WPS GmbH und Ihre Expertise Rund um Architekturanalyse ▪ Architektur-Review und Qualitätsgutachten ▪ Architektur- und Refactoring-Beratung ▪ Architekturstile - Einführung und Entwicklung Rund um IT-Landschaften ▪ Analyse der Ist/Soll-Geschäftsprozesse mit Fachanwendern ▪ Darstellung von komplexen IT- Landschaften ▪ Qualitäts- und Testmanagement Software- Architektur Anforderungs- ermittlung Leitstand und Interaktion Individual- software Business-Software, die Spaß macht!
Architecture Qualification Board e.V. Vereinsziele: ▪ Erstellung und Pflege einheitlicher Lehr- und Ausbildungspläne für Softwarearchitekten (Certified Professional for Software Architecture) ▪ Definition von Zertifizierungsprüfungen auf Basis der CPSA-Lehrpläne ▪ Sicherstellung der fachlich-inhaltlichen Qualität von Lehre, Aus- und Weiterbildung für Softwarearchitektur iSAQB?
Level Aufgaben, Methoden und Techniken für die Entwicklung von Softwarearchitekturen. Alle Aspekte, die für Softwarearchitektur wesentlich sind. Technologische, organisatorische und soziale Faktoren. Advanced Level Vertiefung des Foundation Levels. Der Lehrplan besteht aus einzelnen Modulen, die bestimmte Schwerpunkte haben. Expert Level In Planung
Level ▪ Methodische Kompetenz: Systematisches Vorgehen bei Architekturaufgaben, unabhängig von Technologien. ▪ Technische Kompetenz: Kenntnis und Anwendung von Technologien zur Lösung von Entwurfsaufgaben. ▪ Kommunikative Kompetenz: Fähigkeiten zur produktiven Zusammenarbeit mit unterschiedlichen Stakeholdern, Kommunikation, Präsentation, Argumentation, Moderation. →Alle drei Kompetenzbereiche müssen abgedeckt sein (mindestens 10 Credit Points pro Kompetenzbereich) →Insgesamt sind 70 Credit Points erforderlich →10 Credit Points entsprechen in der Regel einem Schulungstag →Eine Schulung zu einem Lehrplanmodul bringt maximal 30 Credit Points, auch wenn sie länger als 3 Tage ist →Es ist möglich sich bestimmte andere Zertifikate anerkennen zu lassen
Advanced Level Prüfung und Zertifizierung Wenn Sie als CPSA-A geprüft werden möchten, müssen Sie sich bei einer der anerkannten Zertifizierungsstellen anmelden. Die Zertifizierungsstelle schickt Ihnen in Absprache eine Prüfungsaufgabe zu, die Sie in etwa 40 Arbeitsstunden lösen und deren Lösung Sie dokumentieren müssen. Sie schicken die Lösung an die Zertifizierungsstelle ein. Die Zertifizierungsstelle bestellt zwei unabhängige Prüfer und übergibt ihnen Ihre Lösung, so dass sie begutachtet werden kann. Die Prüfer telefonieren anschließend noch mit Ihnen als Teilnehmer. Sie müssen Ihre Lösung in diesem Gespräch erklären und verteidigen. Wenn die Prüfer bestätigen, dass Sie alle Voraussetzungen für den CPSA-A erfüllen, dass Ihre Lösung gut ist und dass Sie die Lösung gut dokumentiert, erklärt und verteidigt haben, stellt Ihnen die Zertifizierungsstelle das CPSA-A Zertifikat aus.
(10 komm. CP, 20 method. CP) Softwaresysteme und -architekturen nach agilen Prinzipien entwerfen und weiterentwickeln ▪ Agile Prinzipien und Ideen auf Architekturarbeit übertragen ▪ Architekturpraktiken sinnvoll in agiles Vorgehen verankern ▪ Arbeiten in selbstorganisierte Teams und gemeinsam wahrgenommene Verantwortung erfordern neue Fähigkeiten, sowohl technischer als auch methodischer und kommunikativer Art. Diese werden theoretisch und praktisch behandelt. Schulungsangebot: https://www.wps.de/schulung/isaqb-agila
(20 method. CP, 10 techn. CP) Softwarearchitekturen anhand ökonomischer und technischer Ziele systematisch verbessern ▪ Grundlagen von Evolution und Verbesserung von Softwarearchitekturen ▪ Ist-Situation analysieren ▪ Probleme und Lösungsansätze schätzen und bewerten ▪ Verbesserung langfristig planen ▪ Typische Ansätze und Beispiele für Verbesserung Schulungsangebot: https://www.wps.de/schulung/isaqb-improve/
Design (10 komm. CP, 20 method. CP) Passgenaue Softwarearchitekturen durch Kommunikation mit den Fachexperten und einheitliche Konstruktionsbausteine entwickeln ▪ Eine gemeinsame Sprache erleichtert die Zusammenarbeit ▪ Software nach fachlichen Gesichtspunkten strukturieren ▪ Kommunikation ist der Schlüssel – miteinander und zwischen Teams ▪ Bausteine von DDD geben team- übergreifende Anleitungen für die Konstruktion Schulungsangebot: https://www.wps.de/schulung/isaqb-ddd/
(10 method. CP, 20 techn. CP) Flexible Architekturkonzepte und Methoden, um Software schnell und mit hoher Qualität in die Produktion zu bringen: ▪ Microservices entwerfen ▪ DevOps und Continuous Delivery umsetzen ▪ Containerisierung ▪ Resiliente Systeme betreiben Schulungsangebot: ▪ https://www.wps.de/schulung/isaqb-flex/
(10 method. CP, 20 techn. CP) Architekturkonzepte und Methoden, um Software in der Cloud sicher und flexibel zu betreiben und das Skalierungspotential auszuschöpfen: ▪ Microservices verstehen ▪ Cloudangebote und deren Anwendung ▪ Containerisierung und Container-Manager einsetzen ▪ Resiliente Systeme betreiben Schulungsangebot: ▪ https://www.wps.de/schulung/isaqb-cloudinfra/
Credit Points ADOK Architektur-Dokumentation: Wie dokumentiert und kommuniziert man Softwarearchitekturen? 20 method. ARCEVAL Architektur-Bewertung: Wie findet man heraus, ob eine Architektur die Erwartungen erfüllt? 20 method. EAM Enterprise Architecture Management: Wie kann man eine große Landschaft von IT-Systemen konsistent halten? 30 method. EMBEDDED Embedded Systems: Wie entwirft man eingebettete Systeme, die direkten Einfluss auf ihre Umgebung nehmen? 10 method. 20 tech. SOA-T Serviceorientierte Architekturen: Wie entwirft man eine SOA? 10 method. 20 tech. SOFT Softskills für Software-Architekten: Wie führt man Gespräche zur Architekturfindung und präsentiert Architektur verständlich? 30 komm. WEB Web-Architekturen: Wie gestaltet man leistungsfähige und sichere webbasierte Systeme? 30 techn.
moderner Infrastrukturen Gängige Architekturkonzepte Cloud Native Journey Hilfreiche Muster Development, CI/CD und Betrieb Automatisierung Case Study Case Study Case Study Case Study Live Demo Terraform + AWS Case Study Live Demo AWS Live Demo + Hands-On Docker Case Study
- Tag 3 Zeit Inhalt 09:00-10:00 Development, CI/CD und Betrieb Grundlagen Deployment & Deployment-Strategien 10:00-10:15 Pause 10:15-11:15 Development, CI/CD und Betrieb Grundlagen Deployment & Deployment-Strategien 11:15-11:30 Pause 11:30-12:30 Development, CI/CD und Betrieb Monitoring, Logging und Alerting 12:30-13:15 Mittagspause
erwarten könnt ▪ Wissen aus der Literatur ▪ Erfahrungen aus der Praxis ▪ Meinungen ▪ Tipps und Tricks ▪ Abwechslung von ▪ Vorträgen ▪ Demos ▪ Übungen ▪ Ein Zertifikat
Cloud? Moderne Applikationen sollen hochverfügbar sein • Verteilung von Last auf eine skalierbare Anzahl von Instanzen eines Services • Verteilung von einem Rechenzentrum als Single-Point-of-Failure (Stromausfall, Störung) auf mehrere, ohne dass dies für Klienten spürbar ist • Potentiell physisch näher am Endkunden (durch geografisch verteilte Serverlokalität) Verlagerung von Kompetenzen und Verantwortung an den Cloud-Anbieter • Bereitstellung von Infrastruktur • Ausfallsicherheit • Verfügbarkeit • Datensicherheit • IT-Sicherheit Einfache Automatisierung durch Infrastructure as Code
Public vs. Private ▪ Anforderungen an beide ▪ Vollständige Virtualisierung und Containerisierung ▪ Dynamisches Hinzunehmen und Entfernen von Rechenleistung ▪ Anforderungen an die Public Cloud ▪ Vollständiges Outsourcing der Hardware ▪ Fremde Rechen- und Speicherleistungen werden auf Bedarf eingekauft ▪ Anforderungen an die Private Cloud ▪ Betrieb eigener Hardware
und Nachteile ▪ Gemeinsamkeiten ▪ Infrastruktur auf Abfrage ▪ Skalierbarkeit ▪ Vorteile Public Cloud ▪ Abgabe von Aufwand und Verantwortung => Reduktion der Fertigungstiefe ▪ Große Menge höherwertiger Dienste ▪ Einfache Automatisierbarkeit ▪ Hoher Reifegrad ▪ Größere Skalierbarkeit als bei Private Cloud ▪ Nachteile Public Cloud ▪ Erfordert aufwändigeren Umgang mit sensiblen Daten, weil der Cloud-Anbieter Zugriff darauf hat ▪ (meist) im Internet => höhere Sicherheitsanforderungen
▪ Software as a Service (SaaS) ▪ E-Mail, virtueller Desktop, Spiele, … ▪ Kunde hat eine Software zur Verfügung, die in einer Cloud läuft ▪ Function as a Service (Serverless) ▪ AWS Lambda, Google Cloud Function ▪ Man definiert nur Funktionscode, komplette Infrastruktur wird abstrahiert ▪ Platform as a Service (PaaS) ▪ Webserver, Datenbanken, Entwicklungsumgebungen, … ▪ Kunde kann Software auf der Cloud-Infrastruktur installieren ▪ Hoher Standardisierungs-Grad! ▪ Infrastructure as a Service (IaaS) ▪ Virtuelle Maschinen, Storage, Load Balancer, … ▪ Kunde kann Betriebssysteme, Datenspeicher und Netzwerke verwalten ▪ Zugrundeliegende Infrastruktur bleibt in der Verantwortung des Anbieters
oder Rechenressourcen? ▪ Abwägungsfrage: ▪ Managed Datenbank vom Cloudanbieter ▪ Oder eine reine VM/VMs auf denen die Datenbank selbst betrieben wird ▪ Häufig abzuwägen: ▪ Schneller Start vs. steile Lernkurve ▪ Für die Masse gute Leistung vs. auf individuellen Bedarf zugeschnittene Leistung ▪ Standardisierung vs. Flexibilität Standardisierung Flexibilität hoch niedrig niedrig hoch IaaS PaaS SaaS FaaS
Application Data Runtime Middleware OS Virtualization Servers Storage Network PaaS Application Data Runtime Middleware OS Virtualization Servers Storage Network Serverless (FaaS) Application Data Runtime Middleware OS Virtualization Servers Storage Network SaaS Application Data Runtime Middleware OS Virtualization Servers Storage Network
Man zahlt für: Rechenleistung, Speicher, Netzwerkverkehr ▪ Kosten skalieren mit den Ressourcen und teilweise mit dem Verbrauch ▪ Gestoppte Instanzen kosten nichts ▪ Preise können höher als bei traditionellen Hostern sein, genau prüfen! ▪ Aber! Man zahlt auch für Instanzen die laufen, aber nichts tun.
Hochfahren: ▪ Manuell nach Erfahrung ▪ Automatisch nach Auslastung ▪ Automatisch nach SLAs (eine Maschine pro X Besucher) ▪ Herunterfahren ▪ Bei geringer Last ▪ Erst nach Abkühl-Phase ▪ Klienten dürfen sich die Instanz nicht lange merken
denn Cloud sein? ▪ Ja wenn, ▪ Ressourcen kurzfristig abgerufen werden sollen ▪ Ressourcen auch mal abgeschaltet werden sollen ▪ Ein hoher Grad an Automatisierung gewünscht ist ▪ Man nicht den Keller voller aktuellem Blech hat ▪ Die Governance/Compliance es zulässt ▪ Nein wenn, ▪ Es von Compliance-Gesichtspunkten nicht möglich ist ▪ Man ein eigenes Rechenzentrum mit entsprechendem Personal besitzt => dann eventuell Aufbau einer Private-Cloud mit Openshift ▪ Es keine besonderen Skalierungsanforderungen gibt ▪ Der Ressourcenbedarf relativ stabil ist
vs Cattle „Server sind wie Haustiere“ Sie bekommen einen Namen, sind einmalig, werden liebevoll aufgezogen und versorgt. Wenn sie krank sind, werden sie gesund gepflegt. „Server sind wie Vieh“ Vieh bekommt Nummern und ist kaum unterscheidbar. Wenn es krank wird, holt man sich neues. Scale Out Scale Up CC-By-Nd “Sick dog large”, Yoel Ben-Avraham
auch Snowflakes genannt ▪ Zwei Pet-Server werden aufgesetzt (gleiches Betriebssystem gleiches Patch-Level) ▪ Über die Zeit werden die Server sich auseinanderentwickeln ▪ Auf dem einen wird ein Patch eingespielt auf dem anderen nicht ▪ Administratoren greifen manuell auf die Server zu und tun Dinge auf dem einen, aber nicht auf dem anderen Server ▪ So entwickeln die Server sich immer weiter auseinander, man spricht auch von Configuration Drift Susi Hektor Zeit Security Patch kommt Server ist offline Server wieder online Ein Admin tweakt das OS von Susi Irgendwie ist der Server langsam
Serverless? ▪ Wie so oft: Es gibt keine einheitliche Definition ▪ „Run code, not Server“ ▪ Entwickler sollen sich nur noch um die Entwicklung fachlicher Bausteine kümmern, nicht um technische Infrastruktur ▪ FaaS = Function as a service ▪ Kosten/Funktionsaufruf => Kosten skalieren ▪ Eventgesteuert ▪ Es gib keine laufenden Serverprozesse. Stattdessen gibt es einen Funktionsaufruf sobald ein Trigger-Event ausgelöst wurde, zum Beispiel ein HTTP-Aufruf
Art von Cloud-Anbieter nutzen? Bare Metal für Legacy-Anwendungen, die nicht virtualisiert funktionieren Notlösung beim Umgang mit sensiblen Daten, wenn noch keine Cloud-gemäßen Sicherheitsmaßnahmen (z.B. Encryption at Rest und TLS) umgesetzt sind ggf. bei gesetzlichen Vorgaben IaaS wenn minimale Bindung an Cloud-Anbieter gewünscht wenn noch wenig Cloud-Erfahrung vorhanden, denn die meisten Konzepte sind bekannt (SSH, IPs, Betriebssysteme, etc.) Betrieb von Open-Source-Software ohne verfügbare gemanagte Lösungen PaaS wenn man Aufwände im Betrieb im Vergleich zu IaaS einsparen möchte, z.B. das Erstellen regelmäßige DB-Backups für einen hohen Reifegrad durch Outsourcing der komplexen Aufgaben an den Cloud-Anbieter für Datenbanken für Container-Manager Serverless wenn Skalierung und Kosteneffizienz wichtig sind wenn die Code-Menge überschaubar ist für langfristige / komplexe Operationen ("Batch-Jobs"), z.B. Machine-Learning-Inferenz für schnelles Prototyping ohne Aufsetzen von jeglicher Infrastruktur SaaS wenn die Funktionalität nicht spezifisch für die eigene Organisation ist (kein eigener Code) Beispiele: CRM, Mail, SCM
▪ Ist mit einer klassischen virtuellen Maschine vergleichbar ▪ Erhält eine IP-Adresse ▪ Wird mit einem Betriebssystem bestückt ▪ Grundlage ist meist ein Betriebssystemimage, das sogenannte AMI (Amazon Machine Image) ▪ Es gibt viele die von AWS bereits bereitgestellt werden ▪ Man kann aber auch eigene bauen etwa mit Packer oder LinuxKit EC2-Instanz
Maschinen, die untereinander kommunizieren sollen ▪ Aber nicht alle Konnektivität zum Internet haben sollen/dürfen ▪ Dabei hilft ein Service wie Virtual Private Cloud ▪ Instanzen lassen sich über Subnets zusammenfassen und von anderen Subnets abschotten Eine AWS-Instanz kommt selten allein EC2-Instanz EC2-Instanz EC2-Instanz App 2 App 1 DB VPC
Subnet trennt Instanzen logisch voneinander ab ▪ Instanzen verschiedener Subnets können also nicht aufeinander zugreifen ▪ Mit einem Internet Gateway können Subnets öffentlich erreichbar gemacht werden ▪ Durch Private Gateways lassen sich auch Verbindungen mit dem eigenen Netzwerk herstellen ▪ Oder man ermöglicht Zugang zu Subnets per VPN AWS VPC Subnets EC2-Instanz EC2-Instanz EC2-Instanz Websh op Backoff ice OLAP VPC EC2-Instanz EC2-Instanz Public Api Payme nt
einer Verfügbarkeitszone kann es mehrere Subnets geben ▪ Ein Subnet kann sich nie über mehrere Verfügbarkeitszonen erstrecken AWS-VPC at Scale – Verfügbarkeitszonen EC2-Instanz EC2-Instanz EC2-Instanz App 2 App 1 DB VPC EC2-Instanz EC2-Instanz EC2-Instanz App 2 App 1 DB Frankfurt Berlin
(Web)-Console ▪ Nicht für Deployments geeignet, da keine Nachvollziehbarkeit gewährleistet wird ▪ Eher um das Serviceangebot zu erkunden und um initial zu verstehen wie ein Service funktioniert ▪ Effizient wird die Verwendung der Cloud erst wenn man Ressourcen automatisiert erzeugt ▪ Als Monitoring-Werkzeug bis man dies endlich professionalisiert hat
und SDK ▪ Per Kommandozeile Zugriff auf AWS ▪ Im Grunde die AWS Web-Console auf der Kommandozeile ▪ Möglichkeit zur Automatisierung im Rahmen von Scripts ▪ Für die meisten Programmiersprachen werden SDKs bereitgestellt ▪ Ermöglicht die Erzeugung von Ressourcen aus der eigenen Anwendung ▪ Aber für die meisten Automatisierungsszenarien läuft es auf selbstgestrickte Lösungen raus
zum Image mit fertigem Betriebssystem ▪ Vorbereitung eines Betriebssystems wie man es braucht ▪ Nach dem Erzeugen der EC2-Instanz sind keine weiteren Installationen nötig.
CloudFormation und Terraform ▪ Ein geeignetes System zur Infrastrukturautomatisierung ▪ CloudFormation: Eine Lösung von und für AWS ▪ Terraform: Ein Werkzeug für viele / alle Cloud-Anbieter ▪ Man beschreibt in einer Datei, welche Ressourcen erzeugt werden sollen ▪ Diese Datei gehört wie anderer Quellcode unter Versionskontrolle ▪ Ausführung der Dateien sorgt via API dafür, dass die entsprechenden Cloudressourcen erzeugt oder eben zerstört werden. ▪ Wegen der Unabhängigkeit sehen wir uns im Weiteren Terraform an.
in vielen Formen ▪ Verschiedene Programmiersprachen ▪ Inkompatible Abhängigkeiten ▪ z.B. python 2.7 vs python 3.x ▪ Dependency Hell ▪ Unterschiede in ▪ Betriebssystem ▪ Rechnerkonfiguration (z.B. PATH, JAVA_HOME, ...) ▪ Java-Version ▪ Application-Server-Version ▪ Application-Server-Konfiguration ▪ Verschiedene Paketierungswege ▪ Z.B. für Java Anwendungen: ▪ Aus Eclipse starten ▪ Als jar-Datei verpacken ▪ Als war in tomcat deployen ▪ Als Service-Dienst in Windows registrieren ➢ Interferenzen zwischen Anwendungen ➢ Unterschiedliches Verhalten je nach System ➢ unvorhergesehene Bugs
Scale ▪ Container liefern ein Artefakt aus und bieten gute Möglichkeiten, sie mit umgebungsspezifischer Konfiguration zu starten ▪ Die Dev/Prod-Parität pro Container ist extrem hoch ▪ Häufig besteht ein System aus einer Vielzahl von Artefakten ▪ Alle Artefakte sollen im Verbund und konsistent konfiguriert gestartet und skaliert werden ▪ Darauf liefern Container für sich keine Antwort ▪ Ebenso nicht wie Container hostübergreifend kommunizieren können
den Containerbetrieb ▪ Realisieren die Verteilung von Containern auf mehrere Hosts ▪ Ermöglichen die hostübergreifende Kommunikation über Overlay-Netzwerke ▪ Wickeln die Umverteilung von Containern ab, wenn ein Host wegbricht
Container-Managern ▪ IT-Betrieb ▪ Kümmert sich um den Aufbau der Container- Management Umgebung ▪ Verantwortet das Sizing des Clusters ▪ Monitoring und Backups auf Clusterebene ▪ Anwendungsspezifische Deployment-Eigenheiten sind nicht mehr direkt Themen des IT-Betriebs ▪ Entwickler ▪ Müssen nicht in die Tiefen der Linux-Administration absteigen ▪ Beschreiben Deployments mit ihnen bekannten Mitteln ▪ Kümmern sich um anwendungsspezifisches Monitoring und Backup ▪ Automatisierungsaufgaben sind nicht umfänglich und fehleranfällig gescriptet, sondern werden bereits durch den Containermanager bereitgestellt Container Manager Host Host Host Storage Backend Monitoring Infrastruktur Host Host Host IT-Betrieb Entwickler Betreibt den Cluster Managen Builds und Code Managen Deployments
Die Infrastruktur selbst betreiben ▪ Microservice Teams oder Ops-Team installieren auf Bare-Metal oder VMs selbst die Infrastruktur (z.B. das DBMS) ▪ Das Team kümmert sich um die Wartung und Updates ▪ Wäre die Zeit nicht besser in die Arbeit am Kernsystem investiert?
vom Cloud-Anbieter ▪ Schnell aufgebaut ▪ Entwickler/Ops können sich voll auf die eigentliche Anwendung konzentrieren. ▪ Einige Betriebsaspekte werden automatisch durchgeführt ▪ Backups ▪ Updates ▪ Security-Checks ▪ Weniger Möglichkeiten in Konfiguration einzugreifen ▪ Der Service kommt von der Stange und ist so konfiguriert, dass es für die meisten passt
oder Rechenressourcen? Managed Service (SaaS, PaaS) Standardisierung Anpassbarkei t ▪ Abwägungsfrage: ▪ Managed Datenbank vom Cloudanbieter ▪ Oder eine reine VM/VMs auf denen die Datenbank selbst betrieben wird ▪ Häufig abzuwägen: ▪ Schneller Start vs. steile Lernkurve ▪ Für die Masse gute Leistung vs. auf individuellen Bedarf zugeschnittene Leistung ▪ Standardisierung vs. Anpassbarkeit
Kapitel 2 – Grundlagen moderner Infrastrukturen ▪ Lesen Sie die Fallstudie inklusive Szenarien ▪ Beantworten Sie folgende Fragen mit Hinblick auf die verschiedenen Bounded Contexts: ▪ Welche Risiken sehen Sie in der Nutzung einer Public und/oder Private Cloud? ▪ Welche Chancen sehen Sie in der Nutzung einer Public und/oder Private Cloud? ▪ Hinweis: Am besten klappt es, wenn Sie Ihre Gedanken frühzeitig in Miro festhalten
▪ Melvin Conway: "Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations." "If you have four groups working on a compiler, you'll get a 4-pass compiler“ Eric Raymond
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst ▪ Unabhängig voneinander deployt ▪ Eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container Micro- service A Micro- service B Micro- service C
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst ▪ Unabhängig voneinander deployt ▪ Eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema Micro- service A Micro- service B Micro- service C
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst ▪ Unabhängig voneinander deployt ▪ Eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema ▪ Kann in unterschiedlichen Technologien und Stylen implementiert sein → keine Wiederverwendung Micro- service A Micro- service B Micro- service C
TECHNOLOGIEFREIHEIT Micro- service A Micro- service B Micro- service C Microservices reden nur über Netzprotokolle miteinander Nur Laufzeitabhängigkeit Freiheit in der Wahl der Technologie ▪ Entscheidungen können schneller getroffen werden ▪ Technologie kann auf jeweiligen Service zugeschnitten werden ▪ Z.B. Graph-DB für Service, der viel mit Relationen hantiert ▪ Keine unnötige Komplexität durch unpassende Sprache / Frameworks / Datenbanken
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst ▪ Unabhängig voneinander deployt ▪ Eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema ▪ Kann in unterschiedlichen Technologien und Stylen implementiert sein → keine Wiederverwendung ▪ Hat manchmal eine GUI, manchmal nicht Micro- service A GUI Micro- service B Micro- service C
WAS IST DAS? ▪ Ein Architekturstil und eine technische Idee, die mit der Modularisierung von Domänen gut zusammenpasst ▪ Unabhängig voneinander deployt ▪ Eigener Prozess (oder sogar eine eigene VM) ▪ Läuft häufig in einem eigenen Container ▪ Hält seine Daten in einer eigenen Datenbank oder einem Schema ▪ Kann in unterschiedlichen Technologien und Stylen implementiert sein → keine Wiederverwendung ▪ Hat manchmal eine GUI, manchmal nicht ▪ Kommuniziert über Netz mit anderen Services durch verschiedene Technologien (synchron/asynchron) Micro- service A Micro- service B Micro- service C
Punkte werden als Must-Have durch ein “muss” im Satz verdeutlicht. Hier gibt es kaum Spielraum die Best Practices nicht umzusetzen ▪ Andere Punkte sind lediglich mit einem “sollte“ versehen und bieten hier aus ISA-Sicht eher Raum sie nicht so umzusetzen ▪ Tiefergehende Beschreibung auf https://isa- principles.org ▪ Alle Aspekte werden im Laufe der Schulung näher betrachtet Die Independent System Architecture (ISA)
einer Independent System Architecture (ISA) 1. Das System muss in verschiedene Module zerlegt werden, die Schnittstellen bereitstellen 2. Das System muss zwei klar getrennte Ebenen von Architekturentscheidungen haben a. Macroarchitektur b. Microarchitektur 3. Die Unabhängigkeit zwischen Modulen muss maximiert werden. Dies erreicht man durch getrennte Prozesse, Container und virtuelle Maschinen 4. Die Integration und Kommunikation muss für das System begrenzt und vereinheitlicht werden 5. Metadaten, z.B. zur Authentifizierung müssen modulübergreifend vereinheitlicht werden 6. Jedes Modul muss seine eigene Continuous Delivery Pipeline haben 7. Der Betrieb (Konfiguration, Deployment, Logging, ...) sollte modulübergreifend vereinheitlicht werden 8. Standards für Betrieb, Integration oder Kommunikation sollten lediglich auf Schnittstellenebene vorgeschrieben sein 9. Module müssen resilient sein https://isa-principles.org
ursprünglich aus Datenbankwelt ▪ Shared Something: ▪ Prozesse teilen sich Ressourcen (RAM, Disk) ▪ Synchronisation muss stattfinden ▪ Single-Point-of-Failure ▪ Shared Nothing: ▪ Prozesse sind unabhängig ▪ Skalierung beliebig möglich ▪ MongoDB lässt sich durch Sharding horizontal skalieren ▪ Shared Everything ▪ Festplatte und RAM geteilt ▪ Oracle RAC, AWS Aurora Shared Something / Shared Nothing Prozess A Shared Disk Prozess B Prozess A Shared Nothing Prozess B Früher vor allem auf der Hardware-Ebene, heute wir der Begriff aber neu interpretiert!
sollen ▪ Unabhängig voneinander deploybar sein ▪ Ihren Dienst fortführen, wenn andere Services Probleme verursachen ▪ Shared Nothing durch Containerisolation Shared Something / Shared Nothing III Prozess A Shared Disk Prozess B Prozess A Shared Nothing Prozess B
Nothing nicht nur im Betrieb, sondern auch in der Entwicklung ▪ Jedes Team hat eigene Entwicklungs- Infrastruktur (Build-Server, Repository, …) ▪ Änderungen an Build-Server oder -Konfiguration betrifft nur einzelnes Team ▪ Kein teamübergreifender Quellcode Shared Infrastructure
Makro-Architekturentscheidungen ▪ Entscheidungen können auf Mikro- oder Makroebene entschieden werden ▪ Makroebene ▪ Einsatz der Gesamtlösung wird eingeschränkt ▪ Unternehmensweite Standards ▪ Mikroebene ▪ Optimale Lösung für den einzelnen Bounded Context ▪ Sorgt für Unabhängigkeit der Teams ▪ Beispiele ▪ Die Programmiersprache ▪ Die Datenbank ▪ Look & Feel ▪ Dokumentation
You build it You run it Firmenkultur Betrieb: Mikro- und Makro-Architektur Betrieb • Konfiguration • Monitoring • Log-Analyse • Deployment-Technologie Mikroarchitektur Makroarchitektur
Microservices ▪ REST ▪ Anbindung der UI an das Backend ▪ Synchron → Rest Ressourcen passend fürs UI gestalten mit Value Objects → Keine Entities oder Aggregate als Ressource ▪ Messaging ▪ Service zu Service ▪ Asynchron → Commands, Events, Request, Response mit Value Objects Service A UI A Service B POST GET PUT DELETE POST, GET, PUT, DELETE
Database) ▪ Mehrere Services arbeiten auf dem gleichen Datenbankschema ▪ Keine Datenredundanz ▪ Schema kann nur gemeinsam weiterentwickelt werden ▪ Das widerspricht dem Konzept „Microservice“ ▪ Nicht zu verwechseln mit Shared Kernel (Context Mapping) Subsystem A Subsystem B
▪ Jeder Microservice hat seine eigene Datenbank oder sein eigenes Datenbankschema ▪ Redundanz der Daten ▪ Datenmigration kann durch „Extract, Transform, Load “- Prozesse (ETL) realisiert sein Micro- service A Micro- service B ETL
Transfer Vorteile ▪ Einfach ohne weitere Software zu realisieren ▪ Auf allen Plattformen und in allen Programmiersprachen verfügbar ▪ Asynchron, sodass die Applikationen getrennt weiter arbeiten können ▪ Lose Kopplung zwischen den Applikationen ▪ Kaum Eingriffe in die Applikation, um den Export zu realisieren ▪ Interna der Apps bleiben verborgen Nachteile ▪ Inkonsistenz zwischen Applikationen wegen großer Zeitintervalle zwischen den Updates der Daten ▪ Viele Absprachen zwischen den Entwicklern notwendig über: ▪ Verzeichnisse und Dateinamen ▪ Zeitpunkt der Fertigstellung und des Löschens eines Exports ▪ Semantik der Daten wird in den Applikationen jeweils lokal festgelegt Voraussetzung ▪ Gemeinsames Dateisystem ▪ Einigung über das Format (Textbasiert, XML, CSV, etc.) ▪ Exporter bzw. Importer verstehen das gleiche Format Micro- service A Micro- service B
(Remote Procedure Call) Vorteile ▪ Funktionalität wird wiederverwendet ▪ Daten sind lokal gekapselt, sodass jede Applikation beliebige eigene Formate wählen kann und die Integrität ihrer eigenen Daten wahrt ▪ Potentiell weniger Codeverdopplung, weil Funktionen wiederverwendet werden Nachteile ▪ Enge Kopplung und geringere Stabilität bei Ausfall einer Applikation ▪ Performanz und Ausfallsicherheit von entfernten Aufrufen ▪ Änderungen an einer Applikation betreffen potentiell alle entfernten Aufrufer ▪ Sich gegenseitig aufrufende Applikationen bilden ein kaum zu entwirrendes Knäuel Voraussetzung ▪ Veröffentlichung von nutzbaren Funktionen für andere Applikationen ▪ Einigung über eine gemeinsame Technologie (z. B. CORBA, COM, .NET, RMI, SOAP mit HTTP) ▪ Berücksichtigung von Ausfällen des Netzwerks bzw. der aufgerufenen Applikation Micro- service A Micro- service B Micro- service A Micro- service B
(Representational State Transfer) Im Vergleich zu RPC ▪ Ähnlich wie RPC (ebenfalls synchrone Kommunikation) ▪ Anstatt von Funktionsaufrufen wird auf Ressourcen gearbeitet ▪ Prinzipien ▪ Zustandslosigkeit ▪ Nachricht enthält alle Informationen, Server speichert keine Zustände zwischen zwei Nachrichten ▪ Caching ▪ HTTP Caching soll verwendet werden ▪ Einheitliche Schnittstelle ▪ Adressierbarkeit von Ressourcen ▪ http://webshop/api/bestellungen ▪ Repräsentationen zur Veränderung von Ressourcen ▪ HTML/JSON/XML ▪ Selbstbeschreibende Nachrichten ▪ Durch HTTP-Verben, GET, POST, DELETE, PUT Micro- service A Micro- service B
klassisch ▪ Konfigurationsdatei ▪ Wird gelegentlich aktualisiert ▪ Probleme bei Microservices ▪ Netzwerk-Adressen nicht statisch ▪ Microservices werden dynamisch gestartet oder gestoppt ▪ Wie wird Load Balancing durchgeführt? Service Client Service Instanz A Service Instanz B Service Instanz C Client oder ein API Gateway Dynamische IP Adressen Skalierung REST API REST API REST API 10.10.2.12:8893 10.10.34.24:8034 10.10.1.99:8238 ?
(Client Side Load Balancing) ▪ Client ist verantwortlich für die Bestimmung von verfügbaren Services und deren Location ▪ Client ist ebenfalls verantwortlich für das Load Balancing ▪ Ablauf ▪ Services melden sich bei der Service Registry an ▪ Client fragt Service Registry nach Services ab ▪ Client verwendet Load-Balancing Algorithmus und spricht Service an Service Instanz A Service Instanz B Service Instanz C REST API REST API REST API 10.10.2.12:8893 10.10.34.24:8034 10.10.1.99:8238 Service Register Client Ein HTTP Client der das Register kennt Register Client Register Client Register Client
(Server Side Load Balancing) ▪ Services melden sich ebenfalls bei der Service Registry an ▪ Ein Load Balancer übernimmt die Aufgabe der Service Auswahl Service Instanz A Service Instanz B Service Instanz C REST API REST API REST API 10.10.2.12:8893 10.10.34.24:8034 10.10.1.99:8238 Service Register Client Register Client Register Client Register Client Load Balancer
Vorteile ▪ Lose Kopplung, ähnlich wie File Transfer ▪ Hohe Ausfallsicherheit des Gesamtsystems, weil Nachrichten aufgehoben werden ▪ Weniger Performance-Probleme wegen Message- Queues ▪ Asynchrone Kommunikation macht Zeitverzögerung übers Netz für Entwickler sichtbar ▪ Über Nachrichten können Daten verschickt und Funktionsaufrufe abgesetzt werden Nachteile ▪ Asynchrone Kommunikation muss beherrscht werden ▪ Semantische Dissonanz zwischen Applikationen wird nicht behoben Voraussetzung ▪ Applikationen sind an einen Message Bus angeschlossen ▪ Entsprechende Technologie wird verwendet (JMS, IBM WebSphereMQ, Microsoft MSMQ, asynchrone WebServices). Micro- service A Micro- service B
(MOM) Grundkonzepte: • Send and Forget • Store and Forward Loose Coupling and Reliability Channels are separate from applications → Removes location dependencies Channels are asynchronous and reliable → Removes temporal dependencies Data is exchanged in self-contained messages → Removes data format dependencies
MOM – Die Queue ▪ Messages werden in einer Queue auf dem Server persistiert ▪ Eine Message kann nur einmal von einem Consumer gelesen werden ▪ Mehrere Producer / Consumer können dieselbe Queue benutzen ▪ Das Verarbeiten kann skaliert werden A B P queue Q message producers message consumers
MOM – Das Topic ▪ Messages werden in einem Topic auf dem Server persistiert ▪ Mehrere unterschiedliche Consumer erhalten die gleichen Nachrichten ▪ Mehrere Producer / Consumer können das gleiche Topic benutzen ▪ Das Verarbeiten kann nicht skaliert werden (außer…) A B P topic Q message producers message consumers
MOM – Kombination aus Queue und Topic ▪ Messages werden in einem Topic auf dem Server persistiert. Jedes Topic ist partitioniert. ▪ Mehrere unterschiedliche Consumer Groups erhalten die gleichen Nachrichten. In einer Consumer Group können sich mehrere Consumer befinden. ▪ Mehrere Producer / Consumer können das gleiche Topic benutzen ▪ Das Verarbeiten kann über Partitionierung skaliert werden A1 B1 P topic Q message producers message consumers A2 B2 A B
MOM ▪ Komplexes Programmiermodell ▪ Event-getriebenes Programmiermodell ▪ Logik wird auf Eventhandler verteilt ▪ Debugging über Prozessgrenzen ▪ Nachrichtenreihenfolge ▪ Nachrichten haben Zustellgarantie, aber evtl. keine Garantie der Reihenfolge ▪ Abhängige Nachrichten müssen resequentialisiert werden ▪ Synchrone Anwendungsszenarien ▪ Anwender gehen von einer synchronen Bearbeitung ihrer Anfrage aus ▪ Anwendung muss entsprechend reagieren ▪ Plattform Support ▪ Proprietäre MOMs oder Plattformen schränken die Möglichkeiten ein ▪ Herstellerabhängigkeit ▪ Trotz Standards wie JMS sind die Implementierungen oft plattformabhängig ▪ Die Integration von integrierten Lösungen ist eine weitere Herausforderung!
(Frontend Monolith) ▪ Es gibt einen Frontend Monolithen ▪ Native Apps ▪ Desktop Anwendung ▪ Single-Page-Applikation ▪ Ggf. ein Team für die Frontendentwicklung ▪ Optional mit API-Gateway ▪ Einheitliches Look & Feel Micro- service A Micro- service B
Frontend) ▪ Integration über ▪ Links ▪ Transklusion (auch: Content Projection) ▪ Übernahme von einem elektronischen Dokument oder Teilen davon in ein oder mehrere andere Dokumente durch einen Hypertext-Verweis ▪ Vorteile ▪ Lose Kopplung ▪ Login und UI in einem Microservice (Ein Team) ▪ Freie Wahl der Frontend-Technologie ▪ Herausforderung ▪ Einheitliches Look & Feel ▪ UI-Änderungen ggf. querschnittlich (Z.B. bei Redesign) Micro- service A Micro- service B
Micro-Frontends ▪ Serverseitige Template-Komposition ▪ Je nach URL-Suffix andere HTML-Datei in index.html inkludieren, oder ▪ Je nach URL-Suffix Teil-HTML von anderem Server abfragen ▪ Buildtime Integration ▪ Im Frontend die „Micro-Frontends“ als versionierte npm-dependencies einbinden ▪ Nachteil: Kopplung auf Release/Deployment-Ebene ▪ Laufzeit-Integration mit iframes ▪ Je nach Route direkt im index.html jeweiligen iframe von unterschiedlichen Ressourcen und unterschiedlichen Servern holen ▪ Laufzeit-Integration mit JavaScript ▪ index.html inkludiert JavaScript-Dateien von allen Micro-Frontends. Je nach Route wird der Entrypoint eines Micro-Frontends aufgerufen, der dann das Rendern übernimmt ▪ Flexibel ▪ Laufzeit-Integration mit WebComponents ▪ Je nach Route WebComponent von jeweiligem Micro-Frontend in den DOM laden ▪ Weniger flexibel, stärker am Web-Standard
System (SCS) ▪ Für Microservices gibt es keine einheitliche Definition ▪ Ein SCS ist eine Ausprägung von Microservices ▪ SCS geben einen Orientierungspunkt, wie eine Microservice-Architektur konkret aussehen kann ▪ SCS sind eine Sammlung von Best Practices ▪ SCS geben Elemente auf der Makro-Architekturebene vor http://scs-architecture.org/
System (SCS) ▪ Jedes SCS ist eine autonome Webanwendung ➔ Jedes SCS besitzt eine UI ▪ Es gibt keine gemeinsame UI ▪ Ein SCS kann optional eine API besitzen ▪ Z.B. für die Anbindung von einer mobilen App ▪ Ein SCS gehört einem Team ▪ Ein SCS kann aus mehreren Microservices bestehen ▪ Z.B. für Skalierung ▪ Priorisierung für die Kommunikation unter SCSs ▪ Prio 1: UI-Integration ▪ Prio 2: asynchrone Kommunikation ▪ Prio 3. synchrone Kommunikation Micro- service A Micro- service B 1 2
+ Enterprise Service Bus) ▪ Zentrale Orchestrierung über Workflow-Engine ▪ Workflow-Engine kann Standalone oder als Bestandteil eines ESBs laufen ▪ Muster eher unüblich für Microservice- Architekturen ▪ Leichtgewichtigere Lösungen werden bevorzugt Microservice Kino- management Microservice Ticketverkauf ESB Microservice Marketing Workflow-Engine
▪ Microservices übernehmen die Orchestrierung ▪ Optional kann eine Workflow-Engine im Microservice laufen ▪ Beispiel: Camunda ▪ Harte Abhängigkeit bleibt zwischen den Services Microservice Ticketverkauf Microservice Marketing Microservice Kinomanagement Workflow-Engine
▪ Event Store ▪ Ereignisse beschreiben etwas, was schon geschehen ist ▪ Alle Zustandsänderungen werden durch Ereignisse ausgelöst ▪ Ereignisse werden gespeichert, nicht der Zustand ▪ Append-only ▪ Es gibt kein Löschen ▪ Aber Stornierende Events ▪ History-Funktion ▪ Commands ▪ Clients fehlt möglicherweise Kontext zur Erzeugung von Events ▪ Commands können Events auslösen
(Command-Query-Separation) ▪ Operationen entweder zustandsändernd (Commands) ▪ Oder sondierend (Queries) ▪ Klassisch für Methoden an Klassen ▪ CQRS (CQ-Responsibility-Segregation) ▪ Trennung der Verantwortlichkeit ▪ Zwei unterschiedliche Objekte/Module für Command und Query ▪ Nicht pro Klasse, sondern in der Architektur Command-Query-Responsibility-Segregation (CQRS) Command Handler Query Handler Daten
weil wir die gleichen Daten verwenden, müssen wir nicht das gleiche Datenmodell verwenden! Command-Query-Responsibility-Segregation (CQRS) Command Handler Query Handler Datenmodell B Datenmodell A
command handler is a flavor of an application service“ Zweiteilung von Domain- und Application-Layer Domain Model (Write Model) View Model (Read Model) Application Services for business tasks Application Services for report requests
Fachmodelle ▪ Queries ▪ Können jetzt mit einem dünnen Lese-Layer gemacht werden ▪ Keine Fachlogik mehr ▪ ➔Reporting ▪ Commands ▪ Behalten richtiges Fachmodell ▪ Können aber schlanker sein, weil sie sich über Datenabfragen keine Gedanken mehr machen müssen ▪ Typischerweise nur noch eine Abfrage getByID()
Commands werden in einer DB gespeichert ▪ Die Queries werden auf einer anderen DB gefahren ▪ Der Command Handler sorgt dafür, dass der Zustand der zweiten DB passend ist ▪ Vorteile: ▪ Unterschiedliche Technologien für CS und DB möglich ▪ Dadurch schnelle Speicherung und schnelles Lesen ▪ Es ist möglich Datenstand für jeden beliebigen Zeitpunkt wieder herzustellen ▪ DB kann aus Command Store wiederhergestellt werden Command Store (auch: Command Sourcing) Command Handler Query Handler Command Store Command Queue Query- Datenbank
Bounded Contexts ▪ CQRS ist nicht für alles der richtige Architekturstil ▪ Sondern in einzelnen Bounded Contexts ▪ Auch möglich: ▪ Command Handler in einem BC, ▪ Query Handler in einem anderen
Kapitel 3 – Gängige Architekturmuster ▪ Betrachtet auch die Szenarien aus der Fallstudie. ▪ Mit Blick auf die geplante Systemlandschaft: Welcher Architekturstil wird den Anforderungen am besten gerecht? ▪ Wie sollten die Systembestandteile integriert werden? ▪ Betrachten Sie CQRS als Integrationsform. Passt der Stil in die Anwendungslandschaft? ▪ Diskutieren der Lösungsvorschläge in der Gruppe
Cloud Native? ▪ Es gibt keine standardisierte Definition. Es ist ein Buzzword ▪ Grobe Idee: Anwendungen so designen, dass diese sich sehr gut („natürlich“) und erfolgreich in der Cloud betreiben lassen ▪ Betrifft ▪ Entwurf ▪ Implementierung ▪ Betrieb
CPSA: "Applications adopting the principles of Microservices, packaged and delivered as Containers, orchestrated by Platforms, running on top of Cloud infrastructure" Microservices Containers Platforms Cloud Infrastructure
as lightweight containers 2. Developed with best-of-breed languages and frameworks 3. Designed as loosely coupled microservices 4. Centered around APIs for interaction and collaboration 5. Architected with a clean separation of stateless and stateful services 6. Isolated from server and operating system dependencies 7. Deployed on self-service, elastic, cloud infrastructure 8. Managed through agile DevOps processes 9. Automated capabilities 10. Defined, policy-driven resource allocation ▪ https://thenewstack.io/10-key-attributes-of-cloud- native-applications/ 1. Designed As Loosely Coupled Microservices 2. Developed With Best-of-breed Languages And Frameworks 3. Centred Around APIs For Interaction And Collaboration 4. Stateless And Massively Scalable 5. Resiliency At The Core Of the Architecture 6. Packaged As Lightweight Containers And Orchestrated 7. Agile DevOps & Automation Using CI/CD 8. Elastic — Dynamic scale-up/down ▪ https://medium.com/walmartlabs/cloud-native- application-architecture-a84ddf378f82 Eigenschaften von Anwendungen
is highly distributed, must operate in a costantly changing environment, and is itself constantly changing. Cornelia Davis, Former VP of Technology at Pivotal
12factor.net ▪ I. Codebase: Eine im Versionsmanagementsystem verwaltete Codebase, viele Deployments ▪ II. Abhängigkeiten: Abhängigkeiten explizit deklarieren und isolieren ▪ III. Konfiguration: Die Konfiguration in Umgebungsvariablen ablegen ▪ IV. Unterstützende Dienste: Unterstützende Dienste als angehängte Ressourcen behandeln ▪ V. Build, release, run: Build- und Run-Phase strikt trennen ▪ VI. Prozesse: Die App als einen oder mehrere Prozesse ausführen ▪ VII. Bindung an Ports: Dienste durch das Binden von Ports exportieren ▪ VIII. Nebenläufigkeit: Mit dem Prozess-Modell skalieren ▪ IX. Einweggebrauch: Robuster mit schnellem Start und problemlosen Stopp ▪ X. Dev-Prod-Vergleichbarkeit: Entwicklung, Staging und Produktion so ähnlich wie möglich halten ▪ XI. Logs: Logs als Strom von Ereignissen behandeln ▪ XII. Admin-Prozesse: Admin/Management-Aufgaben als einmalige Vorgänge behandeln
Container & Orchestrierung ▪ Egal, wie man die Reise gestaltet, für Cloud Native unstrittig ist: ▪ Bereitstellung von Software als Container ▪ Integration mit anderen Diensten nur noch über Netzwerk-Ports ▪ Auslagern der Persistenz aus den eigenen Services, Annäherung an “Zustandslosigkeit“ ▪ Die automatische Steuerung der Integration, des Lebenszyklus und der Skalierung von Containern Container Netzwerk Persistenz Orchestrierung
vollständiges und konsistentes Softwarepaket ▪ Freiheit zur Veränderung für SW-Team ▪ Eindeutige Versionierung des Container-Images ▪ Reproduzierbarkeit des Deployments ▪ Selbes Paket in DEV, TEST, PROD ▪ (Was ist mit der config.ini? Später!) ▪ Unabhängigkeit vom Host-System: ▪ „Build Once, Run Anywhere“, aber anders: ▪ Keine klassische Plattformunabhängigkeit ▪ Aber Unabhängigkeit von der konkreten Umgebung des Hosts Einfaches, konsistentes Lieferartefakt lib.jar util.dll /etc/config.ini executable.bin /etc/config.ini lib.jar util.dll executable.bin
Konfigurationseigenschaften ▪ Ein Container hat nur noch wenige, definierte Zugangspunkte ▪ Aufrufparameter (Entrypoint) & Umgebungsvariablen ▪ Externe Verzeichnisse/Dateien (Volumes) ▪ Ein- und ausgehende Netzwerk-Verbindungen (Ports): ▪ Angebotene Dienste ▪ Benötigte Dienste ▪ Großes Vereinheitlichungspotenzial: Egal welche Anwendung, sie hat nur noch diese definierenden Eigenschaften für denjenigen, der sie in Betrieb nimmt ▪ (oder sogar noch weniger?)
zu starten ▪Dauerhaft laufende(r) Server oder Datenbank ▪docker run -d my-server ▪Kurzlebiges Skript (mit Antwort) ▪docker run --rm ubuntu ls ▪Interaktiver Container ▪docker run –it my-server sh
1. (VII) Dienste immer als Port anbieten • Vereinheitlichtes Nutzungsmodell • Service-Nutzer entkoppelt vom Service-Host 2. (III) Konfiguration immer über Umgebungsvariablen • Simple Konfiguration • Stage-agnostische Container • keine Überraschungen in Produktion wg. abweichender Konfiguration /etc/config.ini lib.jar util.dll executable.bin /var/db/data 80 Volume Entrypoint Port A=B
Durch Port-Binding kann man nun viele Container auf einem Host betreiben. Z.B. ▪ Diverse Stages (Entwicklung, Test, Produktion) meiner einen Anwendung bzw. eines Dienstes ▪ Mehrere Anwendungen oder Services ▪ Oder gar beliebige, auch fremde Container? ▪ Ist sichergestellt, dass diese sich gegenseitig nicht beeinflussen? Mehrere Container auf einem Host CONTAINER 80 CONTAINER 80 CONTAINER 80 5001 5002 5003
Die „alte Welt“ der VMs ▪ Herkömmliche (systembasierte) VMs besitzen einen Hypervisor, der die Zugriffe der Gastsysteme auf die Hardware des Hosts kapselt (Netzwerk, Audio, Grafikkarte, Festplatte, etc.) ▪ Die Kapselung kann durch Hardware-Emulation, Hardware- Virtualisierung oder Paravirtualisierung erfolgen. In jedem Fall denken die Gastsysteme, sie kommunizieren mit der „echten“ Hardware ▪ Gast-Systeme = vollständige, eigenständige Betriebssysteme, die sich unterscheiden können vom Host (z.B. ein Linux-Gast- System auf einem Windows-Host – oder umgekehrt), besitzen einen eigenen Netzwerk-Stack und sind Stateful ▪ Primäres Ziel: Server-Partitionierung – „Warum soll mein Rechner schlafen, nur weil in App 1 nichts passiert?“
Die „neue“ Welt der Container ▪ Container sind quasi „etwas besser isolierte Prozesse“ direkt auf dem Host ▪ Keine Hardware-Emulation: Container teilen sich Ressourcen (CPU, Memory, Festplattenspeicher, etc.) mit dem Host und miteinander und verwenden auch den gleichen Kernel ▪ Deshalb können auf einem Windows-Host auch nur Windows- Container ausgeführt werden. Um Linux-Container auf einem Windows-Host zu starten müssen die Container innerhalb einer VM laufen. ▪ Primäres Ziel: Skalierbarkeit, Performance, Reproduzierbarkeit des Deployments, Leichtgewichtigkeit
„Wie werden die Container denn jetzt voneinander isoliert?“ ▪ „namespaces“ (Isolation) ▪ „limitieren, was von welchen Prozessen gesehen werden kann bzw. darf“ ▪ pid, net, ipc, mount, uts, user ▪ „cgroups“ (Limitierung) ▪ „limitieren Prozesse/Prozessgruppen/Ressourcen wie Memory, CPU, Block, Network“ ▪ z.B. Absicherung vor DOS (Denial of Service) - Attacken Beispiel: pid - namespace
Linux Capabilities ▪ Privilegierte Prozesse ▪ Prozesse, die vom Root-User ausgeführt werden, umgehen Kernel Restriktionen ▪ Der Root-User darf quasi „alles“ ▪ Ergo: Anwendungen innerhalb von Containern sollten in der Regel keine Root- Rechte erhalten! (no-brainer) ▪ Linux Capabilities ▪ Ermöglichen es Prozessen (Usern) eine Teilmenge der Root-Rechte bereitzustellen ▪ Jedes dieser Rechte kann einzeln vergeben werden ▪ Ein normaler (unprivilegierter) User benötigt früher oder später weitere Rechte (z.B. um einen Netzwerk Socket aufzumachen) ▪ Lösung 1 (schlecht): Root-Rechte vergeben (gefährlich) ▪ Lösung 2: Capability CAP_NET_BIND_SERVICE vergeben (Tada, Port 80 ist frei)
AppArmor ▪ Modul des Linux Security Modules (LSM) ▪ Vergibt die Linux Capabilities ▪ Reguliert und beschränkt Zugriffe auf Netzwerk, Dateien und Verzeichnisse ▪ Zählt zu den Mandatory Acess Control (MAC) Sicherheitssystemen ▪ Für Anwendungen können „Anwendungsprofile“ definiert werden, die die Berechtigungen beschreiben, die eine Anwendung besitzen darf ▪ Bevor die AppArmor-Regeln greifen, werden allerdings zunächst die Benutzer- Zugriffsrechte durch das Discretional Access Control (DAC) von Linux überprüft ▪ „AppArmor kann mit den Docker-Containern verwendet werden, die auf einer Container-optimierten OS-Instanz laufen“. Die Container besitzen dann bereits ein Default-Anwendungsprofil
die Nutzung in Containern ▪ Sehr klein ▪ Nur Package Manager und grundlegende Kommandos vorinstalliert ▪ Beispiel: Alpine (5MB) ▪ Nachteil: Viele offizielle Docker-Images, z.B. Jenkins, laufen stabiler mit größeren Basis-Images wie Debian
Container-Hosts Vor- und Nachteile am Beispiel von Googles Container-Optimized OS: ▪ Vorteile ▪ Spezialisiert auf den Umgang mit Containern ▪ Sehr schlank, da nur die nötigsten Programme installiert wurden, um potentielle Angriffsmöglichkeiten auf ein Minimum zu beschränken (z.B. kein Paketmanager!) ▪ Firewall nach Installation vollständig auf Lockdown eingestellt ▪ Zugriffe ausschließlich per SSH ▪ Verbindungen werden per Whitelisting freigegeben ▪ Lädt automatisch wöchentliche Updates im Hintergrund herunter, die bei einem Container-Neustart direkt installiert werden (reduziert Wartung) ▪ Anwendungen können nur innerhalb eines Containers gestartet werden (Sicherheit)
Container-Hosts ▪ Nachteile ▪ Viele Standardprogramme wie z.B. der Paketmanager fehlen ▪ Keine selbstständige Installation von Softwarepaketen möglich ▪ Hierfür benötigt man Werkzeuge wie die CoreOS Toolbox ▪ Anwendungen müssen in einem Container ausgeführt werden ▪ COS läuft nur mit Googles Cloud Engine
Container-Hosts ▪ Googles COS nimmt einem zwar einiges an Aufwand ab bei der Einrichtung von Containern - andere Alternativen bieten einem allerdings sehr viel mehr Freiheiten: ▪ Beispiele: ▪ Fedora CoreOS (ehemals CoreOS Container Linux und Project Atomic) ▪ RancherOS (Rancher) ▪ DCOS (Mesosphere) ▪ Photon (VmWare)
Container vs Virtuelle Maschine (VM) ▪ VMs benötigen Hypervisor ▪ Hohe Isolation (Security) ▪ Performance-Overhead ▪ Container sind quasi „etwas besser isolierte Prozesse“ direkt auf dem Host (Stichworte: cgroups, namespaces, privileged/unprivileged) ▪ Performance ▪ Ressourcennutzung ▪ Nähe zum Host birgt Sicherheitsrisiken (Kompromittierbarkeit)
anderen Service /etc/config.ini lib.jar util.dll executable.bin /var/db/data A=B ▪ Eigener Service ▪ Fremder Service ws://cool-service.foo.bar.com/endpoint ws://cool-service/endpoint Volume Entrypoint Port Link
Ein Vergleich – File Storage ▪ File Storage ▪ Klassisch ▪ Alle unstrukturierten Daten (nicht in DB) auf File Servern / NAS Systemen ▪ Bei großen Datenmengen wird die Skalierung schwierig und resultiert oft in vielen Dateninseln mit hoher Komplexität, Kosten, Aufwand und Risiko und die Performance sinkt erheblich bei größeren Datenmengen
Ein Vergleich – Block Storage ▪ Block Storage ▪ Grundlage für VM-Festplatten ▪ Daten werden in Blöcken fixer Größe gespeichert (daher der Name) ▪ Es gibt keine Metadaten und Dateien sind üblicherweise über etliche Blöcke verteilt ▪ Wird eher für strukturierte Daten (Daten in Datenbanken) verwendet ▪ Vorteilhaft für Transaktionen ▪ Kann über Regionen verteilt werden, allerdings leidet dann die Performance deutlich
Ein Vergleich – Object Storage ▪ Object Storage ▪ Beispiel: AWS S3 ▪ Einfacher zu nutzen als File Storage und Block Storage ▪ Flache Struktur ▪ Jedes Objekt hat ID und optionale Metadaten ▪ Von physischem Speicherort wird abstrahiert ▪ Cloudanbieter übernimmt Verteilung, Ausfallsicherheit usw.
Ein Vergleich – Überblick Typ Geschwindigke it Verteilung Skalierbarkeit Analyse File Storage Gut für kleine Mengen und Dateien Schwierig, meist nur lokal oder in lokalen Netzwerken Millionen von Dateien aber dann ist Schluss Nur vordefinierte Metadaten Block Storage Gut für Datenbanken und transaktionale Daten Hohe Latenzen bei weiter Verteilung Begrenzt durch Adressierungsraum Keine Metadaten Object Storage Besonders gut für große Datenmengen Einfache Verteilung über viele Regionen Kaum Grenzen Sehr gut durch konfigurierbare Metadaten
- Datenspeicherung in der Cloud ▪ In der Cloud spielt Skalierbarkeit eine große Rolle ▪ Dafür sind zustandslose Container erforderlich ▪ Wie soll dann persistiert werden? ▪ Werden Daten im Container gespeichert gehen diese verloren wenn der Container stirbt. ▪ Werden Daten auf dem Host gespeichert gehen diese verloren wenn der Host stirbt.
– RDBMS in der Cloud – Vor- und Nachteile ▪ Datenbanken für Cloud Anwendungen: entweder selbst gehostet oder managed ▪ Nachteile managed: ▪ Lokalität der Daten (compliance) ▪ Vorgaben (wie bspw. die unterstützen DBs) ▪ Bedingt konfigurierbar ▪ Vorteile managed: ▪ Support ▪ Vereinfachte Einrichtung, Skalierbarkeit, Verwaltung ▪ Sehr hohe Geschwindigkeit, sowie Verfügbarkeits- und Sicherheitsstandards ▪ Keine Hardwarebestellung, Datenbankeinrichtung ▪ Automatische Updates und Backups ▪ Pay what you use
– RDBMS in der Cloud - Anbieterauswahl ▪ Amazon bietet AWS RDS: ▪ Amazon Aurora, MySQL, PostgreSQL, MariaDB, Oracle Database, Microsoft SQL Server ▪ Migrationsservice (AWS Database Migration Service) ▪ Automatische Skalierung (nur Aurora) ▪ Zahlen was man nutzt (compute + storage) ▪ Unterstützt lesende horizontale Skalierung durch Replikas ▪ Microsoft Azure: ▪ SQL Database (basiert auf Microsoft SQL Server) ▪ Zahlen was man nutzt, aber es gibt unterschiedliche „tiers“ mit unterschiedlicher Performance, Verfügbarkeit, Speichergröße Support, etc. ▪ Untertützt sharding via „Elastic Database Tools“
– Was ist das und wann brauche ich das? Wie gehe ich mit dem Deployment von riesigen Mengen von Containern um? Wie kann ich bestimmte Container skalieren? Wie kann ich wissen ob alle meine Container gerade stabil laufen? Wie verteile ich meine Container auf meine Hardware? Wie können die Container sich untereinander finden? Wie kann ich die Konfiguration außerhalb der Container lagern? Wie behalte ich einen Überblick über meine Ressourcen?
