Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習 勉強会 #1
Search
xkumiyu
May 06, 2016
Science
850
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習 勉強会 #1
xkumiyu
May 06, 2016
Other Decks in Science
See All in Science
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.5k
やるべきときにMLをやる AIエージェント開発
fufufukakaka
2
1.5k
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
660
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
270
「遂行理論の未来」(松島斉教授最終講義記念セッションの発表資料)
shunyanoda
0
930
Testing the Longevity Bottleneck Hypothesis
chinson03
0
370
検索と推論タスクに関する論文の紹介
ynakano
1
250
見上公一.pdf
genomethica
0
170
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
Wet Active Matter
rajeshrinet
0
120
因果推論と機械学習
sshimizu2006
1
1.2k
データベース06: SQL (3/3) 副問い合わせ
trycycle
PRO
1
1k
Featured
See All Featured
A Modern Web Designer's Workflow
chriscoyier
698
190k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
830
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Producing Creativity
orderedlist
PRO
348
40k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Ethics towards AI in product and experience design
skipperchong
2
330
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Transcript
機械学習 勉強会 #1 2016.5.6 @xkumiyu
⾃⼰紹介 lTwitter ID: @xkumiyu l⼤学:ソーシャルメディアを使ったデー タマイニング的なことをやってました。 l仕事:サービス企画。最近、データ分析 はじめました。 2
今⽇、話すこと lkNN法(k最近傍法)の概要 lPython(scikit-learn)での実装例 最近、読みはじめました。 3
クラス分類(Classfication) l予め与えられたクラスに関する知識に基づいて、未知のパ ターンがどのクラスに属するかを決定すること 4
