WPS GmbH und Ihre Expertise Rund um Architekturanalyse ▪ Architektur-Review und Qualitätsgutachten ▪ Architektur- und Refactoring-Beratung ▪ Architekturstile - Einführung und Entwicklung Rund um IT-Landschaften ▪ Analyse der Ist/Soll-Geschäftsprozesse mit Fachanwendern ▪ Darstellung von komplexen IT- Landschaften ▪ Qualitäts- und Testmanagement Software- Architektur Anforderungs- ermittlung Leitstand und Interaktion Individual- software Business-Software, die Spaß macht!
Level Aufgaben, Methoden und Techniken für die Entwicklung von Softwarearchitekturen. Alle Aspekte, die für Softwarearchitektur wesentlich sind. Technologische, organisatorische und soziale Faktoren. Advanced Level Vertiefung des Foundation Levels. Der Lehrplan besteht aus einzelnen Modulen, die bestimmte Schwerpunkte haben. Expert Level In Planung
LEVEL ▪ Methodische Kompetenz: Systematisches Vorgehen bei Architekturaufgaben, unabhängig von Technologien. ▪ Technische Kompetenz: Kenntnis und Anwendung von Technologien zur Lösung von Entwurfsaufgaben, ▪ Kommunikative Kompetenz: Fähigkeiten zur produktiven Zusammenarbeit mit unterschiedlichen Stakeholdern, Kommunikation, Präsentation, Argumentation, Moderation → Alle drei Kompetenzbereiche müssen abgedeckt sein
ADVANCED LEVEL Prüfung und Zertifizierung Wenn Sie als CPSA-A geprüft werden möchten, müssen Sie sich bei einer der anerkannten Zertifizierungsstellen anmelden. Die Zertifizierungsstelle schickt Ihnen in Absprache eine Prüfungsaufgabe zu, die Sie in etwa 40 Arbeitsstunden lösen und deren Lösung Sie dokumentieren müssen. Sie schicken die Lösung an die Zertifizierungsstelle ein. Die Zertifizierungsstelle bestellt zwei unabhängige Prüfer und übergibt ihnen Ihre Lösung, so dass sie begutachtet werden kann. Die Prüfer telefonieren anschließend noch mit Ihnen als Teilnehmer. Sie müssen Ihre Lösung in diesem Gespräch erklären und verteidigen. Wenn die Prüfer bestätigen, dass Sie alle Voraussetzungen für den CPSA-A erfüllen, dass Ihre Lösung gut ist und dass Sie die Lösung gut dokumentiert, erklärt und verteidigt haben, stellt Ihnen die Zertifizierungsstelle das CPSA-A Zertifikat aus.
(10 komm. CP, 20 method. CP) Softwaresysteme und -architekturen nach agilen Prinzipien entwerfen und weiterentwickeln ▪ Agile Prinzipien und Ideen auf Architekturarbeit übertragen ▪ Architekturpraktiken sinnvoll in agiles Vorgehen verankern ▪ Arbeiten in selbstorganisierte Teams und gemeinsam wahrgenommene Verantwortung erfordern neue Fähigkeiten, sowohl technischer als auch methodischer und kommunikativer Art. Diese werden theoretisch und praktisch behandelt. Schulungsangebot: https://www.wps.de/schulung/isaqb-agila
(20method. CP, 10 techn. CP) Softwarearchitekturen anhand ökonomischer und technischer Ziele systematisch verbessern ▪ Grundlagen von Evolution und Verbesserung von Softwarearchitekturen ▪ Ist-Situation analysieren ▪ Probleme und Lösungsansätze schätzen und bewerten ▪ Verbesserung langfristig planen ▪ Typische Ansätze und Beispiele für Verbesserung Schulungsangebot: https://www.wps.de/schulung/isaqb-improve/
Design (10 komm. CP, 20 method. CP) Passgenaue Softwarearchitekturen durch Kommunikation mit den Fachexperten und einheitliche Konstruktionsbausteine entwickeln ▪ Eine gemeinsame Sprache erleichtert die Zusammenarbeit ▪ Software nach fachlichen Gesichtspunkten strukturieren ▪ Kommunikation ist der Schlüssel – miteinander und zwischen Teams ▪ Bausteine von DDD geben team- übergreifende Anleitungen für die Konstruktion Schulungsangebot: https://www.wps.de/schulung/isaqb-ddd/
(10 method. CP, 20 techn. CP) Flexible Architekturkonzepte und Methoden, um Software schnell und mit hoher Qualität in die Produktion zu bringen: ▪ Microservices entwerfen ▪ DevOps und Continuious Delivery umsetzen ▪ Containerisierung ▪ Resiliente Systeme betreiben Schulungsangebot: ▪ https://www.wps.de/schulung/isaqb-flex/
Credit Points ADOK Architektur-Dokumentation: Wie dokumentiert und kommuniziert man Softwarearchitekturen? 20 method. AWERT Architektur-Bewertung: Wie findet man heraus, ob eine Architektur die Erwartungen erfüllt? 20 method. EAM Enterprise Architecture Management: Wie kann man eine große Landschaft von IT-Systemen konsistent halten? 30 method. EMBEDDED Embedded Systems: Wie entwirft man eingebettete Systeme, die direkten Einfluss auf ihre Umgebung nehmen? 10 method. 20 tech. SOA-T Serviceorientierte Architekturen: Wie entwirft man eine SOA? 10 method. 20 tech. SOFT Softskills für Software-Architekten: Wie führt man Gespräche zur Architekturfindung und präsentiert Architektur präsentiert verständlich? 30 komm. WEB Web-Architekturen: Wie gestaltet man leistungsfähige und sichere webbasierte Systeme? 30 techn.
ERWARTEN KÖNNT ▪ Wissen aus der Literatur ▪ Erfahrungen aus der Praxis ▪ Meinung ▪ Tipps und Tricks ▪ Abwechslung von ▪ Vorträgen ▪ Übungen ▪ Ein Zertifikat
Modularisierung Integration Installation und Rollout Betrieb, Überwachung und Fehleranalyse Resilient Software Design Case Study Case Study Case Study Case Study Case Study Case Study
Wer sind Sie? ▪ Wie lange programmieren Sie schon? In welchen Sprachen? ▪ Was wissen Sie über Microservices? ▪ Machen Sie DevOps? ▪ Arbeiten Sie in einem agilen Projekt? ▪ Haben Sie schon Domain Driven Design gehört? ▪ Was wollen Sie in den nächsten Tagen lernen?
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. ▪ unabhängig voneinander deploybar ▪ eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema ▪ Kann in unterschiedlichen Technologien und Stylen implementiert sein → keine Wiederverwendung ▪ Hat manchmal eine GUI, und manchmal nicht ▪ Kommuniziert über Netz mit anderen Services durch verschiedene Technologien (synchron/asynchron) Micro- service A Micro- service B Micro- service C
▪ Antworten die man oft hört ▪ Schnellere Deployments ▪ Wir müssen weg von unserem Monolithen ▪ Microservices sind Robust ▪ Microservices sind besser wartbar und sind flexibel ▪ Microservices können einzeln skaliert werden ▪ Microservices sind austauschbar ▪ Technologiefreiheit der Teams ▪ Weniger Meetings ▪ Kosten senken ▪ Wir wollen attraktiver für Kunden und Bewerber werden
▪ Antworten die man oft hört ▪ Schnellere Deployments ▪ Wir müssen weg von unserem Monolithen ▪ Microservices sind Robust ▪ Microservices sind besser wartbar und sind flexibel ▪ Microservices können einzeln skaliert werden ▪ Microservices sind austauschbar ▪ Technologiefreiheit der Teams ▪ Weniger Meetings ▪ Kosten senken ▪ Wir wollen attraktiver für Kunden und Bewerber werden
Wasserfallmodell Iterativ (Scrum) Bildquellen: Wikipedia ▪ Organisatorische Antworten auf Time-to-Market ▪ In jeder Iteration/Sprint kommen klassische Phasen der Softwareentwicklung vor ▪ Nach jeder Iteration ein inkrementelles Release ▪ Qualitätsgesichert ▪ Fachliche-Erweiterung (User Story -> Kundennutzen)
An der Softwareentwicklung sind viele Personen/Rollen beteiligt ▪ Personen arbeiten in Teams zusammen ▪ Die Zusammenarbeit führt zu Kommunikation und Abstimmungs- bedarf Z.B: Team A verwendet einen Webservice von Team B PO Tester Entwickler Team A Team B Architekt Kommunikation
Chunking (Bündelung) ▪ George A. Miller (1956) ▪ Aussagen über den Umfang der Kurzzeitgedächtnisspanne ▪ Einzelne Chunks unbedeutend für Kurzzeitbehalten ▪ 7±2 Chunks ▪ Neuere Untersuchungen: 3 bis 4 Chunks ▪ BYGROUPINGITEMSINTOUNITSWEREMEMBERBETTER ▪ BY GROUPING ITEMS INTO UNITS WE REMEMBER BETTER
des Menschen, um Informationen eine Bedeutung zuzuordnen ▪ Komplexe Zusammenhänge werden strukturiert ▪ Eine mentale Wissensstruktur, die Information über ein bestimmtes Objekt oder Konzept in abstrakter, generalisierter Form enthält Schema Schema: Reihenhaus
Mechanismen Bildung von Hierarchien Chunking Aufbau von Schemata Hierarchisierung Modularität Musterkonsistenz These: Microservice-Architekturen sind modular, hierarchisch und haben Muster.
Nicht nur Time-to-Market bei neuen Features ▪ Auch bei Fehlern/Bugs ▪ Modularisierung/Hierarchien ▪ Größenverhältnisse ▪ Separation of Concern (Trennung der Zuständigkeiten ) ▪ Isolation ▪ Fehlerbegrenzung nur auf eine Komponente ▪ Ggf. klare Trennung durch Prozessgrenzen => Fehler in der Kommunikation Kunden- nutzen Zeit Entwicklung Markttest, etc. Launch Risiko, Kosten Risiko, Kosten
alle 1-2 Jahre ▪ Versionen ▪ Version 5.5 – Juli 2000 ▪ Version 6.0 – August 2001 ▪ Version 6.0 SP1 – September 2002 ▪ Version 6.0 SP2 – August 2004 ▪ Version 7.0 – Oktober 2006 ▪ Version 8.0 – März 2009 ▪ Version 9.0 – März 2011 ▪ Version 10.0 – Oktober 2012 ▪ Version 11.0 – Juni 2013 ▪ Tägliche Releases Time-to-Market (Release-Frequenz) ▪ Releases alle sechs Wochen
Testautomatisierung ▪ Testbarkeit durch Einsatz von ▪ Testframeworks ▪ Mocking ▪ Dependency Injection ▪ Klaren Modulgrenzen/Schnittstellen ▪ Automatisierung nicht nur bei Unit Test ▪ Weitere Testarten ▪ Last & Performancetests ▪ Tests von Code-Qualitätsmetriken Akzeptanztests Integrationstests Unit-Tests Testpyramide
EVENT STORMING? ▪ Ein Workshop-Format ▪ Eine Methode… ▪ um die Domäne kennenzulernen ▪ um Geschäftsprozesse zu modellieren ▪ die Spaß macht ➔Keine Diagramme ➔Keine Tische ➔Keine Stühle @ziobrando
BRAUCHT ▪ Die richtigen Leute: Fachexperten und Entwickler ▪ Einen offenen Geist ▪ Eine Sammlung Sticker in verschiedenen Farben ▪ Eine leere Wand die ca. 10 Meter lang ist ▪ Eine lange Rolle Papier, die man auf der Wand befestigen kann
NACH KARTEN GEFRAGT EVENT STORMING IM KINO SAALPLAN GEÖFFNET PLÄTZE GESUCHT KARTE GEDRUCKT KARTE BEZAHLT WOCHENPLAN GEDRUCKT PLÄTZE RESERVIERT KOMMT PER TELEFON
DIE WICHTIGSTEN STICKIES! ERZEUGE EINE SERIE VON DOMAIN EVENTS ▪ Arbeite den Geschäftsprozess als eine Serie von DOMAIN EVENTS aus ▪ Orange Stickies ▪ Verben in der Vergangenheitsform ▪ Relevant für die Fachexperten DOMAIN EVENT
VERANTWORTLICHEN COMMANDS ▪ Für jedes Domain Event erzeugt man einen Command, der ihn verursacht ▪ Blaue Stickies ▪ Im Imperativ ▪ Die Akteure kommen auf kleine grüngelbe Stickies COMMAND DOMAIN EVENT
Event Storming ist eine Workshop-basierte Methode zur Geschäftsprozess-Analyse und - Modellierung ▪ Das Modell wird auf einer breiten Wand entwickelt ▪ Hauptwerkzeug sind Klebezettel (Stickies)
LÖSUNGSRAUM (PROBLEM SPACE VS. SOLUTIONS SPACE) ▪ Problemraum: ▪ Ermöglicht uns, über die geschäftlichen Herausforderungen nachzudenken ▪ Hier befinden wir uns nur in der Fachlichkeit ▪ Lösungsraum: ▪ Konzentriert darauf, wie wir die Software implementieren, die das Problem löst ▪ Hier gibt es auch Technik ▪ (1-n) Bounded Contexts ▪ Eine Menge von spezifischen Softwaremodellen
CONTEXT/SUBDOMAIN ▪ In einem Projekt das auf der grünen Wiese mit Strategischem Design gebaut wurde haben wir eine 1:1-Abbildung von BC und Subdomain ▪ In der echten Welt ist oft ein Mismatch vorhanden ▪ Legacy-Systeme sind oft »Unbounded Contexts« Zwei Seiten einer Medaille
DOMAIN) ▪ Teil der Geschäftsdomäne ▪ Von entscheidender Wichtigkeit für den Unternehmenserfolg ➔Hier muss die Firma sich hervorherben ➔Dieses Projekt sollte die höchste Priorität bekommen ➔Das Softwaresystem, das die Kerndomäne repräsentiert, ist ein Wettbewerbsvorteil, kein notwendiges Übel
ALLGEMEINE SUBDOMÄNE (SUPPORTING AND GENERIC SUBDOMAIN) ▪ Unterstützende Subdomäne ▪ Modelliert einen Aspekt, der entscheidend ist, aber nicht Teil des Kerns ▪ Teilweise spezialisiert für das Geschäft ▪ Allgemeine Subdomäne ▪ Nicht spezialisiert ▪ Notwendig für die Gesamtlösung ➔Nicht unwichtig! ➔Kein Bedarf hier exzellent zu sein
DIE DOMÄNE? ▪ Domäne: Ein abgrenzbares Problemfeld, dem eine Software gewidmet ist ▪ Software entspringt einer Domäne und steht damit in engem Zusammenhang ▪ Es ist verlockend, zu viel Zeit mit dem Code zu verbringen!
DOMAIN-DRIVEN DESIGN? ▪ Eine Herangehensweise an die Entwicklung von Software, ▪ zentraler Bestandteil: Implementierung eines Domänenmodells ▪ Oder mehrerer Domänenmodelle ▪ Es vereint ▪ Entwurf ▪ Entwicklungspraxis
▪ Jedes Modell hat einen Kontext ▪ Kontext = Grundsätzliche Voraussetzungen, damit Begriffe eine bestimmte Bedeutung erhalten ▪ Wird ein Modell aufgespalten, so ist für jedes Teilmodell eine Kontextdefinition erforderlich ▪ Setze explizite Grenzen in der… ▪ Organisation von Teams ▪ Benutzung von Teilen der Applikation ▪ Codebasis ▪ Entwicklung von Datenbank-Schemas
A BOX ▪ Erhalte die Konsistenz innerhalb der Grenzen ▪ Keine Ablenkung durch äußere Angelegenheiten ▪ Freie Gestaltung eines Teilmodells durch das zugehörige Team ▪ Kenne die Restriktionen ▪ Bleibe innerhalb der Modellgrenzen
Strategisches Modellieren (im Großen) ▪ Teile die Domäne in getrennte Bounded Contexts auf ▪ Jeder BC hat seine eigene ubiquitous language und sein eigenes Domänenmodell ▪ Arten von Subdomänen ▪ Kern (Core Domain) ▪ Unterstützende (Supporting Domain) ▪ Allgemeine (Generic Domain)
KINO- BESUCHER WOCHENPLAN << in Arbeit >> GEWÜNSCHTE ANZAHL PLÄTZE SAALPLAN SAALPLAN- STAPEL VERKAUFTE PLÄTZE KARTEN VORSTELLUNG GEFUNDENE PLÄTZE SAALPLAN SAALPLAN WOCHENPLAN << finalisiert >> VERLEIHER KINO- MANAGER WERBE- AGENTUR BUCHUNGSPLAN DER WERBUNG VORGABEN FÜR FILME GESAMTDEUTSCHE BESUCHERZAHLEN VERFÜGBARKEIT VON FILMEN 1 6 2 10 5 3 8 4 7 9 11 12 13 14 SAALPLAN 15 BEGINNT SEINE ARBEIT AN DEM ÜBERPRÜFT VERHANDELT MIT FINALISIERT DEN ERZEUGT FÜR DIE NÄCHSTE WOCHE GELDSUMME KINOKARTEN BEZAHLTE KINOKARTEN FRAGT NACH FÜR EINE ÖFFNET SCHLIESST AUS DEM BIETET AN BEZAHLT AN SUCHT IM IM MARKIERT DRUCKT AUS ÜBERGIBT AN
KINO- BESUCHER WOCHENPLAN << in Arbeit >> GEWÜNSCHTE ANZAHL PLÄTZE SAALPLAN SAALPLAN- STAPEL VERKAUFTE PLÄTZE KARTEN VORSTELLUNG GEFUNDENE PLÄTZE SAALPLAN SAALPLAN WOCHENPLAN << finalisiert >> VERLEIHER KINO- MANAGER WERBE- AGENTUR BUCHUNGSPLAN DER WERBUNG VORGABEN FÜR FILME GESAMTDEUTSCHE BESUCHERZAHLEN VERFÜGBARKEIT VON FILMEN 1 6 2 10 5 3 8 4 7 9 11 12 13 14 SAALPLAN 15 BEGINNT SEINE ARBEIT AN DEM ÜBERPRÜFT VERHANDELT MIT FINALISIERT DEN ERZEUGT FÜR DIE NÄCHSTE WOCHE GELDSUMME KINOKARTEN BEZAHLTE KINOKARTEN FRAGT NACH FÜR EINE ÖFFNET SCHLIESST AUS DEM BIETET AN BEZAHLT AN SUCHT IM IM MARKIERT DRUCKT AUS ÜBERGIBT AN Trigger Trigger
KINO- BESUCHER WOCHENPLAN << in Arbeit >> GEWÜNSCHTE ANZAHL PLÄTZE SAALPLAN SAALPLAN- STAPEL VERKAUFTE PLÄTZE KARTEN VORSTELLUNG GEFUNDENE PLÄTZE SAALPLAN SAALPLAN WOCHENPLAN << finalisiert >> VERLEIHER KINO- MANAGER WERBE- AGENTUR BUCHUNGSPLAN DER WERBUNG VORGABEN FÜR FILME GESAMTDEUTSCHE BESUCHERZAHLEN VERFÜGBARKEIT VON FILMEN 1 6 2 10 5 3 8 4 7 9 11 12 13 14 SAALPLAN 15 BEGINNT SEINE ARBEIT AN DEM ÜBERPRÜFT VERHANDELT MIT FINALISIERT DEN ERZEUGT FÜR DIE NÄCHSTE WOCHE GELDSUMME KINOKARTEN BEZAHLTE KINOKARTEN FRAGT NACH FÜR EINE ÖFFNET SCHLIESST AUS DEM BIETET AN BEZAHLT AN SUCHT IM IM MARKIERT DRUCKT AUS ÜBERGIBT AN Trigger Einmal pro Woche Trigger
KINO- BESUCHER WOCHENPLAN << in Arbeit >> GEWÜNSCHTE ANZAHL PLÄTZE SAALPLAN SAALPLAN- STAPEL VERKAUFTE PLÄTZE KARTEN VORSTELLUNG GEFUNDENE PLÄTZE SAALPLAN SAALPLAN WOCHENPLAN << finalisiert >> VERLEIHER KINO- MANAGER WERBE- AGENTUR BUCHUNGSPLAN DER WERBUNG VORGABEN FÜR FILME GESAMTDEUTSCHE BESUCHERZAHLEN VERFÜGBARKEIT VON FILMEN 1 6 2 10 5 3 8 4 7 9 11 12 13 14 SAALPLAN 15 BEGINNT SEINE ARBEIT AN DEM ÜBERPRÜFT VERHANDELT MIT FINALISIERT DEN ERZEUGT FÜR DIE NÄCHSTE WOCHE GELDSUMME KINOKARTEN BEZAHLTE KINOKARTEN FRAGT NACH FÜR EINE ÖFFNET SCHLIESST AUS DEM BIETET AN BEZAHLT AN SUCHT IM IM MARKIERT DRUCKT AUS ÜBERGIBT AN Trigger Einmal pro Woche Immer wenn ein Kunde kommt Trigger
KINO- BESUCHER WOCHENPLAN << in Arbeit >> GEWÜNSCHTE ANZAHL PLÄTZE SAALPLAN SAALPLAN- STAPEL VERKAUFTE PLÄTZE KARTEN VORSTELLUNG GEFUNDENE PLÄTZE SAALPLAN SAALPLAN WOCHENPLAN << finalisiert >> VERLEIHER KINO- MANAGER WERBE- AGENTUR BUCHUNGSPLAN DER WERBUNG VORGABEN FÜR FILME GESAMTDEUTSCHE BESUCHERZAHLEN VERFÜGBARKEIT VON FILMEN 1 6 2 10 5 3 8 4 7 9 11 12 13 14 SAALPLAN 15 BEGINNT SEINE ARBEIT AN DEM ÜBERPRÜFT VERHANDELT MIT FINALISIERT DEN ERZEUGT FÜR DIE NÄCHSTE WOCHE GELDSUMME KINOKARTEN BEZAHLTE KINOKARTEN FRAGT NACH FÜR EINE ÖFFNET SCHLIESST AUS DEM BIETET AN BEZAHLT AN SUCHT IM IM MARKIERT DRUCKT AUS ÜBERGIBT AN Trigger Einmal pro Woche Immer wenn ein Kunde kommt Abteilung Kinomanagement Abteilung Kartenverkauf Trigger
KINO- BESUCHER WOCHENPLAN << in Arbeit >> GEWÜNSCHTE ANZAHL PLÄTZE SAALPLAN SAALPLAN- STAPEL VERKAUFTE PLÄTZE KARTEN VORSTELLUNG GEFUNDENE PLÄTZE SAALPLAN SAALPLAN WOCHENPLAN << finalisiert >> VERLEIHER KINO- MANAGER WERBE- AGENTUR BUCHUNGSPLAN DER WERBUNG VORGABEN FÜR FILME GESAMTDEUTSCHE BESUCHERZAHLEN VERFÜGBARKEIT VON FILMEN 1 6 2 10 5 3 8 4 7 9 11 12 13 14 SAALPLAN 15 BEGINNT SEINE ARBEIT AN DEM ÜBERPRÜFT VERHANDELT MIT FINALISIERT DEN ERZEUGT FÜR DIE NÄCHSTE WOCHE GELDSUMME KINOKARTEN BEZAHLTE KINOKARTEN FRAGT NACH FÜR EINE ÖFFNET SCHLIESST AUS DEM BIETET AN BEZAHLT AN SUCHT IM IM MARKIERT DRUCKT AUS ÜBERGIBT AN Trigger Einmal pro Woche Immer wenn ein Kunde kommt Trigger Informationsfluss Abteilung Kinomanagement Abteilung Kartenverkauf
ICH MEINE DOMÄNE? ▪ Nach Abteilungen in der Organisation bzw. Gruppen von Domänenexperten ▪ Nach Unterschieden in der Verwendung/Definition von Schlüsselkonzepten in der Domäne ▪ Nach Grenzen im Geschäftsprozess, die die Domänenexperten beschreiben ▪ Information läuft in eine Richtung ▪ Prozesse werden in unterschiedlichen Rhythmen ausgeführt ▪ Prozesse werden von verschiedenen Triggern ausgelöst.
BOUNDARIES ▪ Contextual language ▪ Data uniqueness ▪ Exclusive domain experts ▪ Business process steps ▪ Existing team/department boundaries ▪ Bottlenecks Nick Tune
CONTEXT KANN EIN EIGENES TEAM HABEN ▪ Entwicklung findet parallel statt ▪ Jeder Bounded Context wird von genau einem Team betreut. ▪ Jedes Team ist für einen oder mehrere Bounded Contexts zuständig.
▪ Continuous Integration in Domain-Driven Design… ▪ findet innerhalb eines Bounded Contexts statt. ▪ bedeutet nicht, verschiedene Bounded Contexts miteinander zu integrieren.
– PRAXIS ▪ wird praktiziert durch… ▪ kontinuierliche Weiterentwicklung des Domain-Modells, ▪ frühes Zusammenführen unterschiedlicher Entwicklungsstränge (häufiges Einchecken), ▪ Kommunikation des Teams über das Domain-Modell, um ein gemeinsames Verständnis davon zu erlangen, ▪ automatisiertes Testen, ▪ reviewen, refaktorisieren und bugfixen des Domain-Modells.
Große Projekte werden auf mehrere Teams aufgeteilt ▪ Ein Domänenmodell muss konsistent sein ▪ Definiere einen Bounded Context für jedes Modell ▪ Klare Grenzen ▪ Das allumfassende Modell kann oft nicht gebaut werden ▪ Bounded Contexts kommunizieren oft über Domain Events
IN TEILMODELLE/BOUNDED CONTEXTS ▪ Greifen Sie auf die Fallstudie zurück ▪ Wie lässt sich die Domäne »Hotel« in sinnvolle Bounded Contexts schneiden? ▪ Falls es Ihnen hilft machen Sie gern ein Event-Storming um sich die Domäne zu veranschaulichen.
Modularisierung ist die Aufteilung eines Ganzen in Teile, die als Module, Komponenten, Bauelemente oder Bausteine bezeichnet werden. ▪ Synonyme ▪ Bausteinprinzip ▪ Baukastenprinzip
vermeiden ▪ Ein bekannter Bad Smell - die „Gott-Klasse“: ▪ Sie enthält 90% des Quelltextes und ist für alles zuständig. ▪ Methoden, die mehrere Bildschirmseiten lang sind, sind schlecht wartbar. ▪ Bausteine mit mehreren hundert Methoden oder Exemplarvariablen sind meist zu groß! ▪ Der Monolith. → Gleichmäßig große Bausteine entwerfen.
Yourself (DRY) ▪ Auch „Single Point of Truth“ and „Single Point of Maintenance“ ▪ Programmcode soll nicht dupliziert werden, weil ▪ das die Änderbarkeit erschwert, da Korrekturen an vielen Stellen nachgezogen werden müssen. ▪ das zu Inkonsistenzen führen kann. ▪ „aufgeblähter“ Code die Lesbarkeit verschlechtert.
Simple, Stupid! (KISS) ▪ So-Einfach-wie-möglich-Prinzip ▪ Angemessene Komplexität ▪ Verständlichkeit + Änderbarkeit ▪ Keine Technik oder Fachlichkeit auf Vorrat ▪ Einfachheit ist ein Resultat von Reife:
der Schnittstelle ▪ Bausteine bieten Dienstleistungen als Methoden an ihrer Schnittstelle an. ▪ Diese Dienstleistungen werden von anderen Bausteinen, den Klienten, benutzt. Dazu fordert der Klient eine Dienstleistung des Anbieters an. ▪ Der Anbieter kann selbst wieder Teile seiner Dienstleistung von anderen Dienstleistern einholen (Delegation). Dienst- leistung Dienst- leistung Klient Dienstleister/Klient Dienst- leistung Dienst- leistung fordert an Dienstleister Schnittstelle fordert an
WACHSEN UND VERDICHTEN SICH Start- up Util Tool A Schritt 1: Illegale Aufwärts- beziehung von Util nach Startup. EFFEKT: Aus 3 hierarchisch strukturierten Klassen wird ein ZYKLUS. Start- up Util Tool A Tool B Schritt 2: Tool B wird korrekt(!) eingefügt. EFFEKT: Der Zyklus wächst trotzdem(!) auf 4 Klassen. Start- up Util Tool A Tool B Schritt3: Tool B kann auf Tool A zugreifen, da sich beide Tools im selben Kontext wie Util und Startup befinden müssen. EFFEKT: Der Zyklus verdichtet sich.
VERSCHWIMMEN! Schritt 4: Startup benötigt Util nicht mehr. EFFEKT: Unklar, welche Klasse nun die Spitze der (gewünschten) Hierarchie sein könnte. Start- up Util Tool A Tool B WAS WENN die Klassennamen nicht gut gewählt sind? EFFEKT: Die ursprünglich gewünschte Hierarchie ist evtl. nicht mehr rekonstruierbar! Folge: TEURES REDESIGN!!! ? ? ? ?
WAS IST DAS? ▪ Ein Architekturstil und ein technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. Micro- service A Micro- service B Micro- service C
▪ Melvin Conway: "Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations." "If you have four groups working on a compiler, you'll get a 4-pass compiler“ Eric Raymond
NICHT MICROSERVICES? ▪ Team Client/ Team Server ▪ Team UI, Team Backend, Team DB ➔ Das ist eine Aufteilung nach technischen Aspekten ▪ Probleme: ▪ Viele Abhängigkeiten, viel Kommunikation ▪ Jedes neue Feature muss von allen Teams umgesetzt werden
WAS IST DAS? ▪ Ein Architekturstil und ein technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. ▪ unabhängig voneinander deployt ▪ eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container Micro- service A Micro- service B Micro- service C
WAS IST DAS? ▪ Ein Architekturstil und ein technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. ▪ unabhängig voneinander deployt ▪ eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container Micro- service A Micro- service B Micro- service C
WAS IST DAS? ▪ Ein Architekturstil und ein technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. ▪ unabhängig voneinander deployt ▪ eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema Micro- service A Micro- service B Micro- service C
WAS IST DAS? ▪ Ein Architekturstil und ein technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. ▪ unabhängig voneinander deployt ▪ eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema ▪ Kann in unterschiedlichen Technologien und Stylen implementiert sein → keine Wiederverwendung Micro- service A Micro- service B Micro- service C
TECHNOLOGIEFREIHEIT Micro- service A Micro- service B Micro- service C Microservices reden nur über Netzprotokolle miteinander Nur Laufzeitabhängigkeit Freiheit in der Wahl der Technologie ▪ Entscheidungen können schneller getroffen werden ▪ Technologie kann auf jeweiligen Service zugeschnitten werden ▪ Z.B. Graph-DB für Service, der viel mit Relationen hantiert ▪ Keine unnötige Komplexität durch unpassende Sprache / Frameworks / Datenbanken
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. ▪ unabhängig voneinander deployt ▪ eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema ▪ Kann in unterschiedlichen Technologien und Stylen implementiert sein → keine Wiederverwendung ▪ Hat manchmal eine GUI, und manchmal nicht Micro- service A GUI Micro- service B Micro- service C
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst. ▪ unabhängig voneinander deployt ▪ eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema ▪ Kann in unterschiedlichen Technologien und Stylen implementiert sein → keine Wiederverwendung ▪ Hat manchmal eine GUI, und manchmal nicht ▪ Kommuniziert über Netz mit anderen Services durch verschiedene Technologien (synchron/asynchron) Micro- service A Micro- service B Micro- service C
MICROSERVICES ▪ REST ▪ UI, zum Service ▪ synchron → Rest Resource passen fürs UI gestalten mit Value Objects → keine Entities oder Aggregate als Resource ▪ Messaging ▪ Zu Service ▪ Asynchron → Commands, Events, Request, Response mit Value Objects Service A UI A Service B POST GET PUT DELETE POST, GET, PUT, DELETE
Technologien in welchem Bounded Context? ▪ Wir nehmen die Bounded Contexts, die wir in der vorherigen Übung gefunden haben ▪ Überlegt für jeden Bounded Context: ▪ Welche Technologien setzt ihr ein? ▪ Wie wichtig ist die interne Architektur? ▪ Wie verteilen Sie die Entwickler?
▪ Ausschneiden eines MS aus einem Monolithen ist nur möglich, wenn dieser eine fachliche Architektur hat ➔Es lohnt sich mit DDD zu starten User Interface Domain Application Fachliches Modul B Fachliches Modul A Fachliche Schichtung Technische Schichtung Fachliches Modul C
DEN FRÜHEN 2000ER JAHREN Technische Schichtung Keine fachliche Struktur Wenige Schichten- verletzungen Fast alle 90 fachlichen Komponenten brauchen sich gegenseitig
ICH MEINE DOMÄNE? ▪ Nach Grenzen im Geschäftsprozess, die die Domänenexperten beschreiben ▪ Nach Abteilungen in der Organisation bzw. Gruppen von Domänenexperten ▪ Nach Unterschieden in der Verwendung von fachlichen Begriffen ▪ Exklusive Domänenexperten
DESIGN Ein Monolith mit mehrere miteinander vermengte Domänenmodelle ▪ Vorgehen: ▪ Die vermengten Modelle als einzelne Subdomänen denken ▪ Für jede gedachte Subdomain eine eigene Ubiquitous Language erarbeiten
LEBENDIG ▪ Experimentiere mit alternativen Ausdrucksformen ▪ Das Modell und die Sprache entwickeln sich weiter ▪ Überarbeite dann den Code ▪ Benenne Klassen, Methoden, Module ▪ Entspreche dem neuen Modell ▪ Eine Sprache will gesprochen werden: ▪ Beseitige Unklarheiten durch Konversation
DESIGN Ein Monolith mit mehrere miteinander vermengte Domänenmodelle ▪ Vorgehen: ▪ Die vermengten Modelle als einzelne Subdomänen denken ▪ Für jede gedachte Subdomain eine eigene Ubiquitous Language erarbeiten ▪ Business Klassen bzw. Entities untersuchen, ob Zerlegung und Refactoring möglich. Testabdeckung! ▪ Ggf. Duplizierung der Business Klassen und jeweils schrittweise Ausbau der nicht benötigten Funktionalität
NICHT BAUEN WOLLEN ✘ ANEMIC DOMAIN MODEL ▪ „blutarme“ fachliche Objekte ▪ Schnittstelle ohne Aussagekraft ▪ aus Gettern/Settern ▪ Viele String Parameter ▪ Eigentliche Fachlichkeit außerhalb Entities + Value Objects in Services oder im UI ▪ Viele Util, Helper und Manager Klassen
DESIGN Ein Monolith mit mehrere miteinander vermengte Domänenmodelle ▪ Vorgehen: ▪ Die vermengten Modelle als einzelne Subdomänen denken ▪ Für jede gedachte Subdomain eine eigene Ubiquitous Language erarbeiten ▪ Business Klassen bzw. Entities untersuchen, ob Zerlegung und Refactoring möglich. Testabdeckung! ▪ Ggf. Duplizierung der Business Klassen und jeweils schrittweise Ausbau der nicht benötigten Funktionalität ▪ Aufteilung in Bounded Contexts bzw. Microservices
MAP) ▪ Jedes Team kennt seinen Kontextgrenzen. Wie steht es um die anderen? ▪ Eine Kontextübersicht skizziert ▪ Die verschiedenen begrenzten Kontexte ▪ ihre wechselseitigen Beziehungen ▪ Begrenzte Kontexte sollten benannt sein.
DESIGN Ein Monolith mit mehrere miteinander vermengte Domänenmodelle ▪ Vorgehen: ▪ Die vermengten Modelle als einzelne Subdomänen denken ▪ Für jede gedachte Subdomain eine eigene Ubiquitous Language erarbeiten ▪ Business Klassen bzw. Entities untersuchen, ob Zerlegung und Refactoring möglich. Testabdeckung! ▪ Ggf. Duplizierung der Business Klassen und jeweils schrittweise Ausbau der nicht benötigten Funktionalität ▪ Aufteilung in Bounded Contexts bzw. Microservices ▪ Fachliches von Technischem trennen
DESIGN Weitere Aspekte: ▪ Asynchrone Kommunikation bevorzugen ▪ Verfügbarkeit/Robustheit ▪ Integration über das UI ▪ Legacy verlinkt auf den MS oder umgekehrt ▪ Single-Sign-On integrieren ▪ Risiken minimieren ▪ Mit kleinem unwichtigem Microservice beginnen ▪ Schrittweise migrieren, kein Big Bang ▪ Redundante fachliche Entwicklung vermeiden (Nur noch Änderungen in Microservices) ▪ Integrationstests für Microservices und Legacy-System
zu einer neuen Architektur Refactorings Analyse + Diskussion Maßnahmen festlegen Ubiquitous Language Ist- Architektur Rekonstruktion Source- Code Bounded Contexts Begriff- + Prozessanalyse Architektur- alternativen • Priorisierung der Maßnahmen • Einplanung in den Entwicklungszyklus Verletzungen • Mit den Domänenexperten und dem Team diskutieren und modellieren Event Storming Domain Storytelling Context Mapping
Die Domäne ▪ hat einen Lösungs- und einen Problemraum ▪ Zerfällt in Subdomains ▪ Subdomains sind unterschiedlich wichtig ▪ Die Core Domain ist am wichtigsten ▪ Auch im Brownfield ist strategisches Design möglich
▪ Lesen Sie den zweiten Teil der Fallstudie ▪ Umdenken ▪ Welche Probleme sehen Sie bei dem Altsystem ▪ Welche Maßnahmen wären erforderlich um Grundlagen für eine Integration von REZI zu schaffen? ▪ Diskutieren Sie Migrationsstrategien um REZI in die neue Struktur zu überführen. ▪ Wie passen Ihre ursprünglich identifizierten Bounded Contexts zu denen von REZI?
Makro-Architekturentscheidungen ▪ Entscheidungen können auf Mikro- oder Makroebene entschieden werden ▪ Makroebene ▪ Einsatz der Gesamtlösung wird eingeschränkt ▪ Unternehmensweite Standards ▪ Mikroebene ▪ Optimale Lösung für den einzelnen Bounded Context ▪ Sorgt für Unabhängigkeit der Teams ▪ Beispiele ▪ Die Programmiersprache ▪ Die Datenbank ▪ Look & Feel ▪ Dokumentation
You build it You run it Firmenkultur Betrieb: Mikro- und Makro-Architektur Betrieb • Konfiguration • Monitoring • Log-Analyse • Deployment-Technologie Mikroarchitektur Makroarchitektur
Database) ▪ Mehrere Service arbeiten auf dem gleichen Datenbankschema ▪ Keine Datenredundanz ▪ Schema kann nur gemeinsame weiterentwickelt werden ▪ Das widerspricht dem Konzept „Microservice“ ▪ Nicht zu verwechseln mit Shared Kernel (Context Mapping) Subsystem A Subsystem B
▪ Jeder Microservice hat sein eigene Datenbank oder eigenes Datenbankschema ▪ Redundanz der Daten ▪ Datenmigration kann durch „Extract, Transform, Load “- Prozesse (ETL) realisiert sein Micro- service A Micro- service B ETL
Transfer Vorteile ▪ Einfach ohne weitere Software zu realisieren. ▪ Auf allen Plattformen und in allen Programmiersprachen verfügbar. ▪ Asynchron, sodass die Applikationen getrennt weiter arbeiten können. ▪ Lose Kopplung zwischen den Applikationen. ▪ Kaum Eingriffe in die Applikation, um den Export zu realisieren. ▪ Interna der Apps bleiben verborgen. Nachteile ▪ Inkonsistenz zwischen Applikationen wegen großer Zeitintervalle zwischen den Updates der Daten. ▪ Viele Absprachen zwischen den Entwicklern notwendig über: ▪ Verzeichnisse und Dateinamen, ▪ Zeitpunkt der Fertigstellung und des Löschens eines Exports. ▪ Semantik der Daten wird in den Applikationen jeweils lokal festgelegt. Voraussetzung ▪ Gemeinsames Dateisystem ▪ Einigung über das Format (Textbasiert, XML, CSV, etc.) ▪ Exporter bzw. Importer verstehen das gleiche Format. Micro- service A Micro- service B
(Remote Procedure Call) Vorteile ▪ Funktionalität wird wiederverwendet. ▪ Daten sind lokal gekapselt, sodass jede Applikation beliebige eigene Formate wählen kann und die Integrität ihrer eigenen Daten wahrt. ▪ Potentiell weniger Codeverdopplung, weil Funktionen wiederverwendet werden. Nachteile ▪ Enge Kopplung und geringere Stabilität bei Ausfall einer Applikation. ▪ Performanz und Ausfallsicherheit von entfernten Aufrufen. ▪ Änderungen an einer Applikation betreffen potentiell alle entfernten Aufrufer. ▪ Sich gegenseitig aufrufende Applikationen bilden ein kaum zu entwirrendes Knäuel. Voraussetzung ▪ Veröffentlichung von nutzbaren Funktionen für andere Applikationen. ▪ Einigung über eine gemeinsame Technologie (z. B. CORBA, COM, .NET, RMI, SOAP mit HTTP). ▪ Berücksichtigung von Ausfällen des Netzwerks bzw. der aufgerufenen Applikation. Micro- service A Micro- service B Micro- service A Micro- service B
(Representational State Transfer) Im Vergleich zu RPC ▪ Ähnlich wie RPC (ebenfalls synchrone Kommunikation) ▪ Anstatt Funktionsaufrufen wird auf Ressourcen gearbeitet ▪ Prinzipien ▪ Zustandslosigkeit ▪ Nachricht enthält alle Informationen, Server speichert keine Zustände zwischen zwei Nachrichten ▪ Caching ▪ HTTP Caching soll verwendet werden ▪ Einheitliche Schnittstelle ▪ Adressierbarkeit von Ressourcen ▪ http://webshop/api/bestellungen ▪ Repräsentationen zur Veränderung von Ressourcen ▪ HTML/JSON/XML ▪ Selbstbeschreibende Nachrichten ▪ Durch HTTP-Verben, GET, POST, DELETE, PUT Micro- service A Micro- service B
klassisch ▪ Konfigurationsdatei ▪ Wird gelegentlich aktualisiert ▪ Probleme bei Microservices ▪ Netzwerk-Adressen nicht statisch ▪ Microservices werden dynamisch gestartet oder gestoppt ▪ Wie wird Load Balancing durchgeführt Service Client Service Instanz A Service Instanz B Service Instanz C Client oder ein API Gateway Dynamische IP Adressen Skalierung REST API REST API REST API 10.10.2.12:8893 10.10.34.24:8034 10.10.1.99:8238 ?
(Client Side Load Balancing) ▪ Client ist verantwortlich für die Bestimmung von verfügbaren Services und deren Location ▪ Client ist ebenfalls verantwortlich für das Load Balancing ▪ Ablauf ▪ Services melden sich bei der Service Registry an ▪ Client fragt Service Registry nach Services ab ▪ Client verwendet Load-Balancing Algorithmus und spricht Service an Service Instanz A Service Instanz B Service Instanz C REST API REST API REST API 10.10.2.12:8893 10.10.34.24:8034 10.10.1.99:8238 Service Register Service Instanz A Ein HTTP Client der das Register kennt Register Client Register Client Register Client
(Server Side Load Balancing) ▪ Services melden sich ebenfalls bei der Service Registry an ▪ Ein Load Balancer übernimmt die Aufgabe der Service Auswahl Service Instanz A Service Instanz B Service Instanz C REST API REST API REST API 10.10.2.12:8893 10.10.34.24:8034 10.10.1.99:8238 Service Register Service Instanz A Register Client Register Client Register Client Load Balancer
Vorteile ▪ Lose Kopplung, ähnlich wie File Transfer. ▪ Hohe Ausfallsicherheit des Gesamtsystems, weil Nachrichten aufgehoben werden. ▪ Weniger Performance-Probleme wegen Message- Queues. ▪ Asynchrone Kommunikation macht Zeitverzögerung übers Netz für Entwickler sichtbar. ▪ Über Nachrichten können Daten verschickt und Funktionsaufrufe abgesetzt werden. Nachteile ▪ Asynchrone Kommunikation muss beherrscht werden. ▪ Semantische Dissonanz zwischen Applikationen wird nicht behoben. Voraussetzung ▪ Applikationen sind an einen Message Bus angeschlossen. ▪ Entsprechende Technologie wird verwendet (JMS, IBM WebSphereMQ, Microsoft MSMQ, Asynchrone WebServices). Micro- service A Micro- service B
(MOM) Grundkonzepte: • Send and Forget • Store and Forward Loose Coupling and Reliability Channels are separate from applications → Removes location dependencies Channels are asynchronous and reliable → Removes temporal dependencies Data is exchanged in self-contained messages → Removes data format dependencies
MOM ▪ Messages werden in einer Queue auf dem Server persistiert. ▪ Eine Message kann nur einmal von einem Consumer gelesen werden. ▪ Mehrere Producer / Consumer können dieselbe Queue benutzen. A B P queue Q message producers message consumers
MOM ▪ Komplexes Programmiermodell ▪ Event-getriebenes Programmiermodell. ▪ Logik wird auf Eventhandler verteilt. ▪ Debugging über Prozessgrenzen. ▪ Nachrichtenreihenfolge ▪ Nachrichten haben Zustellgarantie, aber keine Garantie der Reihenfolge. ▪ Abhängige Nachrichten müssen resequentialisiert werden . ▪ Synchrone Anwendungsszenarien ▪ Anwender gehen von einer synchronen Bearbeitung ihrer Anfrage aus. ▪ Anwendung muss entsprechend reagieren. ▪ Performanz ▪ Große Datenmengen zur Initialisierung besser außerhalb des MOM. ▪ Plattform Support ▪ Proprietäre MOMs oder Plattformen schränken die Möglichkeiten ein. ▪ Herstellerabhängigkeit ▪ Trotz Standards wie JMS sind die Implementierungen oft plattformabhängig. ▪ Die Integration von integrierten Lösungen ist eine weitere Herausforderung!
(Frontend Monolith) ▪ Es gibt einen Frontend Monolithen ▪ Native Apps ▪ Desktop Anwendung ▪ Single-Page-Applikation ▪ Ggf. ein Team für die Frontendentwicklung ▪ Optional mit API-Gateway ▪ Einheitliches Look & Feel Micro- service A Micro- service B
Frontend) ▪ Integration über ▪ Links ▪ Transklusion ▪ Übernahme von einem elektronischen Dokument oder Teilen davon in ein oder mehrere andere Dokumente durch einen Hypertext-Verweis ▪ Vorteile ▪ Lose Kooplung ▪ Login und UI in einem Microservice (Ein Team) ▪ Freie Wahl der Frontend-Technologie ▪ Herausforderung ▪ Einheitliches Look & Feel ▪ UI-Änderungen ggf. Querschnittlich (Z.B. bei Redesign) Micro- service A Micro- service B
Micro-Frontends ▪ Serverseitige Template-Komposition ▪ Je nach URL-Suffix andere HTML-Datei in index.html inkludieren, oder ▪ Je nach URL-Suffix Teil-HTML von anderem Server abfragen ▪ Buildtime Integration ▪ Im Frontend die „Micro-Frontends“ als versionierte npm-dependencies einbinden ▪ Nachteil: Kopplung auf Release/Deployment-Ebene ▪ Laufzeit-Integration mit iframes ▪ Je nach Route direkt im index.html jeweiligen iframe von unterschiedlichen Ressourcen und unterschiedlichen Servern holen ▪ Lautzeit-Integration mit JavaScript ▪ index.html inkludiert JavaScript-Dateien von allen Micro-Frontends. Je nach Route wird der Entrypoint eines Micro-Frontends aufgerufen, der dann das Rendern übernimmt ▪ Flexibel ▪ Laufzeit-Integration mit WebComponents ▪ Je nach Route WebComponent von jeweiligem Micro-Frontend in den DOM laden ▪ Weniger flexibel, stärker am Web-Standard
System (SCS) ▪ Für Microservices gibt es keine einheitliche Definition ▪ Ein SCS ist eine Ausprägung von Microservices ▪ SCS geben einen Orientierungspunkt, wie eine Microservice-Architektur konkret aussehen kann ▪ SCS sind eine Sammlung von Best Practices ▪ SCS geben Elemente auf der Makro-Architekturebene vor http://scs-architecture.org/
System (SCS) ▪ Jedes SCS ist eine autonome Webanwendung ➔ Jedes SCS besitzt eine UI ▪ Es gibt keine gemeinsame UI ▪ Ein SCS kann optional eine API besitzen ▪ Z.B. für die Anbindung von einem mobilen App ▪ Ein SCS gehört einem Team ▪ Ein SCS kann aus mehreren Microservices bestehen ▪ Z.B. für Skalierung ▪ Priorisierung für die Kommunikation unter SCSs ▪ Prio 1: UI-Integration ▪ Prio 2: asynchrone Kommunikation ▪ Prio 3. synchrone Kommunikation Micro- service A Micro- service B 1 2
es SOA? 1. Die Ansprüche von Kunden und Partnern steigen (Marktdruck) 2. Viele Geschäftsprozesse funktionieren ausschließlich mit IT-Unterstützung 3. Bestehende IT-Systeme sind häufig Applikationsmonolithen, unflexible und über lange Jahre gewachsene starre Anwendungssilos 4. IT-Budgets werden oftmals für die Entwicklung oder Modernisierung einzelner Anwendungen vergeben, ohne Bezug zu deren aktuellen oder künftigen Wertschöpfungen. → Unternehmen brauchen SOA für unternehmerische Flexibilität mit wertschöpfende Geschäftsprozesse unter geänderten Marktbedingungen → SOA wird ausschließlich durch geschäftliche Argumentation getrieben – Technik ist nur Mittel zum Zweck
SOA? ▪ SOA ist eine unternehmensweite IT-Architektur mit Services (Diensten) als zentralem Konzept, in der die Services Geschäftsfunktionen realisieren oder unterstützen. ▪ Services werden als integrierbare Einheiten entworfen: ▪ Sie sind lose gekoppelt ▪ Sie sind selbständig betriebene, verwaltete und gepflegte Softwareeinheiten ▪ Sie kapseln ihre Funktionen über eine implementierungsunabhängige Schnittstelle. ▪ Zu jeder Schnittstelle gibt es einen Service-Vertrag, der die funktionalen und nichtfunktionalen Merkmale der Schnittstelle beschreibt. ▪ Die Nutzung von Services geschieht über (entfernte) Aufrufe und setzt so weit wie möglich auf offene Standards, wie XML, SOAP, WSDL etc.
Kombinierbare Komponenten einer Benutzeroberfläche ▪ Werden von einem Portalserver angezeigt und verwaltet ▪ Erweiterter Servlet Container ▪ Das Wort „Portlet“ ist abgeleitet von „Servlet“ ▪ Portlets kommunizieren über Events ▪ Geschichte ▪ Erste Drafts 2002 ▪ JSR-286 wude 2008 released Frontend 1 Backend Frontend 2 Frontend 3
+ ESB) ▪ Zentrale Orchestrierung über Workflow-Engine ▪ Workflow-Engine kann Standalone oder als Bestandteil eines ESBs laufen ▪ Muster eher unüblich für Microservice- Architekturen ▪ Leichtgewichtigere Lösungen werden bevorzugt Microservice Kino- management Microservice Ticketverkauf ESB Microservice Marketing Workflow-Engine
▪ Microservices übernehmen die Orchestrierung ▪ Optional kann eine Workflow-Engine im Microservice laufen ▪ Beispiel: Camunda ▪ Harte Abhängigkeit bleibt zwischen den Services Microservice Ticketverkauf Microservice Marketing Microservice Kinomanagement Workflow-Engine
in unterschiedlichen Zusammenhängen auch Reaktionszeit oder Latenz(zeit) genannt, ist der Zeitraum zwischen einer Aktion oder einem Ereignis und dem Eintreten einer Reaktion. Dabei kann die Aktion verborgen sein und sich erst durch die Reaktion zeigen. Diskussion
▪ Nehmen Sie an, jeder Bounded Context ist ein Microservice (falls es Ihnen sinnvoll erscheint, können Sie auch nochmal neu schneiden). ▪ Welche Entscheidungen würden Sie auf Makro- bzw. auf Mikro-Ebene treffen? ▪ Skizzieren Sie, wie Sie Ihre Microservices integrieren würden. ▪ Wie gehen Sie mit Latenzen um?
Abgrenzung der Begriffe ▪ Authentisierung: Nachweis der Identität ▪ Ich weise mich durch Eingabe meines Benutzernamens/Passwortes aus ▪ Ich weise mich mit meinem Personalausweis aus ▪ Authentifizierung: Prüfung des Nachweises ▪ Benutzername/Passwort wird geprüft ▪ Personalausweis und Verknüpfung mit meiner Person werden geprüft ▪ Autorisierung: Prüfung der Berechtigung ▪ Darf der Benutzer auf das Objekt zugreifen. ▪ Der Gast besitzt ein Ticket für sein entsprechenden Film. ▪ Nach der Authentifizierung ist das Subjekt autorisiert entsprechend seiner Berechtigungen zu arbeiten.
Monolith ▪ Oft als zentrales Login implementiert ▪ User-Repository ggf. Bestandteil des Monolithen ▪ User-Info wird an der Session gehalten ➔Authentifizierung und Autorisierung im Monolithen ▪ Microservices ▪ Zentrales User Repository ▪ Verwendung von SSO-Standards ▪ OAuth2 ▪ OpenID Connect ➔Authentifizierung zentral ➔Autorisierung in jedem Microservice
Anwender authentifiziert sich am „Authorization Server“ und erhält einen Access Token ▪ Access Token hat keine Information über den Anwender ▪ Man kann am „Authorization Server“ die Informationen zu einem Anwender abfragen
Resource owner (a.k.a. Anwender) - Eine Entität, welche Zugriff zu geschützten Resourcen gewähren kann. Wenn der Resource Owner eine Person ist, handelt es sich um den Anwender. ▪ Resource server (a.k.a. API server) - Der Server, auf dem die geschützte Resource läuft. Ist fähig Anfragen entgegenzunehmen, welche einen Access Token besitzen. ▪ Client - Eine Anwendung, welche im Namen eines Ressource owner Anfragen an geschützte Resourcen stellt. ▪ Authorization server - Der Server stellt Access Tokens an den Client aus, nachdem sich der Resouce Owner erfolgreich authentifizeirt hat. Der Resource Owner gibt ggf. explizit die Berechtigigung dazu.
▪ Authorization Code: Ein Code, mit dem der Client einen Access Token abfragen kann. ▪ Access Token: „Eintrittskarte“. Berechtigt den Client auf die geschützte Ressource zuzugreifen. ▪ Refresh Token: Der Access Token kann ggf. eine kurze Gültigkeitsdauer besitzen. Mit dem Refresh Token kann dann ein neuer Access Token abgefragt werden.
▪ Authorization code grant ▪ Klassische Web-Applikation (Server-State) ▪ Client erhält einen Authorization Code, womit er sich einen Access Token holen kann. ▪ Implicit grant ▪ Single Page Web App (es werden keine Client-Credentials benötigt.) ▪ Client erhält direkt einen Access Token. ▪ Password (Resource owner credentials grant) ▪ Trusted 1st Party Clients ▪ Username/Passwort im Client eingegeben. Access Token wird ausgestellt, ▪ Client credentials grant ▪ Für Maschine-Zu-Maschie Authentifizierung. ▪ Authentifizeirung erfolgt per Client Credentials. ➔ Keine Anwenderinformationen. ▪ Refresh token grant ▪ Neuer Access Token und Refresh Token wird ausgestellt.
Micro- service A Micro- service B REST REST Micro- service C REST API Gateway Token Token Token Authorization Server Single Page App Token Token REST UserInfo Bei jedem Zugriff-> Abfrage der UserInfo oder Session im Microservice
▪ Baut auf OAuth2 auf ▪ Neben dem Access Token wird ein ID Token ausgestellt ▪ ID Token enthält Informationen über den Anwender ▪ Implementierung basiert auf JWT (JSON Web Token), welcher vom „Authorization Server“ signiert wurde ➔Microservice vertraut dem Token ▪ Durch Token kann Server Stateless bleiben (Token wird im Client gehalten) ➔Horizontale Skalierung
Security Here’s a rule of thumb (attributed to Rob Winch): “if your application or API is going to be accessed by a browser, you need CSRF protection. It’s not that you can’t do it without sessions, it’s just that you’d have to write all that code yourself, and what would be the point because it’s already implemented and works perfectly well on top of HttpSession.” Quelle: https://spring.io/guides/tutorials/spring-security-and-angular-js/
▪ Zuul wird an Edge-Services verwendet ▪ Routing and Filtering ▪ Authentication ▪ Security JWT enthät User Info. Daher ggf. vor dem API Gateway/Ede Service OAuth2 und dahinter JWT.
bezeichnet den Vorgang, eine neue Version eines Services in Produktion zu nehmen. Ziele eines Deployments ▪ Fehlerbehebung ▪ Service-Qualität verbessern ▪ neue Features Rechtliche Maßgaben beachten, ggf. menschlicher “Gatekeeper” notwendig. Bei minimalen Auswirkungen auf die Nutzer des Services! Entwicklungs- umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb
https://martinfowler.com/bliki/DeploymentPipeline.html „One of the challenges of an automated build and test environment is you want your build to be fast, so that you can get fast feedback, but comprehensive tests take a long time to run. A deployment pipeline is a way to deal with this by breaking up your build into stages. Each stage provides increasing confidence, usually at the cost of extra time. Early stages can find most problems yielding faster feedback, while later stages provide slower and more through probing. Deployment pipelines are a central part of Continuous Delivery.“
Downtime ▪ Zugehörige und abhängige Systeme werden während des Deployments vom Netz genommen. ▪ Ops müssen Nacht- oder Frühschichten schieben ▪ Devs sind zeitlich eingeschränkt ▪ unmöglich bei 24/7 Anforderungen ▪ Gibt es eine bessere Lösung?
▪ Risiko minieren: Neue Version erst bei einem Teil der Nutzer ausrollen ▪ Zufällig ausgewählt ▪ Zuerst interne, dann externe ▪ Nach Nutzerdaten ▪ Freiwillige (Beta-Test) ▪ Ziele ▪ Risikominimierung von Fehlern ▪ Kapazitätsplanung ▪ Nutzerverhalten (A/B-Tests) ▪ Alternativversionen parallel betreiben Entwicklungs- umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb
▪ Risiko minieren: Neue Version erst bei einem Teil der Nutzer ausrollen ▪ Zufällig ausgewählt ▪ Zuerst interne, dann externe ▪ Nach Nutzerdaten ▪ Freiwillige (Beta-Test) ▪ Ziele ▪ Risikominimierung von Fehlern ▪ Kapazitätsplanung ▪ Nutzerverhalten (A/B-Tests) ▪ Alternativversionen parallel betreiben Entwicklungs- umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb Fehler gibt es trotzdem! Dauerhaft: ▪ Monitoring und Vergleich mit historischen Daten ▪ Logging, das die Fehlerdiagnose vereinfacht ▪ Problemfälle zum Normalfall machen
Deployment 1. Downtime 2. Blau-/Grün-Deployment 3. Rollierendes Update VM VM VM VM VM VM IST SOLL VM VM VM VM VM VM Load Balancer VM VM VM VM VM VM Load Balancer Load Balancer Load Balancer Load Balancer Load Balancer Load Balancer VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM
Nachteile der Strategien 1. Downtime ▪ Sehr einfach! ▪ Ops müssen Nacht- oder Frühschichten schieben ▪ Devs sind zeitlich eingeschränkt ▪ unmöglich bei 24/7 Anforderungen 2. Blau/Grün-Deployment ▪ Ressourcen-Verbrauch ist höher (oder man nimmt die Staging-Umgebung) ▪ “Big Bang” beim Umschalten ▪ Rollback ist einfach 3. Rollierendes Update ▪ Ressourcen kaum erhöht ▪ Konsistenzprobleme müssen bedacht werden ▪ komplizierter ▪ Rollback in der Mitte ist ein Problem
Was ist mit den Daten? ▪ Es kommt ein letzter Request der die Erstellung eines Users fordert. ▪ Dieser wird auch erzeugt und erhält die ID 1234. ▪ Unmittelbar danach schaltet der Router um und stellt Version 1.1 live POST Request: CREATE USER “Hans Meier“
Was ist mit den Daten? ▪ Danach erfolgt ein GET Request der die User mit dem Namen „Hans Meier“ anfordert. ▪ Wie stellen wir sicher, dass der Hans Meier mit der ID 1234 auch in der Antwort enthalten ist? GET Request: ALL USERS NAMED “Hans Meier“
Gemeinsame Datenbank ▪ Beide Versionen gehen gegen einen Datenbankcluster und die Datenbank erhält mit der neuen Version konservative Änderungen ▪ Die Datenbank bleibt N-1 Kompatibel. ▪ Das Konzept muss von Entwicklern verstanden sein und bei den Datenbank- refactorings berücksichtigt werden. 1.0 & 1.1
parallel betriebenen Versionen Beispiel während der Umstellung: Ich nutze den neuen Kino-Service, um einen neuen Saal anzulegen. Beim alten Kino-Service, schlägt der selbe Aufruf fehl, weil das Feature fehlt! Lösungsansätze ▪ Klient weiß, mit welcher Version er spricht ▪ Neue Features erst nutzen, wenn alle Services ersetzt sind ▪ Vorwärts- und Rückwärts-kompatible Schnittstellen Auch für veränderte DB-Schemata gibt es Lösungsansätze. Alle Lösungen müssen von Software-Entwicklern umgesetzt werden!
umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb • Läuft meist auf Entwickler-Desktop • Log-Level ist sehr hoch • Läuft auf CI-Server • Komponenten werden erzeugt • Umgebung ist so nah an der Betriebs- umgebung wie möglich! • Komponente wird bei einigen Anfragen verwendet und überwacht • Komponente wird auf allen Instanzen in Produktion genommen unveränderte Komponente angepasste Konfiguration Minimale Test- Daten Produktive Daten Neu aufgesetzte, Minimale Test-Daten Realistische Daten
Daten Möglichst gleich wie Produktion halten ▪ Auf Pseudonymisierung oder besser Anonymisierung achten! ▪ Möglichst gleiche Infrastruktur in allen Umgebungen dabei helfen ▪ Automatisierte Deployments ▪ Infrastructure as Code (Docker) ▪ Idealerweise wird die gesamte Infrastruktur mit dem Deployment neu erzeugt
Umgebungen ▪ Konfiguration sollte immer nachvollziehbar sein. ▪ Konfigurationsänderungen sollten reversibel sein ▪ Beides wird gefördert wenn sich die Konfiguration im Repository befindet. ▪ Im Idealfall betreiben wir in jeder Umgebung das gleiche Artefakt ▪ Feature Toggles helfen das hinzu und wegnehmen einzelner Funktionen zentral zu steuern ▪ Features die noch nicht produktionsreif sind werden nur in den vorgelagerten Umgebungen aktiviert
PIPELINE ▪ Lesen Sie Teil 3 der Fallstudie. ▪ Auf der Grundlage der bisher gestalteten Makro Architektur: ▪ Wie könnte eine Deployment-Pipeline aussehen, die den Anforderungen an die Microservices gerecht wird? ▪ Welche Deployment-Strategien sehen Sie als sinnvoll an? ▪ Gibt es Release-Abhängigkeiten? Falls ja wie gehen Sie mit diesen um?
