Share
#22 CA x atmaCup 3rd 振り返り会の登壇資料 https://atma.connpass.com/event/380482/
コンペURLはこちら https://www.guruguru.science/competitions/30/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
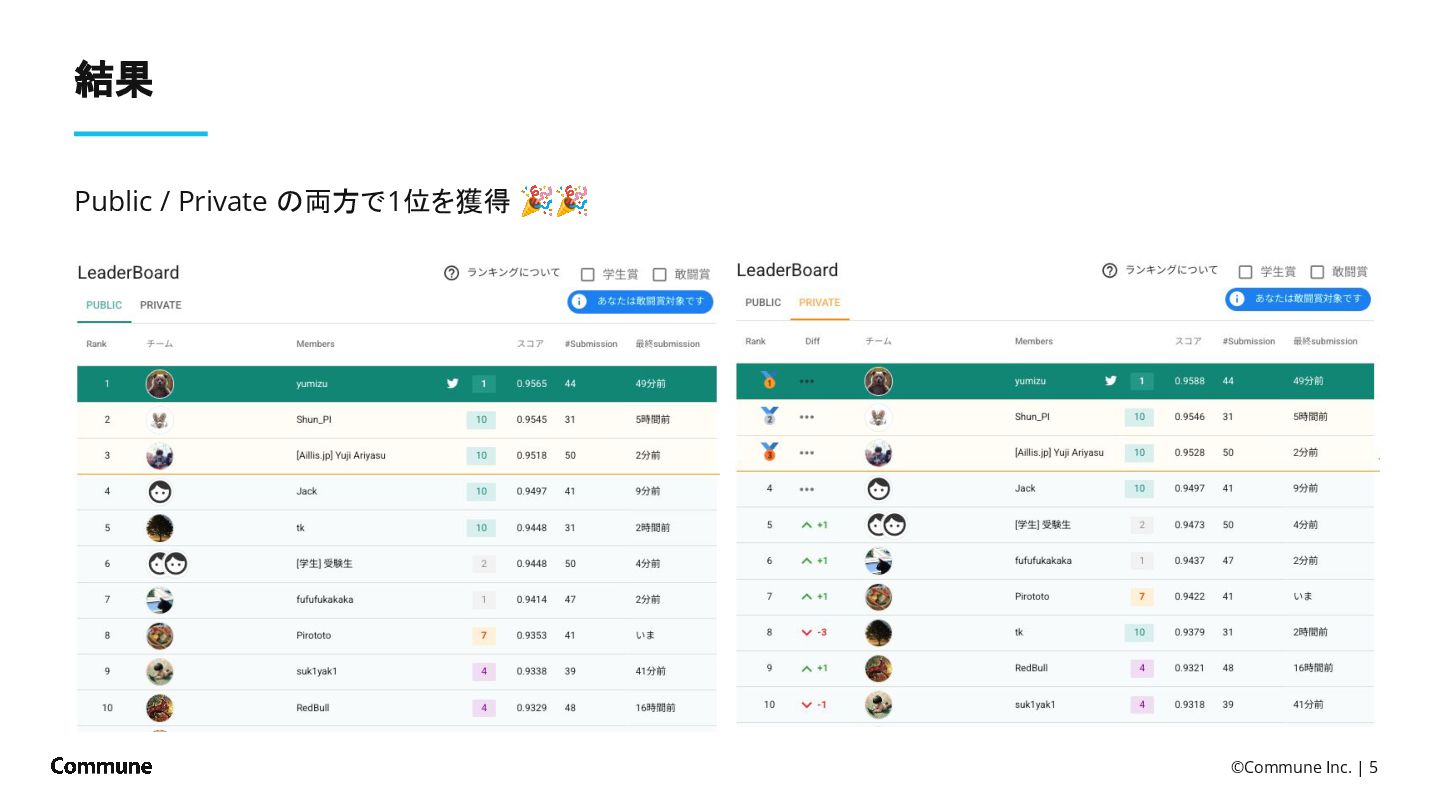{kind=link}
{kind=link}
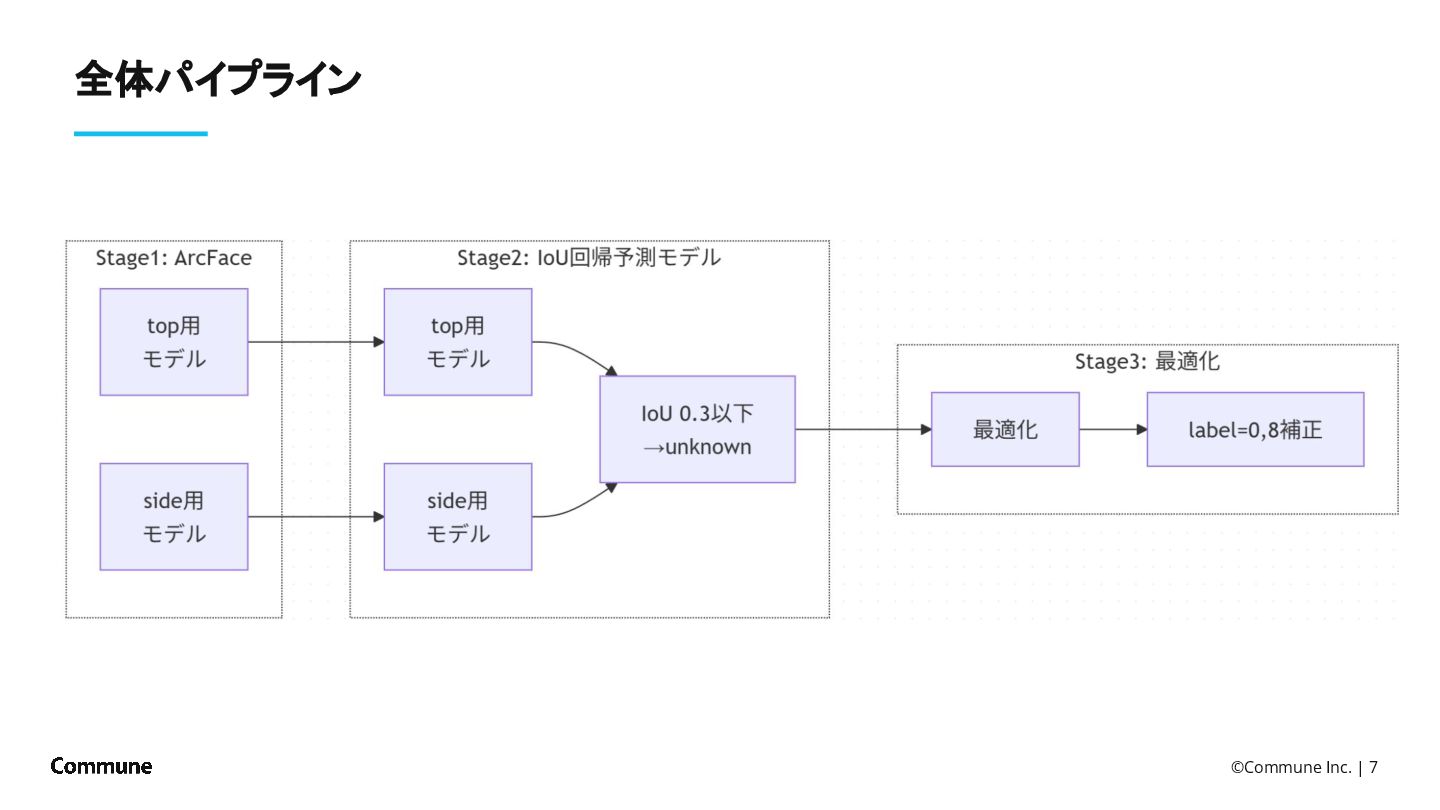{kind=link}
{kind=link}
