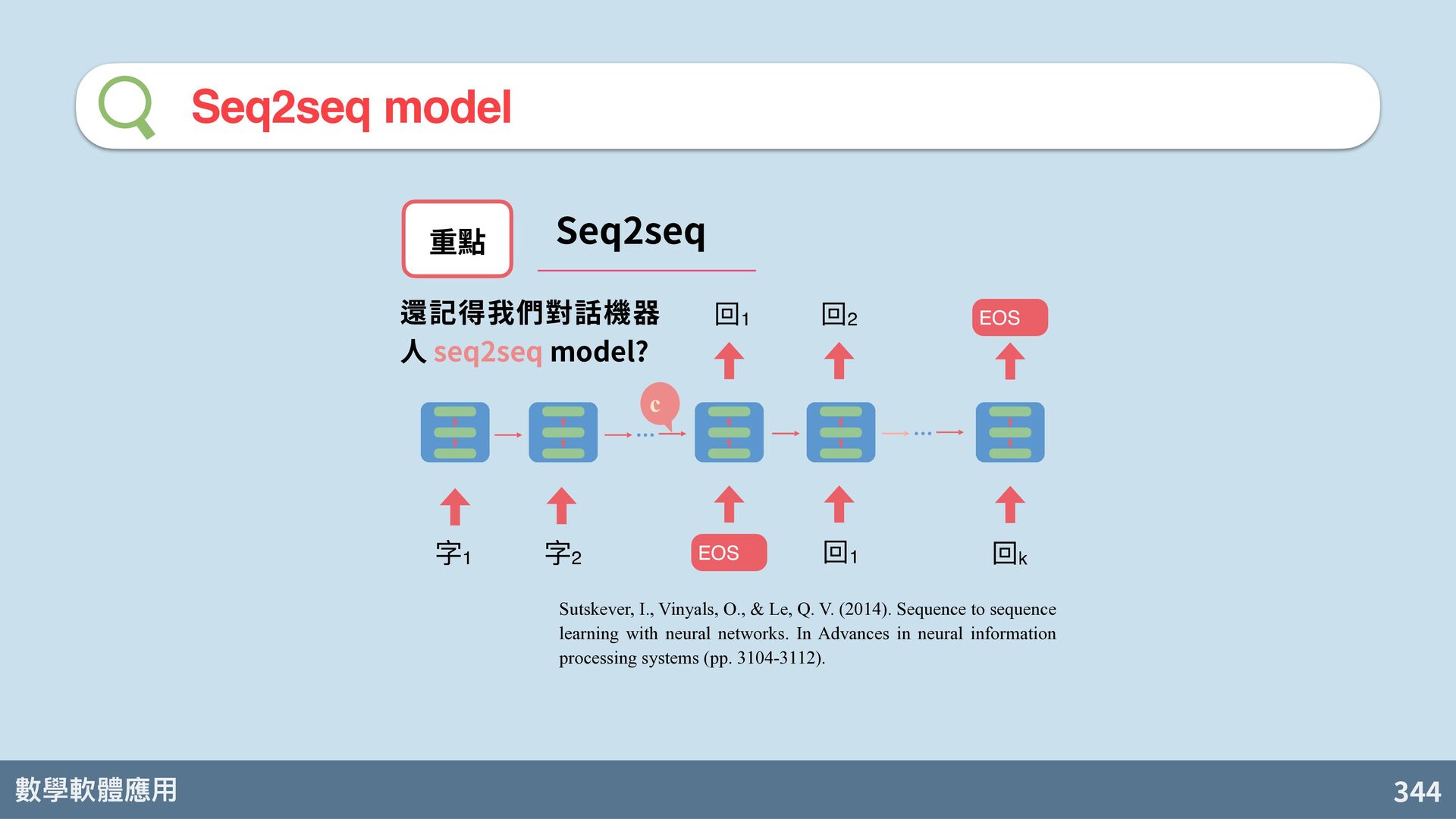
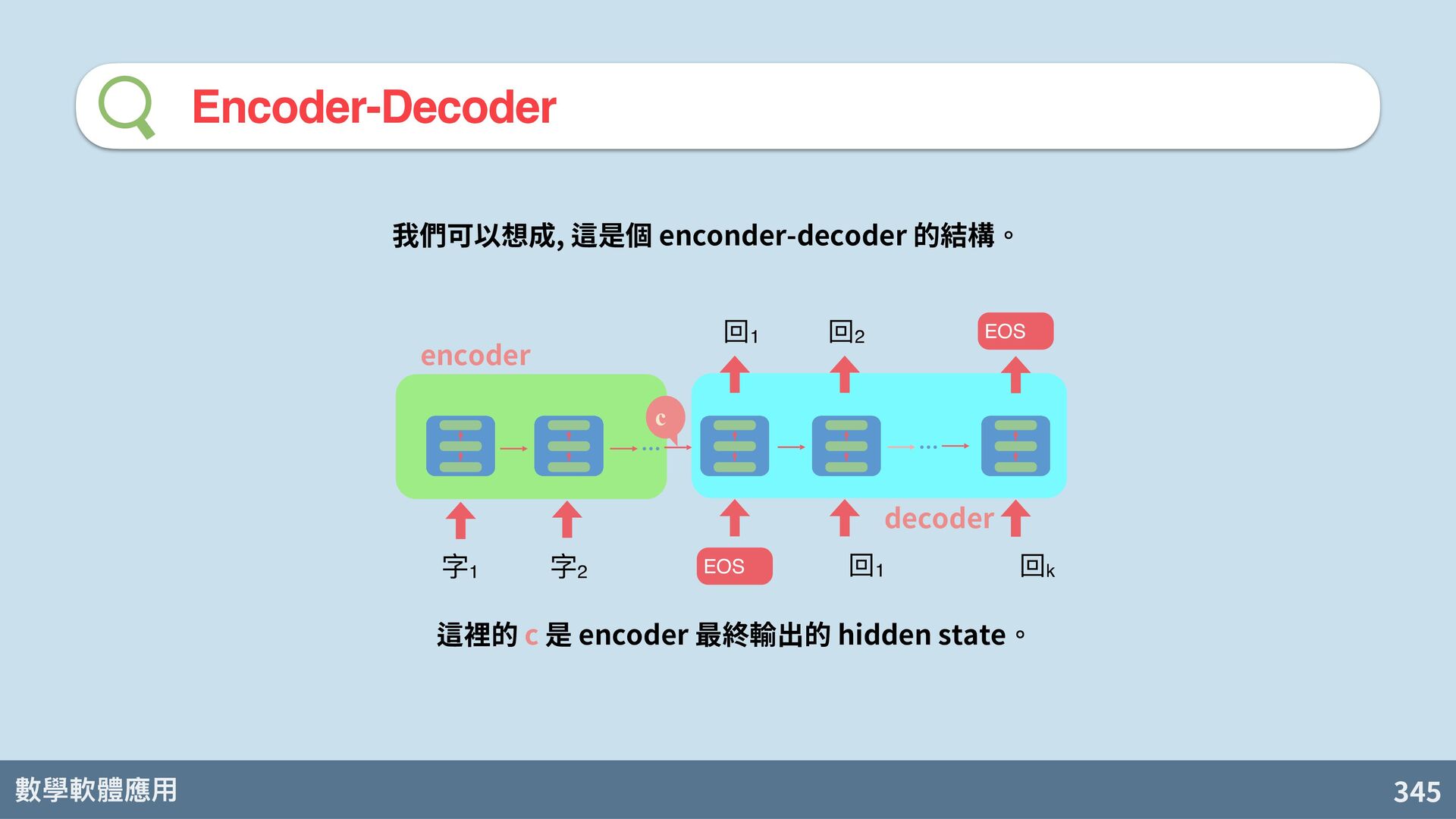
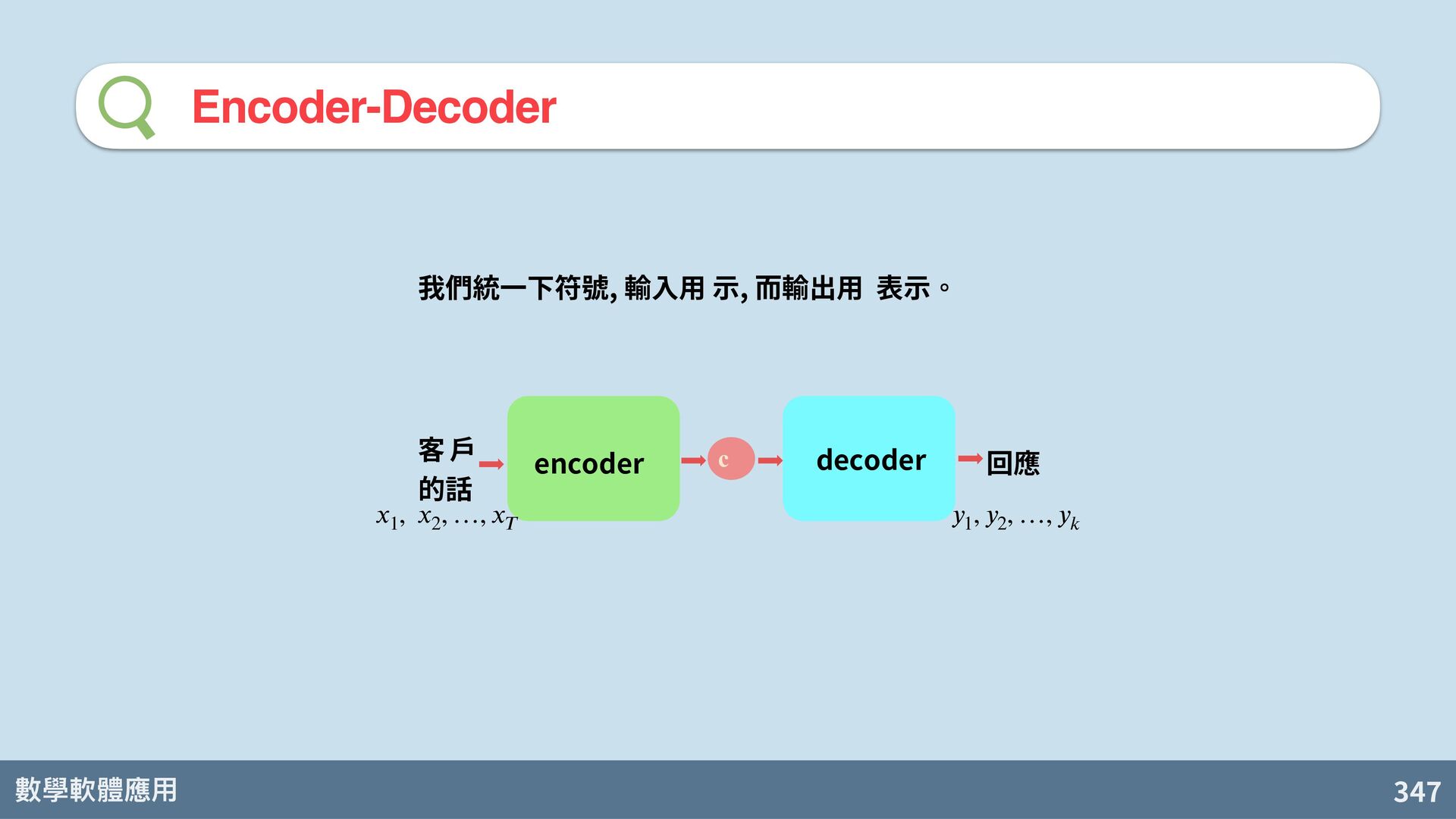
回1 回2 回k EOS Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112). 還記得我們對話機器 人 seq2seq model? c
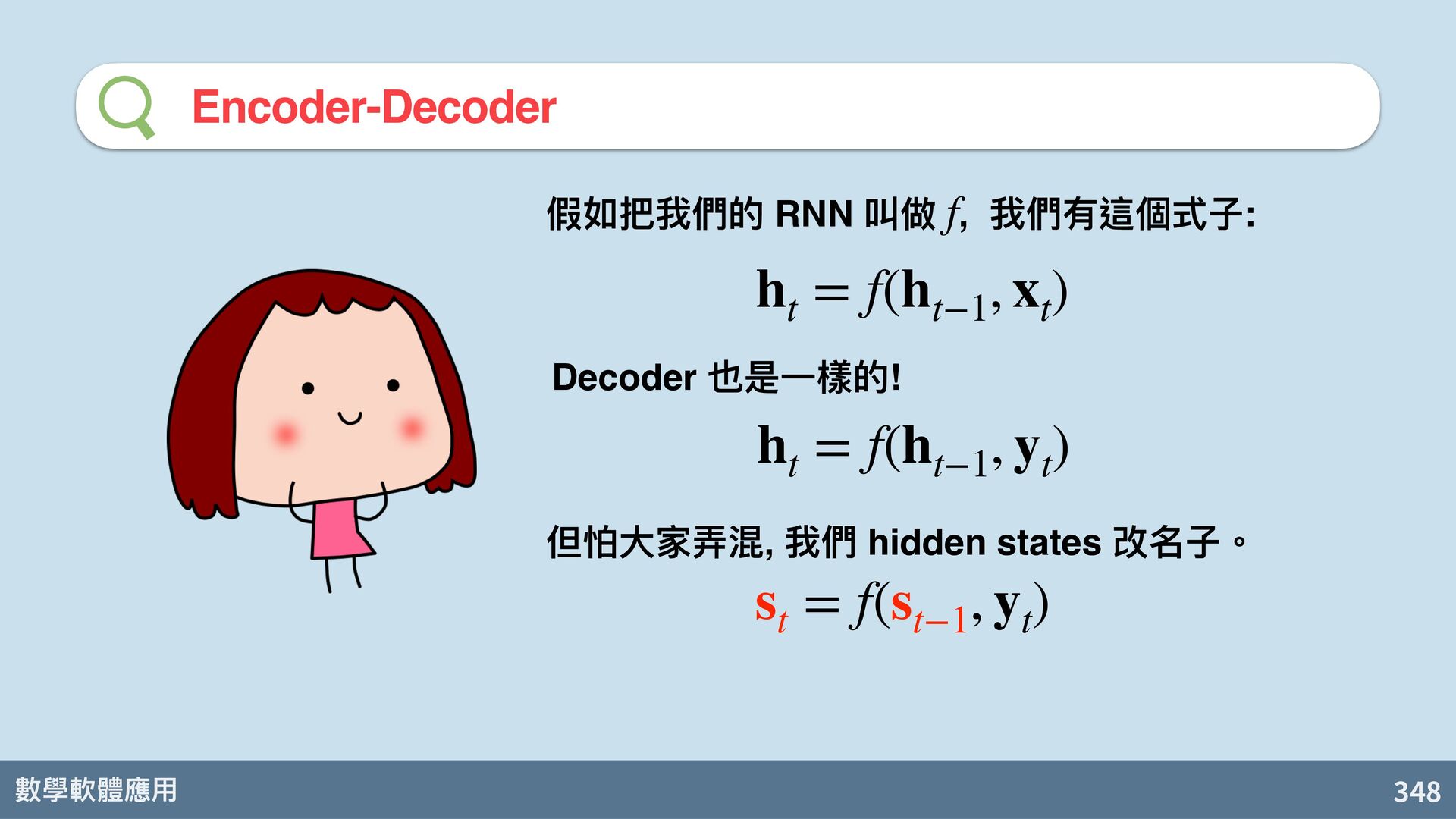
