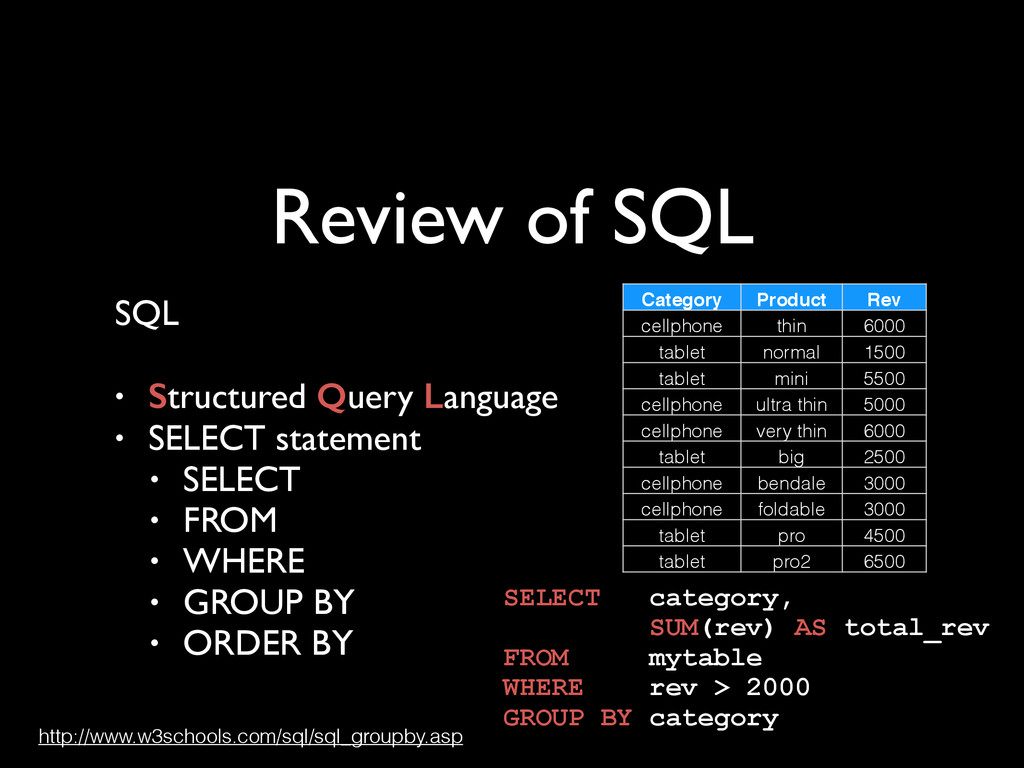
SELECT statement • SELECT • FROM • WHERE • GROUP BY • ORDER BY SELECT category, SUM(rev) AS total_rev FROM mytable WHERE rev > 2000 GROUP BY category http://www.w3schools.com/sql/sql_groupby.asp Category Product Rev cellphone thin 6000 tablet normal 1500 tablet mini 5500 cellphone ultra thin 5000 cellphone very thin 6000 tablet big 2500 cellphone bendale 3000 cellphone foldable 3000 tablet pro 4500 tablet pro2 6500
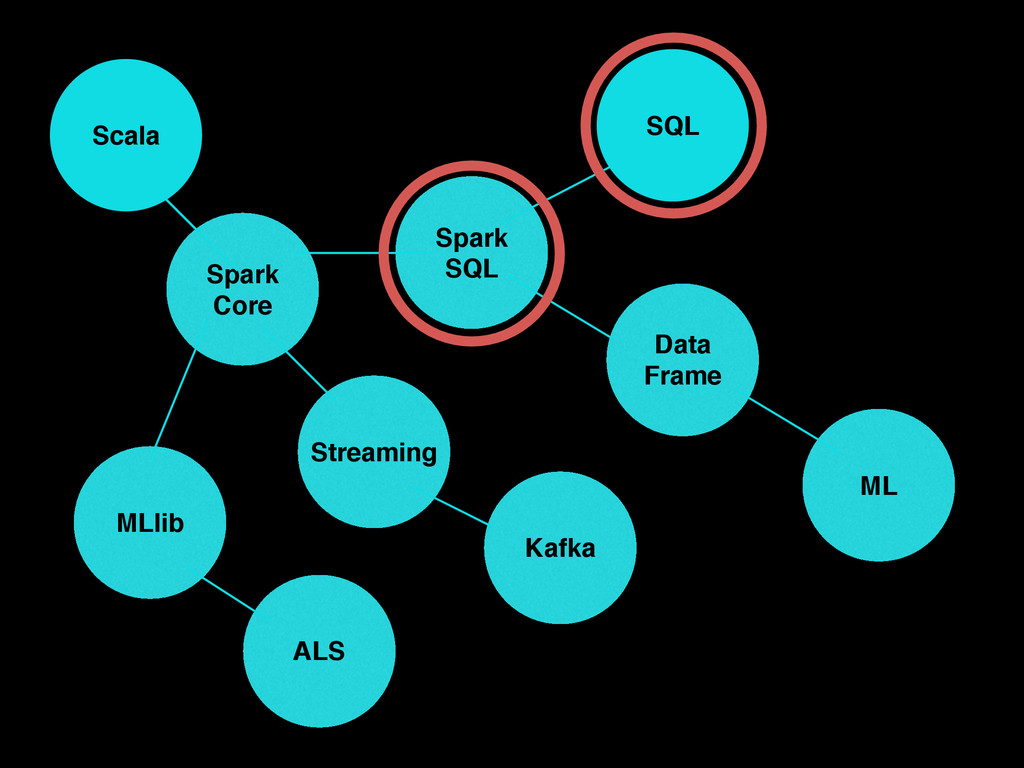
Spark SQL • Support relational processing both within native RDDs and data sources • High performance using established DBMS techniques • Enable extension for graph and machine learning Bye Bye MapReduce
v1.4.1 • Data sources • Input and output • User defined functions • Performance tuning Spark RDD Spark SQL DataFrame Catalyst Optimizer JDBC User Program
