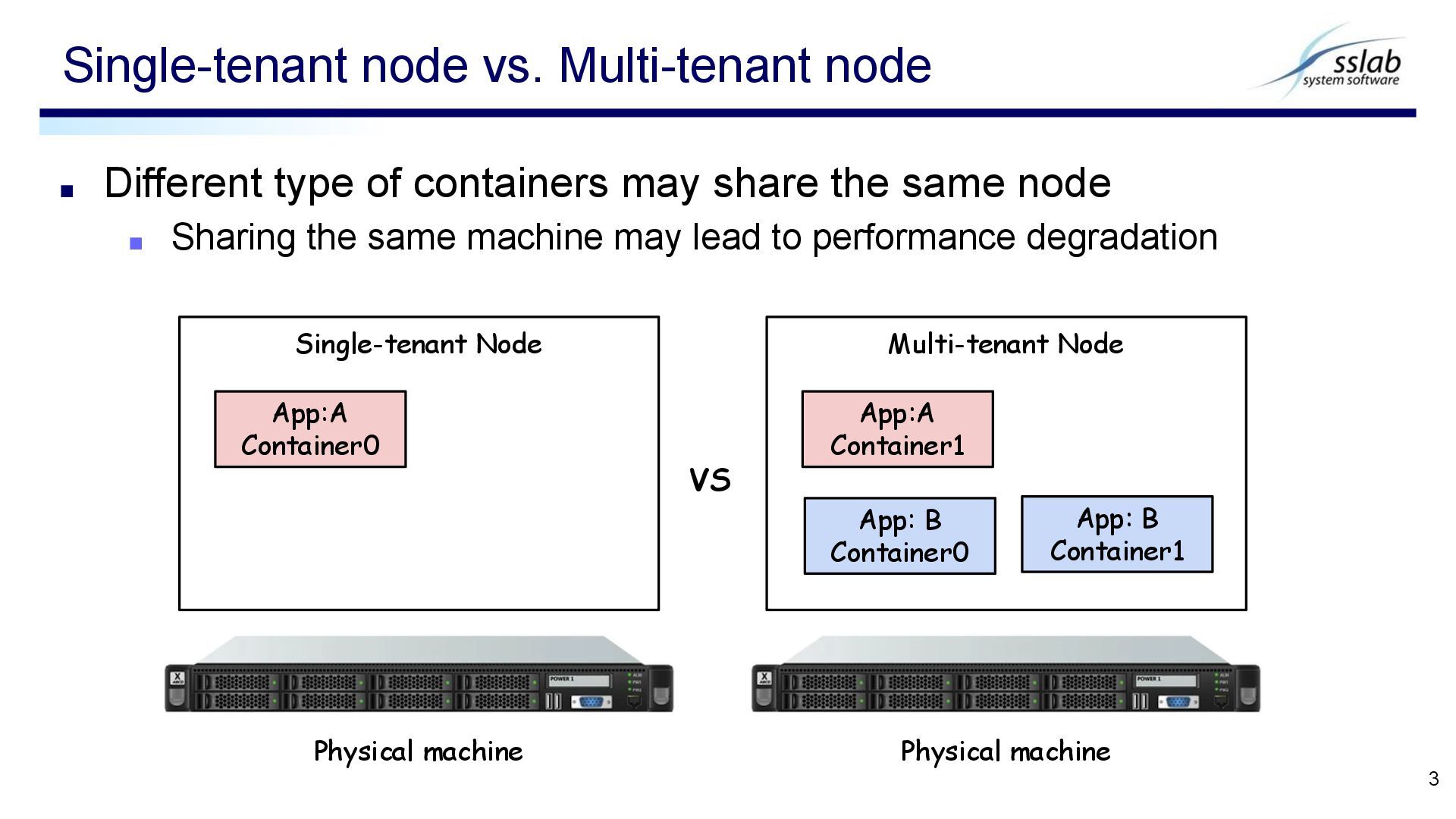
▪ Sharing the same machine may lead to performance degradation Single-tenant node vs. Multi-tenant node 3 Single-tenant Node App:A Container0 Multi-tenant Node App:A Container1 App: B Container0 App: B Container1 VS Physical machine Physical machine
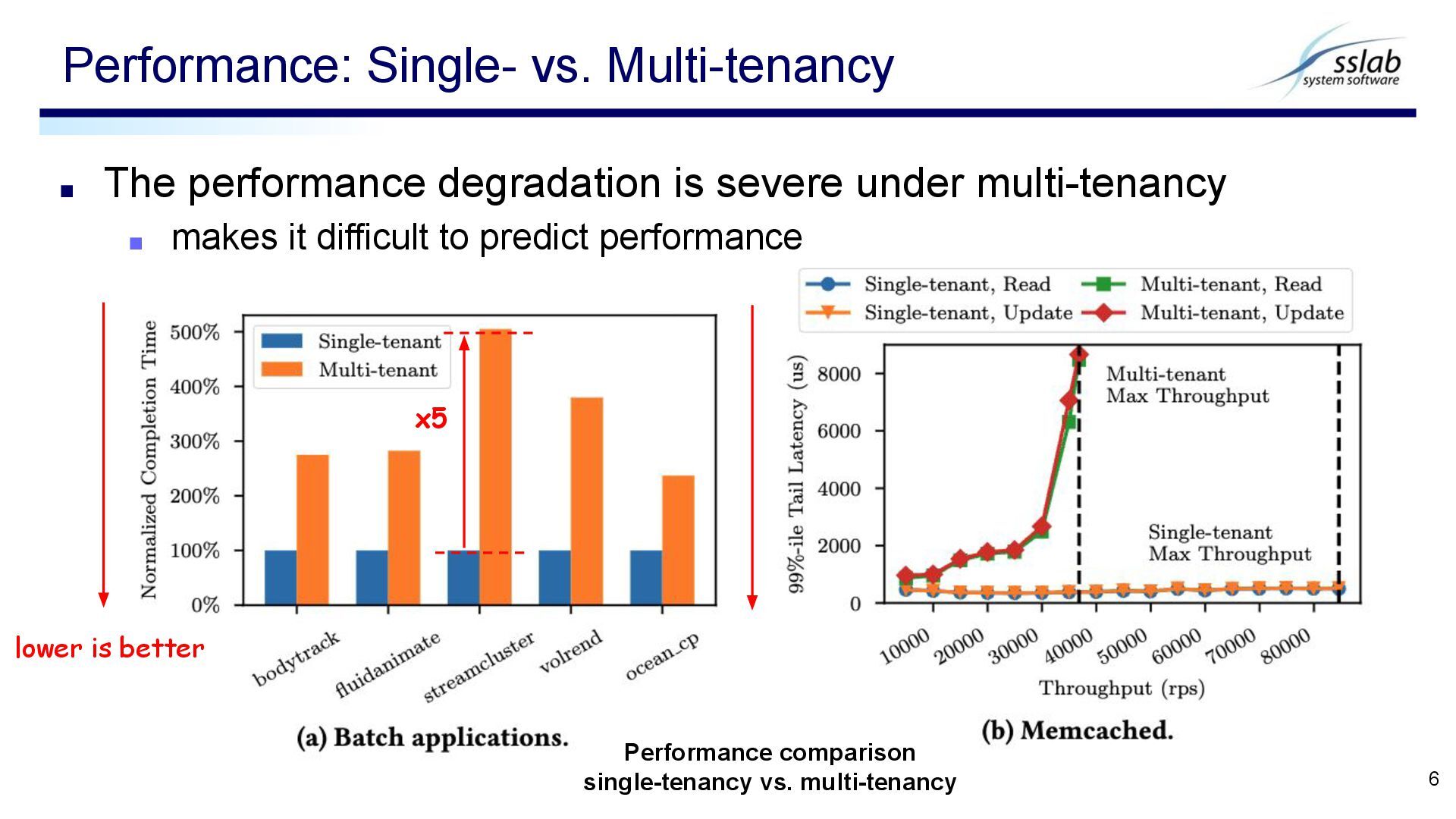
it difficult to predict performance Performance: Single- vs. Multi-tenancy 6 lower is better x5 Performance comparison single-tenancy vs. multi-tenancy
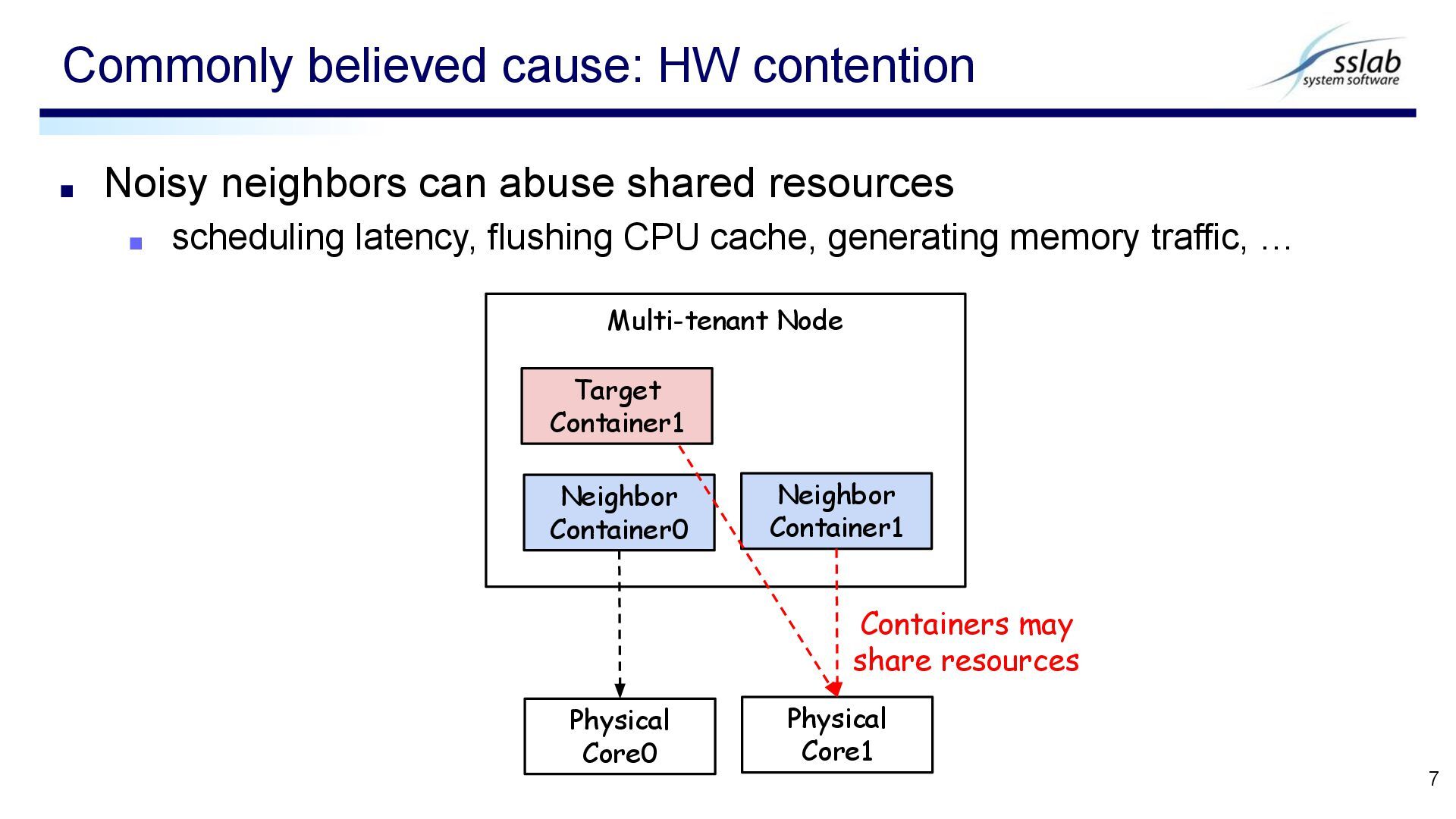
adjusting the degree of contention ▪ Workloads ▪ Prepare 4 options in neighboring application Preliminary experiment2: Impact