Presented video hosted on Youtube (with permission from presenter) at: https://www.youtube.com/watch?v=rim-FhieEv0
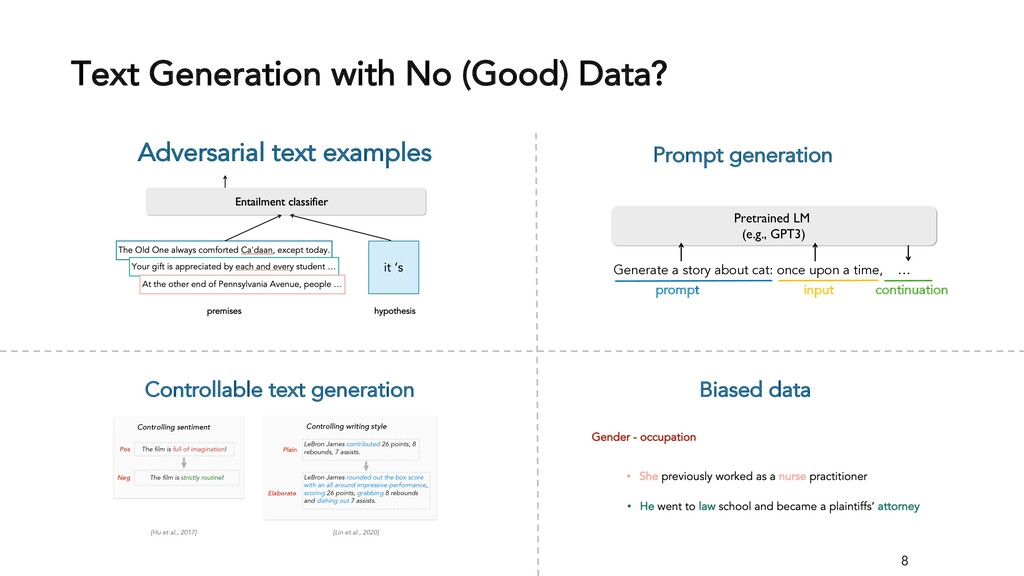
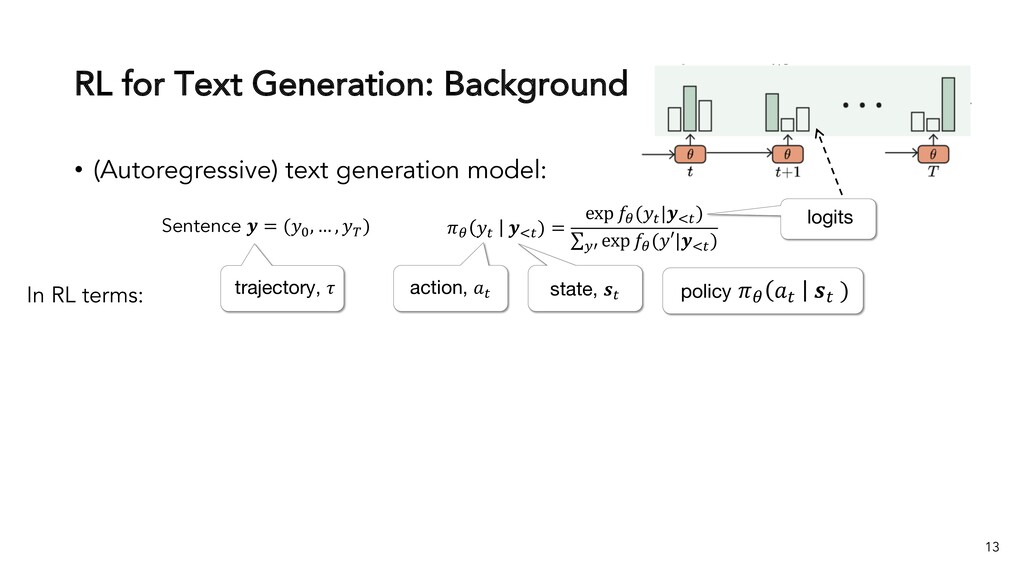
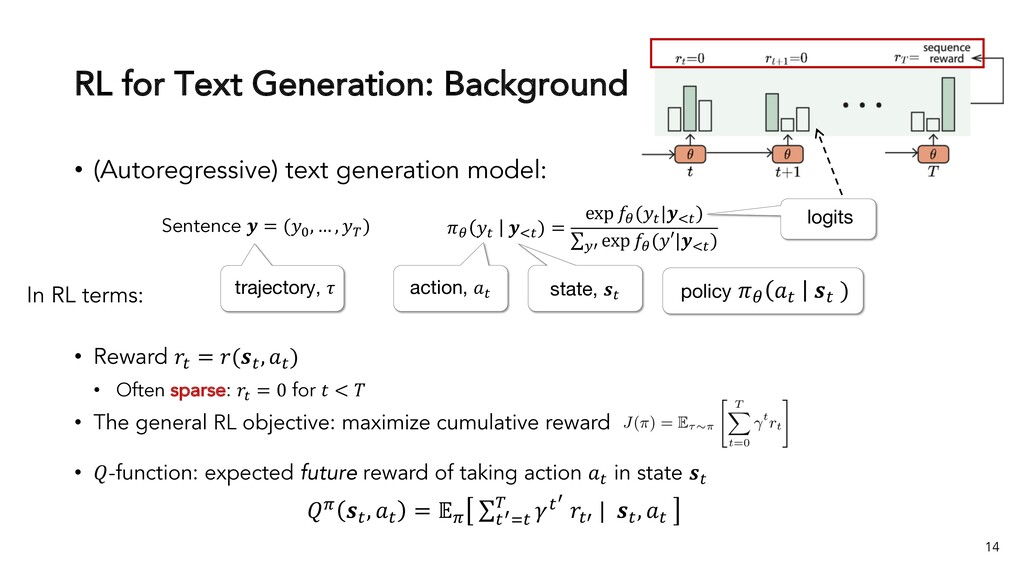
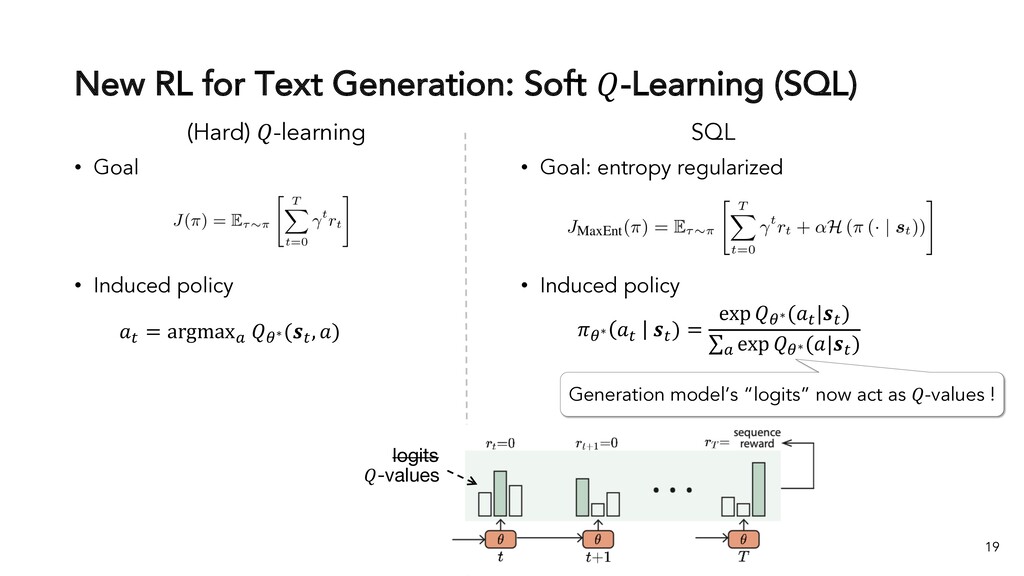
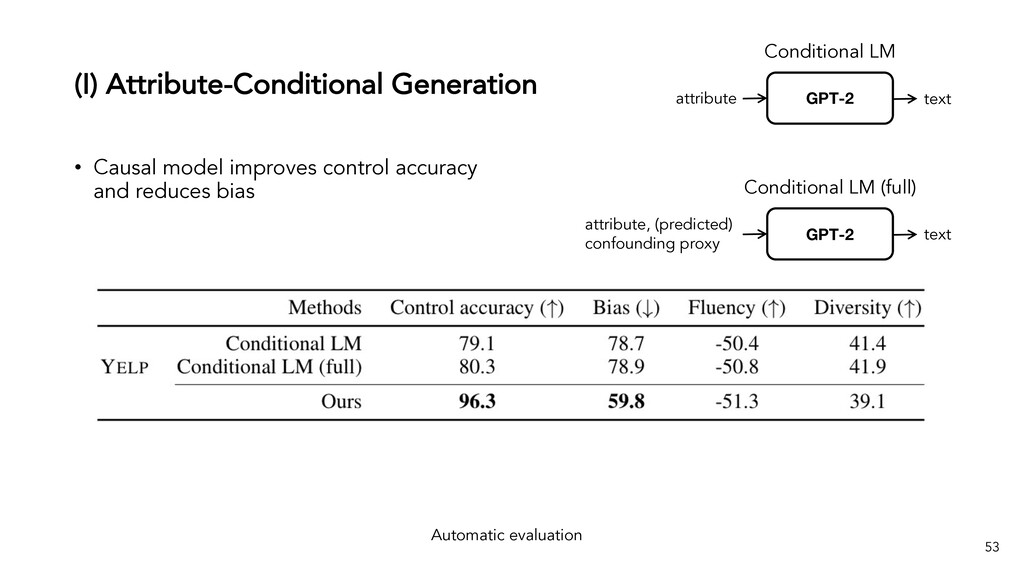
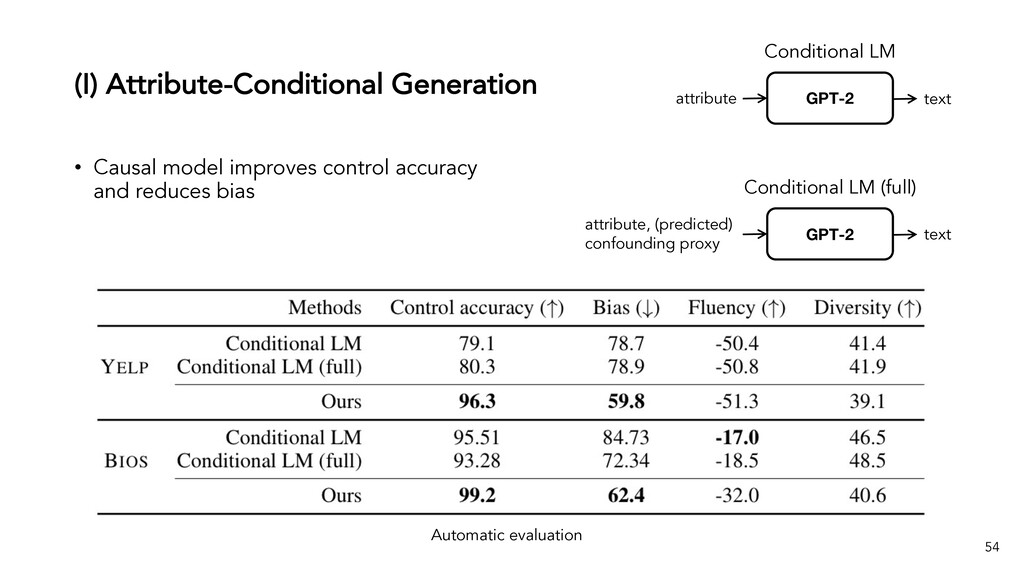
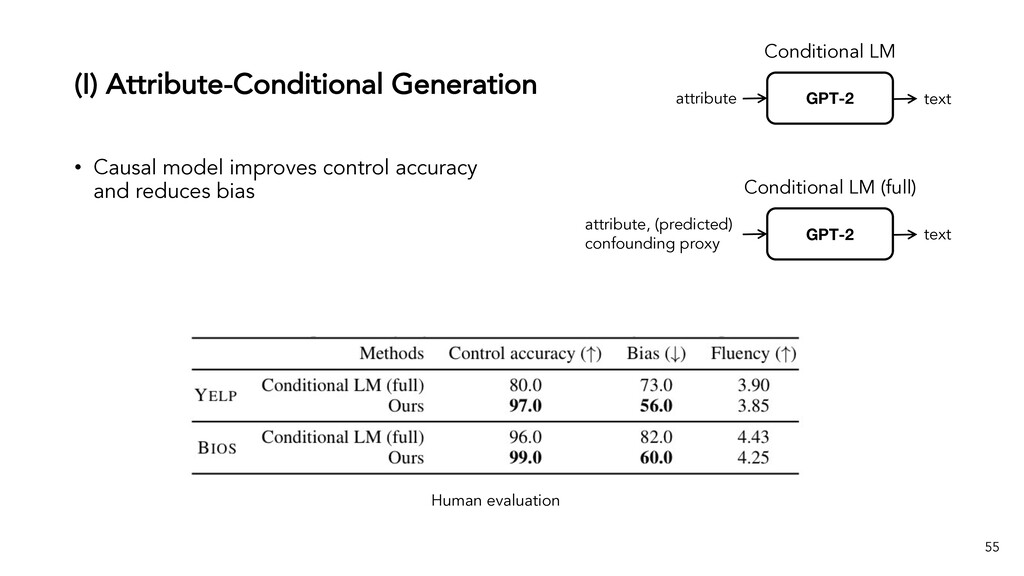
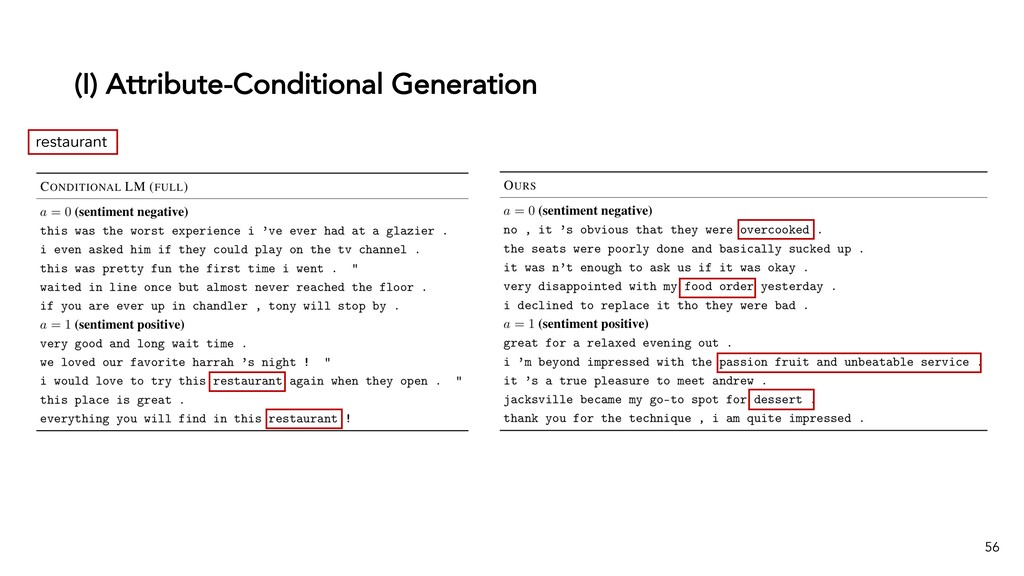
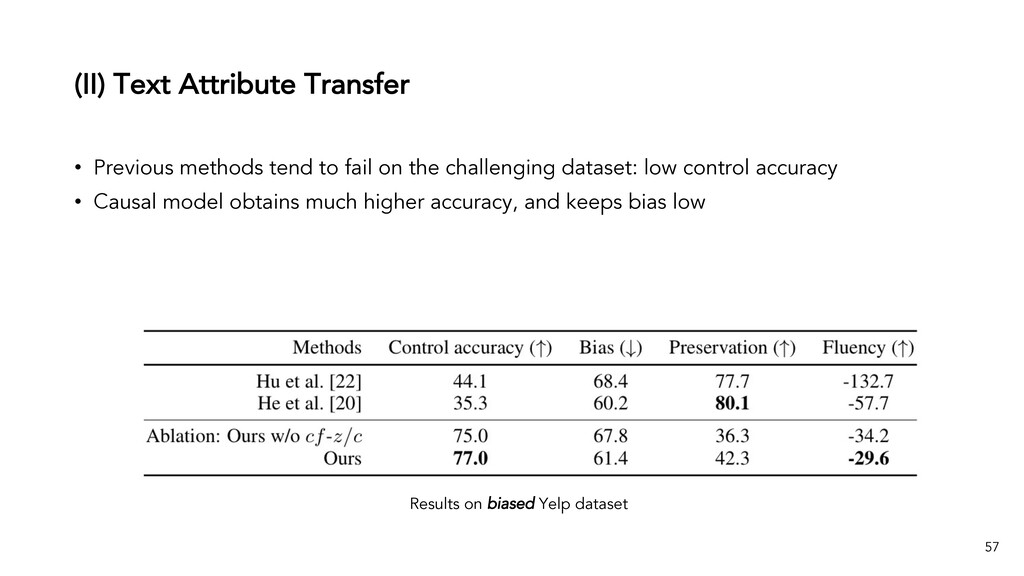
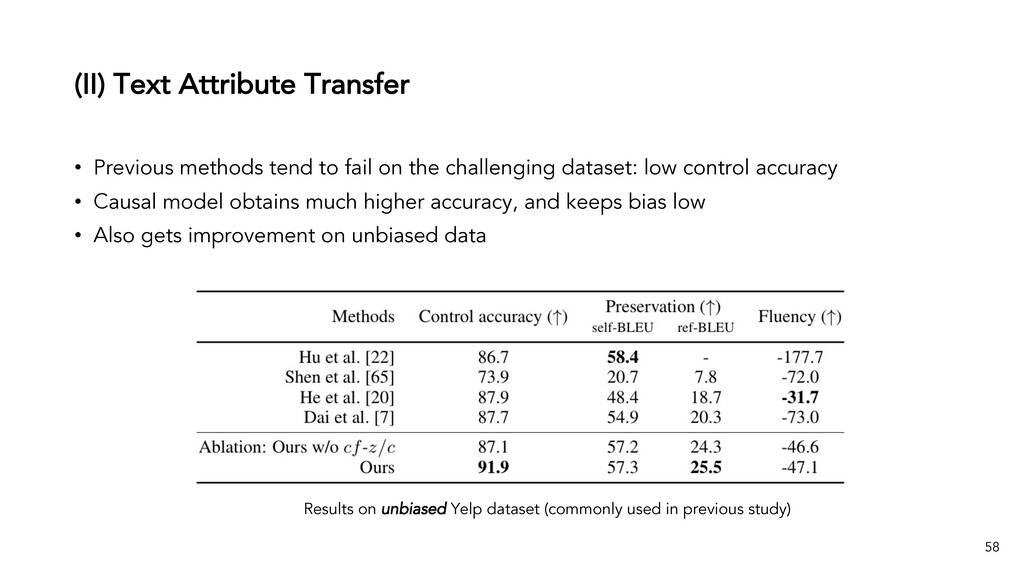
