SNLP2019 Bridging the Gap between Training and Inference for Neural Machine Translation
第11回最先端NLP勉強会で読んだ ACL 2019 Best Long Paper の
Bridging the Gap between Training and Inference for Neural Machine Translation
についての資料です。ニューラル機械翻訳や文書要約、キャプション生成などの文生成タスクにおいて生じる、Exposure Bias と呼ばれる偏りについての解決策を提示する論文です。
(原田・牛久研究室) 2016.9~ 産業技術総合研究所 協力研究員 2016.12~2018.9 国立国語研究所 共同研究員 2018.10~ オムロンサイニックエックス株式会社 Principal Investigator 2019.1~ 株式会社Ridge-i Outside Chief Research Officer [Ushiku+, ACMMM 2012] [Ushiku+, ICCV 2015] 画像キャプション生成 主観的な感性表現を持つ 画像キャプション生成 動画の特定区間と キャプションの相互検索 [Yamaguchi+, ICCV 2017] A guy is skiing with no shirt on and yellow snow pants. A zebra standing in a field with a tree in the dirty background. [Shin+, BMVC 2016] A yellow train on the tracks near a train station.
and gray kitten lying on its side. A white van parked in an empty lot. A white cat rests head on a stone. Silver car parked on side of road. A small gray dog on a leash. A black dog standing in a grassy area. A small white dog wearing a flannel warmer. Input Image A small white dog wearing a flannel warmer. A small gray dog on a leash. A black dog standing in a grassy area. Nearest Captions A small white dog wearing a flannel warm A small gray dog on a leash. A black dog standing in a grassy area. A small white dog standing on a leash.
