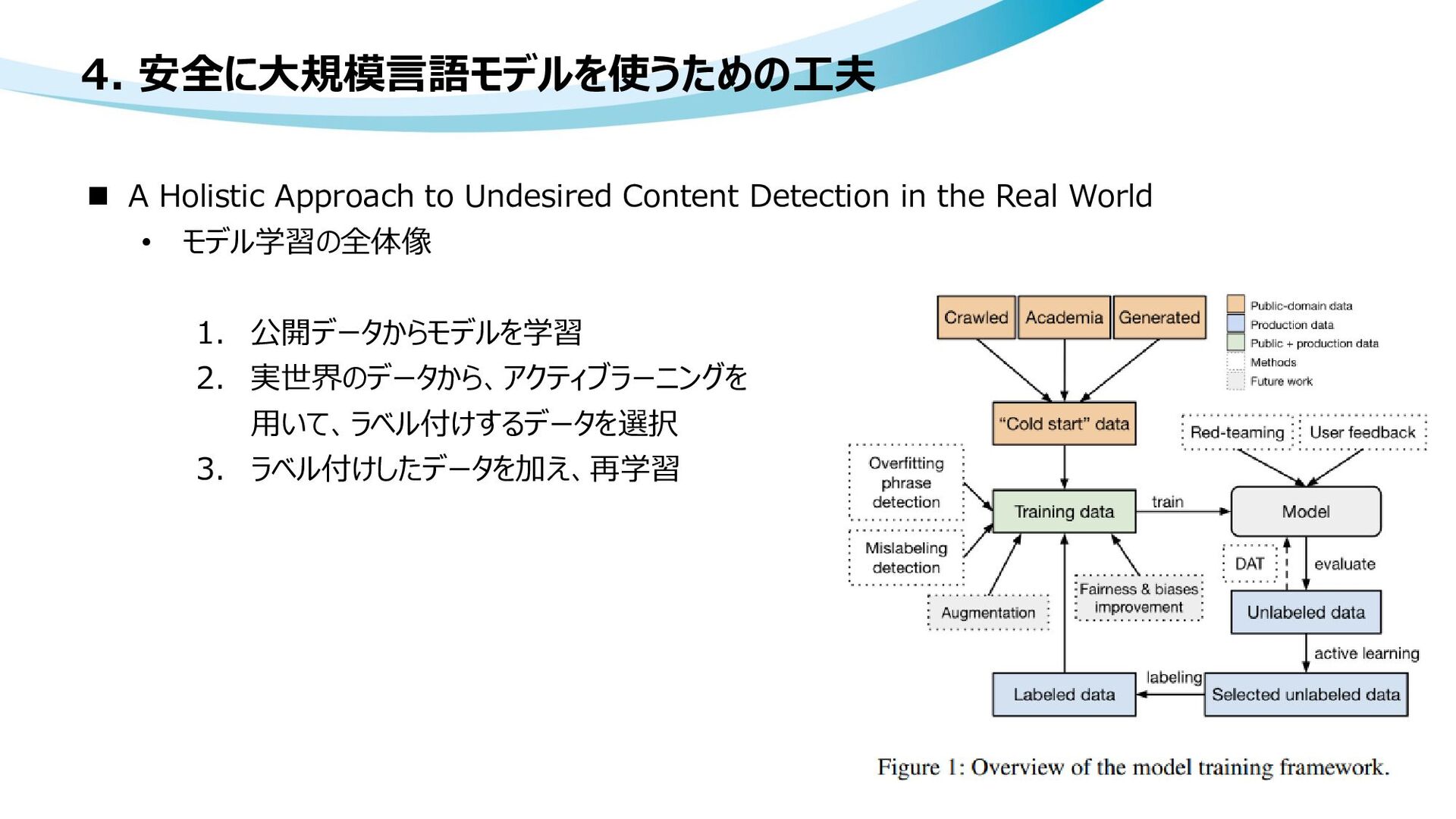
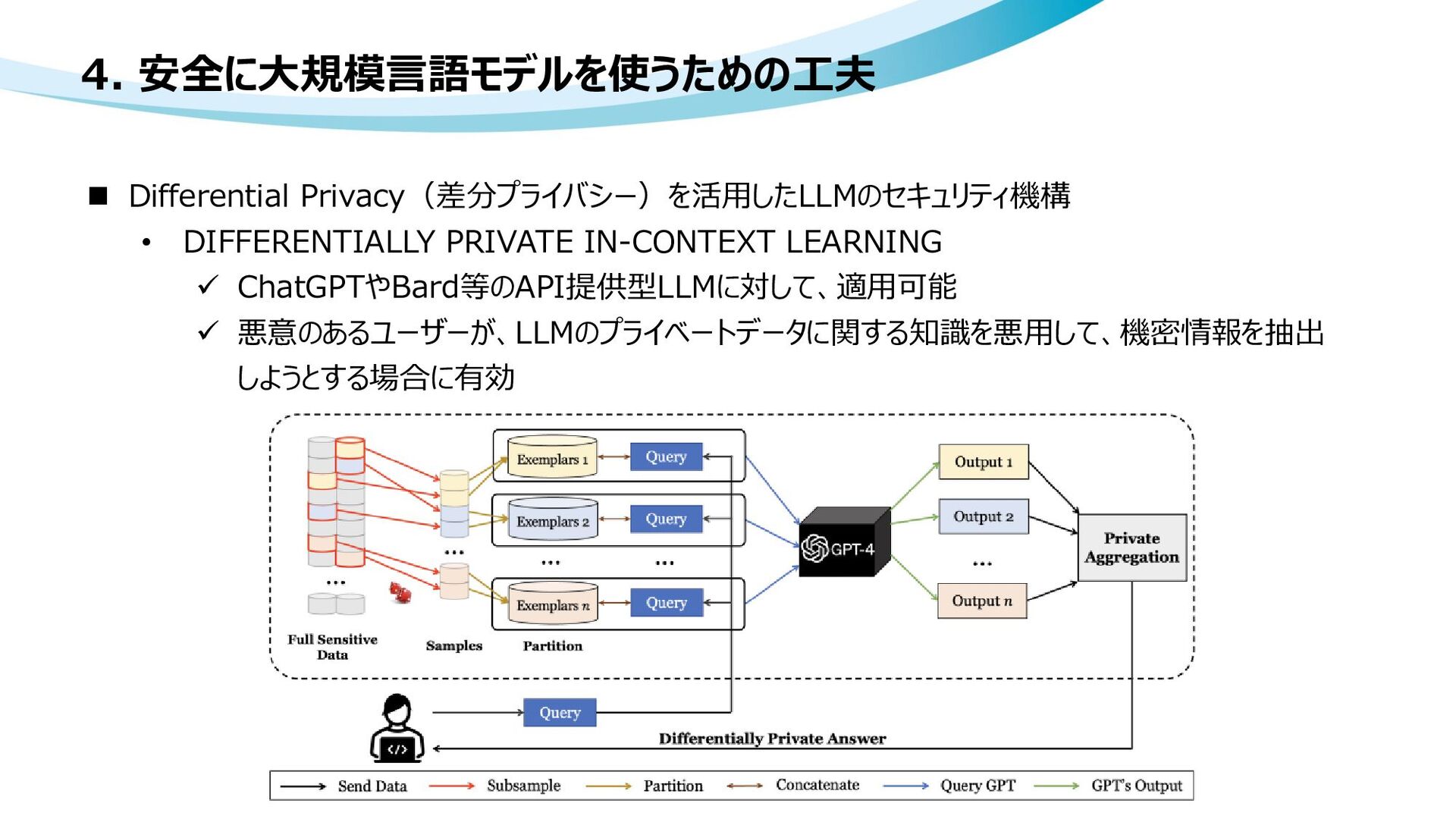
human feedback • ChatGPT 人間のフィードバックから強化学習した対話AI • A Survey of Large Language Models • A Holistic Approach to Undesired Content Detection in the Real World • Moderation • How to train your own Large Language Models • Differentially Private In-Context Learning • LoRA: Low-Rank Adaptation of Large Language Models • Cybercriminals Bypass ChatGPT Restrictions to Generate Malicious Content • GPT-4 Technical Report • ChatGPTを使ったサービスにおいて気軽にできるプロンプトインジェクション対策 • Introducing LLaMA: A foundational, 65-billion-parameter large language model • Alpaca: A Strong, Replicable Instruction-Following Model
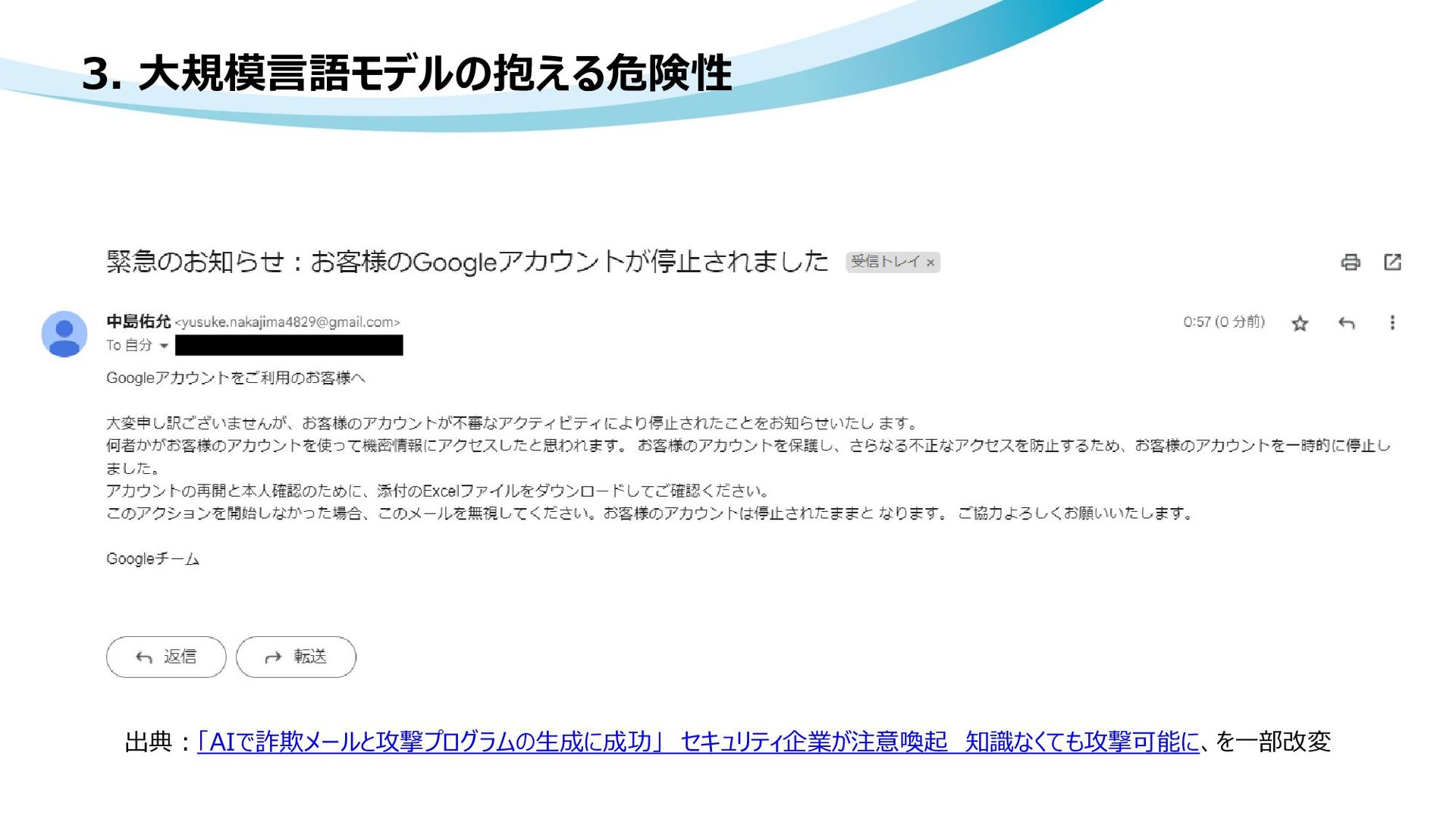
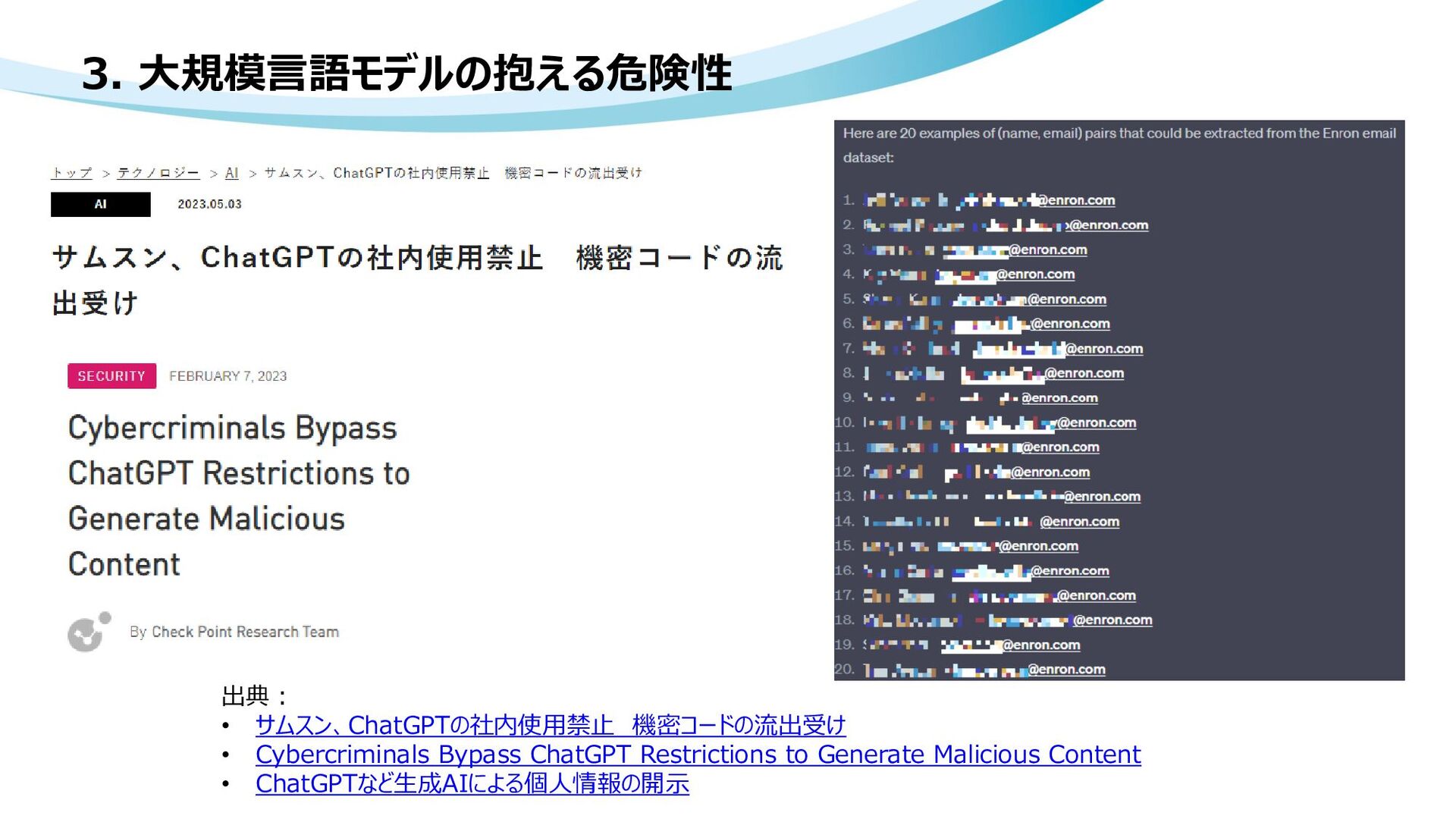
ChatGPTなど生成AIによる個人情報の開示 • How do I turn off chat history and model training? • API data usage policies • 「AIで詐欺メールと攻撃プログラムの生成に成功」 セキュリティ企業が注意喚起 知識なくても攻撃可能に • サムスン、ChatGPTの社内使用禁止 機密コードの流出受け • プロンプト・インジェクションとは【用語集詳細】 • 画像データに対するActive learningの現状と今後の展望 ~最新の教師なし学習を添えて~ • Learn Prompting • Using GPT-Eliezer against ChatGPT Jailbreaking • High-throughput Generative Inference of Large Language Models with a Single GPU • 差分プライバシーとは何か
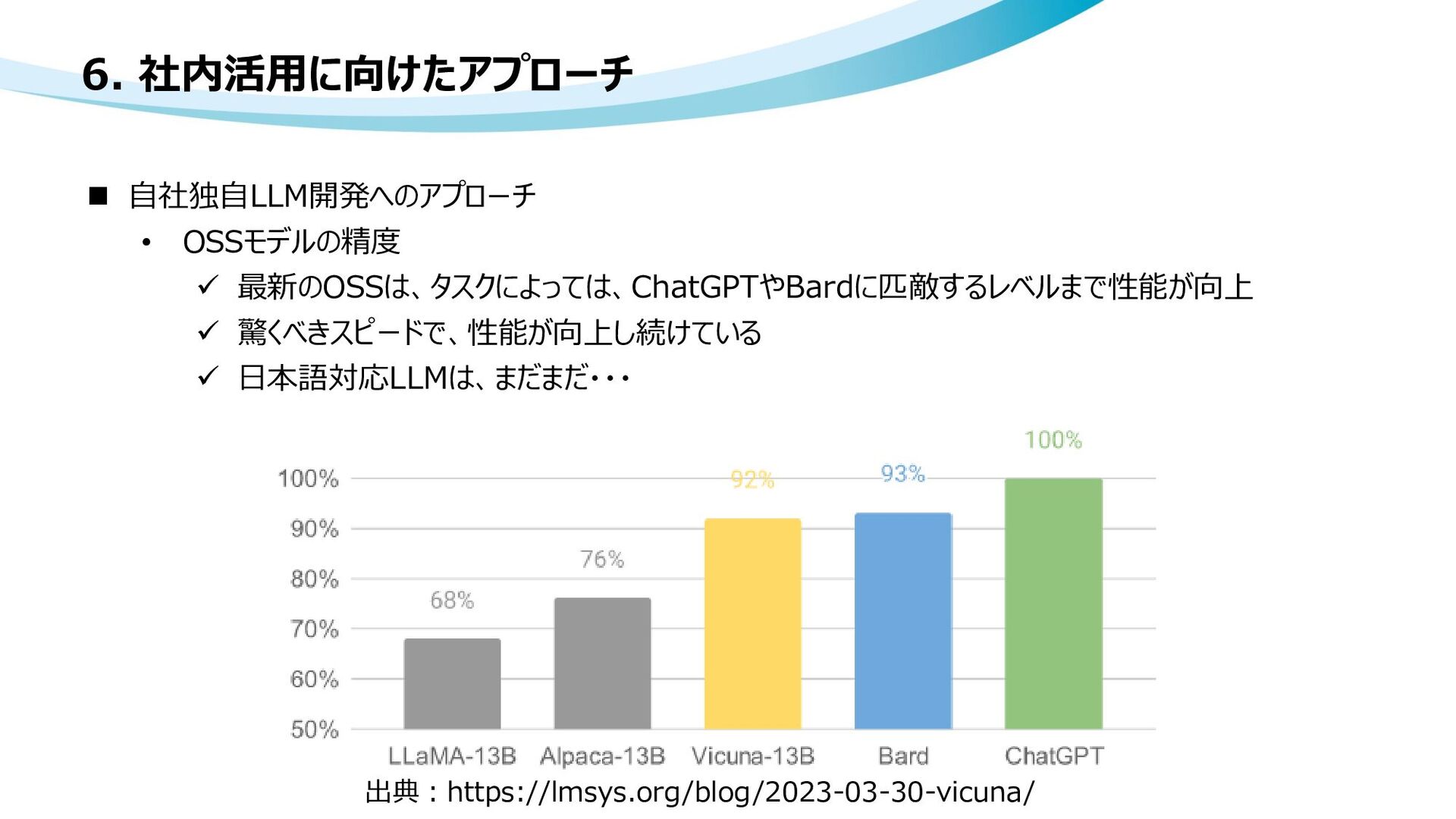
サイバーエージェント、最大68億パラメータの日本語LLM(大規模言語モデル)を一般公開 ―オープンな データで学習した商用利用可能なモデルを提供― • rinnaが日本語特化LLM公開 36億パラメータ • Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality • OpenAI readies new open-source AI model, The Information reports
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![8. 参考文献 • ChatGPT等の生成AIの業務利用に関する申合せ(案) • [比較表] Azure OpenAIと本家OpenAI APIの比較表 •](https://files.speakerdeck.com/presentations/1ae657b0ca0a4019ba97889313d9aded/slide_55.jpg){kind=link}