// ConnectionPool is a static, lazily initialized pool of connections val connection = ConnectionPool.getConnection() partitionOfRecords.foreach(record => connection.send(record)) ConnectionPool.returnConnection(connection) // return to the pool for future reuse } } 3
SQLContext.getOrCreate(rdd.sparkContext) //spark 1.x SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate() //spark 2.0 import sparkSession.implicits._ val wordsDataFrame = rdd.toDF("word") wordsDataFrame // .registerTempTable("words") //spark 1.x .createOrReplaceTempView("words") //spark 2.0 val wordCountsDataFrame = sparkSession.sql("select word, count(*) as total from words group by word") wordCountsDataFrame.show() }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Output • print () • saveAsTextFiles (prefix, [suffix]) • saveAsObjectFiles](https://files.speakerdeck.com/presentations/ce418dd1f8e44527a4333a3c9d9fb08a/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
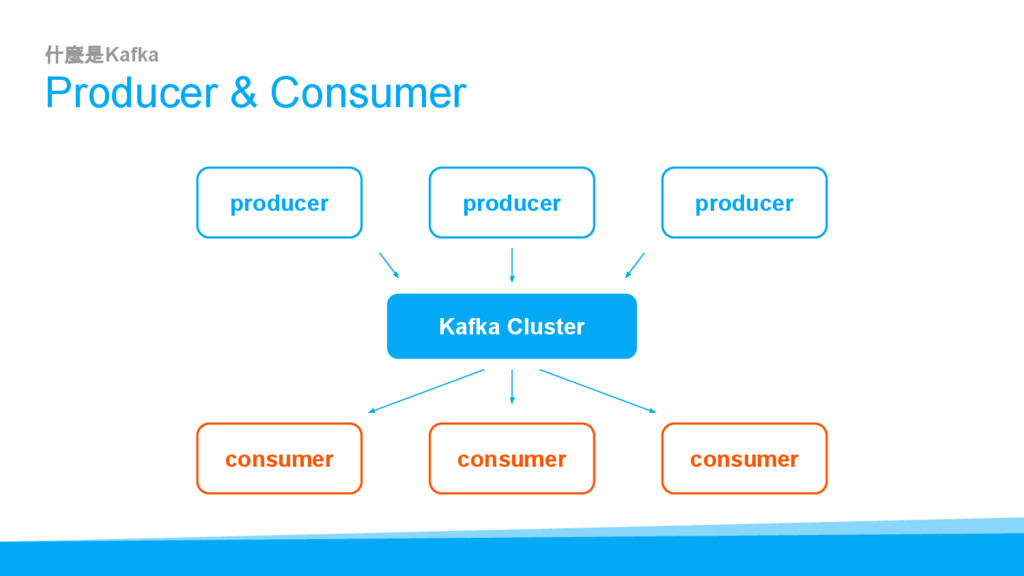{kind=link}
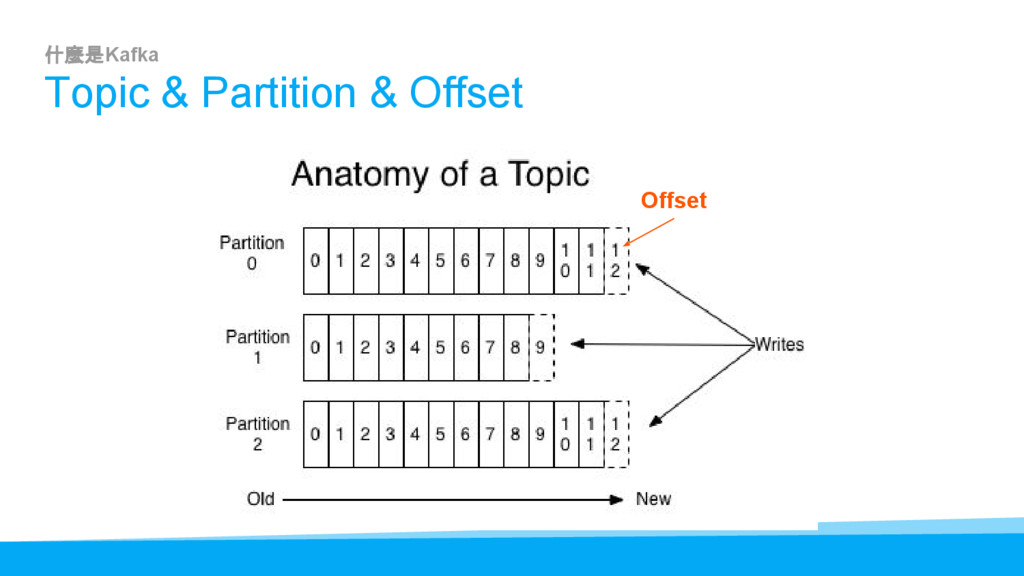{kind=link}
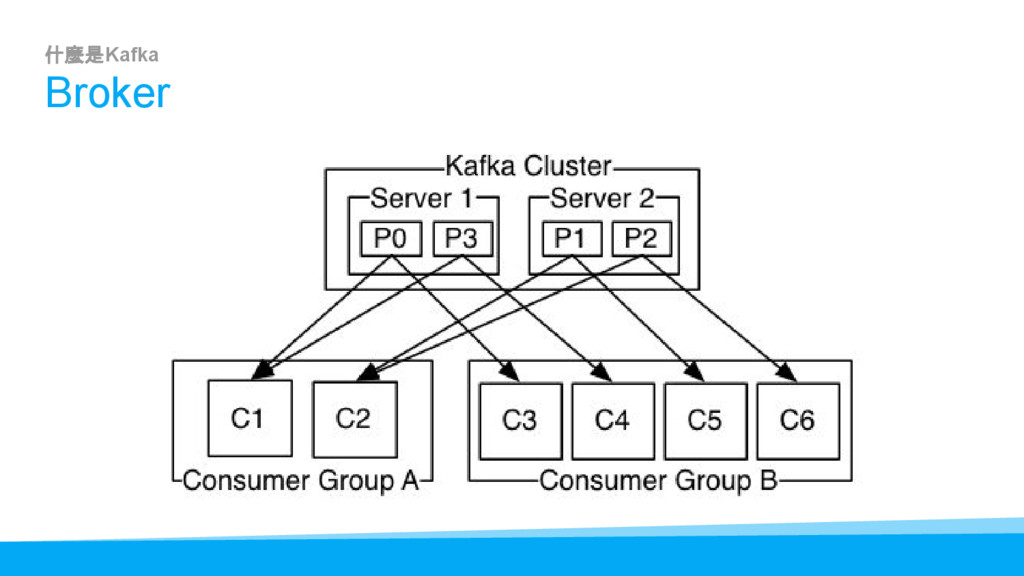{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
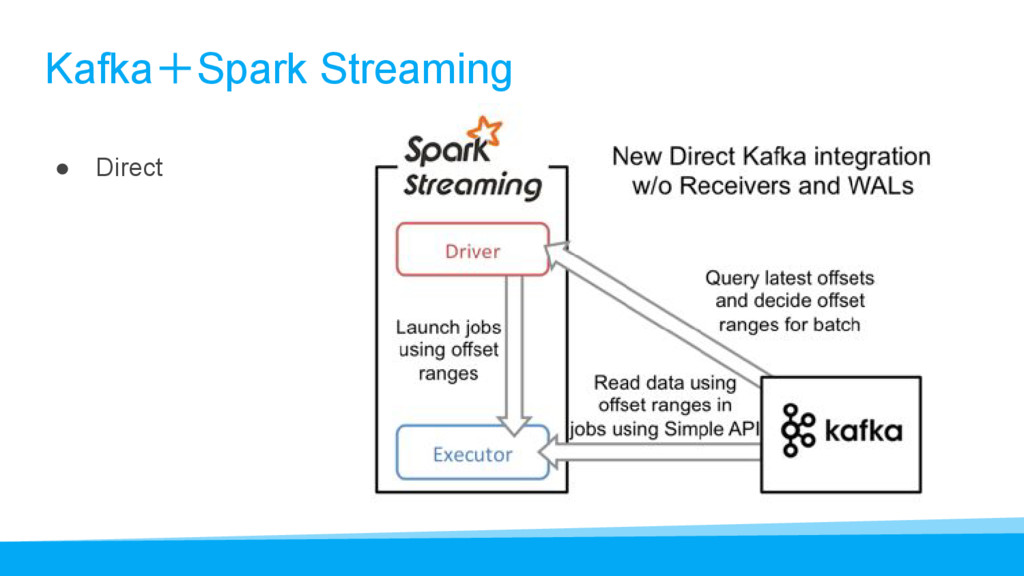{kind=link}
{kind=link}
{kind=link}