Ermöglicht den bessere Auslastung der vorhandenen Systemressource ▪ Ressourcen wie Energie und Platz werden geschont ▪ Anwendungen laufen weiterhin isoliert auf getrennten Betriebssystemen
Alles Dropbox oder was? ▪ Am Anfang war Amazon! ▪ Public Cloud ▪ Vollständiges Outsourcing der Hardware ▪ Fremde Rechen- und Speicherleistungen werden auf Bedarf eingekauft ▪ Private Cloud ▪ Vollständige Virtualisierung und Containerisierung ▪ Dynamisches hinzunehmen und entfernen von Rechenleistung ▪ Betrieb eigener Hardware
▪ Software as a Service (SaaS) ▪ E-Mail, virtueller Desktop, Spiele, … ▪ Kunde hat eine Software zur Verfügung, die in einer Cloud läuft ▪ Platform as a Service (PaaS) ▪ Webserver, Datenbanken, Entwicklungsumgebungen, … ▪ Kunde kann Software auf der Cloud-Infrastruktur installieren ▪ Hoher Standardisierungs-Grad! ▪ Infrastructure as a Service (IaaS) ▪ Virtuelle Maschinen, Storage, Load Balancer, … ▪ Kunde kann Betriebssysteme, Datenspeicher und Netzwerke verwalten ▪ Zugrundeliegende Infrastruktur bleibt in der Verantwortung des Anbieters
oder Rechenressourcen? ▪ Abwägungsfrage: ▪ Managed Datenbank vom Cloudanbieter ▪ Oder eine reine VM/VMs auf denen die Datenbank selbst betrieben wird ▪ Häufig abzuwägen: ▪ Schneller Start vs. steile Lernkurve ▪ Für die Masse gute Leistung vs. auf individuellen Bedarf zugeschnittene Leistung ▪ Standardisierung vs. Flexibilität Standardisierung Flexibilität hoch niedrig niedrig hoch IaaS PaaS SaaS
vs Cattle „Server sind wie Haustiere“ Sie bekommen einen Namen, sind einmalig, werden liebevoll aufgezogen und versorgt. Wenn sie krank sind, werden sie gesund gepflegt. „Server sind wie Vieh“ Vieh bekommt Nummern und ist kaum unterscheidbar. Wenn es krank wird, holt man sich neues. Scale Out Scale Up CC-By-Nd “Sick dog large”, Yoel Ben-Avraham
Hochfahren: ▪ Manuell nach Erfahrung ▪ Automatisch nach Auslastung ▪ Automatisch nach SLAs (eine Maschine pro X Besucher) ▪ Herunterfahren ▪ Bei geringer Last ▪ Erst nach Abkühl-Phase ▪ Klienten dürfen sich die Instanz nicht lange merken
Serverless? ▪ Wie so oft: Es gibt keine einheitliche Definition. ▪ „Run code, not Server“ ▪ Entwickler sollen sich nur noch um die Entwicklung fachlicher Bausteine kümmern, nicht um technische Infrastruktur ▪ FaaS = Function as a service ▪ Kosten/Funktionsaufruf => Kosten skalieren ▪ Eventgesteuert ▪ Es gib keine laufenden Serverprozesse. Stattdessen gibt es einen Funktionsaufruf sobald ein Triggerevent ausgelöst wurde, zum Beispiel ein HTTP-Aufruf. ▪ Teilweise wird „BaaS= Backend as a service“ auch als serverless angesehen ▪ Keine Funktion, sondern Anwendungen
oder Rechenressourcen? ▪ Abwägungsfrage: ▪ Managed Datenbank vom Cloudanbieter ▪ Oder eine reine VM/VMs auf denen die Datenbank selbst betrieben wird ▪ Häufig abzuwägen: ▪ Schneller Start vs. steile Lernkurve ▪ Für die Masse gute Leistung vs. auf individuellen Bedarf zugeschnittene Leistung ▪ Standardisierung vs. Flexibilität Standardisierung Flexibilität hoch niedrig niedrig hoch IaaS PaaS SaaS FaaS
▪ Gleichzeitig fallen mehrere VMs / Service-Instanzen aus ▪ Die betroffenen Maschinen sind nicht “logisch” begrenzt, weil VMs flexibel auf den Hypervisorn verschoben werden 1 Hypervisor fällt aus, was passiert? Hypervisors Virtuelle Maschinen
Nebenwirkungen ▪ höhere Latenzen kommen leichter und öfter vor ▪ VMs können sich gegenseitig beeinflussen (z.B. Zeit klauen) ▪ Ausfälle einzelner VMs kommen öfter vor, weil es viele sind ▪ Hardware-Fehler treffen viele VMs gleichzeitig ▪ Daten-Konsistenz muss bedacht werden ▪ Cluster-Dateisysteme müssen bedacht werden ▪ Viel mehr VMs zu managen
Sprawl-Syndrom kommt wieder ▪ Durch automatische Orchestrierung wird dem entgegen gewirkt ▪ VMs werden dynamisch und bedarfsgerecht dimensioniert ▪ VMs werden je nach Bedarf auf verschiedene physische Maschinen verteilt ▪ Tools zur Orchestrierung belasten das Netz und erfordern aufwändiges Tooling ▪ Es bleibt der Overhead für die Emulation der Hardware und das dedizierte Betriebssystem
Yourself (DRY) ▪ Repetitive Konfigurationsarbeit soll nicht manuell gemacht werden, weil ▪ Konfigurationen nur schwer nachzuvollziehen und zu überwachen sind ▪ es die Änderbarkeit erschwert, da an vielen Rechnern Änderungen nachgezogen werden müssen. ▪ es zu Inkonsistenzen führen kann. ▪ so Rollbacks nur schwer möglich sind ▪ Auch „Single Point of Truth“ und „Single Point of Maintenance“
Bereitstellung Automatisierte Bereitstellung Nachvollziehbarkeit Befehle sollen wiederholbar sein Befehle sollen protokolliert sein Befehle sollen Standardisiert sein Regression Qualitätssicherung, automatisierte Tests Monitoring Rollback, Roll Forward Regelmäßigkeit If it hurts, do it more often Infrastructure as Code: verwalte alle Skripte im selben Repository! Diese Skripte müssen genauso Qualitätsgesichert werden wie Code. Bei manueller Arbeit sind diese Merkmale schwer zu erreichen. Bereitstellungszeit reduzieren Koordinierungs-Aufwand reduzieren Zeit für andere Aufgaben frei machen
Code ▪ Das Deployment der Anwendung in Code festhalten ▪ Den Code der das Deployment beschreibt im Repository einchecken ▪ Code muss getestet werden, z.B. mit Serverspec
Orchestrierung Orchestrierung ~ Prozess, Provisionierung ~ Aufgabe ▪ Provisionierung ist die Versorgung einer Maschine oder VM mit Software ▪ Betriebssystem, Zertifikate, Anwendungen ▪ Orchestrierung ist die übergeordnete Koordinierung ▪ Erschaffen / Migrieren / Vernichten von VMs ▪ Koordinierung von Provisionierungen
vs. Pull Push • Zentrale Konfiguration • Einfacheres Modell Pull • Jede Instanz ist selbst verantwortlich für Updates • Flexibler skalierbar auf mehrere Admins Provisio- nierung Provisio- nierung
Konzepte Inventory • Definiert Hosts und Gruppen von Hosts Playbook • Weist Gruppen Provisionierungen zu • Direkt, oder • Durch Role Role • Beschreibung mehrerer Tasks, die nacheinander ausgeführt werden sollen
Codebasis eines Microservices zum laufenden Verbund ▪ Wie wird der Code eines Microservice gebaut und lauffähig „installiert“? ▪ Das definiert die Container-Spec (z.B. Dockerfile)! ▪ Auf Basis der Container-Spec wird ein Image gebaut. ▪ Das Image sollte im Betrieb weiterhin konfigurierbar bleiben z.B. durch Umgebungsvariablen. ▪ Die Deployment-Spec beschreibt die Betriebsumgebung und Konfiguration des Containers. Z.B. Replica und Umgebungsvariablen Container- Spec Container- Spec Container- Spec Deployment-Spec
- Single-Container Pattern ▪ Oft Ausgangssituation ▪ Einfacher Einstieg ▪ Best practice, solange der Container nur eine Verantwortlichkeit hat ▪ Anti-Pattern, wenn der Container mehrere hat ▪ Z.B. Webserver + Log Prozessor Pod Container 1 Hauptanwendu ng
– Sidecar/Sidekick Pattern - Kommunikation ▪ Kommunikation z.B. über geteiltes Volume oder lokales Netzwerk ▪ Beispiel: ▪ Anwendung schreibt logs einfach aufs Volume, wie lokal ▪ Sidecar liest logs und schickt sie an zentrale Sammelstelle weiter ▪ Die Anwendung weiß nichts von der Komplexität der Weiterleitung / dem zentralen Log Sammler ▪ Anwendung wurde erweitert ohne angepasst zu werden Pod Container 1 Hauptanwendu ng Sidecar Container Log Prozessor geteiltes Volume
anderer Ansatz zur Provisionierung ▪ Statt eine laufende Instanz zu provisionieren bereiten wir provisionierte Images vor ▪ Und liefern das Maschine-Image aus
Terraform: Cloud-Infrastruktur mit Code beschreiben ▪ Deklarative Syntax. Man beschreibt, welche Ressourcen es geben SOLL ▪ „terraform apply“ ▪ berechnet Diff. zwischen SOLL und IST ▪ Erstellt Plan und zeigt den an ▪ Fragt nach Bestätigung ▪ Code ins Git ▪ Versionierung / Auditing out of the box ▪ Team hat alles unter Kontrolle ▪ Konfigurationsdrift direkt erkennbar ▪ Module, Kapselung und Abstraktion möglich
PIPELINE AUTOMATISIEREN ▪ Welche Schritte werden manuell angestoßen/durchgeführt, welche automatisch? ▪ Bei den aktuellen manuellen Arbeitsschritten, wo seht ihr Automatisierungspotential? ▪ Wie testen Sie den Erfolg eines Deployments?
„I too consider myself an artist and a craftsman of server building. With each click of a mouse, I create a work of art. With every option I select, every module I install, every registry tweak I make, every configuration file I edit, I create a unique, one of a kind masterpiece.“ http://tatiyants.com/devops-is-ruining-my-craft/
vs Cattle „Server sind wie Haustiere“ Sie bekommen einen Namen, sind einmalig, werden liebevoll aufgezogen und versorgt. Wenn sie krank sind, werden sie gesund gepflegt. „Server sind wie Vieh“ Vieh bekommt Nummern und ist kaum unterscheidbar. Wenn es krank wird, holt man sich neues. Scale Out Scale Up CC-By-Nd “Sick dog large”, Yoel Ben-Avraham
einreißen und neu aufbauen ▪ Anpassungen der Konfiguration im Betrieb bringen immer Risiken mit ▪ Die Umstellung einer Konfiguration wirkt sich unvorhergesehen aus ▪ Die Test und Produktionsumgebung weichen hinsichtlich ihrer Konfiguration ab ▪ Also passen wir die Konfigurationen im Betrieb einfach nicht mehr an ▪ Wir machen die Infrastruktur unveränderlich ▪ Wir schreiben Code, der unsere Infrastruktur erzeugt ▪ Wenn die Konfiguration angepasst werden muss, wird der erzeugende Code modifiziert ▪ Wir haben Code der unsere Infrastruktur beschreibt ▪ Versionsgesichert ▪ Jederzeit nachvollziehbar ▪ Jederzeit anpassbar
Gesamte Produktivumgebung in Staging doppeln ▪ So identisch wie möglich ▪ Produktions- und Staging- Umgebungen wechseln sich ab Phönix: https://pixabay.com/en/phoenix-bird-of-fire-mythical-fire-28028 Flammen: https://pixabay.com/en/fire-flame-danger-burn-light-306894
Gesamte Produktivumgebung in Staging doppeln ▪ So identisch wie möglich ▪ Produktions- und Staging- Umgebungen wechseln sich ab Phönix: https://pixabay.com/en/phoenix-bird-of-fire-mythical-fire-28028 Flammen: https://pixabay.com/en/fire-flame-danger-burn-light-306894
Gesamte Produktivumgebung in Staging doppeln ▪ So identisch wie möglich ▪ Produktions- und Staging- Umgebungen wechseln sich ab Phönix: https://pixabay.com/en/phoenix-bird-of-fire-mythical-fire-28028 Flammen: https://pixabay.com/en/fire-flame-danger-burn-light-306894
in vielen Formen ▪ Verschiedene Programmiersprachen ▪ Inkompatible Abhängigkeiten ▪ z.B. python 2.7 vs python 3.x ▪ Dependency Hell ▪ Unterschiede in ▪ Betriebssystem ▪ Rechnerkonfiguration (z.B. PATH, JAVA_HOME, ...) ▪ Java-Version ▪ Application-Server-Version ▪ Application-Server-Konfiguration ▪ Verschiedene Paketierungswege ▪ Z.B. für Java Anwendungen: ▪ Aus Eclipse starten ▪ Als jar-Datei verpacken ▪ Als war in tomcat deployen ▪ Als Service-Dienst in Windows registrieren ➢ Interferenzen zwischen Anwendungen ➢ Unterschiedliches Verhalten je nach System ➢ unvorhergesehene Bugs
zu starten ▪Dauerhaft laufende(r) Server oder Datenbank ▪docker run -d my-server ▪Kurzlebinges Skript (mit Antwort) ▪docker run --rm ubuntu ls ▪Interaktiver Container ▪docker run –it my-server sh
Ergänzung der Virtualisierung ▪ Jeder Container ist ein Prozess im System ▪ Jeder Container nimmt sich die Ressourcen die er benötigt. ▪ Statt virtuelle Maschinen zu definieren werden Container isoliert ausgeführt ▪ Die Vorteile der Virtualisierung bleiben (weitestgehend) erhalten ▪ Die Nachteile der Virtualisierung fallen weg Aber Container haben andere Aufgaben als Virtuelle Maschinen! ▪ Virtualisierung sind absolut Isoliert -> Sicherheit & Mandantenfähig ▪ Container wollen die Anwendung mit ihren Abhängigkeiten verpacken -> Unabhängigkeit & Flexibilität
DevOps ist die Praxis von Ops und Devs, im gesamten Software-Lebenszyklus, vom Design über die Entwicklung hin zur Produktion, zusammenzuarbeiten. DevOps is the practice of operations and development engineers participating together in the entire service lifecycle, from design through the development process to production support. http://theagileadmin.com/what-is-devops/
DevOps ist eine Menge an Praktiken, die die Zeit vom Commit einer Änderung bis zur produktiven Inbetriebnahme reduzieren und gleichzeitig eine hohe Qualität sicherstellen. DevOps is a set of practices intended to reduce the time between commiting a change to a system and the change being placed into normal production, while ensuring high quality. DevOps A Software Architect‘s Perspective, Len Bass
Zielkonflikt DevOps viele+stabile Releases QA Ops sind langsam. QA sind nutzlos. Entwickler sind unpünktlich. Nie läuft es rund. Entwickler brauchen immer Extra- würstchen.
Zielkonflikt DevOps viele+stabile Releases QA Korrektheit: Wenige Versionen ▪ Entwicklung einer Kultur der (agilen) Zusammenarbeit ▪ Qualitätssicherung und Effizienz- steigerung durch Automatisierung von Entwicklungs-, QA- und Betriebs- aufgaben
DevOps schnelle Releases + hohe Qualität ▪ Automatisierte Tests und ausgewählte Nutzer ▪ Liefermechanismus mit hoher Qualität ▪ gute Zusammenarbeit von Entwicklung und Betrieb ▪ gesamter Software-Lebenszyklus
UND ROLLOUT ▪ Skizzieren Sie die Umgebungen und das Deployment in Ihrem aktuellen Projekt. ▪ Welche Umgebungen sind VMs, Bare Metal oder Container? ▪ Welche Umgebungen gibt es und wie oft finden in den einzelnen Umgebungen Deployments statt? ▪ Welche Personen sind am Deployment beteiligt?
a framework for developing and sustaining complex products” - Scrum Guide A scrum (short for scrummage) is a method of restarting play in rugby that involves players packing closely together with their heads down and attempting to gain possession of the ball. Scrum
Time-Box von 1 Monat oder weniger ▪ Weit-verbreitet: 2 Wochen ▪ Ergebnis: ein Inkrement im Status „Done“ ▪ Direkt nach dem Sprint startet der nächste ▪ Während des Sprints: ▪ Keine Änderungen ▪ Jedenfalls keine die das Sprintziel gefährden ▪ Keine Verringerung des Qualitätsanspruches ▪ Minimierung von Risiko: das Team läuft nicht länger als der Sprint in die falsche Richtung Foto: Darren Wilkinson/Wikipedia
Kanban? Kanban ist eine Methode um einen kontinuierlichen Verbesserungsprozess in Organisationen einzuführen. Drei Grundprinzipien 1. Beginne dort, wo Du dich im Moment befindest 2. Komme mit anderen Überein, das inkrementelle und evolutionäre Veränderungen angestrebt werden 3. Respektiere den aktuellen Prozess, Rollen, Verantwortlichkeiten und Berufsbezeichnungen
Die fünf Kernpunkte ▪ Visualisiere den Workflow: Mache die laufende Arbeit sichtbar. ▪ Begrenze Work in Progress (WIP): Beschränke die Anzahl offener Arbeitspakete. ▪ Führe Messungen zum Fluss durch und kontrolliere ihn: Messe Kennzahlen (z. B. Durchlaufzeiten) und optimiere anhand der Ergebnisse den Durchsatz. ▪ Mache die Regeln für den Prozess explizit: Formuliere Regeln für den Prozess und erfasse und bewerte Fehler objektiv. ▪ Verwende Modelle, um Chancen für Verbesserung zu erkennen: Nutze bewährte Modelle und Methoden, um den Prozess zu analysieren.
den Workflow – Arbeitspakete / Aufgaben ▪ Zentrales Mittel zur Visualisierung des Workflows ist das Kanban Board. ▪ Auf einem Kanban-Board werden Arbeitspakete (z.B. Stories / Epics) und Aufgaben (z.B. Tasks oder Bugs) in Form von Karten angebracht.
Work in Progress (WIP) ▪ Begrenze die Zahl der offenen Baustellen! ▪ Pro Prozessabschnitt ist nur eine maximale Anzahl an parallel bearbeiteten Arbeitspaketen erlaubt. Fange kein neues Arbeitspaket an, wenn diese Zahl schon erreicht ist! ▪ Grundüberlegung: Eine abgeschlossene Baustelle ist mehr wert als zehn offene Baustellen! ▪ Die Durchlaufzeit eines einzelnen Arbeitspakets steigt mit jedem parallel dazu begonnenen Arbeitspaket. Risiken: ▪ Lange Durchlaufzeiten. ▪ Spätes Feedback!
den Work in Progress (WIP) – Das Pull-Prinzip ▪ Push-Prinzip: Fertige Arbeit wird einfach an die nächste Station zu übergeben ▪ Pull-Prinzip: Jede Station holt sich ihre Arbeit bei der Vorgängerstation ab. ▪ Pull-Prinzip mit Kapazitäten: Sind die Kapazitäten in einem Prozessabschnitt ausgelastet, stauen sich die nachfolgenden Arbeitspakete. Engpässe werden so sofort sichtbar und können optimiert werden.
Fluss Messen und Regeln ▪ Um den Arbeitsfluss zu steuern, werden die Aufgaben bewertet, z.B. nach Priorität, Business Value, Kano, Kosten, Komplexität, Risiken, Dringlichkeit, Fehlerschwere, usw. – was immer im Projektkontext entscheidende Kriterien für unterschiedliche Aufgaben sind. ▪ Beliebt sind sog. Service-Klassen: ▪ Beschleunigt, z.B. Server-Crash beheben. ▪ Festes Datum, z.B. geplanter Versionswechsel eines Drittsystems, von dem unser System abhängt. ▪ Standard, z.B. die kontinuierliche, geplante Weiterentwicklung des Systems. ▪ Für Aufgaben der verschiedenen Bewertungskriterien werden oft Quoten festgelegt (z.B. müssen stets mind. 20% Standard-Aufgaben bearbeitet werden, damit kontinuierlich weiterentwickelt wird.
DIN/ISO 25010 (früher 9126) • Qualität von Softwaresystemen wird immer bezogen auf Eigenschaften oder Merkmale. Die explizite Beachtung der relevanten Qualitätsmerkmale ermöglicht die Langlebigkeit der Anwendung! • Es gibt innere und äußere Qualitätsmerkmale Funktionalität Eignung Verwendba rkeit Genauigkei t Interoperab ilität Sicherheit Zuverlässigkeit Reife Fehlertoler anz Ausfallsich erheit Datensiche rheit Benutzbarkeit Verständlic hkeit Erlernbarke it Bedienbark eit Attraktivität Effizienz Zeitverhalte n Ressource nnutzung Sicherheit Integrität Vertraulichk eit Nachweisb arkeit Authentizit ät Verantwortl ichkeit Kompatibilität Austauschb arkeit Interoperab ilität Complianc e Wartbarkeit Analysierba rkeit Änderbarke it Erweiterbar keit Stabilität Testbarkeit Portierbarkeit Anpassbark eit Installierbar keit Ersetzbarke it Konfigurier barkeit Eigen- schaften Merkmale
tree) & Szenarien ▪ Ein Qualitätsbaum konkretisiert Qualitätsmerkmale ▪ Allgemeine Merkmale weiter links, spezielle Anforderungen rechts ▪ Wird in kleinen Workshops entwickelt ▪ erst Brainstorming dann Organisation der Qualitätsmerkmale in Baum spezifische Qualität Performance Erweiterbarkeit Verfügbarkeit Latenz Durchsatz Neue Middleware Neue Produktkategorie bei Hardwarefehler bei Bedienfehler Szenario Szenario
Qualität - Szenarien ▪ Qualitätsmerkmale können durch Szenarien beschrieben und Qualität so definiert werden. ▪ Szenarien beschreiben, was beim Eintreffen eines Stimulus auf ein System in bestimmten Situationen geschieht. ▪ Die Szenarien beschreiben konkrete Anforderungen bzgl. einzelner Qualitätsmerkmale (z.B. zu Performance oder Verständlichkeit). ▪ 3 Arten von Szenarien: ▪ Anwendungsszenarien beschreiben, wie das System auf einen bestimmten Auslöser reagieren soll ▪ Änderungsszenarien beschreiben eine Modifikation des Systems oder seiner Umgebung ▪ Stress- oder Grenzszenarien beschreiben, wie das System auf Extremsituationen reagiert → Szenarien sind die Grundlage um die Qualität von Architekturen zu bewerten.
Bestandteile von Szenarien: ▪ Auslöser (Stimulus) ▪ Zusammenarbeit des auslösenden Stakeholders mit dem System ▪ Quelle des Auslösers ▪ Woher stammt der Auslöser (intern, extern, Benutzer, Angreifer) ▪ Umgebung ▪ Zustand des Systems zum Zeitpunkt des Auslösers ▪ Systembestandteil ▪ Welcher Bestandteil ist betroffen ▪ Antwort ▪ Wie reagiert das System ▪ Antwortmetrik ▪ Wie kann die Antwort gemessen/bewertet werden
Beispiele Performanz: „Die Antwort auf eine Angebotsanfrage muss Endbenutzern im Regelbetrieb in weniger als 5 Sekunden angezeigt werden. Im Betrieb unter Hochlast (Lastspitzen) darf eine Antwort bis zu 15 Sekunden dauern, in diesem Fall ist ein entsprechender Hinweis anzuzeigen.“ Robustheit: „Bei Eingabe unzulässiger oder fehlerhafter Daten in die Eingabefelder muss das System entsprechende spezifische Hinweistexte ausgeben und danach im Normalbetrieb weiterarbeiten.“ Funktional: „Bei Benutzer-Eingabe eines Wertes in das Feld ‚Postleitzahl‘ wird automatisch der zugehörige Ort aus der Datenbank gelesen und im Feld ‚Wohnort‘ angezeigt.“
▪ Welche Qualitätsaspekte sind für die einzelnen Microservices aus Ihrer Sicht am Wichtigsten. ▪ Skizzieren Sie einen Qualitätsbaum ▪ Formulieren Sie entsprechende Szenarien ▪ Prüfen Sie können die beschriebenen Szenarien gemessen werden?
Ops haben unterschiedliche Fragen Fragen der Devs ▪ In welcher Reihenfolge wird der Code abgearbeitet? ▪ Sind alle notwendigen Schritte erfolgt? ▪ Wo und wann fliegen Exceptions? ▪ Wo stimmen Parameter nicht? ▪ Verhalten sich die Umsysteme wie erwartet? Fragen der Ops ▪ Wie ist die Last auf meinem System? ▪ Verhält sich das System ungewöhnlich? ▪ Ist etwas (teilweise) ausgefallen? ▪ An welcher Stelle muss ich die Ressourcen erhöhen? ▪ Gibt es Sicherheitsverletzungen? ▪ Sind die Verkaufszahlen erwartungskonform? ➢ Ops müssen den Devs sagen, was sie brauchen ➢ Anforderungen der Ops müssen Bestandteil des Architekturkonzepts sein ➢ Verschiedene Log-Level und -Filter
von Monitoring Fehler erkennen • aktuell & nachträglich Verschlechterung der Performance erkennen • einzelne Systeme & Verbund von Systemen Kapazitäten planen • kurz- & langfristig Reaktion der Nutzer verstehen • verschiedene Oberflächen & Kampagnen Sicherheitsverletzungen erkennen • sofort & nachträglich The purpose of computing is insight, not numbers. Richard Hamming
beobachtet werden? ▪ Datenbasis wird auch „Operations Database“, abk. OpsDB genannt (Nygard) ▪ Durch Persistenz können Aussagen über die Vergangenheit und Zukunft getroffen werden Big Data Systeme Business Intelligence Einbruchs- Erkennung … System 1 Anwendung Middleware Betriebssystem System 2 Anwendung Middleware Betriebssystem Monitoring System Datenbasis Visualisierung Alarm- auswertung Andere Systeme ohne agent Agent agenten- basiert extern Benutzer Tracking Logdateien Konfigurations- Management Metriken
Echtzeit ▪ Echtzeit-Monitoring ▪ Wie ist aktuell die Auslastung des Systems? ▪ Werden Schwellwerte überschritten? ▪ Grundlage für Alerting ▪ Historisches Monitoring ▪ Speicherung relevanter Kennzahlen ▪ System- und Anwendungslogdaten ▪ Erweiterte Möglichkeiten durch Datenanalyse ▪ Anomalieerkennung ▪ Langsam entstehende Ressourcenengpässe ▪ Nachbereitung von Ausfällen
Daten ▪ Einzelsysteme werden überwacht, aber Gesamtprozess muss erkennbar bleiben. ▪ Welche Log-Daten gehören zusammen? ▪ Komplexe Prozesse über mehrere Systeme verfolgen ▪ Sortieren nach Zeitstempel ist schwierig ▪ Uhrzeitabweichungen ▪ Latenzen ➢Ähnliche Zeitmessung durch NTP-Server (keine Garantie) ➢Totale Ordnung der Logs durch Vektorzeitstempel (aufwändig) ▪ Kontext ist wichtig! ▪ Welche VM? Welche Instanz? Welche Komponente?
▪ Ein Correlation Identifier hat 6 Attribute. ▪ Requestor: Eine Anwendung, die eine betriebswirtschaftliche Aufgabe ausführt, indem sie eine Anfrage sendet und auf eine Antwort wartet. ▪ Replier: Eine andere Anwendung, die die Anfrage erhält, sie erfüllt und dann die Antwort sendet. Sie holt sich die Request-ID aus dem Request und speichert sie als Korrelations-ID in der Antwort. ▪ Request: Eine Nachricht, die vom Requuestor an den Replier gesendet wird und eine Request-ID enthält. ▪ Reply: Eine Nachricht, die vom Replier an den Requuestor gesendet wird und eine Korrelations-ID enthält. ▪ Request ID: Ein Token im Request, welcher den Request eindeutig identifiziert. ▪ Correlation ID: Ein Token in der Antwort, welcher den gleichen Wert wie die Request-ID im Request hat. ▪ Beispiel: Für einen Reqest gibt es 3 Responses ▪ Correlation Identifier globaler: ▪ Und wenn man die User-ID immer mitsendet?
Weil sich das „Normalverhalten“ ständig ändert, ist es schwer, mit historischen Profilen zu arbeiten ▪ Identifizieren, welche Daten sich nicht ändern ▪ Monitoring-Konfiguration automatisieren! ▪ Schwellwerte, Alarm-Situationen, … ▪ Server automatisch an- und abmelden ▪ Neue Werte aus “Kanarienvogel” ableiten
Monitoring für das Monitoring System ▪ Drei Tage kommt kein Alert ▪ Ist alles gut? ▪ Oder ist das Monitoring System ausgefallen? ▪ Wir benötigen einen Mechanismus der Ausfälle und Leistungsengpässe am Monitoring-System aufdeckt.
Lösungen: ▪ Bestehendes Framework nutzen und Logging-Fassade nutzen um unabhängig vom Logging- Framework zu bleiben ▪ Alle Benutzerinteraktionen protokollieren, um Gang des Benutzers durch die Applikation nachvollziehbar zu machen ▪ Alle Subsystem-/Komponenteninteraktionen protokollieren ▪ Ringpuffer nutzen wenn Platzprobleme drohen ▪ Aspektorientierte Programmierung kann sehr viel „Standard-Loggingcode“ ersetzen ▪ Kein Debug-Loglevel auf Produktivsystemen ▪ Log-Ausgaben für Ops schreiben ▪ Log-Verzeichnis konfigurierbar
NoSQL DB ▪ CRUD über HTTP-Schnittstelle ▪ GET, PUT, POST, DELETE ▪ JSON-basierte Query Language Relationale DB ElasticSearch Database Index Table Type Row Document Column Field Schema Mapping SQL Query DSL GET /bank/_search { "query":{ "match" : { "city":„Hamburg" } } }
und Logging-Infrastruktur ▪ Auf der Grundlage ihrer bisherigen Architektur und Qualitätsanforderungen. ▪ Wie könnte für das Hotel eine geeignete Monitoring- und Logging-Infrastruktur aussehen? ▪ Halten Sie fest, was Sie zu der Entscheidung bewegt hat.
Spezielle Art des Loggings ▪ Enthält Informationen zur Ablaufverfolgung ▪ Meldung beim Einsprung in eine Funktion ▪ Meldung beim Verlassen ▪ Ggf. mit Argumenten Stacktrace bei Exceptions
Metriken ▪ System ▪ Wie ist die CPU-Auslastung? ▪ Wie voll ist die Festplatte? ▪ Anwendung ▪ Wie viele Threads sind im Thread Pool? ▪ Wie ist die mittlere Antwortzeit eines Requests? ▪ Fachliche ▪ Wie viele Bücher wurden verkauft? ▪ Wie viele Benutzer sind angemeldet? ▪ Fachliches Monitoring ist historisch Aufgabe von BI und Controlling ▪ Warum betrachten wir es hier?
Logs ▪ Logging = Protokollierung ▪ Metriken aufgrund von Log-Dateien aufsetzen ▪ Z.B.: Anzahl der 400er-Fehler im Apache-Log ▪ Aufgrund von Logs im eigenen System, Z.B.: Bestellung ausgeführt ▪ Problematisch: Kopplung zwischen Metrik und Log-Ausgabe
Alarm Best Practices Gute Logdateien sollten… ▪ ein konsistentes Format haben! ▪ sagen, warum eine Meldung ausgegeben wurde! ▪ Kontext enthalten: Zeit, Codezeile, PID, Request-ID, VM ID, …! ▪ “Raster”-Informationen enthalten: Schweregrad, Alarm-Level! Warnungen und Alarme sollten… ▪ kontextsensibel sein – z.B. zu bestimmten Tageszeiten oder bei Deployments deaktiviert! ▪ auch prüfen, ob erwartete Dinge nicht passieren! ▪ zusammengefasst werden, wenn gleiche Ursache! ▪ klar definierte Schwere und Dringlichkeits-Level haben!
▪ Probleme: ▪ Millionen von Events und Metriken brauchen Platz und kosten Rechen-Kapazität ▪ Durch häufige Logabfrage wird das Netzwerk belastet ▪ Poll-Frequenz an die aktuelle Systemlast anpassen ▪ Etablierte Frameworks und Systeme nutzen ▪ Log-Level anpassen
▪ Besonders historische Daten verbrauchen viel Platz ▪ Verteilte Speicherung ▪ Verdichten: Detaillierte Daten durch Mittelwertbildung (Bei Metriken) ▪ Beispiel: Alle 5 Minuten Bandbreite abfragen und loggen ▪ Nach 1 Woche nur noch stündliche Mittelwerte behalten ▪ Wegwerfen der Daten nach Zeitüberschreitung ▪ Optional Archivieren auf externem Datenträger ▪ Je nach Anwendungszweck entscheiden ➢Verdichtungs- und Wegwerfgrad konfigurierbar halten
Monitoring hat viele Aufgaben: Fehlererkennung, Performanceprobleme, Kapazitätsplanung, Sicherheitsverletzungen ▪ Jede Aufgabe braucht eigene Daten und Umgang damit ▪ Es gibt viele Monitoring-Systeme aber eine gemeinsame Struktur hilft ▪ Daten müssen miteinander kombiniert werden für sinnvolle Aussagen ▪ Logging und Metriken erfüllen unterschiedliche Zwecke ▪ Anpassbare Konfiguration für verschiedene Monitoring-Zwecke ▪ Die großen Datenmengen sind schwer zu meistern aber es gibt Lösungen ▪ Die großen Datenmengen erlauben komplexe Big-Data Analysen
ÜBERWACHUNG FEHLERANALYSE ▪ Welche Werkzeuge setzen Sie für Betrieb, Überwachung und Fehleranalyse ein? ▪ Welche Logausgeben produzieren Sie? ▪ Welche Metriken erheben Sie? ▪ Fachlich ▪ System ▪ Anwendung ▪ Was fehlt Ihnen?
Microservice-Architekturen ▪ Microservice-Architekturen haben getrennte Datenbanken ▪ Innerhalb eines Microservice kann ACID umgesetzt werden ▪ Microservice-übergreifend ist Konsistenzbewahrung schwierig/unmöglich Micro- service A Micro- service B Getrennte Datenbanken
▪ C = consistency (Konsistenz) ▪ Wenn man verschiedene Knoten nach einem Datum fragt, bekommt man dieselben Informationen. ▪ A = availability (Verfügbarkeit) ▪ Die Verfügbarkeit im Sinne akzeptabler Antwortzeiten. Alle Anfragen an das System werden stets beantwortet. ▪ P = partition tolerance (Ausfallsicherheit) ▪ Die Ausfalltoleranz der Rechner-/Servernetze. Das System arbeitet auch bei Verlust von Nachrichten, einzelner Netzknoten oder Partition des Netzes weiter. Das CAP-Theorem oder Brewers Theorem besagt, dass in einem verteilten System, maximal 2 Eigenschaften garantiert werden können. In der Praxis: Partitionen von Netzen kommen vor. => Daher C oder A
S E = Basically = Soft-state = Eventual Consistency = Available A Die Datenbank funktioniert die meiste Zeit. Der Zustand kann sich ohne Input ändern. Zu einem späteren Zeitpunkt wird Konsistenz erreicht.
Microservices ▪ CP = Durch zentrale Datenhaltung ▪ AP = Durch Replikation von Daten ➔Microservices haben ein eigenes Datenbankschema ➔Sobald man horizontal skaliert, muss man mit Partitionen umgehen (P). Dann kann nur Eventual Consistency zugesichert werden
perfect ▪ Was sind perfekte Systeme? ▪ Software ohne Fehler ▪ Hardware, die nie versagt ▪ Menschen, die immer die richtigen Entscheidungen treffen → Perfekte Systeme gibt es nicht → Es wird immer Fehler geben
A (Verfügbarkeit) soll maximiert werden ▪ Traditionell: MTTF maximieren, + ➔ A => 1 ▪ Redundante Hardware, Cluster, Vermeidung von Fehlern auf Softwareebene ▪ Geht davon aus, dass die Anwendung isoliert läuft ▪ Resilience Ansatz: MTTR minimieren, + ➔ A => 1 ▪ Fehler sind in verteilten Systemen der Normalfall, nicht die Ausnahme, und es ist nicht möglich, sie vorherzusagen. → Do not try to avoid failures. Embrace them.
ist vor allem die Fähigkeit zur Selbstheilung Man definiert, was der Soll-Zustand des Systems ist ▪Welche Services ▪In welcher Anzahl Das System behebt selbstständig Abweichungen vom Soll
zu beheben, muss man sie zunächst erkennen →Monitoring ... und die richtigen Reaktionen ausführen Vorbedingung: Probleme erkennen und beheben Beides muss auf mehreren Ebenen geschehen
wann ein Infrastrukturknoten unzureichende oder ungebrauchte Ressourcen hat ▪CPU, Memory, Disk I/O ▪Tools (Auswahl): ▪AWS Autoscaling Group + AWS CloudWatch ▪Kubernetes Cluster Autoscaler Addon Reagieren ▪Anzahl der Infrastrukturknoten erhöhen oder verringern Ebene: Infrastrukturknoten Anwendung Infrastrukturknoten Hardware
Downtime ▪Automatische Eingriffe und Skalierungen durch Resilience müssen bruchlos vonstatten gehen ▪Voraussetzung: Deployments dürfen keine Downtime bedeuten! ▪Strategien: ▪Blau-/Grün-Deployment ▪Rollierendes Update VM VM VM VM VM VM IST SOLL VM VM VM VM VM VM Load Balancer VM VM VM VM VM VM Load Balancer Load Balancer Load Balancer Load Balancer Load Balancer Load Balancer VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM VM
▪Nicht nur Anzahl lebendiger Knoten überwachen, auch Antwortzeiten und Auslastung ▪Aus Hochrechnungen ableiten, wann Knoten oder Anwendungen überlastet sein werden ▪System skaliert vorausschauend. Das bedeutet auch, dass die Anzahl an Replicas nicht mehr fest definiert ist, sondern dynamisch ermittelt wird. ▪Auch Erfahrungswerte mittels Machine Learning für die Prognose nutzen
▪ Auch (gerade!) Resilience muss getestet werden, ansonsten erlebt man böse Überraschungen ▪ Beispiel: ▪ Infrastruktur ist automatisiert, Cluster konfiguriert, Monitoring und Skalierung vermeintlich auf allen Ebenen aktiviert ▪ Eine Anwendung kommt in eine Endlosschleife und blockiert einen Knoten zu 100% ▪ Der Cluster erkennt, dass die Anwendung nicht mehr erreichbar ist → Cluster erzeugt weitere Replicas der Anwendung ▪ Auf Infrastrukturebene greift das Monitoring nicht, weil der Knoten nur sehr langsam antwortet, aber eben doch antwortet → Der Knoten wird nicht abgeräumt. Es werden keine weiteren Knoten erzeugt ▪ Nach und nach werden weitere Replicas der Anwendung auf den vorhandenen Knoten erzeugt, bis alle Knoten überlastet sind ▪ Der Cluster ist komplett lahmgelegt
Analogie zu den Schottwänden auf Schiffen ▪ Das System darf nicht als Ganzen kaputt gehen ▪ System wird in möglichst unabhängige Einheiten aufgeteilt (Failure Units) ▪ Bulkheads (Schottwand) trennen die Systeme ▪ Keine konkrete Implementierungsanweisung Wie passt das mit Microservices? Schott
Das Bulkhead-Muster sollte man auf mehreren Ebenen anwenden ▪ Prozesse über Container voneinander isolieren ▪ Fachlich und technisch autarke Bounded Contexts / Self-Contained Systems definieren ▪ Infrastruktur in getrennte Netze einteilen ▪ Unterschiedliche Cloud-Accounts für verschiedene Umgebungen nutzen ▪ Dadurch wird jeweils der „Blast Radius“ von Ausfällen, Fehlern und Angriffen reduziert Getrennte Cloud-Anbieter Getrennte Cloud-Accounts Getrennte (virtuelle) Netze, z.B. VPCs Getrennte Cluster Getrennte Namespaces im Cluster Getrennte Self-Contained Systems Getrennte VMs Getrennte Container Getrennte Prozesse
▪ Beispiel ▪ Stehen in der Warteschlange ▪ Am Schalter Zurückweisung, Erst Formular XY ausfüllen ▪ Langsame Antworten sind schlimmer als keine Antworten ▪ Abgrenzung zu Timeouts (Zwei Seiten der Medaille) ▪ Timeouts ▪ Zur Absicherung des Systems gegen Fehlern von anderen ▪ Für Ausgangsnachrichten ▪ Fail Fast ▪ Zum Benachrichtigen, warum man eine Anfrage nicht bearbeiten kann ▪ Für Eingangsnachrichten Asterix erobert Rom
▪ Wie der Schutzschalter im Sicherungsschrank ▪ Wird auf Ressourcen angewendet ▪ Andere Microservices ▪ Thread Pools ▪ Connection Pools ▪ Ist der Schutzschalter geschlossen, arbeitet das System normal ▪ Ab einer bestimmten Anzahl/Frequenz an Fehlern öffnet sich der Schalter ➔Aufrufe werden sofort fehlerhaft beantwortet (fail first) ▪ Nach Ruhezeit wird Schalter wieder geöffnet Schutzschalter
Strategie, wenn ein Fehler erkannt wurde ▪ Sollte Bedürfnisse der Nutzer als auch der Administratoren so gut wie möglich unterstützen ▪ Fehlerbehandlung sollte möglichst vollständig automatisiert erfolgen ▪ Beispiel: Schreibanfrage eines Benutzers per Webanwendung, langsame Datenbank ▪ Fallback Option 1: Fehler an den Benutzer. Bitte versuchen Sie es später ▪ Fallback Option 2: Command in eine Queue und asynchrone Bearbeitung ▪ Nicht: Sanduhr anzeigen Plan A B
Infrastruktur Micro- service Micro- service DB DB REST Messaging Anforderungen an Infrastruktur • Muss viele Services unterstützen • REST und Messaging unterstützen • Resilient Muster unterstützen • Projekte müssen einfach erstellt werden können
App App Webserver Webserver War File Spring Boot JVM Libraries OS Kernel JVM Libraries OS Kernel Support für: • Rest • Messaging • Metriken (Actuator) • Spring MVC • Executable JAR • Einfach zu erstellen • Spring-Boot-Starter @SpringBootApplication public class ApplicationBerth { public static void main(String[] args) { SpringApplication.run(ApplicationBerth.class, args); } }
▪ Setzt auf Spring Boot auf ▪ Bietet Werkzeuge für Entwickler, um schnell gebräuchliche Muster von verteilten Systemen zu entwickeln ▪ 20 Haupt-Projekte ▪ Spring Cloud Config, Zentralisiertes Konfigurationsmanagement ▪ Spring Cloud for Cloud Foundry, Anbindung an Cloud Foundry ▪ Spring Cloud Security, Oauth2, JWT, … ▪ Spring Cloud Sleuth, Distributed Tracing ▪ Spring Cloud Zookeeper, Service Discovery mit Apache Zookeeper ▪ Spring Cloud for Amazon Web Services, Integration in die Amazon Cloud ▪ Spring Cloud Stream, Leichtgewichtiges eventgetriebenes Framework ▪ Spring Cloud Netflix, Der Name sagt es schon…
Netflix ▪ 35 Prozent die höchste Downstream-Bandbreite in den USA ▪ Youtube 15% ▪ Entwicklung einer Microservice-Landschaft 2008 – 2012 ▪ Technische Komponenten und Bibliotheken zur Entwicklung, Überwachung und Skalierung von Microservices ▪ Werden im Netflix Open Source Software Center (Netflix OSS) als freie Software zur Verfügung gestellt
Netflix ▪ Spring Cloud Netflix, ein Unterprojekt von Spring Cloud, benutzt sechs Dienste aus dem Netflix OSS: ▪ Eureka: Service-Registry ▪ Hystrix: Bibliothek, die Fehler beim Zugriff auf externe Dienste isoliert und so die Ausfallsicherheit in einem verteilten System erhöht (Circuit Breaker) ▪ Ribbon: Library für Interprozesskommunikation mit eingebautem Softwarelastverteiler ▪ Archaius: Bibliothek für Konfigurationsmanagement, basiert auf Apache Commons Configuration und erweitert das Projekt für den Cloud-Einsatz ▪ Zuul: Edge-Service für dynamisches Routing, Monitoring, Security, Ausfallsicherheit und einiges andere mehr ▪ Feign: Library, die das Schreiben von HTTP-Clients vereinfacht
Trains ▪ Spring Cloud richtet sich nach den Releases von Spring Boot ▪ Versionen der einzelnen Projekte werden über eine BOM (Bill of Materials) gemanagt Spring Boot Spring Cloud 1.3.x Brixton 1.4.x Camden 1.5.x Dalston, Edgware 2.0.x Finchley 2.1.x Greenwich
Es kann ständig zu kleinen und großen Problemen kommen ▪ Ziel: Cloud-Potential durch Redundanz und Fehlertoleranz heben ▪ Idee: Wilde bewaffnete Affen im Rechenzentrum frei lassen ▪ Wenn wir das überleben, stehen wir auch bei ungeplanten Problemen gut da.
