Financial Question Answering with BERT Language Models
FinBERT-QA is a Question Answering system for retrieving opinionated financial passages from task 2 of the FiQA dataset. The system uses techniques from both information retrieval, natural language processing, and deep learning.
Yuan | August 6, 2020 | Master’s Thesis Final Presentation Examiner: Dr. Wei-Kleiner Second Examiner: Prof. Dr. Josif Grabocka Chair of Databases and Information Systems Department of Computer Science Faculty of Engineering Albert-Ludwigs-University Freiburg
Non-factoid: – Retrieves and selects the most relevant passages 3 Types of QA https://rajpurkar.github.io/mlx/qa-and-squad/er Macedo Maia et al. “WWW’18 Open Challenge: Financial Opinion Mining and Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1941–1942. doi: 10.1145/3184558.3192301. Introduction & Motivation | BERT | Approach | Results | Future Work
and a set of candidate answers, {a 1 , …, a n } – Search for a ranked list of the top-k best candidate answers a 1 , …, a k 4 Introduction & Motivation | BERT | Approach | Results | Future Work
• Problems: – Data Scarcity – Financial Language Specificity • e.g. “There is an increase in the short sells of a company” – Shallow Pre-trained Static Word Embeddings • e.g. word2vec, GloVe 5 Motivation John M. Boyer. “Natural language question answering in the financial domain”. In: Proceedings of the 28th Annual International Conference on Computer Science and Software Engineering, CASCON 2018, Markham, Ontario, Canada, October 29-31, 2018. Ed. by Iosif-Viorel Onut et al. ACM, 2018, pp. 189–200. url: https: //dl.acm.org/citation.cfm?id=3291311. Nam Khanh Tran and Claudia Niederée. “A Neural Network-based Framework for Non-factoid Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1979–1983. doi: 10. 1145/3184558.3191830. Introduction & Motivation | BERT | Approach | Results | Future Work
