Share
IR Reading 2025 秋 での論文紹介に使用したスライドです. https://sigirtokyo.github.io/post/2025-11-15-irreading_2025fall/
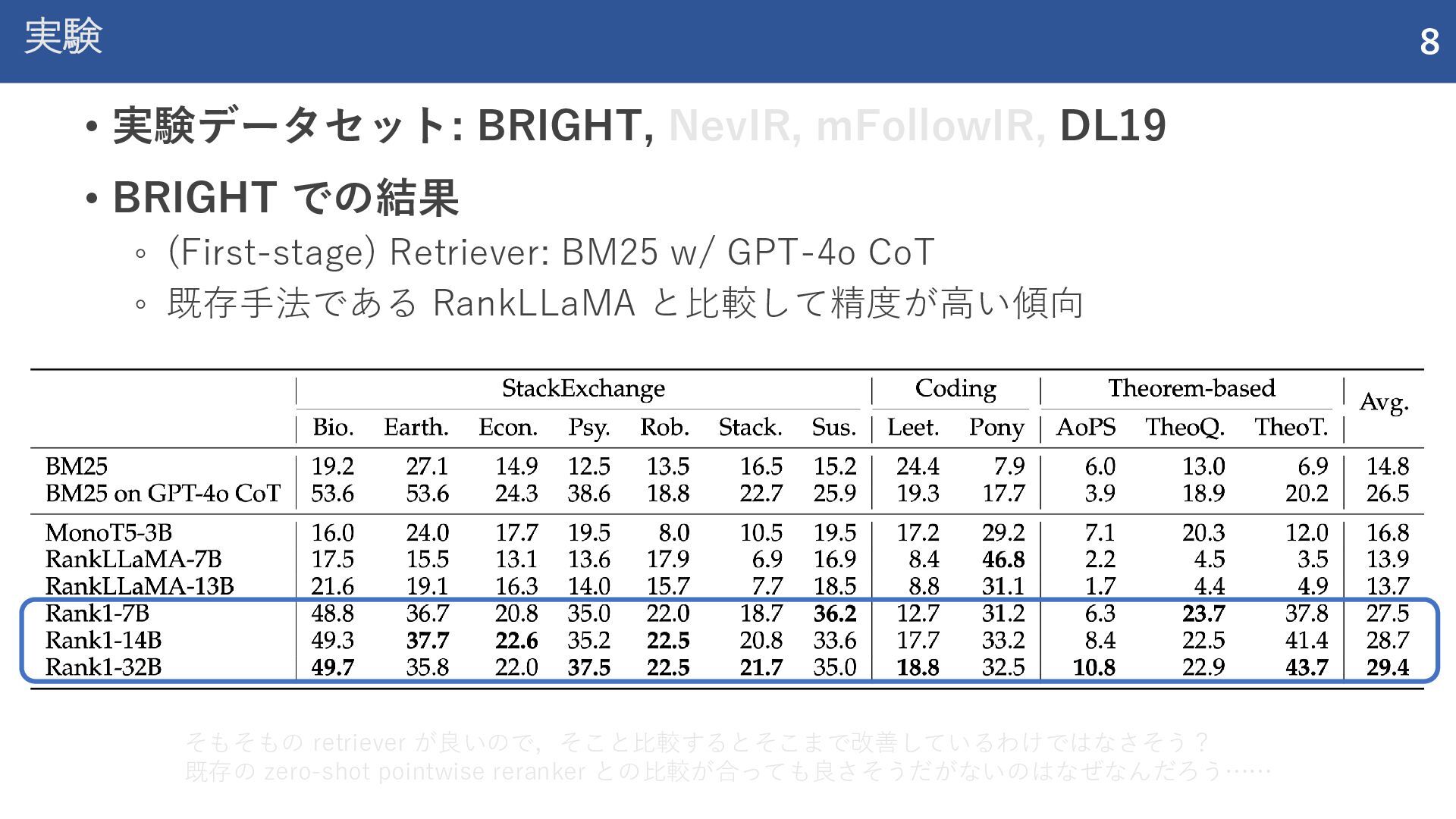