Sucht ungenutzt Ressourcen, um sie wegzuräumen ▪ Läuft einmal am Tag ▪ Regelbasiert ▪ markieren, informieren, löschen ▪ Cluster, Festplatten, Backups, …
Sucht Sicherheits-Verstöße und Lücken, um betroffene Instanzen zu terminieren ▪ Sichert, dass alle SSL-Zertifikate gültig bleiben ▪ Erweiterung vom Conformity-Affen
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
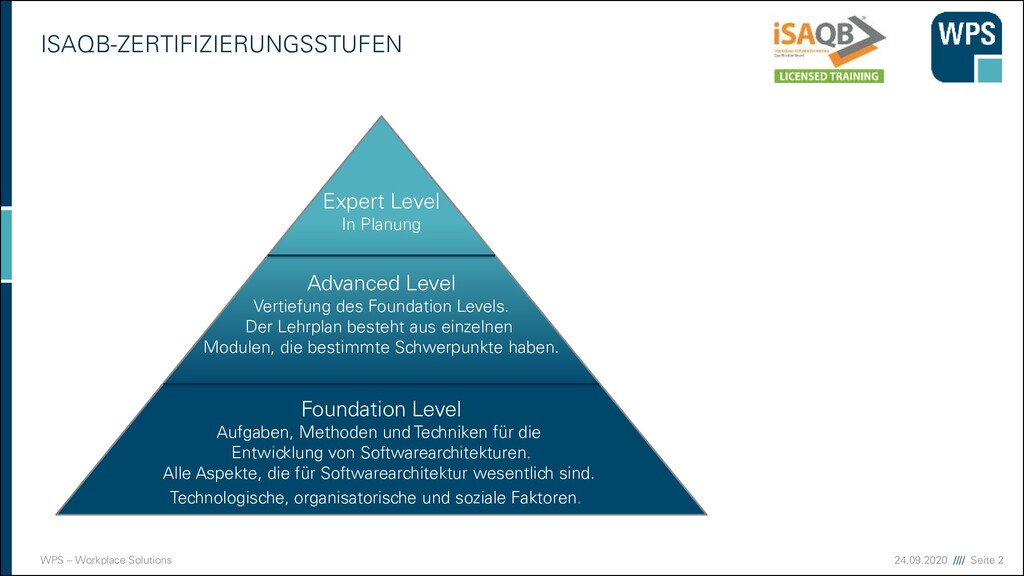{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
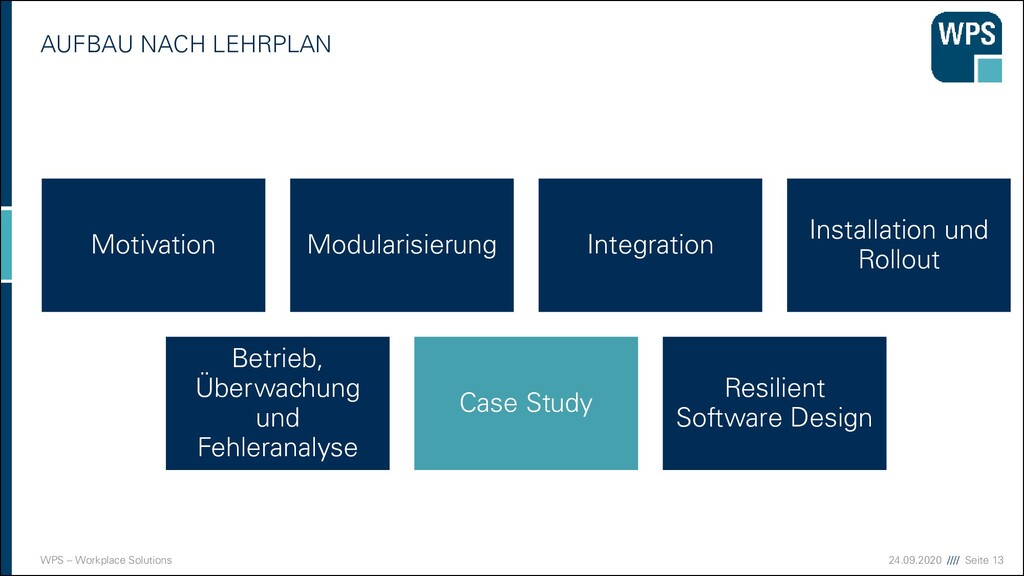{kind=link}
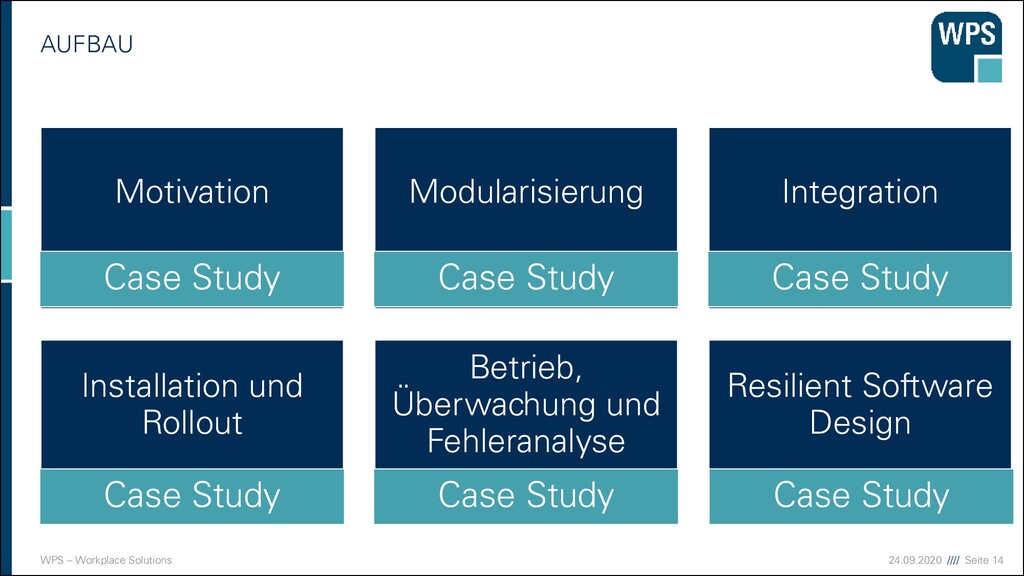{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
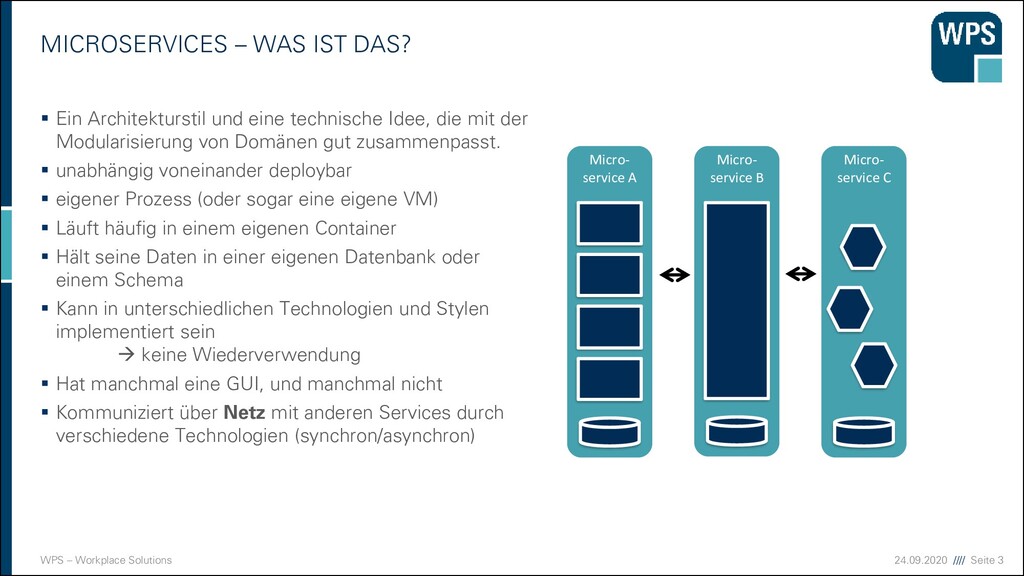{kind=link}
{kind=link}
{kind=link}
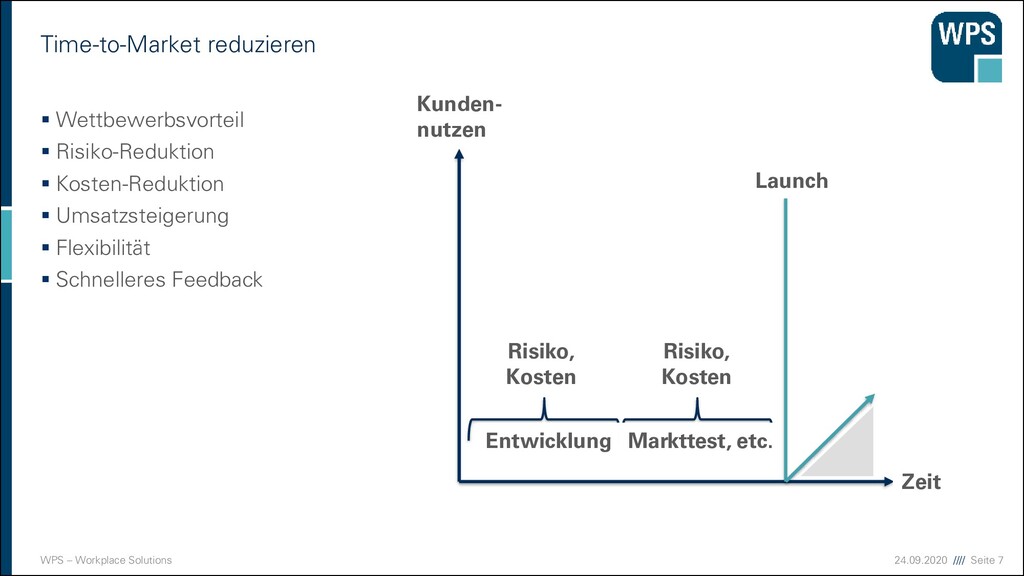{kind=link}
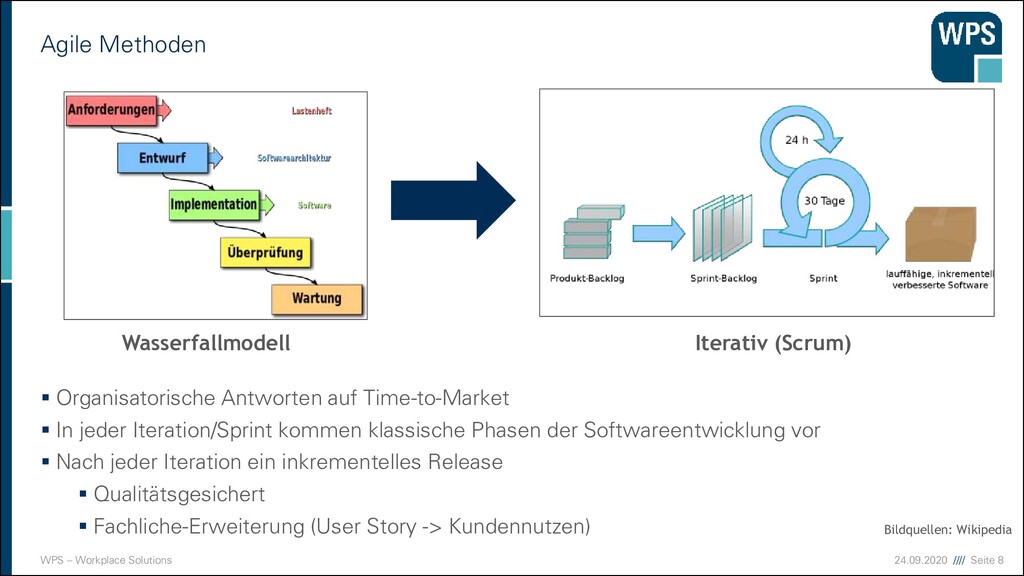{kind=link}
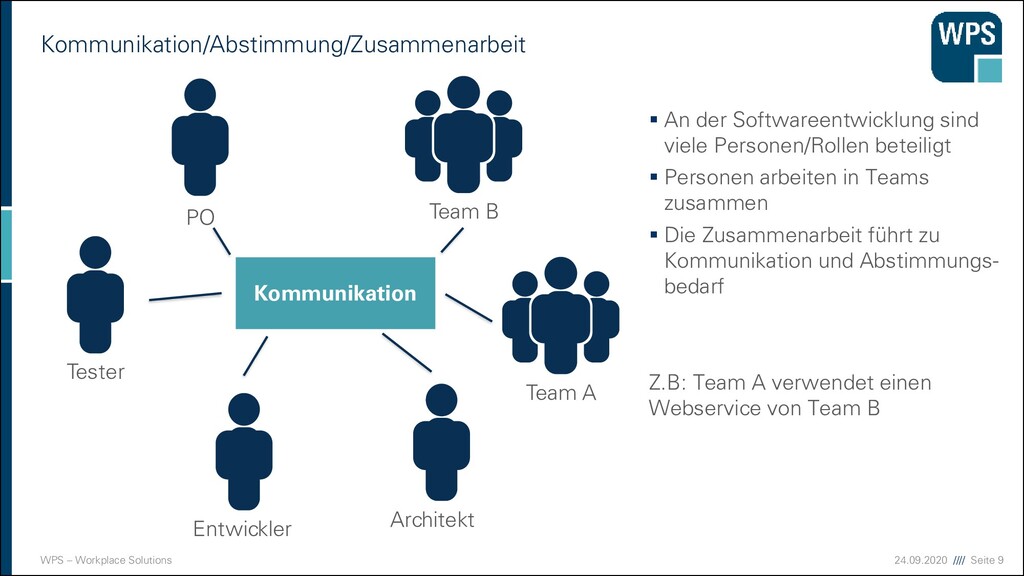{kind=link}
{kind=link}
{kind=link}
{kind=link}
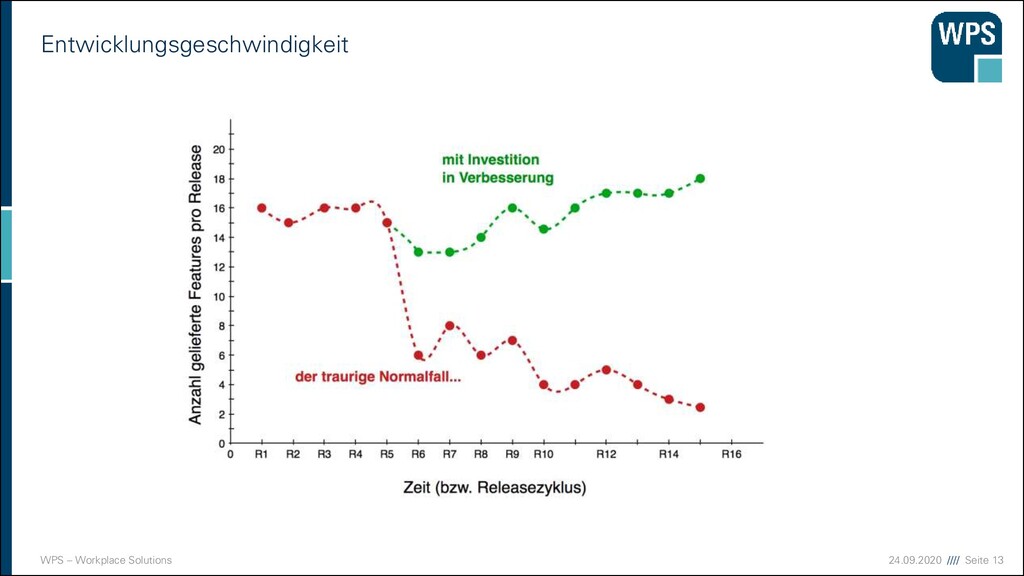{kind=link}
{kind=link}
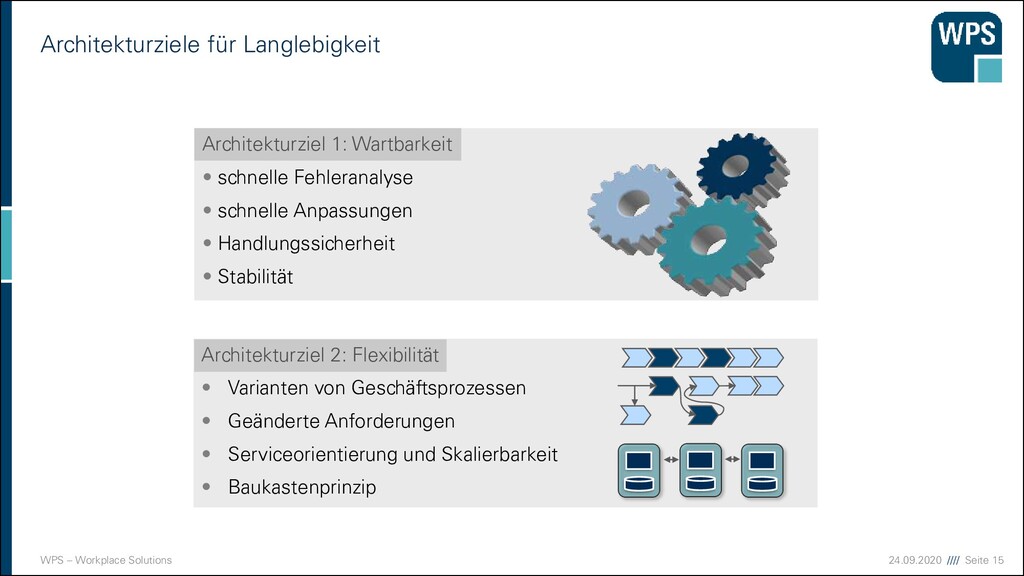{kind=link}
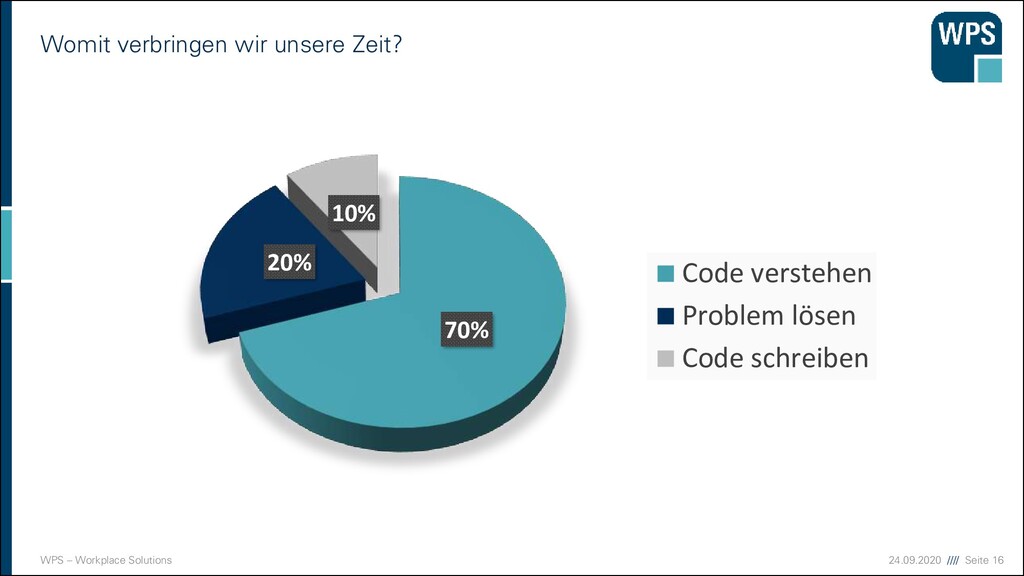{kind=link}
{kind=link}
{kind=link}
{kind=link}
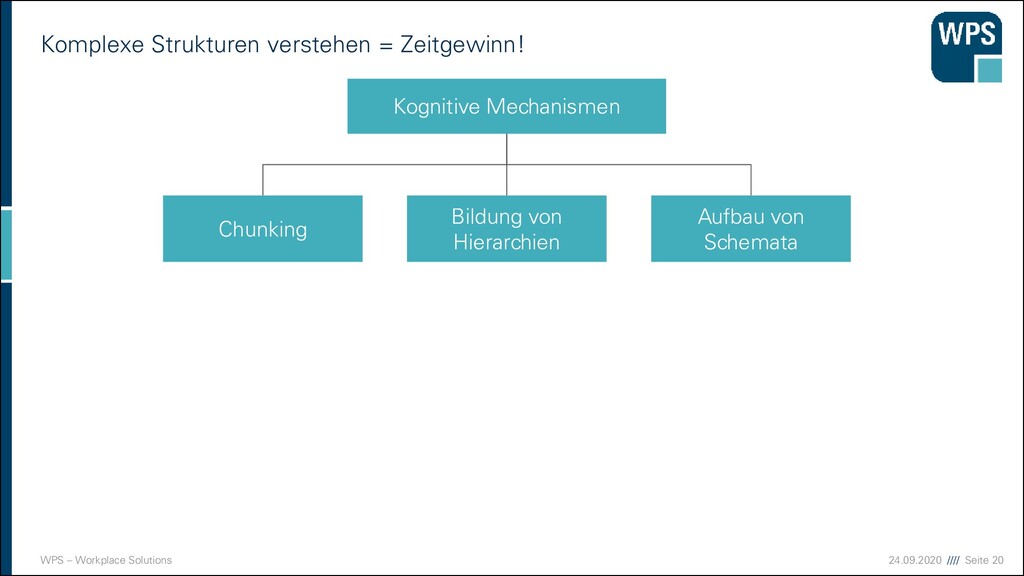{kind=link}
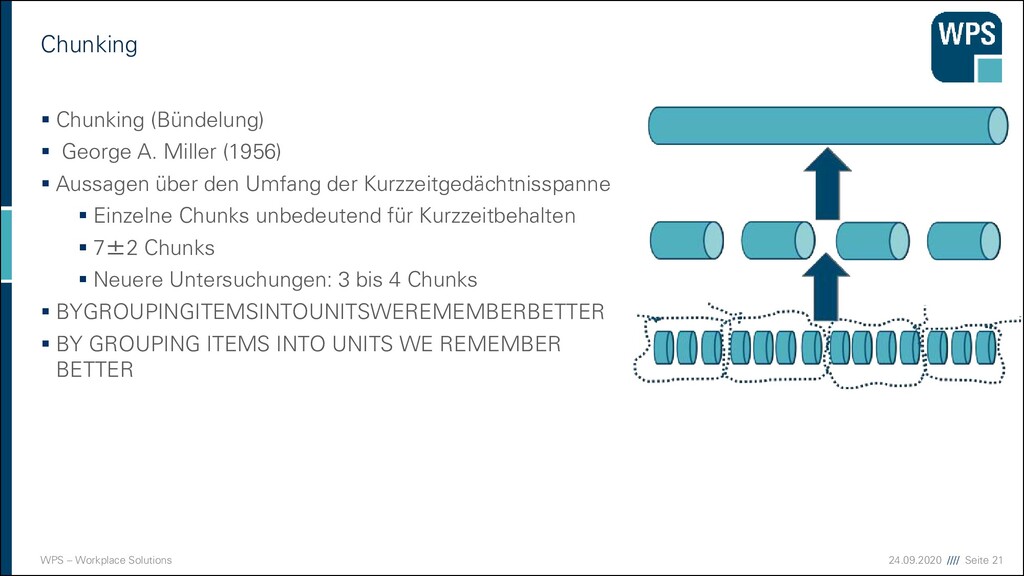{kind=link}
{kind=link}
{kind=link}
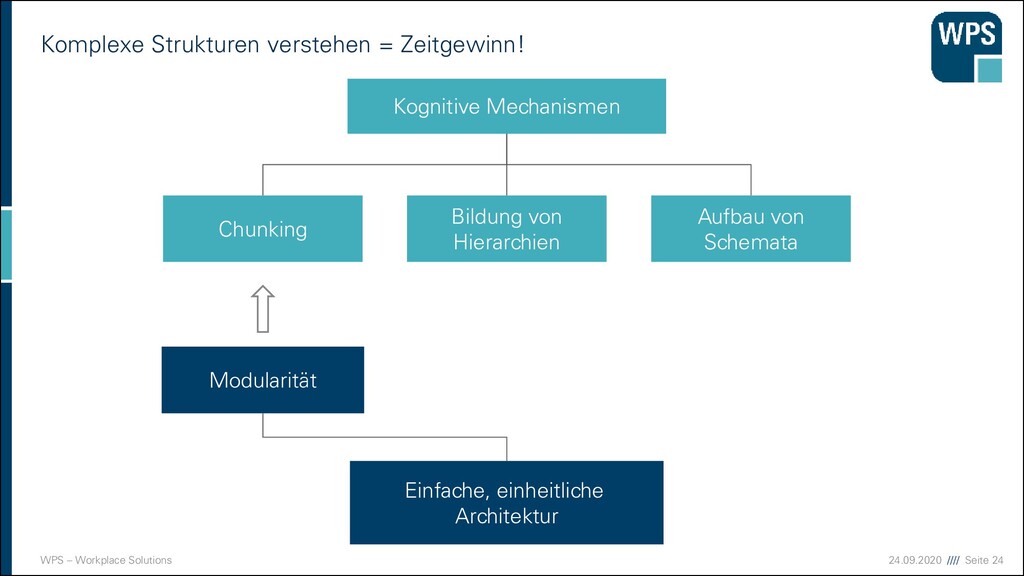{kind=link}
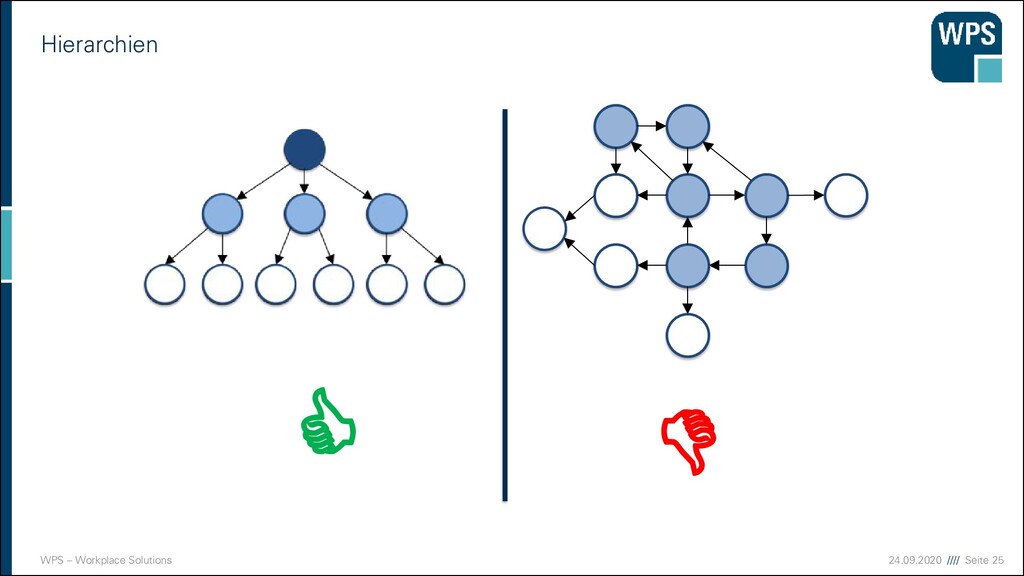{kind=link}
{kind=link}
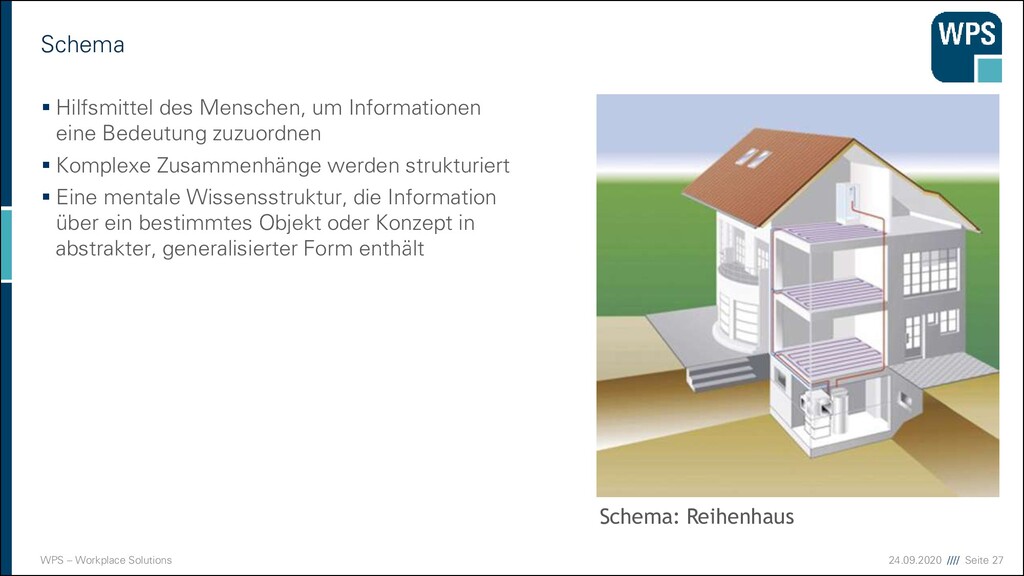{kind=link}
{kind=link}
{kind=link}
{kind=link}
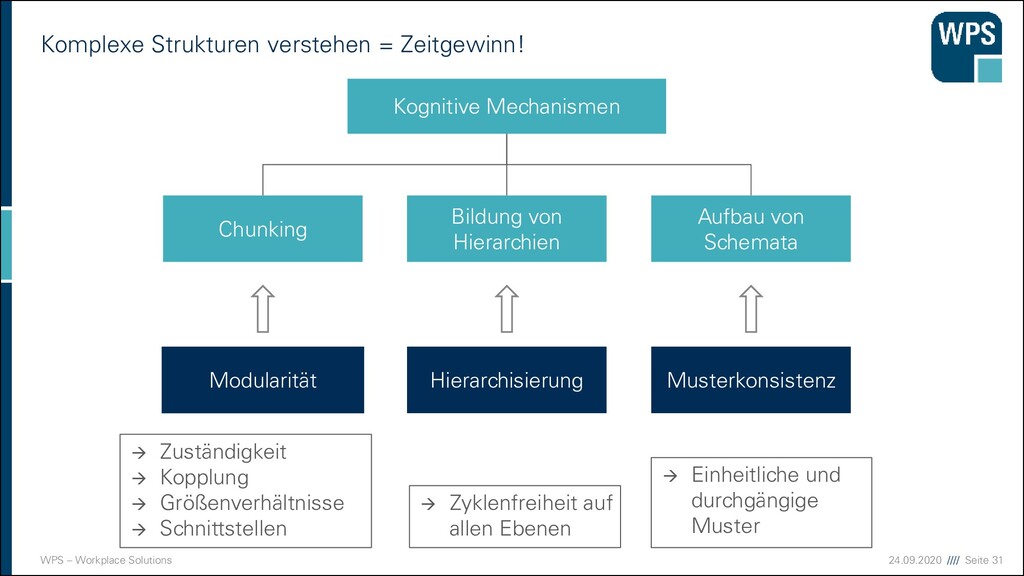{kind=link}
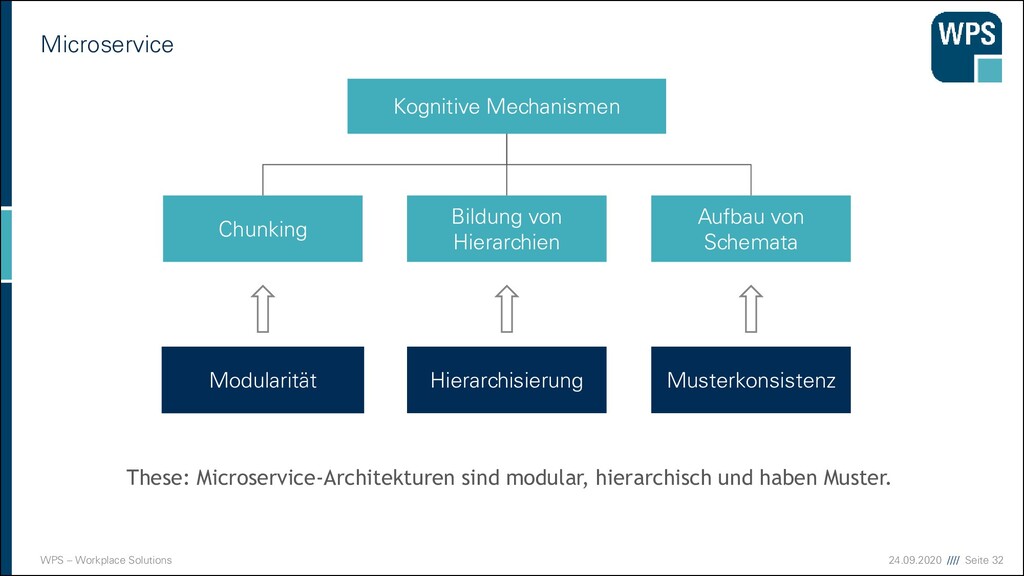{kind=link}
{kind=link}
{kind=link}
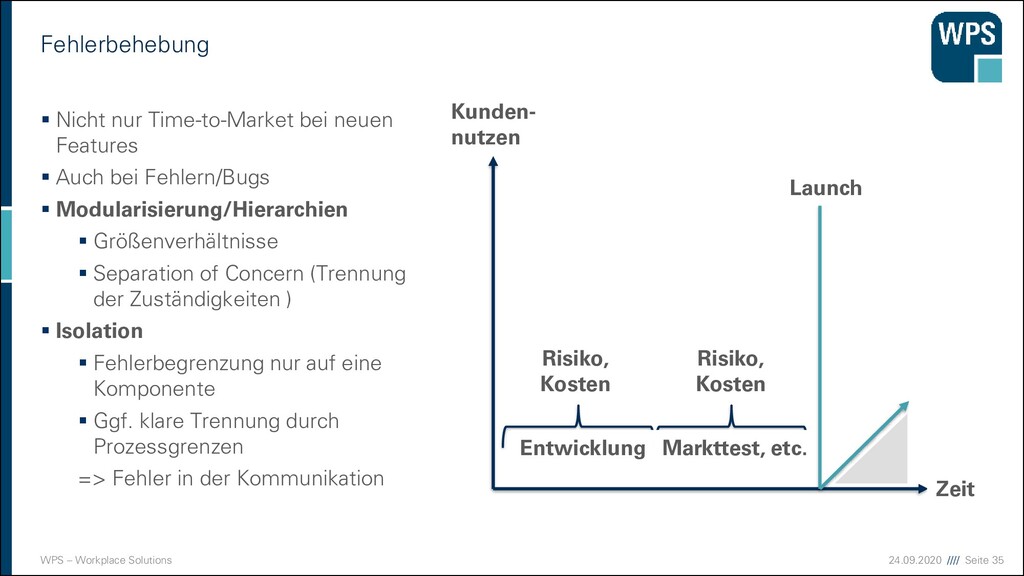{kind=link}
{kind=link}
{kind=link}
{kind=link}
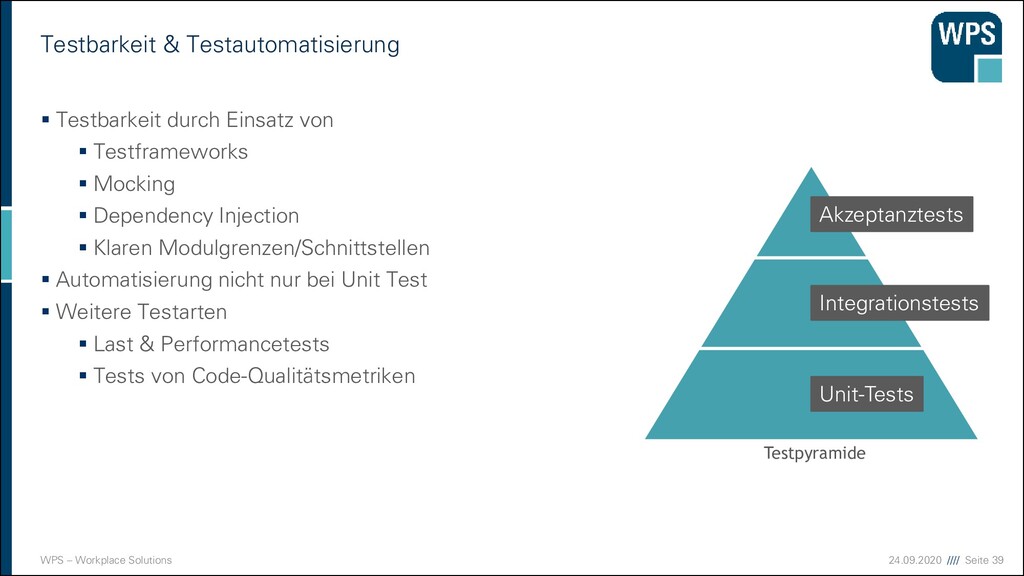{kind=link}
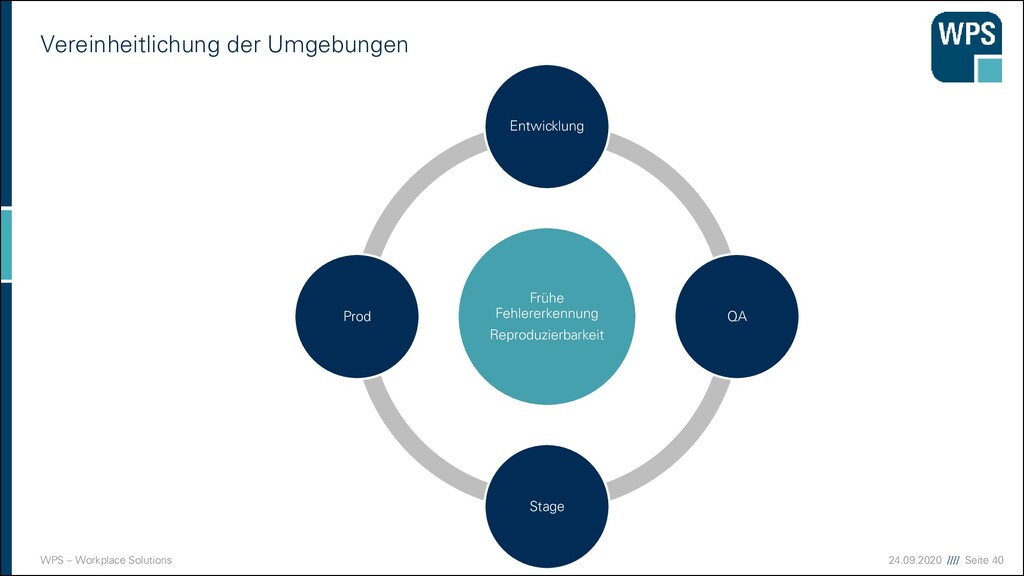{kind=link}
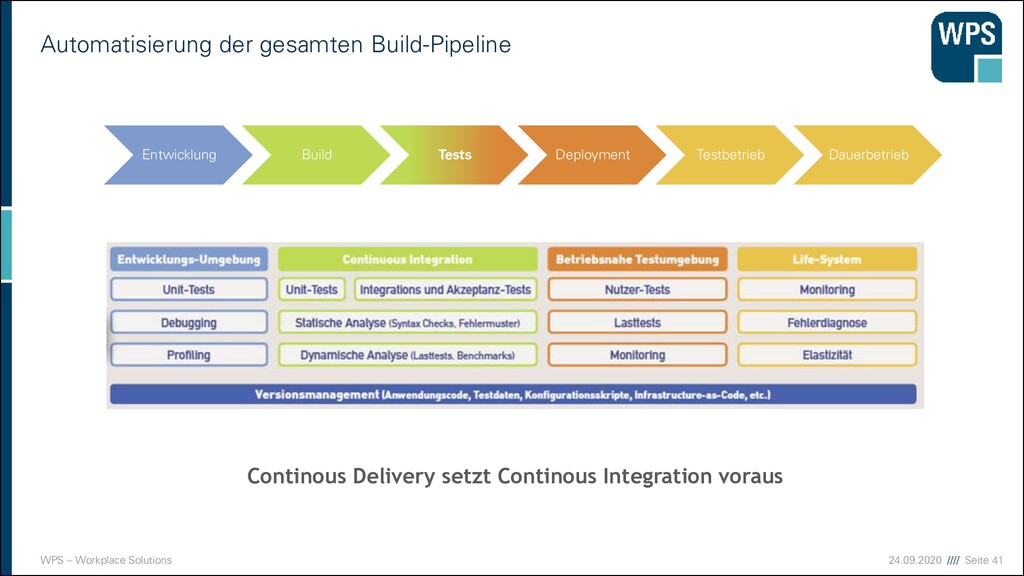{kind=link}
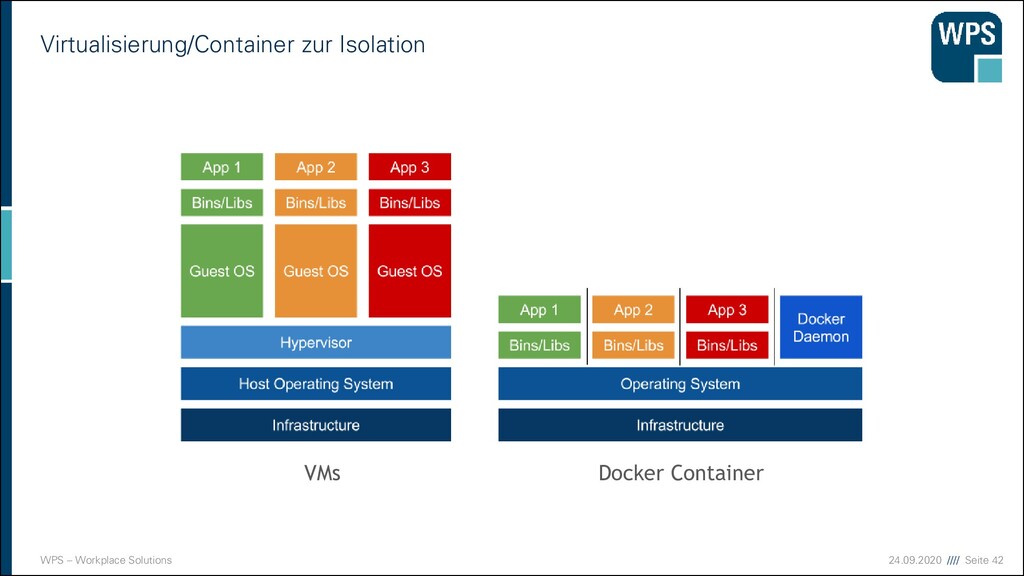{kind=link}
{kind=link}
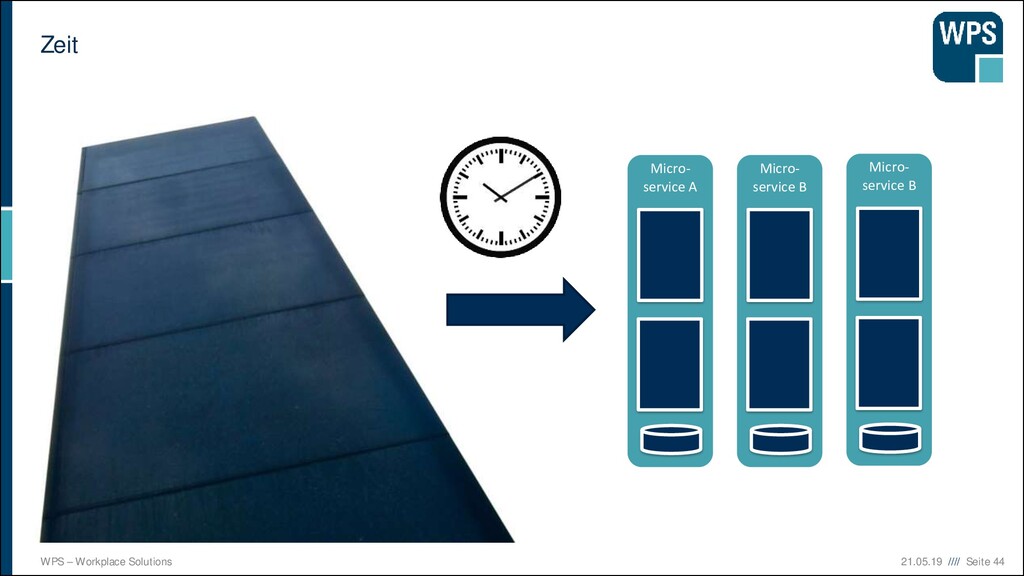{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
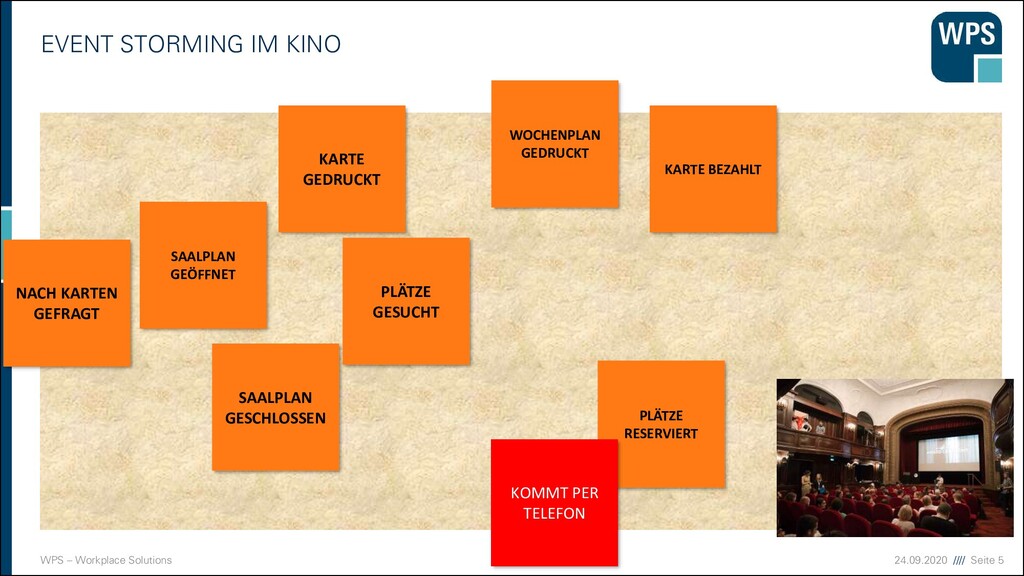{kind=link}
{kind=link}
{kind=link}
{kind=link}
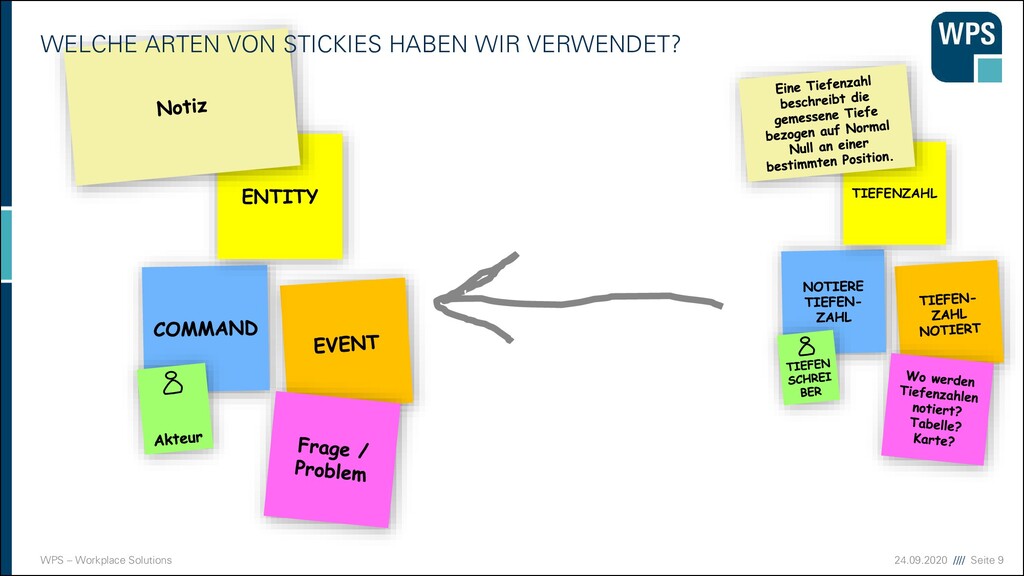{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
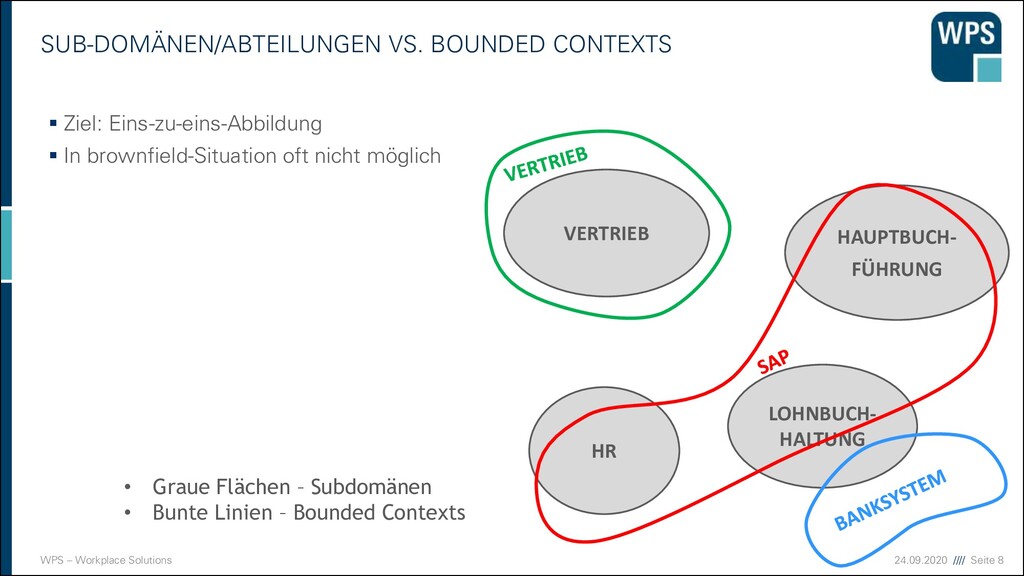{kind=link}
{kind=link}
{kind=link}
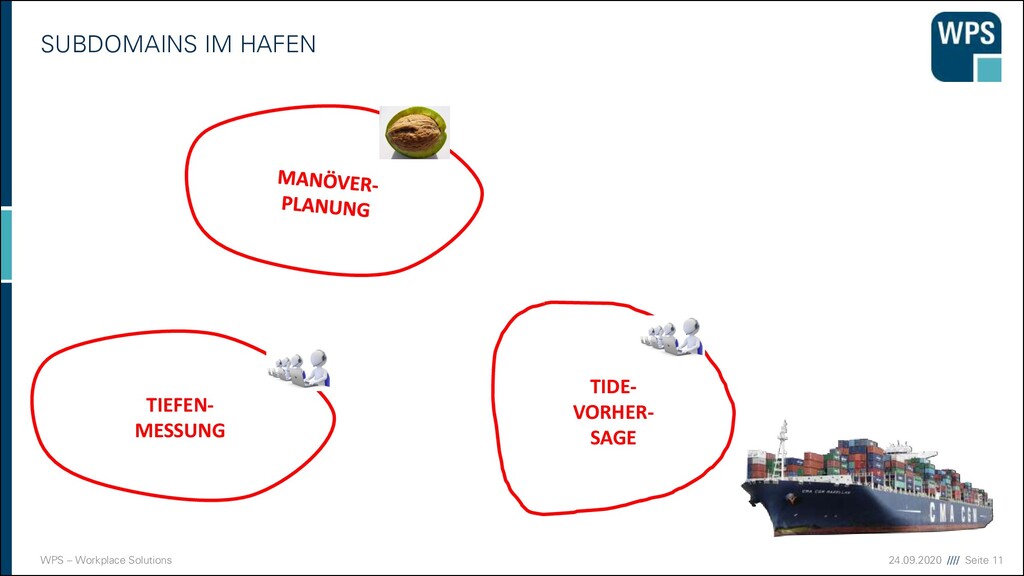{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
