Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データチームの境界を考える
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Atsushi Sumita
June 16, 2022
Technology
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データチームの境界を考える
ナウキャストのストリームアラインドチームと, チームAPIとしてのdbt導入の取り組みについて紹介しています.
Atsushi Sumita
June 16, 2022
More Decks by Atsushi Sumita
See All by Atsushi Sumita
LLMによるデータ構造化の精度管理
yummydum
1
300
Redshift Serverless vs Snowflake 徹底比較!
yummydum
1
2.7k
最強?のデータ組織アーキテクチャ
yummydum
2
650
データを開発するためのDataOps
yummydum
1
1.1k
Jupyter Notebook Ops
yummydum
1
240
SNLP presentation 20190928
yummydum
0
390
Other Decks in Technology
See All in Technology
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
340
AI Driven AI Governance
pict3
0
330
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
720
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
550
生成AIの活用/high_school2026
okana2ki
0
130
知らん間に、回ってる
ming_ayami
0
420
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.1k
Claude Code 珍プレー好プレー
shinyasaita
0
320
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
140
CIで使うClaude
iwatatomoya
0
230
最近評価が難しくなった
maroon8021
0
330
Featured
See All Featured
Why Our Code Smells
bkeepers
PRO
340
58k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
Scaling GitHub
holman
464
140k
From π to Pie charts
rasagy
0
230
The agentic SEO stack - context over prompts
schlessera
0
840
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
New Earth Scene 8
popppiees
3
2.4k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Mobile First: as difficult as doing things right