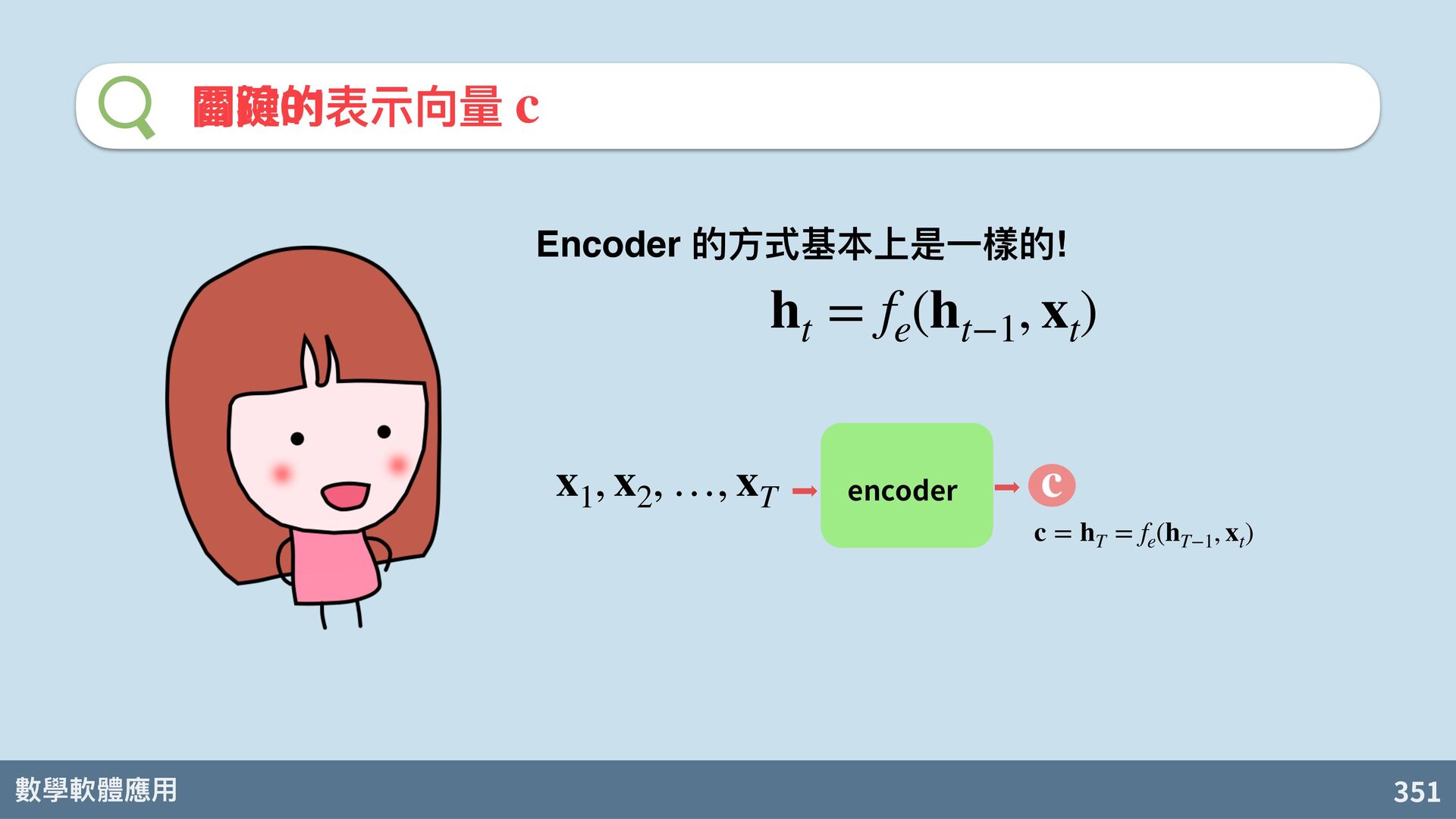
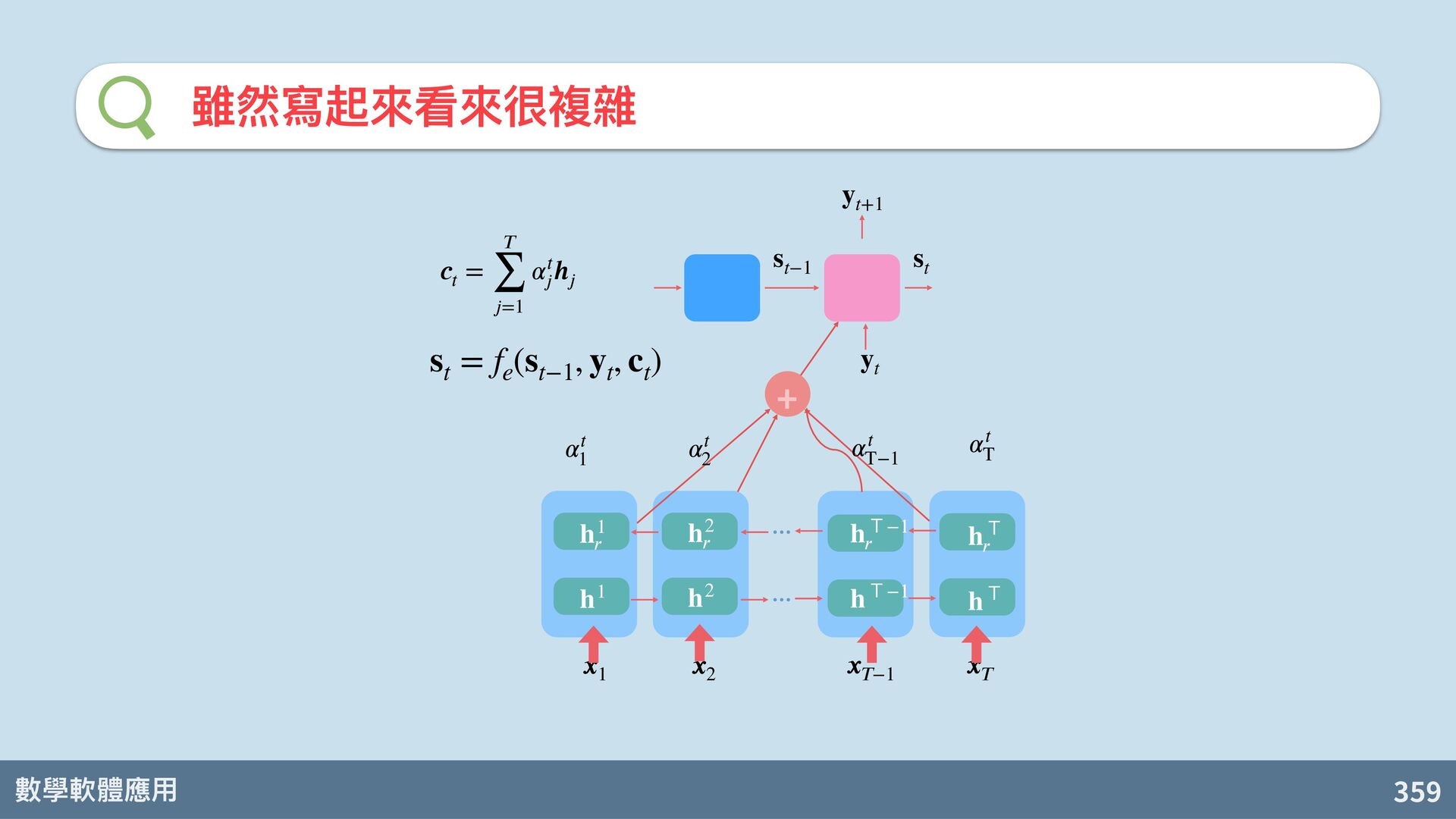
Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv:1406.1078, 2014. s t = f d (s t−1 , y t , c) 關鍵的表⽰向 c
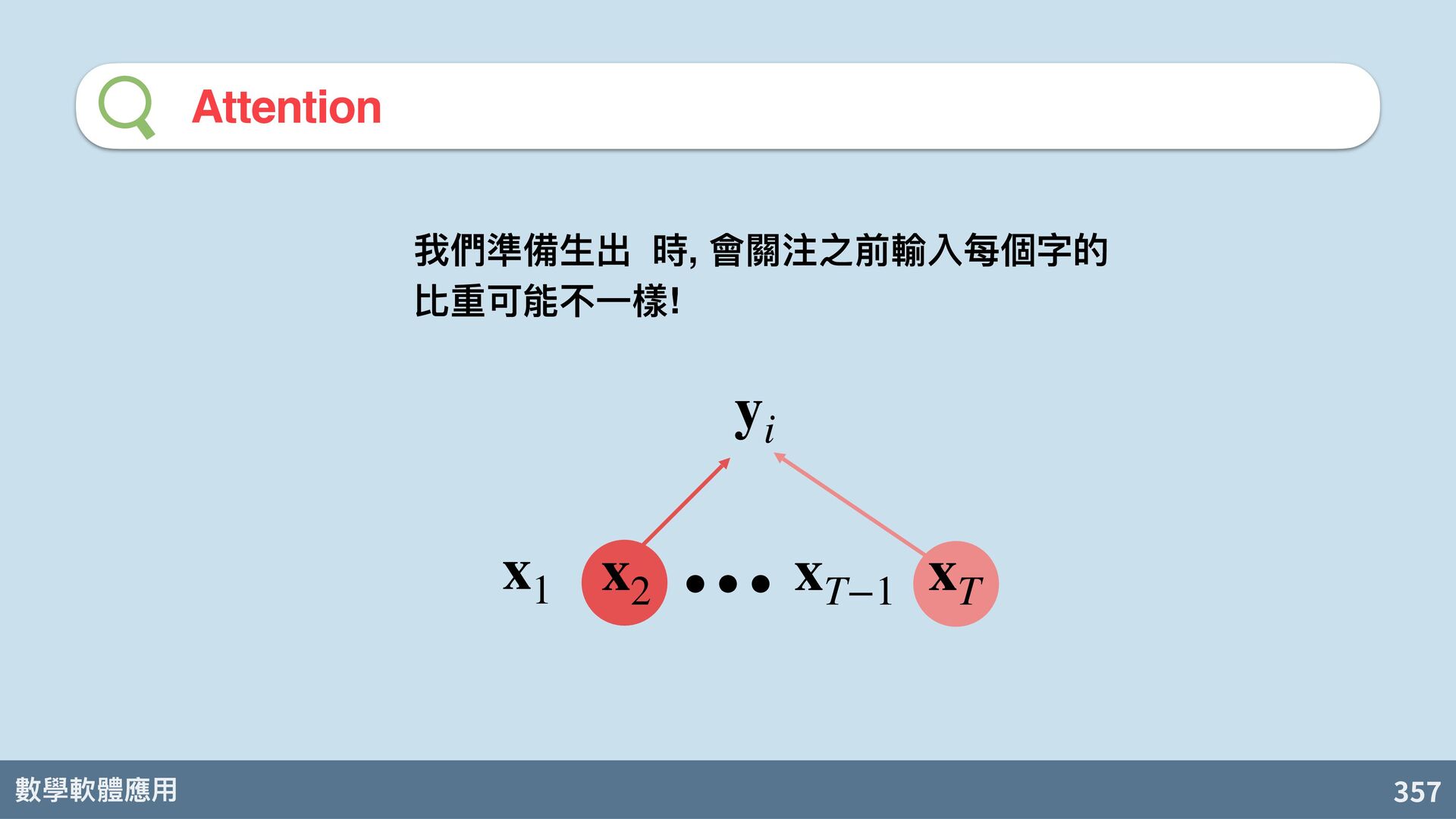
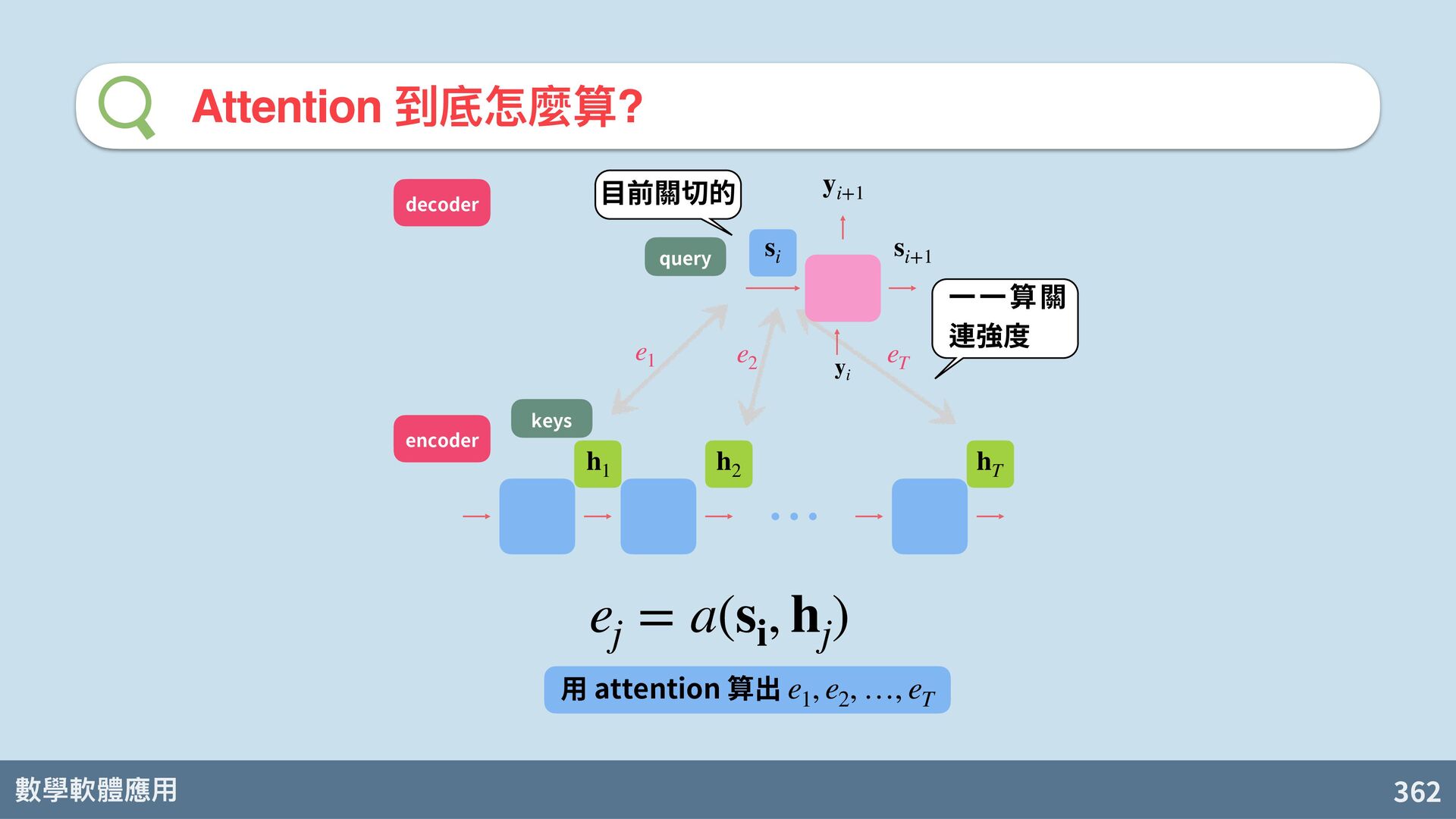
也可以參考所有輸入時的 hidden states 算出來! D. Bahdanau, K. Cho, Y. Bengi. Neural machine translation by jointly learning to align and translate. arXiv:1409.0473. 2014. s t = f d (s t−1 , y t , c) c = q(h1, h2, …, hT) 關鍵的表⽰向 c
Attention 嗎? A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NIPS), 2017. 帶起 transformer 風潮的 FAttention is All You NeedM
有點道理, 但像 Visual Transformer (ViT) 在 ICLR 2021 才發表 (雖然不是唯 ⼀類似⼯作)。 A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit and Neil Houlsby (Google). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations (ICLR), 2021. arXiv: 2010.11929.
Kolesnikov, L. Beyer, X. Zhai, T. Unterthiner, J. Yung, D. Keysers, J. Uszkoreit, M. Lucic and A. Dosovitskiy (Google). MLP-Mixer: An all-MLP Architecture for Vision. arXiv: 2105.01601. 2021/05/04 放上 arXiv! 不⽤ CNN, 不⽤ transformer, 我們來處理圖形! Yann LeCun 說, 並不 是真的沒有⽤到 CNN...