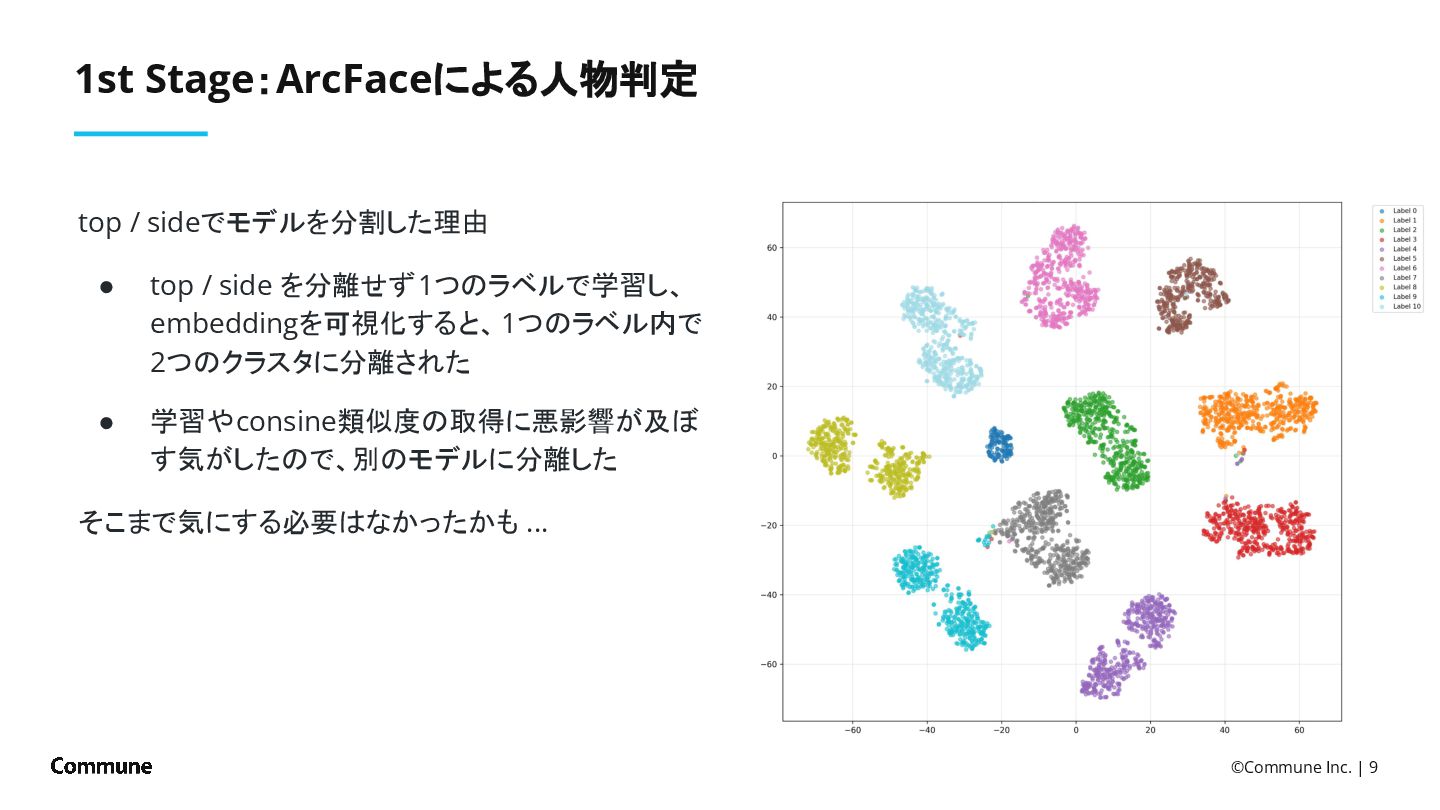{kind=link}
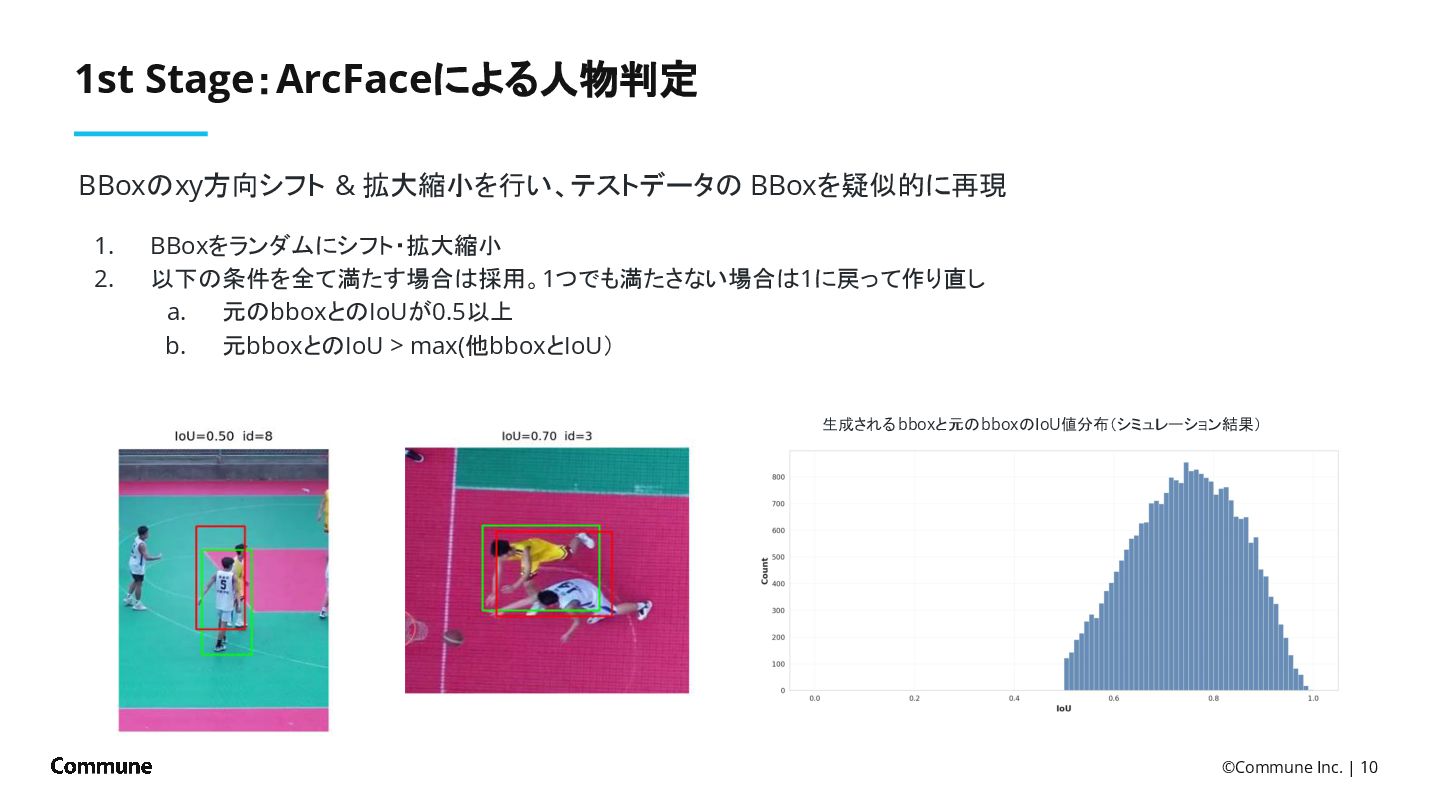{kind=link}
{kind=link}
{kind=link}
{kind=link}