Manager Docker Swarm • Einfach zu benutzen und installieren, wenige Funktionalitäten und geringer Support durch Community Apache Mesos + Marathon • Neben Container Verwaltung auch Ressourcen Verwaltung, persistente Speicher lange in Beta, komplex, weniger Funktionalitäten und geringer Support durch Community Nomad • Wenige Funktionalitäten, Fokus auf Cluster Management, sehr leichtgewichtig, hochskalierbar Kontena, CloudFoundry, AWS ECS, … → Kubernetes
– Kubernetes – Ein Überblick der Vorteile ▪ Bietet (unter anderem) ▪ Service discovery mit Lastverteilung ▪ Speicherorchestrierung ▪ Automatisierte Rollouts und Rollbacks ▪ Ressourcenverwaltung ▪ Selbst heilend ▪ Secret und Config Management ▪ Pod Placement ▪ Kann als deklarative state machine betrachtet werden ▪ Man definiert einen Wunschzustand via YAML Konfigurationsdateien ▪ Kubernetes versucht diesen Zustand zu erstellen und zu halten
- Kubernetes - RBAC ▪ RBAC = Role Based Access Control ▪ Konfiguriert durch kubernetes api ▪ Basiert auf Role, ClusterRole und Permissions ▪ Es gibt nur additive Permissions ▪ Kein Deny! ▪ Role <- existiert in einem Namespace ▪ ClusterRole <- pot. Namespace übergreifend ▪ Rollen werden an User durch RoleBindings angebracht ▪ ClusterRoleBinding für Cluster Roles Bildquelle: https://blog.aquasec.com/kubernetes-rbac
– Kubernetes – Grundlegende Konzepte - Pods ▪ In der Welt von Kubernetes (K8S) werden nicht Container sondern Pods deployt ▪ Ein Pod ist eine Hülle um einen (oder mehrere) Container ▪ Pods ermöglichen Kubernetes Anwendungen zu skalieren ▪ Es sollte nur eine fachliche Anwendung pro Pod laufen ▪ Alle Container im Pod teilen sich ein lokales Netzwerk und Volume ▪ Ein Pod ist ein sogenanntes Kubernetes Object Volume Container Pod
– Kubernetes – Kubernetes Objects ▪ Werden von Controllern (Erklärung folgt) verwaltet und über Konfigurationsdateien (üblicherweise yaml) definiert ▪ Erforderlich sind ▪ apiVersion ▪ kind ▪ metadata ▪ spec ▪ Es gibt extrem viele Kubernetes Objects, aber oft reichen einige wenige aus apiVersion: v1 kind: Pod metadata: name: test-pod labels: app: test spec: containers: - name: test-container image: busybox command: ['sh', '-c', 'echo Hello Word! && sleep 3600'] test-pod.yaml
– Kubernetes – Grundlegende Konzepte – Pods ▪ Wie wird ein Pod deployt? ▪ Alle Kubernetes Objects können in Dateien beschrieben und mit einem Kommandozeilentool (kubectl) an K8S übertragen werden ▪ `kubectl.exe apply –f test-pod.yaml` ▪ Aber ▪ Was passiert wenn der Pod stirbt? (cattle) ▪ Wie skaliere ich nun die Anwendung? apiVersion: v1 kind: Pod metadata: name: test-pod labels: app: test spec: containers: - name: test-container image: busybox command: ['sh', '-c', 'echo Hello Word! && sleep 3600'] test-pod.yaml
– Kubernetes – Grundlegende Konzepte - ReplicaSet ▪ Kubernetes kann eine deklarative Zustandsbeschreibung entgegen nehmen und versuchen diesen kontinuierlich aufrecht zu erhalten ▪ Das Aufrechterhalten geschieht durch sogenannte Controller, welche den aktuellen Zustand beobachten, mit dem Soll-Zustand abgleichen und Änderungen auslösen (Control Loop) ▪ Das ReplicaSet ist ein solcher Controller ReplicaSet
kind: ReplicaSet spec: replicas: 3 template: spec: containers: - name: test-container image: busybox command: ['sh', '-c', 'echo Hello Word! && sleep 3600'] Container Management – Kubernetes – Grundlegende Konzepte – ReplicaSet ▪ Dieses ReplicaSet versucht immer 3 Pods gleichzeitig am Laufen zu halten ▪ Wenn einer stirbt wird ein neuer gestartet ▪ Wie das genau funktioniert wird später erklärt ▪ Aber ▪ Was wenn ich eine neue Version von meiner Anwendung deployen möchte? apiVersion: apps/v1 kind: ReplicaSet metadata: name: test-replicaset labels: app: test spec: replicas: 3 selector: matchLabels: app: test template: metadata: labels: app: test spec: containers: - name: test-container image: busybox command: ['sh', '-c', 'echo Hello Word! && sleep 3600'] test-replicaset.yaml
– Kubernetes – Grundlegende Konzepte - Deployment ▪ Wird in der Regel verwendet statt des ReplicaSet oder Pod ▪ Ermöglicht es unter anderem Deployment Strategien durchzuführen ▪ Ändert sich das Pod template, so wird ein neues ReplicationSet erzeugt welches die neuen Pods startet ▪ Im Beispiel wird gerade v2 deployt. Dazu wird im ReplicaSet von v1 ein Pod entfernt während der erste Pod im ReplicaSet von v2 gestartet wird Deployment v1 v2
– Kubernetes – State Machine ▪ Wie funktioniert die Zustandserhaltung / -erreichung in K8S? ▪ K8S beobachtet mittels kubelet jeden Container über healthchecks ▪ Ist ein Container tot, wird ein neuer gestartet ▪ Aber ▪ Wie kann ich überhaupt einen Pod erreichen? ▪ Wo laufen die kubelets? (kommen wir später zu) ▪ Wie weiß ich ob ein Container tot ist? (kommen wir später zu) ReplicaSet kubelet
– Kubernetes – Grundlegende Konzepte – Service ▪ Ermöglicht das einfache Ansprechen von Pods über den Service Namen oder DNS ▪ Ermöglicht Lastverteilung ▪ Im Beispiel wird ein Service erstellt, der jeden Pod mit dem Label `app=test` auf Port 16325 adressiert und selbst von K8S eine IP zugewiesen bekommt (oft cluster ip genannt) apiVersion: v1 kind: Service metadata: name: test-service spec: selector: app: test ports: - protocol: TCP port: 80 targetPort: 16325 test-service.yaml
– Kubernetes – Load Balancing ▪ Services ▪ Wenn Services genutzt werden, können Anfragen an den Service statt an einen speziellen Pod gestellt werden. ▪ Der Service entscheidet dann welcher der angebundenen Pods mit gleicher Funktionalität die Anfrage erhält. Technisch nutzt der Service dazu den kube-proxy. ▪ Es gibt 2 Modi anhand derer diese Entscheidung gefällt wird. ▪ 1. Zufällige Auswahl ▪ 2. Round Robin ▪ Beides ist keine perfekte Lastverteilung, da die Auslastung der Pods nicht betrachtet wird ▪ Alternativ bieten einige Cloud Anbieter einen speziellen Service vom Typ „LoadBalancer“ an ▪ Bindet einen externen Load Balancer an ▪ Kann clusterweit (default) oder nodeweit (local) konfiguriert werden ▪ Weitere Alternative: Ingress ▪ Je nach Ingress Controller unterschiedliche Möglichkeiten der Lastverteilung
▪ Nur innerhalb des Clusters erreichbar ▪ Oder über Proxy: kubectl proxy --port=8080 ▪ Use Cases: ▪ Debugging ▪ Cluster-interne Kommunikation Service Pod Pod Pod Proxy
▪ Öffnet direkt Port auf Nodes für Zugriff von außen ▪ 1 Port pro Service ▪ Vorteile: ▪ Einfach ▪ Keine zusätzlichen Cloud-Ressourcen nötig ▪ Keine Kosten ▪ Nachteile: ▪ Port muss Aufrufer bekannt sein ▪ Jeder Service braucht unterschiedliche Ports ▪ Kein Loadbalancing -> Skaliert nicht ▪ Aufrufer muss Node-Adressen kennen ▪ Aufrufer muss wissen, auf welchen Nodes welche Service-Pods laufen Service Pod Pod Pod Node Port Node Port Node Port
„dummen“ Loadbalancer außerhalb des Clusters ▪ Cluster muss Cloud-Anbieter kennen und entsprechende Rechte haben ▪ Vorteile: ▪ Performance ▪ Skalierung ▪ Nachteile: ▪ Kosten (jeder Service erzeugt eigenen Loadbalancer) ▪ Jeder Service hat eigene IP Service-Type: LoadBalancer Service Pod Pod Pod Load Balancer
kein Service, sondern eigenes Konzept ▪ Ein Einstiegspunkt für viele Services ▪ Unterscheidung nach Route, Domäne etc. ▪ Meist realisiert durch „smarten“ (L7 HTTP) Loadbalancer vom Cloudanbieter ▪ Vorteile: ▪ Geringe Kosten ▪ Mächtigkeit ▪ SSL etc. einfach umsetzbar ▪ Nachteile: ▪ Hohe Komplexität ▪ Kann Bottleneck werden „Service-Type“: Ingress Service Pod Pod Pod Ingress Service Pod Pod Pod /foo /bar
– Kubernetes – Control vs. Data Plane ▪ Master Nodes (oft Control Plane genannt) ▪ Überwachung und Steuerung des Clusters ▪ Worker Nodes (auch Dataplane) ▪ Führen eigentliche Workloads (Pods) aus ▪ Lokale Netzwerkverwaltung Master Node Scheduler Kube API Server Cloud Controller Manager Kube Controller Manager Cluster Storage Worker Node n Worker Node 1 Kubelet Kube-proxy Kube-proxy Pod 1 Pod n Container Runtime
– Wie funktioniert die Kommunikation? ▪ Unterschiedliche Pods können auf unterschiedlichen Nodes liegen, wie können diese nun kommunizieren? ▪ Hier helfen Overlay Networks: ▪ Arbeitet auf dem Layer 3 des OSI Modells (IP) durch Hinzufügen eines weiteren äußeren Headers ▪ Herstellung von virtuellen privaten Netzen ▪ Subnetze werden getunnelt für einfache Kommunikation ▪ Vorteile: ▪ Vereinfachtes IP-Adressen Management ▪ Einfach skalierbar ▪ Sicherheit durch private Netzwerke
– Kubernetes – Master Components 1/2 ▪ Kube API Server ▪ API Schnittstelle zur Master Node (inkl. Authorisierung) ▪ Akzeptiert Kommandos zur Ansicht und Änderung des Cluster Zustands (z.B. gestartete Pods) ▪ Baut Verbindung zu kubelets der Worker Nodes auf ▪ Cluster Storage ▪ Persistiert den Status, die Konfiguration und den aktuellen Ausführungs-Plan des Clusters ▪ Oft mittels etcd realisiert Master Node Scheduler Kube API Server Cloud Controller Manager Kube Controller Manager Cluster Storage
– Kubernetes – Master Components 2/2 ▪ Kube Scheduler ▪ Evaluiert die Anforderungen von Pods und plant die Verteilung auf Nodes ▪ Behält Überblick über Status der Pods sowie den Rahmenbedingungen (Hardware, Software und Richtlinien) ▪ Kube Controller Manager ▪ Beobachtet den Zustand des Clusters und versucht den gewollten Zustand des Clusters zu regulieren (Stichwort control loop) mittels mehrerer Controller die Kubernetes Objects beobachten ▪ Node Controller, Replication Controller, Endpoints Controller, … ▪ Cloud Controller Manager ▪ Wie Kube Controller Manager nur für Cloud Provider Master Node Kube Scheduler Kube API Server Cloud Controller Manager Kube Controller Manager Cluster Storage
– Kubernetes – Node Components ▪ Kubelet ▪ Stellt sicher dass die von Kubernetes gestarteten Container im Pod funktionsfähig sind (healthchecks) ▪ Informiert den Kube API Server ▪ Startet Pods mittels Container Runtime (meist Docker) ▪ Kube-proxy ▪ Verwaltet das lokale Node-Netwerk (IP, iptables, IPVS, Netzwerkrichtlinien) ▪ Stellt sicher dass alle Pods im Cluster miteinander kommunizieren können Worker Node 1 Kubelet Kube-proxy Pod 1 Pod n Container Runtime
- Cloud Native Storage – Beispiel Kubernetes ▪ Container Dateisystem ▪ Einfach im Dateisystem des Containers speichern ▪ Daten gehen verloren sobald der Container stirbt ▪ Lokales Volume ▪ Dateien ins Volume des Pods speichern ▪ Daten gehen verloren sobald der Pod stirbt ▪ Persistent Volume ▪ Pods geben an was sie für einen Speicher brauchen (Persistent Volume Claim) und bekommen beim Start einen zugewiesen ▪ Daten bleiben erhalten solange das Cluster lebt (also auch wenn eine Node stirbt)
und Persistent Volume Claim 15GB 50GB 50GB 15GB 5GB 5GB Cluster- Admin Erzeugt Persistent Volumes Dev / DevOps Deployt Pod der persistenten Speicher braucht, daher erstellt er auch ein PVC Pod Persistent Volume Claim (PVC) Ein PersistentVolumeClai m Formuliert anforderungen an den Speicher (z.B. Größe) Der Cluster weist aus den bestehenden Volumes mindestens eines zu welches den Anforderungen des PVC entpricht
– Kubernetes – Weitere Kubernetes Objects ▪ Ingress = Kontrollierter Eingang für von extern (außerhalb des Clusters) eingehenden Netzwerkverkehr ▪ Zugriff initial gesperrt und muss explizit geöffnet werden ▪ Service = Gruppierung von Pods für einheitlichen Zugriff ▪ Es gibt unterschiedliche Arten (ClusterIP, NodePort, LoadBalancer, ExternalName) ▪ Sinnvoll insbesondere wenn ein Pod repliziert vorhanden ist und Last verteilt werden soll ▪ Namespace = virtuelles Cluster zur Gruppierung und Organisation ▪ Ermöglicht Ressourcen Verteilung ▪ Schränkt naming scope ein ▪ Ermöglicht einfache Zugriffskontrolle ▪ Bewahrt Überblick ▪ Diverse andere
– Kubernetes - Finite Workloads ▪ Wie unterstützt mich Kubernetes bei der Bearbeitung von endlichen Arbeitspaketen? ▪ CronJobs erlauben es einen Job zu erstellen. Dieser wiederum startet Pods die die endlichen Arbeitspakete abarbeiten und sich dann selbst terminieren. ▪ CronJob ▪ definiert wann der Job gestartet wird (wie auch aus Linux cron jobs bekannt) ▪ definiert ob ein alter Job im Fehler-/Verzugsfall ersetzt wird, erhalten bleibt und der neue nicht startet oder ob ein weiterer parallel gestartet wird ▪ Job ▪ definiert welche Container gestartet werden und wie diese konfiguriert sind ▪ definiert wie mit failures umgegangen wird (Abbruch? Neustart? Wie oft?)
– Kubernetes – Initialisierung 1 ▪ Jeder Pod hat eine Phase und mehrere Conditions ▪ Die Phase ist der aggregierte Gesamtzustand ▪ Conditions sind feingranular ▪ Haben Status: True, False oder Unknown ▪ Merken sich Details wie lastTransitionTime Pending Running Succeeded (erfolgreich terminiert) Failed Unknown (meistens Kommunikations problem) PodScheduled Ready Initialized Unschedulable Containers Ready
– Kubernetes – Initialisierung 3: Probes ▪ Probes dienen dazu, den Zustand der Container im Pod festzustellen ▪ exec Befehl im Container mit erwartetem Status 0 ▪ TCP-Socket-Check mit erwartetem offenem Port ▪ HTTP GET mit erwartetem Status-Code >= 200 && < 400 ▪ 2 Arten: Liveness Probe und Readiness Probe Liveness Probe • Bei Fehlschlag erst SIGTERM dann SIGKILL Readiness Probe • Bei Erfolg Aufnahme ins Loadbalancing • Bei Fehlschlag Entfernung aus Loadbalancing
– Kubernetes – Placement 1/2 ▪ Der Kube Scheduler verteilt Pods auf Nodes ▪ Betrachtet dafür: ▪ Container Ressourcen Anforderungen (deswegen wichtig zu definieren!) ▪ Verfügbare Ressourcen der Nodes ▪ Konfigurierte Placement / Scheduling Policies ▪ Abhängigkeiten ▪ Placement / Scheduling Policies ▪ Es gibt ein Standard Set ▪ Dieses kann um eigene erweitert werden ▪ Es gibt filternde und sortierende policies
– Kubernetes – Placement 2/2 ▪ Es kann mehrere Scheduler geben und ein Pod kann den gewünschten Scheduler in der Pod Spezifikation angeben ▪ Das Placement durch den Scheduler kann umgangen werden indem ein Pod eine Placement Node in der Spezifikation angibt ▪ Mittels der „Node Affinity“ können weitere Filter- und Sortierregeln für einen Pod spezifiziert werden ▪ Mittels „Pod Affinity“ und „Pod Antiaffinity“ können Pods spezifizieren ob sie möglichst auf gleiche Nodes oder möglichst verteilt platziert werden möchten ▪ Bei fast allen dieser Regeln wird spezifiziert ob sie auf das Scheduling und/oder die Execution beziehen ▪ Es gibt einen weiteren Opt-In Mechanismus für die Pod Platzierung namens „taints and tolerations“ ▪ Nodes definieren ein „taint“ (Makel) ▪ Nur Pods die eine „toleration“ (Toleranz) gegenüber diesen Makel haben werden platziert ▪ Dabei sind die Makel entweder „hard“ (keine Platzierung), „soft“ (Platzierung nur wenn notwendig) oder gar „evict“ (Bereits laufende Pods die keine Toleranz haben werden entfernt)
Kubernetes Objekte können über Dateien konfiguriert werden. Diese müssen dann nur noch dem Cluster mitgeteilt werden. Dies funktioniert i.d.R. über das Command-Line-Tool kubectl ▪ Es wird erst eine Konfigurationsdatei für jeden Context (verschiedene Stages, namespaces etc) angelegt ▪ Dann können Dateien „applied“ werden oder Zustände abgefragt werden Container Management – Kubernetes – Kubectl kubectl Kubernetes Cluster API deployment .yaml apply -f deployment.yaml
– Kubernetes – Helm Helm ist ein Package Manager für Kubernetes ▪ Gruppierung / Kapselung mehrerer Kubernetes-Objekte in einem Helm-Chart ▪ Charts können in Repositories abgelegt, versioniert und verteilt werden ▪ Ermöglicht Templating
Kapitel 4 – Cloud Native Journey Der Controller von Happiness steht einem Betrieb in der Cloud äußerst skeptisch gegenüber. ▪ Wie gehen Sie damit um? Bauen Sie eine Cloud/No-Cloud-Brücke oder versuchen Sie ihn vom Betrieb in der Cloud zu überzeugen? ▪ Sammeln Sie Argumente und schlüssige Stichpunkte, mit denen Sie dem Controller seine Sorgen nehmen wollen. ▪ Mit Blick auf das Gesamtsystem: Welche Clouddienste würden Sie in Anspruch nehmen? ▪ Skizzieren Sie die Systemlandschaft und halten Sie Ihre Entscheidungen fest.
ist vor allem die Fähigkeit zur Selbstheilung Man definiert, was der Soll-Zustand des Systems ist ▪Welche Services ▪In welcher Anzahl Das System behebt selbstständig Abweichungen vom Soll
zu beheben, muss man sie zunächst erkennen →Monitoring ... und die richtigen Reaktionen ausführen Vorbedingung: Probleme erkennen und beheben Beides muss auf mehreren Ebenen geschehen
Analogie zu den Schottwänden auf Schiffen ▪ Das System darf nicht als Ganzes kaputt gehen ▪ System wird in möglichst unabhängige Einheiten aufgeteilt (Failure Units) ▪ Bulkheads (Schottwand) trennen die Systeme ▪ Keine konkrete Implementierungsanweisung Wie passt das zu Microservices? Schott
Das Bulkhead-Muster sollte man auf mehreren Ebenen anwenden ▪ Prozesse über Container voneinander isolieren ▪ Fachlich und technisch autarke Bounded Contexts / Self-Contained Systems definieren ▪ Infrastruktur in getrennte Netze einteilen ▪ Unterschiedliche Cloud-Accounts für verschiedene Umgebungen nutzen ▪ Dadurch wird jeweils der „Blast Radius“ von Ausfällen, Fehlern und Angriffen reduziert Getrennte Cloud-Anbieter Getrennte Cloud-Accounts Getrennte (virtuelle) Netze, z.B. VPCs Getrennte Cluster Getrennte Namespaces im Cluster Getrennte Self-Contained Systems Getrennte VMs Getrennte Container Getrennte Prozesse
▪ Beispiel ▪ Stehen in der Warteschlange ▪ Am Schalter Zurückweisung, Erst Formular XY ausfüllen ▪ Langsame Antworten sind schlimmer als keine Antworten ▪ Abgrenzung zu Timeouts (Zwei Seiten der Medaille) ▪ Timeouts ▪ Zur Absicherung des Systems gegen Fehler von Anderen ▪ Für Ausgangsnachrichten ▪ Fail Fast ▪ Zum Benachrichtigen, warum man eine Anfrage nicht bearbeiten kann ▪ Für Eingangsnachrichten Asterix erobert Rom
▪ Wie der Schutzschalter im Sicherungsschrank ▪ Wird auf Ressourcen angewendet ▪ Andere Microservices ▪ Thread Pools ▪ Connection Pools ▪ Ist der Schutzschalter geschlossen, arbeitet das System normal ▪ Ab einer bestimmten Anzahl/Frequenz an Fehlern öffnet sich der Schalter ➔Aufrufe werden sofort fehlerhaft beantwortet (fail fast) ▪ Nach Ruhezeit wird Schalter wieder geöffnet Schutzschalter
Strategie, wenn ein Fehler erkannt wurde ▪ Fehlerbehandlung sollte möglichst vollständig automatisiert erfolgen ▪ Beispiel: Schreibanfrage eines Benutzers per Webanwendung, langsame Datenbank ▪ Fallback Option 1: Fehler an den Benutzer. Bitte versuchen Sie es später ▪ Fallback Option 2: Command in eine Queue und asynchrone Bearbeitung ▪ Nicht: Sanduhr anzeigen Plan A B
▪ Hystrix ist eine deprecated library ▪ Hystrix empfiehlt Resilience4j als Alternative ▪ Open Source ▪ Für Java 8+, da funktional ▪ Leichtgewichtig (nur eine transitive Abhängigkeit: Vavr) ▪ Arbeitet mit dem Decorator pattern -> requests können um modulare Funktionalitäten angereichert werden (retry, circuit breaker, …) ▪ Unterstützt hoch und niedrig frequentierte Systeme dadurch dass Daten nicht wie bei Hystrix in timed buckets geschrieben werden sondern in einen zeitunabhängigen Ringpuffer konfigurierbarer Größe
▪ Bisher wurden Frameworks als Beispiele vorgestellt ▪ Vorteil: ▪ Fein granulare Konfigurationsmöglichkeiten für jeden Service ▪ Nachteil: ▪ Kein „Big Picture“ ▪ Skaliert schlecht ▪ Aufwendig ▪ Möglicher Wildwuchs bei vielen Services ▪ Alternativ können beispielsweise Container Manager oder Service Meshes verwendet werden → folgende Kapitel
– Kubernetes – ein kurzer Rückblick ▪ Bietet (unter anderem) ▪ Service discovery mit Lastverteilung ▪ Speicherorchestrierung ▪ Automatisierte Rollouts und Rollbacks ▪ Ressourcenverwaltung ▪ Selbst heilend ▪ Secret und Config Management ▪ Pod Placement ▪ Kann als deklarative state machine betrachtet werden ▪ Man definiert einen Wunschzustand via YAML Konfigurationsdateien ▪ Kubernetes versucht diesen Zustand zu erstellen und zu halten
zwischen Applikation und der Konfiguration ▪ Via ConfigMap ▪ kann in Umgebungsvariablen gesetzt oder in ein Volume gemounted werden ▪ Via Secret ▪ kann in Umgebungsvariablen gesetzt oder in ein Volume gemounted werden ▪ Werden nicht auf die Platte einer Node geschrieben sondern im Speicher gehalten (tempfs). ▪ Können Ende zu Ende verschlüsselt werden, so dass sie nicht in etcd lesbar sind apiVersion: v1 kind: ConfigMap metadata: name: game-demo data: player_initial_lives: "3" ui_properties_file_name: "user- interface.properties" game.properties: | enemy.types=aliens,monsters player.maximum-lives=5 user-interface.properties: | color.good=purple color.bad=yellow allow.textmode=true Kubernetes Patterns – Konfiguration configmap.yaml:
– Skalierung ▪ Kubernetes unterstützt Autoskalierung ▪ CPU Nutzung als Standard Metrik ▪ Andere Metriken können via Metrik Server (z.B. Prometheus) auch genutzt werden (z.B. Arbeitsspeicher, Anzahl der Anfragen, benutzerdefinierte Metriken) ▪ Die Skalierung von Pods wird von Strategien beeinflusst (siehe nächste Folie) Horizontal Pod Autoscaler (HPA) Vertical Pod Autoscaler (VPA) Cluster Autoscaler
– Disruption Strategies ▪ Unterschiedliche Anwendungen haben unterschiedliche Anforderungen bzgl. Verfügbarkeit und Shutdown handling ▪ Es können sogenannte PodDisruptionBudgets (PDB) konfiguriert werden an den die prozentuale oder absolute Anzahl minimal verfügbarer oder maximal nicht verfügbarer Pods eines Sets definiert werden kann ▪ Beispiele ▪ 1: Zustandloses Frontend ▪ Ich möchte einfach nur genug Nutzer bedienen können ▪ Z.B. „minAvailable“ von 80% ▪ 2: Zustandsbehaftete skalierte Anwendung (z.B. Kafka oder etcd) ▪ Ich möchte Quorum und Replikationsbedingungen erfüllen ▪ Z.B. „maxUnavailable“ von 1 ▪ …
– Controller und Operator Pattern ▪ Controller reagieren auf Abweichungen vom Soll-Zustand der Kubernetes-Objekte ▪ Beispiel: ReplicaSet-Controller ▪ Es ist ein ReplicaSet mit „replicas: 3“ spezifiziert ▪ Der ReplicaSet-Controller stellt fest, dass aktuell nur 2 Pods aktiv sind ▪ Der Controller startet einen weiteren Pod ▪ Operator ▪ Operator sind Controller, die benutzerdefinierte Objekte beobachten
- Single-Container Pattern ▪ Oft Ausgangssituation ▪ Einfacher Einstieg ▪ Best Practice, solange der Container nur eine Verantwortlichkeit hat ▪ Anti-Pattern, wenn der Container mehrere hat ▪ Z.B. Webserver + Log Prozessor ▪Pod Container 1 Haupt- anwendung
– Sidecar/Sidekick Pattern - Erklärung ▪ Erweitern den Hauptcontainer um neue Funktionalität ▪ Es wird ein (meist technischer) Container neben dem Applikationscontainer ausgeführt ▪ Sinvoll für die Trennung von fachlichen Aufgaben (Applikationscontainer) und technischen Aufgaben (sidecar) ▪ Sidecar einfach austauschbar ▪ Beispiele: Log Processor Circuit Breaker Traffic Shifting Fault Injection
– Sidecar/Sidekick Pattern - Kommunikation ▪ Kommunikation z.B. über geteiltes Volume oder lokales Netzwerk ▪ Beispiel: ▪ Anwendung schreibt logs einfach aufs Volume, wie lokal ▪ Sidecar liest logs und schickt sie an zentrale Sammelstelle weiter ▪ Die Anwendung weiß nichts von der Komplexität der Weiterleitung / dem zentralen Log Sammler ▪ Anwendung wurde erweitert ohne angepasst zu werden ▪Pod Container 1 Haupt- anwendung Sidecar Container Log Prozessor geteiltes Volume
– Adapter Pattern ▪ Standardisierung unterschiedlicher Container Outputs ▪ eine wiederverwendbare Lösung ▪ Erweiterung / Spezifizierung des Sidecar Patterns ▪ Beispiel: ▪ Logs / Metriken aus vielen Anwendungen in ein Standardformat bringen ▪ Konkreter: ▪ Metriken sind in proprietärem Formaten in Datei vorhanden ▪ Prometheus benötigt Webschnittelle die gecrawlt werden kann ▪ Für Serviceübergreifende Dashboards / Analysen wird einheitliches Format benötigt ▪ Adapter Sidecar liest Datei, formatiert in Standardformat und bietet die Metriken über Webserver zum crawlen an
– Ambassador Pattern - Vorteile ▪ Abstraktion von Servermenge, für die Applikation ist nur ein Server sichtbar ▪ Einfaches Interface für den Aufruf anderer Services ▪ Simplifizierung da lokal und in Cloud über das lokale Netzwerk kommuniziert wird ▪ Trennt Konfiguration und Anwendungslogik ▪ Vermindert Komplexität in der Hauptanwendung ▪ Kann wiederverwendet werden ▪ Hauptanwendung ist nicht mehr an bestimmte Bibliotheken gebunden (z.B. Hystrix, resilience4j)
– Init Container Pattern ▪ Wenn eine Initialisierung der Hauptanwendung notwendig ist ▪ Datenbank Schema / Migration ▪ Rechte auf Betriebssystem ▪ Oft sind besondere Rechte oder Werkzeuge zur Initialisierung notwendig, welche im laufenden Betrieb nicht vorhanden sein sollten ▪ Init Container werden vor anderen und sequentiell gestartet. Wenn alle erfolgreich durchgelaufen sind werden die anderen gestartet (diese laufen i.d.R. alle parallel)
Patterns – Leader election Pattern ▪ Problem: Replication / Sharing among nodes, nicht idempotente Aufgaben ▪ Leader auswählen ▪ Logik der Leader Election aus Applikation heraushalten ▪ Nicht an eine Programmiersprache gebunden ▪ Beispiel Kubernetes: ▪ Erster Pod versucht einen Endpoint zu erstellen und diesem ein Label zu verpassen mit seiner id in einer leader property, einer lease time und einem Zeitstempel der letzten Aktualisierung. Andere pods prüfen das label regelmäßig und versuchen sich selbst als leader einzutragen wenn die lease abgelaufen ist
Patterns – Work Queue design Pattern ▪ Ist ein sogenanntes „Batch Computational Pattern“, was bedeutet, dass es ein kurzläufiges Verarbeiten großer Datenmengen ist und kein dauerhaftes Verarbeiten. Beispiele: ▪ Tägliche Reports erstellen ▪ Aggregationen über Daten erstellen ▪ Video Dateien transkodieren ▪ Vorgehen: ▪ Große Aufgabe in unabhängige „Work Items“ splitten ▪ Evtl Container / Pods spawnen ▪ Arbeit verteilen Work Queue Manager Worker Worker Worker Work items Work item Work item Work item
Patterns – Scatter and gather Pattern ▪ Problem: Eine ressourcenintensive Anfrage soll schnell beantwortet werden ▪ Lösung: ▪ Aufteilung der zu erledigenden Aufgabe in Teilaufgaben ▪ Aufteilung der Pods in einen Leader und mehrere Follower ▪ Leader verteilt Teilaufgaben an Follower ▪ Follower melden Teilergebnisse ▪ Leader berechnet und meldet Gesamtergebnis aus Teilergebnissen ▪ Skalierung auf Ebene der Zeit durch Parallelisierung einer Aufgabe im Vergleich zu ▪ Skalierung auf Ebene der Verarbeiteten requests pro Zeit ▪ Durch Skalierung der verfügbaren Nodes / Pods ▪ Skalierung auf Ebene der Datenmenge ▪ Durch sharding der Daten
Patterns – Scatter and gather Pattern – Ein Beispiel ▪ Thalia macht eine Suchanfrage über alle Bücher um solche zu filtern, welche ein bestimmtes Wort beinhalten ▪ Mögliche klassische Lösungen wären: ▪ Mehr Ressourcen: bessere CPU / mehr Cores, schnellere Festplatten ▪ Indizierung oder Caching ▪ Scatter and gather (kann natürlich mit klassischem Vorgehen kombiniert werden): ▪ Teilt die zu durchsuchenden Dokumente in Gruppen und überträgt jedem Follower eine Gruppe ▪ Sammelt und vereint die Teilergebnisse ▪ Antwortet dem Anfragenden Leader Follower Follower Follower Alle Dokumente Einige Dokumente Einige Dokumente Einige Dokumente
Patterns – Scatter and gather Pattern - Diskussion ▪ Performanzbetrachtung: Wie viele Follower sind am effektivsten? ▪ Jeder Follower reduziert die Verarbeitungsdauer (wenn wir davon ausgehen, dass die Aufgabe so klein schneidbar ist, was im vorherigen Beispiel solange gegeben ist wie #Follower < #Bücher) ▪ Dennoch wird durch jeden Follower ein overhead erzeugt ▪ Netzwerkverkehr, Request parsing, Deployment, … ▪ Weiterhin gibt es das sogenannte „straggler“ (Nachzügler) Problem, denn da der Leader auf alle Follower warten muss entscheidet der langsamste Follower über die Gesamtlaufzeit. ▪ Man stelle sich vor die Latenz beträgt in einem von 100 Requests 2 Sekunden und in allen anderen Fällen nur wenige ms ▪ Bei einem Follower hat man zu 1% eine Gesamtdauer von mindestens 2 Sekunden ▪ Bei 100 Followern hat man zu etwa 63% eine Gesamtdauer von mindestens 2 Sekunden (1- 0,99^100) ▪ Gleiches Problem bei der Verfügbarkeit, denn die Nicht-Verfügbarkeit steigt mit der Anzahl der Follower
Service Mesh – Beispiel Istio – Architektur ▪ Besteht aus ▪ Control Plane ▪ Pilot (verteilt Konfiguration auf Proxies) ▪ Mixer (nimmt Telemetriedaten entgegen) ▪ Citadel (verteilt Zertifikate an Proxies) ▪ Galley (überprüft Konfiguration) ▪ Nicht alle verpflichtend und es gibt weitere Zusatzdienste (ingress, egress, …) ▪ Data Plane ▪ Envoy Proxies als Sidecars (steuern und berichten) Istio Control Plane (Pilot, Mixer, Citadel, …) Pod A Container Container Envoy Anwendung Pod B Container Container Envoy Anwendung
Service Mesh – Beispiel Istio – Vor- und Nachteile ▪ Vorteile ▪ Quasi geschenkte Resilience (in K8S sehr einfach zu installieren) ▪ Trennung von Applikationslogik und Resilience ▪ Exzessive Monitoring Möglichkeiten (Grafana ist bereits inklusive) ▪ Einfache Steuerung ▪ Nachteile ▪ Latenz, CPU, Speicher ▪ Komplexität (weiterer Layer) ▪ Ein paar Probleme z.B. bei mTLS Verschlüsselung kann ein kubelet keine healtchecks mehr auf dem Standard Weg ausführen
Kapitel 5 – Hilfreiche Muster ▪ Unter Einbeziehung Ihrer bisherigen Ergebnisse, welche Resilienzmuster wären hilfreich um einen adäquaten Betrieb der Systeme zu gewährleisten? ▪ Diskutieren Sie mögliche Ansätze in der Gruppe und begründen Sie ihre Entscheidung
tree) & Szenarien ▪ Ein Qualitätsbaum konkretisiert Qualitätsmerkmale ▪ Allgemeine Merkmale weiter links, spezielle Anforderungen rechts ▪ Wird in kleinen Workshops entwickelt ▪ erst Brainstorming dann Organisation der Qualitätsmerkmale in Baum spezifische Qualität Performance Erweiterbarkeit Verfügbarkeit Latenz Durchsatz Neue Middleware Neue Produktkategorie bei Hardwarefehler bei Bedienfehler Szenario Szenario
Qualität - Szenarien ▪ Qualitätsmerkmale können durch Szenarien beschrieben und Qualität so definiert werden ▪ Szenarien beschreiben, was beim Eintreffen eines Stimulus auf ein System in bestimmten Situationen geschieht ▪ Die Szenarien beschreiben konkrete Anforderungen bzgl. einzelner Qualitätsmerkmale (z.B. zu Performance oder Verständlichkeit) ▪ 3 Arten von Szenarien: ▪ Anwendungsszenarien beschreiben, wie das System auf einen bestimmten Auslöser reagieren soll ▪ Änderungsszenarien beschreiben eine Modifikation des Systems oder seiner Umgebung ➢Deployments ➢Infrastrukturänderungen ▪ Stress- oder Grenzszenarien beschreiben, wie das System auf Extremsituationen reagiert → Szenarien sind die Grundlage um die Qualität von Architekturen zu bewerten
Bestandteile von Szenarien: ▪ Auslöser (Stimulus) ▪ Zusammenarbeit des auslösenden Stakeholders mit dem System ▪ Quelle des Auslösers ▪ Woher stammt der Auslöser (intern, extern, Benutzer, Angreifer) ▪ Umgebung ▪ Zustand des Systems zum Zeitpunkt des Auslösers ▪ Systembestandteil ▪ Welcher Bestandteil ist betroffen ▪ Antwort ▪ Wie reagiert das System ▪ Antwortmetrik ▪ Wie kann die Antwort gemessen/bewertet werden
Beispiele Performanz: „Die Antwort auf eine Angebotsanfrage muss Endbenutzern im Regelbetrieb in weniger als 5 Sekunden angezeigt werden. Im Betrieb unter Hochlast (Lastspitzen) darf eine Antwort bis zu 15 Sekunden dauern, in diesem Fall ist ein entsprechender Hinweis anzuzeigen.“ Robustheit: „Bei Eingabe unzulässiger oder fehlerhafter Daten in die Eingabefelder muss das System entsprechende spezifische Hinweistexte ausgeben und danach im Normalbetrieb weiterarbeiten.“ Funktional: „Bei Benutzer-Eingabe eines Wertes in das Feld ‚Postleitzahl‘ wird automatisch der zugehörige Ort aus der Datenbank gelesen und im Feld ‚Wohnort‘ angezeigt.“
ist die Praxis von Betrieb und Entwicklung, im gesamten Software-Lebenszyklus, vom Design über die Entwicklung hin zur Produktion, zusammenzuarbeiten“ DevOps is the practice of operations and development engineers participating together in the entire service lifecycle, from design through the development process to production support. – http://theagileadmin.com/what-is-devops/
DevOps ist eine Menge an Praktiken, die die Zeit vom Commit einer Änderung bis zur produktiven Inbetriebnahme reduzieren und gleichzeitig eine hohe Qualität sicherstellen. DevOps is a set of practices intended to reduce the time between commiting a change to a system and the change being placed into normal production, while ensuring high quality. DevOps A Software Architect‘s Perspective, Len Bass
Zielkonflikt DevOps viele+stabile Releases QA Ops sind langsam. QA sind nutzlos. Entwickler sind unpünktlich. Nie läuft es rund. Entwickler brauchen immer Extra- würstchen.
Zielkonflikt ▪ Entwicklung einer Kultur der (agilen) Zusammenarbeit ▪ Qualitätssicherung und Effizienz- steigerung durch Automatisierung von Entwicklungs-, QA- und Betriebs- aufgaben DevOps viele+stabile Releases QA Korrektheit Wenige Versionen
umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb • Läuft meist auf Entwickler-Desktop • Log-Level ist sehr hoch • Läuft auf CI-Server • Komponenten werden erzeugt • Umgebung ist so nah an der Betriebs- umgebung wie möglich! • Komponente wird bei einigen Anfragen verwendet und überwacht • Komponente wird auf allen Instanzen in Produktion genommen unveränderte Komponente angepasste Konfiguration Minimale Test- Daten Produktive Daten Neu aufgesetzte, Minimale Test-Daten Realistische Daten
Umgebungen ▪ Konfiguration sollte immer nachvollziehbar sein ▪ Konfigurationsänderungen sollten reversibel sein ▪ Beides wird gefördert wenn sich die Konfiguration im Repository befindet ▪ Im Idealfall betreiben wir in jeder Umgebung das gleiche Artefakt ▪ Feature Toggles helfen das hinzu und wegnehmen einzelner Funktionen zentral zu steuern ▪ Features die noch nicht produktionsreif sind werden nur in den vorgelagerten Umgebungen aktiviert
umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb Wurden Features Erwartungsgemäß umgesetzt? Test/Review auf Code- ebene Visuell richtig umgesetzt? Abnahme durch Kunde/Anwe nder Test in Real Life Funktionieren bereits bestehende Features noch?
Was installiert? ▪ Bis zur Produktivschaltung erfolgen mindestens 2-3 Installationen ▪ Erfolgen sie automatisiert oder manuell? ▪ Wer hat die Verantwortung? ▪ Wer oder was verifiziert den Erfolg einer Installation? ▪ Wer oder was benötigt und erhält Zugriff auf Produktivdaten? ▪ Wie erfolgen Akzeptanztests? ▪ Wer gibt das go für die Produktivschaltung?
Codebasis eines Microservices zum laufenden Verbund ▪ Wie wird der Code eines Microservice gebaut und lauffähig „installiert“? ▪ Das definiert die Container-Spec (z.B. Dockerfile)! ▪ Auf Basis der Container-Spec wird ein Image gebaut ▪ Das Image sollte im Betrieb weiterhin konfigurierbar bleiben z.B. durch Umgebungsvariablen ▪ Die Deployment-Spec beschreibt die Betriebsumgebung und Konfiguration des Containers. Z.B. Replica und Umgebungsvariablen Container- Spec Container- Spec Container- Spec Deployment-Specs
Multi Stage Docker Build FROM golang:1.7.3 AS builder WORKDIR /go/src/github.com/alexellis/href-counter/ RUN go get -d -v golang.org/x/net/html COPY app.go . RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app . FROM alpine:latest RUN apk --no-cache add ca-certificates WORKDIR /root/ COPY --from=builder /go/src/github.com/alexellis/href-counter/app . CMD ["./app"] https://docs.docker.com/develop/develop-images/multistage-build/
sich häufig in mehrere Aspekte ▪ Zusammensetzen der Einzelkomponenten ▪ Einbinden externer wie etwa einer Datenbank ▪ Umgebungsspezifische Konfiguration und Secrets bzw. Secret-Management Deployment-Spec Konfiguration der Umgebung ▪ Datenbank
für Lifecycle Management Grundlage für alles: Pod Für typische, stateless Anwendungen: ▪ ReplicationController (ist deprecated) ▪ ReplicaSet ▪ Deployment Für zustandsbehaftete und nicht skalierbare Anwendungen: ▪ StatefulSet Für zeitlich begrenzte Jobs: ▪ Job ▪ CronJob Für Infrastrukturaufgaben: ▪ DaemonSet
eine Menge gleichartiger Pods (=Replicas) mit einer gewünschten Anzahl ▪ ReplicaSet sorgt dafür, dass die Anzahl eingehalten wird ▪ Grundlage dafür: Liveness-Probe ▪ Wird meist nicht selbst erzeugt, sondern von höherer Abstraktion Deployment ReplicaSet apiVersion: apps/v1 kind: ReplicaSet metadata: name: frontend labels: app: guestbook tier: frontend spec: # modify replicas according to your case replicas: 3 selector: matchLabels: tier: frontend template: metadata: labels: tier: frontend spec: containers: - name: php-redis image: gcr.io/google_samples/gb-frontend:v3 Quelle: https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
über ReplicaSet, die auch Versionsverwaltung und Deployments übernimmt ▪ Wird sehr ähnlich wie ReplicaSet beschrieben ▪ Deklarative Beschreibung von Pod und Deployment-Strategie ▪ Verwaltet unter der Haube ReplicaSets und deren Historie ▪ Ändert man die spec.containers eines Deployments, so wird die Deploymentstrategie ausgeführt ▪ Dazu später mehr apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 strategy: type: RollingUpdate rollingUpdate: maxSurge: 1 maxUnavailable: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 Deployment Quelle: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
▪ Es gibt mehrere Ebenen, auf der wir die Container und Deploymentspezifikationen versionieren können ▪ Source Code können wir über Commits, Branches und Tags versionieren ▪ Deploymentspezifikationen können und sollten als yaml-Dateien im Git eingecheckt werden ▪ Docker Images können innerhalb eines Repositories mit einem Tag versehen werden, z.B. ▪ my-registry/my-image:1.0 ▪ my-registry/my-image:1.1
▪ Deployments (das Kubernetes Konzept) halten eine “Rollout History“ mit Änderungsgrund vor $ kubectl rollout history deployment.v1.apps/nginx-deployment deployments "nginx-deployment" REVISION CHANGE-CAUSE 1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml --record=true 2 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record=true 3 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.91 --record=true ▪ Helm-Charts haben auch eine Version, die unabhängig von den darin genutzten Docker-Images ist apiVersion: v1 description: A single-sentence description of this project name: my-helm-chart version: 0.1.0
bezeichnet den Vorgang, eine neue Version eines Services in eine Umgebung zu nehmen. Ziele eines Deployments ▪ Fehlerbehebung ▪ Service-Qualität verbessern ▪ neue Features Rechtliche Maßgaben beachten, ggf. menschlicher “Gatekeeper” notwendig. Bei minimalen Auswirkungen auf die Nutzer des Services! Entwicklungs- umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb
https://martinfowler.com/bliki/DeploymentPipeline.html „One of the challenges of an automated build and test environment is you want your build to be fast, so that you can get fast feedback, but comprehensive tests take a long time to run. A deployment pipeline is a way to deal with this by breaking up your build into stages. Each stage provides increasing confidence, usually at the cost of extra time. Early stages can find most problems yielding faster feedback, while later stages provide slower and more through probing. Deployment pipelines are a central part of Continuous Delivery.“
Downtime ▪ Zugehörige und abhängige Systeme werden während des Deployments vom Netz genommen ▪ Ops müssen Nacht- oder Frühschichten schieben ▪ Devs sind zeitlich eingeschränkt ▪ unmöglich bei 24/7 Anforderungen
minieren: Neue Version erst bei einem Teil der Nutzer ausrollen ▪ Zufällig ausgewählt ▪ Zuerst interne, dann externe ▪ Nach Nutzerdaten ▪ Freiwillige (Beta-Test) ▪ Ziele ▪ Risikominimierung von Fehlern ▪ Kapazitätsplanung ▪ Nutzerverhalten (A/B-Tests) ▪ Alternativversionen parallel betreiben Eingeschränkter Betrieb Entwicklungs- umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb
minieren: Neue Version erst bei einem Teil der Nutzer ausrollen ▪ Zufällig ausgewählt ▪ Zuerst interne, dann externe ▪ Nach Nutzerdaten ▪ Freiwillige (Beta-Test) ▪ Ziele ▪ Risikominimierung von Fehlern ▪ Kapazitätsplanung ▪ Nutzerverhalten (A/B-Tests) ▪ Alternativversionen parallel betreiben Eingeschränkter Betrieb Entwicklungs- umgebung Integrations- umgebung Stagingumgebung eingeschränkter Betrieb vollständiger Betrieb Fehler gibt es trotzdem! Dauerhaft: ▪ Monitoring und Vergleich mit historischen Daten ▪ Logging, das die Fehlerdiagnose vereinfacht ▪ Problemfälle zum Normalfall machen
Nachteile der Strategien 1. Downtime ▪ Sehr einfach! ▪ Ops müssen Nacht- oder Frühschichten schieben ▪ Devs sind zeitlich eingeschränkt ▪ unmöglich bei 24/7 Anforderungen 2. Blau/Grün-Deployment ▪ Ressourcen-Verbrauch ist höher (oder man nimmt die Staging-Umgebung) ▪ “Big Bang” beim Umschalten ▪ Rollback ist (fast) einfach ▪ (bereits im neuen Release angefallene Daten müssen ggf. nach Rollback gerettet werden) 3. Rollierendes Update ▪ Ressourcen kaum erhöht ▪ Konsistenzprobleme müssen bedacht werden ▪ komplizierter ▪ Rollback in der Mitte ist ein Problem
kommt ein letzter Request der die Erstellung eines Users fordert. ▪ Dieser wird auch erzeugt und erhält die ID 1234. ▪ Unmittelbar danach schaltet der Router um und stellt Version 1.1 live Blau-/Grün-Deployment – Was ist mit den Daten? POST Request: CREATE USER “Hans Meier“
erfolgt ein GET Request der die User mit dem Namen „Hans Meier“ anfordert. ▪ Wie stellen wir sicher, dass der Hans Meier mit der ID 1234 auch in der Antwort enthalten ist? Blau-/Grün-Deployment – Was ist mit den Daten? GET Request: ALL USERS NAMED “Hans Meier“
Versionen gehen gegen einen Datenbankcluster und die Datenbank erhält mit der neuen Version konservative Änderungen ▪ Die Datenbank bleibt N-1 kompatibel. ▪ Das Konzept muss von Entwicklern verstanden sein und bei den Datenbankrefactorings berücksichtigt werden. Blau-/Grün-Deployment – Gemeinsame Datenbank 1.0 & 1.1
parallel betriebenen Versionen Beispiel während der Umstellung: Ich nutze den neuen Kino-Service, um einen neuen Saal anzulegen. Beim alten Kino-Service schlägt der selbe Aufruf fehl, weil das Feature fehlt! Lösungsansätze ▪ Klient weiß, mit welcher Version er spricht ▪ Neue Features erst nutzen, wenn alle Services ersetzt sind ▪ Vorwärts- und rückwärtskompatible Schnittstellen Auch für veränderte DB-Schemata gibt es Lösungsansätze. Alle Lösungen müssen von Software-Entwicklern umgesetzt werden!
▪ Downtime- und Rollierende Deployments sind direkt über Kubernetes-Deployments möglich über ▪ spec.strategy.type: Recreate bzw. ▪ spec.strategy.type: RollingUpdate ▪ Achtung: Das ältere, imperative kubectl rolling-update sollte man nicht mehr verwenden ▪ Blau/Grün-Deployments muss man ohne Service Mesh oder Knative händisch aus den Kubernetes- Bausteinen scripten ▪ Z.B. Durch die manuelle Nutzung von 2 ReplicaSets (1 Blau, 1 Grün) und einem vorgeschalteten Service, den man jeweils umschaltet
Zugriffskontrolle ▪ Um eine hohe Autonomie einzelner Teams zu erreichen, ist es sinnvoll Infrastrukturgrenzen zwischen ihnen zu ziehen (s. Bulkhead-Muster aus Kapitel 5) ▪ Auch aus Sicherheitsgründen ist eine Abschottung sinnvoll ▪ Sorgt für einfaches Rechte-Management, denn innerhalb seiner „Zone“ kann einem Team volle Autorität gewährt werden ▪ Möglichkeiten: ▪ Bei Cloud-Provider 1 Sub-Account pro Team ▪ Eigene(r) Cluster oder Namespace pro Team ▪ Eigener Namespace im Cluster. Mit Ressource-Quotas können den Teams Grenzen gesetzt werden ▪ Trennung von Prod- und anderen Umgebungen auf verschieden Cloud-Accounts bzw. Cluster ▪ Es bleibt ein Trade-Off: Die Autonomie und Sicherheit erkauft man sich durch weniger Standardisierung und deutlich mehr Infrastrukturaufgaben pro Team
Haupt-Account Account Projekt 1 Account Projekt 2 Account Projekt 3 ▪ Jedes Projekt bekommt eigenen Cloud-Account → Bulkhead ▪ Team kann volle Kontrolle über eigenen Account bekommen ▪ Umsetzbar z.B. mit AWS Organizations ▪ Kosten sind einzeln nachvollziehbar, Rechnungen kommen im Haupt-Account zusammen ▪ Nutzer verwaltet man idealerweise nur einmal im Haupt-Account
Möglichkeiten, Komponenten zu gruppieren: ▪ Tags für Cloud-Provider Ressourcen ▪ Kubernetes Labels und Namespaces ▪ Labels für fachliche/funktionale Gruppierung (Umgebung, App, SCS, Frontend/Backend/DB, Version) ▪ Empfohlene Labels nutzen ▪ Namespaces für Verantwortungsbereiche ▪ Helm Charts Best Practices zur Komponentengruppierung Quelle: https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ Key Description Example Type app.kubernetes.io/ name The name of the application mysql string app.kubernetes.io/ instance A unique name identifying the instance of an application wordpress-abcxzy string app.kubernetes.io/ version The current version of the application (e.g., a semantic version, revision hash, etc.) 5.7 .21 string app.kubernetes.io/ component The component within the architecture database string app.kubernetes.io/ part-of The name of a higher level application this one is part of wordpress string app.kubernetes.io/ managed-by The tool being used to manage the operation of an application helm string
von Monitoring Fehler erkennen • aktuell & nachträglich Verschlechterung der Performance erkennen • einzelne Systeme & Verbund von Systemen Kapazitäten planen • kurz- & langfristig Reaktion der Nutzer verstehen • verschiedene Oberflächen & Kampagnen Sicherheitsverletzungen erkennen • sofort & nachträglich The purpose of computing is insight, not numbers. Richard Hamming
wann ein Infrastrukturknoten unzureichende oder ungebrauchte Ressourcen hat ▪CPU, Memory, Disk I/O ▪Tools (Auswahl): ▪AWS Autoscaling Group + AWS CloudWatch ▪Kubernetes Cluster Autoscaler Addon Reagieren ▪Anzahl der Infrastrukturknoten erhöhen oder verringern Ebene: Infrastrukturknoten Anwendung Infrastrukturknoten Hardware
beobachtet werden? ▪ Datenbasis wird auch „Operations Database“, abk. OpsDB genannt (Nygard) ▪ Durch Persistenz können Aussagen über die Vergangenheit und Zukunft getroffen werden Big Data Systeme Business Intelligence Einbruchs- Erkennung … System 1 System 2 Anwendung Middleware Betriebssystem Anwendung Middleware Betriebssystem Monitoring System Datenbasis Visualisierung Alarm- auswertung Andere Systeme ohne agent Agent agenten- basiert extern Benutzer Tracking Logdateien Konfigurations- Management Metriken
Echtzeit ▪ Echtzeit-Monitoring ▪ Wie ist aktuell die Auslastung des Systems? ▪ Werden Schwellwerte überschritten? ▪ Grundlage für Alerting ▪ Historisches Monitoring ▪ Speicherung relevanter Kennzahlen ▪ System- und Anwendungslogdaten ▪ Erweiterte Möglichkeiten durch Datenanalyse ▪ Anomalieerkennung ▪ Langsam entstehende Ressourcenengpässe ▪ Nachbereitung von Ausfällen
Daten ▪ Einzelsysteme werden überwacht, aber Gesamtprozess muss erkennbar bleiben ▪ Welche Log-Daten gehören zusammen? ▪ Komplexe Prozesse über mehrere Systeme verfolgen ▪ Sortieren nach Zeitstempel ist schwierig ▪ Uhrzeitabweichungen ▪ Latenzen ➢Ähnliche Zeitmessung durch NTP-Server (keine Garantie) ➢Totale Ordnung der Logs durch Vektorzeitstempel (aufwändig) ▪ Kontext ist wichtig! ▪ Welche VM? Welche Instanz? Welche Komponente?
Echtzeitmonitoring sollte vor allem durch Alarme geschehen, die automatisch bei der Verletzung definierter Metrik-Thresholds gesendet werden ▪ Typische Ziele: Mail-Verteiler, Slack-Channel Alerting Grafana-Alarm ab 85% Speicherauslastung einer Instanz
Monitoring für das Monitoring System ▪ Drei Tage kommt kein Alert ▪ Ist alles gut? ▪ Oder ist das Monitoring System ausgefallen? ▪ Wir benötigen einen Mechanismus der Ausfälle und Leistungsengpässe am Monitoring-System aufdeckt Wer monitort eigentlich das Monitoringsystem?
Logging? ▪ Verhalten der Anwendung nachvollziehen ▪ Analyse… ▪ im Fehlerfall (wichtig: Exceptions zusammenhängend loggen) ▪ bei seltsamer Entwicklung der Metriken ▪ Eignen sich weniger gut um Metriken zu persistieren
NoSQL DB ▪ CRUD über HTTP-Schnittstelle ▪ GET, PUT, POST, DELETE ▪ JSON-basierte Query Language Relationale DB ElasticSearch Database Index Table Type Row Document Column Field Schema Mapping SQL Query DSL GET /bank/_search { "query":{ "match" : { "city":„Hamburg" } } }
Datenschutz ▪ Aufgepasst beim Logging personenbezogener Daten! => DSGVO ▪ Falls personenbezogene Daten geloggt werden müssen, ist der Anwender zu informieren ▪ IP-Adressen können auch personenbezogene Daten sein!
Spezielle Art des Loggings ▪ Enthält Informationen zur Ablaufverfolgung ▪ Meldung beim Einsprung in eine Funktion ▪ Meldung beim Verlassen ▪ Ggf. mit Argumenten Stacktrace bei Exceptions
für Distributed Tracing ▪ Nutzt Nomenklatur und Ideen von Dapper ▪ Services nutzen API, um Traces zu erzeugen, strukturieren und mit Informationen zu versehen ▪ Laufzeit: Ein Tracer implementiert diese API und übermittelt Daten an Sammler ▪ Beispiele für Tracer: Zipkin, Jaeger, LightStep, Instana, … OpenTracing
Alternative zu Zipkin ▪ Entstanden bei Uber auf Basis von Zipkin ▪ OpenTracing kompatibel ▪ OpenSource seit 2017 ▪ Standard Sidecar bei Istio und OpenShift Jaeger
Sleuth mit Zipkin und LogStash Bildquelle: https://medium.com/swlh/distributed-tracing-in-micoservices-using-spring-zipkin-sleuth-and-elk-stack-5665c5fbecf
Metriken ▪ System ▪ Wie ist die CPU-Auslastung? ▪ Wie voll ist die Festplatte? ▪ Anwendung ▪ Wie viele Threads sind im Thread Pool? ▪ Wie ist die mittlere Antwortzeit eines Requests? ▪ Fachliche ▪ Wie viele Bücher wurden verkauft? ▪ Wie viele Benutzer sind angemeldet? ▪ Fachliches Monitoring ist historisch Aufgabe von BI und Controlling ▪ Warum betrachten wir es hier?
Logs ▪ Logging = Protokollierung ▪ Metriken aufgrund von Log-Dateien aufsetzen ▪ Z.B.: Anzahl der 400er-Fehler im Apache-Log ▪ Aufgrund von Logs im eigenen System, Z.B.: Bestellung ausgeführt ▪ Problematisch! Kopplung zwischen Metrik und Log-Ausgabe
▪ Benötigte Pod-Ressourcen sollte man unbedingt angeben. Sie sind Grundlage für: ▪ Berechnung der Clustergröße ▪ Platzierung der Pods ▪ Skalierung ▪ Arten benötigter Ressourcen: ▪ CPU ▪ RAM ▪ GPU ▪ Laufzeitabhängigkeiten ▪ PersistentVolumes über persistentVolumeClaim ▪ ConfigMaps ▪ Secrets
perfect ▪ Was sind perfekte Systeme? ▪ Software ohne Fehler ▪ Hardware, die nie versagt ▪ Menschen, die immer die richtigen Entscheidungen treffen → Perfekte Systeme gibt es nicht → Es wird immer Fehler geben
A (Verfügbarkeit) soll maximiert werden ▪ Traditionell: MTTF maximieren, + ➔ A => 1 ▪ Redundante Hardware, Cluster, Vermeidung von Fehlern auf Softwareebene ▪ Geht davon aus, dass die Anwendung isoliert läuft ▪ Resilience Ansatz: MTTR minimieren, + ➔ A => 1 ▪ Fehler sind in verteilten Systemen der Normalfall, nicht die Ausnahme, und es ist nicht möglich, sie vorherzusagen. → Do not try to avoid failures. Embrace them.
▪ Gleichzeitig fallen mehrere VMs / Service-Instanzen aus ▪ Die betroffenen Maschinen sind nicht “logisch” begrenzt, weil VMs flexibel auf den Hypervisorn verschoben werden 1 Hypervisor fällt aus, was passiert? Hypervisors Virtuelle Maschinen
Nebenwirkungen ▪ höhere Latenzen kommen leichter und öfter vor ▪ VMs können sich gegenseitig beeinflussen (z.B. Zeit klauen) ▪ Ausfälle einzelner VMs kommen öfter vor, weil es viele sind ▪ Hardware-Fehler treffen viele VMs gleichzeitig ▪ Daten-Konsistenz muss bedacht werden ▪ Cluster-Dateisysteme müssen bedacht werden ▪ Viel mehr VMs zu managen
Kapitel 6 – Development, CI/CD und Betrieb ▪ Wie funktioniert das Deployment? Bei welchem Bounded Context reicht Downtime, wo gibt es komplexere Strategien? ▪ Skizzieren Sie, welche Pipeline(s) für das System existieren ▪ Welche Umgebungen existieren für die Systeme? ▪ Anhand welcher Kriterien wird eine Version in die nächste Umgebung überführt? ▪ Angenommen Sie sollen ein Monitoringsystem aufsetzen. Welche fachlichen Aspekte sollten betrachtet werden?