of HW contention 8 Burstable: container is allowed to use more CPU when idle CPU exists specified via k8s YAML
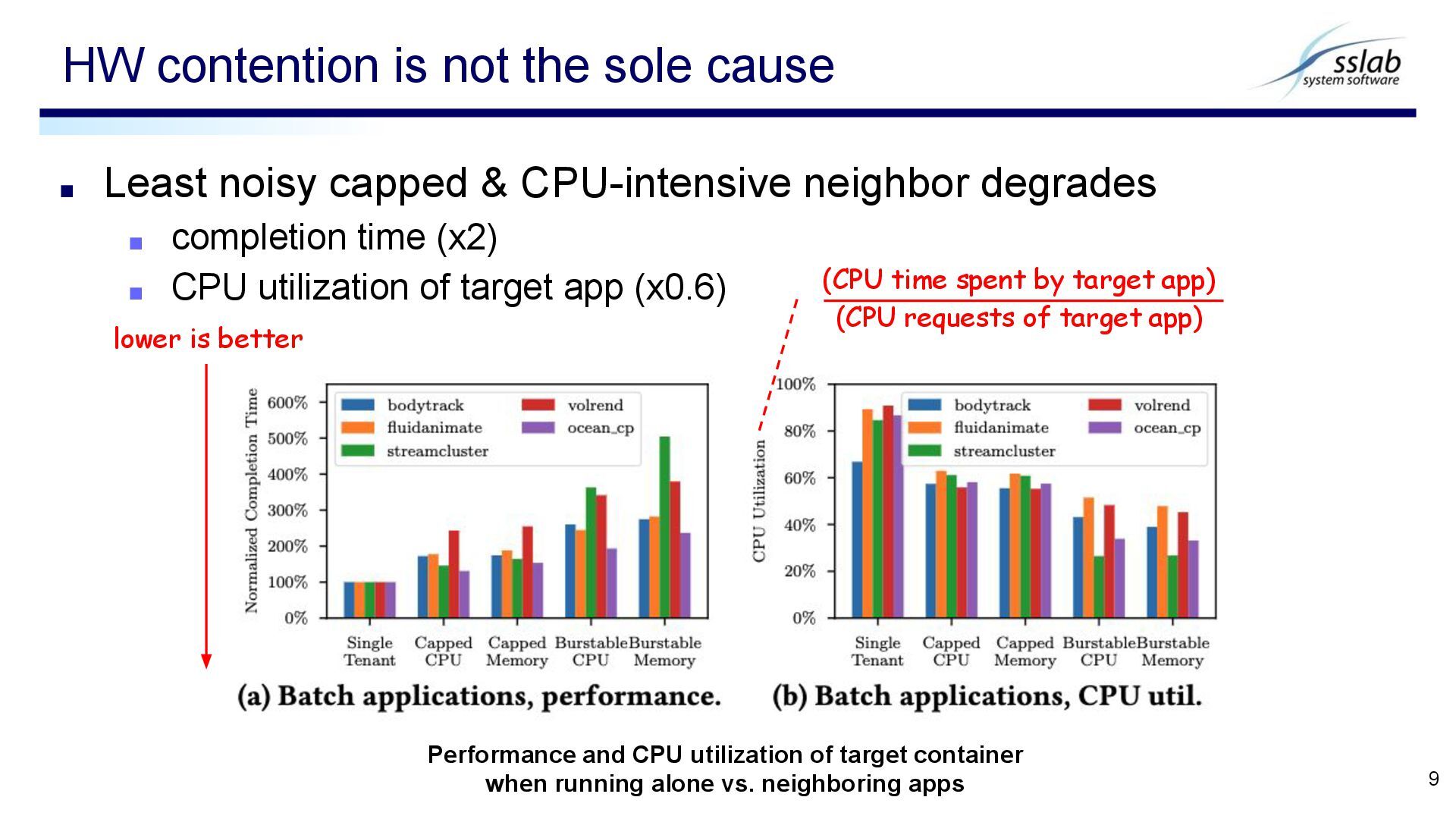
time (x2) ▪ CPU utilization of target app (x0.6) HW contention is not the sole cause 9 lower is better Performance and CPU utilization of target container when running alone vs. neighboring apps (CPU time spent by target app) (CPU requests of target app)
over-committed in nodes ▪ Capped neighbors cannot use more CPU than they reserve Why the target’s CPU usage degrades? 10 Available CPU (24 core) Target App (R core, Capped) Neighbor App (22 - R core, Capped) System (2 core) Not fully utilized!!
