Wang1∗, Jifeng Dai2,1∗, Zhe Chen3,1∗, Zhenhang Huang1∗, Zhiqi Li3,1∗, Xizhou Zhu4∗, Xiaowei Hu1, Tong Lu3, Lewei Lu4, Hongsheng Li5, Xiaogang Wang4,5, Yu Qiao1 1Shanghai AI Laboratory 2Tsinghua University 3Nanjing University 4SenseTime Research 5The Chinese University of Hong Kong *equal contribution 発表者 @yuukicammy 第59回 コンピュータビジョン勉強会@関東(後編) Aug. 26, 2023
{kind=link}
{kind=link}
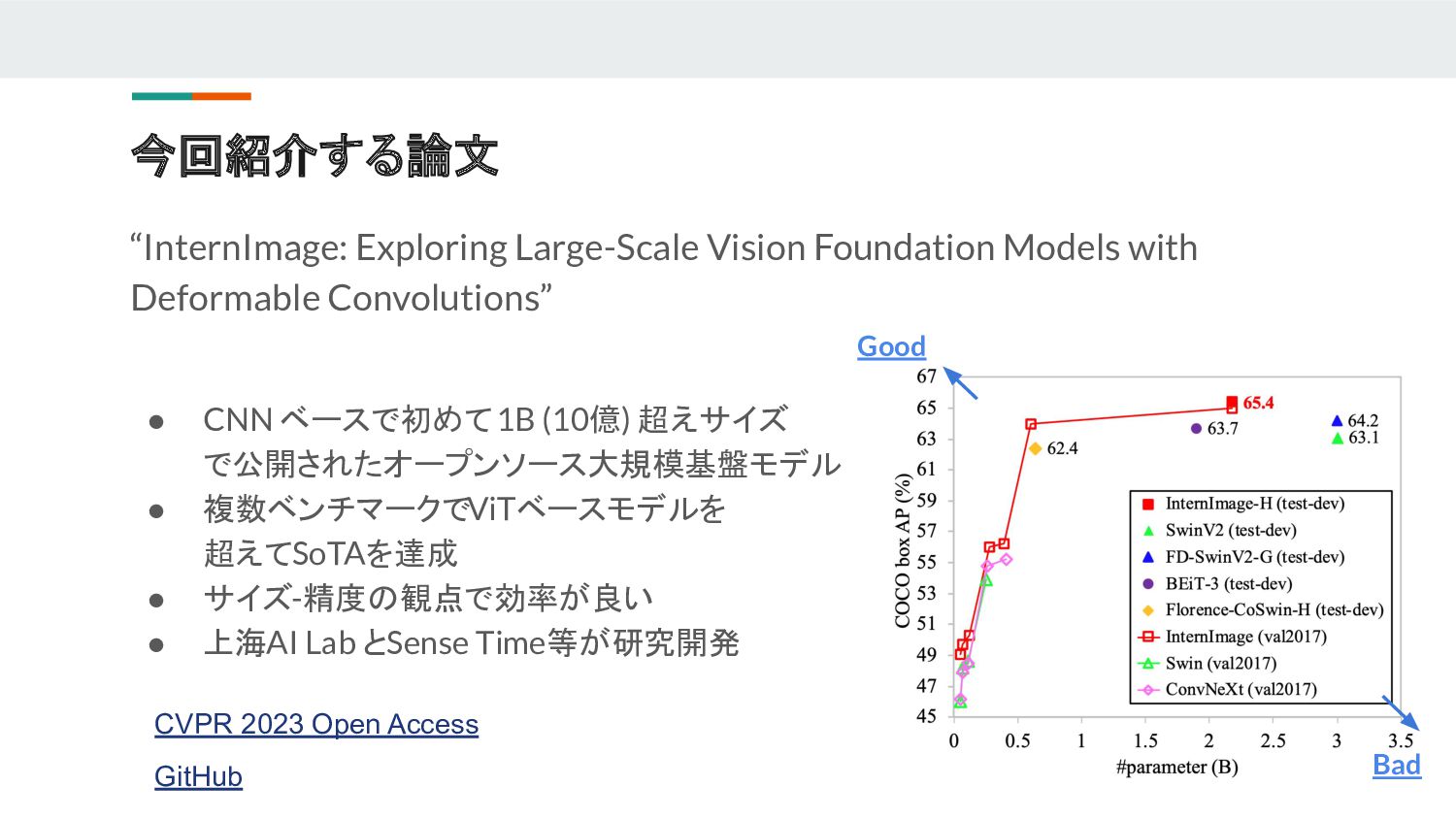{kind=link}
