improvements ◦ Spark 2.0 can run all the 99 TPC-DS queries, which require many of the SQL:2003 features ◦ Visualization of dataframe query plan on webUI ◦ Multiple version of Hive (0.12 - 1.2.1) ◦ Reading several Parquet variants, e.g. impala, avro, thrift, Hive, etc ◦ ... 10
◦ Upper point: HiveContext ◦ What’s the difference? ▪ HiveContext has more complete parser function, it is recommened for most use cases • Datasets (1.6+) & DataFrames 11
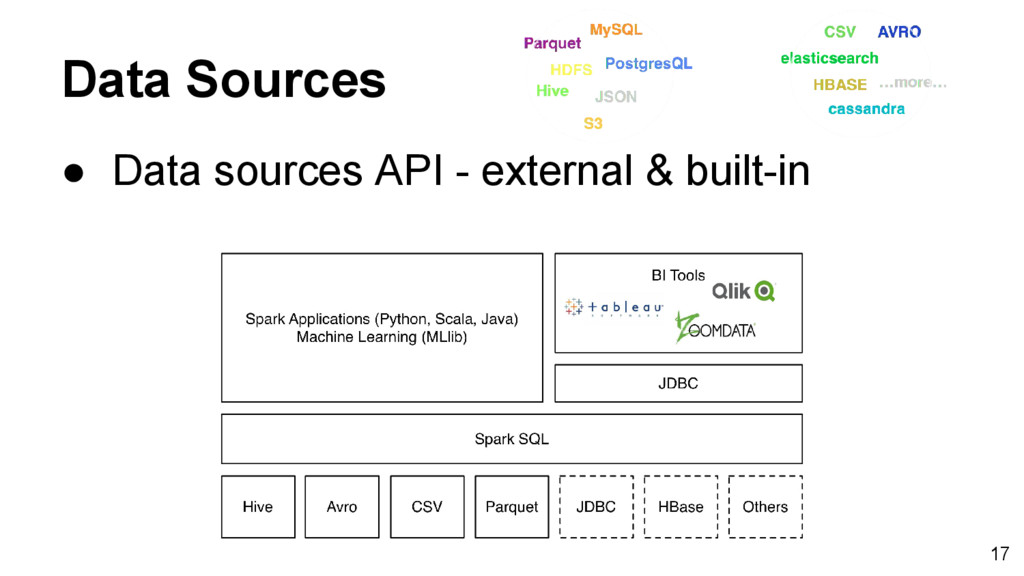
named columns ◦ Structured data files, tables in Hive, external databases, or existing RDDs • Datasets ◦ A distributed collection of data ▪ Available on Scala & Java ▪ Haven’t support on Python & R 12
DataFrame API are unified ◦ Scala & Java - Dataset ◦ Python & R - DataFrame • For example ◦ unionAll -> union ◦ registerTempTable -> createOrReplaceTempView 13
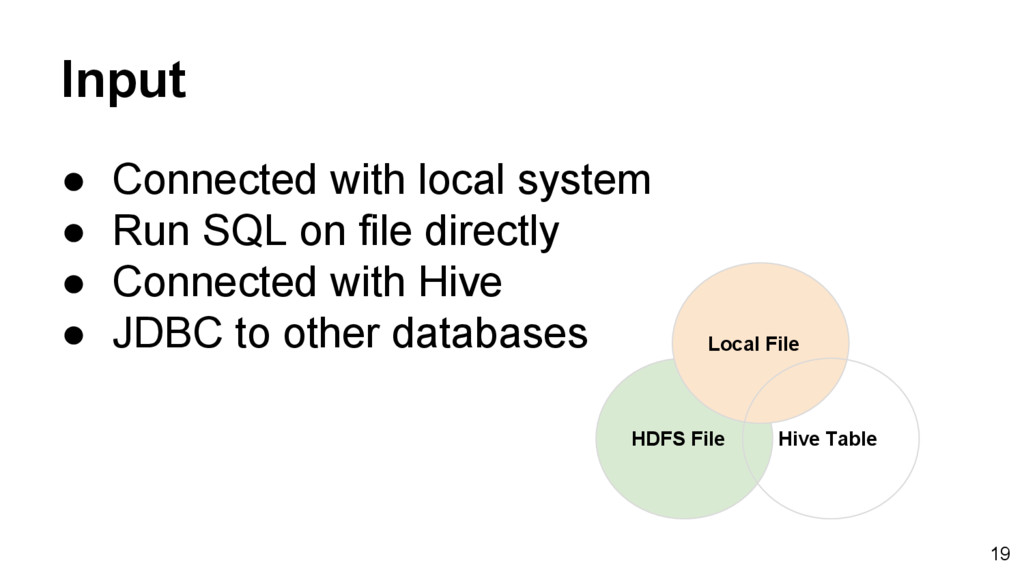
stored in Hive ◦ The Hive dependency is not included in the default Spark distribution • Check the configuration of Hive in conf/. ◦ hive-site.xml ◦ core-site.xml ◦ hdfs-site.xml 23
on spark classpath • From the remote DB bin/spark-shell --driver-class-path postgresql-9.4.1207.jar --jars postgresql-9.4.1207.jar Python df = spark.read.format(source="jdbc",url="jdbc:postgresql:dbserver",dbtable ="schema.tablename").load() 24
exists, an exception is expected to be thrown. SaveMode.Append append DataFrame are expected to be appended to existing data. SaveMode.Overwrite overwrite Data is expected to be overwritten by the contents of the DataFrame. SaveMode.Ignore ignore Like ‘CREATE TABLE IF NOT EXISTS’ 26
Idea from Python Pandas and R data frames • Create DataFrame in three ways ◦ an existing RDD ◦ running SQL query ▪ spark.sql("SELECT * FROM table") ◦ data sources ▪ spark.read.json("s3n://path/data.json","json") 28
file and convert each line to a Row. lines = sc.textFile("examples/src/main/resources/people.txt") parts = lines.map(lambda l: l.split(",")) people = parts.map(lambda p: Row(name=p[0], age=int(p[1]))) # Infer the schema, and register the DataFrame as a table. schemaPeople = spark.createDataFrame(people) schemaPeople.createOrReplaceTempView("people") 33
l.split(",")) people = parts.map(lambda p: (p[0], p[1].strip())) schemaString = "name age" fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()] schema = StructType(fields) # Apply the schema to the RDD. schemaPeople = spark.createDataFrame(people, schema) # Creates a temporary view using the DataFrame schemaPeople.createOrReplaceTempView("people") 34
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}