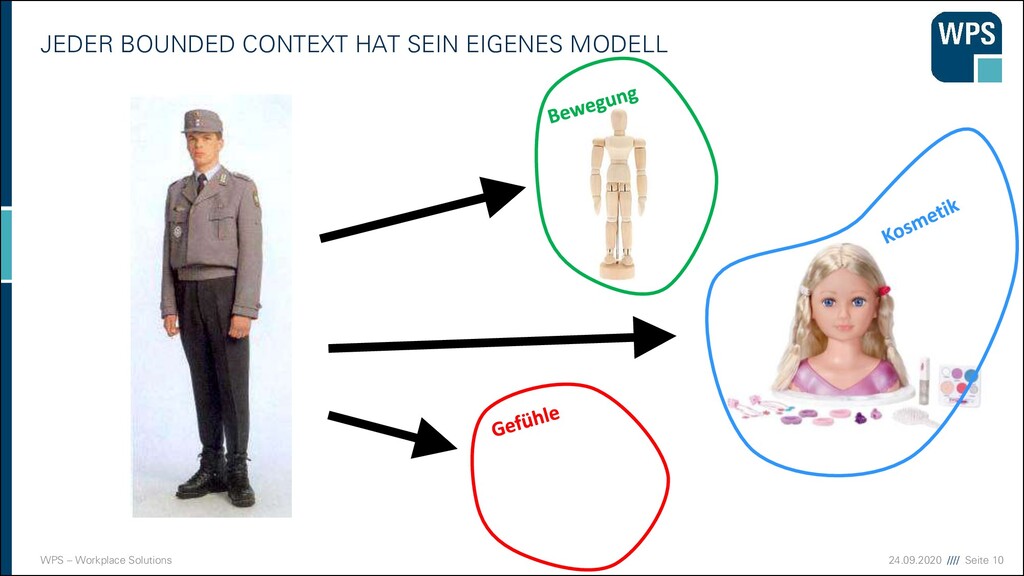{kind=link}
{kind=link}
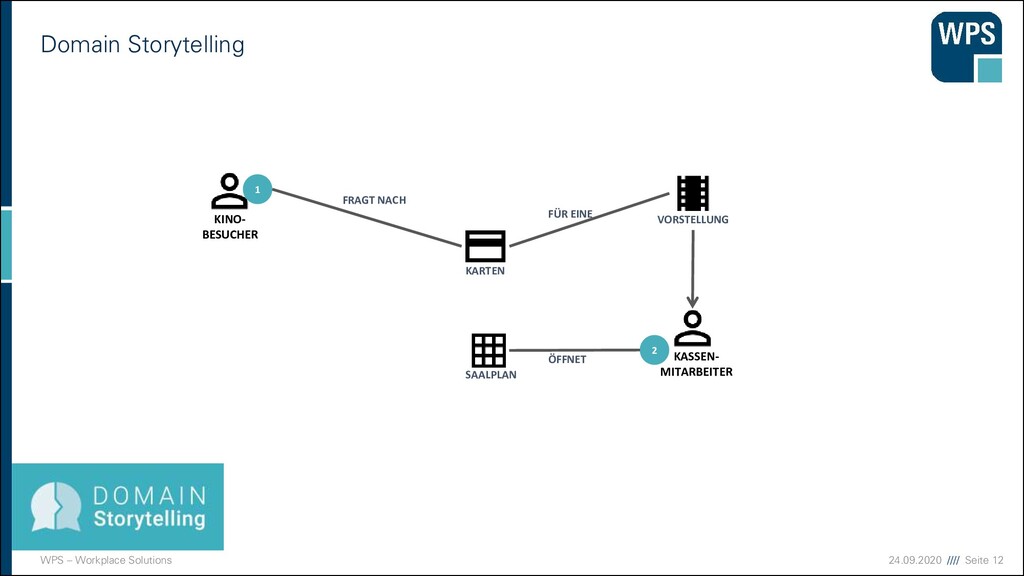{kind=link}
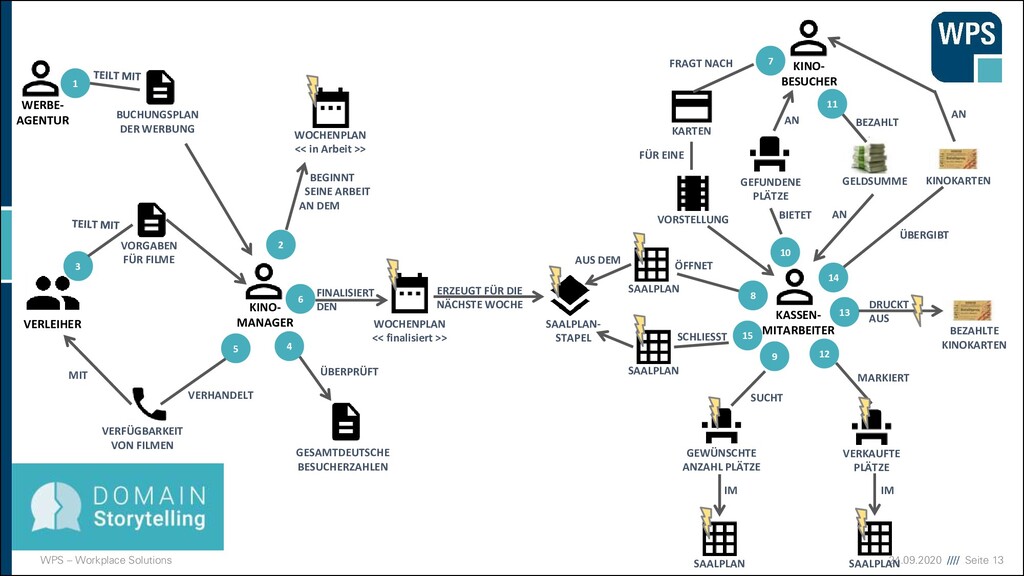{kind=link}
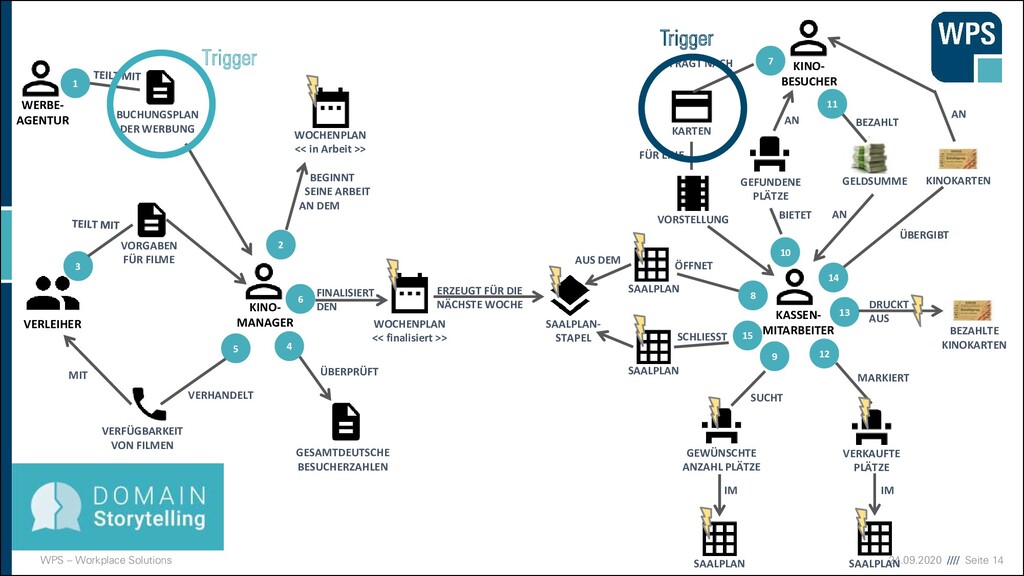{kind=link}
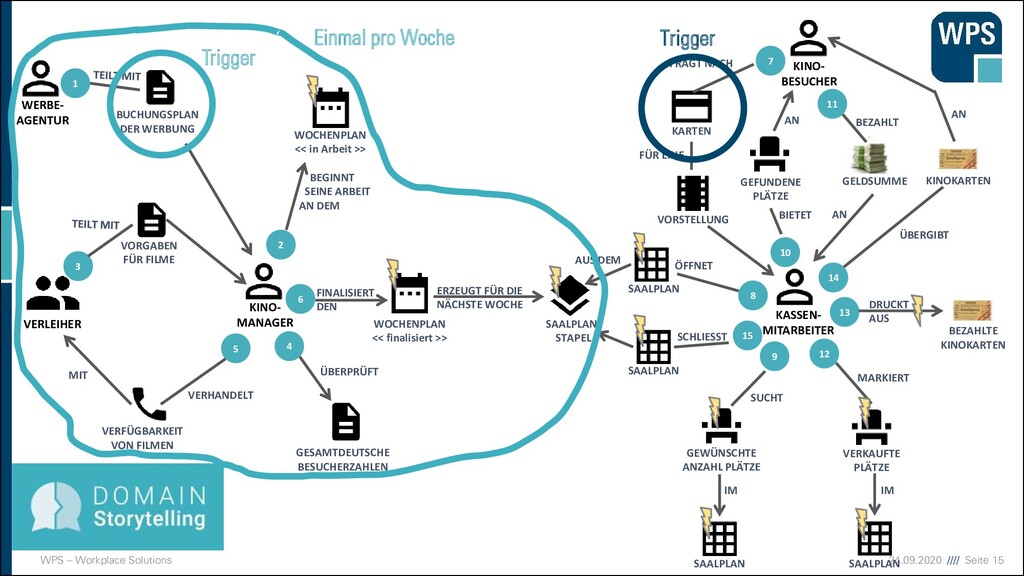{kind=link}
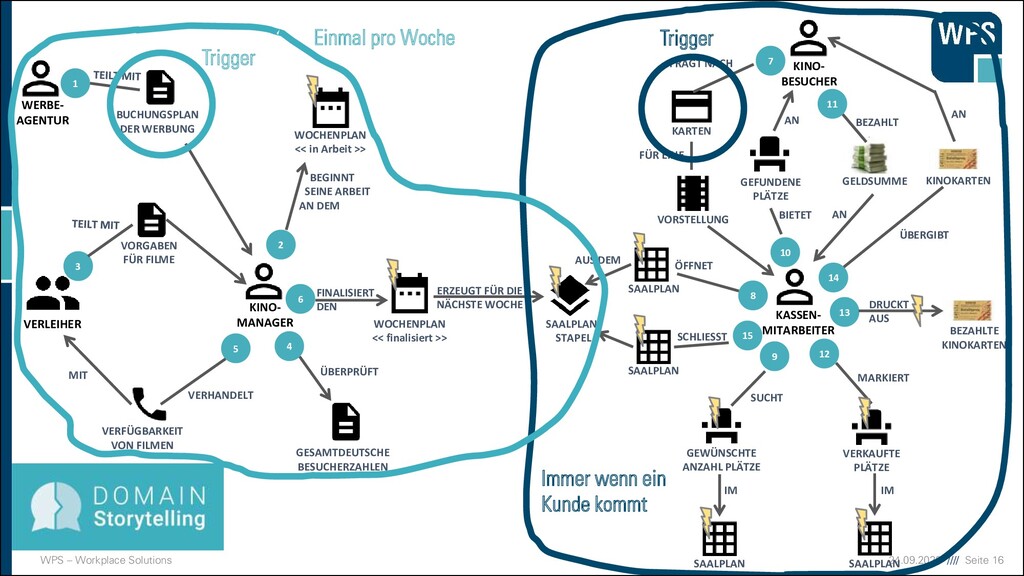{kind=link}
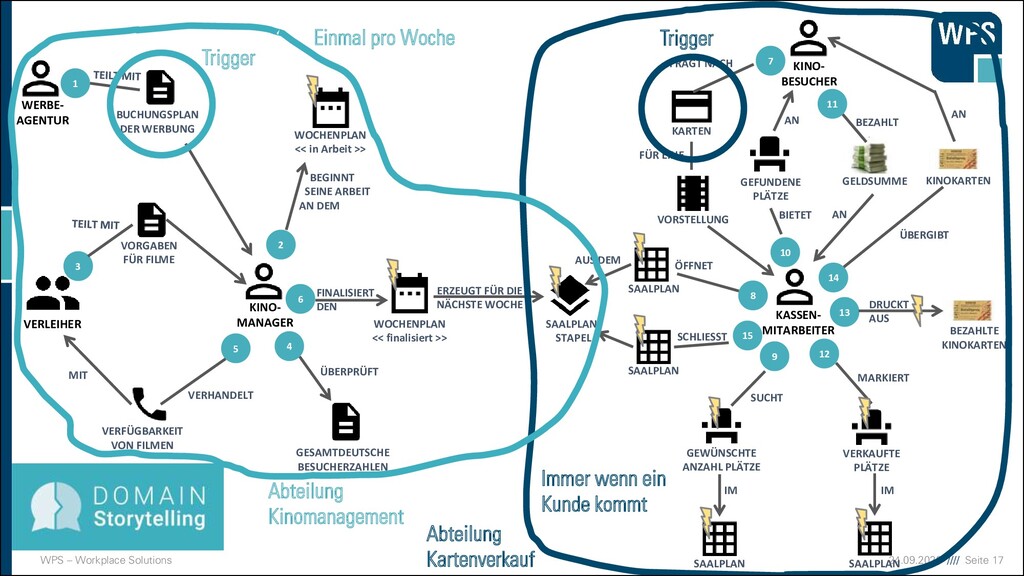{kind=link}
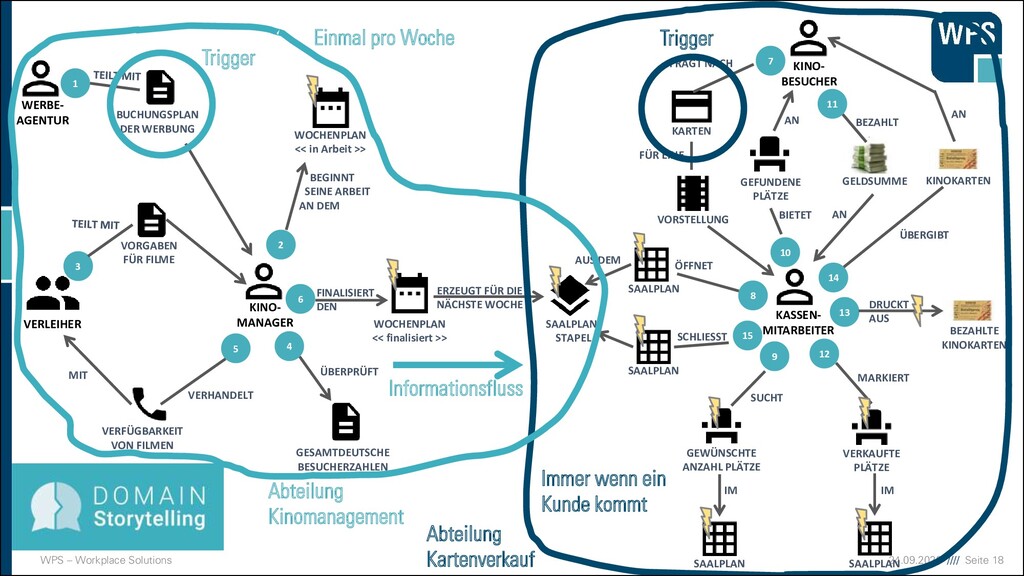{kind=link}
{kind=link}
{kind=link}
{kind=link}
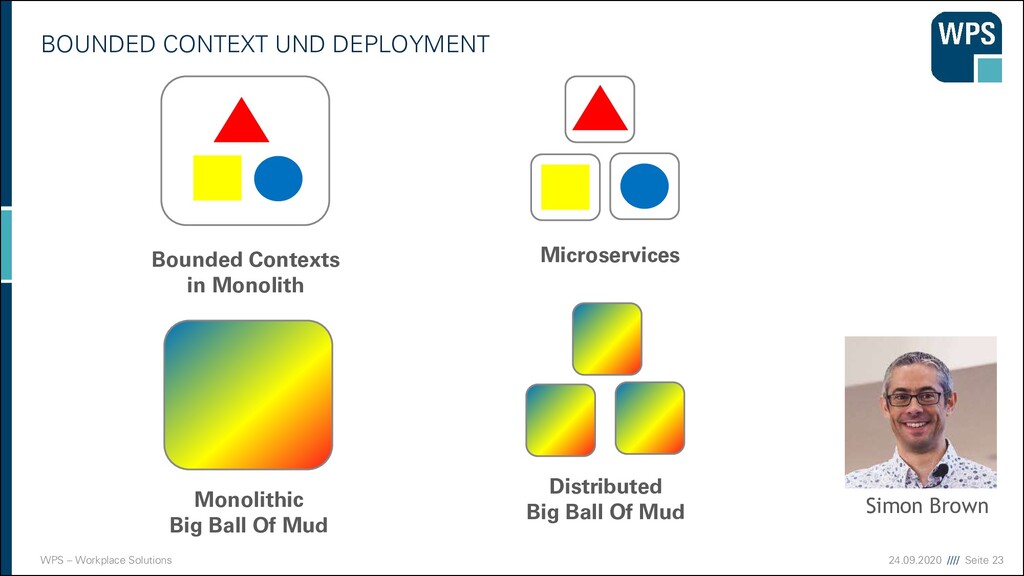{kind=link}
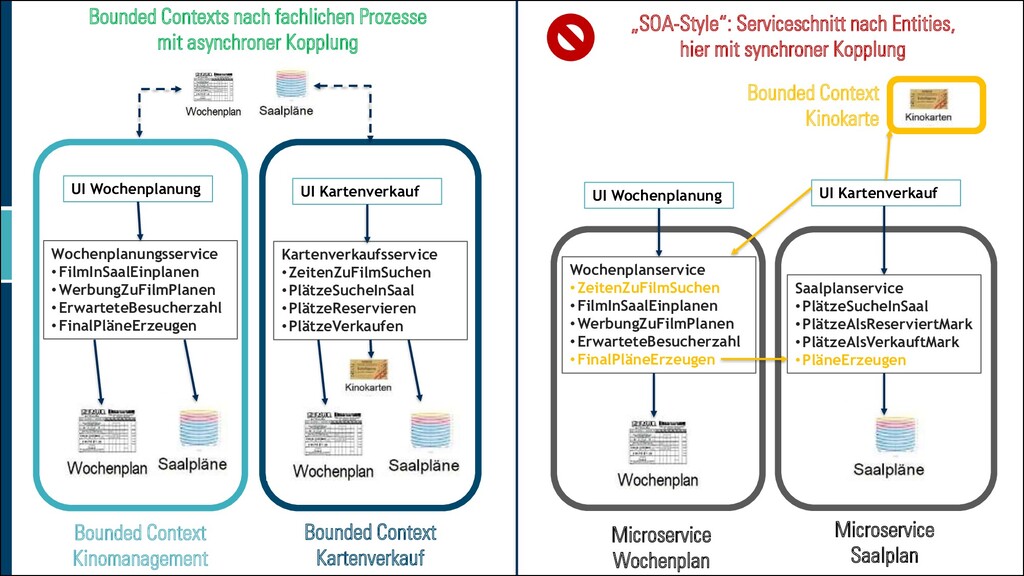{kind=link}
{kind=link}
{kind=link}
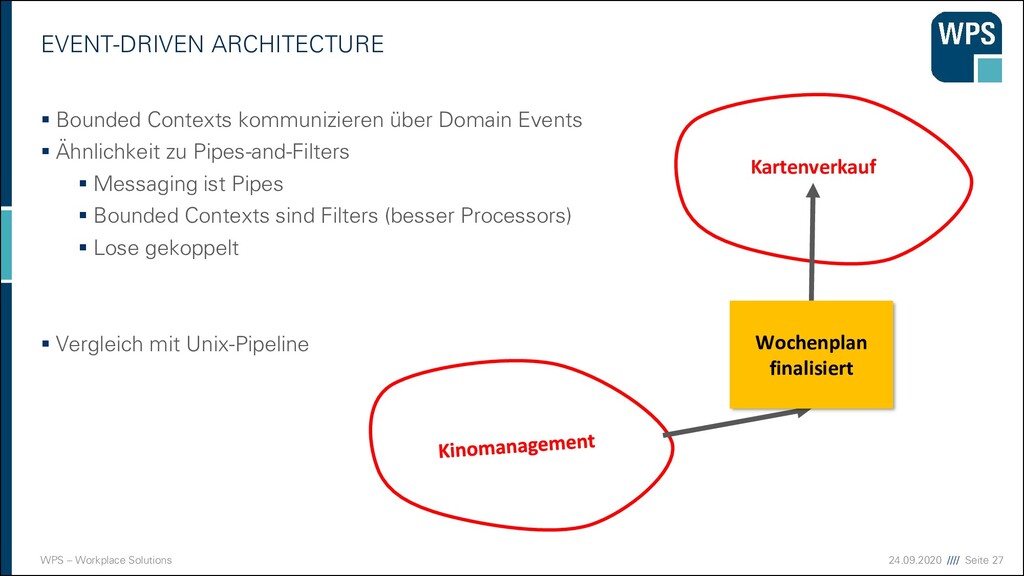{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
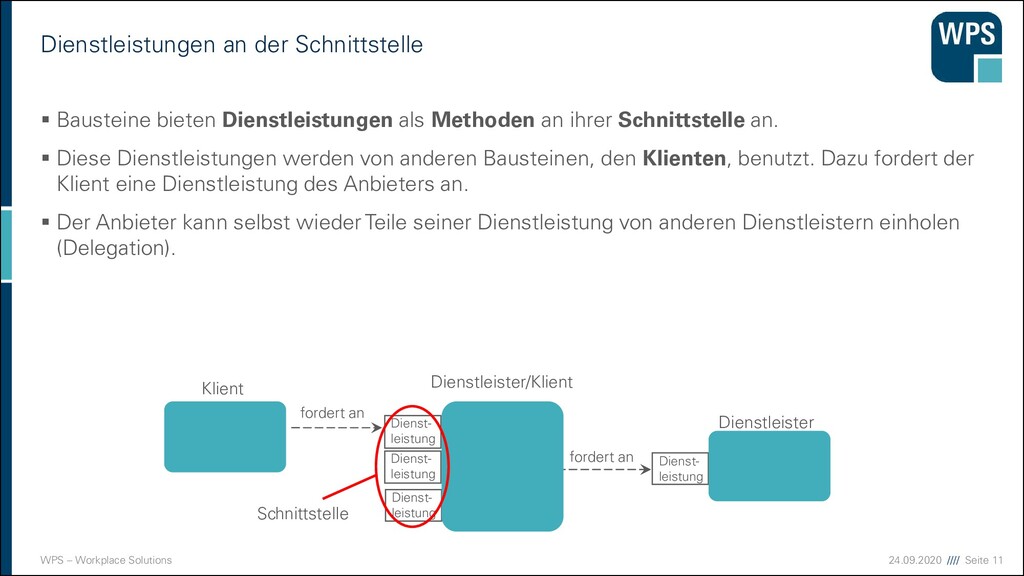{kind=link}
{kind=link}
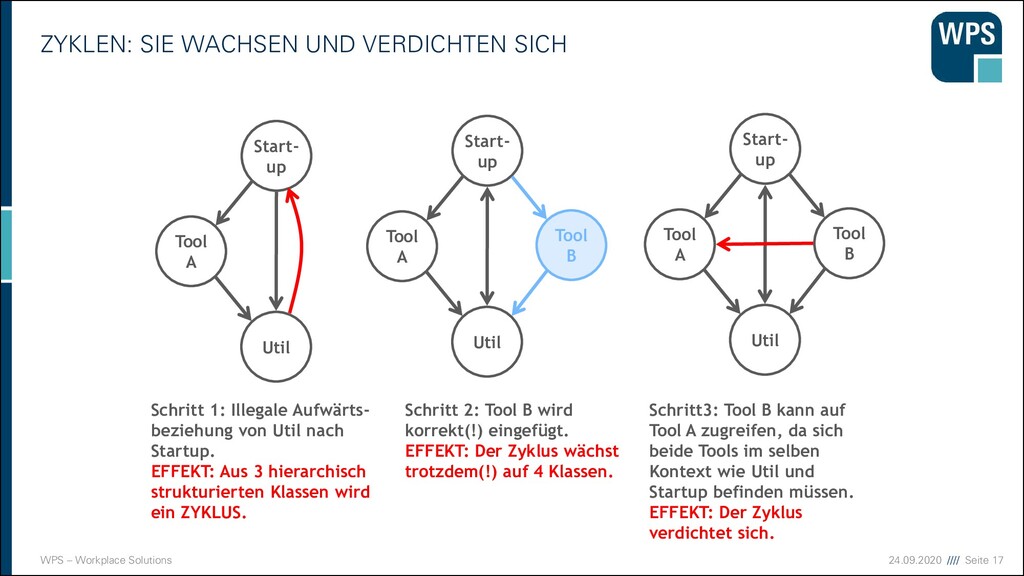{kind=link}
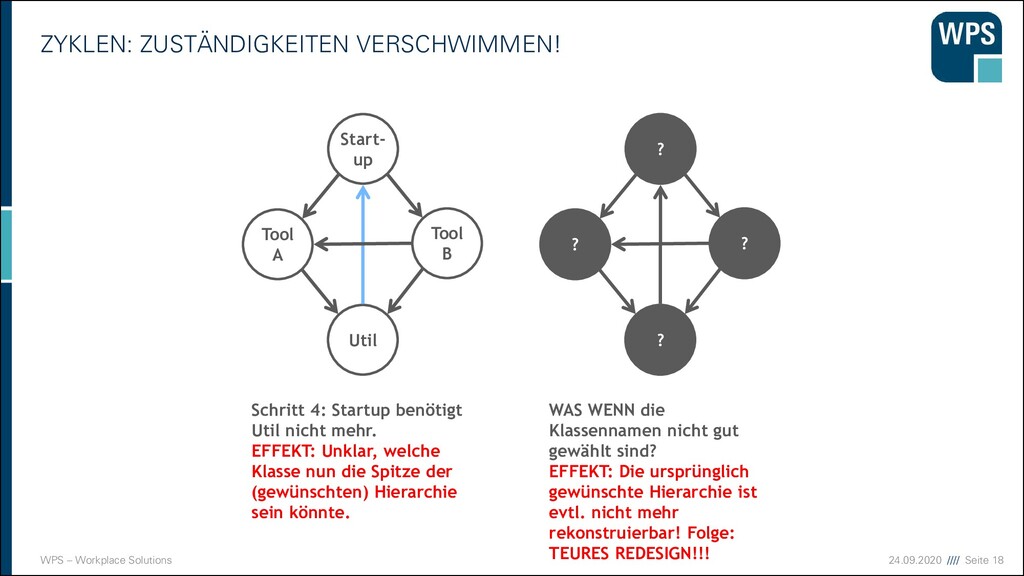{kind=link}
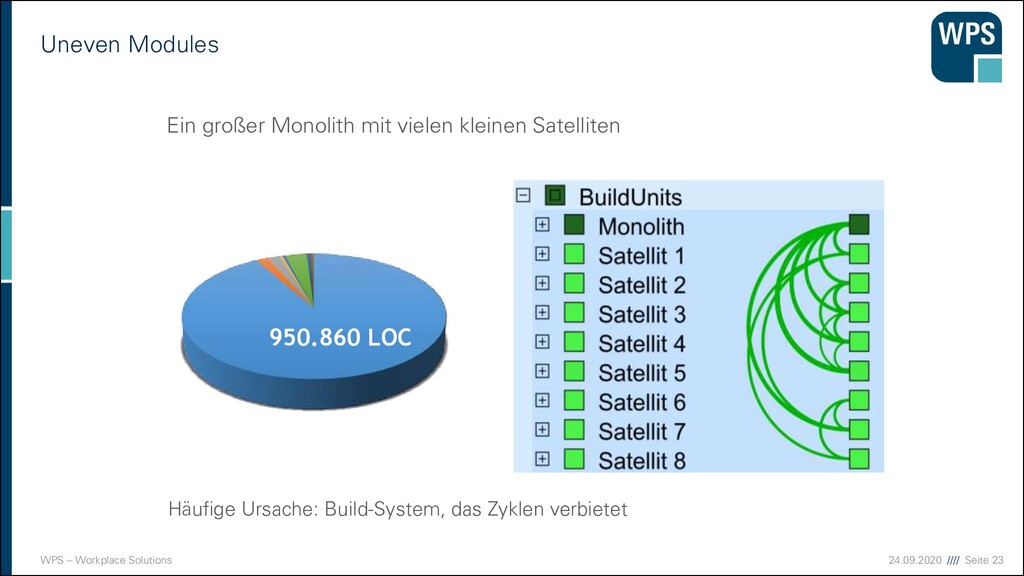{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
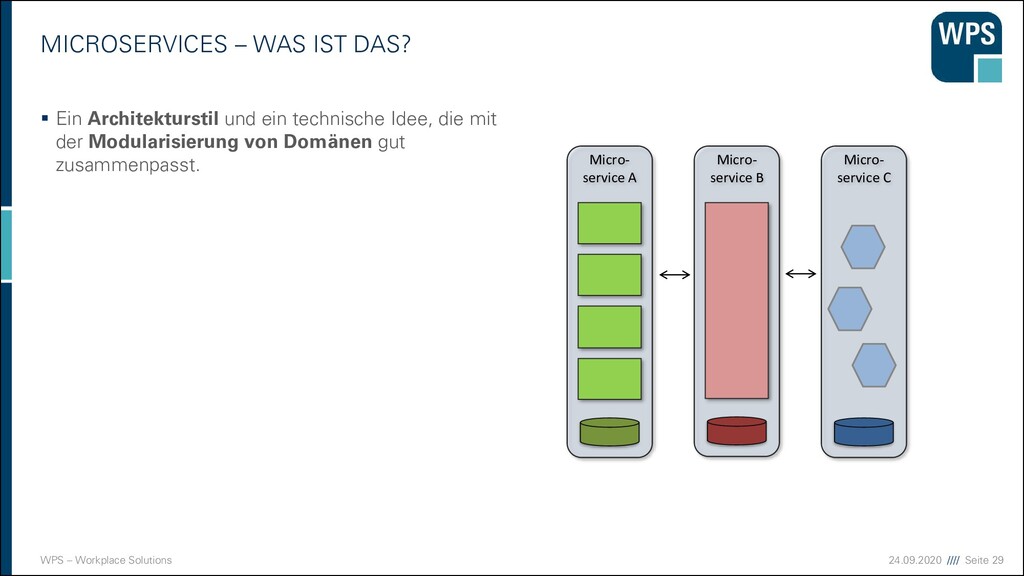{kind=link}
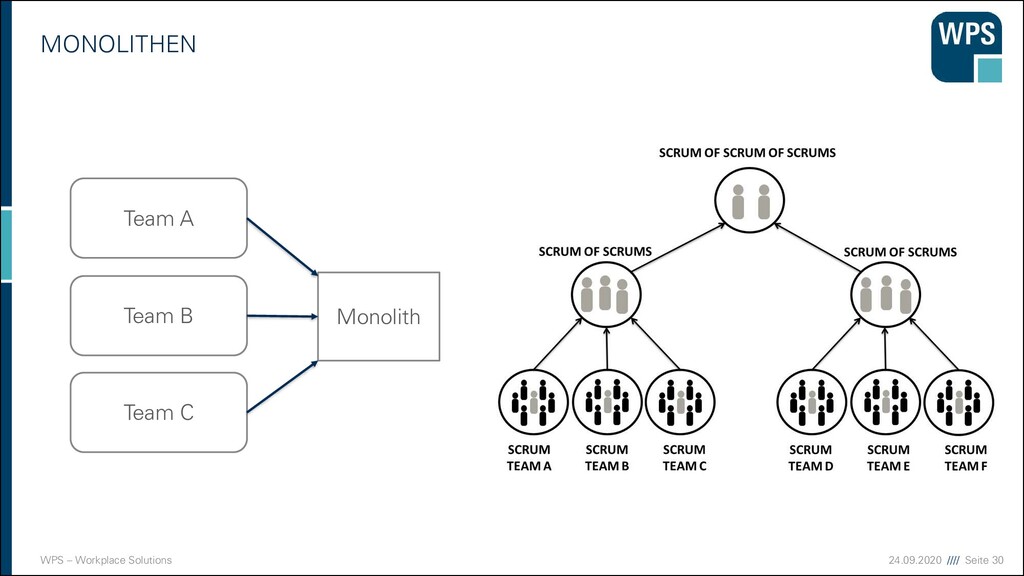{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
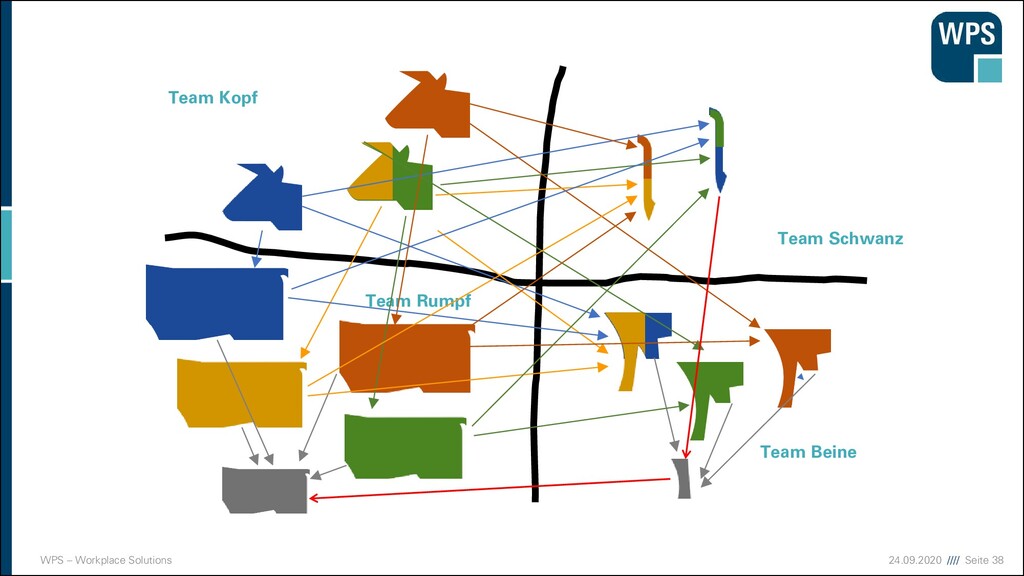{kind=link}
{kind=link}
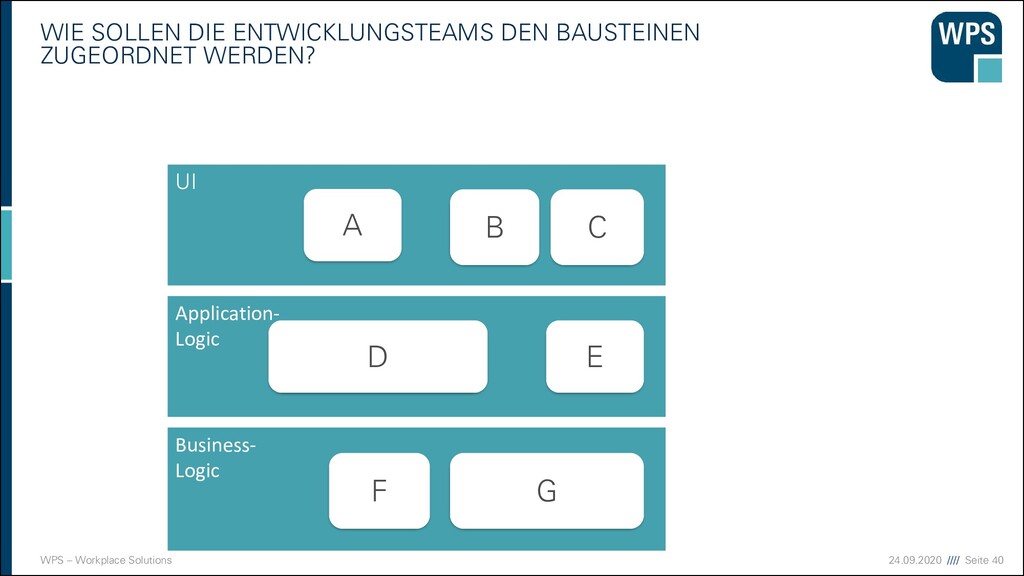{kind=link}
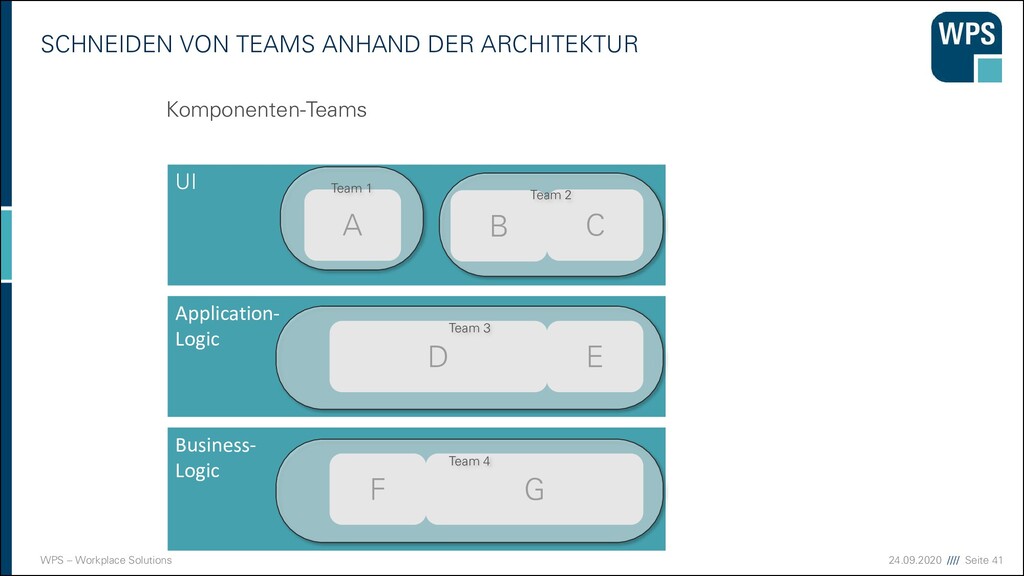{kind=link}
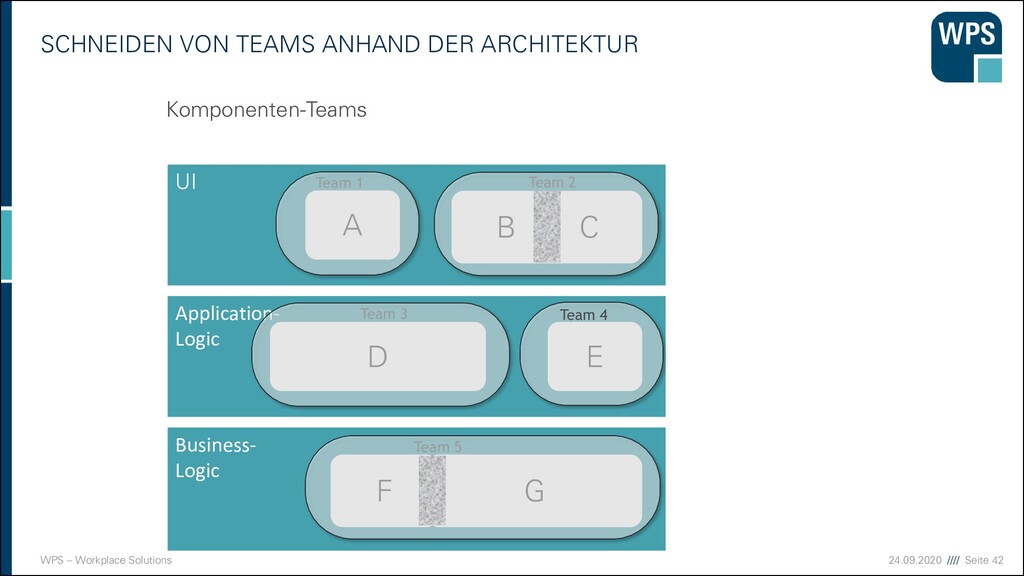{kind=link}
{kind=link}
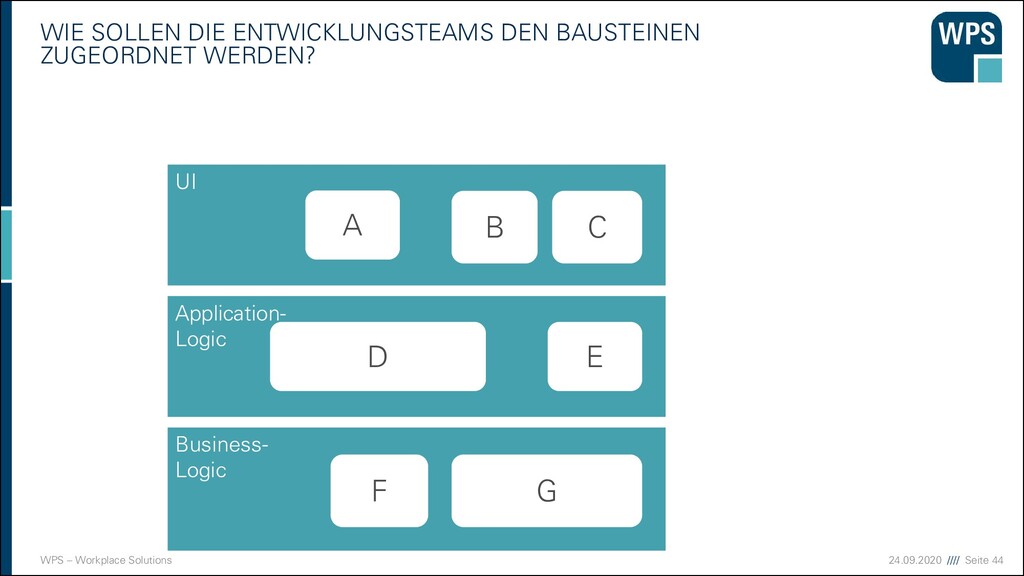{kind=link}
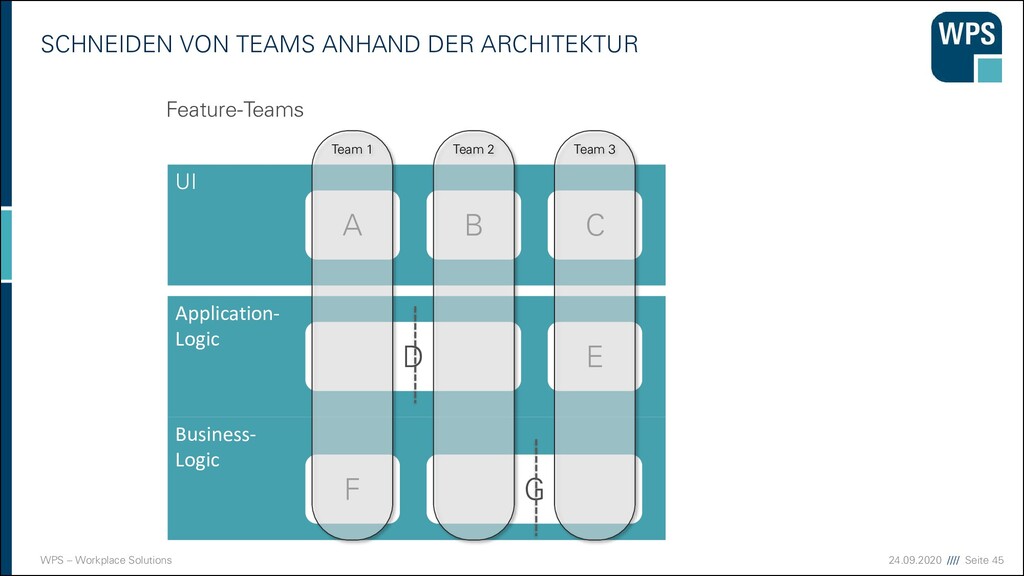{kind=link}
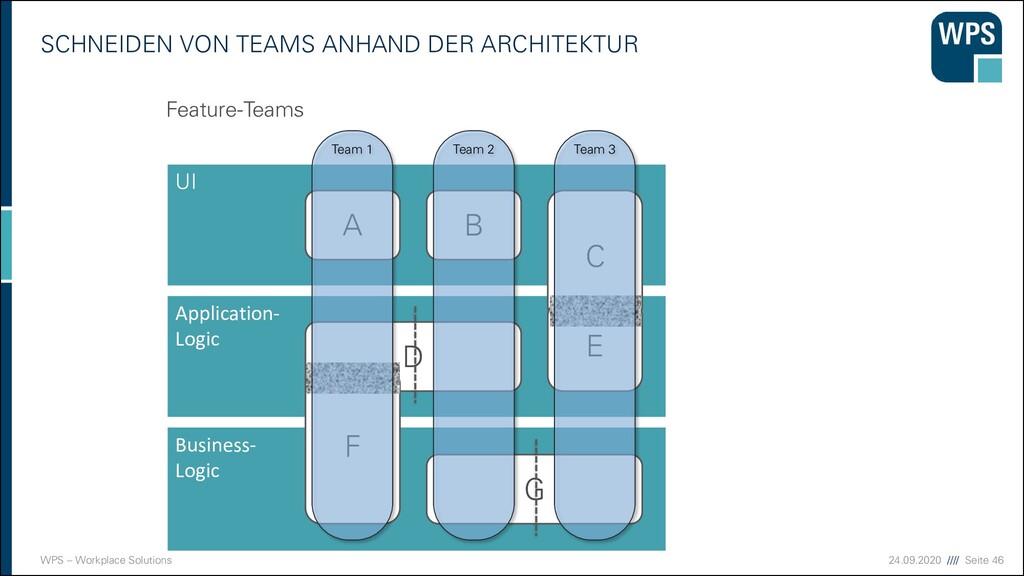{kind=link}
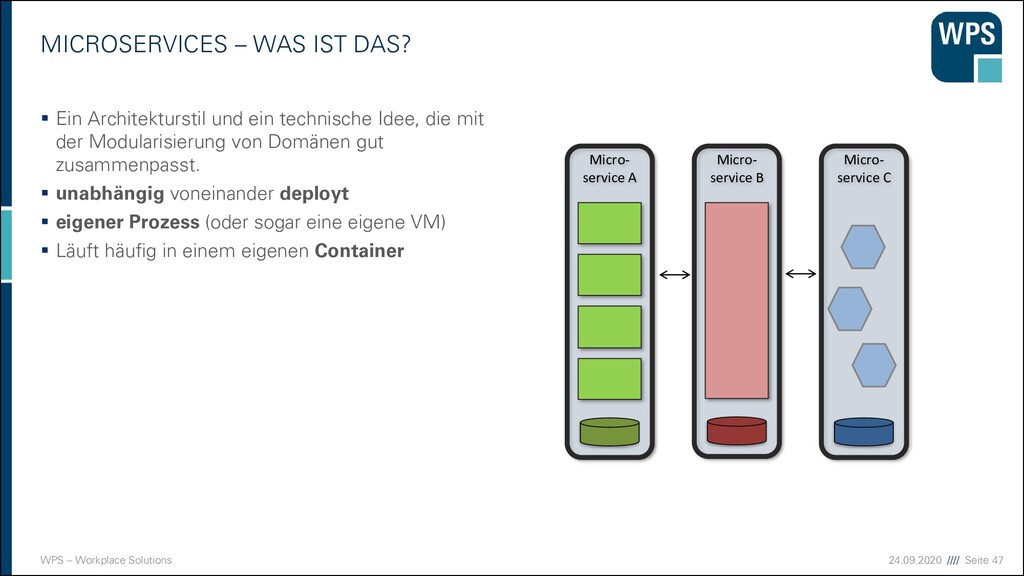{kind=link}
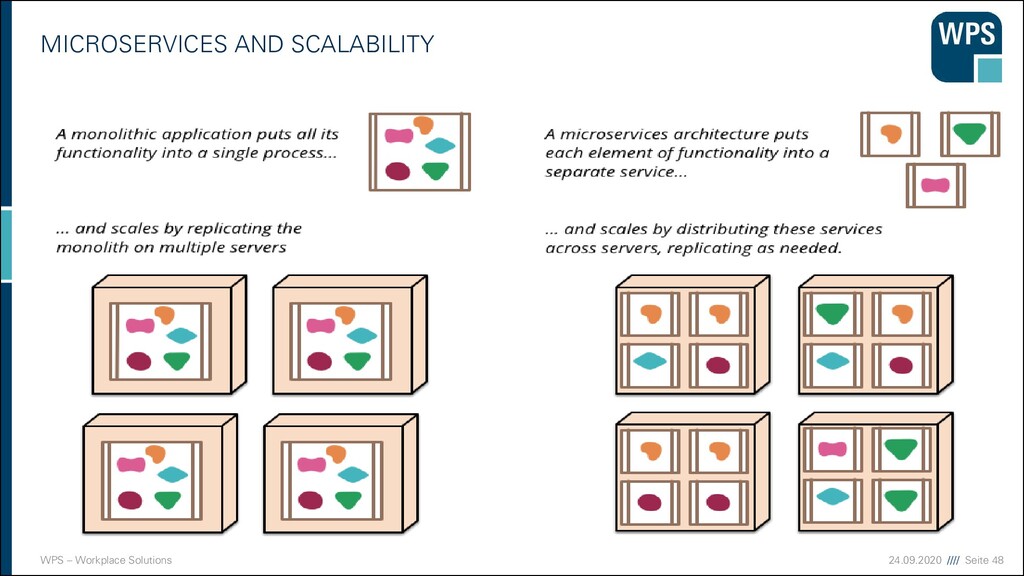{kind=link}
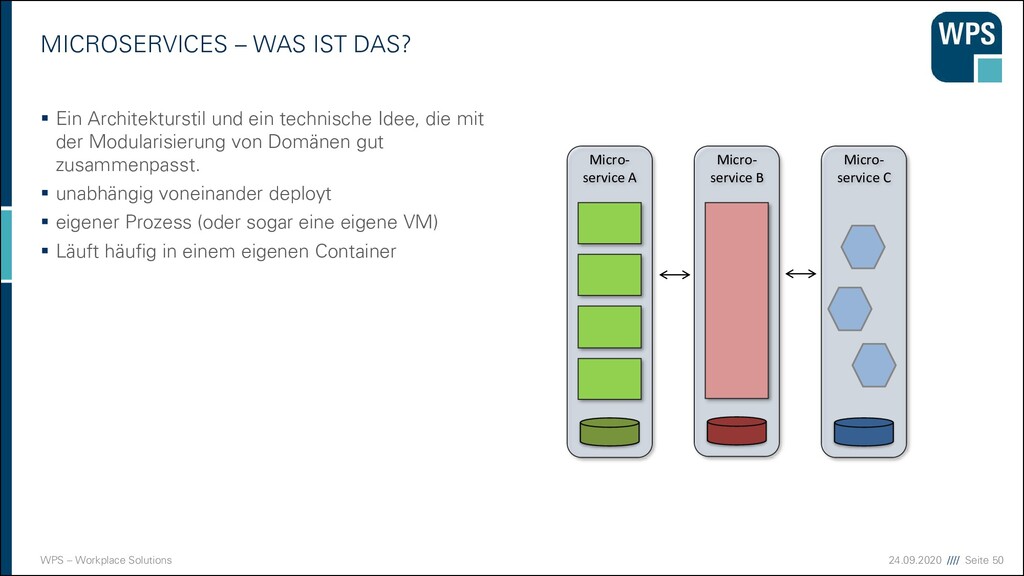{kind=link}
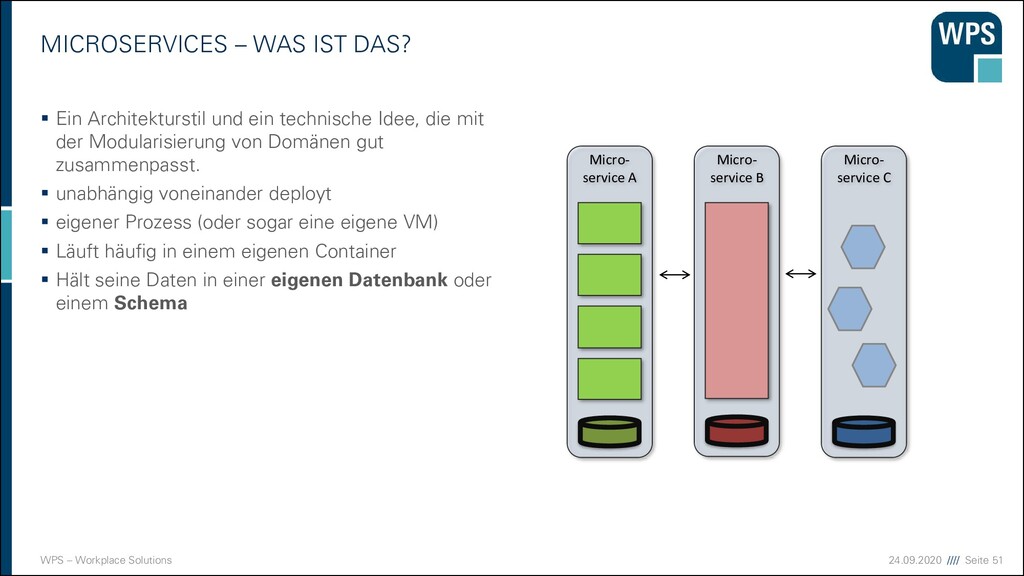{kind=link}
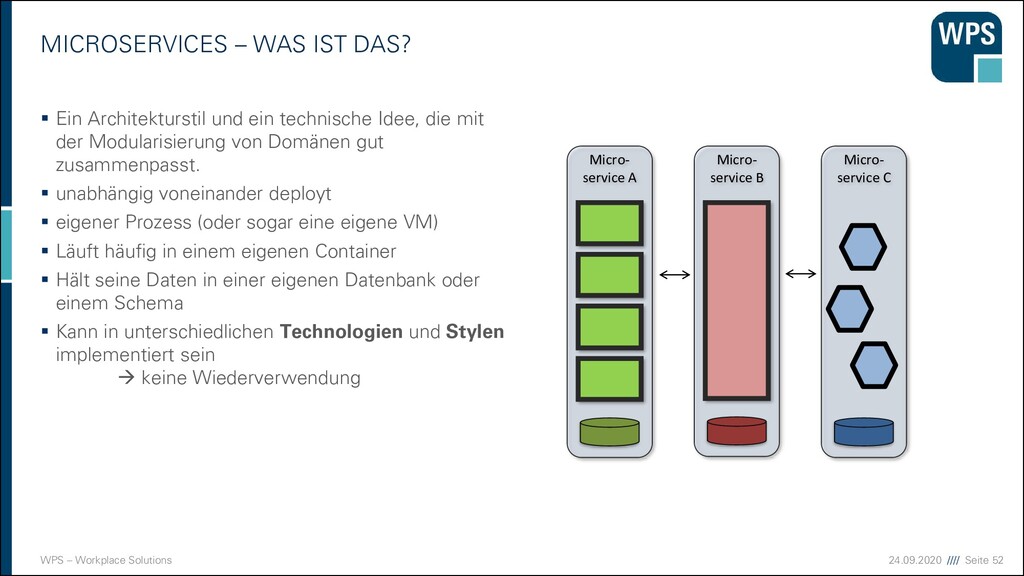{kind=link}
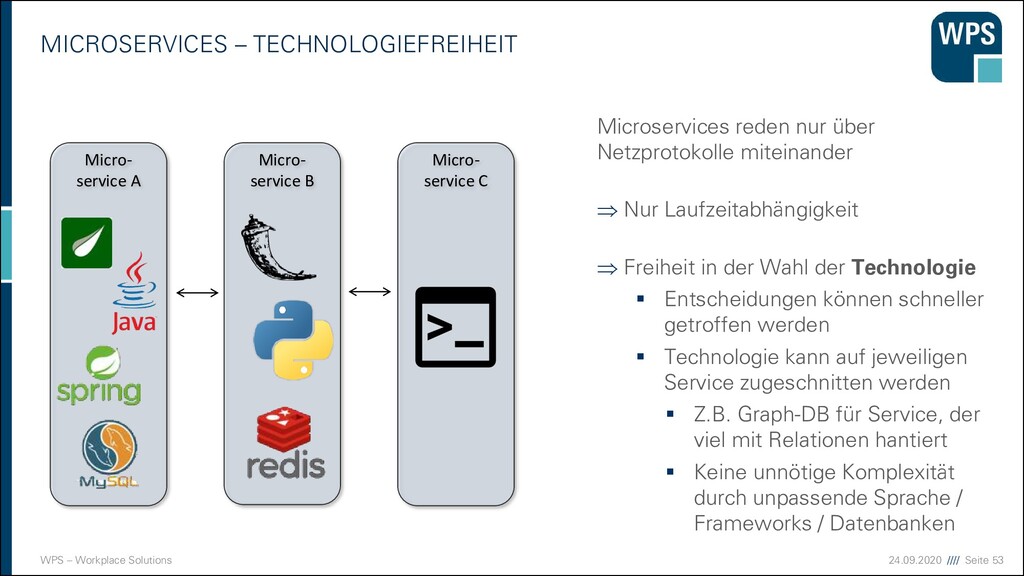{kind=link}
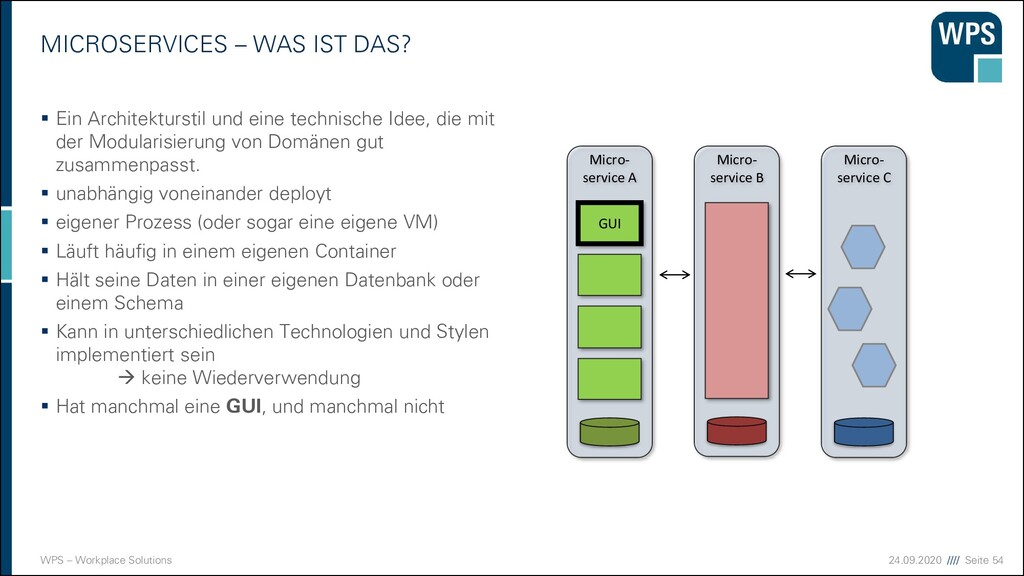{kind=link}
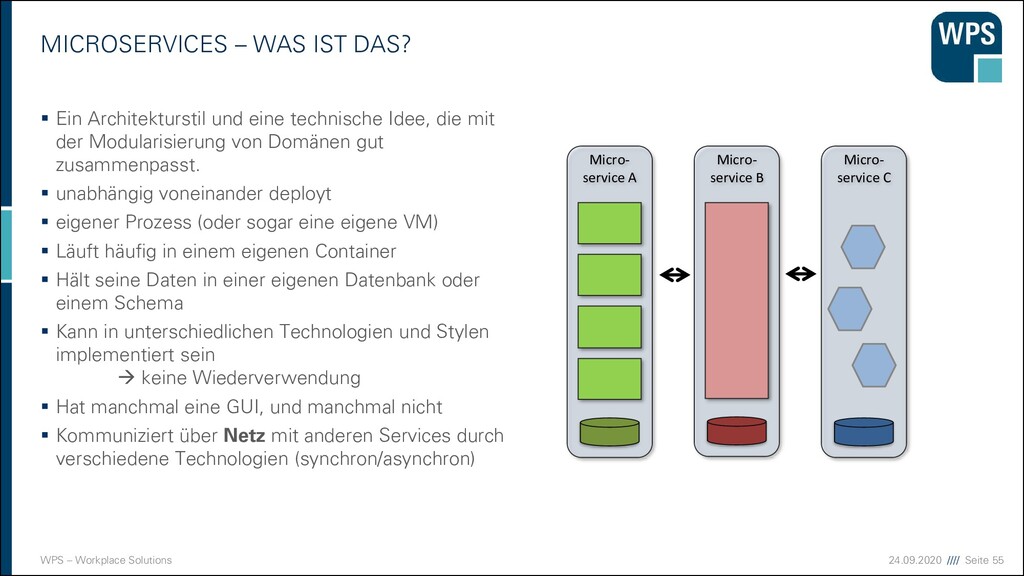{kind=link}
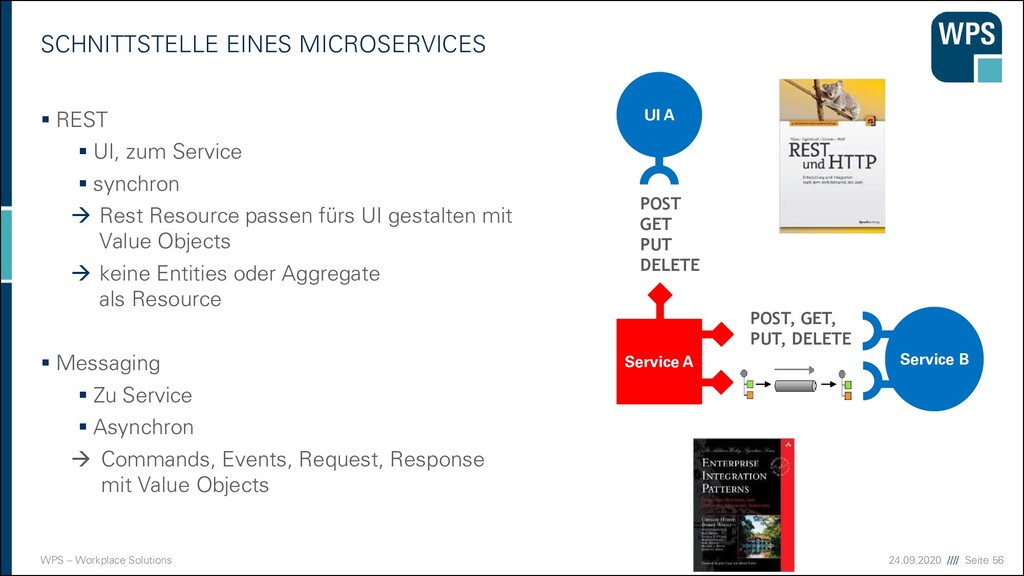{kind=link}
{kind=link}
{kind=link}
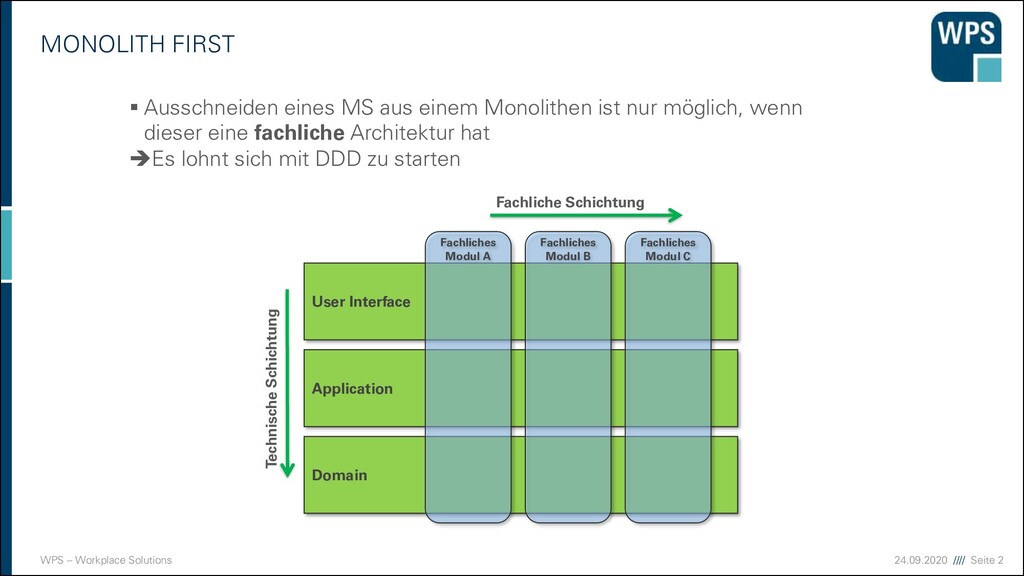{kind=link}
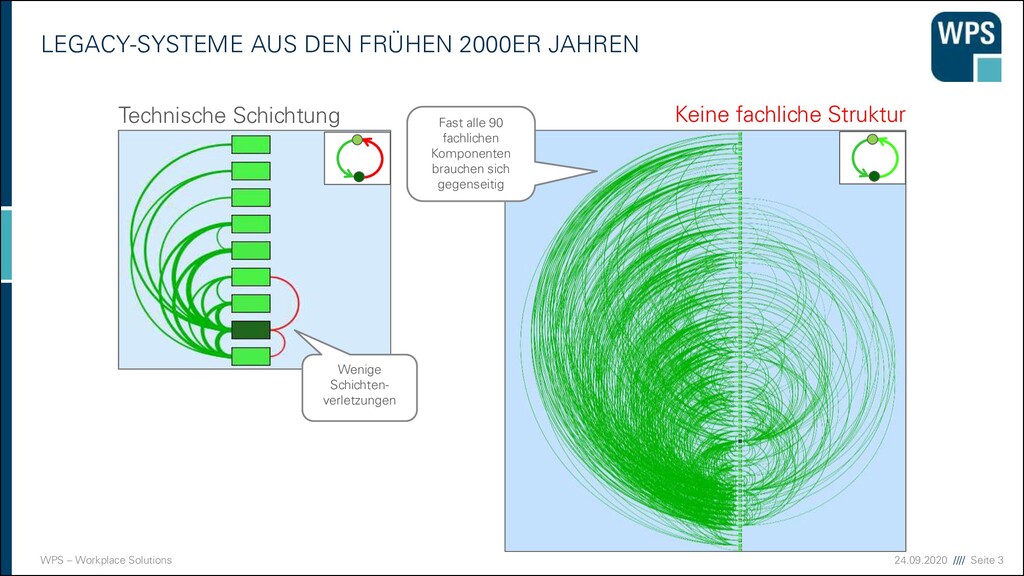{kind=link}
{kind=link}
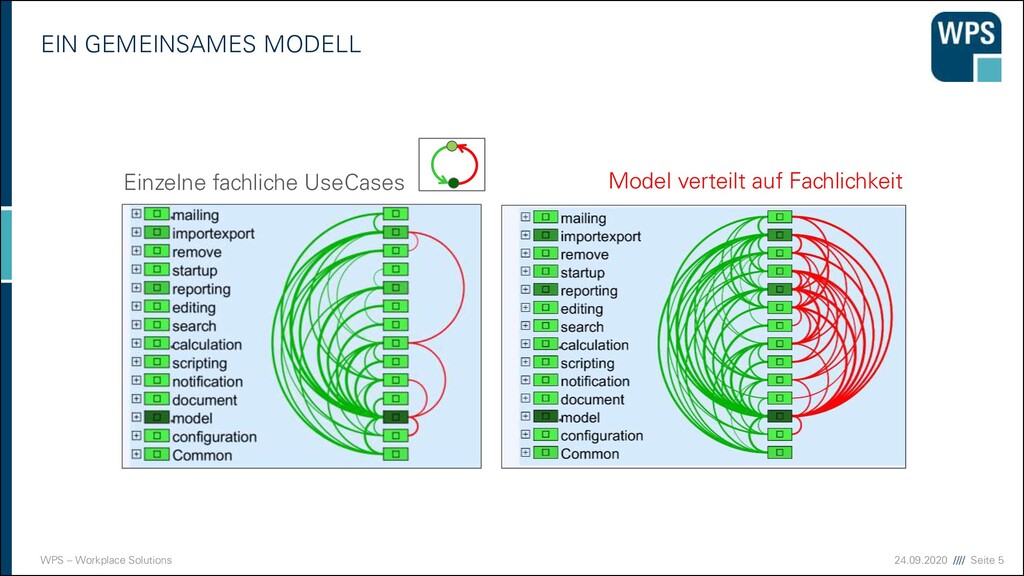{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
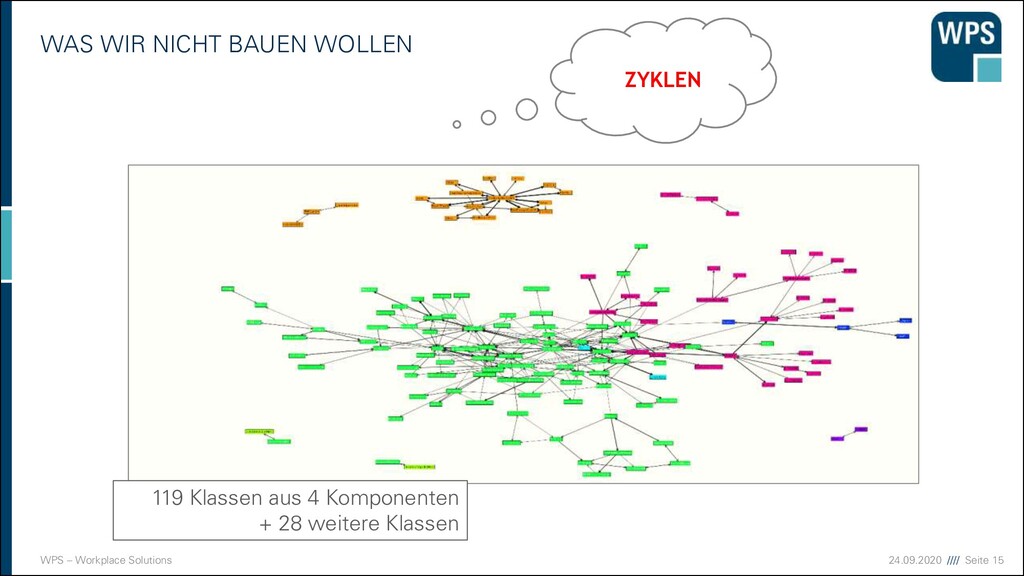{kind=link}
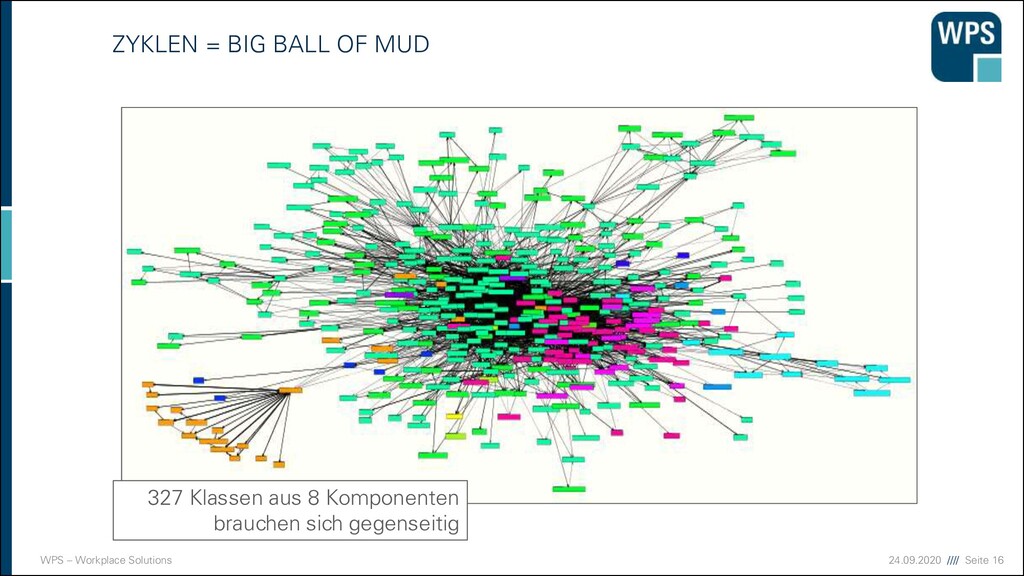{kind=link}
{kind=link}
