Introduce Spark and its ecosystem to students. In this lecture, you will learn what is spark, spark features, spark architect, RDD, how to install spark, and best practice on it.
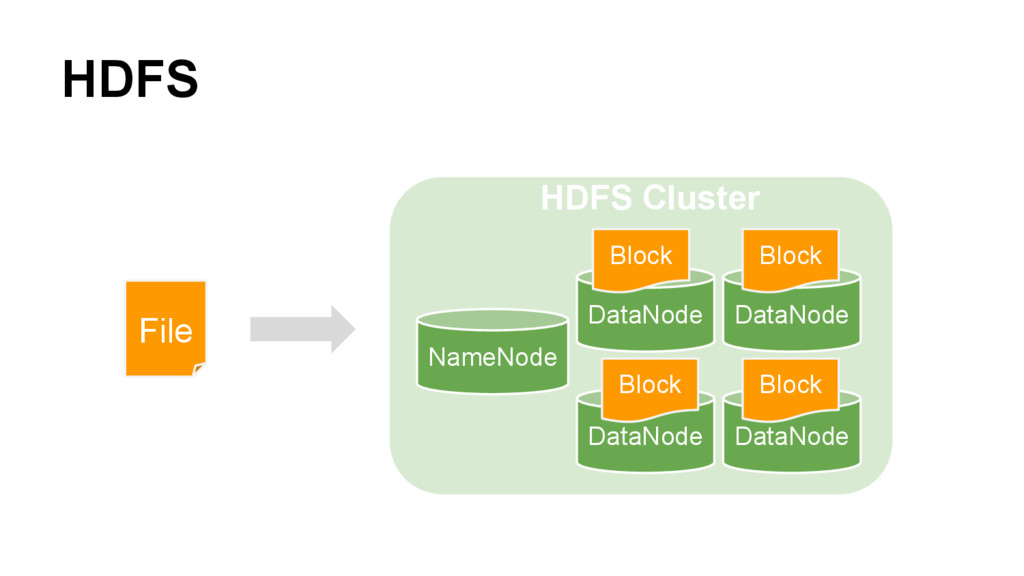
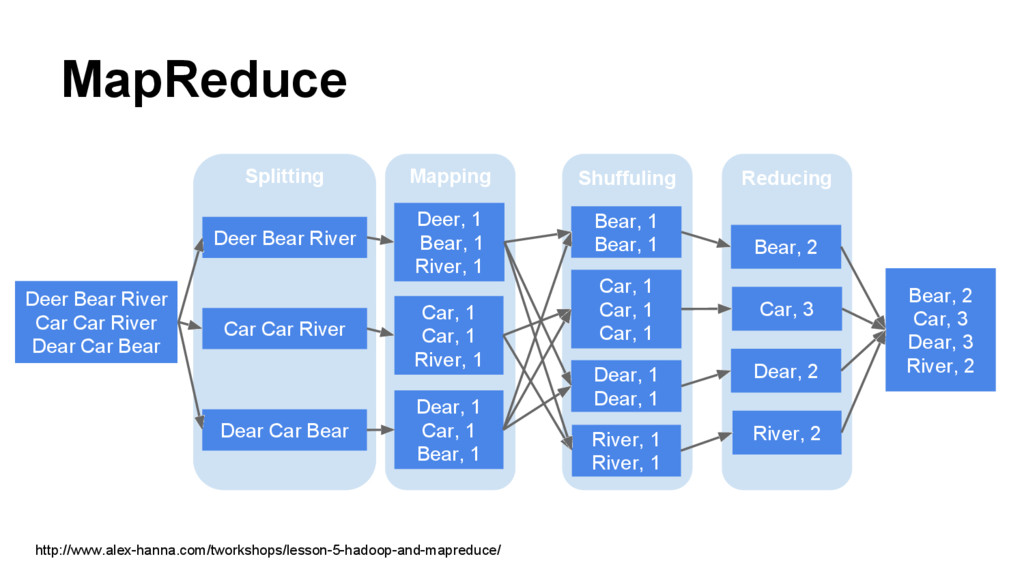
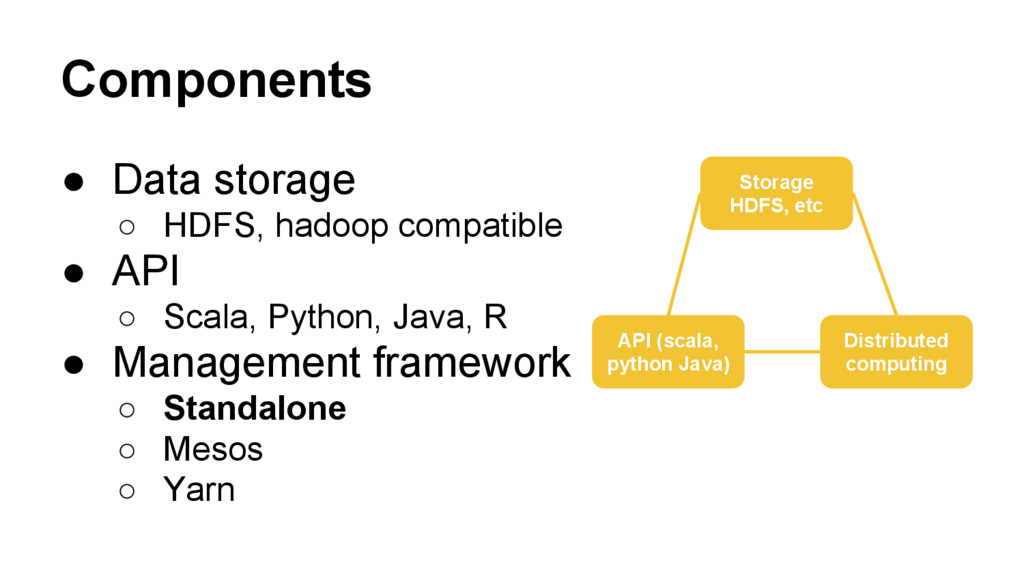