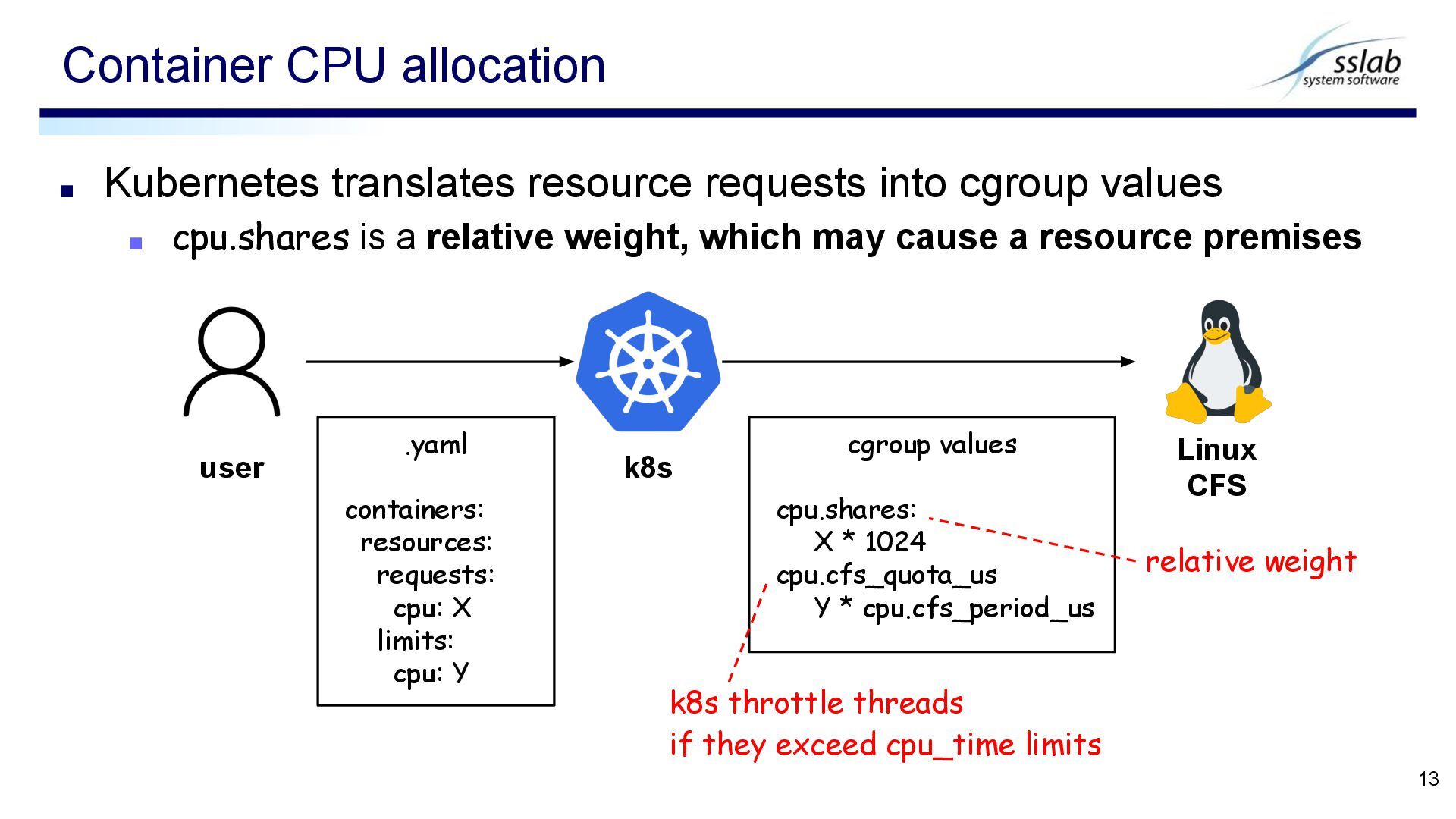
is a relative weight, which may cause a resource premises Container CPU allocation 13 user k8s .yaml containers: resources: requests: cpu: X limits: cpu: Y cgroup values cpu.shares: X * 1024 cpu.cfs_quota_us Y * cpu.cfs_period_us Linux CFS relative weight k8s throttle threads if they exceed cpu_time limits
▪ 1. Forced Runqueue Sharing ◆ One container may be forced to share the runqueue with neighboring containers ▪ 2. Phantom CPU Time ◆ Kubernetes throttle the proceeding threads after using up reserved CPU ◆ However, target applications fail to utilize reserved CPU because of insufficient threads Root cause of performance degradation 14