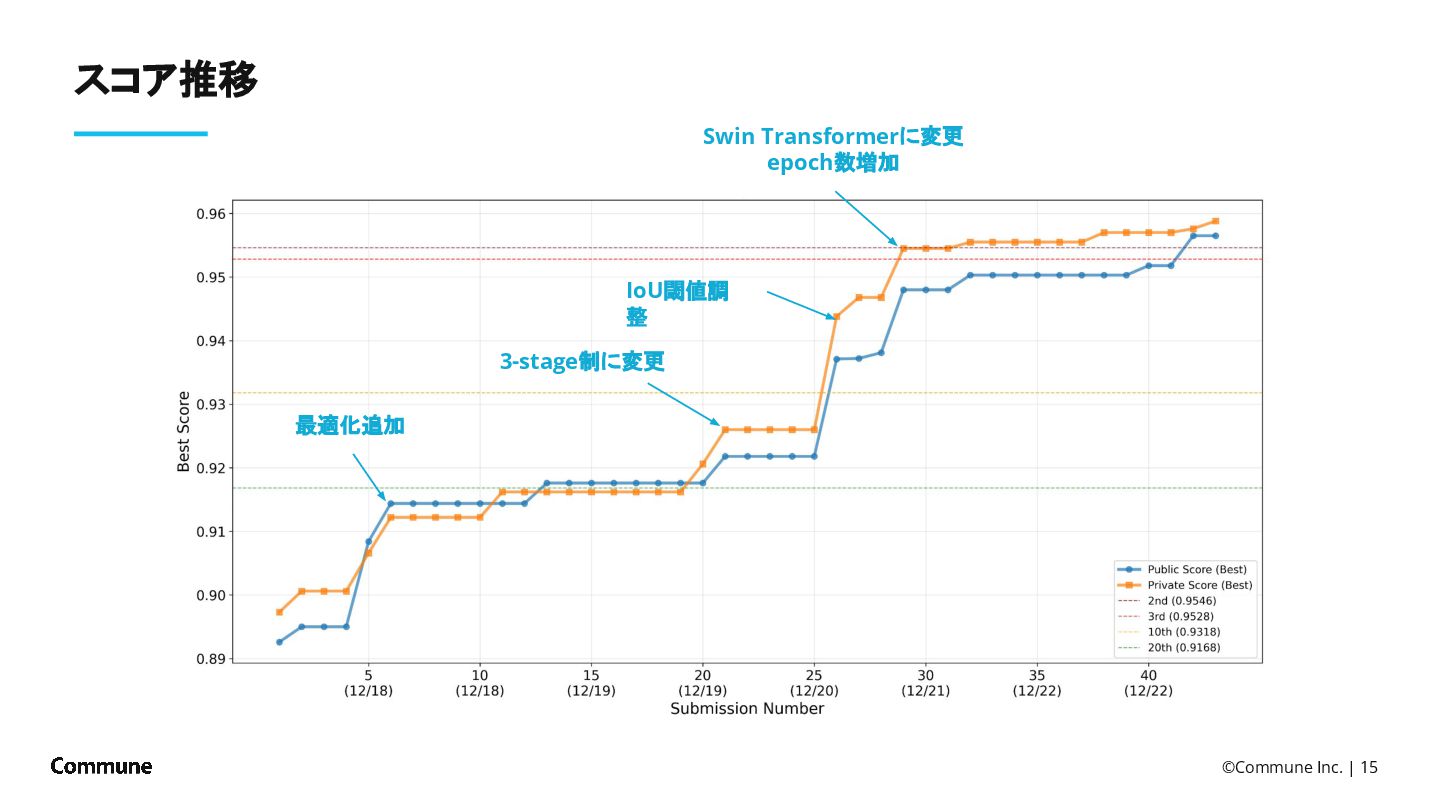
![©Commune Inc. | 14 3rd Stage:最適化 [0.8570] ⇒ [0.9549] かなり精度が上がるかもしれない個数制約付き最大化による後処理](https://files.speakerdeck.com/presentations