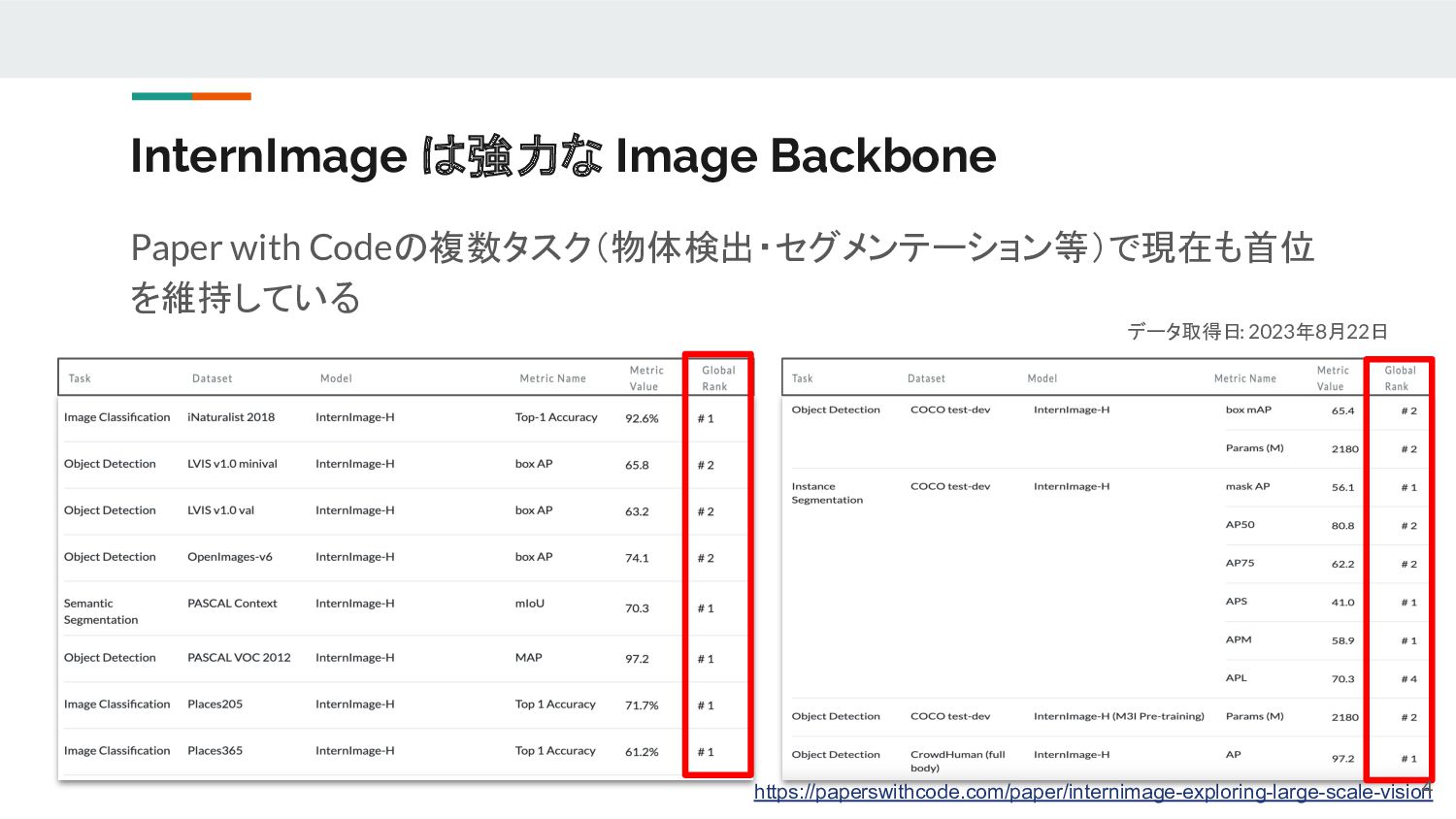{kind=link}
{kind=link}
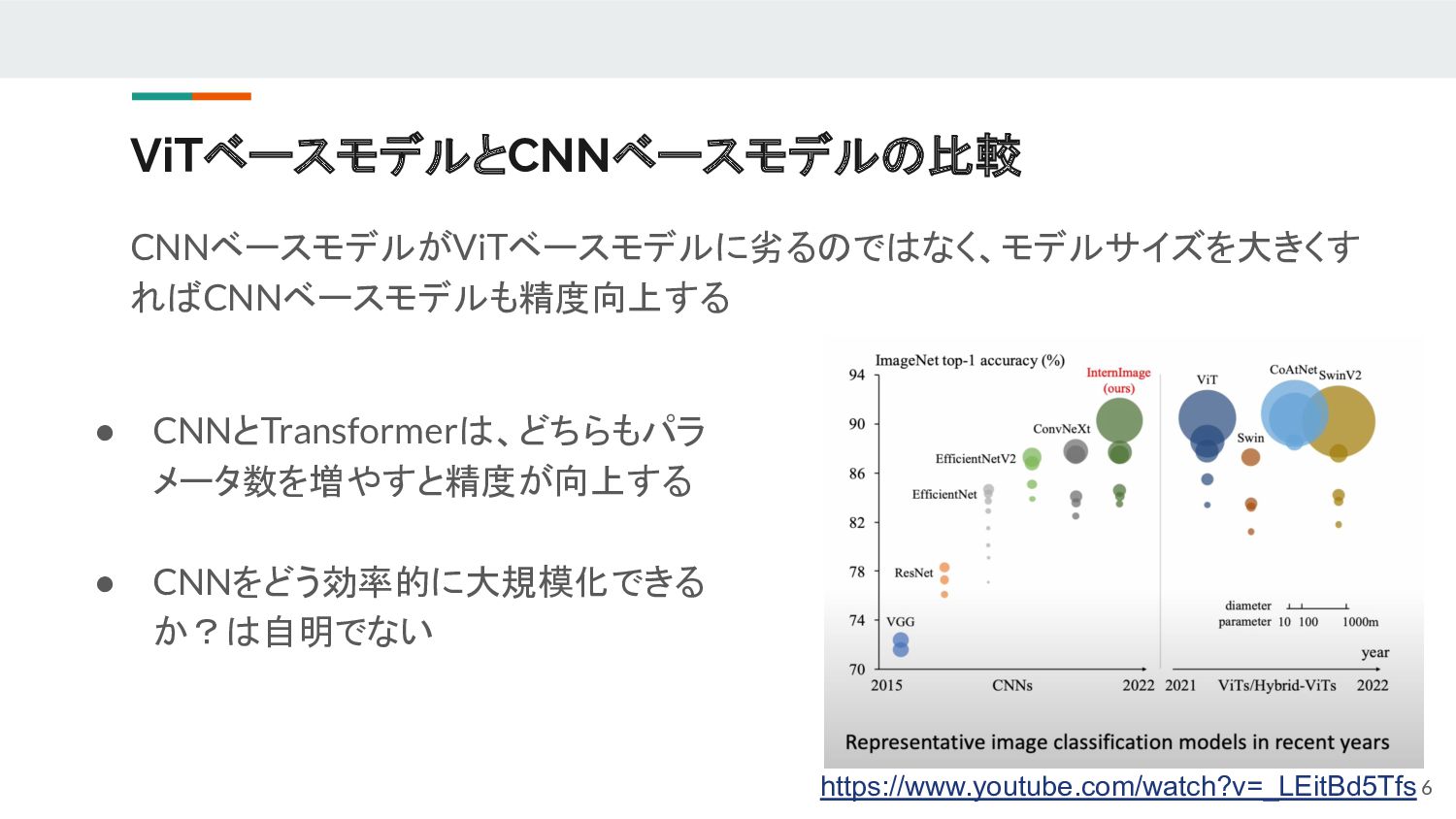{kind=link}
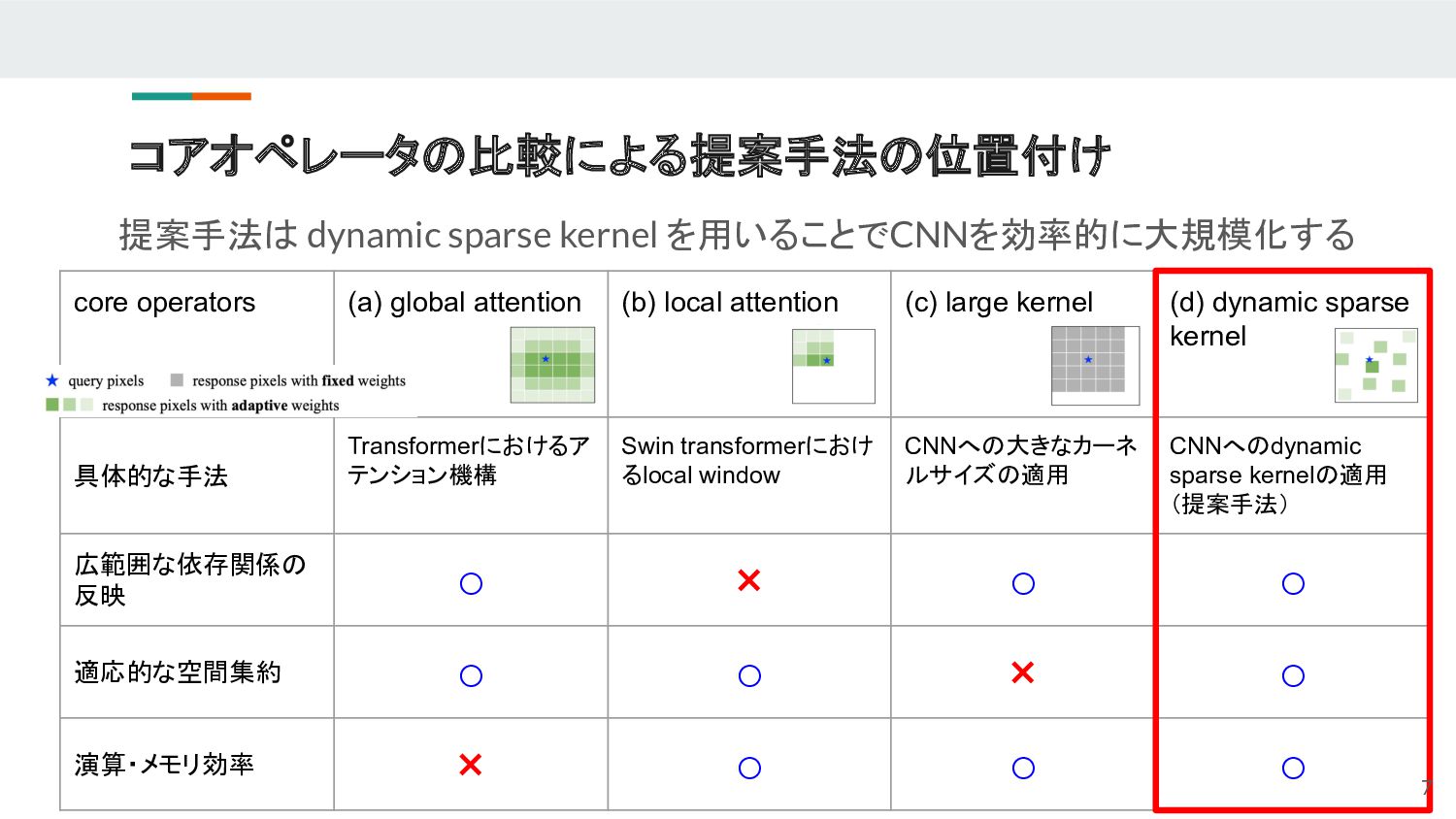