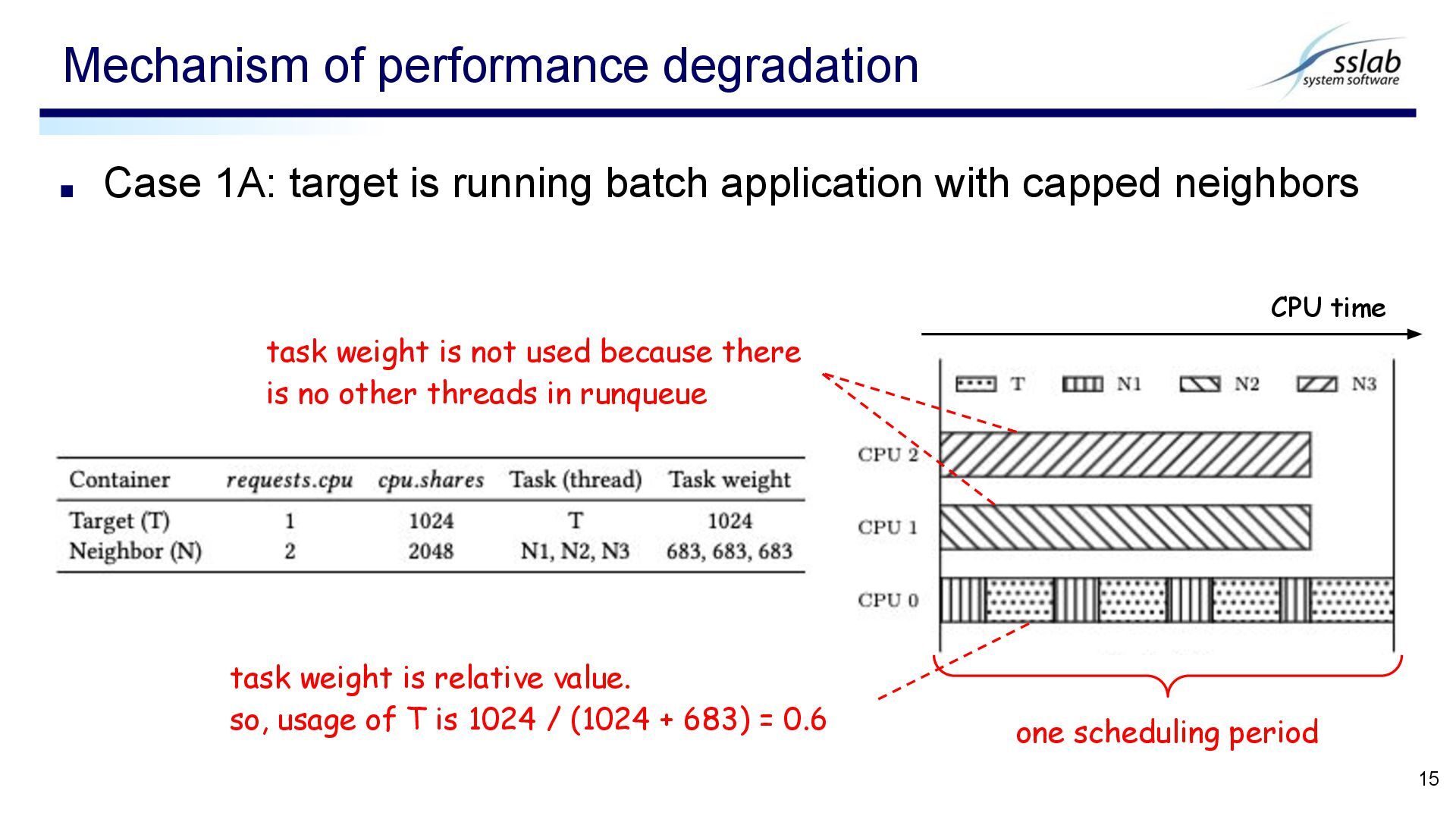
neighbors Mechanism of performance degradation 15 one scheduling period task weight is not used because there is no other threads in runqueue task weight is relative value. so, usage of T is 1024 / (1024 + 683) = 0.6 CPU time
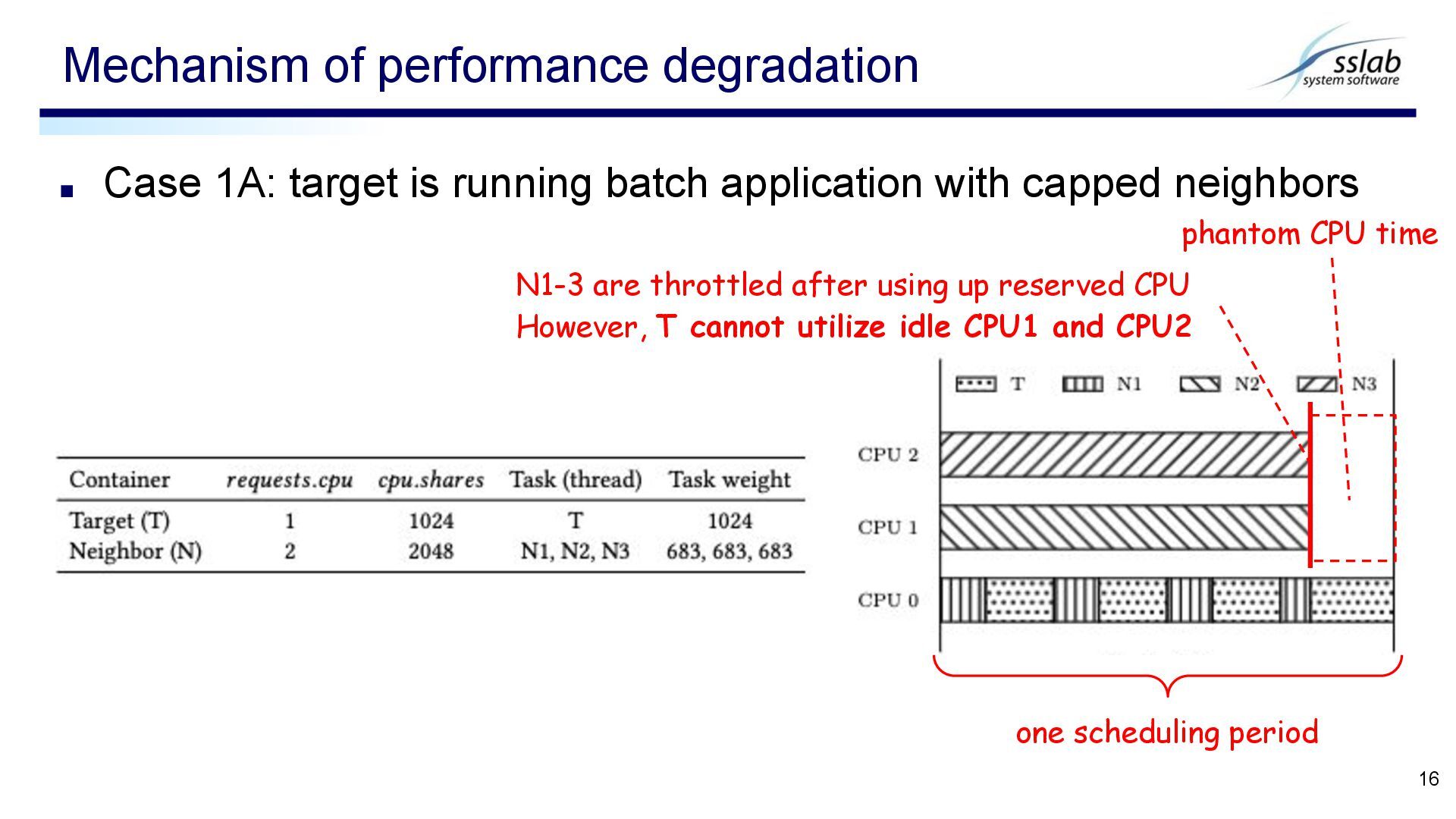
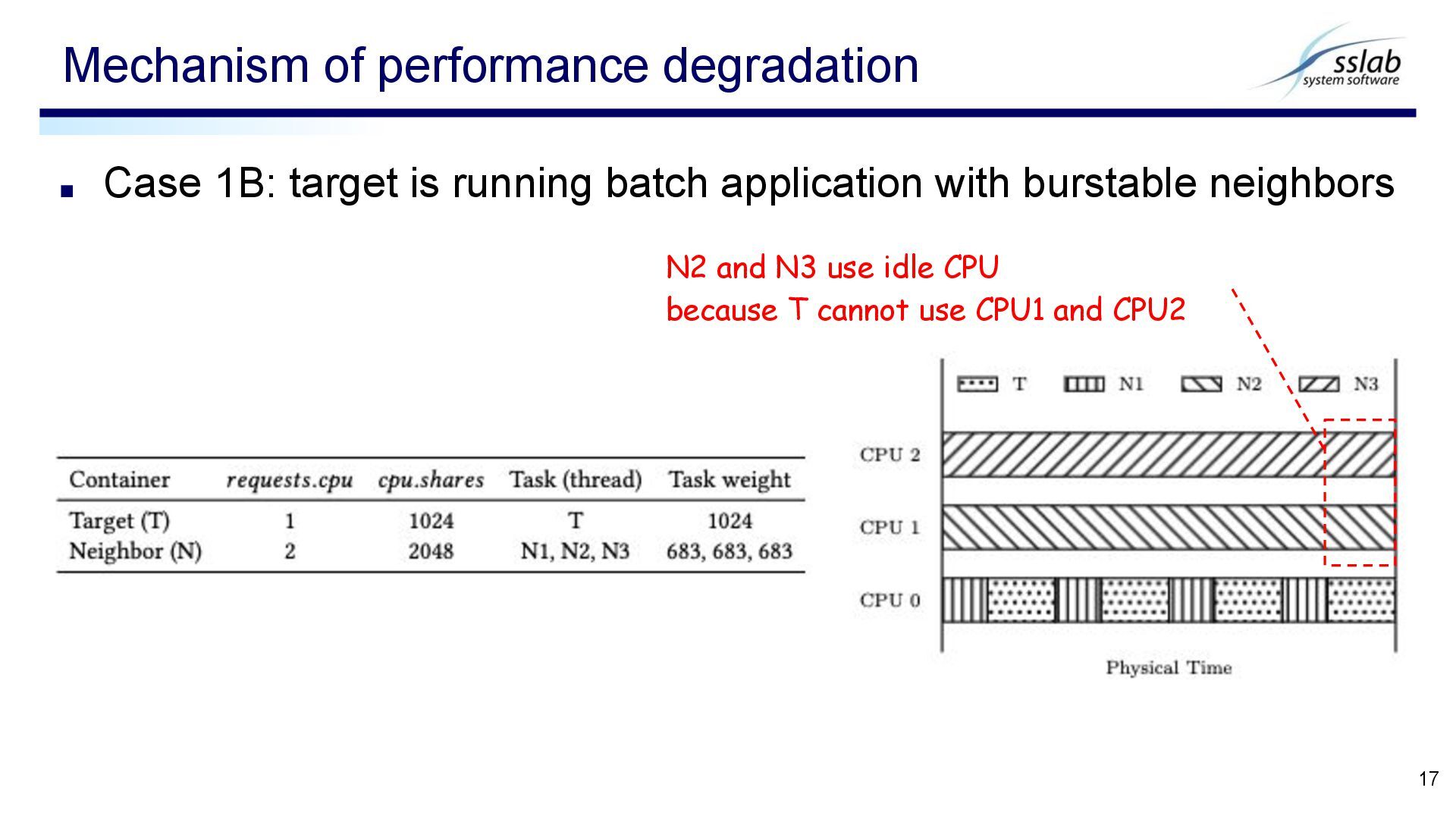
neighbors Mechanism of performance degradation 16 one scheduling period N1-3 are throttled after using up reserved CPU However, T cannot utilize idle CPU1 and CPU2 phantom CPU time
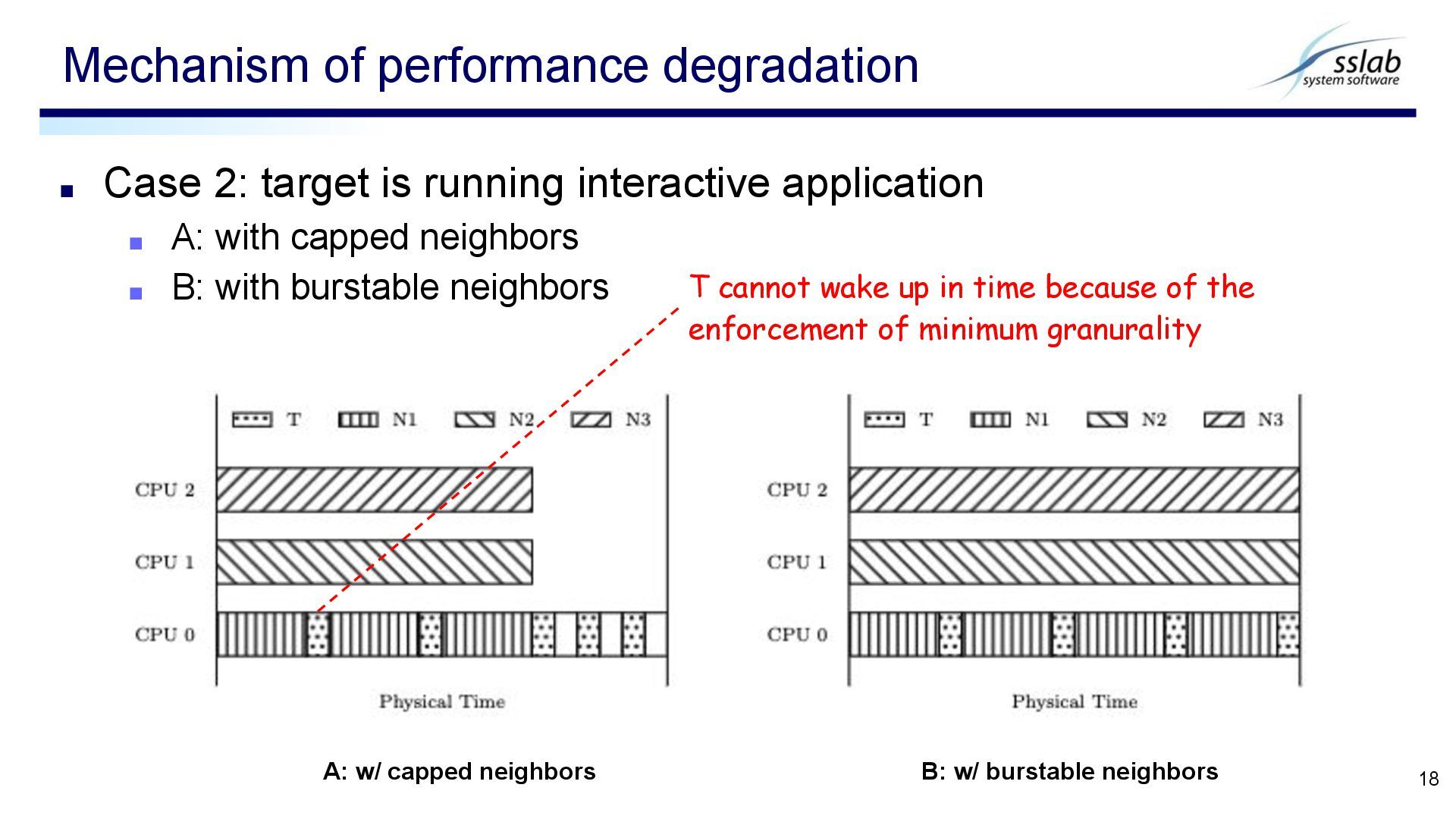
with capped neighbors ▪ B: with burstable neighbors Mechanism of performance degradation 18 A: w/ capped