- Invited talk at 9th International Workshop on Symbolic-Neural Learning (SNL2025), Oct 29, 2025 @Osaka, Japan, https://im.sanken.osaka-u.ac.jp/snl2025/
- Keynote at 3rd International Workshop on Deep Multimodal Generation and Retrieval at ACMMM 2025, Oct 27, 2025 @Dublin, Ireland, https://videorelation.nextcenter.org/MMGR2025/
Yusuke Matsui (The University of Tokyo)
https://yusukematsui.me/index.html
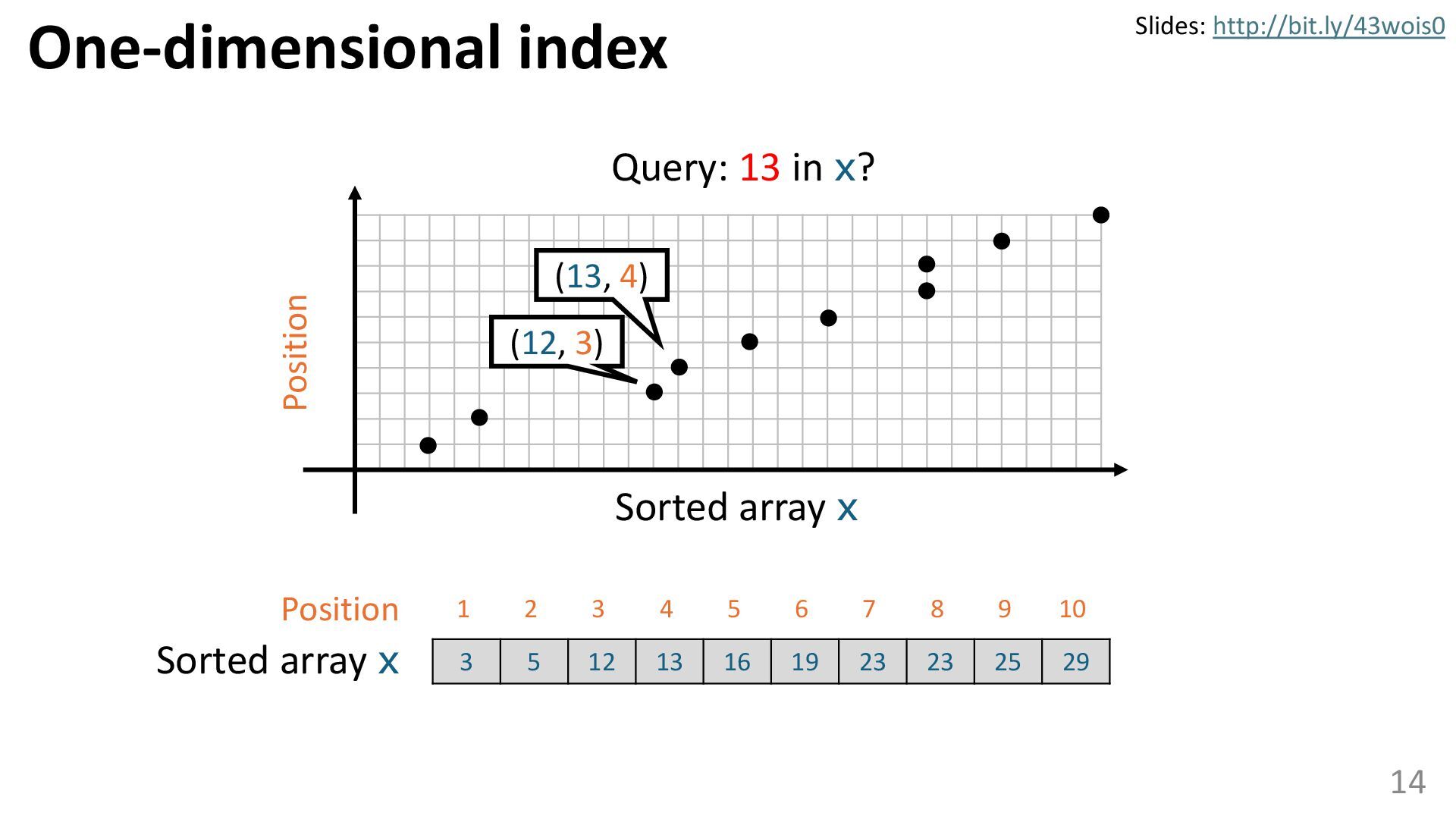
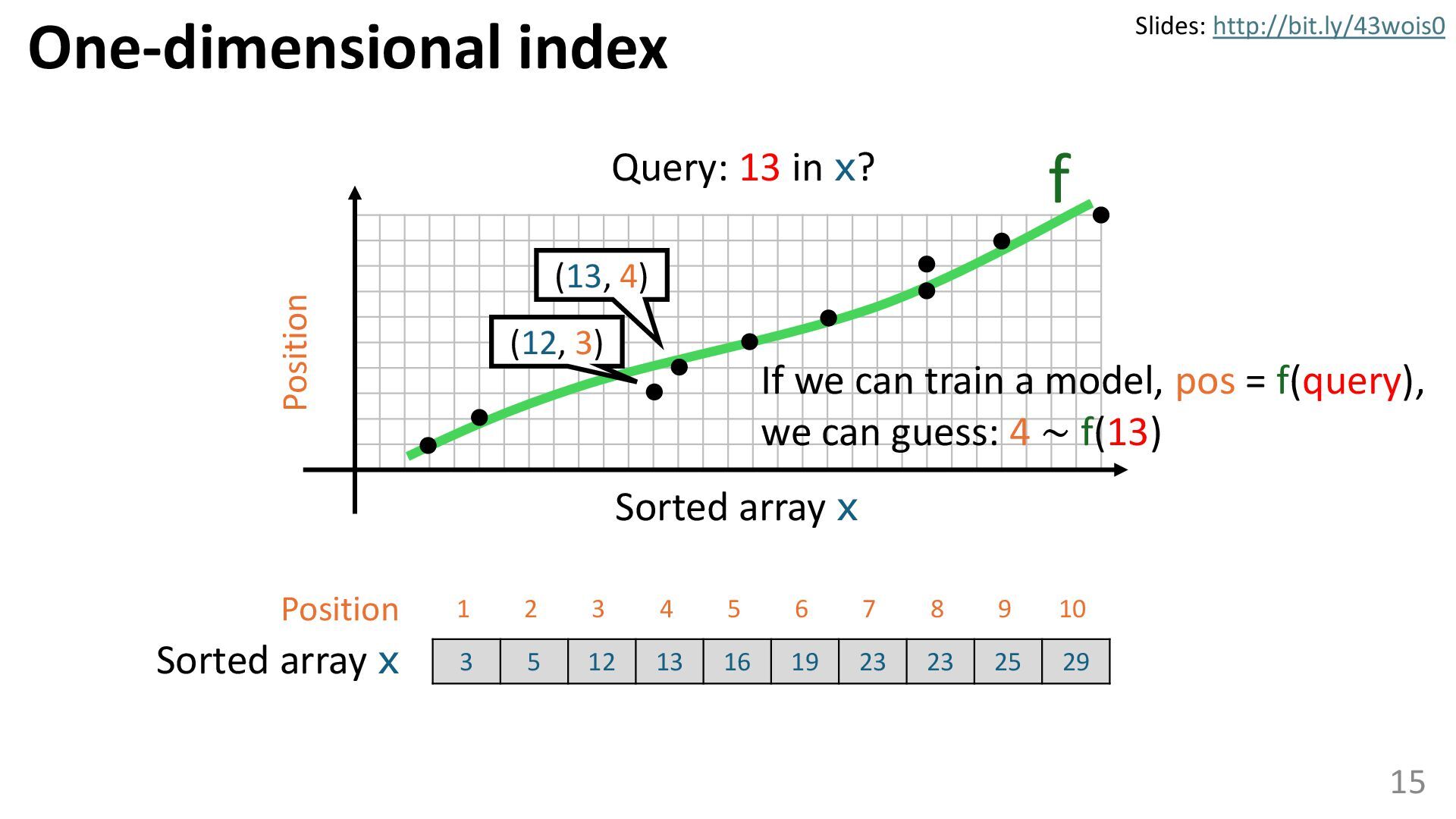
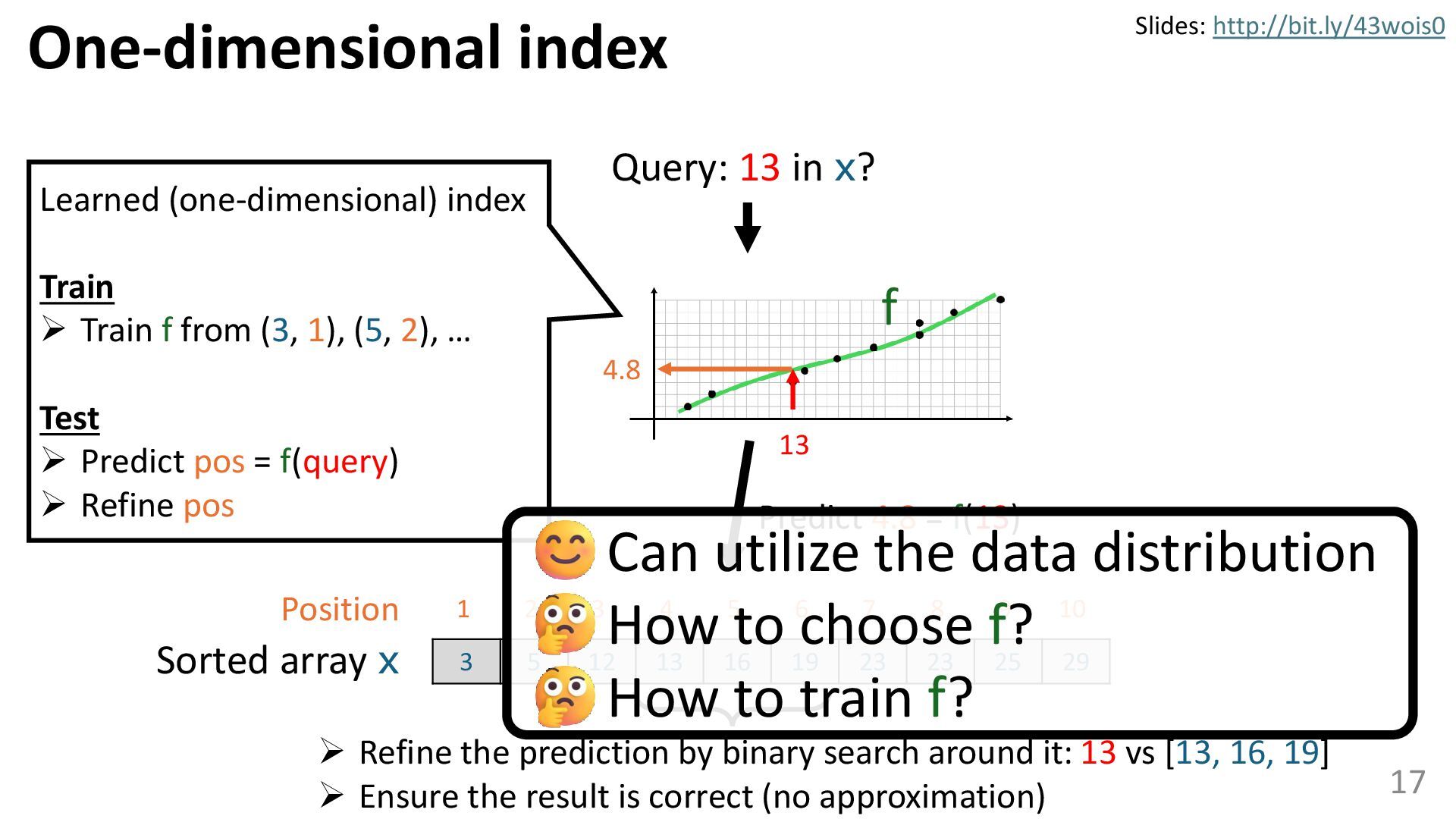
Learned data structures are a new type of data structure that enhances the performance of classical data