MongoDB. Focused on building a MVP. • MongoDB was new hot tech • MVP was success, moved on to new products, didn’t worry about Mongo • We kept building and growing
lock percentages. • Mongo has a per-database shared-exclusive lock, preference to writers • Per database as of 2.2! Whole server before • Not per-collection • We needed to buy time - early startup • We only had ~300GB of data at the time. • Enter hi1.4xlarge - 2TB of SSD
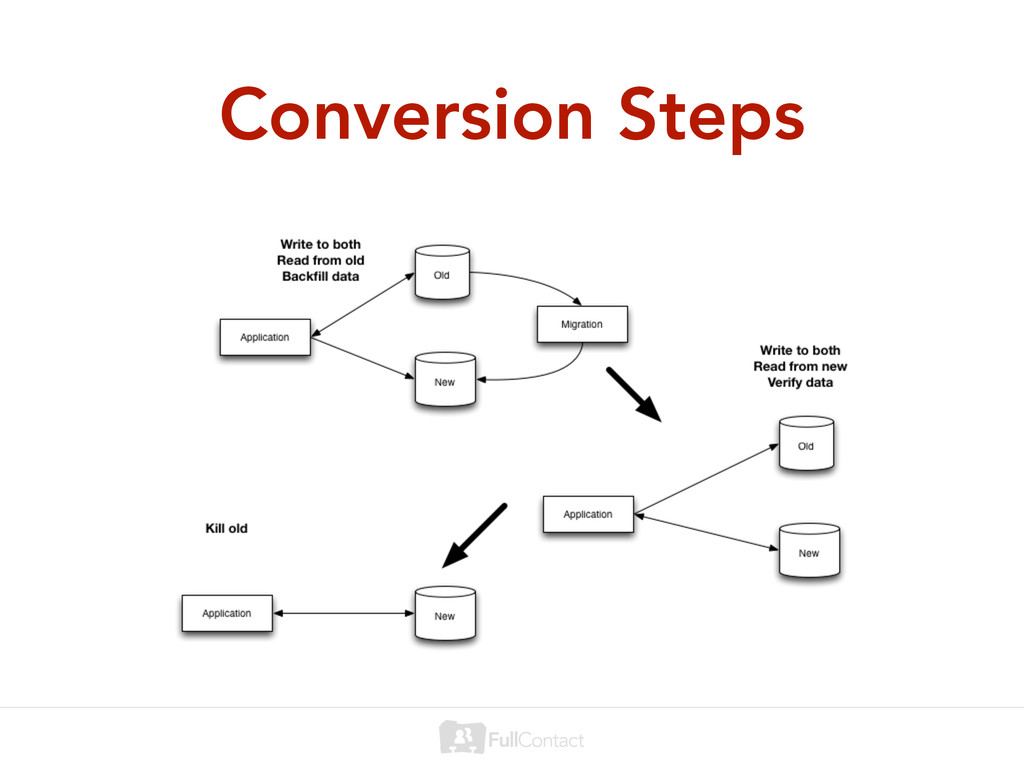
data (~8ms @ 99.5th) • But we kept adding data (it happens, weird) • When we had the bandwidth to handle it a year later, we were already approaching 2TB of data • Dirty solution: Second MongoDB cluster and handle “sharding” at the app layer
good things. Netflix’s usage was a big pro for us. • We knew MongoDB was bad for our write load already. • DynamoDB: Complexity around values > 64KB. Uncertain costs, but also probably would have been a solid choice. • RDBMSes: No relational benefit, really just delegating down to underlying storage engine anyways with KV data. But stable. • Other tech: Too young, no experience
Easy multi-AZ deployments • All our clusters are deployed in 3 ASGs, 1 per AZ • Machine fails? ASG replaces and it autobootstraps c/o Priam • Mostly transparent failure handling. Node failures aren’t emergencies, just a way of life on AWS • Linear storage scalability • More storage? Double the ring. • BigTable-like, we have experience with HBase which is also like BigTable. CQL3 even hides this from us.
machines & increase replication factor if we need tighter latencies • We don’t need perfect consistency. Enter eventual consistency. • We write & read at LOCAL_QUORUM. 2 nodes. • Our data compresses well, on-disk compression helps us do more with less.
experimentation • Not ACID (but we didn’t need it) • Write-optimized not read-optimized • We’re about 60/40 r/w, it works decently • Cassandra is still a young technology. It has incredible backing from DataStax, Netflix, Facebook (again) and other organizations though.