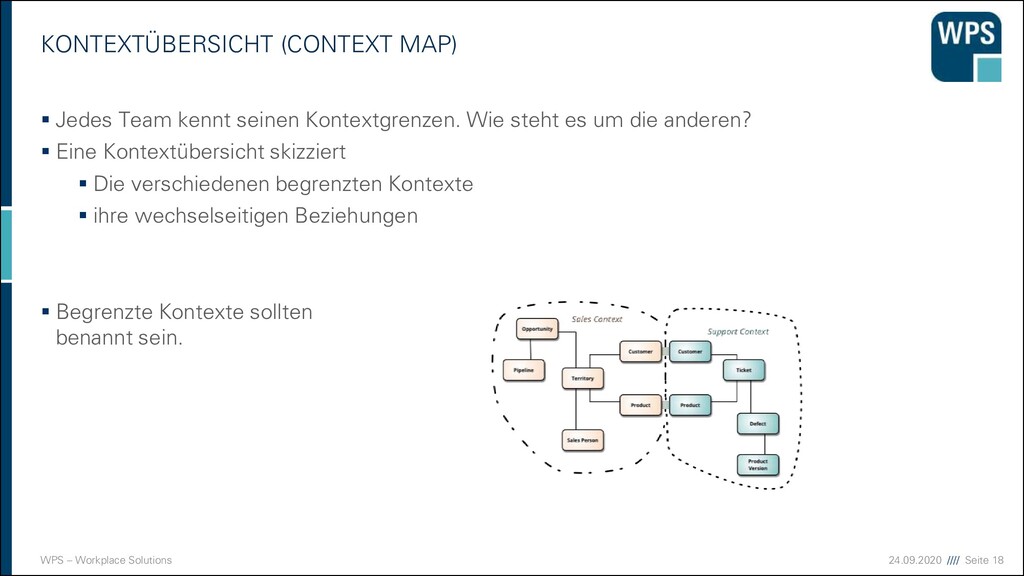{kind=link}
{kind=link}
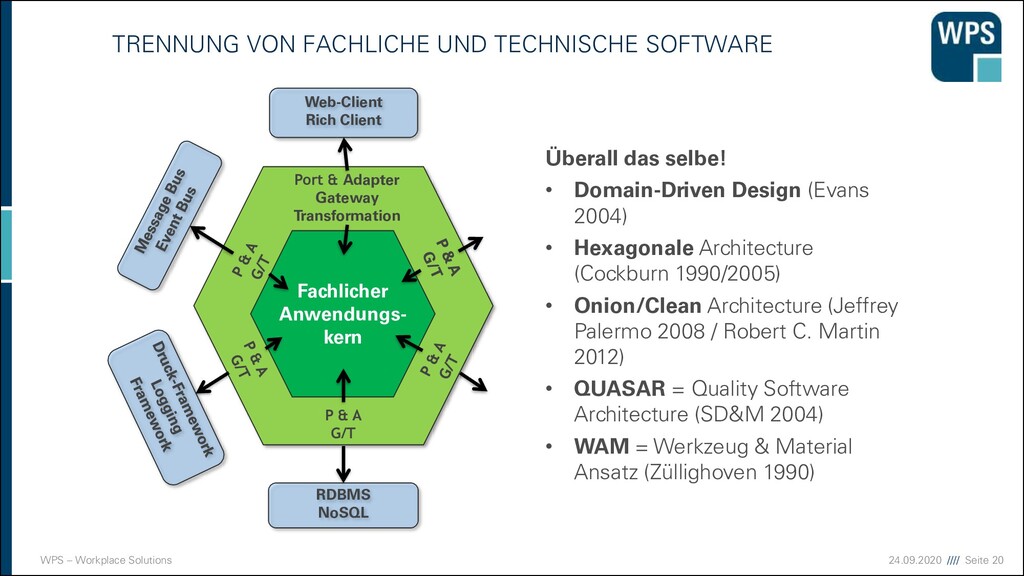{kind=link}
{kind=link}
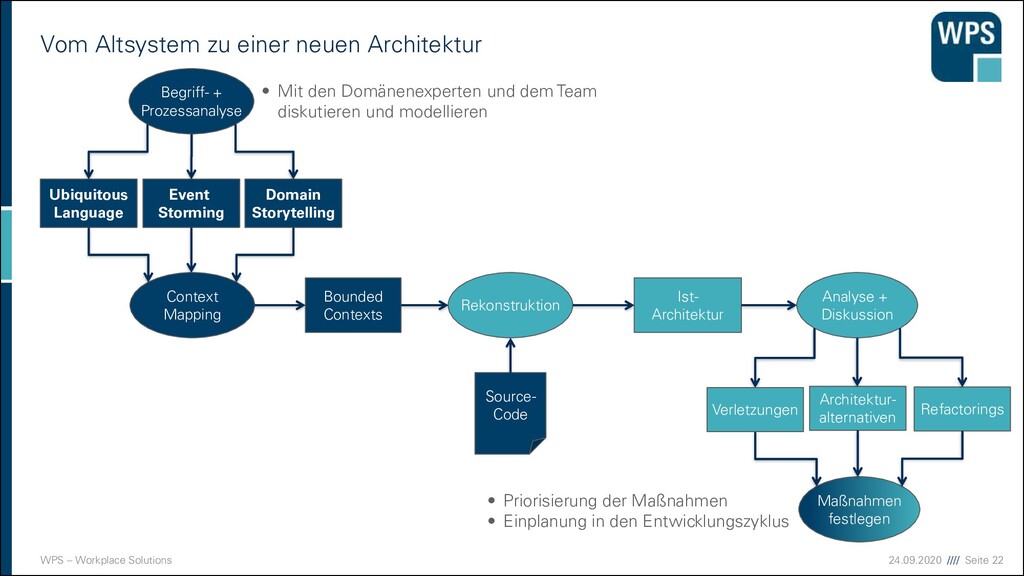{kind=link}
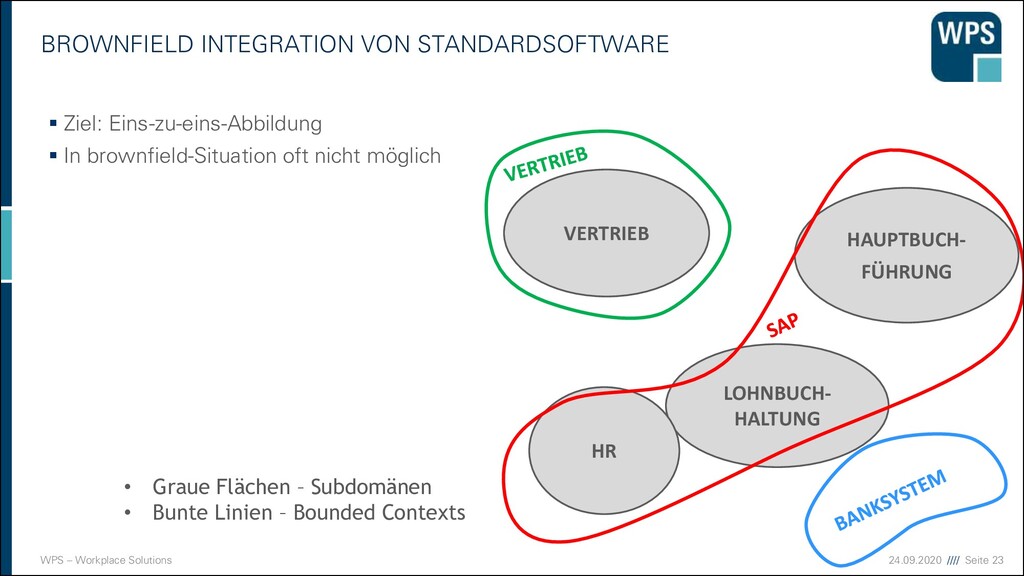{kind=link}
{kind=link}
{kind=link}
{kind=link}
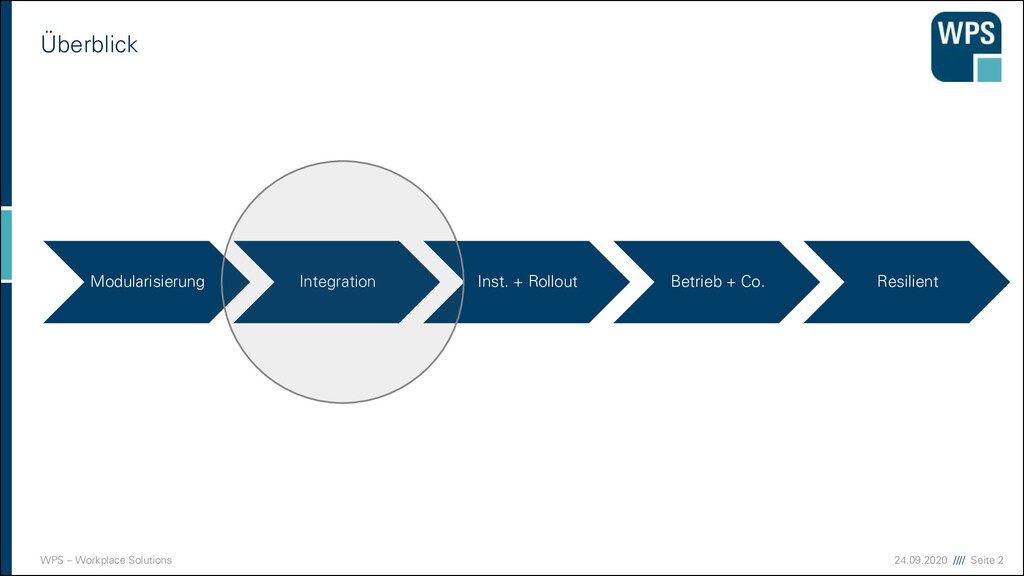{kind=link}
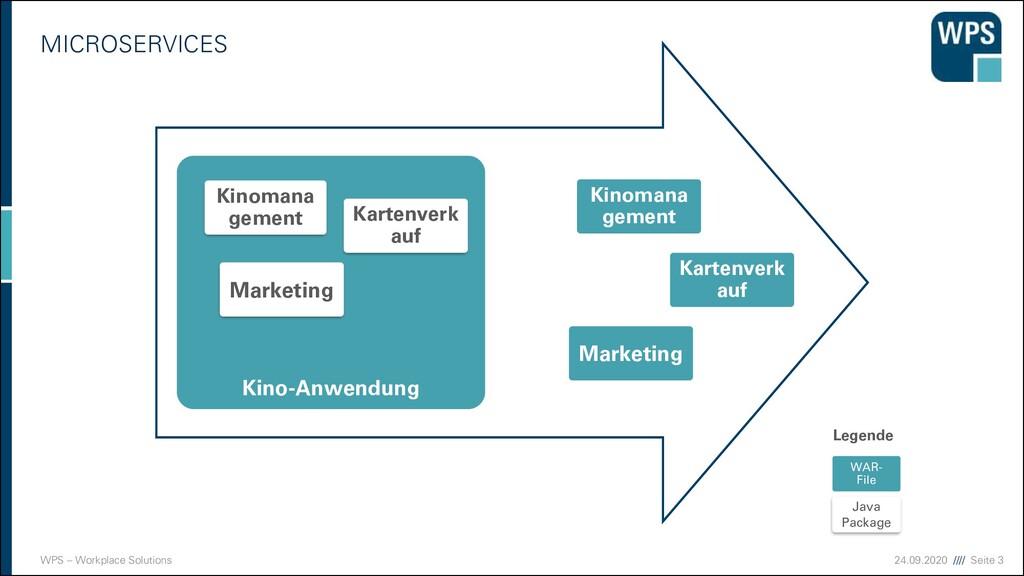{kind=link}
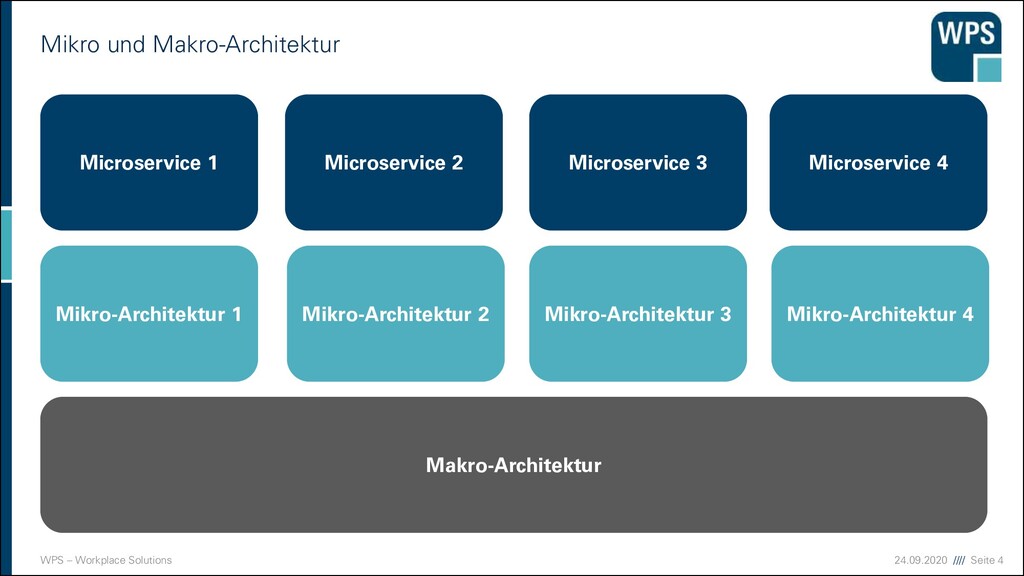{kind=link}
{kind=link}
{kind=link}
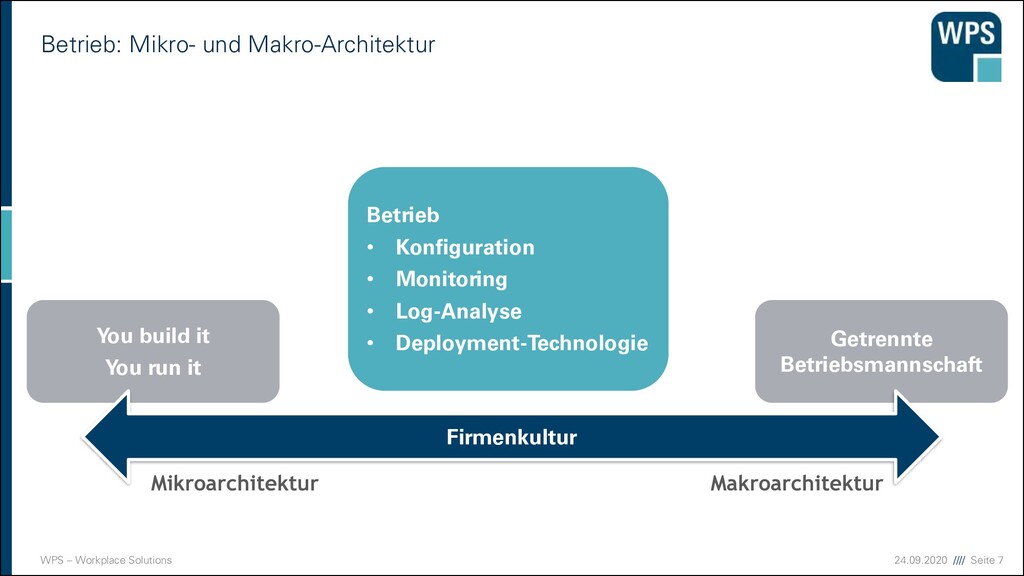{kind=link}
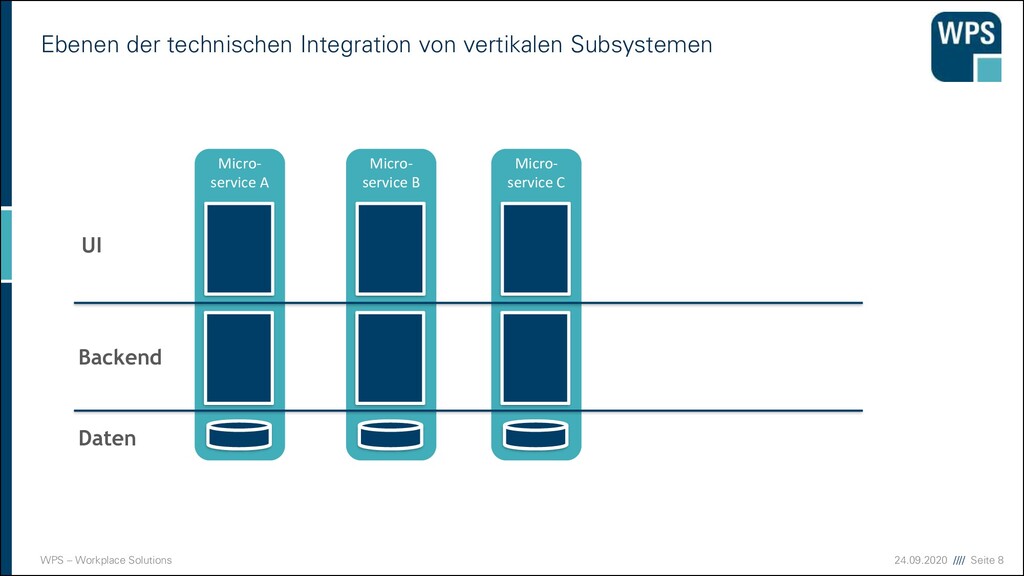{kind=link}
{kind=link}
{kind=link}
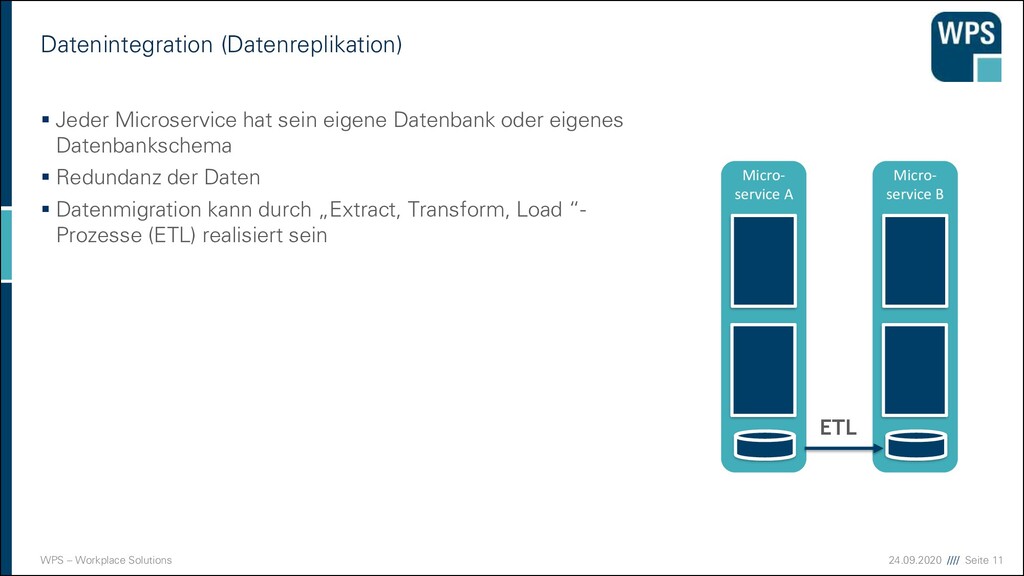{kind=link}
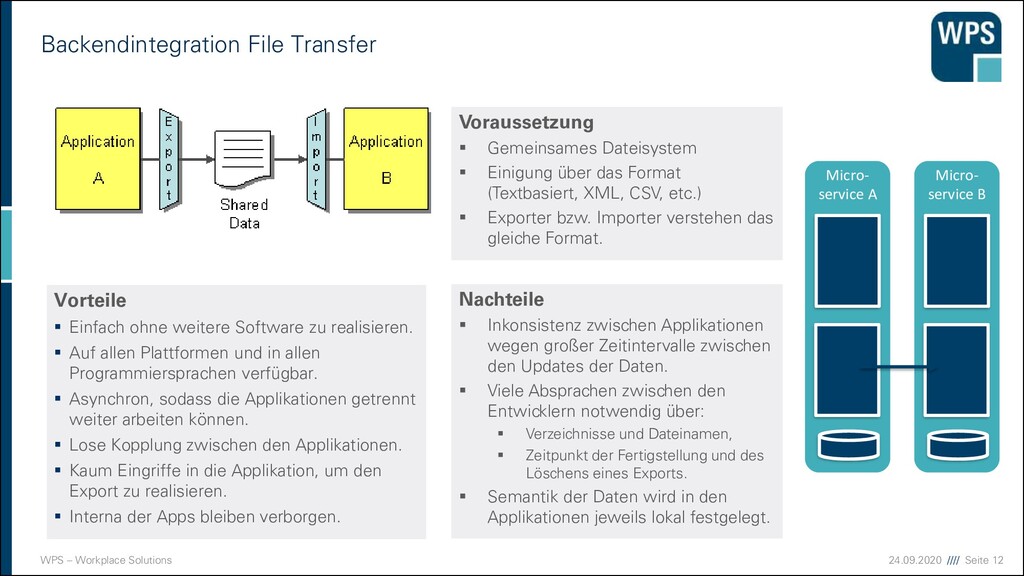{kind=link}
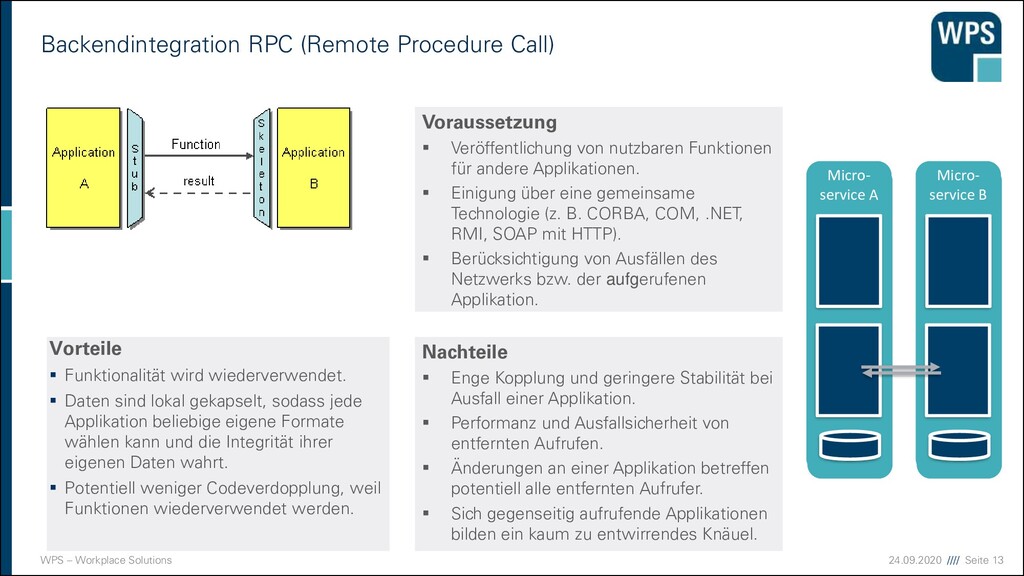{kind=link}
{kind=link}
{kind=link}
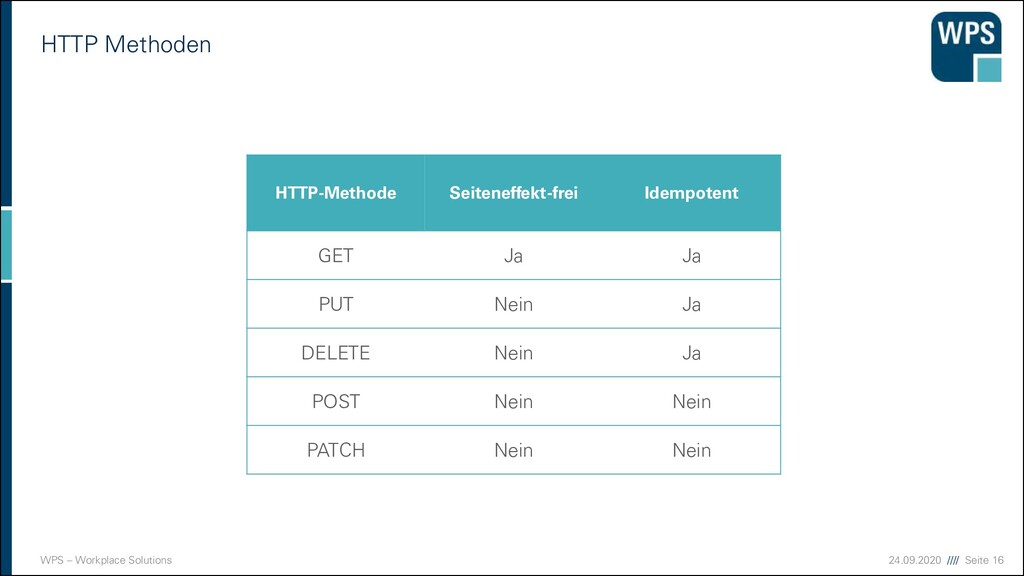{kind=link}
{kind=link}
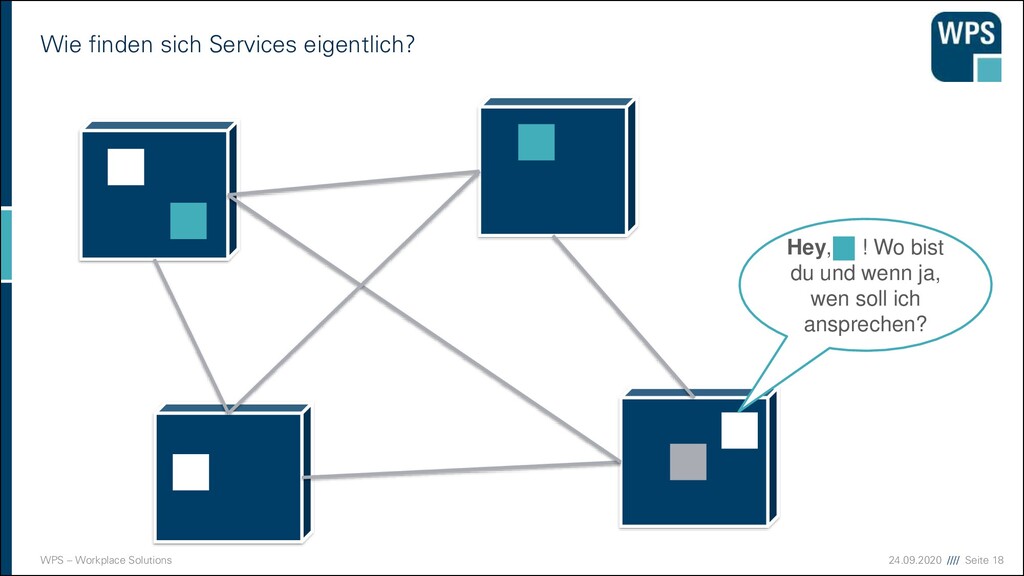{kind=link}
{kind=link}
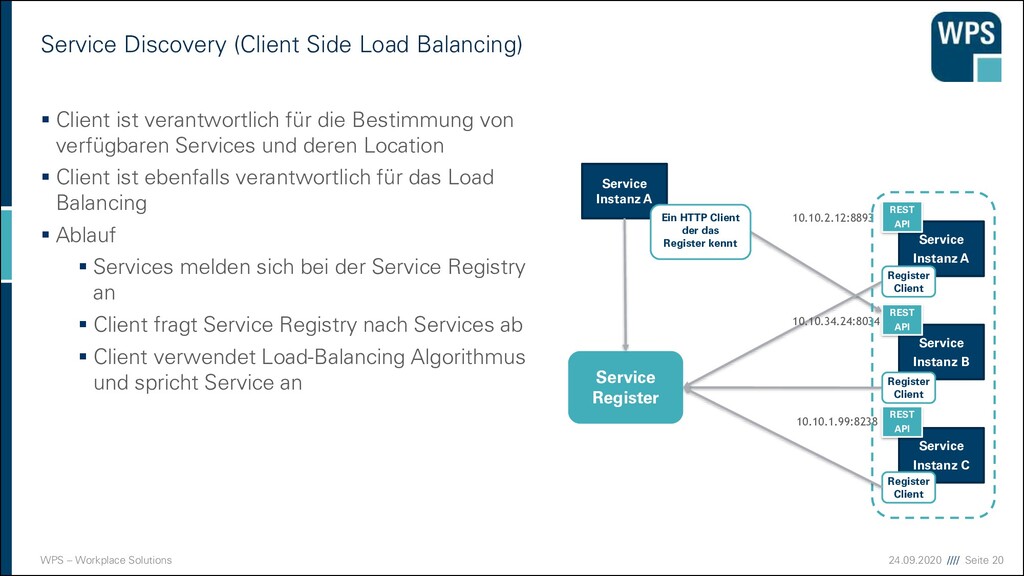{kind=link}
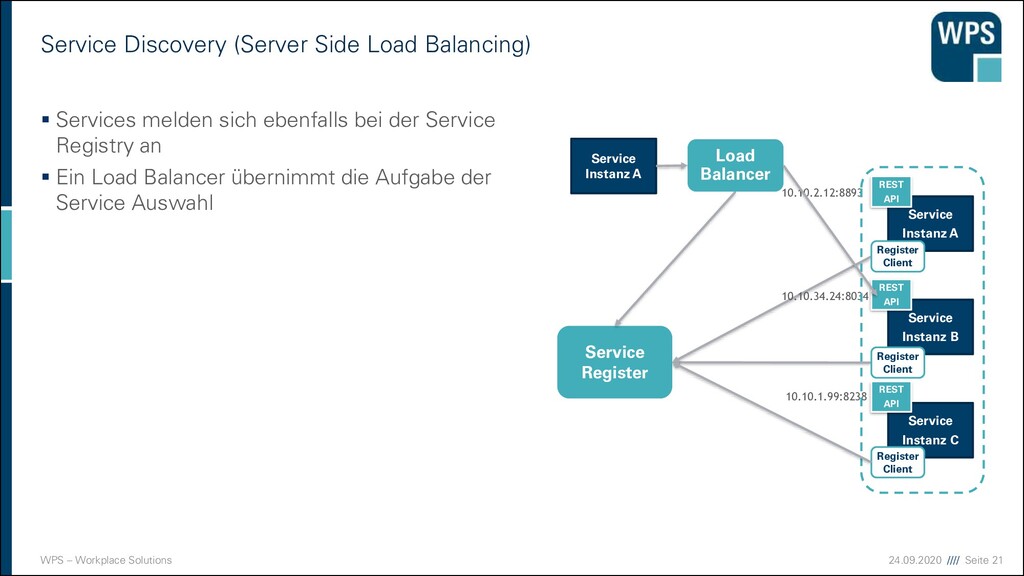{kind=link}
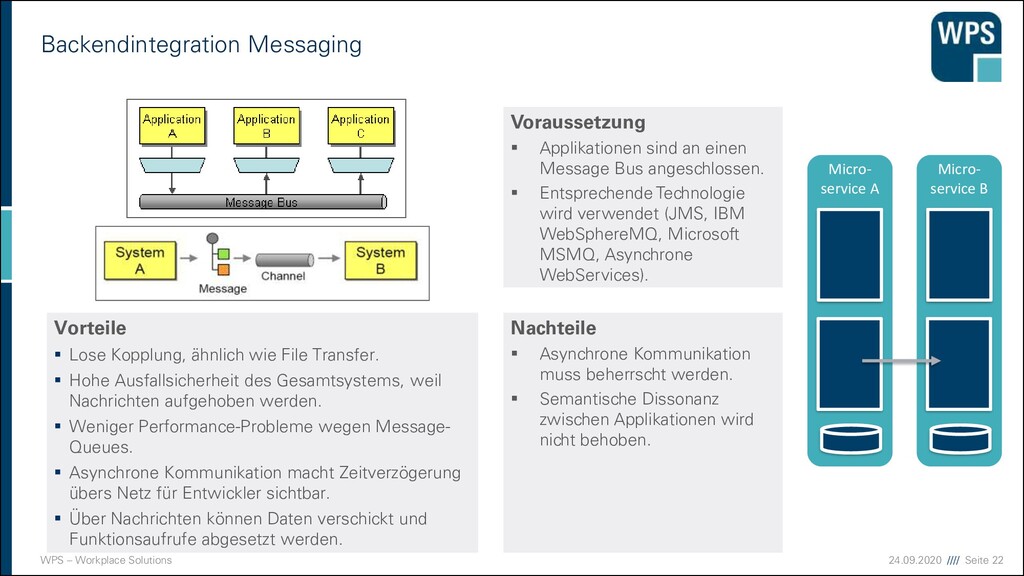{kind=link}
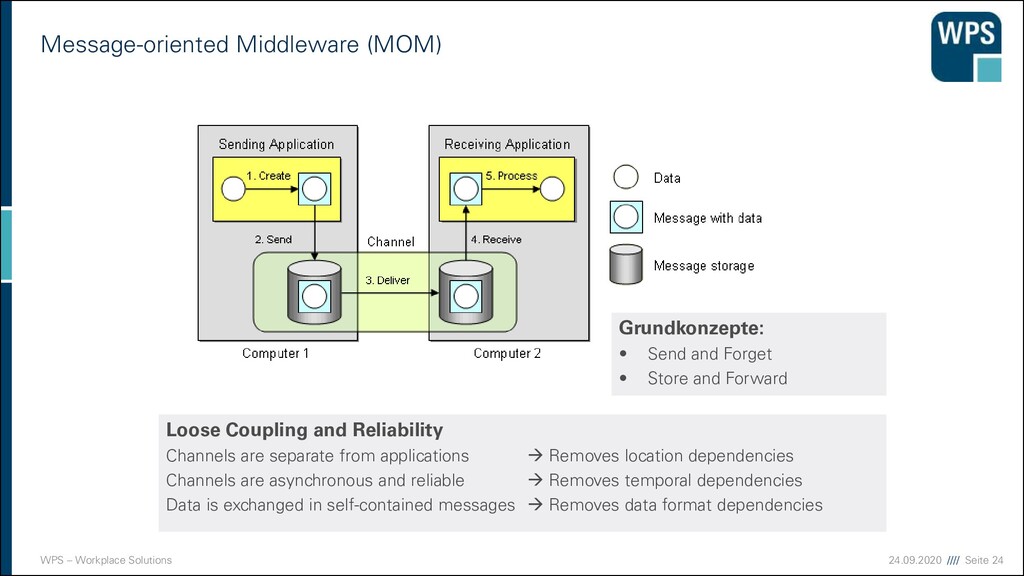{kind=link}
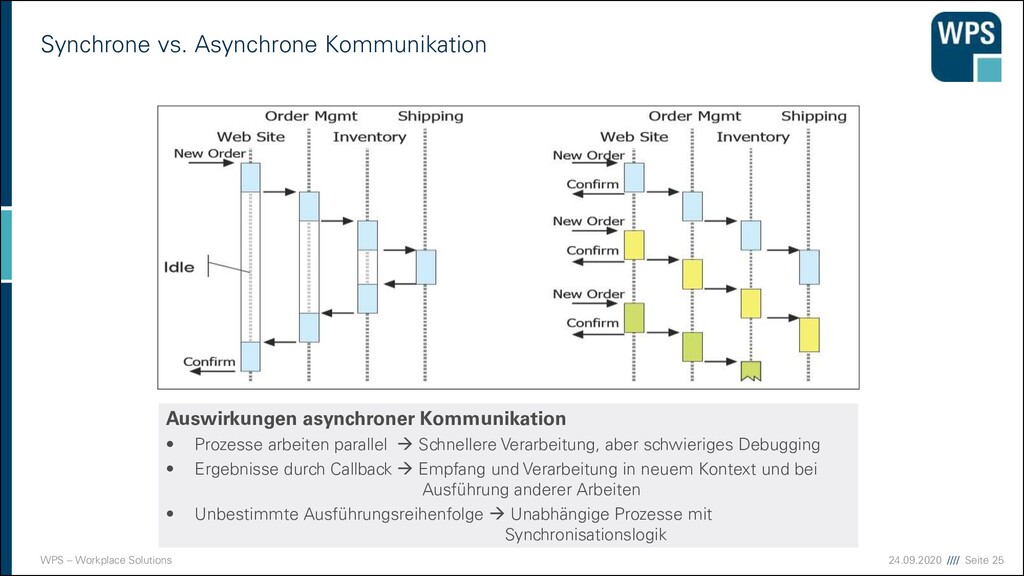{kind=link}
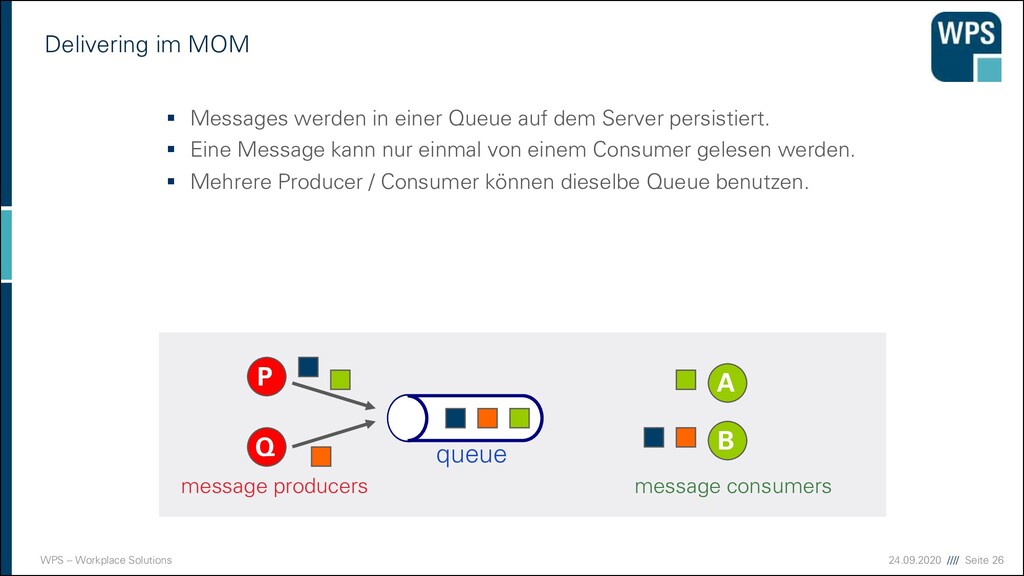{kind=link}
{kind=link}
{kind=link}
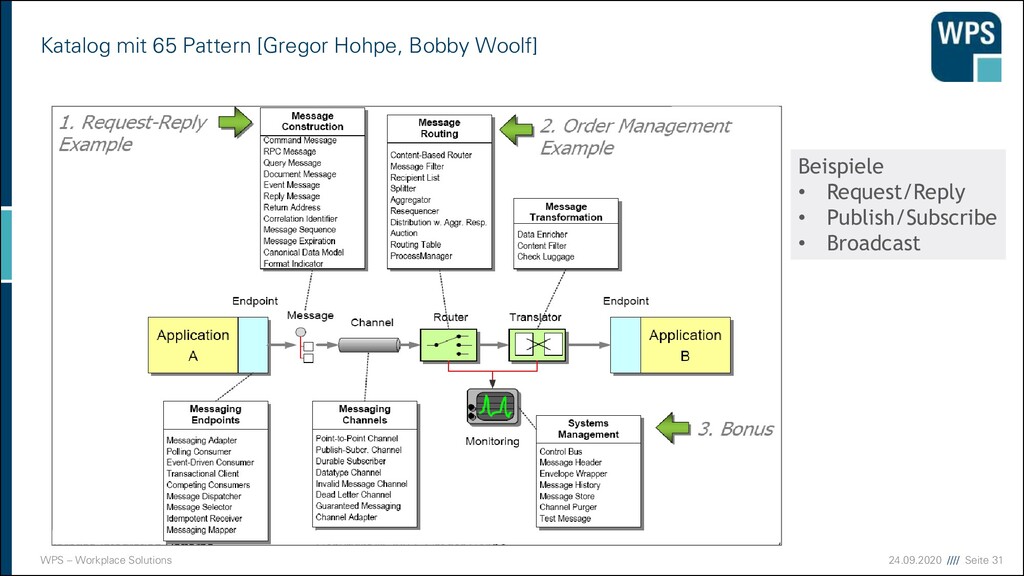{kind=link}
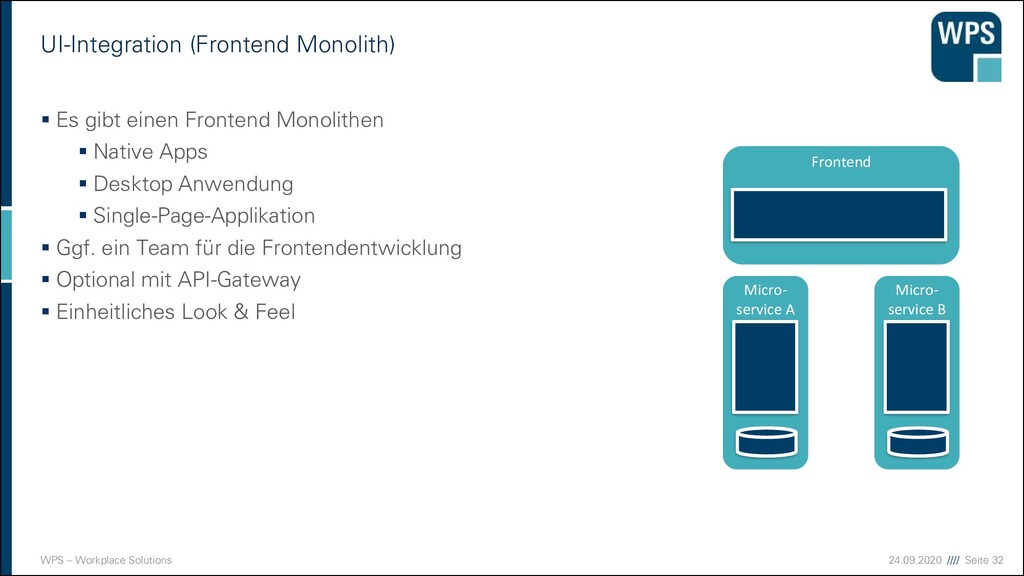{kind=link}
{kind=link}
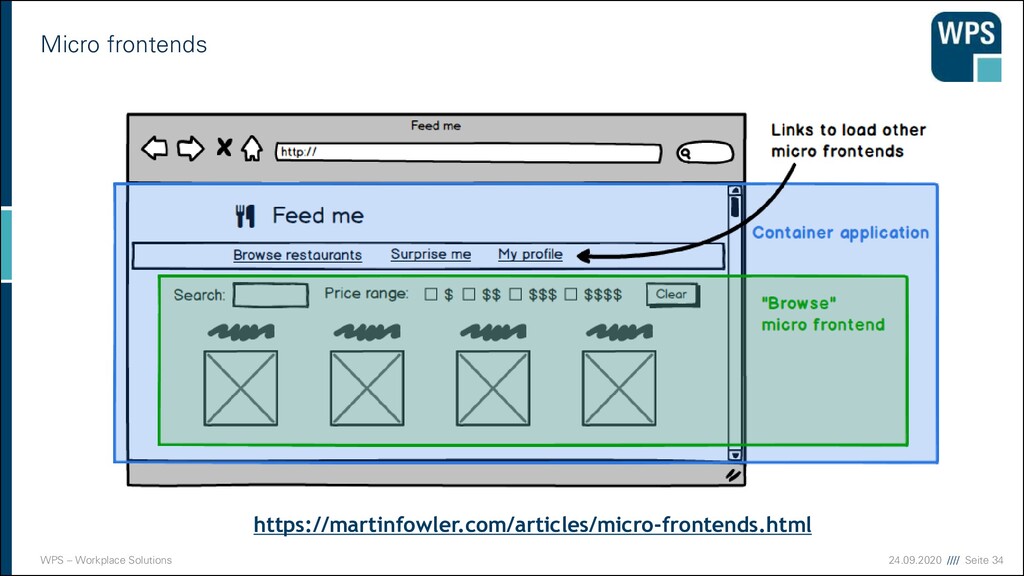{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
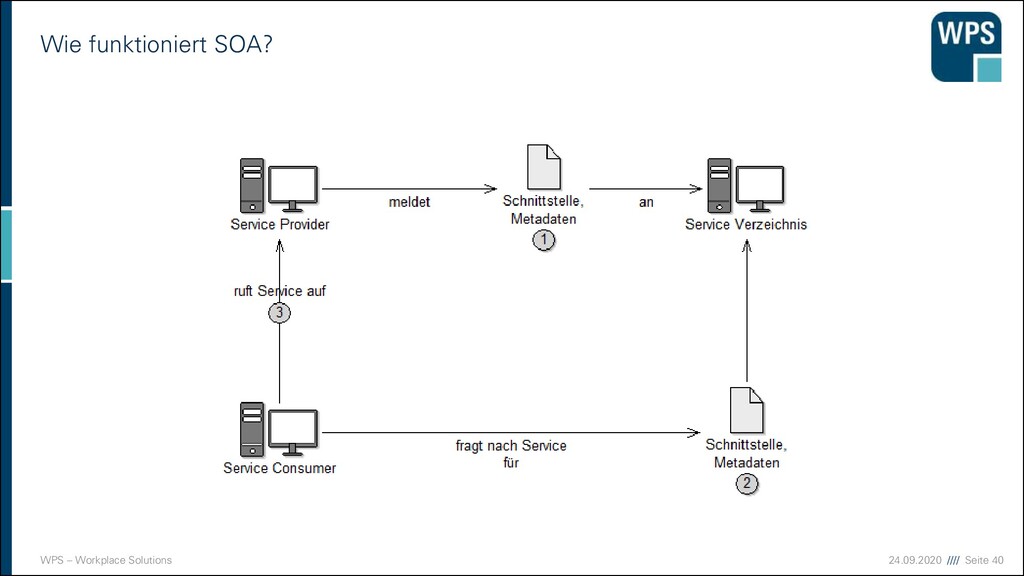{kind=link}
{kind=link}
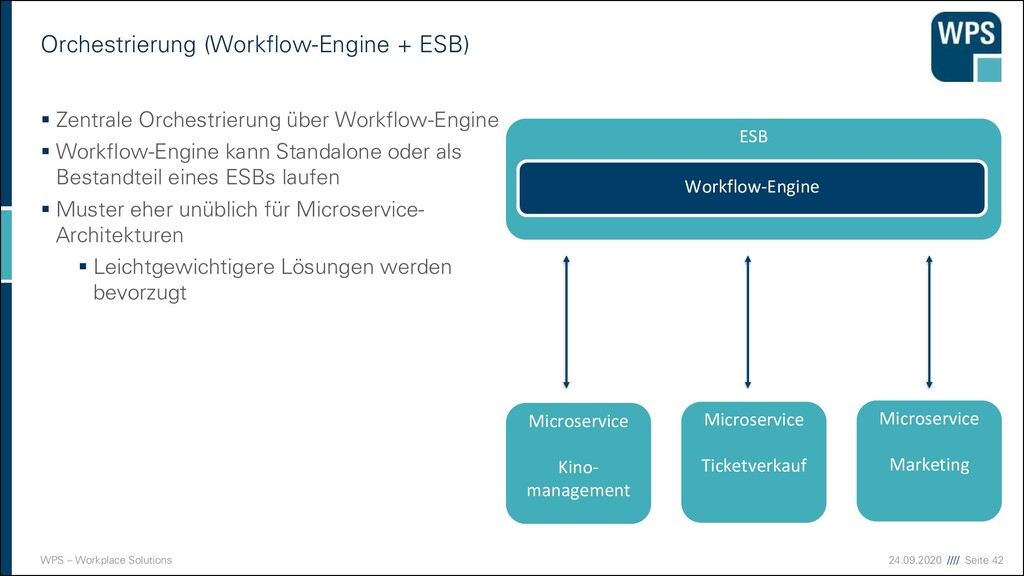{kind=link}
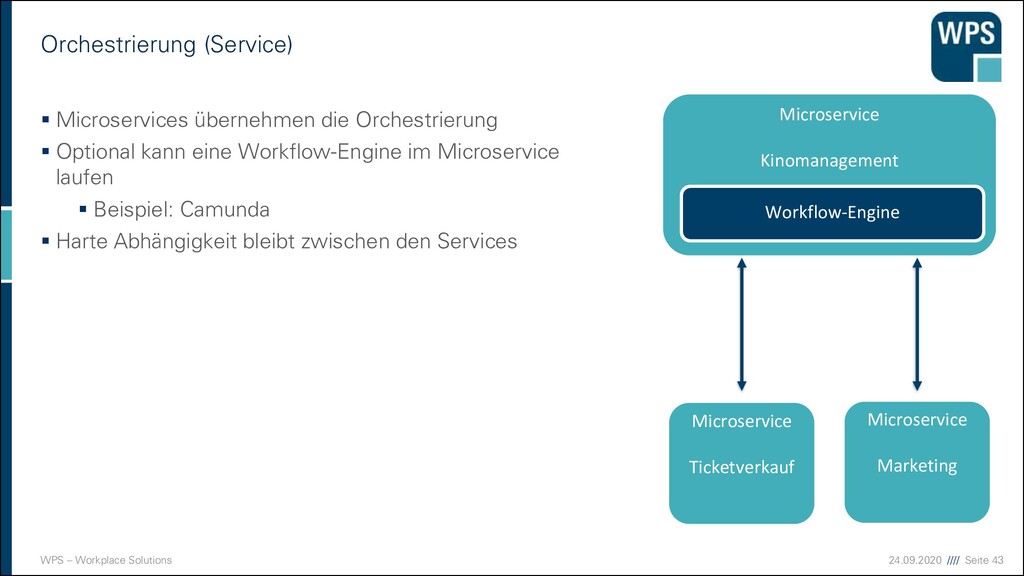{kind=link}
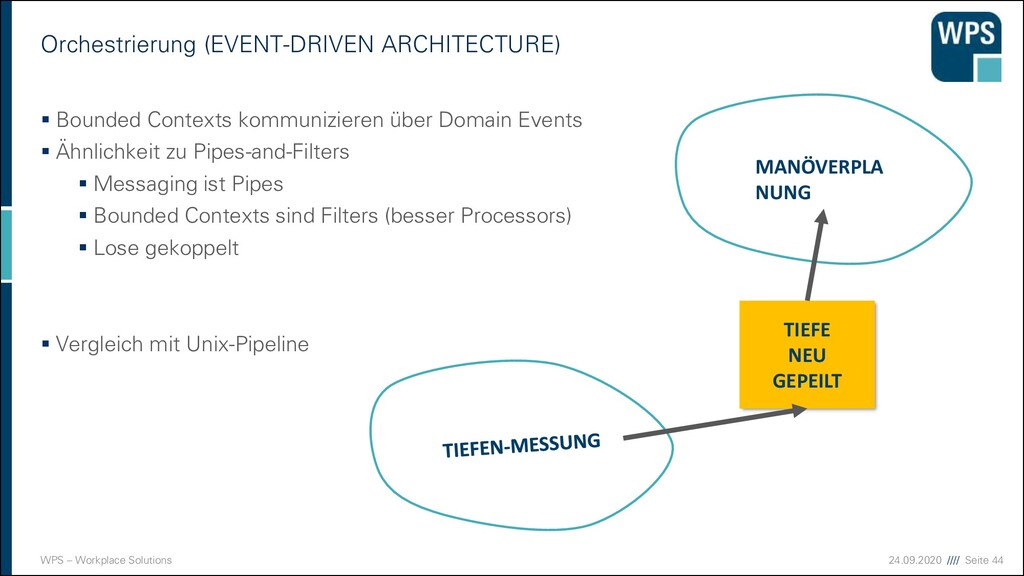{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
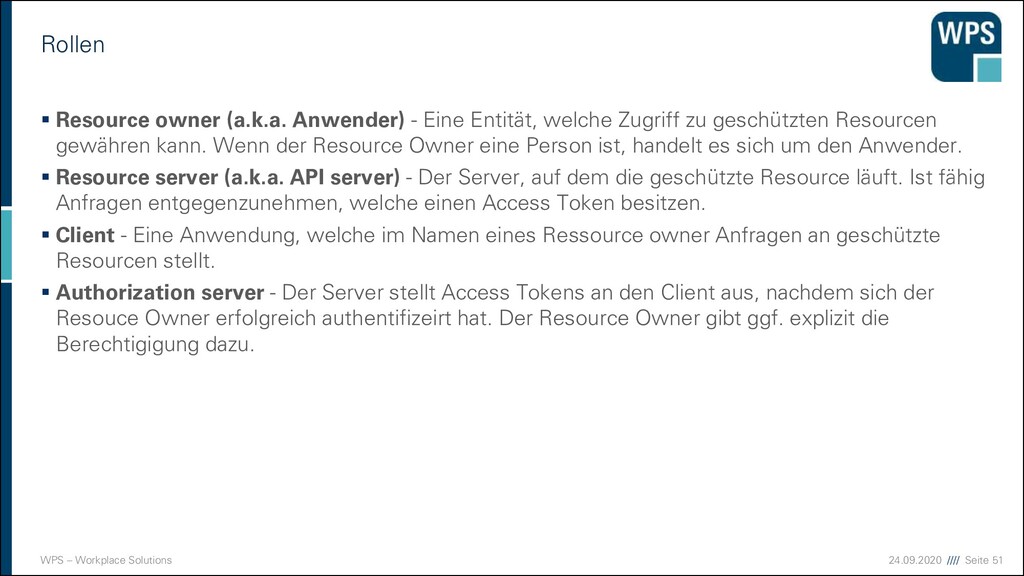{kind=link}
{kind=link}
{kind=link}
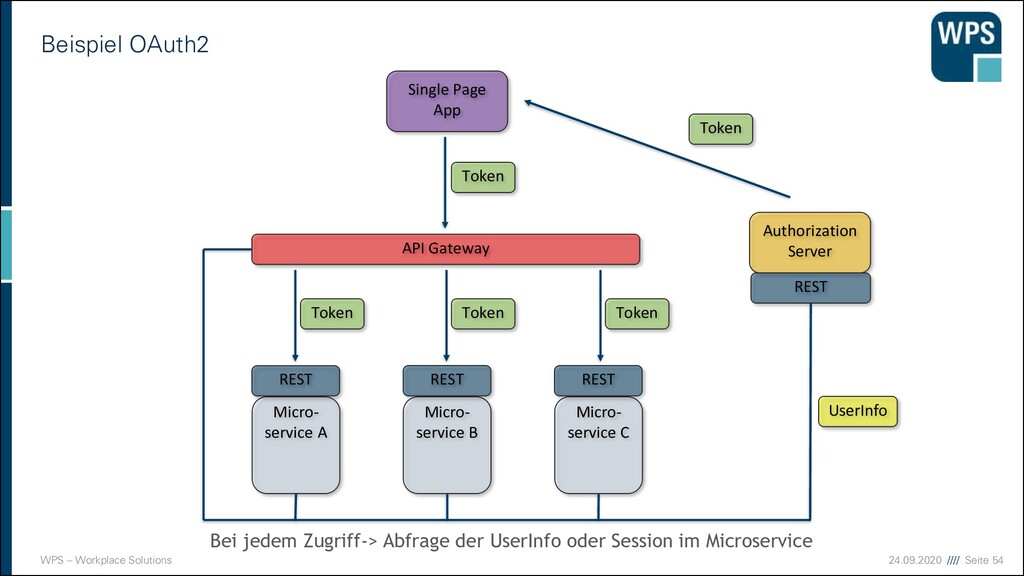{kind=link}
{kind=link}
{kind=link}
{kind=link}
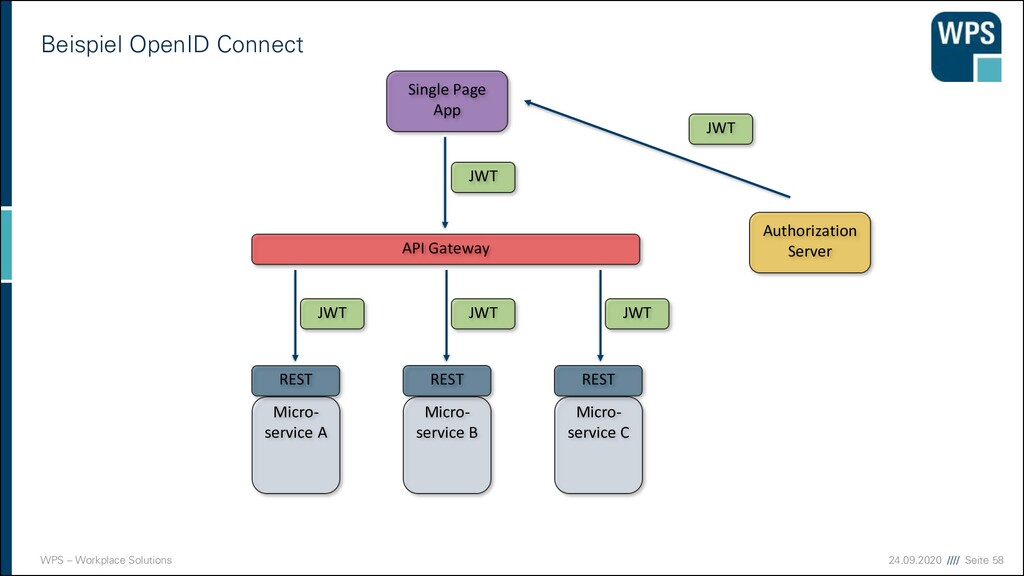{kind=link}
{kind=link}
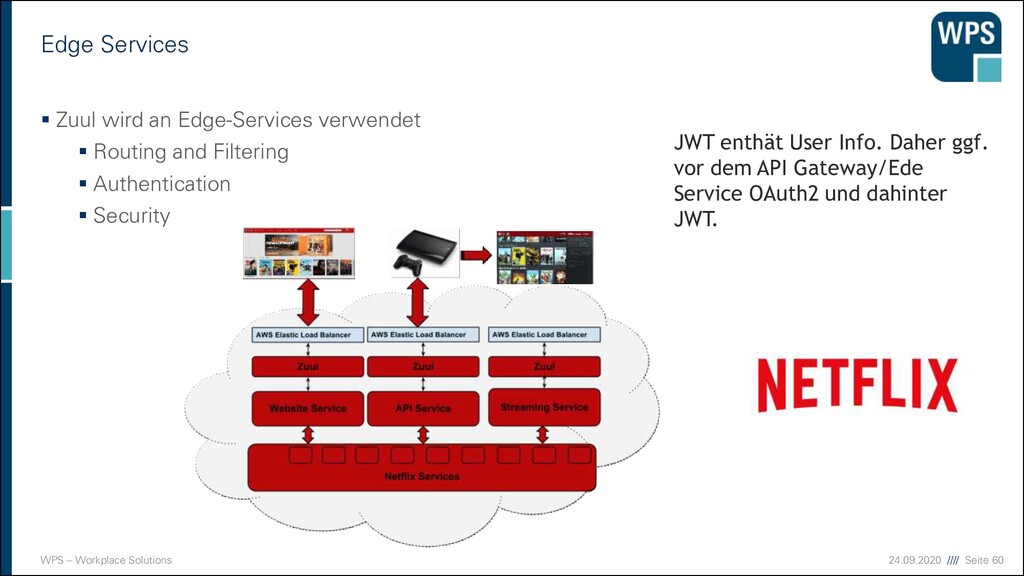{kind=link}
{kind=link}
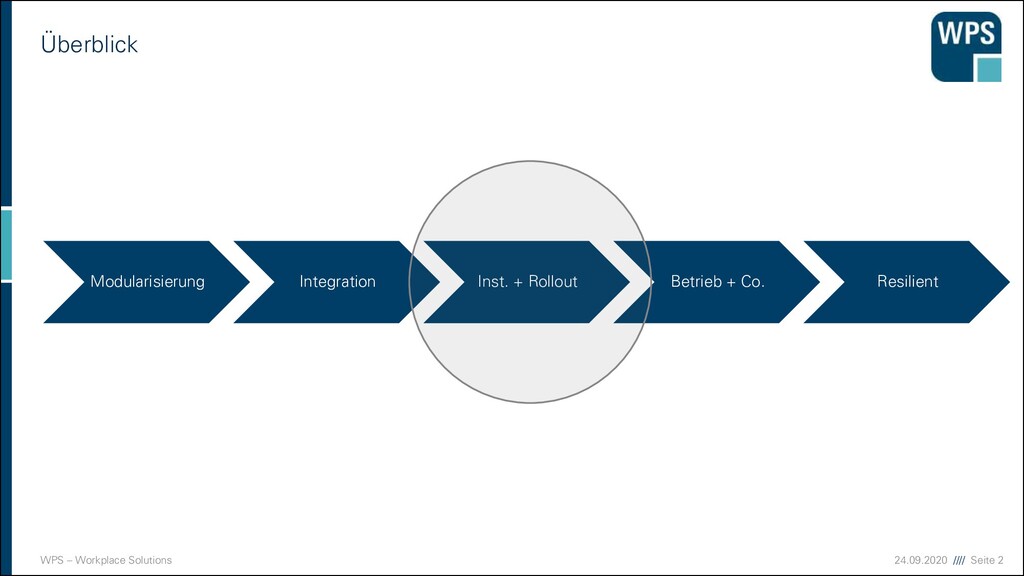{kind=link}
{kind=link}
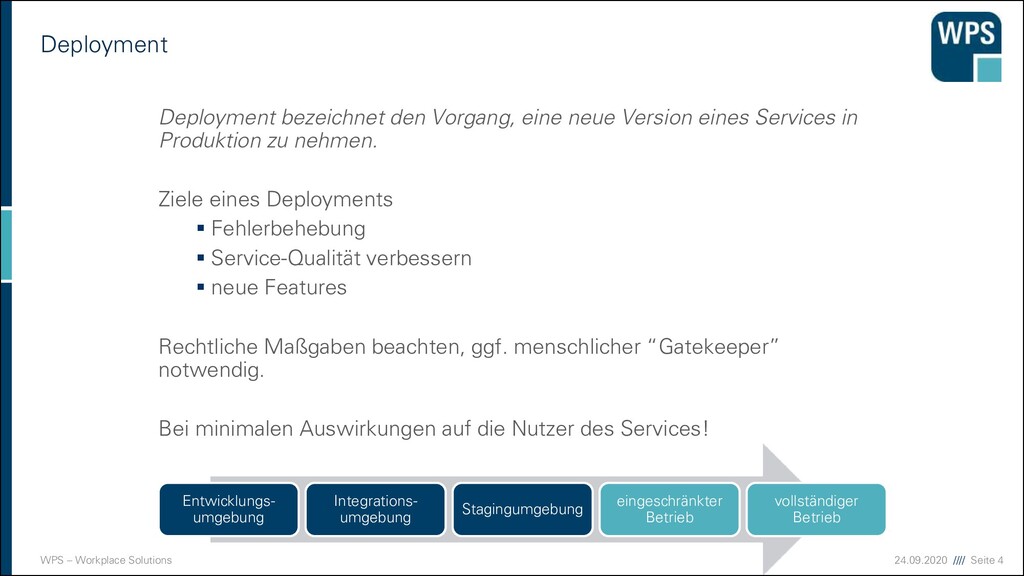{kind=link}
{kind=link}
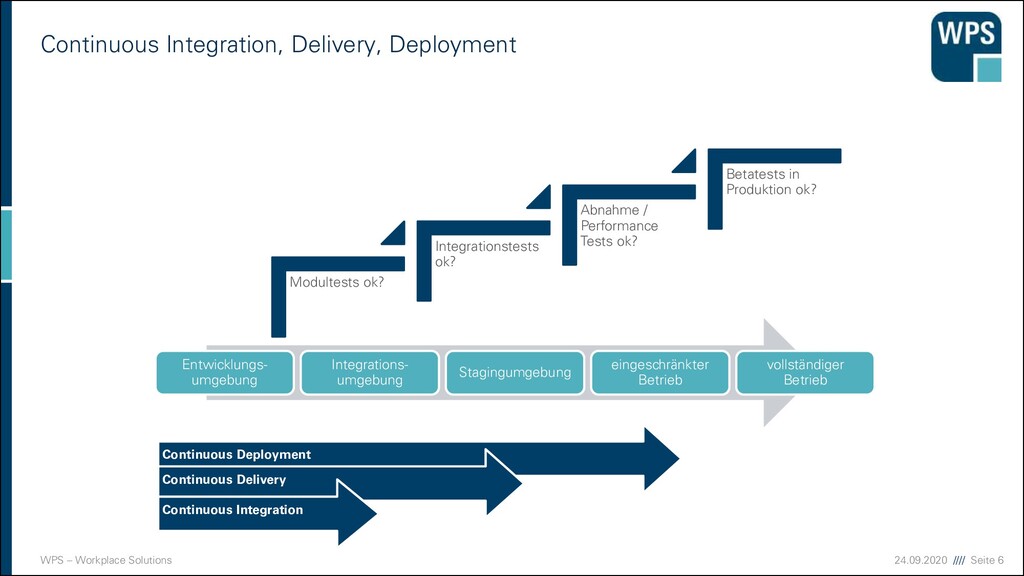{kind=link}
{kind=link}
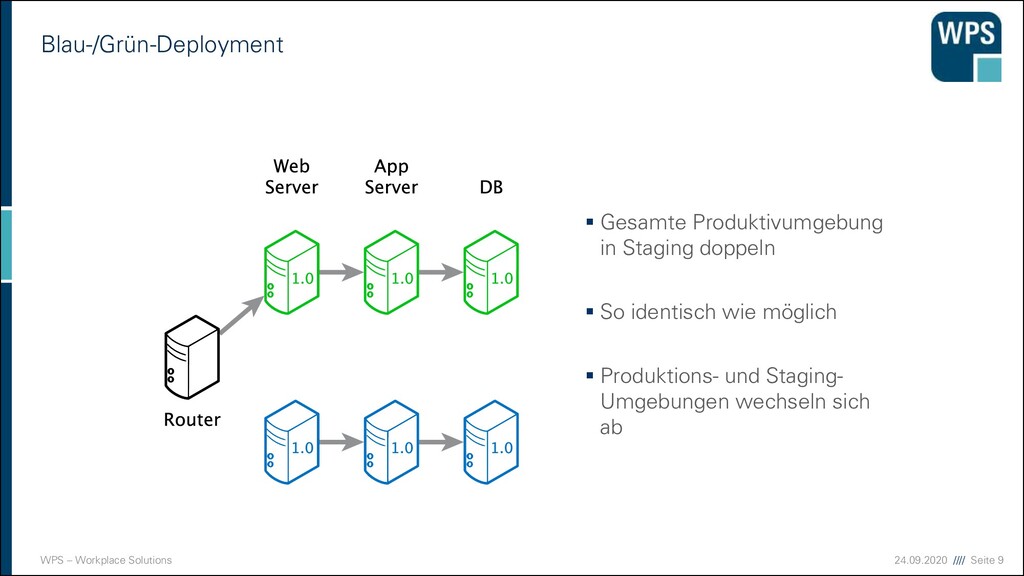{kind=link}
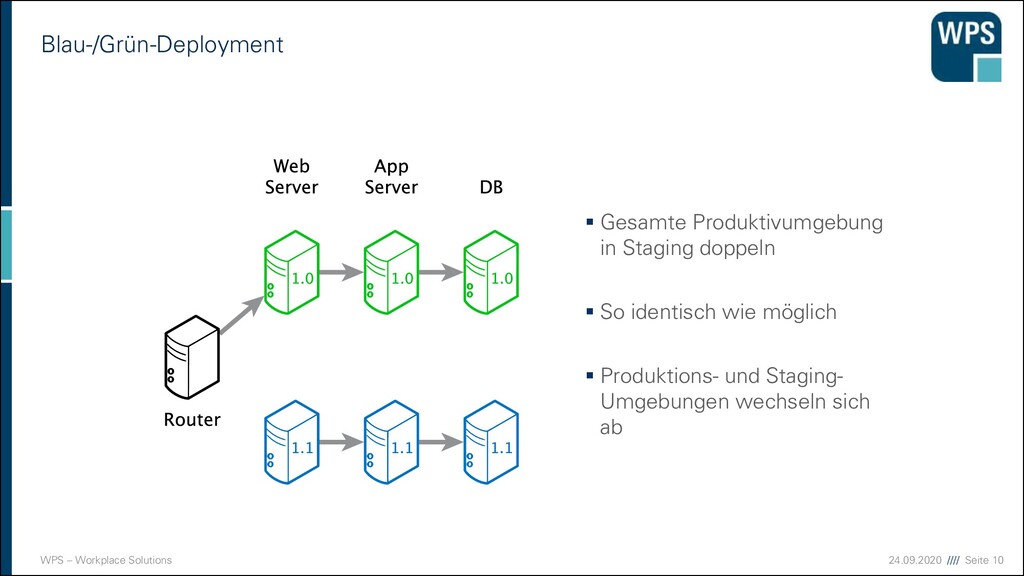{kind=link}
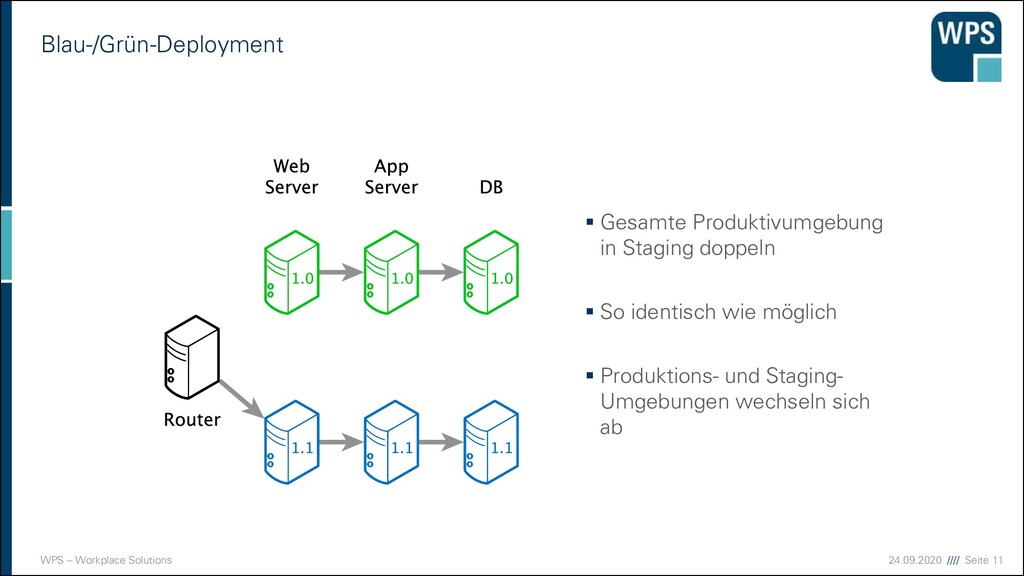{kind=link}
