targets of our work are Science, Technology, Engineering, and Mathematics (STEM) documents. Example Papers, Textbooks, and Manuals, etc. STEM documents are: essence of human knowledge well organized (semi-structured) texts with mathematical formulae 2 / 17
Computational Conversion STEM Documents (Natural Language + Formulae) Papers, textbooks, manuals, etc. Conversion Computational Form (Formal Language) Executable code, first-order logic, etc. The conversion enables us to: construct databases of mathematical knowledge search for formulae 3 / 17
Importance of formulae in STEM documents Mathematical expressions are commonly used in scientific communication in numerous fields. E.g. Mathematics, Physics, Informatics, etc. They often express key ideas in STEM documents. [Kohlhase+, 2014] Interaction among texts and formulae Texts and formulae are complimentary to each other: Texts explains formulae (and vice versa) Texts in formulae E.g. { ∈ N | is prime} Notations and verbalizations E.g. 1 + 2 and “one plus two” Integration of NLP and formulae analysis is required! 4 / 17
Finding groups of tokens (math words) which refer to mathematical concepts 2. Associating a corresponding mathematical concept to each group cf. Entity linking + Co-reference analysis in NLP 6 / 17
Various ambiguities similar to natural languages [Kohlhase+, 2014] A symbol (token) can be used in several meanings Syntactic ambiguity E.g. ƒ( + b) Formulae cannot be understood without reading surrounding texts Common sense and domain knowledge may be required E.g. π is Archimedes’ constant Usage of character y in the first chapter of PRML (except exercises) Text fragment from PRML Chap. 1 Meaning of y . . . can be expressed as a function y(x) . . . a function which takes an image as input . . . an output vector y, encoded in . . . an output vector of function y(x) . . . two vectors of random variables x and y . . . a vector of random variables Suppose we have a joint distribution p(x, y) . . . a part of pairs of values, corresponding to x 7 / 17
NTCIR-10 Math Pilot Task Annotating a description for each token in formulae Hard to directly use this dataset for the conversion [Stathopoulos+, 2018] Variable Typing Assigning a mathematical type for each token E.g. set, monoid, etc. A sort of subtask for our grounding Only targeting simple formulae that consist of single tokens [Youssef+, 2017] Part-of-Math Tagging Tagging akin to Part-of-Speech tagging for NLP E.g. indexes, functions, left-delimiter, etc. A sort of subtask for our grounding 8 / 17
all identifiers in an academic paper. Identifiers a type of token; <mi> in Presentation MathML a letter or a string E.g. , y, θ, sin, etc. Target Paper We chose from the arXMLiv dataset: A Very Brief Introduction to Machine Learning With Applications to Communi- cation Systems [Simeone, 2018] Basic statistics of the target paper #words in texts 10,616 #<mi> tags 937 #sections 7 #inline math 331 #pages (in PDF) 20 #display math 23 Let me show you a demonstration! 11 / 17
worked for the annotation: Annotator 1 created the dictionary and did the annotation Annotator 2 & 3 only performed the annotation part with the dictionary created by the Annotator 1 The agreements Agreements Affixes mismatches Annotator 2 904/937 (96.48%) 2/33 (6.06%) Annotator 3 824/937 (87.94%) 60/113 (53.10%) Example (Affixes mismatch) Annotator 1 says p is a part of p(· | ·, ·) [a parameterized true distribution] but another says it is a part of p(· | ·) [a parameterized true distribution]. 12 / 17
cascading effects ∵) meanings of identifiers depend on that of others disagreements between Annotator 1 & 2 are mostly due to a single disagreement for D some declarations are not clear enough 113 disagreements between Annotator 1 & 3 can be categorized into 40 patterns we are given a training set D of N training points (n, tn), with n = 1, . . . , N, where the variables n are the inputs [Simeone, 2018] Under this assumption, the data set D is not necessary, since the mapping between input and output is fully described by the distribution p(, t). [Simeone, 2018] 13 / 17
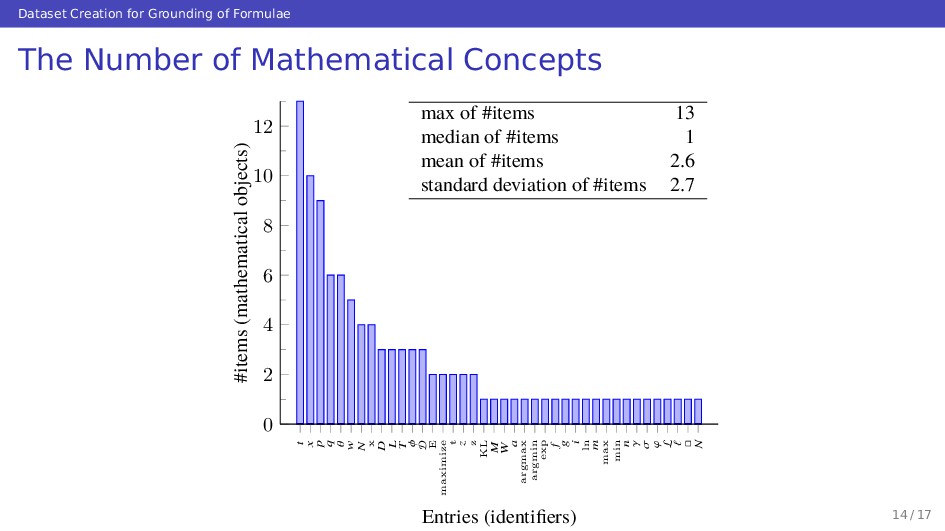
Concepts x D E maximize t z KL argmax argmin exp ln max min L ℓ N 0 2 4 6 8 10 12 Entries (identifiers) #items (mathematical objects) max of #items 13 median of #items 1 mean of #items 2.6 standard deviation of #items 2.7 14 / 17
Ambiguity a type of identifier is used in several meanings (referring to mathematical objects) Scopes there are loose scopes Meta-declaration for notation usages There are sentences like the following: Throughout, we use Roman font to denote random variables and the corresponding letter in regular font for realizations. [Simeone, 2018] 16 / 17
Summary Intergration of NLP and Formulae analysis is crucial We propose a new task grounding of formulae Associating each math token to mathematical concept It is like a combination of entity linking and co-reference analysis We start creating a dataset with our special annotation tool Future Direction Automating the grounding process Enlarge the dataset with semi-automatic methods Thanks for your time! Questions? 17 / 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Dataset Creation for Grounding of Formulae Related Work [Aizawa+, 2013]](https://files.speakerdeck.com/presentations/93d84264c3314058b9a4c04d54bc5048/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}