I’d like to give a shout out to the rest of my team who couldn’t attend today. Scott, our CTO and leader and Brandon Vargo the other member of our team. The work I’m talking about today is definitely a team effort, not solely my own. Ken Michie, another long time FullContact employee also played an important role in helping us with this project.
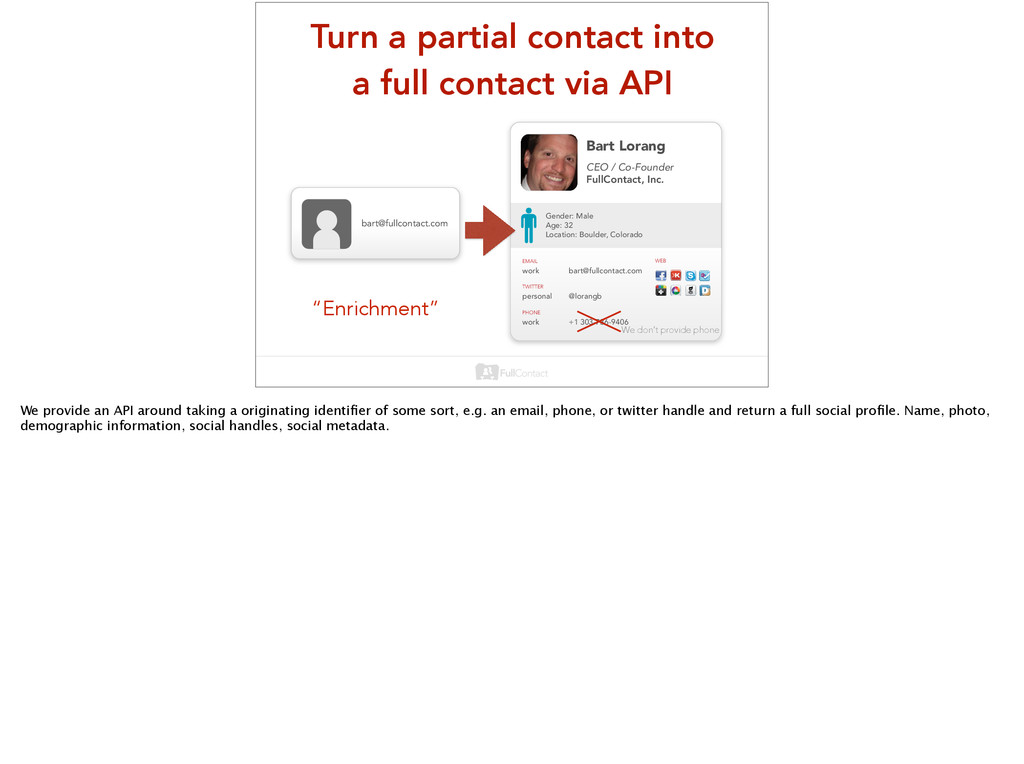
[email protected] Bart Lorang CEO / Co-Founder FullContact, Inc. EMAIL work [email protected] TWITTER personal @lorangb PHONE work +1 303-736-9406 Gender: Male Age: 32 Location: Boulder, Colorado WEB “Enrichment” We don’t provide phone We provide an API around taking a originating identifier of some sort, e.g. an email, phone, or twitter handle and return a full social profile. Name, photo, demographic information, social handles, social metadata.