{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
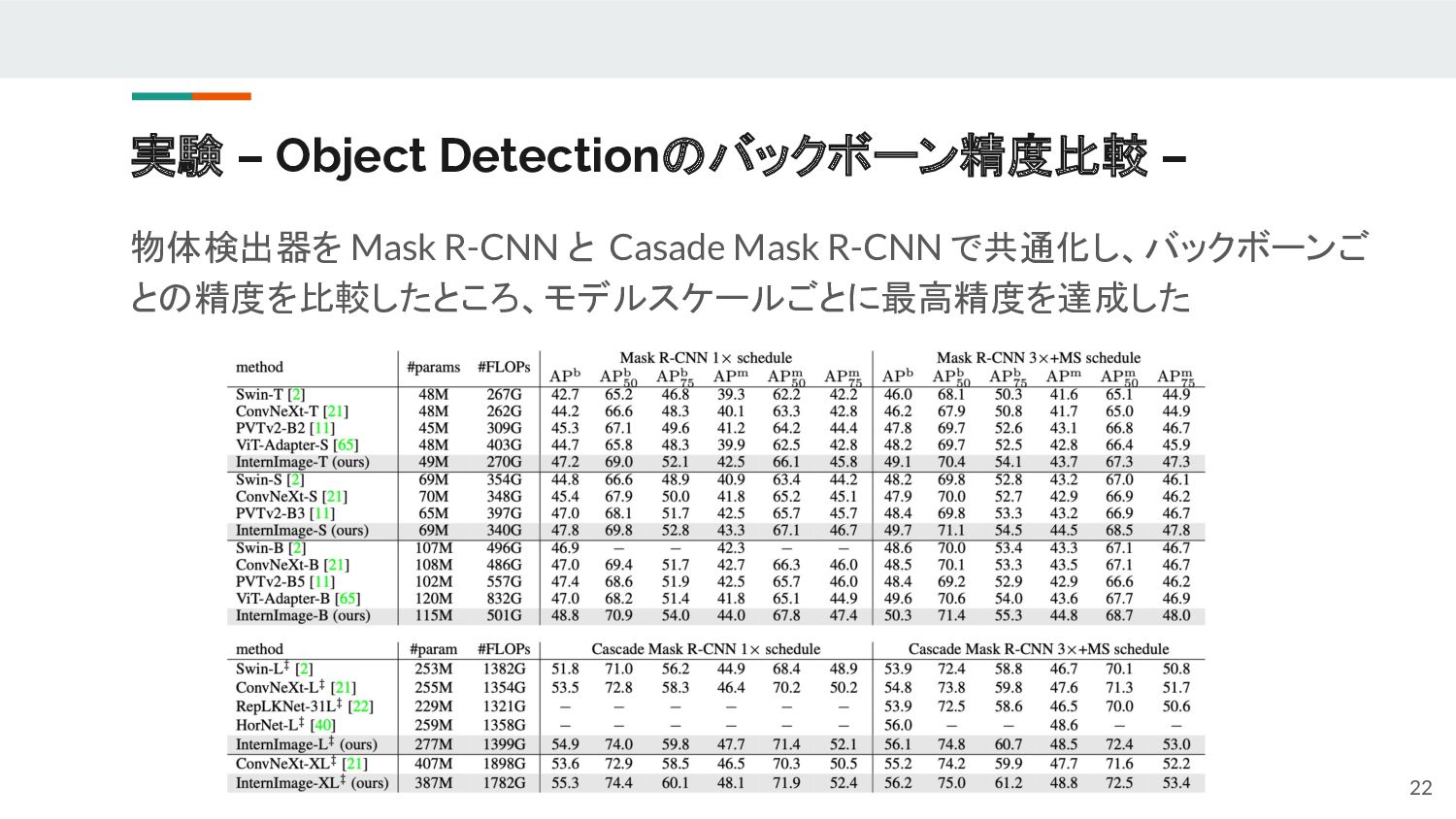{kind=link}
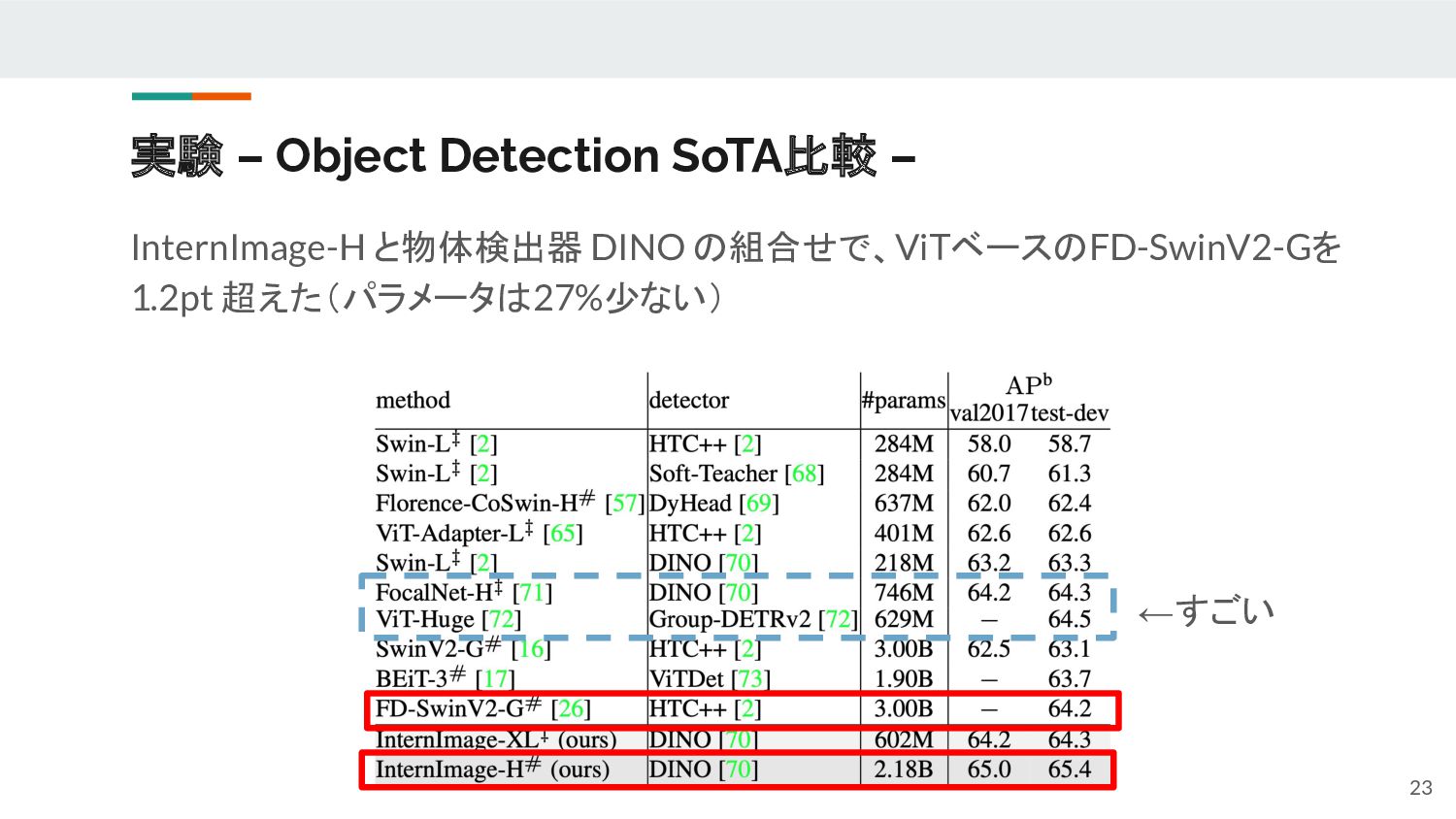{kind=link}
