information assets that require new forms of processing to enable enhanced decision making, insight discovery and process optimization. - Doug Laney 2012
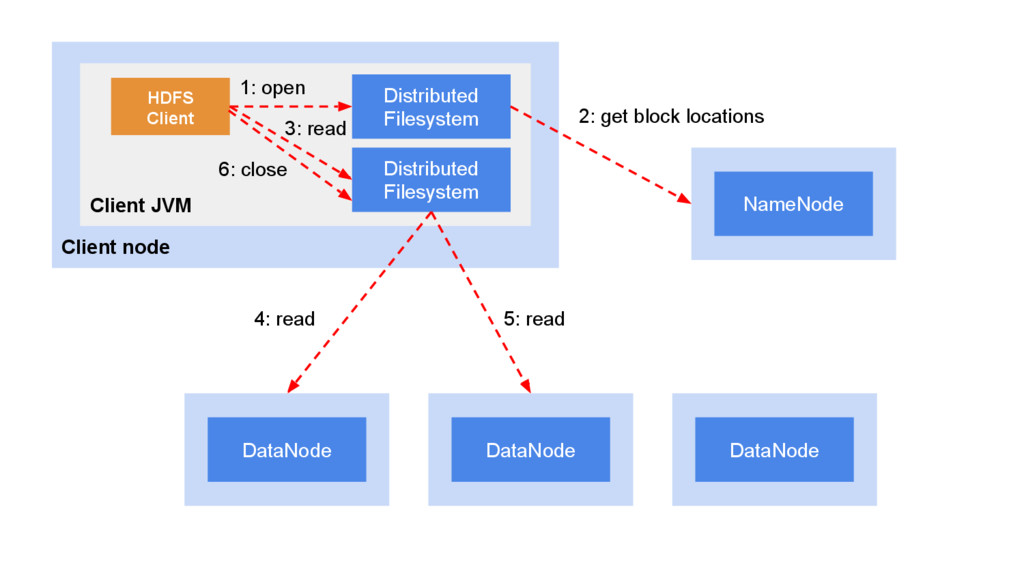
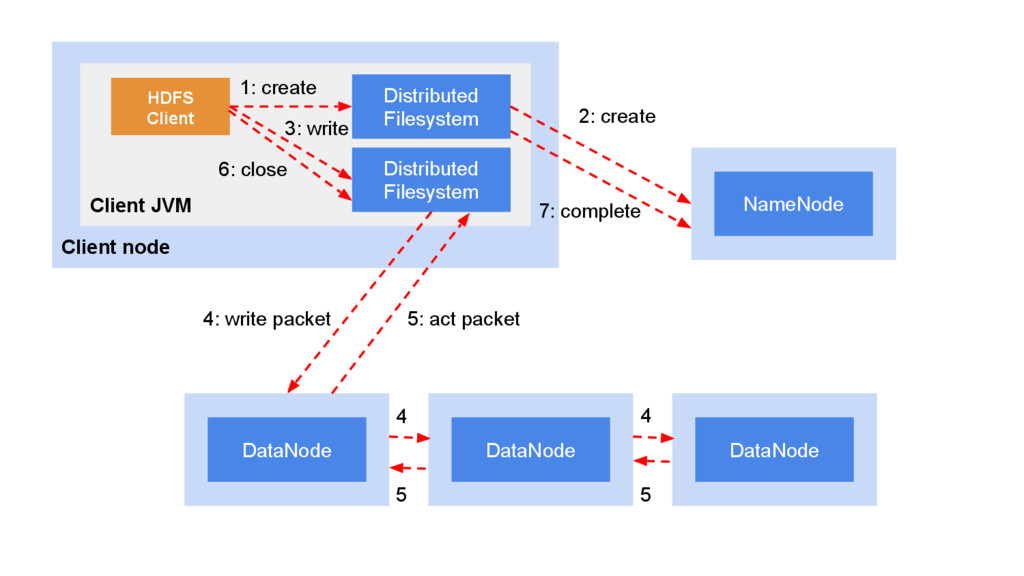
• Receive delete command from NameNode NameNode • File system meta • File system name -> blocks • block -> replicas • File system image • Edit log for every file system modification
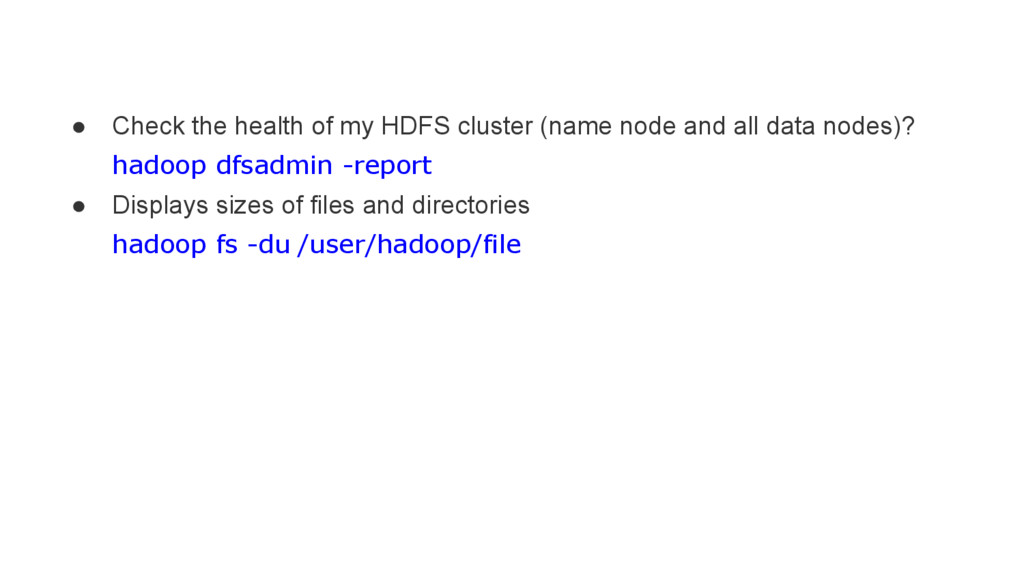
Recursive version of ls hadoop fs -lsr / • Create a directory hadoop fs -mkdir /test • Copy src from local to HDFS hadoop