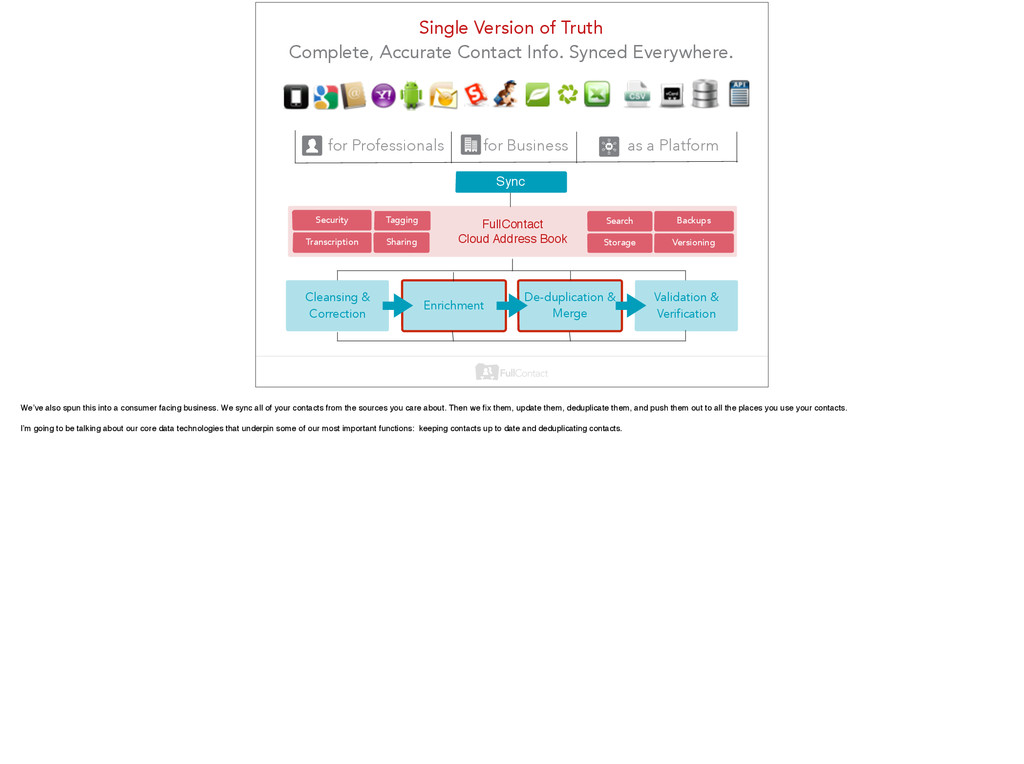
Truth Complete, Accurate Contact Info. Synced Everywhere. FullContact Cloud Address Book Security Transcription Backups Versioning Cleansing & Correction Enrichment De-duplication & Merge Validation & Verification Sync Tagging Search Sharing Storage We’ve also spun this into a consumer facing business. We sync all of your contacts from the sources you care about. Then we fix them, update them, deduplicate them, and push them out to all the places you use your contacts. I’m going to be talking about our core data technologies that underpin some of our most important functions: keeping contacts up to date and deduplicating contacts.
API Identibase ... Note: Not a literal cloud [email protected] { [...] "contactInfo":{ "familyName":"Lorang", "fullName":"Bart Lorang", "givenName":"Bart" } [...] } Merged Profiles I’ll focus on our Enrichment system that as it’s the primary provider of information into our data pipeline. Here’s the way it works. A user (internal or external) calls into the Person API. The Person API checks for already merged profiles and if it has a recent one it serves it up. Otherwise it tosses a message onto a queue for a service called Sherlock to work on. Sherlock scours the web for clues about identity, merges a profile from the clues, and dumps it in the database. Meanwhile, each response from each data provider (APIs, scrapers) we have is dumped into a database I’ll call WebObservations. Previously, this was powered by 18 Cassandra nodes. You can imagine the recursive nature of this system could lead to some funky results, especially if someone put someone else’s usernames in one of their profiles. This is where Identibase comes in. I’ve bolded a component labelled as Identibase because Identibase is the lynchpin of this entire system. It’s our secret sauce, and I’m about to reveal (some) of the ingredients.
fields • email & phone, phone & name • .:. email -> name • Full graph database on top of HBase • Also tracks source/privacy metadata for every piece of information. • Powers Person API & AddressBook deduplication Essentially a giant adjacency list in HBase
3 4 5 1 2 3 4 5 ABC DEF 1 2 3 4 5 5 1,4 2 3 ABC DEF Identibase provides identity resolution. What do we mean by that? Lets consider two contacts, one with 3 fields and one with two. If you model contacts instead as a directed graph of co-occurrences and merge the resultant graphs you end up with a joined graph. You can imagine this is fairly useful for finding new information on contacts as well as helping to deduplicate contacts, even if they share no common information!
from a program called Identiviz. It built a graphical representation of my profile and everyone else I’m linked to in some way (e.g. test accounts, shared phones, etc.) It can get as large as you might imagine, and I’m not even the most connected person around.
Query ... HBase I’ve cut out Person API as it’s not really important to this pipeline. Here you can see that Sherlock writes those observations into a database, then Hadoop magic happens, and we produce an HBase table used by the Identibase system.
