SPSS in yearly citations by 2020. The implications are clear: • If you use SPSS in your business or research, move to R now rather than later. • Do not ask for SPSS competences in job postings. You will scare away the good candidates. • We are doing students a disservice by teaching SPSS. Switch to JASP for simple one-off analyses and R for complex or repeated analyses. Rstudio Desktop is a highly recommended interface to R.” Source: http://lindeloev.net/spss-is-dying/
for the more popular software (those with 250 jobs or more, 2/2017). Jobs trends for R (blue & lower) and Python (orange & upper). http://r4stats.com/articles/popularity/
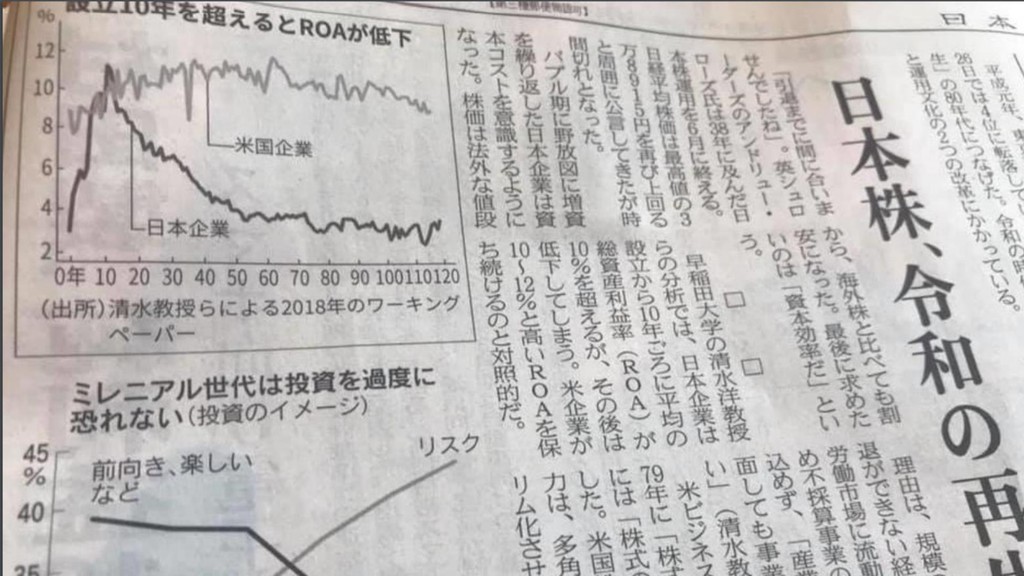
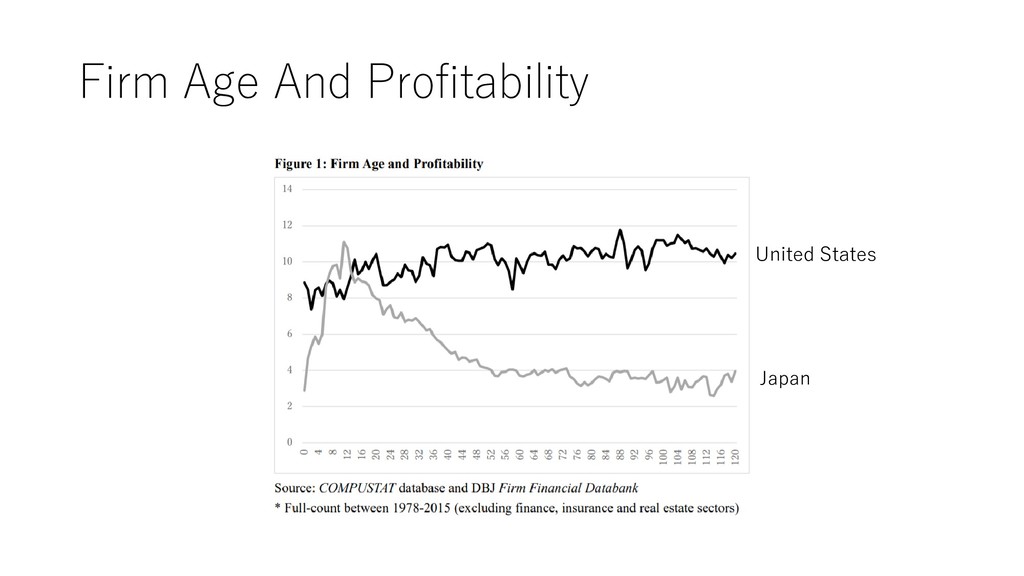
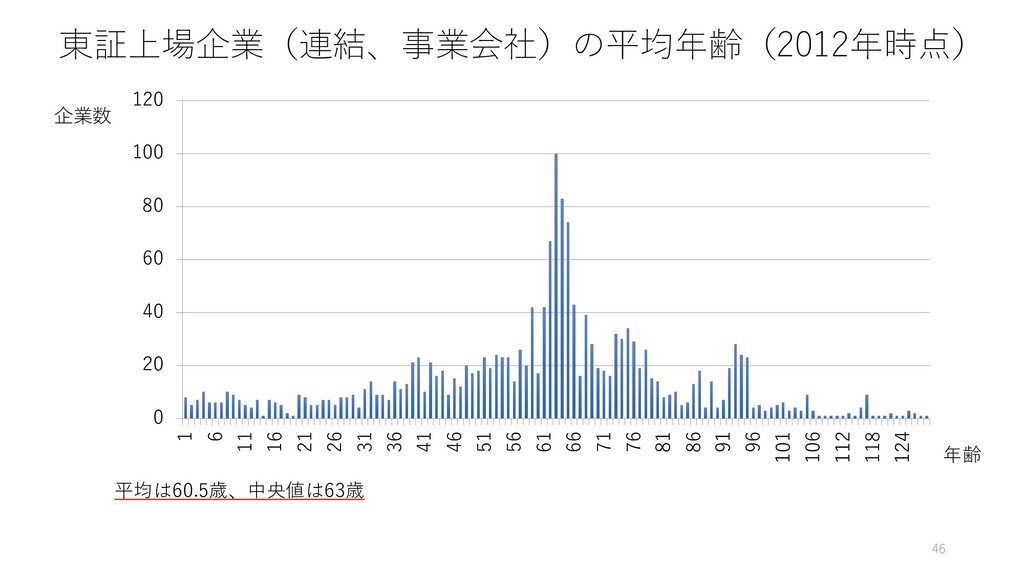
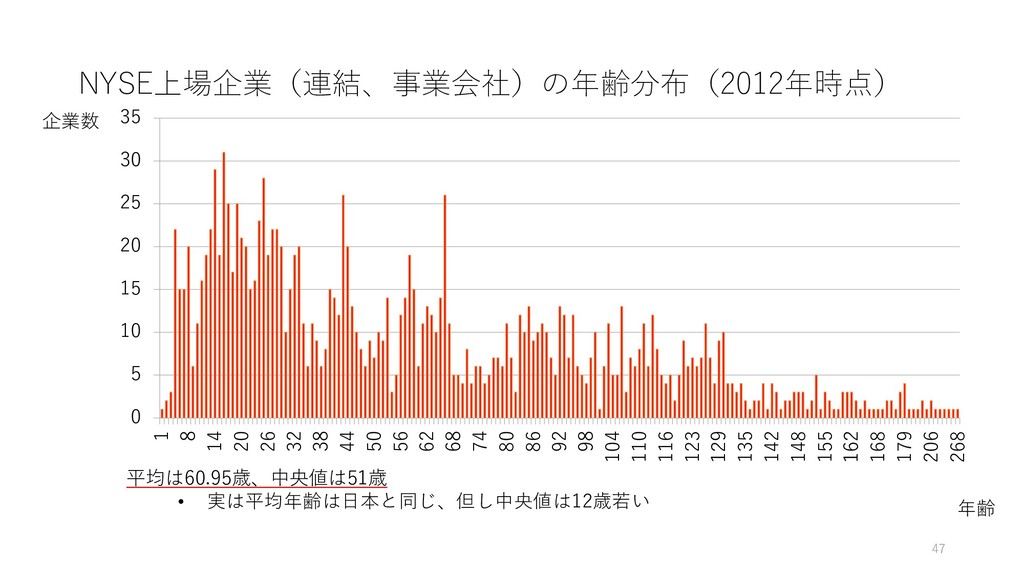
4月の終わりの日経新聞や, 経産省, 内閣官房の資料で「引用」 • 一橋大学イノベーション研究センターの Working Paper として 昨年発表 • Yamaguchi, Nitta, Hara, and Shimizu (2018) Staying Young at Heart or Wisdom of Age: Longitudinal. Analysis of Age and Performance in US and Japanese Firms., IIR Working Paper,
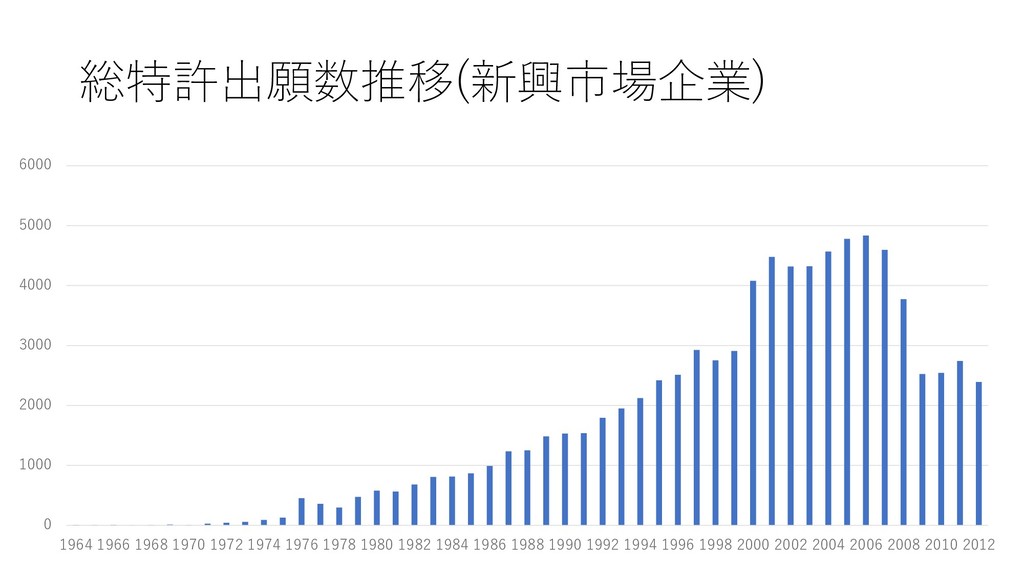
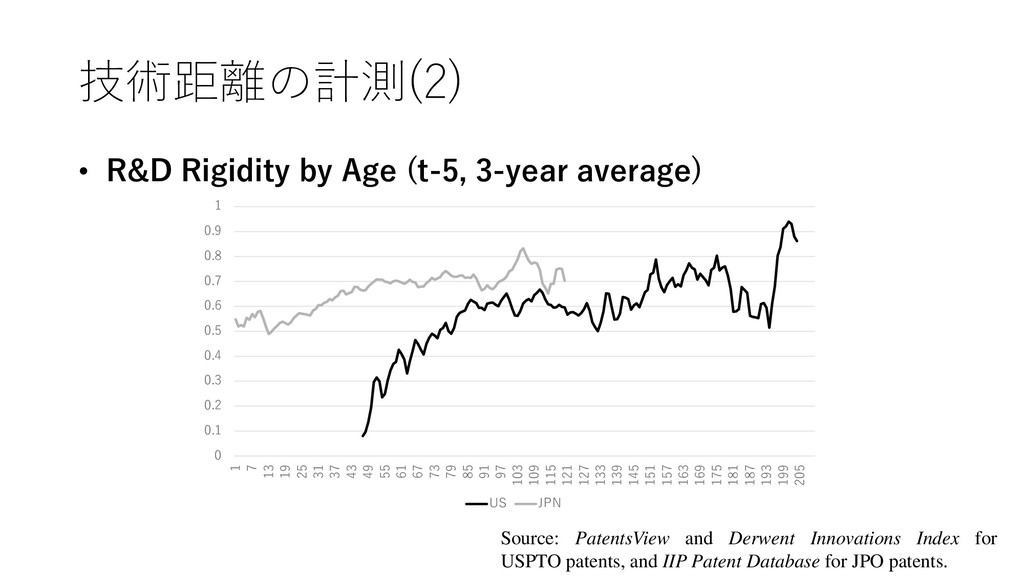
R&D rigidity. • The technological distance construct, proposed by Jaffe (1986), was originally intended as a measure of the degree of similarity between technological investment portfolios (which Jaffe called ‘technological positions’) of two different firms. • Thus, we estimated R&D rigidity by calculating the similarity between a firm’s current and previous technological investment portfolio. The more similar a firm’s current and previous portfolios, the more rigid its R&D resource allocation. Technological distance was calculated as follows.
