Share
2026年6月12日開催 Women in Data Science Tokyo @ IBM AI SPEECH RESEARCH TALK 資料
Speaker: Sashi Novitasari (ノビタサリ サシ) 日本アイ・ビー・エム株式会社 東京基礎研究所 AIテクノロジーズ スタッフ・リサーチ・サイエンティスト
https://widstokyoibm2026.pages.dev/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
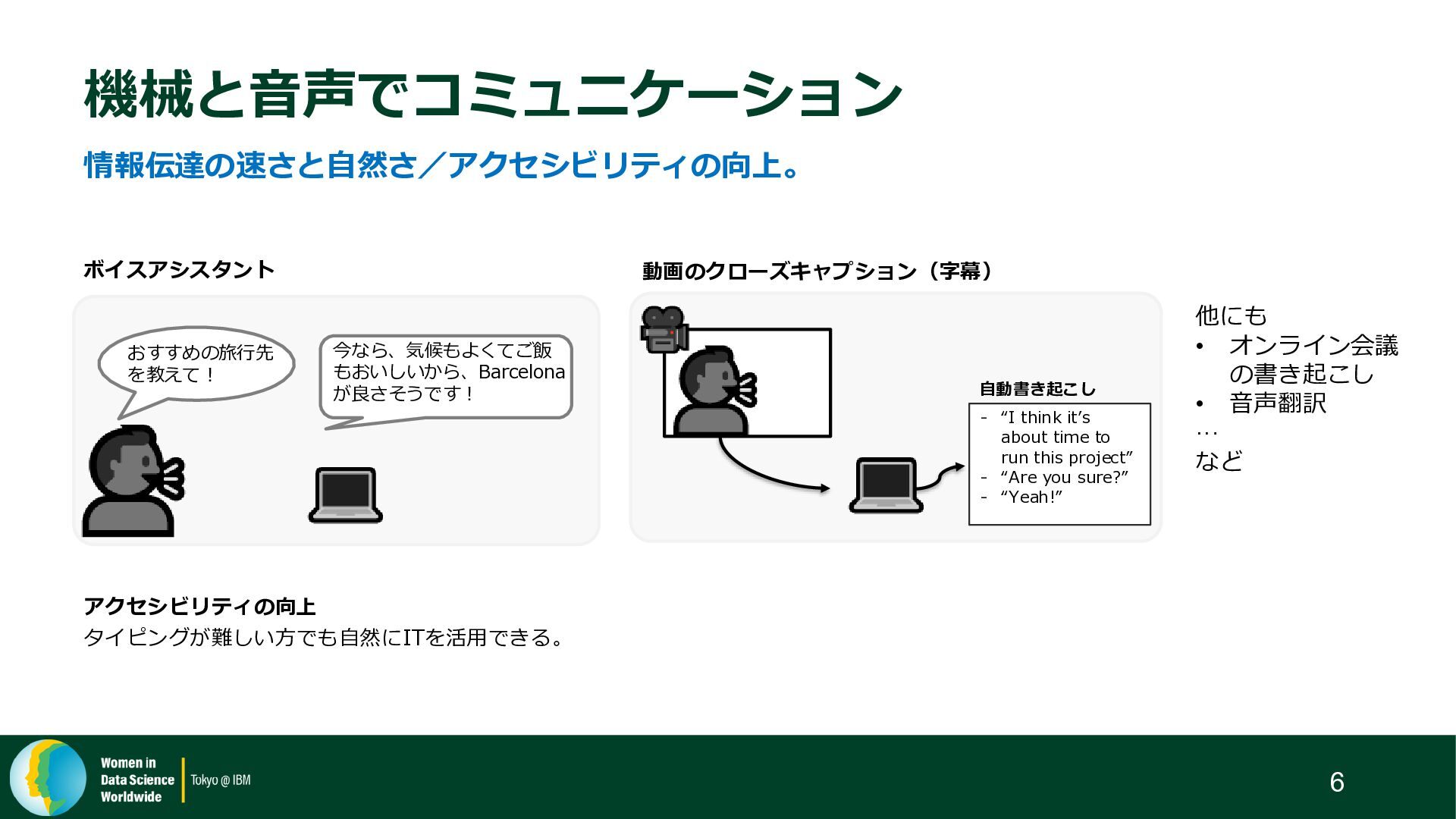{kind=link}
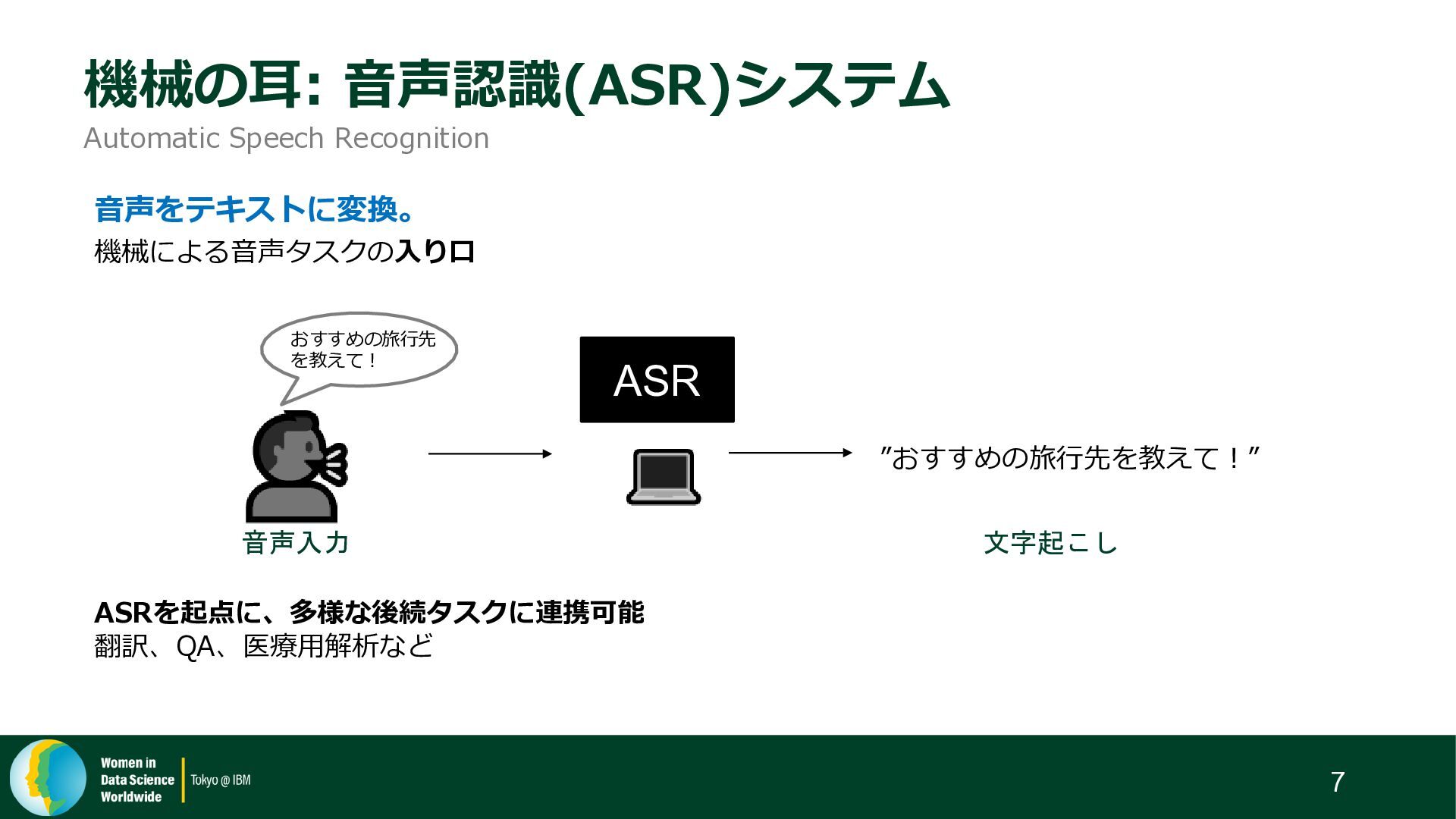{kind=link}
{kind=link}
