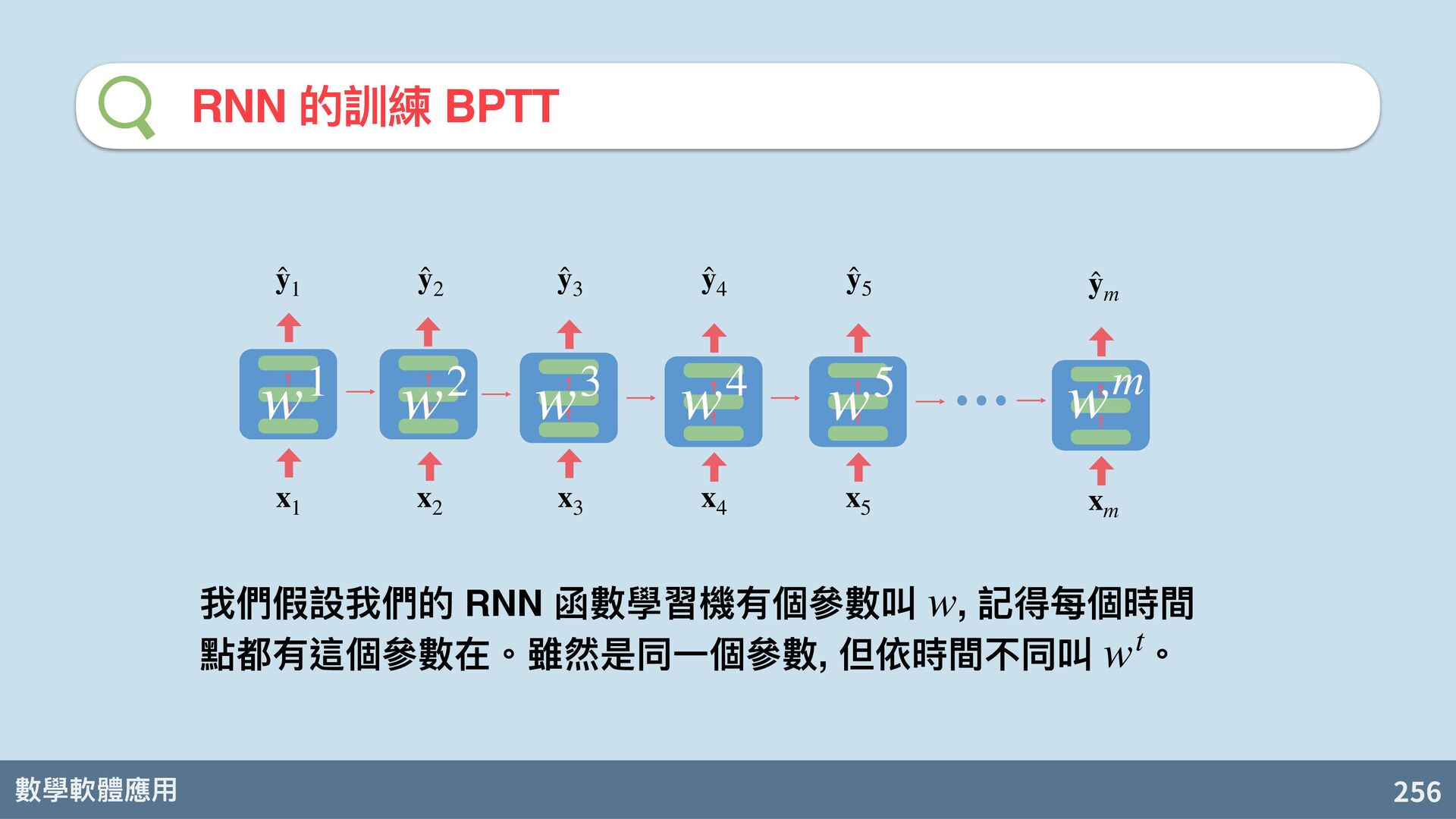
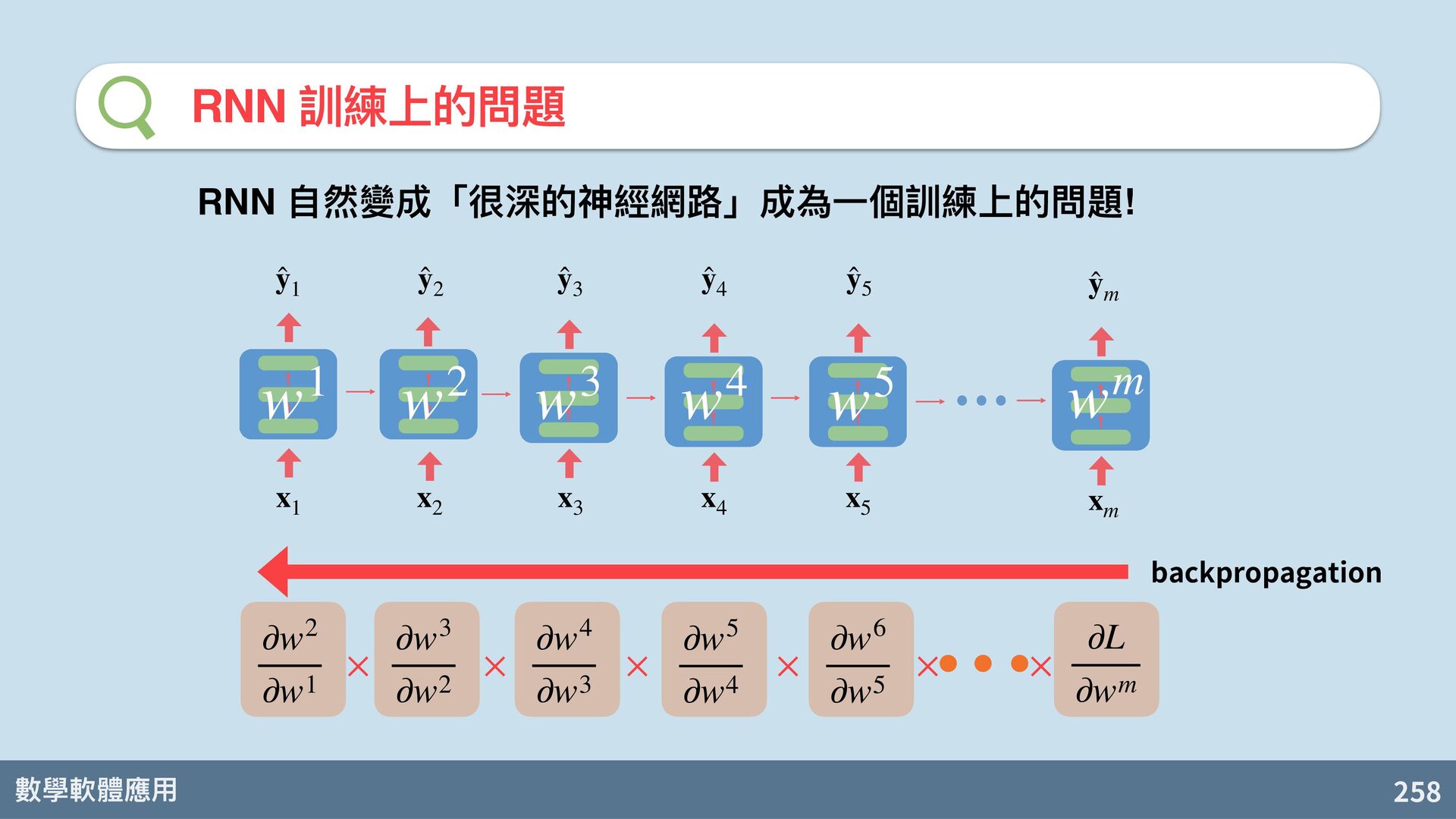
backpropagation RNN ⾃然變成「很深的神經網路」成為⼀個訓練上的問題! ∂L ∂wm ∂w6 ∂w5 ∂w5 ∂w4 ∂w4 ∂w3 ∂w3 ∂w2 ∂w2 ∂w1 × × × × × × x 3 x 4 x 5 ̂ y 3 x m x 2 x 1 ̂ y 1 ̂ y 2 ̂ y 4 ̂ y 5 ̂ y m
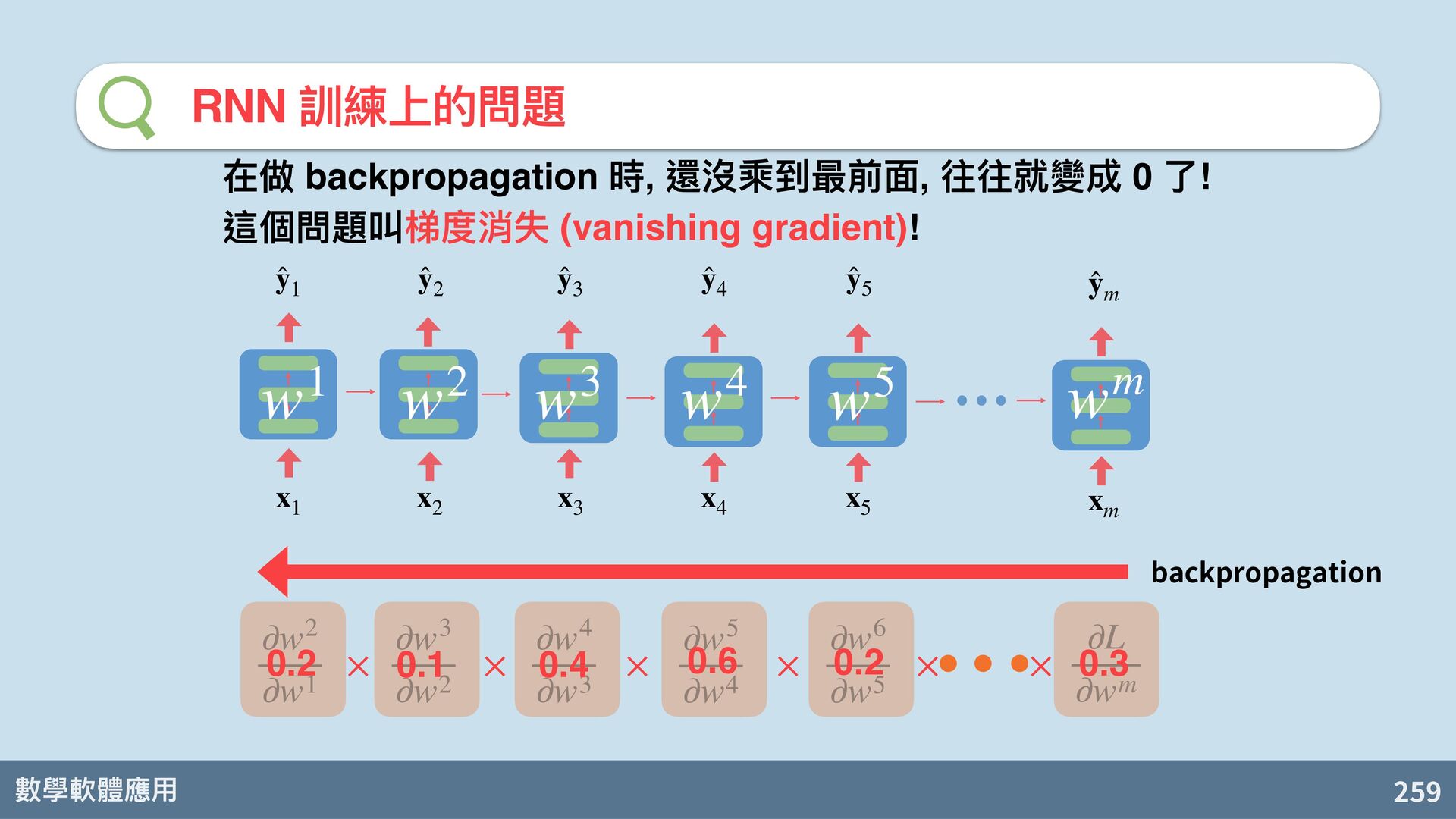