structures, such as B-trees, by leveraging the power of machine learning. Learned data structures have been actively studied in the database field and hold the potential to accelerate many procedures across various domains. However, their capabilities are not yet widely recognized. In this talk, I will explore whether learned data structures can be applied to tasks in computer vision, and also discuss how applications in computer vision may influence learned data structures. In this discussion, I explore the potential of learned data structures, next-generation data structures incorporating machine learning.
{kind=link}
{kind=link}
![http://bit.ly/43wois0 Slides: http://bit.ly/43wois0 3 3D reconstruction [1] [1] Wang+, “VGGT:](https://files.speakerdeck.com/presentations/c5e65f898302456badd849e0a3767651/slide_2.jpg){kind=link}
![http://bit.ly/43wois0 Slides: http://bit.ly/43wois0 4 3D reconstruction [1] [1] Wang+, “VGGT:](https://files.speakerdeck.com/presentations/c5e65f898302456badd849e0a3767651/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
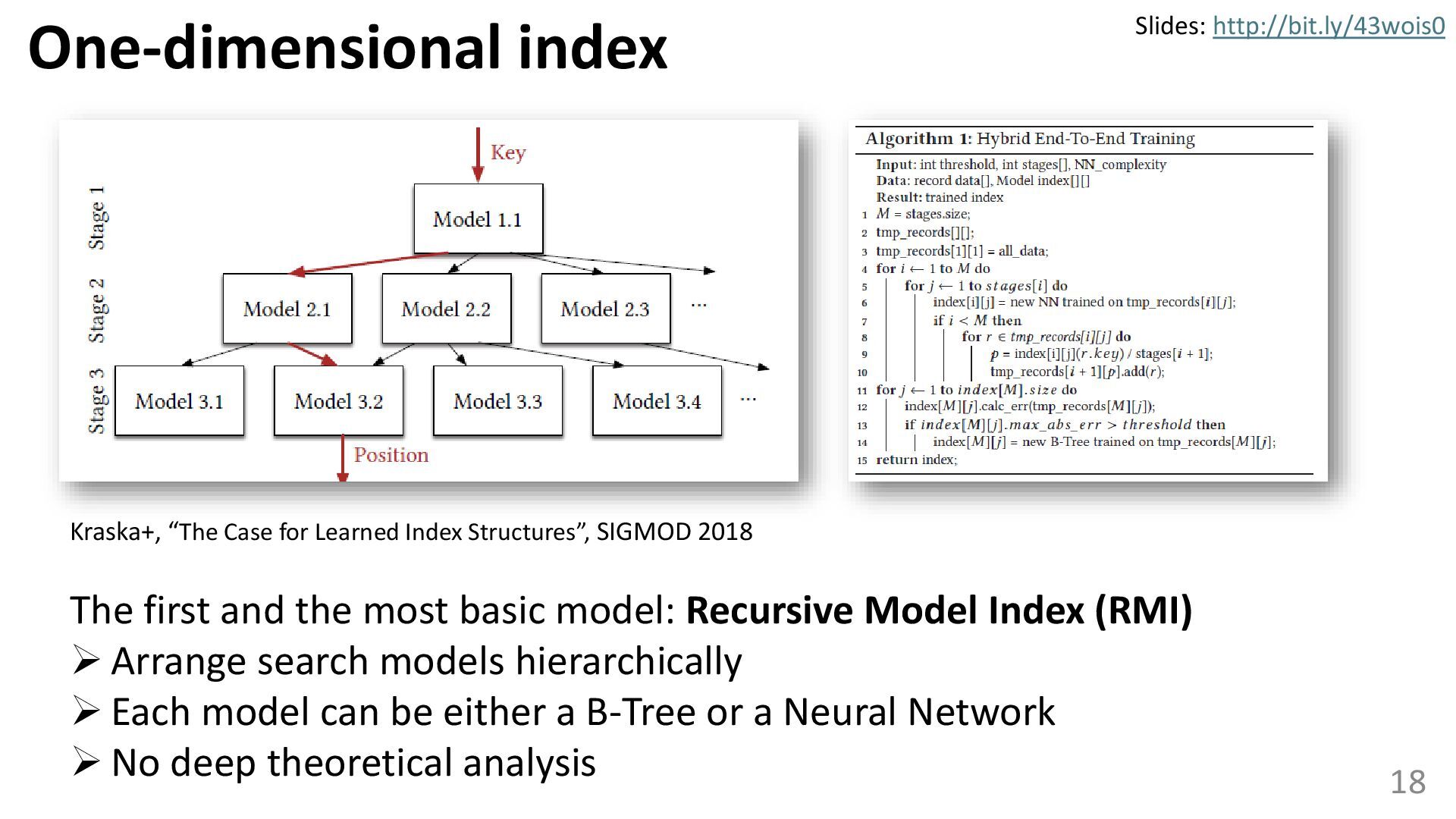{kind=link}
{kind=link}
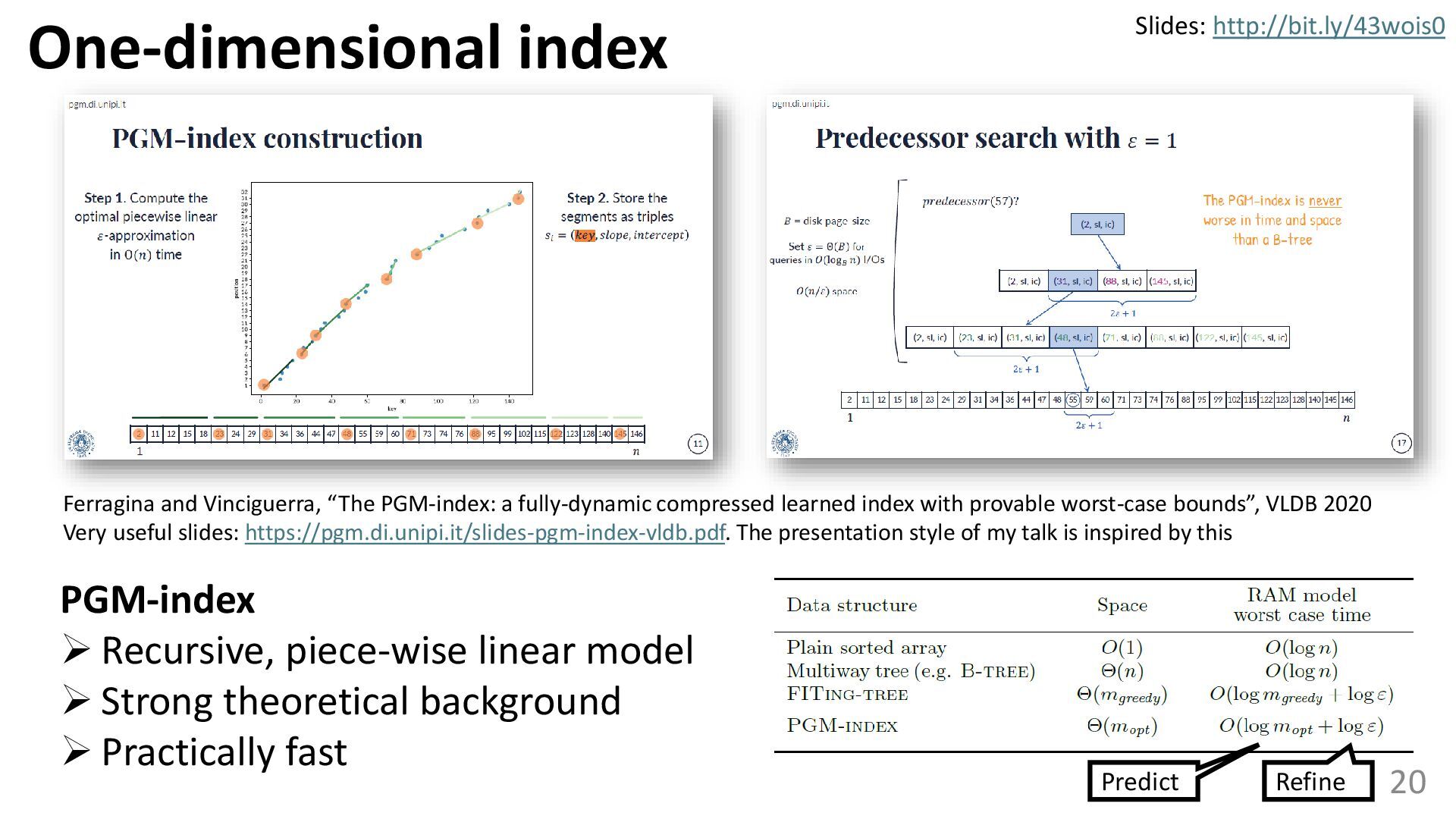{kind=link}
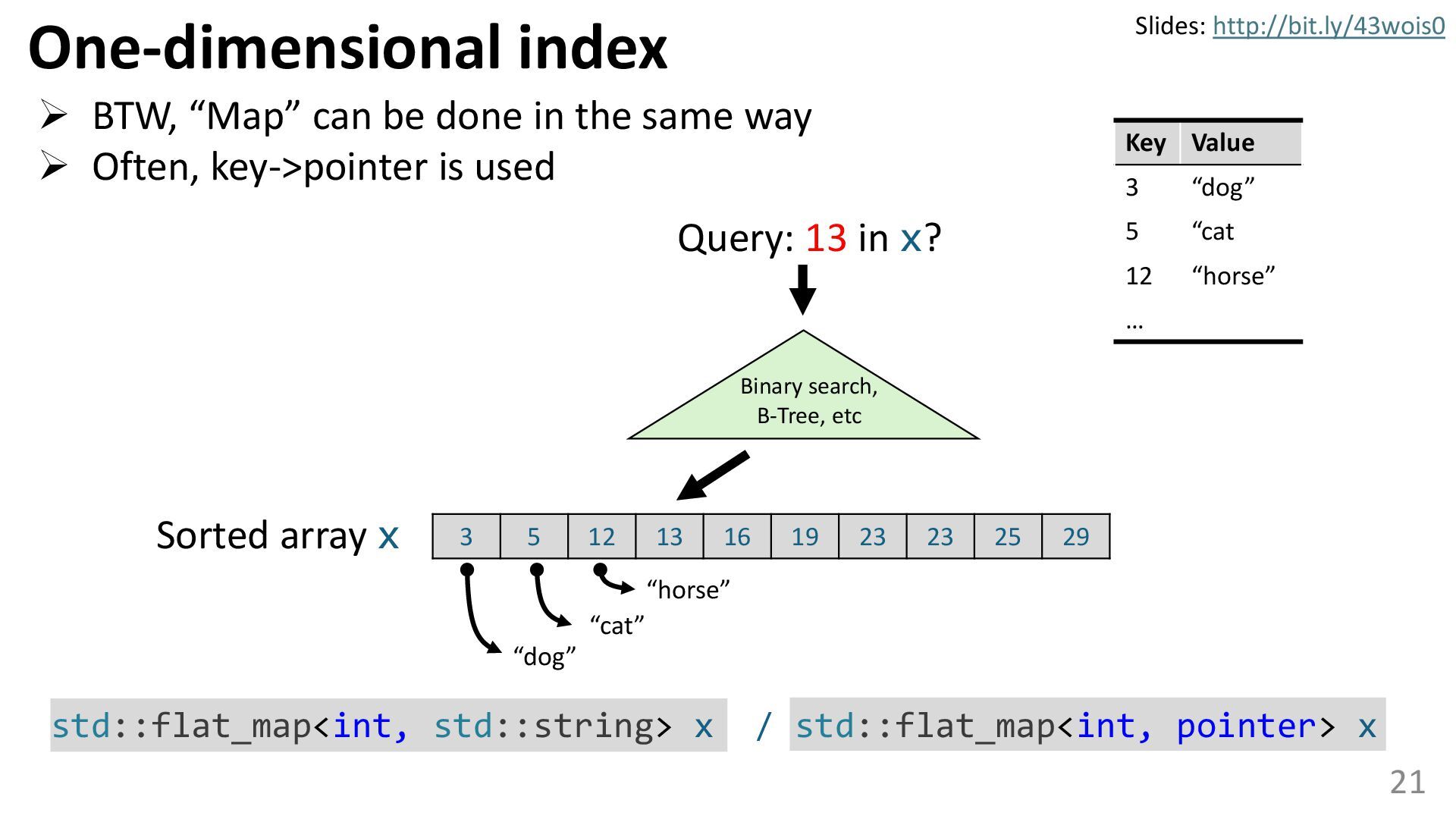{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