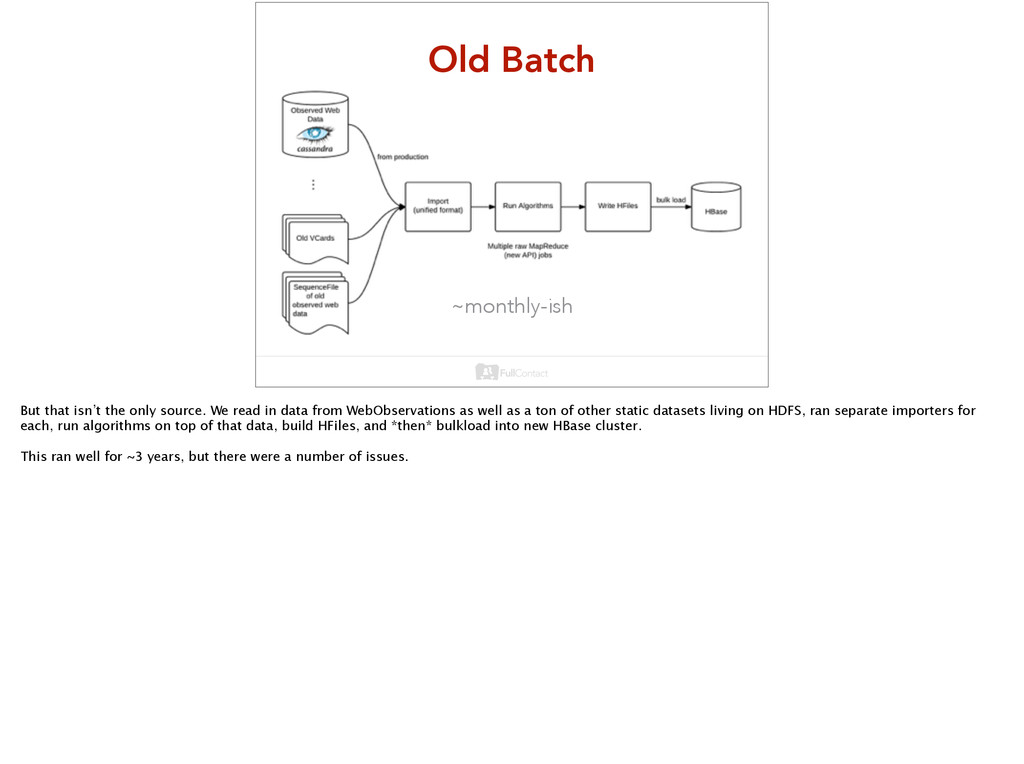
read in data from WebObservations as well as a ton of other static datasets living on HDFS, ran separate importers for each, run algorithms on top of that data, build HFiles, and *then* bulkload into new HBase cluster. This ran well for ~3 years, but there were a number of issues.
graph algorithm built on top of chained MapReduce jobs • Hard to reason about, especially for a newcomer • Run monthly, bulk load to HBase • Pulled data directly from source systems • C* cluster with web observations was never happy about this • Job wasn’t frequent enough to have “analytics” second DC • Pulled lots of other static data
data • Open up new use cases not possible on a batch schedule (e.g. subscriptions) • Still maintain batch pipeline for big changes • Redo underlying storage architecture to support future extensions • Avoid impacting production datastores • Simplify pipeline code, reuse as much code as possible
a means of sharing data between systems • Process to ingest this information Requirement: Keep batch pipeline too (lambda architecture) • Still need MapReduce • Reuse existing code where possible Requirement: Unified data model / no live DB reads • Backfill old data into a unified model • Archive new data for batch process
More developer friendly than Pig/Hive (in many cases) • Modeled after Google’s FlumeJava • Flexible Data Types: PCollection<T>, PTable<K,V> • Simple but Powerful Operations: parallelDo(), groupByKey(), combineValues(), flatten(), count(), join(), sort(), top() • Robust join strategies: reduce-side, map-side, sharded joins, bloom- filter joins, cogroups, etc. • Three runner pipelines: MRPipeline (Hadoop), SparkPipeline, MemPipeline So for these reasons, we decided to give Apache Crunch a try. Crunch is an abstraction layer for defining data pipelines that under the covers compile to a series of map-reduce jobs Distinct from other abstraction layers like say Pig and Hive it’s geared less towards data scientists and more towards developers. More like Cascading/Scalding if you are familiar with those. The Crunch API itself is modeled after Googles FlumeJava project, which is what they use for this at Google. Their goal is to be simple & flexible. We found that with some tweaks, Crunch actually enabled us to meet all of our goals. So let me just jump right into what we did…
• Efficient - OS sympathy • Trivial horizontal scalability • Boring in production! • It’s a log, not a queue: Rewind, Replay, Multiple consumers. • Systems don’t have to know about each other • The log is a unified abstraction for real-time processing Advantages source: LinkedIn
(“Frizzle”) has producer/consumer helpers, common message envelope w/ metadata, and serializable POJOs for each unique topic/ system. • Schemas become the interface between systems. • Systems at FullContact publish to Kafka what they would write to a DB e.g.: • Web observations (crawl data) • Contact versions • User activity • Databus Archiver consumes all topics, archives to S3 as Hadoop SequenceFiles (long offset, byte[] serialized). Based on Pinterest’s Secor.