– Each word embedding is a function of the entire input sentence – Different embeddings for the same word in different context – Accurate feature representation better performance → – Deep representations – Output: pre-trained vectors and models 7 Motivation https://nlp.stanford.edu/seminar/details/jdevlin.pdf Introduction & Motivation | BERT | Approach | Results | Future Work
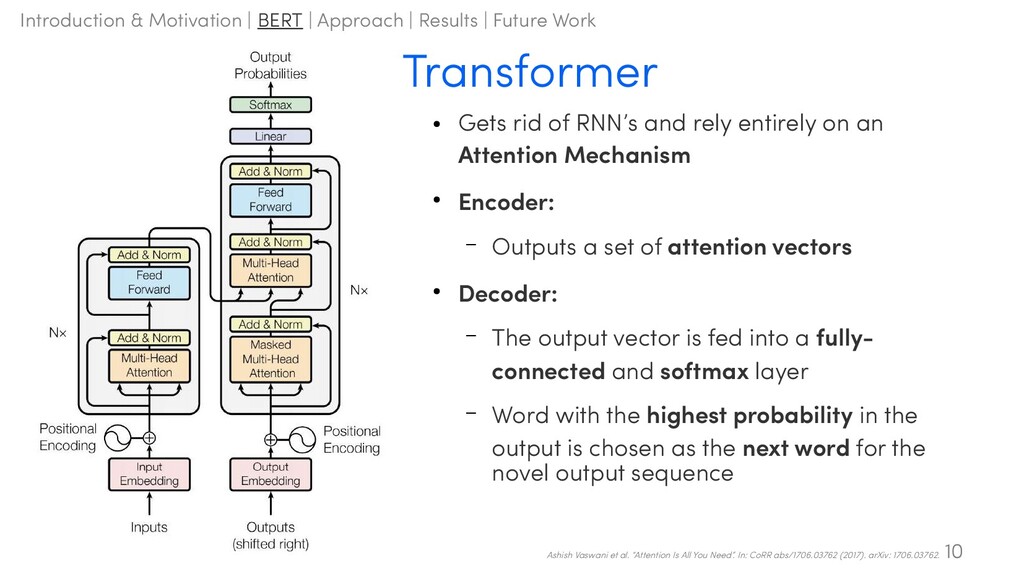
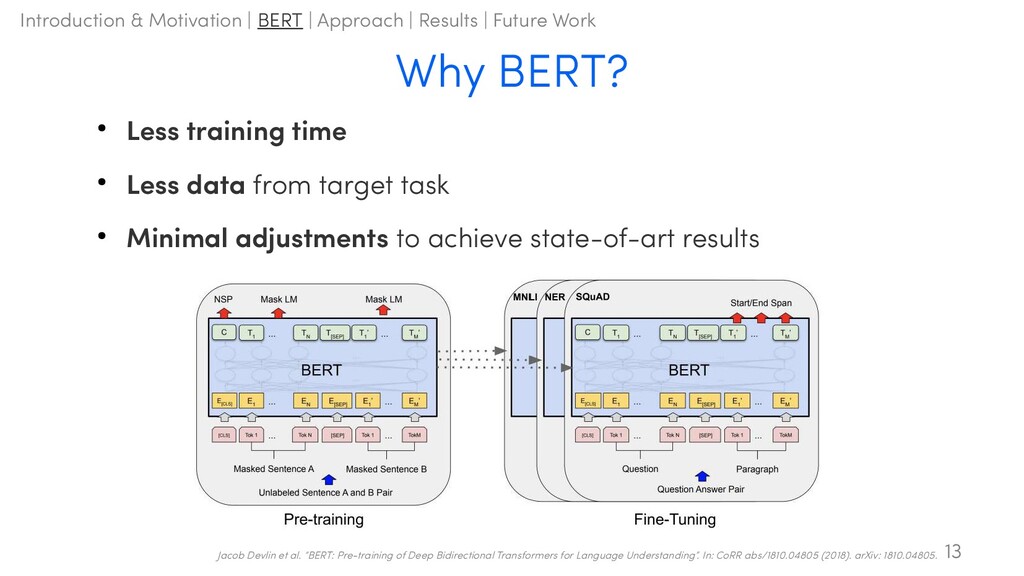
QA! – BERT: Bidirectional Encoder Representations from Transformers [Devlin et al., 2018], Google • Transformer-based architecture 8 Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. In: CoRR abs/1810.04805 (2018). arXiv: 1810.04805. Motivation Introduction & Motivation | BERT | Approach | Results | Future Work
an Attention Mechanism • Encoder: – Outputs a set of attention vectors • Decoder: – The output vector is fed into a fully- connected and softmax layer – Word with the highest probability in the output is chosen as the next word for the novel output sequence 10 Ashish Vaswani et al. “Attention Is All You Need”. In: CoRR abs/1706.03762 (2017). arXiv: 1706.03762. Introduction & Motivation | BERT | Approach | Results | Future Work
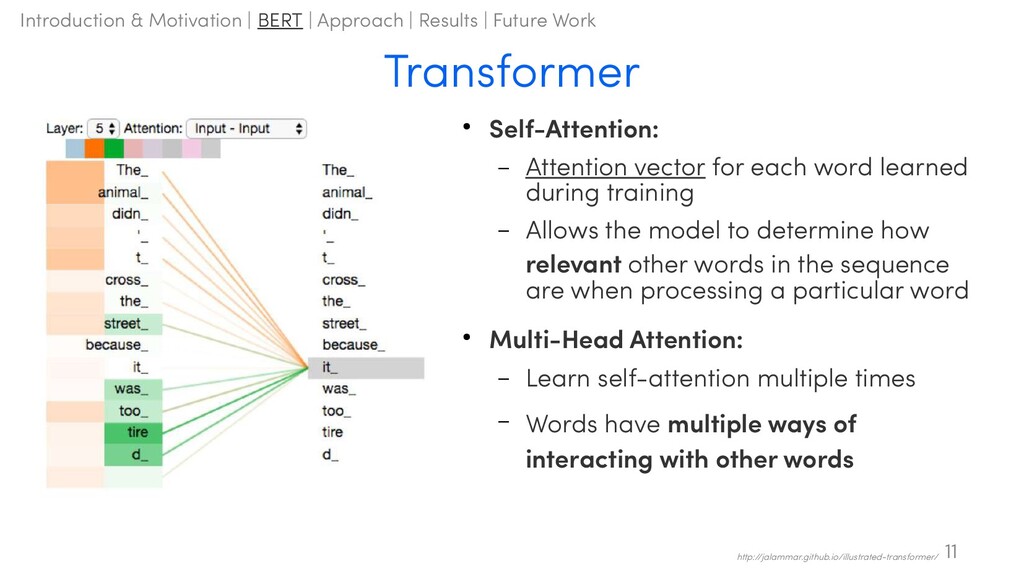
during training – Allows the model to determine how relevant other words in the sequence are when processing a particular word • Multi-Head Attention: – Learn self-attention multiple times – Words have multiple ways of interacting with other words 11 http://jalammar.github.io/illustrated-transformer/ Introduction & Motivation | BERT | Approach | Results | Future Work
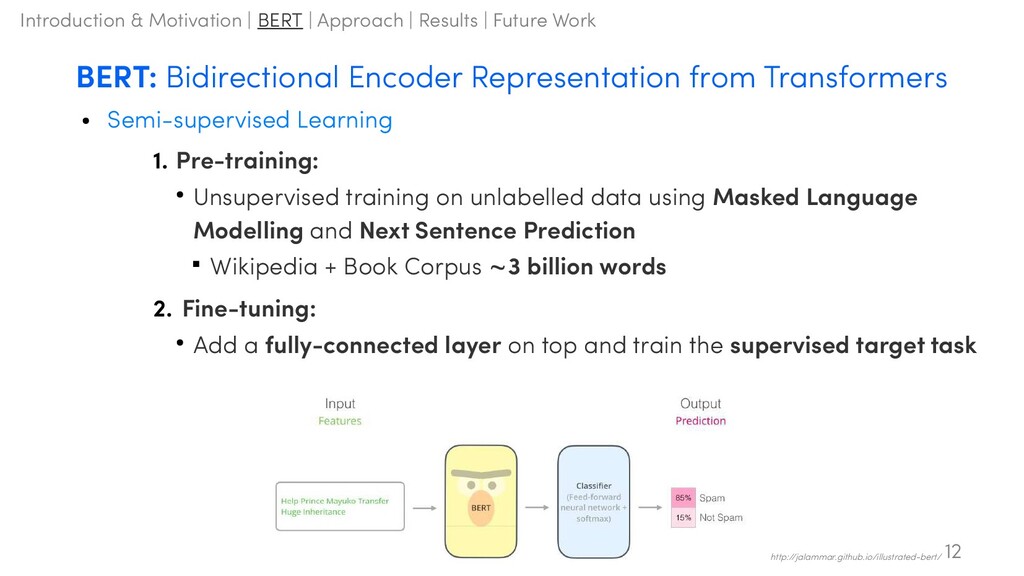
Pre-training: • Unsupervised training on unlabelled data using Masked Language Modelling and Next Sentence Prediction Wikipedia + Book Corpus 3 billion words ~ 2. Fine-tuning: • Add a fully-connected layer on top and train the supervised target task 12 http://jalammar.github.io/illustrated-bert/ Introduction & Motivation | BERT | Approach | Results | Future Work
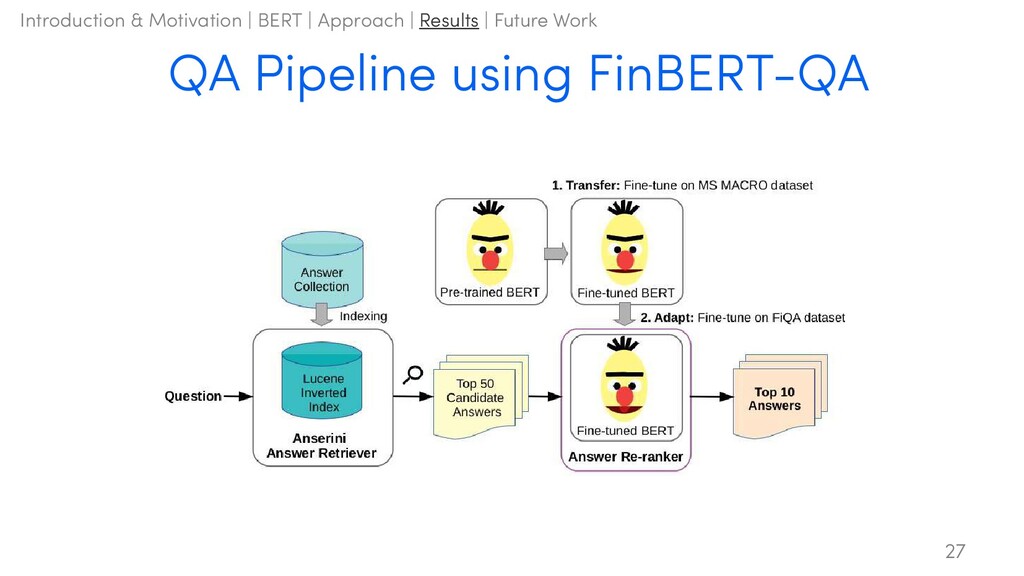
