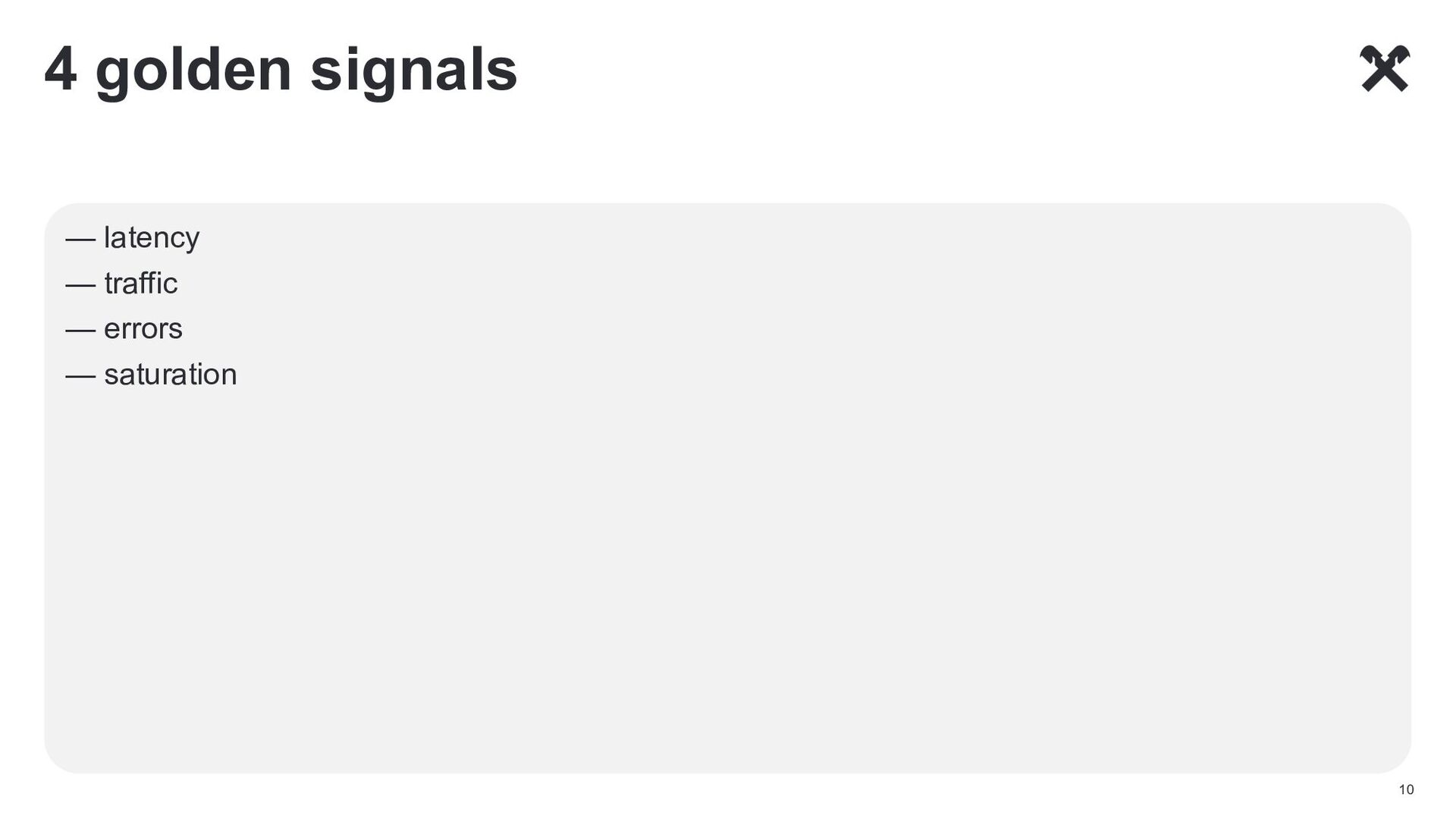
Современные сервисы и особенно микро-сервисы требуют обширного мониторинга. Но дело в том, что кроме общих соображений и статей вроде 4 golden signals не так уж и много информации как и что мониторить. И каждый раз приходится эту проблему решать вновь.