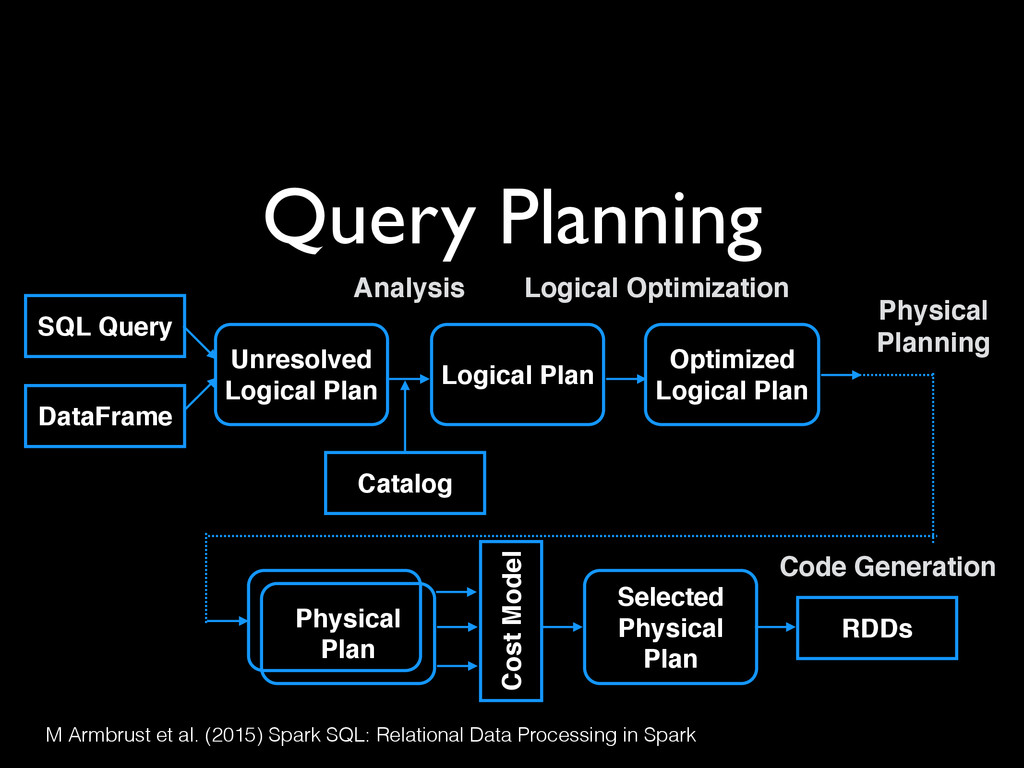
Data Processing in Spark SQL Query DataFrame Unresolved! Logical Plan Logical Plan Optimized! Logical Plan Physical! Plan Cost Model Selected! Physical Plan RDDs Catalog Analysis Logical Optimization Physical! Planning Code Generation
functions registerFunction() • Of course with Hive UDF, UDAF, make sure the jar sqlContext.registerFunction( \ 'strLength',\ lambda x: len(x)) UDAF in DF? https://issues.apache.org/jira/browse/SPARK-6802
memory • How to speed up the performance of query execution? spark.sql.shuffle.partitions spark.sql.inMemoryColumnarStorage.batchSize sqlContext.cacheTable('df') sqlContext.sql('CACHE TABLE df') sqlContext.uncacheTable('df') sqlContext.setConf('spark.sql.shuffle.partitions','200')
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}