backpropagation 在做 backpropagation 時, 還沒乘到最前⾯, 往往就變成 0 了! 這個問題叫梯度消失 (vanishing gradient)! ∂L ∂wm ∂w6 ∂w5 ∂w5 ∂w4 ∂w4 ∂w3 ∂w3 ∂w2 ∂w2 ∂w1 × × × × × × 0.3 0.2 0.6 0.4 0.1 0.2 x 3 x 4 x 5 ̂ y 3 x m x 2 x 1 ̂ y 1 ̂ y 2 ̂ y 4 ̂ y 5 ̂ y m
{kind=link}
{kind=link}
{kind=link}
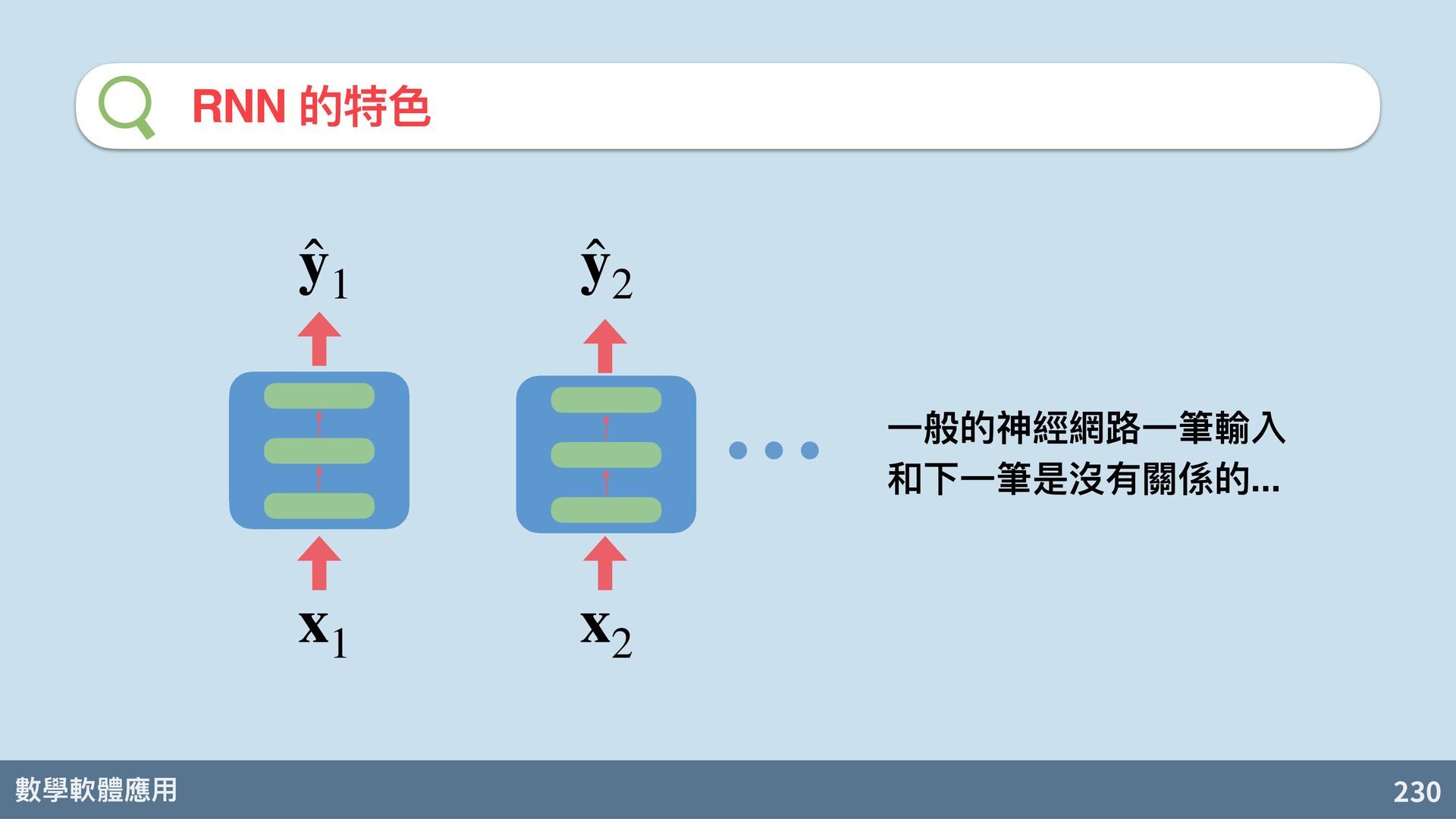{kind=link}
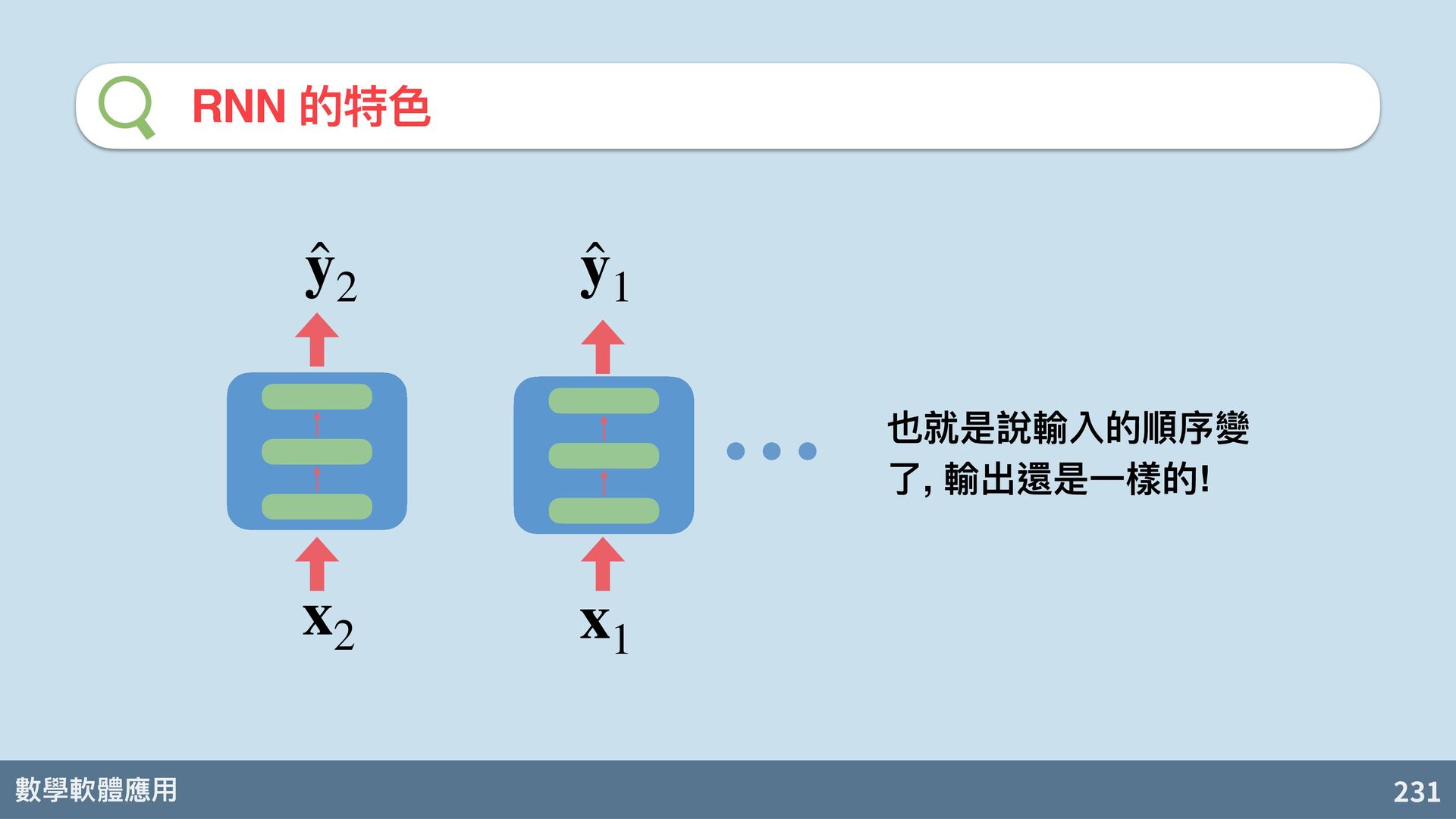{kind=link}