• = 1 , 2 , ⋯ , • F it is 1 ☓ j vector, NP it denotes the number of patents obtained by firm i in year t and NP ijt is the number of patents obtained by firm i in field j in year t • Technological distance (P it ) between firm i’s technological position in year t (F it ) and year t-1 (F it-1 ) is obtained from • = Τ ∙ −1 ′ ∙ ′ −1 ∙ −1 ′ 1/2 • Technological distance assumes a value between 0 and 1, and it is unity if the two vectors are identical, which implies that the firm did not changes its investment profile at all between t-1 and t, and zero if the two vectors are orthogonal, which implies that the firm changed its technological position completely.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Jupyter Notebook のインストール(1) • 2. [Download] をクリックする](https://files.speakerdeck.com/presentations/a2921325b23c48f492db5e24263ba765/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
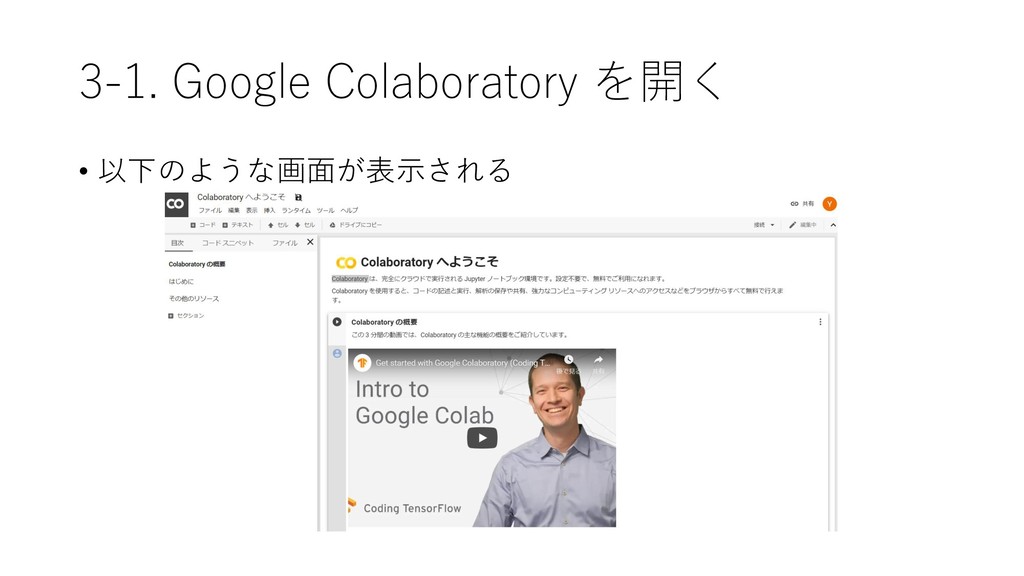{kind=link}
![3-2. 新しいnotebook を作成する • [ファイル]-[python3 の新しいノートブック] を選択する](https://files.speakerdeck.com/presentations/a2921325b23c48f492db5e24263ba765/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
