H., 2000. Automatic recognition of multi-word terms:. the c-value/nc-value method. International Journal on Digital Libraries, 3(2), pp.115-130. Mihalcea, R. and Tarau, P., 2004, July. TextRank: Bringing order into texts. Association for Computational Linguistics. Blei, D.M. and Lafferty, J.D., 2009. Topic models. Text mining: classification, clustering, and applications, 10(71), p.34. Danilevsky, M., Wang, C., Desai, N., Ren, X., Guo, J. and Han, J., 2014, April. Automatic construction and ranking of topical keyphrases on collections of short documents. In Proceedings of the 2014 SIAM International Conference on Data Mining (pp. 398-406). Society for Industrial and Applied Mathematics. Church, K., Gale, W., Hanks, P. and Hindle, D., 1991. Using statistics in lexical analysis. Lexical acquisition: exploiting on-line resources to build a lexicon, 115, p.164. El-Kishky, A., Song, Y., Wang, C., Voss, C.R. and Han, J., 2014. Scalable topical phrase mining from text corpora. Proceedings of the VLDB Endowment, 8(3), pp.305-316. Parameswaran, A., Garcia-Molina, H. and Rajaraman, A., 2010. Towards the web of concepts: Extracting concepts from large datasets. Proceedings of the VLDB Endowment, 3(1-2), pp.566-577. Liu, J., Shang, J., Wang, C., Ren, X. and Han, J., 2015, May. Mining quality phrases from massive text corpora. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (pp. 1729-1744). ACM. Shang, J., Liu, J., Jiang, M., Ren, X., Voss, C.R. and Han, J., 2017. Automated Phrase Mining from Massive Text Corpora. arXiv preprint arXiv:1702.04457.
{kind=link}
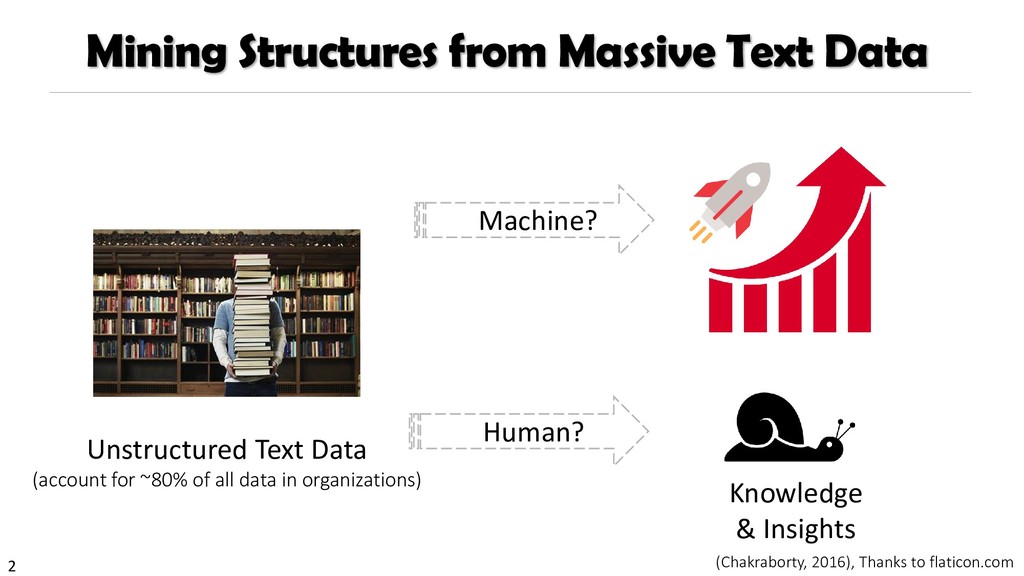{kind=link}
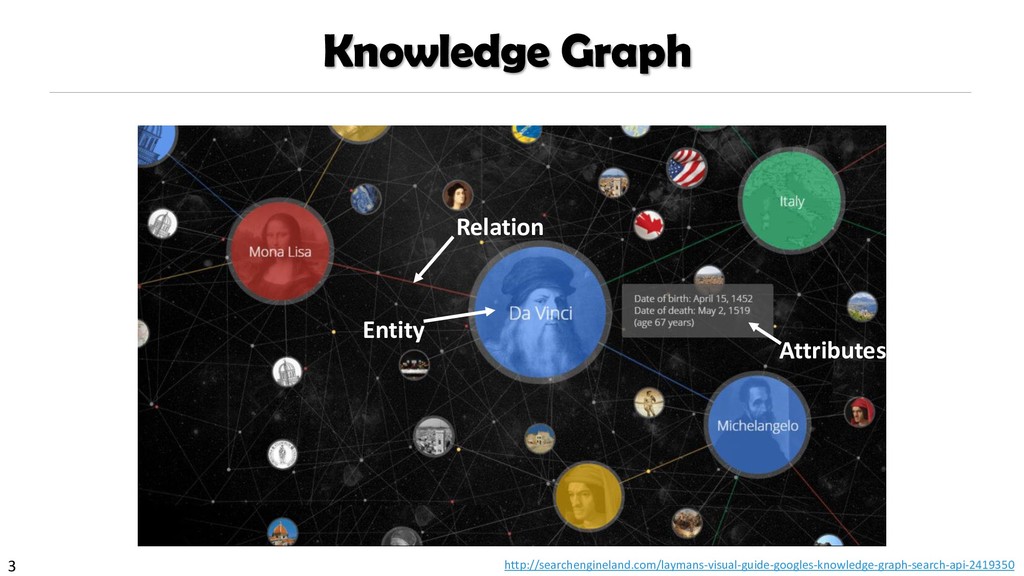{kind=link}
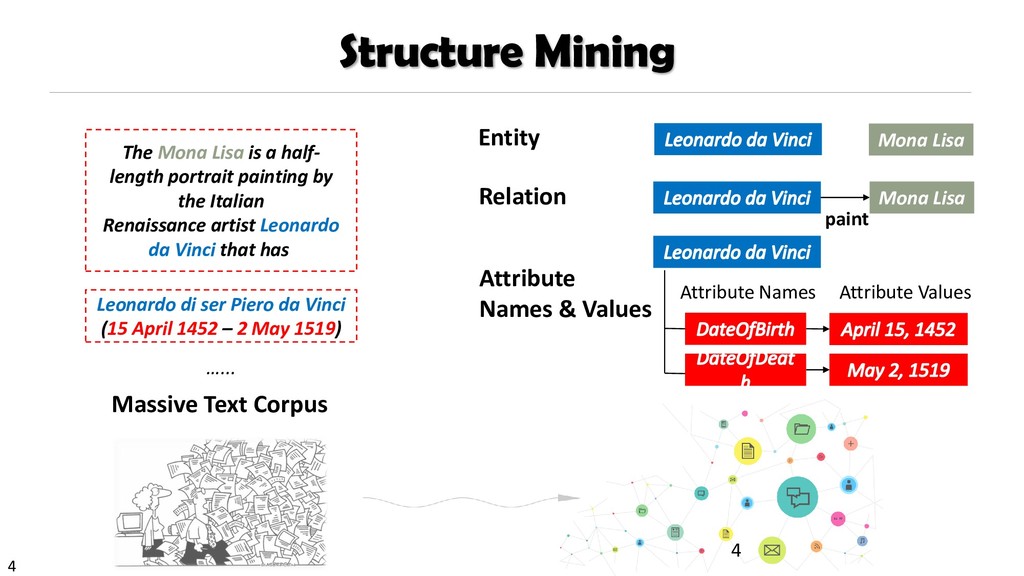{kind=link}
{kind=link}