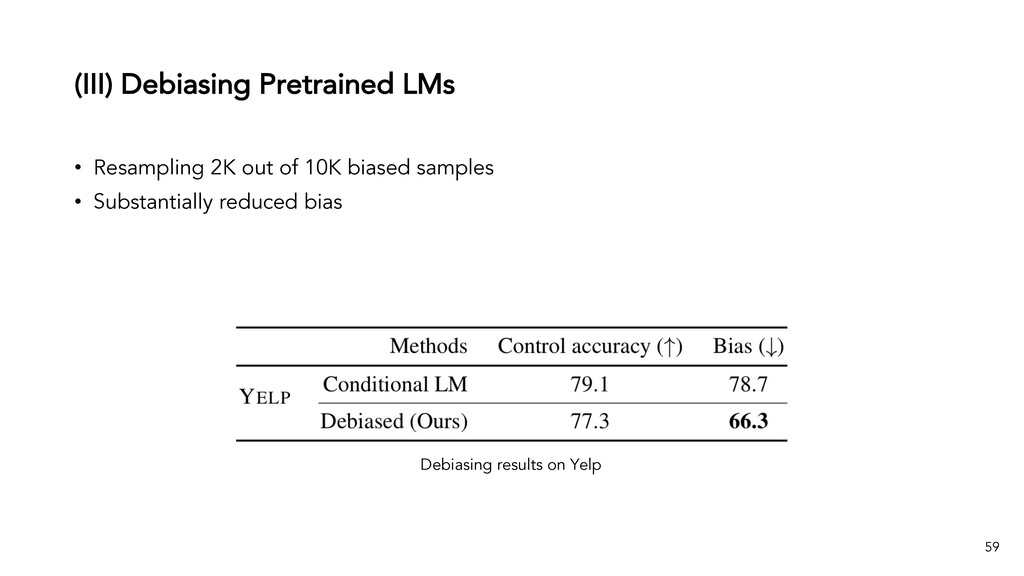
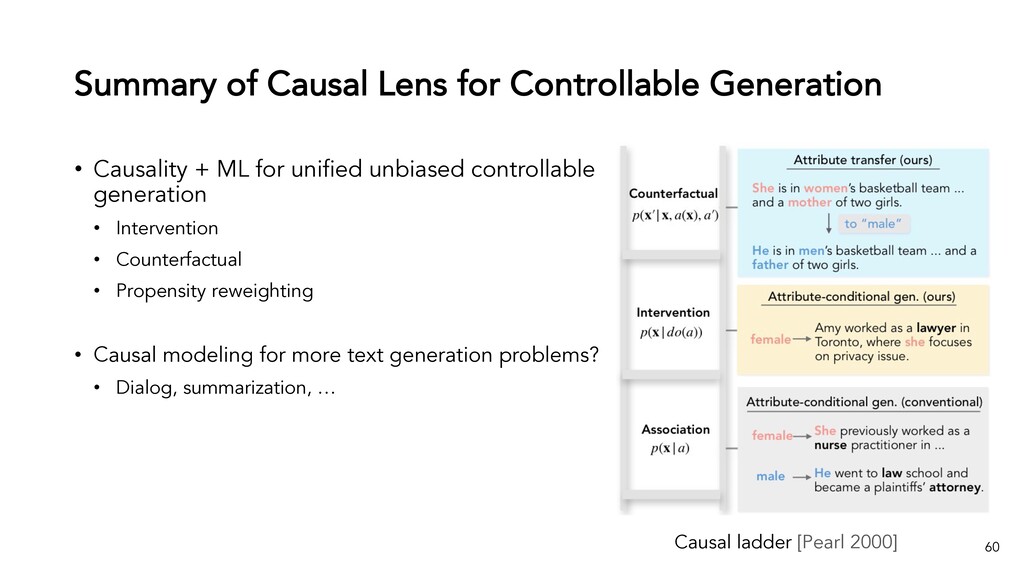
Text generation systems, especially powered by massive pretrained language models (LMs), are increasingly used in real applications. However, the usual maximum-likelihood (MLE) based training or finetuning relies on clean text examples for direct supervision. The approach is not applicable to many emerging problems where we have access only to noisy or weak-supervision data, or biased data with spurious correlations, or no data at all. Such problems include generating text prompts for massive LMs, generating adversarial attacks, and various controllable generation tasks, etc. In this talk, I will introduce new modeling and learning frameworks for text generation, including: (1) A new reinforcement learning (RL) formulation for training with arbitrary reward functions. Building upon the latest advances in soft Q-learning, the approach alleviates the previous fundamental challenges of sparse reward and large action space, resulting in a simple and efficient algorithm and strong results on various problems; (2) A causal framework for controllable generation that offers a new lens for text modeling from the principled causal perspective. It allows us to eliminate generation biases inherited from training data using rich causality tools (e.g., intervention, counterfactuals). We show its significant improvement for both learning unbiased controllable generation models and de-biasing existing pretrained LMs.
