい 設定: エネルギー関数 , ℎ = − , ℎ, ∗ , + ℎ, − , , subject to (,)∈ ℎ, ≤ 1 , ∀, によって,入力層から隠れ層・プーリング層 を推論するための条件付き確率が求まる (67)
まとめ 生成的なネットワークとして, • Restricted Boltzmann Machine • Deep Belief Network
• Deep Boltzmann Machine をみた. ネットワークの種類によって,推論に用いる条件付き確率が 異なる ネットワークの学習には勾配降下法を使い, 勾配の計算にはギブスサンプリングやCD法を利用する CNNへも生成的アプローチを適用できる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![KL情報量最小化 ∗ = argmin [ 0 || ; ] (37)](https://files.speakerdeck.com/presentations/95dd90a5cbe6434aa310ebaf67c027b7/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RBMの学習まとめ ∗ = argmin [ 0 || ; ] (37)](https://files.speakerdeck.com/presentations/95dd90a5cbe6434aa310ebaf67c027b7/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}