two components: • Answer Retriever: – Return the top 50 candidate answers → Reduce the answer pool size – Anserini’s BM25 implementation • Weighted TF-IDF: Information Retrieval (IR) approach • e.g. “the” occurs with a high frequency TF-IDF score will be low → • Answer Re-ranker: – Re-ranks and outputs the top-k relevant answers – Baseline: BM25, QA-LSTM – Advanced: Variants of BERT using different pre-training and fine-tuning methods • BERT was pre-trained on a general corpus, but financial texts are specific • How might we improve this? 14 Introduction & Motivation | BERT | Approach | Results | Future Work
WWW 2018 Open Challenge – Task 2: Opinion-based Financial QA – Passages from Stackexchange, Reddit, Stocktwits under the Investment topic • After pre-processing: – 6,648 Questions & 57,600 Answers – Generate negative answers from the top 50 candidate answers – Each sample: [question id, [ground truth answer ids], [negative answer ids]] 15 Macedo Maia et al. “WWW’18 Open Challenge: Financial Opinion Mining and Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1941–1942. doi: 10.1145/3184558.3192301. Introduction & Motivation | BERT | Approach | Results | Future Work
and Answer representations are learned independently using a shared biLSTM – Max Pooling to create a single vector representation – Cosine Similarity to measure the distance 16 Ming Tan, Bing Xiang, and Bowen Zhou. “LSTM-based Deep Learning Models for non-factoid answer selection”. In: CoRR abs/1511.04108 (2015). arXiv: 1511. 04108. Introduction & Motivation | BERT | Approach | Results | Future Work
2019]’s Passage Re-ranking with BERT 1. Use BERT BASE as initialization for the parameters 2. Transform the QA task into a binary classification task • Input is a concatenation of the question and answer separated by the [SEP] token 3. Use the [CLS] vector as the input into a fully-connected layer • [CLS] encodes the entire input sequence aggregate → sentence-level representation • Final hidden state corresponding to this token is used as the sequence representation in classification tasks 4. Apply softmax to the output a relevance probability 17 Rodrigo Nogueira and Kyunghyun Cho. “Passage Re-ranking with BERT”. In: CoRR abs/1901.04085 (2019). arXiv: 1901.04085. Introduction & Motivation | BERT | Approach | Results | Future Work