![機械は音声を「数字」として「理解する」 おすすめの旅行先 を教えて! [0.130 2.455 …. 4.145] 話し方・環境によるもの • 言葉の区切りの違い・息の使い方](https://files.speakerdeck.com/presentations/5babe99363304eaab48ffc0a16c2ba9e/slide_8.jpg){kind=link}
{kind=link}
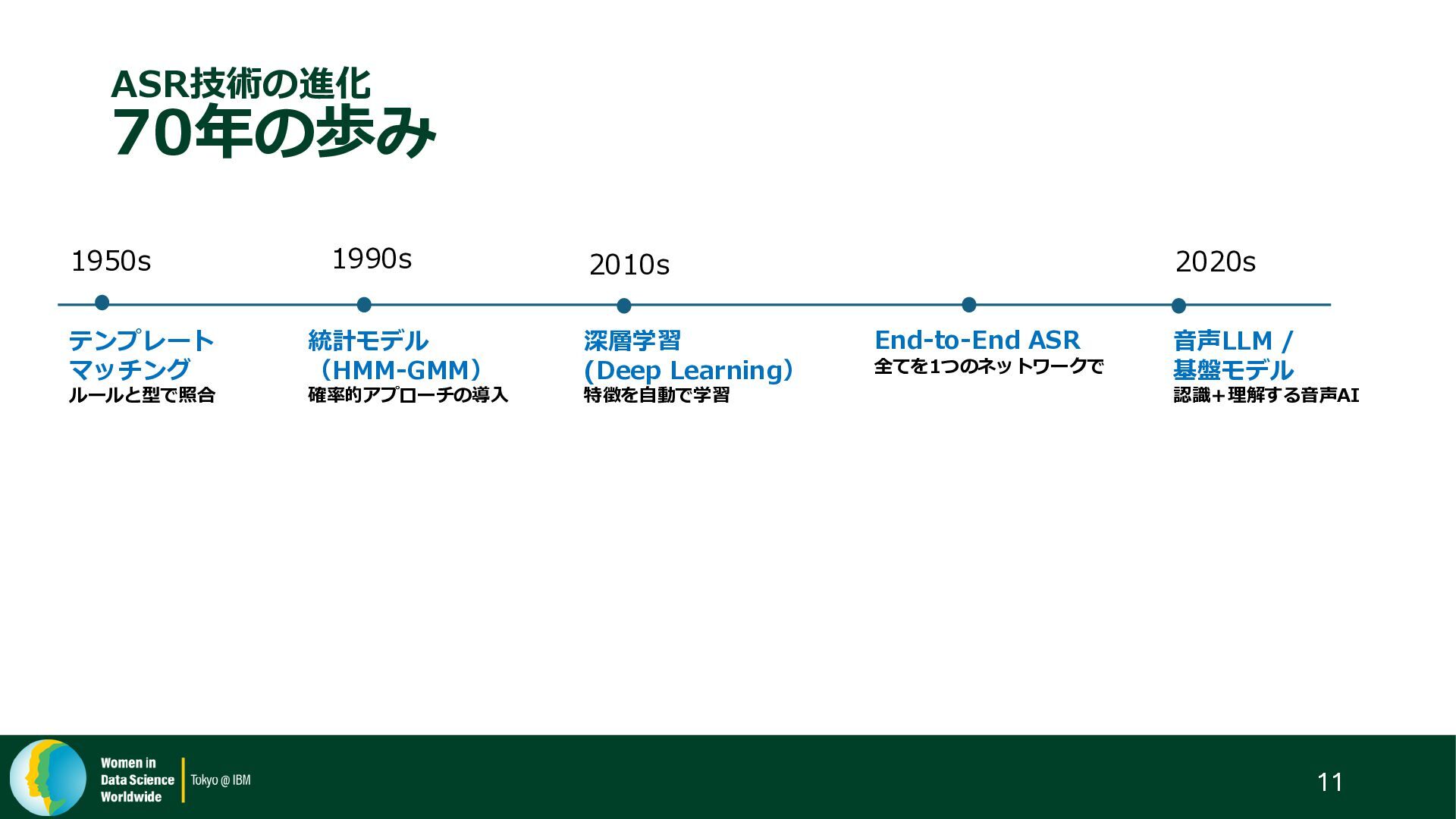{kind=link}