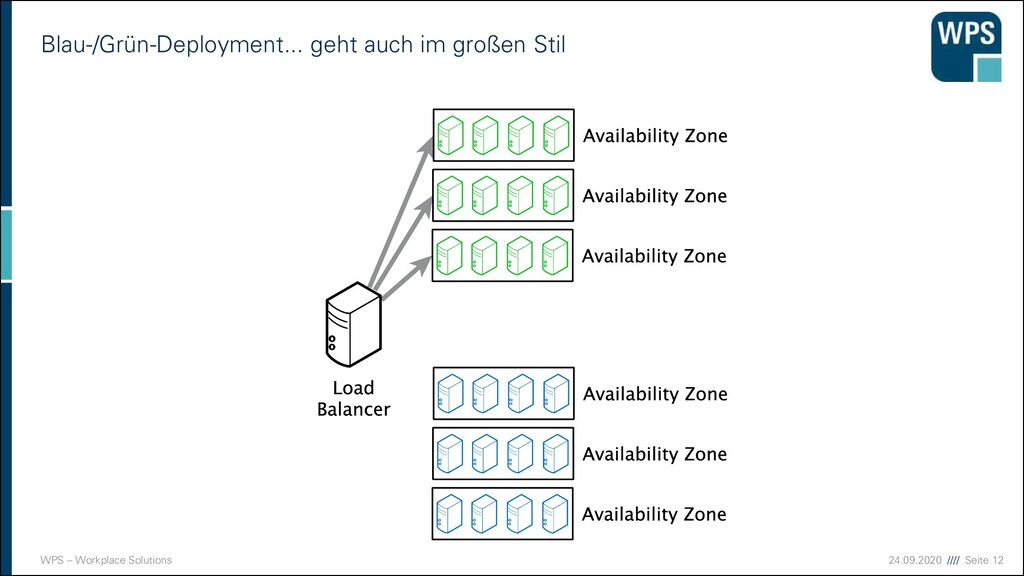{kind=link}
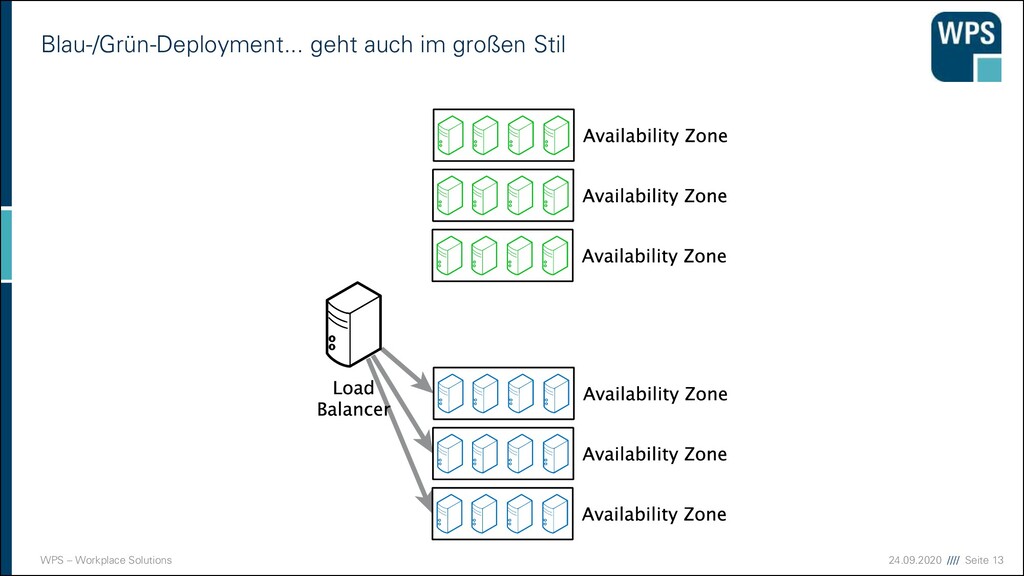{kind=link}
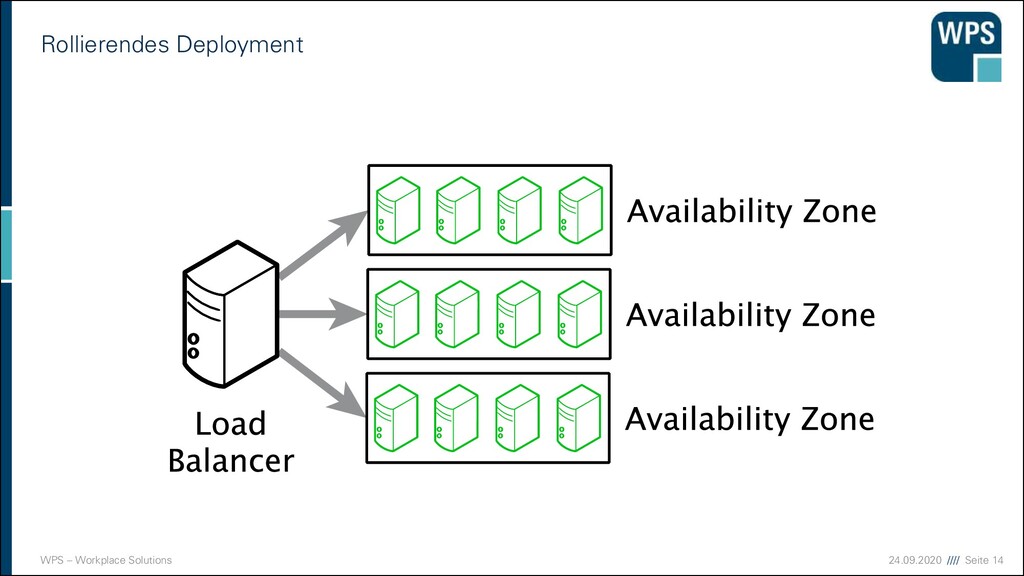{kind=link}
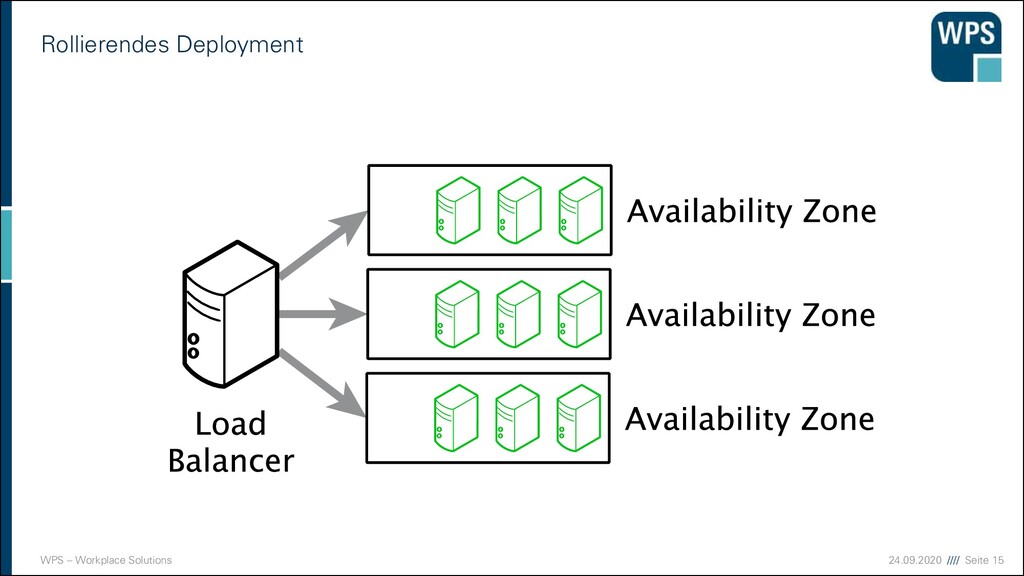{kind=link}
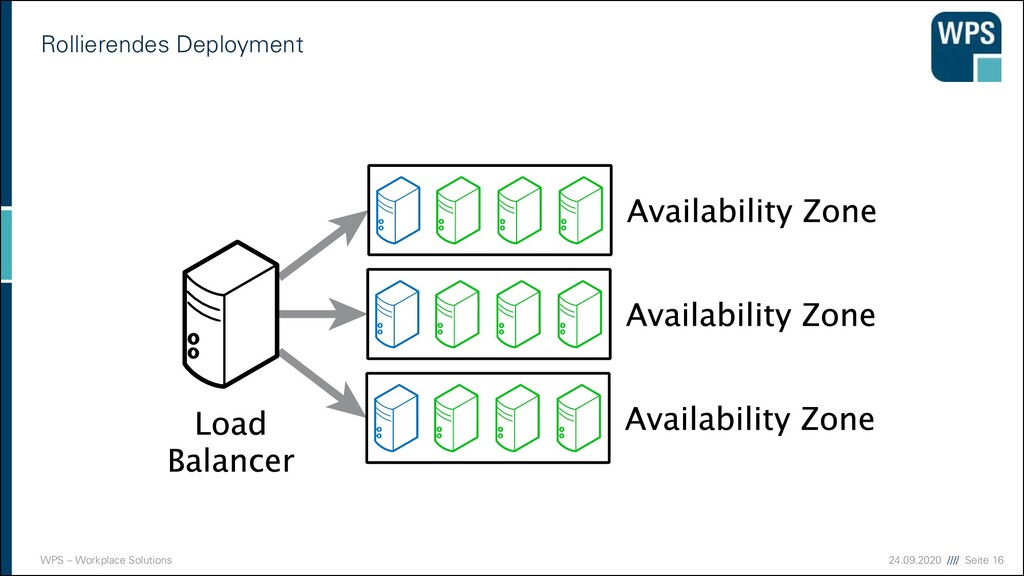{kind=link}
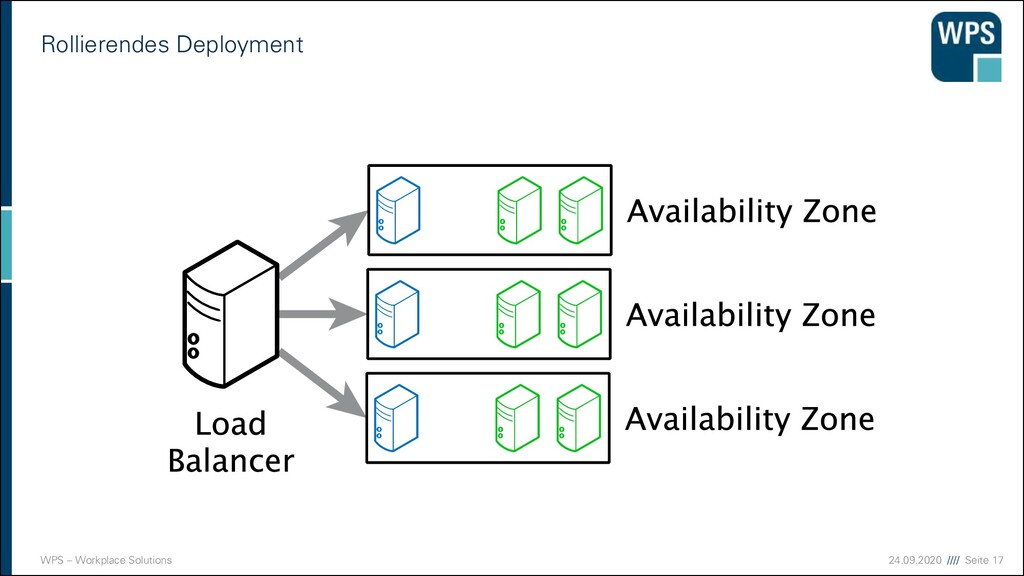{kind=link}
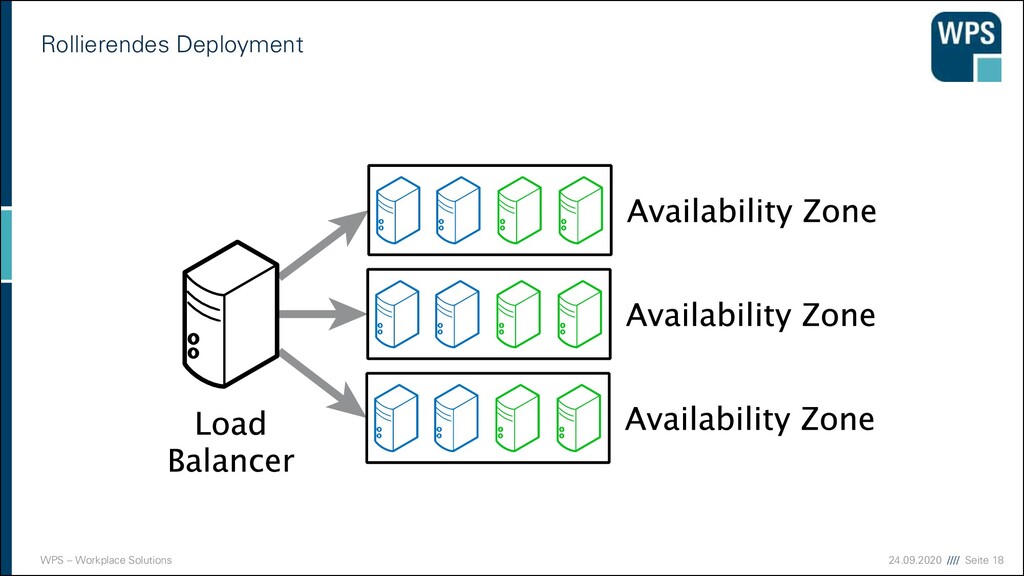{kind=link}
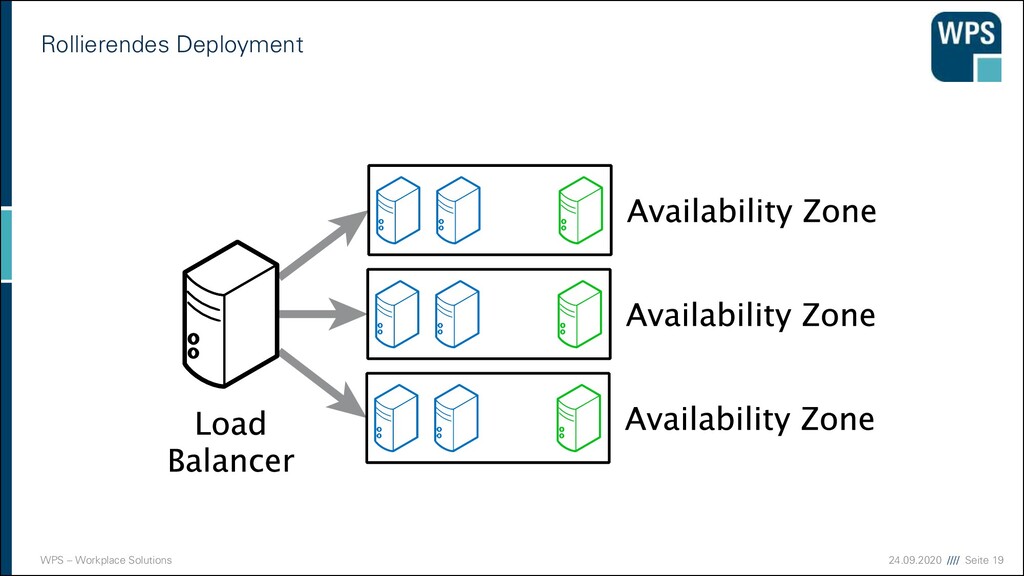{kind=link}
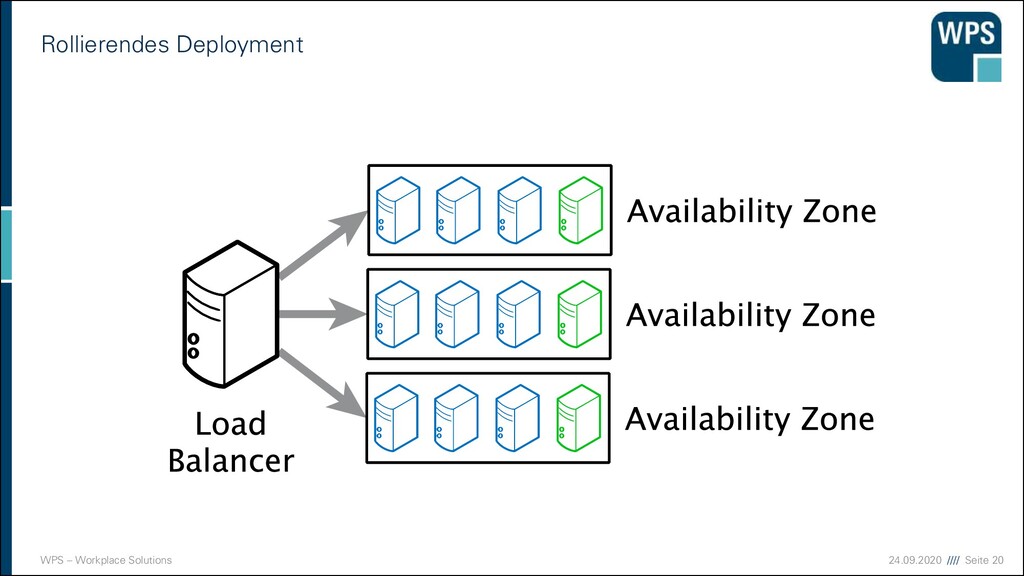{kind=link}
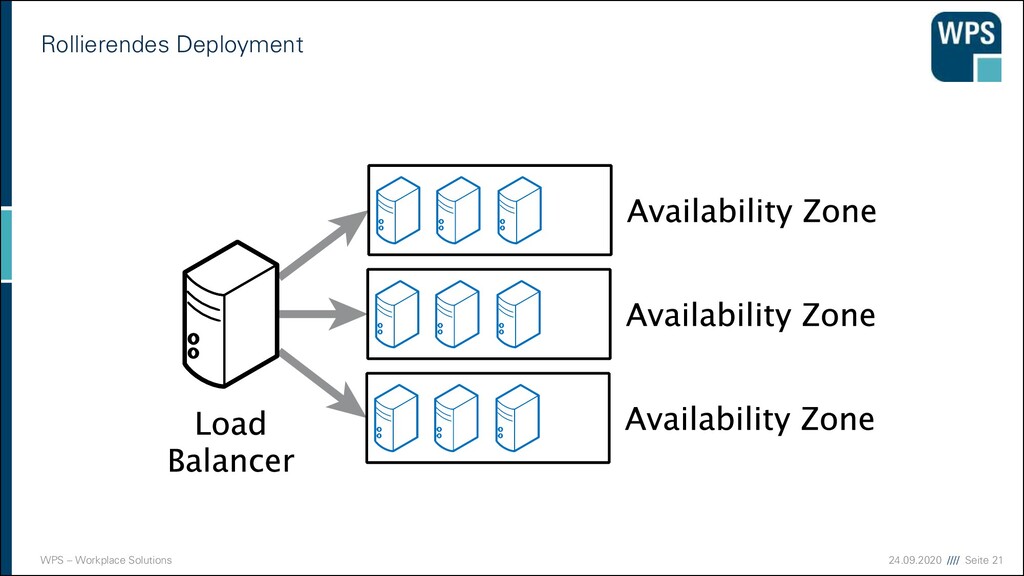{kind=link}
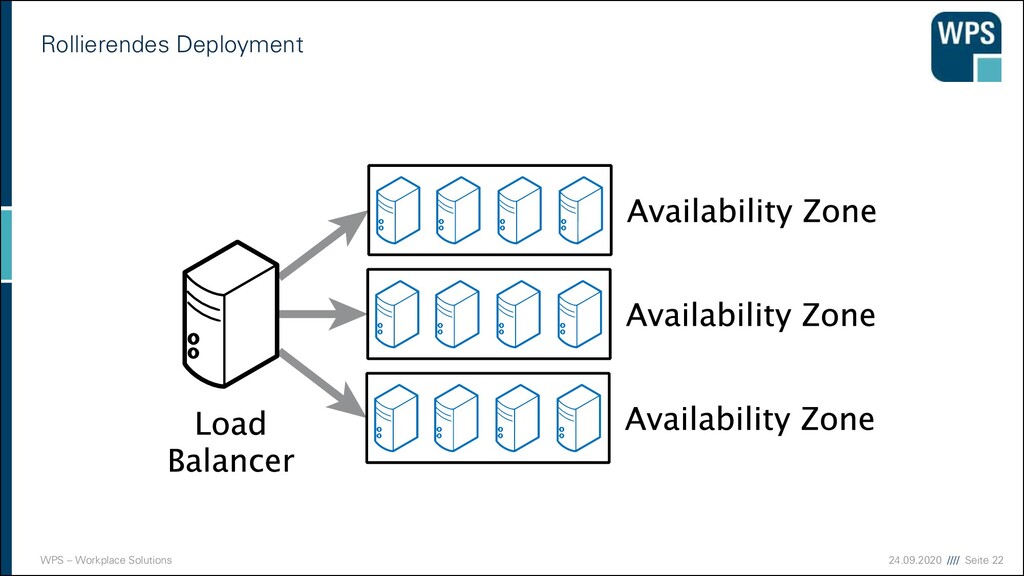{kind=link}
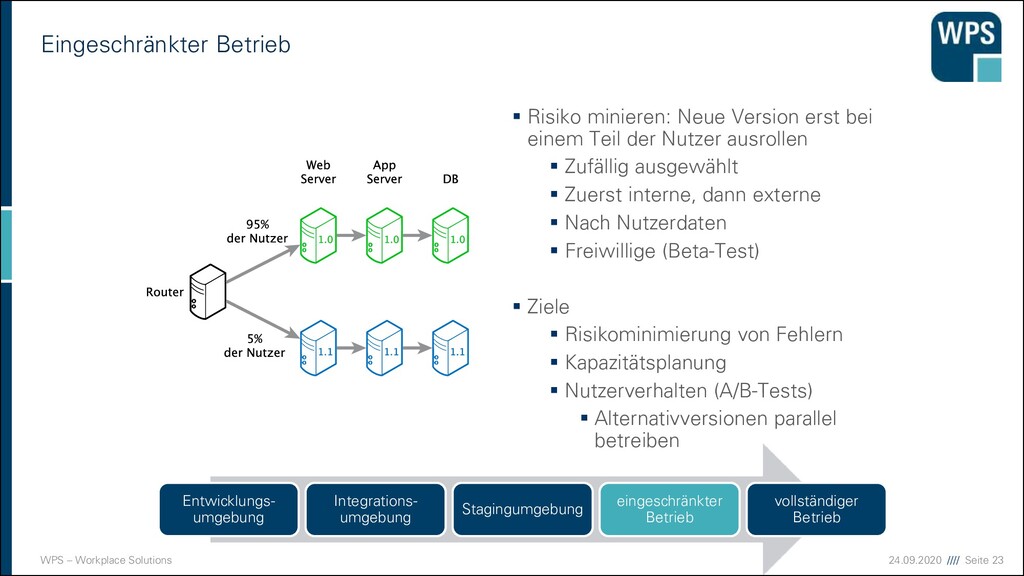{kind=link}
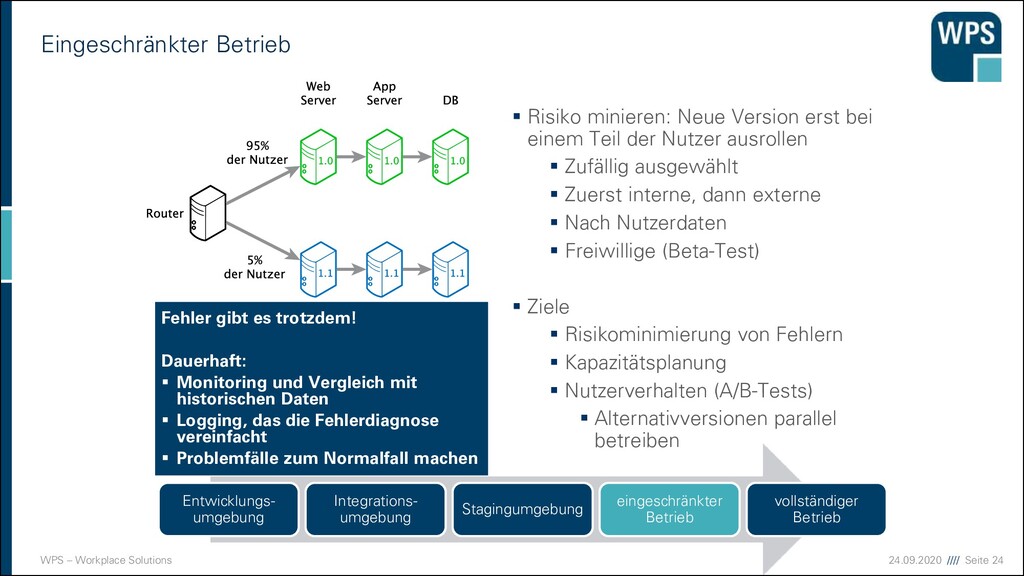{kind=link}
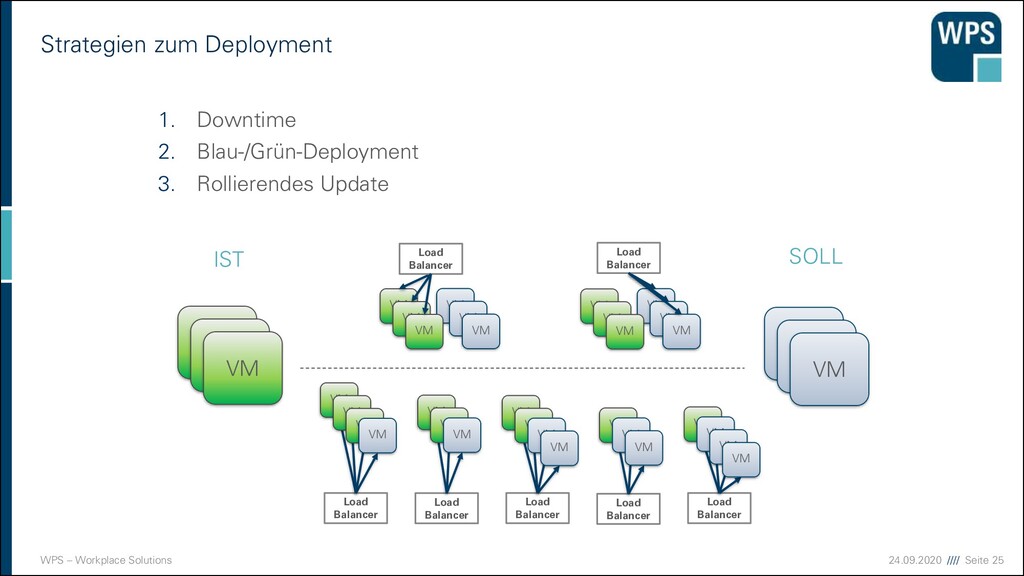{kind=link}
{kind=link}
{kind=link}
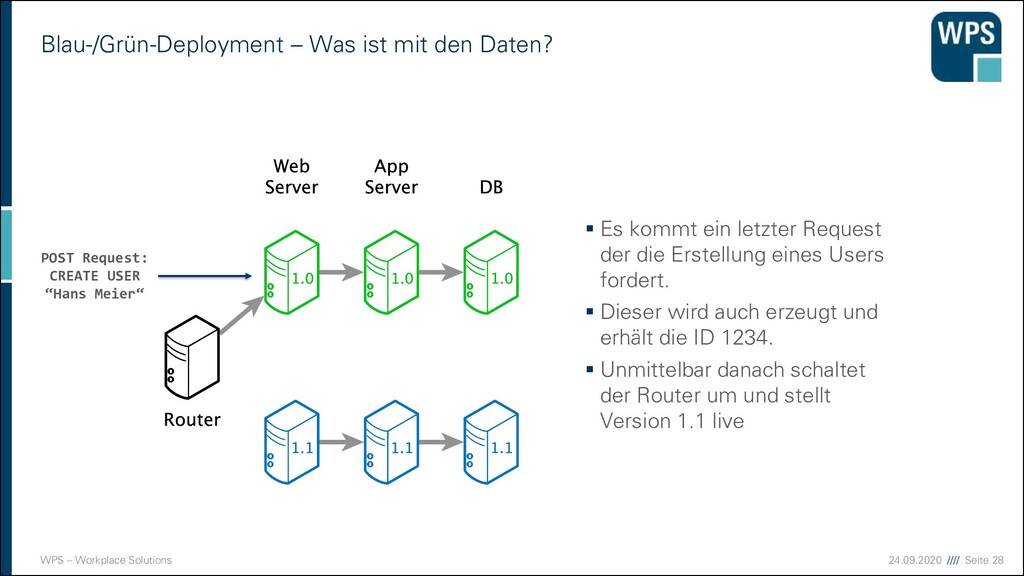{kind=link}
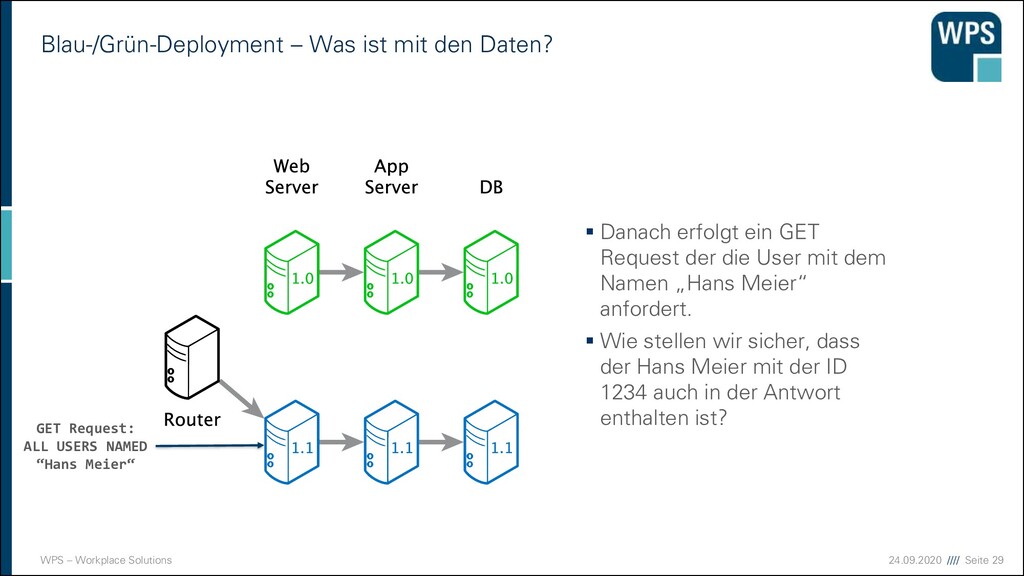{kind=link}
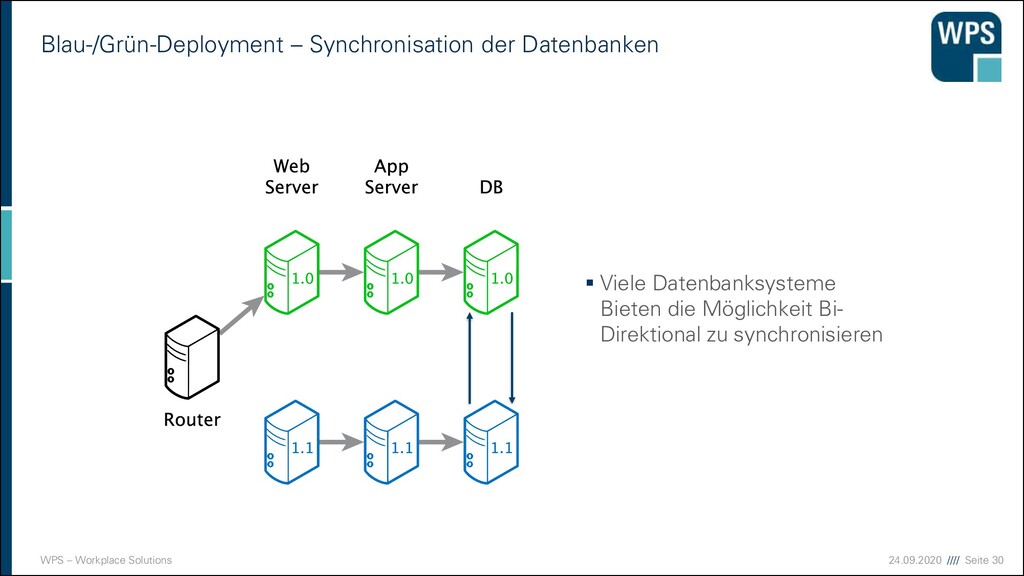{kind=link}
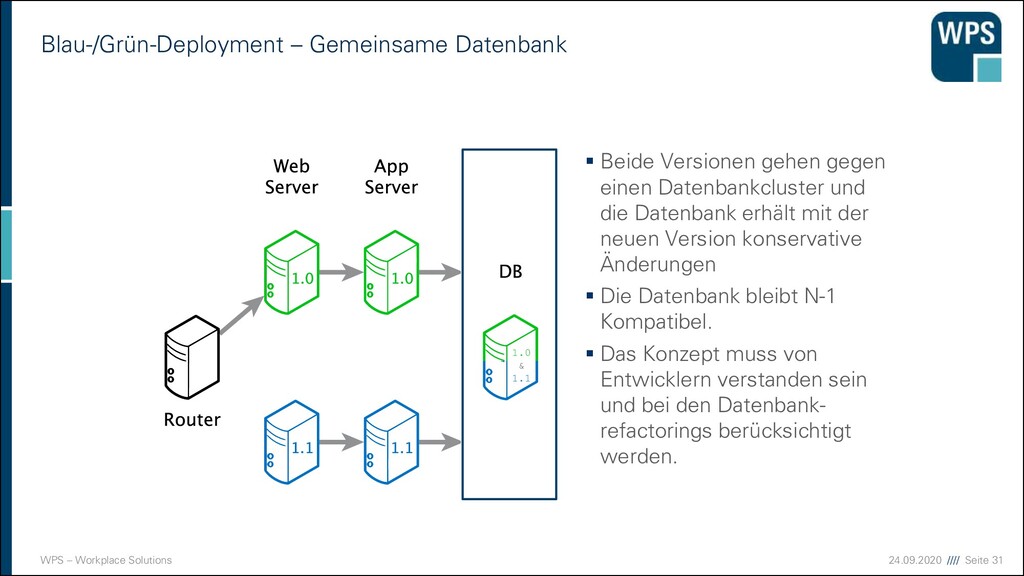{kind=link}
{kind=link}
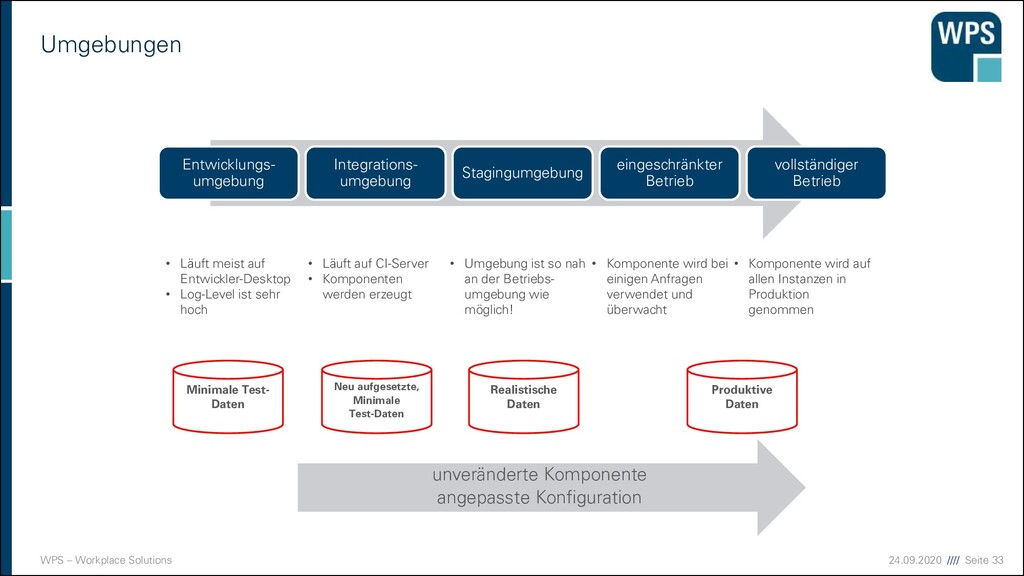{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
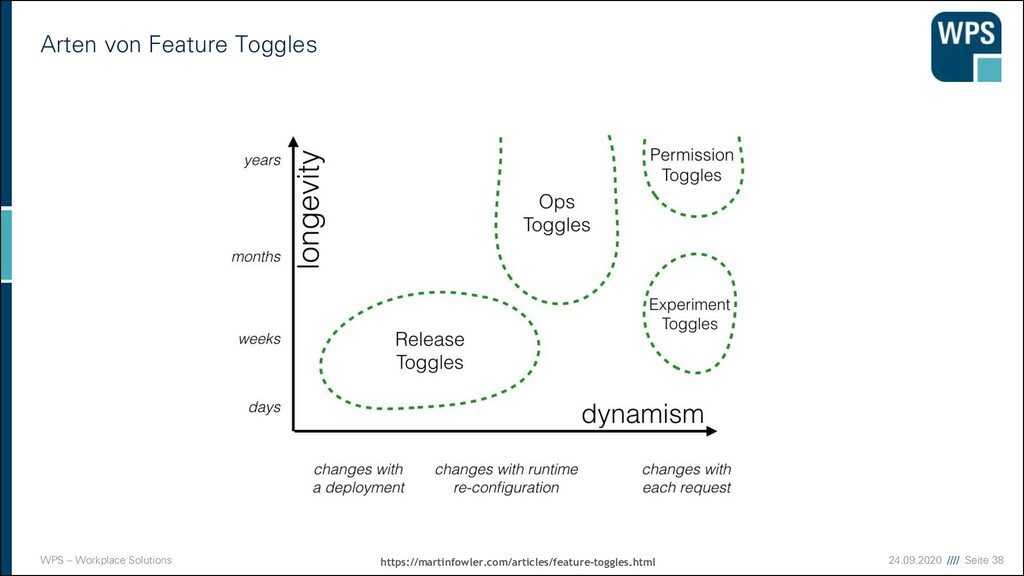{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
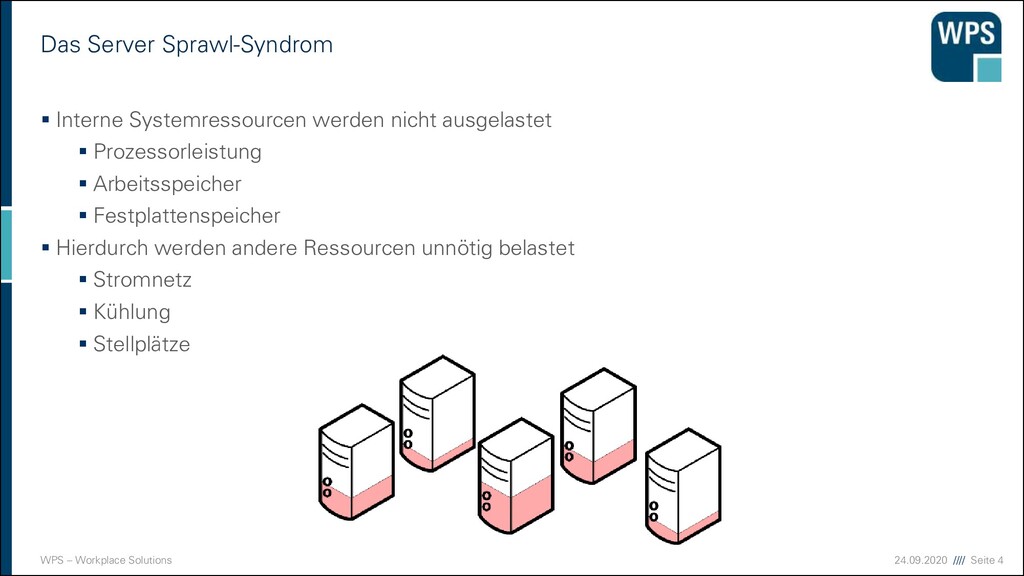{kind=link}
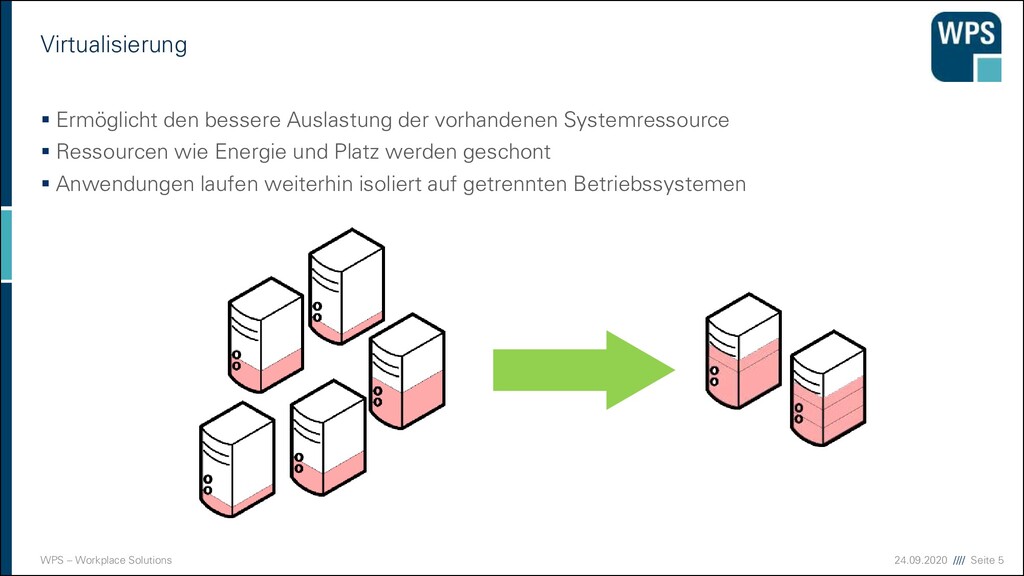{kind=link}
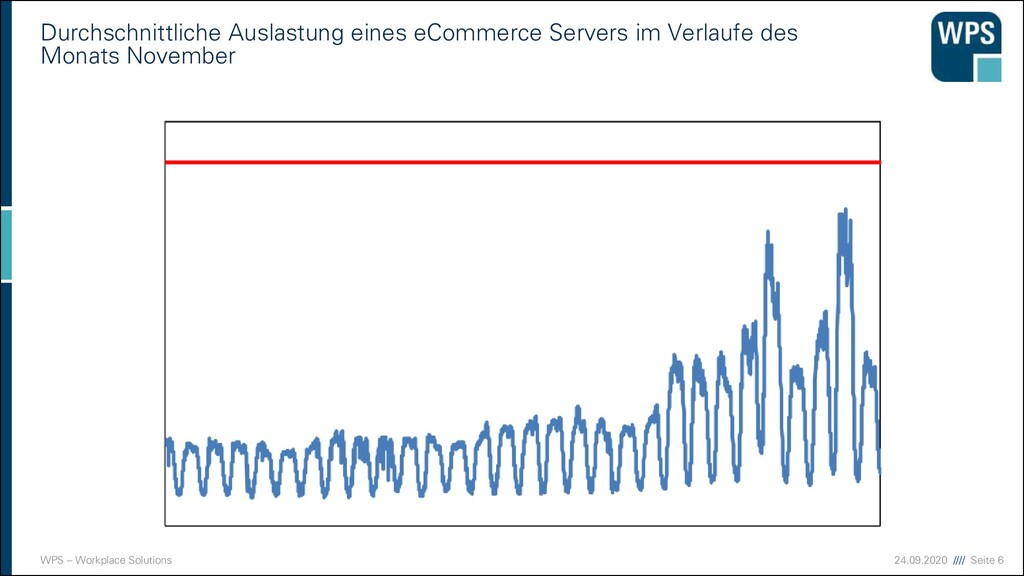{kind=link}
{kind=link}
{kind=link}
{kind=link}
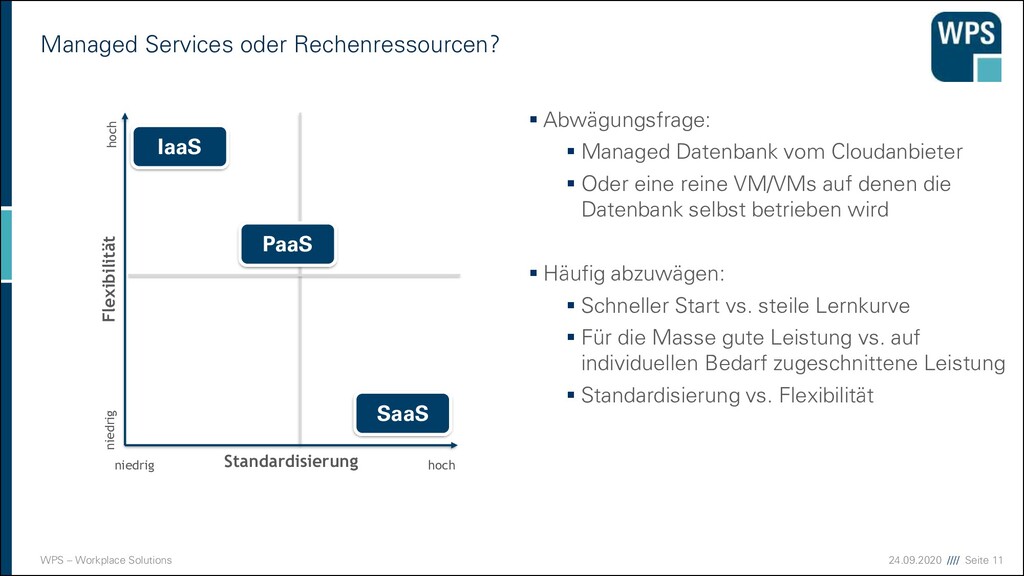{kind=link}
{kind=link}
{kind=link}
{kind=link}
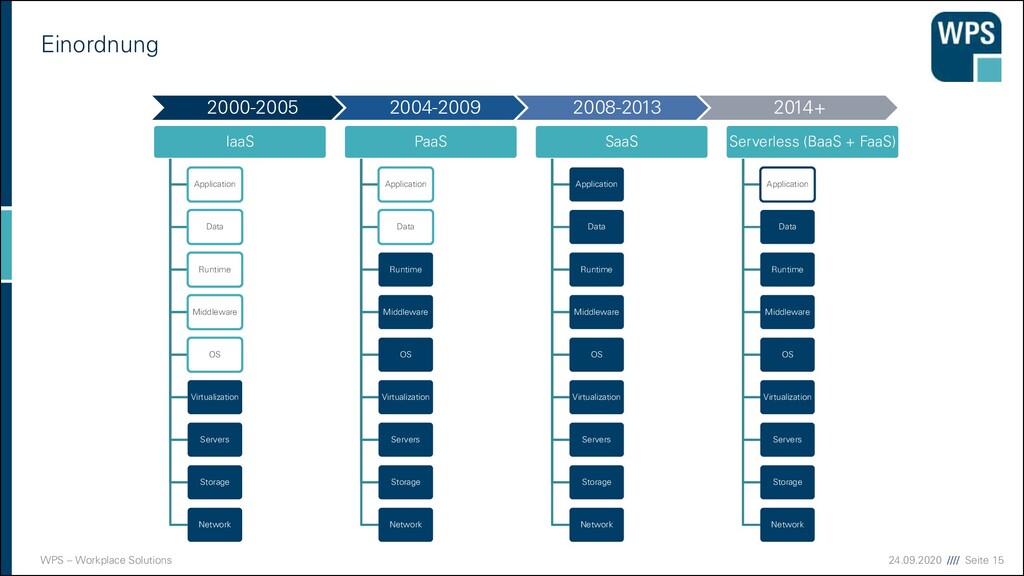{kind=link}
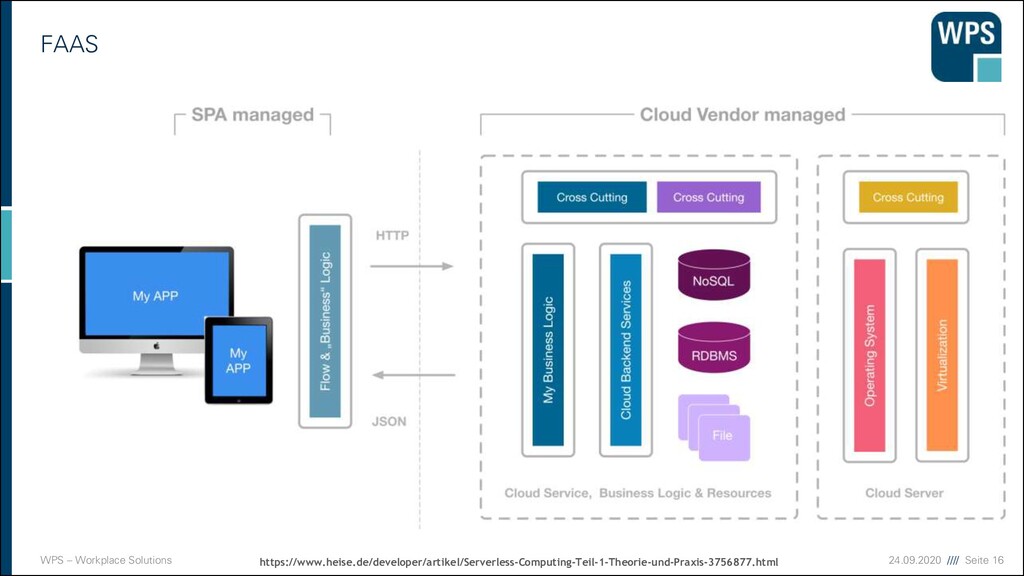{kind=link}
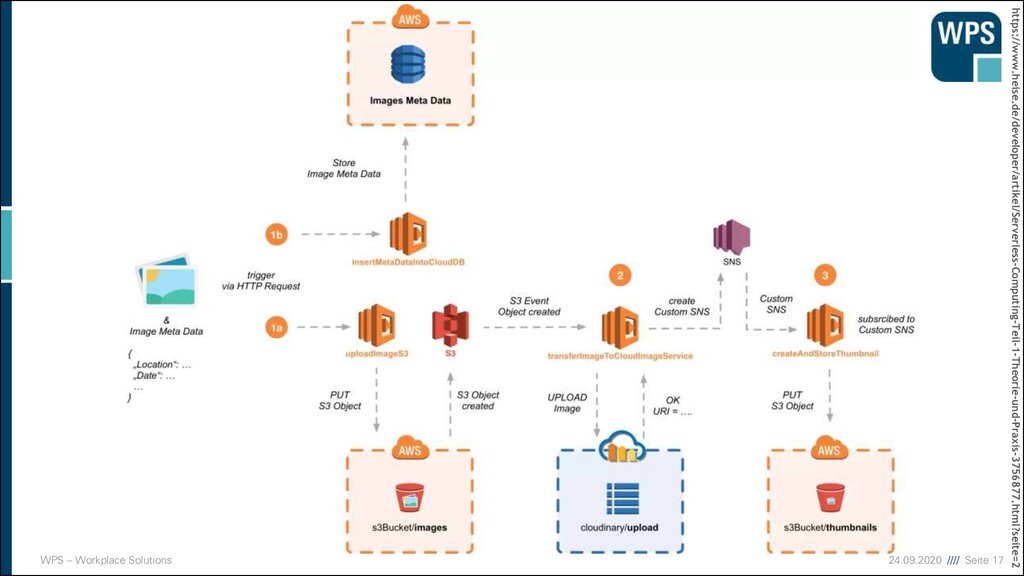{kind=link}
{kind=link}
{kind=link}
{kind=link}
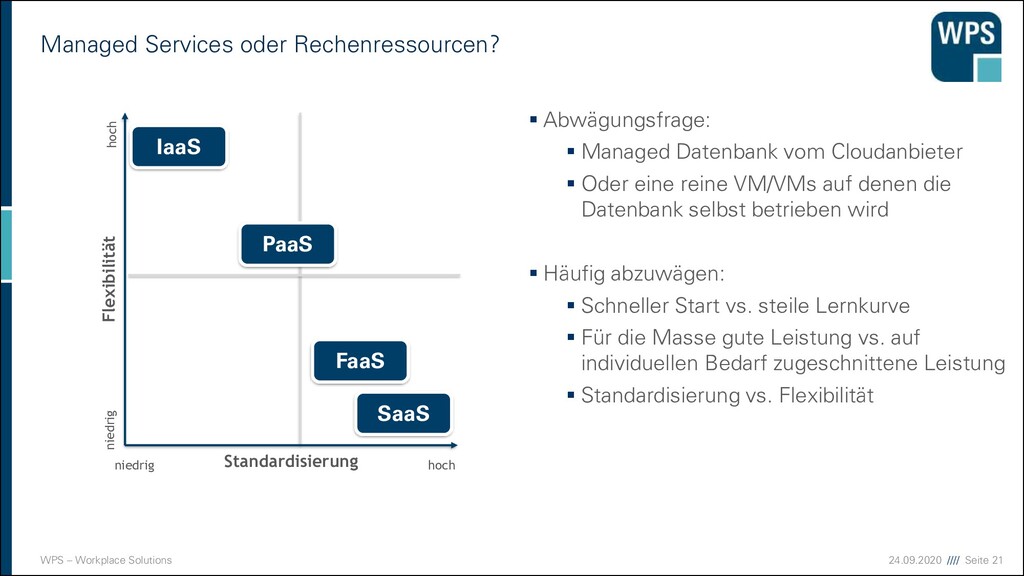{kind=link}
{kind=link}
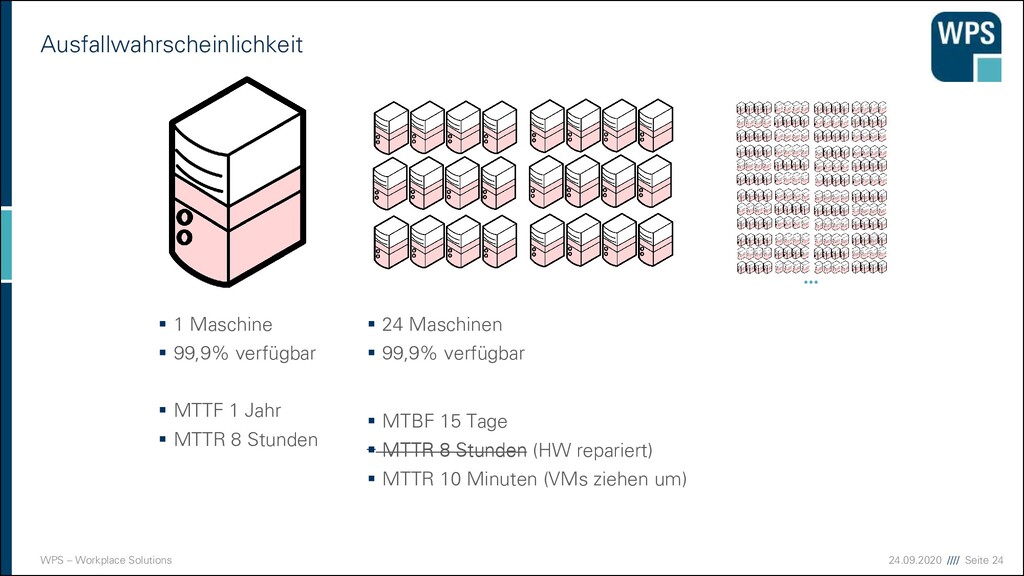{kind=link}
{kind=link}
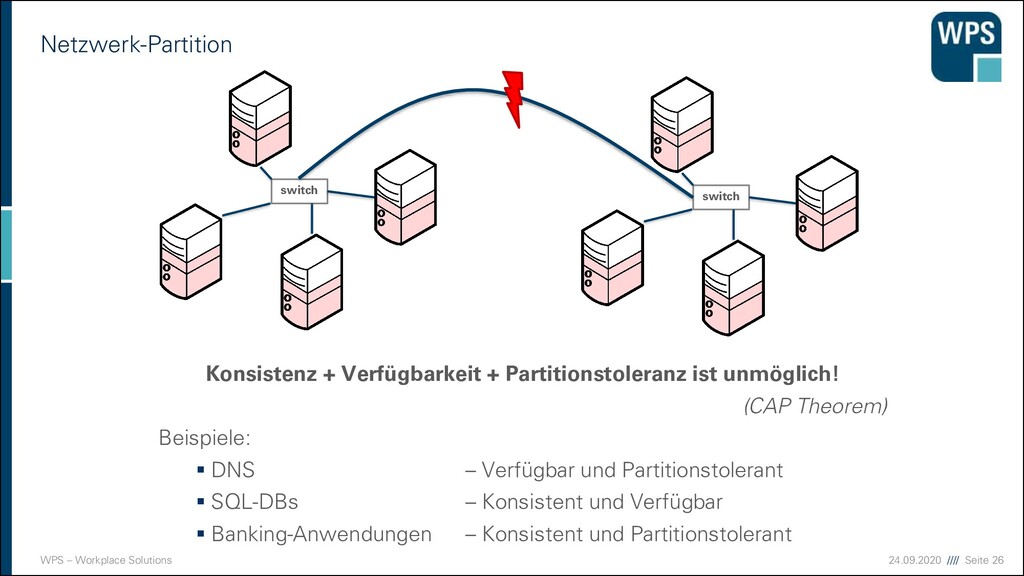{kind=link}
{kind=link}
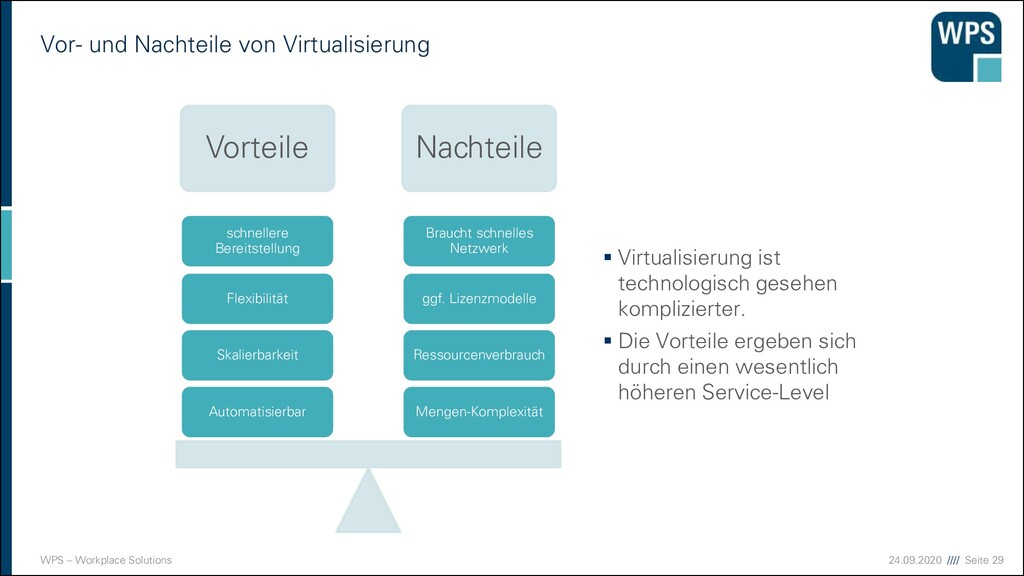{kind=link}
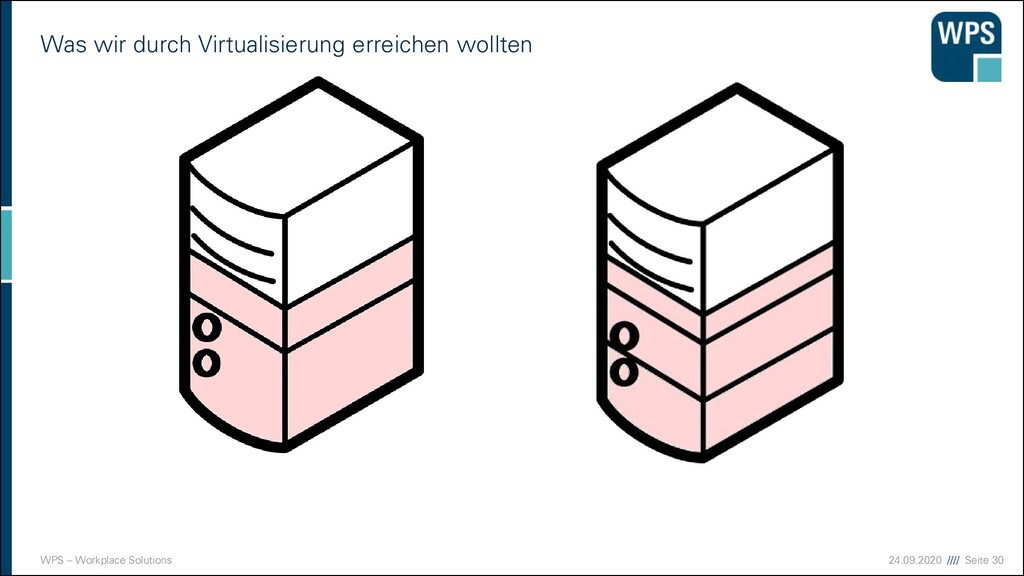{kind=link}
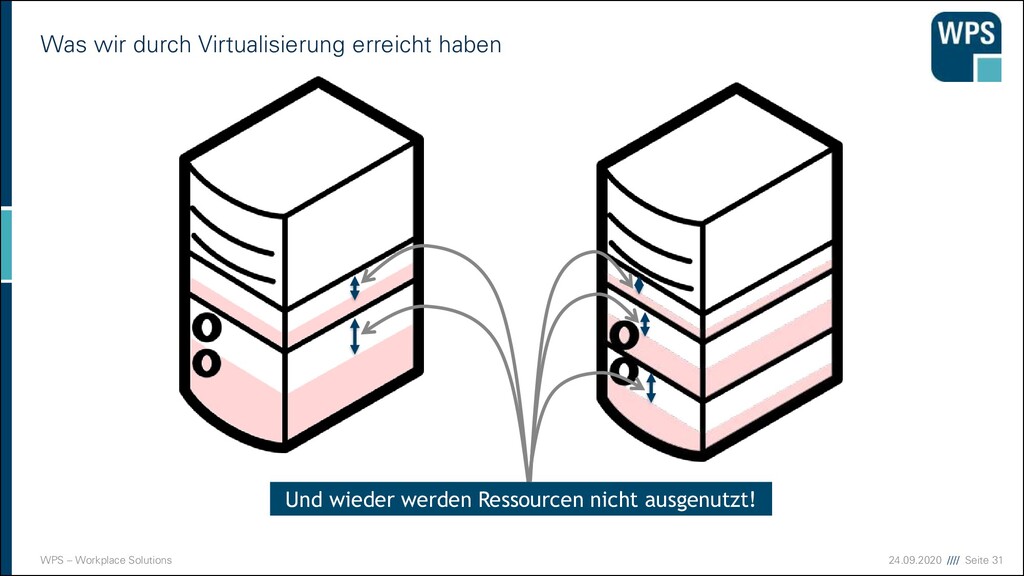{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
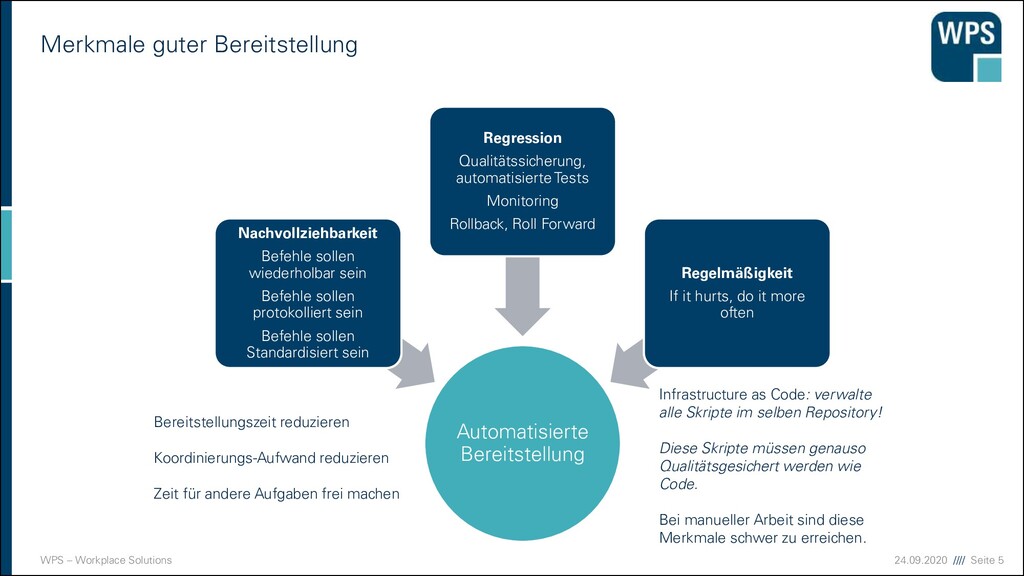{kind=link}
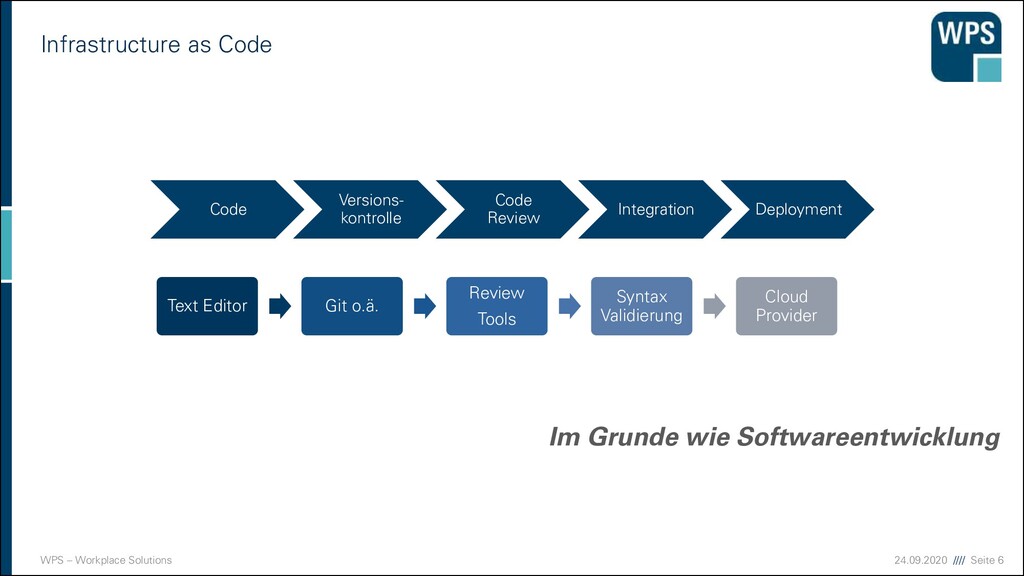{kind=link}
{kind=link}
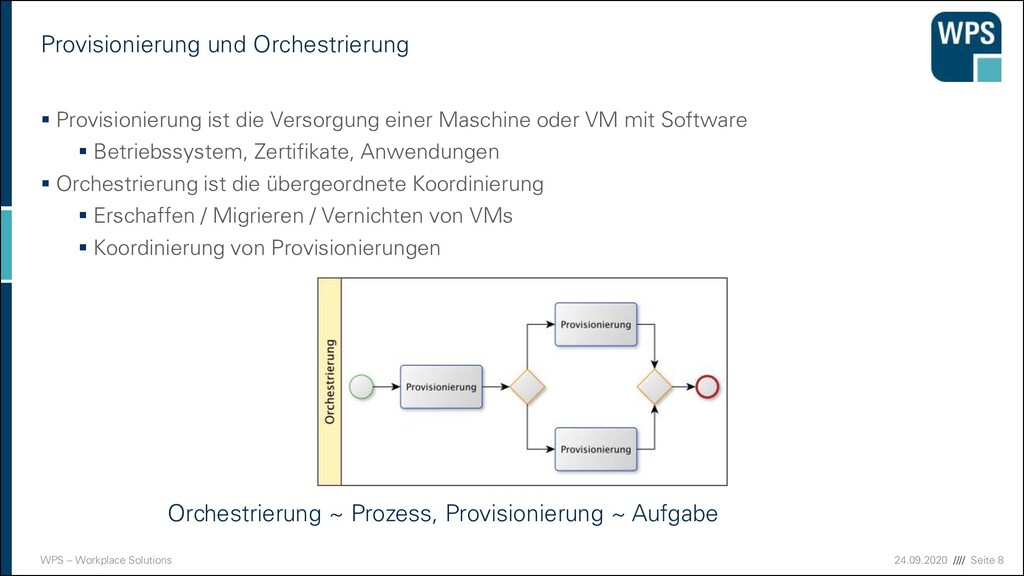{kind=link}
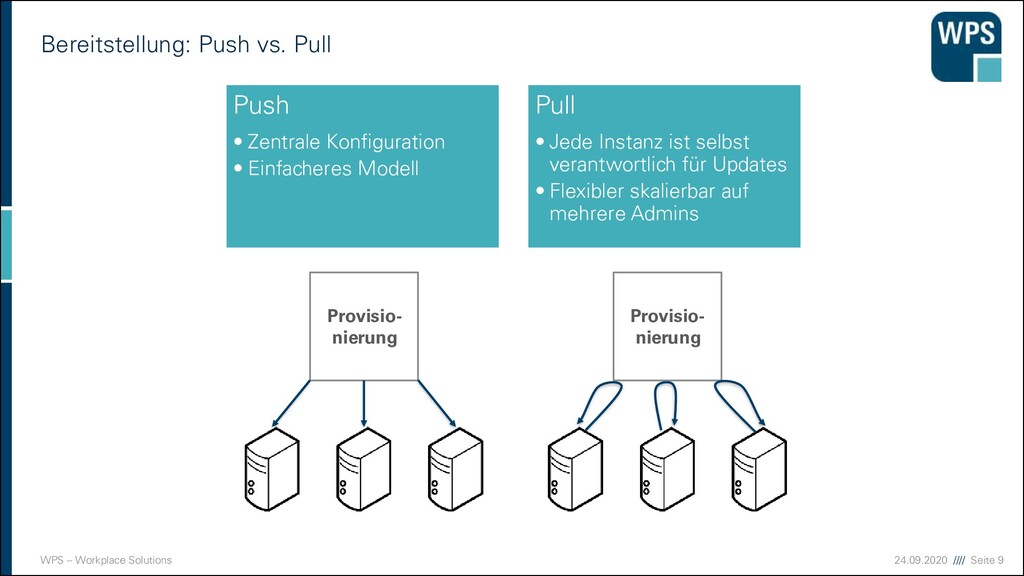{kind=link}
{kind=link}
{kind=link}