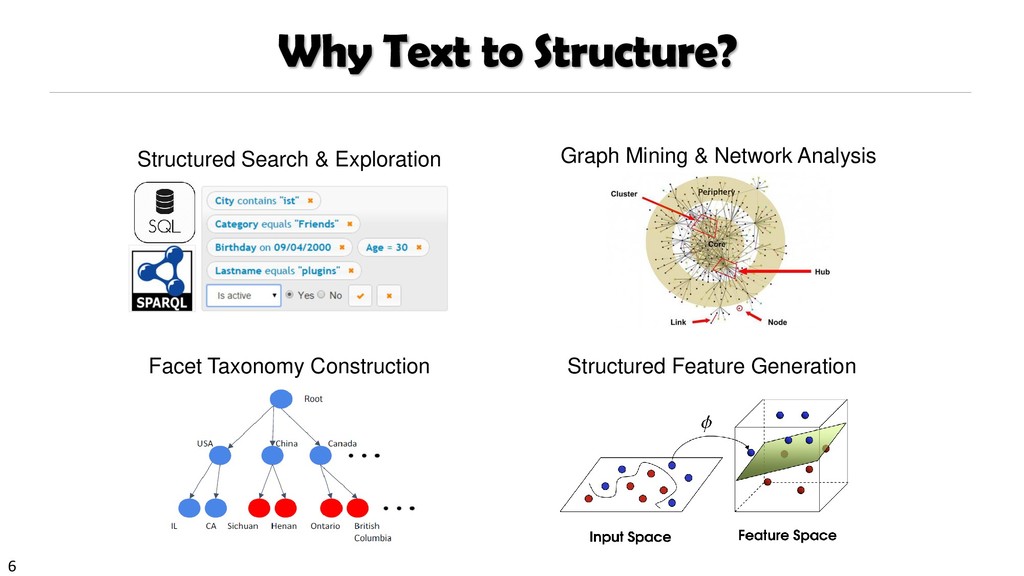{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
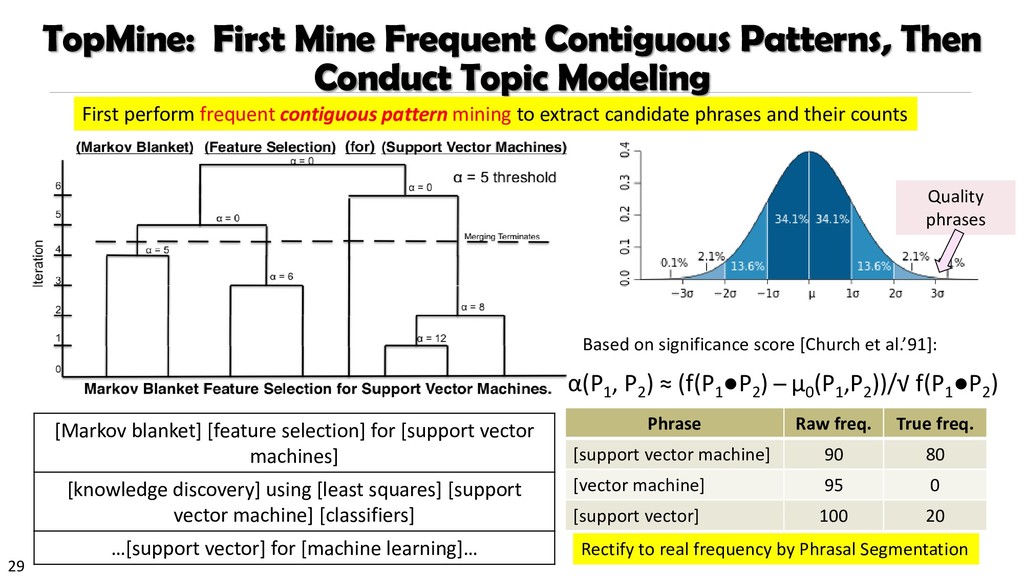
![28 Significance score Significance score [Church et al.’91] ](https://files.speakerdeck.com/presentations/3d9779a8664944ff8ce446b2a1e81bec/slide_27.jpg){kind=link}
{kind=link}
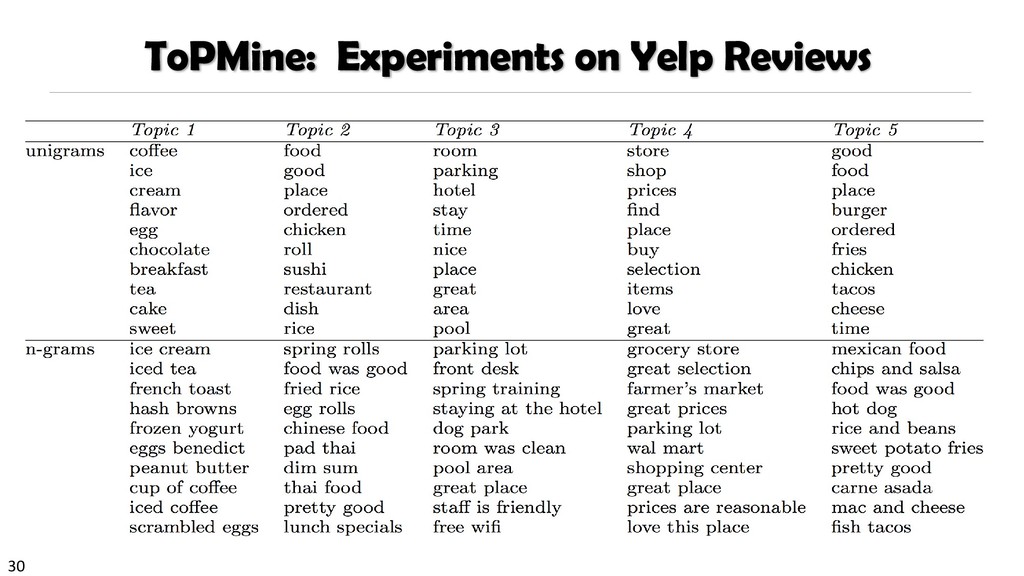{kind=link}
{kind=link}
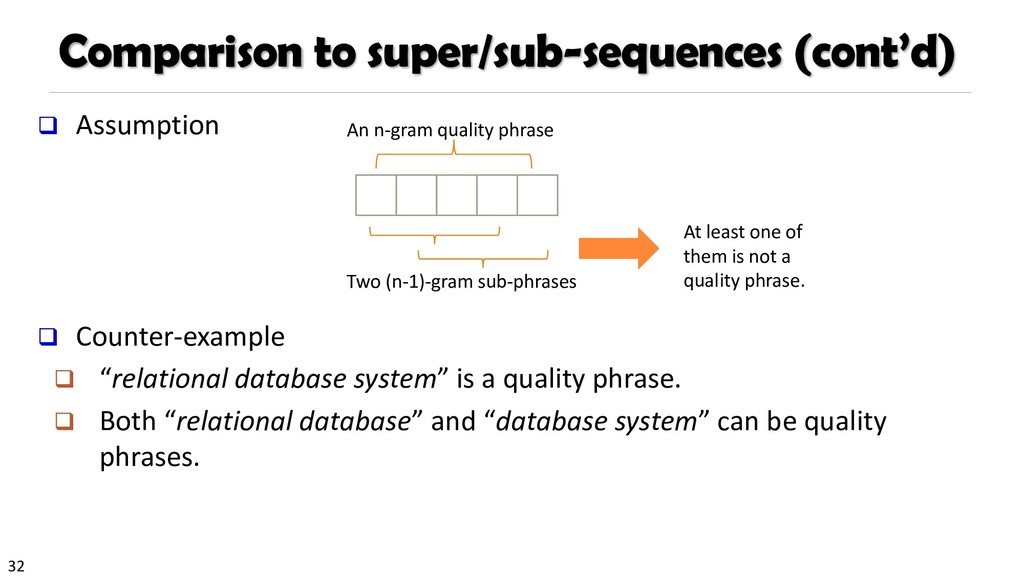{kind=link}
{kind=link}
{kind=link}
