Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【深度學習】03 神經網路是怎麼學的
Search
[email protected]
March 14, 2022
Technology
290
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【深度學習】03 神經網路是怎麼學的
2022 政大應數「數學軟體應用」深度學習課程 03
[email protected]
March 14, 2022
More Decks by
[email protected]
See All by
[email protected]
【深度學習】08 強化學習
yenlung
0
440
Contrastive Self-Supervised Learning
yenlung
0
530
【深度學習】07 生成模式和 GAN
yenlung
0
480
【深度學習】06 RNN 實務與 Transformers
yenlung
0
410
【深度學習】05 有記憶的神經網路 RNN
yenlung
0
330
【深度學習】04 圖形辨識的天王 CNN
yenlung
0
370
【深度學習】02 AI 就是問個好問題
yenlung
0
290
咖啡沖煮簡介
yenlung
0
1.4k
深度學習入門
yenlung
0
480
Other Decks in Technology
See All in Technology
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.5k
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
320
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
480
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
310
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
5k
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
370
CIで使うClaude
iwatatomoya
0
290
「AIに依存している」と 「AIを使いこなしている」の違い
k8yasuma
0
110
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
130
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
550
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
3
1.1k
Featured
See All Featured
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
What's in a price? How to price your products and services
michaelherold
247
13k
Paper Plane (Part 1)
katiecoart
PRO
1