big data (HDFS) and parallel execution model (MapReduce) • Spark ◦ An open source parallel processing framework that enables users to run large-scale data analytics applications across clustered computers
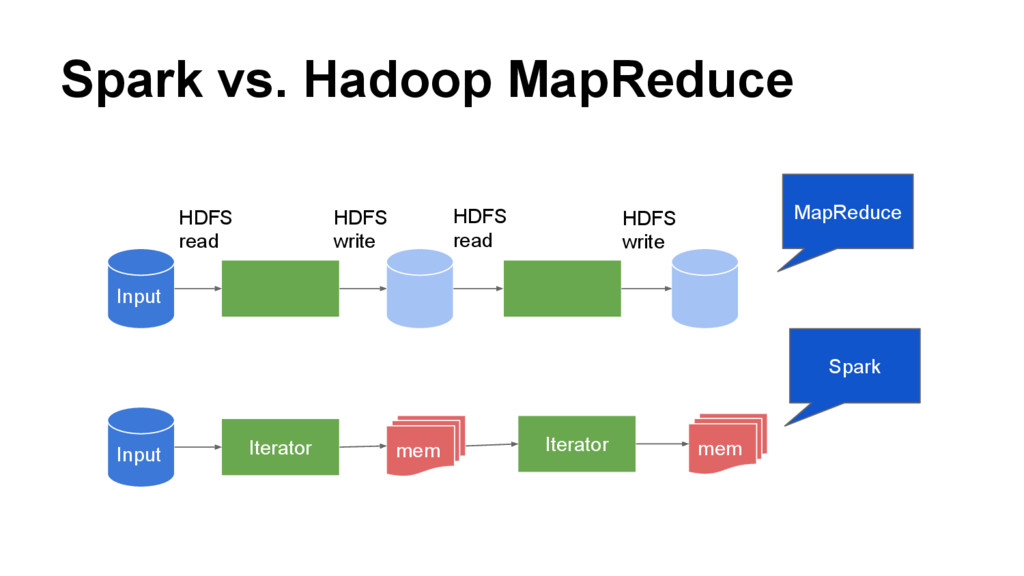
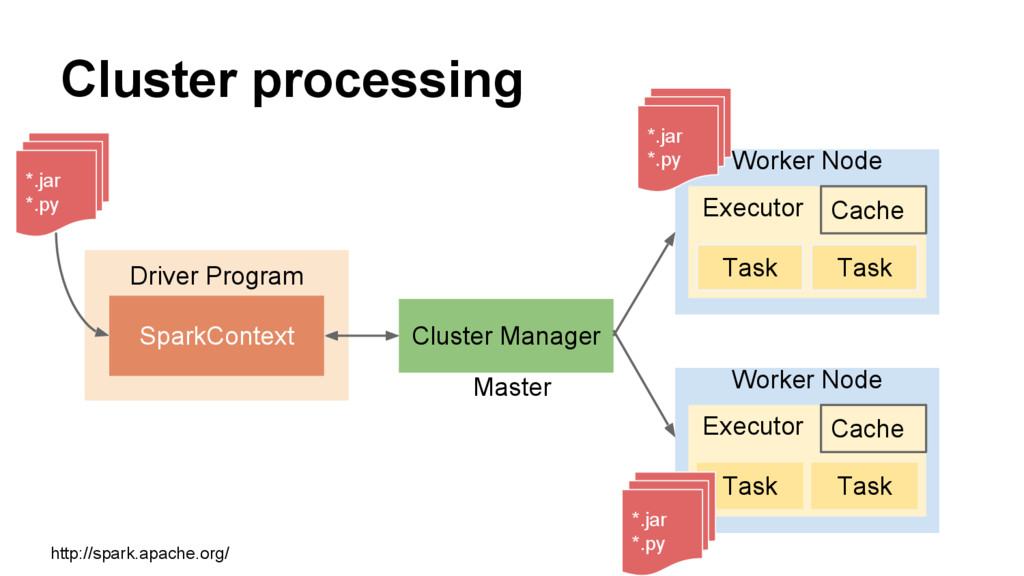