/ddaeb29c293e45c796899673ab3e3155/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
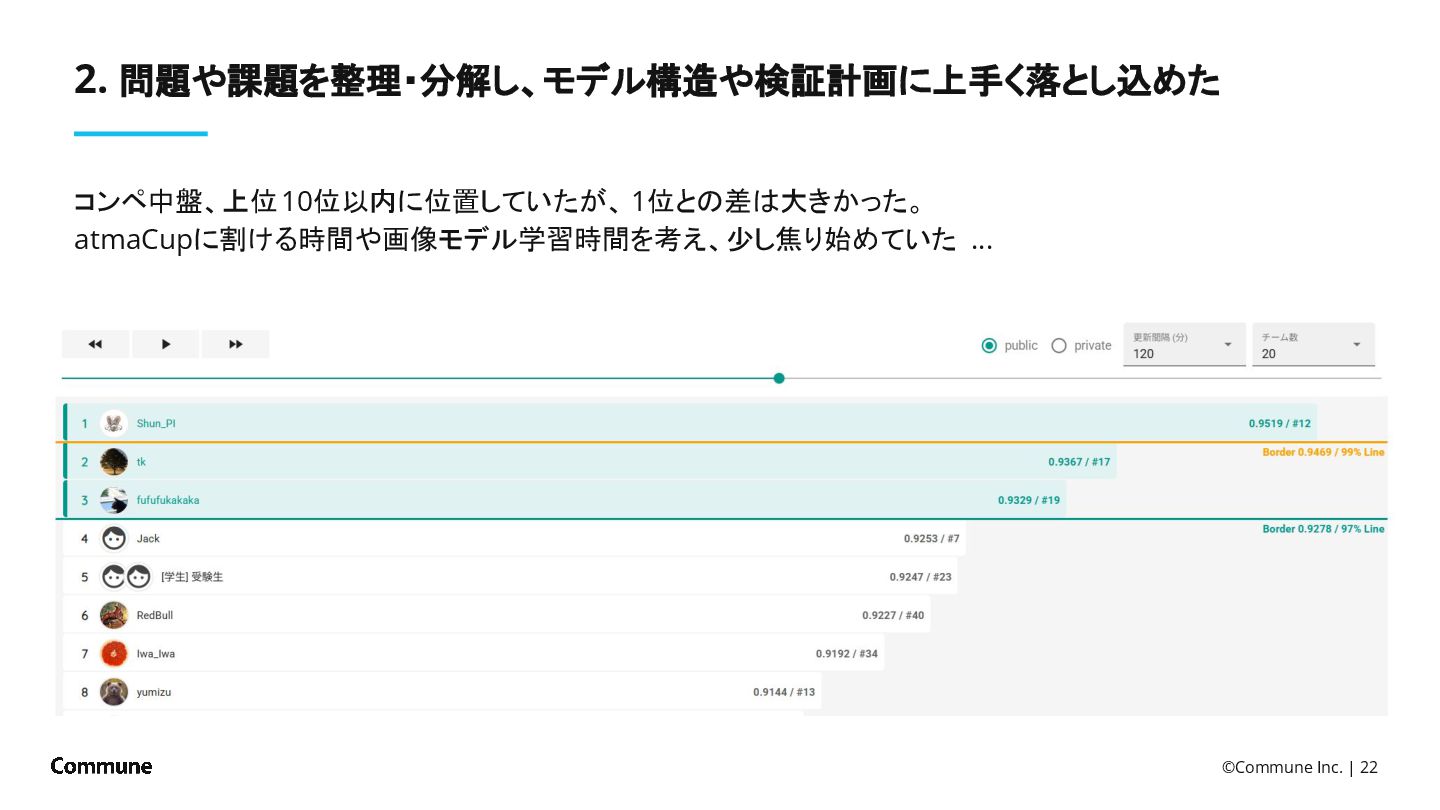
![©Commune Inc. | 21 