{kind=link}
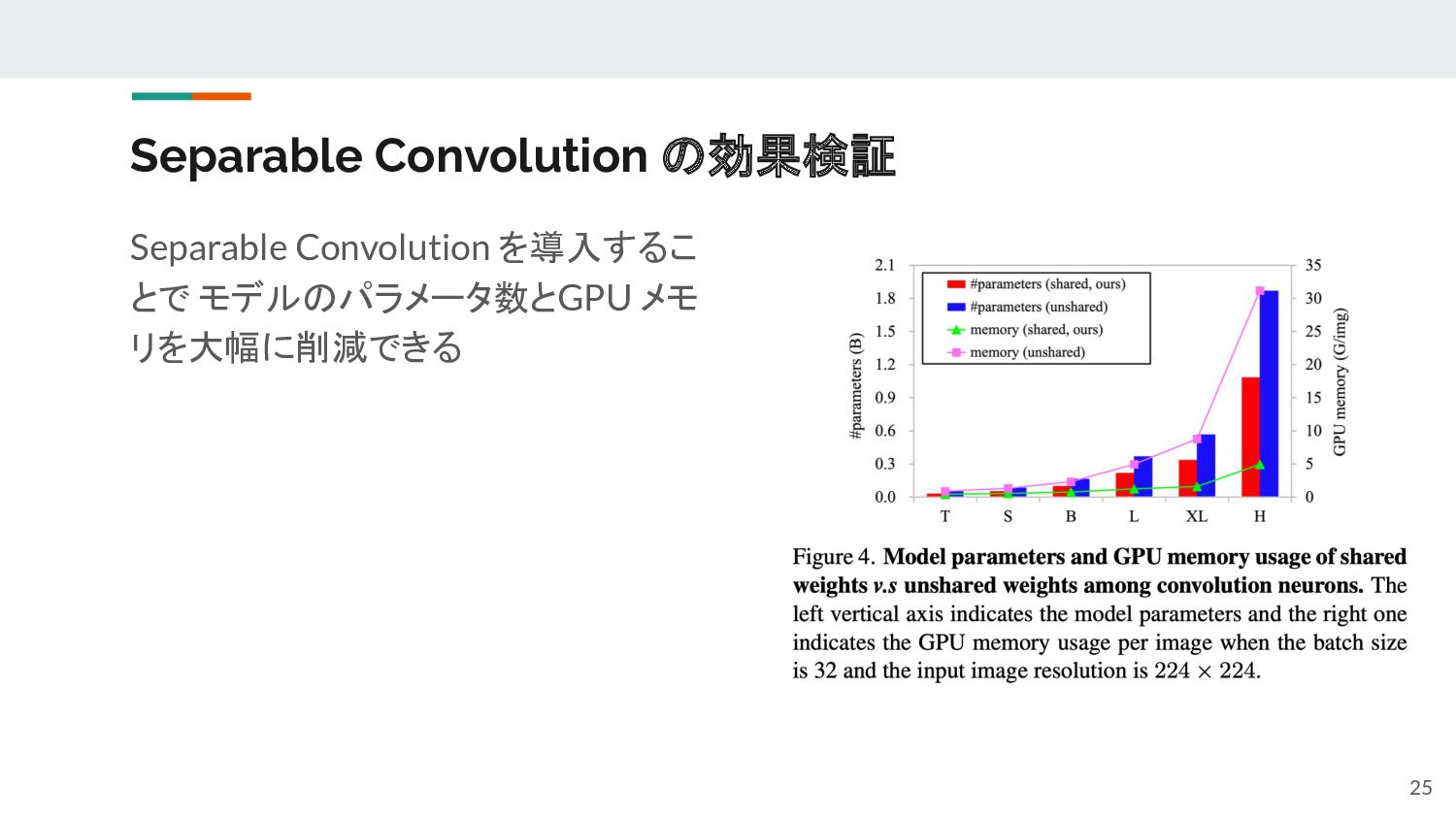{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
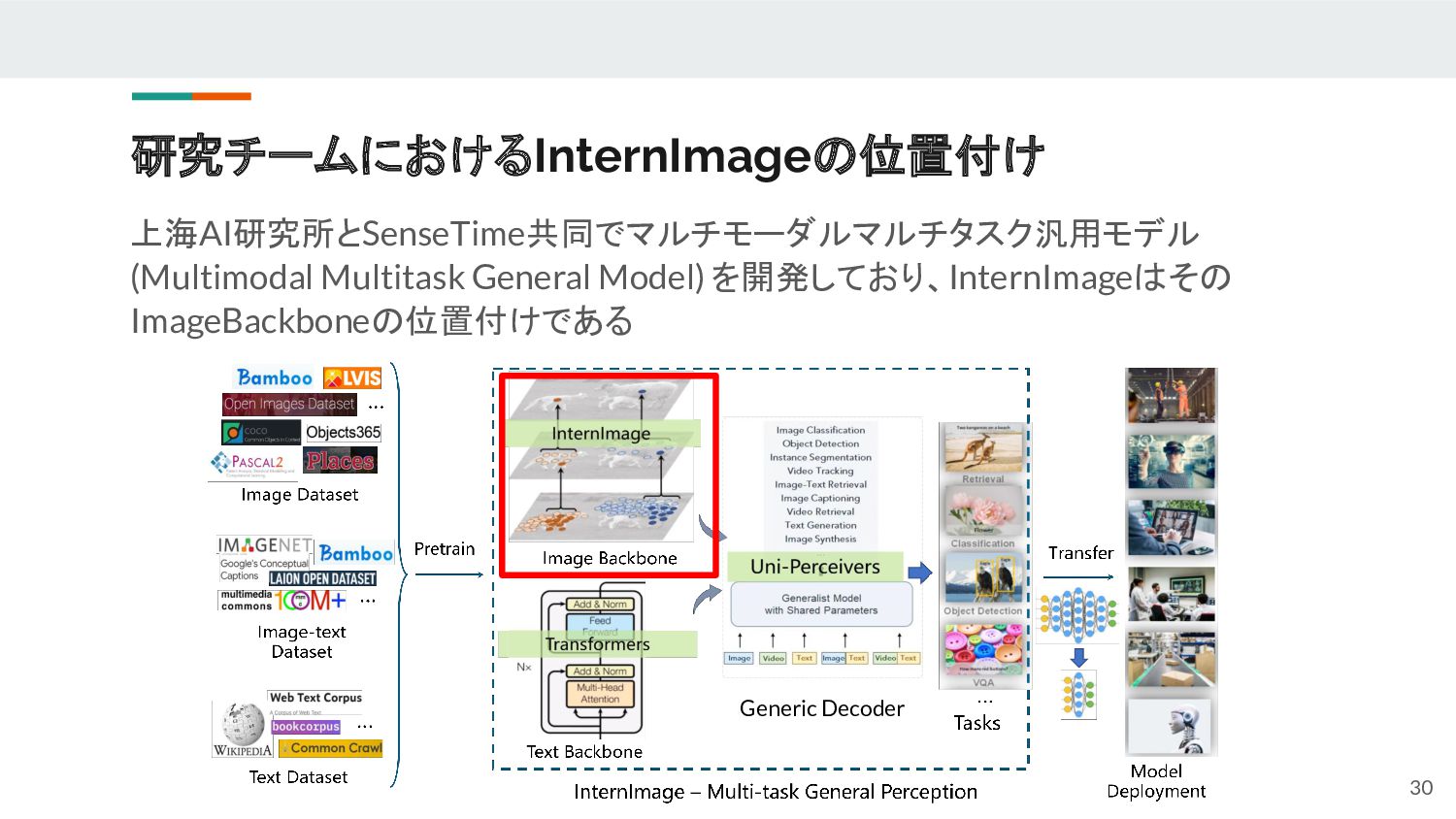
![研究チームはInternImage以外にも注目研究が多い Generic Decoder 大規模基盤モデル構築から自動運転応用まで多様な切り口で研究開発がなさ れ、CVPR 2023 だけでも6件の発表がされた(うち1件はベスト賞) 事前学習手 法:[CVPR2023] M3I-Pretraining](https://files.speakerdeck.com/presentations/bfead039a0604da9a5e074af25ebb5c7/slide_30.jpg){kind=link}
{kind=link}
{kind=link}