neighbors B: w/ burstable neighbors T cannot wake up in time because of the enforcement of minimum granurality
significantly improves performance in multi-tenant nodes ▪ Solution ▪ Set CPU affinity for individual containers ▪ Enforce CPU reservation by using cpuset.cpus of Linux cgroup ◆ e.g: cpuset.cpus=0-1,3: only CPU0, CPU1, CPU3 are available ▪ Implementation ▪ Build rKube prototype based on kubernetes v1.17.3 ▪ Add new field named “policy” to the kubernetes templete ◆ standard policy : use cpu.shares ◆ strict policy (rKube) : use cpuset.cpus Makeshift solution: rKube 19
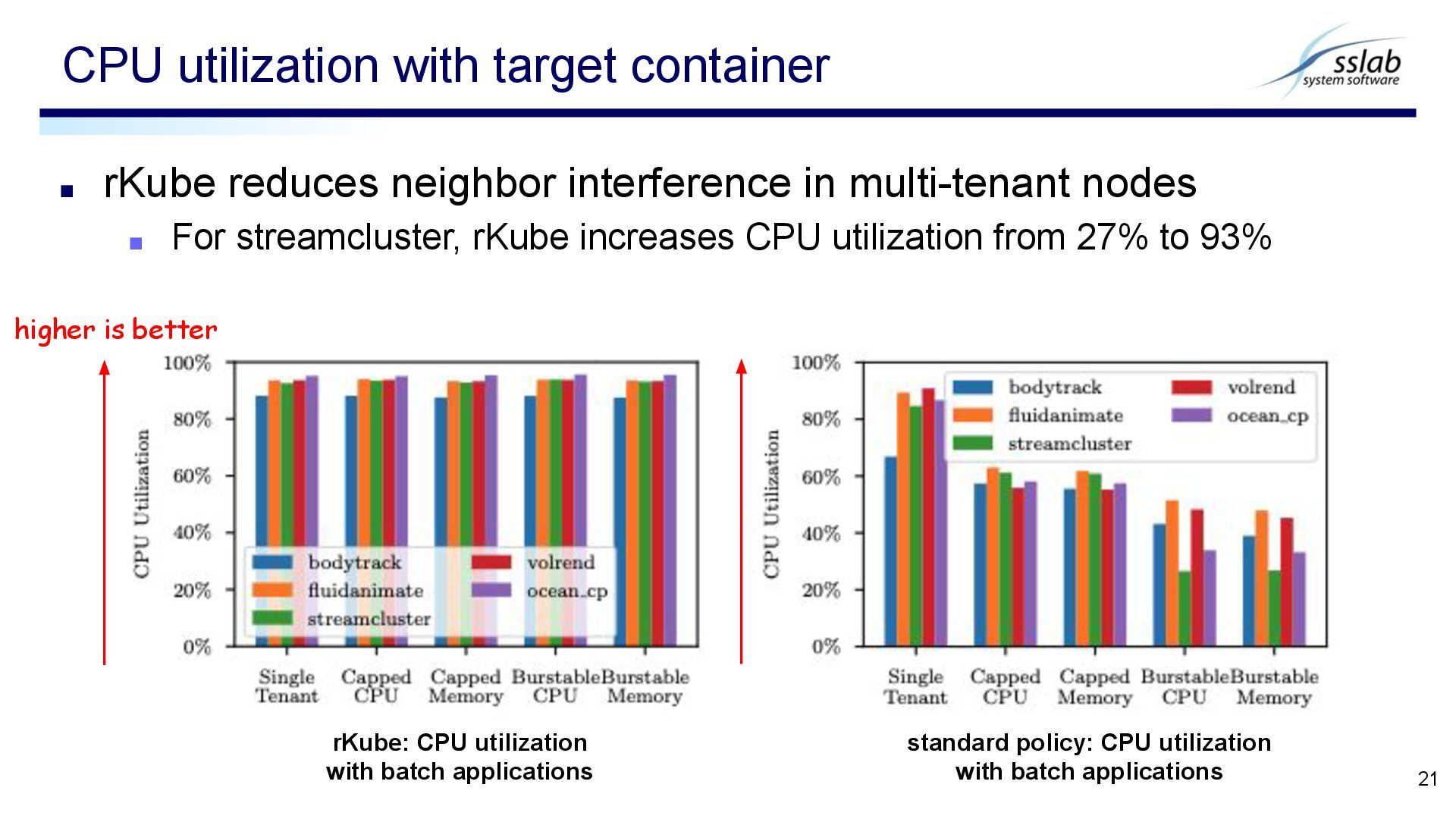