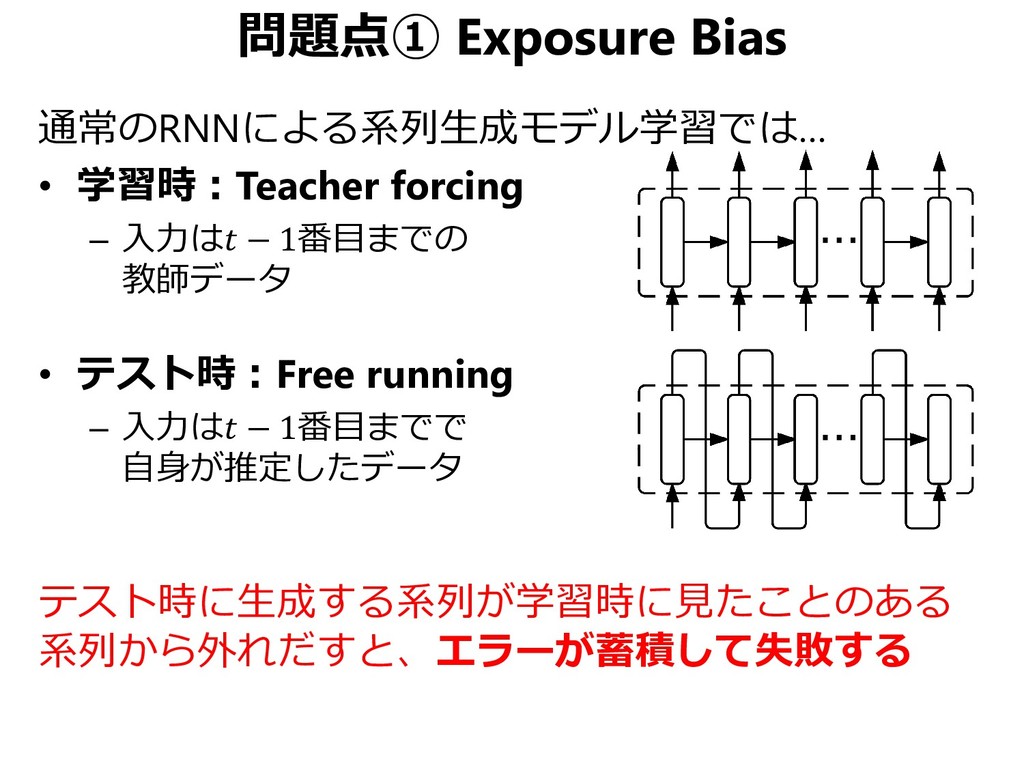
rule. 私たちはその規則を守るべきだ。 • cand1: We should abide with the rule. 私たちはその規則のもとにとどまるべきだ。 comply with と abide with の違い(abide を使うなら by が正しい) • cand2: We should abide by the law. 私たちは法律を守るべきだ。 単語 abide のあとに by を正しく推定できても、その後の単語列が by につられて参照訳と違うものになる可能性がある • cand3: We should abide by the rule. 私たちは規則を守るべきだ。 これが望ましい出力例である
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Encoder-Decoder による文生成タスク • Encoder が文特徴抽出 – 機械翻訳 [Sutskever+, NIPS 2014]](https://files.speakerdeck.com/presentations/1ea55c6af05f4ce4a79f2e8af9907dcf/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![解決アプローチ① 文生成中の条件の工夫 Scheduled sampling [Venkatraman+, AAAI 2015] Data As Demonstrator](https://files.speakerdeck.com/presentations/1ea55c6af05f4ce4a79f2e8af9907dcf/slide_8.jpg){kind=link}
{kind=link}
![解決アプローチ② 強化学習の利用 MIXER [Ranzato+, ICLR 2016] • 評価指標を報酬として、方策勾配による強化学習 • Exposure](https://files.speakerdeck.com/presentations/1ea55c6af05f4ce4a79f2e8af9907dcf/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
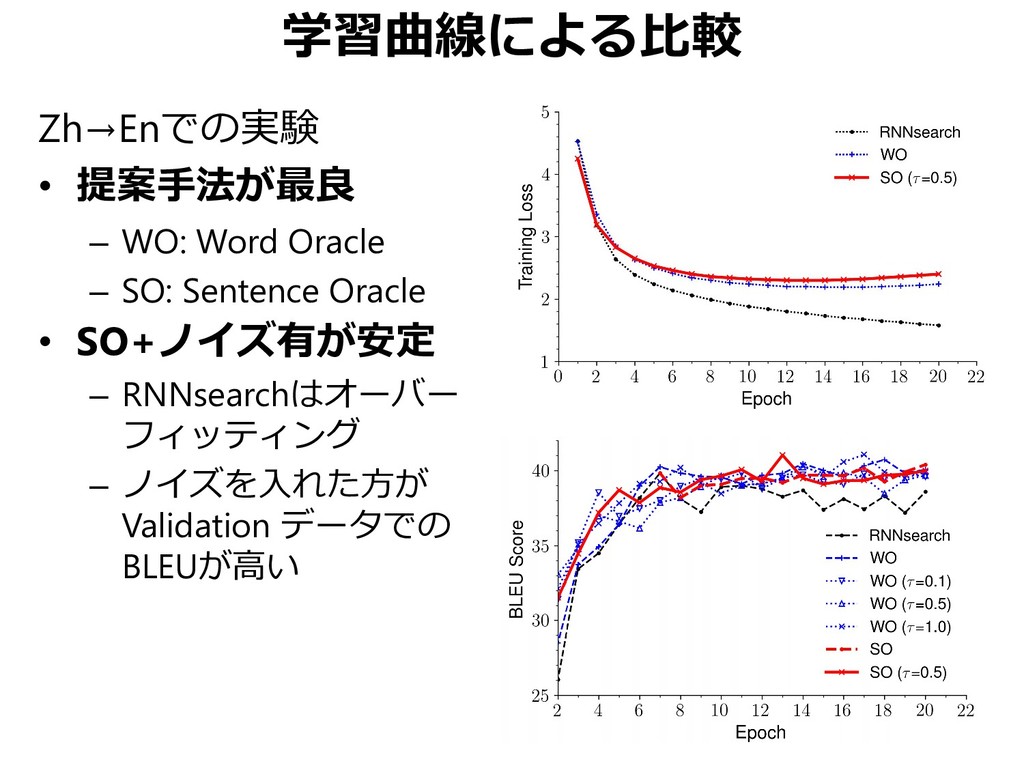{kind=link}
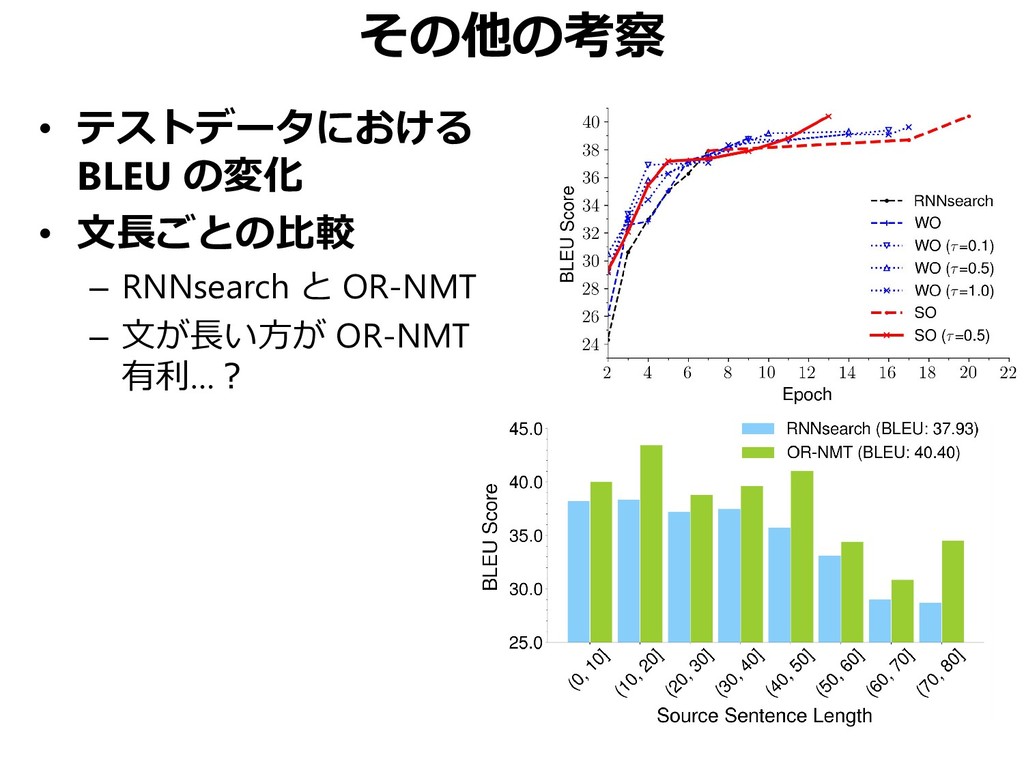{kind=link}
{kind=link}
{kind=link}
{kind=link}