fs -put localfile /user/hadoop/hadoopfile • Copy file to local system hadoop fs -get /user/hadoop/file localfile • Output file in text format hadoop fs -text /user/hadoop/file • Delete files hadoop fs -rm /user/hadoop/file https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html hadoop fs -help ls
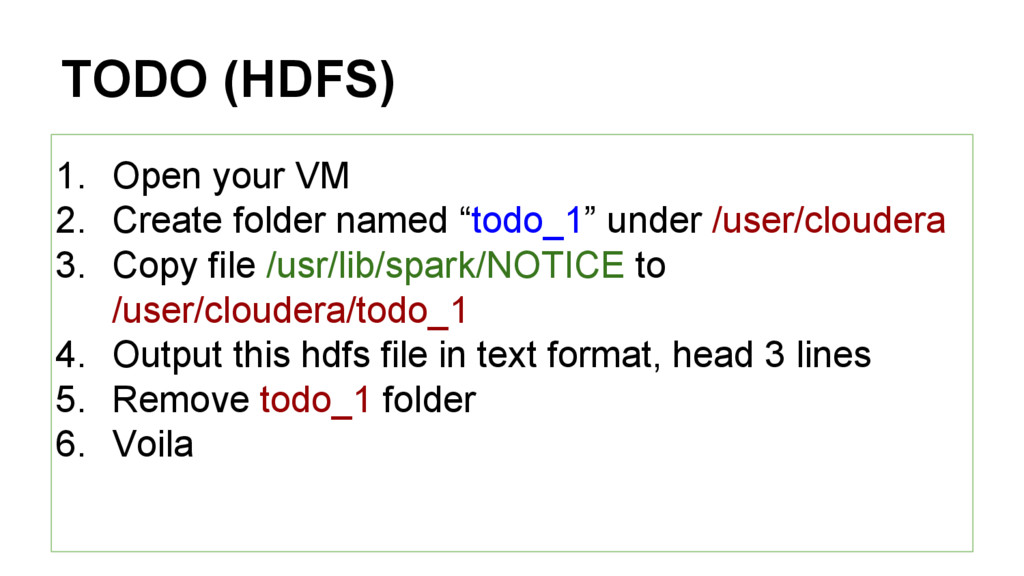
“todo_1” under /user/cloudera 3. Copy file /usr/lib/spark/NOTICE to /user/cloudera/todo_1 4. Output this hdfs file in text format, head 3 lines 5. Remove todo_1 folder 6. Voila
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}