than Hadoop MapReduce in memory, or 10x faster on disk. 2014 Sort Benchmark Competition 機器數量 時間 Hadoop MapR 2100 72m Spark 207 23m Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. http://spark.apache.org/
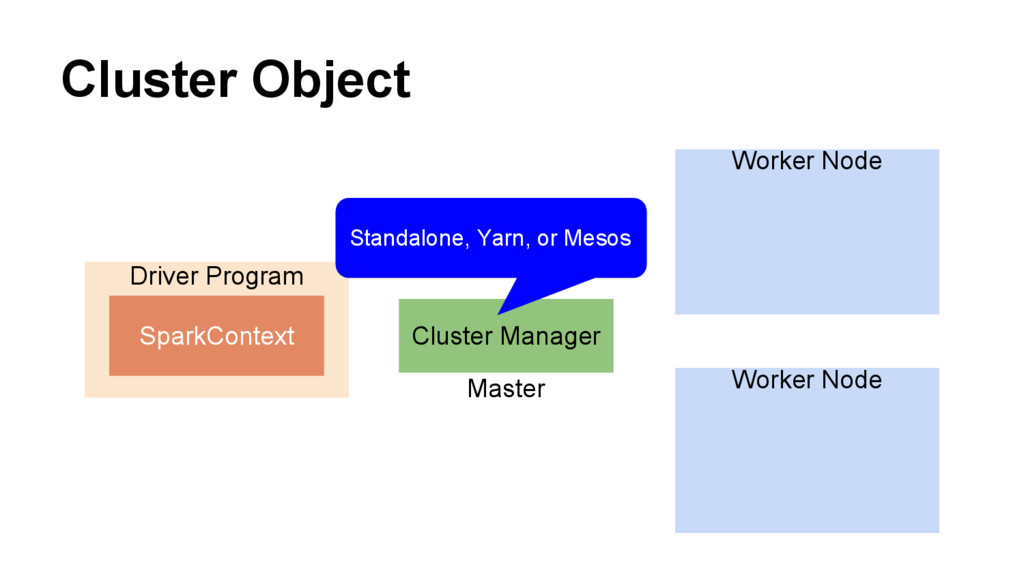
val sc = new SparkContext(conf) • Python conf = SparkConf().setAppName(appName).setMaster(master) sc = SparkContext(conf=conf) A name of your application to show on cluster UI
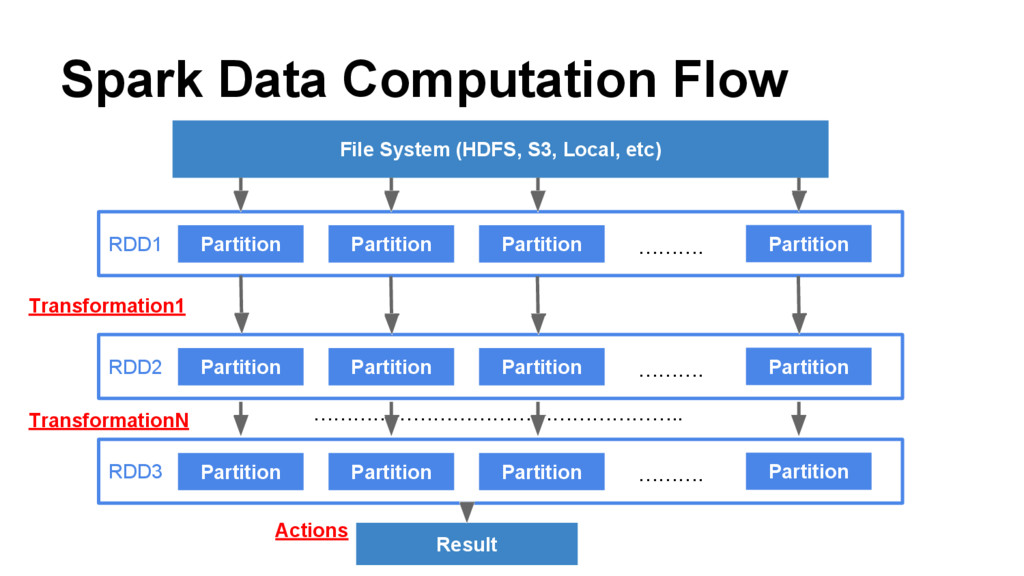
a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop- supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.” What’s RDD “Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.” Partition1 Partition2 ...