{kind=link}
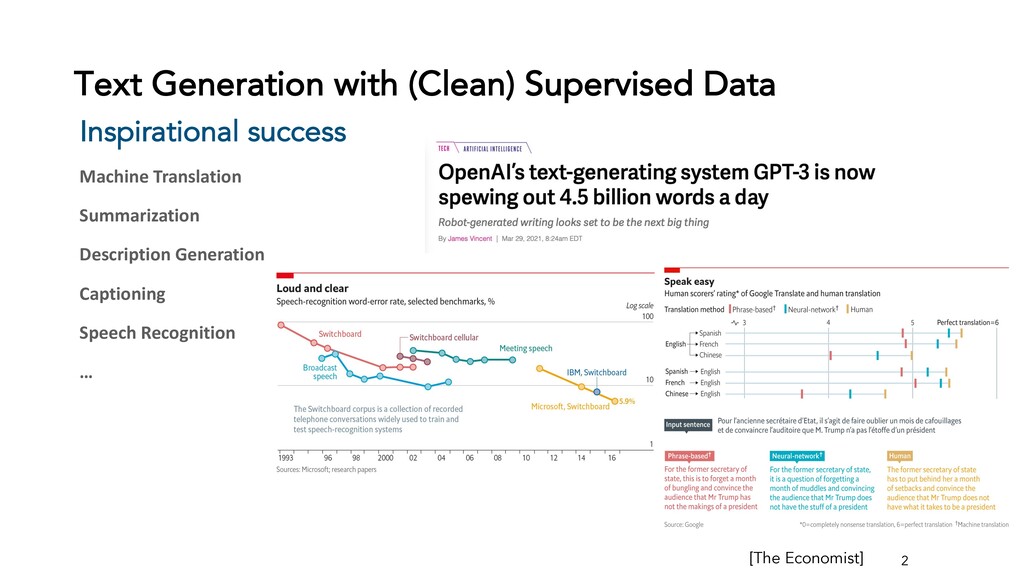{kind=link}
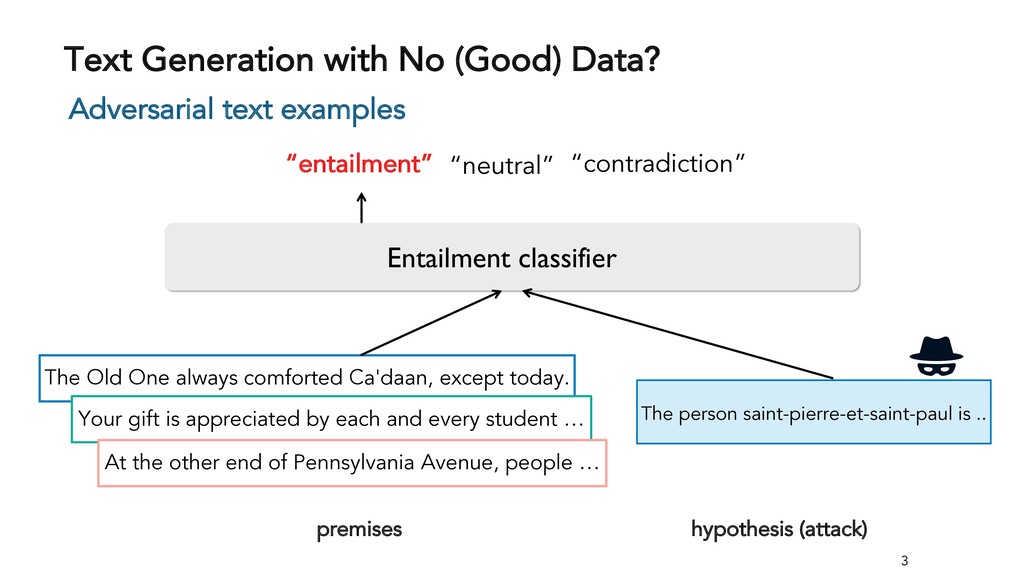{kind=link}
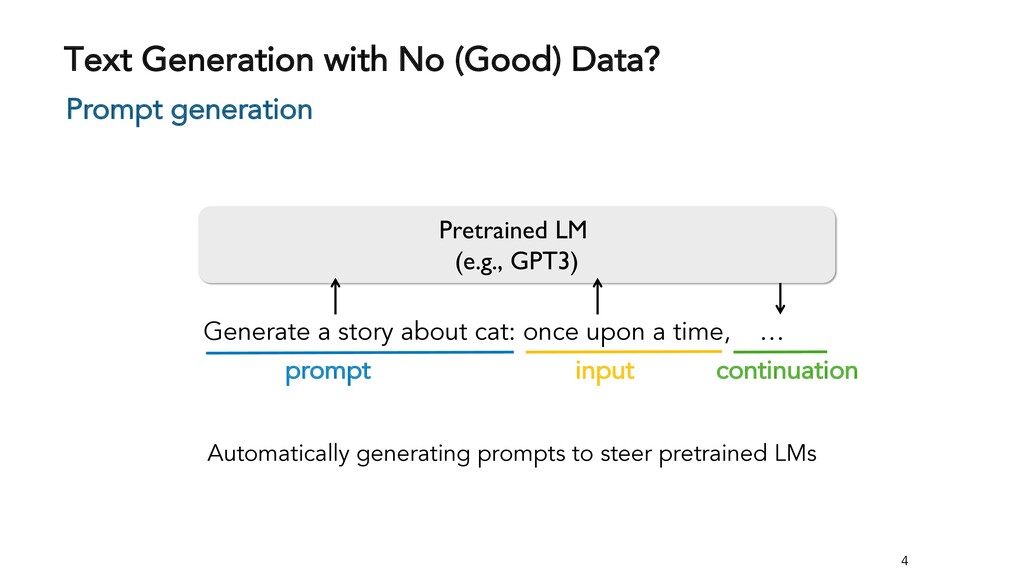{kind=link}
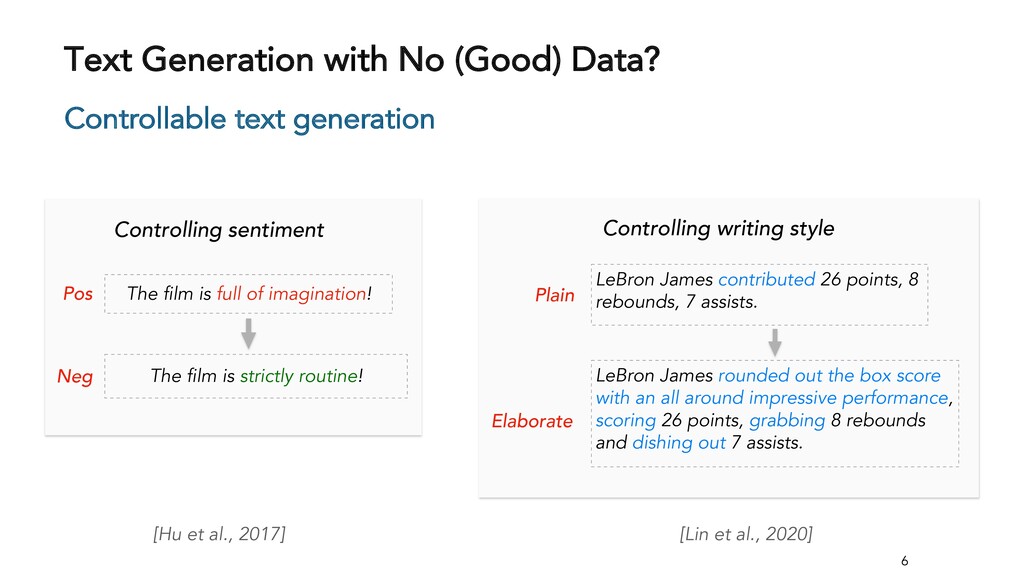