クラス分類の⽅法 l事後確率による⽅法 l確率分布を仮定して、事後確率が最⼤のクラスに分類 l例)ベイズの最⼤事後確率法(単純ベイズ分類器?) l距離による⽅法 l⼊⼒ベクトルとクラスの代表ベクトルとの距離が⼀番近いクラスに分類 l例)最近傍法 l関数値による⽅法 l関数f(x)の正負または最⼤値でクラスを決める l例)パーセプトロン、サポートベクターマシン
l決定⽊による⽅法 l識別規則の真偽に応じて、次の識別規則を順次適応し、クラスを決める l例)決定⽊ 5
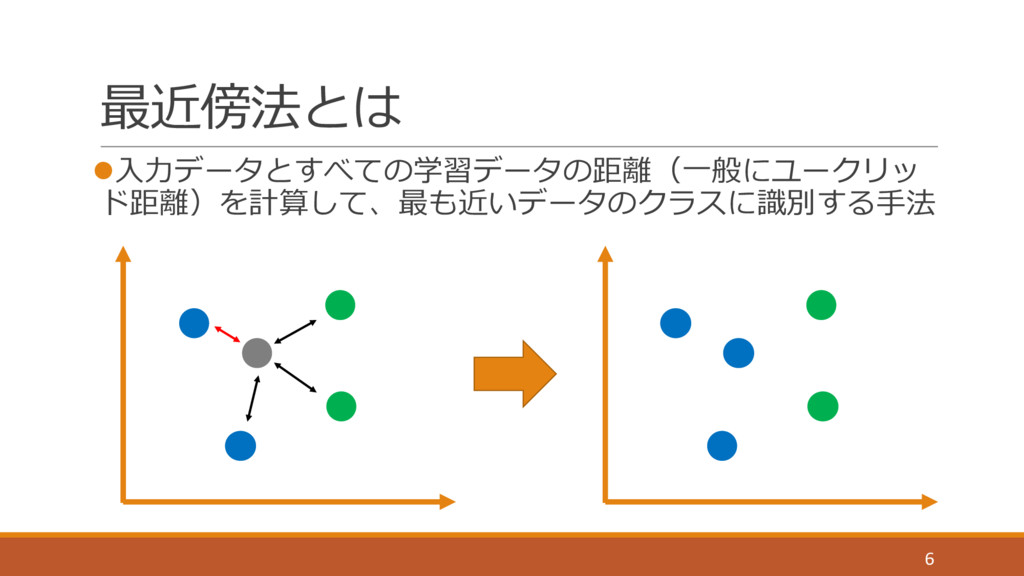
最近傍法とは l⼊⼒データとすべての学習データの距離(⼀般にユークリッ ド距離)を計算して、最も近いデータのクラスに識別する⼿法 6
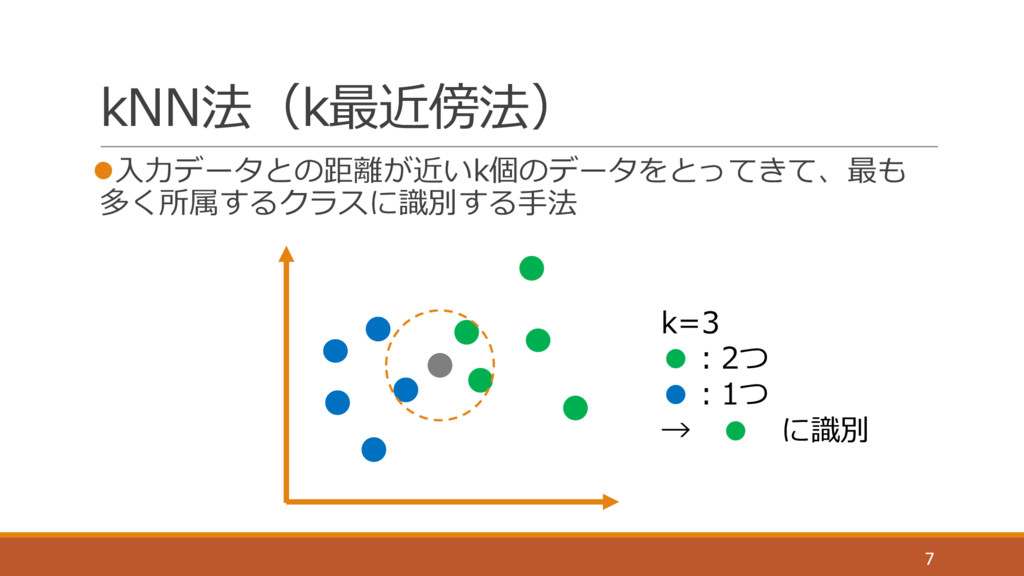
kNN法(k最近傍法) l⼊⼒データとの距離が近いk個のデータをとってきて、最も 多く所属するクラスに識別する⼿法 7 k=3 •:2つ •:1つ → • に識別
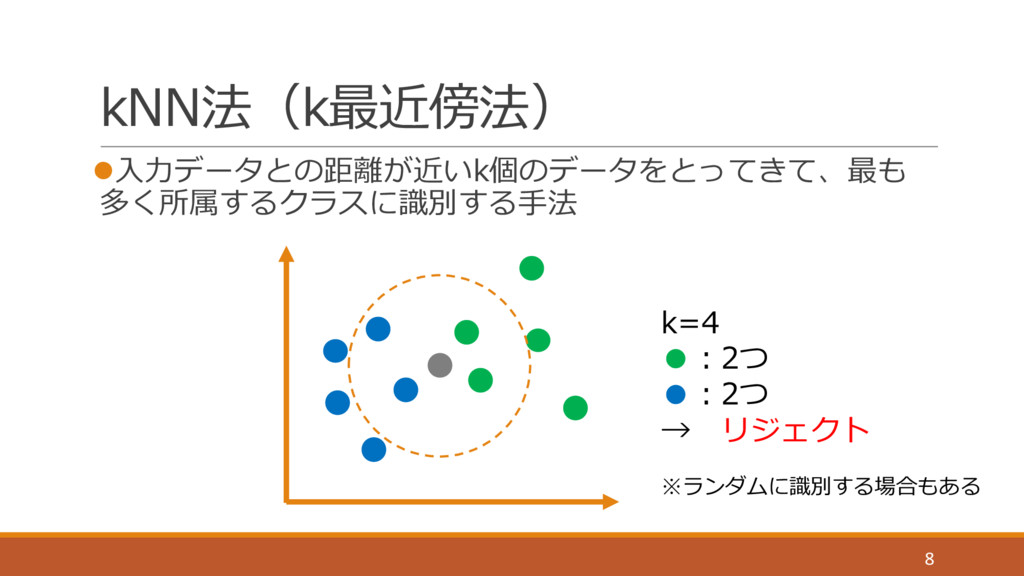
kNN法(k最近傍法) l⼊⼒データとの距離が近いk個のデータをとってきて、最も 多く所属するクラスに識別する⼿法 8 k=4 •:2つ •:2つ → リジェクト ※ランダムに識別する場合もある
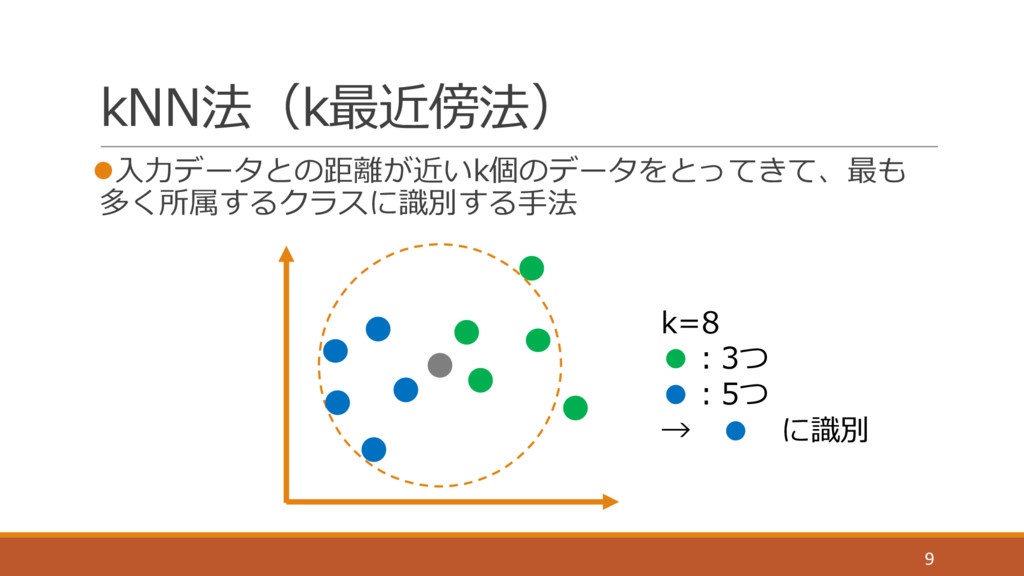
kNN法(k最近傍法) l⼊⼒データとの距離が近いk個のデータをとってきて、最も 多く所属するクラスに識別する⼿法 9 k=8 •:3つ •:5つ → • に識別