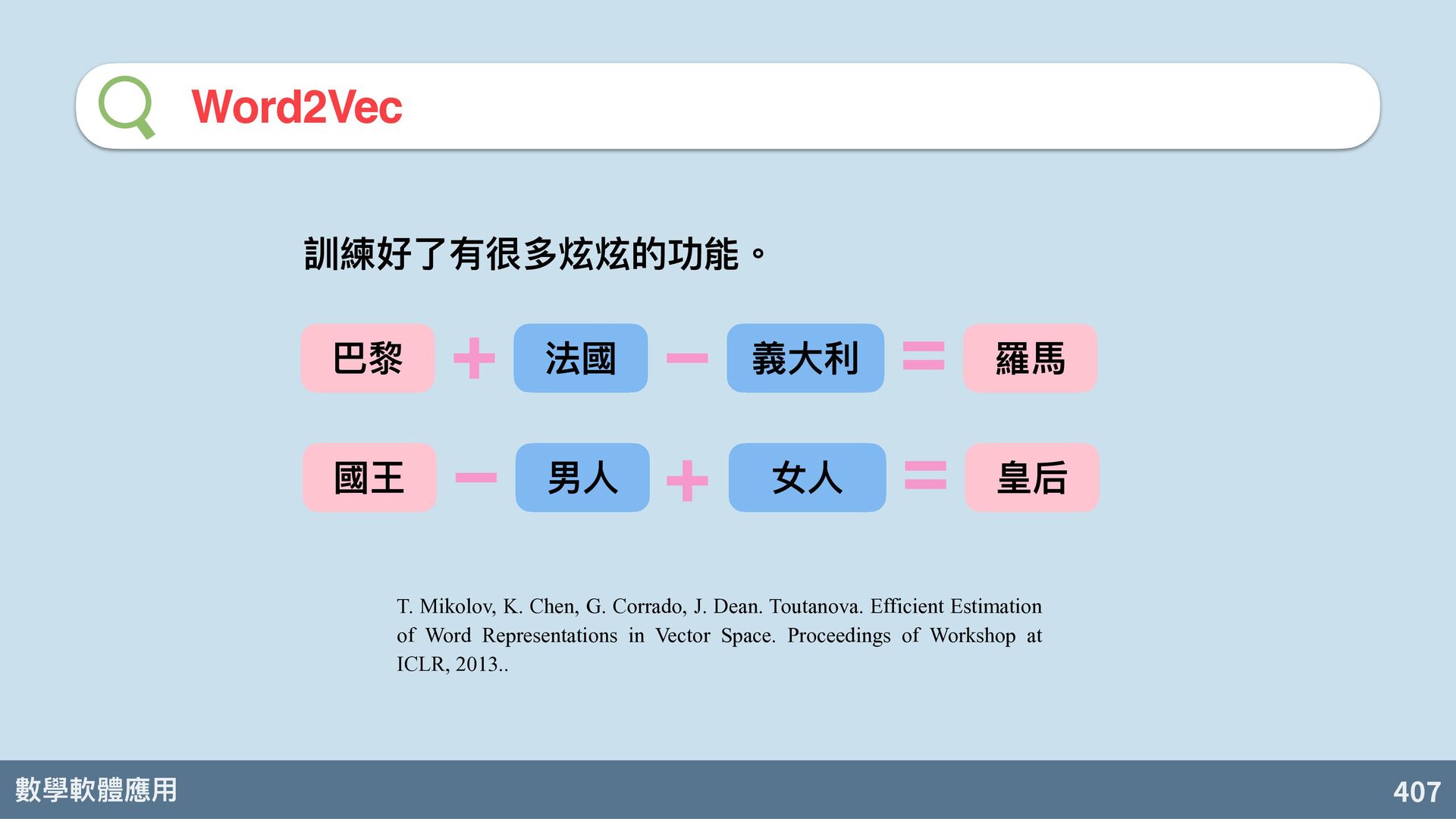
Dean. Toutanova. Efficient Estimation of Word Representations in Vector Space. Proceedings of Workshop at ICLR, 2013.. 訓練好了有很多炫炫的功能。 巴黎 法國 義⼤利 羅⾺ 國王 男⼈ 女⼈ 皇后
J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (pp. 5998-6008). 運⽤ self-attention, 避開 RNN 的缺點!
再帶起 Transformer 風潮, 甚⾄ ELMo 都出現... M. E. Peters, M. Neumann, L. Zettlemoyer, W.-T. Yih. Dissecting Contextual Word Embeddings: Architecture and Representation. EMNLP 2018.