scary • We knew MongoDB & MySQL pretty well, warts and all, but not Cassandra • Our second MongoDB cluster bought us time • We moved a less critical, higher-throughput cache layer from HBase to Cassandra • Learned about the weakness of the Cassandra Hadoop tools
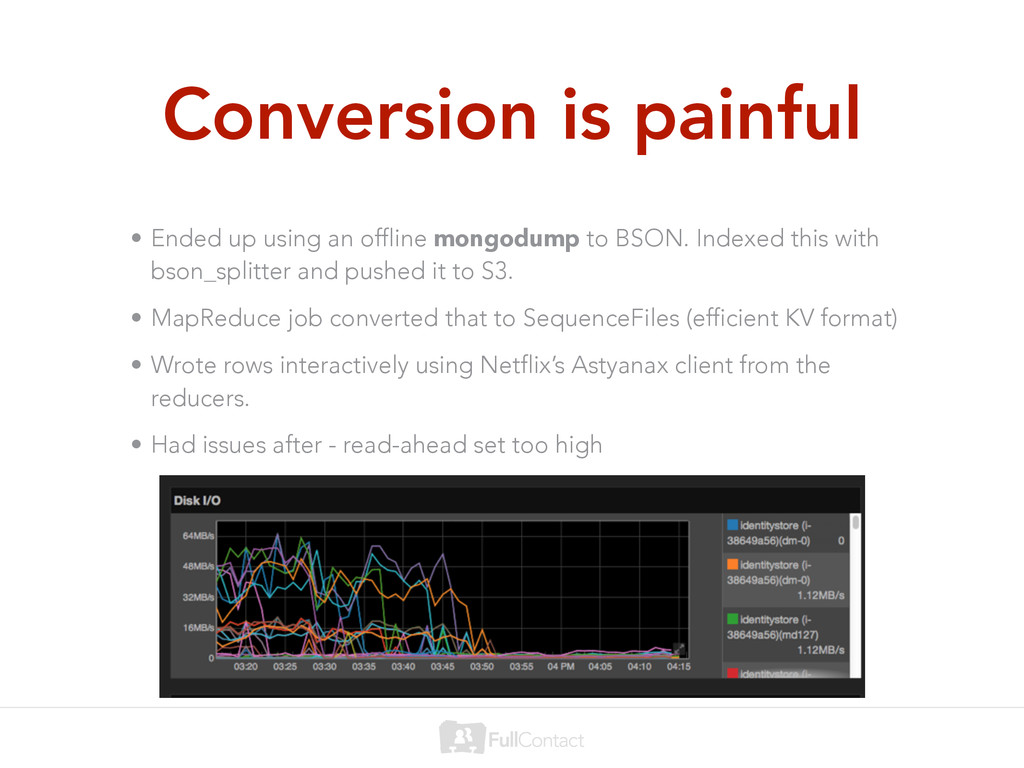
to BSON. Indexed this with bson_splitter and pushed it to S3. • MapReduce job converted that to SequenceFiles (efficient KV format) • Wrote rows interactively using Netflix’s Astyanax client from the reducers. • Had issues after - read-ahead set too high
and 12 nodes • Cluster per workload • m1.xlarges. are far cheaper than hi1.4xlarges • 4x800GB disks in RAID0 • All data stored in dmcrypt • Cassandra 1.2.16 (2.x soon maybe) • Priam runs along side C* doing token management and daily backups to S3 • Approaching 12TB over 4B records between all three • We don’t miss SSDs that much
Uses Thrift tables or CQL3 over Thrift • More feature-rich than DataStax client • Token-aware GETs == less latency • Beta can use DataStax client under the hood for native protocol
that aligned well to our goal of resilience and performance. • It wasn’t a leap for us, we knew the data model. Be sure that it aligns to your goals before plunging in. • There’s always going to be something that goes wrong. For us, it was disk tuning. Plan ahead, newer databases haven’t had time to mature. I’d call them “fiddly.” • Nothing is ever easy. There is always friction. Don’t be seduced into tech you don’t need. • Corollary: Definition of need is flexible.
to ask questions here, shoot me an email ([email protected]), or hit me up on Twitter @Xorlev ! • Obligatory: We’re hiring, check us out. AOL keyword “fullcontact”
{kind=link}
{kind=link}
{kind=link}
![GET /v2/[email protected]](https://files.speakerdeck.com/presentations/2e88c550d9a10131bc8f4277db5bbc05/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}