"apple", "apple", "apple", "lemon", "lemon", "lemon", "banana", "banana", "banana", "banana", "banana", "banana", "apple", "apple", "apple", "apple"] wordsRDD = sc.parallelize(wordsList, 4) # Print out the type of wordsRDD print type(wordsRDD) def makePlural(word): # Adds an 's' to `word` return word + 's' print makePlural('cat') # TODO: Now pass each item in the base RDD into a map() pluralRDD = wordsRDD.<FILL IN> print pluralRDD.collect() # TODO: Let's create the same RDD using a `lambda` function. pluralLambdaRDD = wordsRDD.<FILL IN> print pluralLambdaRDD.collect() # TODO: Now use `map()` and a `lambda` function to return the number of characters in each word. pluralLengths = (pluralRDD.<FILL IN>) print pluralLengths # TODO: The next step in writing our word counting program is to create a new type of RDD, called a pair RDD # Hint: # We can create the pair RDD using the `map()` transformation with a `lambda()` function to create a new RDD. wordPairs = wordsRDD.<FILL IN> print wordPairs.collect()
type `('word', iterator)` wordsGrouped = wordPairs.<FILL IN> for key, value in wordsGrouped.collect(): print '{0}: {1}'.format(key, list(value)) # TODO: Use `mapValues() to obtain the counts wordCountsGrouped = wordsGrouped.<FILL IN> print wordCountsGrouped.collect() # TODO: Counting using `reduceByKey` wordCounts = wordPairs.<FILL IN> print wordCounts.collect() # TODO: put all together wordCountsCollected = (wordsRDD.<FILL IN>) print wordCountsCollected https://github. com/wlsherica/StarkTechnology/tree/ master