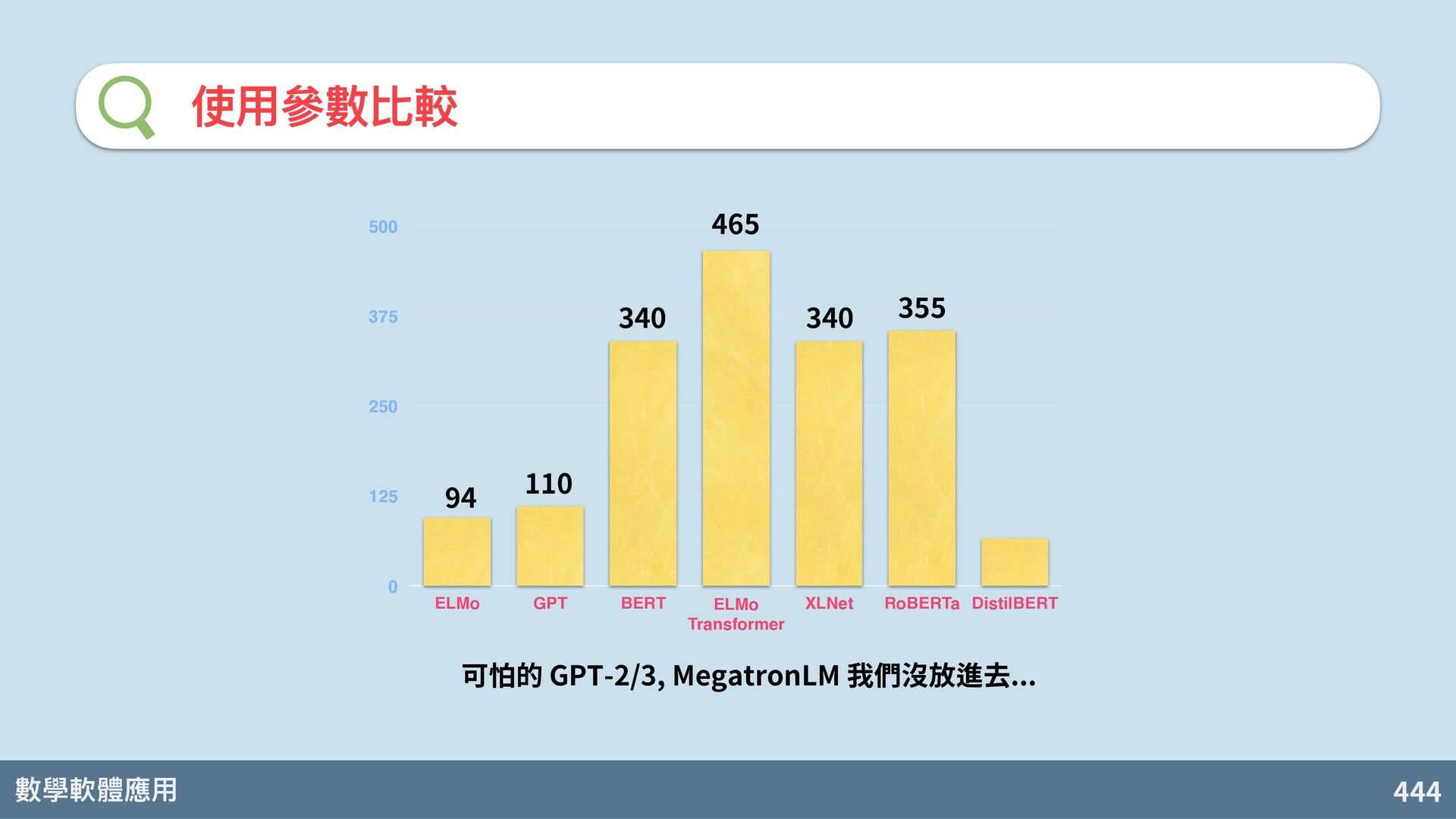
OpenAI 還有改善 BERT 不太會⽣⽂章、(當年) ⼤到可怕的... A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 2019. 1,500* 個 參數 * 單位都是百萬
J. Carbonell, R. Salakhutdinov, Q. V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. NeruIPS 2019. 使⽤ Transformer XL 使⽤ permutation 訓練法
A. Patwary, P. Puri, P. LeGresley, J. Casper, B. Catanzaro, Megatron-LM: Training Multi-Billion Parameter Language Models Using GPU Model Parallelism. arXiv:1909.08053 2019.