3つの気付きをもとに、早々に高スコアを獲得することができた ※ Restart前 1. RedBullさんの[0.8448]baseline notebook同様にモデルを学習](https://files.speakerdeck.com/presentations/ddaeb29c293e45c796899673ab3e3155/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
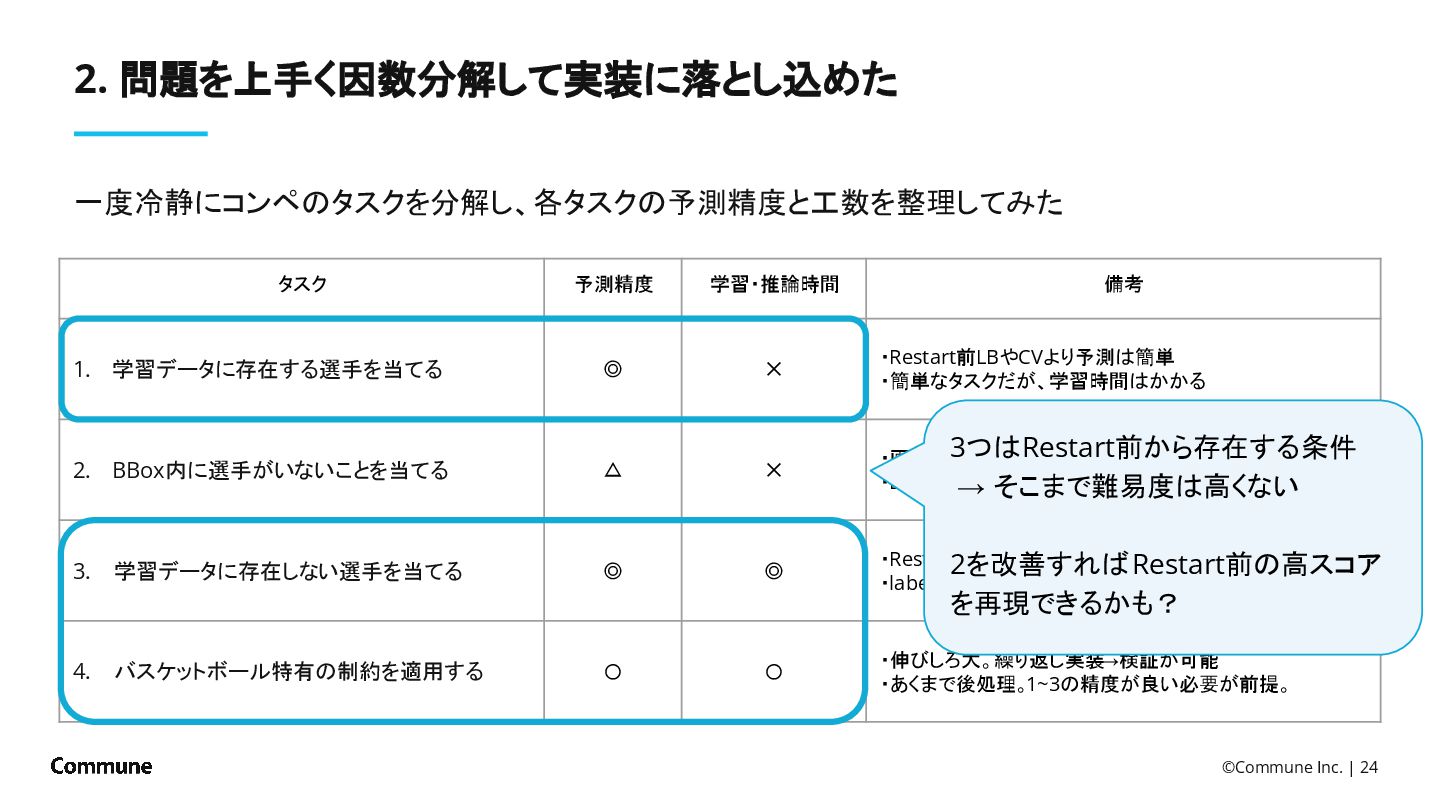{kind=link}
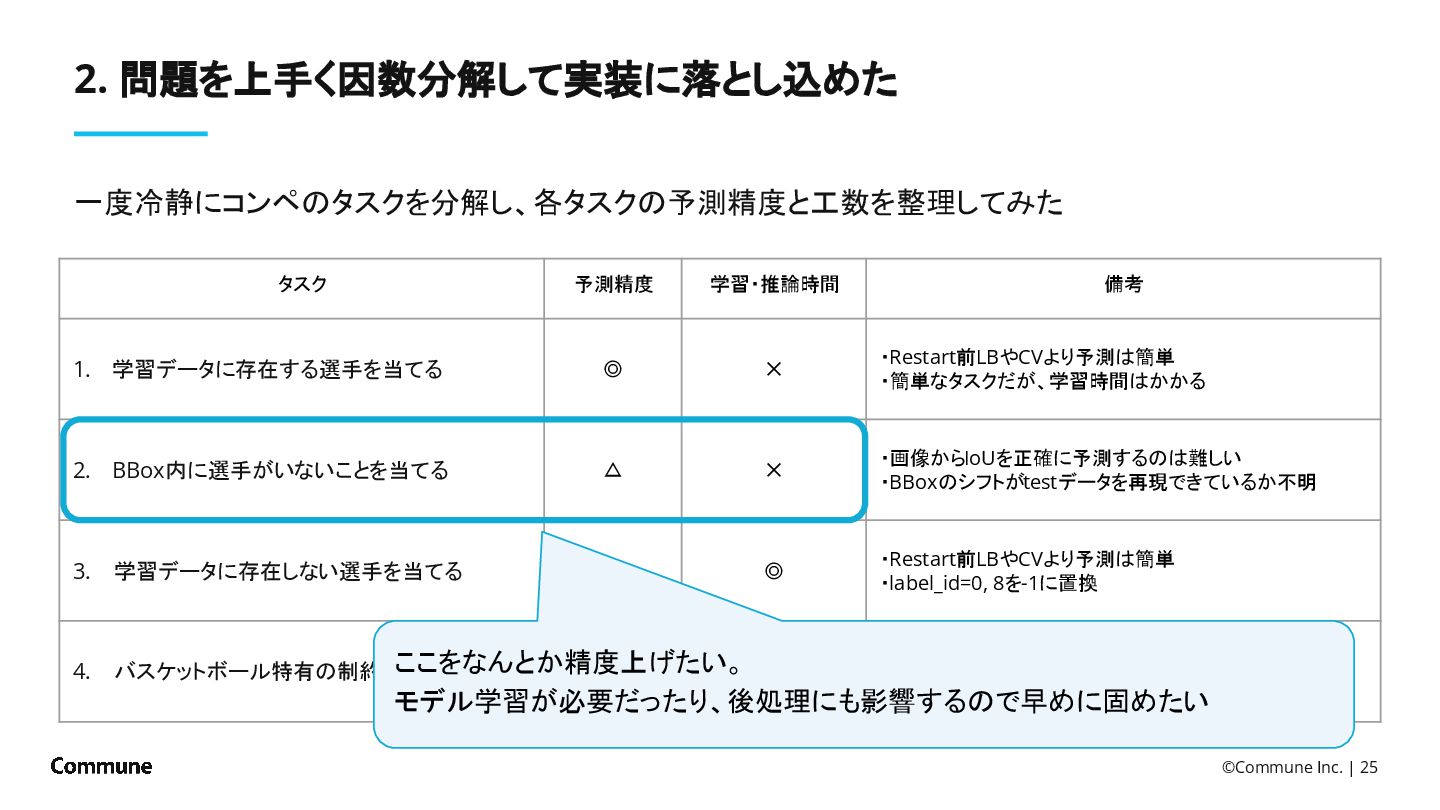{kind=link}