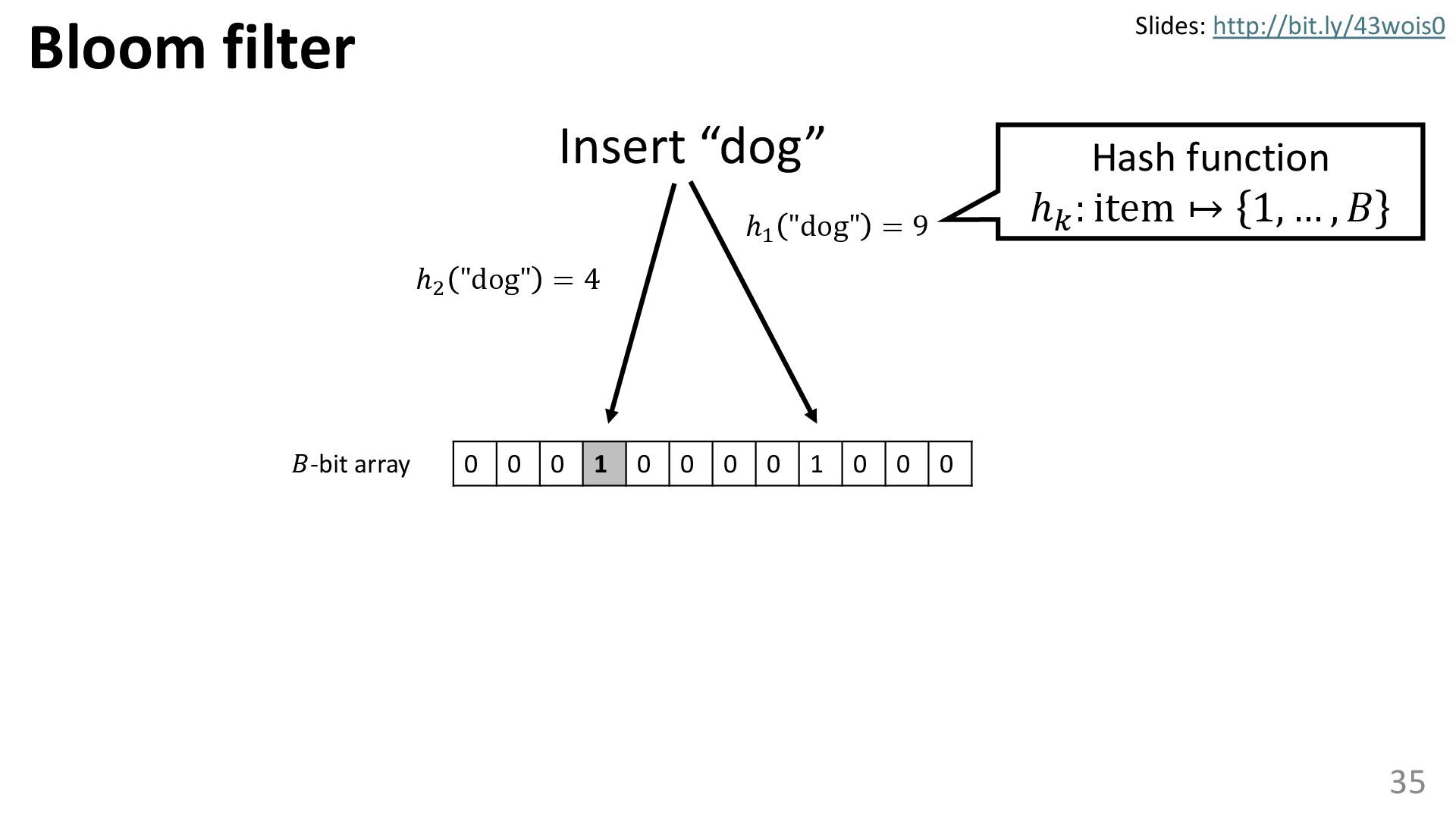{kind=link}
{kind=link}
{kind=link}
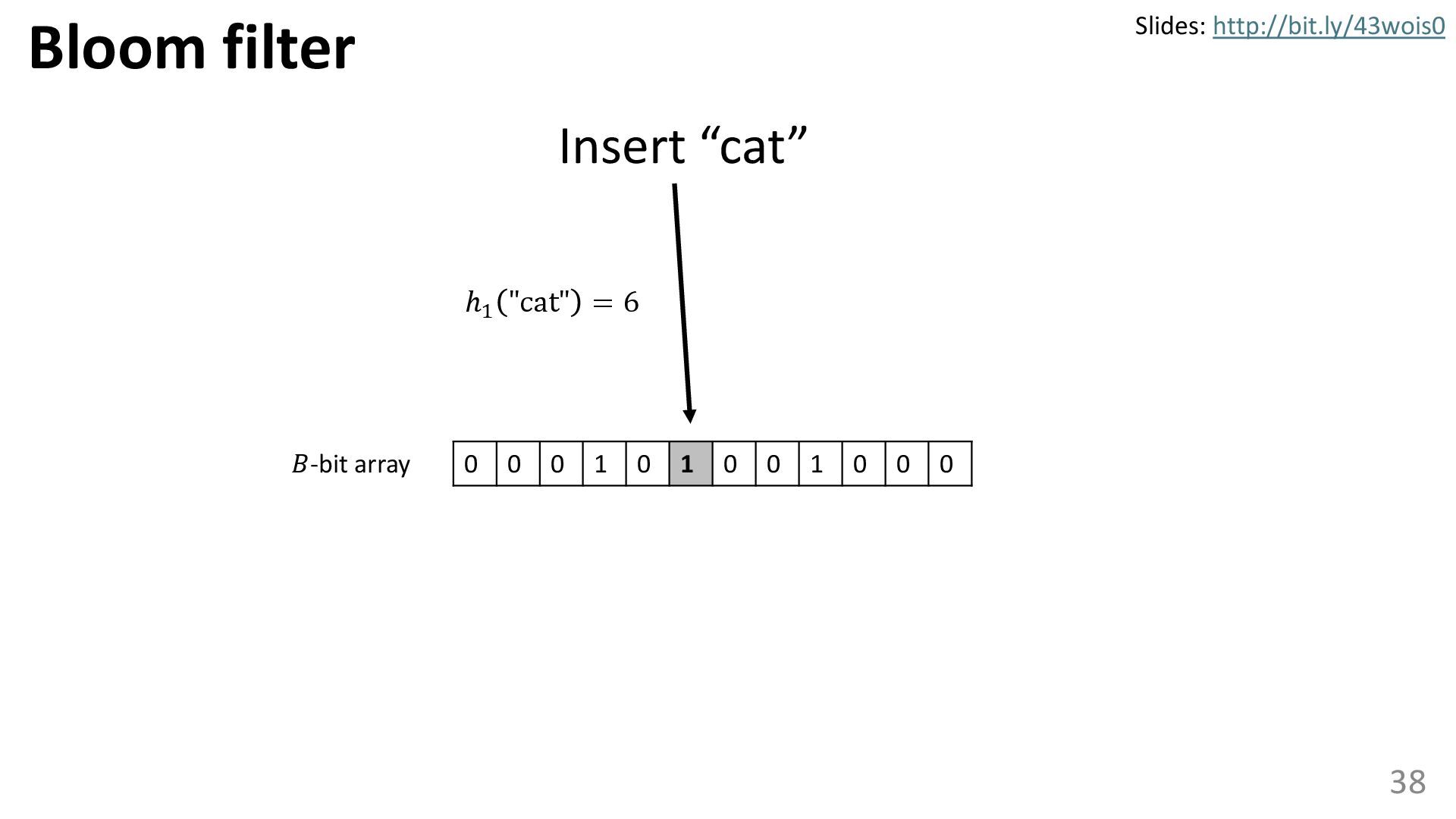{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
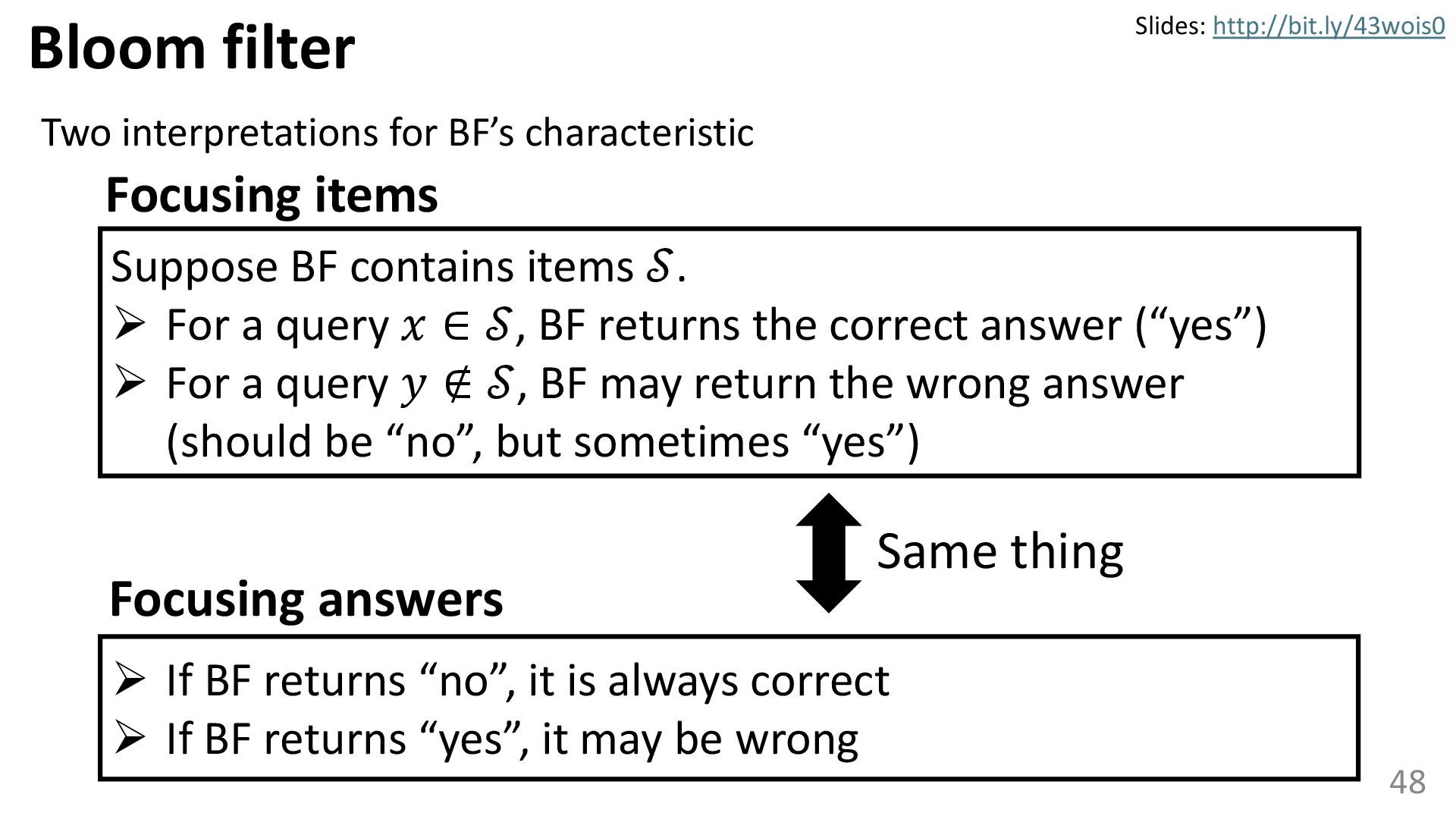{kind=link}
{kind=link}
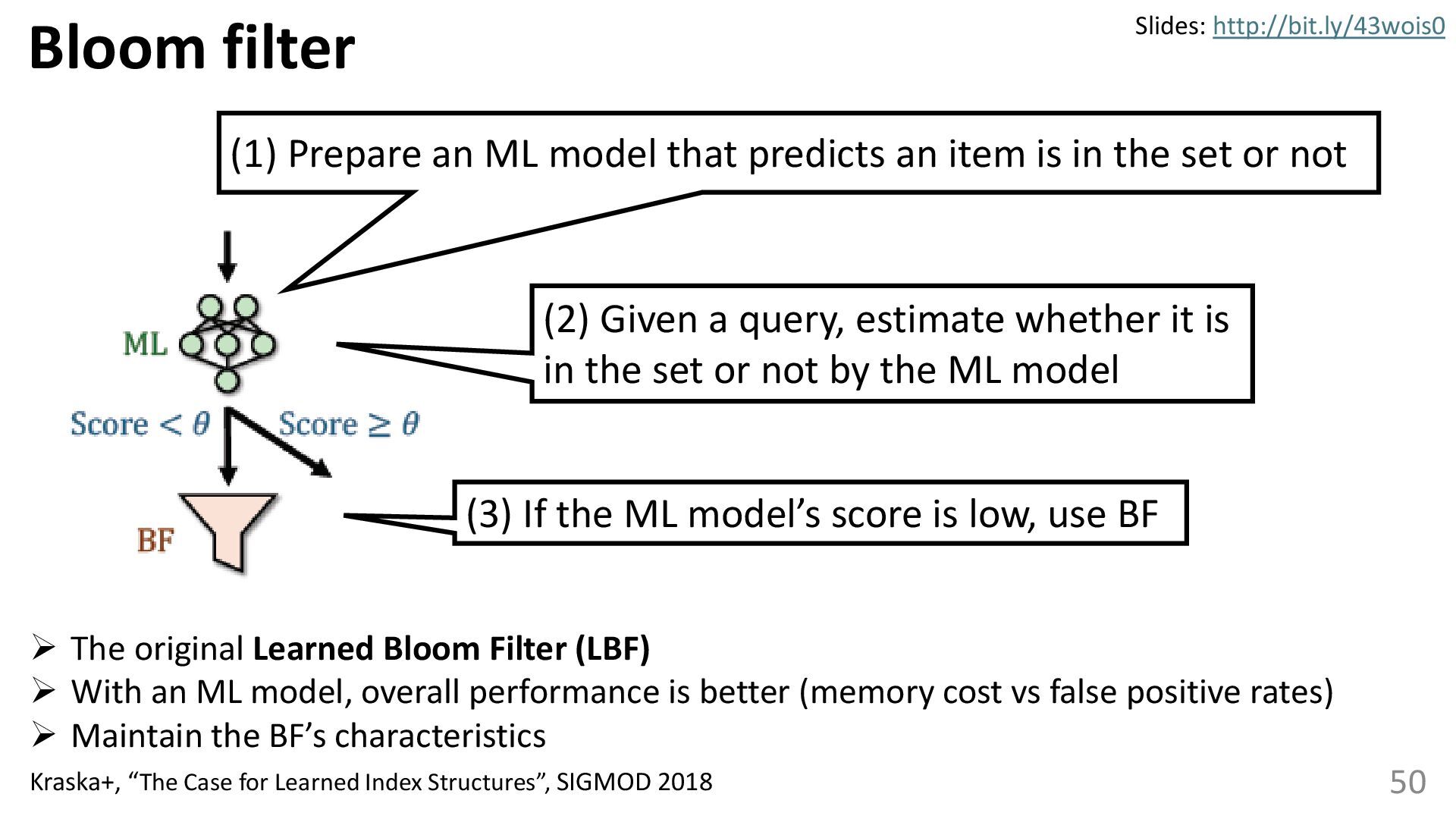{kind=link}