streamcluster, rKube increases CPU utilization from 27% to 93% CPU utilization with target container 21 rKube: CPU utilization with batch applications standard policy: CPU utilization with batch applications higher is better
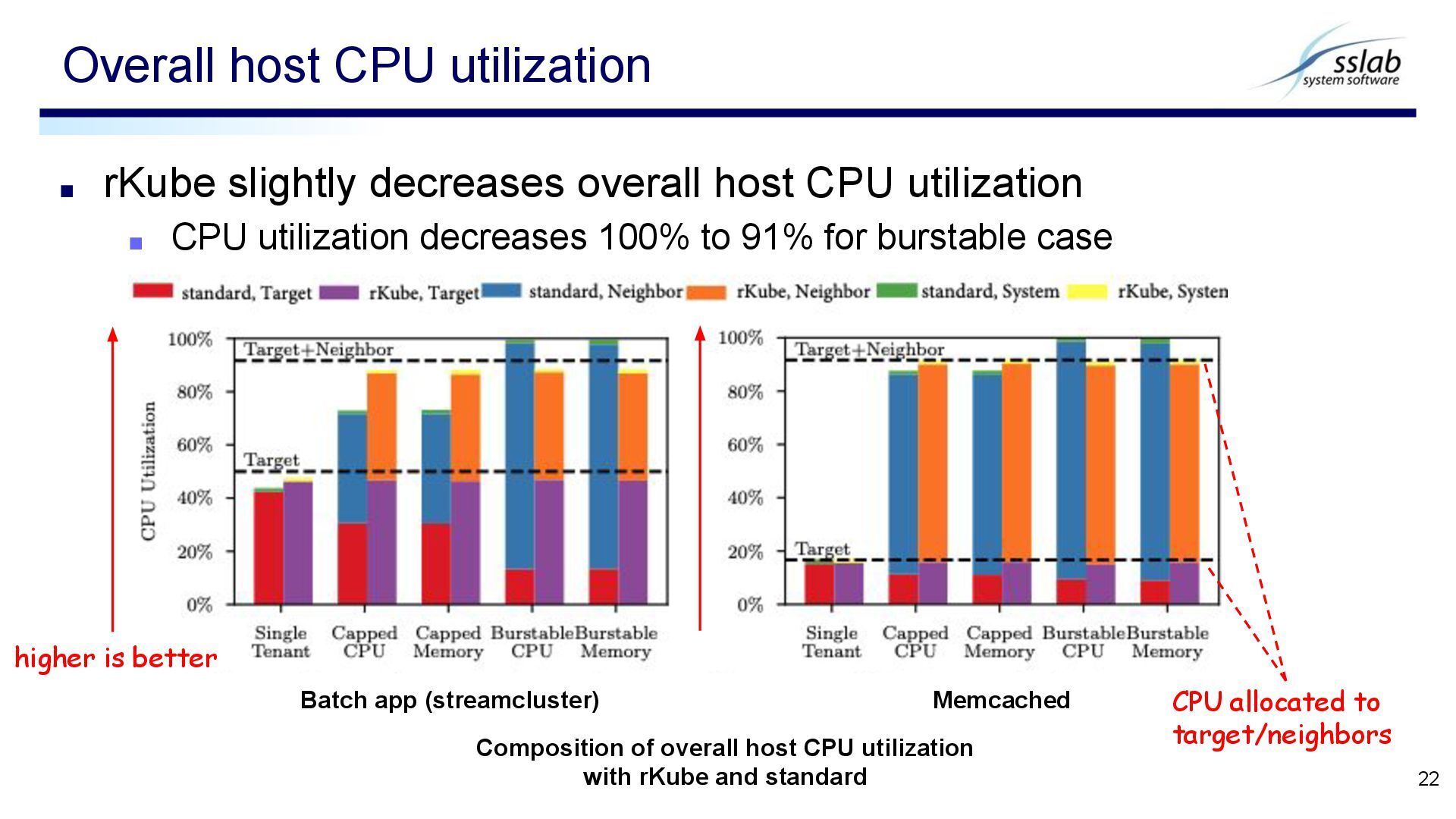
utilization decreases 100% to 91% for burstable case Overall host CPU utilization 22 higher is better Batch app (streamcluster) Memcached Composition of overall host CPU utilization with rKube and standard CPU allocated to target/neighbors
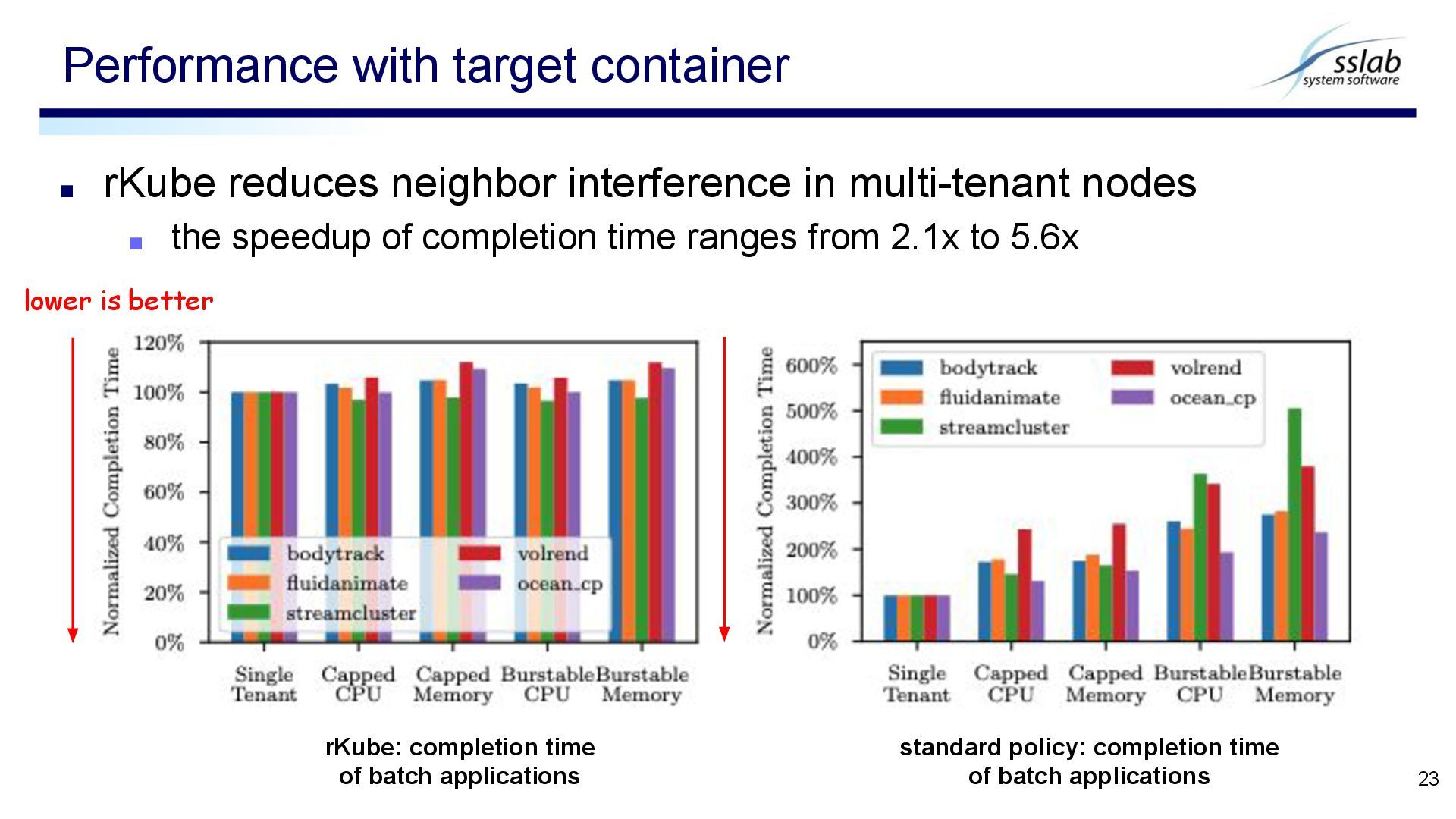
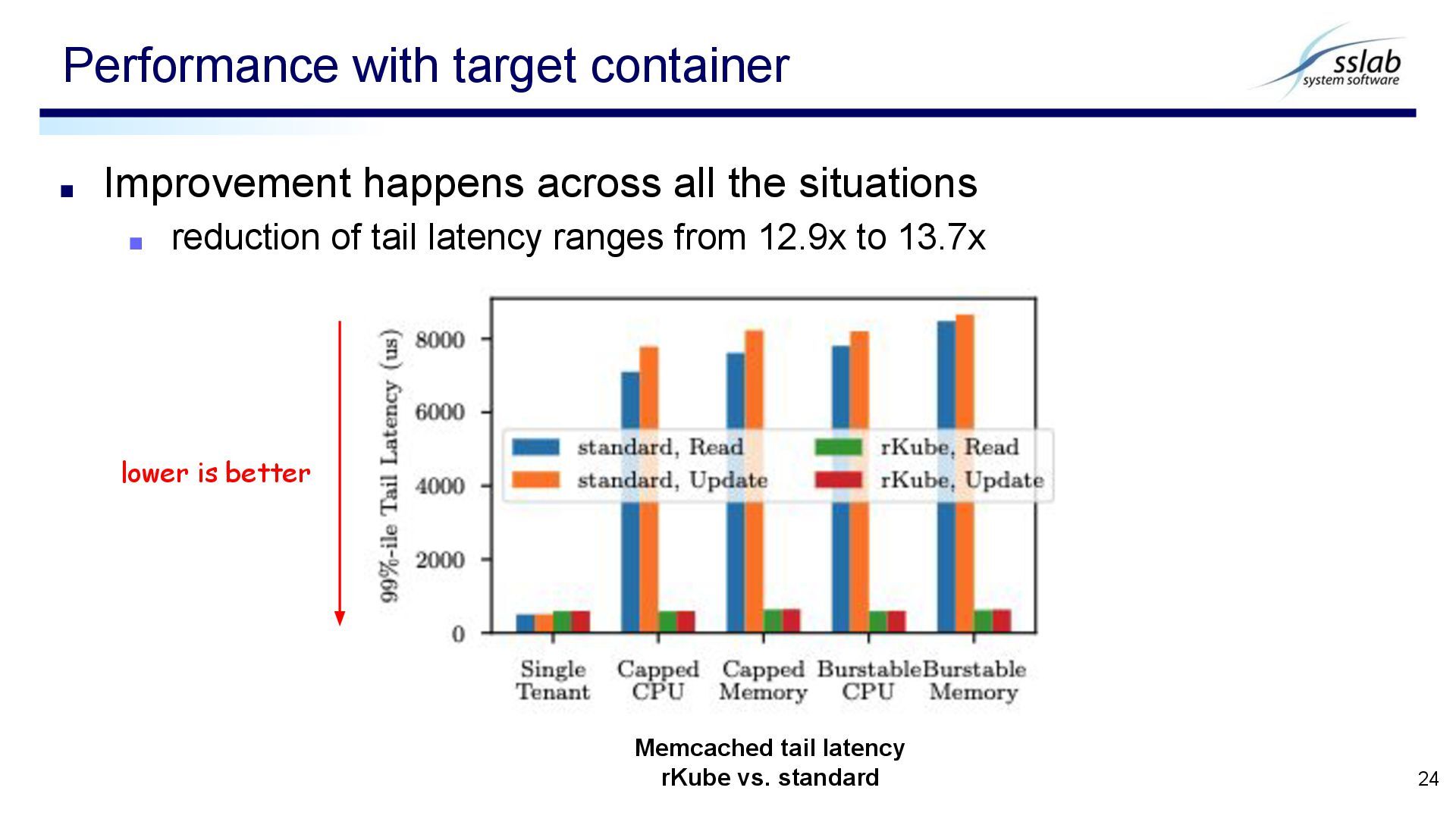
speedup of completion time ranges from 2.1x to 5.6x Performance with target container 23 rKube: completion time of batch applications standard policy: completion time of batch applications lower is better