swwweet
225
10k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Transcript
© 2015 - 2022 Nowcast Inc. データチームの境界を考える 株式会社ナウキャスト 隅田 敦
1
© 2013 - 2022 Finatext Ltd. 2 目次 これまでのナウキャストのチーム構造 -
データエンジニアが主役となる組織 - チームトポロジー: Stream Aligned Team / Platform Team / チームAPI - Stream Aligned Data Engineering Teamによる効率的な開発 - 課題: チームAPIが整備されていないことによる非効率性 チーム境界とプラットフォームチーム - チームAPIとしてのdbt - Data hub platformに向けた取り組み - Platformチームは中央集権型のデータエンジニアチームではない
© 2013 - 2022 Finatext Ltd. 3 これまでのナウキャストのチーム構造
© 2013 - 2022 Finatext Ltd. 4 データエンジニアが主役となる組織 データの保有側・利用側の双方に価値を提供するAlternative Dataの
Two-Sided Platformを展開
© 2013 - 2022 Finatext Ltd. 5 チームトポロジー: Stream Aligned
Team / Platform Team / チームAPI • Stream Aligned Team ◦ 価値のデリバリーをend to endで担う ◦ 要求探索から本番運用まで他チームへの引き継ぎ無しで行える • Platform Team ◦ Stream Aligned Teamを支援する内部プロダクトの開発を担う ◦ インフラなど下位の機能を横断的に抽象化したツールを提供 • チームAPI ◦ チームとやり取りするための方法を記述した仕様 ◦ コードであれば, ランタイムのエンドポイント, ライブラリ, UI ◦ データの場合はどうか? これを考えるのが本発表の目的
© 2013 - 2022 Finatext Ltd. 6 The Bezos Mandate
(2002) 私とAWSの15年 あるいはThe Bezos Mandateの話 - NRIネットコムBlog
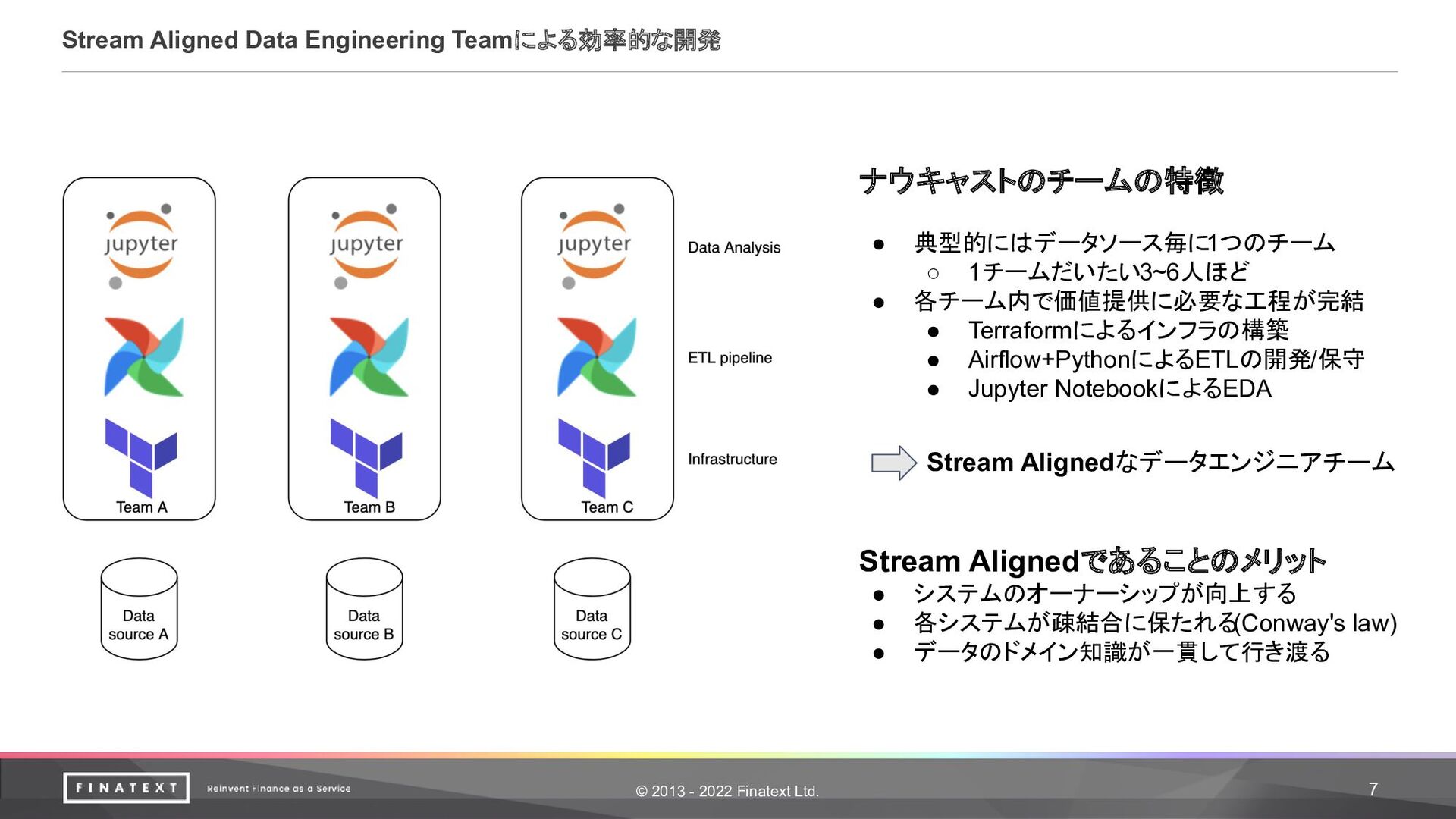
© 2013 - 2022 Finatext Ltd. 7 Stream Aligned Data
Engineering Teamによる効率的な開発 ナウキャストのチームの特徴 • 典型的にはデータソース毎に1つのチーム ◦ 1チームだいたい3~6人ほど • 各チーム内で価値提供に必要な工程が完結 • Terraformによるインフラの構築 • Airflow+PythonによるETLの開発/保守 • Jupyter NotebookによるEDA Stream Alignedなデータエンジニアチーム Stream Alignedであることのメリット • システムのオーナーシップが向上する • 各システムが疎結合に保たれる (Conway's law) • データのドメイン知識が一貫して行き渡る
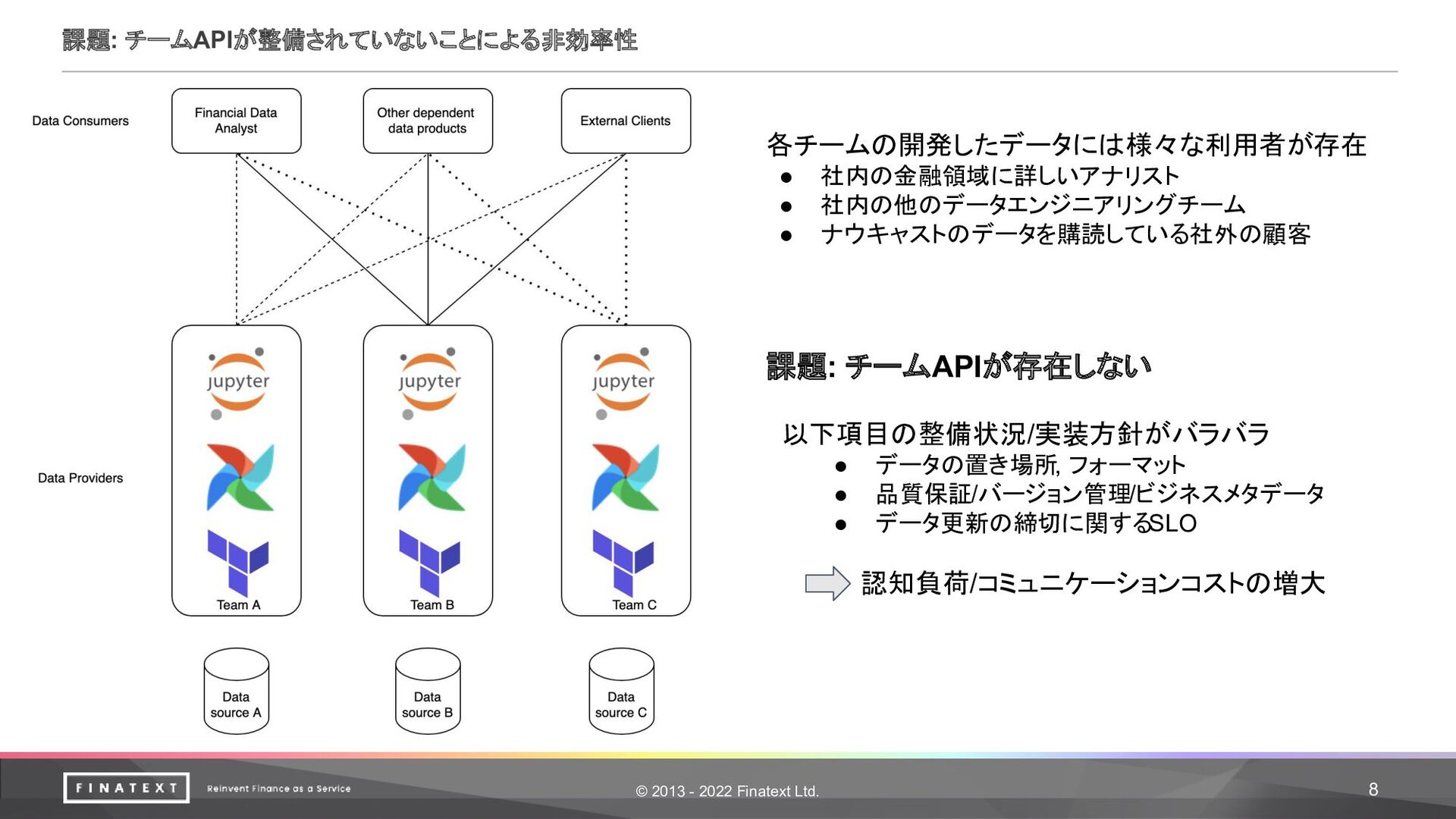
© 2013 - 2022 Finatext Ltd. 8 課題: チームAPIが整備されていないことによる非効率性 各チームの開発したデータには様々な利用者が存在