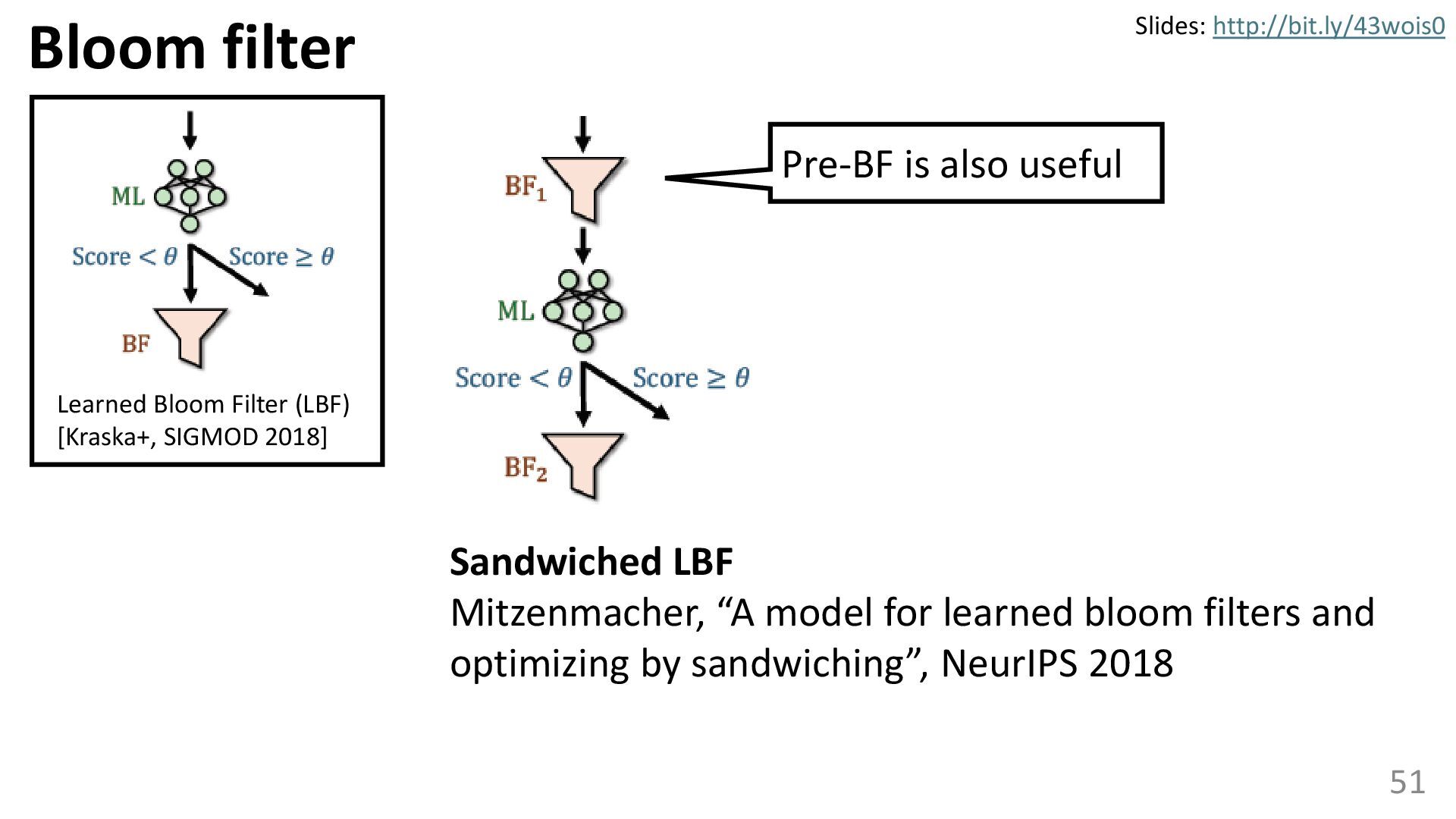{kind=link}
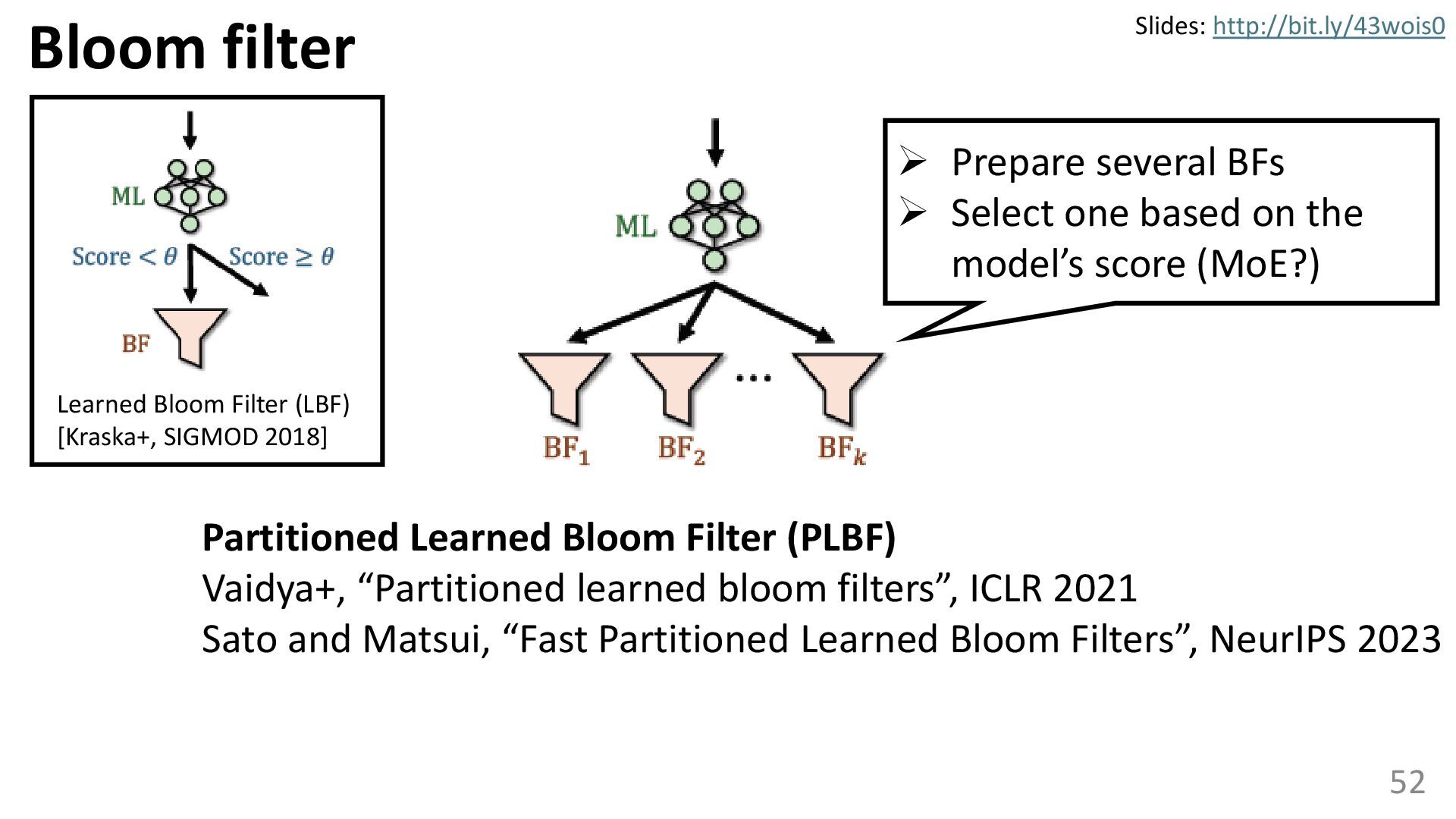{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
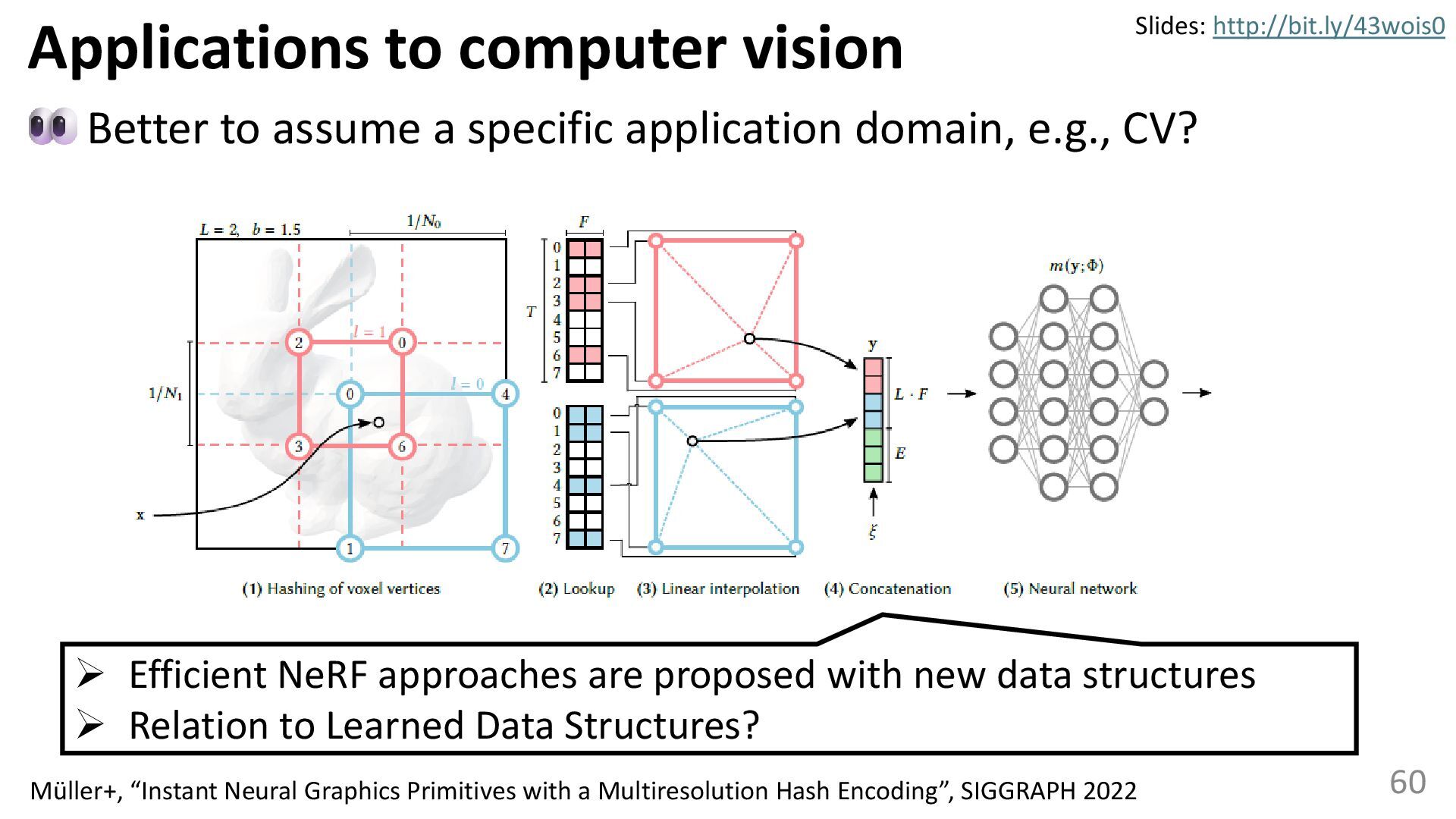{kind=link}
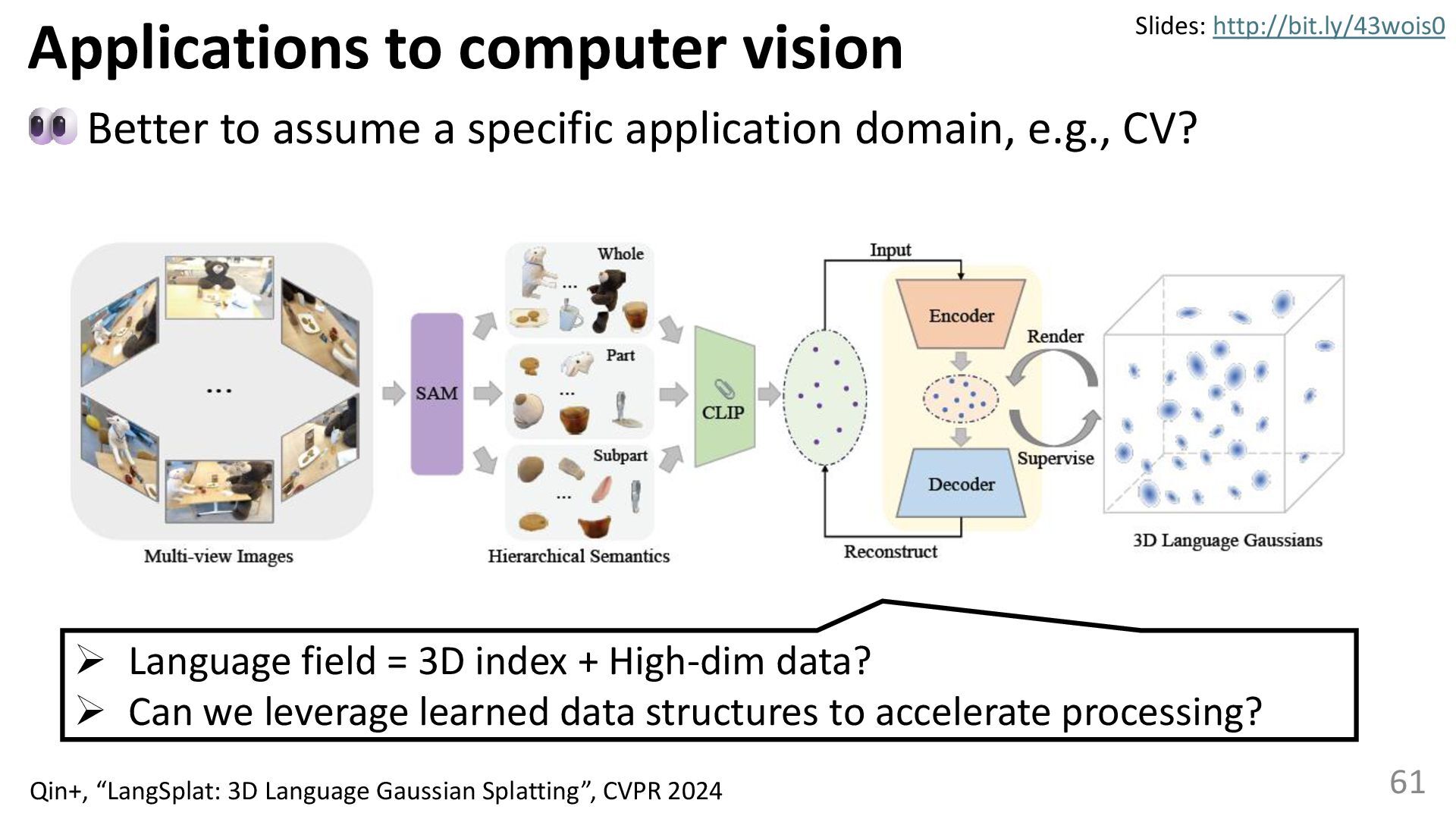{kind=link}
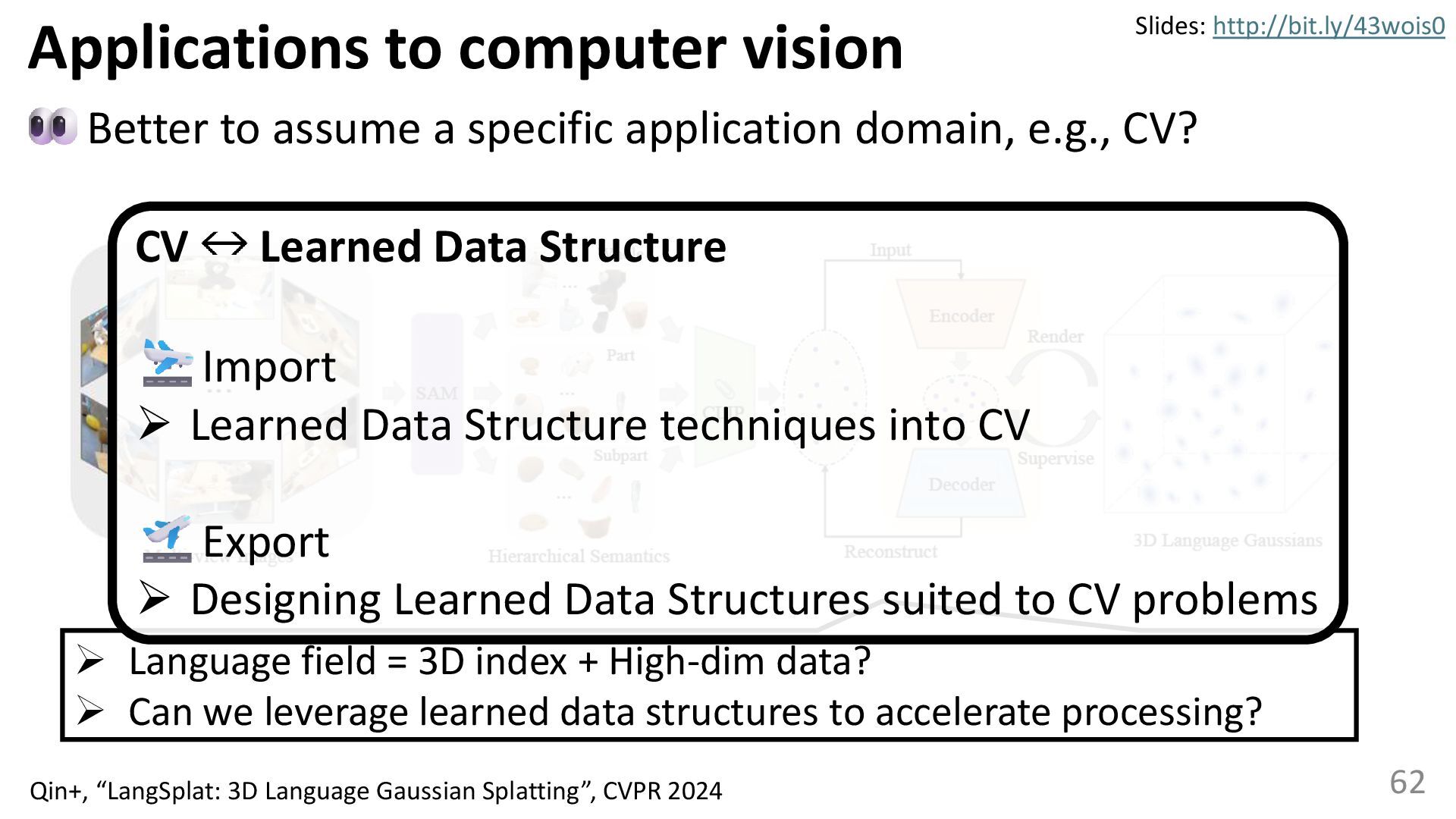{kind=link}
{kind=link}
{kind=link}