size of 30,000 (learn + update) • Segment Embeddings: Indicate if token belongs to Sentence A or B • Position Embeddings: Information about the order of words (randomly initialized and updated) 18 Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. In: CoRR abs/1810.04805 (2018). arXiv: 1810.04805. Introduction & Motivation | BERT | Approach | Results | Future Work
further pre-trained BERT on Reuters TRC2-Financial (24M words) • Enrich BERT with domain-specific context – Use FinBERT as initialization for fine-tuning • FinBERT-Task: – Further pre-train BERT BASE on the target FiQA dataset before fine-tuning – Enrich BERT with task-specific context 20 Dogu Araci. “FinBERT: Financial Sentiment Analysis with Pre-trained Language Models”. In: CoRR abs/1908.10063 (2019). arXiv: 1908.10063. Introduction & Motivation | BERT | Approach | Results | Future Work
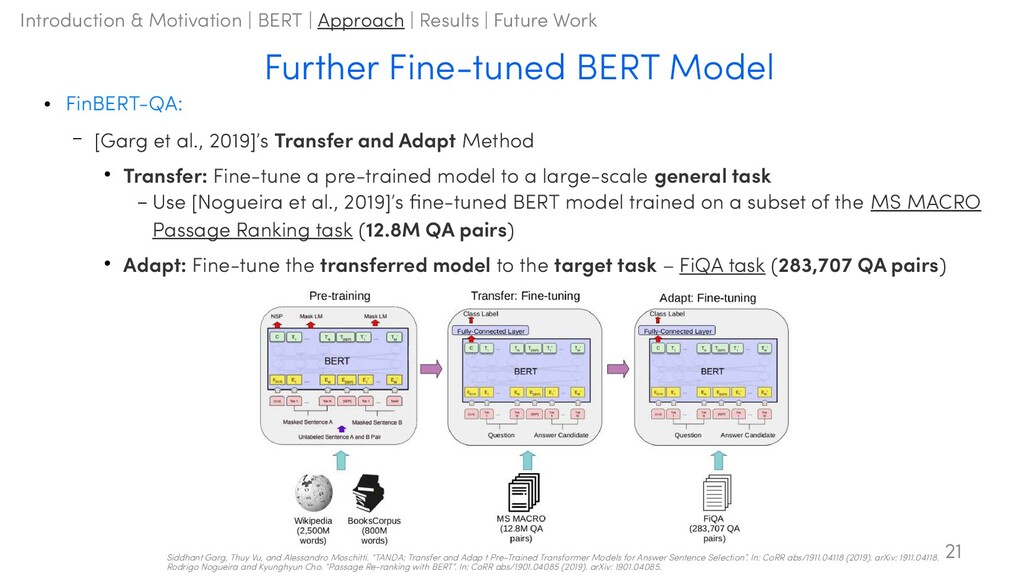
2019]’s Transfer and Adapt Method • Transfer: Fine-tune a pre-trained model to a large-scale general task – Use [Nogueira et al., 2019]’s fine-tuned BERT model trained on a subset of the MS MACRO Passage Ranking task (12.8M QA pairs) • Adapt: Fine-tune the transferred model to the target task – FiQA task (283,707 QA pairs) 21 Siddhant Garg, Thuy Vu, and Alessandro Moschitti. “TANDA: Transfer and Adap t Pre-Trained Transformer Models for Answer Sentence Selection”. In: CoRR abs/1911.04118 (2019). arXiv: 1911.04118. Rodrigo Nogueira and Kyunghyun Cho. “Passage Re-ranking with BERT”. In: CoRR abs/1901.04085 (2019). arXiv: 1901.04085. Introduction & Motivation | BERT | Approach | Results | Future Work