В этом докладе я постараюсь дать довольно обширный список того, что вам нужно будет мониторить, а так же опишу некоторые типовые проблемы организации мониторинга.
Я не пытаюсь объять всё возможное, но если вы пишите back сервисы, используете rest, вебсокеты, event driven архитектуру и пока не успели обрасти мониторингом, то в этом докладе вы сможете найти много полезного.
Выступление на весенней Стачке 2024
https://ul24.nastachku.ru/%D1%87%D1%82%D0%BE-%D0%BC%D0%BE%D0%BD%D0%B8%D1%82%D0%BE%D1%80%D0%B8%D0%BC
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
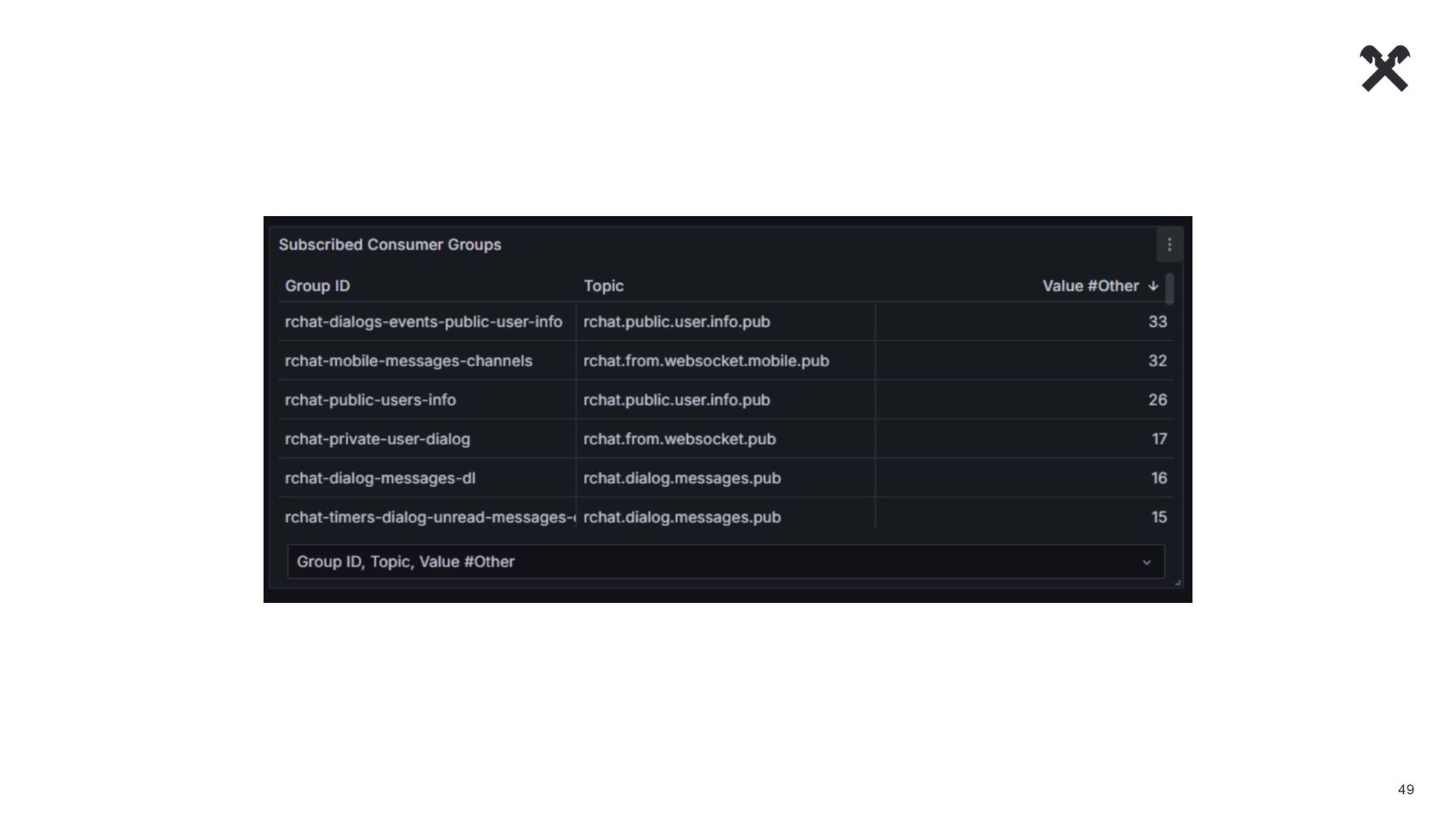{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
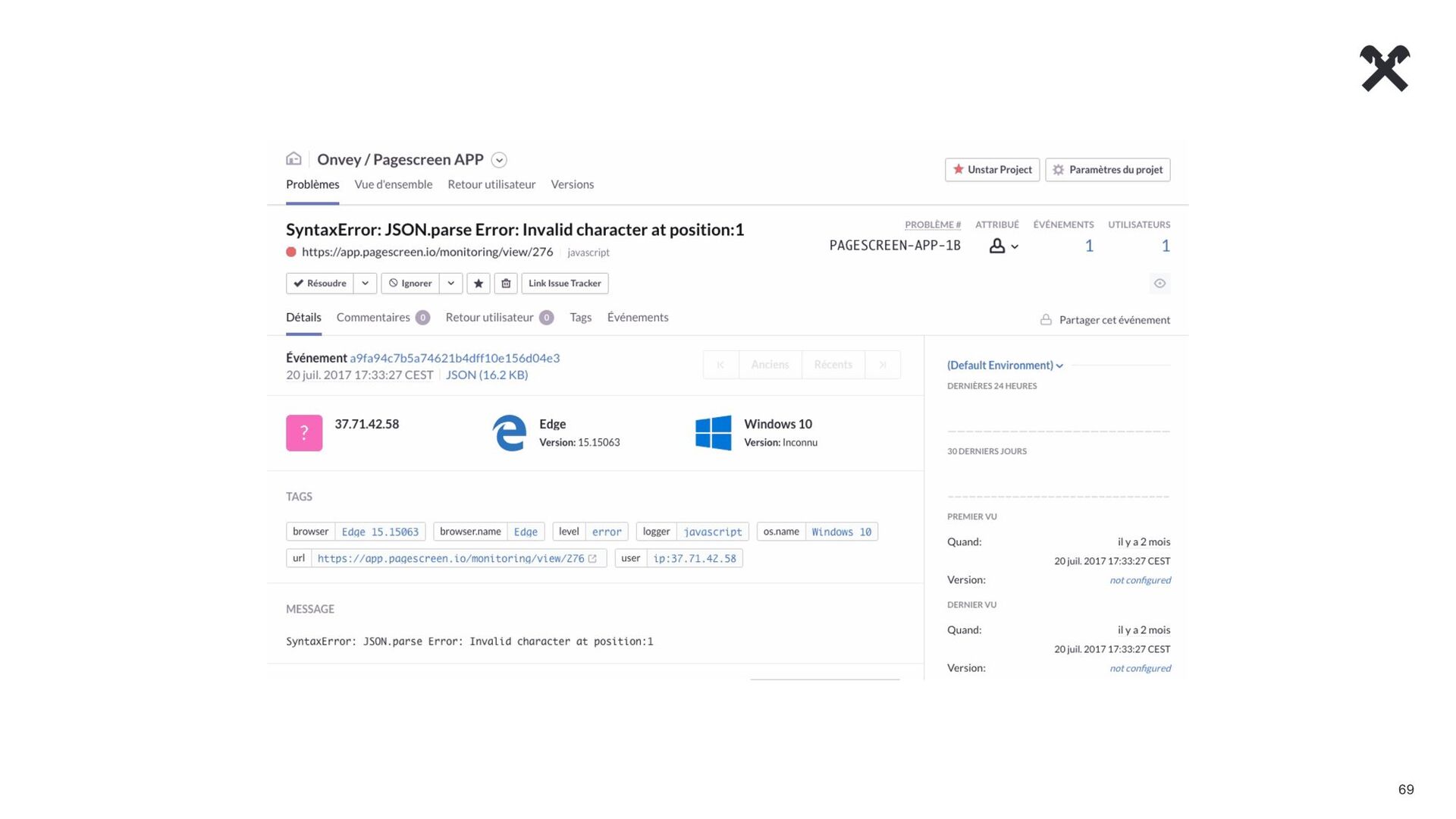{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}