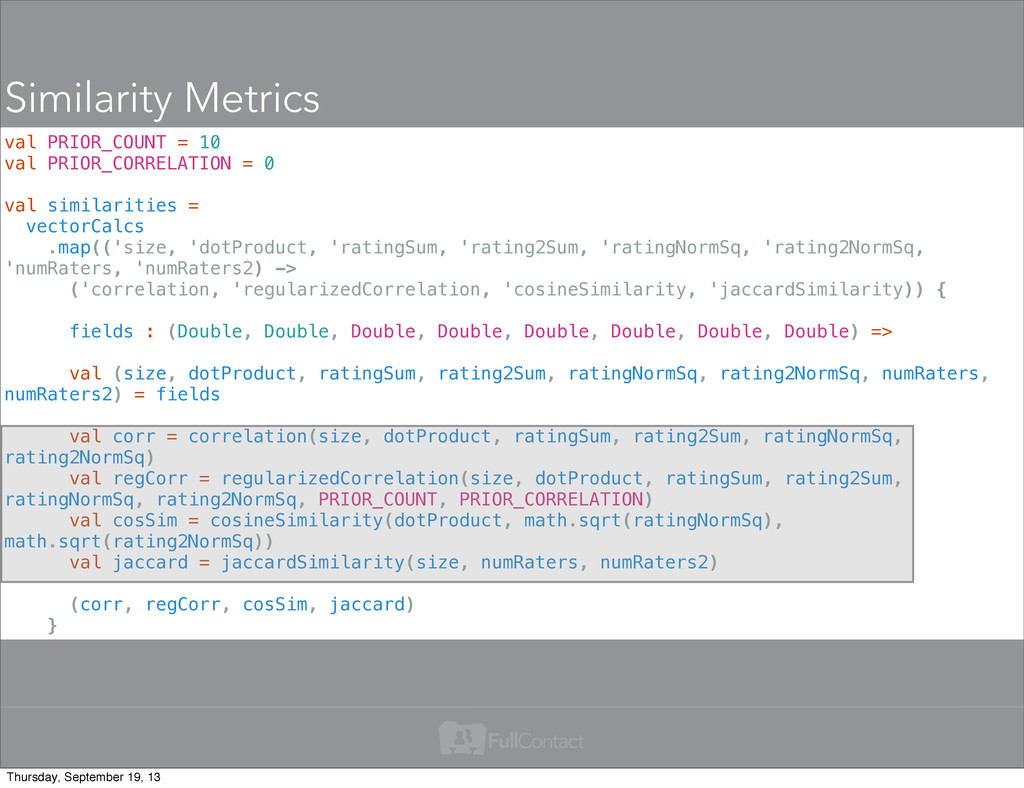
= vectorCalcs .map(('size, 'dotProduct, 'ratingSum, 'rating2Sum, 'ratingNormSq, 'rating2NormSq, 'numRaters, 'numRaters2) -> ('correlation, 'regularizedCorrelation, 'cosineSimilarity, 'jaccardSimilarity)) { fields : (Double, Double, Double, Double, Double, Double, Double, Double) => val (size, dotProduct, ratingSum, rating2Sum, ratingNormSq, rating2NormSq, numRaters, numRaters2) = fields val corr = correlation(size, dotProduct, ratingSum, rating2Sum, ratingNormSq, rating2NormSq) val regCorr = regularizedCorrelation(size, dotProduct, ratingSum, rating2Sum, ratingNormSq, rating2NormSq, PRIOR_COUNT, PRIOR_CORRELATION) val cosSim = cosineSimilarity(dotProduct, math.sqrt(ratingNormSq), math.sqrt(rating2NormSq)) val jaccard = jaccardSimilarity(size, numRaters, numRaters2) (corr, regCorr, cosSim, jaccard) } Similarity Metrics Thursday, September 19, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}