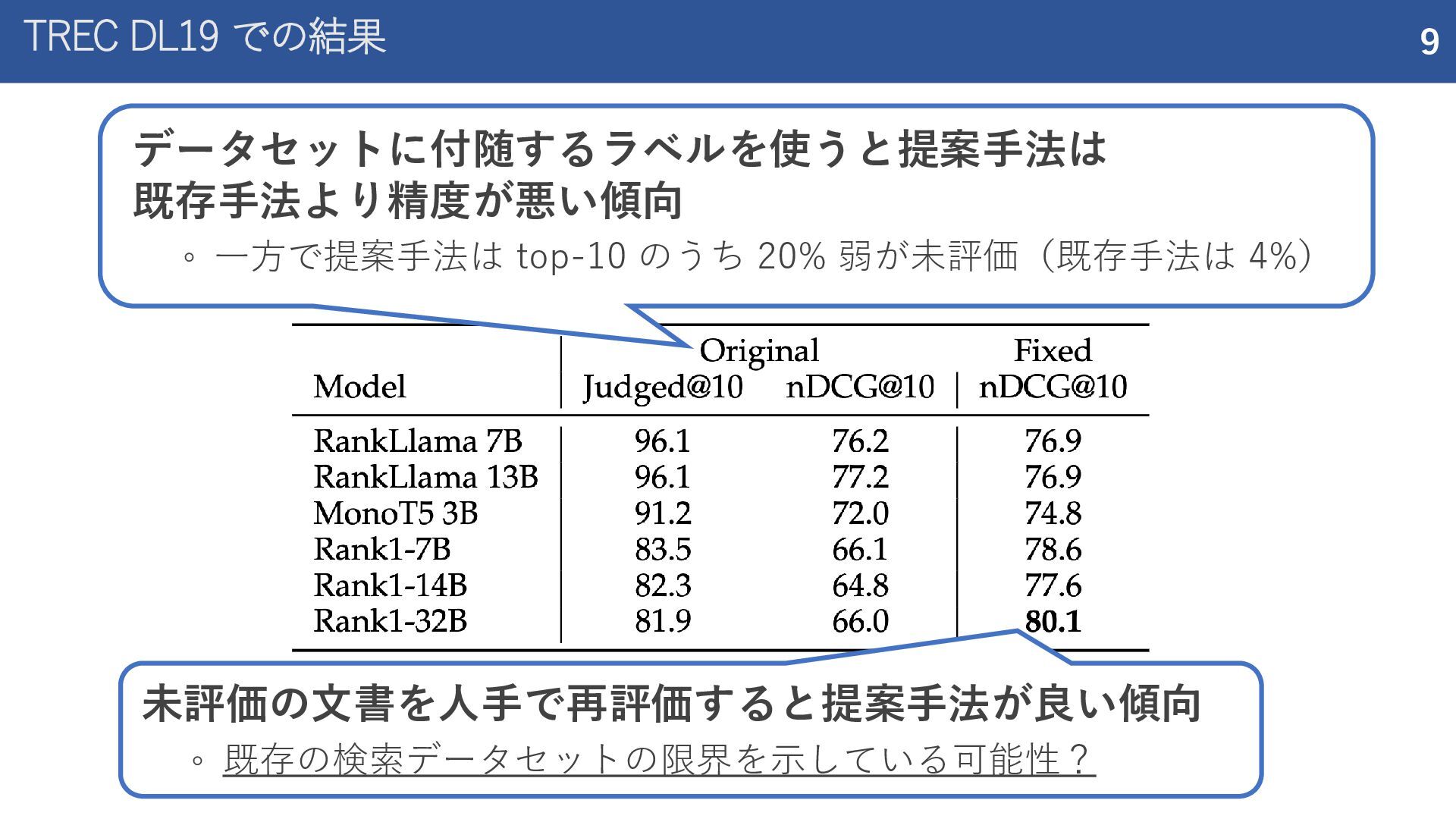
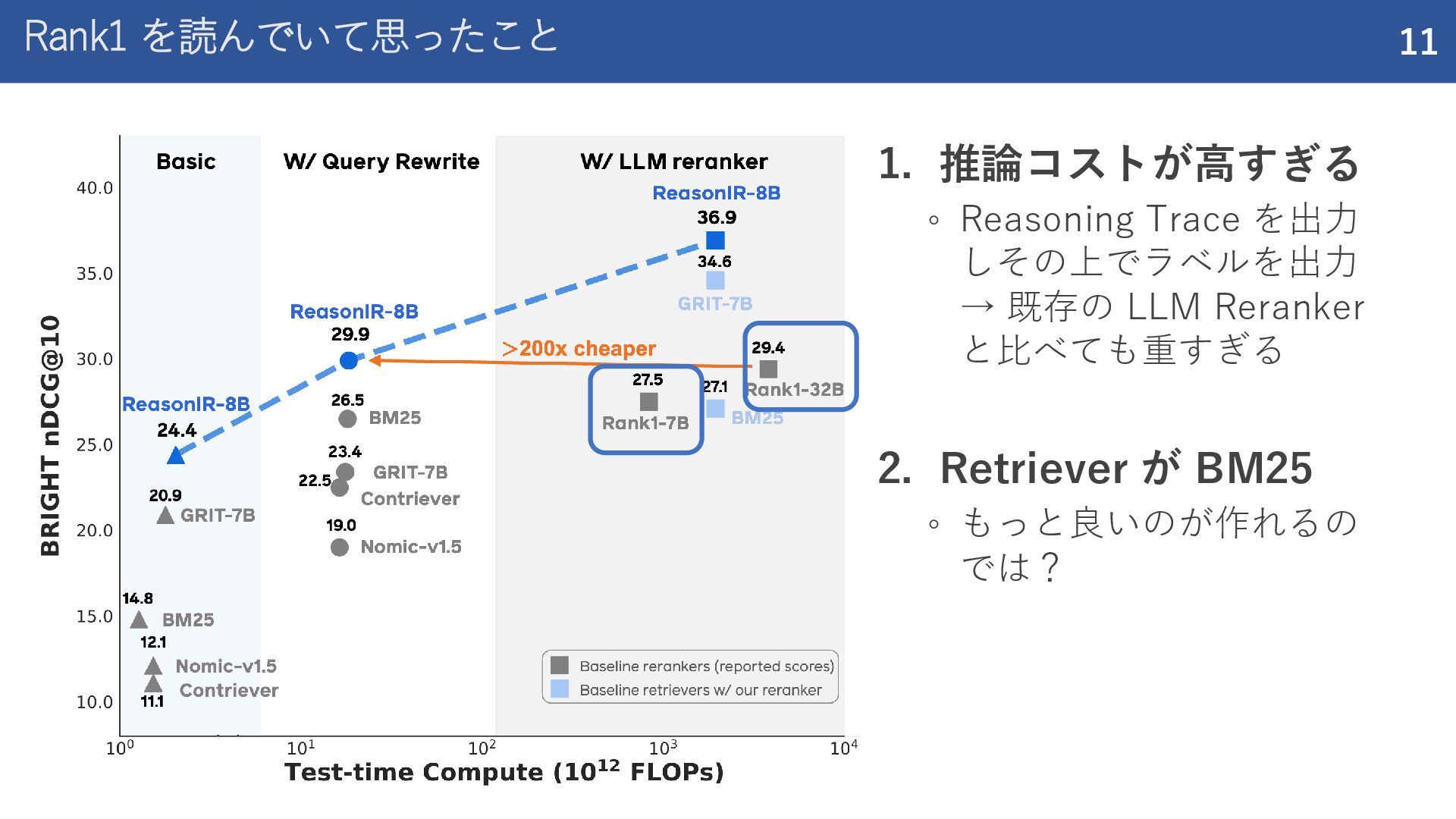