Yourself (DRY) ▪ Repetitive Konfigurationsarbeit soll nicht manuell gemacht werden, weil ▪ Konfigurationen nur schwer nachzuvollziehen und zu überwachen sind ▪ es die Änderbarkeit erschwert, da an vielen Rechnern Änderungen nachgezogen werden müssen. ▪ es zu Inkonsistenzen führen kann. ▪ so Rollbacks nur schwer möglich sind ▪ Auch „Single Point of Truth“ und „Single Point of Maintenance“
Bereitstellung Automatisierte Bereitstellung Nachvollziehbarkeit Befehle sollen wiederholbar sein Befehle sollen protokolliert sein Befehle sollen Standardisiert sein Regression Qualitätssicherung, automatisierte Tests Monitoring Rollback, Roll Forward Regelmäßigkeit If it hurts, do it more often Infrastructure as Code: verwalte alle Skripte im selben Repository! Diese Skripte müssen genauso Qualitätsgesichert werden wie Code. Bei manueller Arbeit sind diese Merkmale schwer zu erreichen. Bereitstellungszeit reduzieren Koordinierungs-Aufwand reduzieren Zeit für andere Aufgaben frei machen
vs. Pull Push • Zentrale Konfiguration • Einfacheres Modell Pull • Jede Instanz ist selbst verantwortlich für Updates • Flexibler skalierbar auf mehrere Admins Provisio- nierung Provisio- nierung
Konzepte Inventory • Definiert Hosts und Gruppen von Hosts Playbook • Weist Gruppen Provisionierungen zu • Direkt, oder • Durch Role Role • Beschreibung mehrerer Tasks, die nacheinander ausgeführt werden sollen
Inventory [controllers] control01.baremetal control02.baremetal [nodes] node01.baremetal node02.baremetal [baremetals:children] controllers nodes ▪ Das Inventory definiert Hosts und Gruppen von Hosts ▪ control01.baremetal ist ein Host ▪ controllers und nodes sind Gruppen ▪ baremetals enthält alle Hosts, die in controllers und nodes enthalten sind
Ressourcen ▪ Terraform erkennt Abhängigkeiten zwischen Ressourcen großteils automatisch durch Referenzen ▪ Ressourcen werden entsprechend in der richtigen Reihenfolge erzeugt oder abgeräumt my_security_group my_instance Abhängigkeit
▪ Tatsächlicher Zustand wird in „State“ gemerkt ▪ Nur bekannte Ressourcen werden von Terraform beachtet ▪ Sollte im Git oder besser in einem Backend gespeichert werden Code x State Welt y x y z a b
& Fallstricke ▪ Teilweise erkennt Terraform nicht alle Konsequenzen automatisch ▪ Beispiel: aws_instance mit aws_route53_record auf die Public-IP ▪ instance_type von t2.medium auf t2.large ändern ▪ terraform apply sagt: Update-in-Place, keine weiteren Auswirkungen ▪ Tatsächlich: ▪ Neustart erforderlich ▪ Public-IP und Public-DNS ändern sich ▪ Erst zweiter Aufruf von terraform apply erkennt geänderte Public-IP und ändert den aws_route53_record ▪ Im Zweifel: terraform apply doppelt ausführen
▪ Terraform: Cloud-Infrastruktur mit Code beschreiben ▪ Deklarative Syntax. Man beschreibt, welche Ressourcen es geben SOLL ▪ „terraform apply“ ▪ berechnet Diff. zwischen SOLL und IST ▪ Erstellt Plan und zeigt den an ▪ Fragt nach Bestätigung ▪ Code ins Git ▪ Versionierung / Auditing out of the box ▪ Team hat alles unter Kontrolle ▪ Konfigurationsdrift direkt erkennbar ▪ Module, Kapselung und Abstraktion möglich
Konfigurationen ▪ Packer Dateien ▪ Vorbereitung eines Host Images (reduziert Provisionierungsaufwand nach Allokation) ▪ Erhöht allerdings Verwaltungsaufwand weil man ein weiteres Artefakt verwalten muss ▪ Terraformdateien ▪ Zur Allokation von Infrastrukturessourcen in der Cloud ▪ Segmentierung des Netzerks ▪ Definition von Zugriffsrechten ▪ Ansible Playbook ▪ Provisionierung des Hosts nachdem die Ressource Allokiert wurde ▪ Verschiedene Konfigurationen der Kernanwendung
von weaveworks 2017 publiziert https://www.weave.works/technologies/gitops/ ▪ Sämtliche Infrastrukturanpassungen werden durch einen git commit getriggert ▪ Zwei Repositories ▪ Das Code-Repository an dem die Build Pipeline hängt die lauffähige Artefakte produziert und diese bereitstellt ▪ Das ConfigRepository bildet die Grundlage zur Durchführung von Deployments oder Infrastrukturanpassungen ▪ Denkbar sind auch eigene Repositories je Umgebung. GitOps