9.7k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
The Cost Of JavaScript in 2023
addyosmani
55
10k
A better future with KSS
kneath
240
18k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Music & Morning Musume
bryan
47
7.3k
The Limits of Empathy - UXLibs8
cassininazir
1
500
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Believing is Seeing
oripsolob
1
170
Transcript
政⼤應數。數學軟體應⽤ 蔡炎龍 神經網路是怎麼學 的? 政治⼤學應⽤數學系 深度學習入⾨ 03.
神經網路怎麼學的 08.
數學軟體應⽤ 139 訓練我們的神經網路 神經網路需要經過訓練! ⽅式是 把我們的「考古題」(訓練資料) ⼀次次拿給神經網路學。學習法 叫 backpropagation。
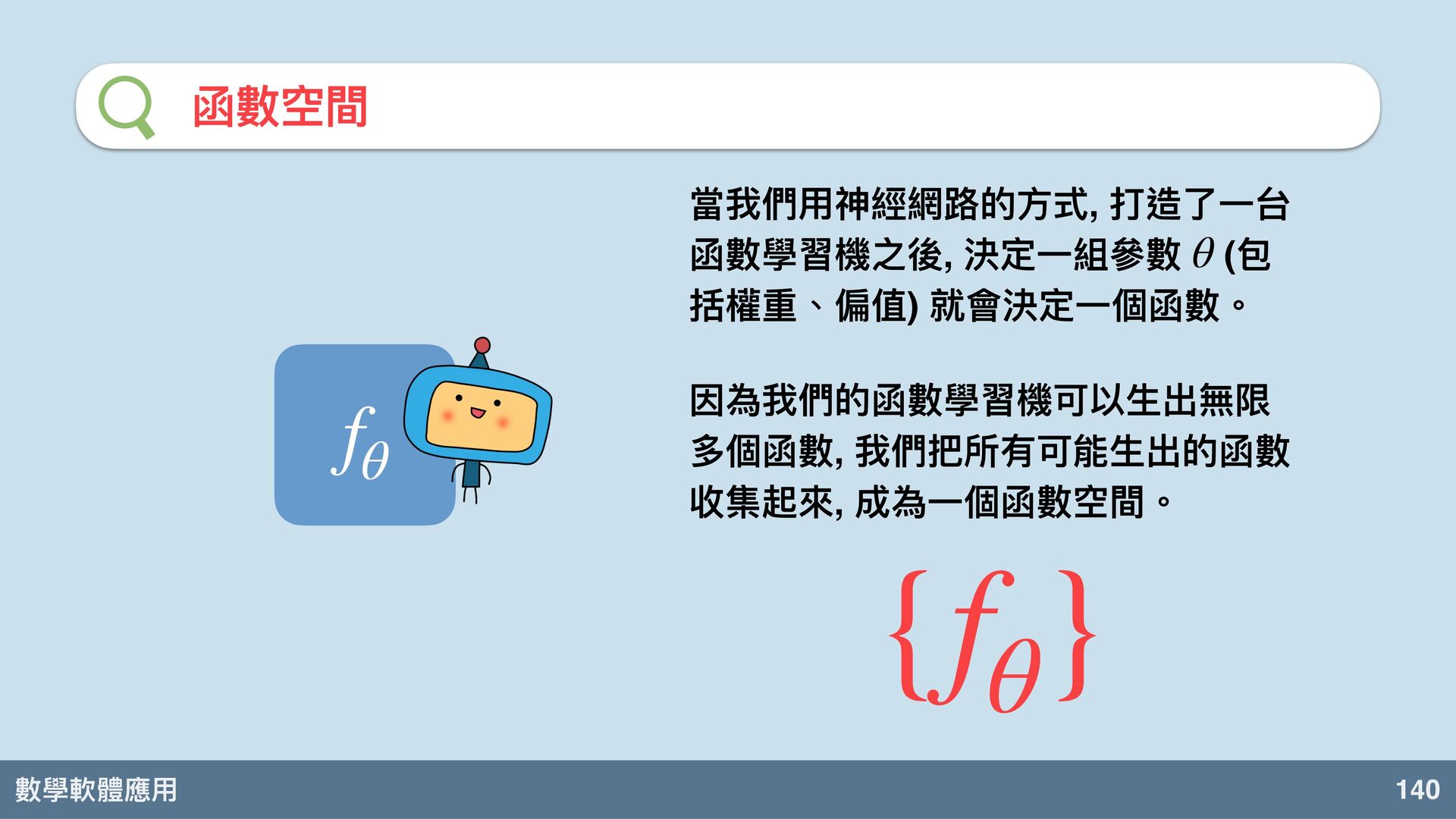
數學軟體應⽤ 140 函數空間 f θ 當我們⽤神經網路的⽅式, 打造了⼀台 函數學習機之後, 決定⼀組參數 (包
括權 、偏值) 就會決定⼀個函數。 因為我們的函數學習機可以⽣出無限 多個函數, 我們把所有可能⽣出的函數 收集起來, 成為⼀個函數空間。 θ {f θ }
數學軟體應⽤ 141 函數空間 f θ 我們的⽬標是要挑出⼀組最好的 , 意思就是這樣做出來的 和⽬標函 數最接近。
θ* f θ* θ*
數學軟體應⽤ 142 Loss Function 我們會⽤⼀個叫 loss function 的, 計算訓練資料中, 我們的神經
網路輸出和正確答案有多⼤的差 距。 ⾃然我們希望 loss function 的 值是越⼩越好。
數學軟體應⽤ 143 Loss Function 假設我們有訓練資料 {(x 1 , y 1
), (x 2 , y 2 ), …, (x k , y k )} 意思是輸入 , 正確答案應該是 。 x i y i f 輸入 輸出 x i y i
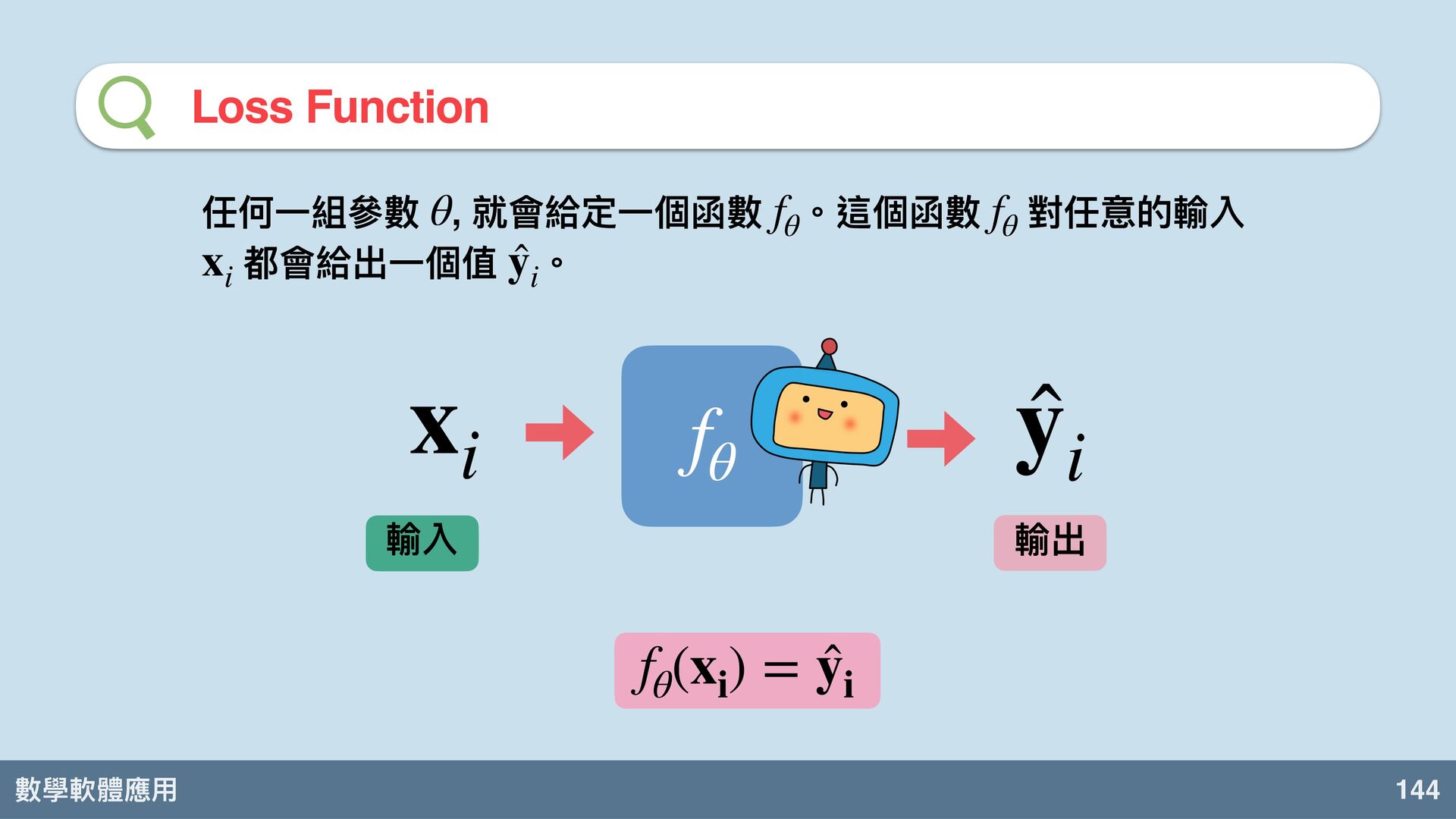
數學軟體應⽤ 144 Loss Function 輸入 輸出 x i ̂ y
i f θ f θ (x i ) = ̂ y i 任何⼀組參數 , 就會給定⼀個函數 。這個函數 對任意的輸入 都會給出⼀個值 。 θ f θ f θ x i ̂ y i
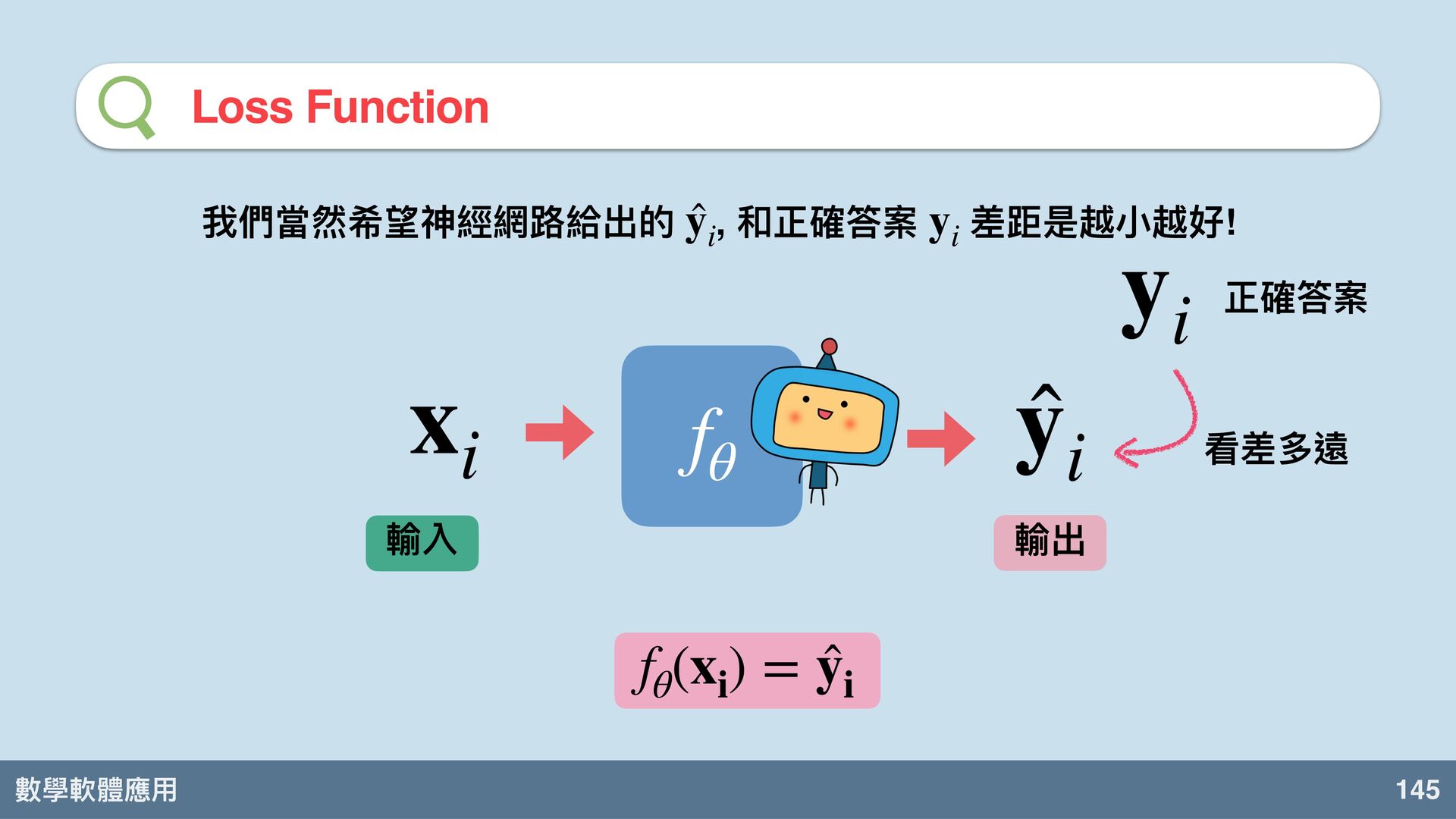
數學軟體應⽤ 145 Loss Function 輸入 輸出 x i ̂ y
i f θ f θ (x i ) = ̂ y i 我們當然希望神經網路給出的 , 和正確答案 差距是越⼩越好! ̂ y i y i y i 正確答案 看差多遠
數學軟體應⽤ 146 Loss Function L(θ) = 1 2 k ∑
i=1 ∥y i − f θ (x i )∥2 Loss function 就是計算神經網路給的答 案, 和正確答案差距多少的函數。例如說 以下是常⾒的 loss function: 這什麼啊!?