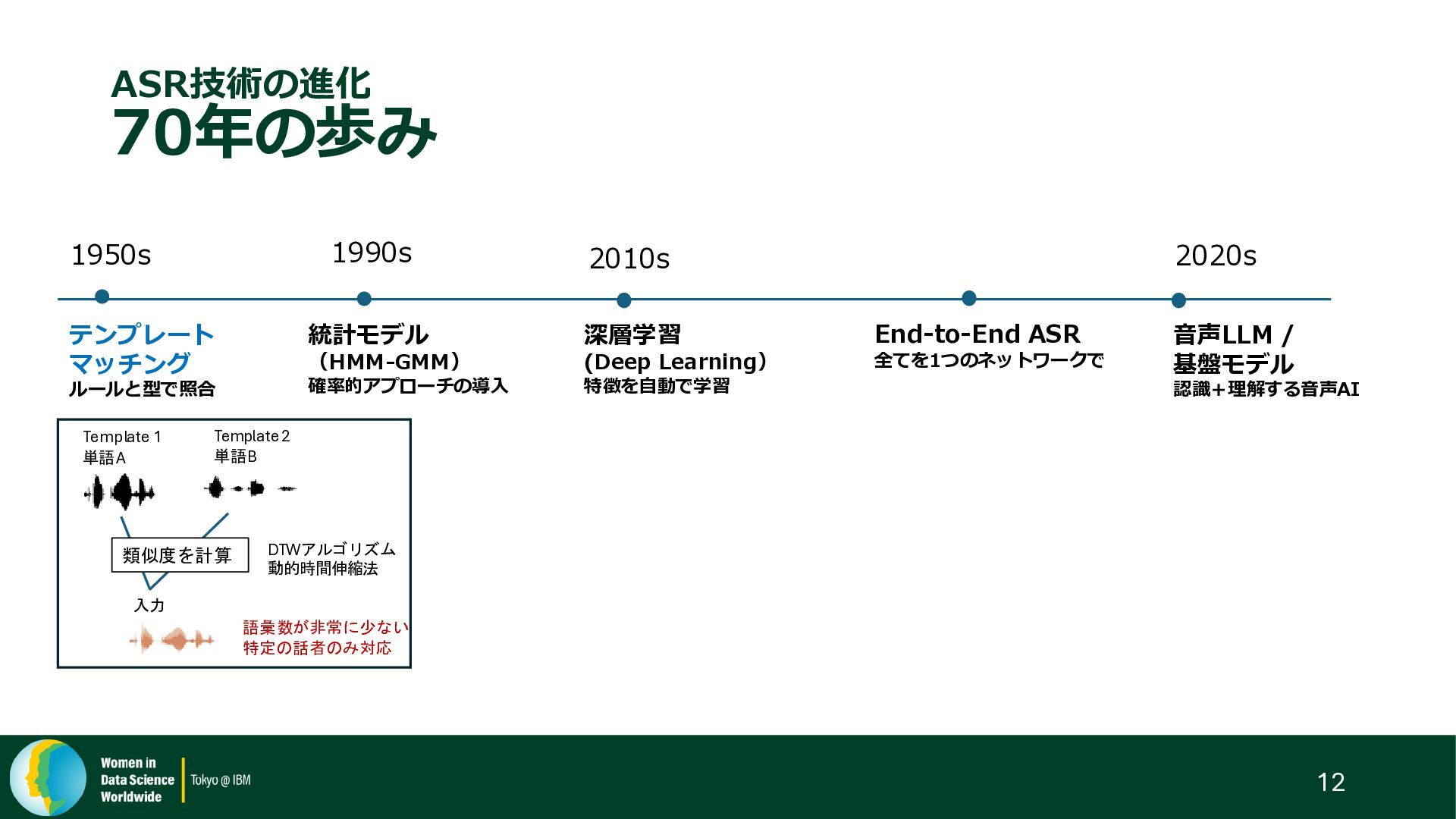{kind=link}
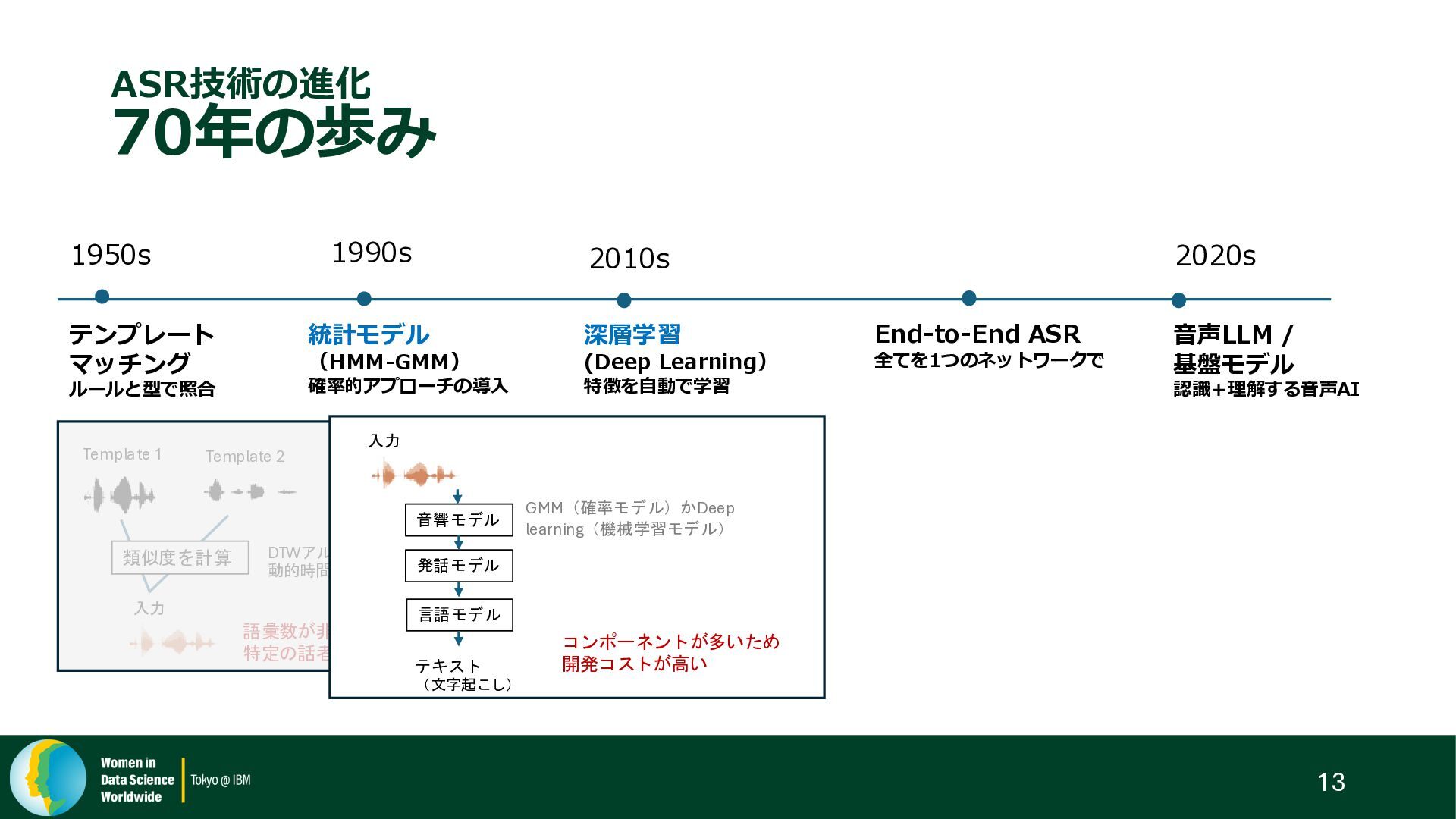{kind=link}
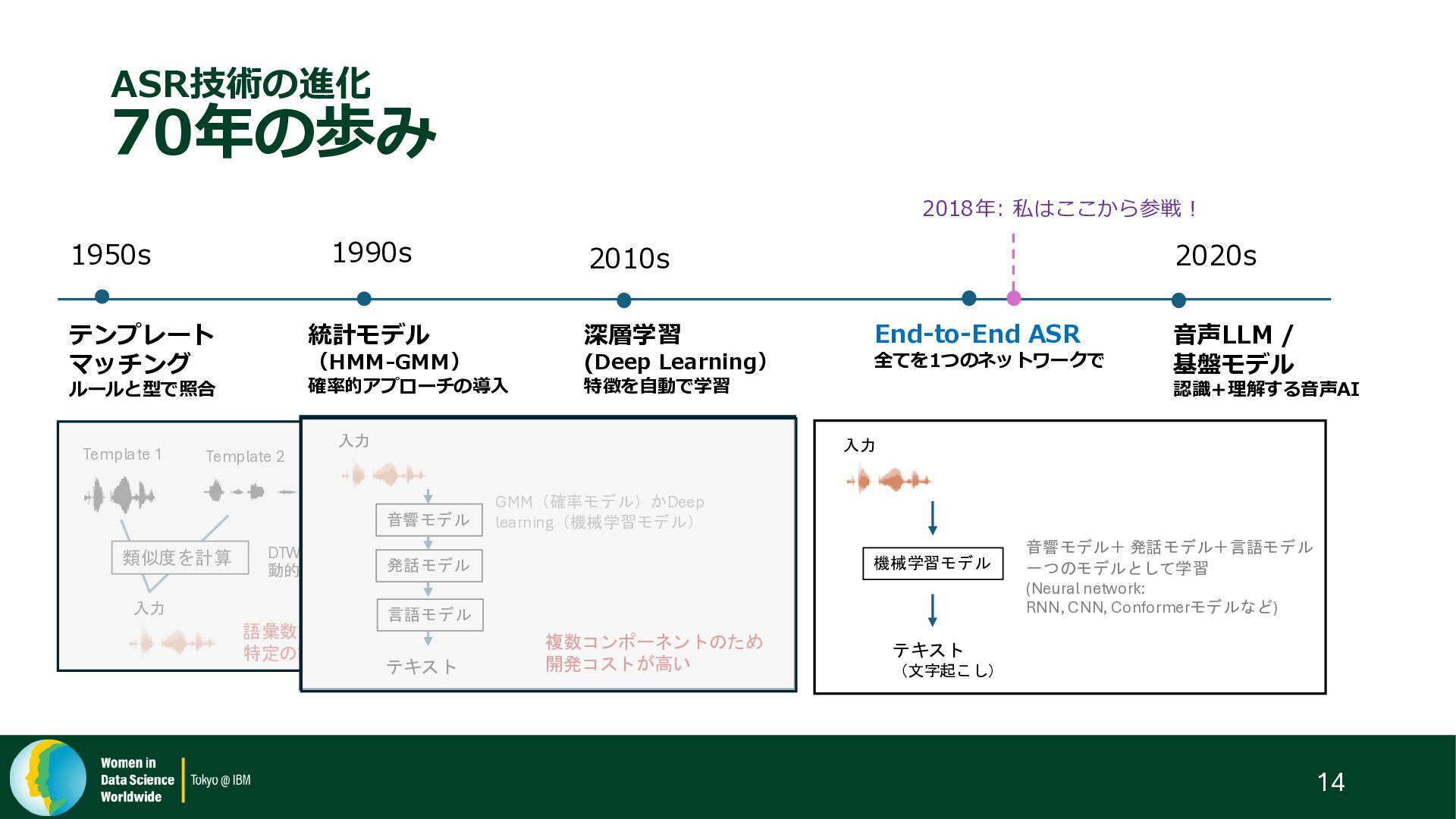