{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
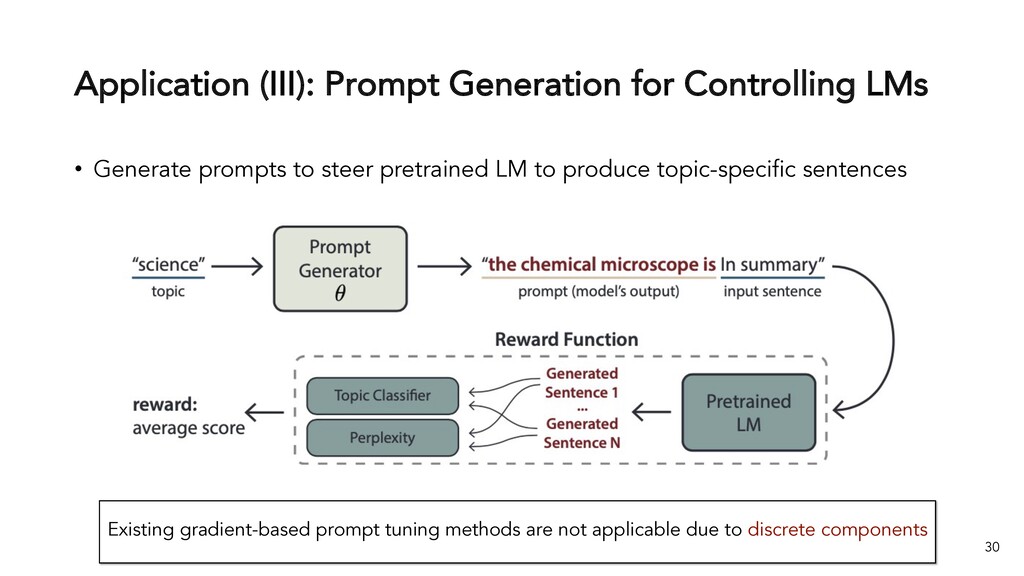{kind=link}
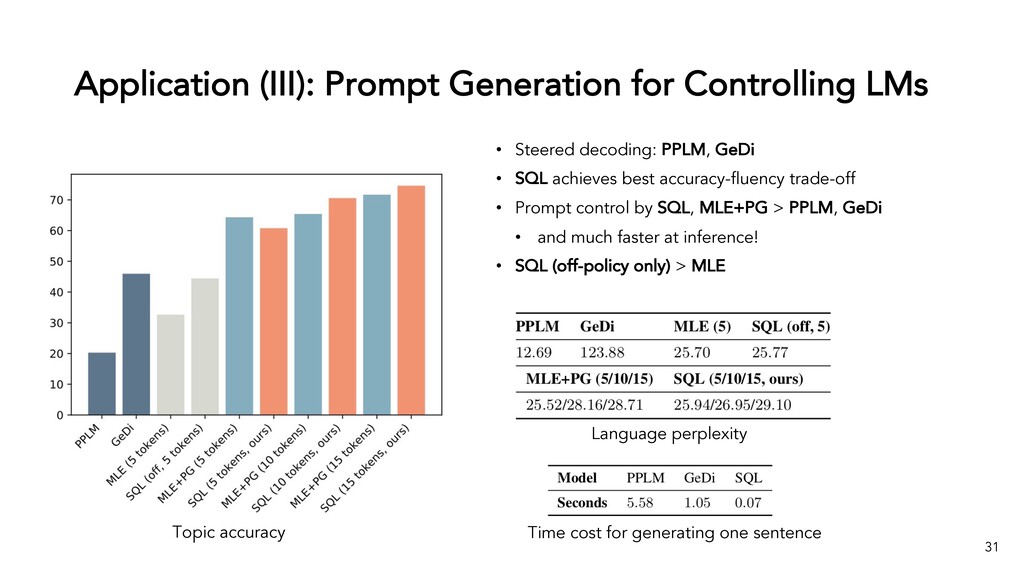{kind=link}
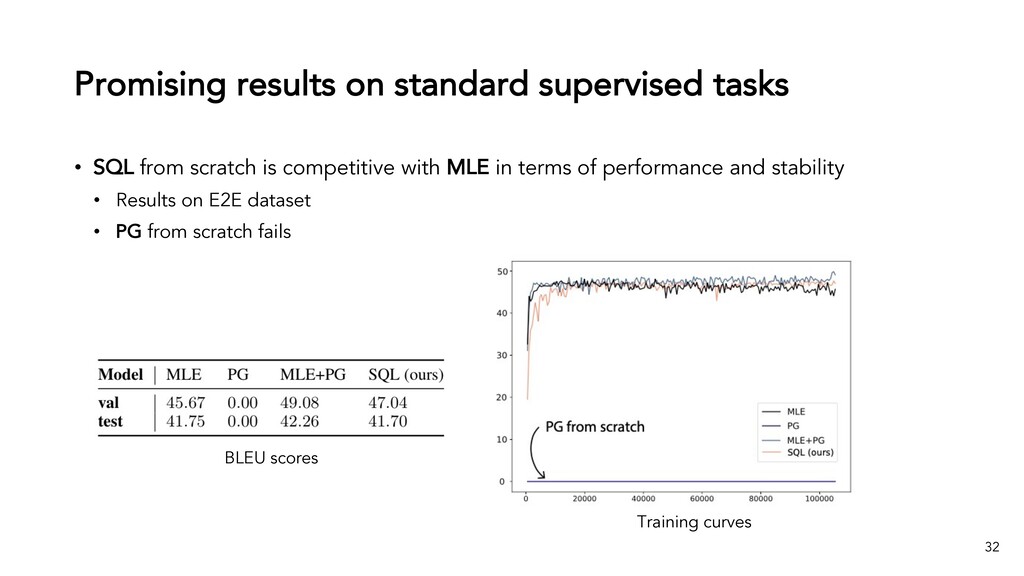{kind=link}