vereinfacht Deployment und Betrieb ▪ Es standardisiert die Verfahren zum Deployment von Anwendungen. ▪ Es standardisiert den Betrieb von Anwendungen ▪ Vanilla Kubernetes bringt aber auch Aufwand ▪ Steile Lernkurve für Betrieb und Entwickler ▪ Aufwändiges Aufsetzen neuer Cluster ▪ Betrieb des/der Cluster bringt weiteren Aufwand ▪ Kubernetes “Installer“ und “Management Plattformen“ versuchen die Nachteile zu mildern Container Management Plattform ( Rancher / OpenShift) Kubernetes Automatisierte Deployments Konzepte zum Betrieb verteilter Systeme Terraform Automatisierte Erzeugung von Cloud- Ressourcen Kubernetes Fluch oder Segen?
Kubernetes Kubernetes „Installer“ • kops: CLI-Tool zum Aufsetzen von Kubernetes bei AWS (experimentell auch bei GCP) • Erstellt Infrastruktur und darauf Kubernetes-Cluster • kubeadmin: CLI-Tool zum Aufsetzen von Kubernetes auf bestehender Linux-Infrastruktur Kubernetes als Managed Service auch Kubernetes as a Service (KaaS) • EKS bei AWS • GKE bei Google Cloud • AKS bei Azure Container Management Platformen zur „Fernsteuerung“ von Kubernetes • Rancher: UI zur Verwaltung von Kubernetes-Clustern • Gardener: ähnlich wie Rancher Kubernetes Distributionen, die versuchen das Setup und Management zu vereinfachen • OpenShift: Eine Kubernetes-Distribution,die einige Kubernetes Implementationsdetails versteckt
Container-Managern Die Container-Manager-Lösungen unterscheiden sich in verschiedenen Merkmalen: On Premise vs. On Cloud Selbst gemanagt vs. Händler-gemanagt Public oder Private • Teilt man sich den Container-Manager mit anderen Mandanten? • Gegenseitige Performance-Beeinflussung • Sicherheit Um welche Art von Container-Manager handelt es sich? • Pures („vanilla“) Kubernetes • Kubernetes mit Drumherum • Anderes (z.B. AWS ECS)
▪ Open Source Tool ▪ Ermöglicht Cluster selber zu managen ▪ Viel manueller Aufwand ▪ Zwei Modi: ▪ Kops verwaltet direkt den Cluster über eigene Konfigurationsdateien ▪ Kops generiert Terraform-Code zur Verwaltung des Clusters ▪ Nur AWS voll supported
▪ kops benötigt als minimale Vorraussetzungen: ▪ AWS User oder Rolle mit weitreichendem Zugriff ▪ Vollzugriff auf EC2, Route53, S3, IAM, VPC ▪ S3 Bucket als State Store ▪ Route53-gemanagte DNS-Zone, die auflösbar ist ▪ Alternative: Verzicht auf DNS mit .k8s.local-Domain ▪ nur für Testzwecke geeignet ▪ kops unterstützt nicht bei der Einrichtung dieser Ressourcen
▪ Erzeugte Cluster-Konfiguration besteht aus ca. 100 Ressourcen-Definitionen VPC Subnetze Routing- Tabellen Autoscaling- Gruppen Geheimnisse Security Groups Volumes Rollen SSH- Schlüsselpaare
& Contra ▪ Volle eigene Kontrolle über den Cluster ▪ Geringe Kopplung an Cloud-Provider ▪ Erfordert sehr hohen Grad an Cloud-Expertise ▪ Viel Trial & Error mit Rechten, Domänen, etc. ▪ Aufräumen von Cluster-Resten und Clusterkonfigurationen in State Store ist müßig Empfehlung: ▪ Nur in leerem Cloud-Account ausprobieren ▪ Mit AWS CloudTrail o.ä. nachvollziehen, was alles passiert ▪ Nachschauen, dass nach Cluster-Löschung wirklich alle Ressourcen abgeräumt wurden
▪ Kam Anfang 2016 ▪ Ein Manager für Container Manager ▪ Und ein Container Manager ▪ Hatte einen eigenen Container-Manager namens Cattle ▪ Konnte bekannte weitere Manager aufsetzen, beobachten und steuern ▪ Insbesondere: Docker Swarm, Mesos und Kubernetes ▪ Manager für Cloudienste ▪ Schnittstellen zu gängigen IaaS-Anbietern und Fähigkeit dort Ressourcen zu managen ▪ Spannt virtuelles Netzwerk zwischen Ressourcen von verschiedenen Cloudanbietern ▪ Um seinen Cluster etwa über mehrere Cloudanbieter zu verteilen