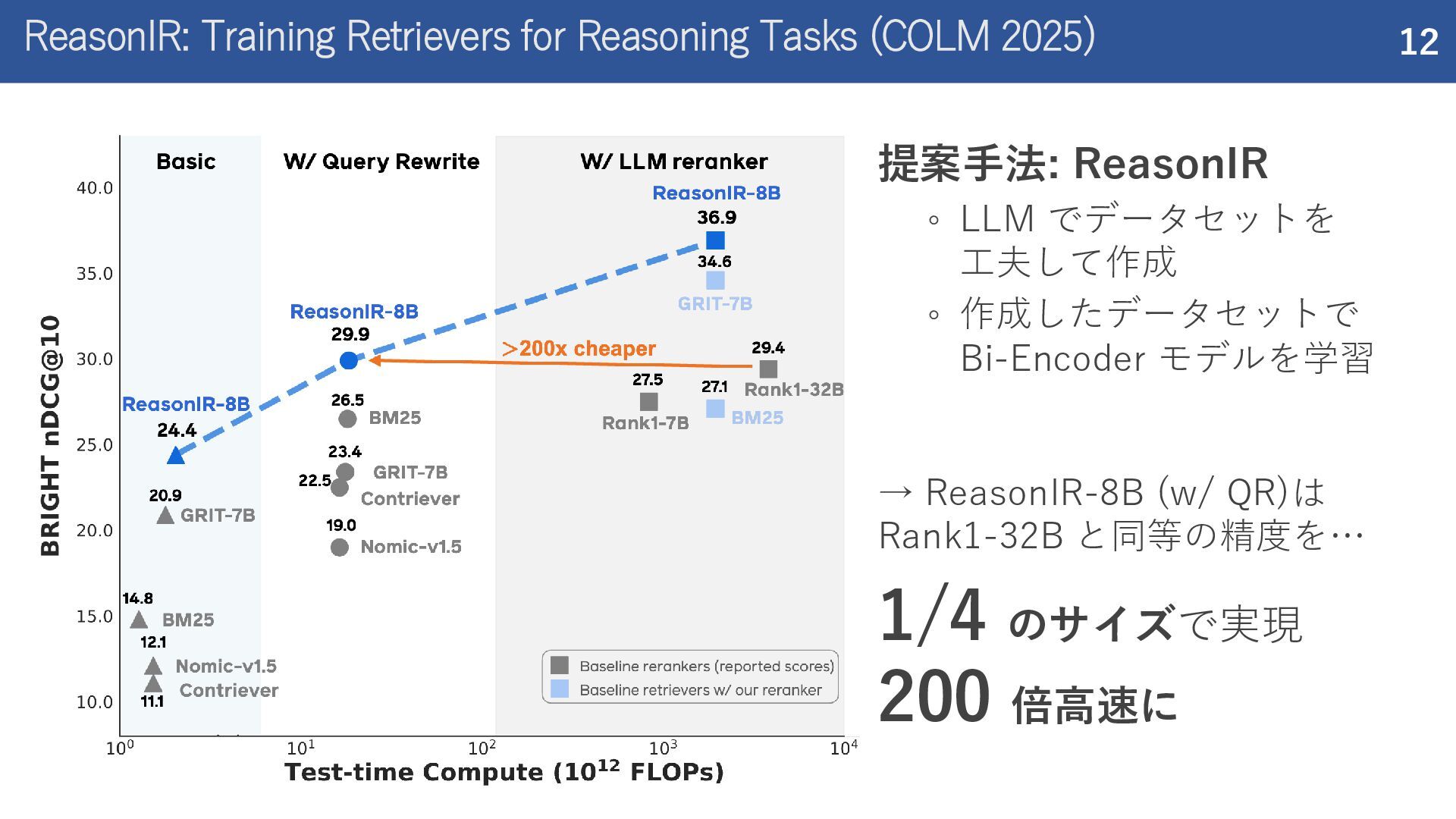
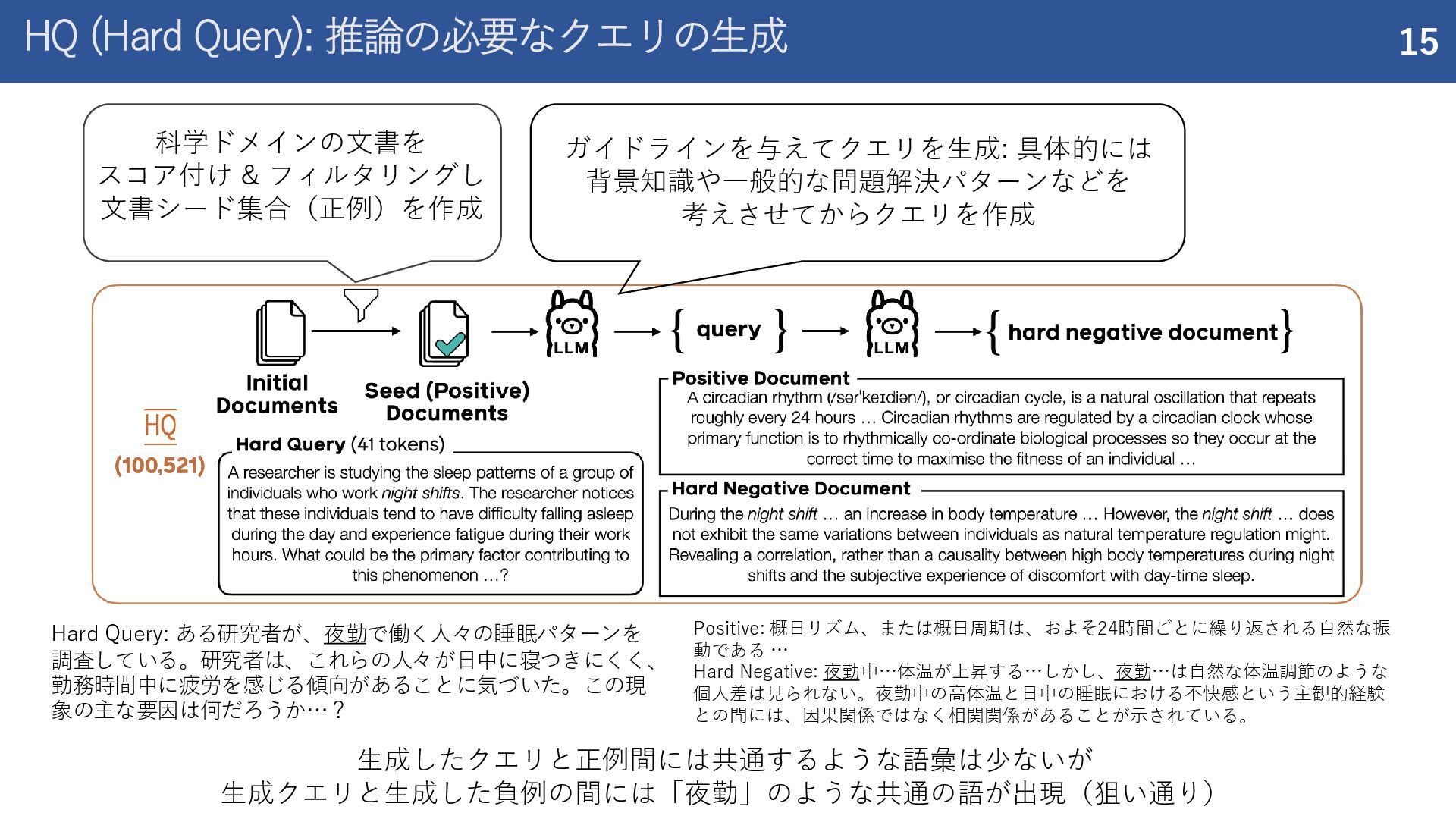