數學軟體應⽤ 147 Loss Function L(θ) = 1 2 k ∑
i=1 ∥y i − f θ (x i )∥2 其實就是計算和正確答案的差距! 我們希望誤差 越⼩越好! 正確答案 函數學習機 給的答案
數學軟體應⽤ 148 參數調整 那是怎麼調整的呢? 對於某個參數 來 說, 其實就是⽤這「簡單的」公式: w 這可怕的東⻄
是什麼意思? −η ∂L ∂w
數學軟體應⽤ 149 參數調整 記得 loss function 是所有權 和偏值 等等參數的函數。 L
w 1 , w 2 , b 1 , … 我們來破解函 數學習機學習 的秘密!
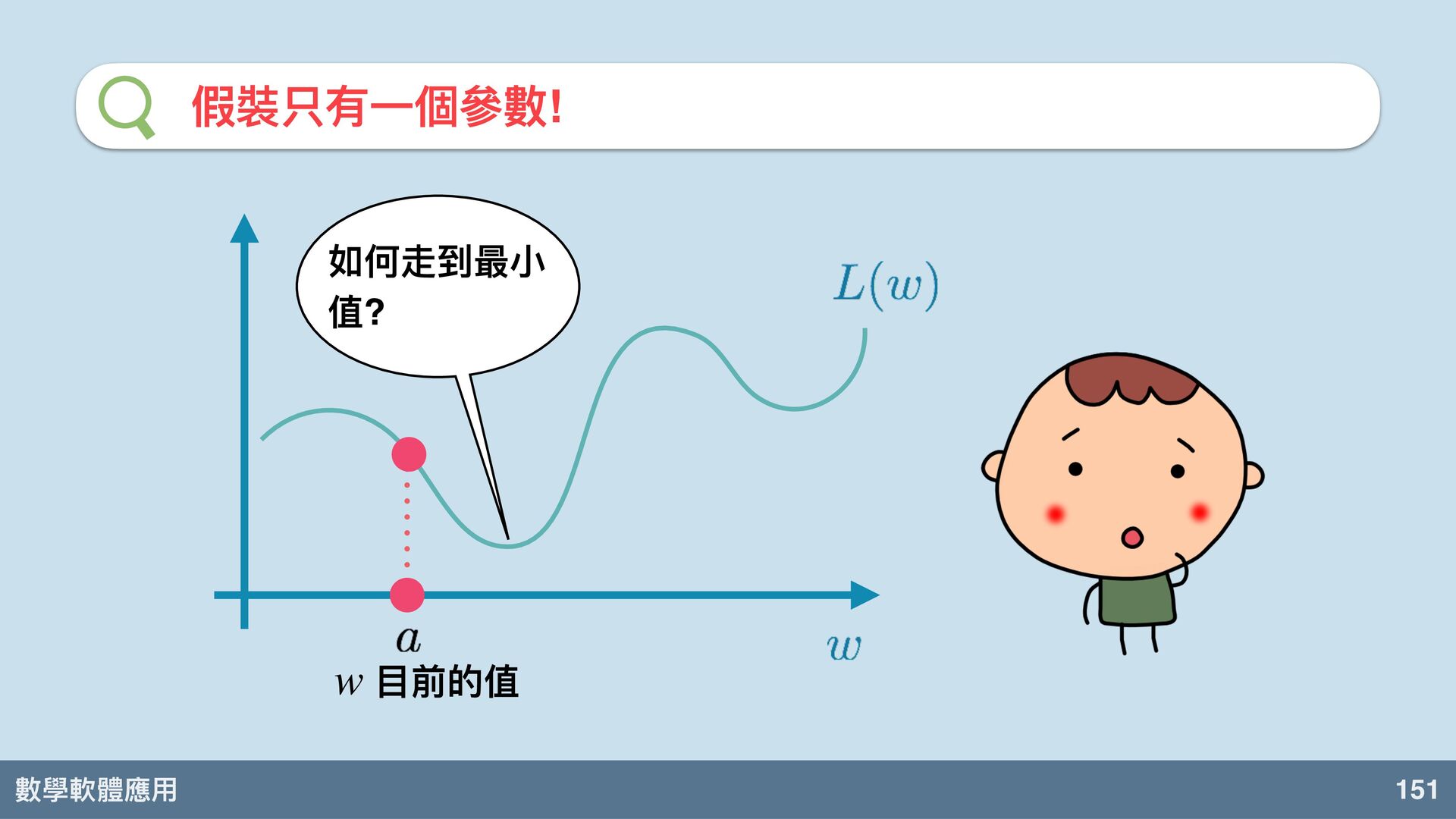
數學軟體應⽤ 150 假裝只有⼀個參數! 數學家都會先簡化問題。 假設我們⽤深度學 習打造的函數學習 機只有 ⼀個參 數! w
真的可以嗎!?
數學軟體應⽤ 151 假裝只有⼀個參數! ⽬前的值 w 如何走到最⼩ 值?
數學軟體應⽤ 152 假裝只有⼀個參數! ⽬前的值 w 我知道, 點要向右移動! w = a
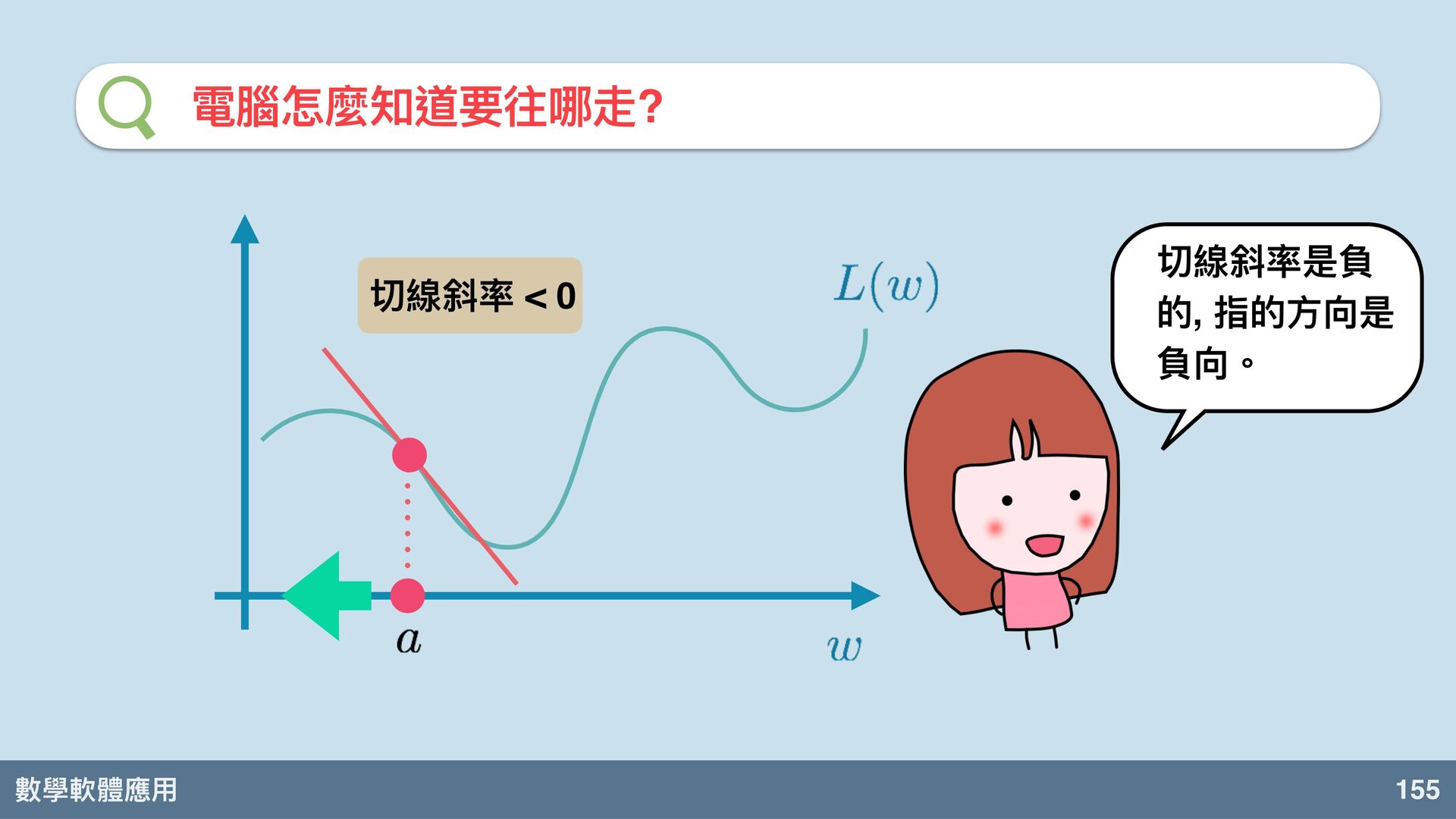
數學軟體應⽤ 153 電腦怎麼知道要往哪走? 電腦是怎麼「看」 出來的?