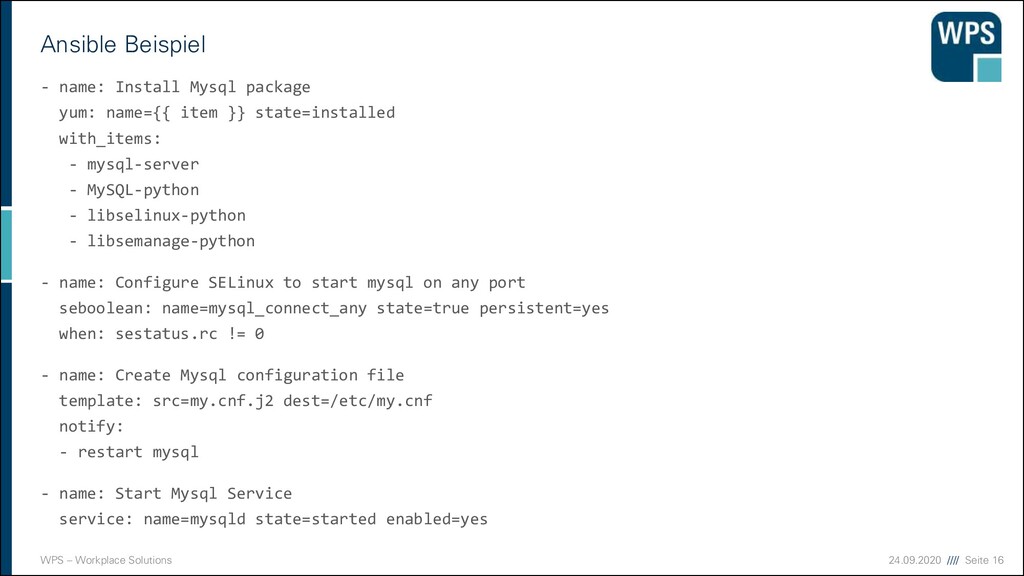{kind=link}
{kind=link}
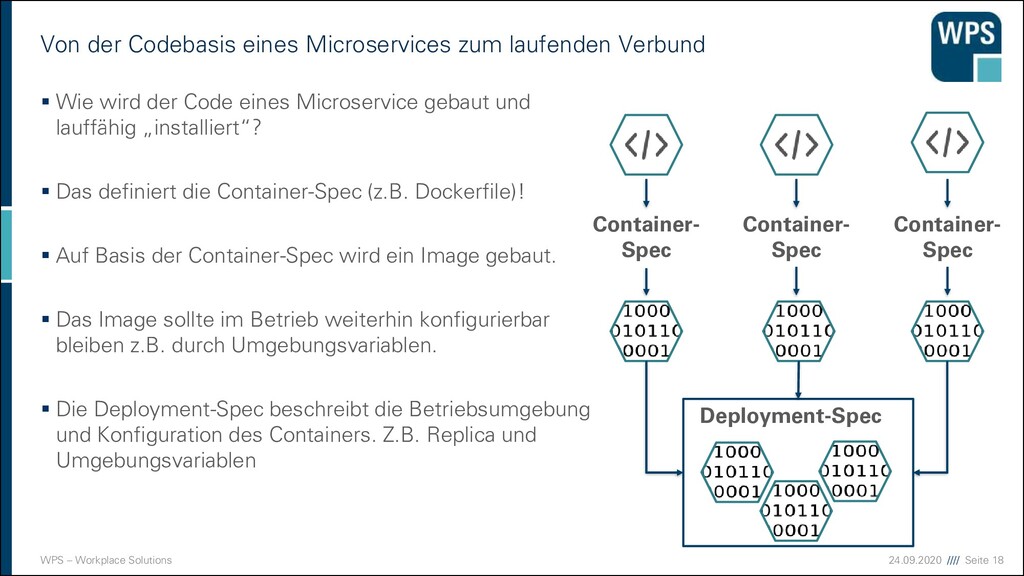{kind=link}
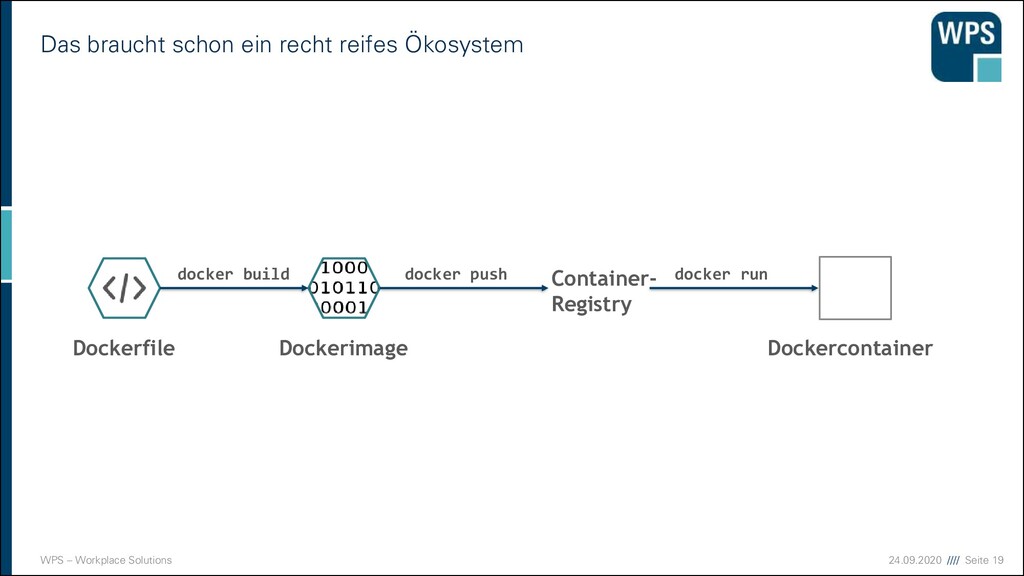{kind=link}
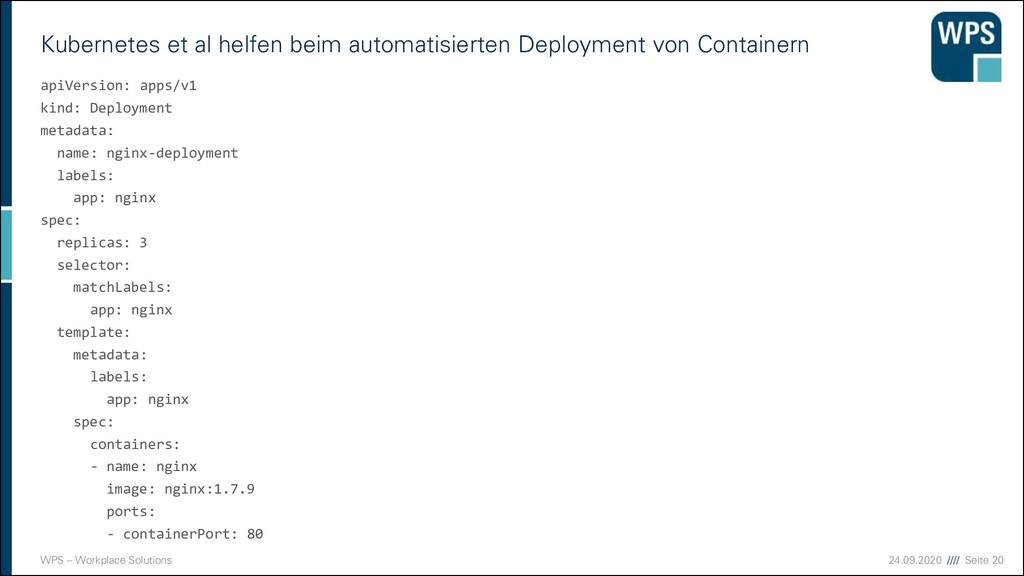{kind=link}
{kind=link}
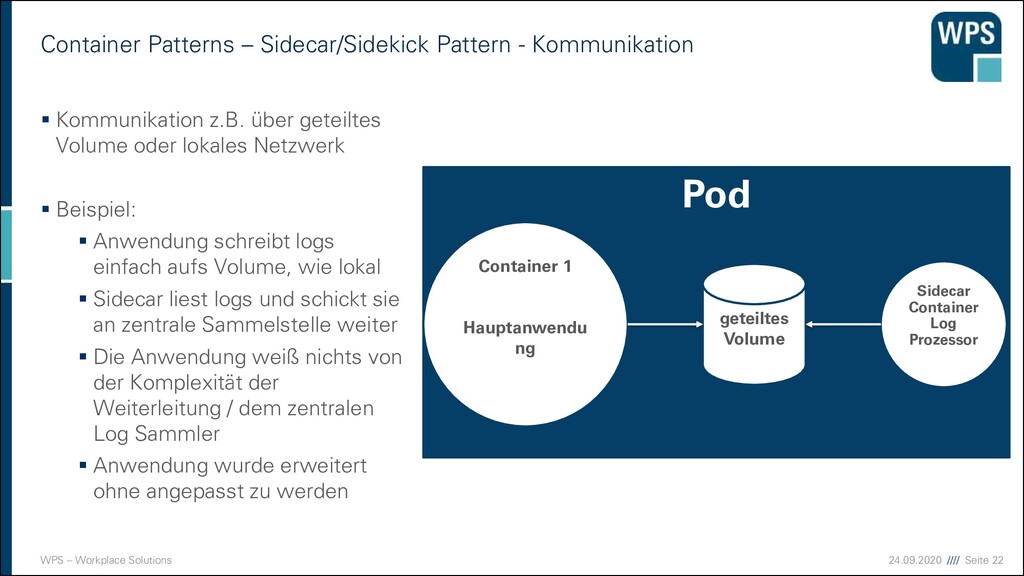{kind=link}
{kind=link}
{kind=link}
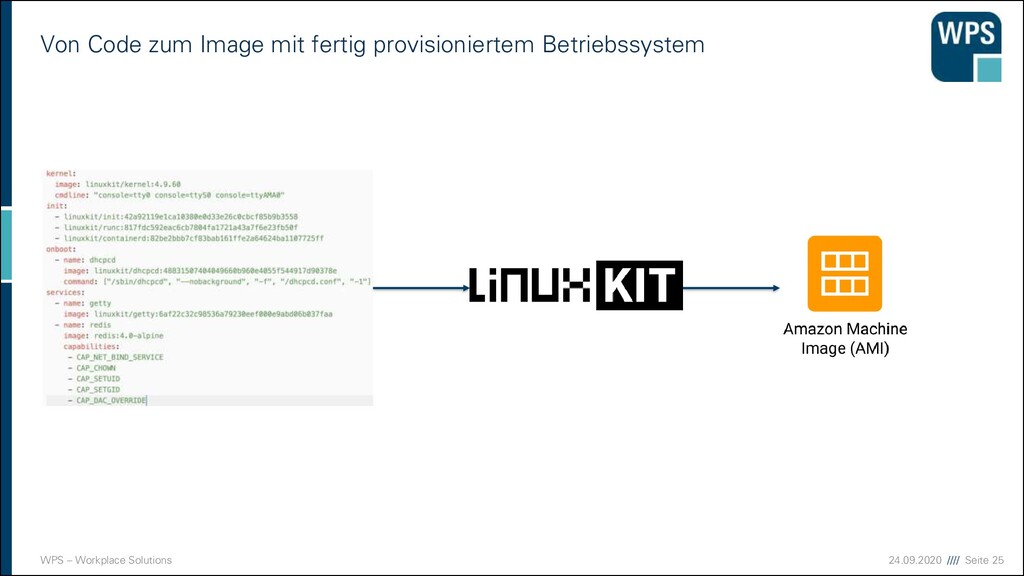{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
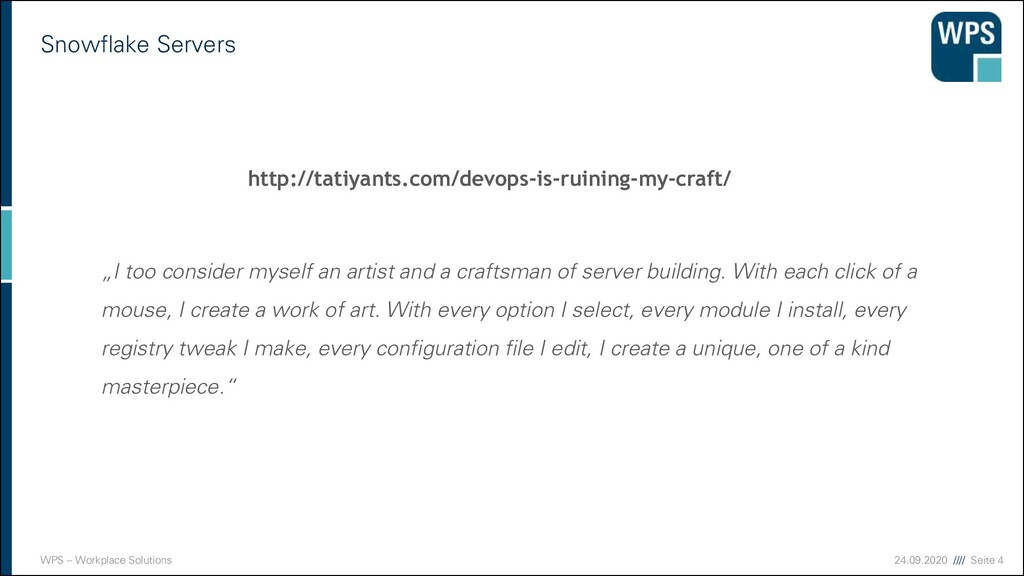{kind=link}
{kind=link}
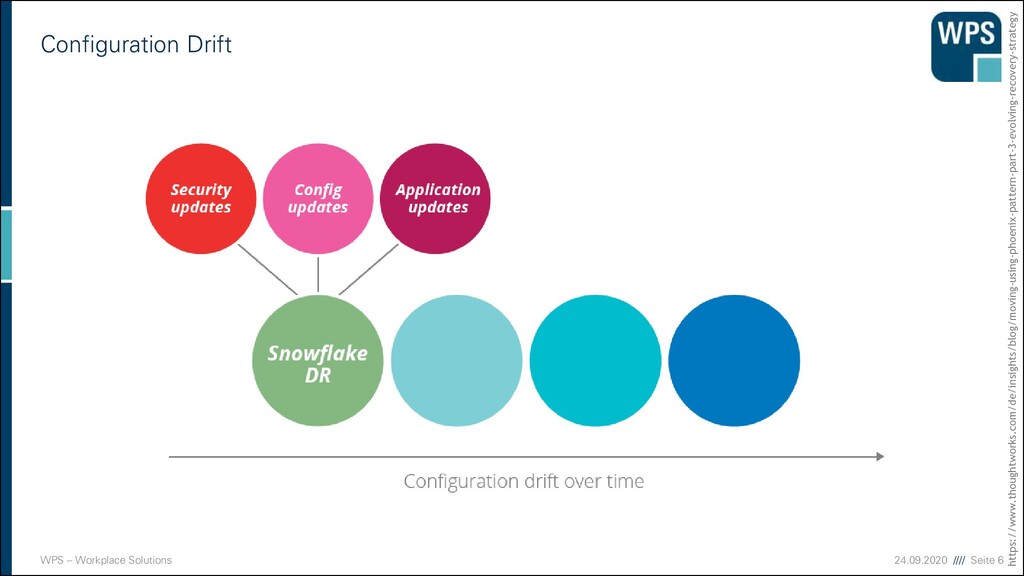{kind=link}
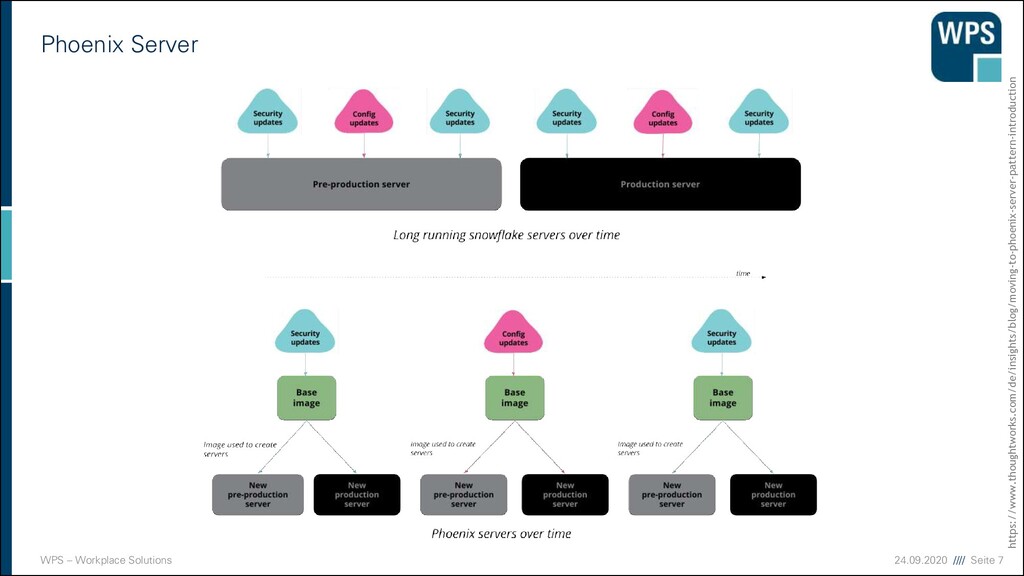{kind=link}
{kind=link}
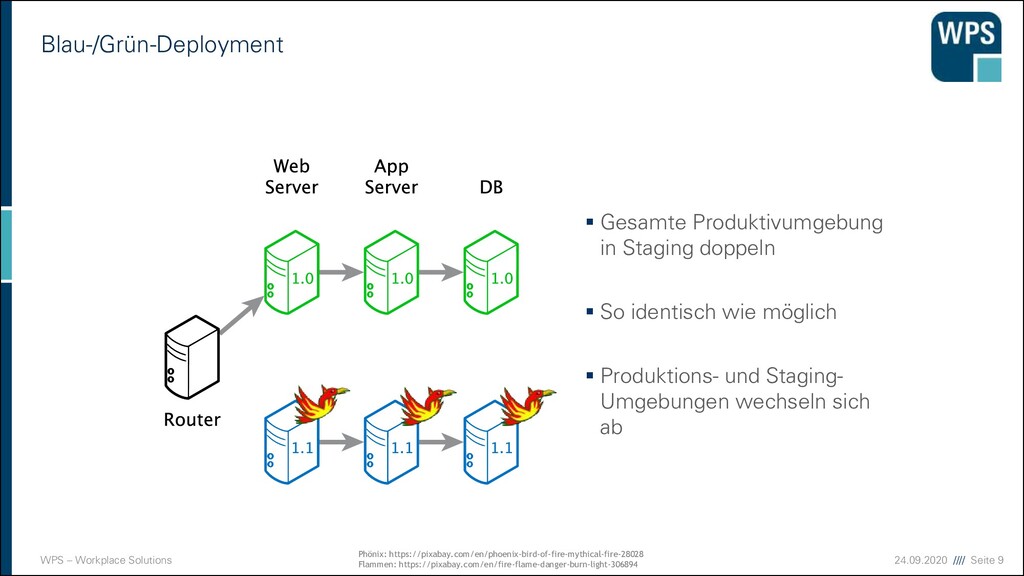{kind=link}
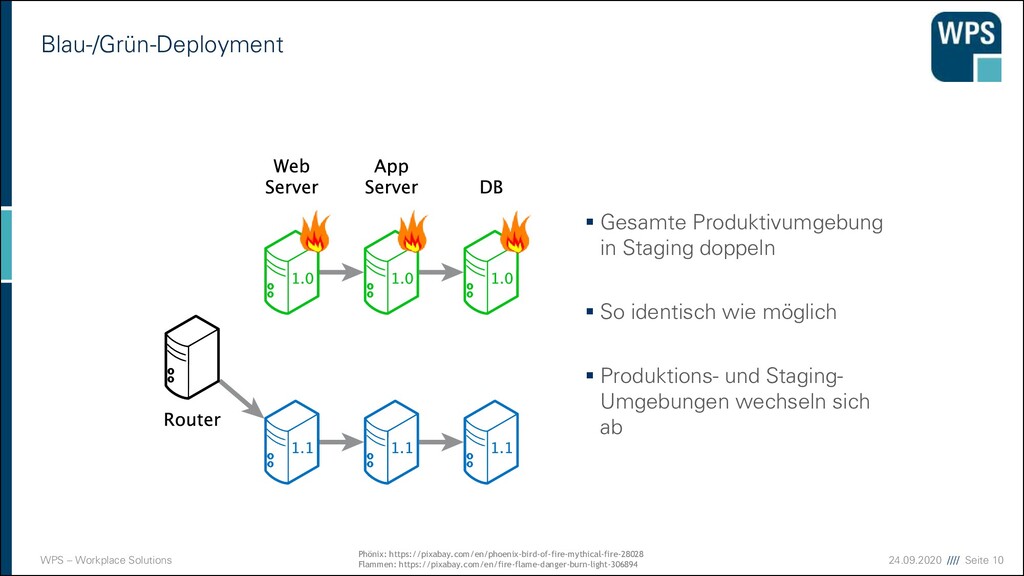{kind=link}
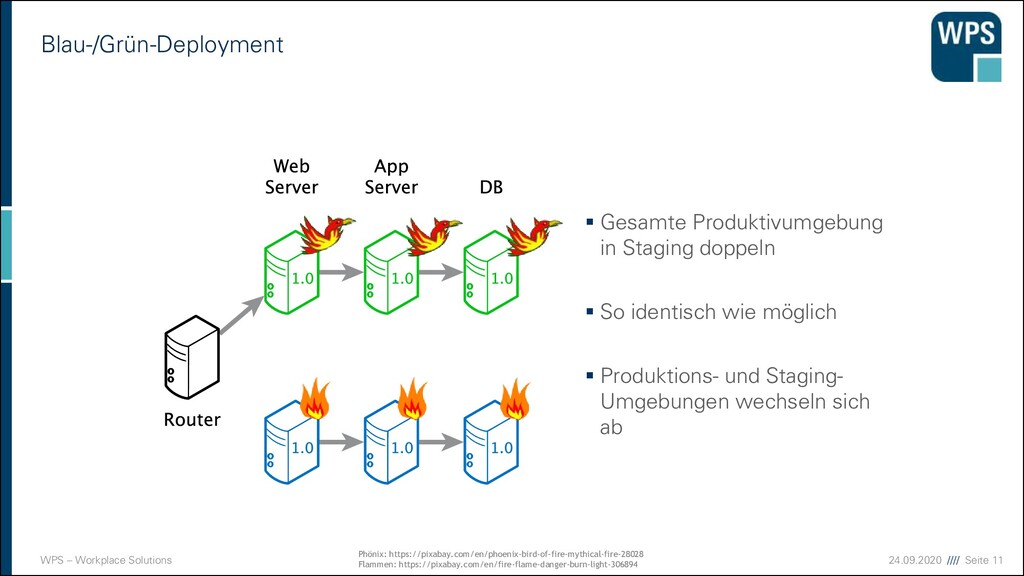{kind=link}
{kind=link}
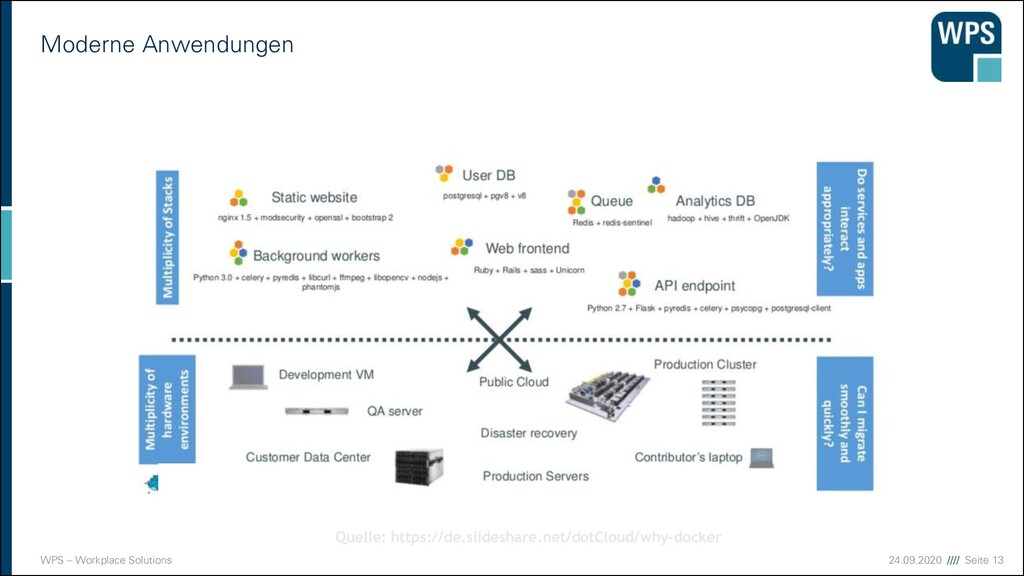{kind=link}
{kind=link}
{kind=link}
{kind=link}
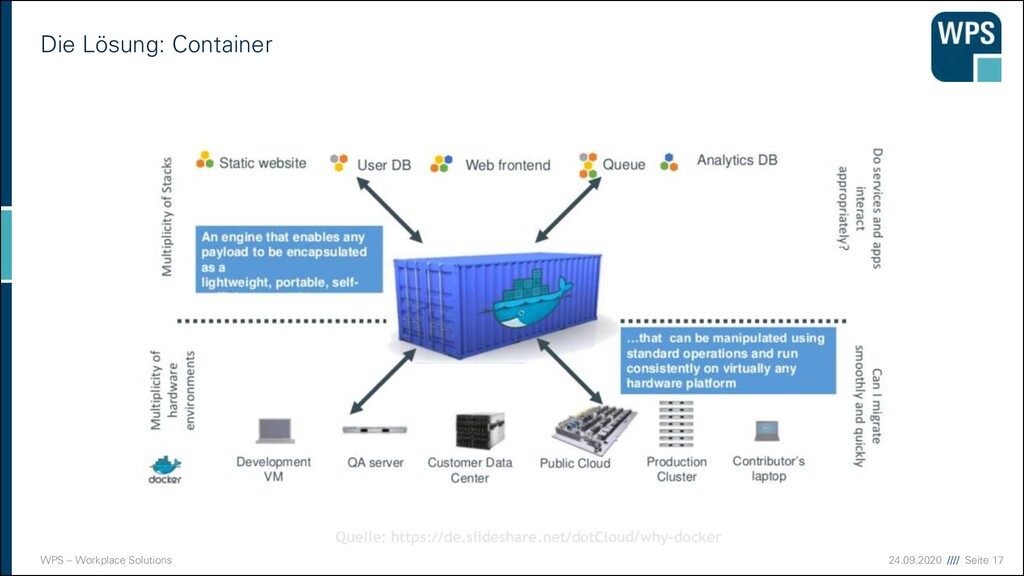{kind=link}
{kind=link}
{kind=link}
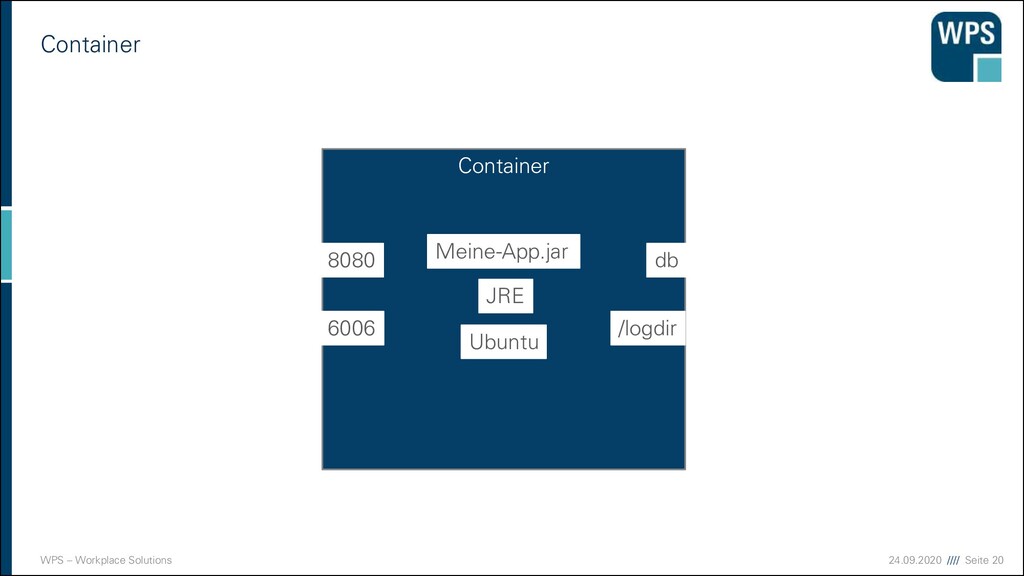{kind=link}
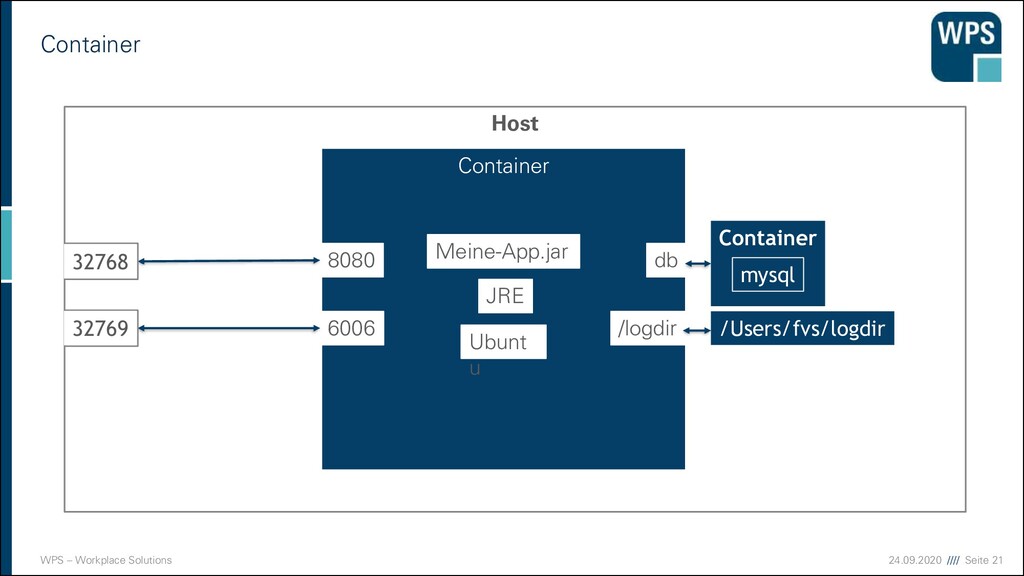{kind=link}
{kind=link}
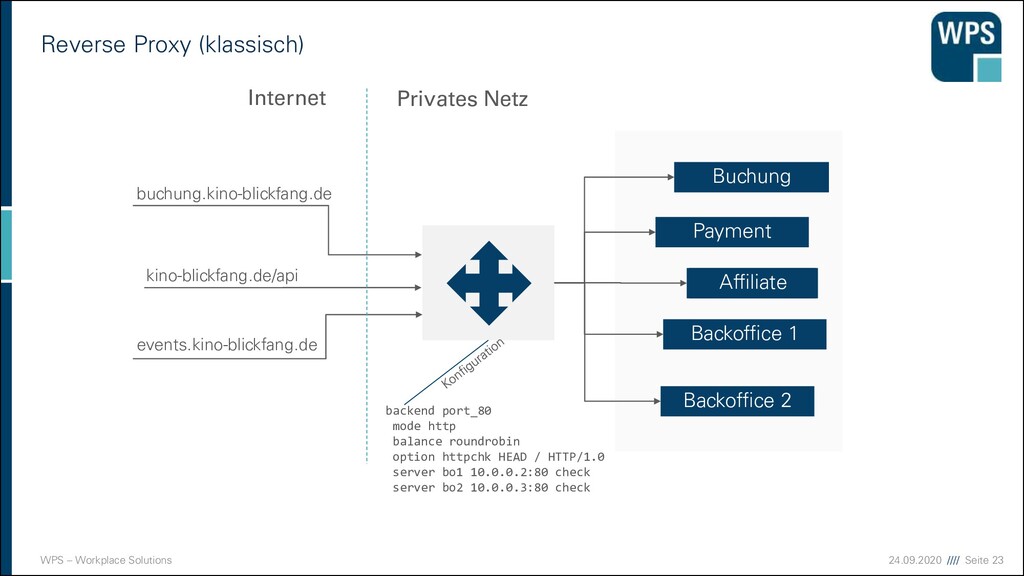{kind=link}
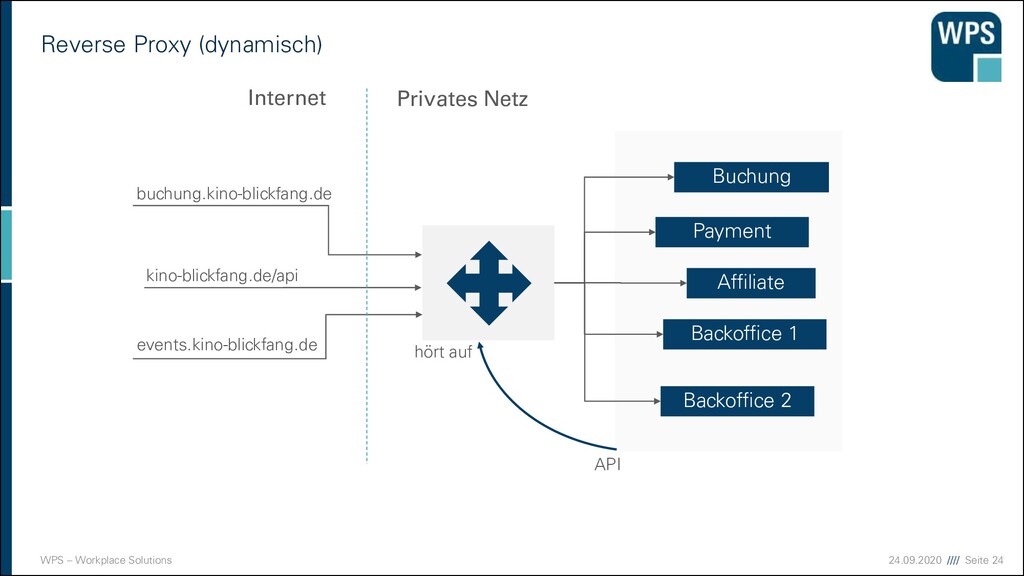{kind=link}
{kind=link}
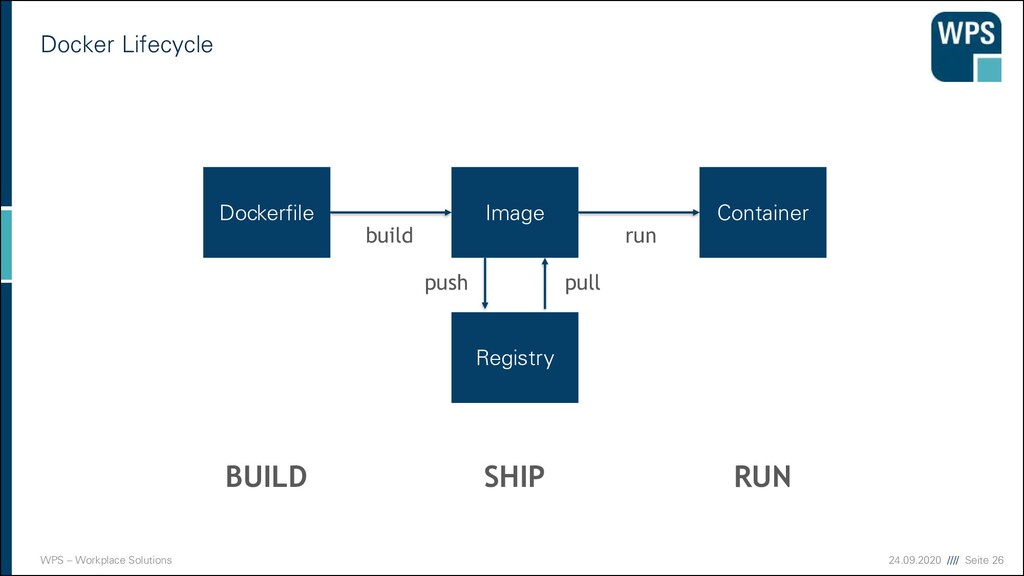{kind=link}
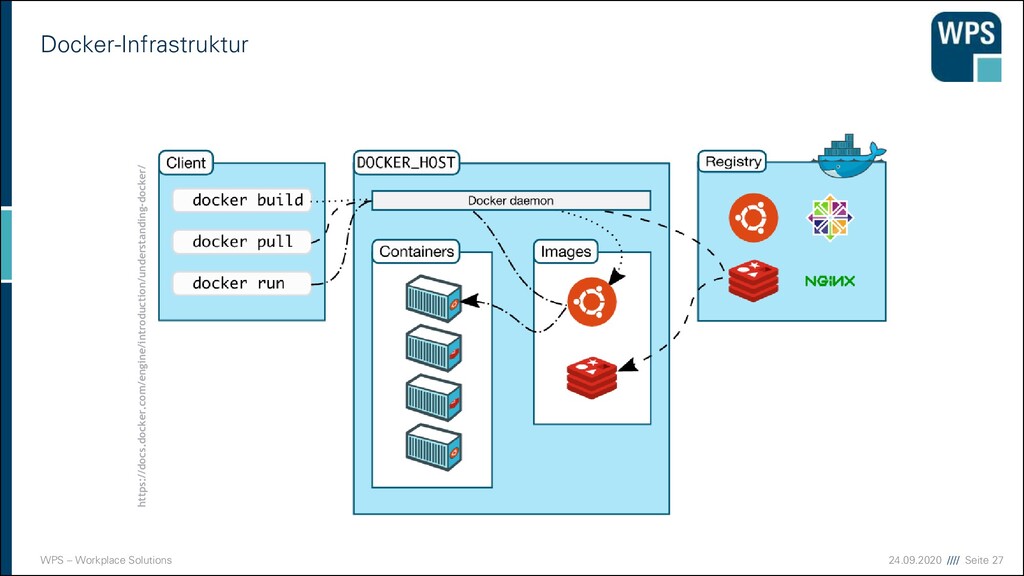{kind=link}
{kind=link}
{kind=link}
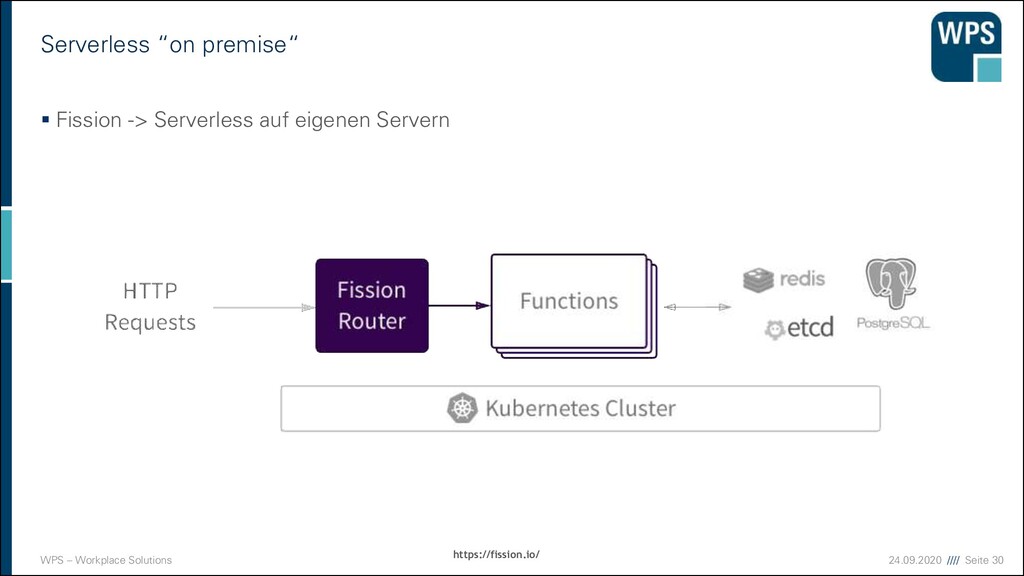{kind=link}
{kind=link}
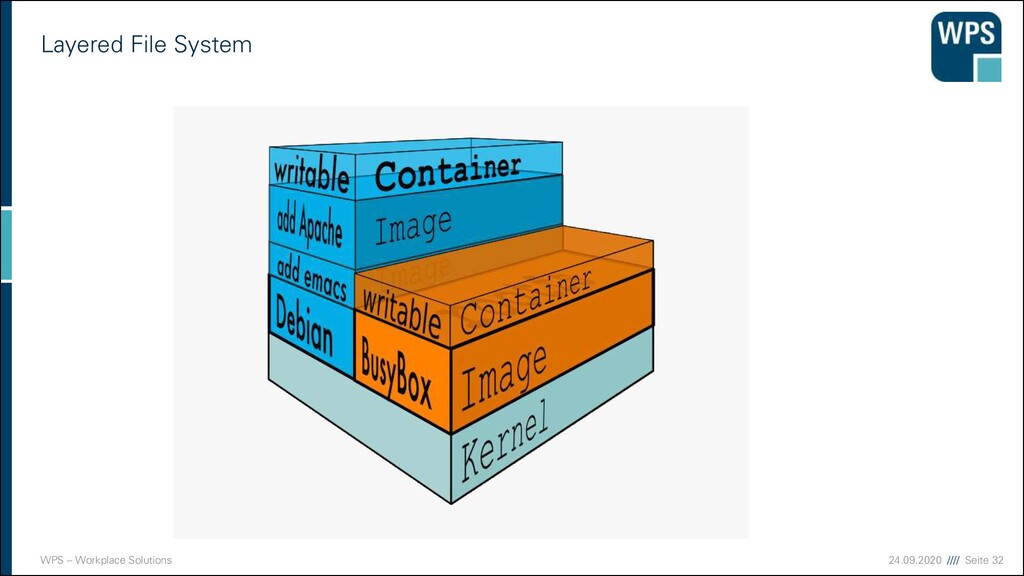{kind=link}
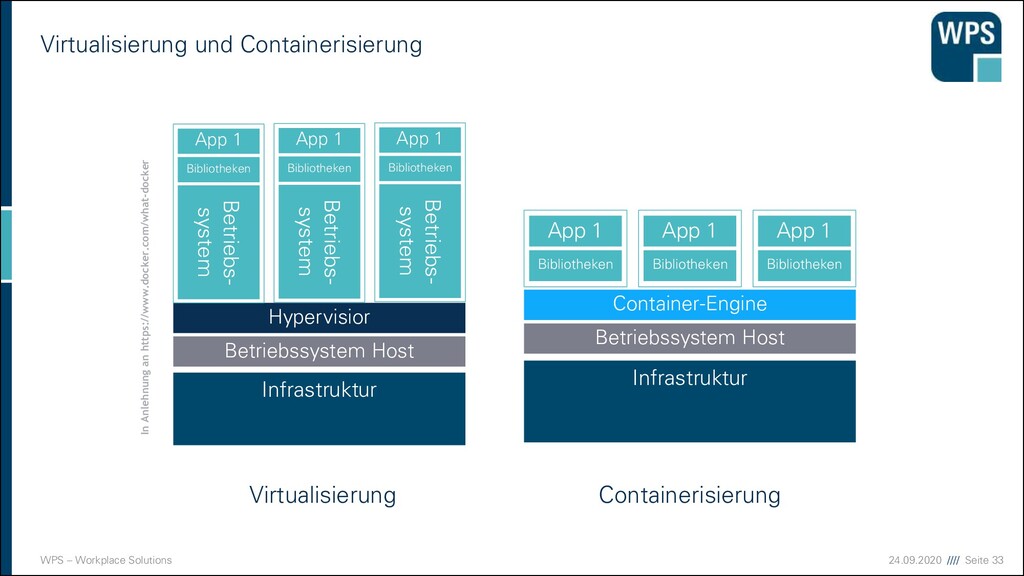{kind=link}
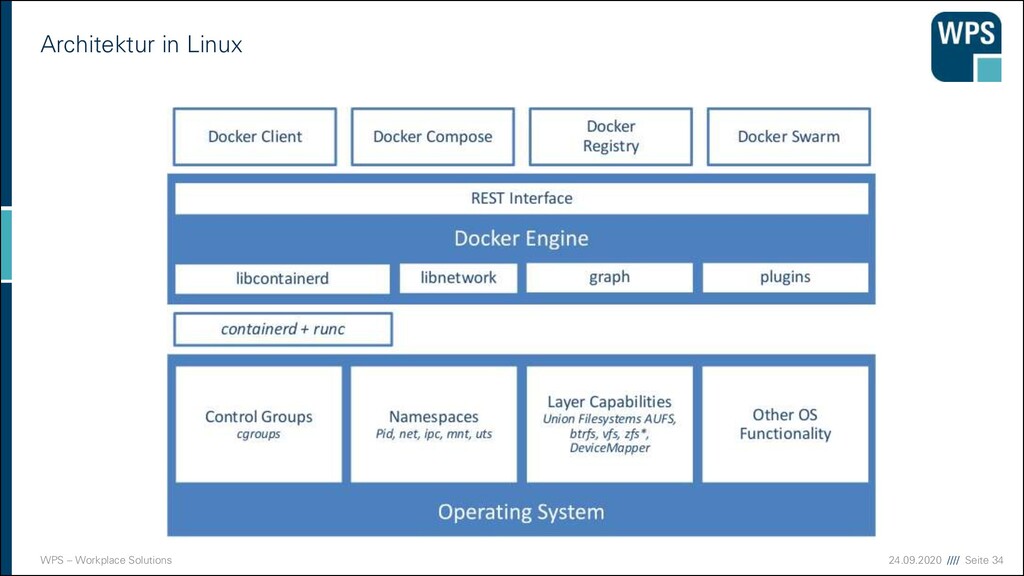{kind=link}
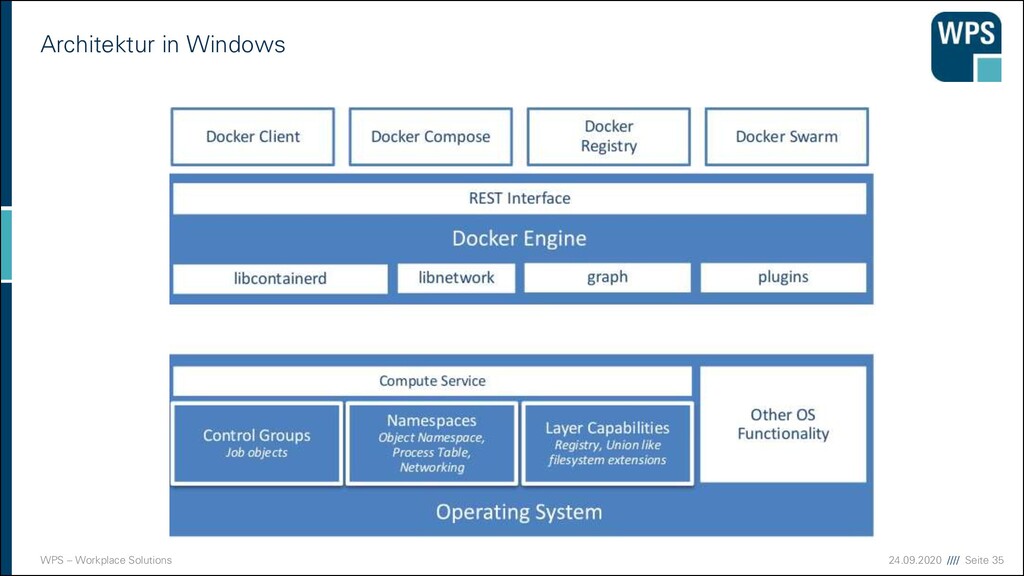{kind=link}
{kind=link}
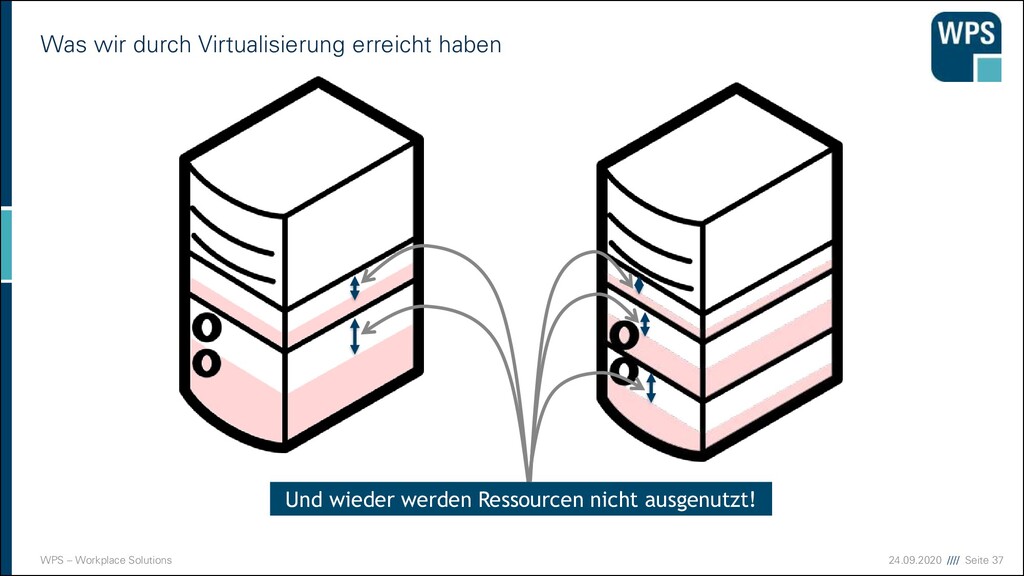{kind=link}
{kind=link}
{kind=link}
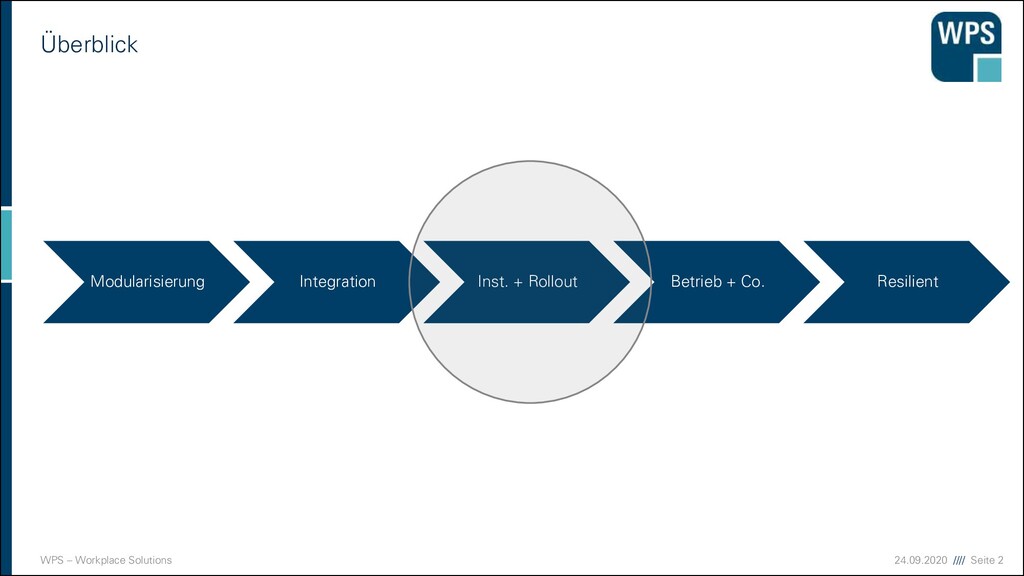{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
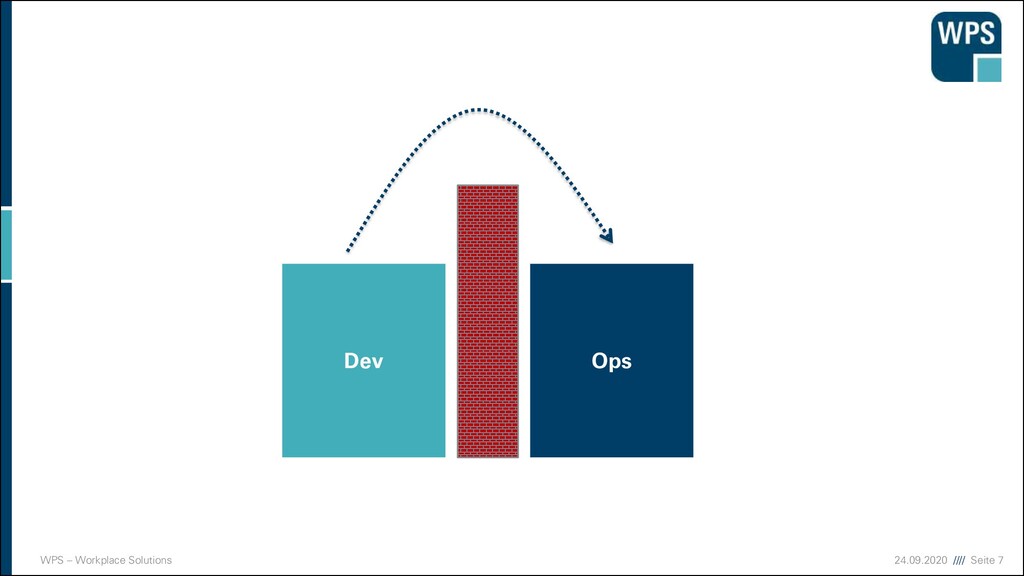{kind=link}
{kind=link}
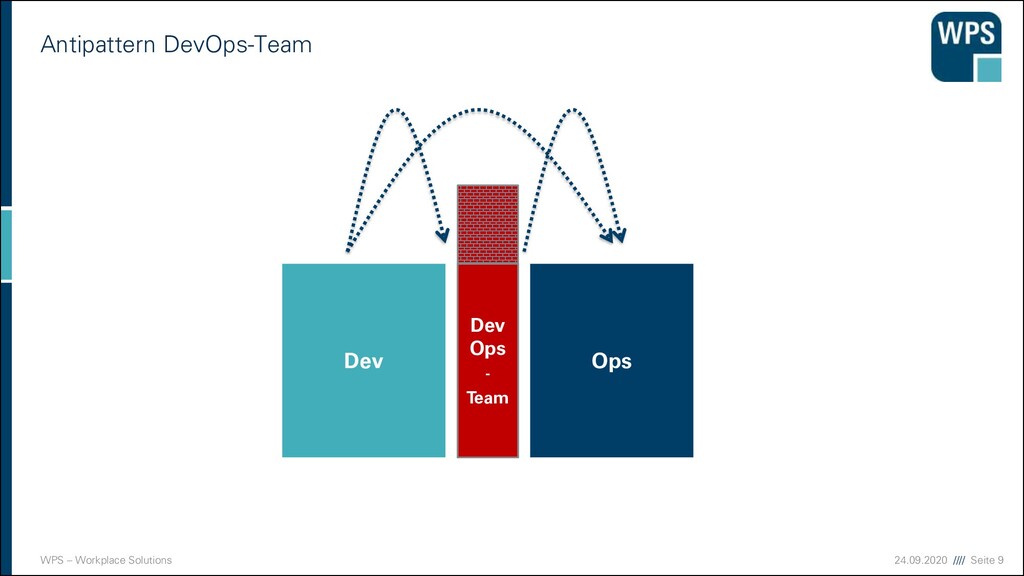{kind=link}
{kind=link}
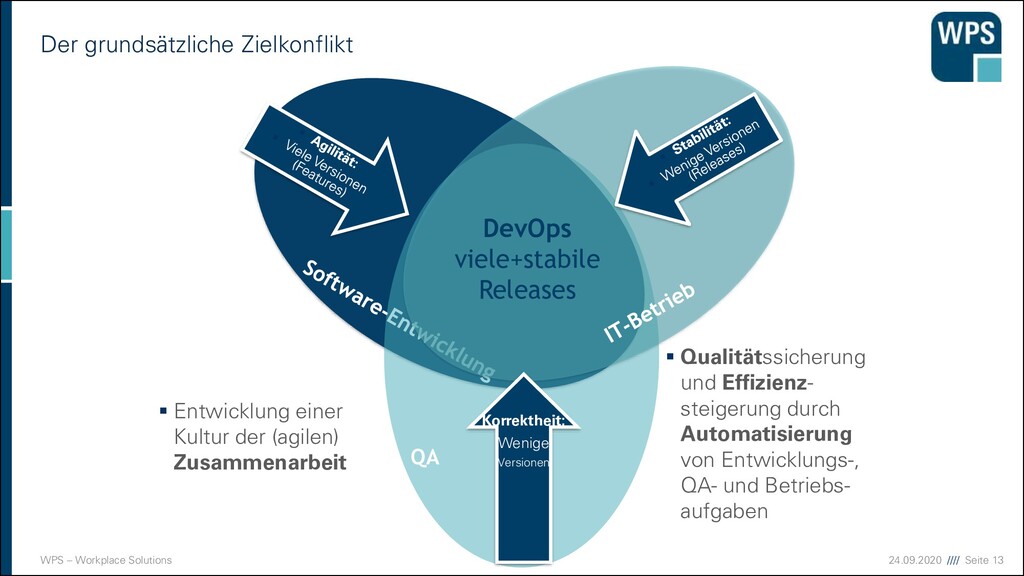{kind=link}
{kind=link}
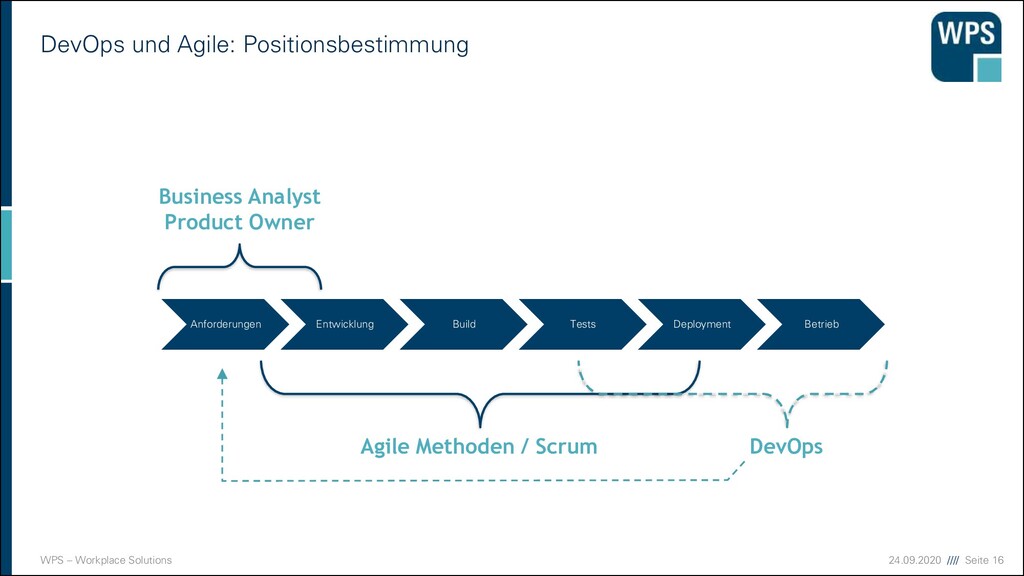{kind=link}
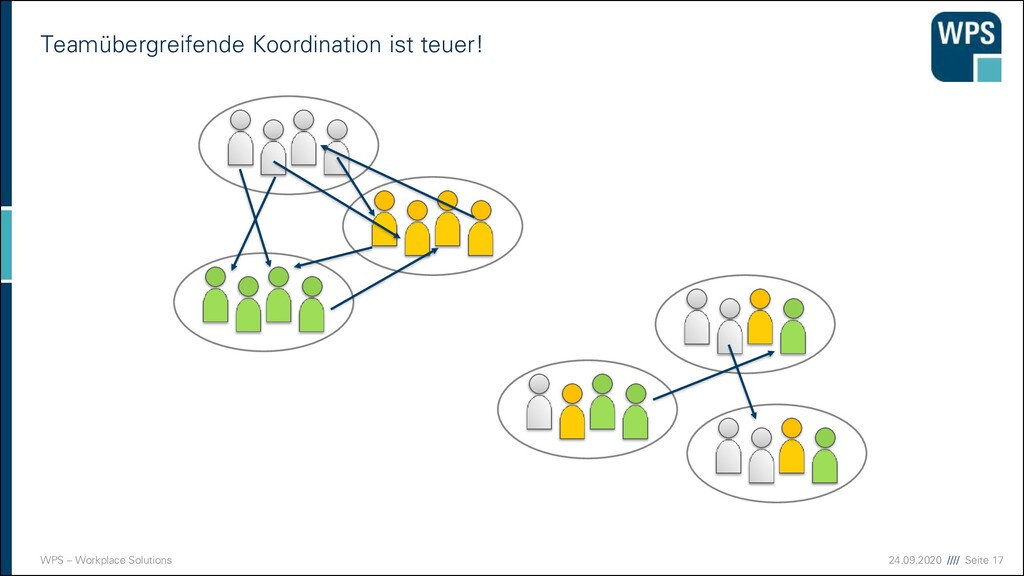{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
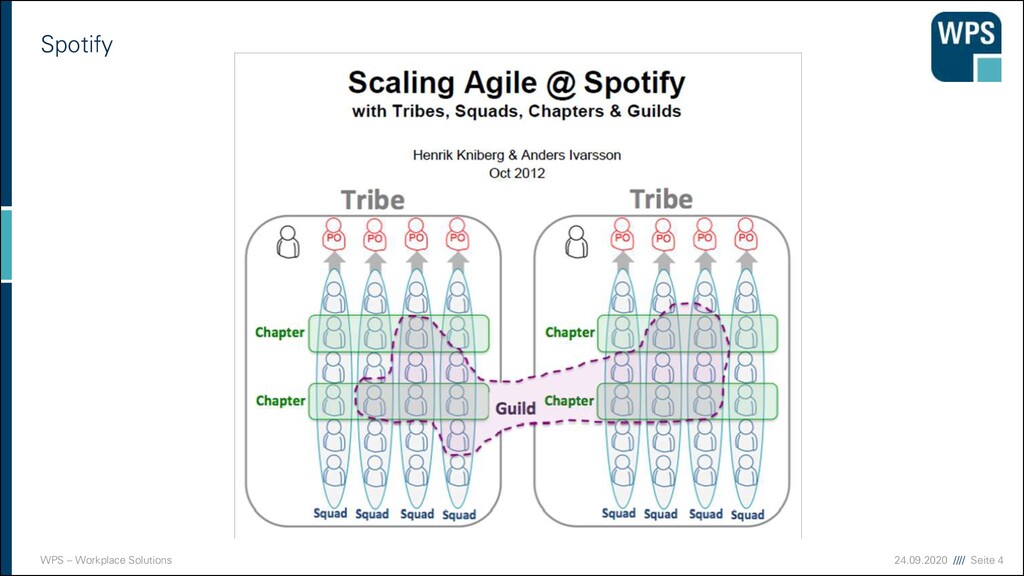{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
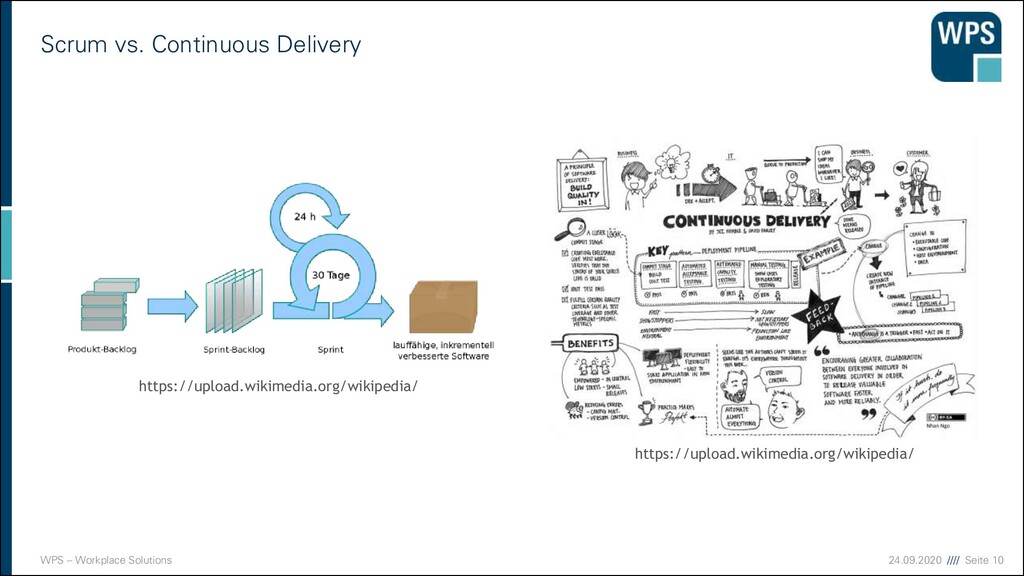{kind=link}
{kind=link}
{kind=link}
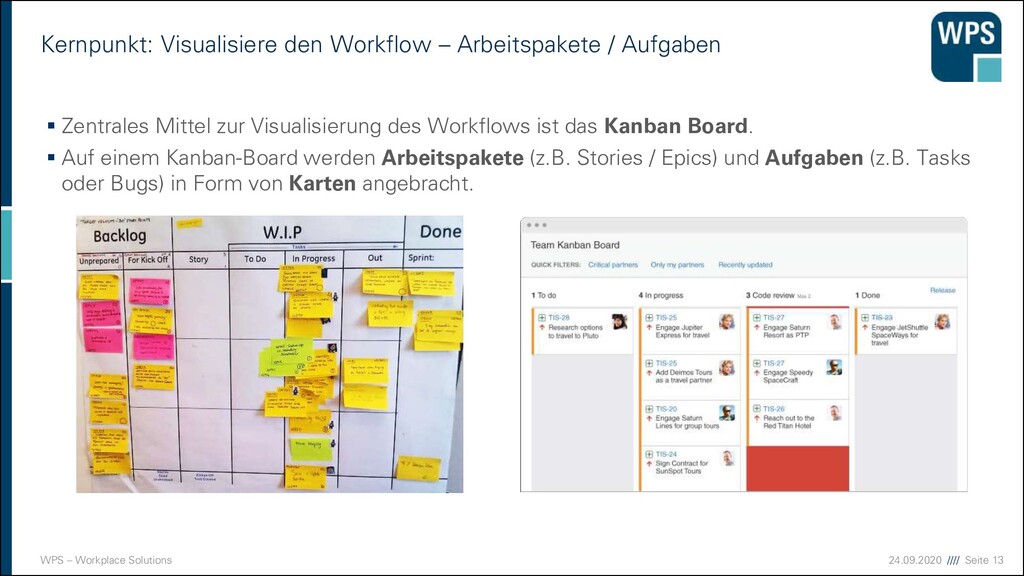{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