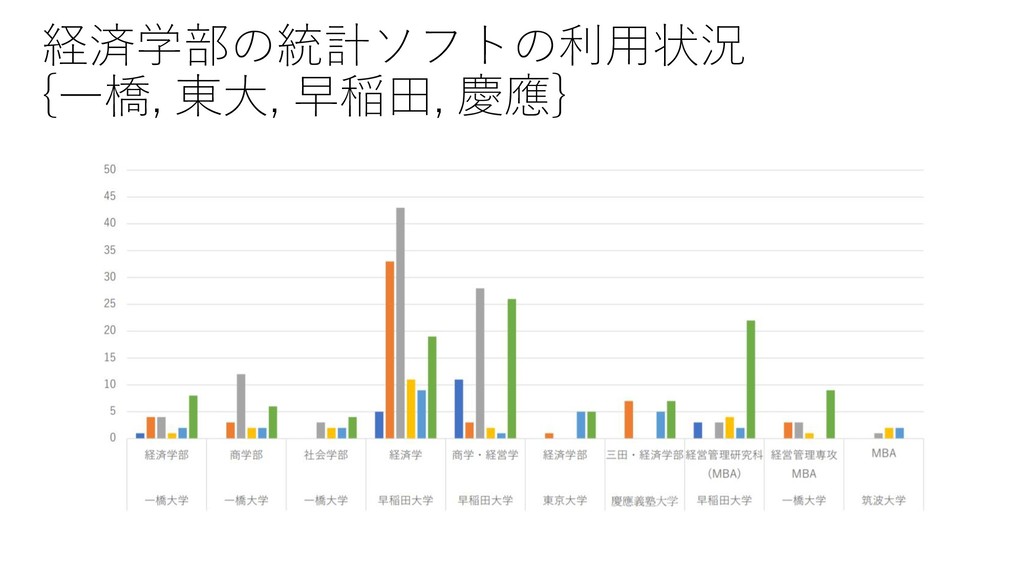{kind=link}
{kind=link}
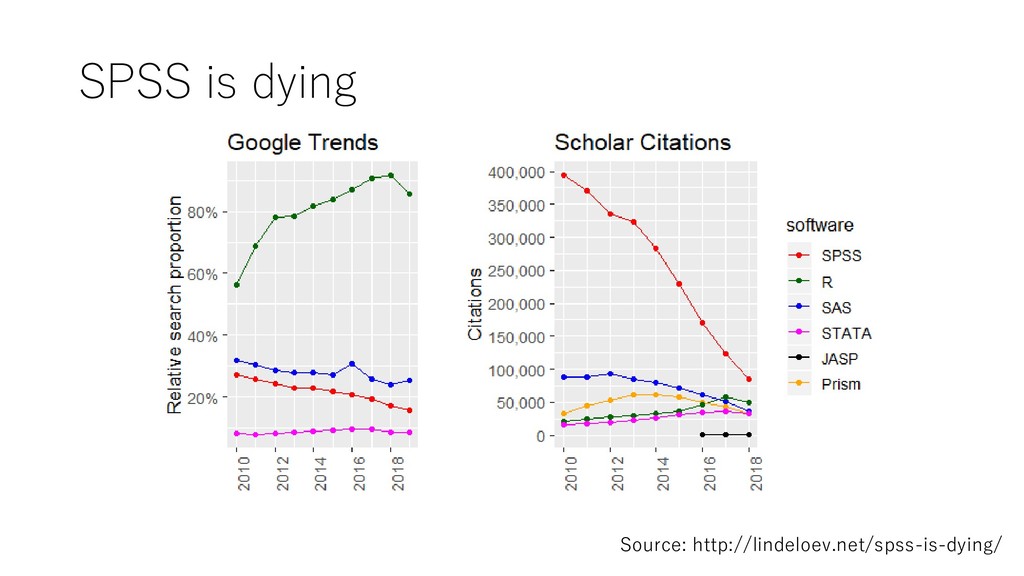{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
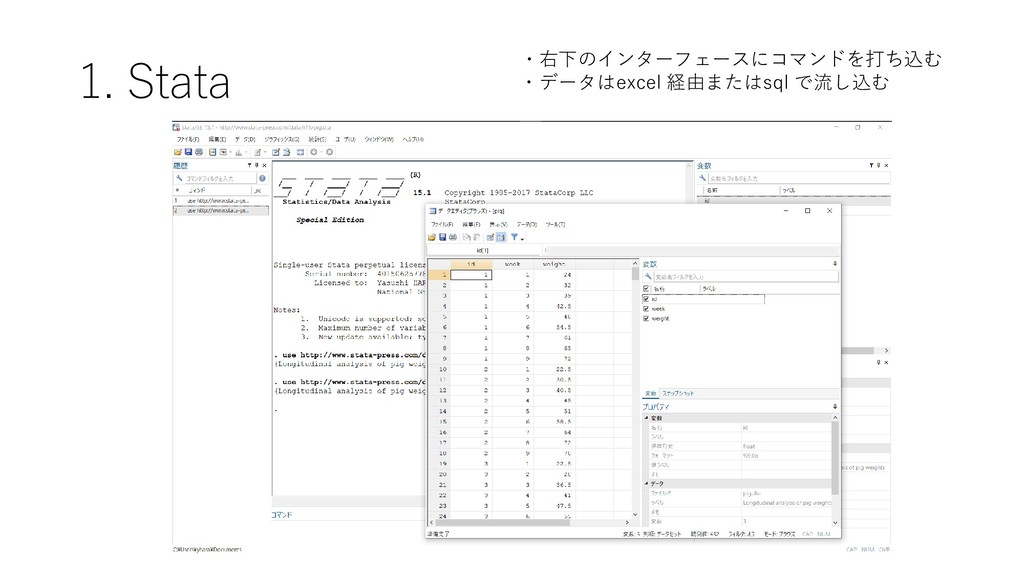{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
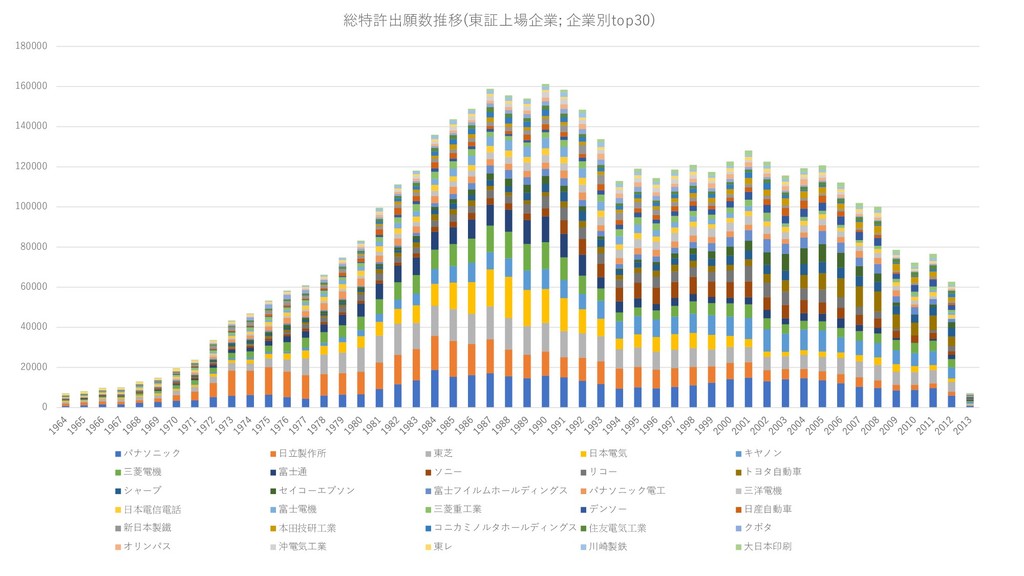{kind=link}
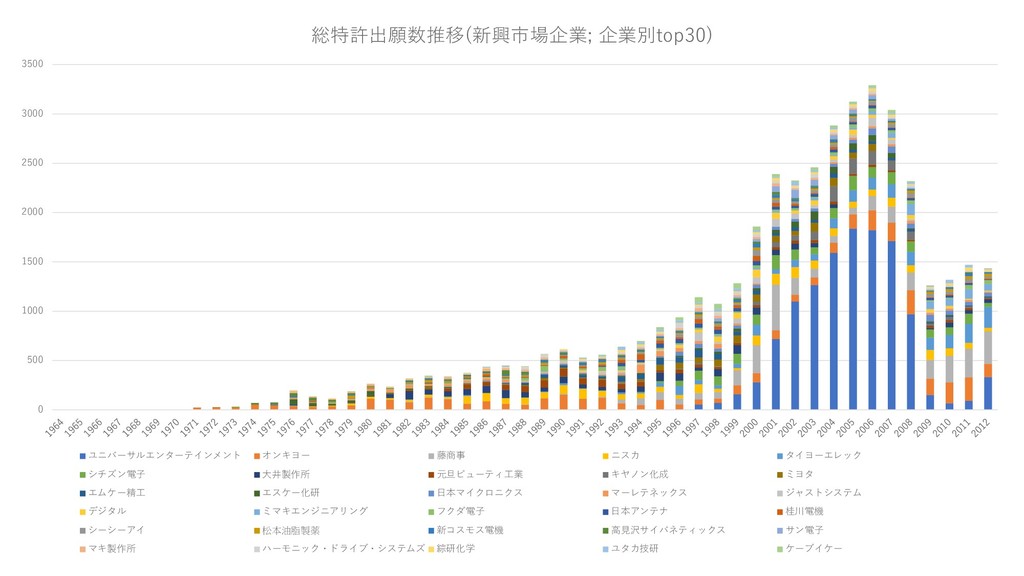{kind=link}
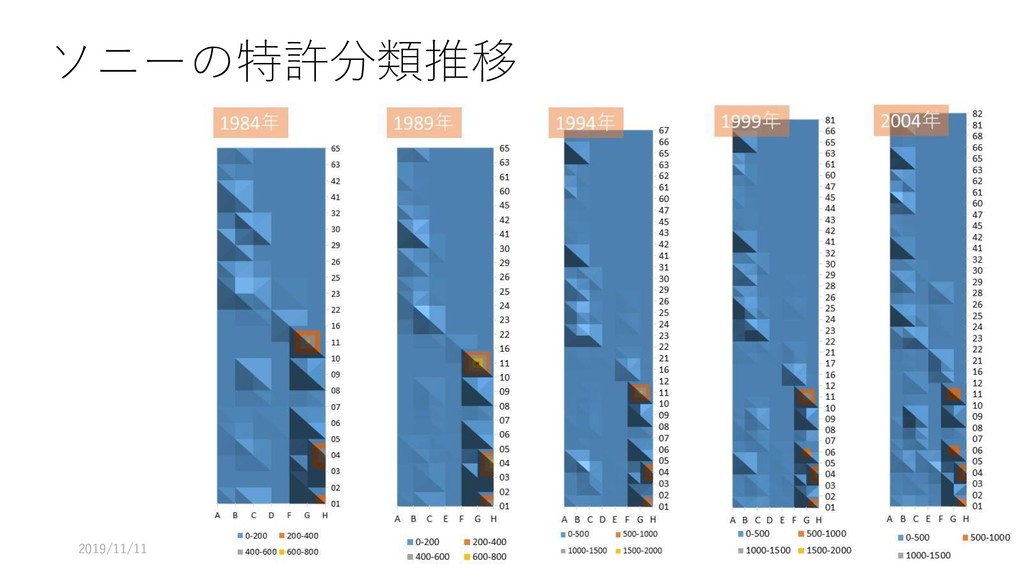{kind=link}
{kind=link}
{kind=link}
{kind=link}