數學軟體應⽤ 154 電腦怎麼知道要往哪走? 切線是關鍵!
數學軟體應⽤ 155 電腦怎麼知道要往哪走? 切線斜率是負 的, 指的⽅向是 負向。 切線斜率 < 0
數學軟體應⽤ 156 電腦怎麼知道要往哪走? 切線斜率 > 0 切線斜率是正 的, 指的⽅向是 正向。
數學軟體應⽤ 157 電腦怎麼知道要往哪走? 切線斜率指的⽅向和我們應 該要走的極⼩值⽅向是相反 的! 事實上切線斜率指的⽅向正 是 (局部) 極⼤值的⽅向!
數學軟體應⽤ 158 切線斜率炫炫的符號 在 點的切線斜率符號是這樣: w = a 對任意的 點來說,
我們寫成函數形 式是這樣: w L′ (w) = dL dw L′ (a) 我們在微積分很會 算這些!
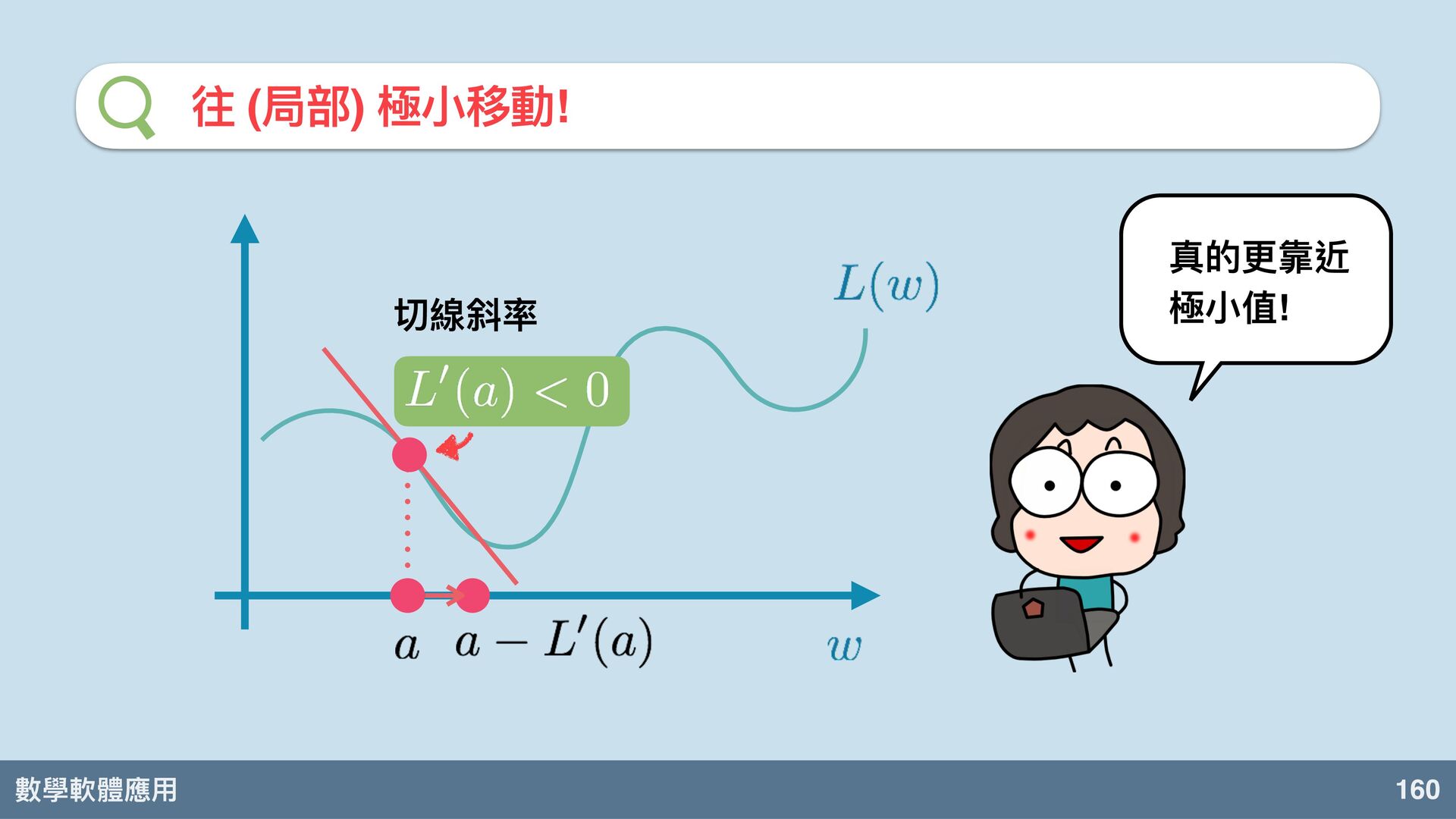
數學軟體應⽤ 159 往 (局部) 極⼩移動! 在 我們可以調整新的 值為: w =
a w a − L′ (a) 對任意的 點來說, 我們會有這樣⼦ 的公式去調整 的值。 w w w − dL dw 是不是真的可以 呢? 有點緊張。
數學軟體應⽤ 160 往 (局部) 極⼩移動! 切線斜率 真的更靠近 極⼩值!
數學軟體應⽤ 161 往 (局部) 極⼩移動! 切線斜率 這次跑過頭 了!
數學軟體應⽤ 162 Learning Rate w − η dL dw 為了不要跑過頭,
我們 不要⼀次調太⼤, 我們 會乘上⼀個⼩⼩的數, 叫 Learning Rate。
數學軟體應⽤ 163 不只⼀個參數怎麼辦呢? 看起來很美好。 可是參數不只⼀個 該怎麼辦呢?
數學軟體應⽤ 164 數學家比我們想像中邪惡 還是假裝只有⼀個參數!
數學軟體應⽤ 165 假裝只有⼀個參數 L(w 1 , w 2 , b
1 ) = (b 1 + 2w 1 − w 2 − 3)2 假設我們的神經網路有三個參數 , ⽽ loss function 長這樣: w 1 , w 2 , b 1 設我們把這個神經網路初始化, 各參數的值 如下: w 1 = 1,w 2 = − 1,b 1 = 2 假設⼀個簡單、多 參數的狀況!
數學軟體應⽤ 166 假裝只有⼀個參數 我們現在假裝只有 ⼀個參數! w 1 不要問我為什麼...