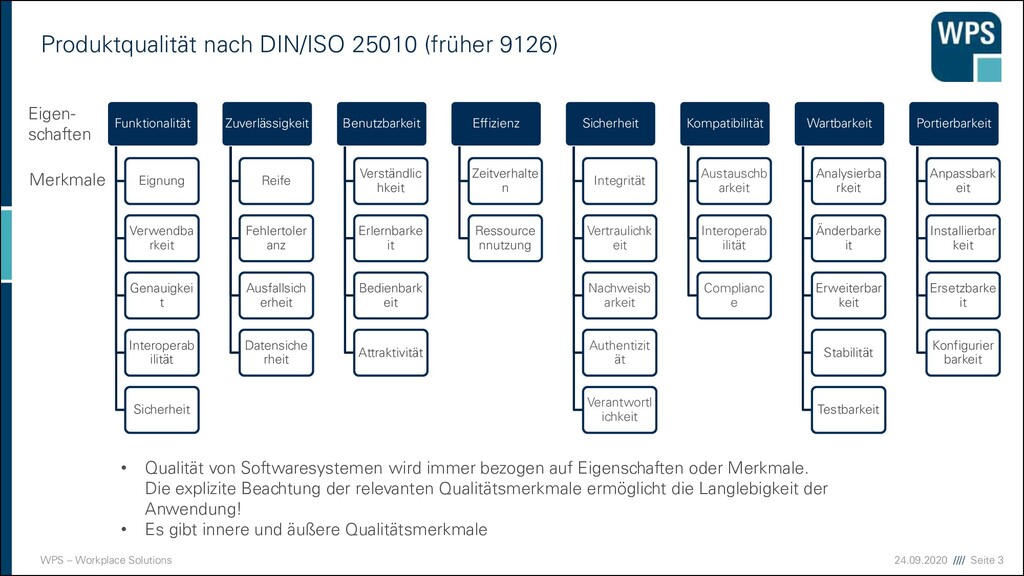{kind=link}
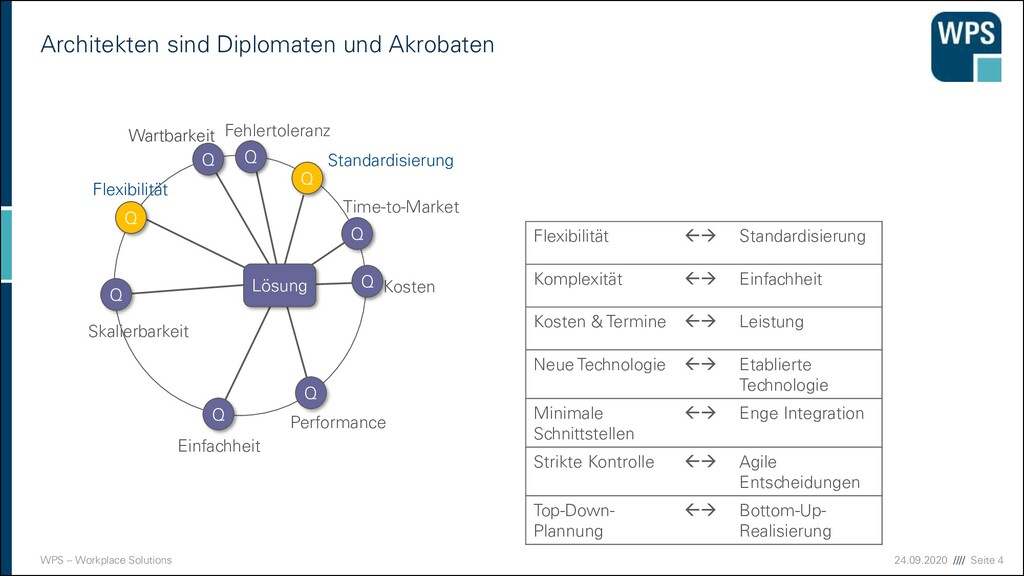{kind=link}
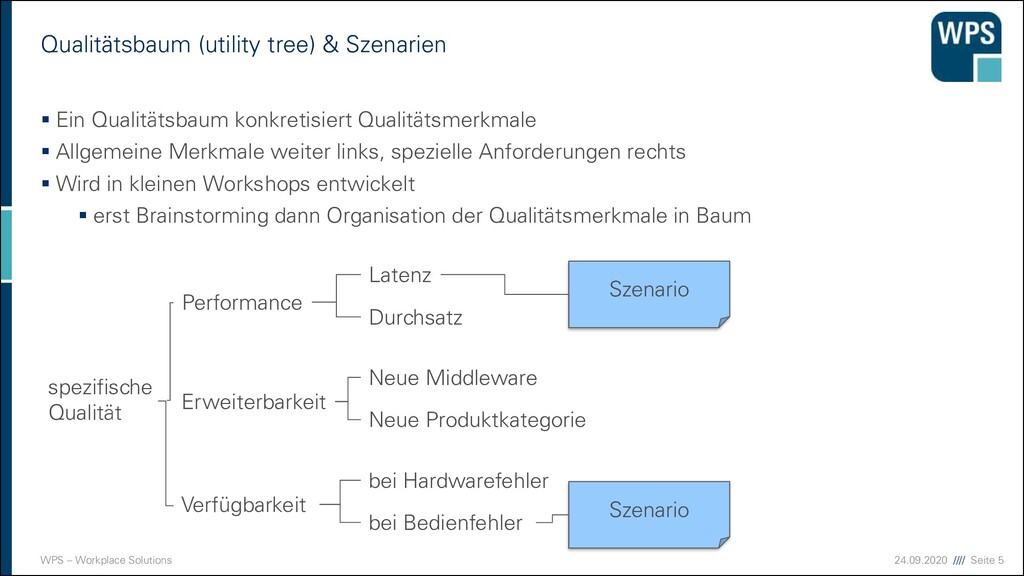{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
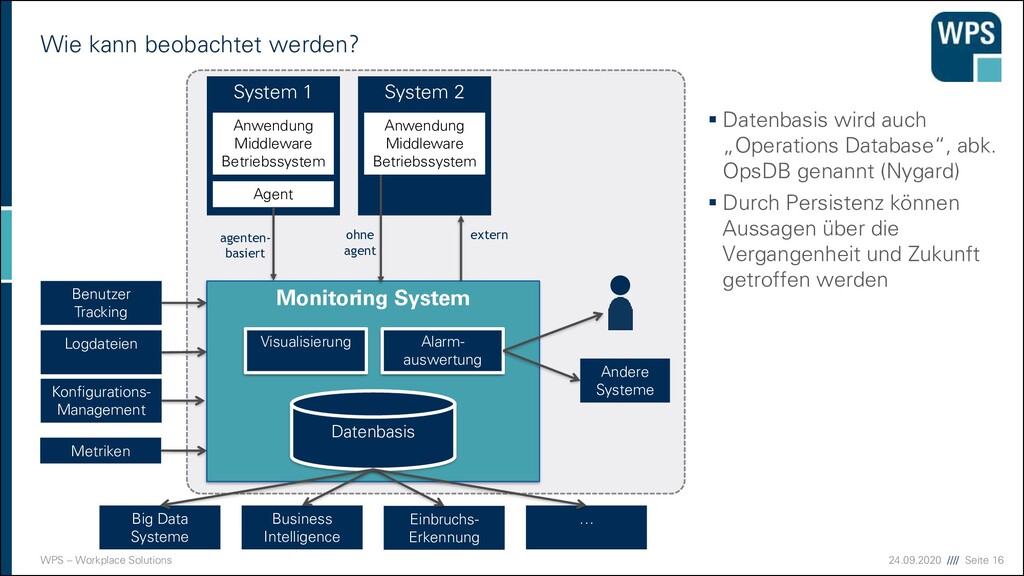{kind=link}
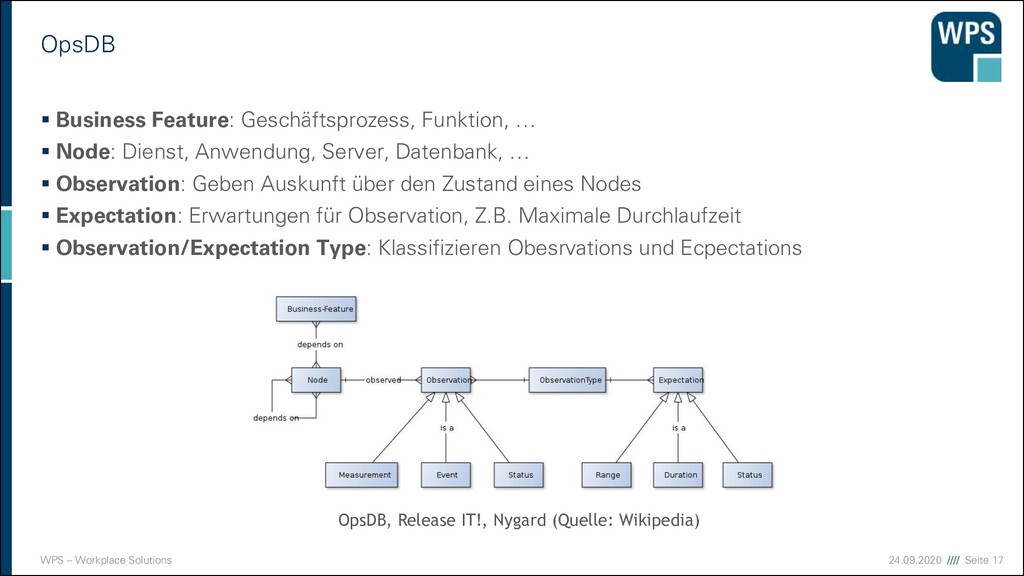{kind=link}
{kind=link}
{kind=link}
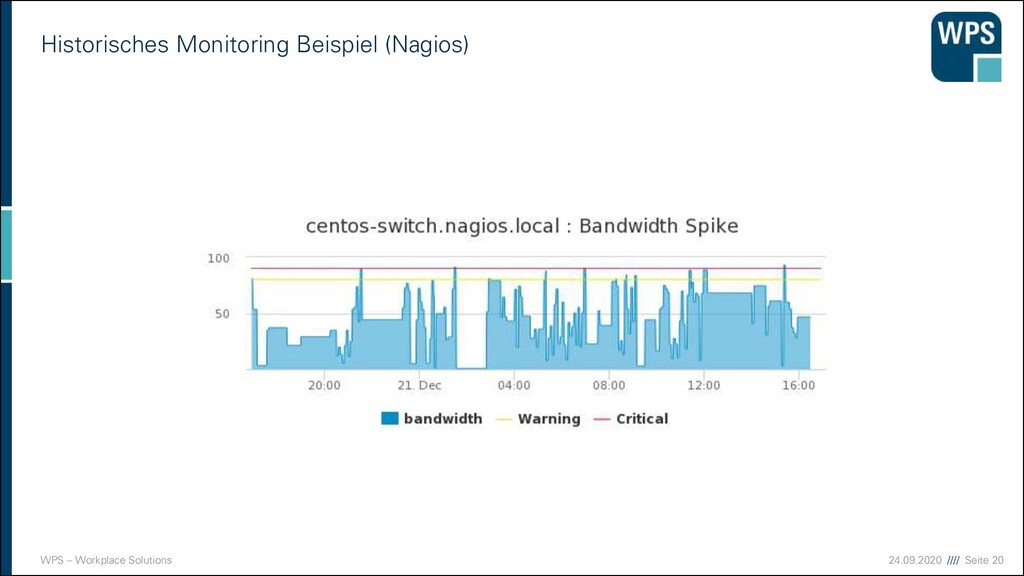{kind=link}
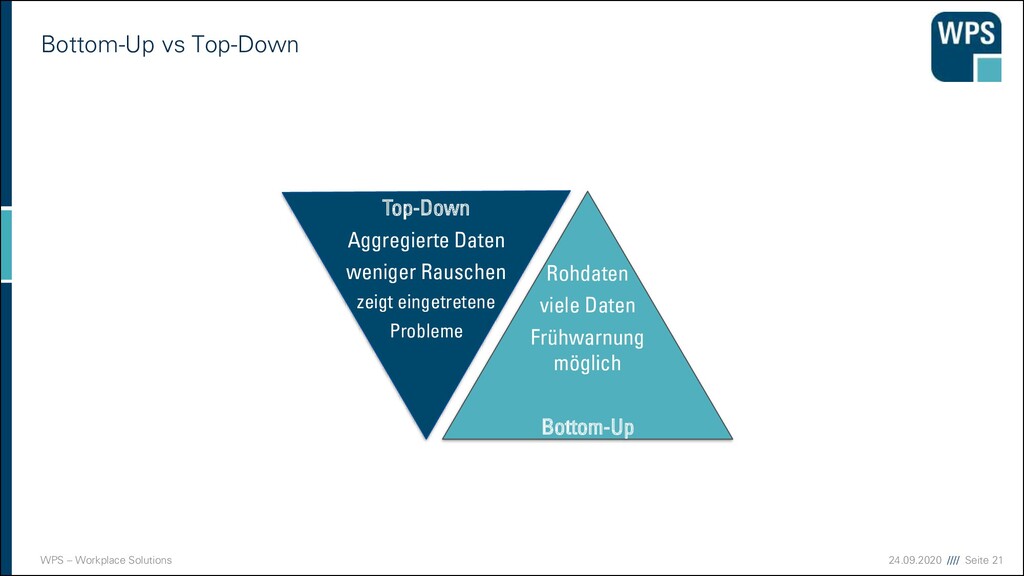{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
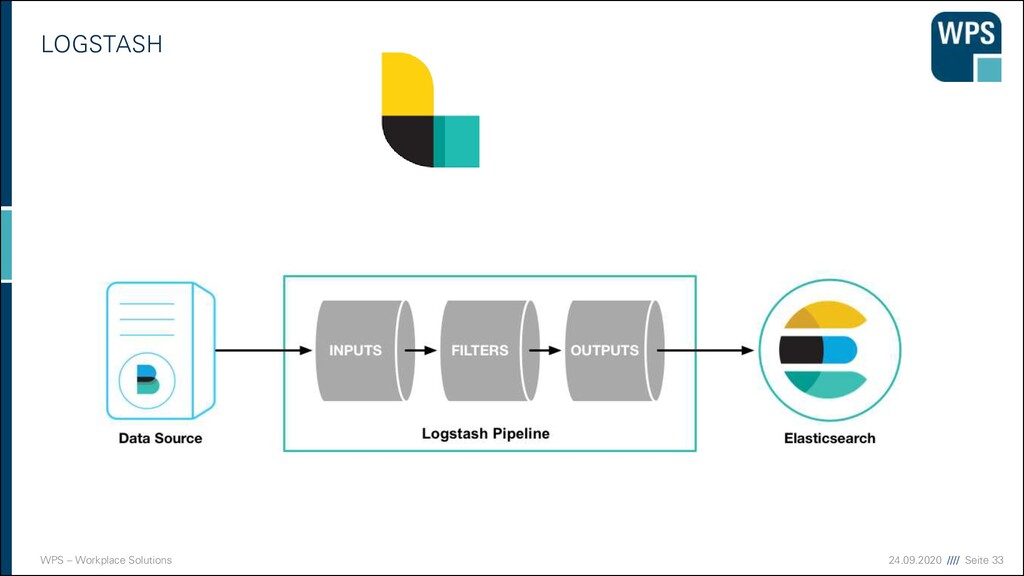{kind=link}
{kind=link}
{kind=link}
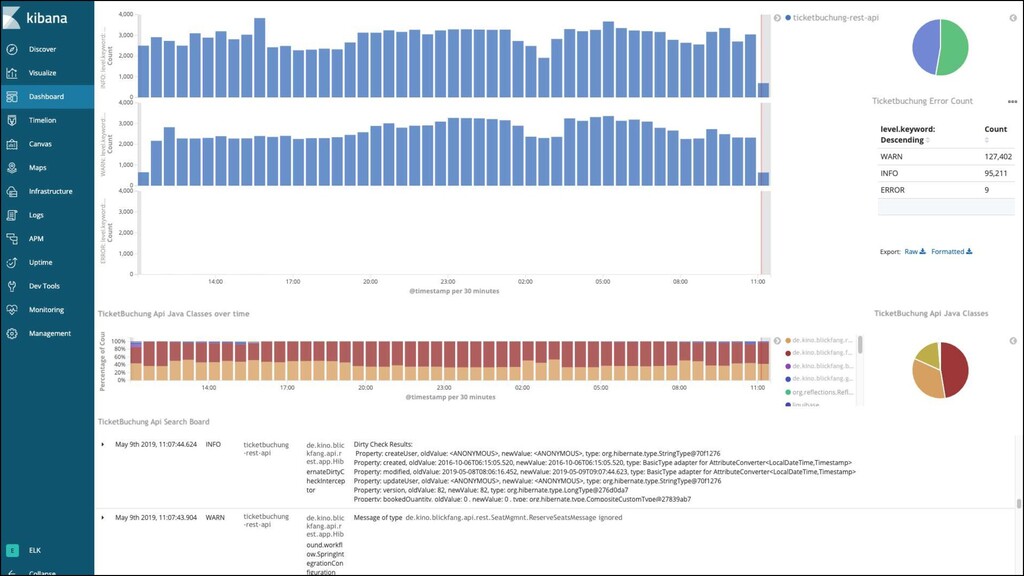{kind=link}
{kind=link}
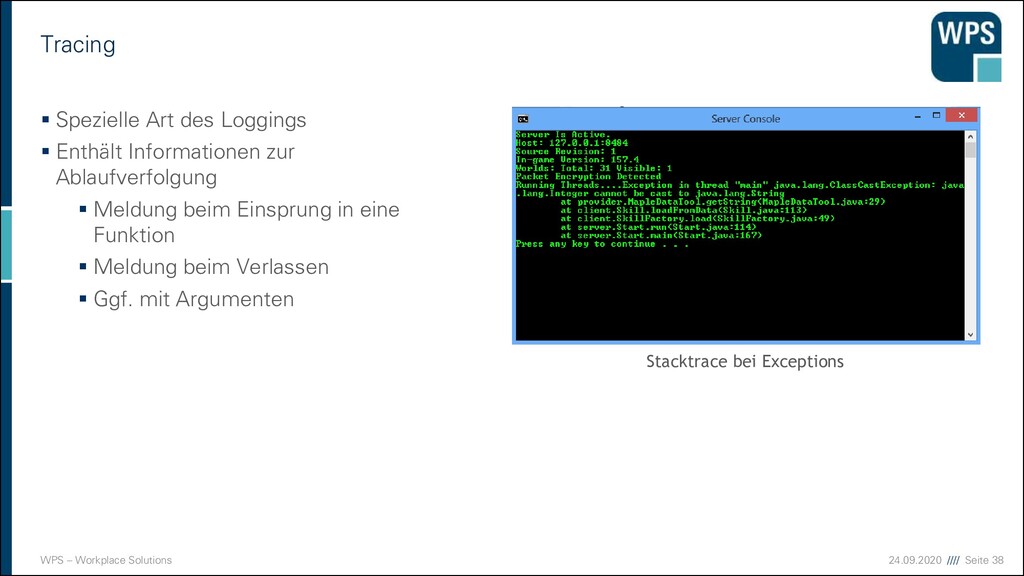{kind=link}
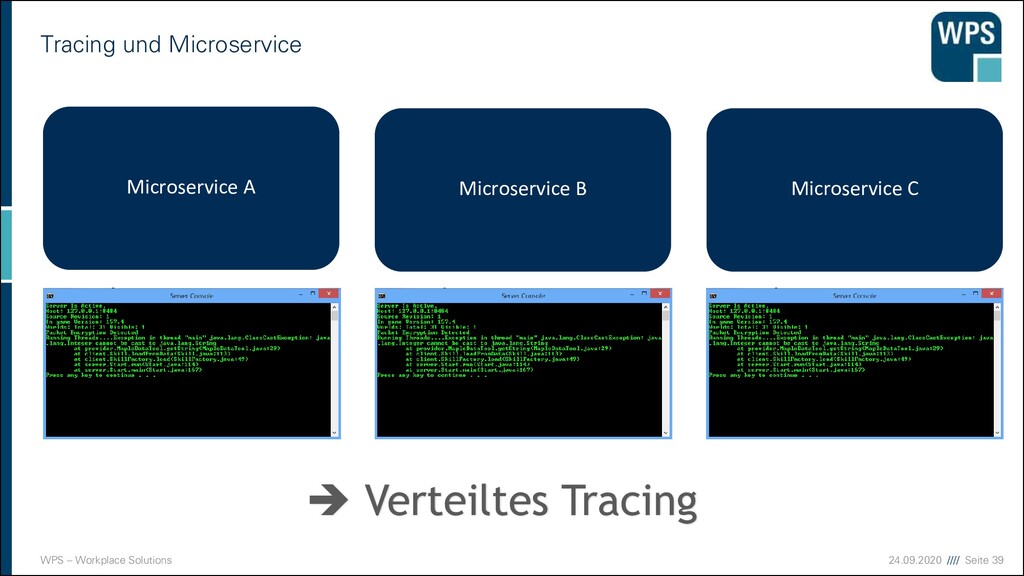{kind=link}
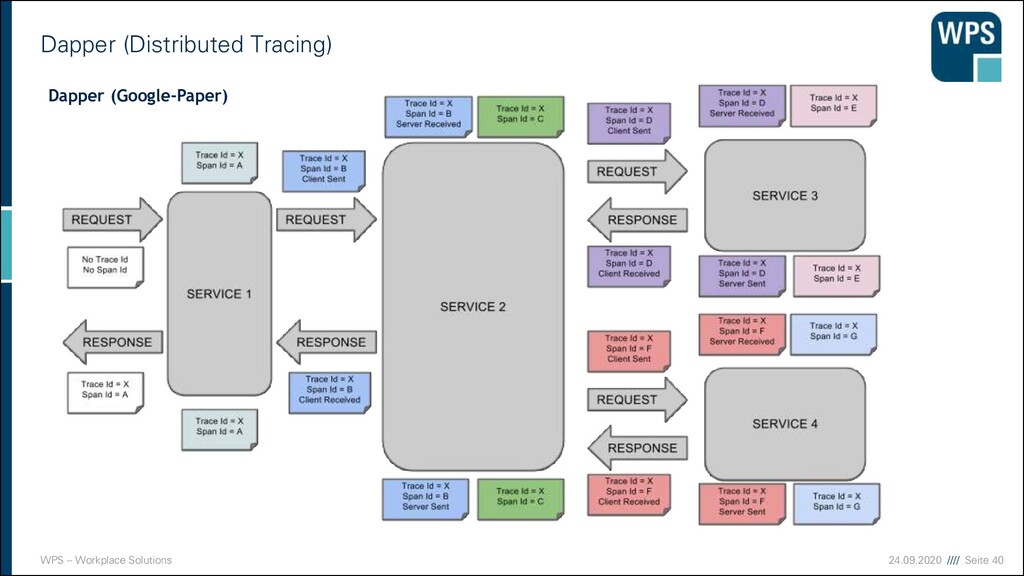{kind=link}
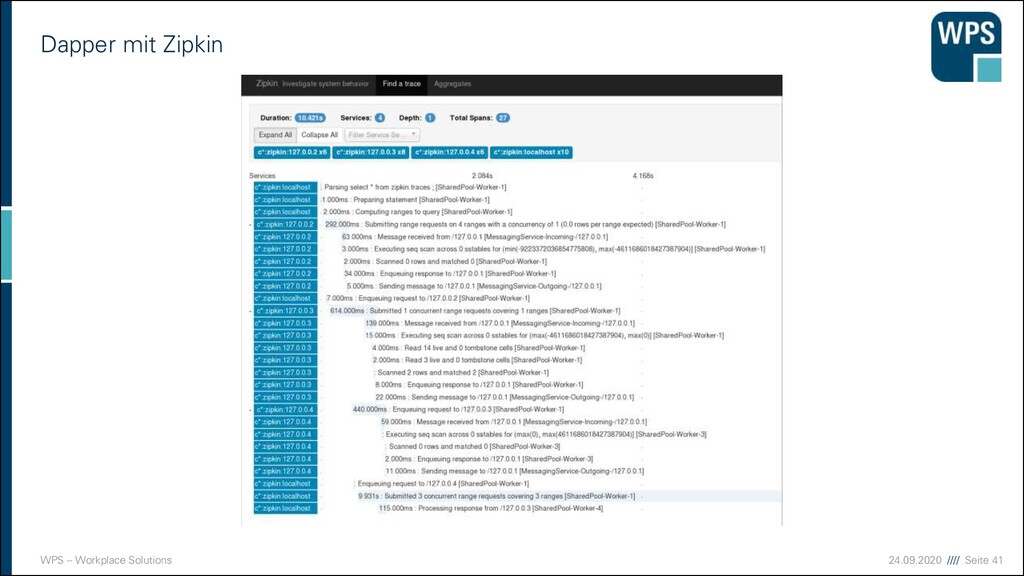{kind=link}
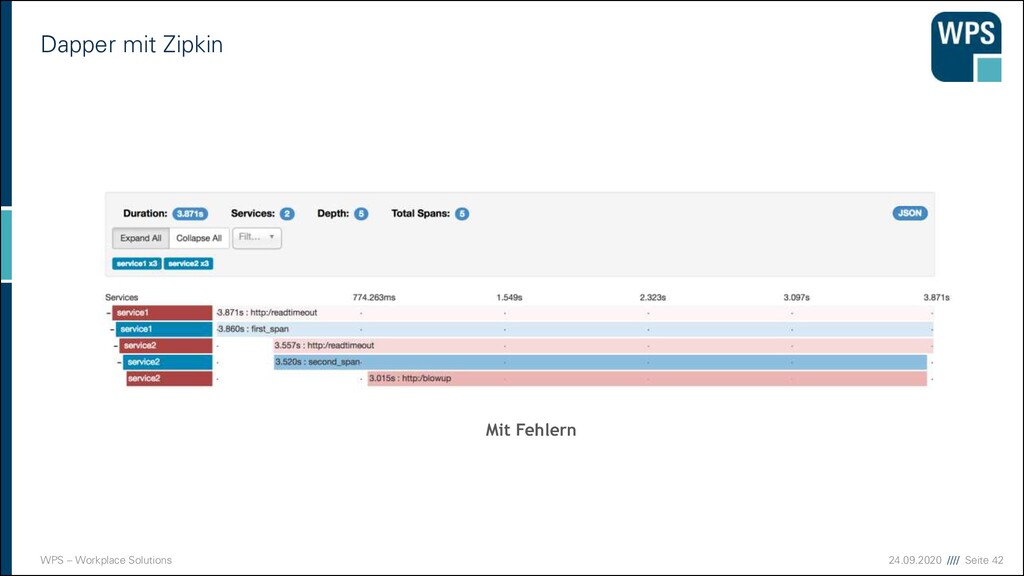{kind=link}
{kind=link}
{kind=link}
{kind=link}
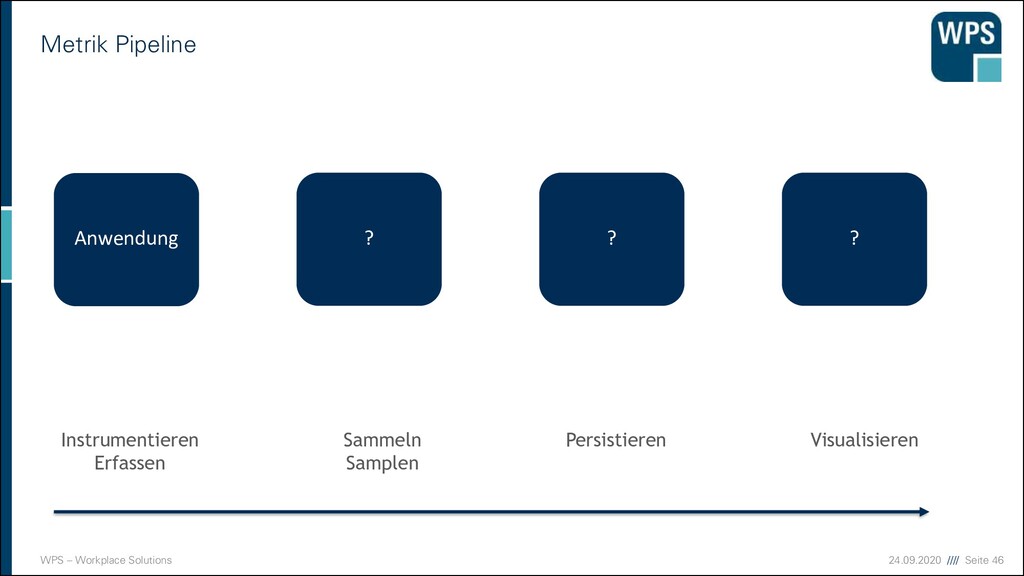{kind=link}
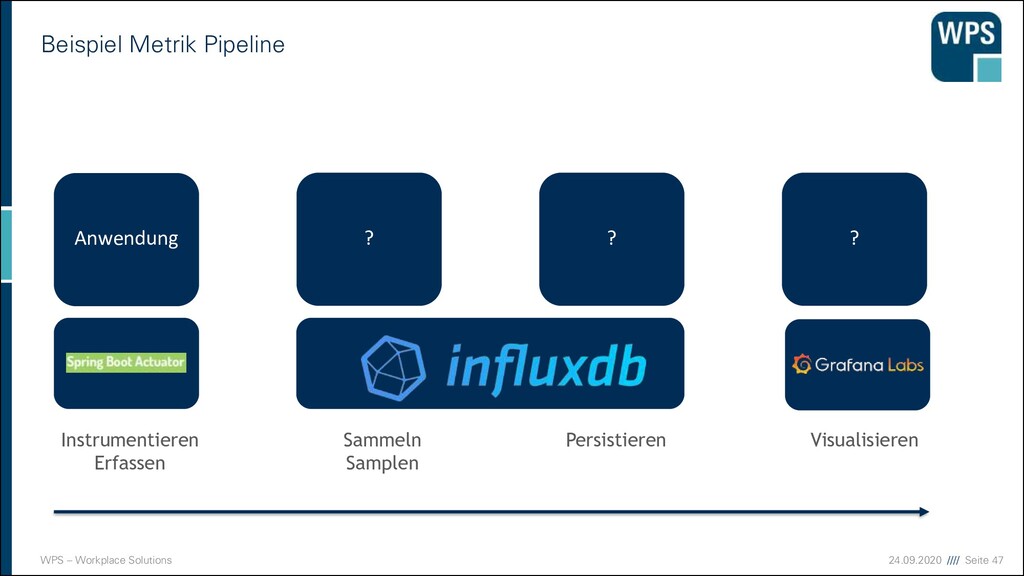{kind=link}
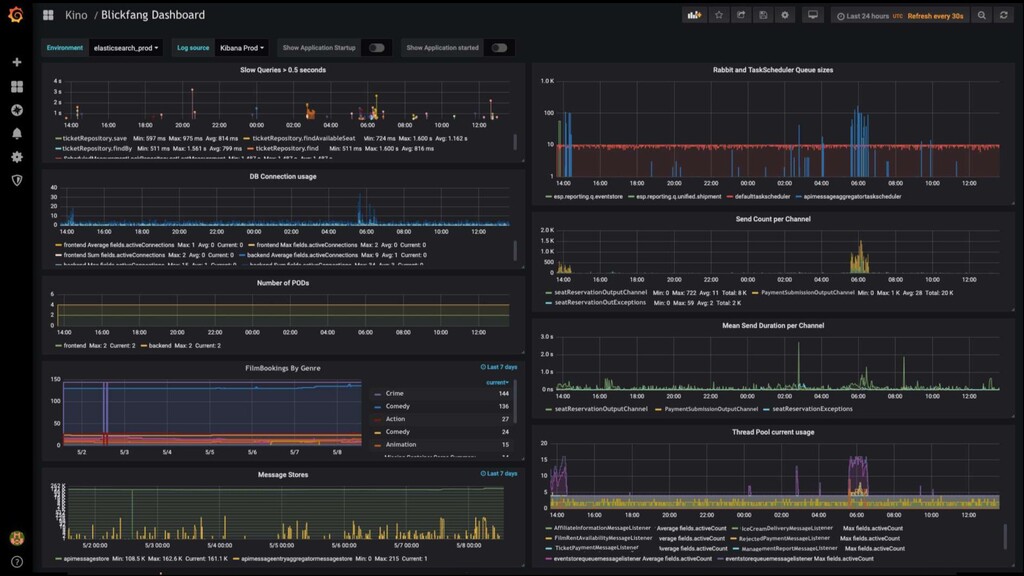{kind=link}
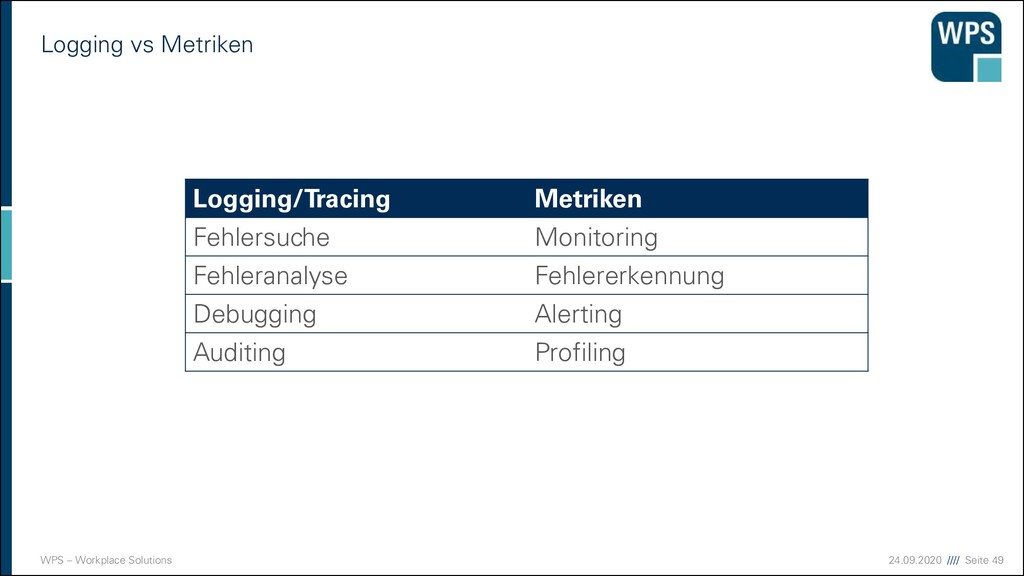{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
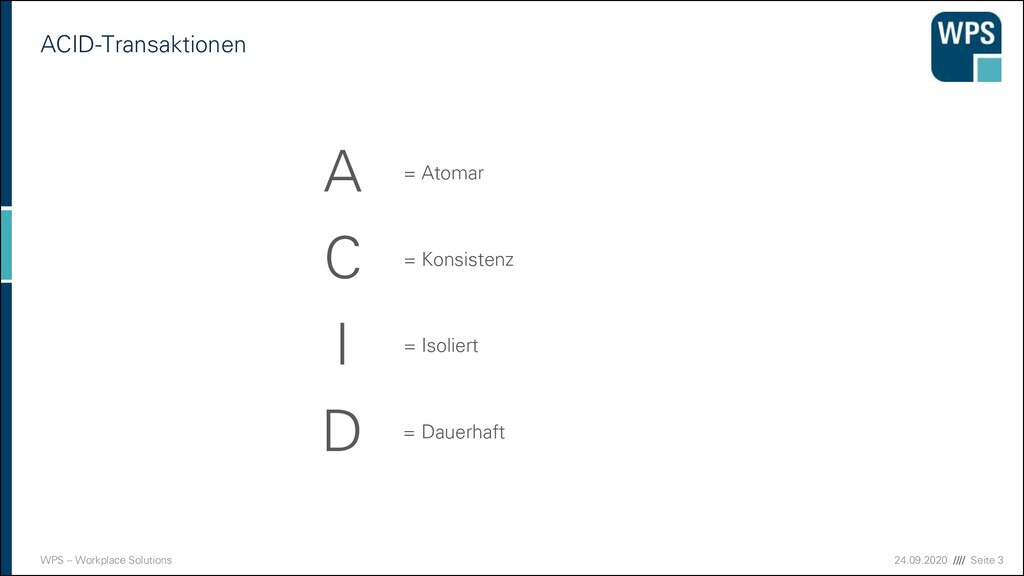{kind=link}
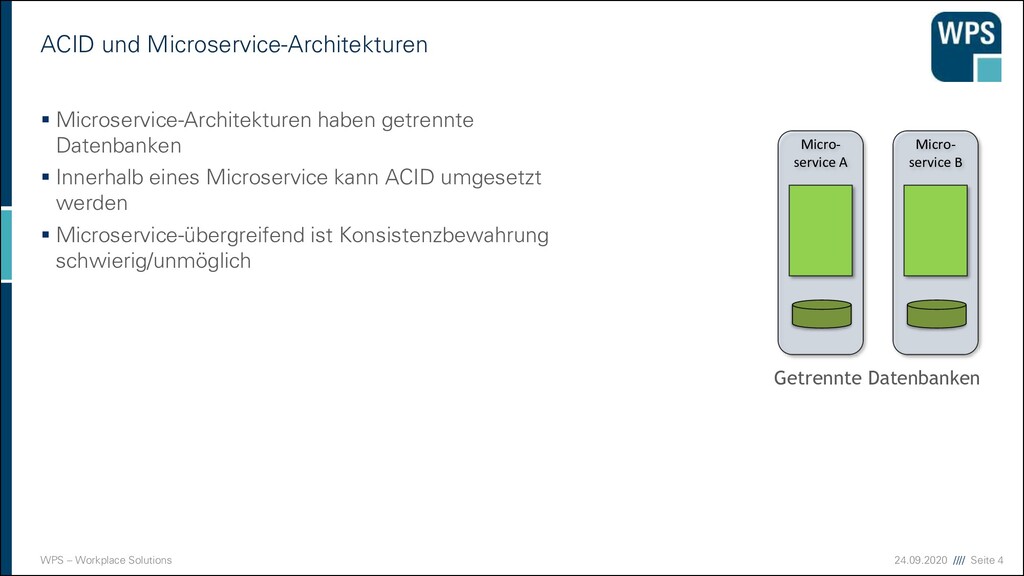{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
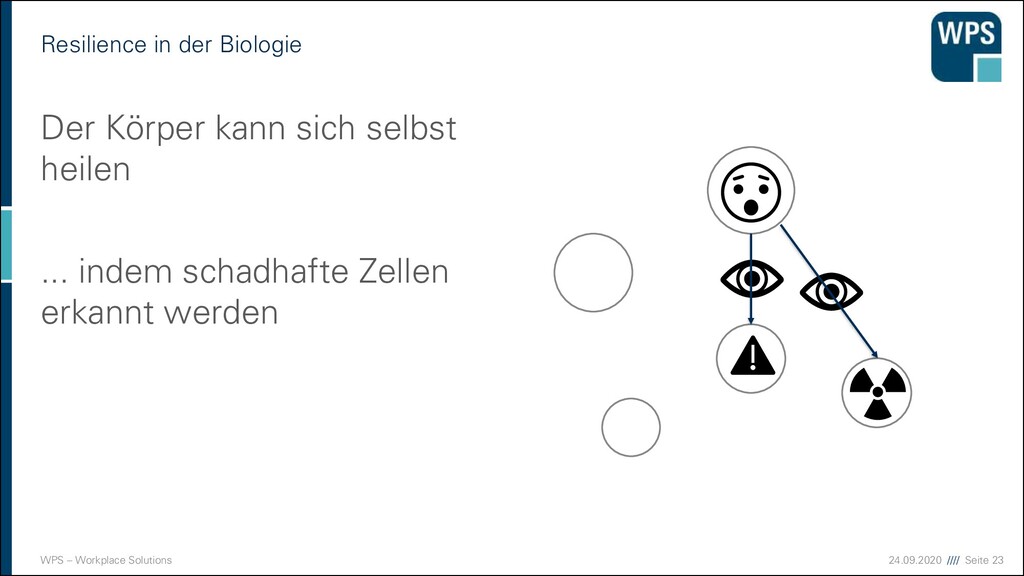{kind=link}
{kind=link}
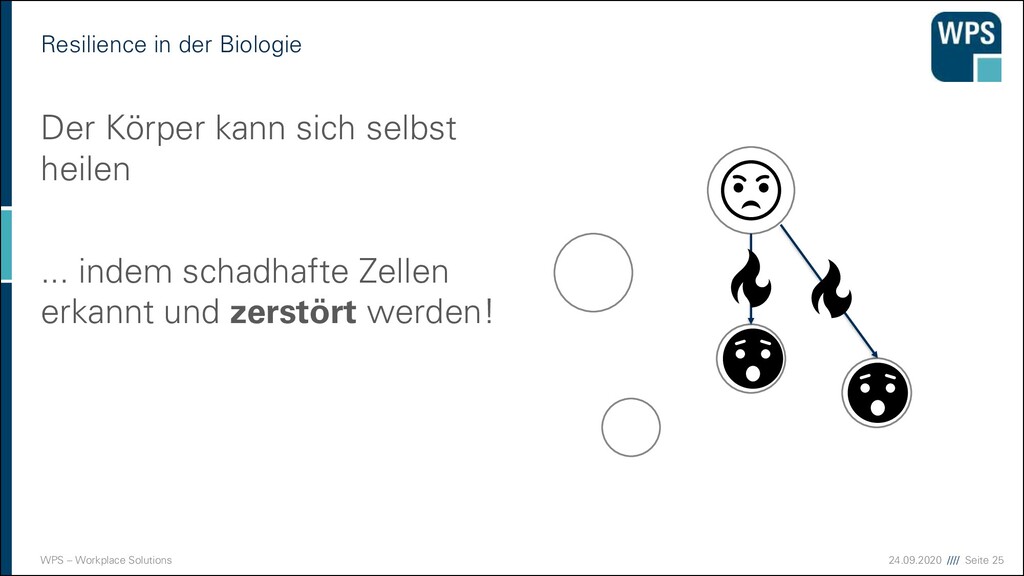{kind=link}
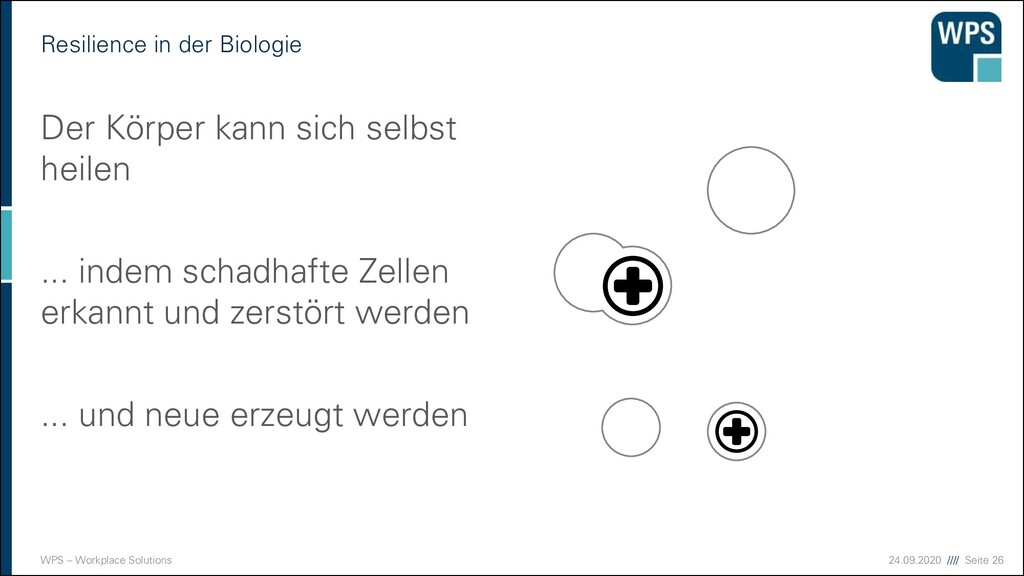{kind=link}
{kind=link}
{kind=link}
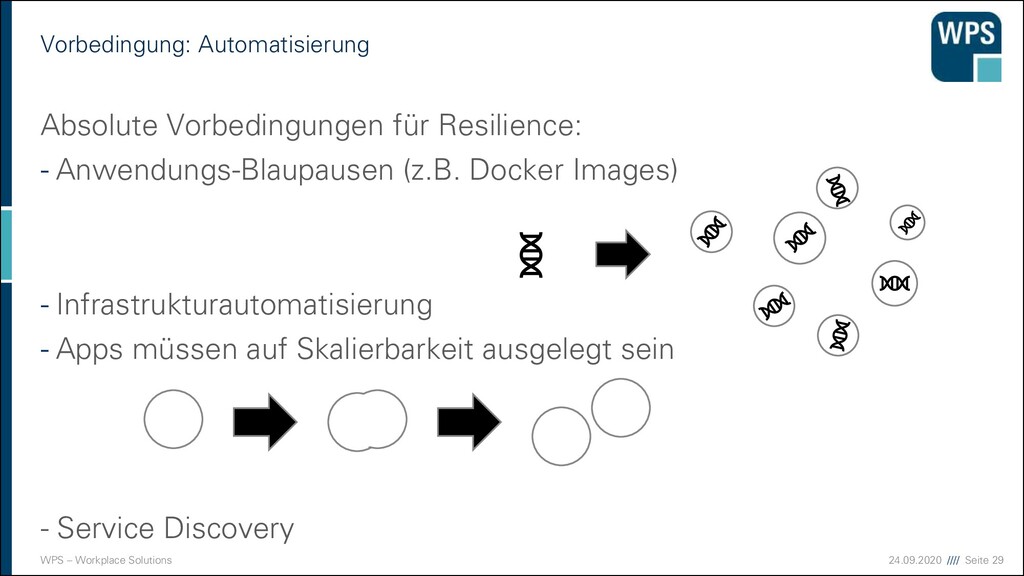{kind=link}
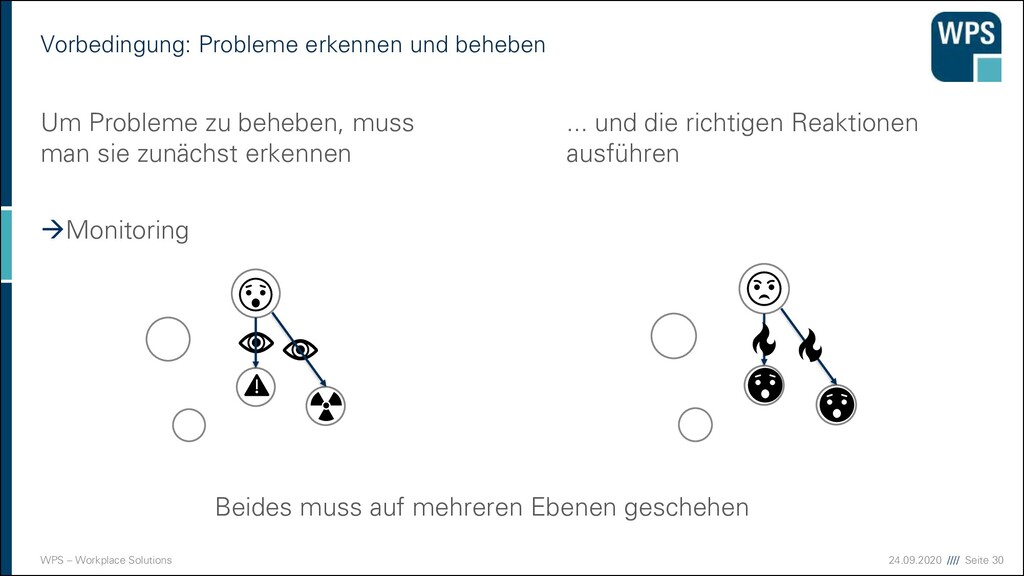{kind=link}
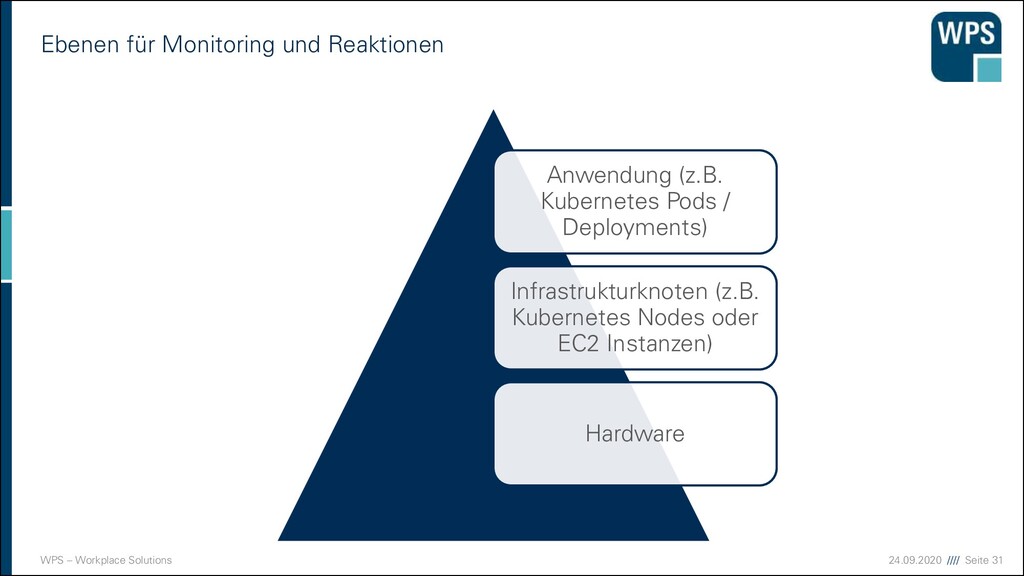{kind=link}
{kind=link}
{kind=link}
{kind=link}
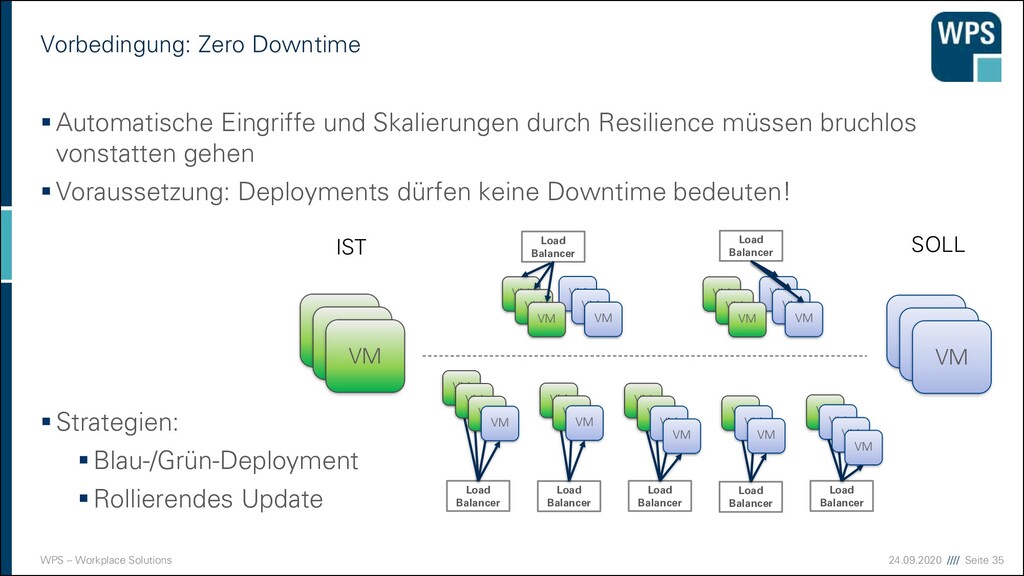{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
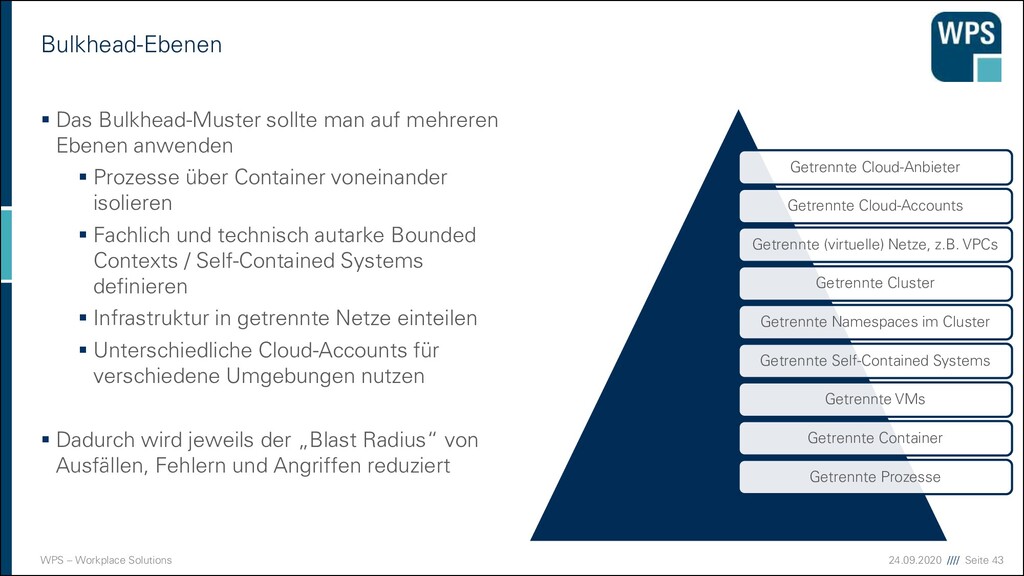{kind=link}
{kind=link}
{kind=link}
{kind=link}
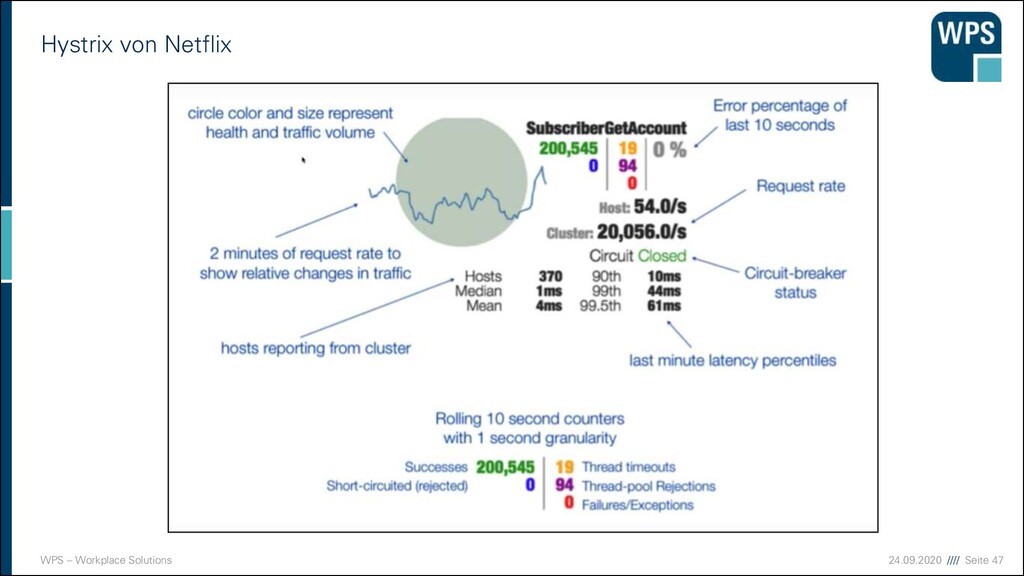{kind=link}
{kind=link}
{kind=link}
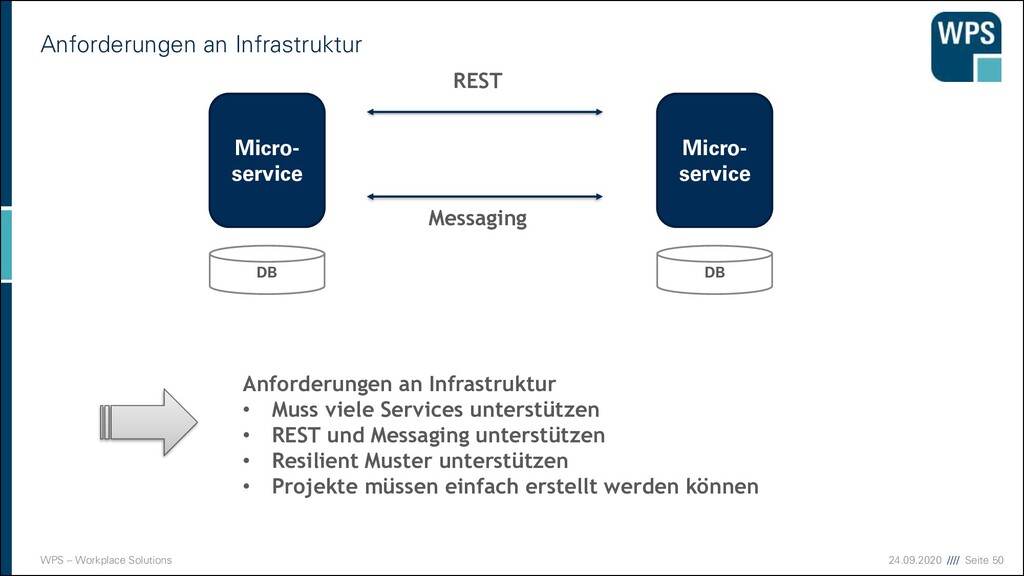{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
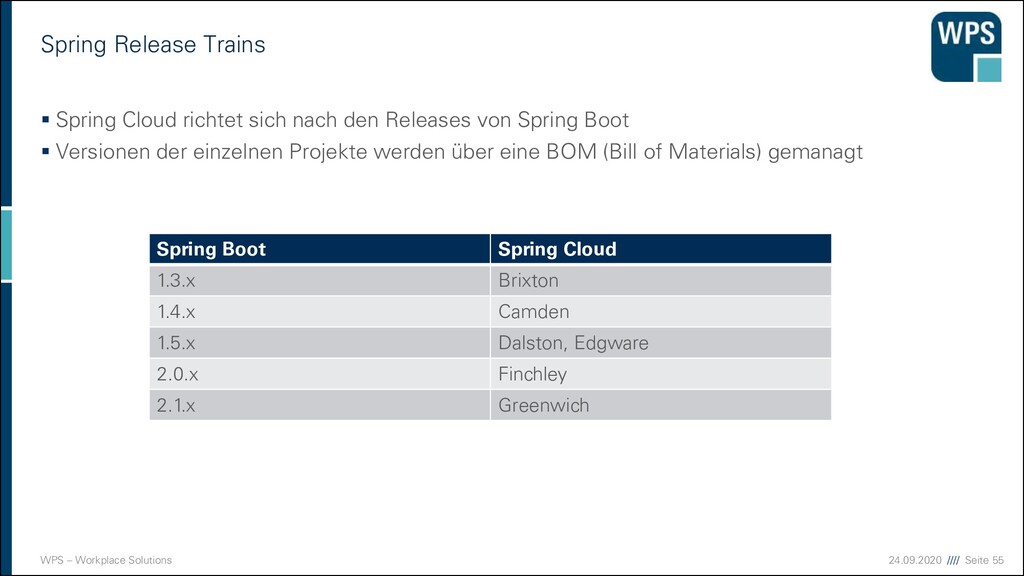{kind=link}
{kind=link}
{kind=link}
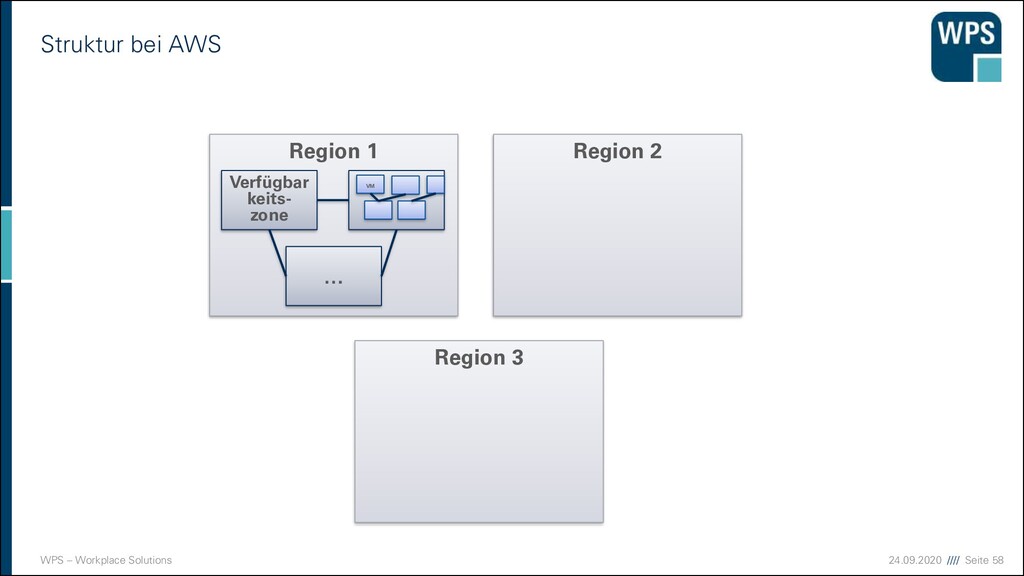{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
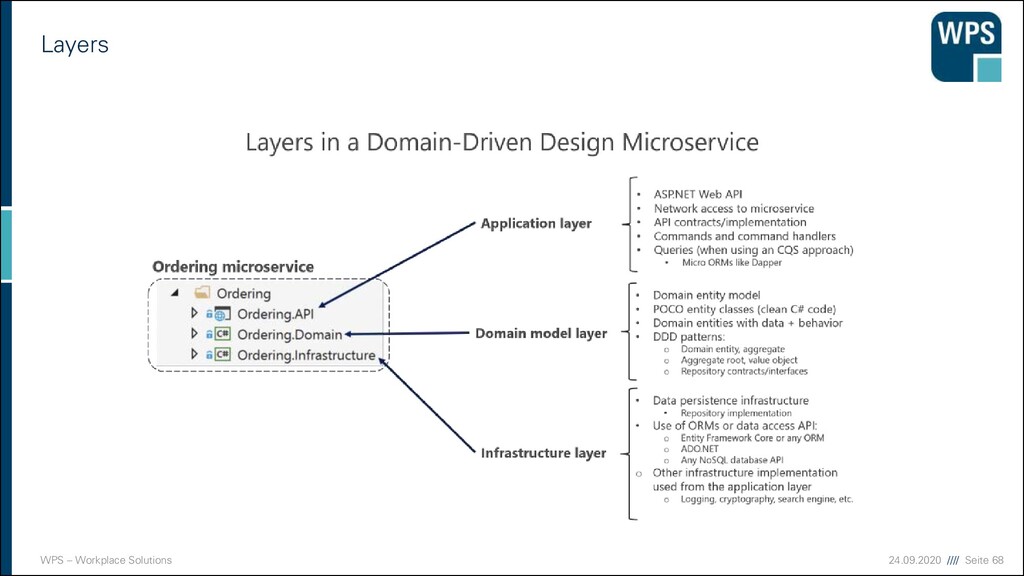{kind=link}
{kind=link}
{kind=link}