Rank across multiple queries • Normalized Discounted Cumulative Gain (NDCG) – DCG: Penalize relevant docs appearing lower in a result list Reduce relevance value → – IDCG: Ideal maximum possible DCG • Precision@1 – % of relevant retrieved answer passages at the top 1 position Evaluation Metrics 22 https://en.wikipedia.org/wiki/Mean_reciprocal_rank Introduction & Motivation | BERT | Approach | Results | Future Work
BERT? – Pointwise learning approach is only slightly better and more efficient – Pairwise approach needs to compute the relevance scores of both the positive and negative QA pairs Results 23 Introduction & Motivation | BERT | Approach | Results | Future Work
on a large financial-domain corpus and a target-domain financial QA corpus? – FinBERT-Domain has slightly better Precision@1 – Performance of BERT BASE was already good that there was not much room for improvement Results 24 Macedo Maia et al. “WWW’18 Open Challenge: Financial Opinion Mining and Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1941–1942. doi: 10.1145/3184558.3192301. Nam Khanh Tran and Claudia Niederée. “A Neural Network-based Framework for Non-factoid Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1979–1983. doi: 10. 1145/3184558.3191830. Introduction & Motivation | BERT | Approach | Results | Future Work
approach compare with furthered pre-trained BERT models? – FinBERT-QA has the highest MRR and NDCG – MS MACRO corpus (12.8M QA pairs) ~45 times larger than the target FIQA dataset (283,707 QA pairs) – MS MACRO corpus already contained QA’s from the financial domain • e.g. “What is a bank transit number?”, “How much can I contribute to non-deductible ira?” Results 25 Macedo Maia et al. “WWW’18 Open Challenge: Financial Opinion Mining and Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1941–1942. doi: 10.1145/3184558.3192301. Nam Khanh Tran and Claudia Niederée. “A Neural Network-based Framework for Non-factoid Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1979–1983. doi: 10. 1145/3184558.3191830. Introduction & Motivation | BERT | Approach | Results | Future Work
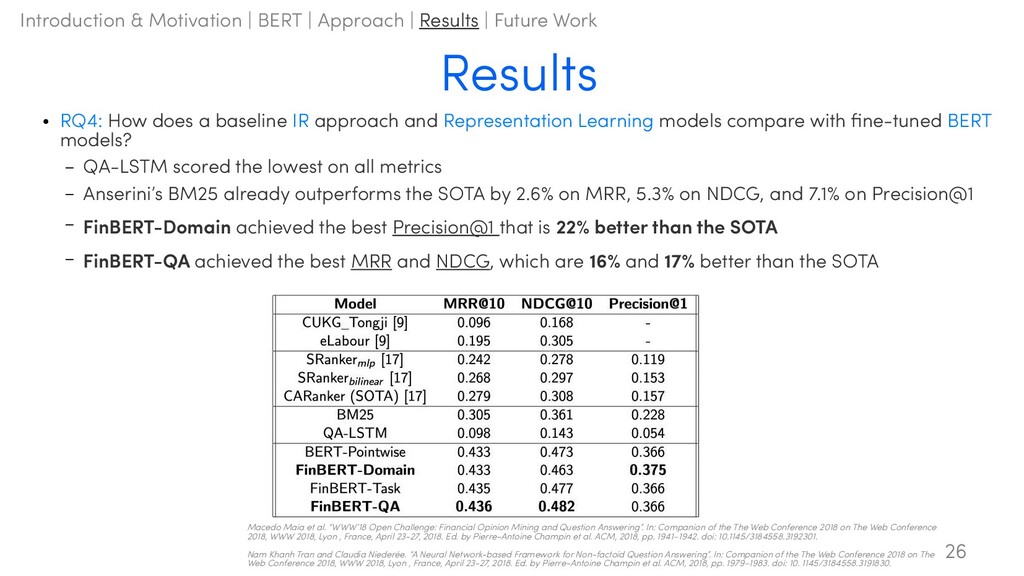