{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
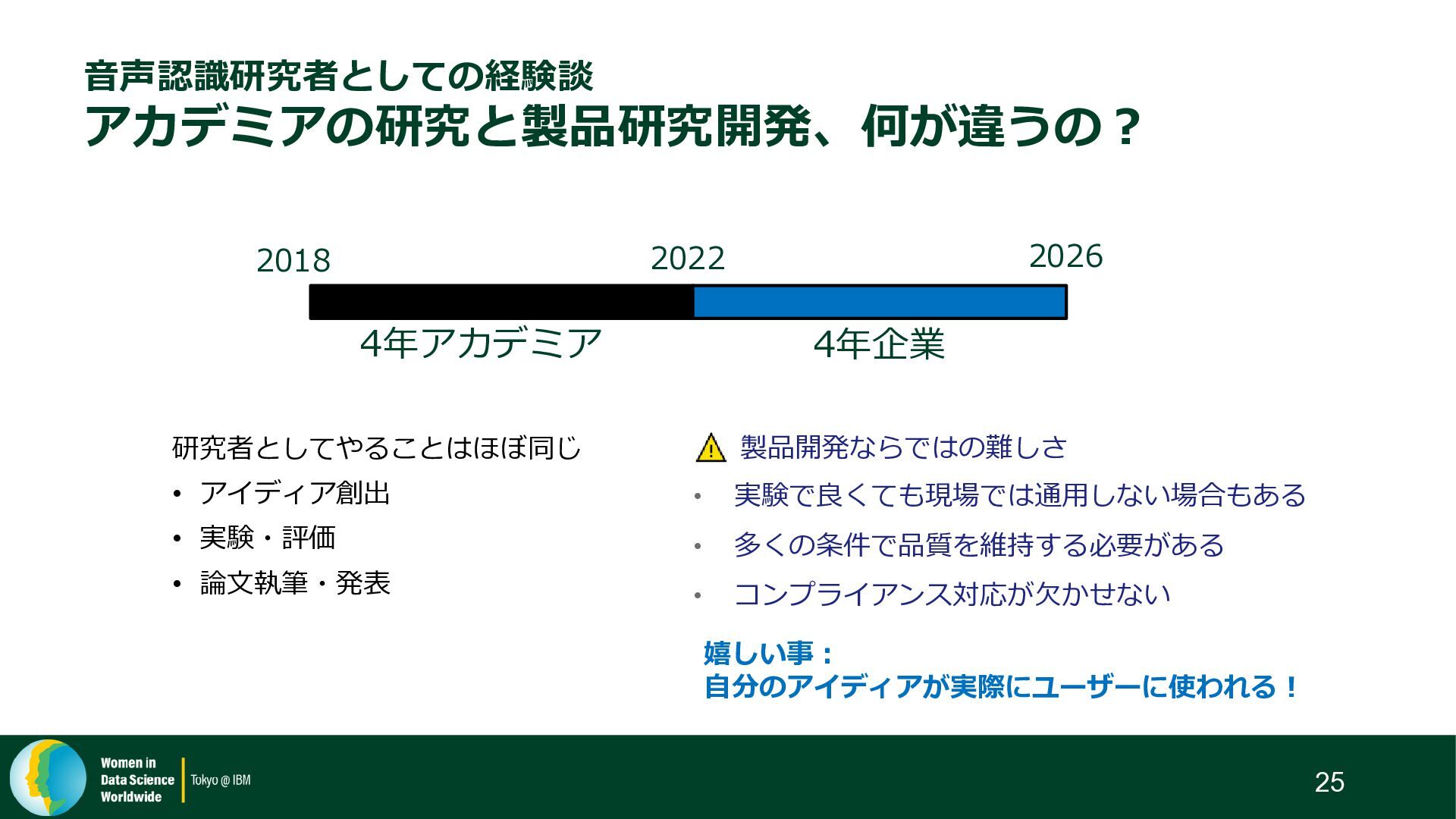{kind=link}
{kind=link}