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![數學軟體應⽤ 401 但基本上我們無法準備訓練資料! 除非是這麼明顯的例⼦... f 輸出 輸入 [ 94 87]](https://files.speakerdeck.com/presentations/fc3679236a804cbc871bab4c45559fea/slide_89.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
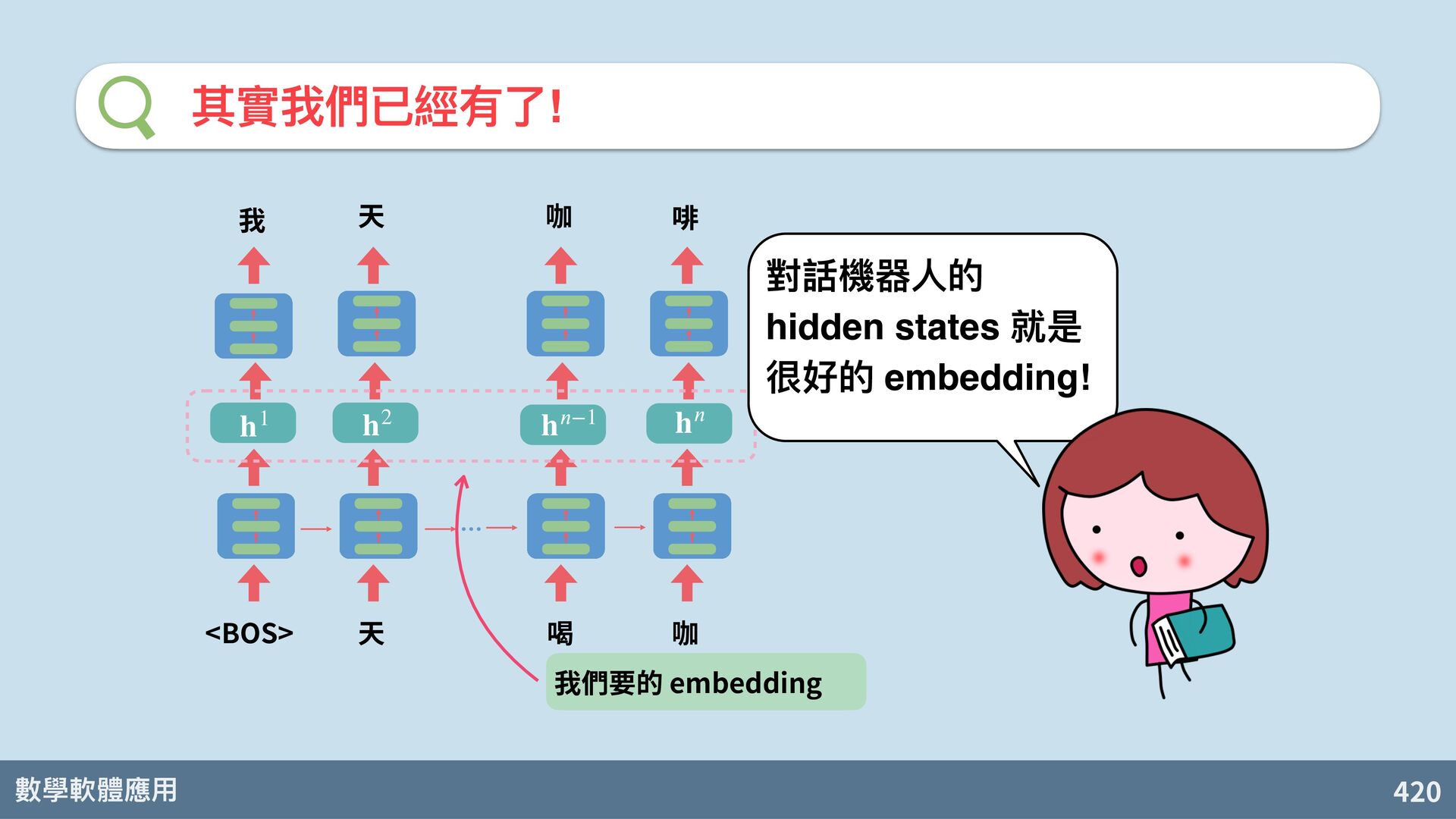{kind=link}
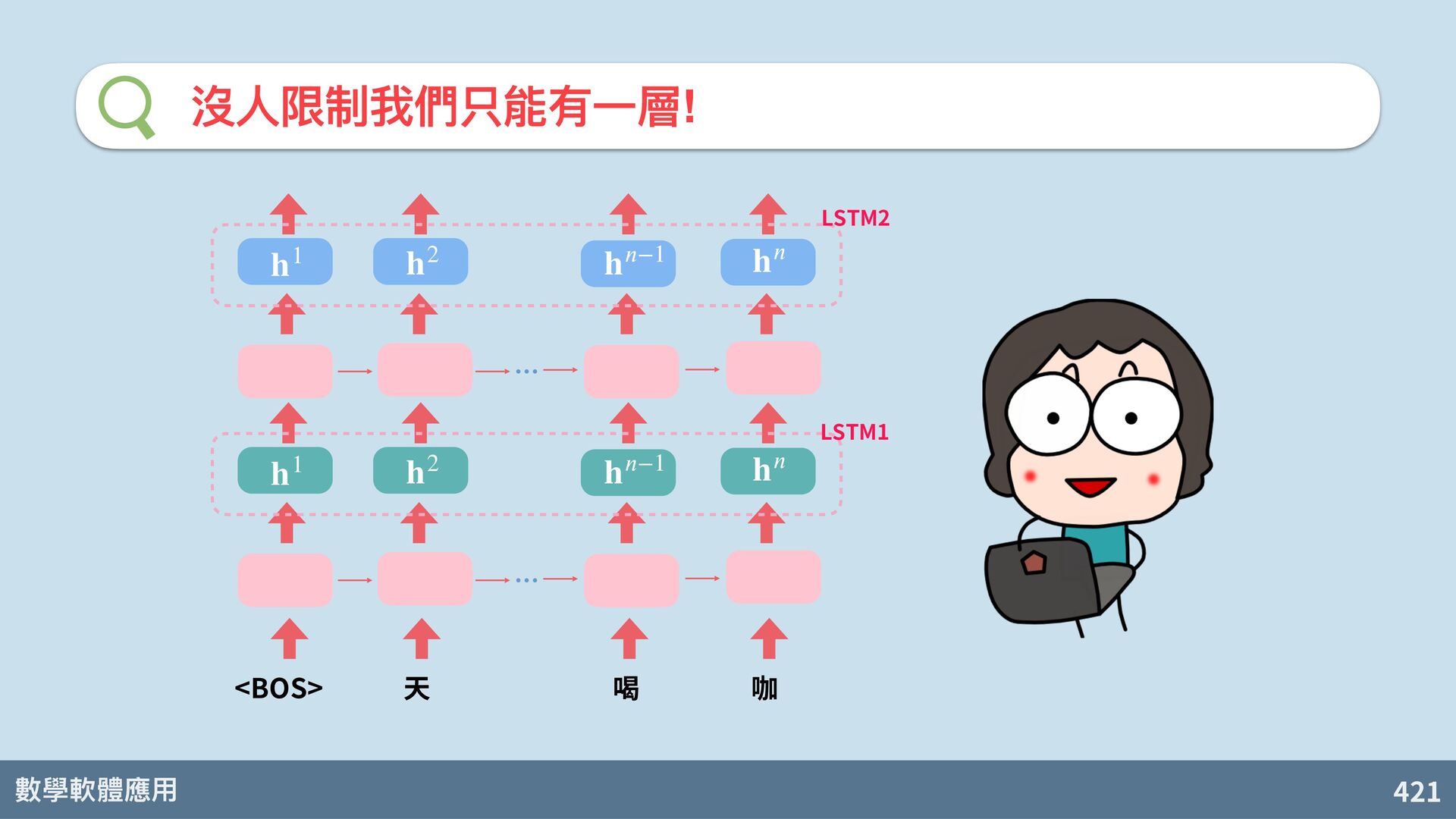{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
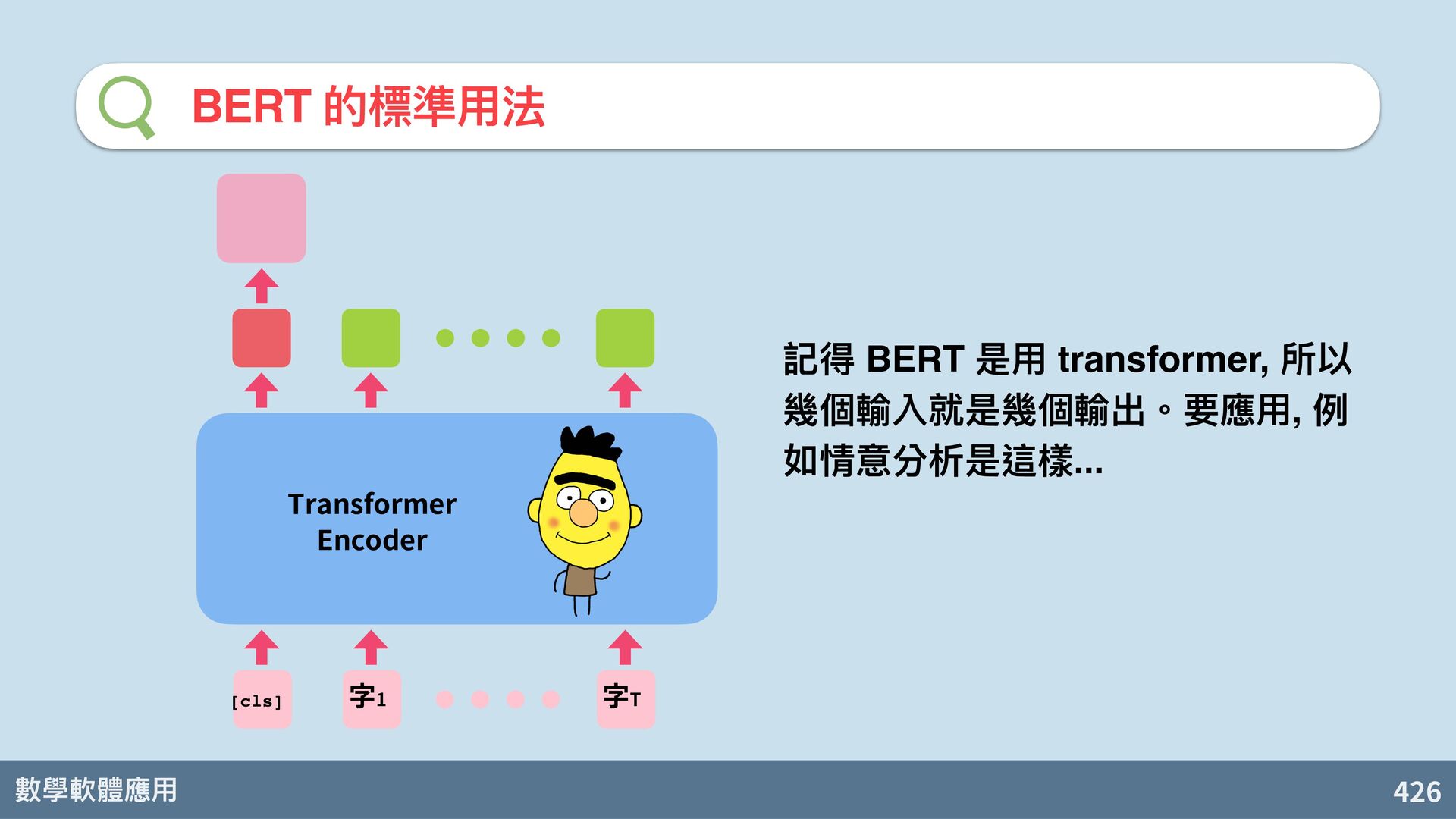{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}