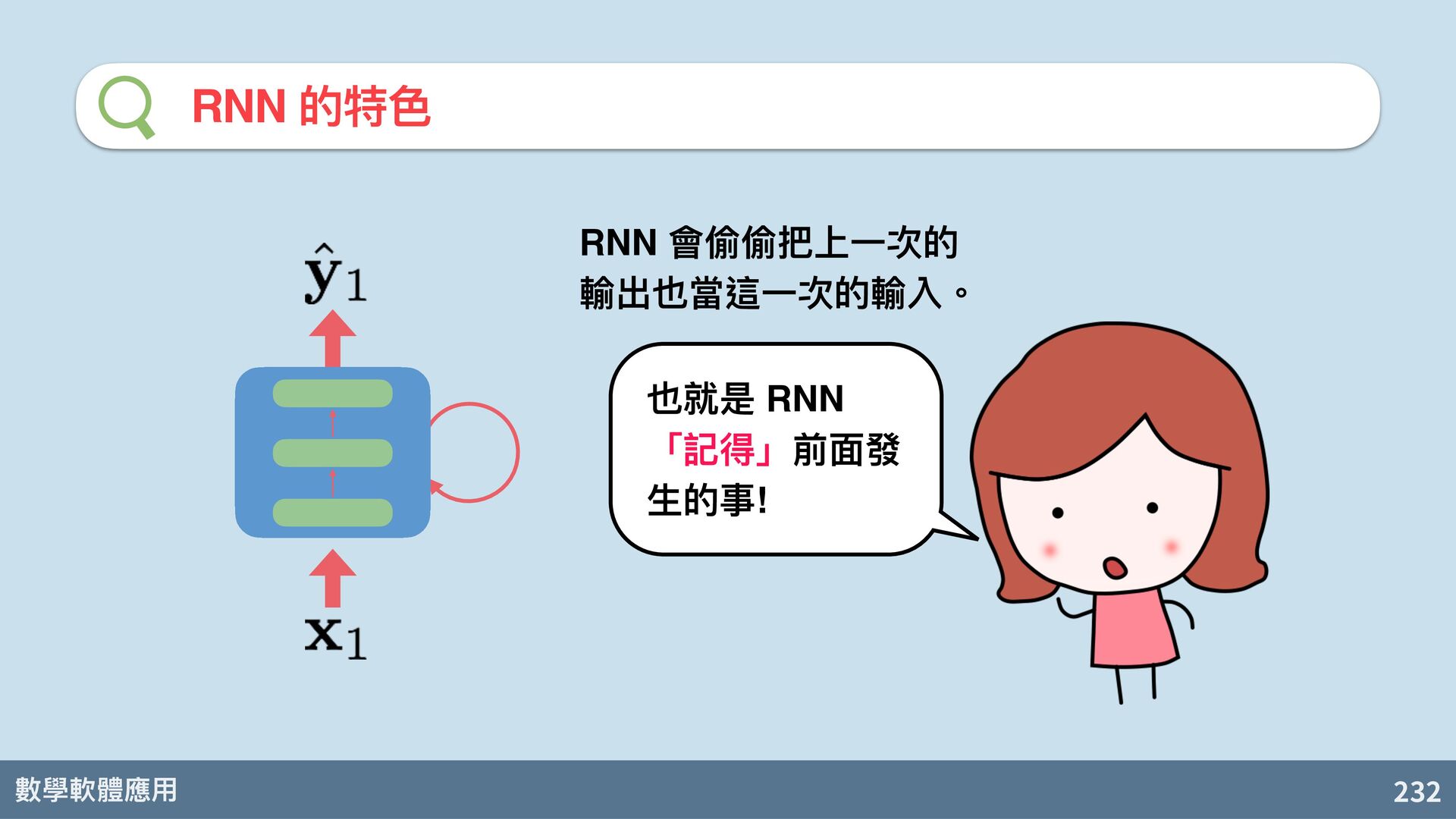{kind=link}
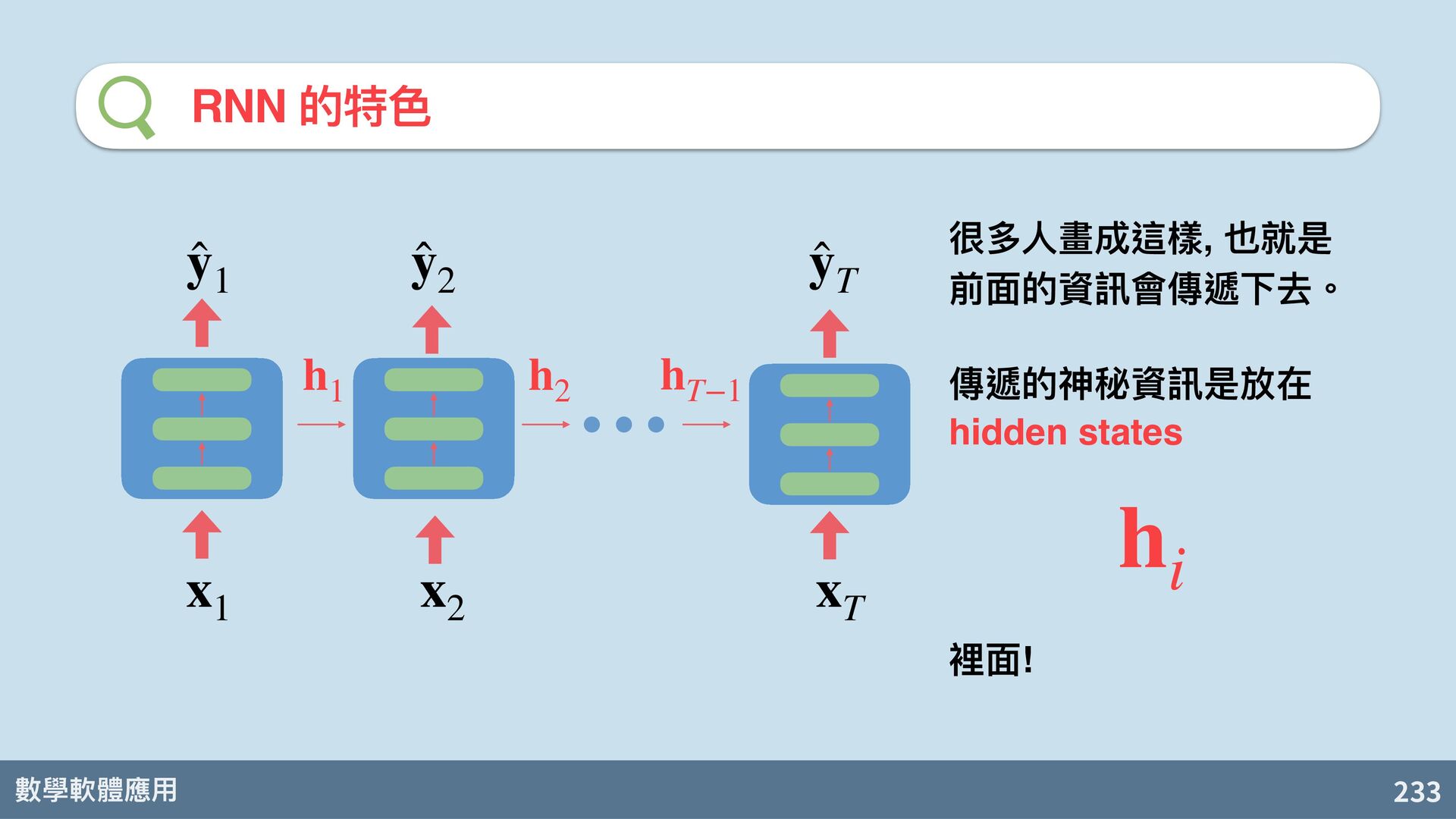{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