數學軟體應⽤ 167 假裝只有⼀個參數 中只要保留 這 個變數, 其他值都直 接代入! 於是 當場
只剩⼀個參數! L w 1 L L(w 1 , w 2 , b 1 ) = (b 1 + 2w 1 − w 2 − 3)2 w 1 = 1,w 2 = − 1,b 1 = 2 L w1 (w 1 ) = L(w 1 , − 1,2) = 4w2 1
數學軟體應⽤ 168 假裝只有⼀個參數 然後我們就可以⽤ ⼀個變數調整的⽅ 式, 去調整我們的權 ! w 1
− η dL w1 dw1 w 1
數學軟體應⽤ 169 偏微分 多變數函數, 假裝只 有⼀個變數的微分 ⽅式就叫偏微分。 ∂L ∂w1 =
dL w1 dw1 意思是我們會把 調整為 w 1 w 1 − η ∂L ∂w1
數學軟體應⽤ 170 其實就是⼀⼀調整! 和之前⼀個變 數⼀樣的⽅法! w 1 − η ∂L
∂w1 w 2 − η ∂L ∂w2 b 1 − η ∂L ∂b1 w 1 w 2 b 1
數學軟體應⽤ 171 三個式⼦寫在⼀起 我們把三個式 ⼦寫在⼀起是 這樣! w 1 w 2
b 1 w 1 w 2 b 1 − η ∂L ∂w1 ∂L ∂w2 ∂L ∂b1
數學軟體應⽤ 172 Gradient 梯度 w 1 w 2 b 1
− η ∂L ∂w1 ∂L ∂w2 ∂L ∂b1 這關鍵的向 我們稱為 的梯度 (gradient), 記為: L ∇L
數學軟體應⽤ 173 Gradient Descent w 1 w 2 b 1
− η∇L 調整參數的公式就可以寫成這 樣, 我們稱這個⽅法為: Gradient Descent