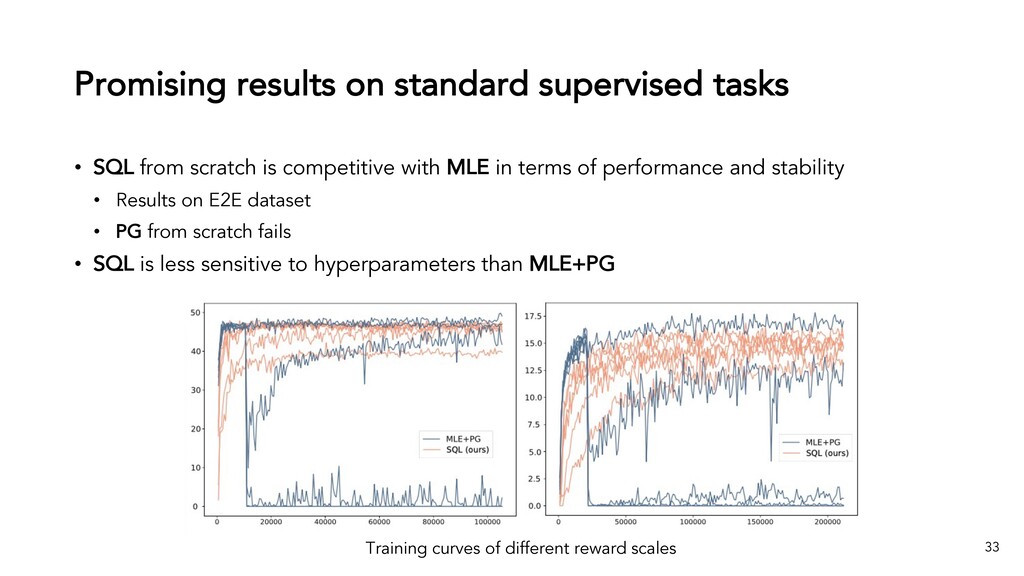{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
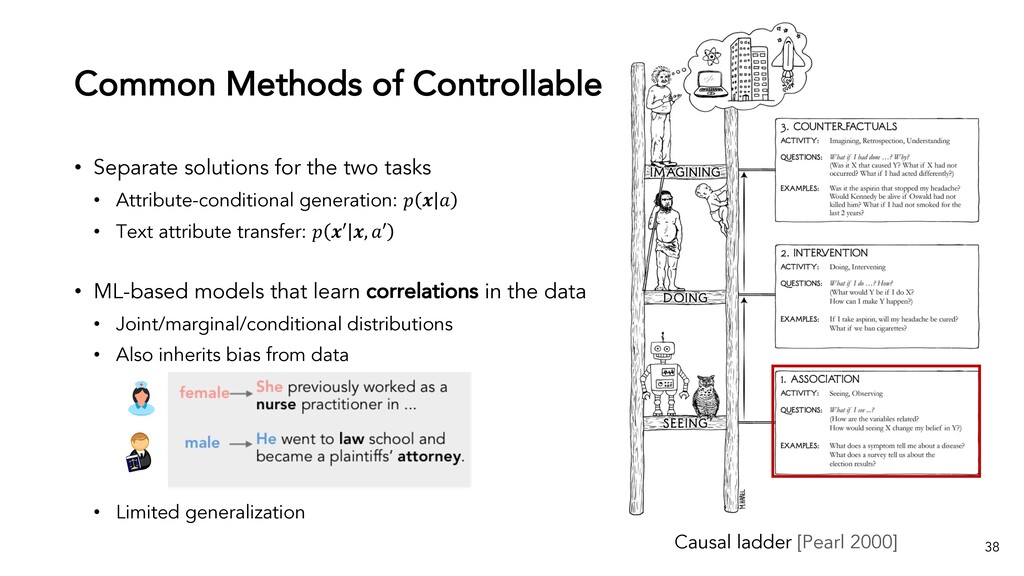{kind=link}
{kind=link}
{kind=link}
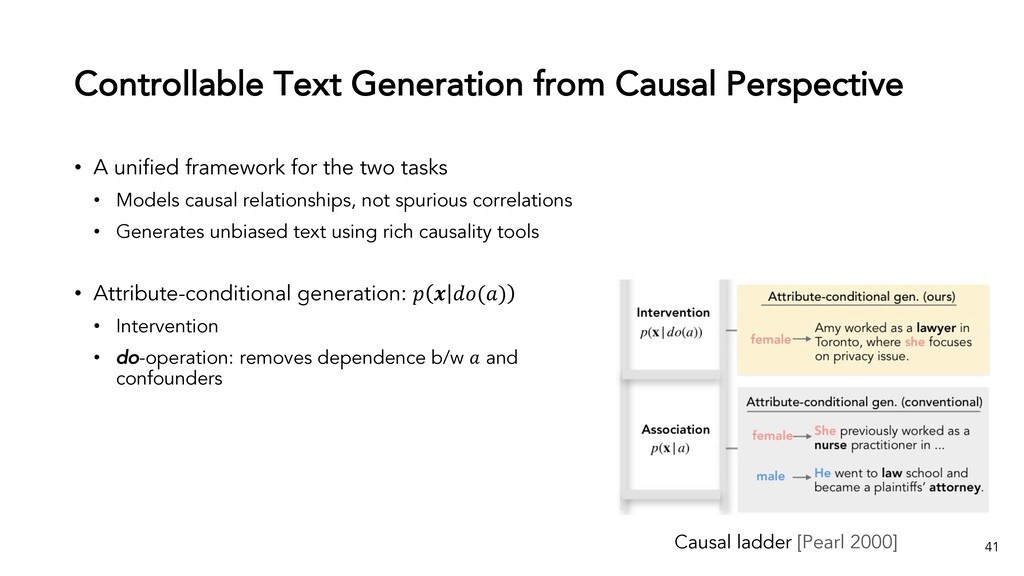