▪ Kam Mitte 2018 ▪ Noch immer ein Manager für Container Manager ▪ Arbeitet nur noch mit Kubernetes und den Managed Kubernetes Angeboten der großen Cloudanbieter ▪ Kann also Kubernetes, GKE und EKS aufsetzen, beobachten und steuern ▪ Das ist geblieben: Manager für Cloudienste ▪ Schnittstellen zu gängigen IaaS-Anbietern und Fähigkeit dort Ressourcen zu managen ▪ Spannt virtuelles Netzwerk zwischen Ressourcen von verschiedenen Cloudanbietern ▪ Die Kernidee ▪ Rancher macht das Erzeugen und Management von einem Cluster derart einfach, dass Teams sich nach Bedarf leichtgewichtig eigene Cluster erzeugen können ▪ Rancher stellt die Management und Monitoringinfrastruktur bereit, die dann Teamübergreifend vereinheitlicht wird.
Eine Management Plattform für Kubernetes • Management mehrerer Kubernetes Cluster • Management von Ressourcen bei Cloudprovidern • Clusterübergreifendes Access Management Google Kubernetes Engine Google Cloud Platform Selbst gemanagter Kubernetes Cluster Auf Bare oder VMs Web-UI CLI
Von Red Hat ▪ Ursprünglich (2011, vor Docker und Kubernetes) mit eigener Container-Technologie “Gears“ ▪ Mittlerweile bilden Docker und Kubernetes den Kern ▪ Im Unterschied zu Rancher hat OpenShift Kubernetes direkt im Bauch. ▪ Es ist sozusagen eine Kubernetes-Distribution ▪ Und sattelt noch eine Reihe Features drauf ▪ Container Registry ▪ Service Mesh-Artige Funktionalität ▪ Monitoring
OpenShift Online • Voll gemanagt • In Public Cloud • Geteilt mit anderen Mandanten OpenShift Dedicated • Voll gemanagt • In Virtual Private Cloud (d.h. abgetrennter Bereich in Public Cloud) OpenShift Container Platform • Nicht gemanagt • On Premise
Ähnlich zu Kubernetes Namespace ▪ Hat zusätzlich: ▪ Striktere Validierung ▪ Über Templates erzeugbar ▪ Ressource Limits (mittlerweile auch bei Namespaces)
Gab es in OpenShift bevor es Deployments in Kubernetes gab ▪ Ein paar zusätzliche Features zu Deployments: ▪ Verdrahtet mit ImageStreams ▪ Explizite Angabe von Triggern ▪ ImageChange: Image hat neue Version ▪ ConfigChange: Die Konfiguration wurde geändert ▪ Deployment-Strategien neben RollingUpdate ▪ Blue-Green ▪ A/B ▪ Lifecycle Hooks, die vor oder nach einem Deployment ausgeführt werden
Erweitert Kubernetes um CI/CD-Kapazitäten ▪ Ein Build ist ein innerhalb von OpenShift ablaufender Build-Prozess, der Container-Images als Grundlage für einen Pod baut ▪ Wird durch BuildConfig (eine yaml-Datei) konfiguriert
Ähnlich zu Kubernetes Ingress, mit leicht anderen Features ▪ Macht einen Service öffentlich unter einem Hostnamen verfügbar Feature Ingress bei OpenShift Route bei OpenShift Standard Kubernetes-Object X Externer Zugriff auf Services X X Sticky Sessions X X Load-balancing Strategies (z.B. round robin) X X Rate-limit und Throttling X X IP-Whitelisting X X TLS-Edge-Termination X X Erneute TLS-Verschlüsselung X TLS Passthrough X Split Traffic X Generierte Hostnames nach Muster X Wildcard-Domains X Route / Ingress Service Pods macht extern verfügbar macht intern verfügbar und verteilt Last
▪ oc ist ein CLI-Tool ▪ Hat die selben Befehle wie kubectl ▪ Ergänzt um reine OpenShift-Kommandos, z.B. für BuildConfigs oc login --token=<TOKEN> --server=https://api.us-east-1.online-starter.openshift.com:6443 oc new-project nodejs-echo oc new-app https://github.com/sclorg/nodejs-ex -l name=myapp
Kapitel 7 – Automatisierung Mit Blick auf die Fallstudie, sowie ihre bisherigen Designentscheidungen: ▪ Würden Sie eine der Containermanagement- Plattformen in Erwägung ziehen? Begründen Sie! ▪ Welche weiteren Tools zur Automatisierung würden Sie zu welchem Zweck einsetzen?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
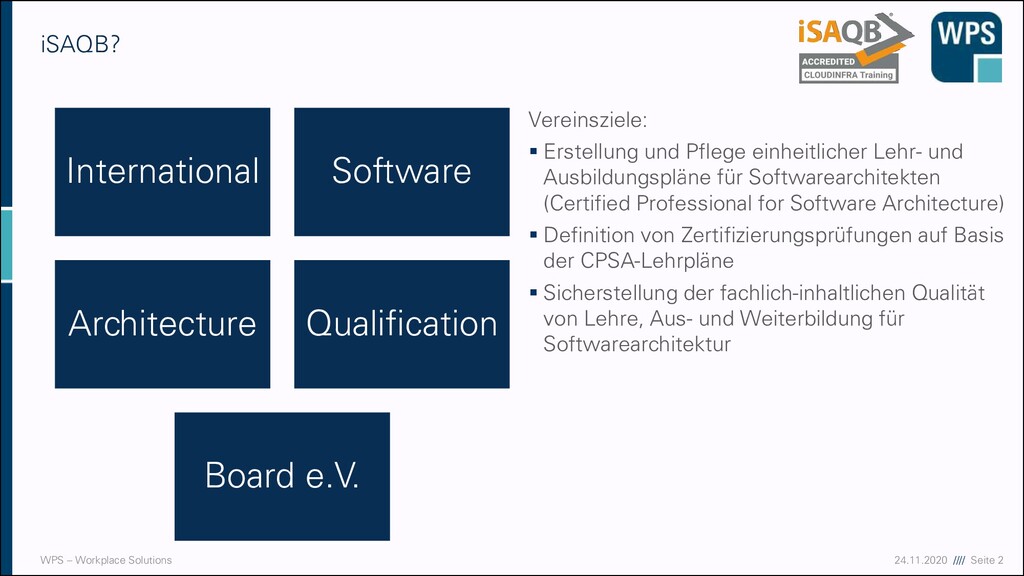{kind=link}
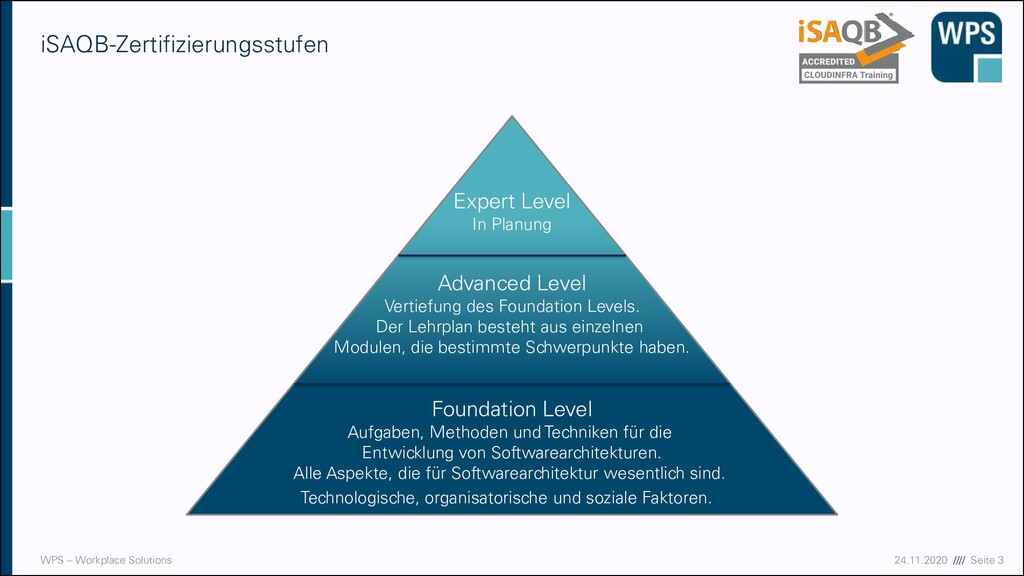{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
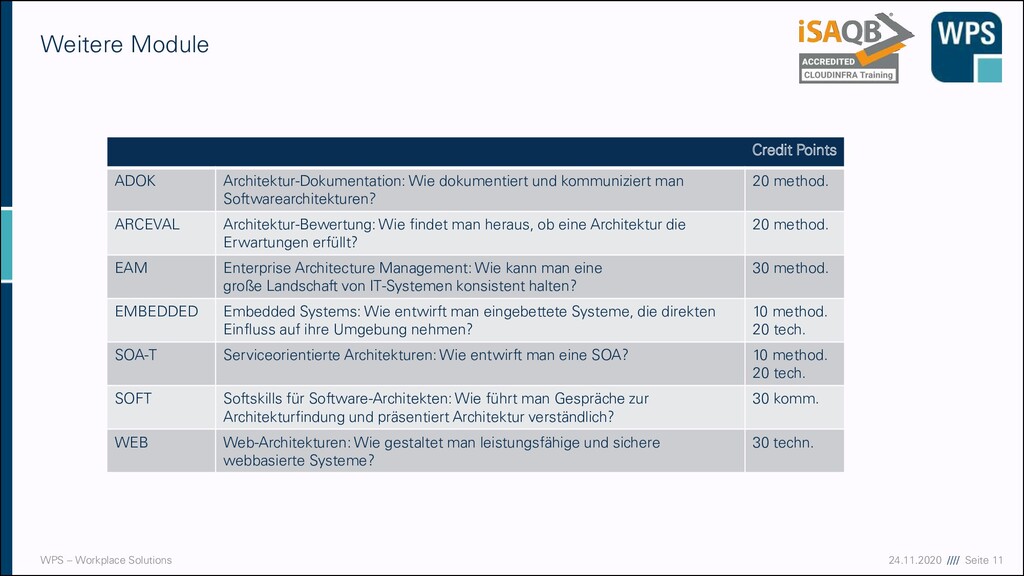{kind=link}
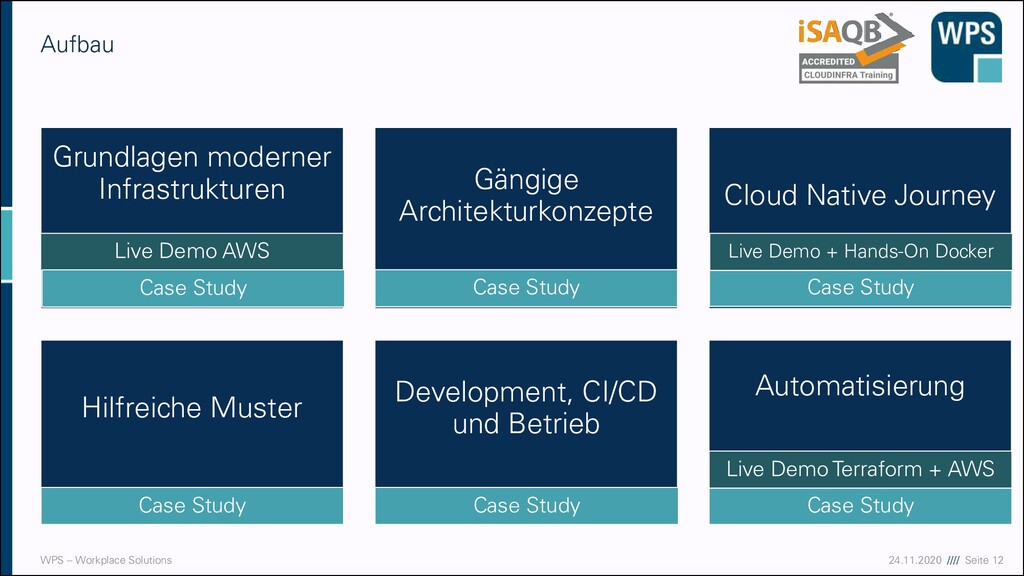{kind=link}
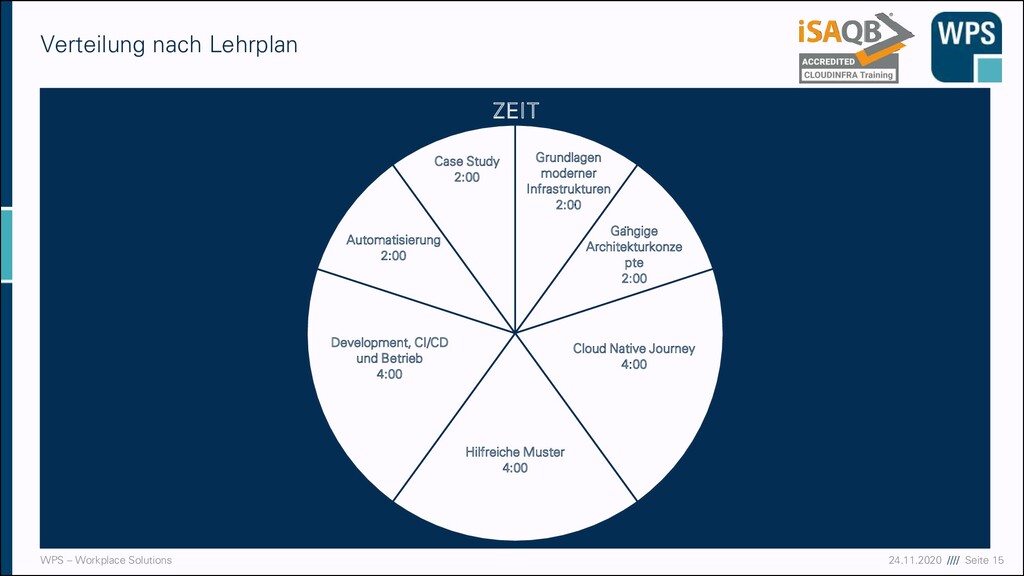{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
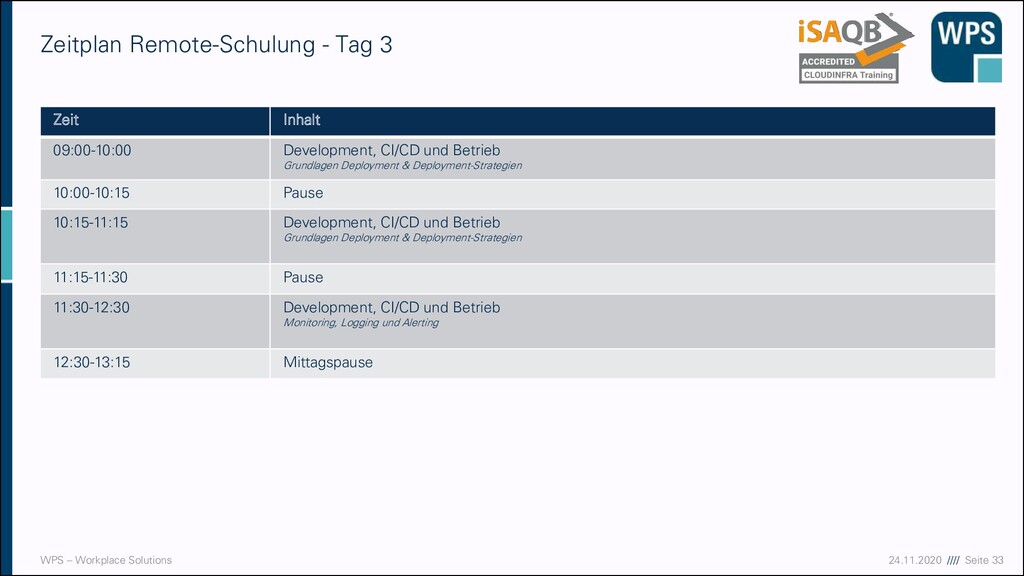{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
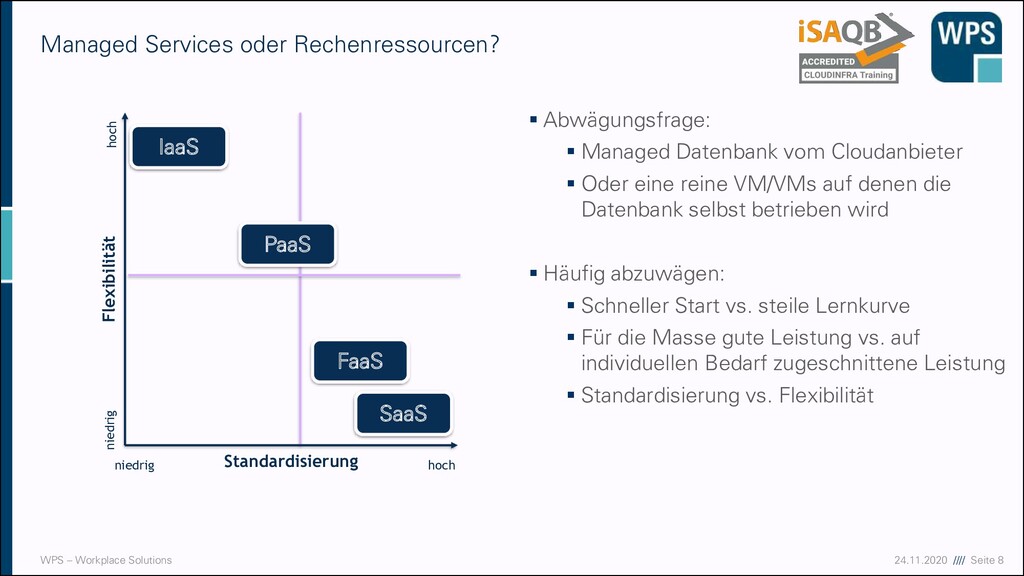{kind=link}
{kind=link}
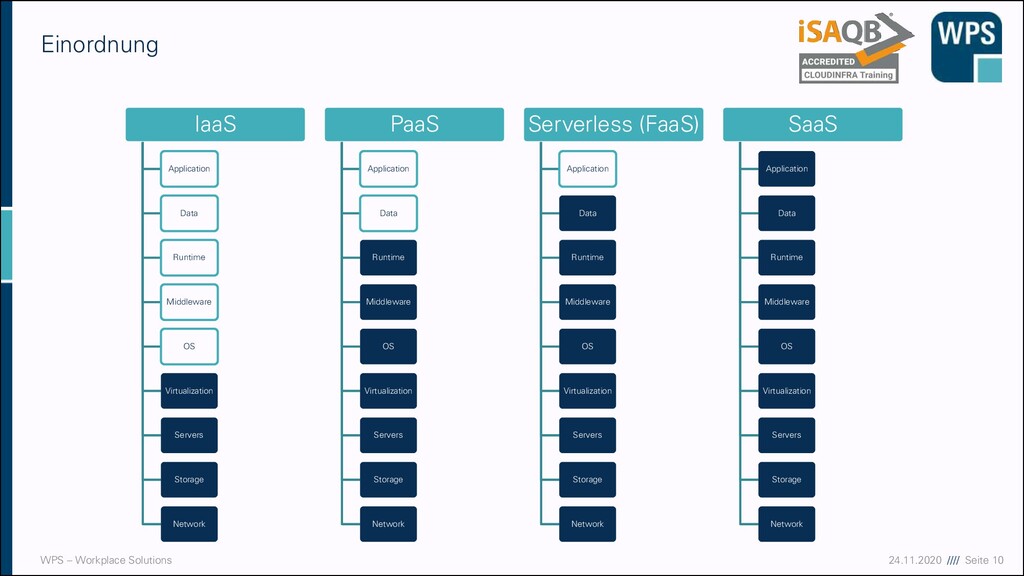{kind=link}