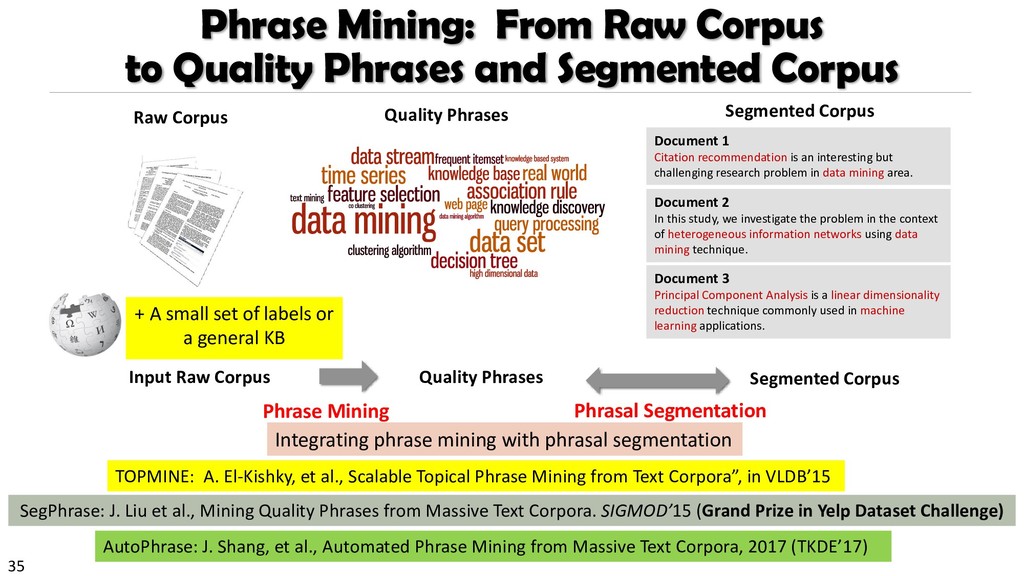{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
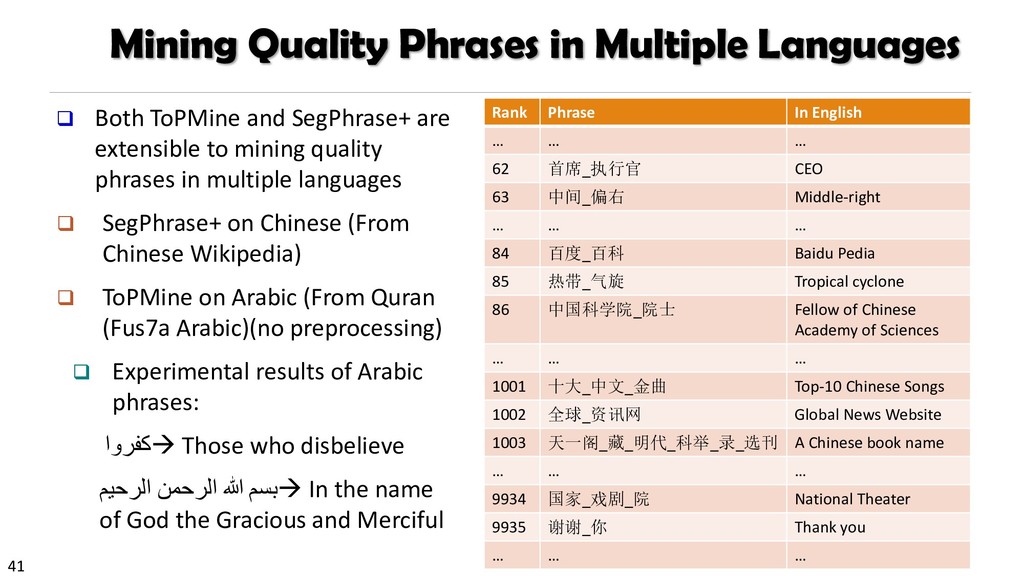{kind=link}
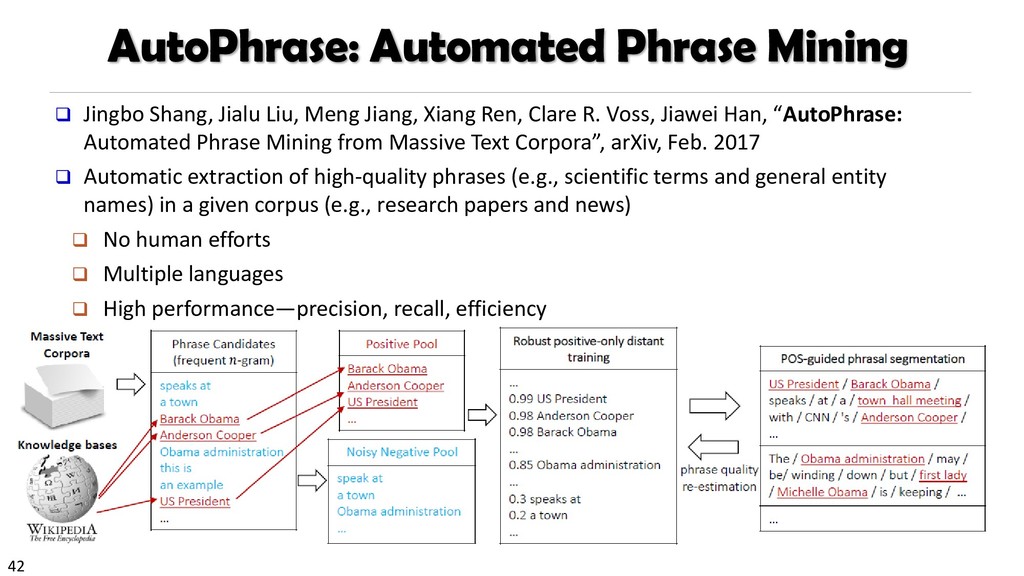{kind=link}
{kind=link}
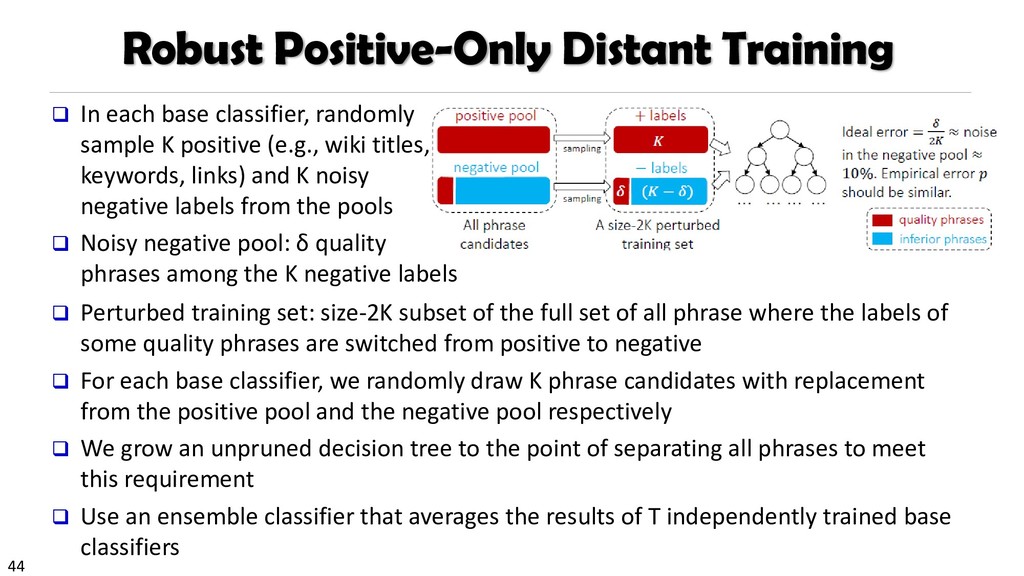{kind=link}
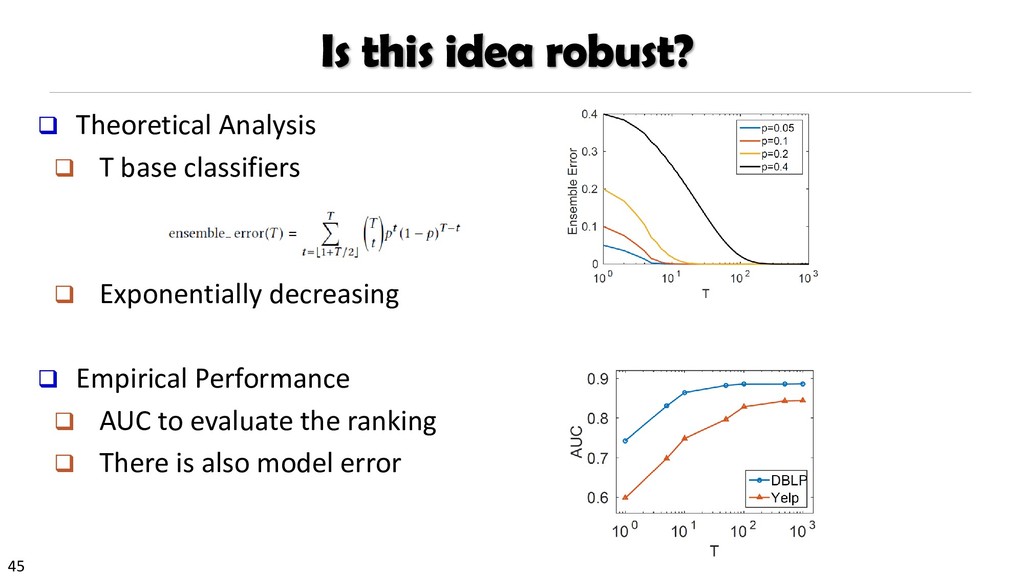{kind=link}
{kind=link}
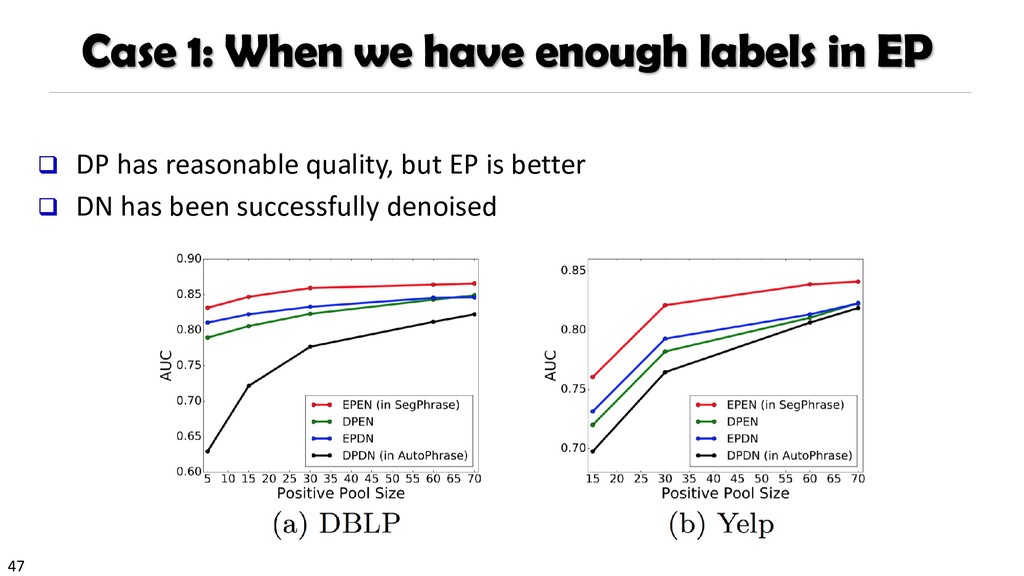{kind=link}
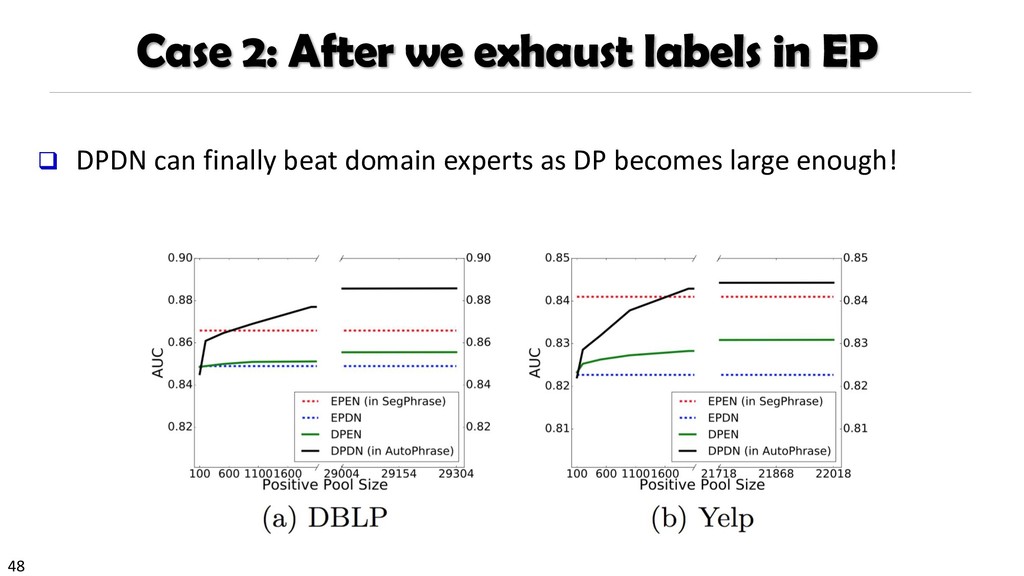{kind=link}
{kind=link}
{kind=link}