We wanted to pretend we always had Kafka and the databus • Backfilled all prod data and all backups of prod data into the same SequenceFile format, put on S3. Which, btw, was over 100TB of Cassandra backups and HBase backups. We were able to prune backups after that which made Ops very happy.
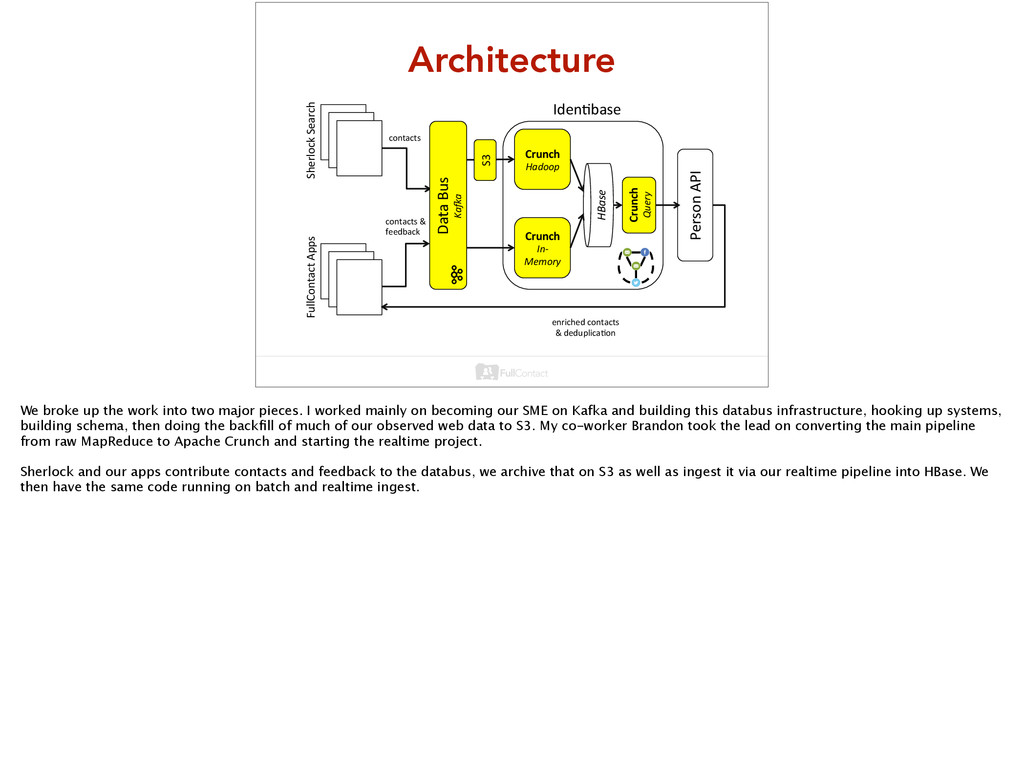
Ka(a& Crunch' In+ Memory& Crunch' Hadoop& Crunch' Query& FullContact'Apps' Sherlock'Search' S3' We broke up the work into two major pieces. I worked mainly on becoming our SME on Kafka and building this databus infrastructure, hooking up systems, building schema, then doing the backfill of much of our observed web data to S3. My co-worker Brandon took the lead on converting the main pipeline from raw MapReduce to Apache Crunch and starting the realtime project. Sherlock and our apps contribute contacts and feedback to the databus, we archive that on S3 as well as ingest it via our realtime pipeline into HBase. We then have the same code running on batch and realtime ingest.
jobs • 17 jobs, many run in parallel • Totally tested end-to-end with in-memory runner • Code is easy to follow • Tons of code reused from old implementation • Reads archived Kafka data (+backfill) from S3 • Same output. Totally different pipeline.