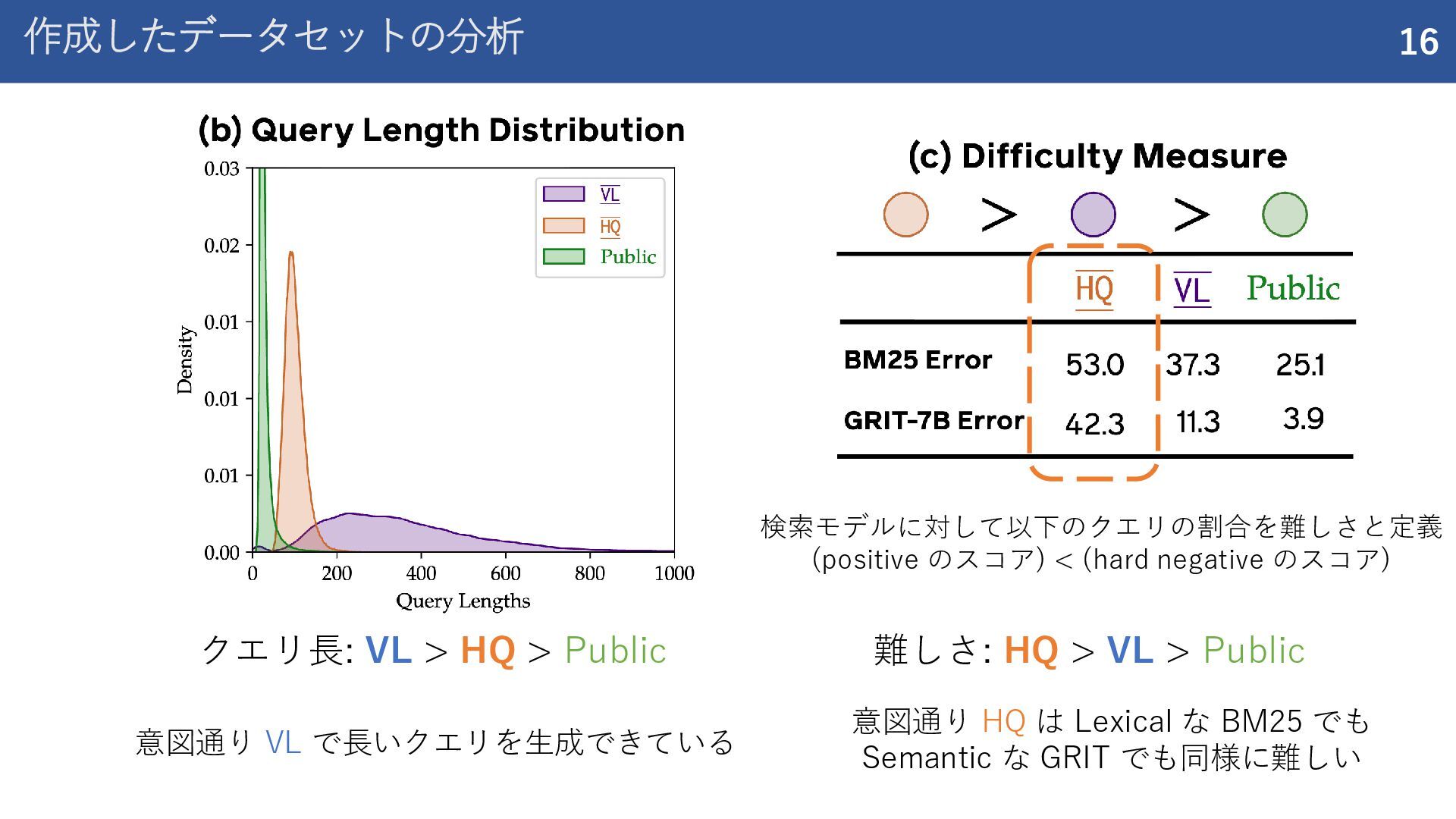
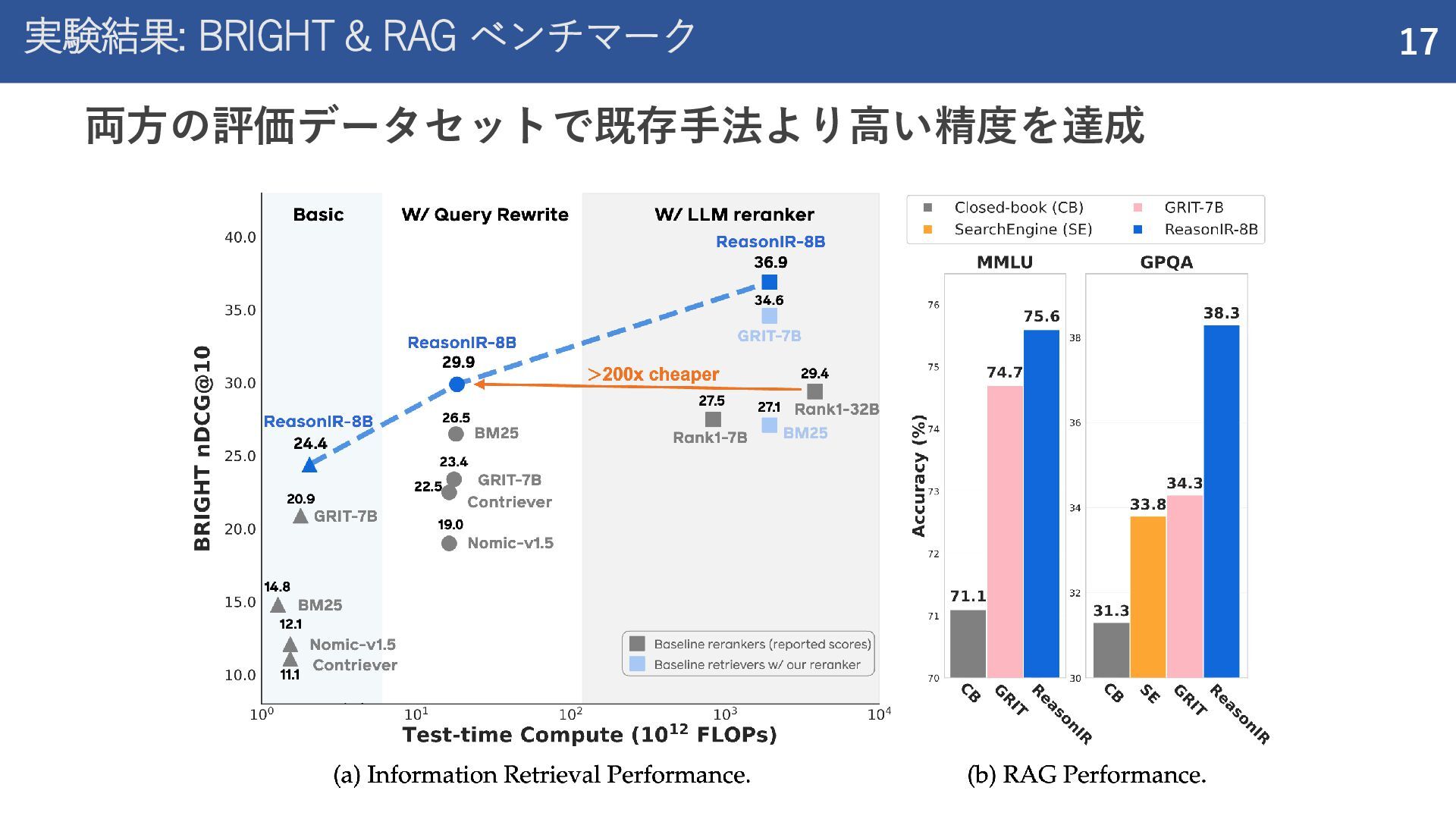