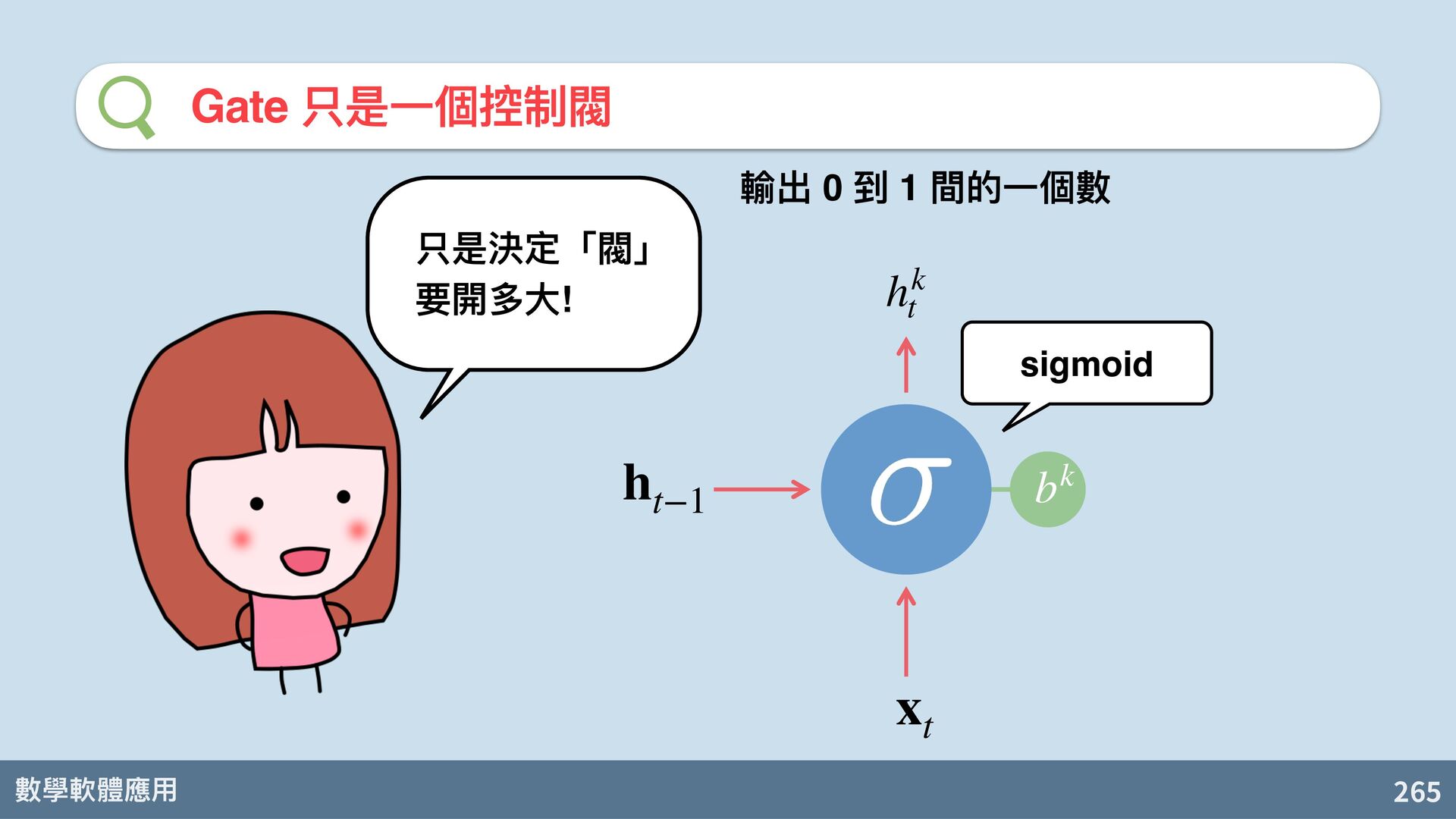{kind=link}
{kind=link}
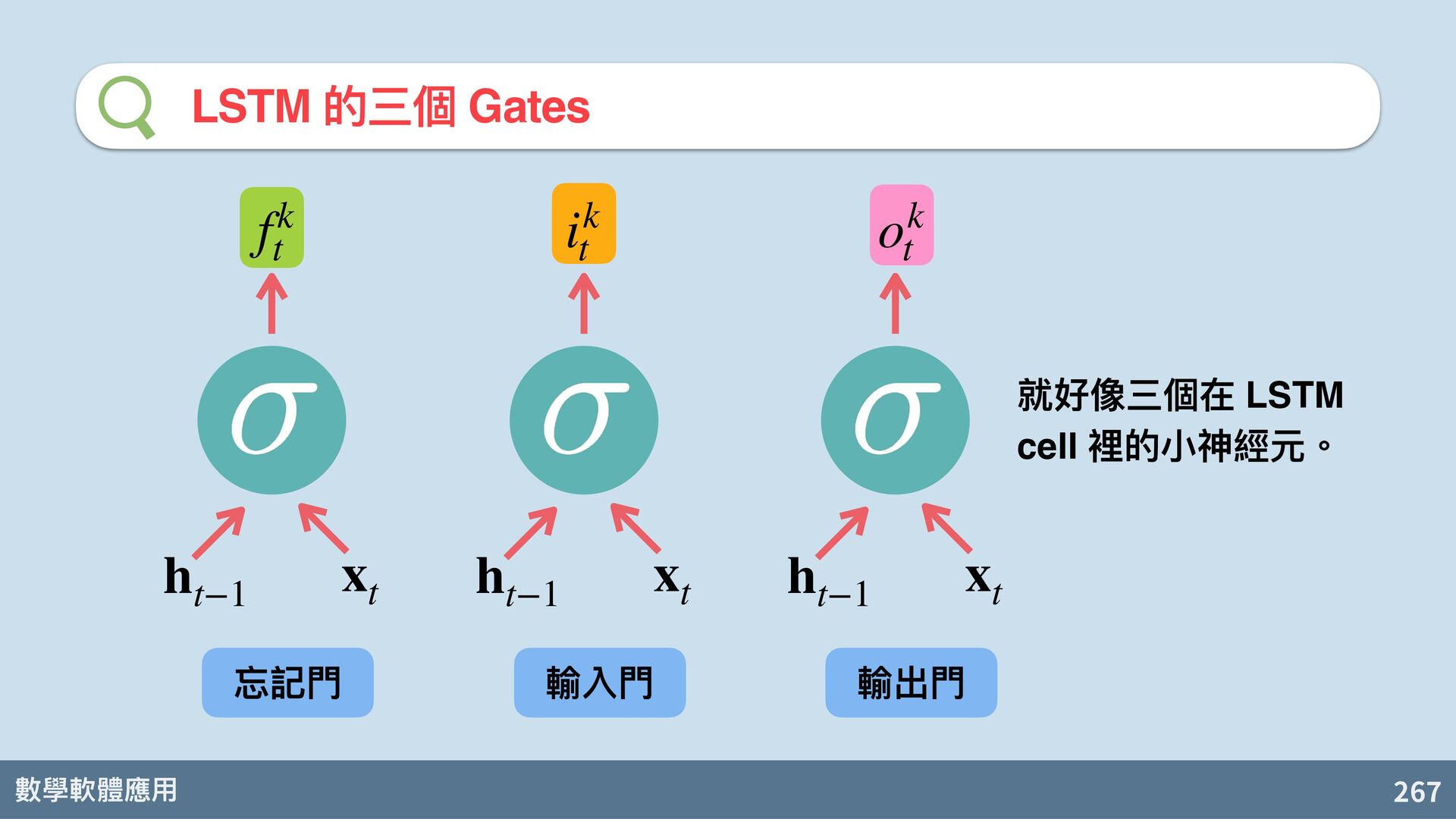{kind=link}
{kind=link}