數學軟體應⽤ 174 Gradient Descent 不管你的深度學習函數學習機 是怎麼架的, 不管你選什麼 loss function, 你都可以使⽤
gradient descent 去訓練你的 神經網路!
打造第⼀個神經網路 09.
數學軟體應⽤ 176 TensorFlow 現在我們準備⼀起打造⼀個神經網路, 我們準 備⽤有名的 TensorFlow 這個 Python 套件。
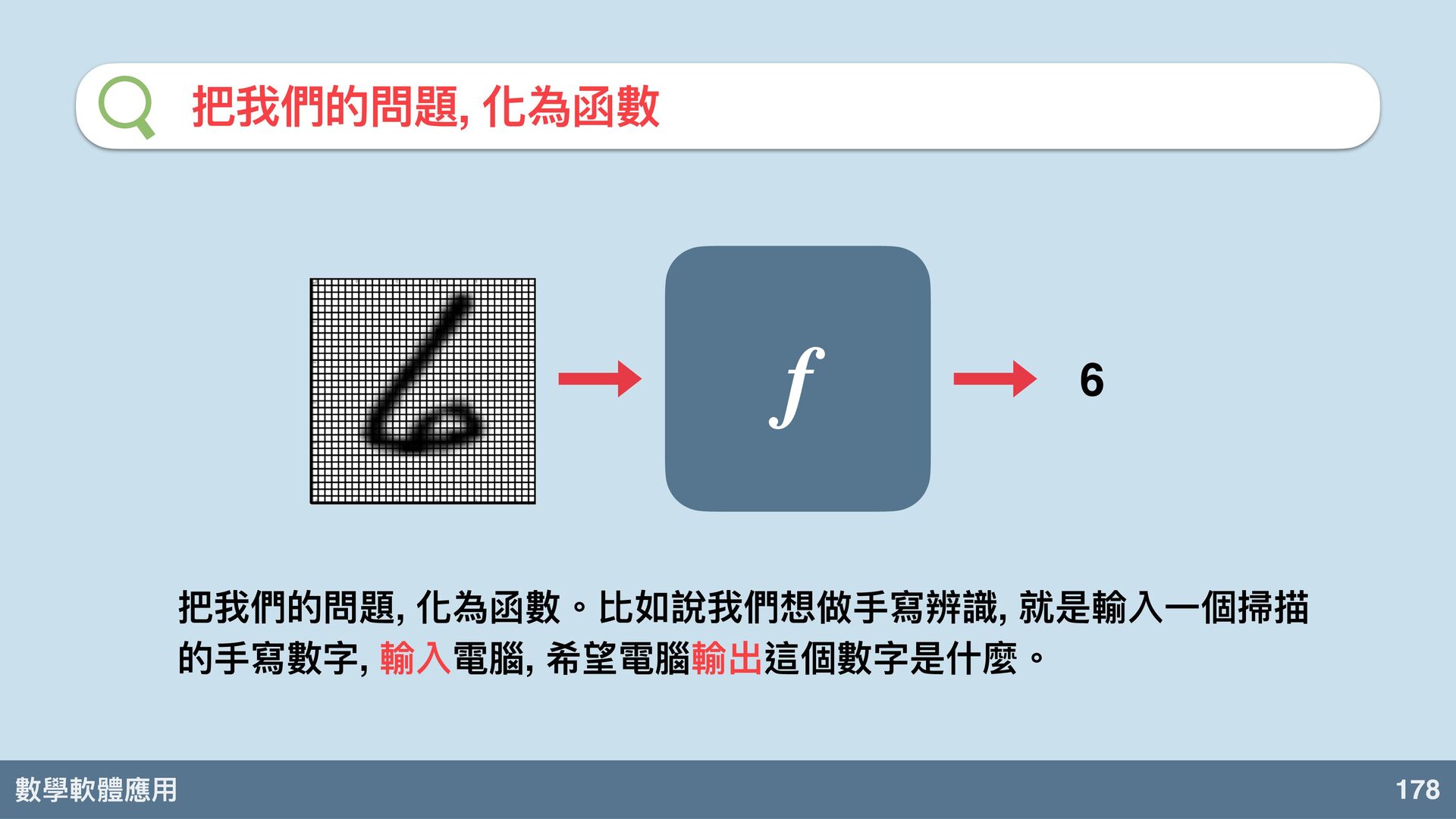
數學軟體應⽤ 177 MNIST 數據集 MNIST 我們介紹⼀個非常有名的數據集。 Modified 美國國家標準暨技術研究院 這是⼿寫數字 辨識的資料。
數學軟體應⽤ 178 把我們的問題, 化為函數 f 6 把我們的問題, 化為函數。比如說我們想做⼿寫辨識, 就是輸入⼀個掃描 的⼿寫數字,
輸入電腦, 希望電腦輸出這個數字是什麼。
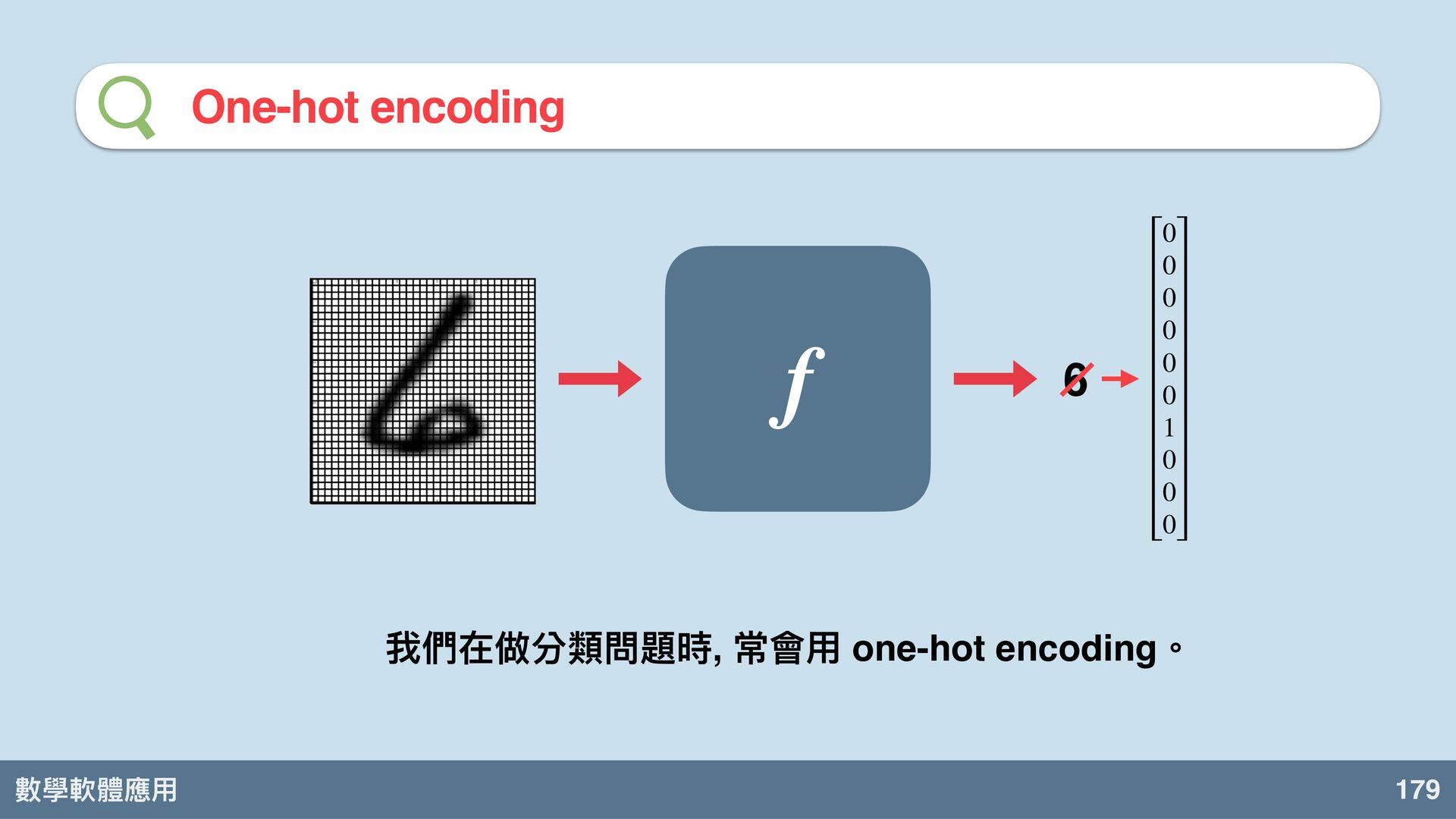
數學軟體應⽤ 179 One-hot encoding f 我們在做分類問題時, 常會⽤ one-hot encoding。 0
0 0 0 0 0 1 0 0 0 6
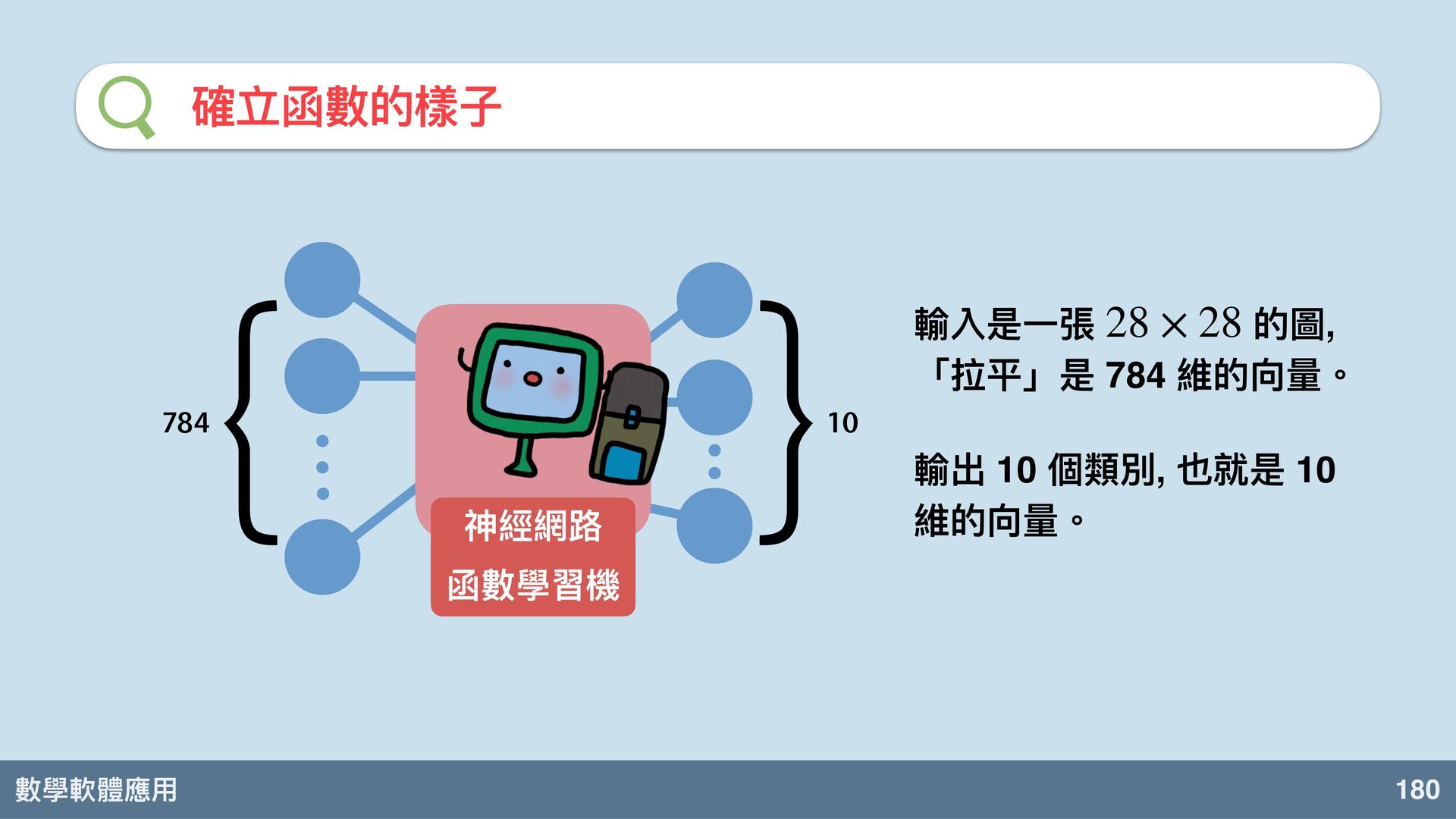
數學軟體應⽤ 180 確立函數的樣⼦ 暗黑魔法 { } 784 10 神經網路 函數學習機
輸入是⼀張 的圖, 「拉平」是 784 維的向 。 輸出 10 個類別, 也就是 10 維的向 。 28 × 28
數學軟體應⽤ 181 Softmax 若⼲個數字, 我們希望經過⼀個轉換, 加起來等於 1。但⼤的 還是⼤的, ⼩的還是⼩的, 該怎麼做呢?
