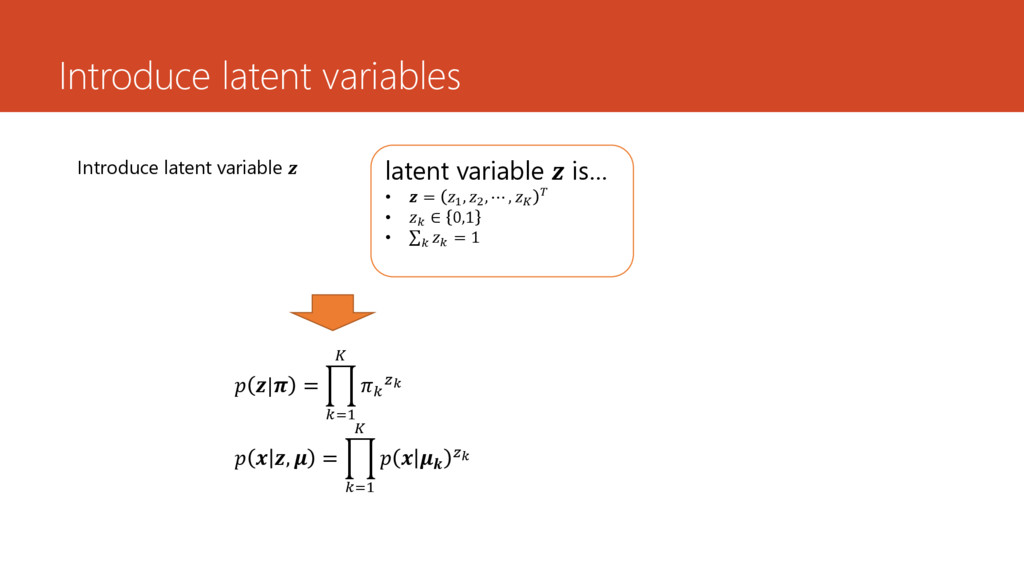
, ) : Mixing coefficient (| , ): Normal distribution or k-th component of GMM • : Mean of k-th component • : Variance-covariance matrix of k-th component
, 2. Evaluate by using , , =E (expectation) step 3. Re-estimate , , by using =M (maximization) step = 1 =1 ( ) = 1 =1 − − = = =1 ( ) where = (| , ) =1 (| , ) No closed-form solution ※ Each update to the parameters resulting from an E step followed by an M step is guaranteed to increase the log likelihood function. (PRML Sec. 9.4) 4. Stop if the log likelihood or parameters converge
(| , ) : Mixing coefficient (| , ): Normal distribution or k-th component of GMM • : Mean of k-th component • : Variance-covariance matrix of k-th component
= 1 = (| , ) Example: How to consider a generative model of GMM with latent variable (K=3) 1. Probabilistically select = 0, 1, 0 2. Generate a data point from a selected distribution by ~( , ) → component 2 1
= 1 = (| , ) Example: How to consider a generative model of GMM with latent variable (K=3) 1. Probabilistically select = 1, 0, 0 2. Generate a data point from a selected distribution by ~( , ) → component 1 1
= 1 = (| , ) Example: How to consider a generative model of GMM with latent variable (K=3) 1. Probabilistically select 2. Generate a data point from a selected distribution by 1
EM algorithm: To find maximum likelihood solutions for models having latent variables Observed data: = ( , , ⋯ , ) All latent variables: = ( , , ⋯ , ) All model parameters: ln | = ln , | Log likelihood function
parameters 2. E step: Evaluate (|, ) 3. M step: Evaluate Given by = argmax (, ) where , = (|, ) ln (, |) 4. Check for convergence of either the log likelihood or the parameter values. If the convergence criterion is not satisfied, then let ← and return to step 2. ln | = ln , | Expectation of ln (, |) under the posterior distribution of Complex solution • (, |) can be solved straightforward • But we can not obtain the latent variable → Maximize the expectation
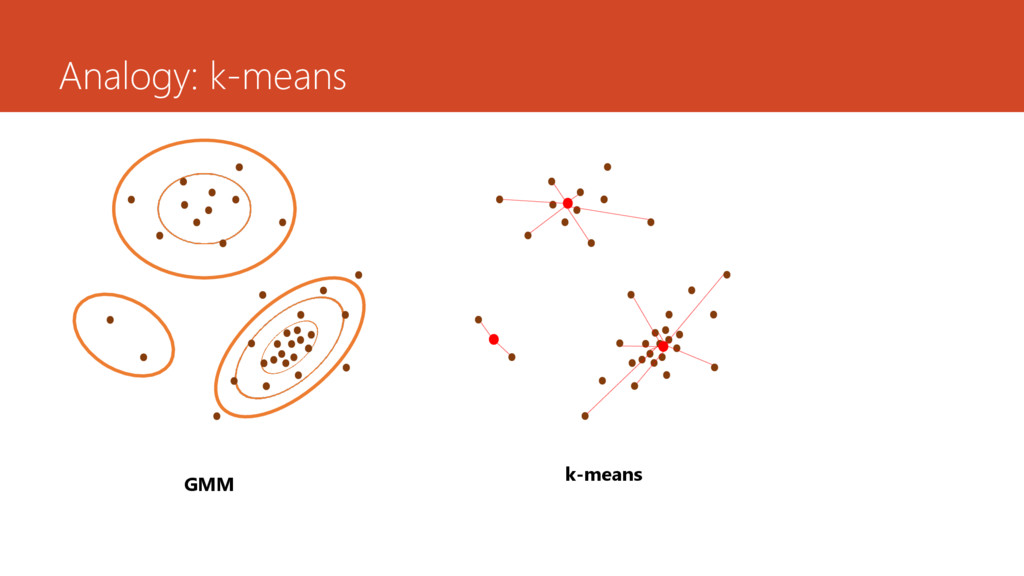
( ) = 1 =1 − − = E step: Finding centroids M step: maximize ln , , , with respect to , , Re-assignment data points to centroids to minimize distances between centroids and assigned data points = → 0 = : assignment variable = 1 = argmin − 2 0 ℎ =1 =1 − 2 (⇔data point is assigned to centroid )
solutions for models having latent variables For example: • Gaussian Mixture Models • Mixtures of Bernoulli distributions If you want to learn more, see PRML Sec. 9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}