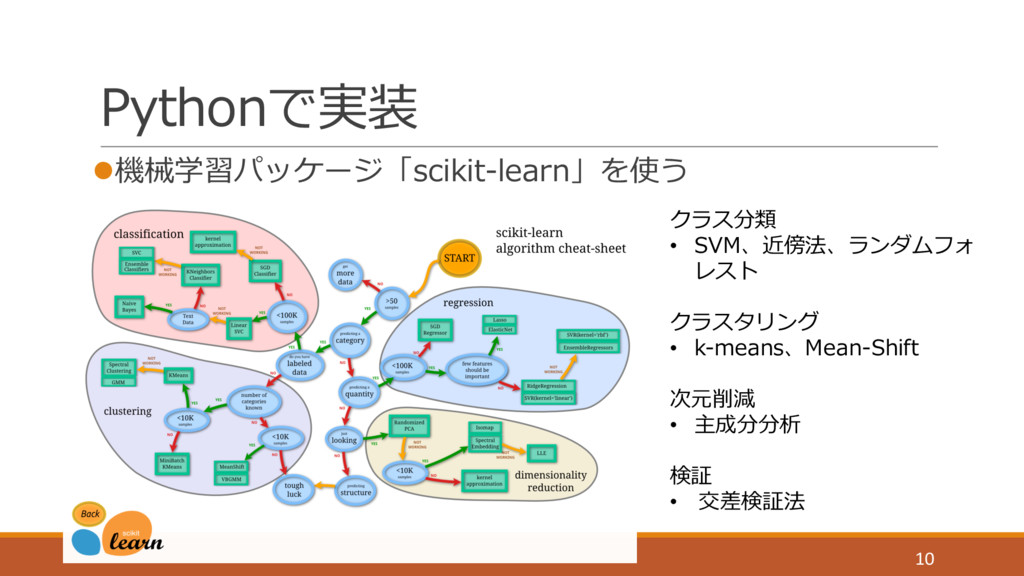
Pythonで実装 l機械学習パッケージ「scikit-learn」を使う 10 クラス分類 • SVM、近傍法、ランダムフォ レスト クラスタリング • k-means、Mean-Shift
次元削減 • 主成分分析 検証 • 交差検証法
scikit-learnを使う 11 メソッド fit(X, y) 学習データをモデルに適⽤(学習)、 Xがデータで、yがラベル(クラス) predict(X) ⼊⼒データのクラスを予測 score(X,
y) テストデータXと正解クラスyを与え た時の正答率を算出 ※他のモデルでも使い⽅は同じ(らしい)
Cross-Validationもscikit-learnで 12
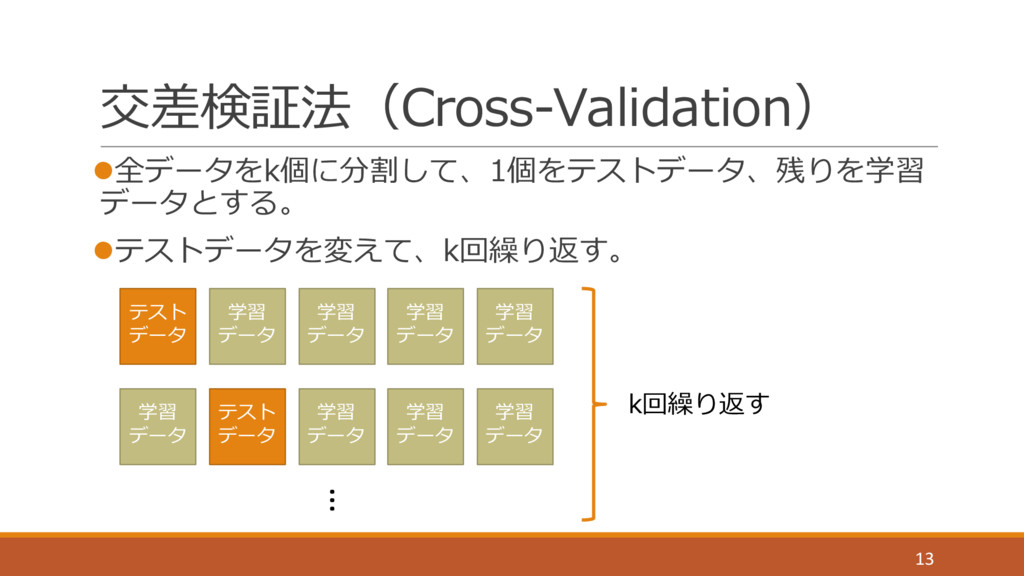
交差検証法(Cross-Validation) l全データをk個に分割して、1個をテストデータ、残りを学習 データとする。 lテストデータを変えて、k回繰り返す。 13 テスト データ 学習 データ 学習
データ 学習 データ 学習 データ テスト データ 学習 データ 学習 データ 学習 データ 学習 データ … k回繰り返す
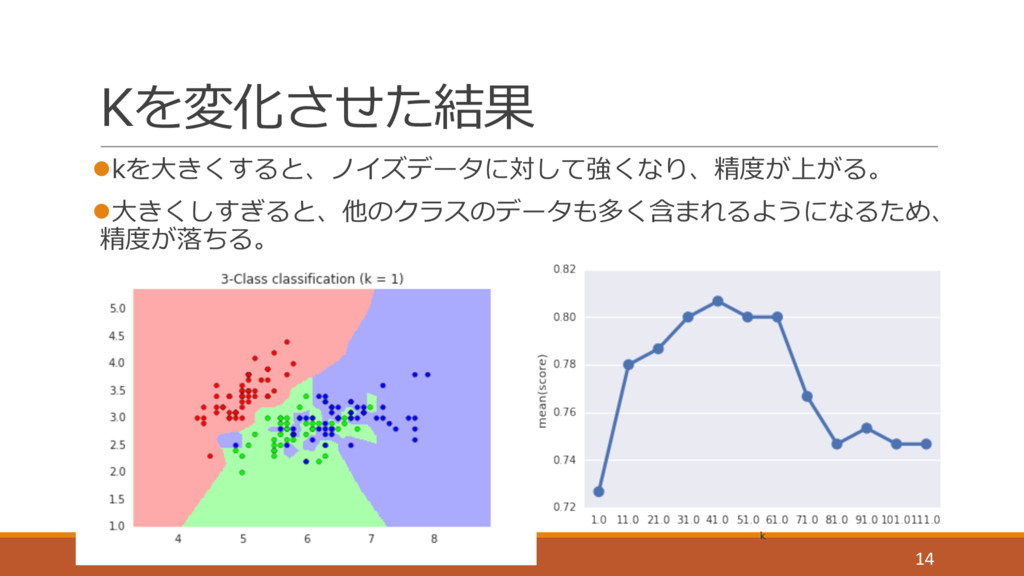
Kを変化させた結果 lkを⼤きくすると、ノイズデータに対して強くなり、精度が上がる。 l⼤きくしすぎると、他のクラスのデータも多く含まれるようになるため、 精度が落ちる。 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}