a b c α β γ α + β + γ = 1
數學軟體應⽤ 182 Softmax a b c 很⾃然我們會這麼做: ea eb ec
毎個數字經 指數轉換 按比例 ea/T eb/T ec/T T = ea + eb + ec 這就叫 softmax
數學軟體應⽤ 183 01 讀入基本套件 這裡⼤概是所有數 據分析共通的。
數學軟體應⽤ 184 02 打造深度學習函數學習機的函式 做 one-hot encoding 的⼯具 Sequential: 標準打造⼀台深度學習
函數學習機的⽅式。 Dense: 做全連結的隱藏層。 SGD: 標準的 gradient descent。
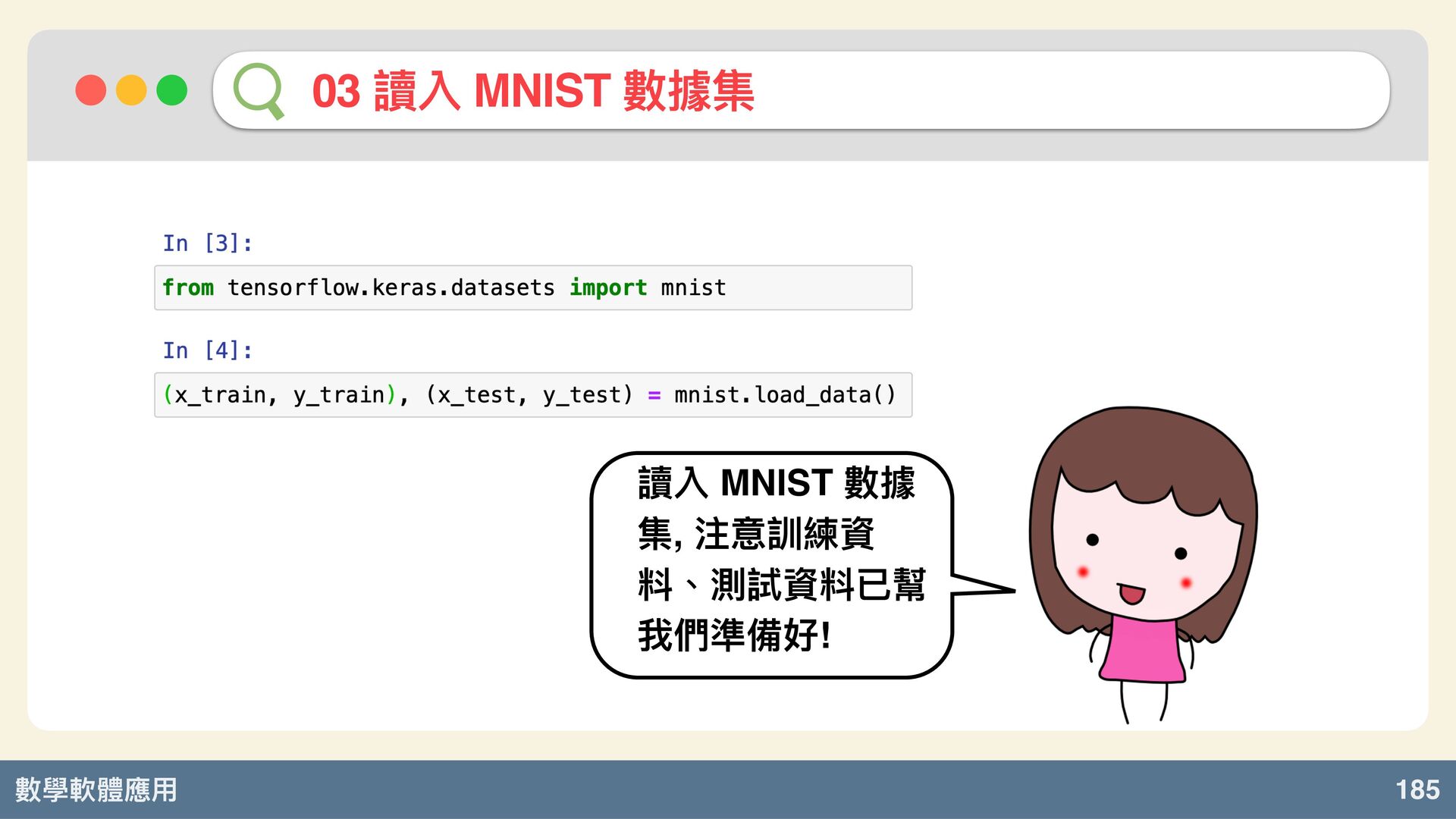
數學軟體應⽤ 185 03 讀入 MNIST 數據集 讀入 MNIST 數據 集,
注意訓練資 料、測試資料已幫 我們準備好!
數學軟體應⽤ 186 04 整理訓練、測試資料 整理⼀下資料! 訓練資料: 拉平、nomalization。 測試資料: 做 one-hot
encoding。
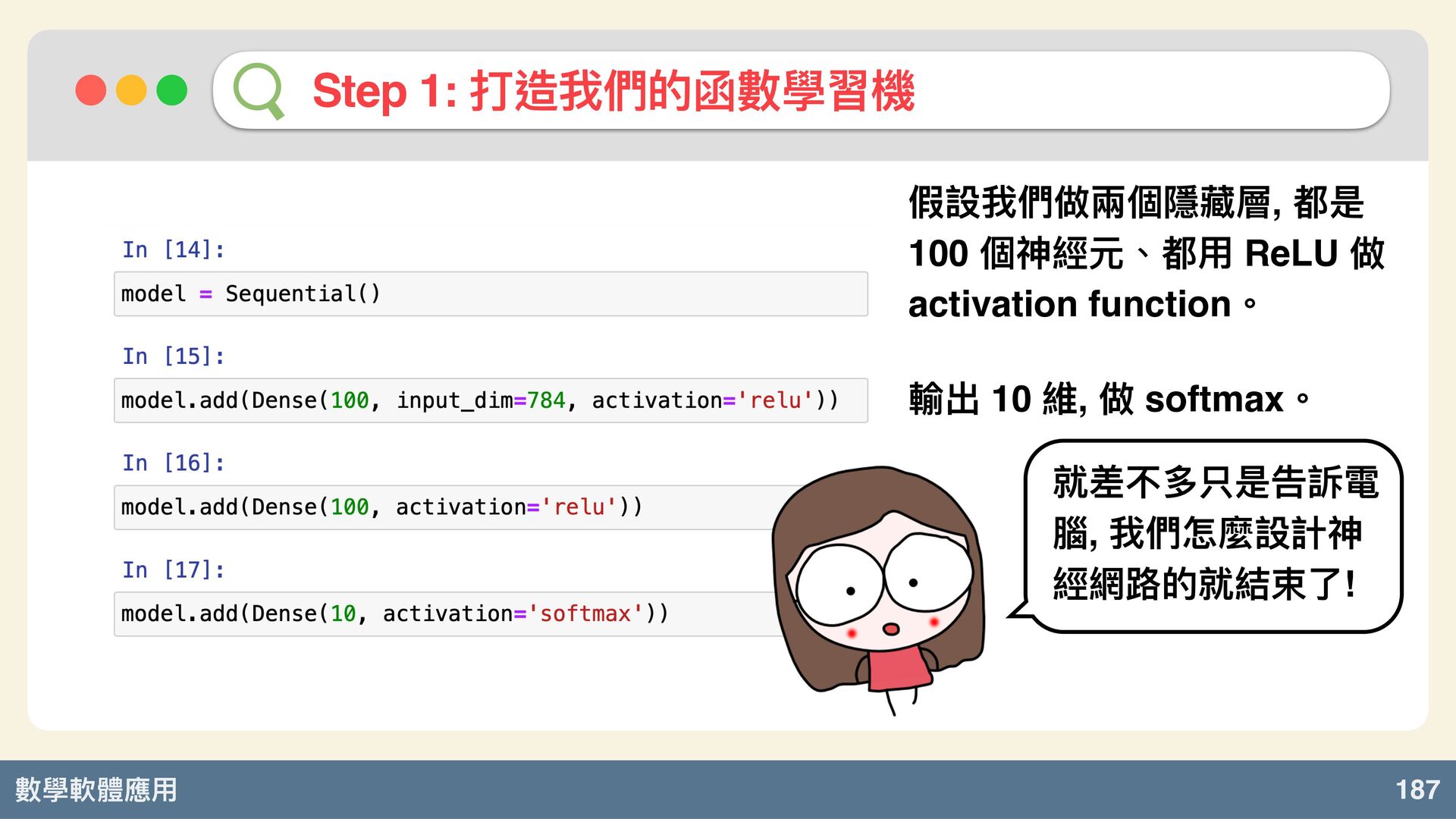
數學軟體應⽤ 187 Step 1: 打造我們的函數學習機 假設我們做兩個隱藏層, 都是 100 個神經元、都⽤ ReLU
做 activation function。 輸出 10 維, 做 softmax。 就差不多只是告訴電 腦, 我們怎麼設計神 經網路的就結束了!