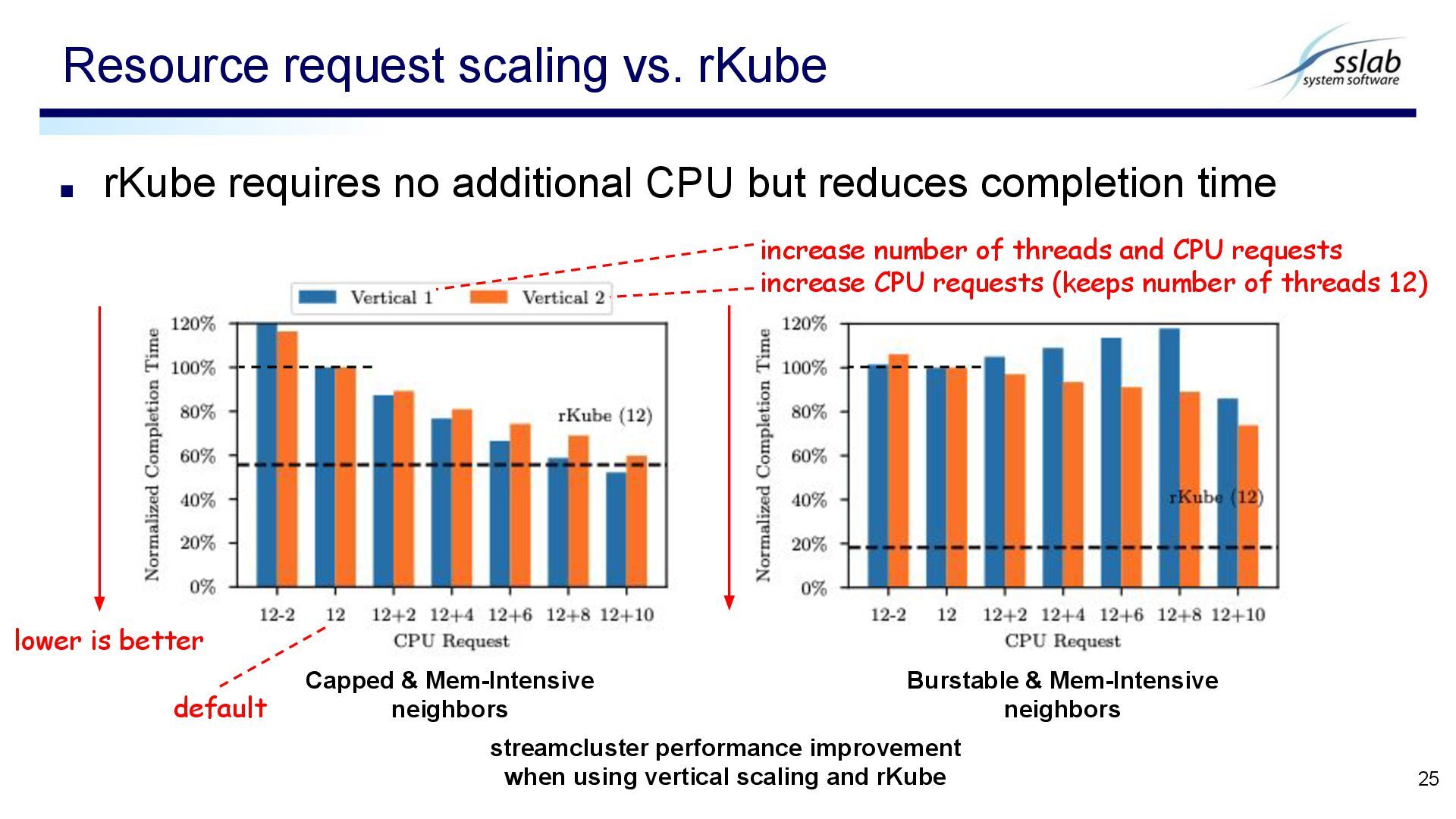
Resource request scaling vs. rKube 25 Capped & Mem-Intensive neighbors Burstable & Mem-Intensive neighbors streamcluster performance improvement when using vertical scaling and rKube lower is better increase number of threads and CPU requests increase CPU requests (keeps number of threads 12) default
’13] ◆ Detect offender jobs by monitoring cycles-per-instruction (CPI) and throttle them ◆ Less predictable in performance because it throttles jobs after suffering damage ▪ Investigate issues of task scheduling ▪ The Linux scheduler: a decade of wasted cores [Lozi+, Eurosys ’16] ◆ Demonstrate