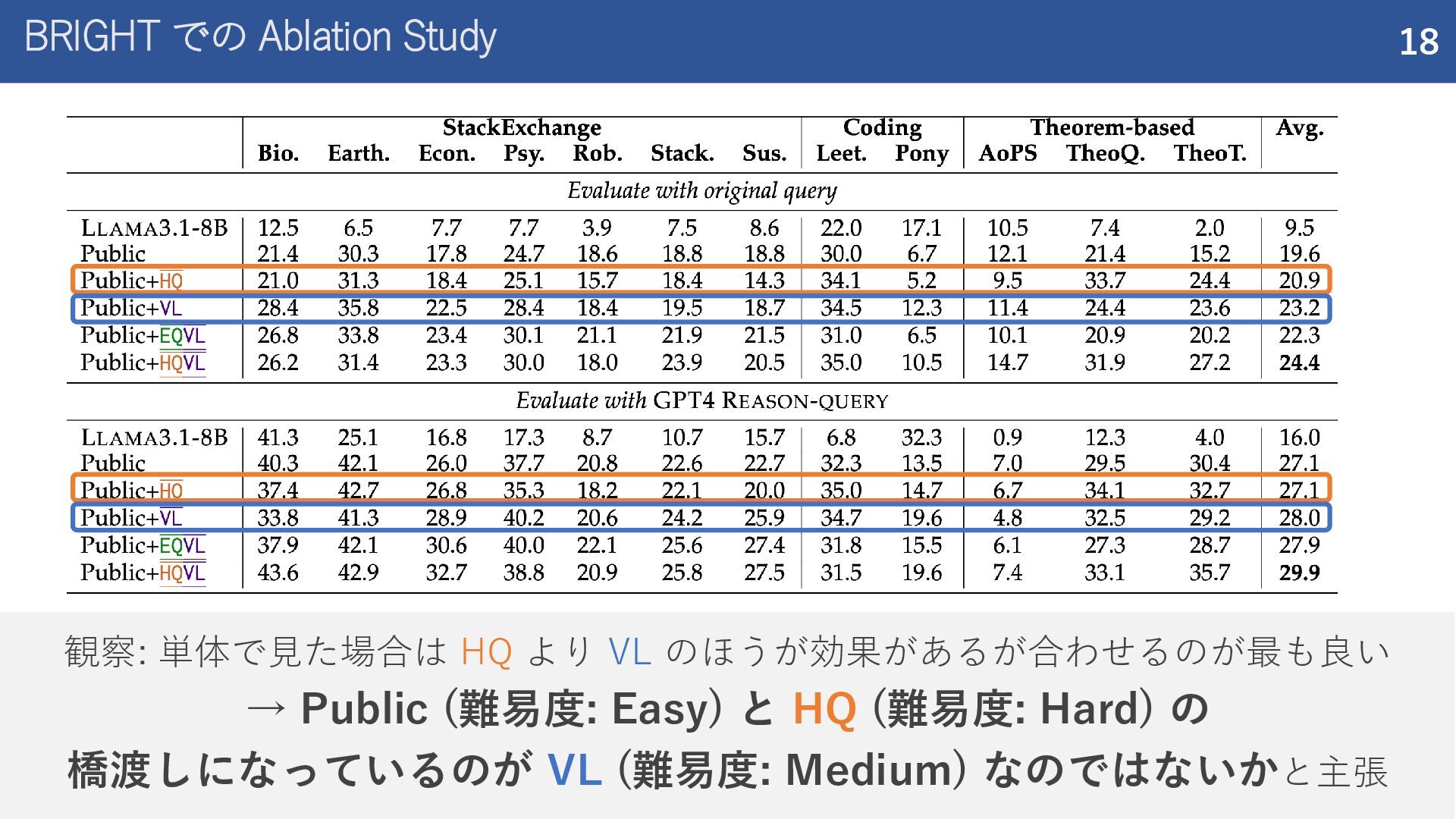
紹介した論文 Rank1: Test-Time Compute for Reranking in Information Retrieval (COLM 2025) ReasonIR: Training Retrievers for Reasoning Tasks (COLM 2025)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}