• 社内の金融領域に詳しいアナリスト • 社内の他のデータエンジニアリングチーム • ナウキャストのデータを購読している社外の顧客 課題: チームAPIが存在しない 以下項目の整備状況/実装方針がバラバラ • データの置き場所, フォーマット • 品質保証/バージョン管理/ビジネスメタデータ • データ更新の締切に関するSLO 認知負荷/コミュニケーションコストの増大
© 2013 - 2022 Finatext Ltd. 9 チーム境界とプラットフォームチーム
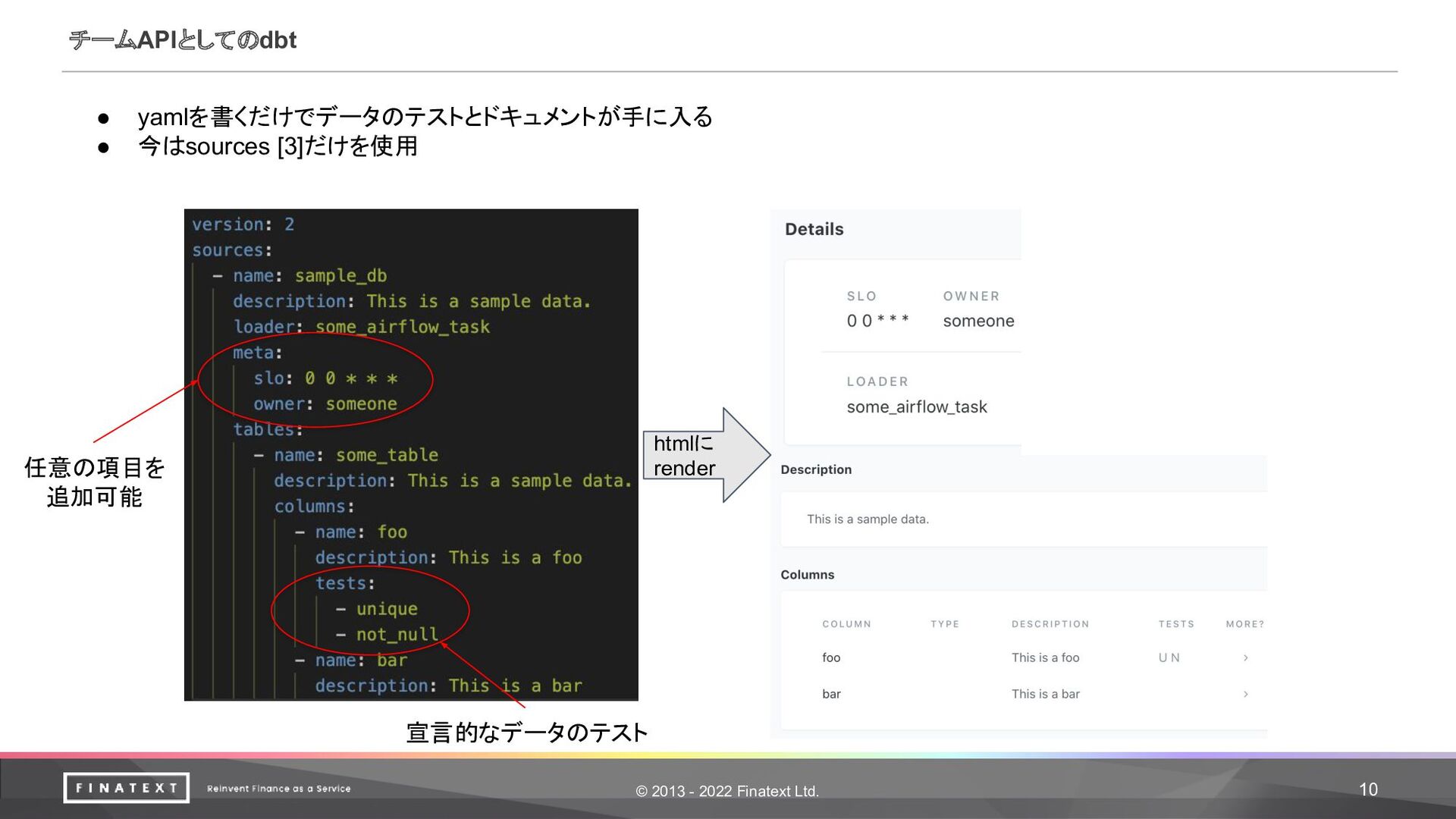
© 2013 - 2022 Finatext Ltd. 10 チームAPIとしてのdbt • yamlを書くだけでデータのテストとドキュメントが手に入る
• 今はsources [3]だけを使用 htmlに render 宣言的なデータのテスト 任意の項目を 追加可能
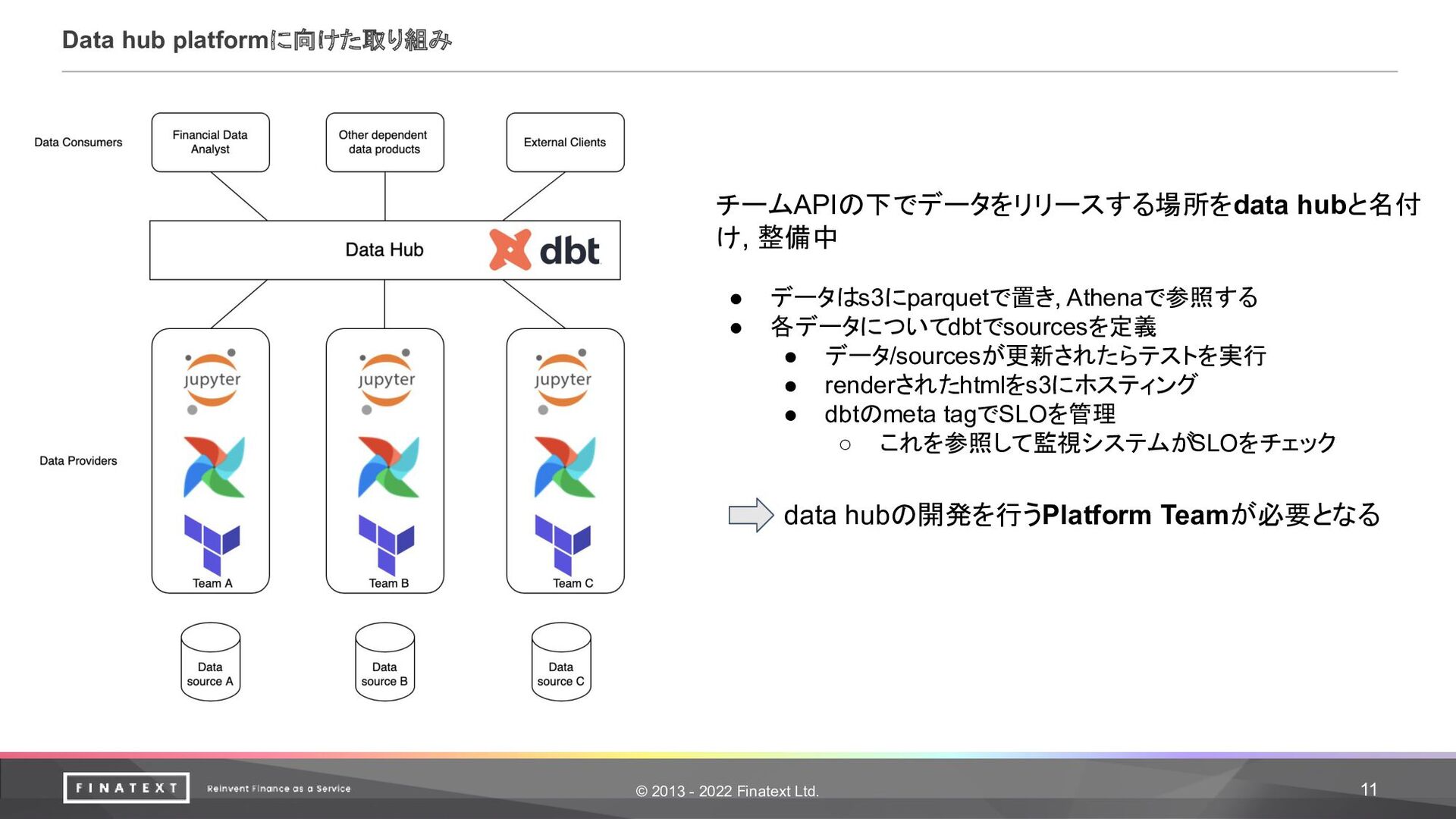
© 2013 - 2022 Finatext Ltd. 11 Data hub platformに向けた取り組み
チームAPIの下でデータをリリースする場所をdata hubと名付 け, 整備中 • データはs3にparquetで置き, Athenaで参照する • 各データについてdbtでsourcesを定義 • データ/sourcesが更新されたらテストを実行 • renderされたhtmlをs3にホスティング • dbtのmeta tagでSLOを管理 ◦ これを参照して監視システムがSLOをチェック data hubの開発を行うPlatform Teamが必要となる
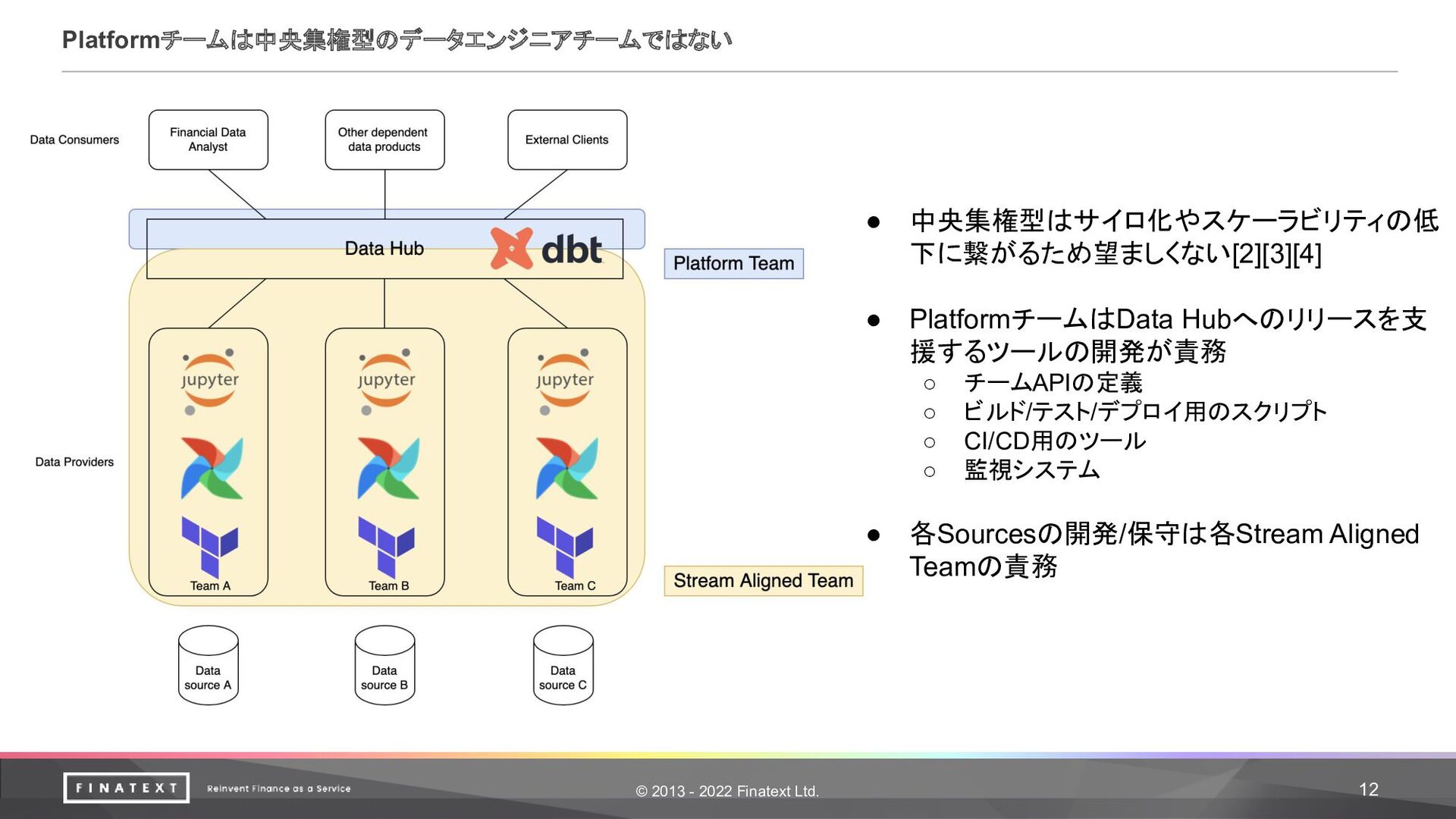
© 2013 - 2022 Finatext Ltd. 12 Platformチームは中央集権型のデータエンジニアチームではない • 中央集権型はサイロ化やスケーラビリティの低
下に繋がるため望ましくない[2][3][4] • PlatformチームはData Hubへのリリースを支 援するツールの開発が責務 ◦ チームAPIの定義 ◦ ビルド/テスト/デプロイ用のスクリプト ◦ CI/CD用のツール ◦ 監視システム • 各Sourcesの開発/保守は各Stream Aligned Teamの責務
© 2013 - 2022 Finatext Ltd. 13 Reference [1] Team
Topologies [2] 私とAWSの15年 あるいはThe Bezos Mandateの話 - NRIネットコムBlog [3] Sources | dbt Docs [4] How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh [5] Data Mesh Principles and Logical Architecture [6] Data Management at Scale
© 2013 - 2022 Finatext Ltd. 14 End
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© 2013 - 2022 Finatext Ltd. 13 Reference [1] Team](https://files.speakerdeck.com/presentations/cbd2be134fcf4bb5b11f1792fbbe9405/slide_12.jpg){kind=link}
{kind=link}