數學軟體應⽤ 188 Step 1: 打造我們的函數學習機 loss: ⽤哪個 loss function。 optimizer:
我們⽤ SGD, 設 learning rate。 metrics: 這裡是顯⽰⽬前正確率。
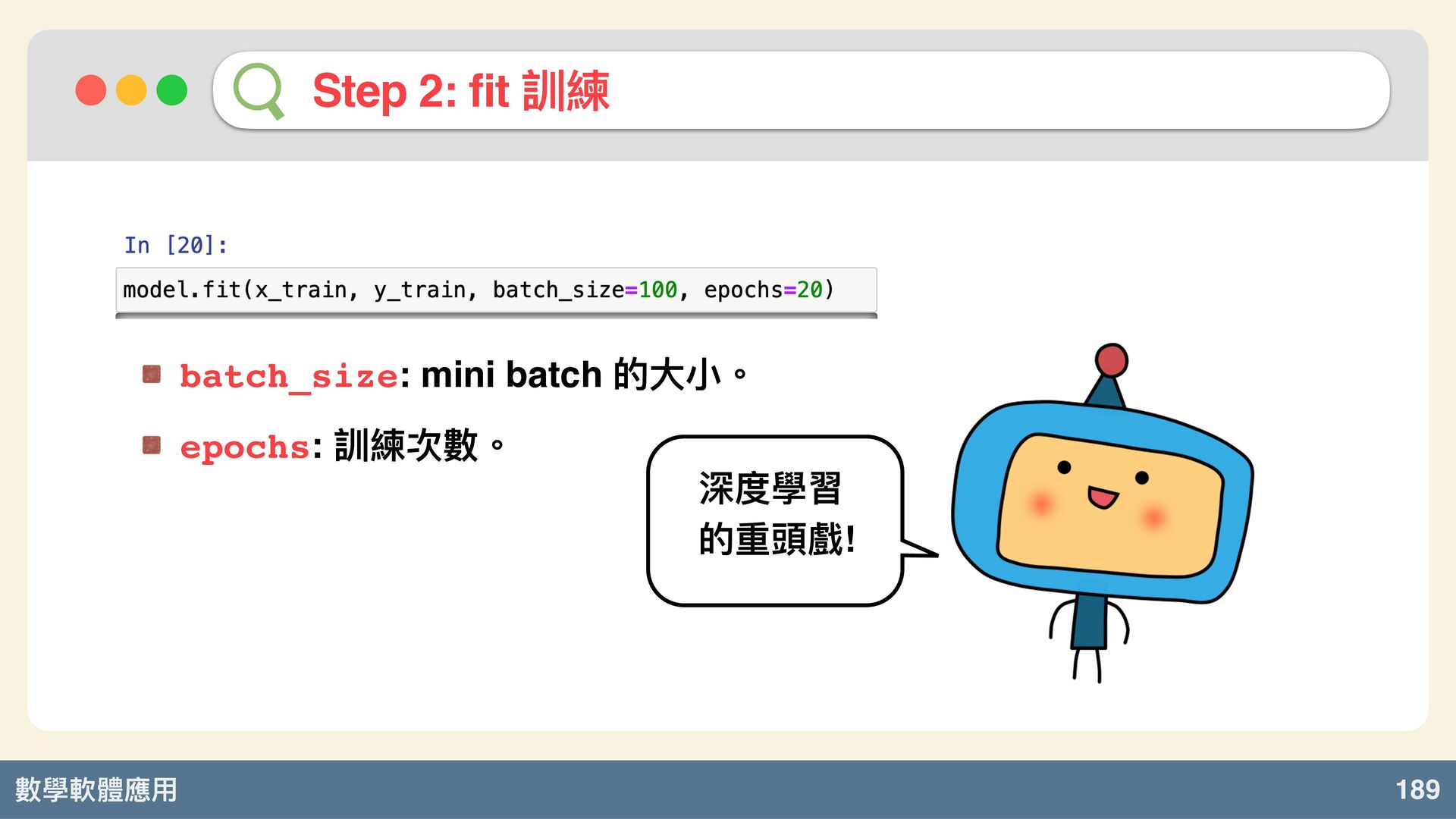
數學軟體應⽤ 189 Step 2: fit 訓練 batch_size: mini batch 的⼤⼩。
epochs: 訓練次數。 深度學習 的 頭戲!
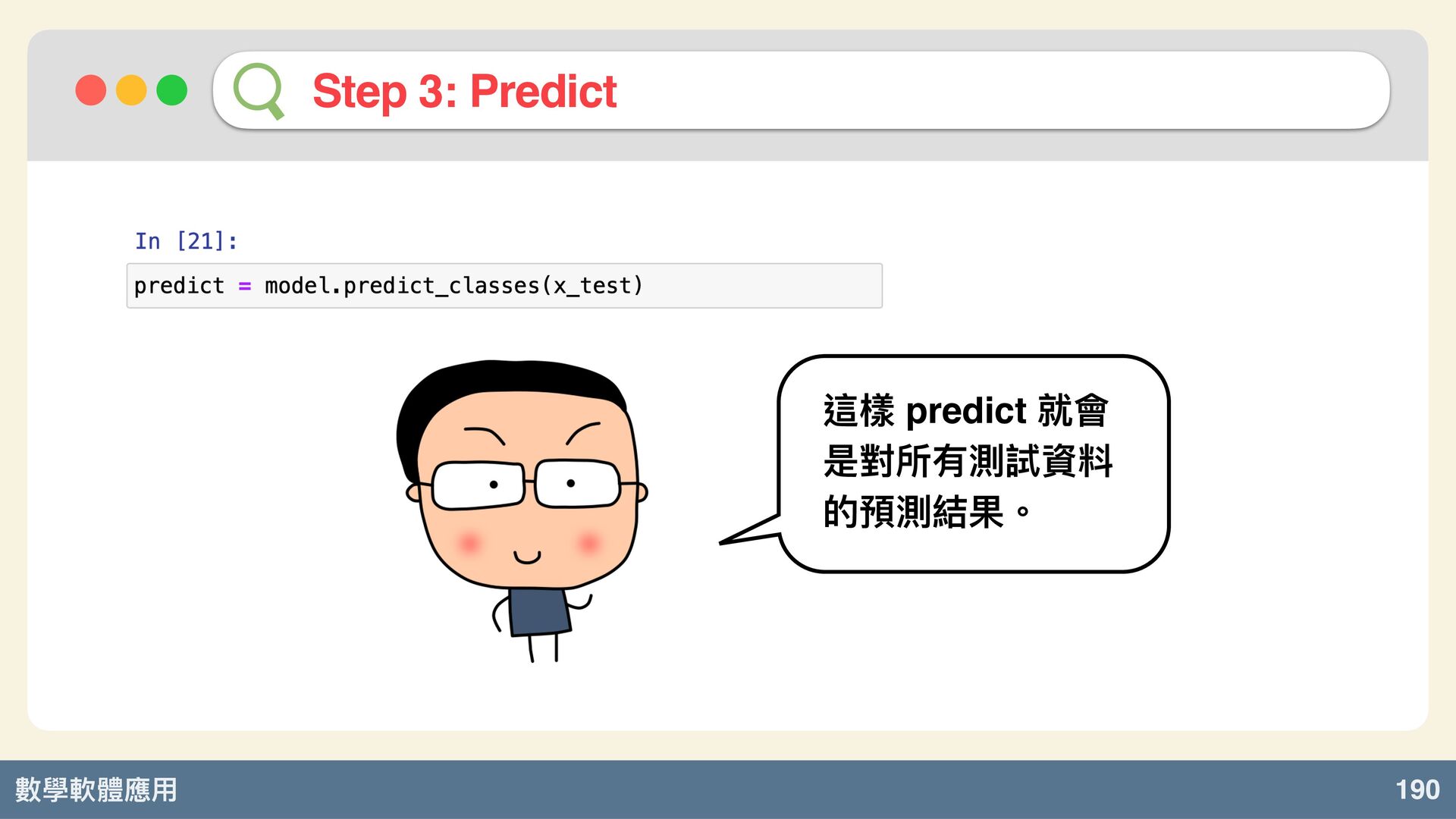
數學軟體應⽤ 190 Step 3: Predict 這樣 predict 就會 是對所有測試資料 的預測結果。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}