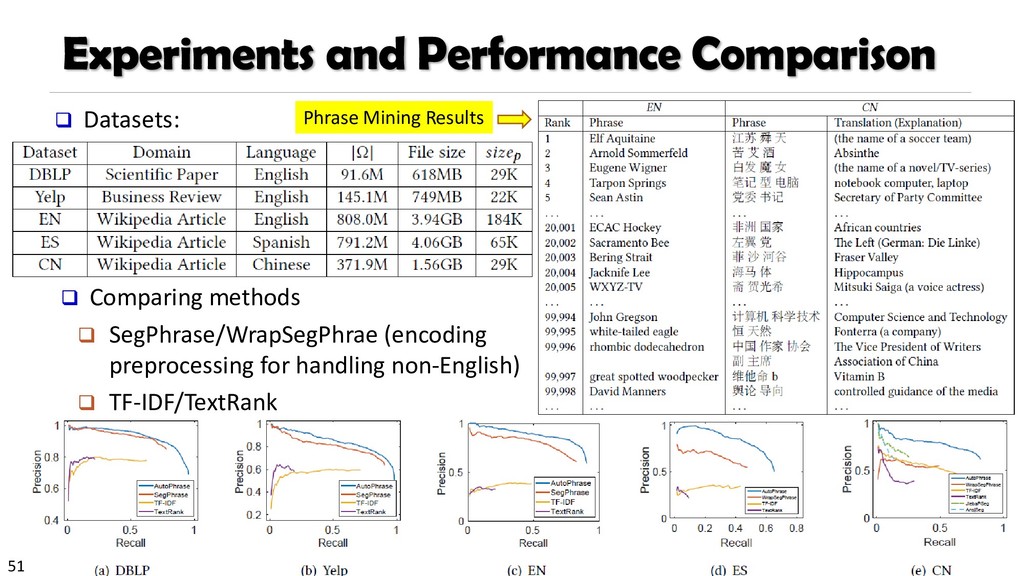{kind=link}
{kind=link}
{kind=link}
{kind=link}
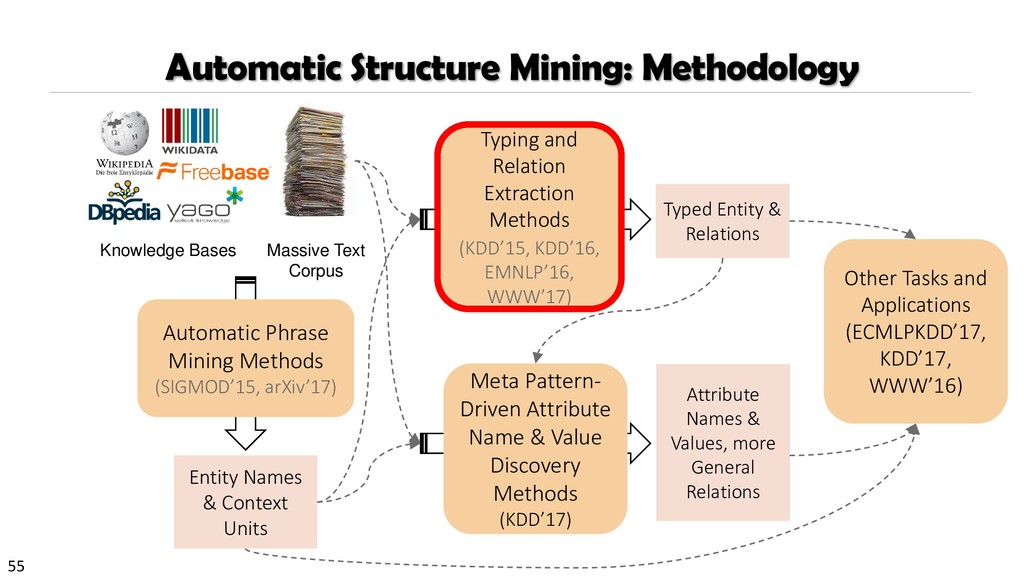{kind=link}
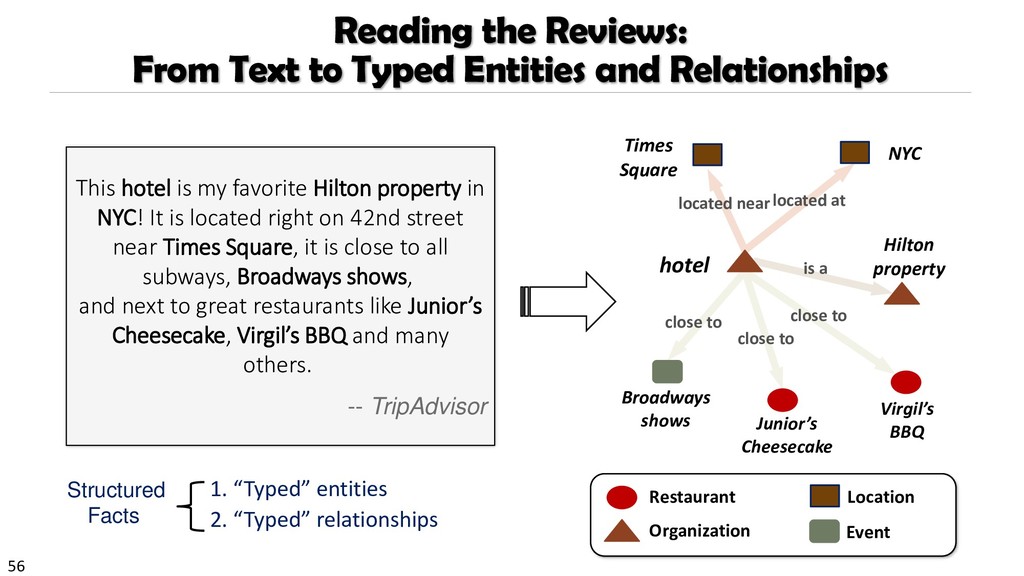{kind=link}
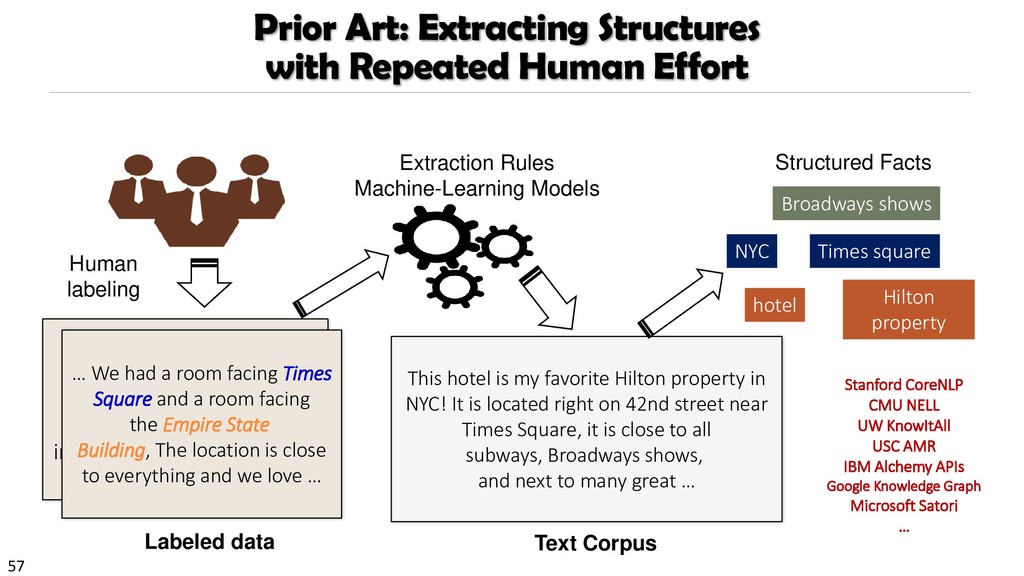{kind=link}
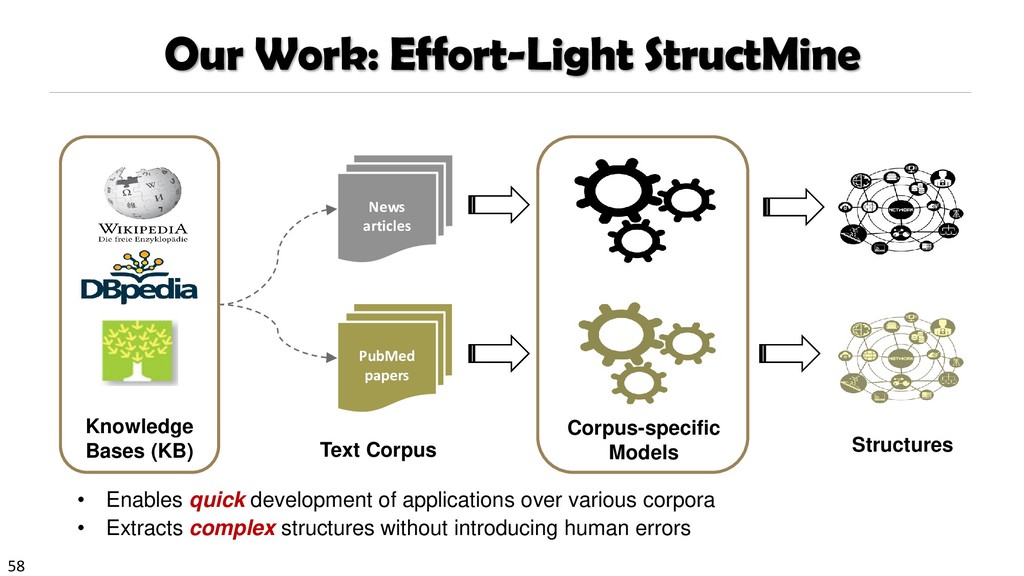{kind=link}
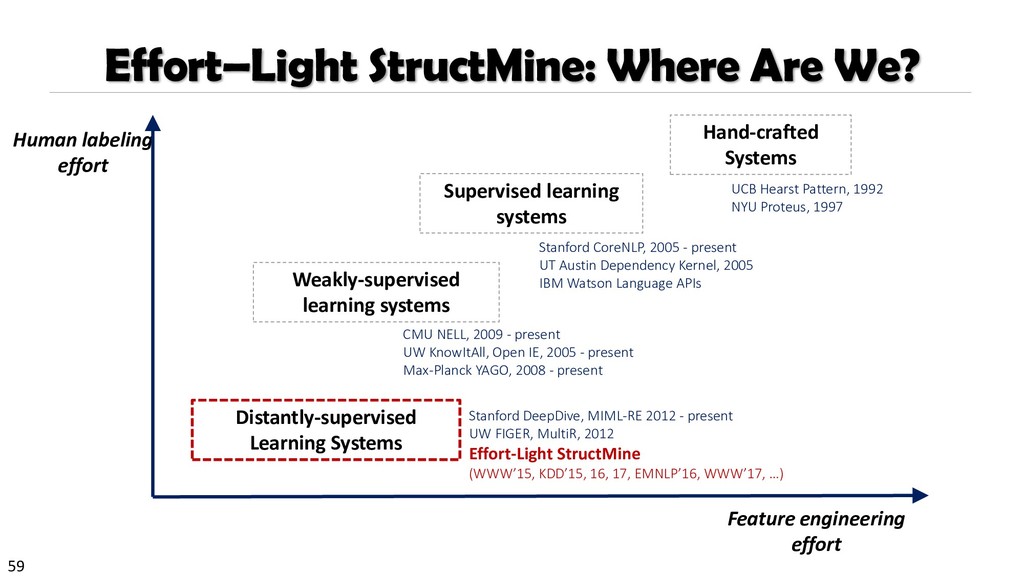{kind=link}
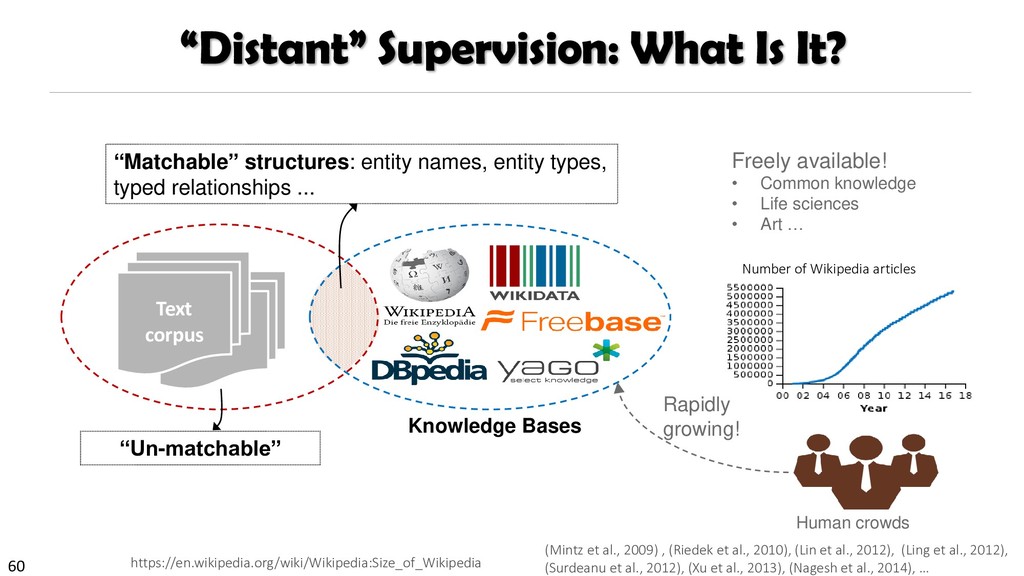{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