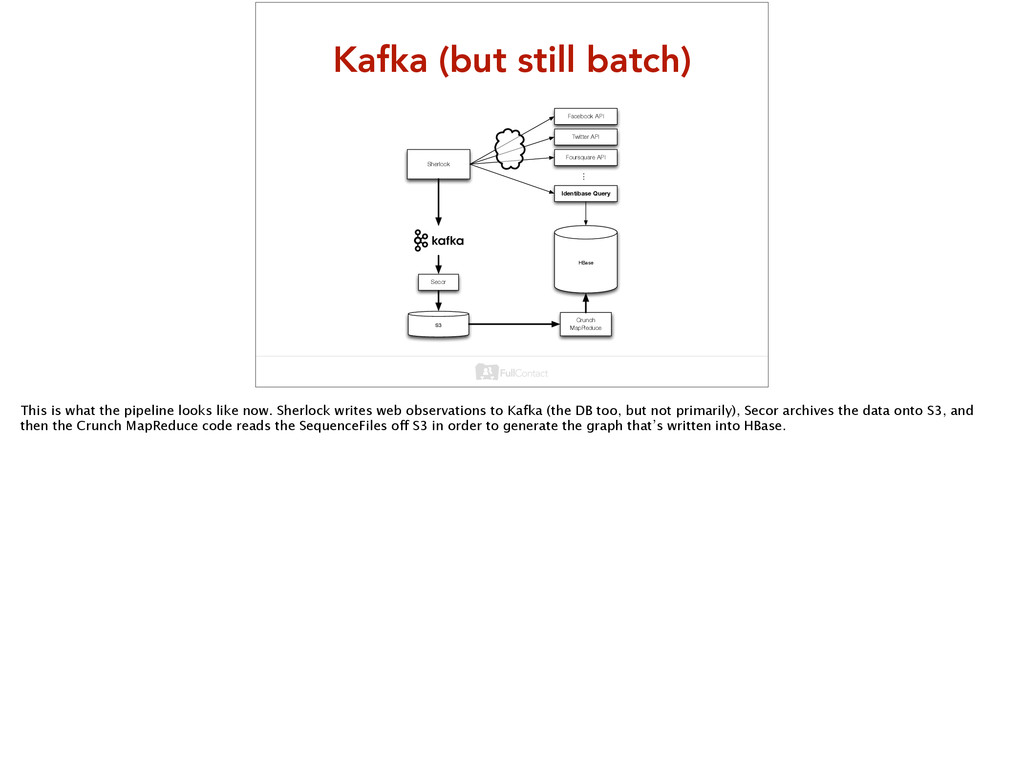
API Identibase Query ... S3 Secor HBase Crunch MapReduce This is what the pipeline looks like now. Sherlock writes web observations to Kafka (the DB too, but not primarily), Secor archives the data onto S3, and then the Crunch MapReduce code reads the SequenceFiles off S3 in order to generate the graph that’s written into HBase.
no code reuse • Summingbird • Very elegant, complex. • Sparse documentation • Analytics focused • Storm • Pure realtime • Would have to completely rewrite our logic • Something else (raw kafka consumer) Spark - relative unknown to us, had issues with running on cluster Summingbird - sparse documentation, felt analytics focused. Would be awesome if you worked at Twitter with the internal integrations Storm - Would require totally separate implementation It looked like we might need to do an implementation on top of Spark or try and share code as much as possible with our batch pipeline.
• Re-use our existing code in realtime • One codebase, 2 great usecases (what a deal!) • Kafka consumer reads data, bundles into related batches, feeds into runner
outstanding work • We’re indexing people, we batch around a search • Batch of work is all fed into the exact same code* as the Hadoop job, only in-memory runner • Expensive calculations cached, otherwise only stores raw inputs • Instead of outputting to SequenceFiles, generates HBase mutations * +/- a few code blocks only relevant to one or the other
process • Start batch process (~2-3 days), reads SequenceFiles from S3 • Launch brand new HBase cluster once done • Bulk load to HBase • Start new set realtime ingestors at snapshotted offsets (now()-2 days) • Allow catchup • Point query servers at new HBase cluster • Spin down old HBase cluster once everything looks good
Ka(a& Crunch' In+ Memory& Crunch' Hadoop& Crunch' Query& FullContact'Apps' Sherlock'Search' S3' What’s interesting is that this pipeline is really just implementing a graph-optimized materialized view over a log of contact observations.
workloads in mind • Recreating Hadoop Configuration on each pipeline invocation — expensive! • Excessive locking around counters, can’t rely on elision • Serialization verification • We forked Crunch, very few changes necessary • Disabling serialization verification
• Flexibility paving the way for new capabilities • Batch, realtime ingest, realtime queries • Query: 1000+qps, ~20ms@95th • Ingest: 150-500 batches/s depending on mix of data • Writing an average of 5,000 edges/s into HBase, with spikes >250,000/s (large cached profiles)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Identibase identity resolution [email protected] [email protected] scott.brave [email protected] @sbrave 1 2](https://files.speakerdeck.com/presentations/22b4b62726cc4e74bae178caaec7554d/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}