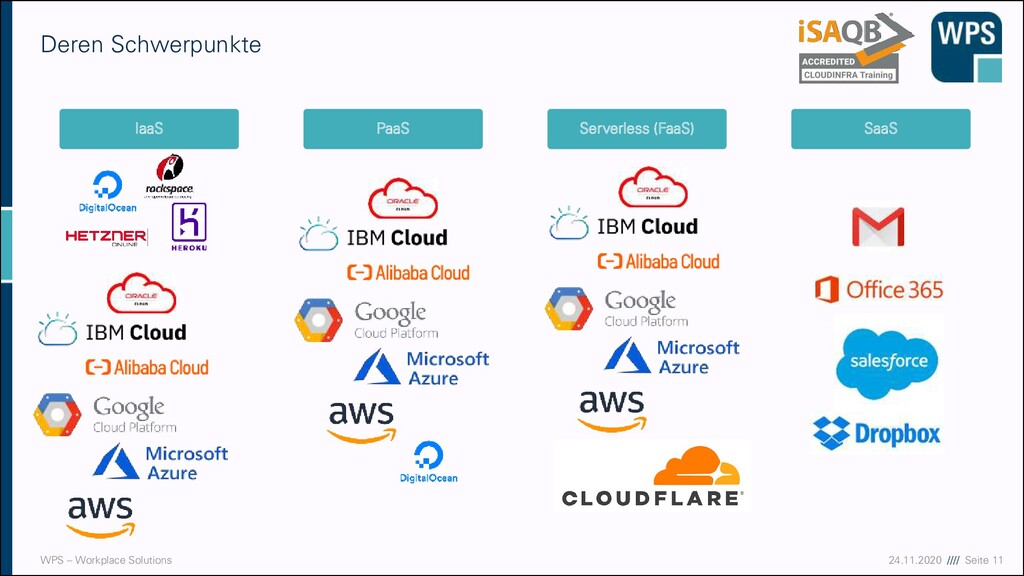{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
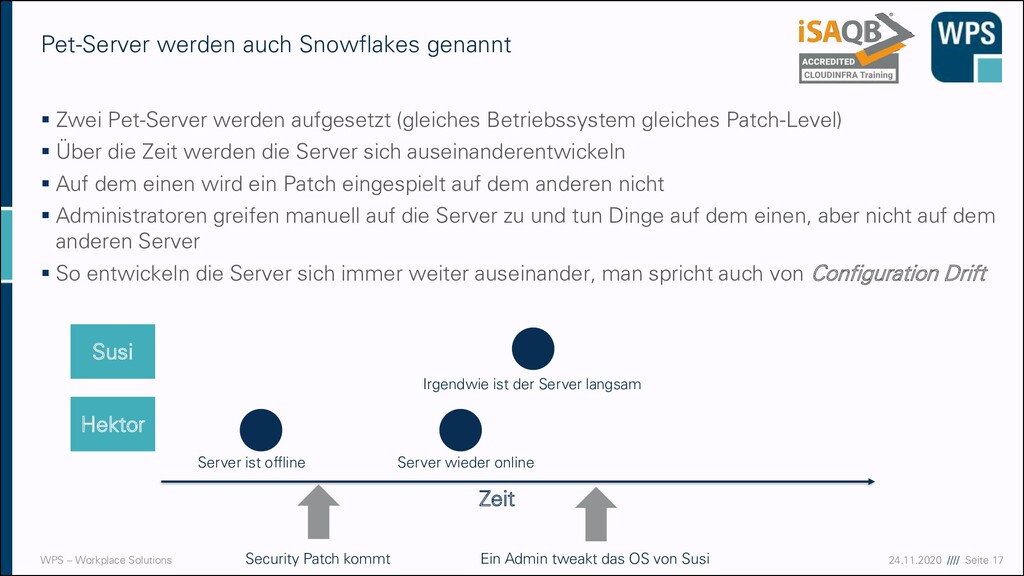{kind=link}
{kind=link}
{kind=link}
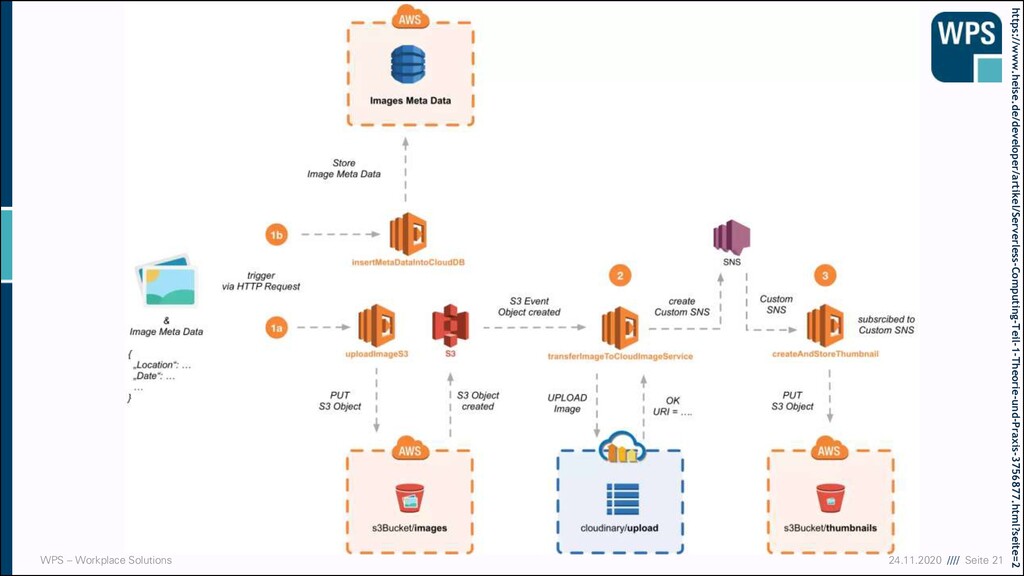{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
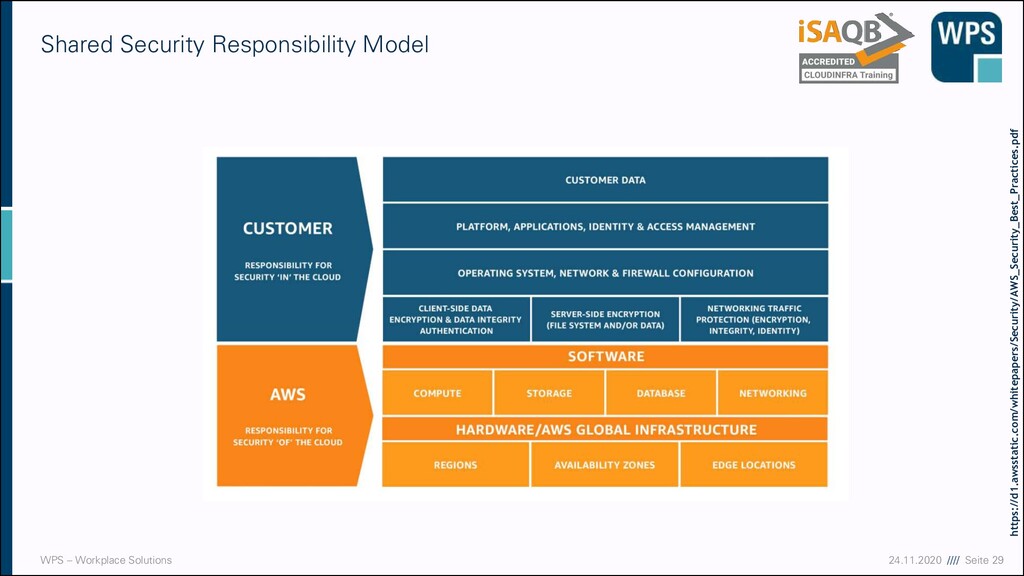{kind=link}
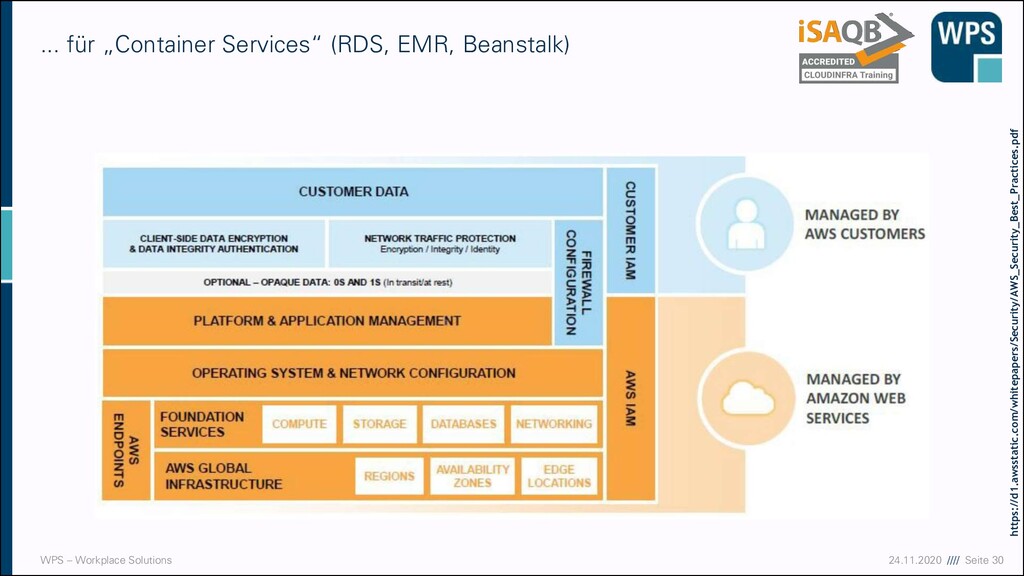{kind=link}
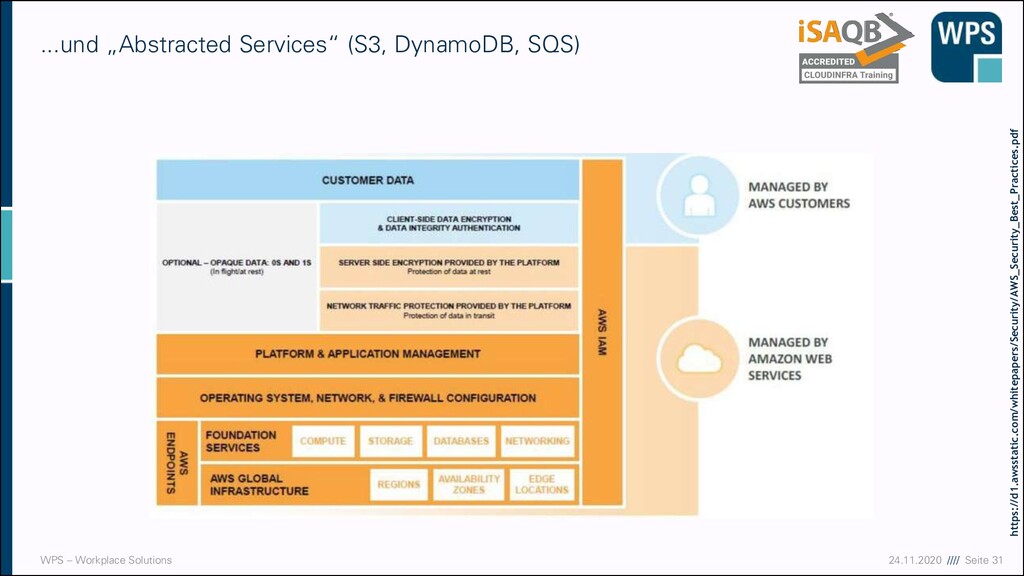{kind=link}
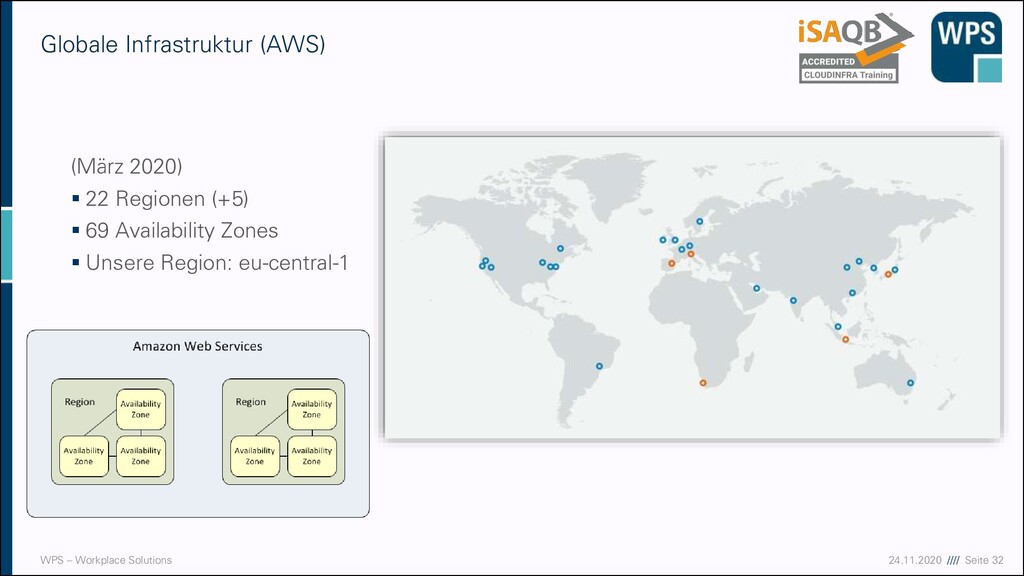{kind=link}
{kind=link}
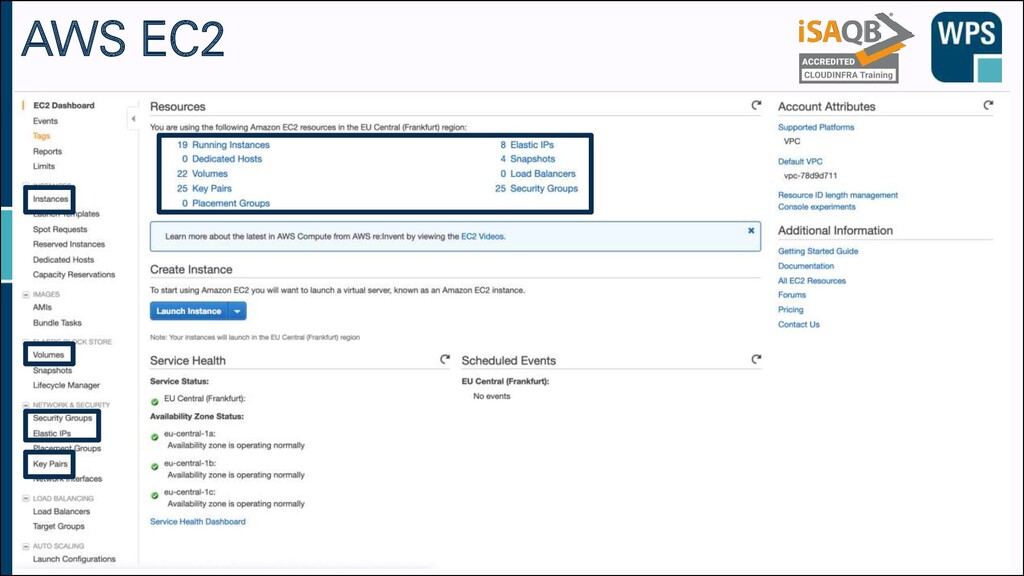{kind=link}
{kind=link}
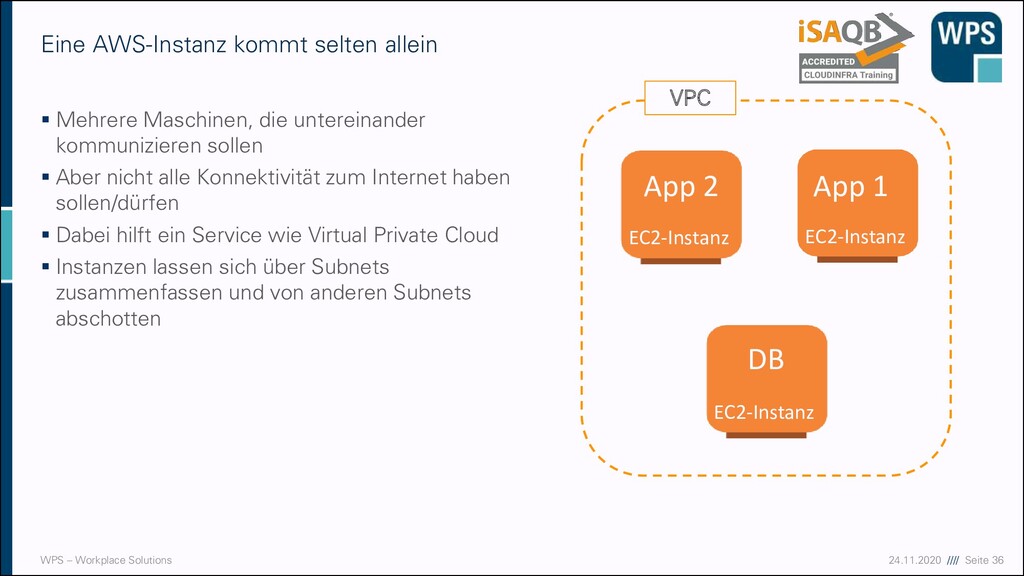{kind=link}
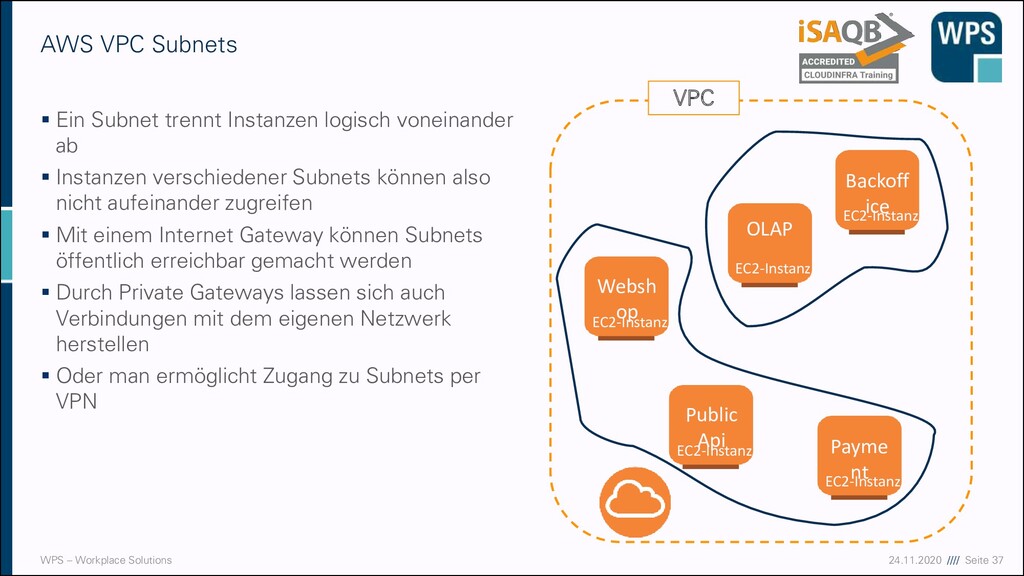{kind=link}
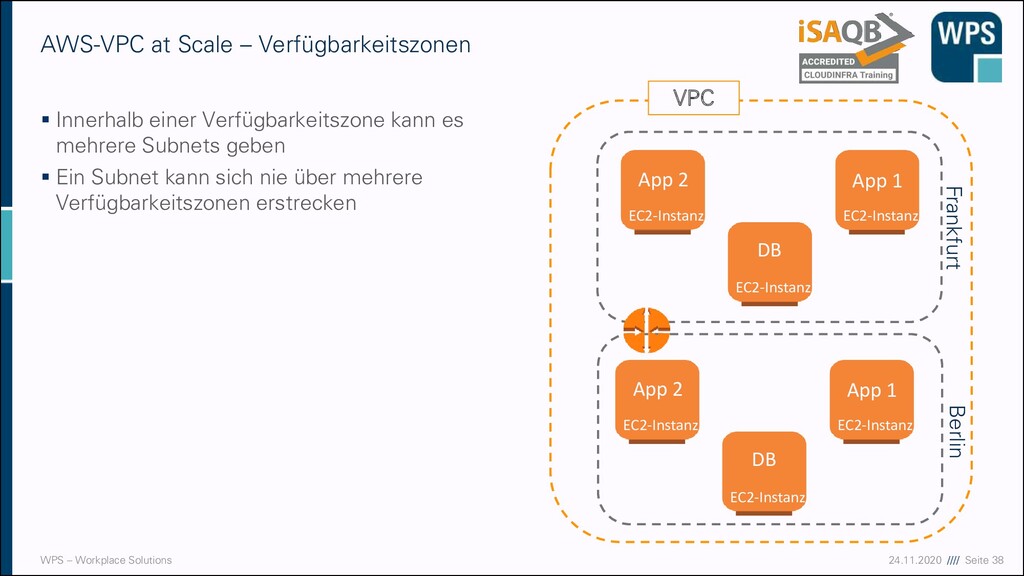{kind=link}
{kind=link}
{kind=link}
{kind=link}
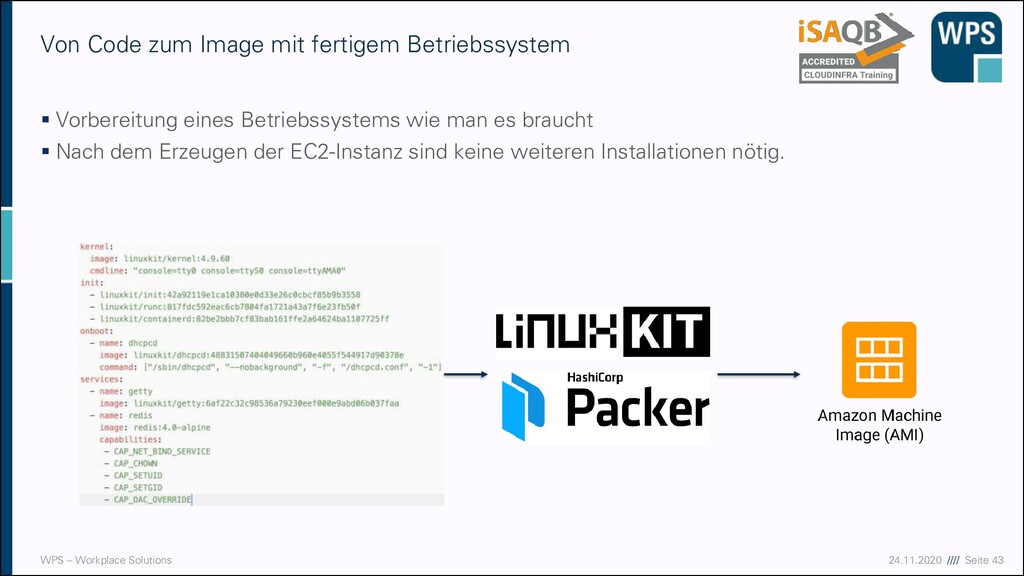{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
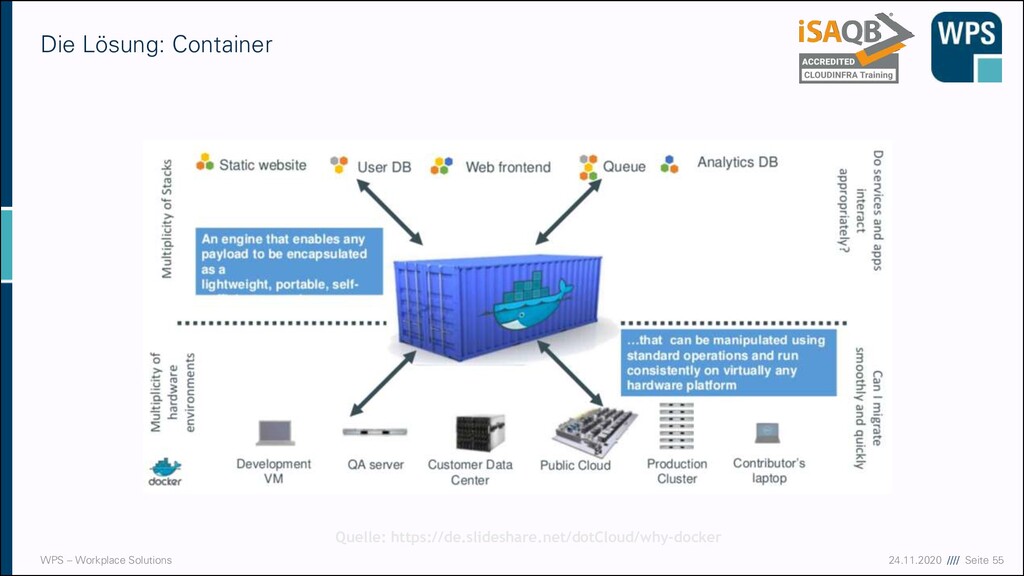{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
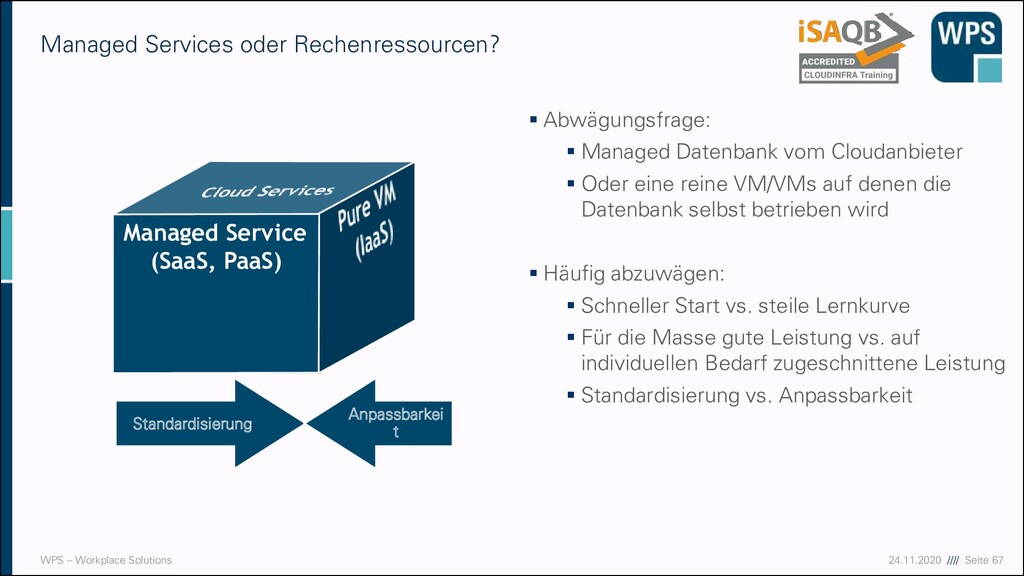{kind=link}
{kind=link}
{kind=link}
{kind=link}
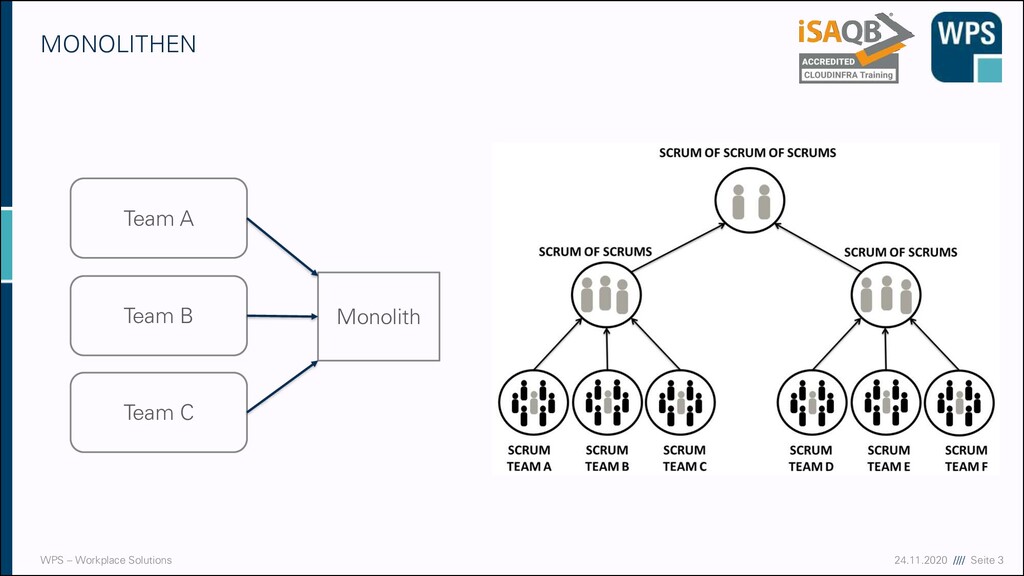{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
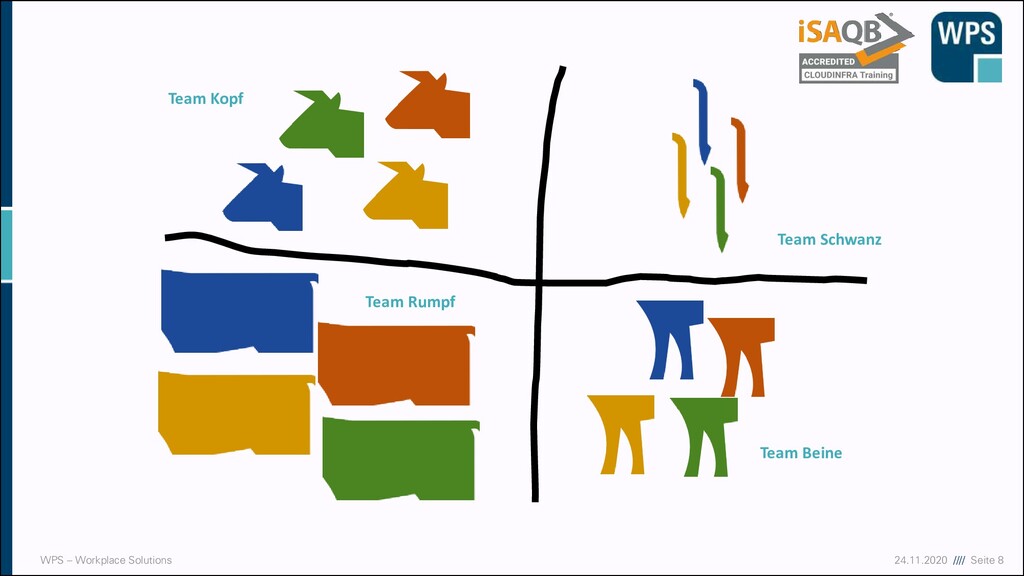{kind=link}
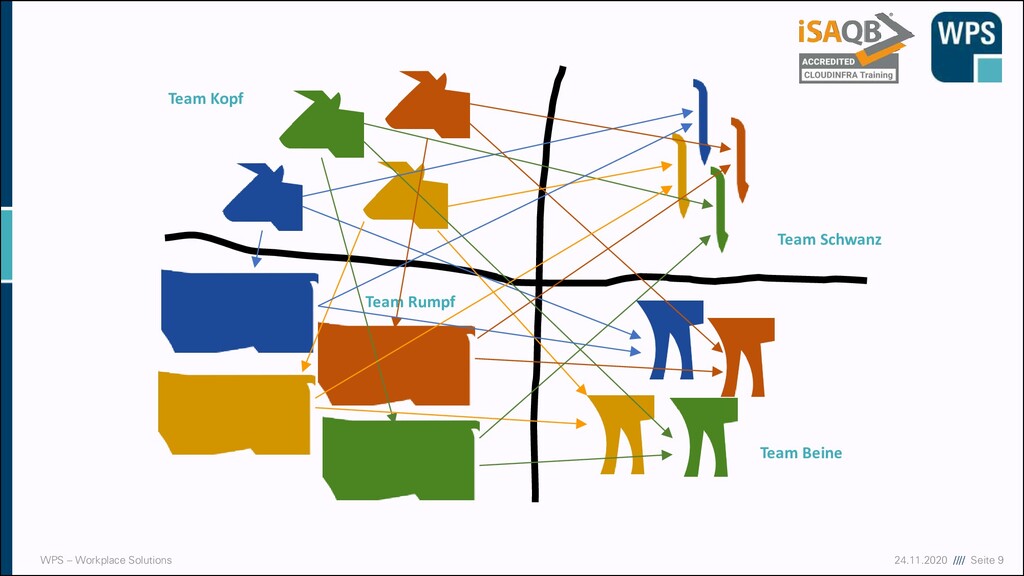{kind=link}
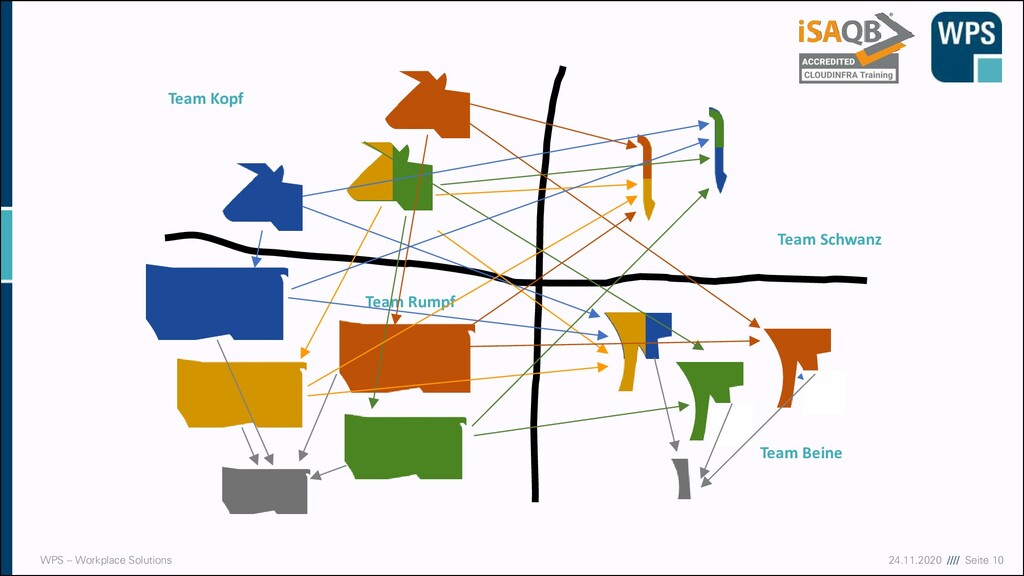{kind=link}
{kind=link}
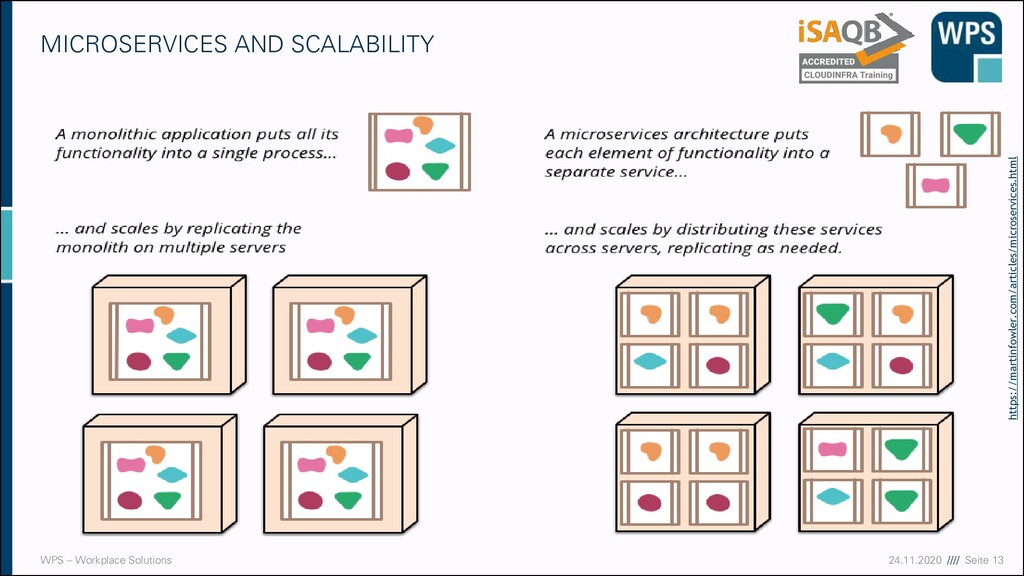{kind=link}
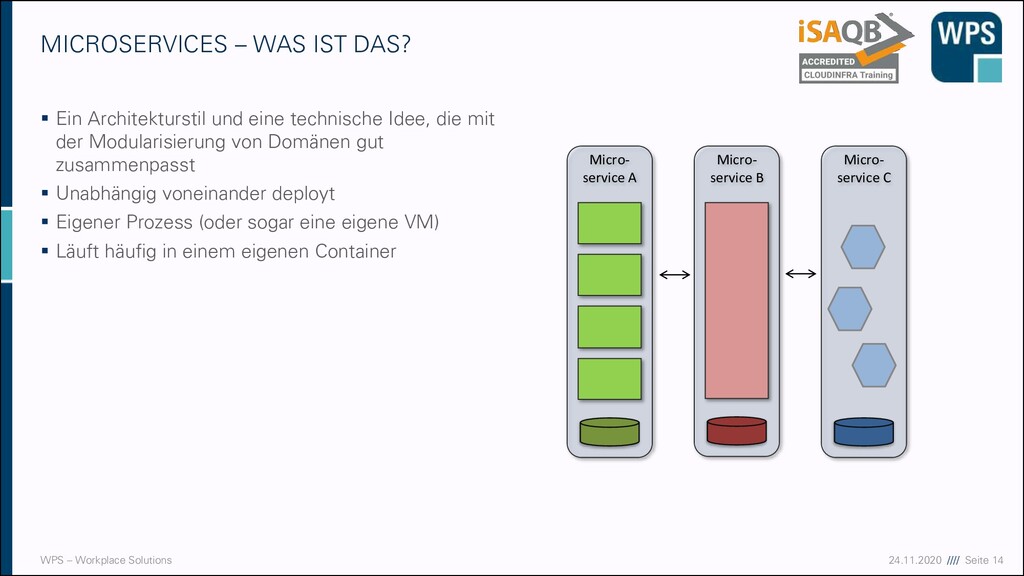{kind=link}
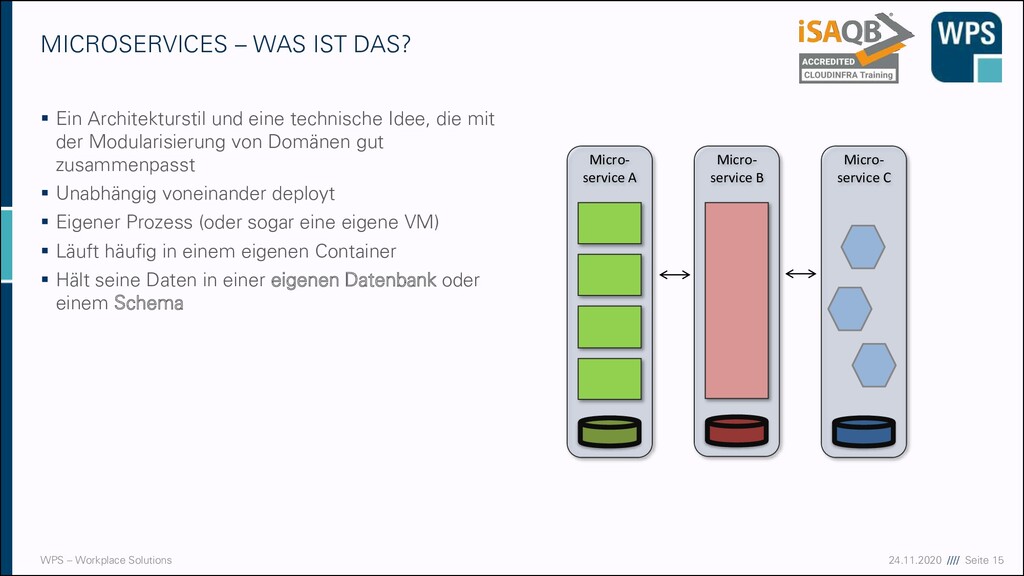{kind=link}
{kind=link}
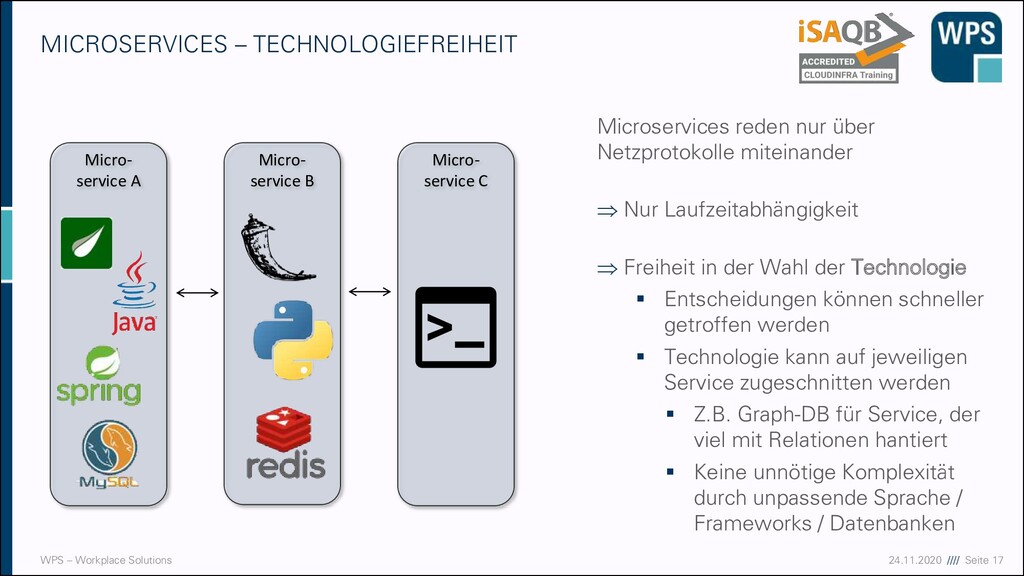{kind=link}
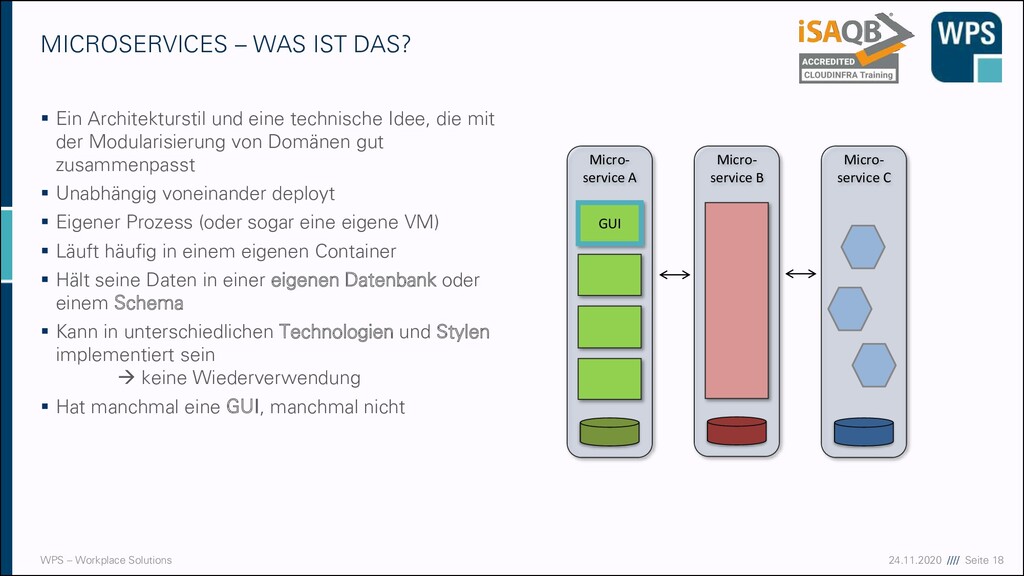{kind=link}
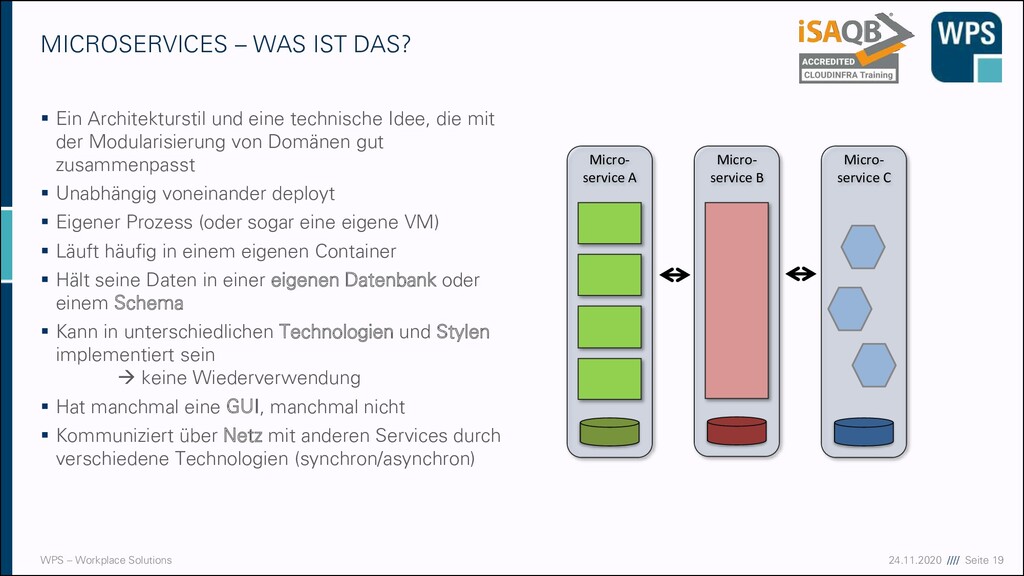{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
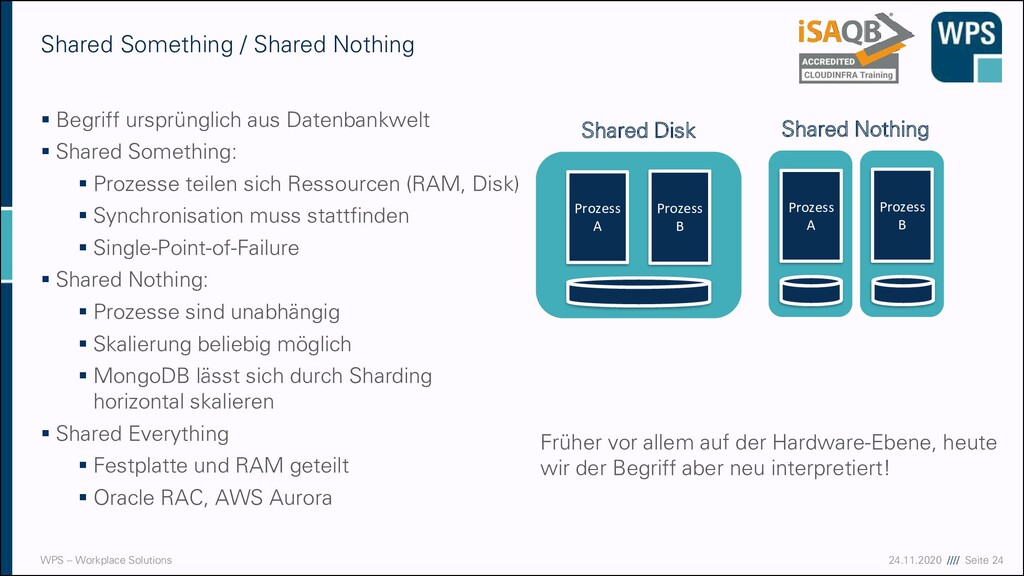{kind=link}
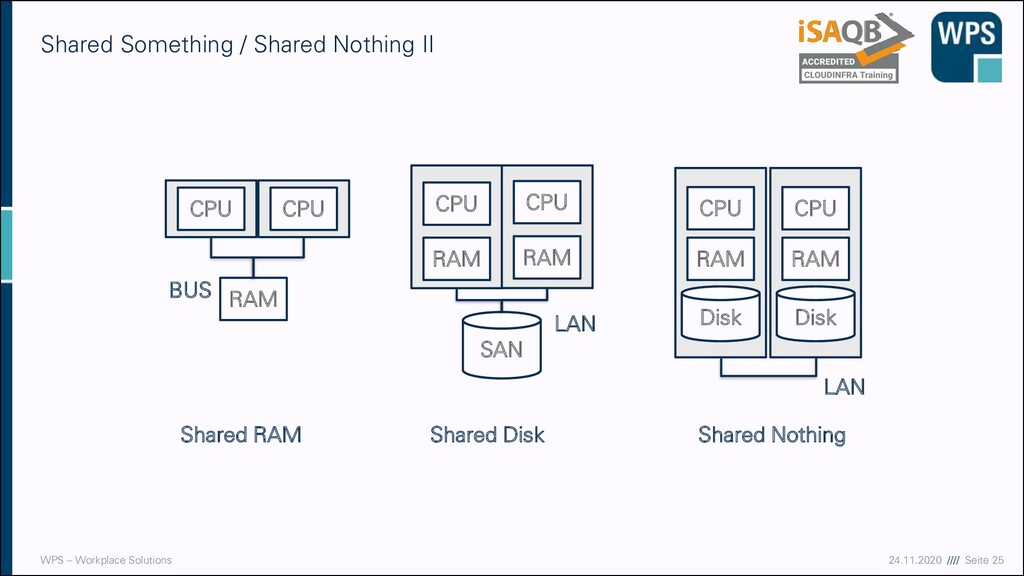{kind=link}
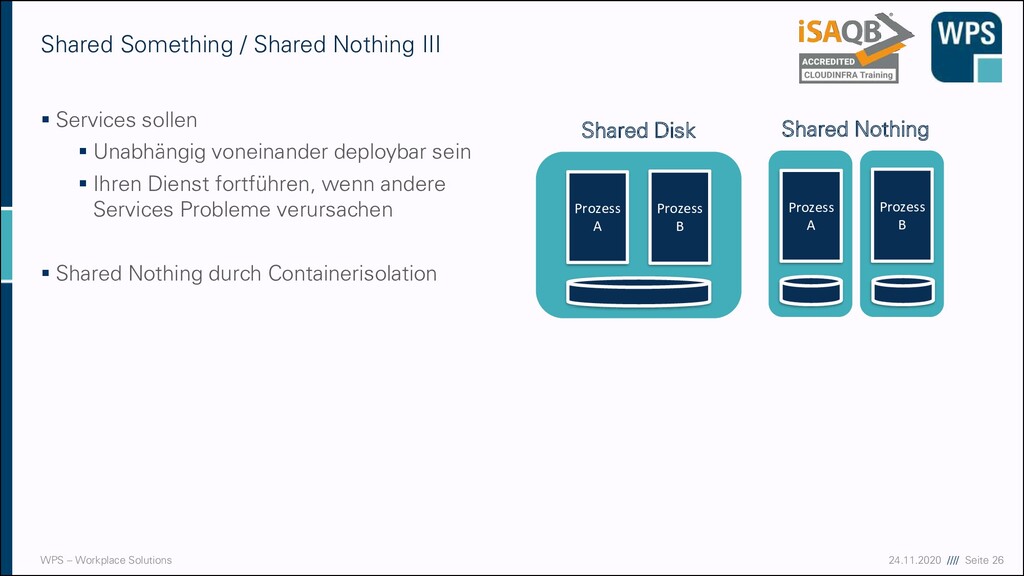{kind=link}
{kind=link}
{kind=link}
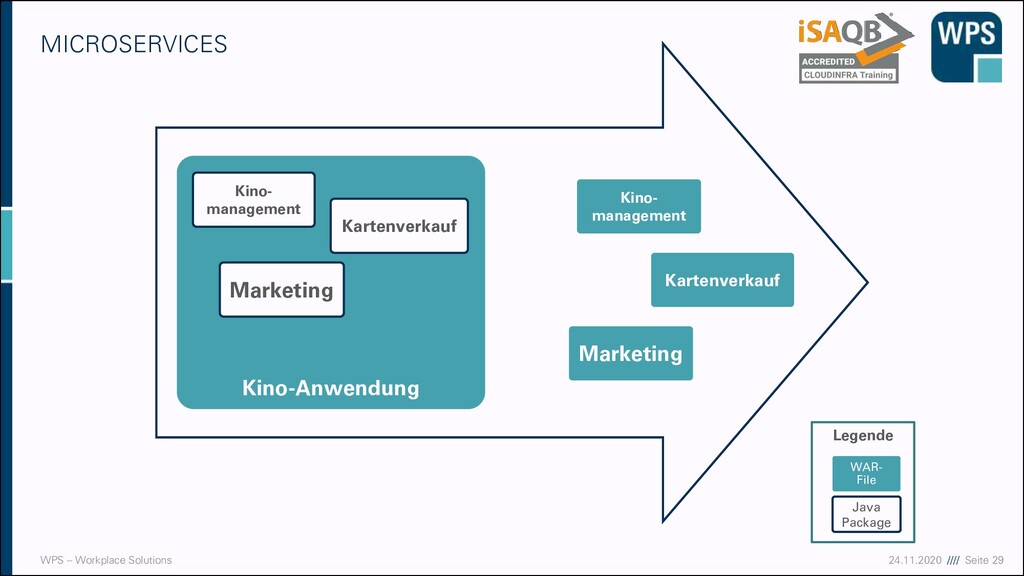{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
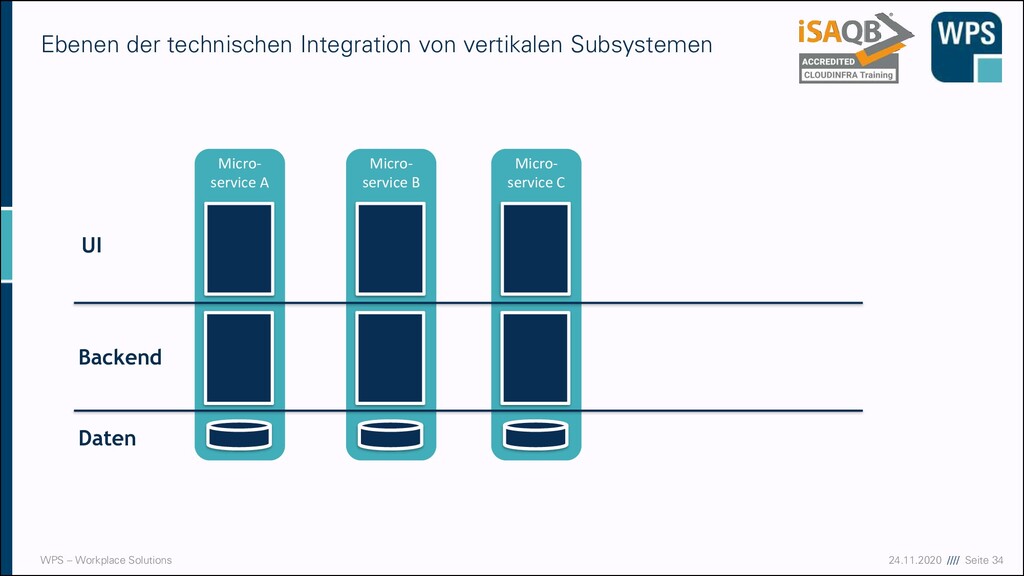{kind=link}
{kind=link}
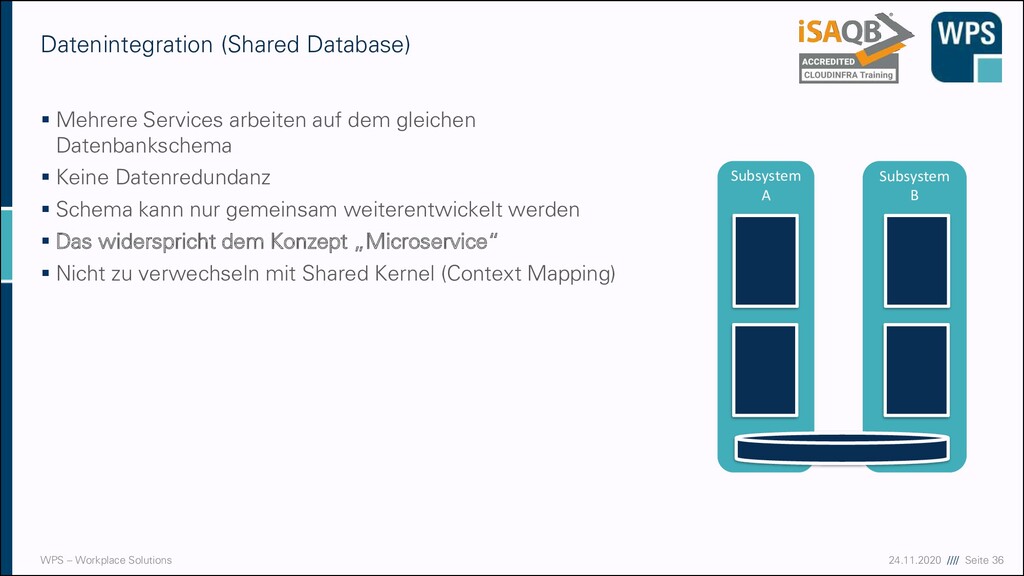{kind=link}
{kind=link}
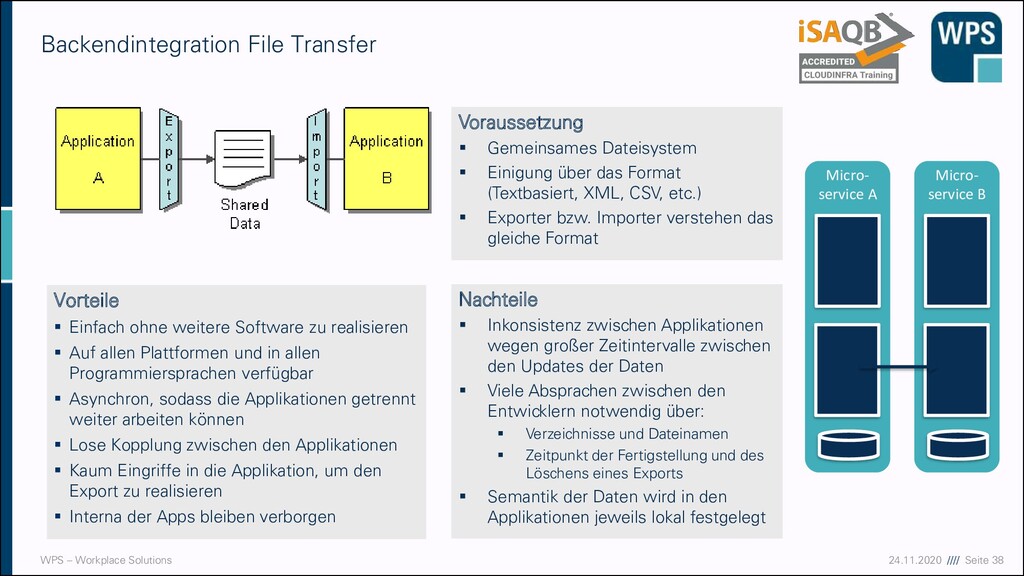{kind=link}
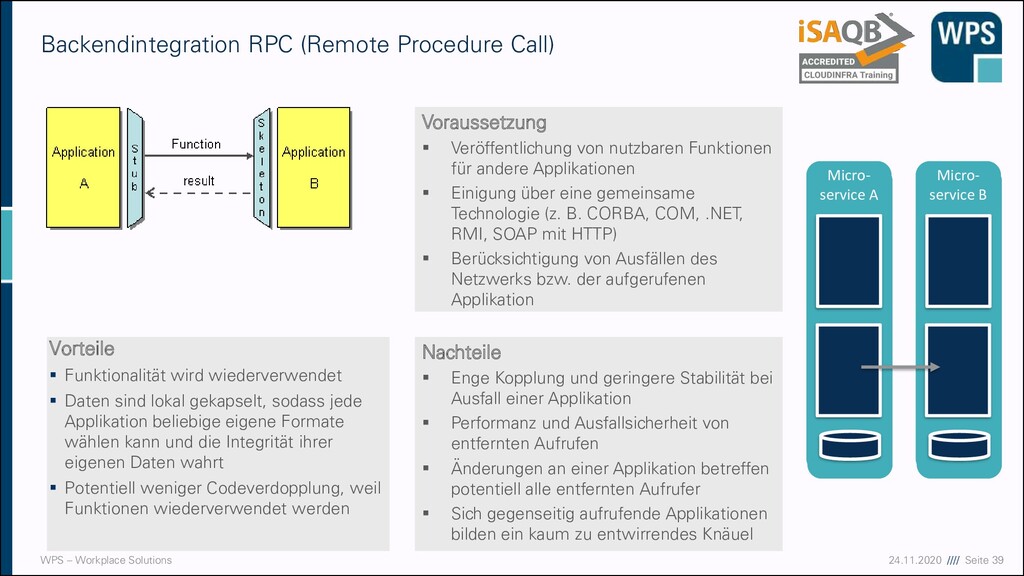{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
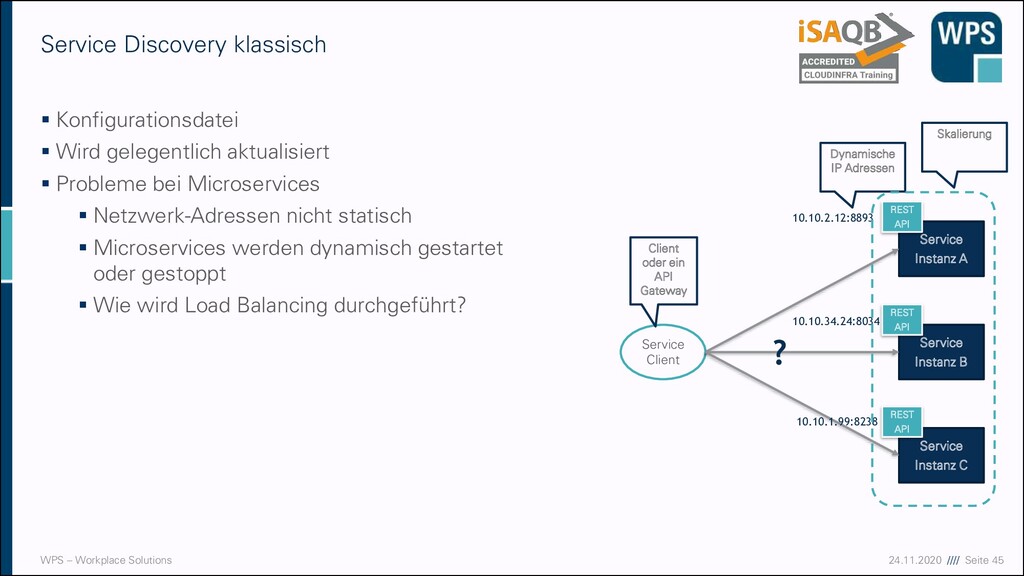{kind=link}
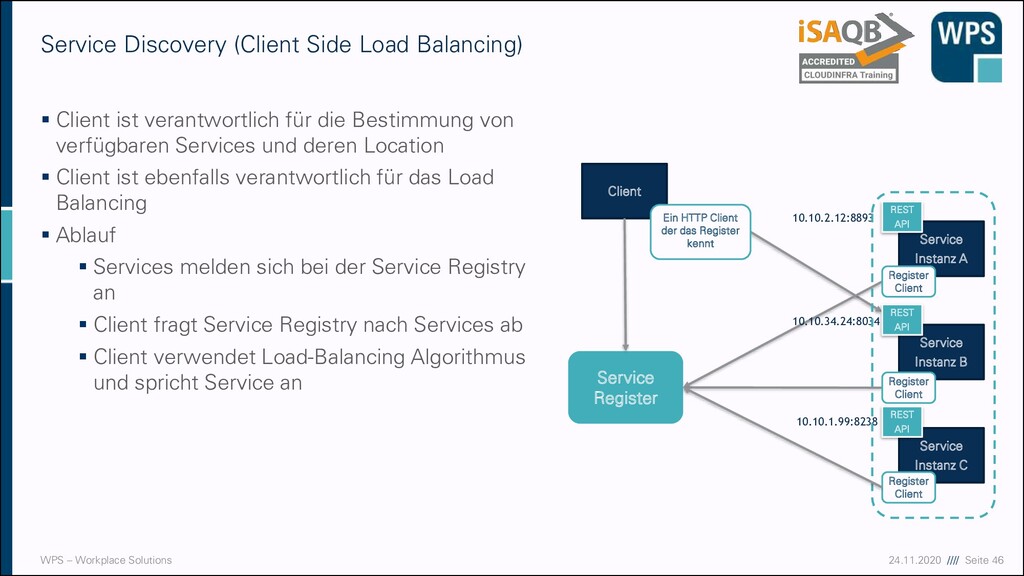{kind=link}
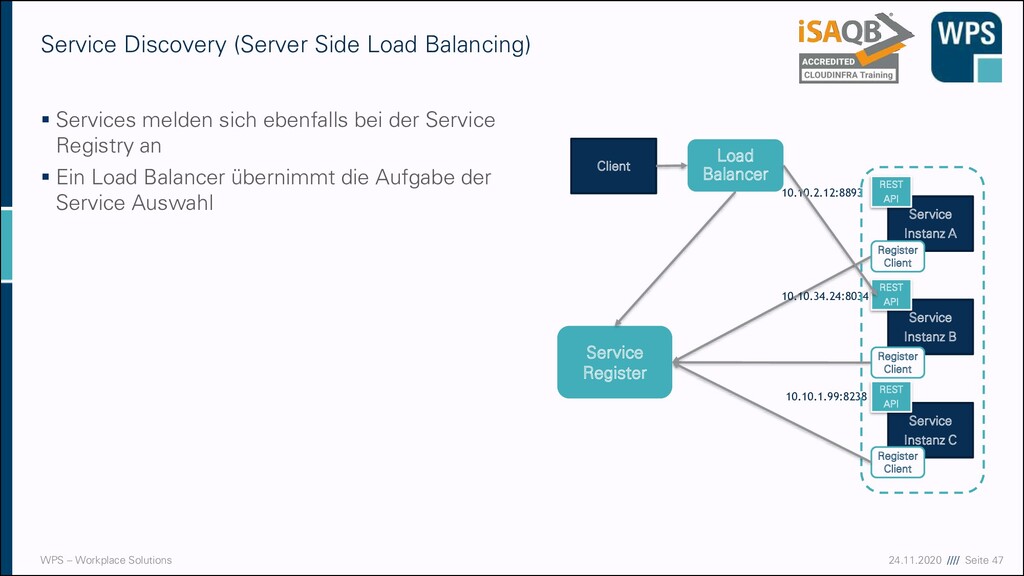{kind=link}
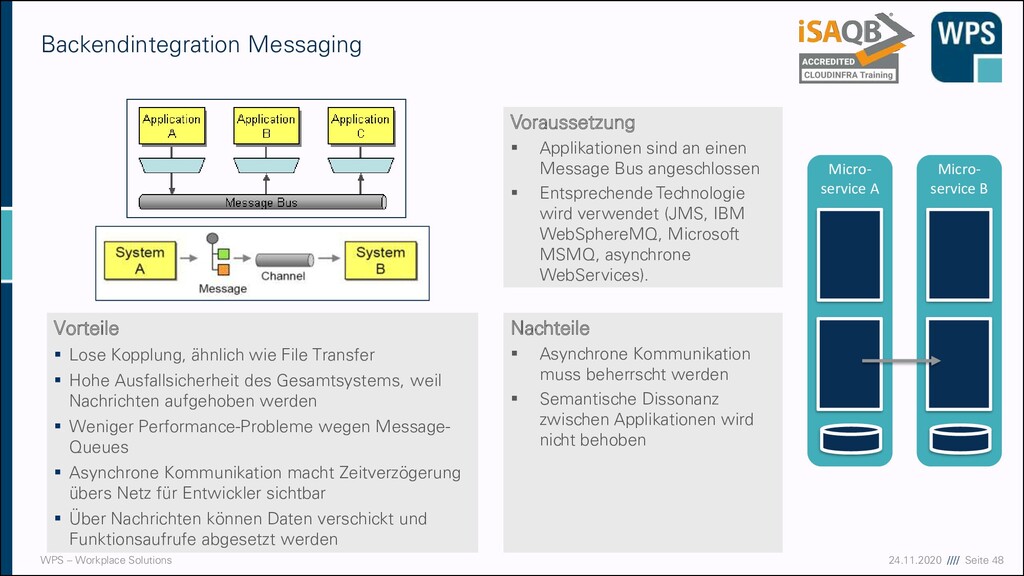{kind=link}
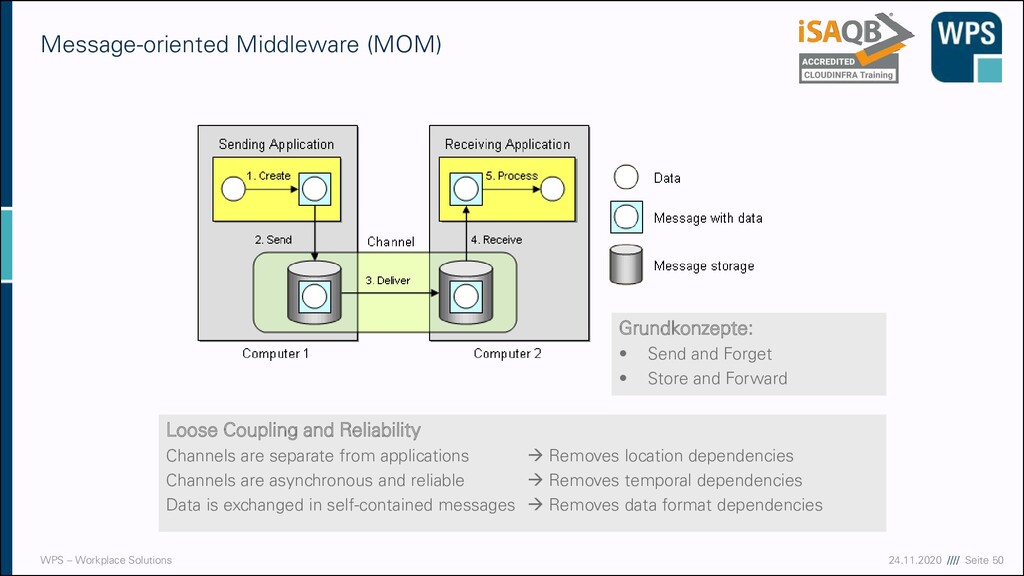{kind=link}
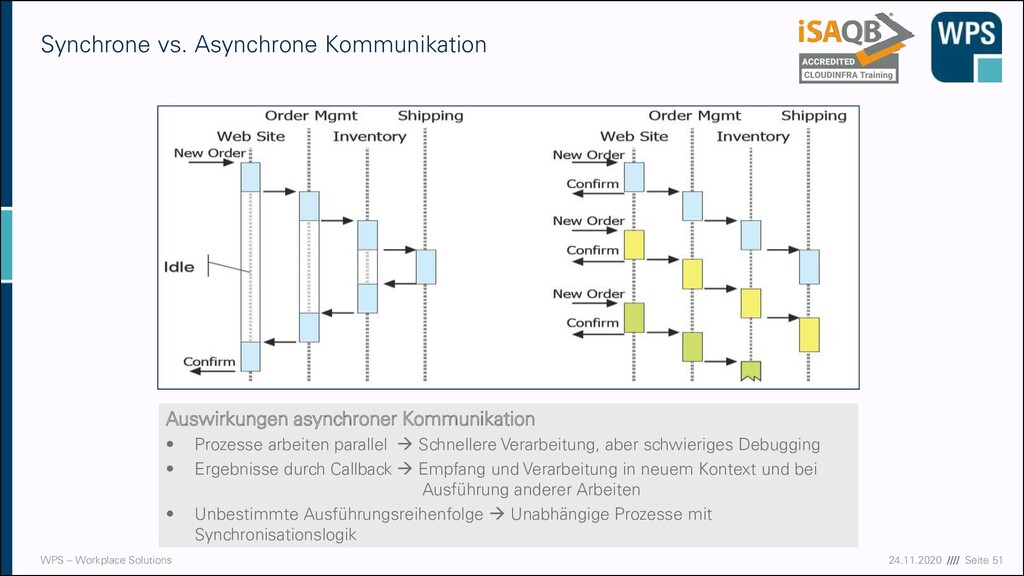{kind=link}
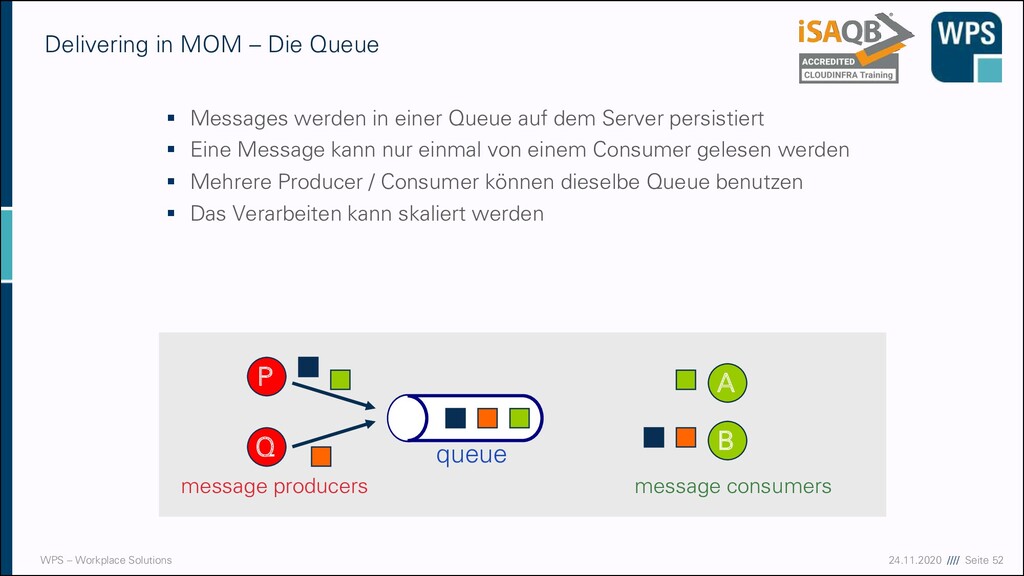{kind=link}
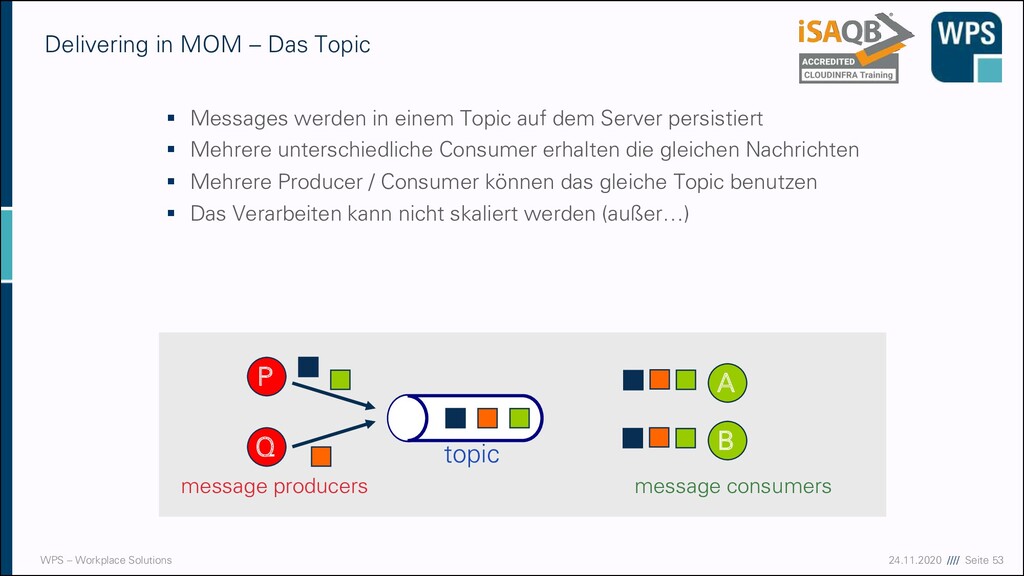{kind=link}
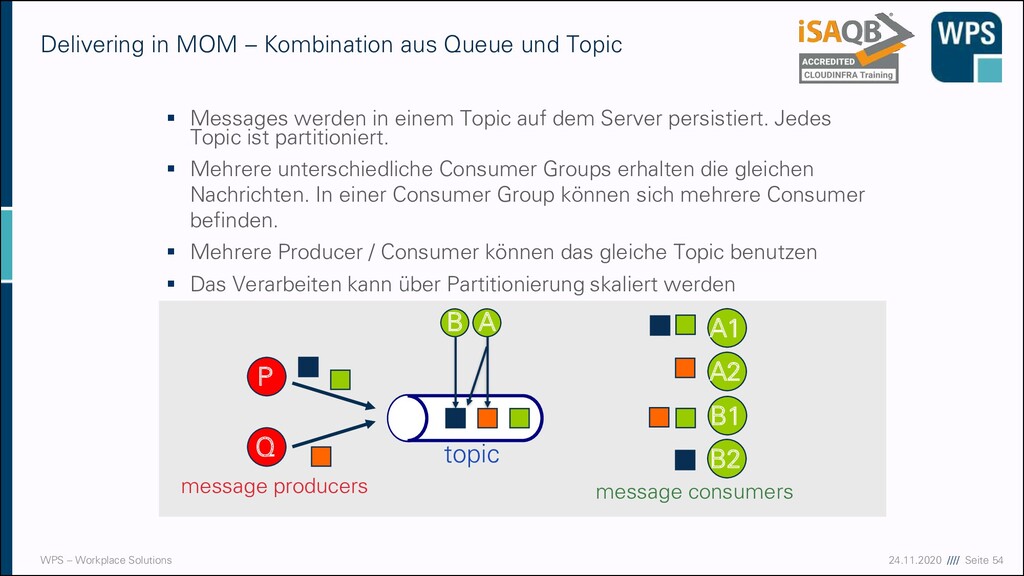{kind=link}
{kind=link}
{kind=link}
{kind=link}
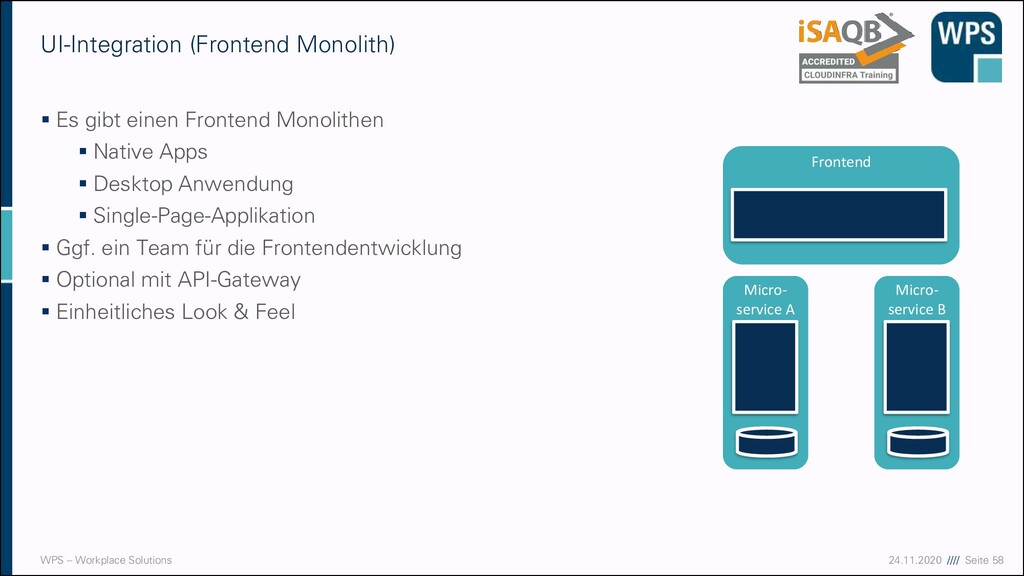{kind=link}
{kind=link}
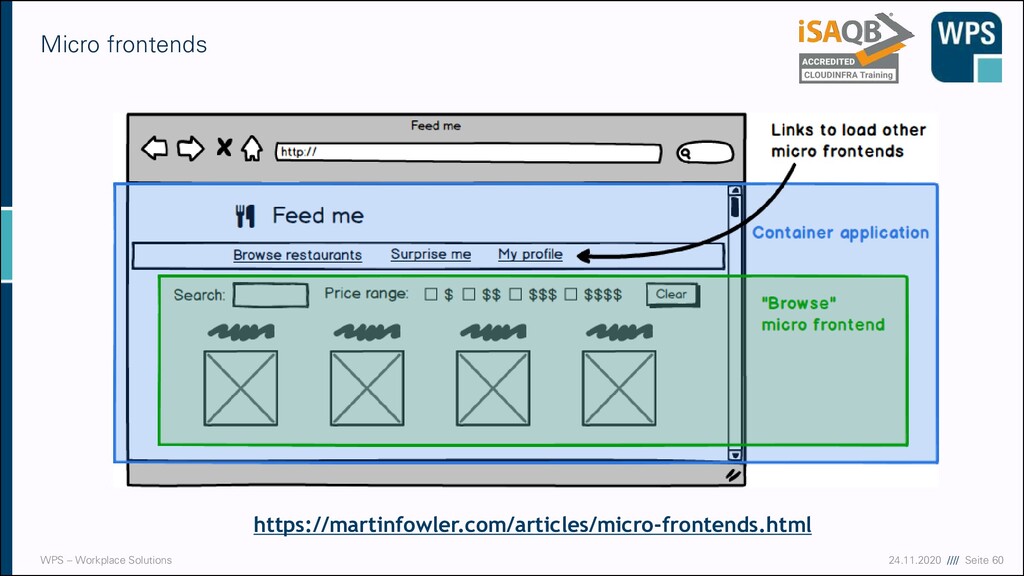{kind=link}
{kind=link}
{kind=link}
{kind=link}
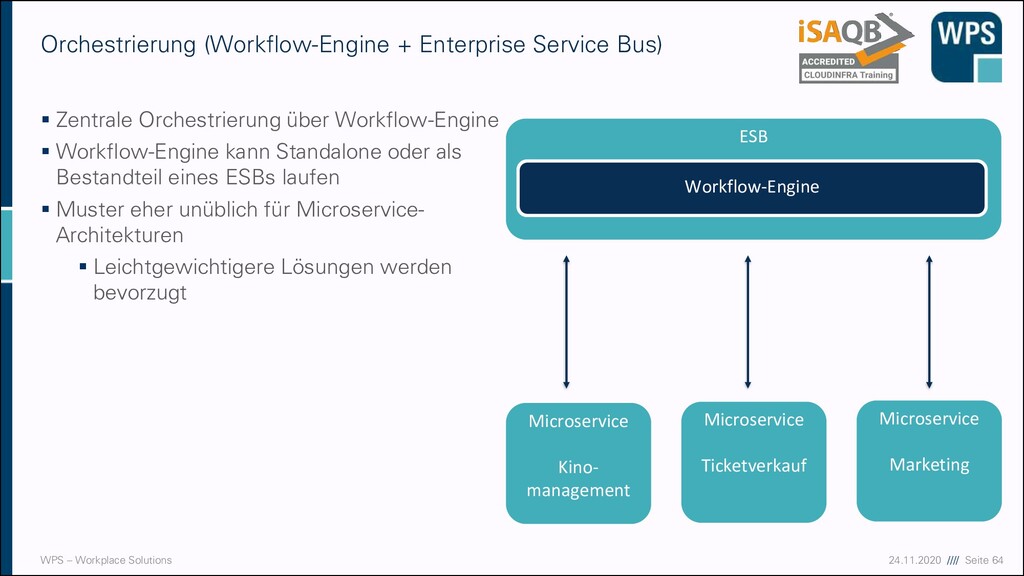{kind=link}
{kind=link}
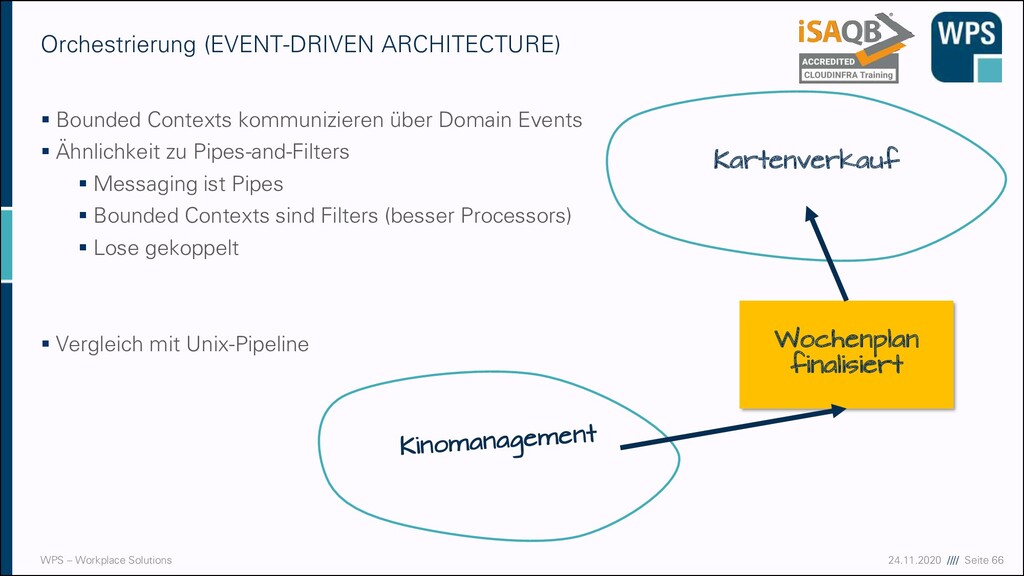{kind=link}
{kind=link}
{kind=link}
{kind=link}
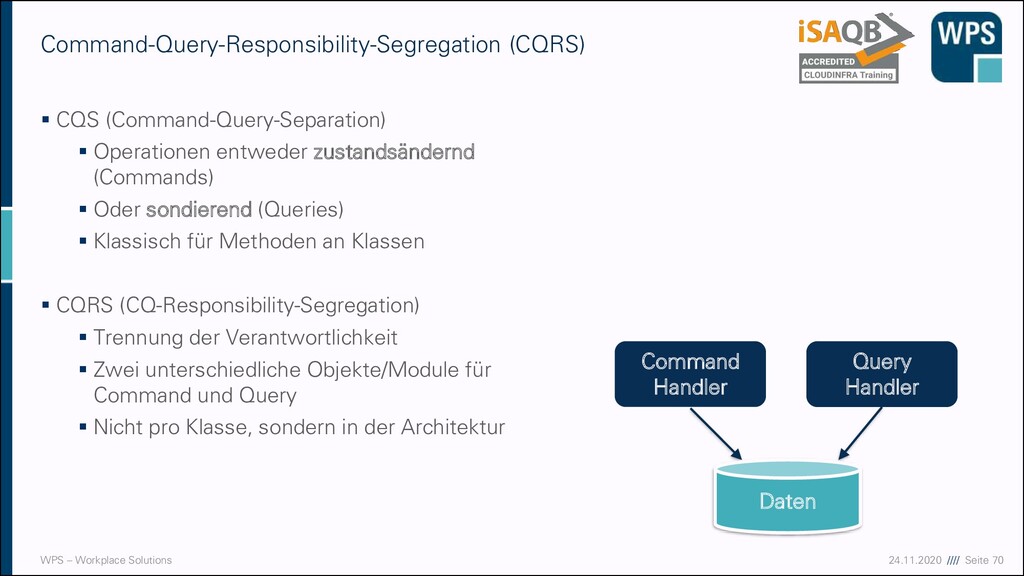{kind=link}
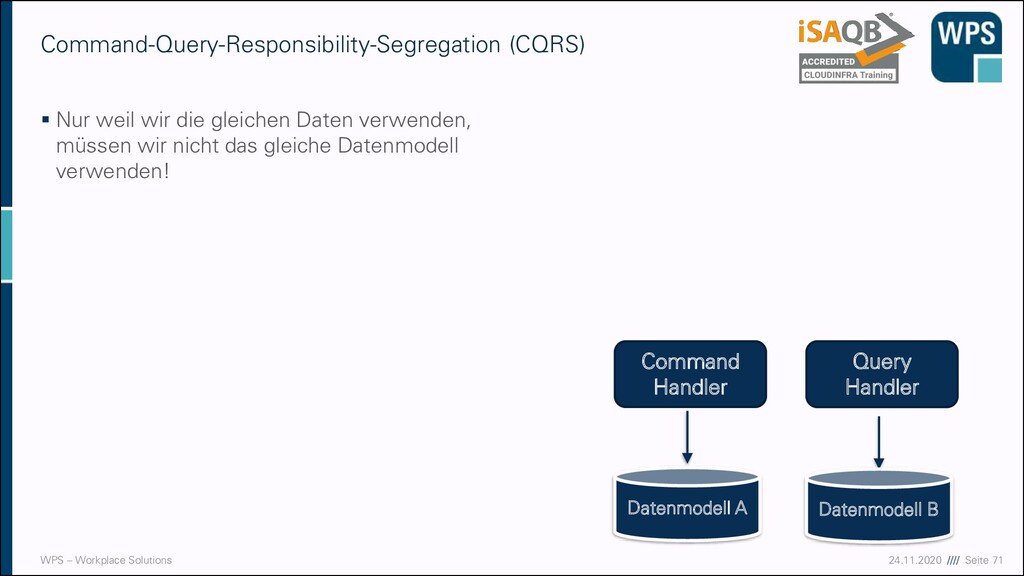{kind=link}
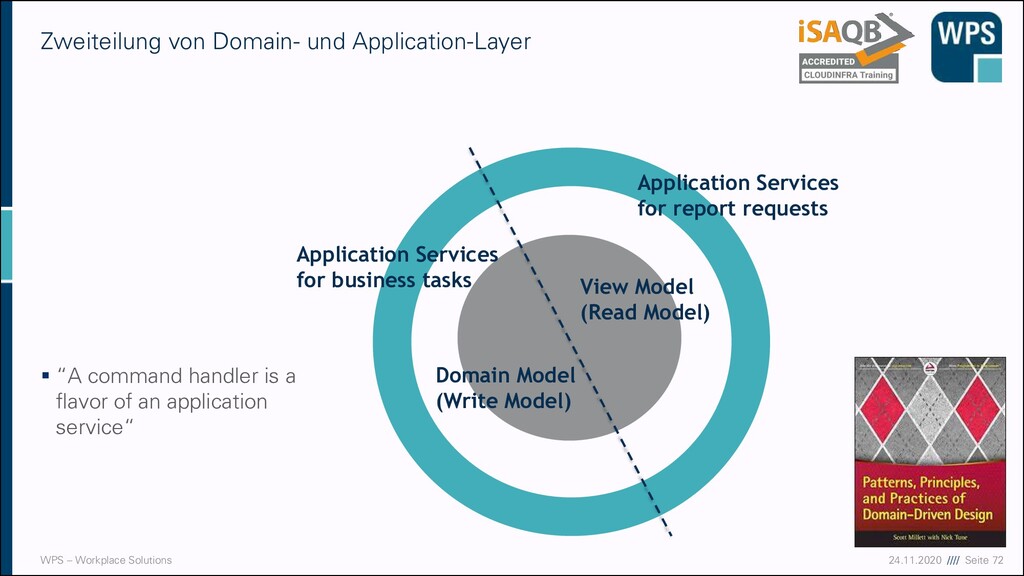{kind=link}
{kind=link}
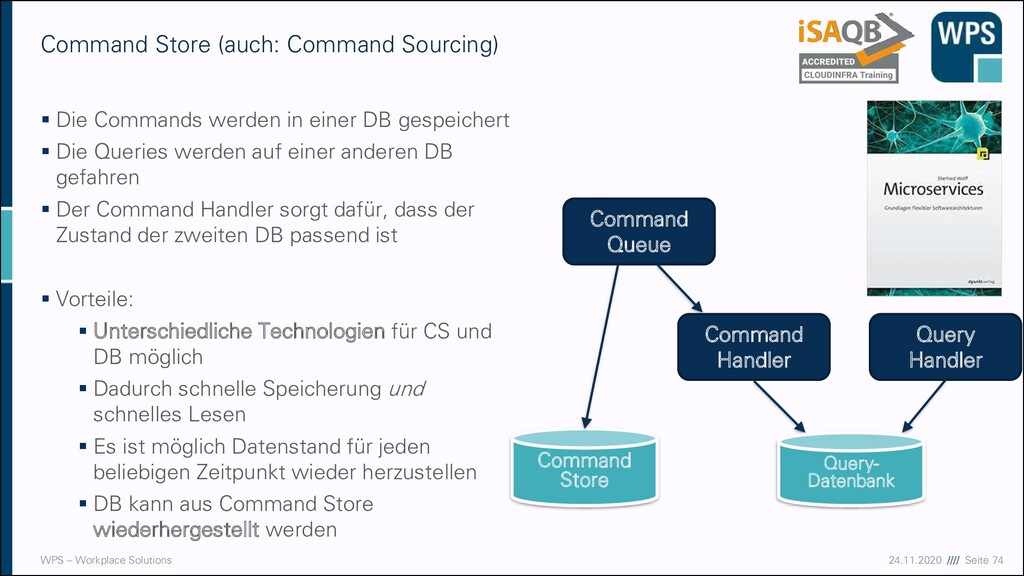{kind=link}
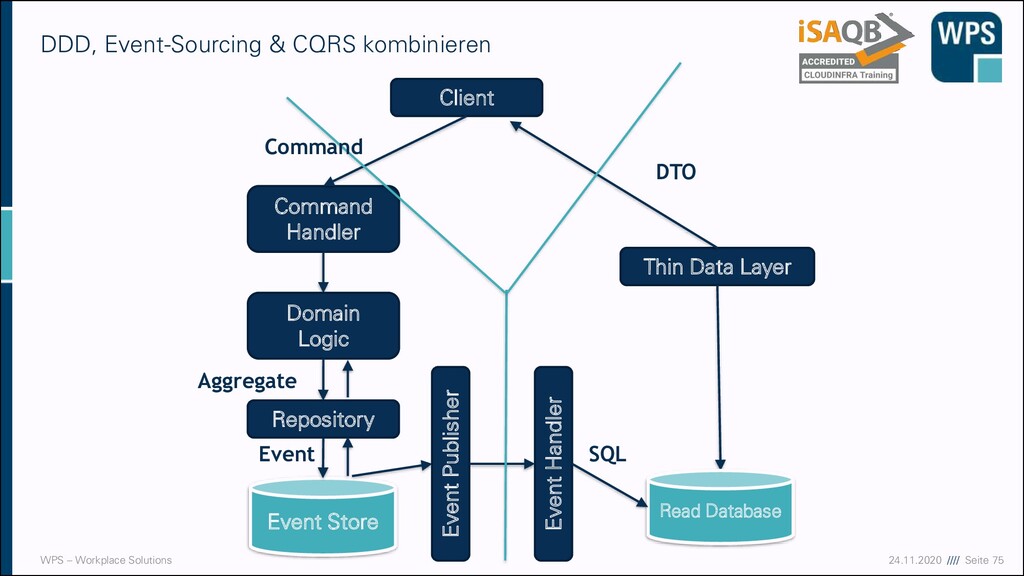{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
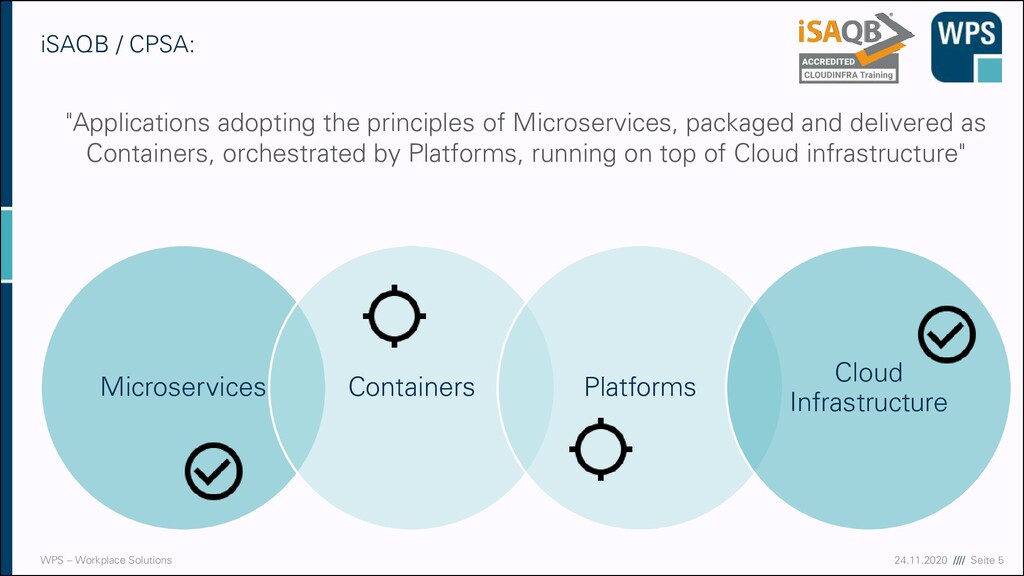{kind=link}
{kind=link}
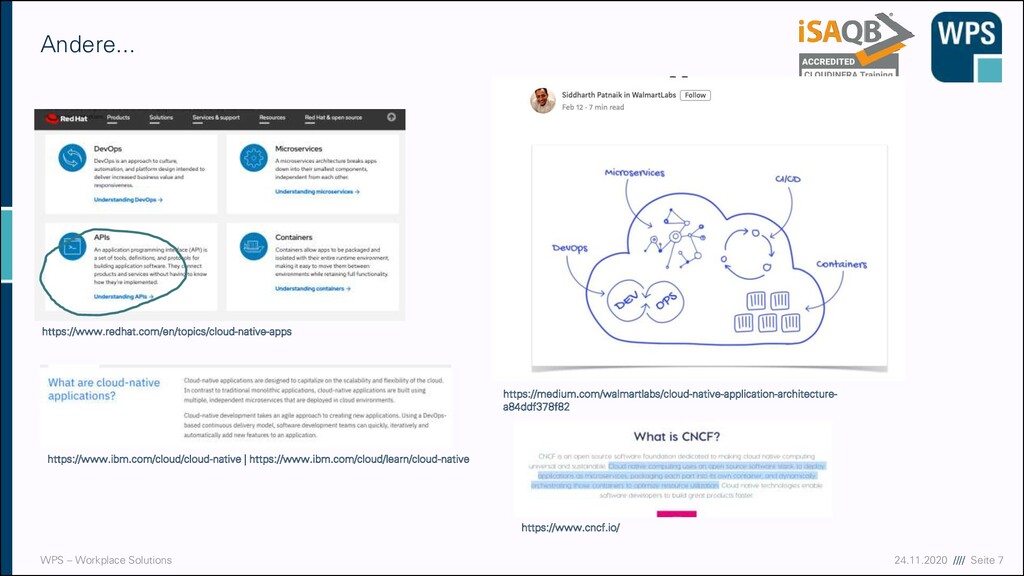{kind=link}
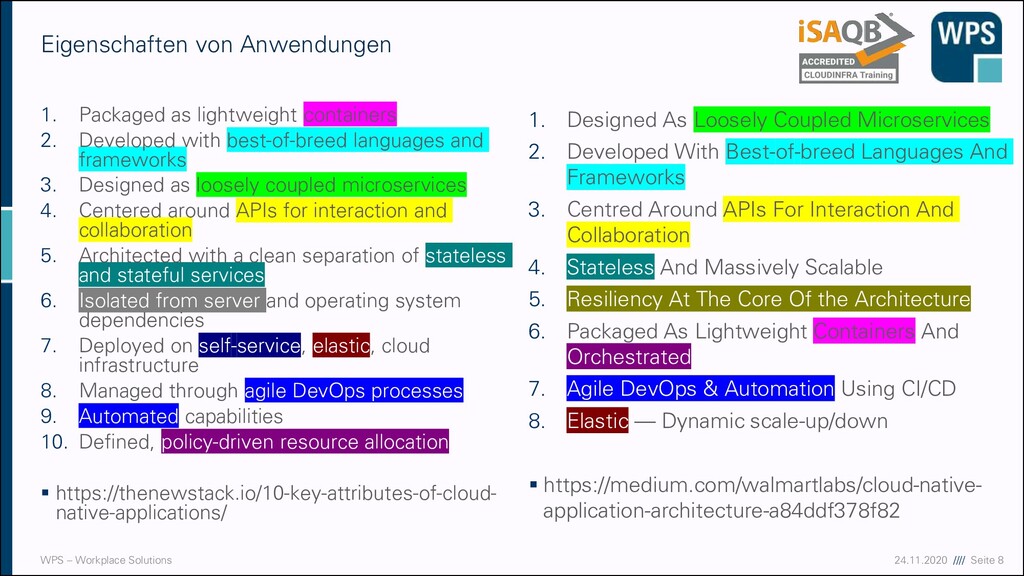{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
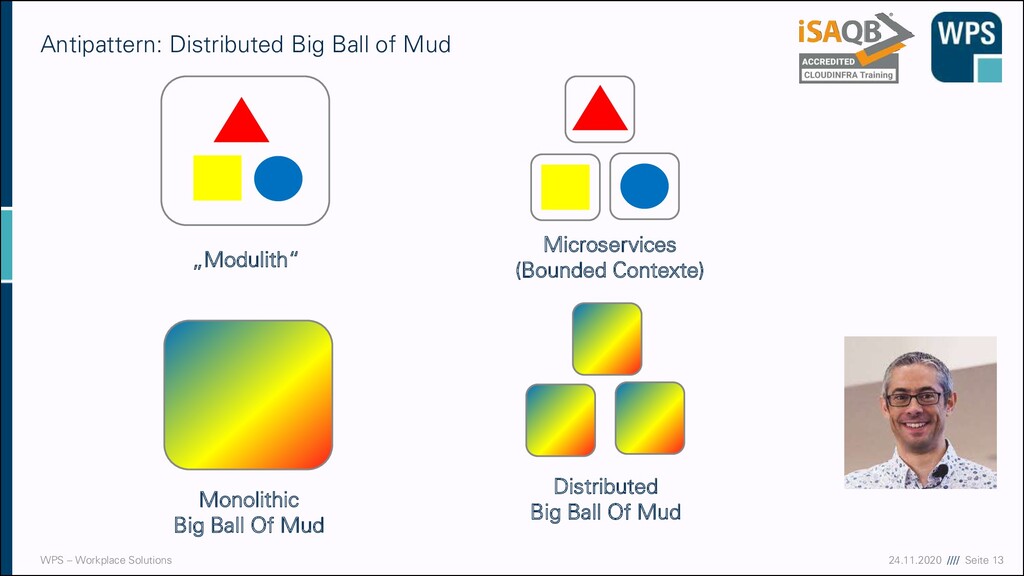{kind=link}
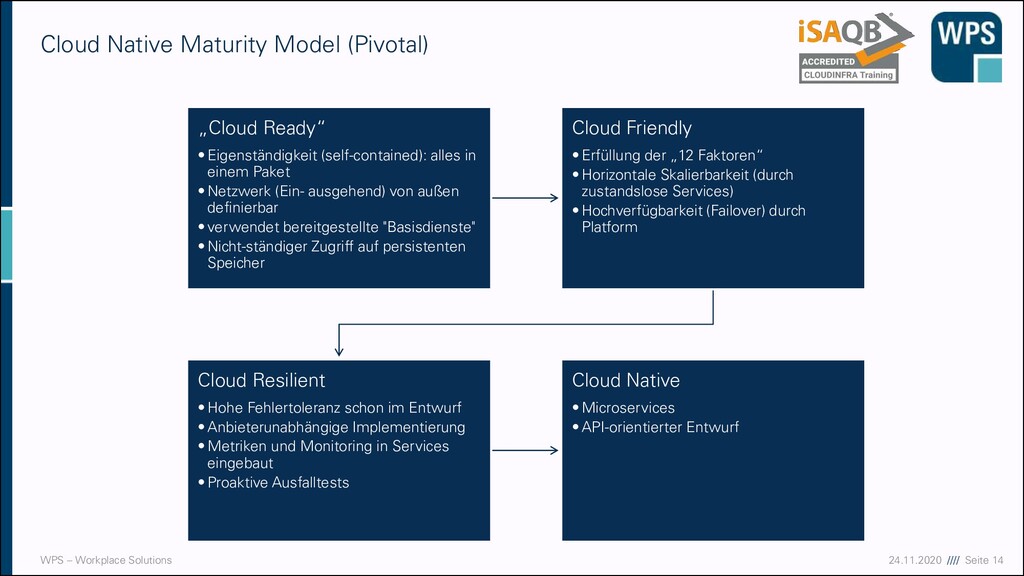{kind=link}
{kind=link}
{kind=link}
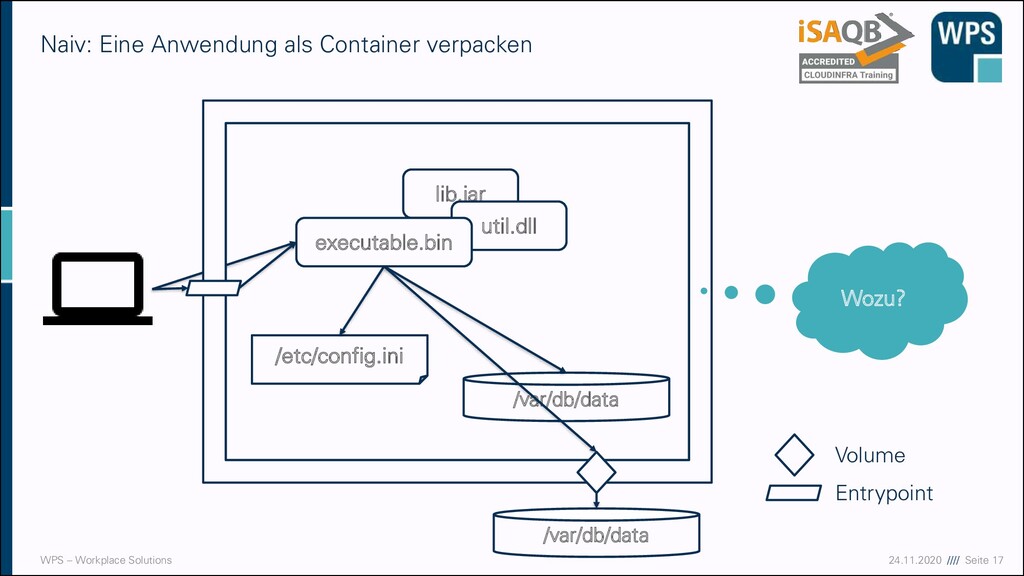{kind=link}
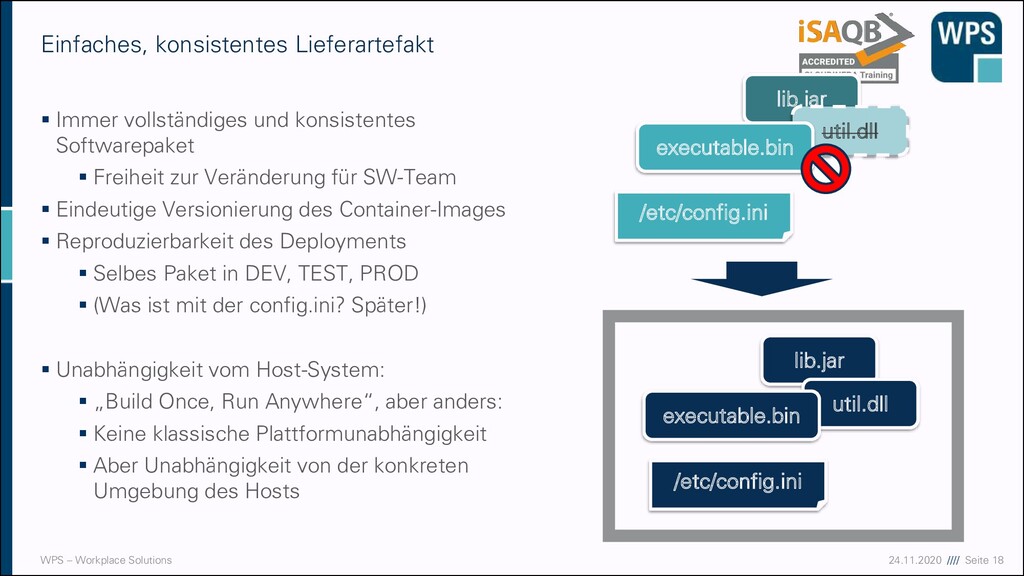{kind=link}
{kind=link}
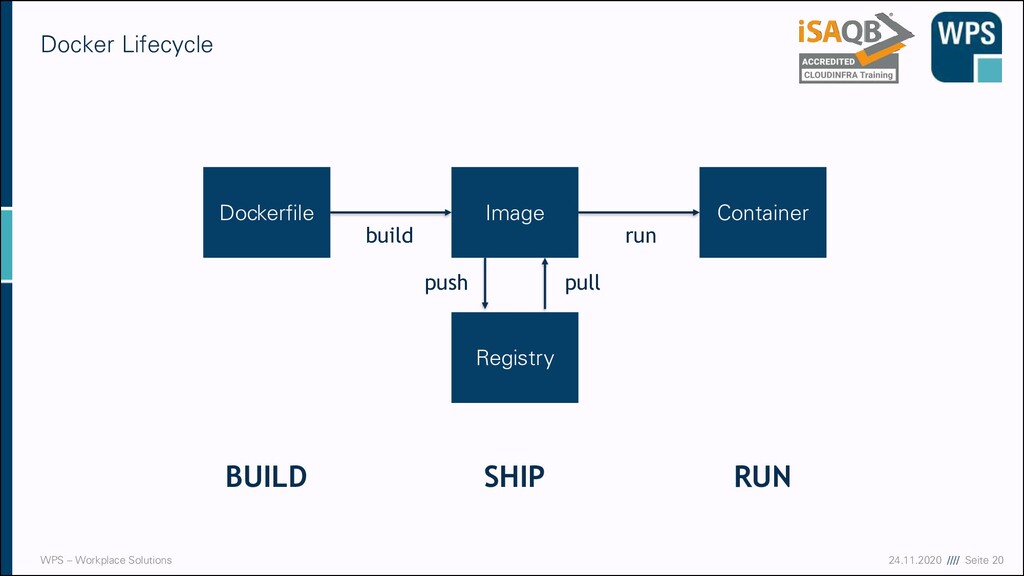{kind=link}
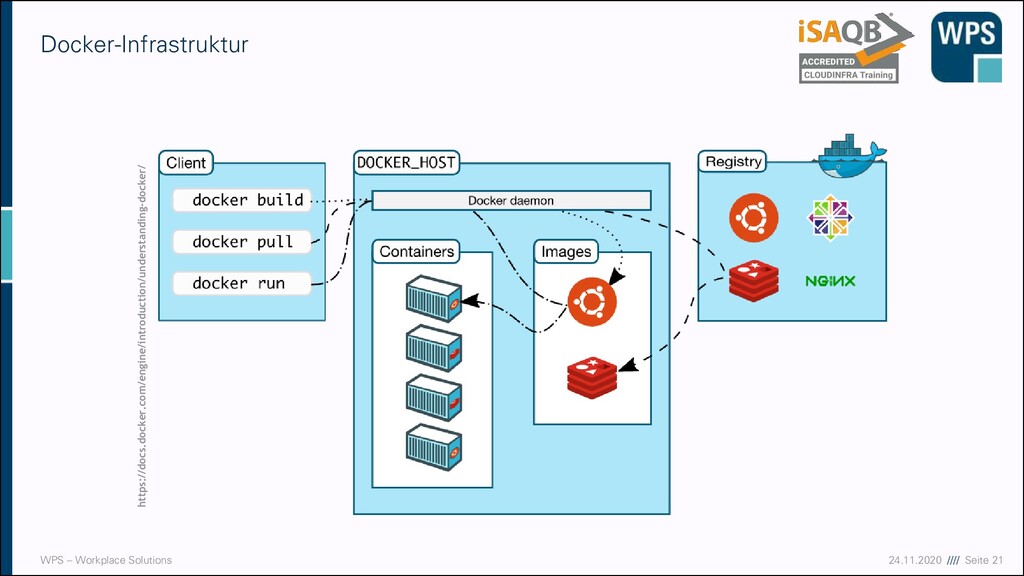{kind=link}
{kind=link}
{kind=link}
{kind=link}
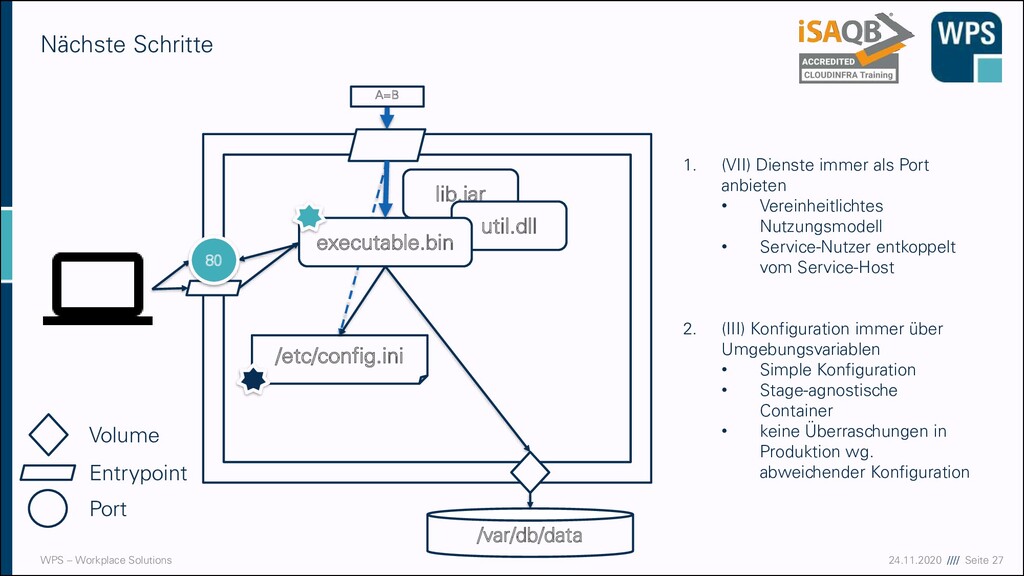{kind=link}