Learning models compare with fine-tuned BERT models? – QA-LSTM scored the lowest on all metrics – Anserini’s BM25 already outperforms the SOTA by 2.6% on MRR, 5.3% on NDCG, and 7.1% on Precision@1 – FinBERT-Domain achieved the best Precision@1 that is 22% better than the SOTA – FinBERT-QA achieved the best MRR and NDCG, which are 16% and 17% better than the SOTA Results 26 Macedo Maia et al. “WWW’18 Open Challenge: Financial Opinion Mining and Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1941–1942. doi: 10.1145/3184558.3192301. Nam Khanh Tran and Claudia Niederée. “A Neural Network-based Framework for Non-factoid Question Answering”. In: Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018. Ed. by Pierre-Antoine Champin et al. ACM, 2018, pp. 1979–1983. doi: 10. 1145/3184558.3191830. Introduction & Motivation | BERT | Approach | Results | Future Work
| Results | Future Work • RoBERTa, Robustly optimized BERT approach [Liu et al., 2019] – Retrained BERT for longer and with bigger batches over more data – Uses 160 GB of text for pre-training including the 16 GB of the original data used to pre-train BERT – Outperforms BERT achieving SOTA results on multiple NLP tasks • Transfer and Adapt method using RoBERTa Yinhan Liu et al. “RoBERTa: A Robustly Optimized BERT Pretraining Approach”. In: CoRR abs/1907.11692 (2019). arXiv: 1907.11692.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Previous Work: – Representation Learning [Tran et al., 2018]](https://files.speakerdeck.com/presentations/005fcb309f2f4b64b6d7989628ab13a9/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Baseline Model • QA-LSTM [Tan et al., 2016] – Question](https://files.speakerdeck.com/presentations/005fcb309f2f4b64b6d7989628ab13a9/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Further Pre-trained BERT Models • FinBERT-Domain: – FinBERT: [Araci, 2019]](https://files.speakerdeck.com/presentations/005fcb309f2f4b64b6d7989628ab13a9/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}