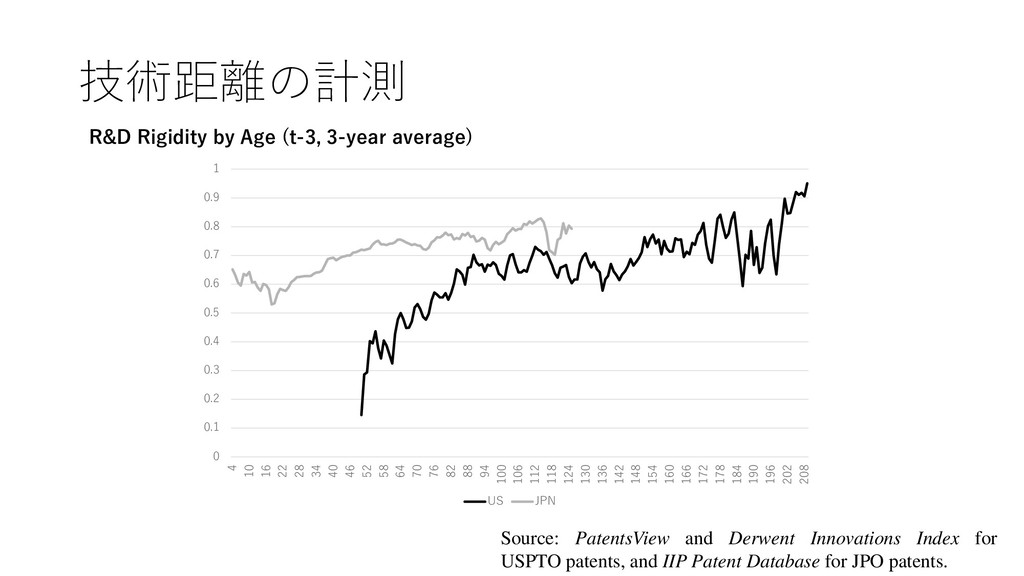{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Tips; Google Colaboratory 上で Notebook をコピーする [ドライブにコピーを保存] を選択する](https://files.speakerdeck.com/presentations/a2921325b23c48f492db5e24263ba765/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![次回予告; (人力や Web スクレイピングやRPA で)データを集めてきて処理をするまでの長く 険しい道 [座学、実習] • データといっても、そのほとんどは実のところ定型化されてい ません。Web](https://files.speakerdeck.com/presentations/a2921325b23c48f492db5e24263ba765/slide_95.jpg){kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/a2921325b23c48f492db5e24263ba765/slide_97.jpg){kind=link}