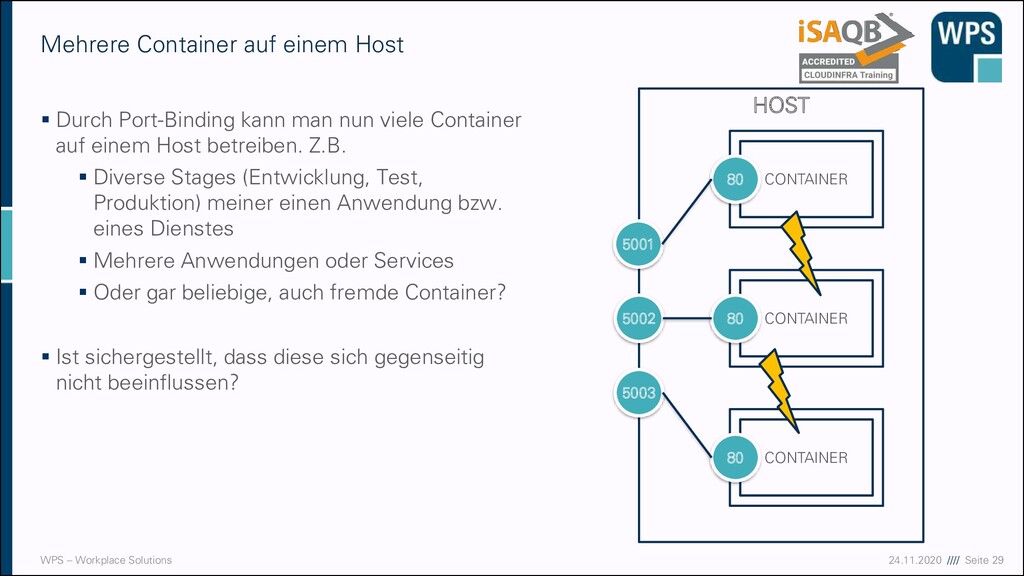{kind=link}
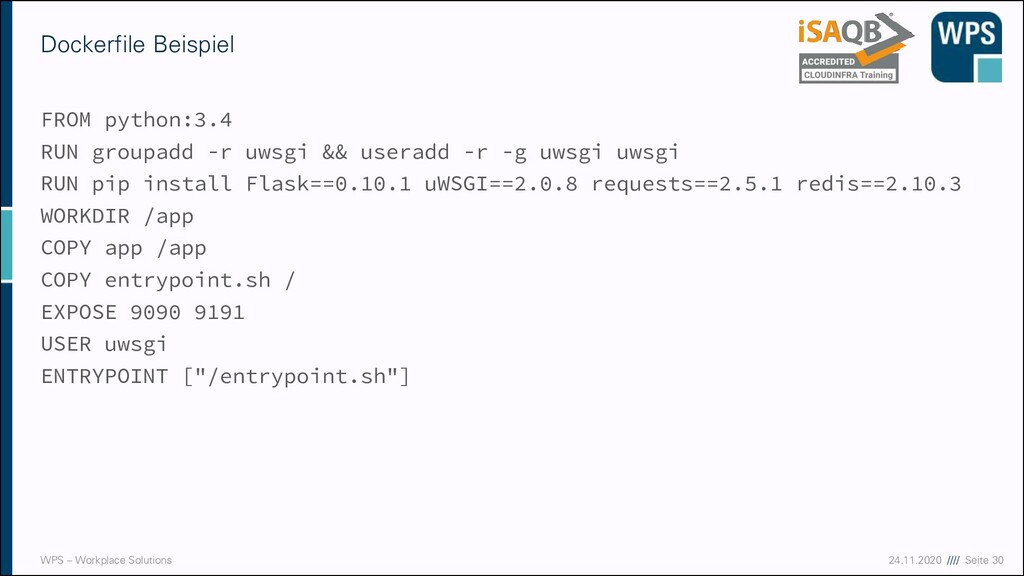{kind=link}
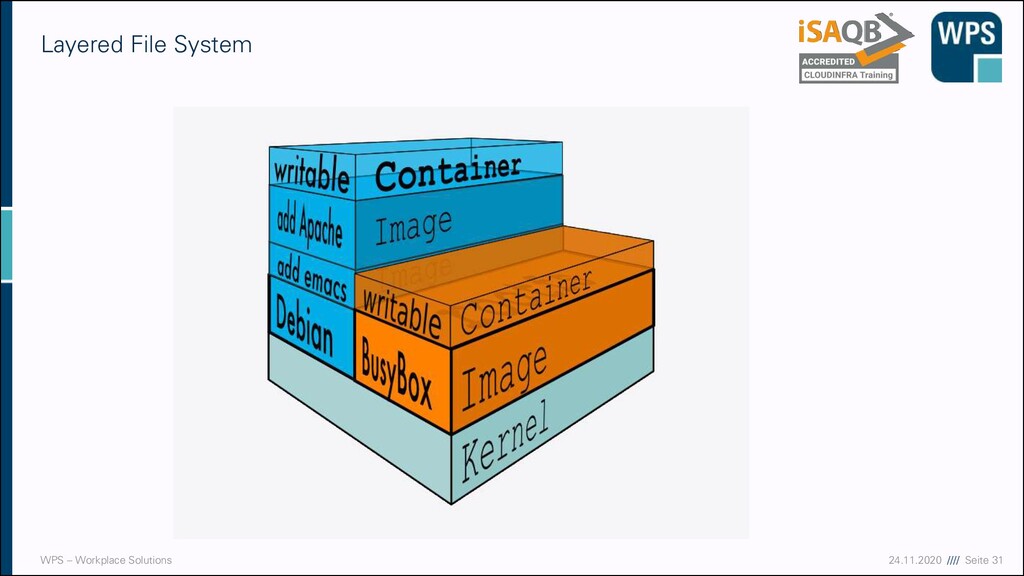{kind=link}
{kind=link}
{kind=link}
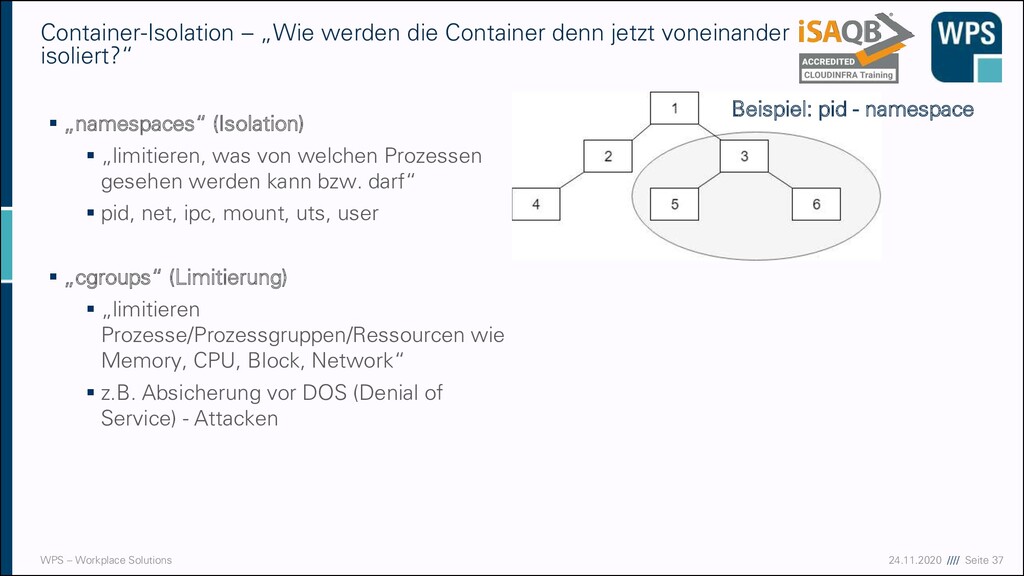{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
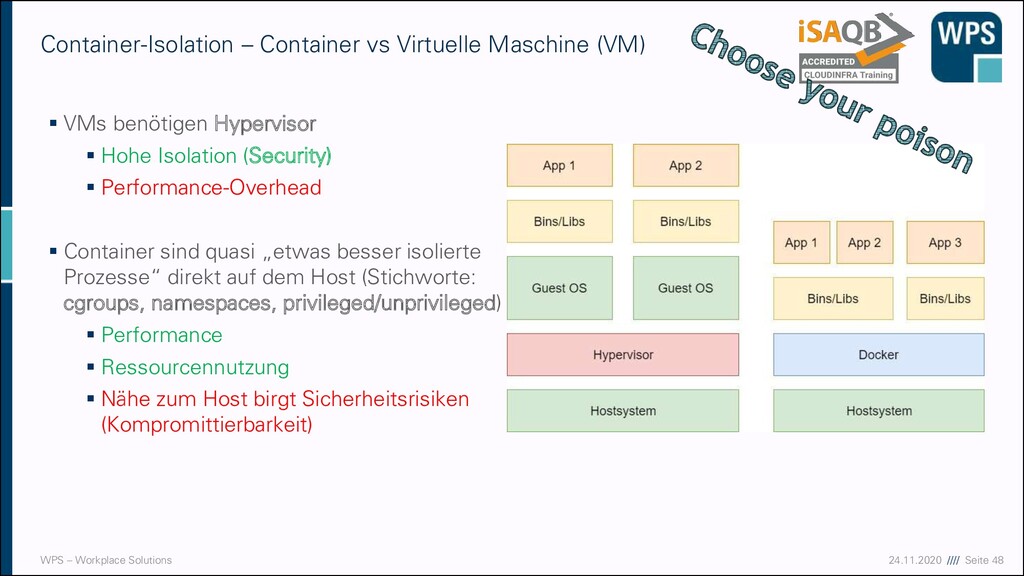{kind=link}
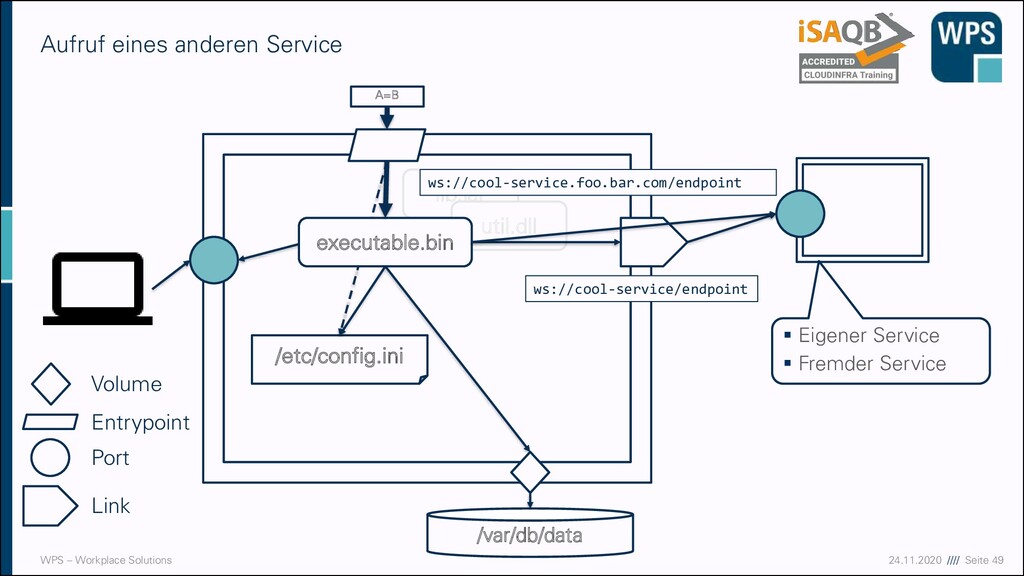{kind=link}
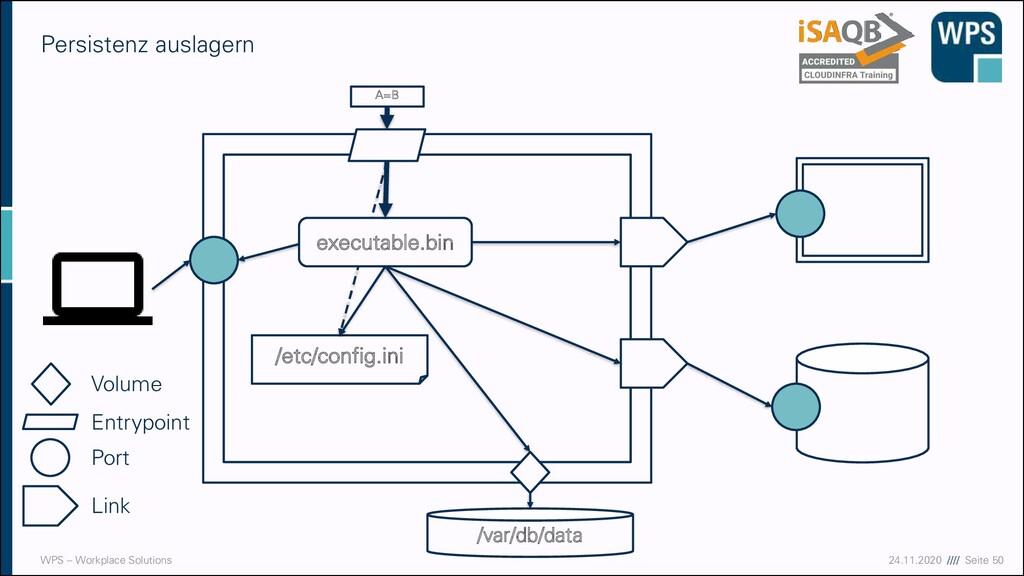{kind=link}
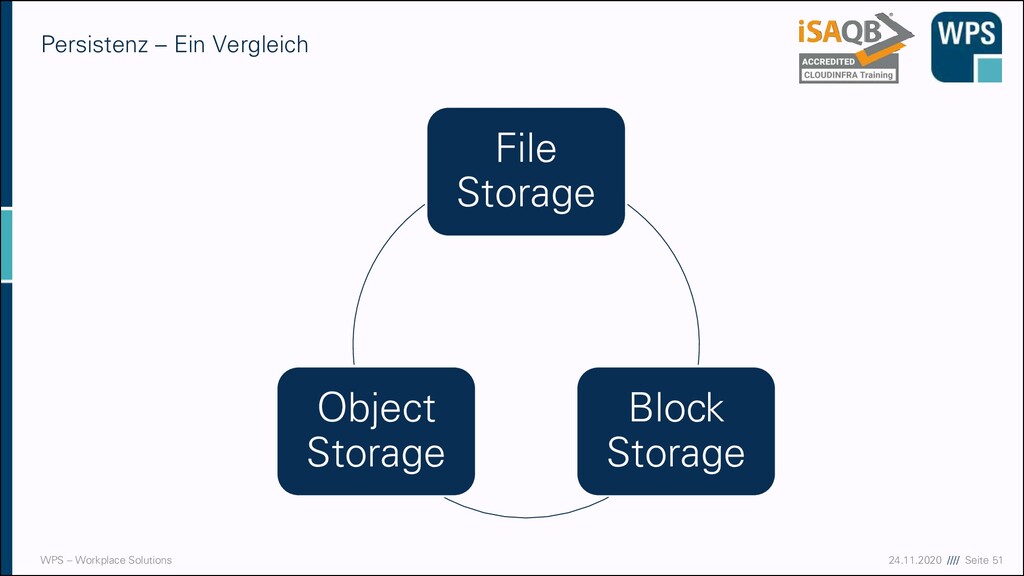{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
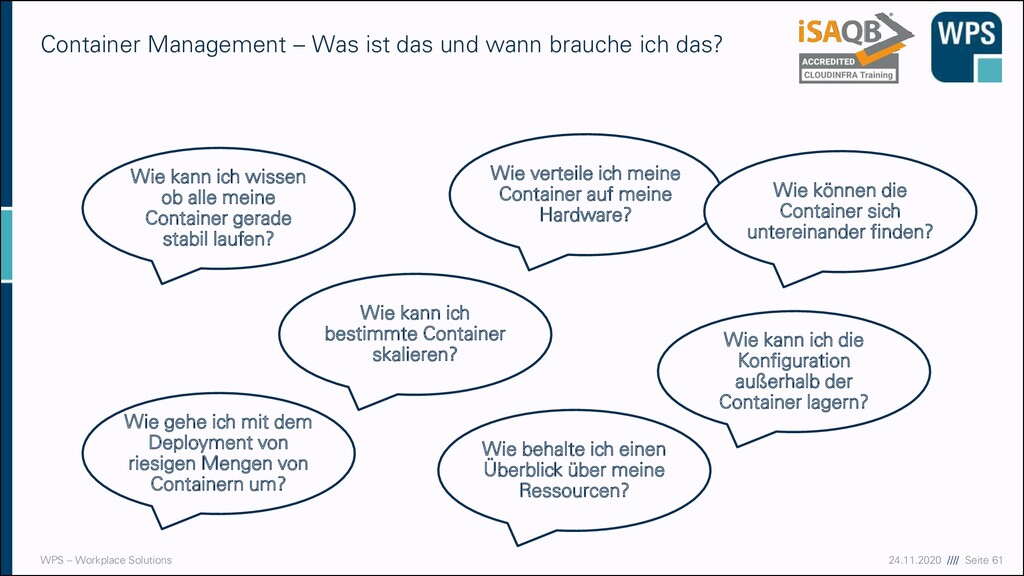{kind=link}
{kind=link}
{kind=link}
{kind=link}
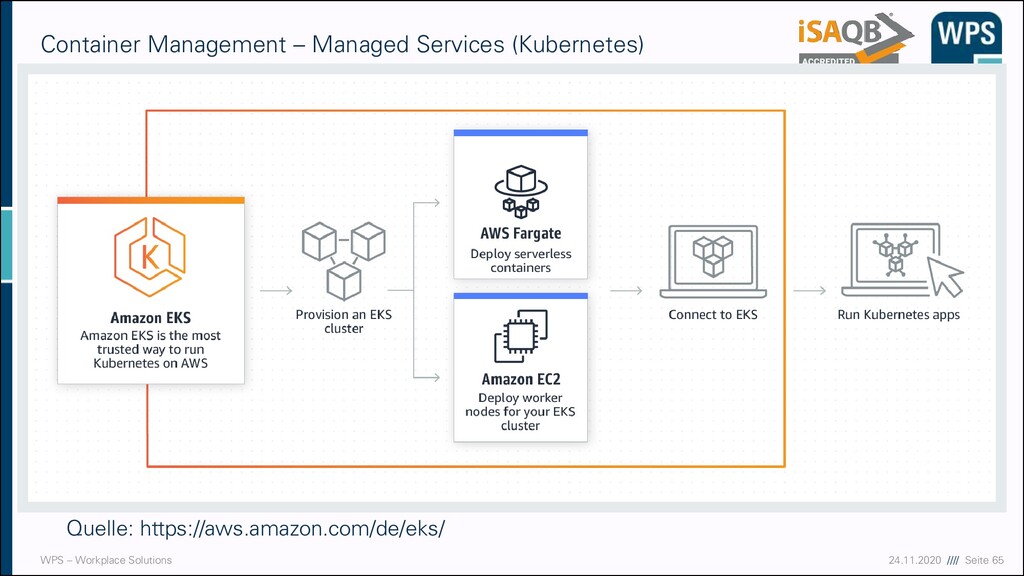{kind=link}
{kind=link}
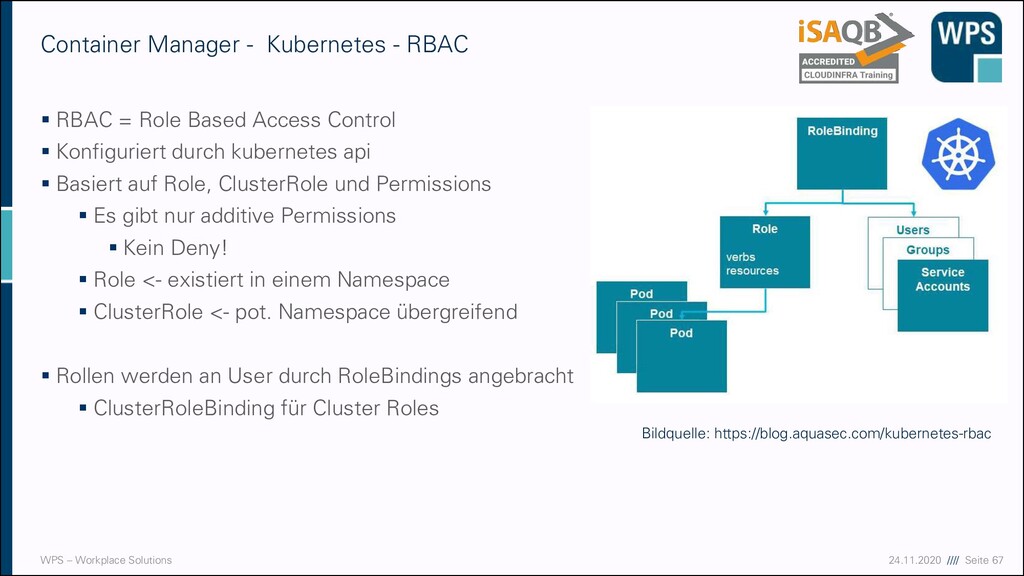{kind=link}
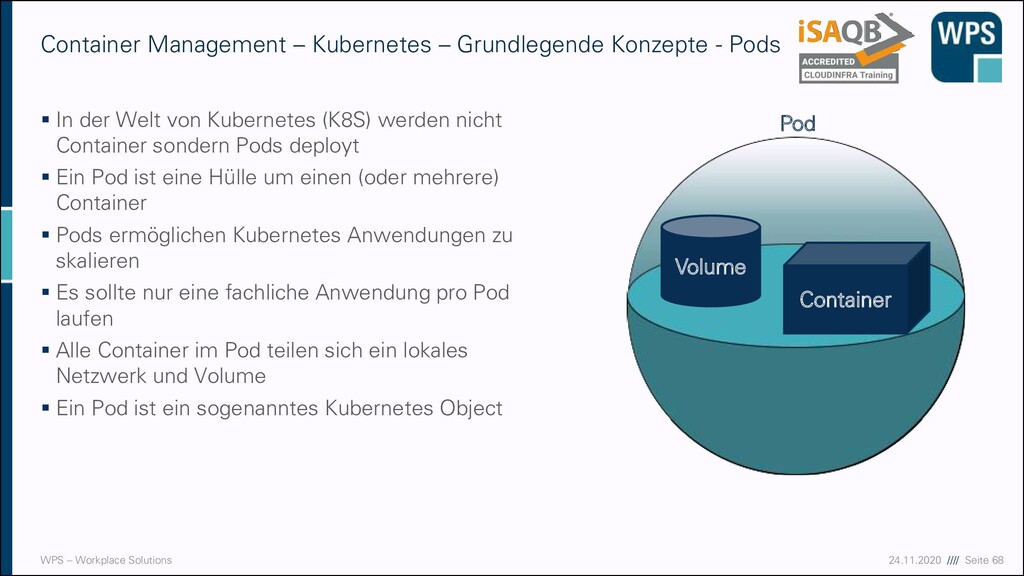{kind=link}
{kind=link}
{kind=link}
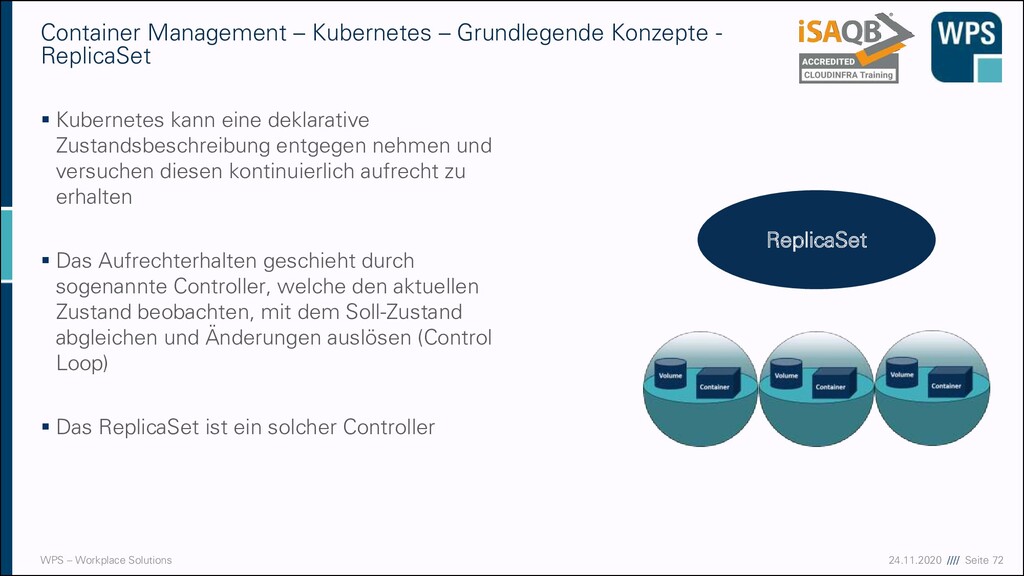{kind=link}
{kind=link}
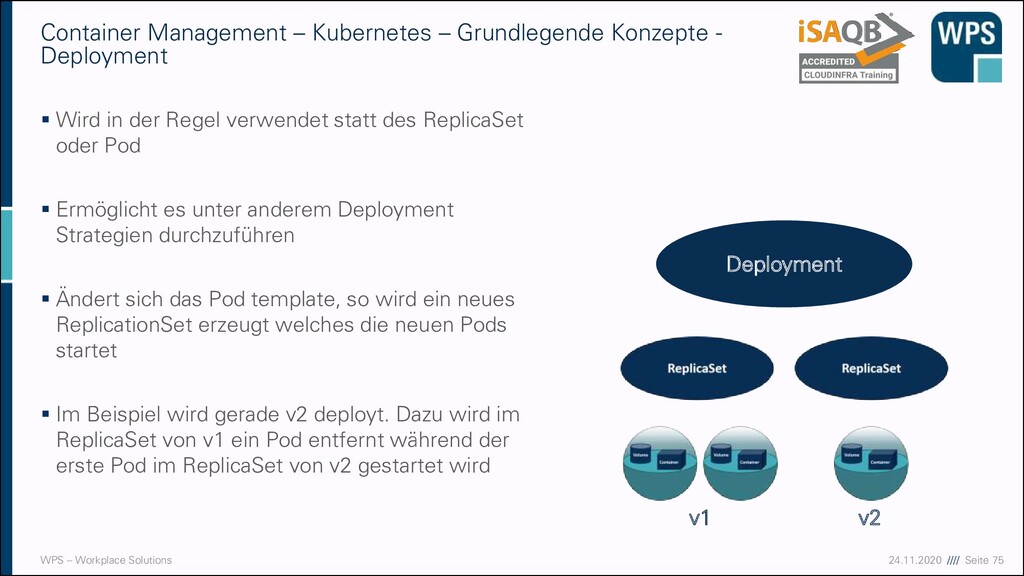{kind=link}
{kind=link}
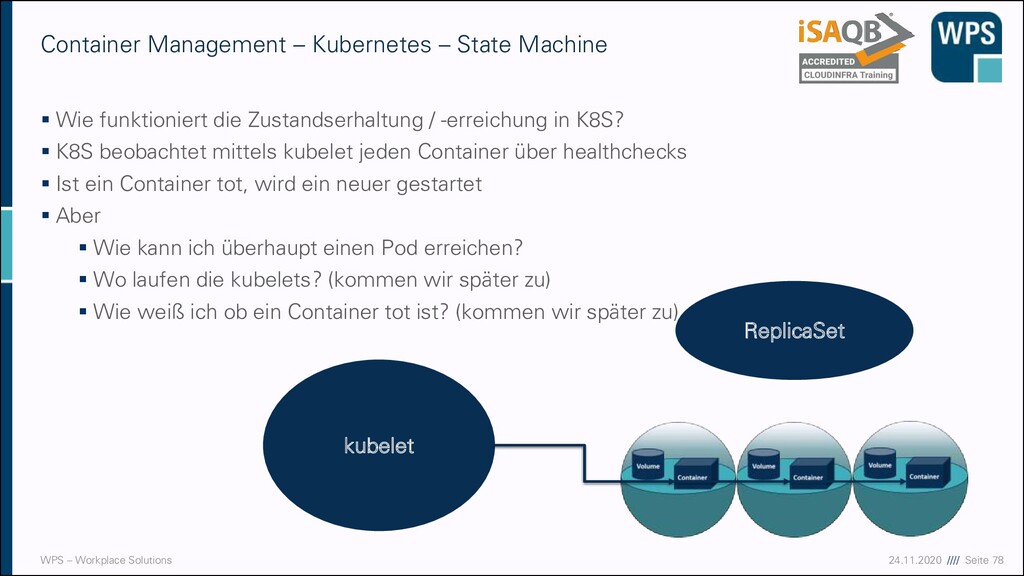{kind=link}
{kind=link}
{kind=link}
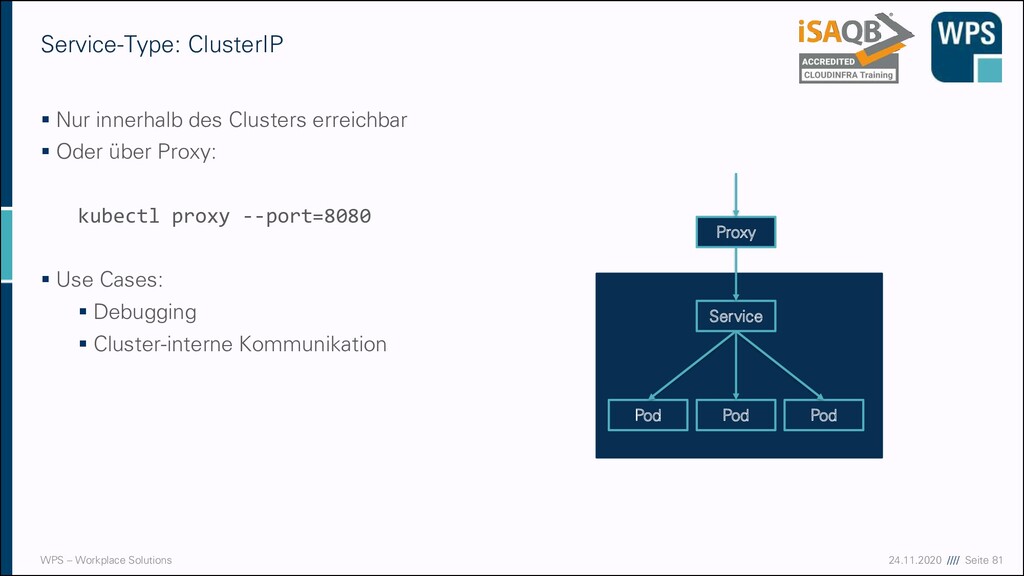{kind=link}
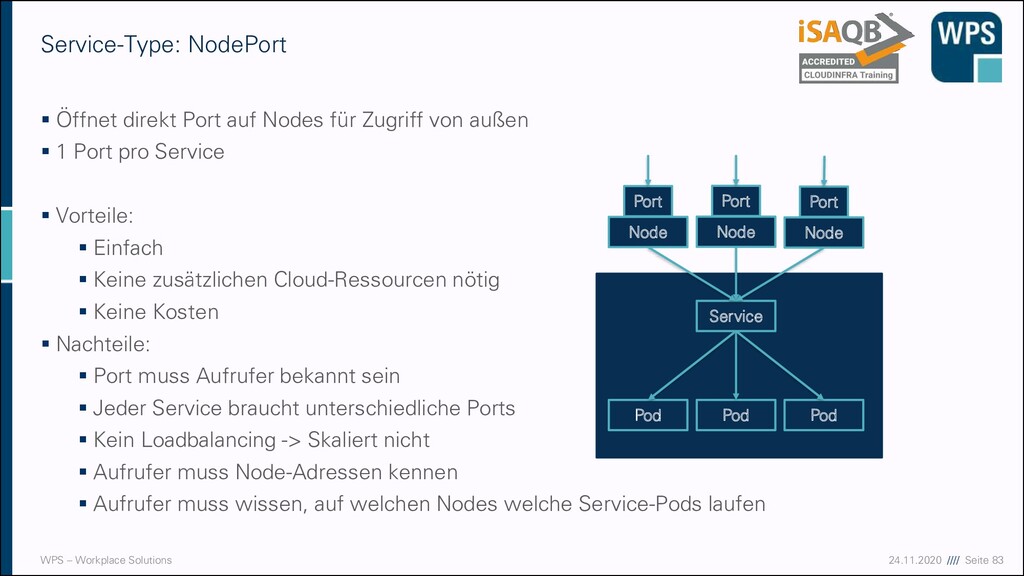{kind=link}
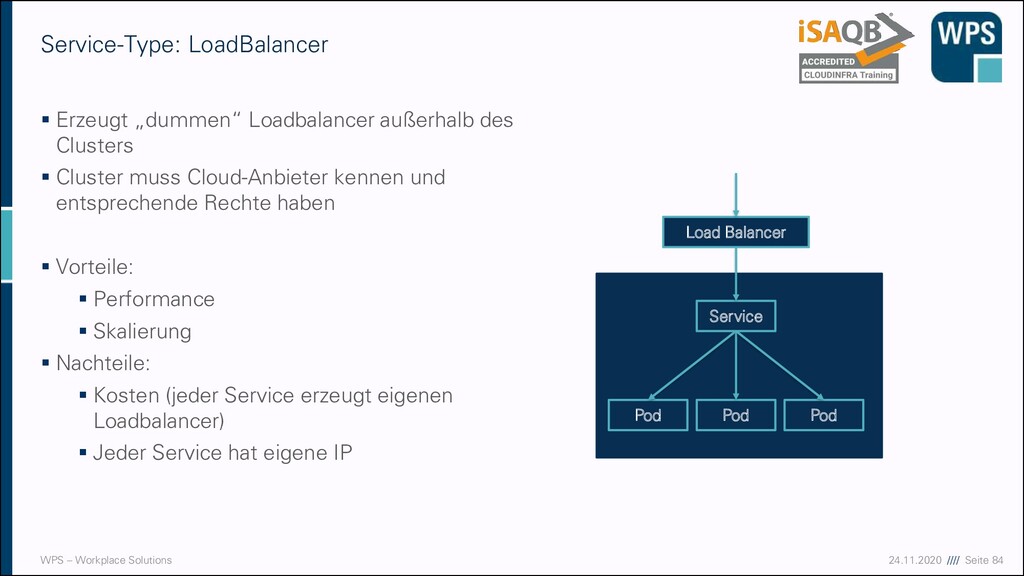{kind=link}
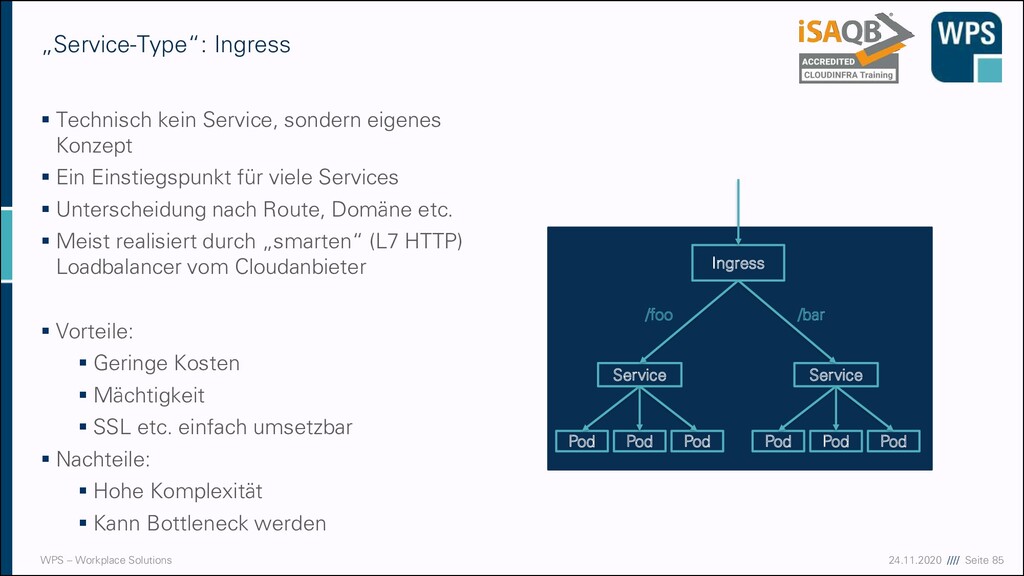{kind=link}
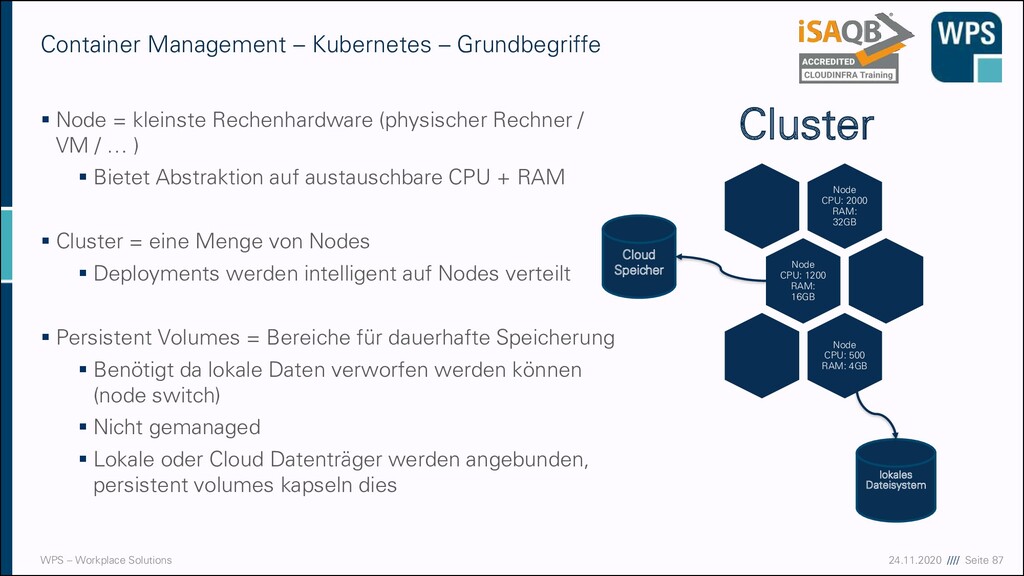{kind=link}
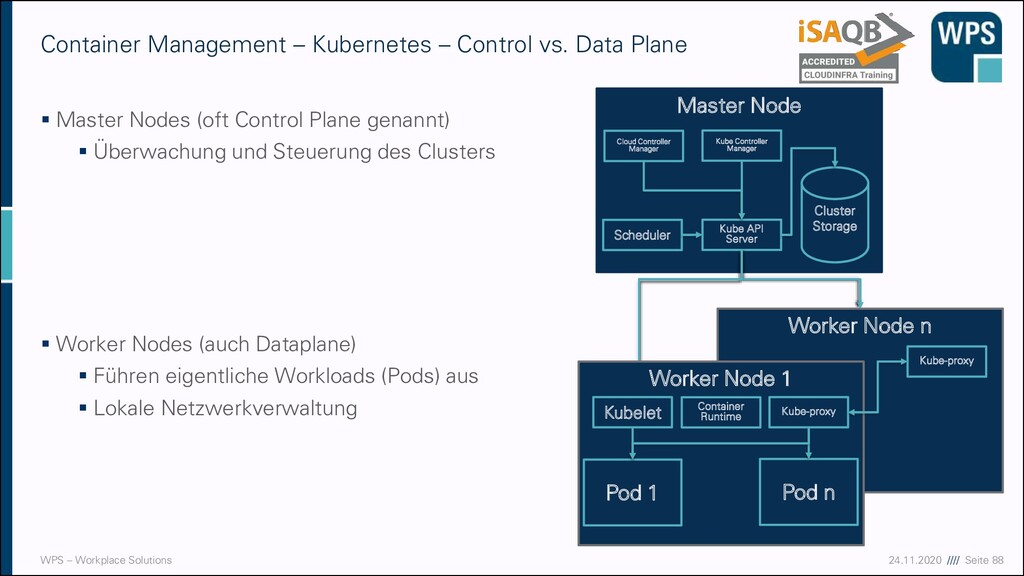{kind=link}
{kind=link}
{kind=link}
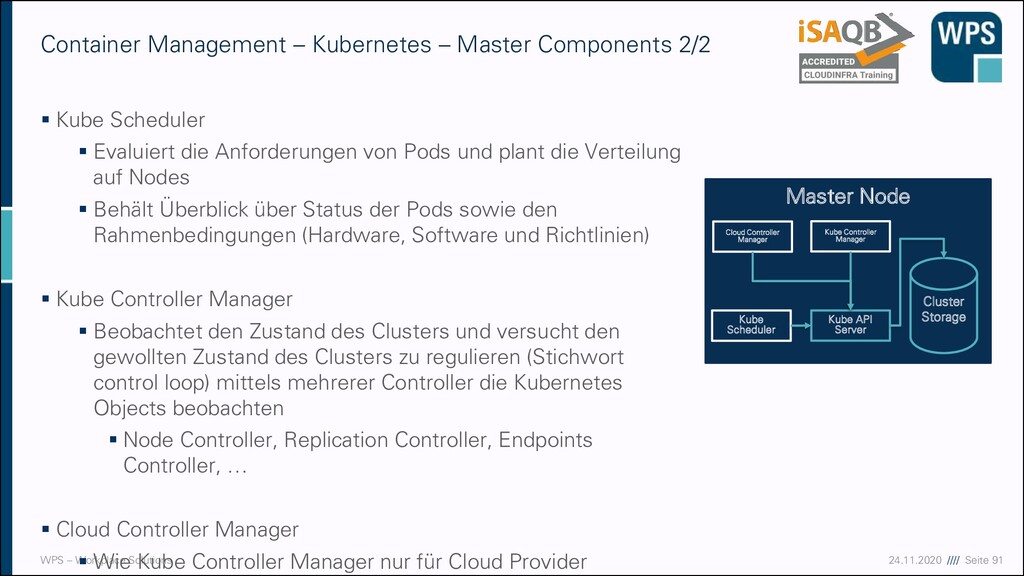{kind=link}
{kind=link}
{kind=link}
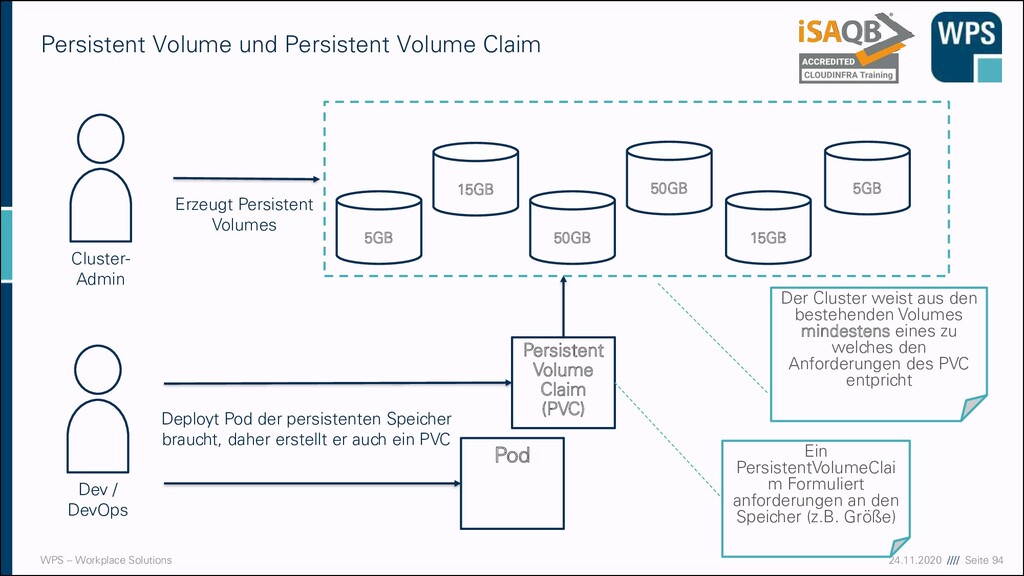{kind=link}
{kind=link}
{kind=link}
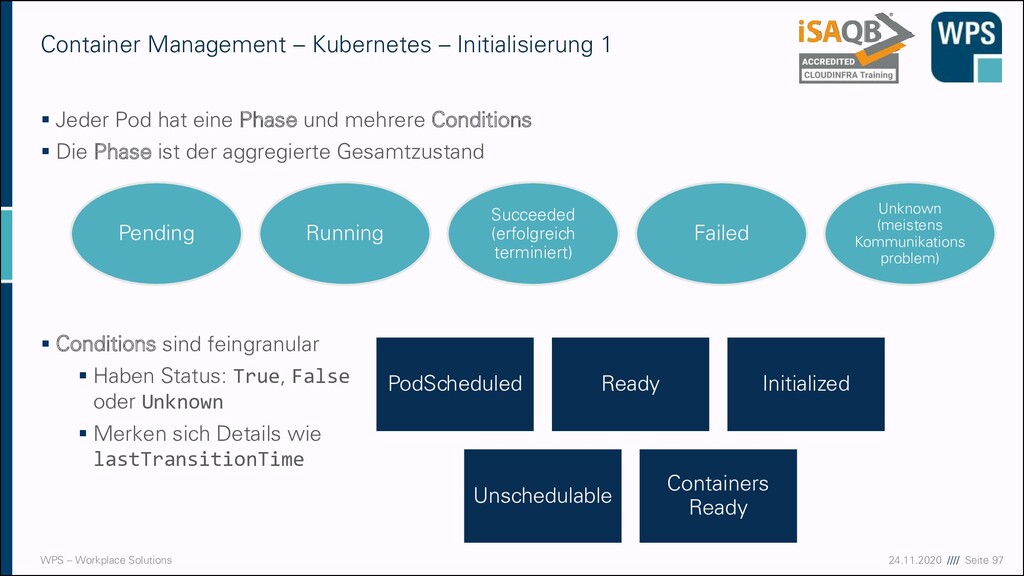{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
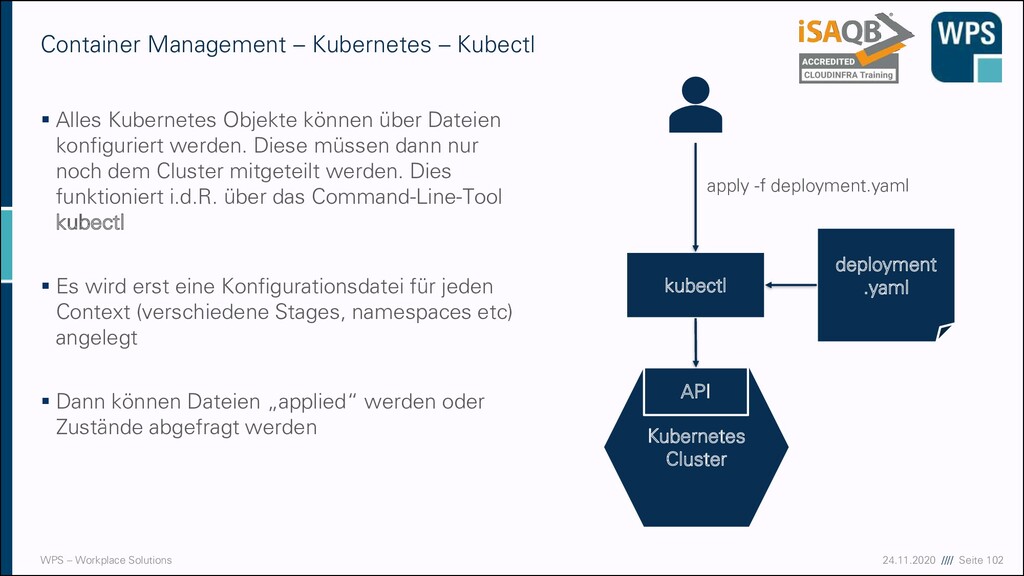{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
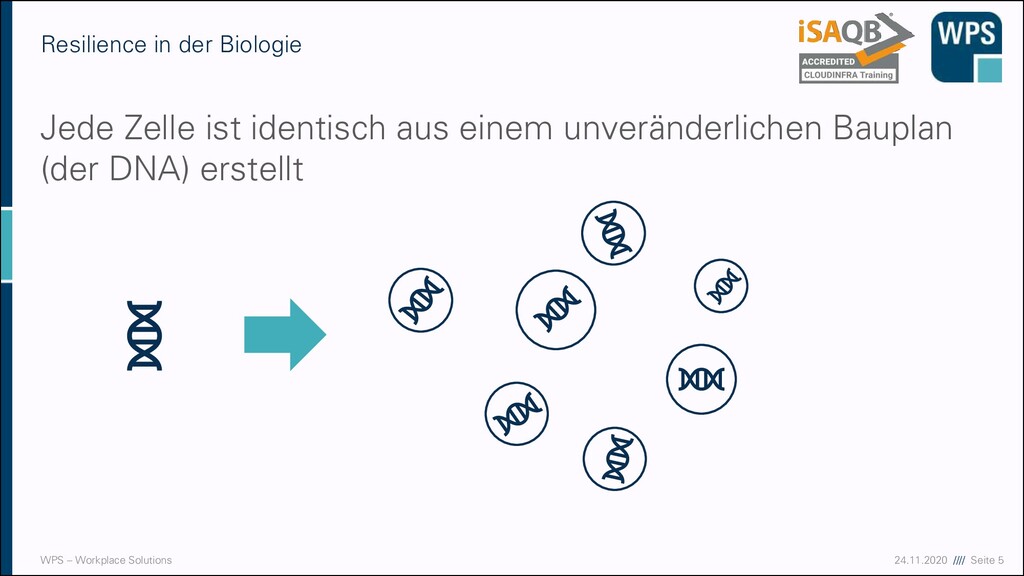{kind=link}
{kind=link}
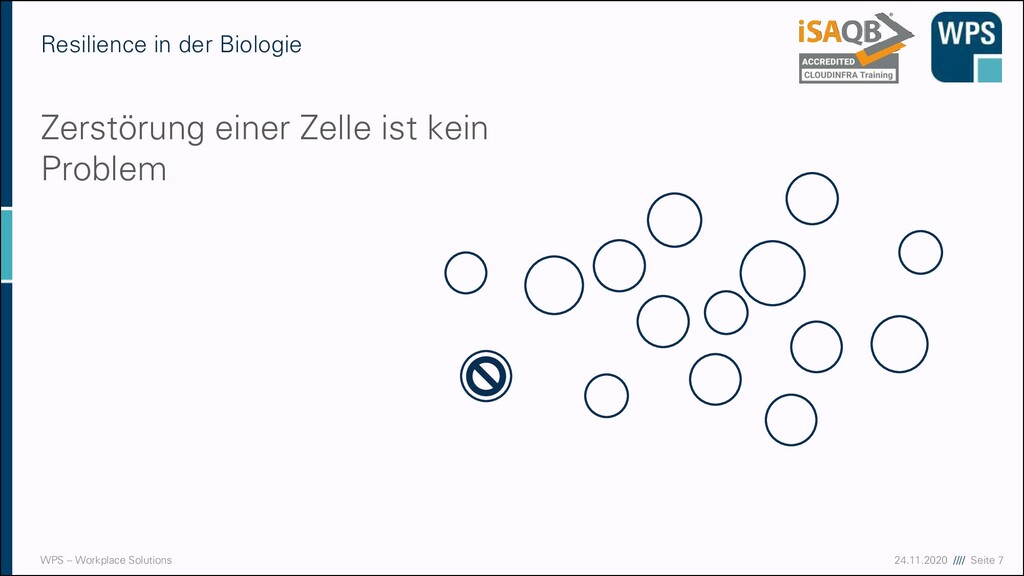{kind=link}
{kind=link}
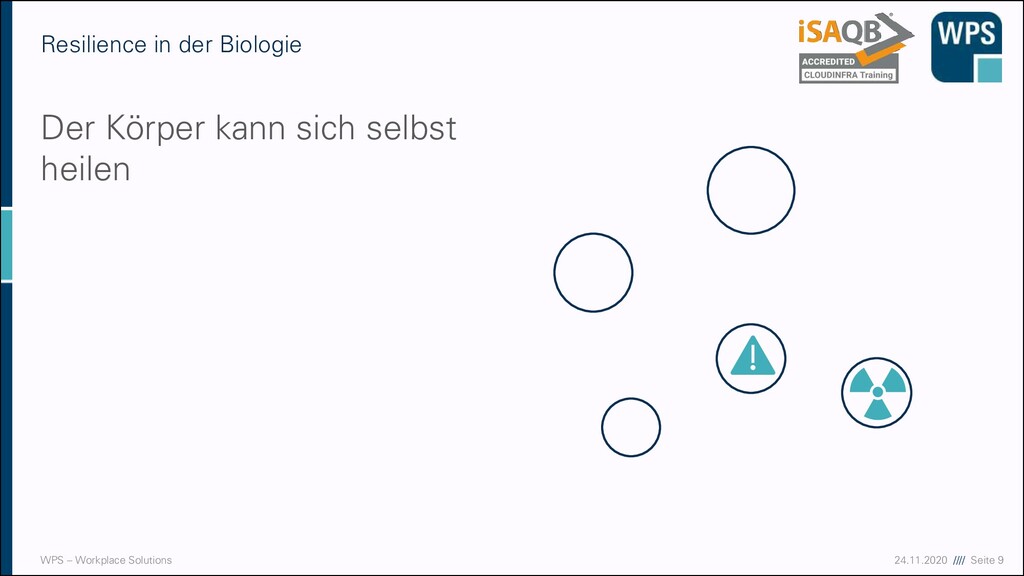{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
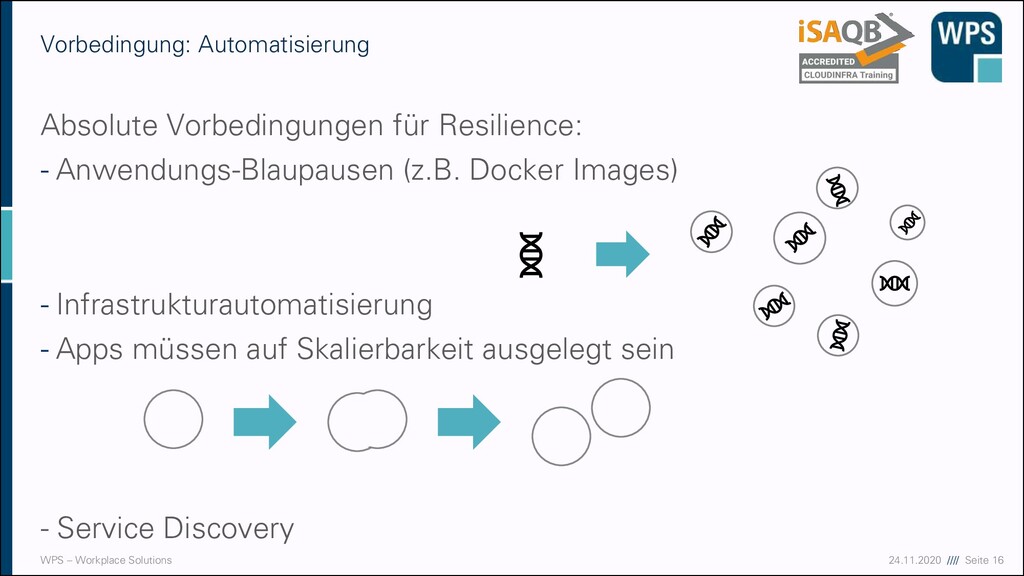{kind=link}
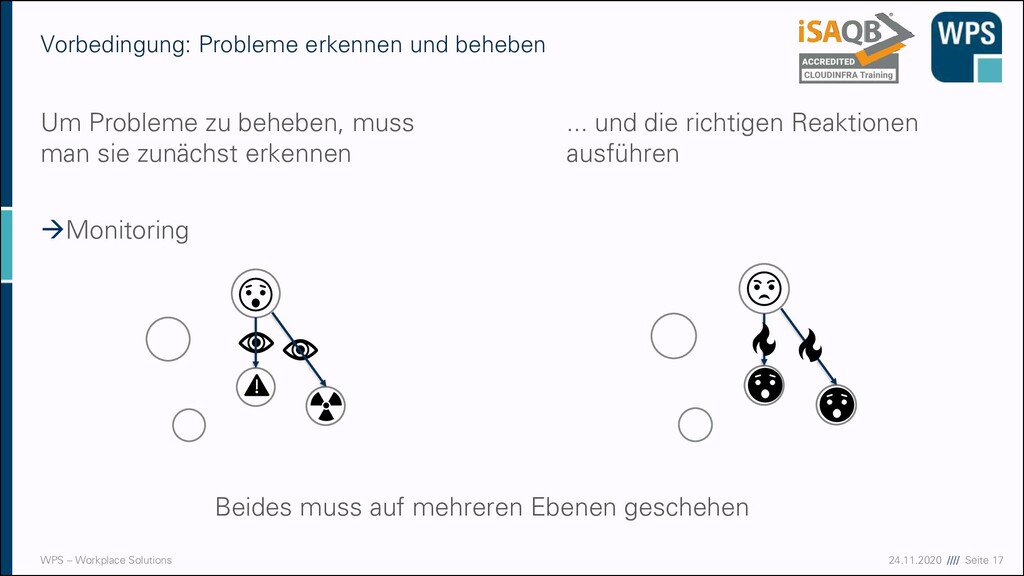{kind=link}
{kind=link}
{kind=link}
{kind=link}
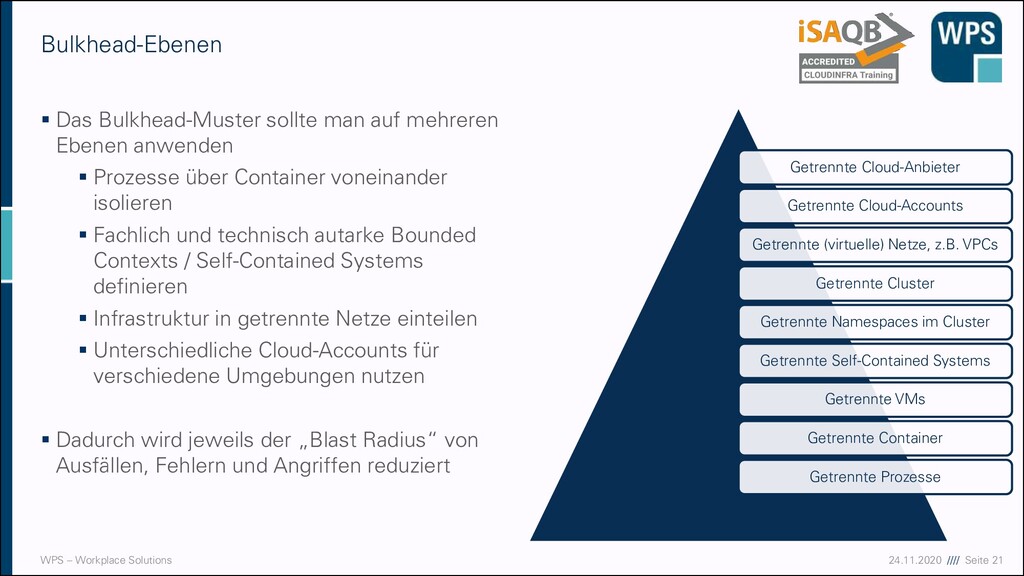{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
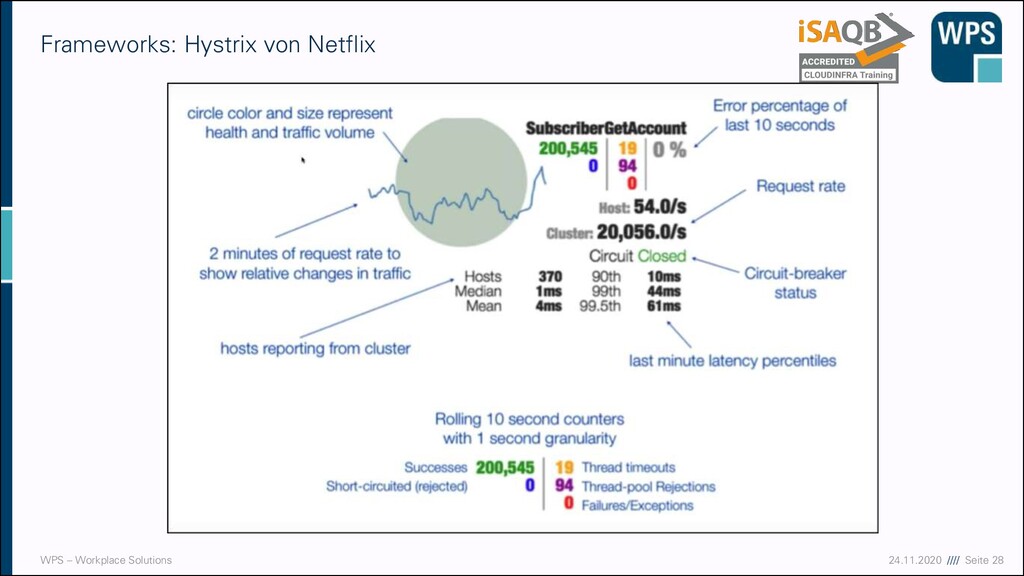{kind=link}
{kind=link}
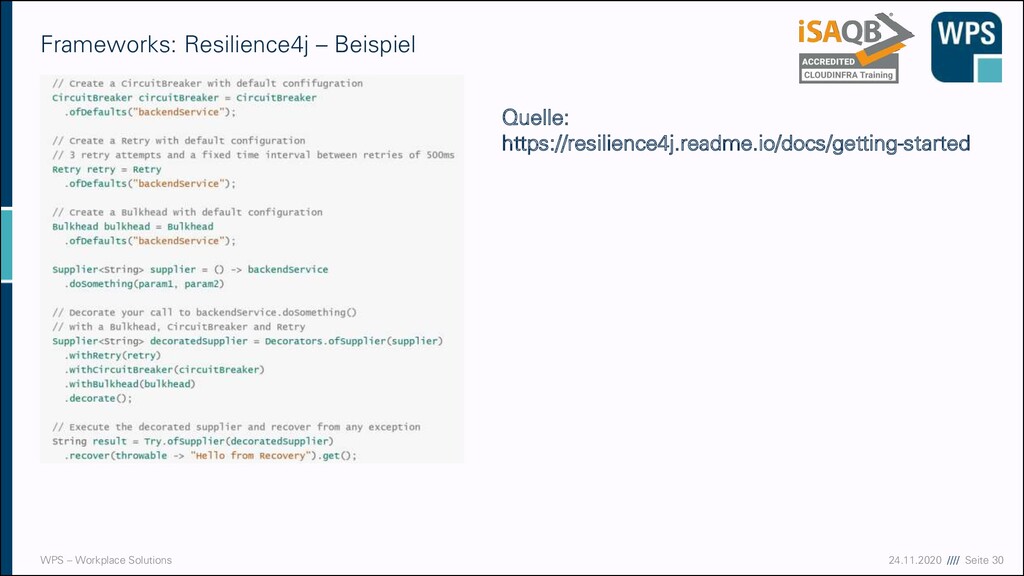{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
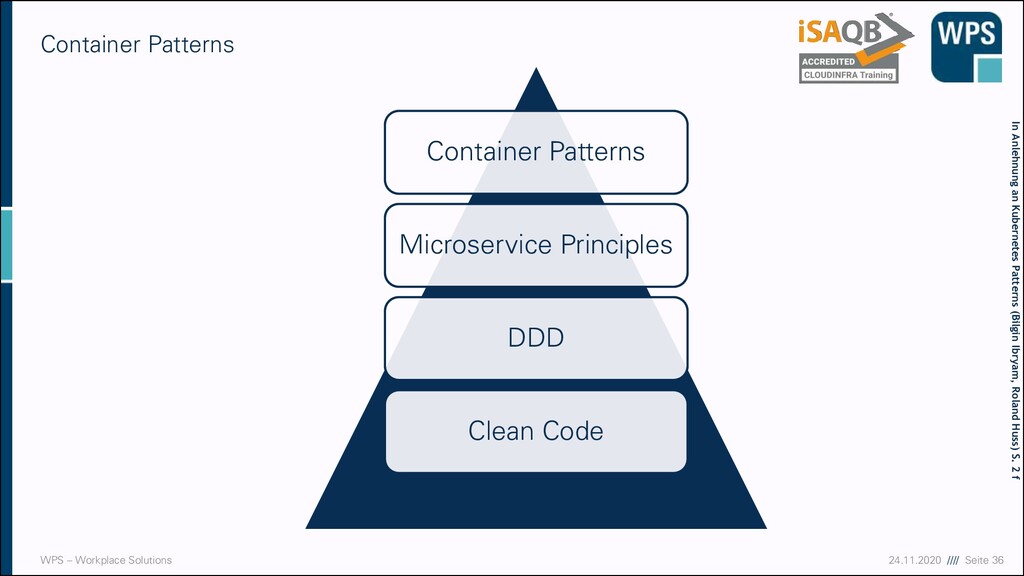{kind=link}
{kind=link}
{kind=link}
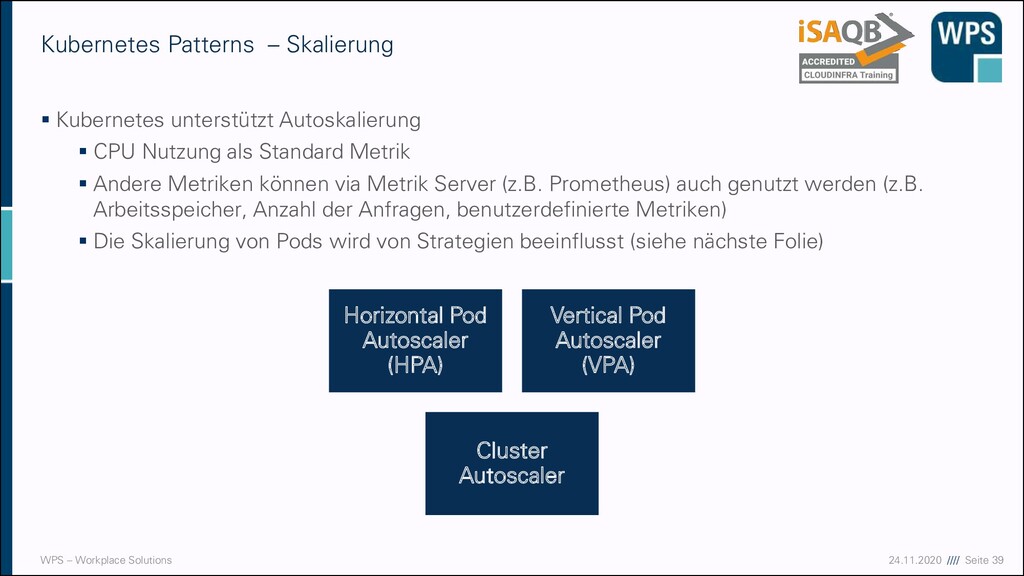{kind=link}
{kind=link}
{kind=link}
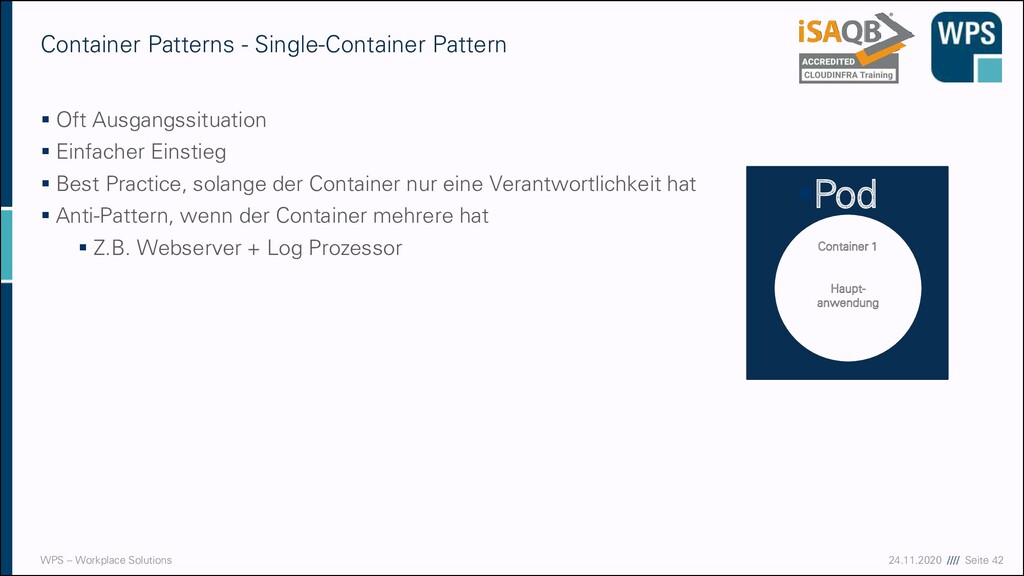{kind=link}
{kind=link}
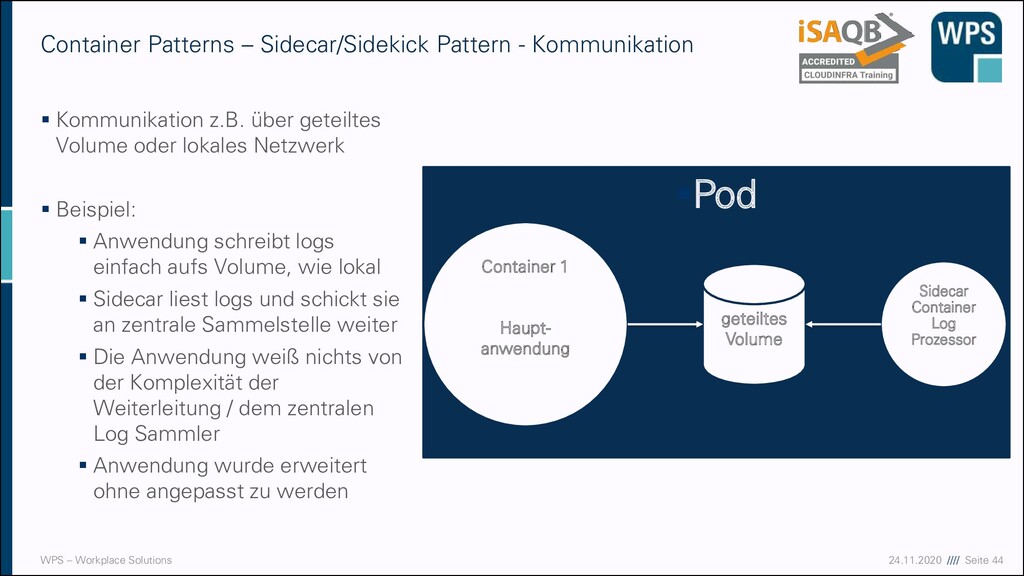{kind=link}
{kind=link}
{kind=link}
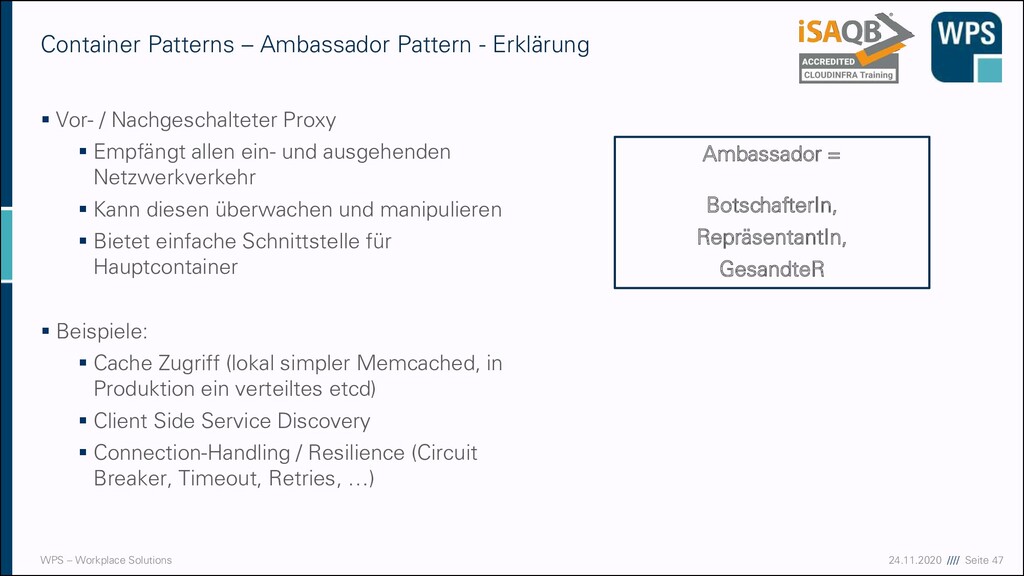{kind=link}
{kind=link}
{kind=link}
{kind=link}
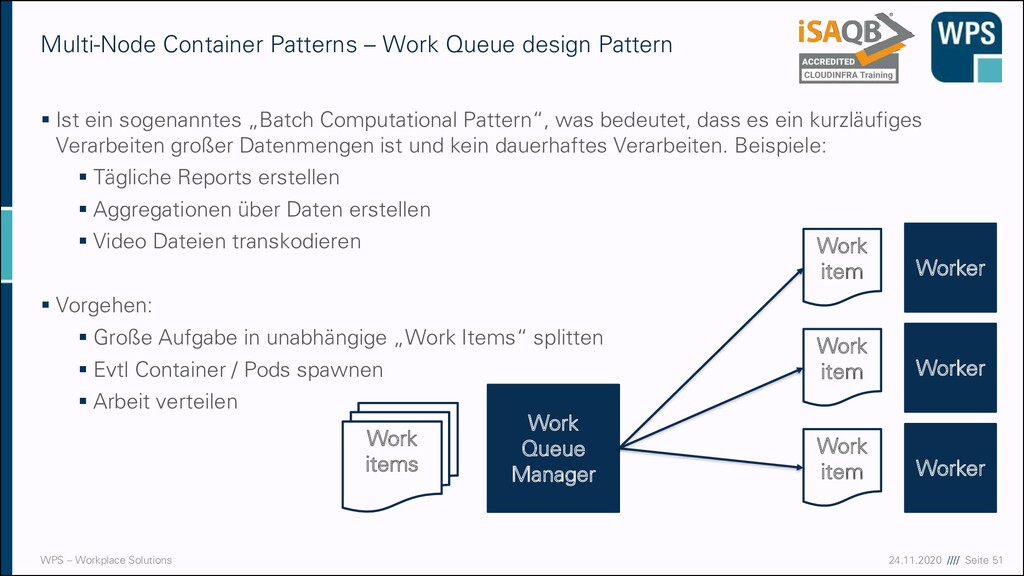{kind=link}
{kind=link}
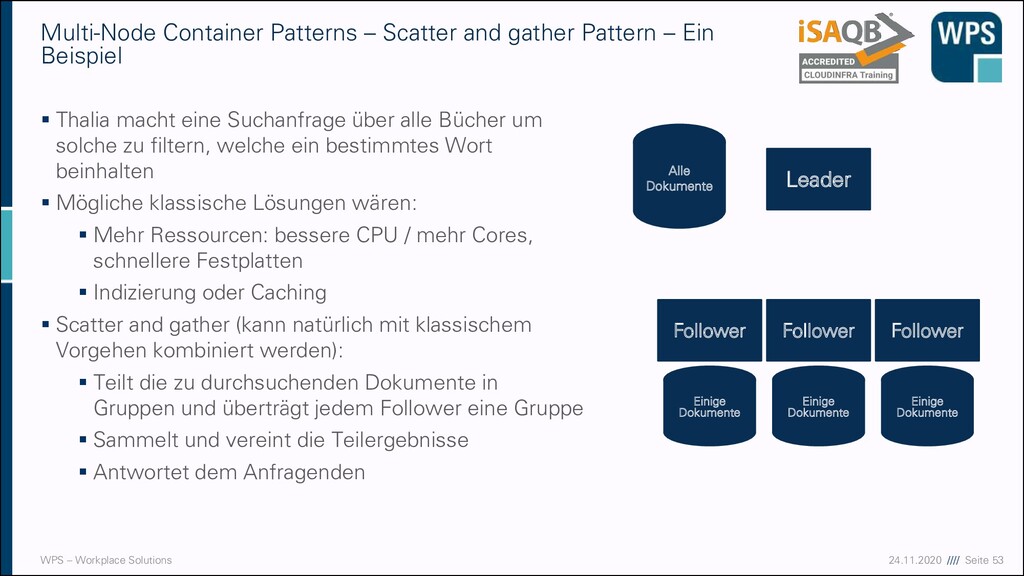{kind=link}
{kind=link}
{kind=link}
{kind=link}
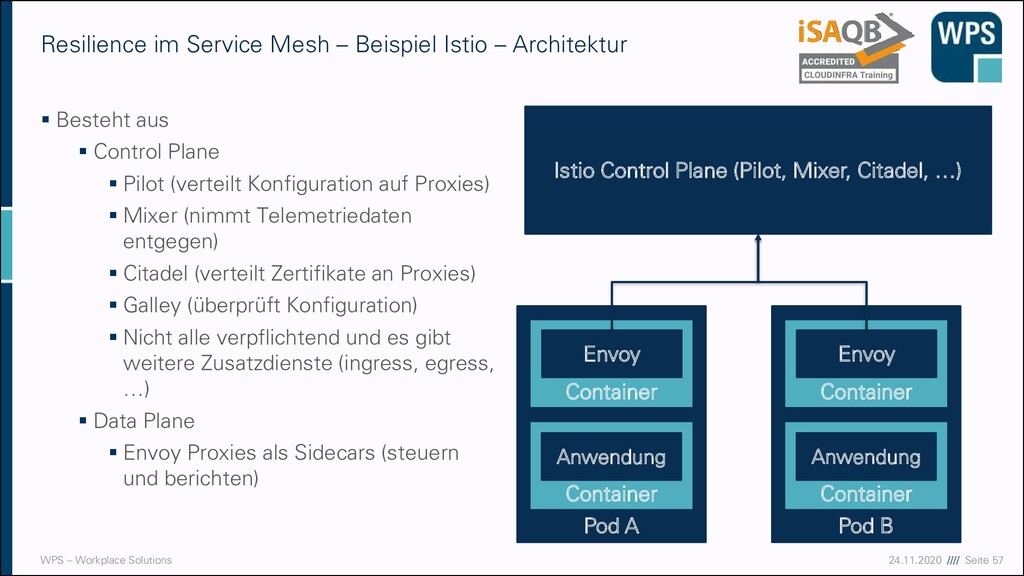{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
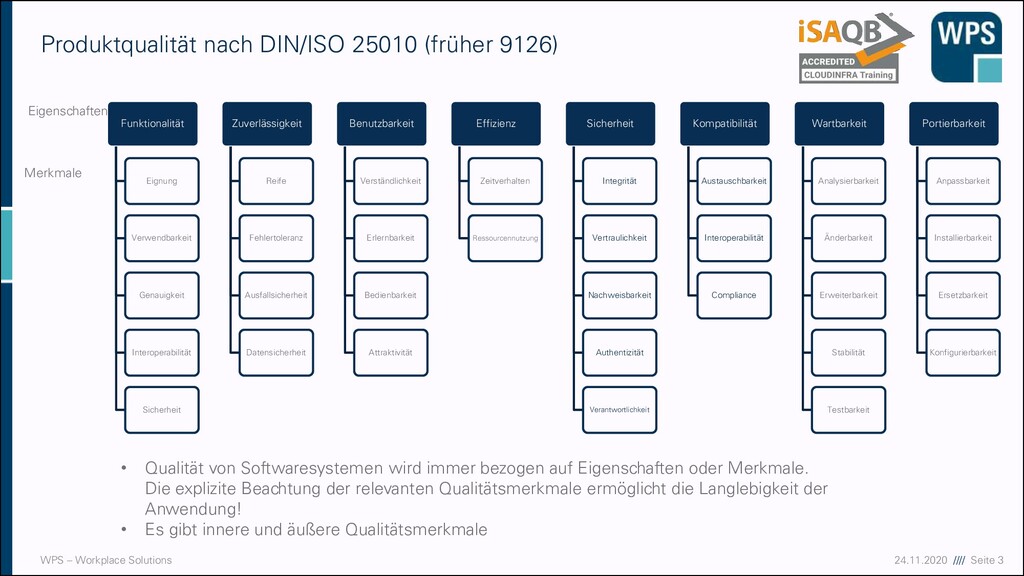{kind=link}
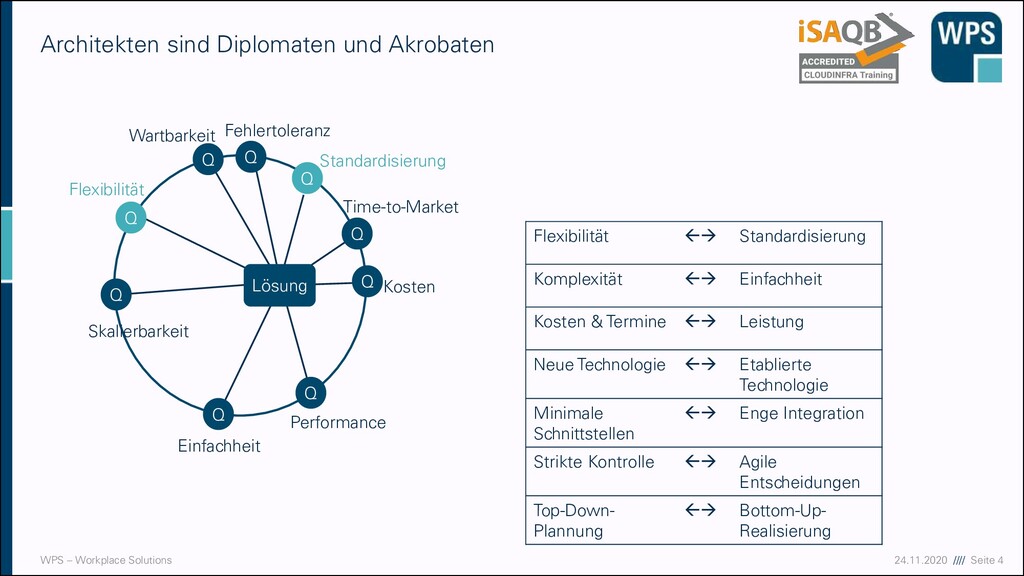{kind=link}
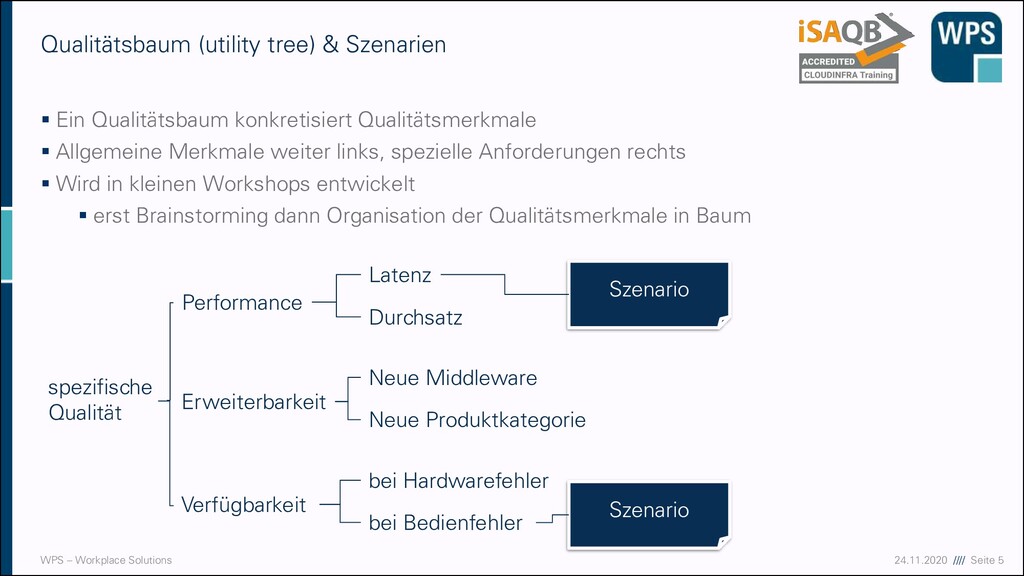{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
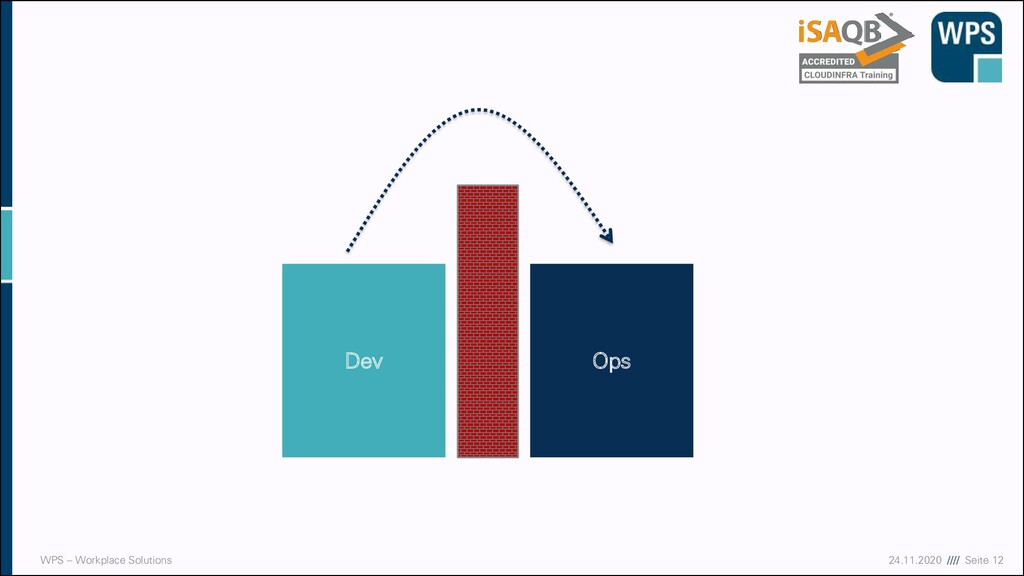{kind=link}
{kind=link}
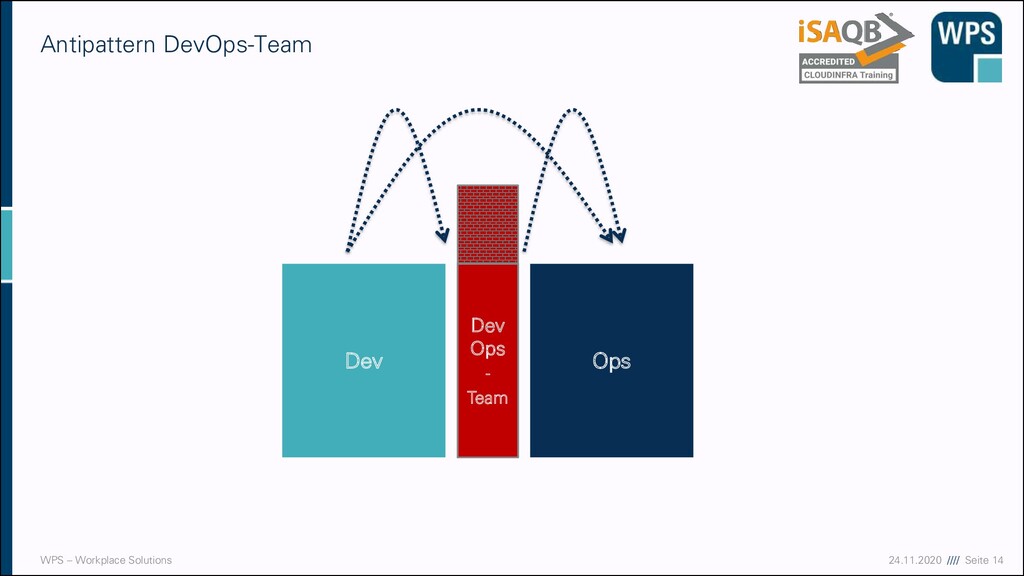{kind=link}
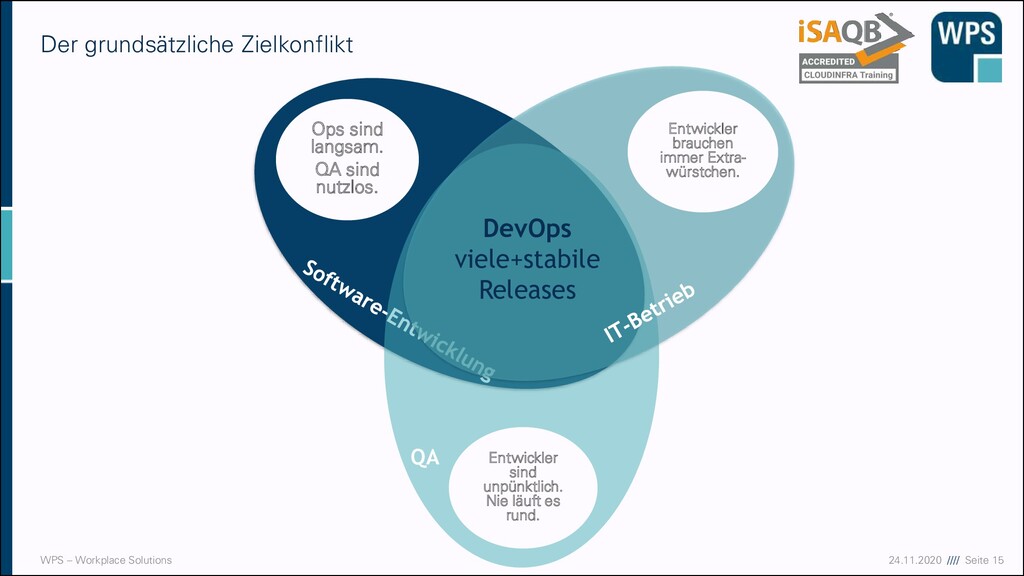{kind=link}
{kind=link}
{kind=link}
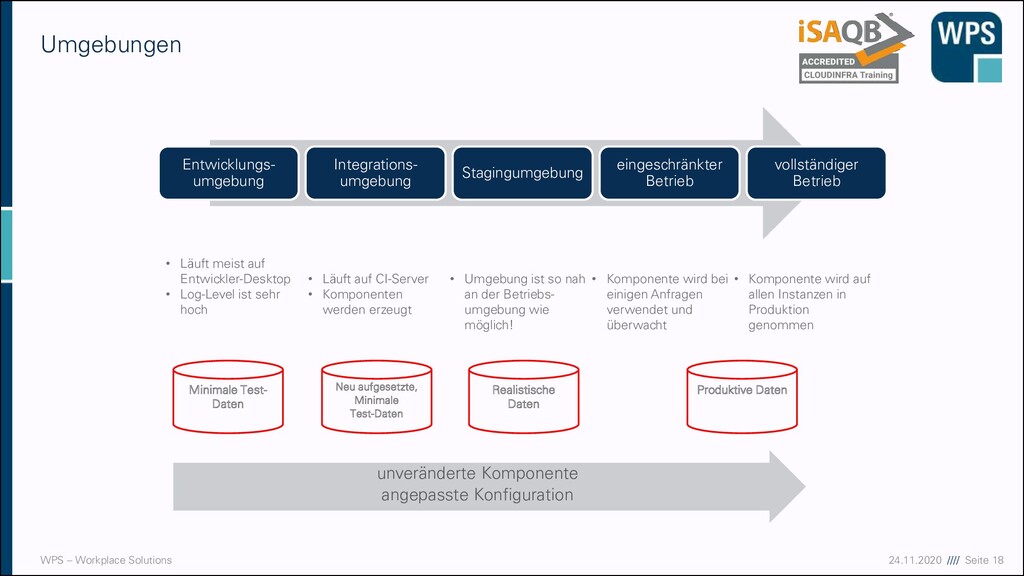{kind=link}
{kind=link}
{kind=link}
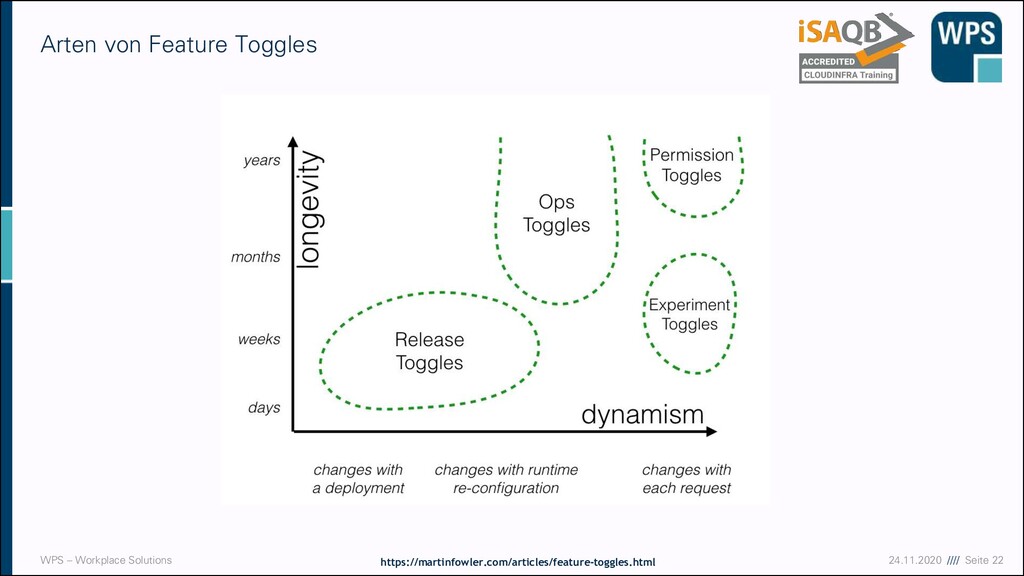{kind=link}
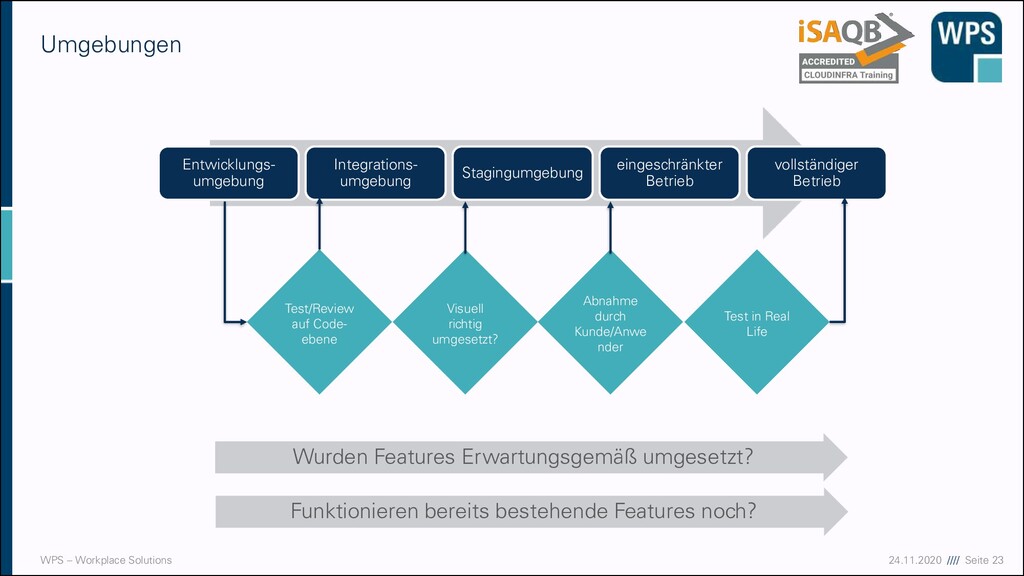{kind=link}
{kind=link}
{kind=link}
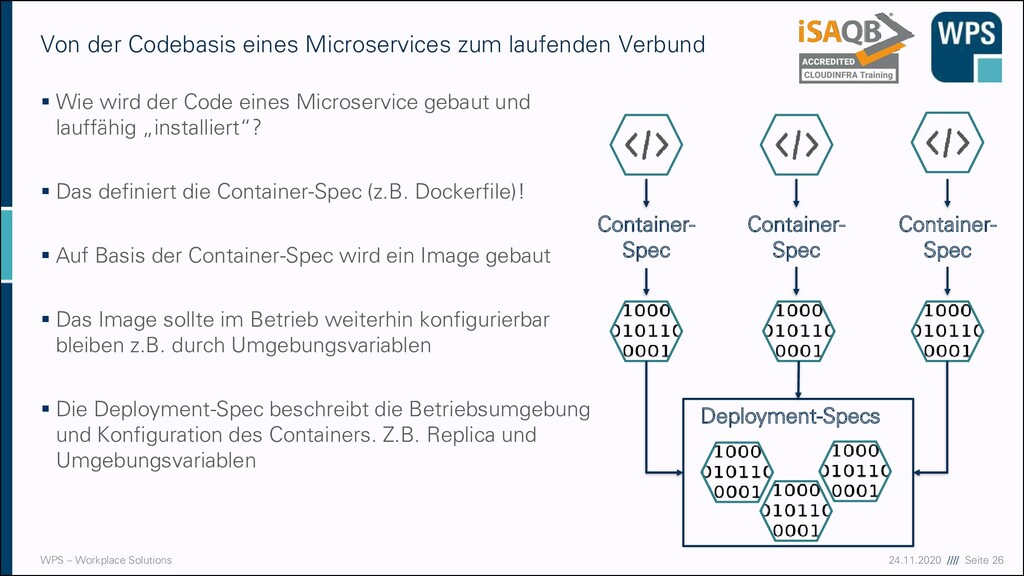{kind=link}
{kind=link}
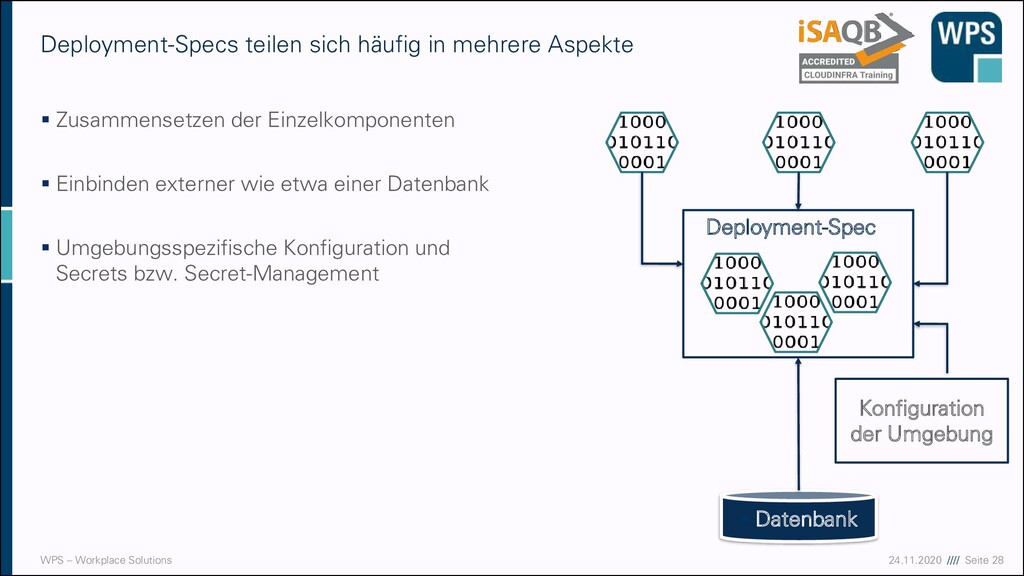{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
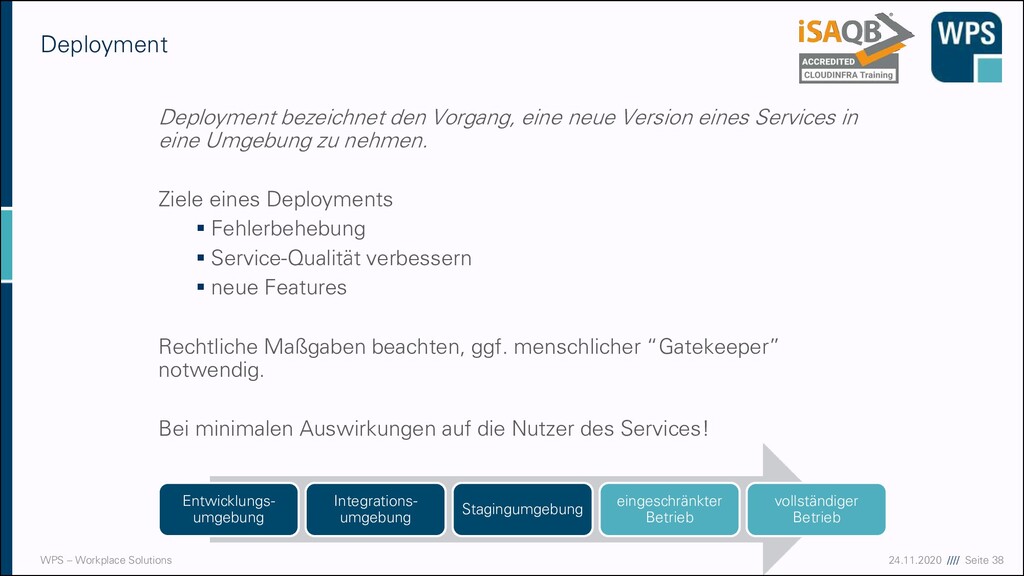{kind=link}
{kind=link}
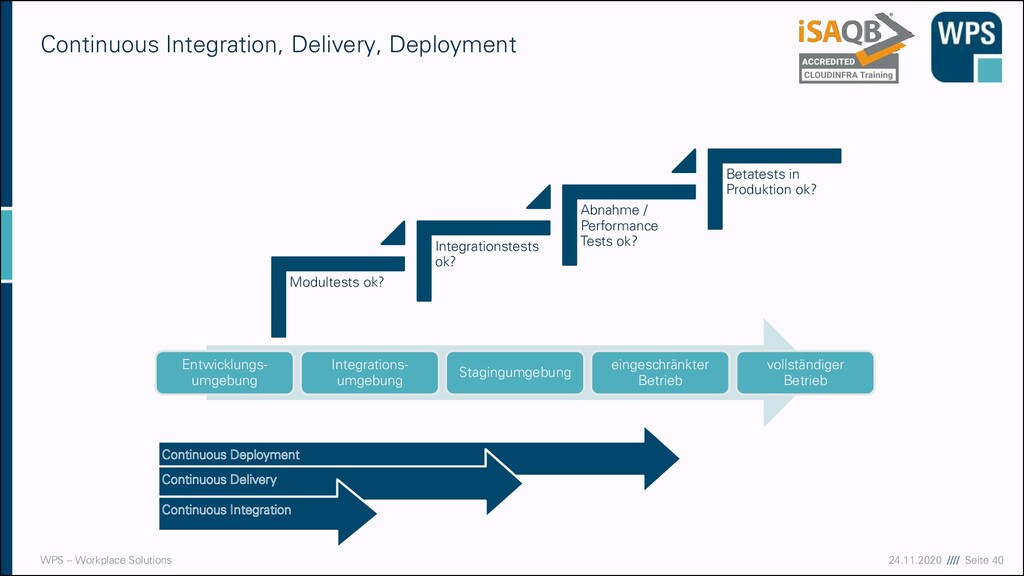{kind=link}
{kind=link}
{kind=link}
{kind=link}
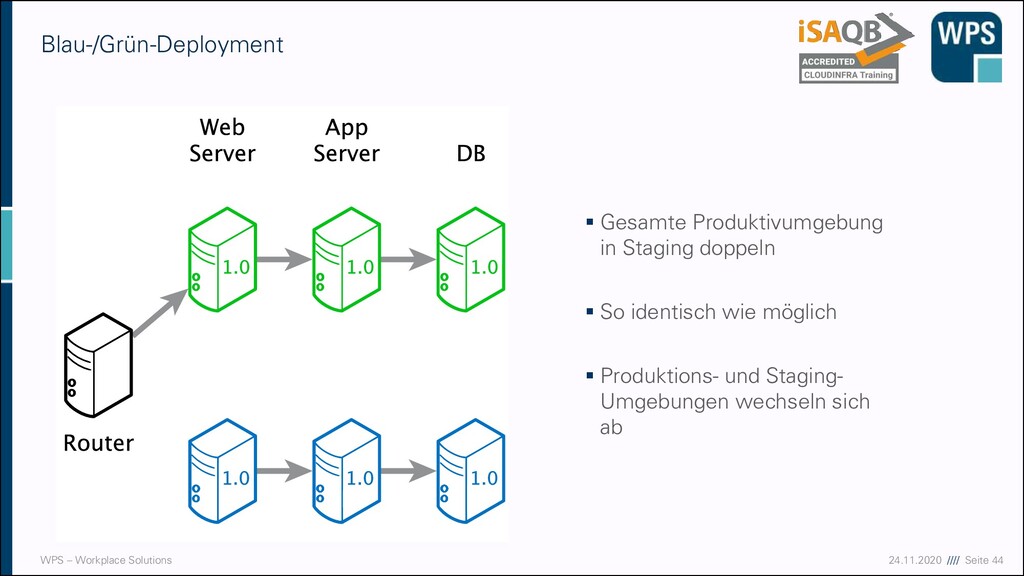{kind=link}
{kind=link}
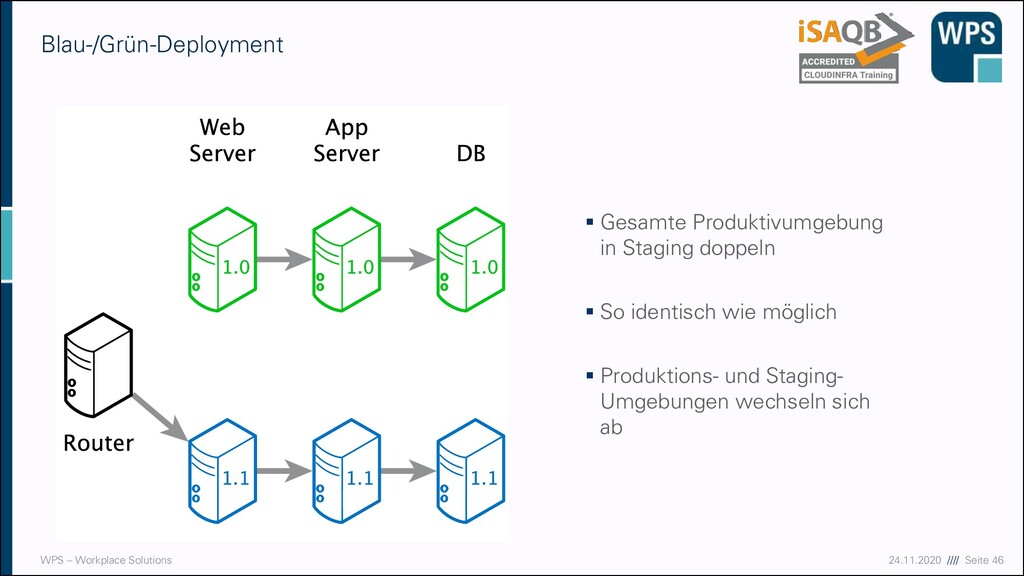{kind=link}