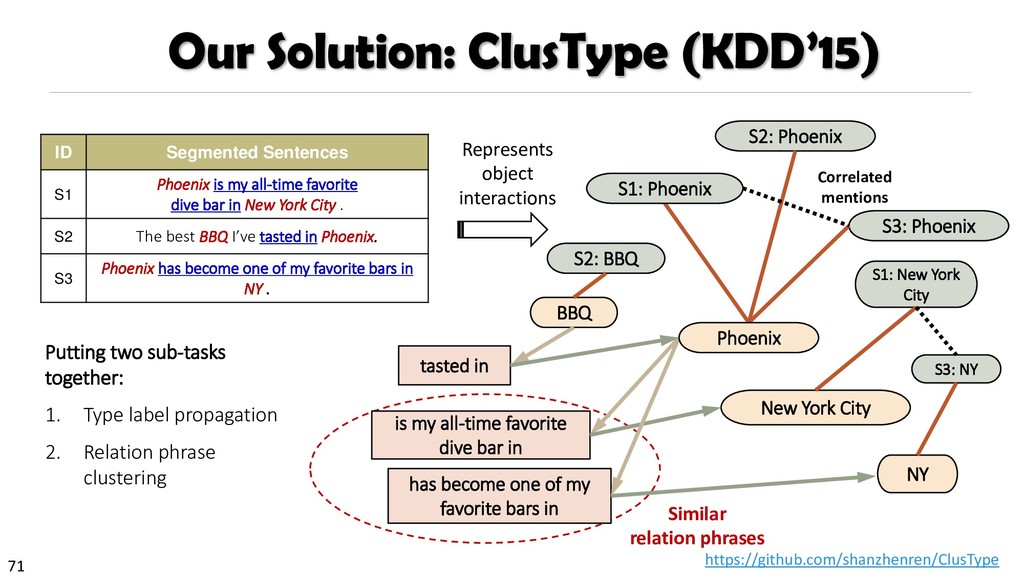{kind=link}
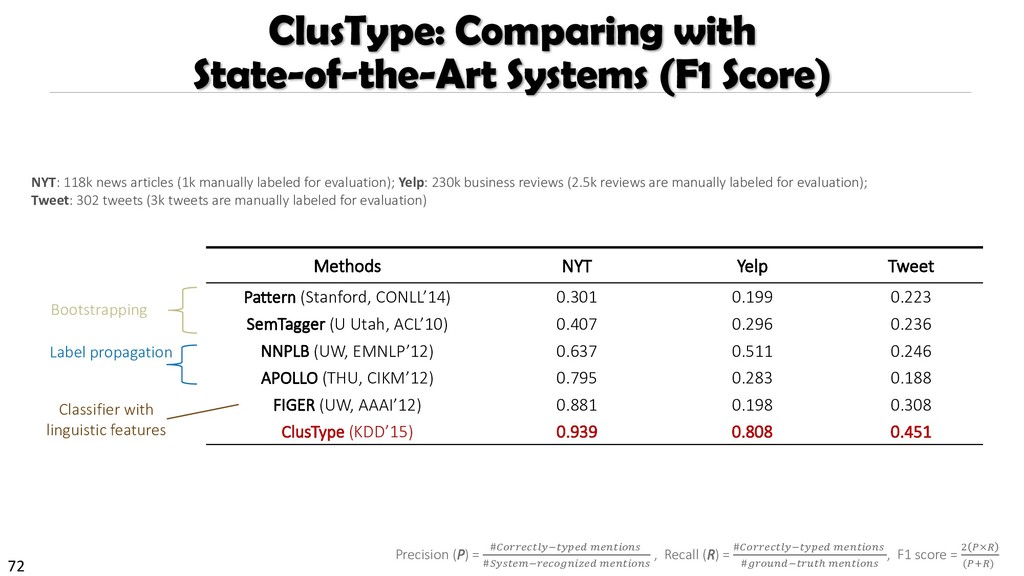{kind=link}
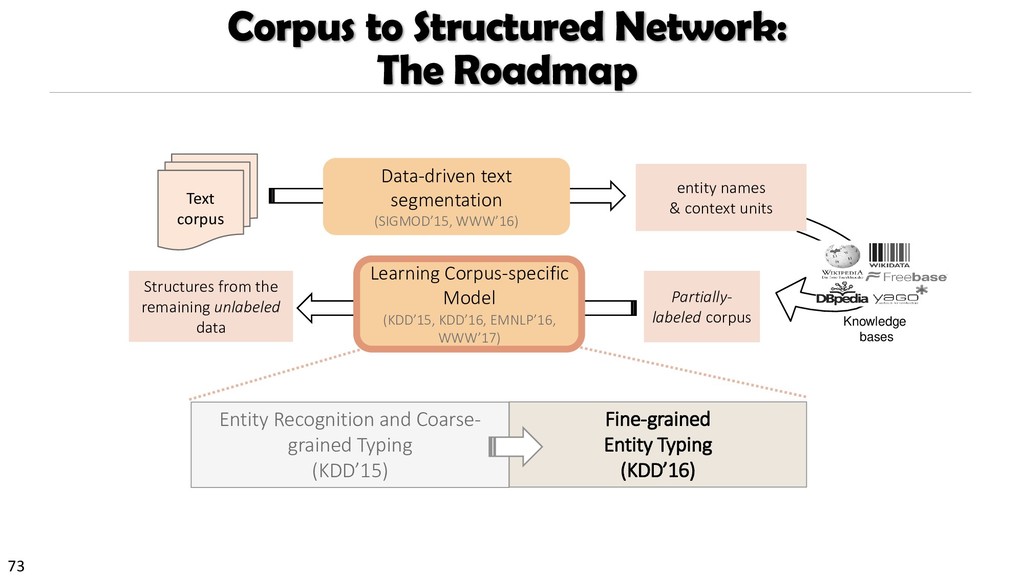{kind=link}
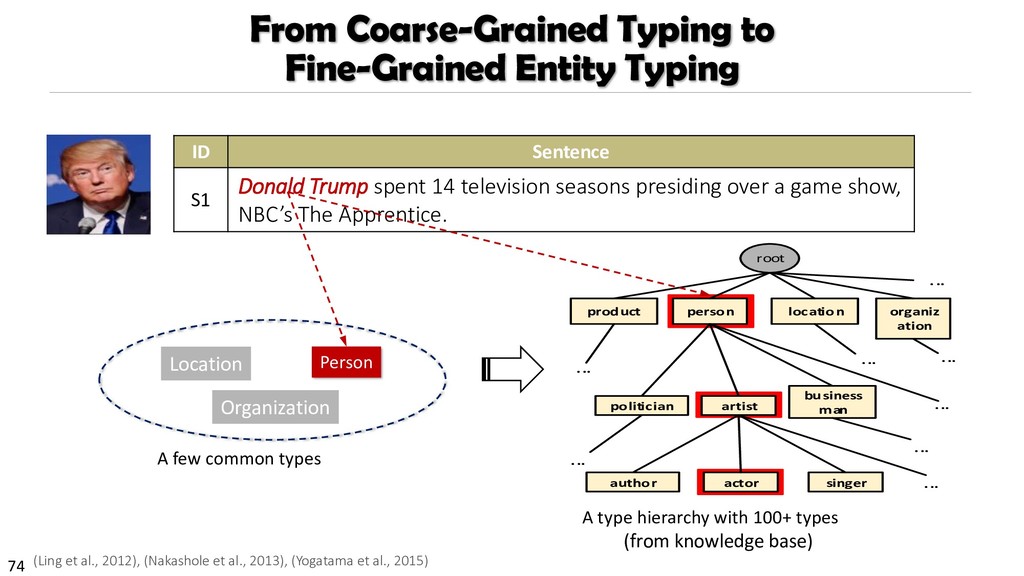{kind=link}
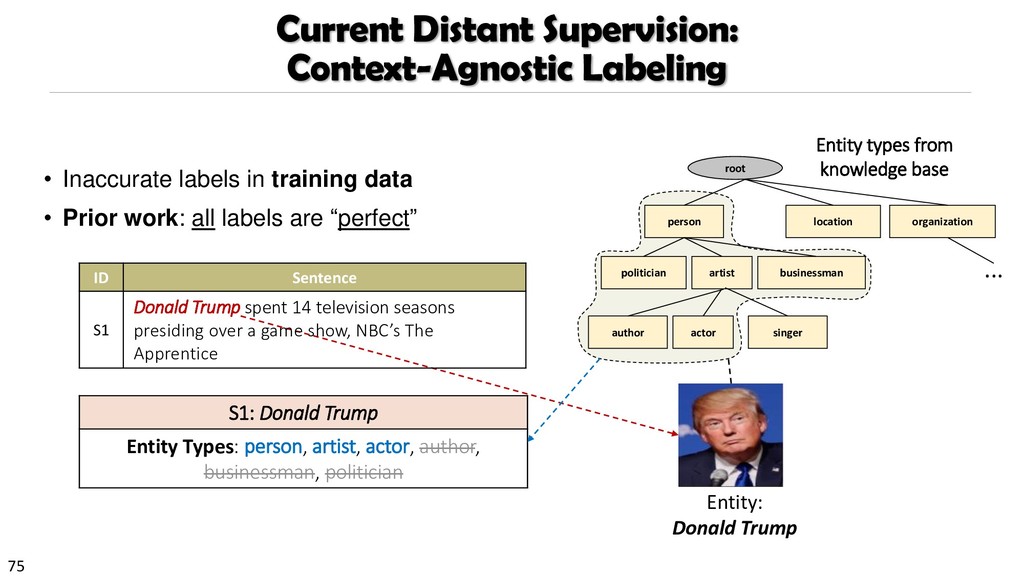{kind=link}
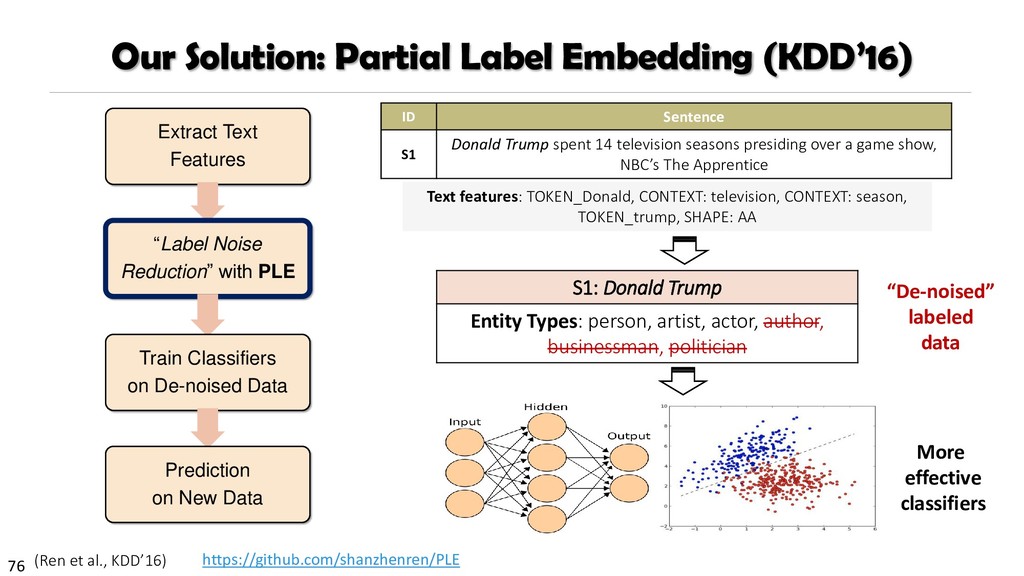{kind=link}
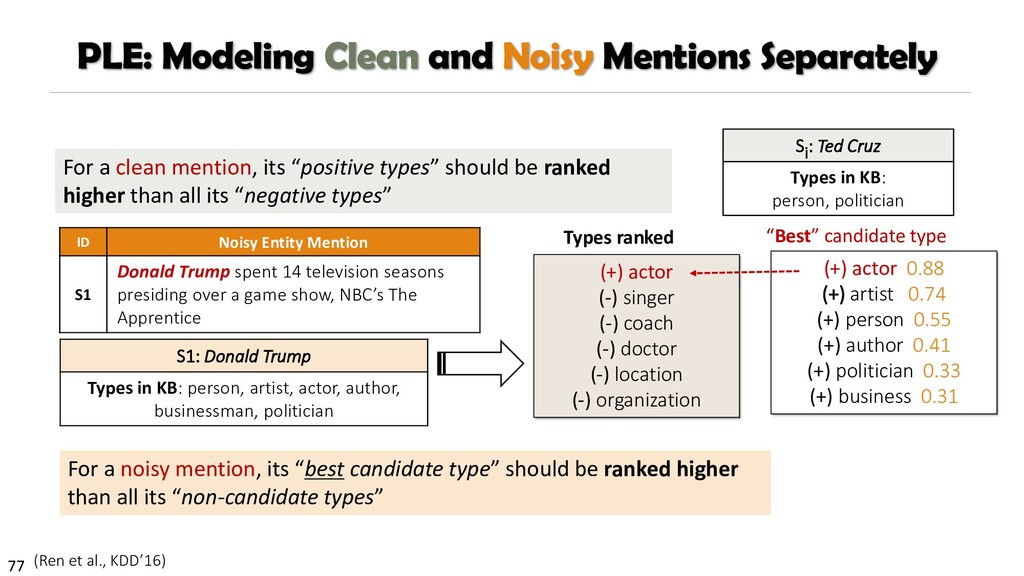{kind=link}
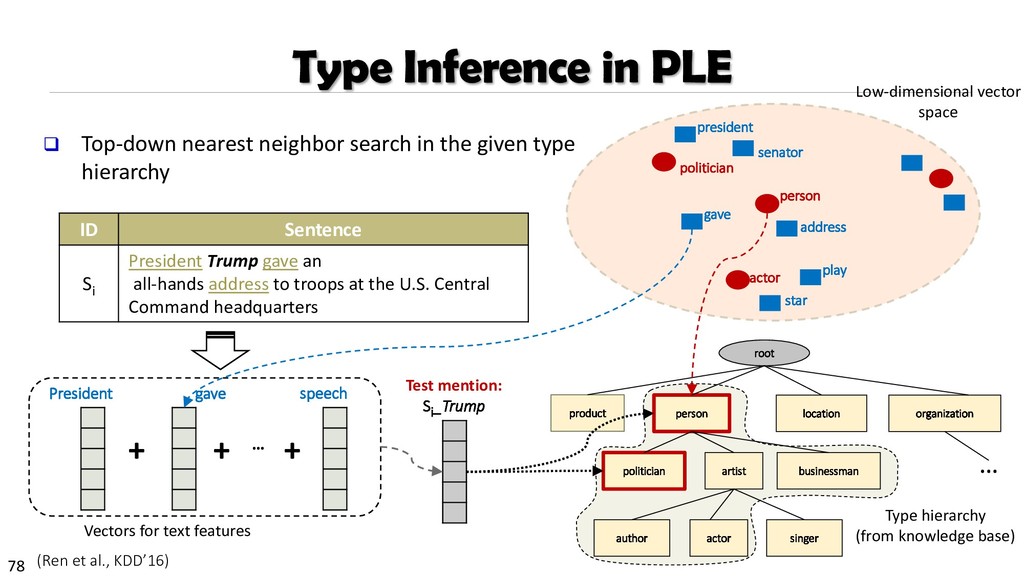{kind=link}
{kind=link}
{kind=link}