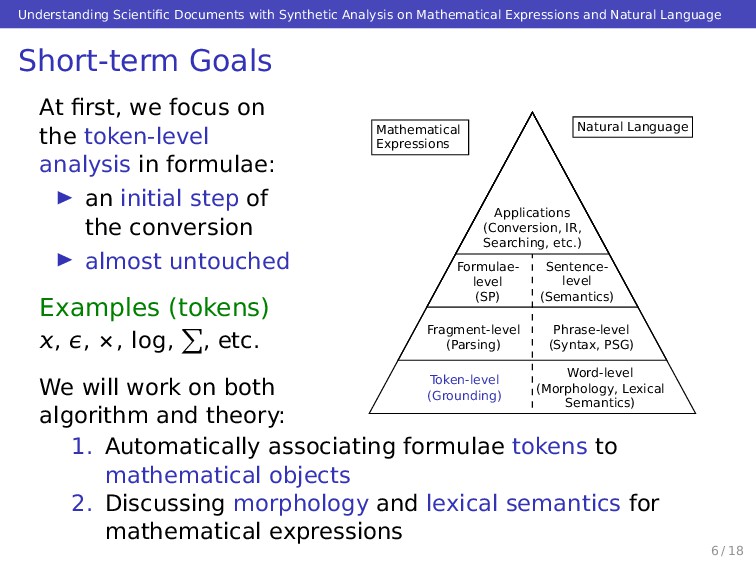
Converting science, technology, engineering and mathematics documents to formal expressions is beneficial. To achieve that conversion it is necessary to analyze both on formulae and texts interactively. We began to tackle the conversion from two foundational parts for the synthetic analyses. In this abstract, we briefly introduce our aim, planning approaches, and current status of the work.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}