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
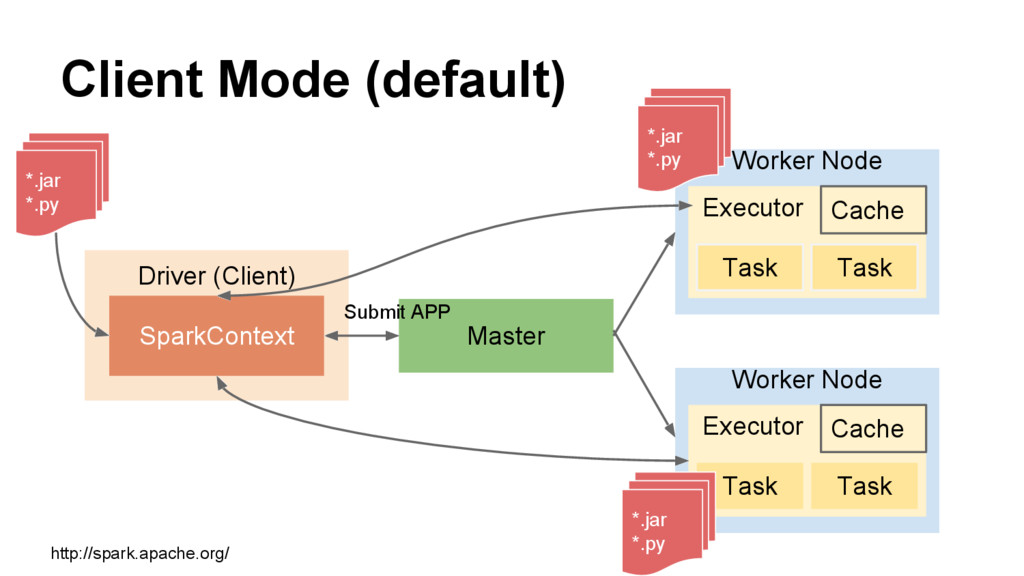{kind=link}
{kind=link}
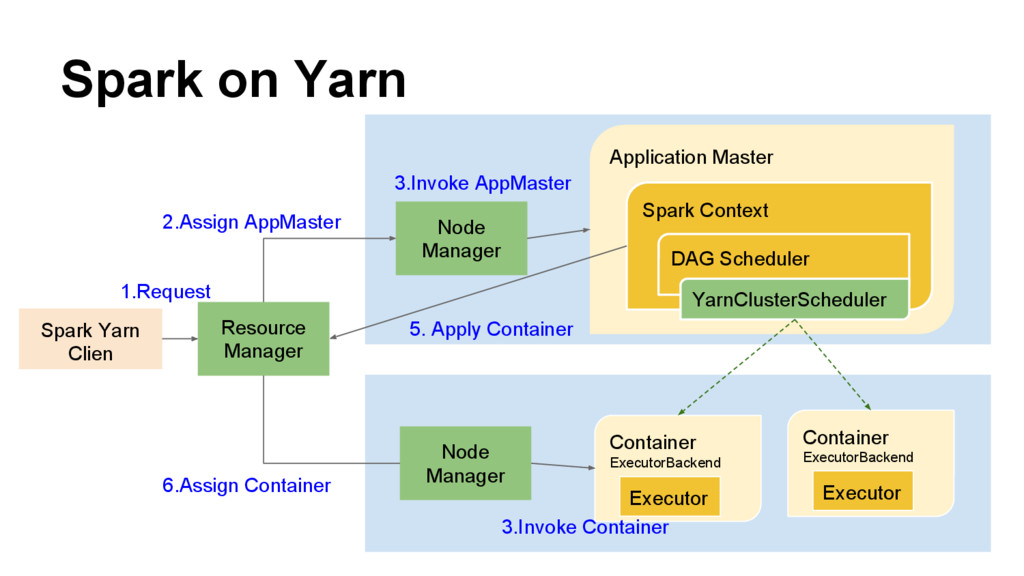{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Spark Shell • Scala ./bin/spark-shell --master local[4] ./bin/spark-shell --master local[4]](https://files.speakerdeck.com/presentations/5df42cb59e7242cfb9f8b0a805d22bd7/slide_32.jpg){kind=link}
{kind=link}
![master URLs • local, local[K], local[*] • spark://HOST:PORT • mesos://HOST:PORT](https://files.speakerdeck.com/presentations/5df42cb59e7242cfb9f8b0a805d22bd7/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![How