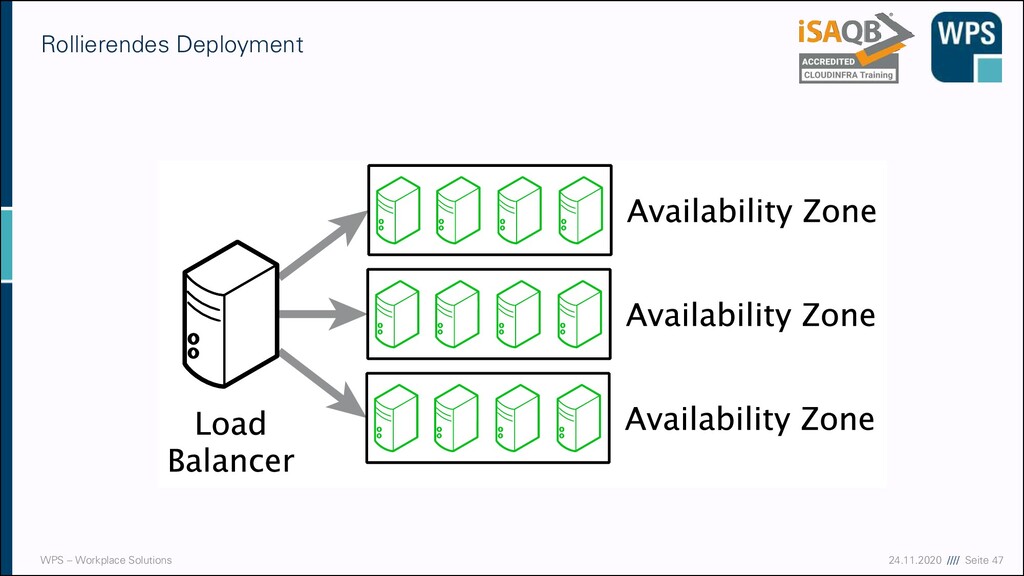{kind=link}
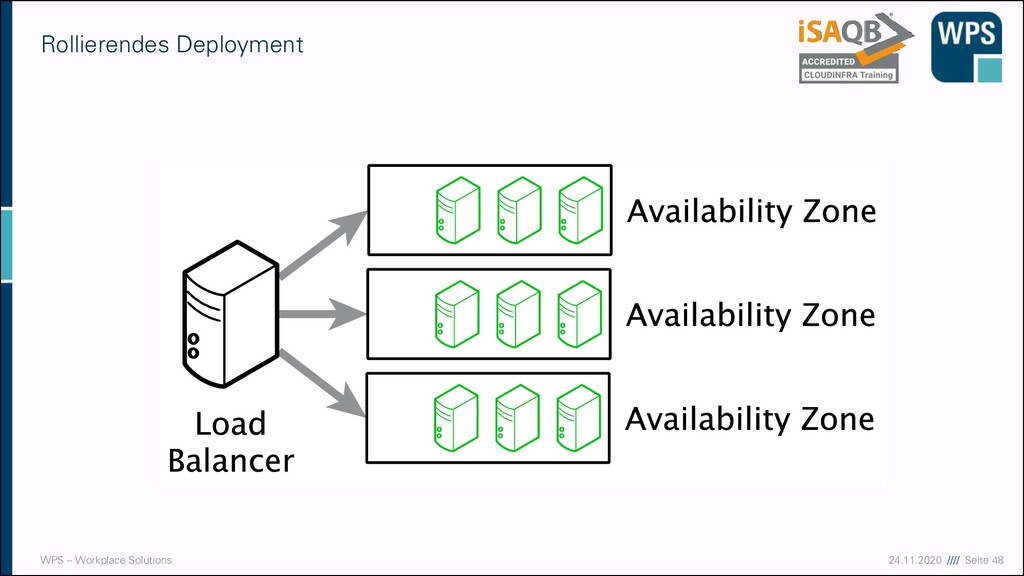{kind=link}
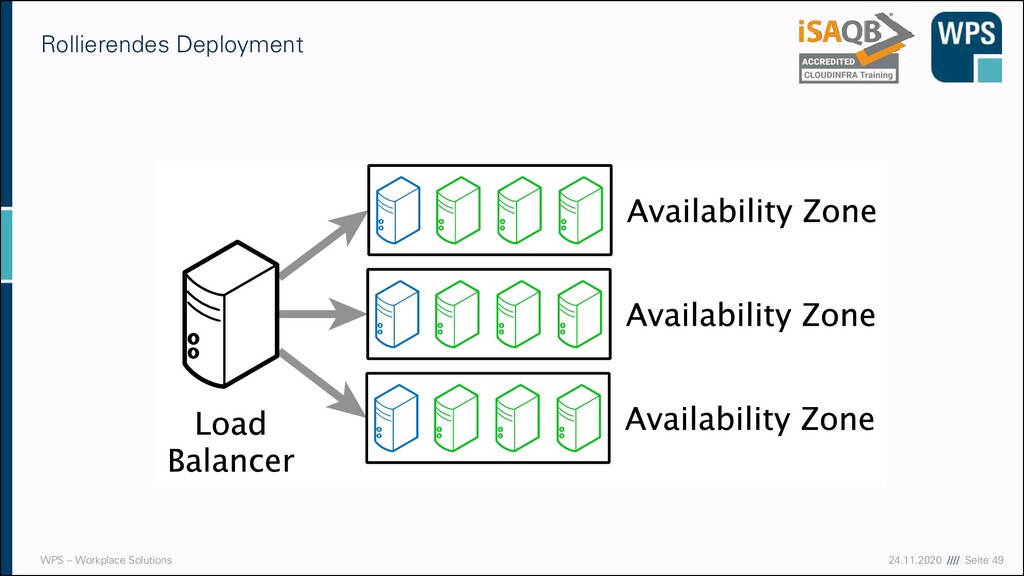{kind=link}
{kind=link}
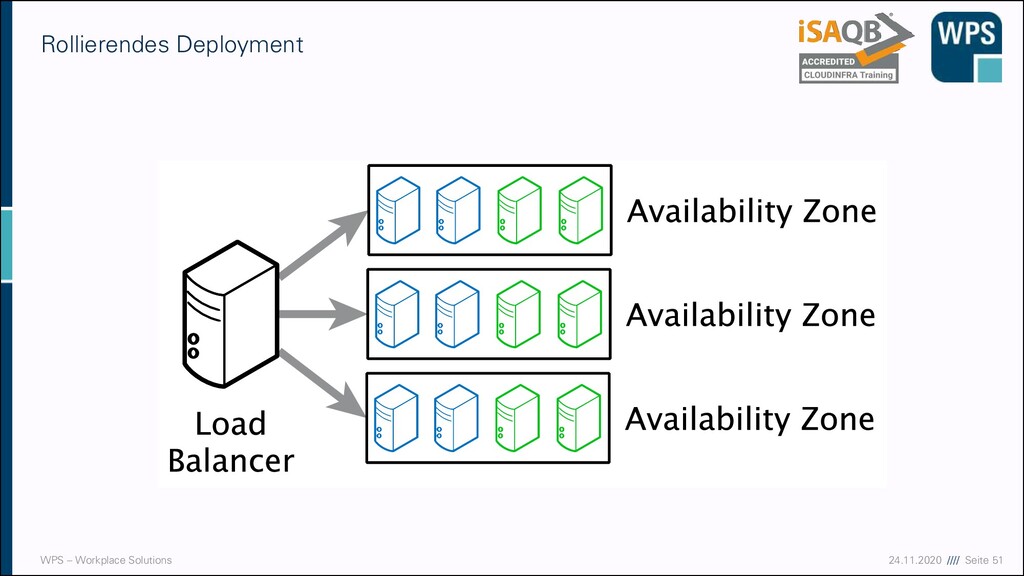{kind=link}
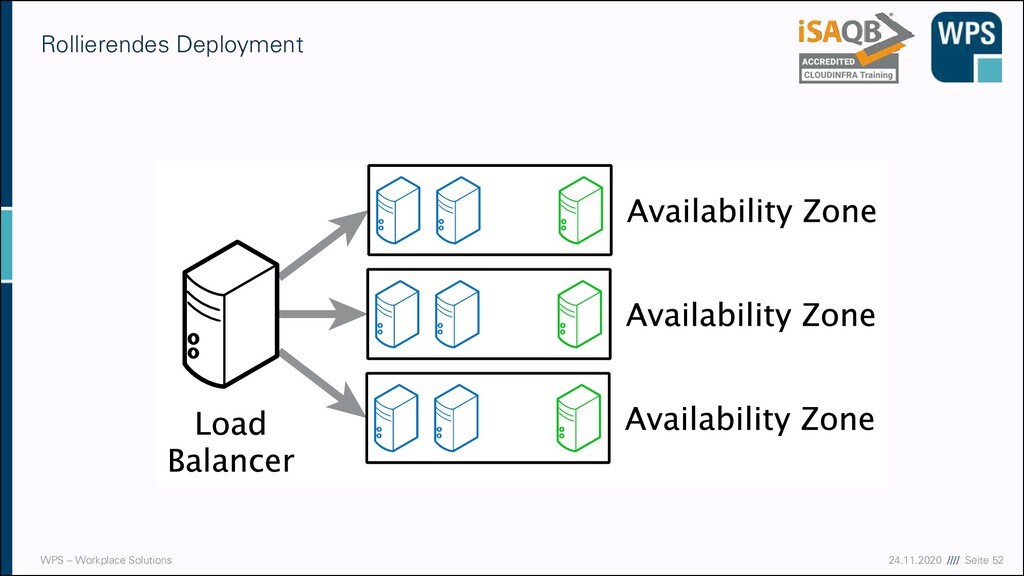{kind=link}
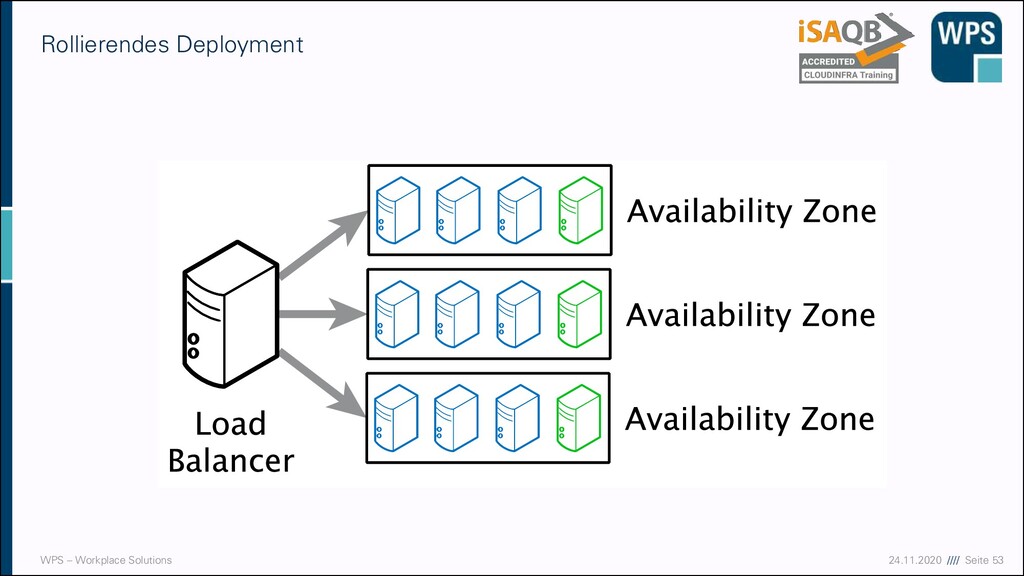{kind=link}
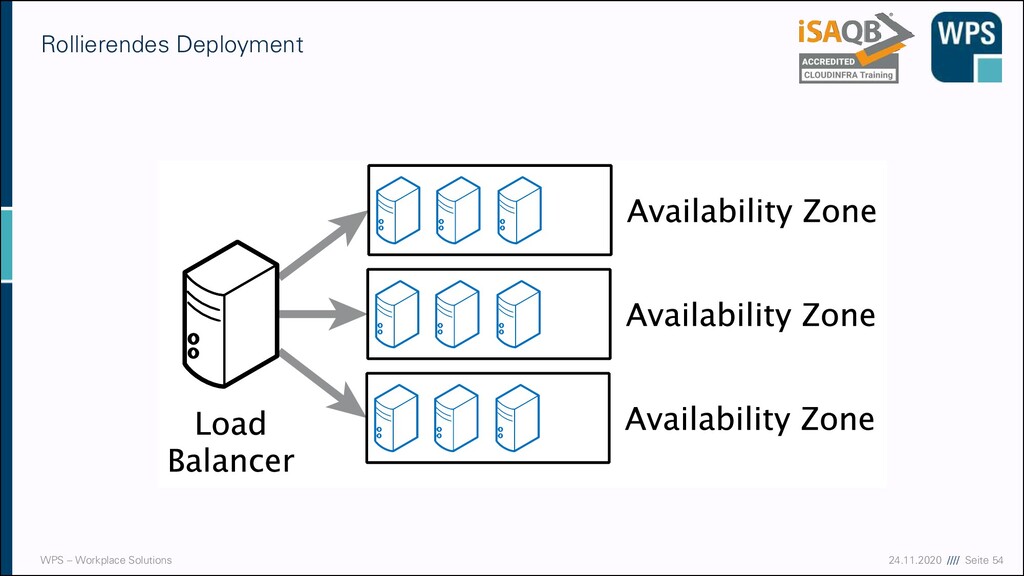{kind=link}
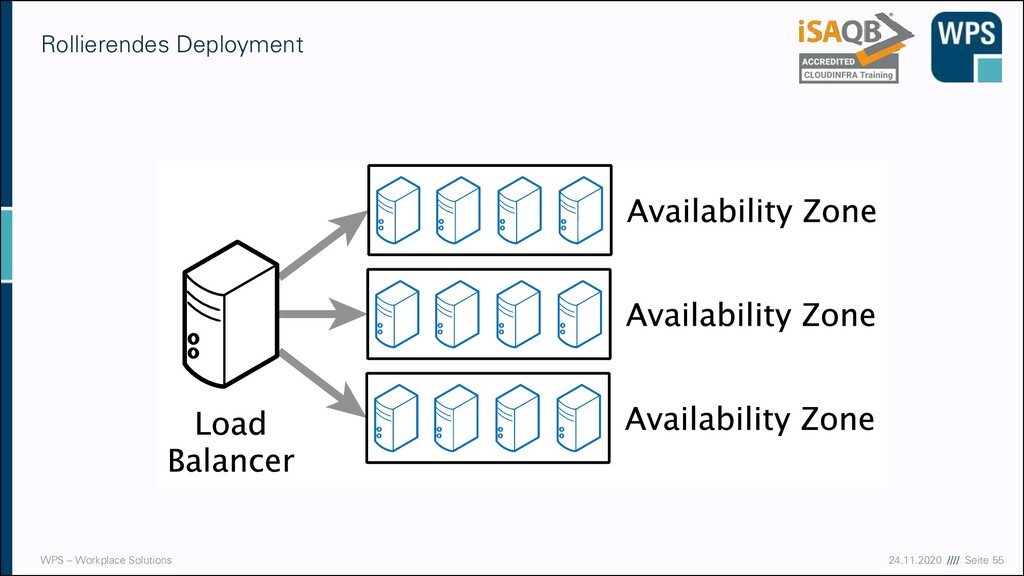{kind=link}
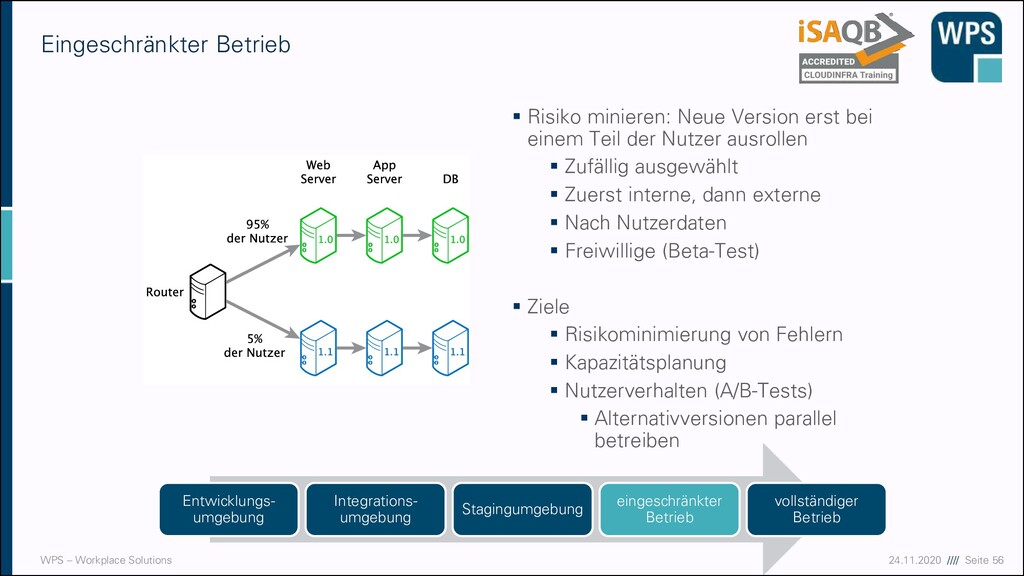{kind=link}
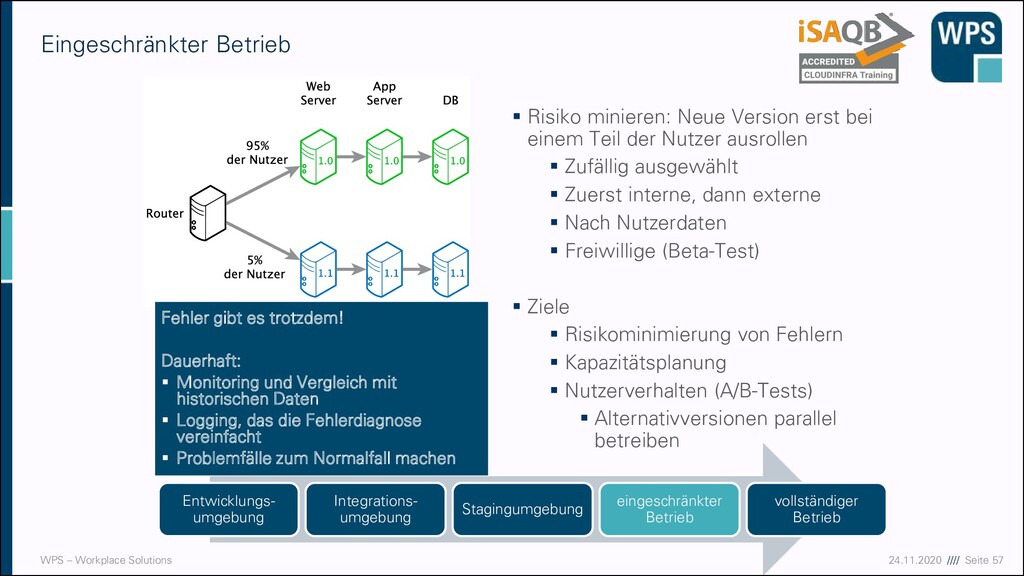{kind=link}
{kind=link}
{kind=link}
{kind=link}
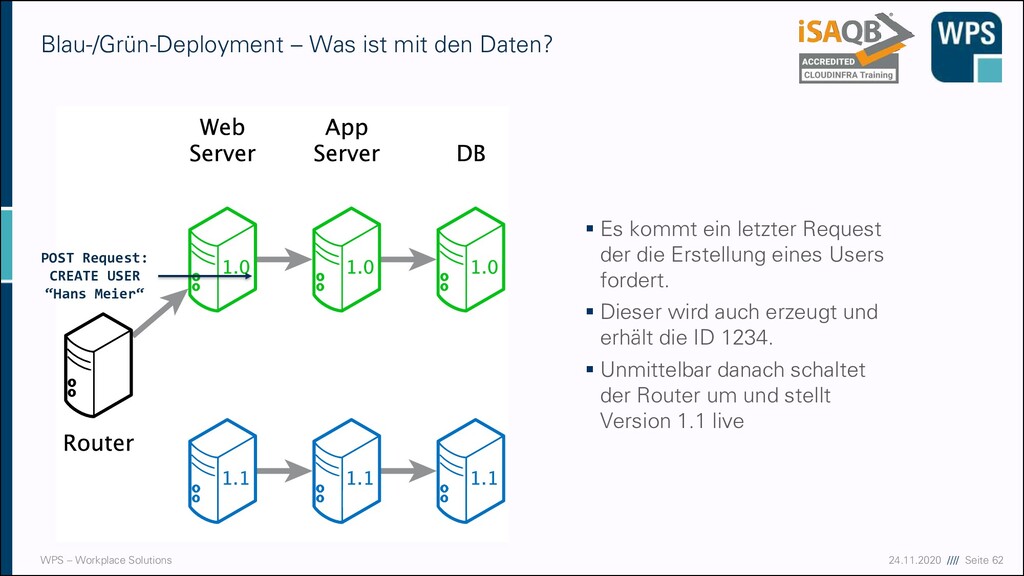{kind=link}
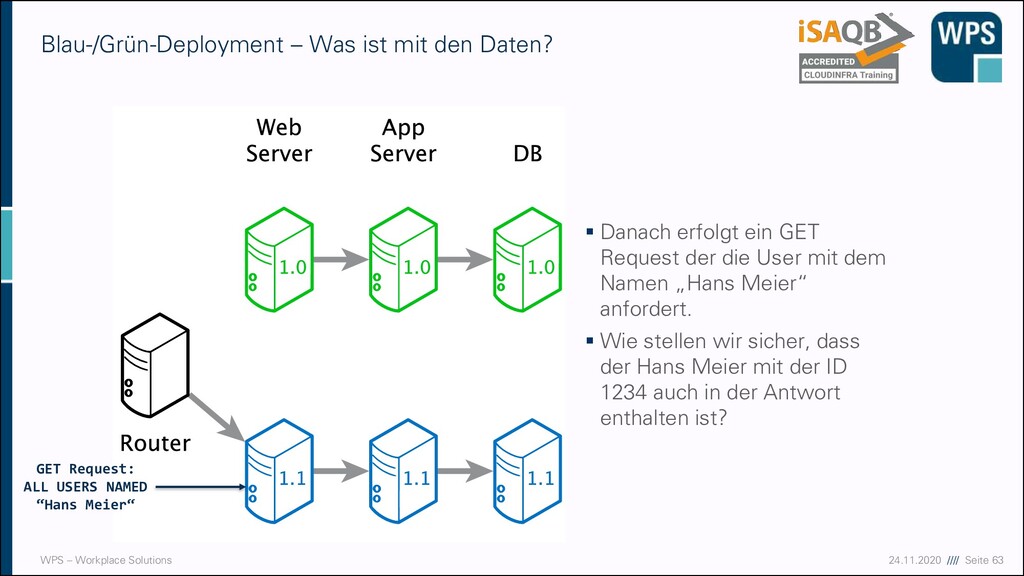{kind=link}
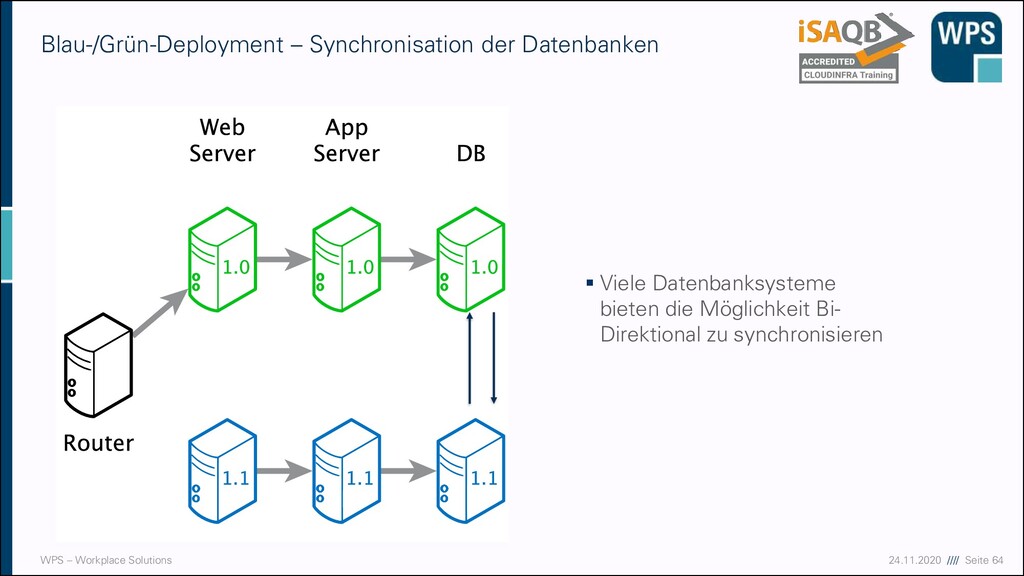{kind=link}
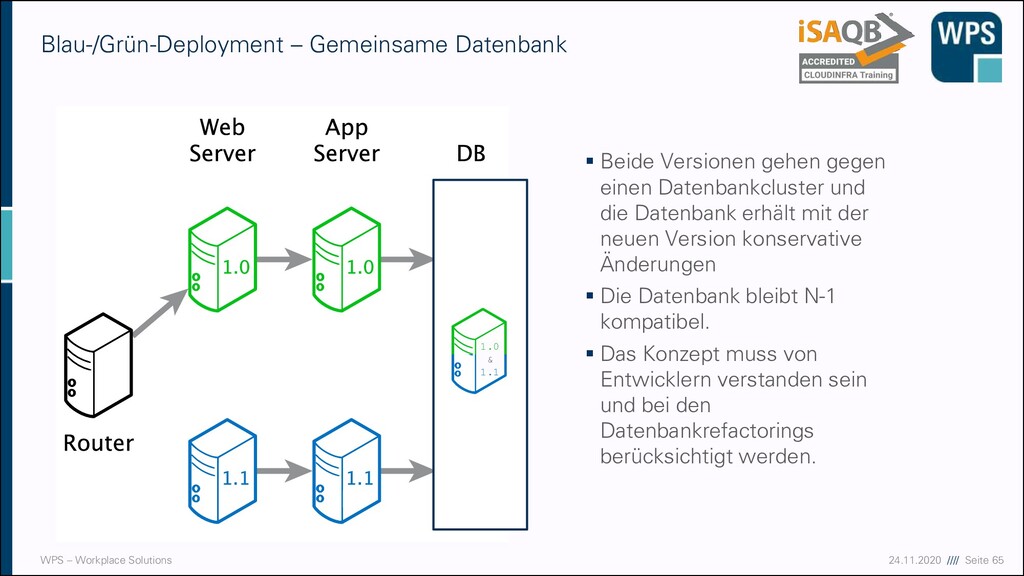{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
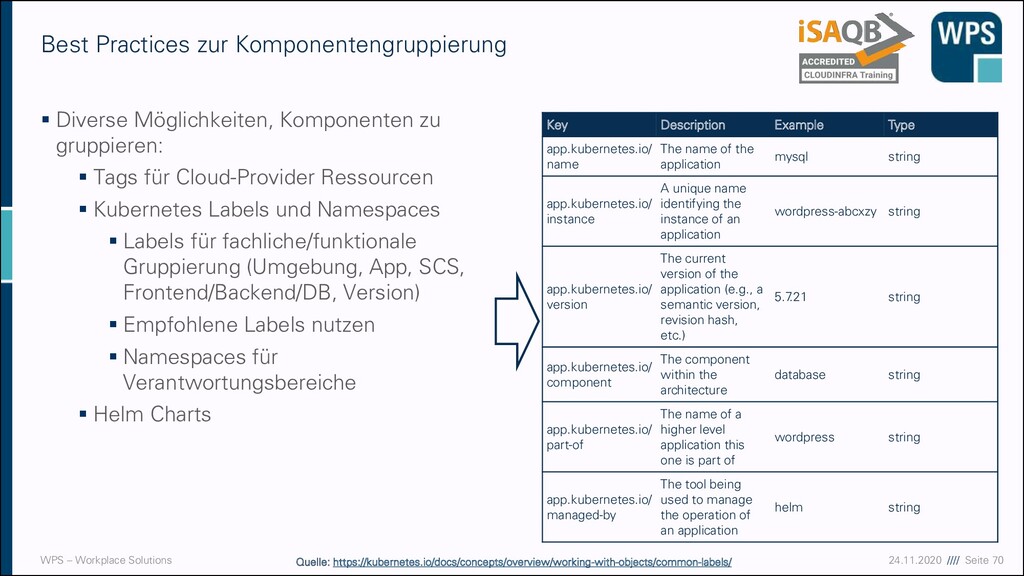{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
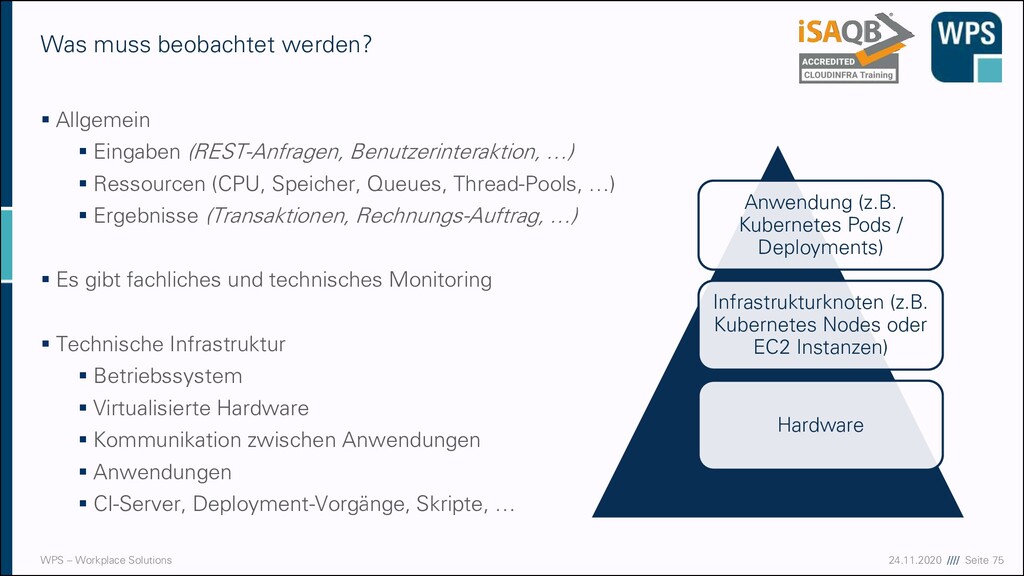{kind=link}
{kind=link}
{kind=link}
{kind=link}
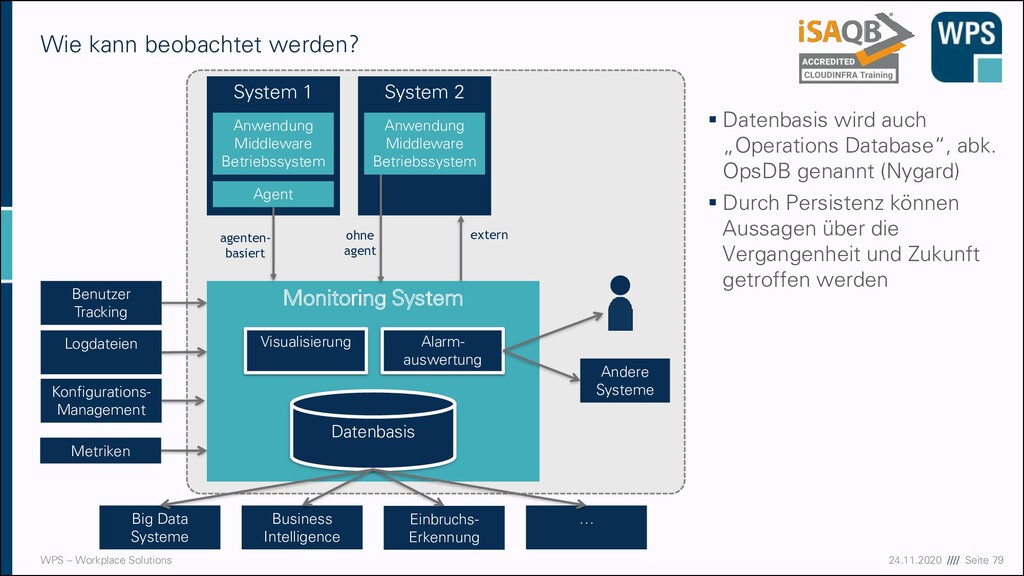{kind=link}
{kind=link}
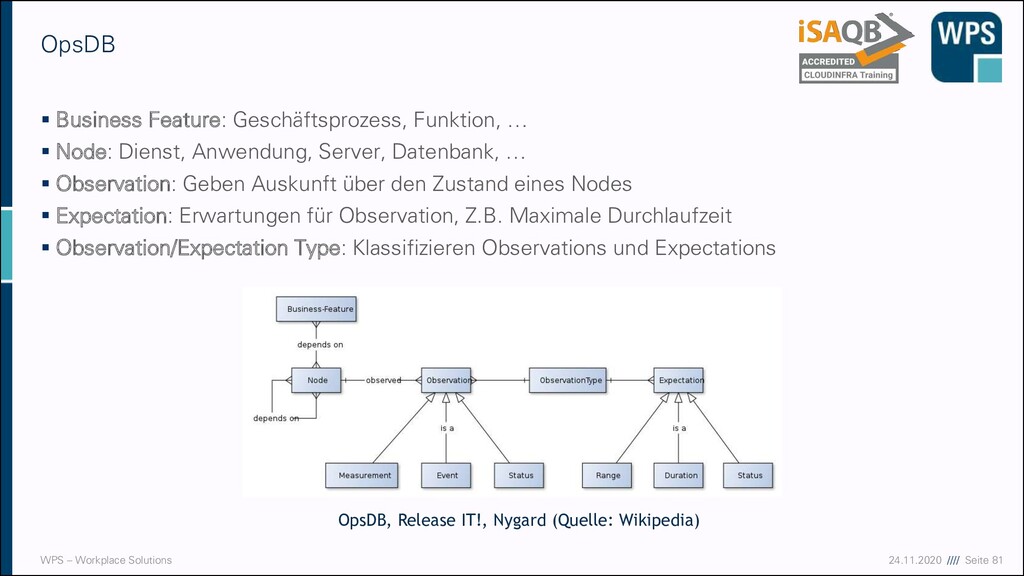{kind=link}
{kind=link}
{kind=link}
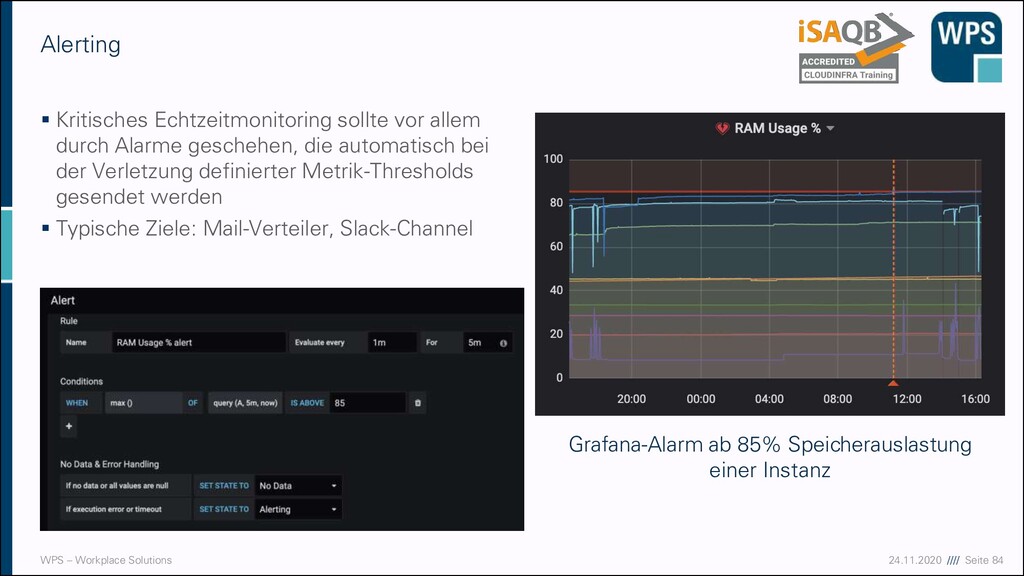{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
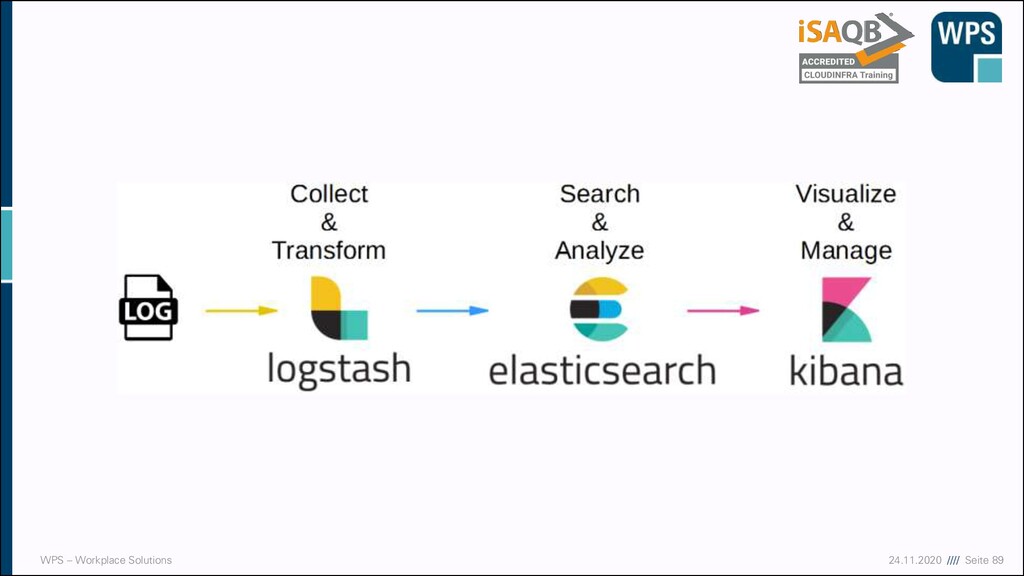{kind=link}
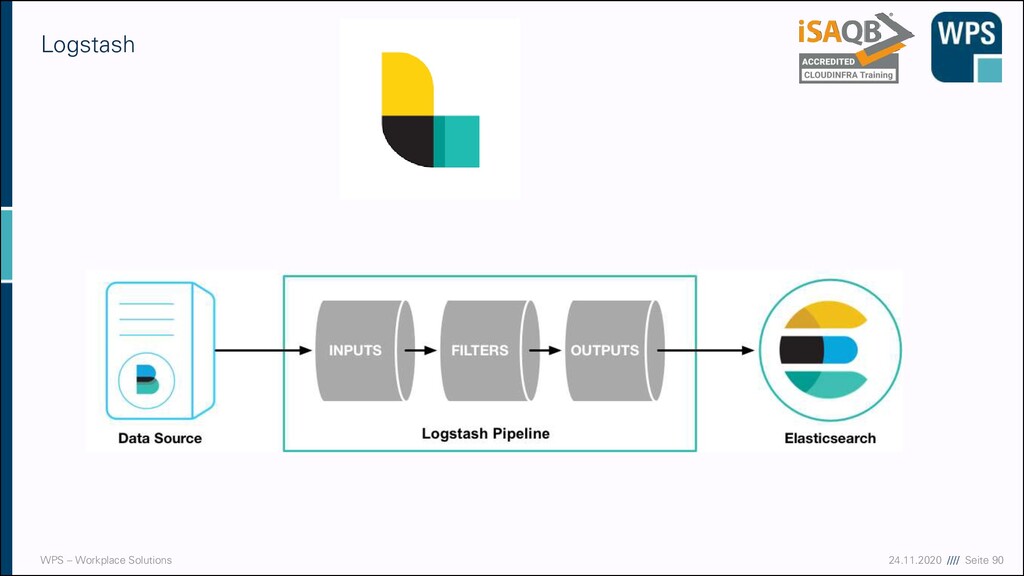{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
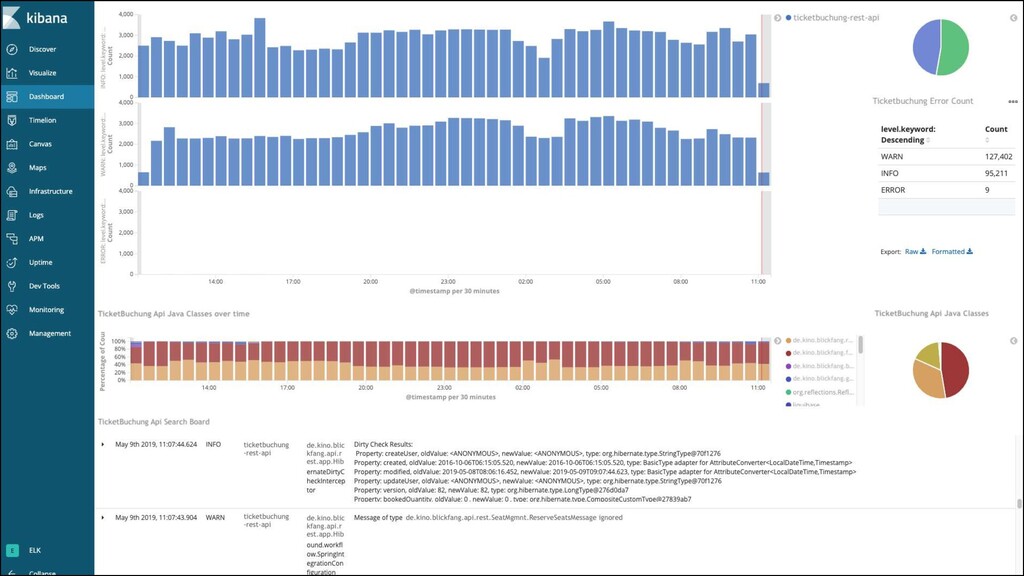{kind=link}
{kind=link}
{kind=link}
{kind=link}
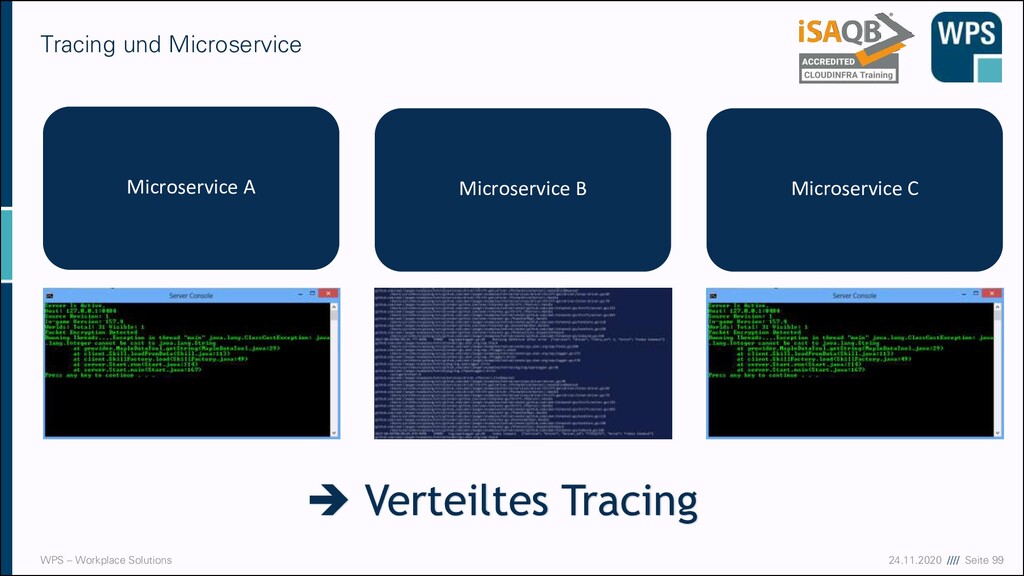{kind=link}
{kind=link}
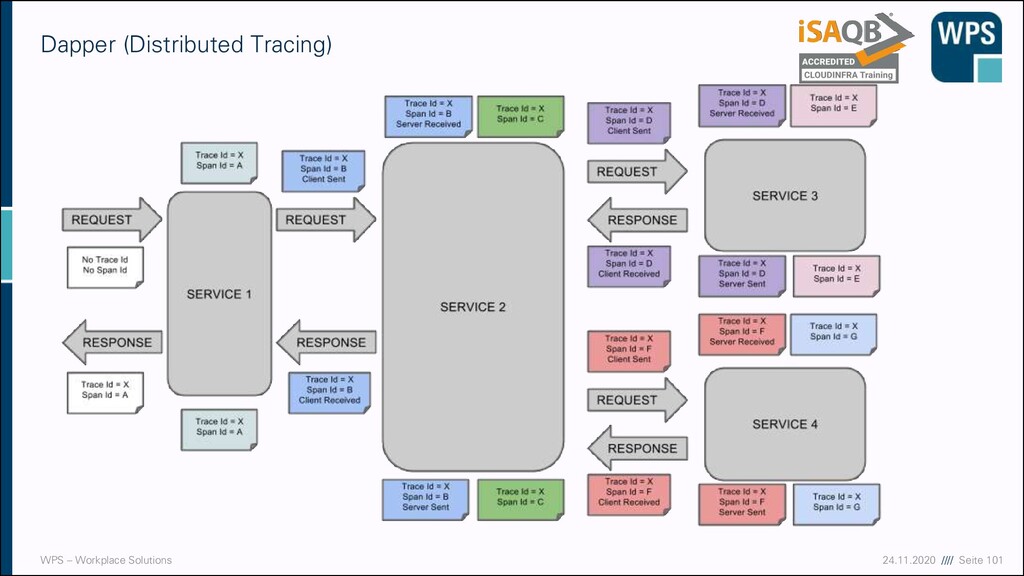{kind=link}
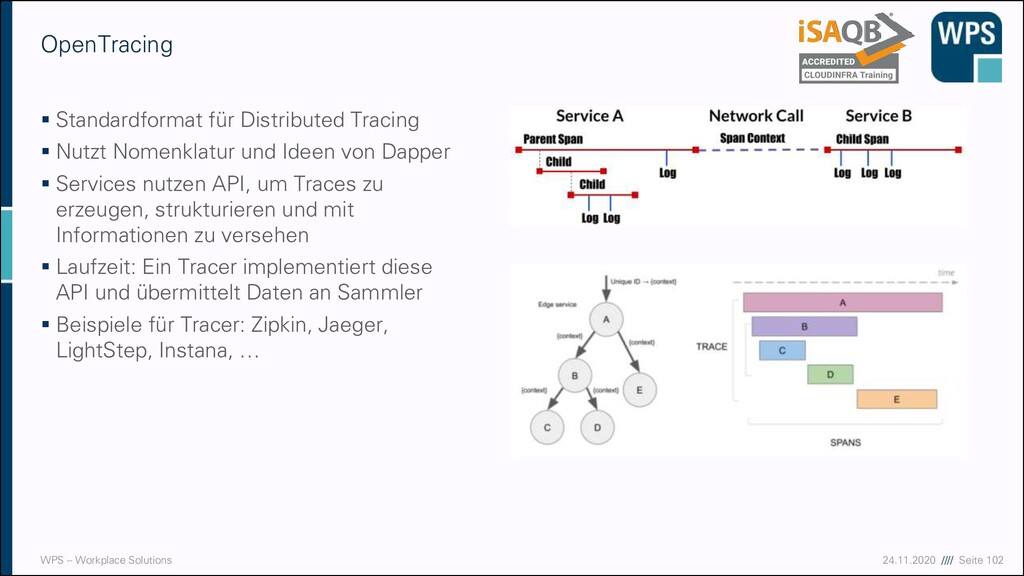{kind=link}
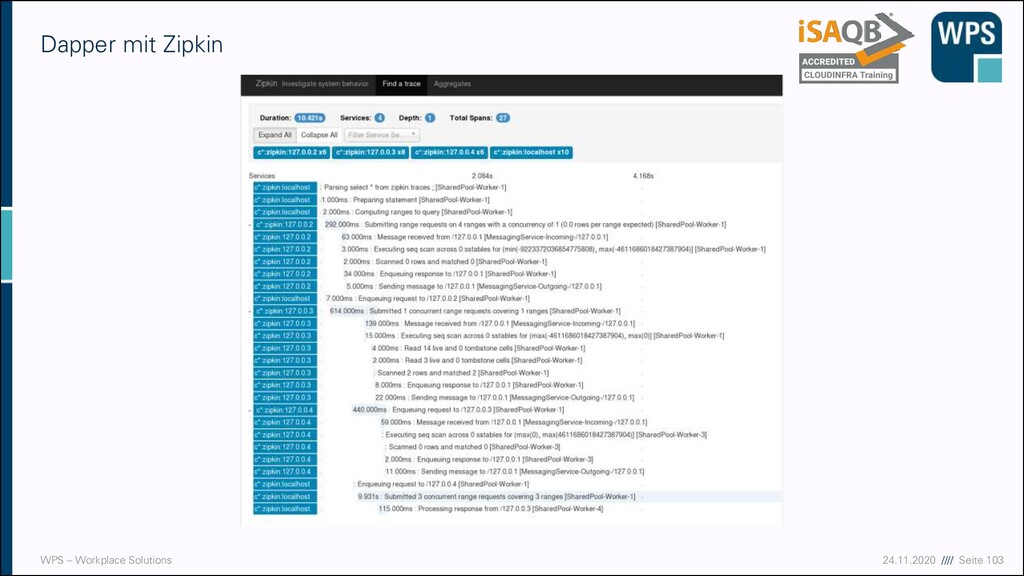{kind=link}
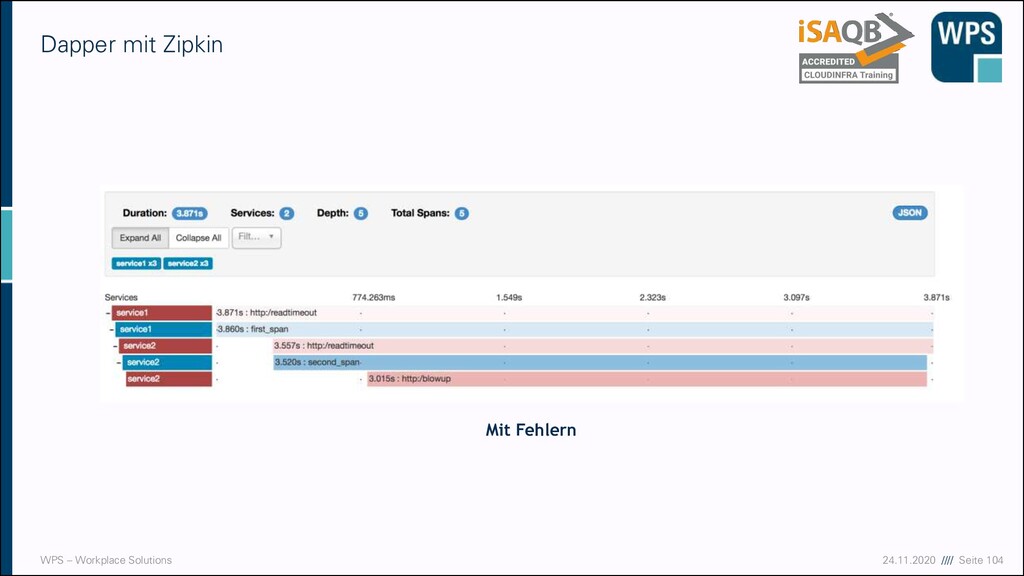{kind=link}
{kind=link}
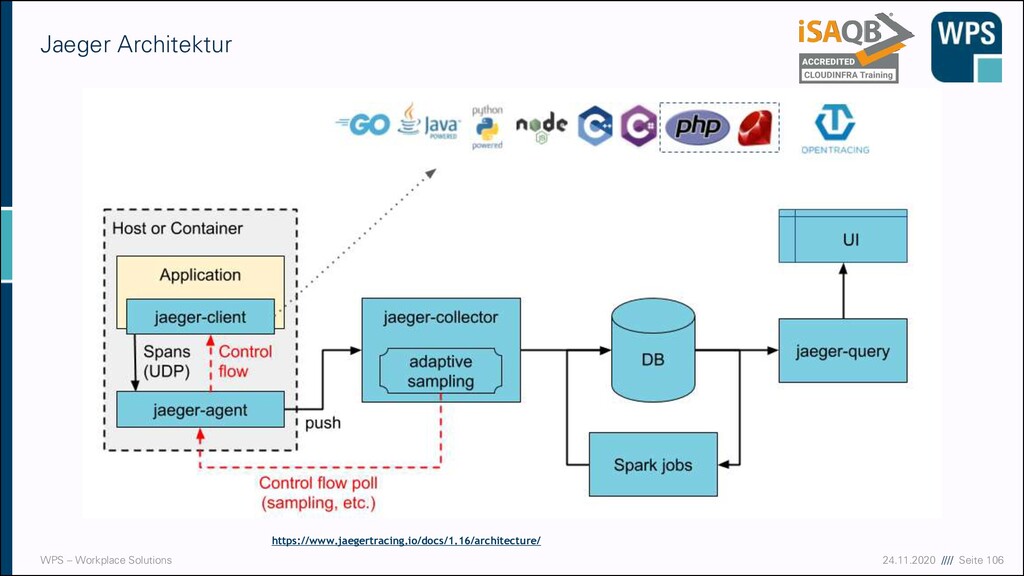{kind=link}
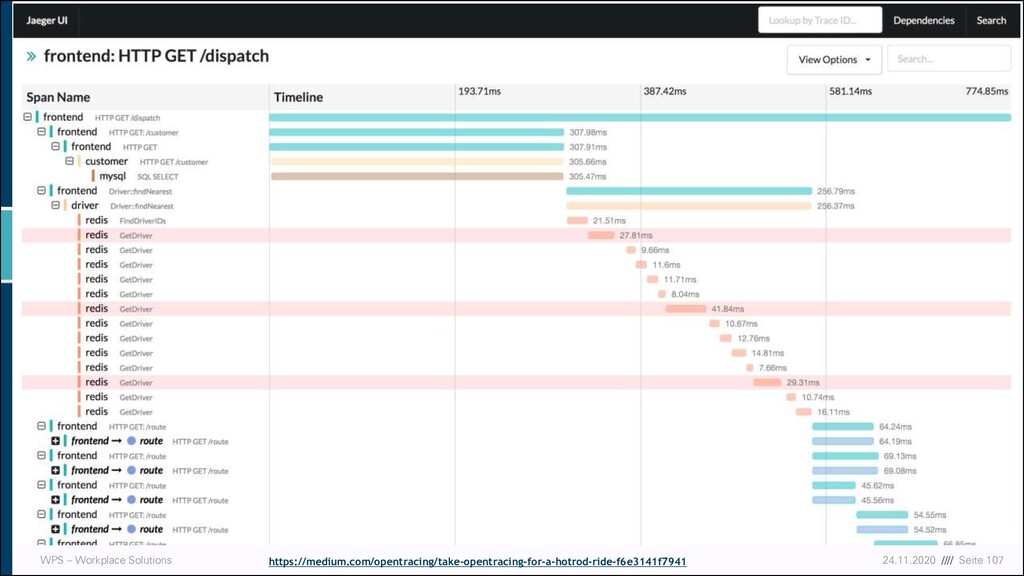{kind=link}
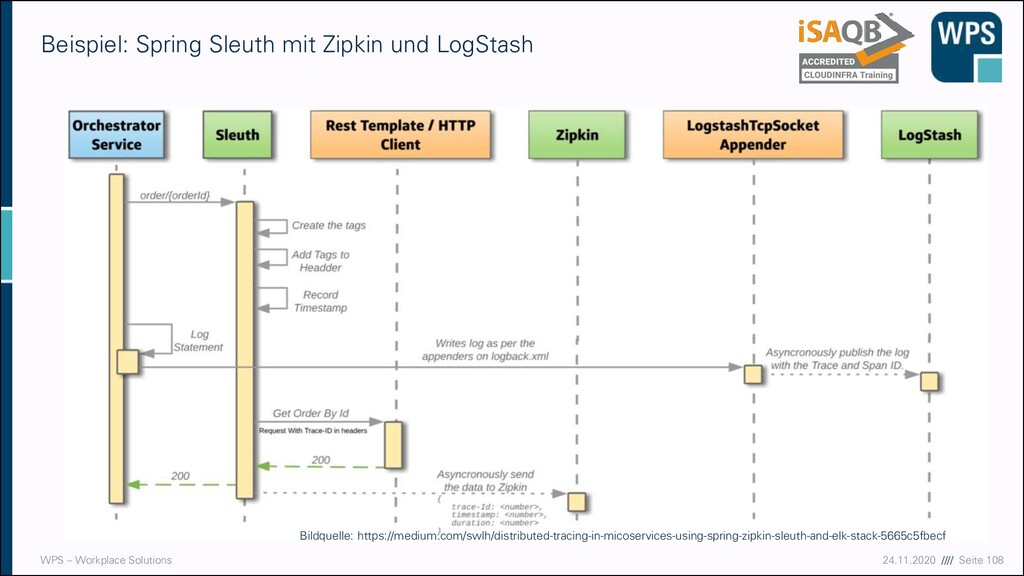{kind=link}
{kind=link}
{kind=link}
{kind=link}
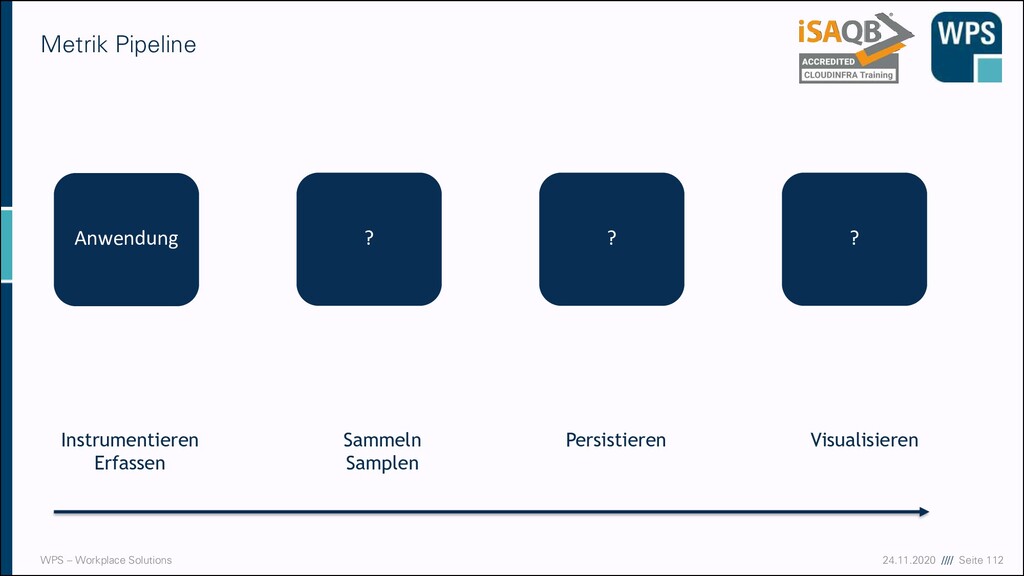{kind=link}
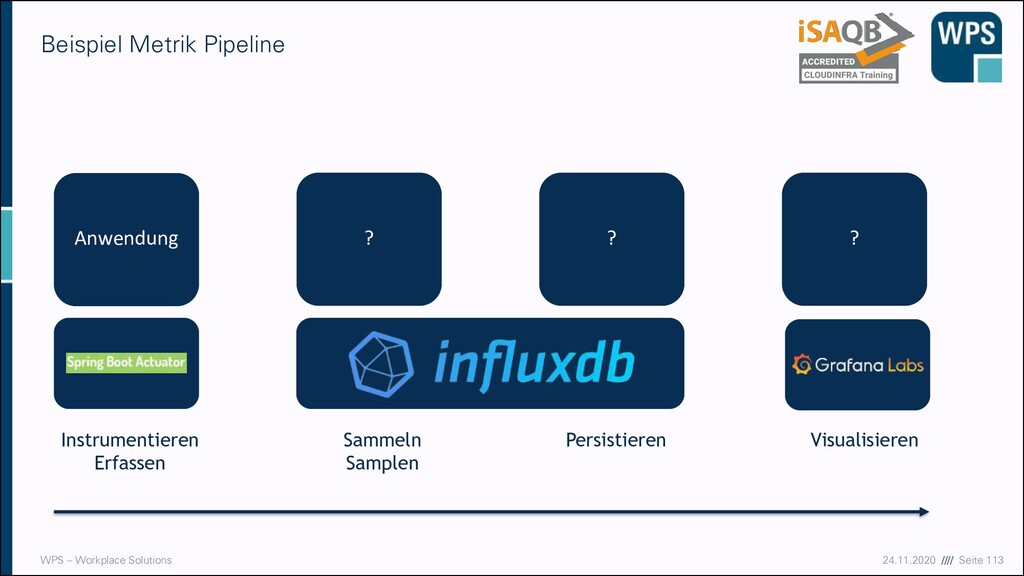{kind=link}
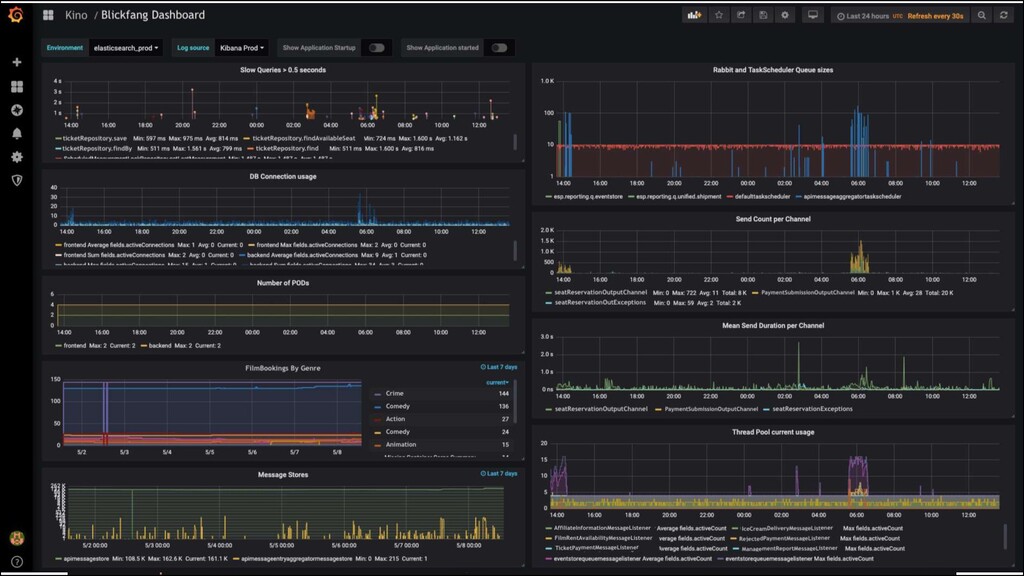{kind=link}
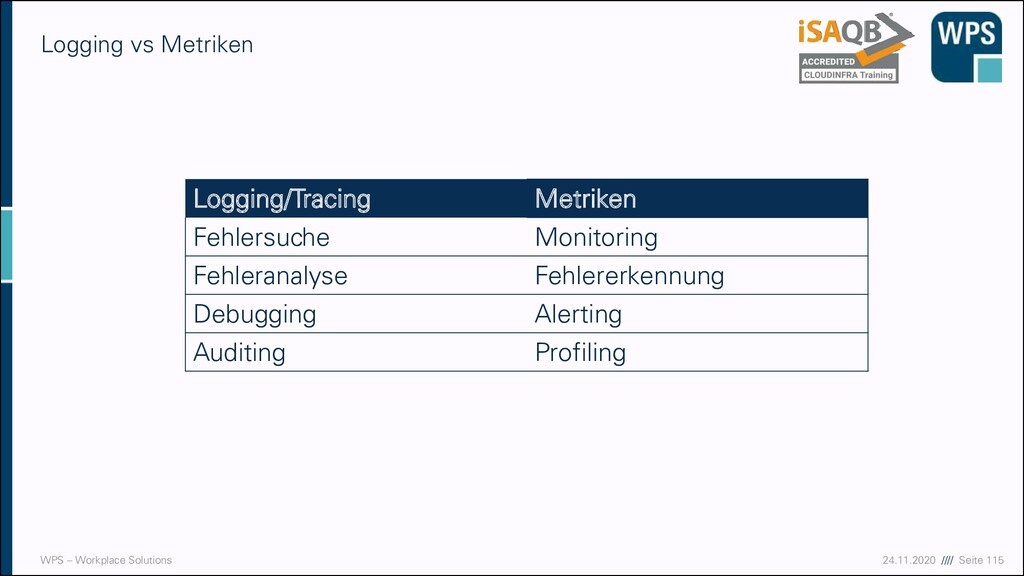{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
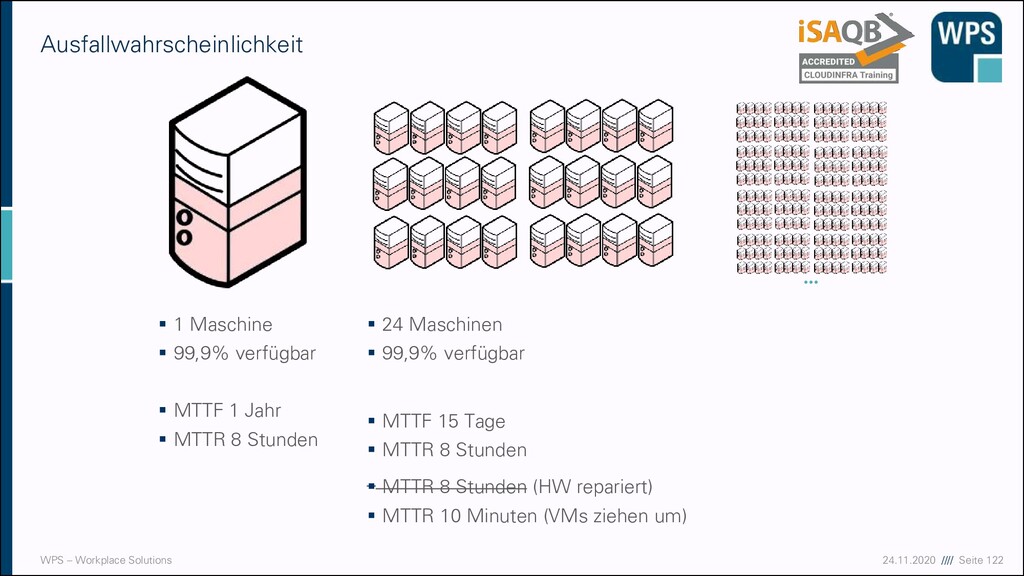{kind=link}
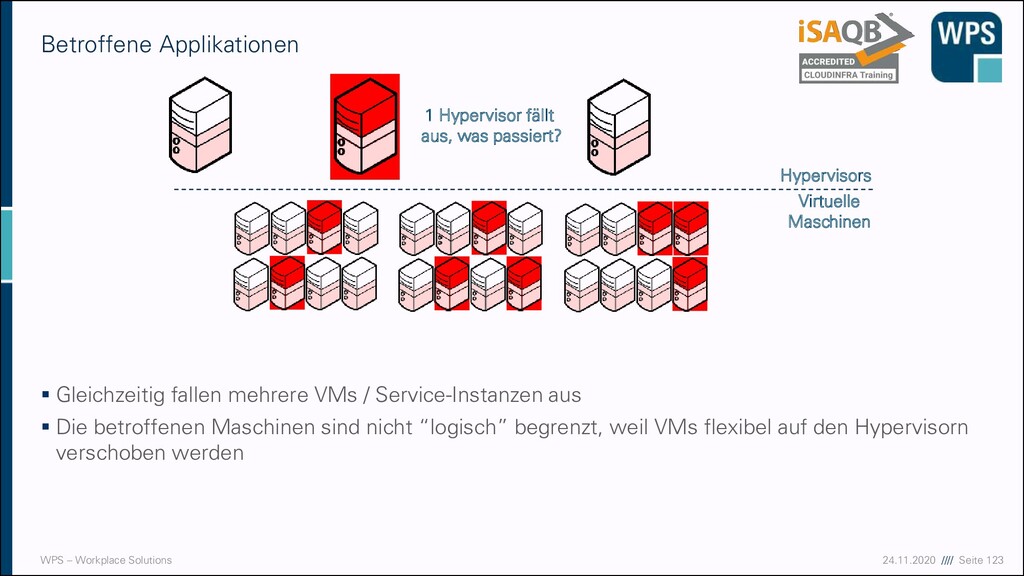{kind=link}
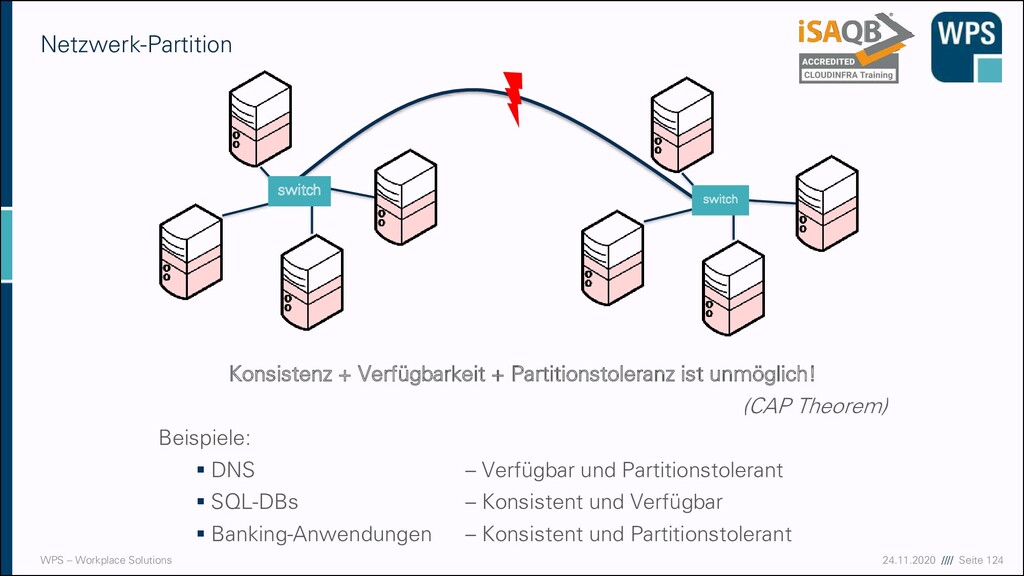{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
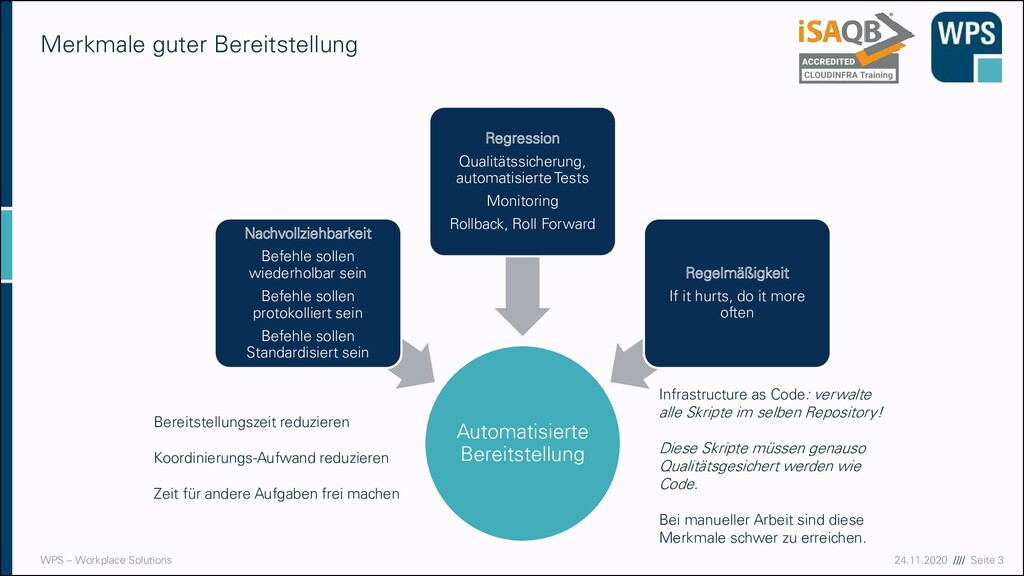{kind=link}
{kind=link}
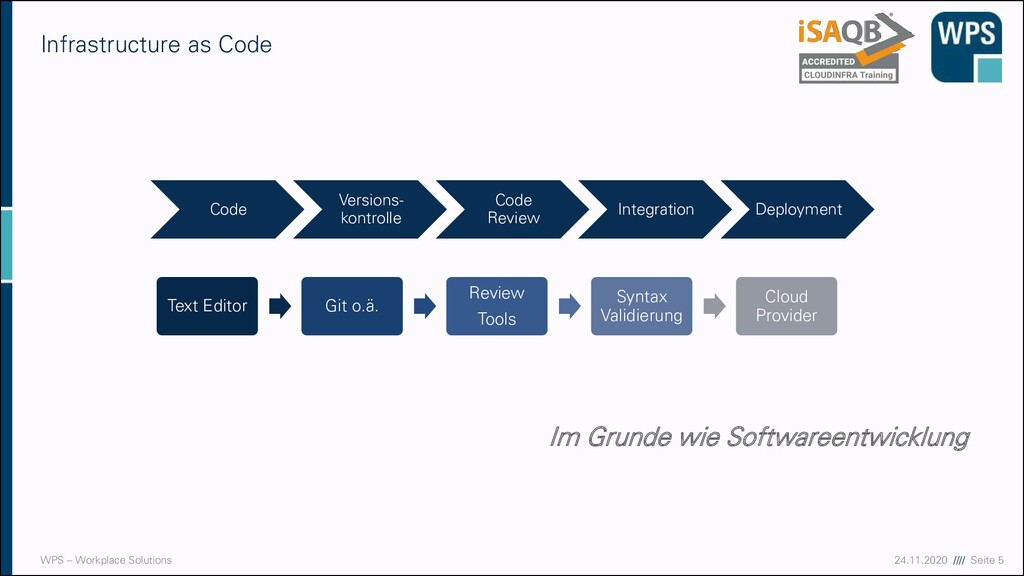{kind=link}
{kind=link}
{kind=link}
{kind=link}
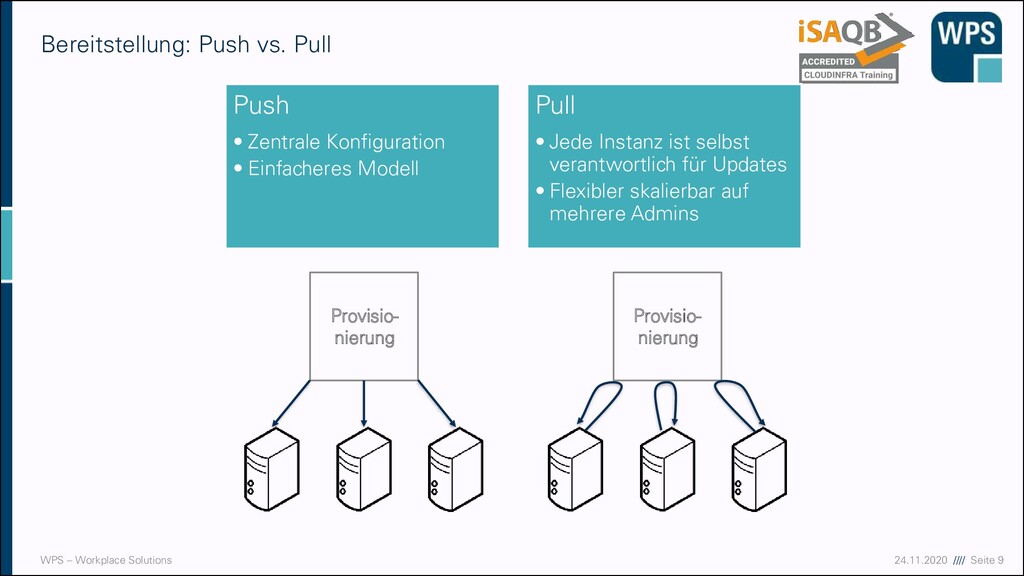{kind=link}
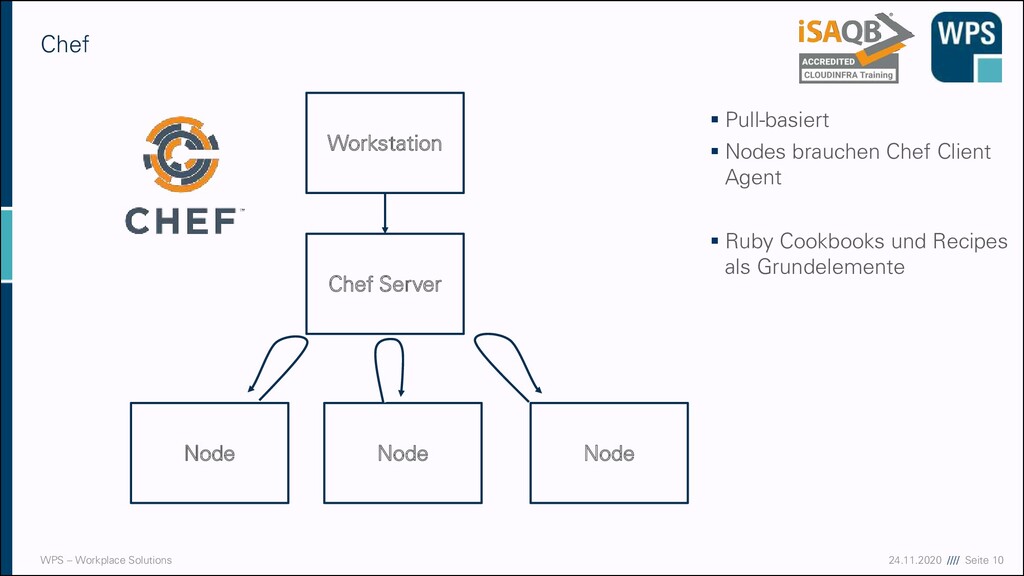{kind=link}
{kind=link}
{kind=link}
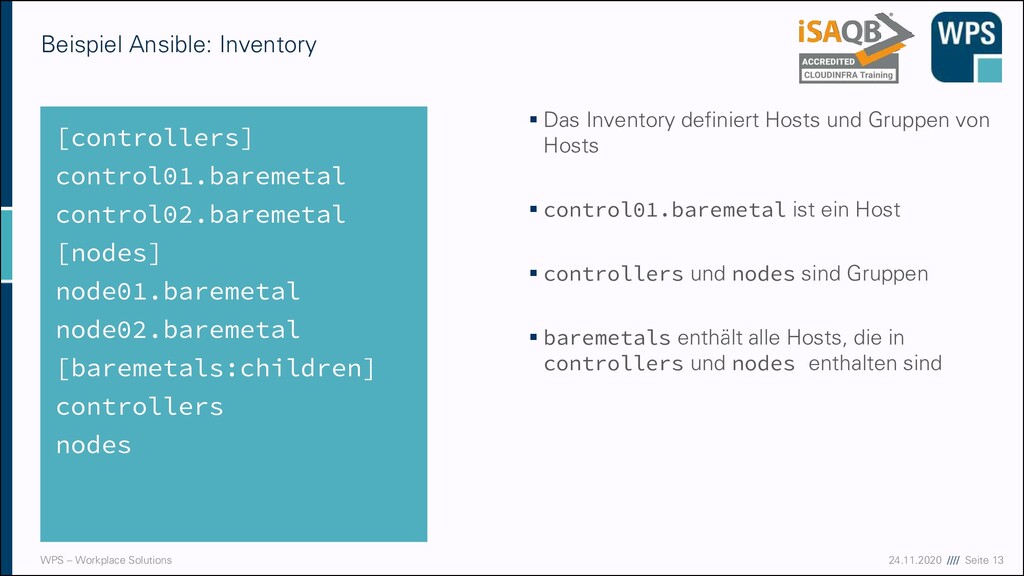{kind=link}
{kind=link}
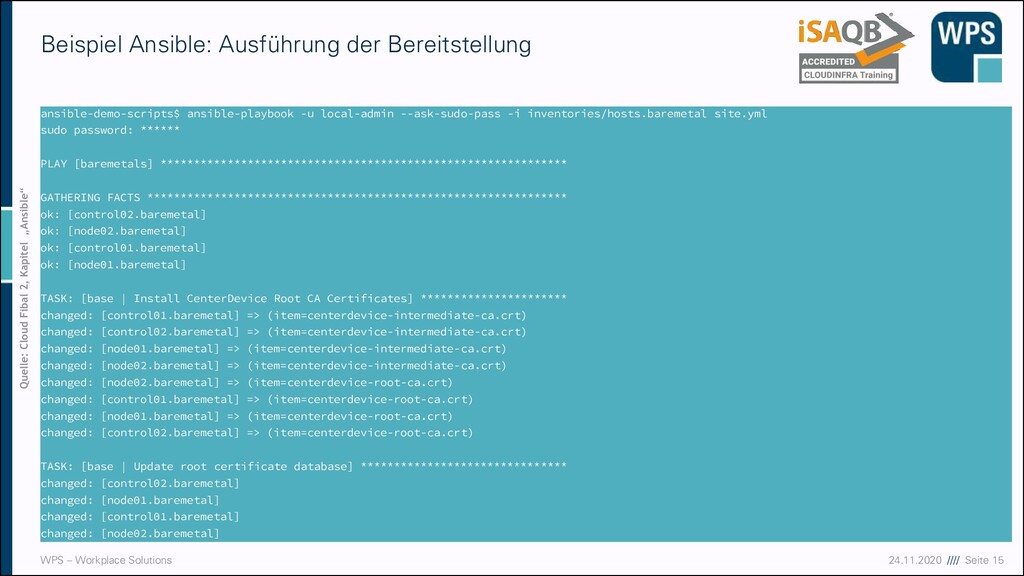{kind=link}
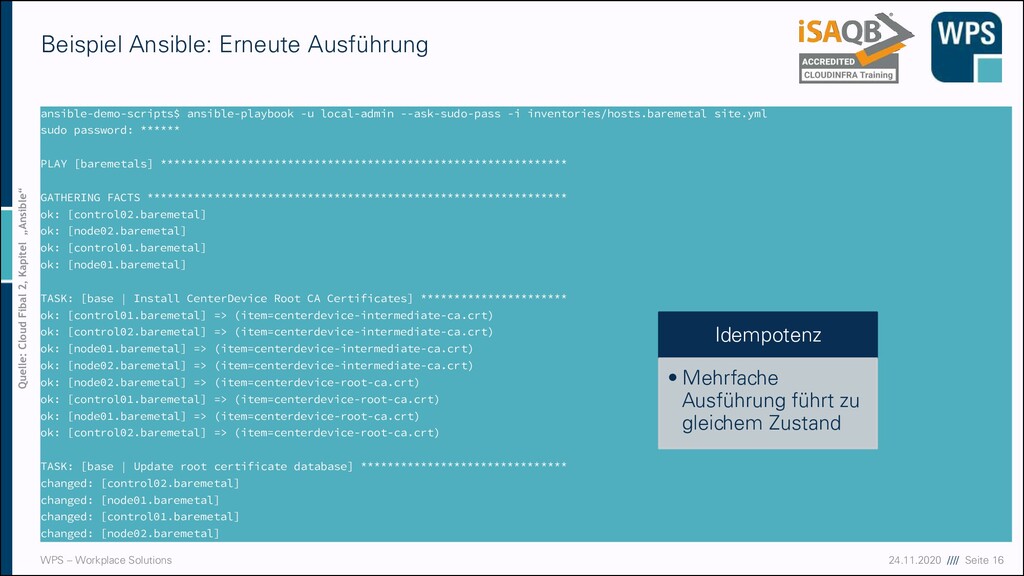{kind=link}
{kind=link}
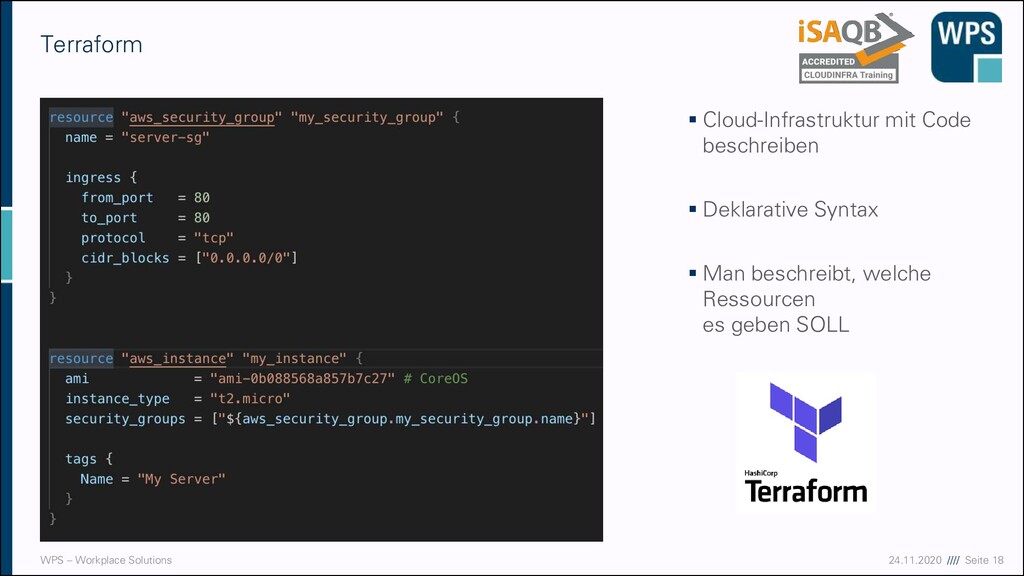{kind=link}
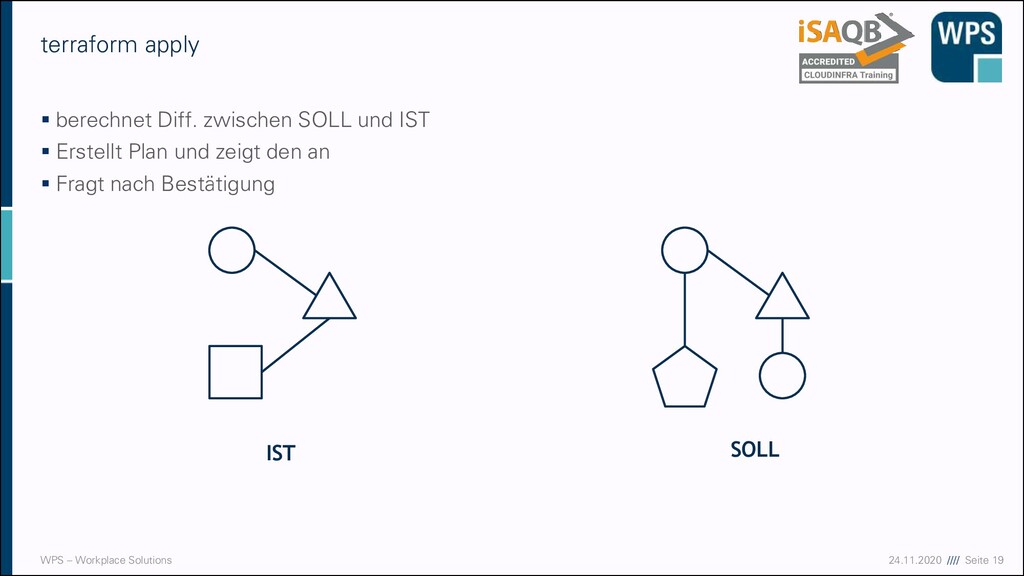{kind=link}
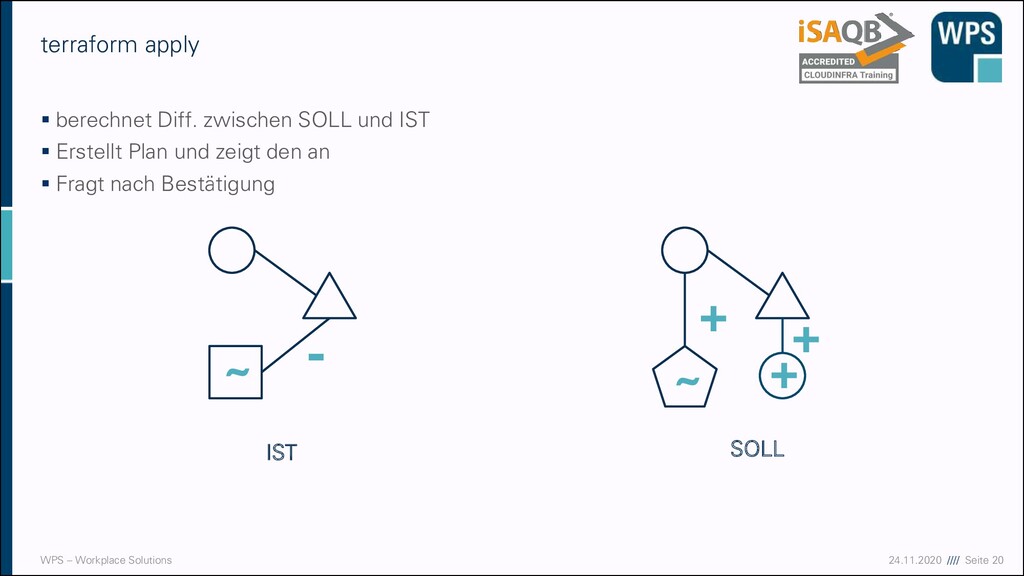{kind=link}
{kind=link}
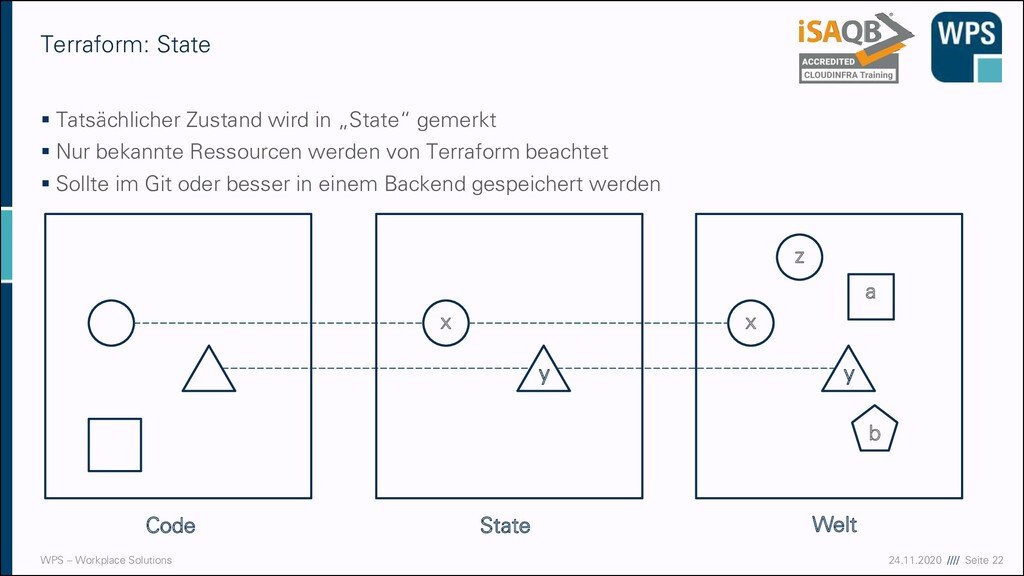{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
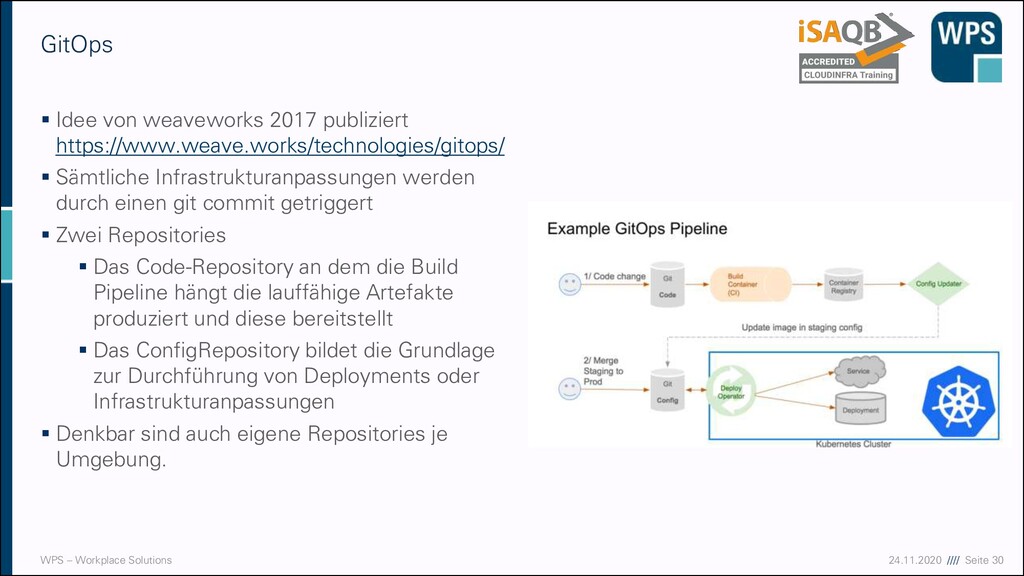{kind=link}
{kind=link}
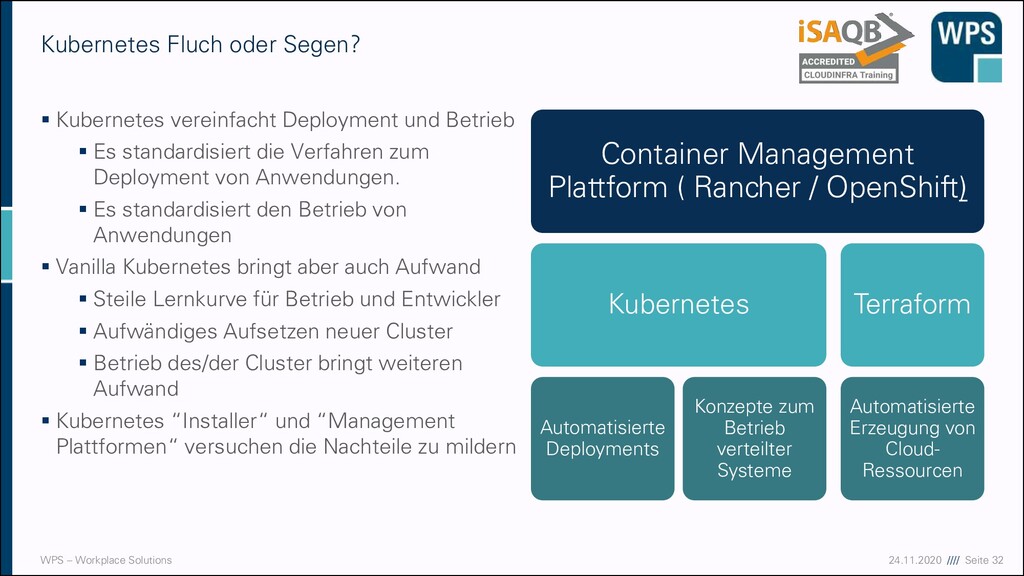{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
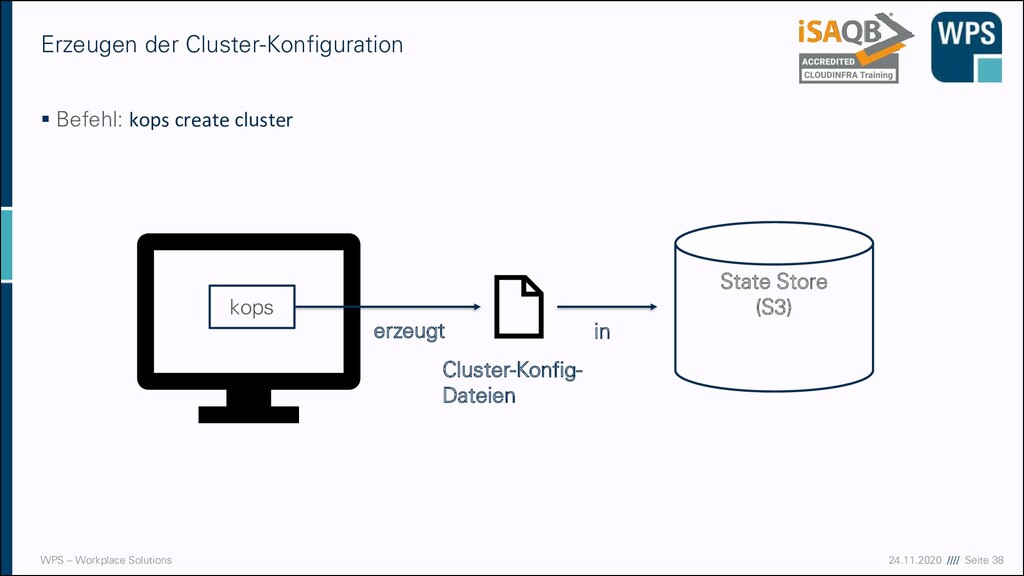{kind=link}
{kind=link}
{kind=link}
{kind=link}
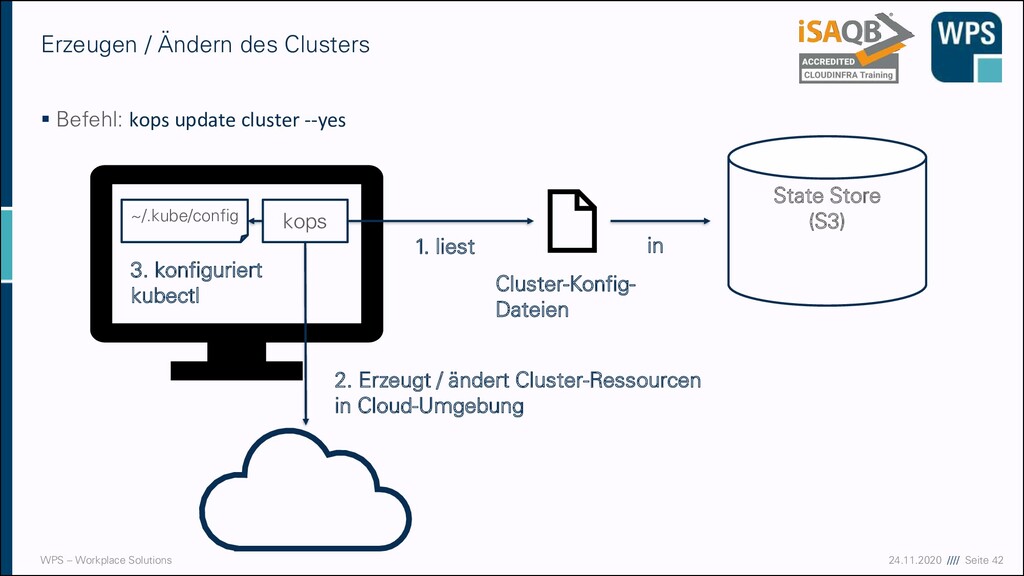{kind=link}
{kind=link}
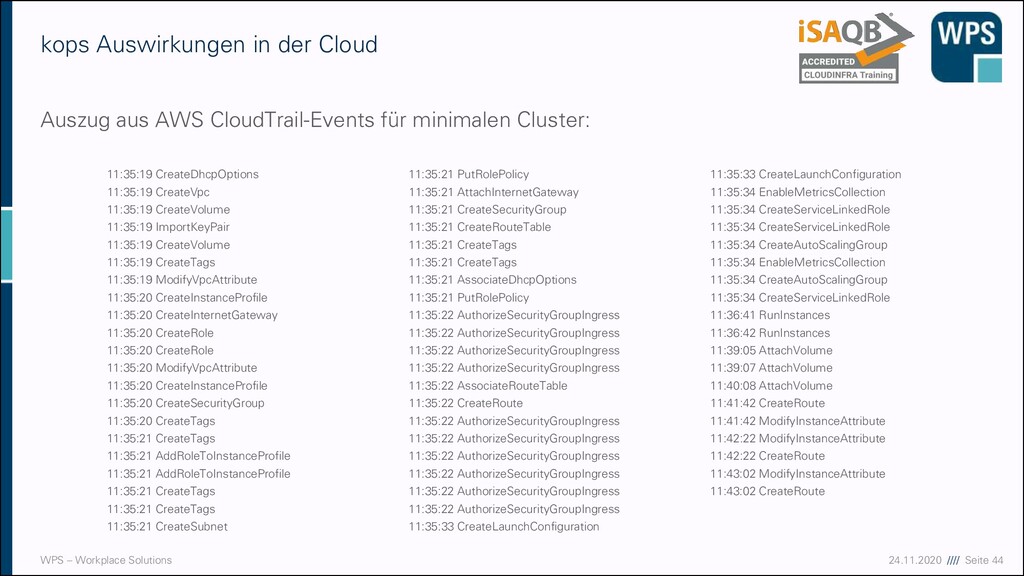{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
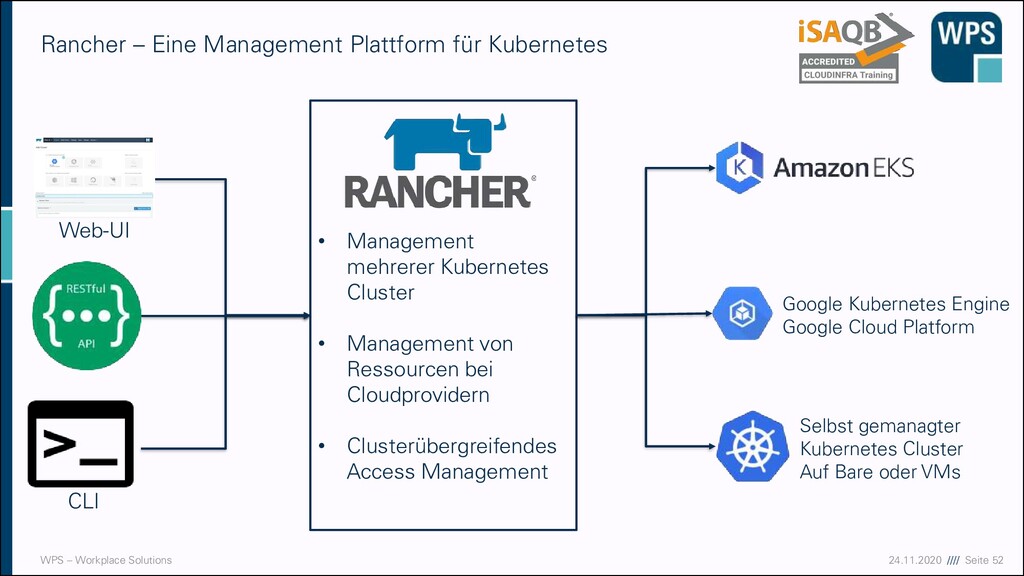{kind=link}
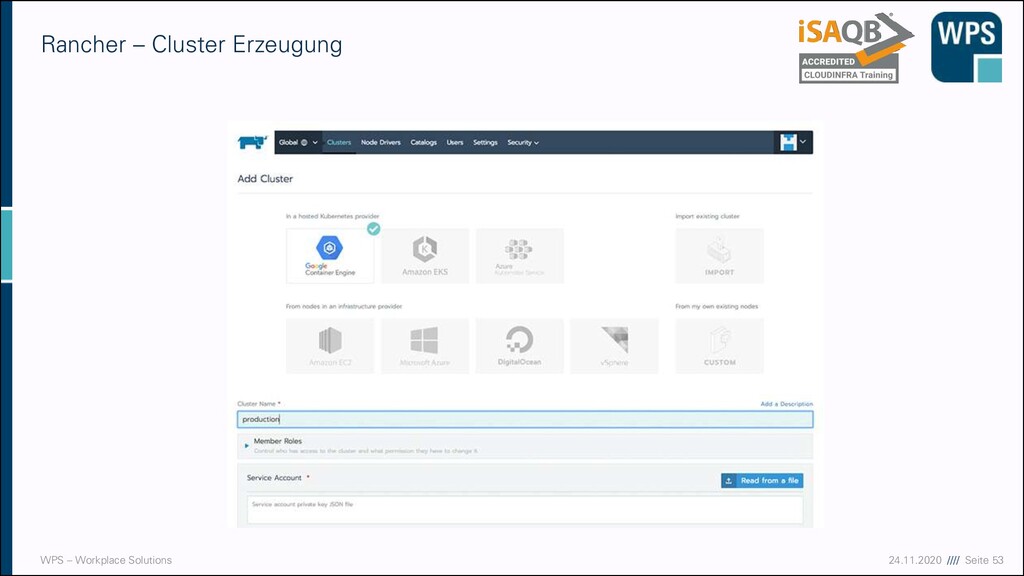{kind=link}
{kind=link}
{kind=link}
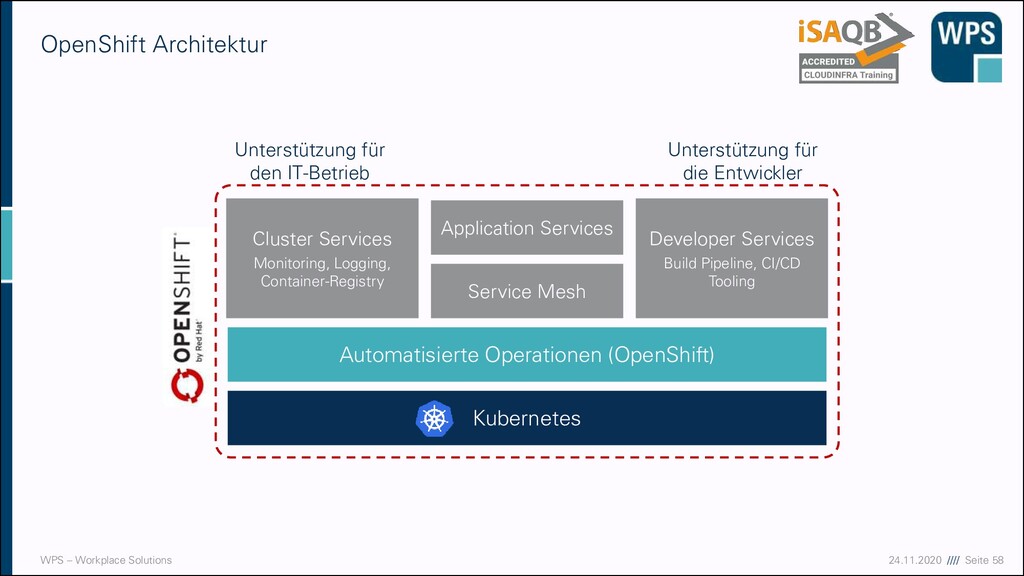{kind=link}
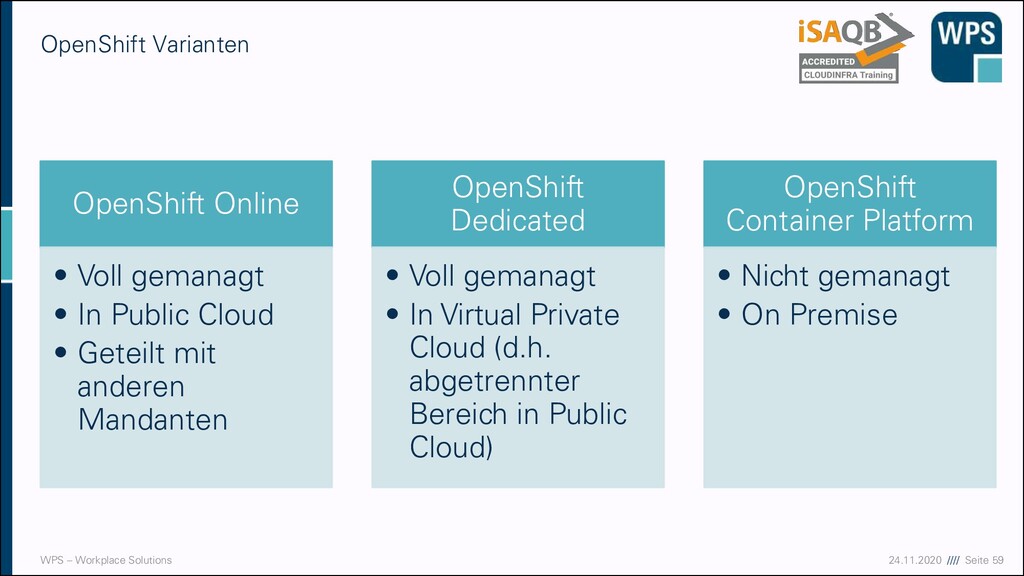{kind=link}
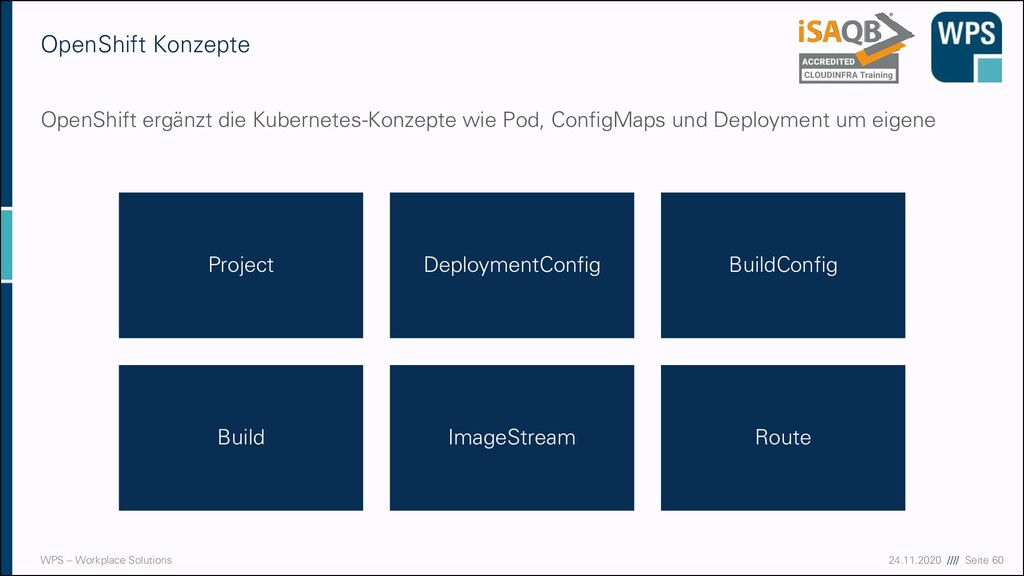{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
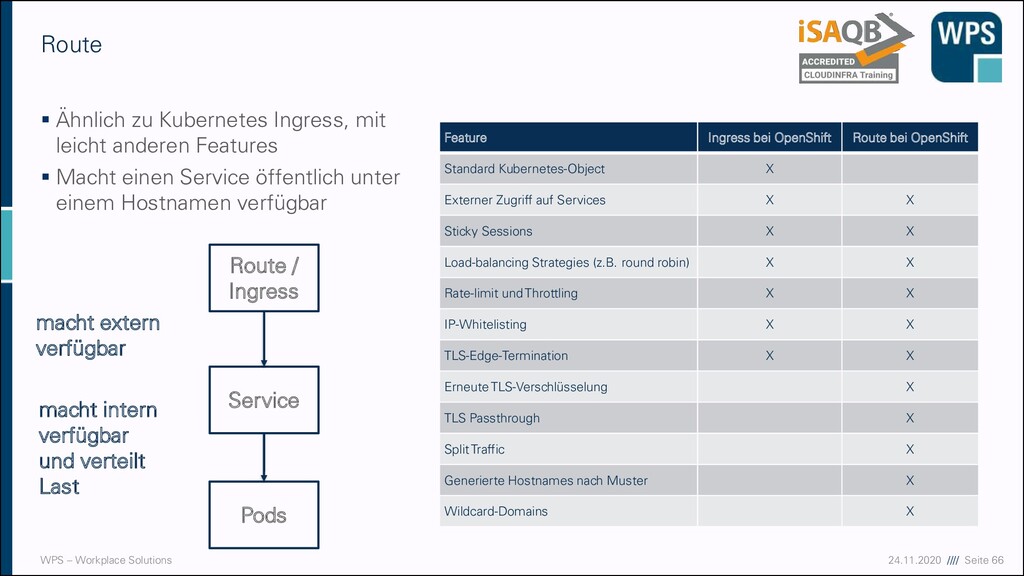{kind=link}
{kind=link}
{kind=link}