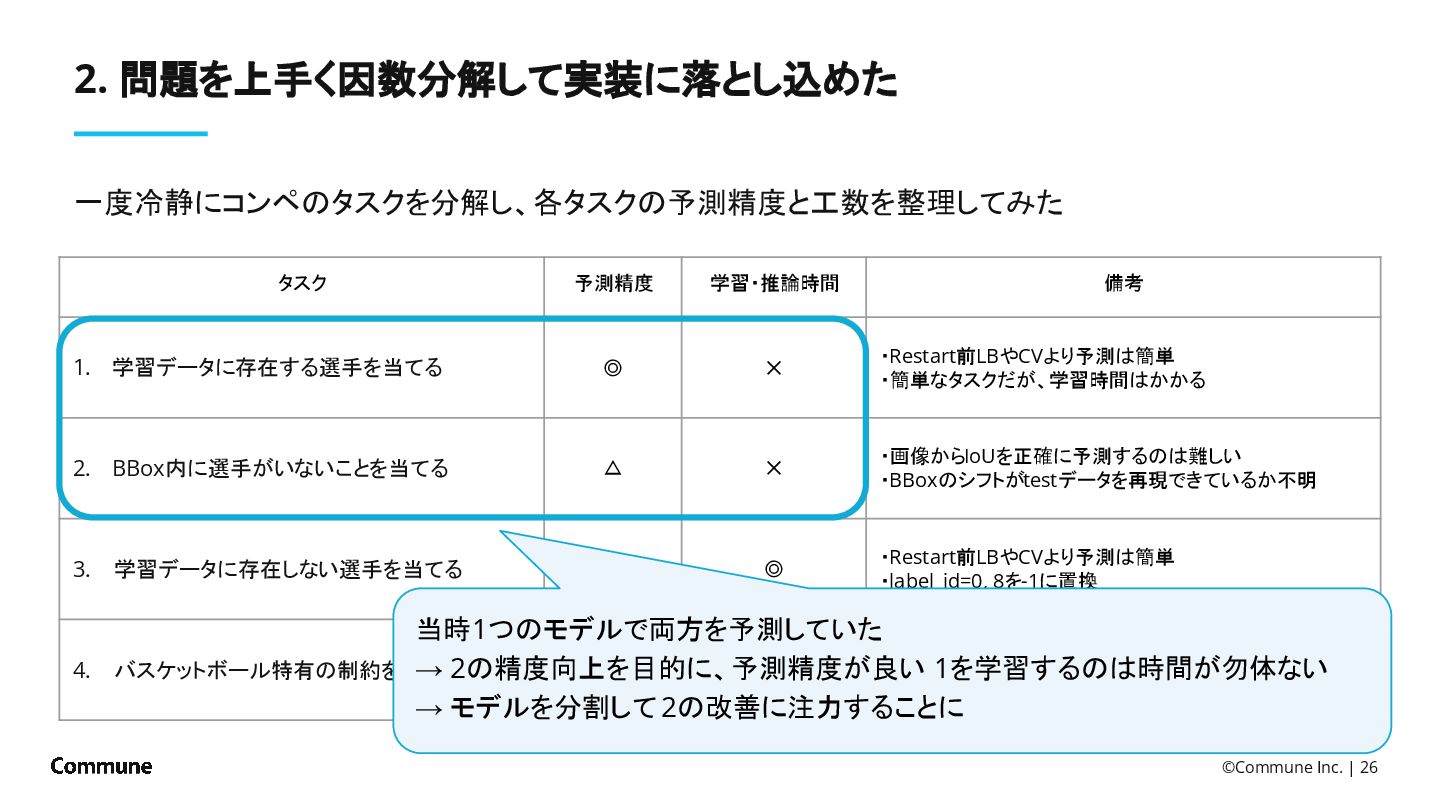{kind=link}
{kind=link}
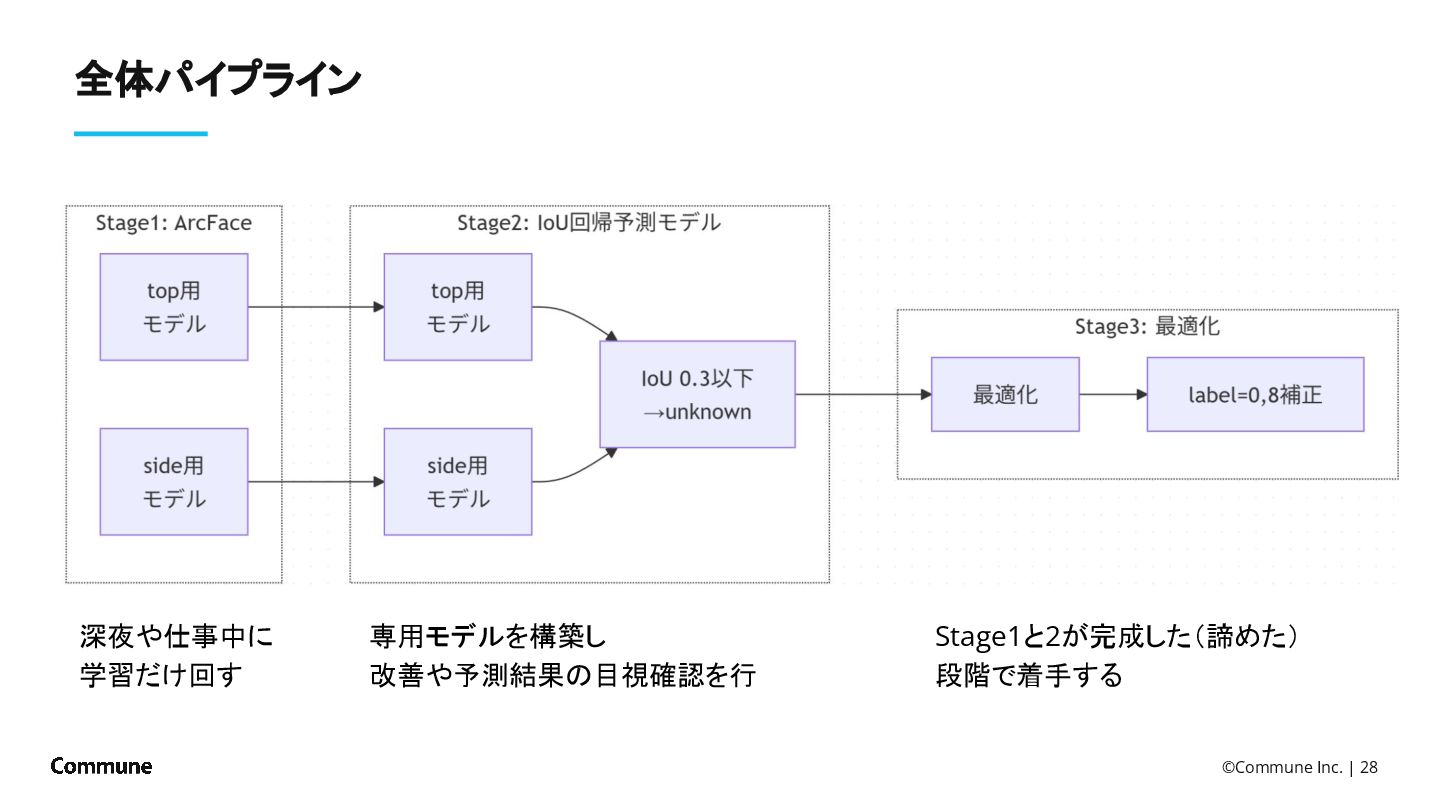{kind=link}
{kind=link}
{kind=link}
{kind=link}