the work conserving bugs in the Linux kernel ▪ The Battle of the Schedulers: FreeBSD ULE vs. Linux CFS [Bouron+, USENIX ATC ’18] ◆ Replace the Linux kernel’s scheduler with FreeBSD ULE policy scheduler ◆ Compare the performance with different scheduling policy Related Works 27
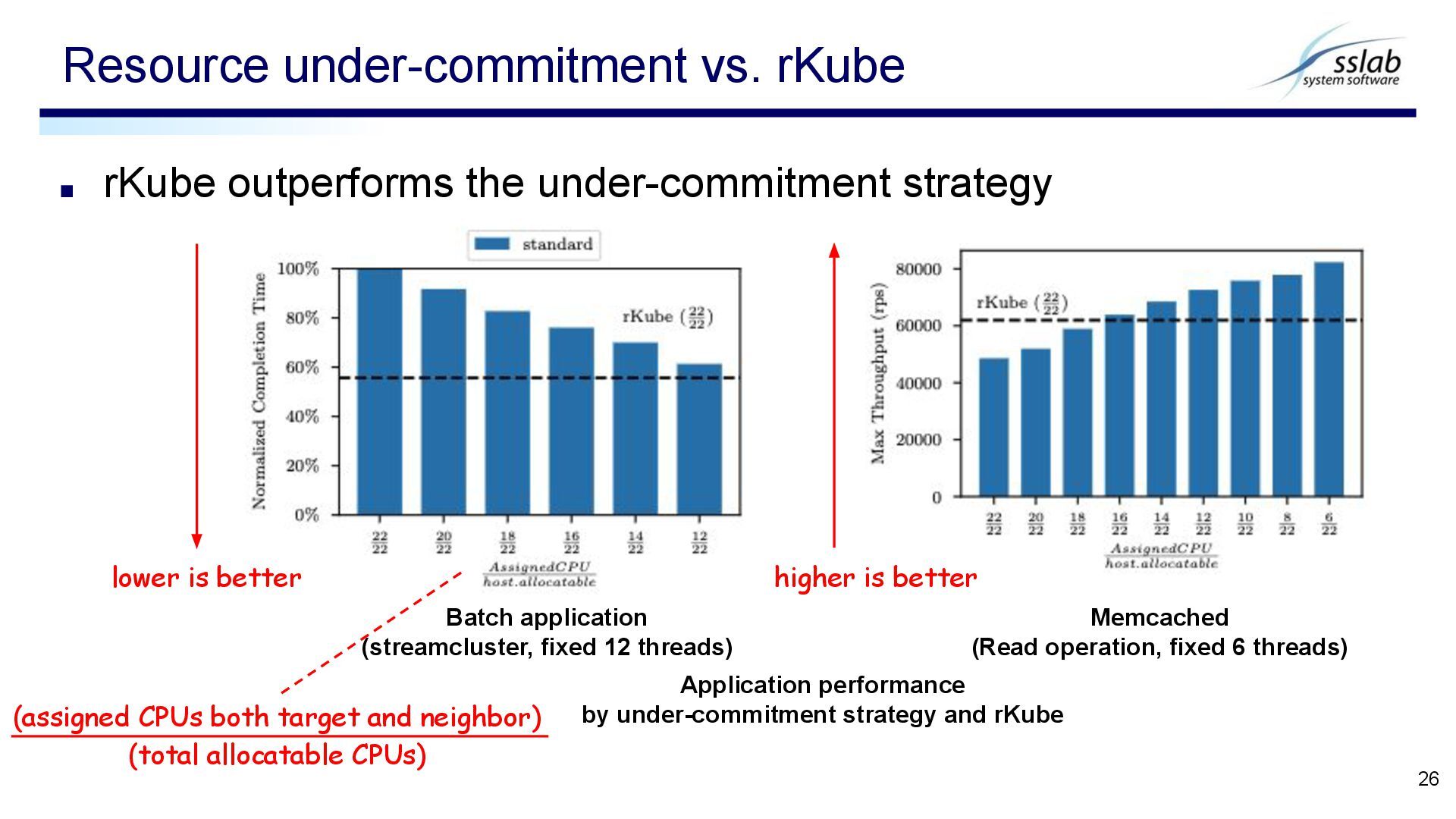
▪ CPU utilization degradation is a major contributor ▪ Found that Linux CFS fails to fulfill CPU reservations ▪ Forced Runqueue Sharing ▪ Phantom CPU Time ▪ Implement a makeshift solution: rKube ▪ Demonstrated that an enforced CPU reservations significantly improves performance in multi-tenant nodes Conclusion 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}