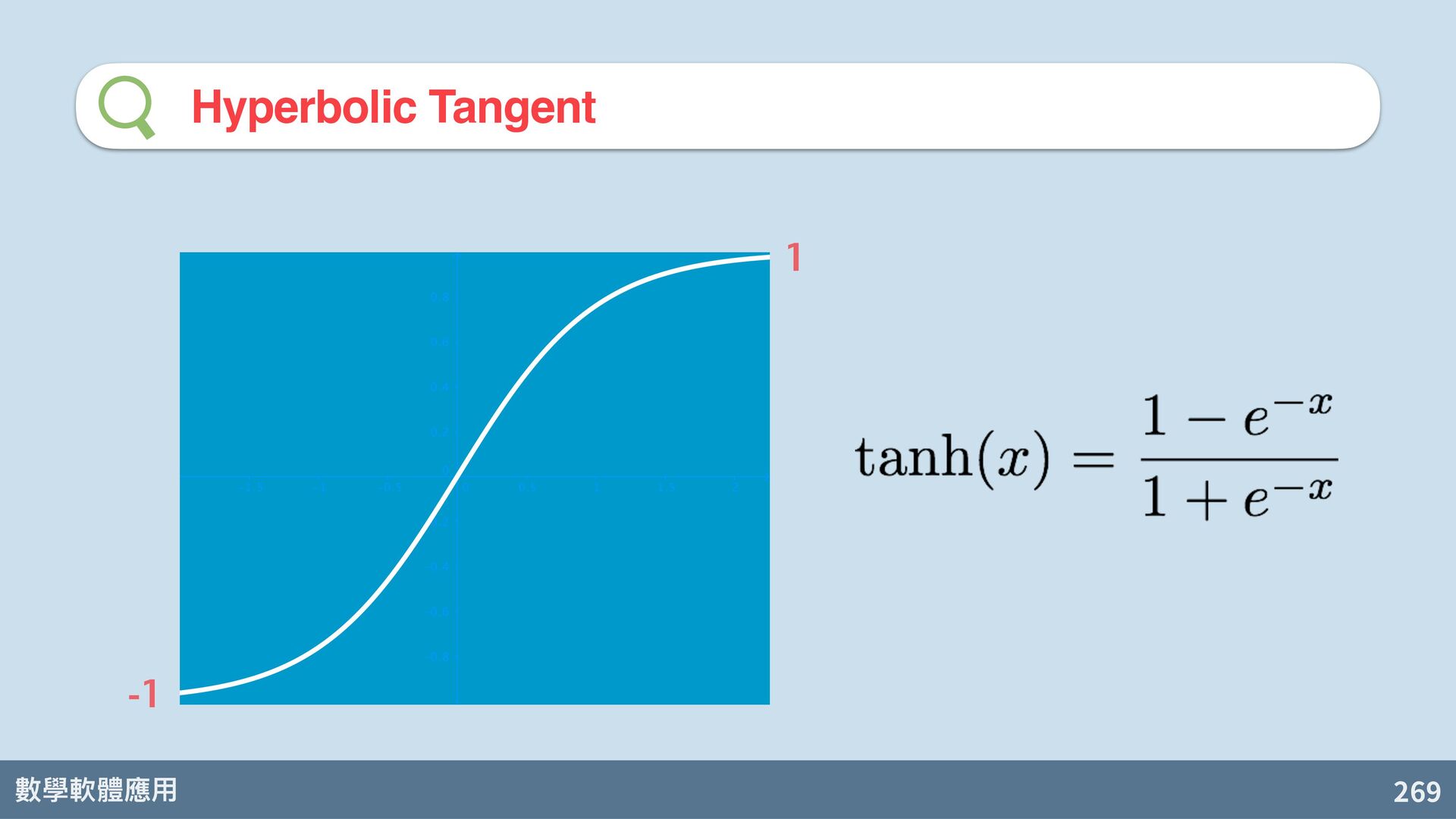{kind=link}
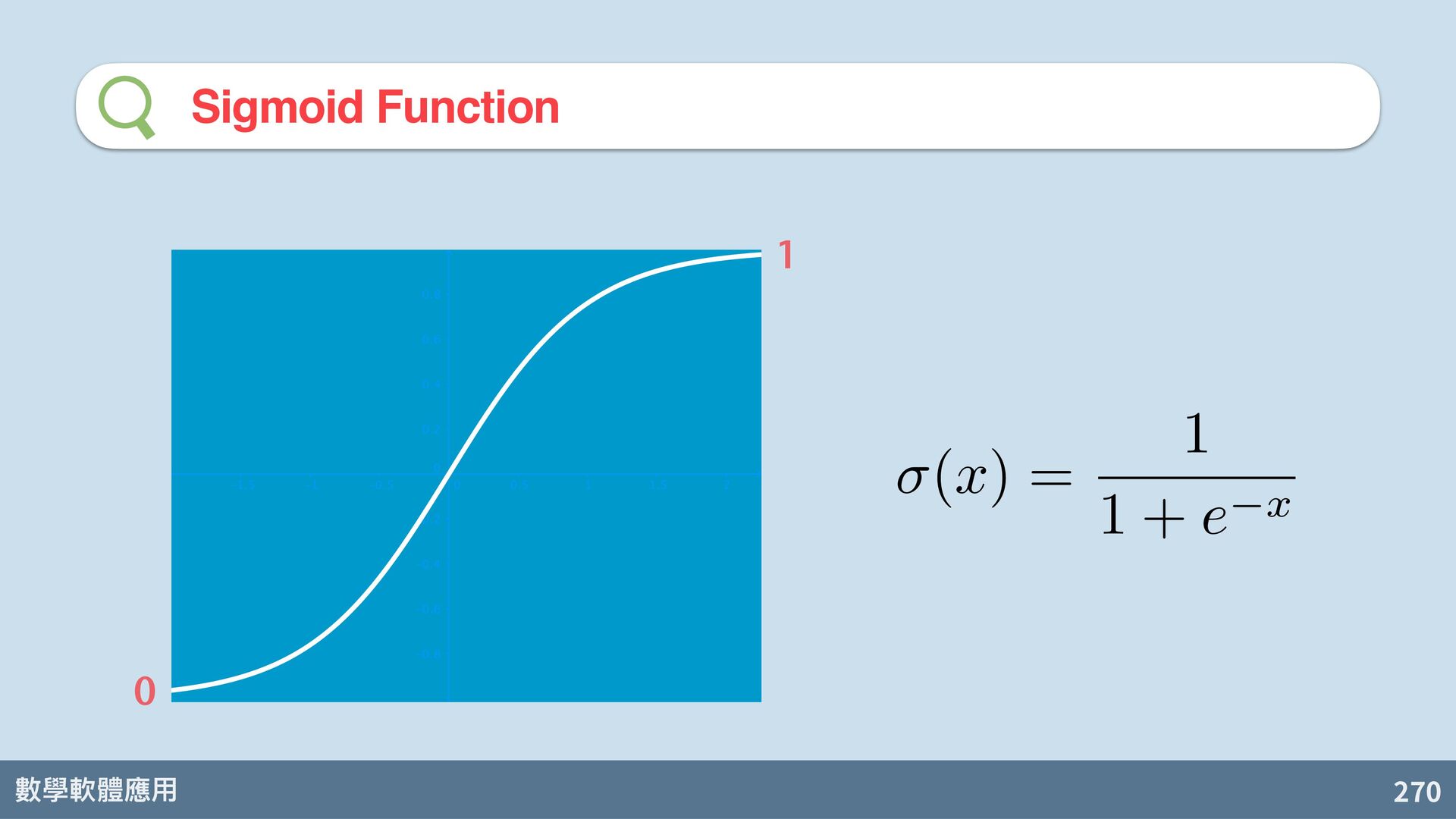{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}