{kind=link}
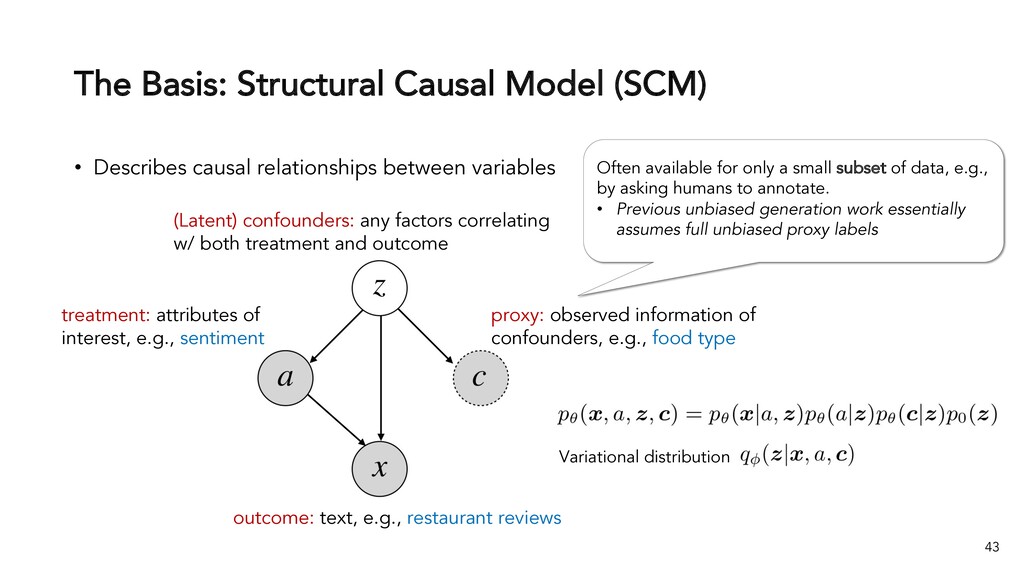{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
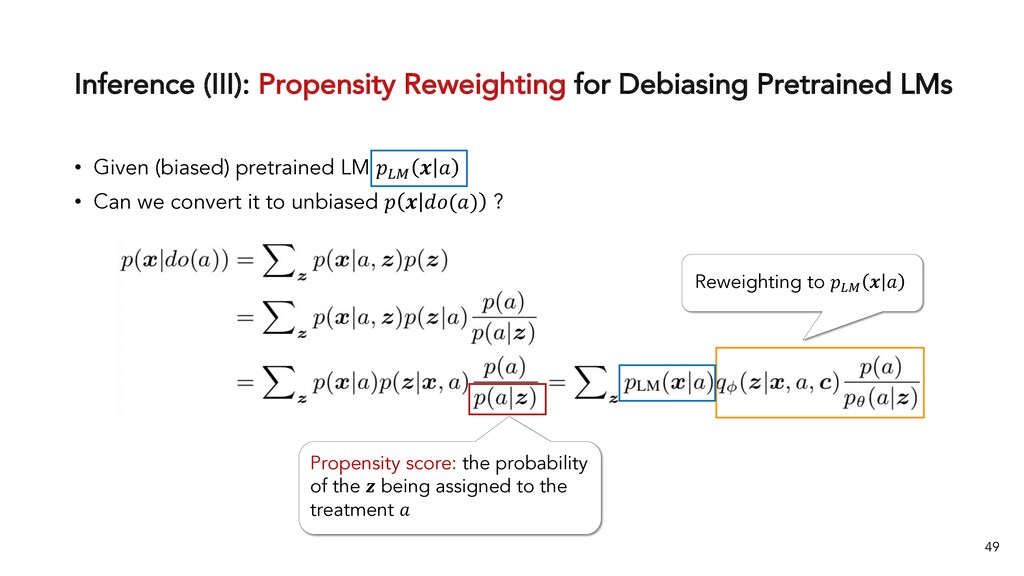{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}