to Create RDD • Scala val rddStr:RDD[String] = sc.textFile("hdfs://..")](https://files.speakerdeck.com/presentations/5df42cb59e7242cfb9f8b0a805d22bd7/slide_40.jpg){kind=link}
{kind=link}
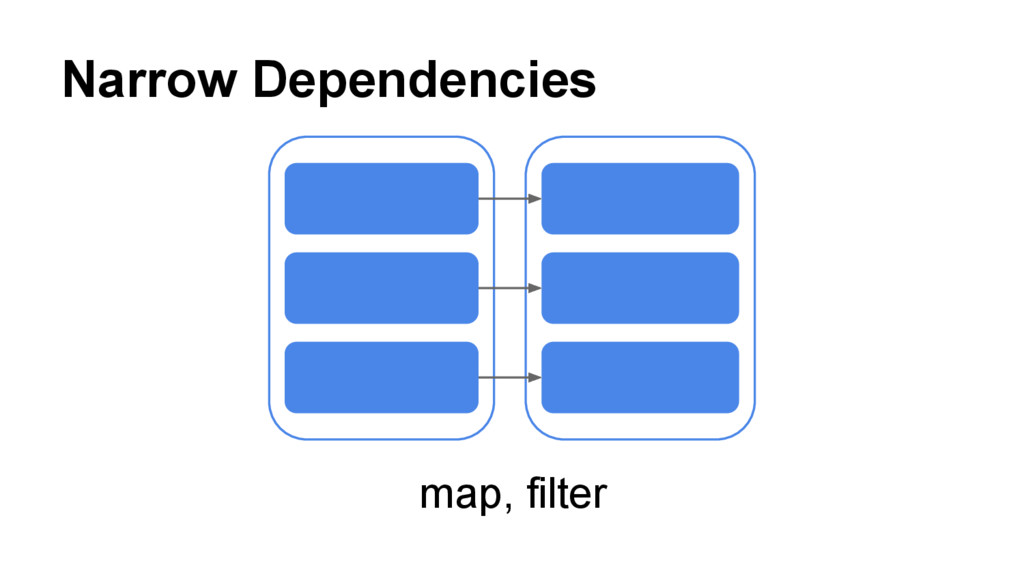{kind=link}
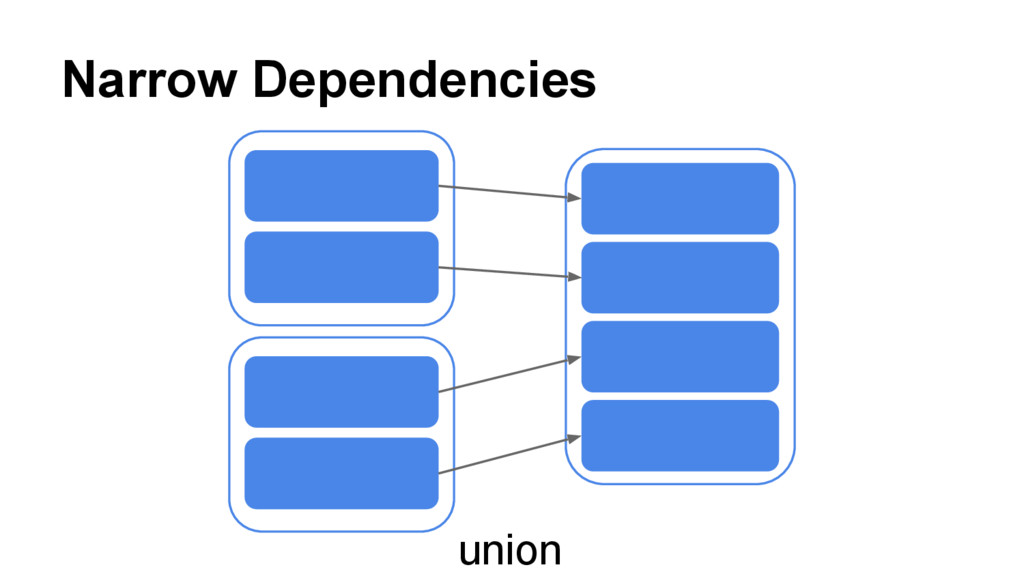{kind=link}
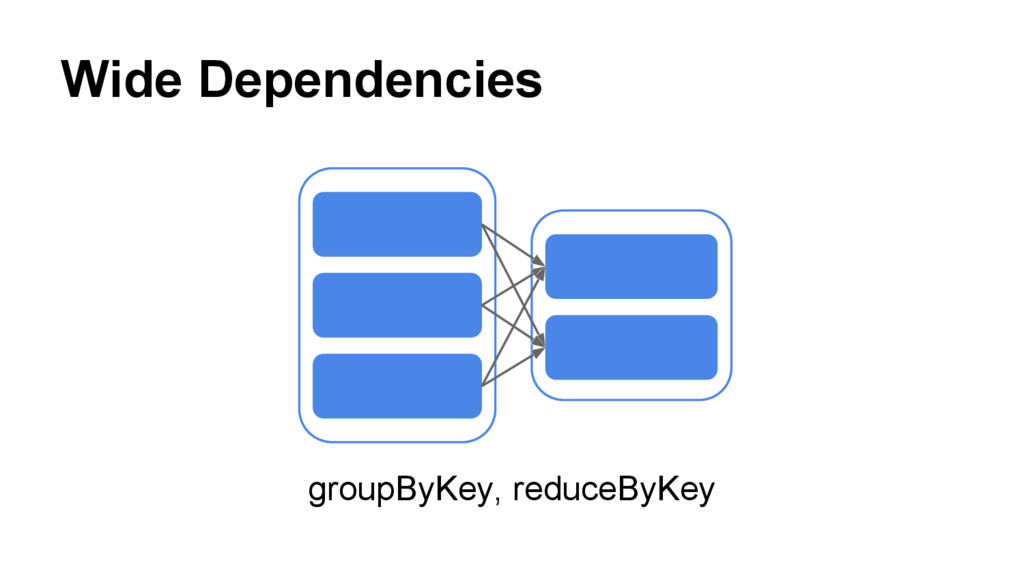{kind=link}
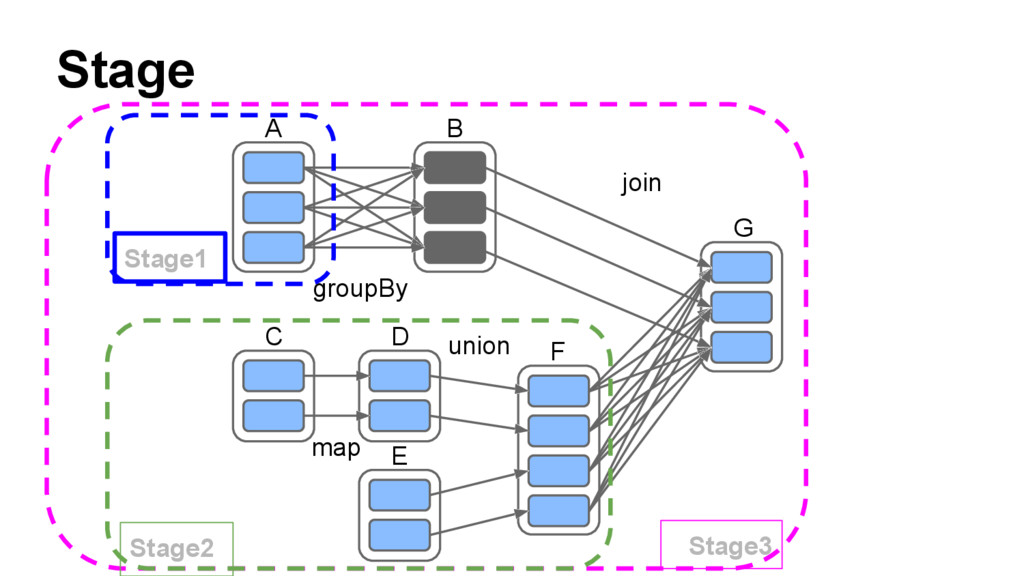{kind=link}
{kind=link}
![Shared Variables • Broadcast variables broadcastVar = sc.broadcast([100, 200, 300])](https://files.speakerdeck.com/presentations/5df42cb59e7242cfb9f8b0a805d22bd7/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
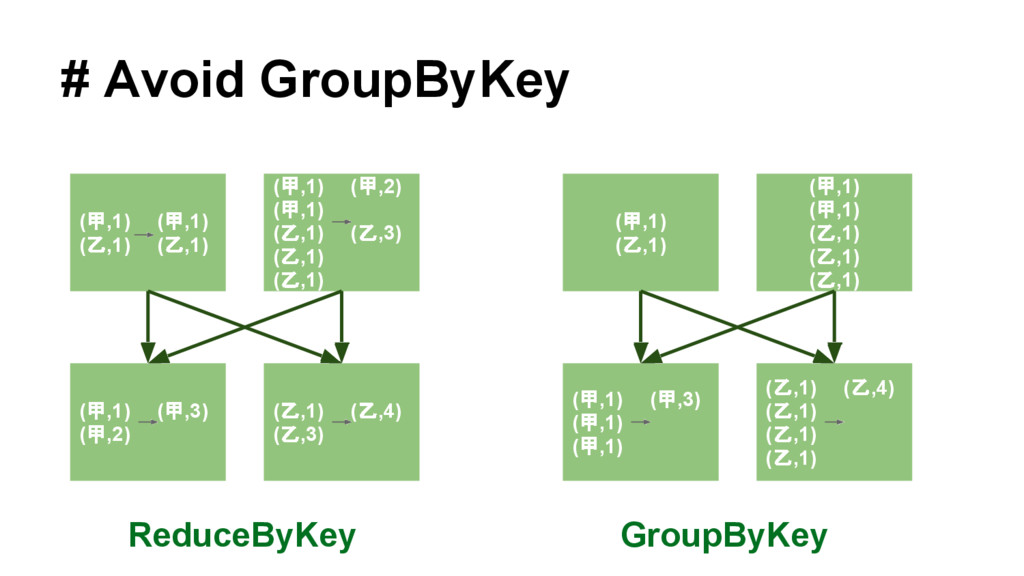{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}